



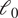
Impact Statement
This research paper describes a super-resolution method improving the spatial resolution of images acquired by common fluorescence microscopes and conventional blinking/fluctuating fluorophores. The problem is formulated in terms of a sparse and convex/nonconvex optimization problem in the covariance domain for which a well-detailed algorithmic and numerical description are provided. It is addressed to an audience working at the interface between applied mathematics and biological image analysis. The proposed approach is validated on several synthetic datasets and shows promising results also when applied to real data, thus paving the way for new future research directions.
1. Introduction
In the field of fluorescence (or, more generally, light) microscopy, the main factor characterizing the microscope resolution is the limit imposed by the diffraction of light: structures with size smaller than the diffraction barrier (typically around 250 nm in the lateral direction) cannot be well distinguished nor localized. The need to investigate small subcellular entities thus led to the implementation of a plethora of super-resolution methods.
A large and powerful family of imaging techniques achieving nanometric resolution are the ones often known as single molecule localization microscopy (SMLM) techniques, see, for example, Refs. (Reference Sage, Kirshner and Pengo1) and (Reference Sage, Pham and Babcock2) for a review. Among them, methods such as photo-activated localization microscopy (PALM)(Reference Betzig, Patterson and Sougrat3) and stochastic optical reconstruction microscopy (STORM)(Reference Rust, Bates and Zhuang4) are designed so as to create a super-resolved image (achieving around 20 nm of resolution) by activating and precisely localizing only a few molecules in each of thousands of acquired frames at a time. For their use, these methods need specific photoactivatable, photoswitchable, and binding-activated fluorophores, among others(Reference Li and Vaughan5), as well as, a large number (typically thousands) of sparse acquired frames leading to a poor temporal resolution and large exposure times which can significantly damage the sample. A different technique improving spatial resolution is well-known under the name of stimulated emission depletion (STED) microscopy(Reference Hell and Wichmann6). Similarly to SMLM, STED techniques are based on a time-consuming and possibly harmful acquisition procedure requiring special equipment. In STED microscopy, the size of the point spread function (PSF) is reduced as a depletion beam of light will induce stimulated emission from molecules outside the region of interest and thus switch them off. Structured illumination microscopy (SIM)(Reference Gustafsson7) methods use patterned illumination to excite the sample; differently from the aforementioned approaches, images here can be recovered with high temporal-resolution via high-speed acquisitions that cause comparatively little damage to the sample, but at the cost of a relatively low spatial resolution and, more importantly, the requirement of a specific illumination setup. Note that in this paper, we address grid-based super-resolution approaches, that is, the ones that formalize the super-resolution problem as the task of retrieving a well-detailed image on a fine grid from coarse measurements. More recently, off-the-grid super-resolution approaches have started to be studied in the literature, such as the one of Candès et al. (Reference Candès and Fernandez-Granda8), with applications to SMLM data in Denoyelle et al. (Reference Denoyelle, Duval, Peyré and Soubies9), as well as DAOSTORM(Reference Holden, Uphoff and Kapanidis10), a high-density super-resolution microscopy algorithm. The great advantage of the gridless approaches is that there are no limitations imposed by the size of the discrete grid considered. However, both the theoretical study of the problem and its numerical realization become very hard due to the infinite-dimensional and typically nonconvex nature of the optimization.
During the last decade, a new approach taking advantage of the independent stochastic temporal fluctuations/blinking of conventional fluorescent emitters appeared in the literature. A stack of images is acquired at a high temporal rate, typically 20–100 images/s, by means of common microscopes (such as widefield, confocal, or total internal reflection fluorescence [TIRF] ones) using standard fluorophores, and then their independent fluctuations/blinking are exploited so as to compute a super-resolved image. Note that no specific material is needed here, neither for the illumination setup nor for fluorophores. Several methods exploiting the sequence of images have been proposed over the last years. Due to standard acquisition settings, temporal resolution properties are drastically improved. To start with, super-resolution optical fluctuation imaging (SOFI)(Reference Dertinger, Colyer, Iyer, Weiss and Enderlein11) is a powerful technique where second and/or higher-order statistical analysis is performed, leading to a significant reduction of the size of the PSF. An extension of SOFI that combines several cumulant orders and achieves better resolution levels than SOFI is the method bSOFI(Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12). However, spatial resolution still cannot reach the same levels of PALM/STORM. Almost the same behavior has been noticed in super-resolution radial fluctuations (SRRF)(Reference Gustafsson, Culley, Ashdown, Owen, Pereira and Henriques13) microscopy, where super-resolution is achieved by calculating the degree of local symmetry at each frame. Despite its easy manipulation and broad applicability, SRRF creates significant reconstruction artifacts which may limit its use in view of accurate analysis. Other methods which belong to the same category and are worth mentioning are: the method 3B(Reference Cox, Rosten and Monypenny14), which uses Bayesian analysis and takes advantage of the blinking and bleaching events of standard fluorescent molecules, the method entropy-based super-resolution imaging (ESI)(Reference Yahiatene, Hennig, Müller and Huser15) that computes entropy values pixel-by-pixel, weighted with higher-order statistics and the method spatial covariance reconstructive (SCORE)(Reference Deng, Sun, Lin, Ma and Shaevitz16) that analyzes intensity statistics, similarly to SOFI, but further reduces noise and computational cost by computing only a few components that have a significant contribution to the intensity variances of the pixels. In addition, the approach sparsity-based super-resolution correlation microscopy (SPARCOM)(Reference Solomon, Mutzafi, Segev and Eldar17, Reference Solomon, Eldar, Mutzafi and Segev18) exploits, as SOFI, both the lack of correlation between distinct emitters as well as the sparse distribution of the fluorescent molecules via the use of an  $ {\mathrm{\ell}}_1 $ regularization defined on the emitters’ covariance matrix. Along the same lines, a deep-learning method exploiting algorithmic unfolding, called learned SPARCOM (LSPARCOM)(Reference Dardikman-Yoffe and Eldar19), has recently been introduced. Differently from plain SPARCOM, the advantage of LSPARCOM is that neither previous knowledge of the PSF nor any heuristic choice of the regularization parameter for tuning the sparsity level is required. As far as the reconstruction quality is concerned, both SPARCOM and LSPARCOM create some artifacts under challenging imaging conditions, for example, when the noise and/or background level are relatively high. Finally, without using higher-order statistics, a constrained tensor modeling approach that estimates a map of local molecule densities and their overall intensities, as well as, a matrix-based formulation that promotes structure sparsity via an
$ {\mathrm{\ell}}_1 $ regularization defined on the emitters’ covariance matrix. Along the same lines, a deep-learning method exploiting algorithmic unfolding, called learned SPARCOM (LSPARCOM)(Reference Dardikman-Yoffe and Eldar19), has recently been introduced. Differently from plain SPARCOM, the advantage of LSPARCOM is that neither previous knowledge of the PSF nor any heuristic choice of the regularization parameter for tuning the sparsity level is required. As far as the reconstruction quality is concerned, both SPARCOM and LSPARCOM create some artifacts under challenging imaging conditions, for example, when the noise and/or background level are relatively high. Finally, without using higher-order statistics, a constrained tensor modeling approach that estimates a map of local molecule densities and their overall intensities, as well as, a matrix-based formulation that promotes structure sparsity via an  $ {\mathrm{\ell}}_0 $-type regularizer, are available in Ref. (Reference Goulart, Blanc-Féraud, Debreuve and Schaub20). These approaches can achieve excellent temporal resolution levels, but the spatial resolution is limited.
$ {\mathrm{\ell}}_0 $-type regularizer, are available in Ref. (Reference Goulart, Blanc-Féraud, Debreuve and Schaub20). These approaches can achieve excellent temporal resolution levels, but the spatial resolution is limited.
1.1. Contribution
In this paper, we propose a method for live-cell super-resolution imaging based on the sparse analysis of the stochastic fluctuations of molecule intensities. The proposed approach provides a good level of both temporal and spatial resolution, thus allowing for both precise molecule localization and intensity estimation at the same time, while relaxing the need for special equipment (microscope, fluorescent dyes) typically encountered in state-of-the-art super-resolution methods such as, for example, SMLM. The proposed method is called COL0RME, which stands for covariance-based super-resolution microscopy with intensity estimation.The principles of COL0RME are shown in Figure 1. Similarly to SPARCOM(Reference Solomon, Eldar, Mutzafi and Segev18), COL0RME enforces signal sparsity in the covariance domain by means of sparsity-promoting terms, either of convex ( $ {\mathrm{\ell}}_1 $, TV) or nonconvex (
$ {\mathrm{\ell}}_1 $, TV) or nonconvex ( $ {\mathrm{\ell}}_0 $-based)-type. Differently from SPARCOM, COL0RME allows also for an accurate estimation of the noise variance in the data and is complemented with an automatic selection strategy of the model hyperparameters. Furthermore, and more importantly, COL0RME allows for the estimation of both signal and background intensity, which are relevant pieces of information for biological studies. By exploiting information on the estimated noise statistics, the parameter selection in this step is also made fully automatic, based on the standard discrepancy principle. We remark that an earlier version of COL0RME has been already introduced by the authors in Ref. (Reference Stergiopoulou, Goulart, Schaub, Calatroni and Blanc-Féraud21). Here, we consider an extended formulation combined with automatic parameter selection strategies which allows for the analysis of more challenging data having, for example, spatially varying background. The method is validated on simulated and tested on challenging real data. Our results show that COL0RME outperforms competing methods in terms of localization precision, parameter tuning and removal of background artifacts.
$ {\mathrm{\ell}}_0 $-based)-type. Differently from SPARCOM, COL0RME allows also for an accurate estimation of the noise variance in the data and is complemented with an automatic selection strategy of the model hyperparameters. Furthermore, and more importantly, COL0RME allows for the estimation of both signal and background intensity, which are relevant pieces of information for biological studies. By exploiting information on the estimated noise statistics, the parameter selection in this step is also made fully automatic, based on the standard discrepancy principle. We remark that an earlier version of COL0RME has been already introduced by the authors in Ref. (Reference Stergiopoulou, Goulart, Schaub, Calatroni and Blanc-Féraud21). Here, we consider an extended formulation combined with automatic parameter selection strategies which allows for the analysis of more challenging data having, for example, spatially varying background. The method is validated on simulated and tested on challenging real data. Our results show that COL0RME outperforms competing methods in terms of localization precision, parameter tuning and removal of background artifacts.

Figure 1. Principles of COL0RME. (a) An overview of the two steps (support estimation and intensity estimation) by visualizing the inputs/outputs of each, as well as the interaction between them. (b) The two main outputs of COL0RME are: the support  $ \Omega \subset {\unicode{x211D}}^{L^2} $ containing the locations of the fine-grid pixels with at least one fluorescent molecule, and the intensity
$ \Omega \subset {\unicode{x211D}}^{L^2} $ containing the locations of the fine-grid pixels with at least one fluorescent molecule, and the intensity  $ \mathbf{x}\in {\unicode{x211D}}^{L^2} $ whose non-null values are estimated only on
$ \mathbf{x}\in {\unicode{x211D}}^{L^2} $ whose non-null values are estimated only on  $ \Omega $.
$ \Omega $.
2. Mathematical Modeling
For real scalars  $ T,M>1 $ and
$ T,M>1 $ and  $ t\hskip0.2em \in \left\{1,2,\dots, T\right\} $, let
$ t\hskip0.2em \in \left\{1,2,\dots, T\right\} $, let  $ {\mathbf{Y}}_t\hskip0.2em \in {\unicode{x211D}}^{M\times M} $ be the blurred, noisy, and down-sampled image frame acquired at time
$ {\mathbf{Y}}_t\hskip0.2em \in {\unicode{x211D}}^{M\times M} $ be the blurred, noisy, and down-sampled image frame acquired at time  $ t $. We look for a high-resolution image
$ t $. We look for a high-resolution image  $ \mathbf{X}\hskip0.2em \in {\unicode{x211D}}^{L\times L} $ being defined as
$ \mathbf{X}\hskip0.2em \in {\unicode{x211D}}^{L\times L} $ being defined as  $ \mathbf{X}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{X}}_t $ with
$ \mathbf{X}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{X}}_t $ with  $ L= qM $ and defined on a
$ L= qM $ and defined on a  $ q $-times finer grid, with
$ q $-times finer grid, with  $ q\hskip0.2em \in \unicode{x2115} $. Note that in the following applications, we typically set
$ q\hskip0.2em \in \unicode{x2115} $. Note that in the following applications, we typically set  $ q=4 $. The image formation model describing the acquisition process at each
$ q=4 $. The image formation model describing the acquisition process at each  $ t $ can be written as:
$ t $ can be written as:
 $$ {\mathbf{Y}}_t={\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)+\mathbf{B}+{\mathbf{N}}_{\mathbf{t}}, $$
$$ {\mathbf{Y}}_t={\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)+\mathbf{B}+{\mathbf{N}}_{\mathbf{t}}, $$where  $ {\mathcal{M}}_q:{\unicode{x211D}}^{L\times L}\to {\unicode{x211D}}^{M\times M} $ is a down-sampling operator summing every
$ {\mathcal{M}}_q:{\unicode{x211D}}^{L\times L}\to {\unicode{x211D}}^{M\times M} $ is a down-sampling operator summing every  $ q $ consecutive pixels in both dimensions,
$ q $ consecutive pixels in both dimensions,  $ \mathcal{H}:{\unicode{x211D}}^{L\times L}\to {\unicode{x211D}}^{L\times L} $ is a convolution operator defined by the PSF of the optical imaging system and
$ \mathcal{H}:{\unicode{x211D}}^{L\times L}\to {\unicode{x211D}}^{L\times L} $ is a convolution operator defined by the PSF of the optical imaging system and  $ \mathbf{B}\hskip0.2em \in {\unicode{x211D}}^{M\times M} $ models the background, which collects the contributions of the out-of-focus (and the ambient) fluorescent molecules. Motivated by experimental observations showing that the blinking/fluctuating behavior of the out-of-focus molecules is not visible after convolution with wide de-focused PSFs, we assume that the background is temporally constant (
$ \mathbf{B}\hskip0.2em \in {\unicode{x211D}}^{M\times M} $ models the background, which collects the contributions of the out-of-focus (and the ambient) fluorescent molecules. Motivated by experimental observations showing that the blinking/fluctuating behavior of the out-of-focus molecules is not visible after convolution with wide de-focused PSFs, we assume that the background is temporally constant ( $ \mathbf{B} $ does not depend on
$ \mathbf{B} $ does not depend on  $ t $), while we allow it to smoothly vary in space. Finally,
$ t $), while we allow it to smoothly vary in space. Finally,  $ {\mathbf{N}}_t\hskip0.2em \in {\unicode{x211D}}^{M\times M} $ describes the presence of noise modeled here as a matrix of independent and identically distributed (i.i.d.) Gaussian random variables with zero mean and variance
$ {\mathbf{N}}_t\hskip0.2em \in {\unicode{x211D}}^{M\times M} $ describes the presence of noise modeled here as a matrix of independent and identically distributed (i.i.d.) Gaussian random variables with zero mean and variance  $ s\hskip0.2em \in {\unicode{x211D}}^{+} $ taking into account both the underlying electronic noise and the noise bias induced by
$ s\hskip0.2em \in {\unicode{x211D}}^{+} $ taking into account both the underlying electronic noise and the noise bias induced by  $ \mathbf{B} $ (see Remark 1 for more details on the approximation considered). We assume that the molecules are located at the center of each pixel and that there is no displacement of the specimen during the imaging period, which is a reasonable assumption whenever short time acquisitions are considered.
$ \mathbf{B} $ (see Remark 1 for more details on the approximation considered). We assume that the molecules are located at the center of each pixel and that there is no displacement of the specimen during the imaging period, which is a reasonable assumption whenever short time acquisitions are considered.
Remark 1. A more appropriate model taking also into account the presence of signal-dependent Poisson noise in the data would be the following:
 $$ {\mathbf{Y}}_t=P\left({\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)+\mathbf{B}\right)+{\mathbf{E}}_{\mathbf{t}}=P\left({\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)\right)+P\left(\mathbf{B}\right)+{\mathbf{E}}_t,\hskip2em \forall t=1,2,\dots, T, $$
$$ {\mathbf{Y}}_t=P\left({\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)+\mathbf{B}\right)+{\mathbf{E}}_{\mathbf{t}}=P\left({\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)\right)+P\left(\mathbf{B}\right)+{\mathbf{E}}_t,\hskip2em \forall t=1,2,\dots, T, $$where, for  $ \mathbf{W}\hskip0.2em \in {\unicode{x211D}}^{M\times M} $,
$ \mathbf{W}\hskip0.2em \in {\unicode{x211D}}^{M\times M} $,  $ P\left(\mathbf{W}\right) $ represents the realization of a multivariate Poisson variable of parameter
$ P\left(\mathbf{W}\right) $ represents the realization of a multivariate Poisson variable of parameter  $ \mathbf{W} $ and
$ \mathbf{W} $ and  $ {\mathbf{E}}_{\mathbf{t}}\hskip0.2em \in {\unicode{x211D}}^{M\times M} $ models electronic noise with a matrix of i.i.d. Gaussian entries of zero mean and constant variance
$ {\mathbf{E}}_{\mathbf{t}}\hskip0.2em \in {\unicode{x211D}}^{M\times M} $ models electronic noise with a matrix of i.i.d. Gaussian entries of zero mean and constant variance  $ {\sigma}^2\hskip0.2em \in {\unicode{x211D}}_{+} $. Note that the second equality in (Reference Sage, Pham and Babcock2) holds due to the independence between
$ {\sigma}^2\hskip0.2em \in {\unicode{x211D}}_{+} $. Note that the second equality in (Reference Sage, Pham and Babcock2) holds due to the independence between  $ {\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right) $ and
$ {\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right) $ and  $ \mathbf{B} $. Model (Reference Sage, Pham and Babcock2) is indeed the one we used for the generation of the simulated data, see Section 6.1. However, to simplify the reconstruction process, we simplified (Reference Sage, Pham and Babcock2) by assuming that
$ \mathbf{B} $. Model (Reference Sage, Pham and Babcock2) is indeed the one we used for the generation of the simulated data, see Section 6.1. However, to simplify the reconstruction process, we simplified (Reference Sage, Pham and Babcock2) by assuming that  $ \mathbf{B} $ has sufficiently large entries, so that
$ \mathbf{B} $ has sufficiently large entries, so that  $ P\left(\mathbf{B}\right) $ can be approximated as
$ P\left(\mathbf{B}\right) $ can be approximated as  $ P\left(\mathbf{B}\right)\approx \hat{\mathbf{B}} $ with
$ P\left(\mathbf{B}\right)\approx \hat{\mathbf{B}} $ with  $ {\hat{\mathbf{B}}}_{i,j}\sim \mathcal{N}\left({\mathbf{B}}_{i,j},{\mathbf{B}}_{i,j}\right) $, where
$ {\hat{\mathbf{B}}}_{i,j}\sim \mathcal{N}\left({\mathbf{B}}_{i,j},{\mathbf{B}}_{i,j}\right) $, where  $ \left(i,j\right)\hskip0.2em \in {\left\{1,\dots, M\right\}}^2 $, thus considering:
$ \left(i,j\right)\hskip0.2em \in {\left\{1,\dots, M\right\}}^2 $, thus considering:
 $$ {\mathbf{Y}}_t=P\left({\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)\right)+\hat{\mathbf{B}}+{\mathbf{E}}_t,\hskip2em \forall t=1,2,\dots, T. $$
$$ {\mathbf{Y}}_t=P\left({\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)\right)+\hat{\mathbf{B}}+{\mathbf{E}}_t,\hskip2em \forall t=1,2,\dots, T. $$By now further approximating the variance of  $ \hat{\mathbf{B}} $ with a constant
$ \hat{\mathbf{B}} $ with a constant  $ b\hskip0.2em \in {\unicode{x211D}}_{+} $ to be interpreted as the average of
$ b\hskip0.2em \in {\unicode{x211D}}_{+} $ to be interpreted as the average of  $ \mathbf{B} $, we have that by simple manipulations:
$ \mathbf{B} $, we have that by simple manipulations:
 $$ \hat{\mathbf{B}}+{\mathbf{E}}_t=\mathbf{B}+{\mathbf{N}}_t, $$
$$ \hat{\mathbf{B}}+{\mathbf{E}}_t=\mathbf{B}+{\mathbf{N}}_t, $$where the independence between  $ \hat{\mathbf{B}} $ and
$ \hat{\mathbf{B}} $ and  $ {\mathbf{E}}_t $ has been exploited. We can thus retrieve (Reference Sage, Kirshner and Pengo1) from (Reference Betzig, Patterson and Sougrat3) by neglecting the Poisson noise dependence in
$ {\mathbf{E}}_t $ has been exploited. We can thus retrieve (Reference Sage, Kirshner and Pengo1) from (Reference Betzig, Patterson and Sougrat3) by neglecting the Poisson noise dependence in  $ P\left({\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)\right) $ and that the variance of every entry of the random term
$ P\left({\mathcal{M}}_q\left(\mathcal{H}\left({\mathbf{X}}_t\right)\right)\right) $ and that the variance of every entry of the random term  $ {\mathbf{N}}_t $ is
$ {\mathbf{N}}_t $ is  $ s={\sigma}^2+b $. A more detailed and less approximated modeling taking into account the signal-dependent nature of the noise in the data could represent a very interesting area of future research.
$ s={\sigma}^2+b $. A more detailed and less approximated modeling taking into account the signal-dependent nature of the noise in the data could represent a very interesting area of future research.
In vectorized form, model (Reference Sage, Kirshner and Pengo1) reads:
 $$ {\mathbf{y}}_t=\boldsymbol{\Psi} {\mathbf{x}}_t+\mathbf{b}+{\mathbf{n}}_t, $$
$$ {\mathbf{y}}_t=\boldsymbol{\Psi} {\mathbf{x}}_t+\mathbf{b}+{\mathbf{n}}_t, $$where  $ \boldsymbol{\Psi} \hskip0.2em \in {\unicode{x211D}}^{M^2\times {L}^2} $ is the matrix representing the composition
$ \boldsymbol{\Psi} \hskip0.2em \in {\unicode{x211D}}^{M^2\times {L}^2} $ is the matrix representing the composition  $ {\mathcal{M}}_q\circ \mathcal{H} $, while
$ {\mathcal{M}}_q\circ \mathcal{H} $, while  $ {\mathbf{y}}_t\hskip0.2em \in {\unicode{x211D}}^{M^2} $,
$ {\mathbf{y}}_t\hskip0.2em \in {\unicode{x211D}}^{M^2} $,  $ {\mathbf{x}}_t\hskip0.2em \in {\unicode{x211D}}^{L^2} $,
$ {\mathbf{x}}_t\hskip0.2em \in {\unicode{x211D}}^{L^2} $,  $ \mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2} $, and
$ \mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2} $, and  $ {\mathbf{n}}_t\hskip0.2em \in {\unicode{x211D}}^{M^2} $ are the column-wise vectorizations of
$ {\mathbf{n}}_t\hskip0.2em \in {\unicode{x211D}}^{M^2} $ are the column-wise vectorizations of  $ {\mathbf{Y}}_t $,
$ {\mathbf{Y}}_t $,  $ {\mathbf{X}}_t $,
$ {\mathbf{X}}_t $,  $ \mathbf{B} $, and
$ \mathbf{B} $, and  $ {\mathbf{N}}_t $ in (Reference Sage, Kirshner and Pengo1), respectively.
$ {\mathbf{N}}_t $ in (Reference Sage, Kirshner and Pengo1), respectively.
For all  $ t $ and given
$ t $ and given  $ \boldsymbol{\Psi} $ and
$ \boldsymbol{\Psi} $ and  $ {\mathbf{y}}_t $, the problem can thus be formulated as
$ {\mathbf{y}}_t $, the problem can thus be formulated as
 $$ \mathrm{find}\hskip1em \mathbf{x}=\frac{1}{T}\sum \limits_{t=1}^T\;{\mathbf{x}}_t\hskip0.2em \in {\unicode{x211D}}^{L^2},\mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2}\mathrm{and}\hskip0.5em s>0\hskip1em \mathrm{s}.\mathrm{t}.\hskip1em {\mathbf{x}}_t\hskip1em \mathrm{s}\mathrm{olves}\;(4). $$
$$ \mathrm{find}\hskip1em \mathbf{x}=\frac{1}{T}\sum \limits_{t=1}^T\;{\mathbf{x}}_t\hskip0.2em \in {\unicode{x211D}}^{L^2},\mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2}\mathrm{and}\hskip0.5em s>0\hskip1em \mathrm{s}.\mathrm{t}.\hskip1em {\mathbf{x}}_t\hskip1em \mathrm{s}\mathrm{olves}\;(4). $$In order to exploit the statistical behavior of the fluorescent emitters, we reformulate the model in the covariance domain. This idea was previously exploited by the SOFI approach(Reference Dertinger, Colyer, Iyer, Weiss and Enderlein11) and was shown to significantly reduce the full-width-at-half-maximum (FWHM) of the PSF. In particular, the use of second-order statistics for a Gaussian PSF corresponds to a reduction factor of the FWHM of  $ \sqrt{2} $.
$ \sqrt{2} $.
To formulate the model, we consider the frames  $ {\left({\mathbf{y}}_t\right)}_{t\hskip0.2em \in \left\{1,\dots, T\right\}} $ as
$ {\left({\mathbf{y}}_t\right)}_{t\hskip0.2em \in \left\{1,\dots, T\right\}} $ as  $ T $ realizations of a random variable
$ T $ realizations of a random variable  $ \mathbf{y} $ with covariance matrix defined by:
$ \mathbf{y} $ with covariance matrix defined by:
 $$ {\mathbf{R}}_{\mathbf{y}}={\unicode{x1D53C}}_{\mathbf{y}}\left\{\left(\mathbf{y}-{\unicode{x1D53C}}_{\mathbf{y}}\left\{\mathbf{y}\right\}\right){\left(\mathbf{y}-{\unicode{x1D53C}}_{\mathbf{y}}\left\{\mathbf{y}\right\}\right)}^{\intercal}\right\}, $$
$$ {\mathbf{R}}_{\mathbf{y}}={\unicode{x1D53C}}_{\mathbf{y}}\left\{\left(\mathbf{y}-{\unicode{x1D53C}}_{\mathbf{y}}\left\{\mathbf{y}\right\}\right){\left(\mathbf{y}-{\unicode{x1D53C}}_{\mathbf{y}}\left\{\mathbf{y}\right\}\right)}^{\intercal}\right\}, $$where  $ {\unicode{x1D53C}}_{\mathbf{y}}\left\{\cdot \right\} $ denotes the expected value computed w.r.t. to the unknown law of
$ {\unicode{x1D53C}}_{\mathbf{y}}\left\{\cdot \right\} $ denotes the expected value computed w.r.t. to the unknown law of  $ \mathbf{y} $. We estimate
$ \mathbf{y} $. We estimate  $ {\mathbf{R}}_{\mathbf{y}} $ by computing the empirical covariance matrix, that is,
$ {\mathbf{R}}_{\mathbf{y}} $ by computing the empirical covariance matrix, that is,
 $$ {\mathbf{R}}_{\mathbf{y}}\approx \frac{1}{T-1}\sum \limits_{t=1}^T\left({\mathbf{y}}_t-\overline{\mathbf{y}}\right){\left({\mathbf{y}}_t-\overline{\mathbf{y}}\right)}^{\intercal }, $$
$$ {\mathbf{R}}_{\mathbf{y}}\approx \frac{1}{T-1}\sum \limits_{t=1}^T\left({\mathbf{y}}_t-\overline{\mathbf{y}}\right){\left({\mathbf{y}}_t-\overline{\mathbf{y}}\right)}^{\intercal }, $$where  $ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_t $ denotes the empirical temporal mean. From (Reference Rust, Bates and Zhuang4) and (Reference Li and Vaughan5), we thus deduce the relation:
$ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_t $ denotes the empirical temporal mean. From (Reference Rust, Bates and Zhuang4) and (Reference Li and Vaughan5), we thus deduce the relation:
 $$ {\mathbf{R}}_{\mathbf{y}}=\boldsymbol{\Psi} {\mathbf{R}}_{\mathbf{x}}{\boldsymbol{\Psi}}^{\intercal }+{\mathbf{R}}_{\mathbf{n}}, $$
$$ {\mathbf{R}}_{\mathbf{y}}=\boldsymbol{\Psi} {\mathbf{R}}_{\mathbf{x}}{\boldsymbol{\Psi}}^{\intercal }+{\mathbf{R}}_{\mathbf{n}}, $$ where  $ {\mathbf{R}}_{\mathbf{x}}\hskip0.2em \in {\unicode{x211D}}^{L^2\times {L}^2} $ and
$ {\mathbf{R}}_{\mathbf{x}}\hskip0.2em \in {\unicode{x211D}}^{L^2\times {L}^2} $ and  $ {\mathbf{R}}_{\mathbf{n}}\hskip0.2em \in {\unicode{x211D}}^{M^2\times {M}^2} $ are the covariance matrices of
$ {\mathbf{R}}_{\mathbf{n}}\hskip0.2em \in {\unicode{x211D}}^{M^2\times {M}^2} $ are the covariance matrices of  $ {\left({\mathbf{x}}_t\right)}_{t\hskip0.2em \in \left\{1,\dots, T\right\}} $ and
$ {\left({\mathbf{x}}_t\right)}_{t\hskip0.2em \in \left\{1,\dots, T\right\}} $ and  $ {\left({\mathbf{n}}_t\right)}_{t\hskip0.2em \in \left\{1,\dots, T\right\}}, $ respectively. As the background is stationary by assumption, the covariance matrix of
$ {\left({\mathbf{n}}_t\right)}_{t\hskip0.2em \in \left\{1,\dots, T\right\}}, $ respectively. As the background is stationary by assumption, the covariance matrix of  $ \mathbf{b} $ is zero. Recalling now that the emitters are uncorrelated by assumption, we deduce that
$ \mathbf{b} $ is zero. Recalling now that the emitters are uncorrelated by assumption, we deduce that  $ {\mathbf{R}}_{\mathbf{x}} $ is diagonal. We thus set
$ {\mathbf{R}}_{\mathbf{x}} $ is diagonal. We thus set  $ {\mathbf{r}}_{\mathbf{x}}:= \operatorname{diag}\left({\mathbf{R}}_{\mathbf{x}}\right)\hskip0.2em \in {\unicode{x211D}}^{L^2} $. Furthermore, by the i.i.d. assumption on
$ {\mathbf{r}}_{\mathbf{x}}:= \operatorname{diag}\left({\mathbf{R}}_{\mathbf{x}}\right)\hskip0.2em \in {\unicode{x211D}}^{L^2} $. Furthermore, by the i.i.d. assumption on  $ {\mathbf{n}}_t $, we have that
$ {\mathbf{n}}_t $, we have that  $ {\mathbf{R}}_{\mathbf{n}}=s{\mathbf{I}}_{{\mathbf{M}}^{\mathbf{2}}} $, where
$ {\mathbf{R}}_{\mathbf{n}}=s{\mathbf{I}}_{{\mathbf{M}}^{\mathbf{2}}} $, where  $ s\hskip0.2em \in {\unicode{x211D}}_{+} $ and
$ s\hskip0.2em \in {\unicode{x211D}}_{+} $ and  $ {\mathbf{I}}_{{\mathbf{M}}^{\mathbf{2}}} $ is the identity matrix in
$ {\mathbf{I}}_{{\mathbf{M}}^{\mathbf{2}}} $ is the identity matrix in  $ {\unicode{x211D}}^{M^2\times {M}^2} $. Note that the model in equation (6) is similar to the SPARCOM one presented in Ref. (Reference Solomon, Eldar, Mutzafi and Segev18), with the difference that here we consider also noise contributions by including in the model the diagonal covariance matrix
$ {\unicode{x211D}}^{M^2\times {M}^2} $. Note that the model in equation (6) is similar to the SPARCOM one presented in Ref. (Reference Solomon, Eldar, Mutzafi and Segev18), with the difference that here we consider also noise contributions by including in the model the diagonal covariance matrix  $ {\mathbf{R}}_{\mathbf{n}} $. Finally, the vectorized form of the model in the covariance domain can thus be written as:
$ {\mathbf{R}}_{\mathbf{n}} $. Finally, the vectorized form of the model in the covariance domain can thus be written as:
 $$ {\mathbf{r}}_{\mathbf{y}}=\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right){\mathbf{r}}_{\mathbf{x}}+s{\mathbf{v}}_{\mathbf{I}}, $$
$$ {\mathbf{r}}_{\mathbf{y}}=\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right){\mathbf{r}}_{\mathbf{x}}+s{\mathbf{v}}_{\mathbf{I}}, $$where  $ \odot $ denotes the Khatri–Rao (column-wise Kronecker) product,
$ \odot $ denotes the Khatri–Rao (column-wise Kronecker) product,  $ {\mathbf{r}}_{\mathbf{y}}\hskip0.2em \in {\unicode{x211D}}^{M^4} $ is the column-wise vectorization of
$ {\mathbf{r}}_{\mathbf{y}}\hskip0.2em \in {\unicode{x211D}}^{M^4} $ is the column-wise vectorization of  $ {\mathbf{R}}_{\mathbf{y}} $ and
$ {\mathbf{R}}_{\mathbf{y}} $ and  $ {\mathbf{v}}_{\mathbf{I}}=\mathrm{vec}\left({\mathbf{I}}_{{\mathbf{M}}^{\mathbf{2}}}\right) $.
$ {\mathbf{v}}_{\mathbf{I}}=\mathrm{vec}\left({\mathbf{I}}_{{\mathbf{M}}^{\mathbf{2}}}\right) $.
3. COL0RME, Step I: Support Estimation for Precise Molecule Localization
Similarly to SPARCOM(Reference Solomon, Eldar, Mutzafi and Segev18), our approach makes use of the fact that the solution  $ {\mathbf{r}}_{\mathbf{x}} $ is sparse, while including further the estimation of
$ {\mathbf{r}}_{\mathbf{x}} $ is sparse, while including further the estimation of  $ s>0 $ for dealing with more challenging scenarios. In order to compare specific regularity a priori constraints on the solution, we make use of different regularization terms, whose importance is controlled by a regularization hyperparameter
$ s>0 $ for dealing with more challenging scenarios. In order to compare specific regularity a priori constraints on the solution, we make use of different regularization terms, whose importance is controlled by a regularization hyperparameter  $ \lambda >0 $. By further introducing some non-negativity constraints for both variables
$ \lambda >0 $. By further introducing some non-negativity constraints for both variables  $ {\mathbf{r}}_{\mathbf{x}} $ and
$ {\mathbf{r}}_{\mathbf{x}} $ and  $ s $, we thus aim to solve:
$ s $, we thus aim to solve:
 $$ \underset{{\mathbf{r}}_{\mathbf{x}}\ge 0,\hskip0.3em s\ge 0}{\arg \hskip0.1em \min}\mathcal{F}\left({\mathbf{r}}_{\mathbf{x}},s\right)+\mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right), $$
$$ \underset{{\mathbf{r}}_{\mathbf{x}}\ge 0,\hskip0.3em s\ge 0}{\arg \hskip0.1em \min}\mathcal{F}\left({\mathbf{r}}_{\mathbf{x}},s\right)+\mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right), $$where the data fidelity term is defined by:
 $$ \mathcal{F}\left({\mathbf{r}}_{\mathbf{x}},s\right)=\frac{1}{2}\parallel {\mathbf{r}}_{\mathbf{y}}-\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right){\mathbf{r}}_{\mathbf{x}}-s{\mathbf{v}}_{\mathbf{I}}{\parallel}_2^2, $$
$$ \mathcal{F}\left({\mathbf{r}}_{\mathbf{x}},s\right)=\frac{1}{2}\parallel {\mathbf{r}}_{\mathbf{y}}-\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right){\mathbf{r}}_{\mathbf{x}}-s{\mathbf{v}}_{\mathbf{I}}{\parallel}_2^2, $$and  $ \mathcal{R}\left(\cdot; \lambda \right) $ is a sparsity-promoting penalty. Ideally, one would like to make use of the
$ \mathcal{R}\left(\cdot; \lambda \right) $ is a sparsity-promoting penalty. Ideally, one would like to make use of the  $ {\mathrm{\ell}}_0 $ norm to enforce sparsity. However, as it is well-known, solving the resulting noncontinuous, nonconvex, and combinatorial minimization problem is an NP-hard problem. A way to circumvent this difficulty consists in using the continuous exact relaxation of the
$ {\mathrm{\ell}}_0 $ norm to enforce sparsity. However, as it is well-known, solving the resulting noncontinuous, nonconvex, and combinatorial minimization problem is an NP-hard problem. A way to circumvent this difficulty consists in using the continuous exact relaxation of the  $ {\mathrm{\ell}}_0 $ norm (CEL0) proposed by Soubies et al. in Ref. (Reference Soubies, Blanc-Féraud and Aubert22). The CEL0 regularization is continuous, nonconvex and preserves the global minima of the original
$ {\mathrm{\ell}}_0 $ norm (CEL0) proposed by Soubies et al. in Ref. (Reference Soubies, Blanc-Féraud and Aubert22). The CEL0 regularization is continuous, nonconvex and preserves the global minima of the original  $ {\mathrm{\ell}}_2-{\mathrm{\ell}}_0 $ problem while removing some local ones. It is defined as follows:
$ {\mathrm{\ell}}_2-{\mathrm{\ell}}_0 $ problem while removing some local ones. It is defined as follows:
 $$ \mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right)={\Phi}_{\mathrm{CEL}0}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right)=\sum \limits_{i=\unicode{x1D7D9}}^{L^2}\lambda -\frac{\parallel {\mathbf{a}}_i{\parallel}^2}{2}{\left(|{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i|-\frac{\sqrt{2\lambda }}{\parallel {\mathbf{a}}_i\parallel}\right)}^2{\unicode{x1D7D9}}_{\left\{|{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i|\le \frac{\sqrt{2\lambda }}{\parallel {\mathbf{a}}_i\parallel}\right\}}, $$
$$ \mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right)={\Phi}_{\mathrm{CEL}0}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right)=\sum \limits_{i=\unicode{x1D7D9}}^{L^2}\lambda -\frac{\parallel {\mathbf{a}}_i{\parallel}^2}{2}{\left(|{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i|-\frac{\sqrt{2\lambda }}{\parallel {\mathbf{a}}_i\parallel}\right)}^2{\unicode{x1D7D9}}_{\left\{|{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i|\le \frac{\sqrt{2\lambda }}{\parallel {\mathbf{a}}_i\parallel}\right\}}, $$where  $ {\mathbf{a}}_i={\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right)}_i $ denotes the
$ {\mathbf{a}}_i={\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right)}_i $ denotes the  $ i $th column of the operator
$ i $th column of the operator  $ \mathbf{A}:= \boldsymbol{\Psi} \odot \boldsymbol{\Psi} $.
$ \mathbf{A}:= \boldsymbol{\Psi} \odot \boldsymbol{\Psi} $.
A different, convex way of favoring sparsity consists in taking as regularizer the  $ {\mathrm{\ell}}_1 $ norm, that is,
$ {\mathrm{\ell}}_1 $ norm, that is,
 $$ \mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right)=\lambda \parallel {\mathbf{r}}_{\mathbf{x}}{\parallel}_1. $$
$$ \mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right)=\lambda \parallel {\mathbf{r}}_{\mathbf{x}}{\parallel}_1. $$Besides convexity and as it is well-known, the key difference between using the  $ {\mathrm{\ell}}_0 $ and the
$ {\mathrm{\ell}}_0 $ and the  $ {\mathrm{\ell}}_1 $-norm is that the
$ {\mathrm{\ell}}_1 $-norm is that the  $ {\mathrm{\ell}}_0 $ provides a correct interpretation of sparsity by counting only the number of the nonzero coefficients, while the
$ {\mathrm{\ell}}_0 $ provides a correct interpretation of sparsity by counting only the number of the nonzero coefficients, while the  $ {\mathrm{\ell}}_1 $ depends also on the magnitude of the coefficients. However, its use as a sparsity-promoting regularizer is nowadays well-established (see, e.g., Ref. (Reference Candès, Wakin and Boyd23)) and also used effectively in other microscopy applications, such as SPARCOM(Reference Solomon, Eldar, Mutzafi and Segev18).
$ {\mathrm{\ell}}_1 $ depends also on the magnitude of the coefficients. However, its use as a sparsity-promoting regularizer is nowadays well-established (see, e.g., Ref. (Reference Candès, Wakin and Boyd23)) and also used effectively in other microscopy applications, such as SPARCOM(Reference Solomon, Eldar, Mutzafi and Segev18).
Finally, in order to model situations where piece-wise constant structures are considered, we consider a different regularization term favoring gradient-sparsity using the total variation (TV) regularization defined in a discrete setting as follows:
 $$ \mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right)=\lambda TV\left({\mathbf{r}}_{\mathbf{x}}\right)=\lambda \sum \limits_{i=1}^{L^2}{\left({\left|{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i-{\left({\mathbf{r}}_{\mathbf{x}}\right)}_{n_{i,1}}\right|}^2+{\left|{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i-{\left({\mathbf{r}}_{\mathbf{x}}\right)}_{n_{i,2}}\right|}^2\right)}^{\frac{1}{2}}, $$
$$ \mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right)=\lambda TV\left({\mathbf{r}}_{\mathbf{x}}\right)=\lambda \sum \limits_{i=1}^{L^2}{\left({\left|{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i-{\left({\mathbf{r}}_{\mathbf{x}}\right)}_{n_{i,1}}\right|}^2+{\left|{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i-{\left({\mathbf{r}}_{\mathbf{x}}\right)}_{n_{i,2}}\right|}^2\right)}^{\frac{1}{2}}, $$where  $ \left({n}_{i,1},{n}_{i,2}\right)\hskip0.2em \in {\left\{1,\dots, {L}^2\right\}}^2 $ indicate the locations of the horizontal and vertical nearest neighbor pixels of pixel
$ \left({n}_{i,1},{n}_{i,2}\right)\hskip0.2em \in {\left\{1,\dots, {L}^2\right\}}^2 $ indicate the locations of the horizontal and vertical nearest neighbor pixels of pixel  $ i $, as shown in Figure 2. For the computation of the TV penalty, Neumann boundary conditions have been used.
$ i $, as shown in Figure 2. For the computation of the TV penalty, Neumann boundary conditions have been used.

Figure 2. The one-sided nearest horizontal and vertical neighbors of the pixel  $ i $ used to compute the gradient discretization in (Reference Dertinger, Colyer, Iyer, Weiss and Enderlein11).
$ i $ used to compute the gradient discretization in (Reference Dertinger, Colyer, Iyer, Weiss and Enderlein11).
To solve (Reference Gustafsson7), we use the alternate minimization algorithm between  $ s $ and
$ s $ and  $ {\mathbf{r}}_{\mathbf{x}} $(Reference Attouch, Bolte, Redont and Soubeyran24), see the pseudo-code reported in Algorithm 1. Note that, at each
$ {\mathbf{r}}_{\mathbf{x}} $(Reference Attouch, Bolte, Redont and Soubeyran24), see the pseudo-code reported in Algorithm 1. Note that, at each  $ k\ge 1 $, the update for the variable
$ k\ge 1 $, the update for the variable  $ s $ can be efficiently computed through the following explicit expression:
$ s $ can be efficiently computed through the following explicit expression:
 $$ {s}^{k+1}=\frac{1}{M^2}{{\mathbf{v}}_{\mathbf{I}}}^{\intercal}\left({\mathbf{r}}_{\mathbf{y}}-\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right){{\mathbf{r}}_{\mathbf{x}}}^k\right). $$
$$ {s}^{k+1}=\frac{1}{M^2}{{\mathbf{v}}_{\mathbf{I}}}^{\intercal}\left({\mathbf{r}}_{\mathbf{y}}-\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right){{\mathbf{r}}_{\mathbf{x}}}^k\right). $$ Concerning the update of  $ {\mathbf{r}}_{\mathbf{x}}\hskip-0.2em $, different algorithms were used depending on the choice of the regularization term in (Reference Denoyelle, Duval, Peyré and Soubies9)–(Reference Dertinger, Colyer, Iyer, Weiss and Enderlein11). For the CEL0 penalty (Reference Denoyelle, Duval, Peyré and Soubies9), we used the iteratively reweighted
$ {\mathbf{r}}_{\mathbf{x}}\hskip-0.2em $, different algorithms were used depending on the choice of the regularization term in (Reference Denoyelle, Duval, Peyré and Soubies9)–(Reference Dertinger, Colyer, Iyer, Weiss and Enderlein11). For the CEL0 penalty (Reference Denoyelle, Duval, Peyré and Soubies9), we used the iteratively reweighted  $ {\mathrm{\ell}}_1 $ algorithm (IRL1)(Reference Ochs, Dosovitskiy, Brox and Pock25), following Gazagnes et al. (Reference Gazagnes, Soubies and Blanc-Féraud26) with fast iterative shrinkage-thresholding algorithm (FISTA)(Reference Beck and Teboulle27) as inner solver. If the
$ {\mathrm{\ell}}_1 $ algorithm (IRL1)(Reference Ochs, Dosovitskiy, Brox and Pock25), following Gazagnes et al. (Reference Gazagnes, Soubies and Blanc-Féraud26) with fast iterative shrinkage-thresholding algorithm (FISTA)(Reference Beck and Teboulle27) as inner solver. If the  $ {\mathrm{\ell}}_1 $ norm (Reference Holden, Uphoff and Kapanidis10) is chosen, FISTA is used. Finally, when the TV penalty (Reference Dertinger, Colyer, Iyer, Weiss and Enderlein11) is employed, the primal-dual splitting method in Ref. (Reference Condat28) was considered.
$ {\mathrm{\ell}}_1 $ norm (Reference Holden, Uphoff and Kapanidis10) is chosen, FISTA is used. Finally, when the TV penalty (Reference Dertinger, Colyer, Iyer, Weiss and Enderlein11) is employed, the primal-dual splitting method in Ref. (Reference Condat28) was considered.
Algorithm 1 COL0RME, Step I: Support Estimation
Require:  $ {\mathbf{r}}_{\mathbf{y}}\hskip0.2em \in {\unicode{x211D}}^{M^4},{{\mathbf{r}}_{\mathbf{x}}}^0\hskip0.2em \in {\unicode{x211D}}^{L^2},\lambda >0 $.
$ {\mathbf{r}}_{\mathbf{y}}\hskip0.2em \in {\unicode{x211D}}^{M^4},{{\mathbf{r}}_{\mathbf{x}}}^0\hskip0.2em \in {\unicode{x211D}}^{L^2},\lambda >0 $.
repeat
 $ {s}^{k+1}=\underset{s\hskip0.2em \in {\unicode{x211D}}_{+}}{\arg \hskip0.1em \min}\mathcal{F}\left({{\mathbf{r}}_{\mathbf{x}}}^k,s\right) $
$ {s}^{k+1}=\underset{s\hskip0.2em \in {\unicode{x211D}}_{+}}{\arg \hskip0.1em \min}\mathcal{F}\left({{\mathbf{r}}_{\mathbf{x}}}^k,s\right) $
 $ {{\mathbf{r}}_{\mathbf{x}}}^{k+1}=\underset{{\mathbf{r}}_{\mathbf{x}}\hskip0.2em \in {\unicode{x211D}}_{+}^{L^2}}{\arg \hskip0.1em \min}\mathcal{F}\left({\mathbf{r}}_{\mathbf{x}},{s}^{k+1}\right)+\mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right) $
$ {{\mathbf{r}}_{\mathbf{x}}}^{k+1}=\underset{{\mathbf{r}}_{\mathbf{x}}\hskip0.2em \in {\unicode{x211D}}_{+}^{L^2}}{\arg \hskip0.1em \min}\mathcal{F}\left({\mathbf{r}}_{\mathbf{x}},{s}^{k+1}\right)+\mathcal{R}\left({\mathbf{r}}_{\mathbf{x}};\lambda \right) $
until convergence.
return  $ {\Omega}_{\mathbf{x}},s $.
$ {\Omega}_{\mathbf{x}},s $.
Following the description provided by Attouch et al. in Ref. (Reference Attouch, Bolte, Redont and Soubeyran24), convergence of Algorithm 1 can be guaranteed only if an additional quadratic term is introduced in the objective function of the second minimization subproblem. Nonetheless, empirical convergence was observed also without such additional terms.
To evaluate the performance of the first step of the method COL0RME using the different regularization penalties described above, we created two noisy simulated datasets, with low background (LB) and high background (HB), respectively and used them to apply COL0RME and estimate the desired sample support. More details on the two datasets are available in the following Section 6.1. The results obtained using the three different regularizers are reported in Figure 3. In this example, we chose the regularization parameter  $ \lambda $ heuristically, while more details about the selection of the parameter are given in the Section 5.1.
$ \lambda $ heuristically, while more details about the selection of the parameter are given in the Section 5.1.

Figure 3. (a) Noisy simulated dataset with low background (LB) and stack size:  $ T=500 $ frames, (b) Noisy simulated high-background (HB) dataset, with
$ T=500 $ frames, (b) Noisy simulated high-background (HB) dataset, with  $ T=500 $ frames. From left to right: Superimposed diffraction limited image (temporal mean of the stack) with 4× zoom on ground truth support (blue), CEL0 reconstruction,
$ T=500 $ frames. From left to right: Superimposed diffraction limited image (temporal mean of the stack) with 4× zoom on ground truth support (blue), CEL0 reconstruction,  $ {\mathrm{\ell}}_1 $ reconstruction and total variation (TV) reconstruction.
$ {\mathrm{\ell}}_1 $ reconstruction and total variation (TV) reconstruction.
Despite its continuous and smooth reconstruction, we observe that the reconstruction obtained by the TV regularizer does not provide precise localization results. For example, the separation of the two filaments on the top-right corner is not visible and while the junction of the other two filaments on the bottom-left should appear further down, we clearly see that those filaments are erroneously glued together. Nonetheless, the choice of an appropriate regularizer tailored to favor fine structures as the ones observed in the GT image constitutes a challenging problem that should be addressed in future research.
The Jaccard indices (JIs) of both the results obtained when using the CEL0 and  $ {\mathrm{\ell}}_1 $ regularizer, that allow for more precise localization, have been computed. The JI is a quantity in the range
$ {\mathrm{\ell}}_1 $ regularizer, that allow for more precise localization, have been computed. The JI is a quantity in the range  $ \left[0,1\right] $ computed as the ratio between correct detections (CD) and the sum of correct detections, false positives (FP) and false negatives (FN), that is,
$ \left[0,1\right] $ computed as the ratio between correct detections (CD) and the sum of correct detections, false positives (FP) and false negatives (FN), that is,  $ \mathrm{JI}:= \mathrm{CD}/\left(\mathrm{CD}+\mathrm{FN}+\mathrm{FP}\right), $ up to a tolerance
$ \mathrm{JI}:= \mathrm{CD}/\left(\mathrm{CD}+\mathrm{FN}+\mathrm{FP}\right), $ up to a tolerance  $ \delta >0 $, measure in nm. A correct detection occurs when one pixel at most
$ \delta >0 $, measure in nm. A correct detection occurs when one pixel at most  $ \delta $ nm away from a ground truth pixel is added to the support. In order to match the pixels from the estimated support to the ones from the ground truth, we employ the standard Gale–Shapley algorithm(Reference Gale and Shapley29). Once the matching has been performed, we can simply count the number of ground truth pixels which have not been detected (false negatives) and also the number of pixels in the estimated support which have not been matched to any ground truth pixel (false positives).
$ \delta $ nm away from a ground truth pixel is added to the support. In order to match the pixels from the estimated support to the ones from the ground truth, we employ the standard Gale–Shapley algorithm(Reference Gale and Shapley29). Once the matching has been performed, we can simply count the number of ground truth pixels which have not been detected (false negatives) and also the number of pixels in the estimated support which have not been matched to any ground truth pixel (false positives).
Figure 4 reports the average JI computed from 20 different noise realizations, as well as, an error bar (vertical lines) that represent the standard deviation, for several stack sizes. According to the figure, a slightly better JI is obtained when the CEL0 regularizer is being used, while an increase in the number of frames, when both regularizers being used, leads to better JI, hence better localization. As the reader may notice, such quantitative assessment could look inconsistent with the visual results reported in Figure 3. By definition, the JI tends to assume higher values whenever more CD are found even in presence of more FP (as it happens for the CEL0 reconstruction), while it gets more penalized when FN happen, as they affect the computation “twice,” reducing the numerator and increasing the denominator.

Figure 4. Jaccard Index values with tolerance  $ \delta =40\;\mathrm{nm} $ for the low-background (LB) and high-background (HB) datasets, for different stack sizes and regularization penalty choices. The tolerance,
$ \delta =40\;\mathrm{nm} $ for the low-background (LB) and high-background (HB) datasets, for different stack sizes and regularization penalty choices. The tolerance,  $ \delta =40 $ nm, is set so that we allow the correct detections, that needed to be counted for the computation of the Jaccard Index, to be found not only in the same pixel but also to any of the 8-neighboring pixels.
$ \delta =40 $ nm, is set so that we allow the correct detections, that needed to be counted for the computation of the Jaccard Index, to be found not only in the same pixel but also to any of the 8-neighboring pixels.
3.1. Accurate noise variance estimation
Along with the estimations of the emitter’s temporal sparse covariance matrix, the estimation of the noise variance in the joint model (Reference Gustafsson7) allows for much more precise results even in challenging acquisition conditions. In Figure 5, we show the relative error between the computed noise variance  $ s $ and the constant variance of the electronic noise
$ s $ and the constant variance of the electronic noise  $ {\sigma}^2 $ used to produce simulated LB and HB data. The relative error is higher in the case of the HB dataset, something that is, expected, as in our noise variance estimation
$ {\sigma}^2 $ used to produce simulated LB and HB data. The relative error is higher in the case of the HB dataset, something that is, expected, as in our noise variance estimation  $ s $ there is a bias coming from the background (see Remark 1). In the case of the LB dataset, as the background is low, the bias is sufficiently small so that it is barely visible in the error graph. In our experiments, a Gaussian noise with a corresponding SNR of approximately 16 dB is being used, while the value of
$ s $ there is a bias coming from the background (see Remark 1). In the case of the LB dataset, as the background is low, the bias is sufficiently small so that it is barely visible in the error graph. In our experiments, a Gaussian noise with a corresponding SNR of approximately 16 dB is being used, while the value of  $ {\sigma}^2 $ is in average equal to
$ {\sigma}^2 $ is in average equal to  $ 7.11\times {10}^5 $ for the LB dataset and
$ 7.11\times {10}^5 $ for the LB dataset and  $ 7.13\times {10}^5 $ for the HB dataset. Note that, in general, the estimation of the noise variance
$ 7.13\times {10}^5 $ for the HB dataset. Note that, in general, the estimation of the noise variance  $ s $ obtained by COL0RME is very precise.
$ s $ obtained by COL0RME is very precise.

Figure 5. The relative error in noise variance estimation, defined as: Error =  $ \frac{\mid s-{\sigma}^2\mid }{\mid {\sigma}^2\mid } $, where
$ \frac{\mid s-{\sigma}^2\mid }{\mid {\sigma}^2\mid } $, where  $ {\sigma}^2 $ is the constant variance of the electronic noise. The error is computed for 20 different noise realizations, presenting in the graph the mean and the standard deviation (error bars).
$ {\sigma}^2 $ is the constant variance of the electronic noise. The error is computed for 20 different noise realizations, presenting in the graph the mean and the standard deviation (error bars).
4. COL0RME, Step II: Intensity Estimation
From the previous step, we obtain a sparse estimation of  $ {\mathbf{r}}_{\mathbf{x}}\hskip0.2em \in {\unicode{x211D}}^{L^2} $. Its support, that is, the location of nonzero variances, can thus be deduced. This is denoted in the following by
$ {\mathbf{r}}_{\mathbf{x}}\hskip0.2em \in {\unicode{x211D}}^{L^2} $. Its support, that is, the location of nonzero variances, can thus be deduced. This is denoted in the following by  $ \Omega := \left\{i:{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i\ne 0\right\}\subset \left\{1,\dots, {L}^2\right\} $. Note that this set corresponds indeed to the support of the desired
$ \Omega := \left\{i:{\left({\mathbf{r}}_{\mathbf{x}}\right)}_i\ne 0\right\}\subset \left\{1,\dots, {L}^2\right\} $. Note that this set corresponds indeed to the support of the desired  $ \mathbf{x} $, hence in the following we will use the same notation to denote both sets.
$ \mathbf{x} $, hence in the following we will use the same notation to denote both sets.
We are now interested in enriching COL0RME with an additional step where intensity information of the signal  $ \mathbf{x} $ can be retrieved in correspondence with the estimated support
$ \mathbf{x} $ can be retrieved in correspondence with the estimated support  $ \Omega $. To do so, we thus propose an intensity estimation procedure for
$ \Omega $. To do so, we thus propose an intensity estimation procedure for  $ \mathbf{x} $ restricted only to the pixels of interest. Under this modeling assumption, it is thus reasonable to consider a regularization term favoring smooth intensities on
$ \mathbf{x} $ restricted only to the pixels of interest. Under this modeling assumption, it is thus reasonable to consider a regularization term favoring smooth intensities on  $ \Omega $, in agreement to the intensity typically found in real images.
$ \Omega $, in agreement to the intensity typically found in real images.
In order to take into account the modeling of blurry and out-of-focus fluorescent molecules, we further include in our model (Reference Rust, Bates and Zhuang4) a regularization term for smooth background estimation. We can thus consider the following joint minimization problem:
 $$ \underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}_{+}^{\mid \Omega \mid },\mathbf{b}\hskip0.2em \in {\unicode{x211D}}_{+}^{M^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel {\boldsymbol{\Psi}}_{\boldsymbol{\Omega}}\mathbf{x}-\left(\overline{\mathbf{y}}-\mathbf{b}\right){\parallel}_2^2+\frac{\mu }{2}\parallel {\nabla}_{\Omega}\mathbf{x}{\parallel}_2^2+\frac{\beta }{2}\parallel \nabla \mathbf{b}{\parallel}_2^2, $$
$$ \underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}_{+}^{\mid \Omega \mid },\mathbf{b}\hskip0.2em \in {\unicode{x211D}}_{+}^{M^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel {\boldsymbol{\Psi}}_{\boldsymbol{\Omega}}\mathbf{x}-\left(\overline{\mathbf{y}}-\mathbf{b}\right){\parallel}_2^2+\frac{\mu }{2}\parallel {\nabla}_{\Omega}\mathbf{x}{\parallel}_2^2+\frac{\beta }{2}\parallel \nabla \mathbf{b}{\parallel}_2^2, $$where the data term models the presence of Gaussian noise,  $ \mu, \beta >0 $ are regularization parameters and the operator
$ \mu, \beta >0 $ are regularization parameters and the operator  $ {\boldsymbol{\Psi}}_{\boldsymbol{\Omega}}\hskip0.2em \in {\unicode{x211D}}^{M^2\times \mid \Omega \mid } $ is a matrix whose
$ {\boldsymbol{\Psi}}_{\boldsymbol{\Omega}}\hskip0.2em \in {\unicode{x211D}}^{M^2\times \mid \Omega \mid } $ is a matrix whose  $ i $th column is extracted from
$ i $th column is extracted from  $ \boldsymbol{\Psi} $ for all indices
$ \boldsymbol{\Psi} $ for all indices  $ i\hskip0.2em \in \Omega $. Finally, the regularization term on
$ i\hskip0.2em \in \Omega $. Finally, the regularization term on  $ \mathbf{x} $ is the squared norm of the discrete gradient restricted to
$ \mathbf{x} $ is the squared norm of the discrete gradient restricted to  $ \Omega $, that is,
$ \Omega $, that is,
 $$ \parallel {\nabla}_{\Omega}\mathbf{x}{\parallel}_2^2:= \sum \limits_{i\hskip0.2em \in \Omega}\sum \limits_{j\hskip0.2em \in \mathcal{N}(i)\cap \Omega}{\left({x}_i-{x}_j\right)}^2, $$
$$ \parallel {\nabla}_{\Omega}\mathbf{x}{\parallel}_2^2:= \sum \limits_{i\hskip0.2em \in \Omega}\sum \limits_{j\hskip0.2em \in \mathcal{N}(i)\cap \Omega}{\left({x}_i-{x}_j\right)}^2, $$where  $ \mathcal{N}(i) $ denotes the 8-pixel neighborhood of
$ \mathcal{N}(i) $ denotes the 8-pixel neighborhood of  $ i\hskip0.2em \in \Omega $. Note that, according to this definition,
$ i\hskip0.2em \in \Omega $. Note that, according to this definition,  $ {\nabla}_{\Omega}\mathbf{x} $ denotes a (redundant) isotropic discretization of the gradient of
$ {\nabla}_{\Omega}\mathbf{x} $ denotes a (redundant) isotropic discretization of the gradient of  $ \mathbf{x} $ evaluated for each pixel in the support
$ \mathbf{x} $ evaluated for each pixel in the support  $ \Omega $. Note that this definition coincides with the standard one for
$ \Omega $. Note that this definition coincides with the standard one for  $ \nabla \mathbf{x} $ restricted to points in the support
$ \nabla \mathbf{x} $ restricted to points in the support  $ \Omega $.
$ \Omega $.
The non-negativity constraints on  $ \mathbf{x} $ and
$ \mathbf{x} $ and  $ \mathbf{b} $ as well as the one restricting the estimation of
$ \mathbf{b} $ as well as the one restricting the estimation of  $ \mathbf{x} $ on
$ \mathbf{x} $ on  $ \Omega $ can be relaxed using suitable smooth penalty terms, so that, finally, the following optimization problem can be addressed:
$ \Omega $ can be relaxed using suitable smooth penalty terms, so that, finally, the following optimization problem can be addressed:
 $$ \underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2},\mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}-\left(\overline{\mathbf{y}}-\mathbf{b}\right){\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}{\parallel}_2^2+\frac{\beta }{2}\parallel \nabla \mathbf{b}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\mathbf{x}}_i\right)\right]}^2+\sum \limits_{i=1}^{M^2}\;{\left[\phi \left({\mathbf{b}}_i\right)\right]}^2\right), $$
$$ \underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2},\mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}-\left(\overline{\mathbf{y}}-\mathbf{b}\right){\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}{\parallel}_2^2+\frac{\beta }{2}\parallel \nabla \mathbf{b}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\mathbf{x}}_i\right)\right]}^2+\sum \limits_{i=1}^{M^2}\;{\left[\phi \left({\mathbf{b}}_i\right)\right]}^2\right), $$where the parameter  $ \alpha \gg 1 $ can be chosen arbitrarily high to enforce the constraints,
$ \alpha \gg 1 $ can be chosen arbitrarily high to enforce the constraints,  $ {\mathbf{I}}_{\boldsymbol{\Omega}} $ is a diagonal matrix acting as characteristic function of
$ {\mathbf{I}}_{\boldsymbol{\Omega}} $ is a diagonal matrix acting as characteristic function of  $ \Omega $, that is, defined as:
$ \Omega $, that is, defined as:

and  $ \phi :\unicode{x211D}\to \unicode{x211D} $ is used to penalize negative entries, being defined as:
$ \phi :\unicode{x211D}\to \unicode{x211D} $ is used to penalize negative entries, being defined as:
 $$ \phi (z):= \left\{\begin{array}{cc}0& \mathrm{if}\;z\ge 0,\\ {}z& \mathrm{if}\;z<0,\end{array}\right.\hskip2em \forall z\hskip0.2em \in \unicode{x211D}. $$
$$ \phi (z):= \left\{\begin{array}{cc}0& \mathrm{if}\;z\ge 0,\\ {}z& \mathrm{if}\;z<0,\end{array}\right.\hskip2em \forall z\hskip0.2em \in \unicode{x211D}. $$We anticipate here that considering the unconstrained problem (Reference Gustafsson, Culley, Ashdown, Owen, Pereira and Henriques13) instead of the original, constrained, one (Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12), will come in handy for the design of an automatic parameter selection strategy, as we further detail in Section 5.2.
To solve the joint-minimization problem (Reference Gustafsson, Culley, Ashdown, Owen, Pereira and Henriques13), we use the Alternate Minimization algorithm, see Algorithm 2. In the following subsections, we provide more details on the solution of the two minimization subproblems.
Algorithm 2 COL0RME, Step II: Intensity Estimation.
Require:  $ \overline{\mathbf{y}}\hskip0.2em \in {\unicode{x211D}}^{M^2},{\mathbf{x}}^0\hskip0.2em \in {\unicode{x211D}}^{L^2},{\mathbf{b}}^0\hskip0.2em \in {\unicode{x211D}}^{M^2},\mu, \beta >0 $,
$ \overline{\mathbf{y}}\hskip0.2em \in {\unicode{x211D}}^{M^2},{\mathbf{x}}^0\hskip0.2em \in {\unicode{x211D}}^{L^2},{\mathbf{b}}^0\hskip0.2em \in {\unicode{x211D}}^{M^2},\mu, \beta >0 $,  $ \alpha \gg 1 $.
$ \alpha \gg 1 $.
repeat
 $ {\mathbf{x}}^{k+1}=\underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}-\left(\overline{\mathbf{y}}-{\mathbf{b}}^{\mathbf{k}}\right){\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+{\sum}_{i=1}^{L^2}\;{\left[\phi \left({\mathbf{x}}_i\right)\right]}^2\right) $
$ {\mathbf{x}}^{k+1}=\underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}-\left(\overline{\mathbf{y}}-{\mathbf{b}}^{\mathbf{k}}\right){\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+{\sum}_{i=1}^{L^2}\;{\left[\phi \left({\mathbf{x}}_i\right)\right]}^2\right) $
 $ {\mathbf{b}}^{k+1}=\underset{\mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel \mathbf{b}-\left(\overline{\mathbf{y}}-\boldsymbol{\Psi} {\mathbf{x}}^{k+1}\right){\parallel}_2^2+\frac{\beta }{2}\parallel \nabla \mathbf{b}{\parallel}_2^2+\frac{\alpha }{2}{\sum}_{i=1}^{M^2}\;{\left[\phi \left({\mathbf{b}}_i\right)\right]}^2 $
$ {\mathbf{b}}^{k+1}=\underset{\mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel \mathbf{b}-\left(\overline{\mathbf{y}}-\boldsymbol{\Psi} {\mathbf{x}}^{k+1}\right){\parallel}_2^2+\frac{\beta }{2}\parallel \nabla \mathbf{b}{\parallel}_2^2+\frac{\alpha }{2}{\sum}_{i=1}^{M^2}\;{\left[\phi \left({\mathbf{b}}_i\right)\right]}^2 $
until convergence.
return  $ \mathbf{x},\mathbf{b} $.
$ \mathbf{x},\mathbf{b} $.
4.1. First subproblem: update of x
In order to find at each  $ k\ge 1 $ the optimal solution
$ k\ge 1 $ the optimal solution  $ {\mathbf{x}}^{k+1}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ for the first subproblem, we need to solve a minimization problem of the form:
$ {\mathbf{x}}^{k+1}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ for the first subproblem, we need to solve a minimization problem of the form:
 $$ {\mathbf{x}}^{k+1}=\underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}}{\arg \hskip0.1em \min }g\left(\mathbf{x};{\mathbf{b}}^k\right)+h\left(\mathbf{x}\right), $$
$$ {\mathbf{x}}^{k+1}=\underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}}{\arg \hskip0.1em \min }g\left(\mathbf{x};{\mathbf{b}}^k\right)+h\left(\mathbf{x}\right), $$where, for  $ {\mathbf{b}}^k\hskip0.2em \in {\unicode{x211D}}^{M^2} $ being fixed at each iteration
$ {\mathbf{b}}^k\hskip0.2em \in {\unicode{x211D}}^{M^2} $ being fixed at each iteration  $ k\ge 1 $,
$ k\ge 1 $,  $ g\left(\cdot; {\mathbf{b}}^k\right):{\unicode{x211D}}^{M^2}\to {\unicode{x211D}}_{+} $ is a proper and convex function with Lipschitz gradient, defined as:
$ g\left(\cdot; {\mathbf{b}}^k\right):{\unicode{x211D}}^{M^2}\to {\unicode{x211D}}_{+} $ is a proper and convex function with Lipschitz gradient, defined as:
 $$ g\left(\mathbf{x};{\mathbf{b}}^k\right):= \frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}-\left(\overline{\mathbf{y}}-{\mathbf{b}}^k\right){\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}{\parallel}_2^2, $$
$$ g\left(\mathbf{x};{\mathbf{b}}^k\right):= \frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}-\left(\overline{\mathbf{y}}-{\mathbf{b}}^k\right){\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}{\parallel}_2^2, $$and where the function  $ h:{\unicode{x211D}}^{L^2}\to \unicode{x211D} $ encodes the penalty terms:
$ h:{\unicode{x211D}}^{L^2}\to \unicode{x211D} $ encodes the penalty terms:
 $$ h\left(\mathbf{x}\right)=\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\mathbf{x}}_i\right)\right]}^2\right). $$
$$ h\left(\mathbf{x}\right)=\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\mathbf{x}}_i\right)\right]}^2\right). $$Solution of (Reference Yahiatene, Hennig, Müller and Huser15) can be obtained iteratively, using, for instance, the proximal gradient descent algorithm, whose iteration can be defined as follows:
 $$ {\mathbf{x}}^{n+1}={\mathbf{prox}}_{h,\tau}\left({\mathbf{x}}^n-\tau \nabla g\left({\mathbf{x}}^n\right)\right),\hskip1em n=1,2,\dots, $$
$$ {\mathbf{x}}^{n+1}={\mathbf{prox}}_{h,\tau}\left({\mathbf{x}}^n-\tau \nabla g\left({\mathbf{x}}^n\right)\right),\hskip1em n=1,2,\dots, $$where  $ \nabla g\left(\cdot \right) $ denotes the gradient of
$ \nabla g\left(\cdot \right) $ denotes the gradient of  $ g $,
$ g $,  $ \tau \hskip0.2em \in \left(0,\frac{1}{L_g}\right] $ is the algorithmic step-size chosen inside a range depending on the Lipschitz constant of
$ \tau \hskip0.2em \in \left(0,\frac{1}{L_g}\right] $ is the algorithmic step-size chosen inside a range depending on the Lipschitz constant of  $ \nabla g $, here denoted by
$ \nabla g $, here denoted by  $ {L}_g $, to guarantee convergence. The proximal update in (Reference Solomon, Eldar, Mutzafi and Segev18) can be computed explicitly using the computations reported in Appendix A. One can show in fact that, for each
$ {L}_g $, to guarantee convergence. The proximal update in (Reference Solomon, Eldar, Mutzafi and Segev18) can be computed explicitly using the computations reported in Appendix A. One can show in fact that, for each  $ \mathbf{w}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ there holds element-wise:
$ \mathbf{w}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ there holds element-wise:
 $$ {\left({\mathrm{prox}}_{h,\tau}\left(\mathbf{w}\right)\right)}_i={\mathrm{prox}}_{h,\tau}\left({\mathbf{w}}_i\right)=\left\{\begin{array}{cc}\frac{{\mathbf{w}}_i}{1+\alpha \tau {\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)}& \hskip-0.5em \mathrm{if}\hskip0.5em {\mathbf{w}}_i\ge 0,\\ {}\frac{{\mathbf{w}}_i}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+1\right)}& \mathrm{if}\hskip0.5em {\mathbf{w}}_i<0.\end{array}\right. $$
$$ {\left({\mathrm{prox}}_{h,\tau}\left(\mathbf{w}\right)\right)}_i={\mathrm{prox}}_{h,\tau}\left({\mathbf{w}}_i\right)=\left\{\begin{array}{cc}\frac{{\mathbf{w}}_i}{1+\alpha \tau {\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)}& \hskip-0.5em \mathrm{if}\hskip0.5em {\mathbf{w}}_i\ge 0,\\ {}\frac{{\mathbf{w}}_i}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+1\right)}& \mathrm{if}\hskip0.5em {\mathbf{w}}_i<0.\end{array}\right. $$ Remark 2. As the reader may have noted, we consider the proximal gradient descent algorithm (Reference Solomon, Eldar, Mutzafi and Segev18) for solving (Reference Yahiatene, Hennig, Müller and Huser15), even though both functions  $ g $ and
$ g $ and  $ h $ in (Reference Deng, Sun, Lin, Ma and Shaevitz16) and (Reference Solomon, Mutzafi, Segev and Eldar17) respectively, are smooth and convex, hence, in principle, (accelerated) gradient descent algorithms could be used. Note, however, that the presence of the large penalty parameter
$ h $ in (Reference Deng, Sun, Lin, Ma and Shaevitz16) and (Reference Solomon, Mutzafi, Segev and Eldar17) respectively, are smooth and convex, hence, in principle, (accelerated) gradient descent algorithms could be used. Note, however, that the presence of the large penalty parameter  $ \alpha \gg 1 $ would significantly slow down convergence speed in such case as the step size
$ \alpha \gg 1 $ would significantly slow down convergence speed in such case as the step size  $ \tau $ in this case would be constrained to the smaller range
$ \tau $ in this case would be constrained to the smaller range  $ \left(0,\frac{1}{L_g+\alpha}\right] $. By considering the penalty contributions in terms of their proximal operators, this limitation does not affect the range of
$ \left(0,\frac{1}{L_g+\alpha}\right] $. By considering the penalty contributions in terms of their proximal operators, this limitation does not affect the range of  $ \tau $ and convergence is still guaranteed( Reference Combettes and Wajs30) in a computationally fast way through the update (Reference Dardikman-Yoffe and Eldar19).
$ \tau $ and convergence is still guaranteed( Reference Combettes and Wajs30) in a computationally fast way through the update (Reference Dardikman-Yoffe and Eldar19).
4.2. Second subproblem: update of b
As far as the estimation of the background is concerned, the minimization problem we aim to solve at each  $ k\ge 1 $ takes the form:
$ k\ge 1 $ takes the form:
 $$ {\mathbf{b}}^{k+1}=\underset{\mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2}}{\arg \hskip0.1em \min }r\left(\mathbf{b};{\mathbf{x}}^{k+1}\right)+q\left(\mathbf{b}\right), $$
$$ {\mathbf{b}}^{k+1}=\underset{\mathbf{b}\hskip0.2em \in {\unicode{x211D}}^{M^2}}{\arg \hskip0.1em \min }r\left(\mathbf{b};{\mathbf{x}}^{k+1}\right)+q\left(\mathbf{b}\right), $$where
 $$ r\left(\mathbf{b};{\mathbf{x}}^{k+1}\right):= \frac{1}{2}\parallel \mathbf{b}-\left(\overline{\mathbf{y}}-\boldsymbol{\Psi} {\mathbf{x}}^{k+1}\right){\parallel}_2^2+\frac{\beta }{2}\parallel \nabla \mathbf{b}{\parallel}_2^2,\hskip2em q\left(\mathbf{b}\right):= \frac{\alpha }{2}\sum \limits_{i=1}^{M^2}\;{\left[\phi \left({\mathbf{b}}_i\right)\right]}^2. $$
$$ r\left(\mathbf{b};{\mathbf{x}}^{k+1}\right):= \frac{1}{2}\parallel \mathbf{b}-\left(\overline{\mathbf{y}}-\boldsymbol{\Psi} {\mathbf{x}}^{k+1}\right){\parallel}_2^2+\frac{\beta }{2}\parallel \nabla \mathbf{b}{\parallel}_2^2,\hskip2em q\left(\mathbf{b}\right):= \frac{\alpha }{2}\sum \limits_{i=1}^{M^2}\;{\left[\phi \left({\mathbf{b}}_i\right)\right]}^2. $$Note that  $ r\left(\cdot; {\mathbf{x}}^{k+1}\right):{\unicode{x211D}}^{M^2}\to {\unicode{x211D}}_{+} $ is a convex function with
$ r\left(\cdot; {\mathbf{x}}^{k+1}\right):{\unicode{x211D}}^{M^2}\to {\unicode{x211D}}_{+} $ is a convex function with  $ {L}_r $-Lipschitz gradient and
$ {L}_r $-Lipschitz gradient and  $ q:{\unicode{x211D}}^{M^2}\to {\unicode{x211D}}_{+} $ encodes (large, depending on
$ q:{\unicode{x211D}}^{M^2}\to {\unicode{x211D}}_{+} $ encodes (large, depending on  $ \alpha \gg 1 $) penalty contributions. Recalling Remark 2, we thus use again the proximal gradient descent algorithm for solving (Reference Goulart, Blanc-Féraud, Debreuve and Schaub20). The desired solution
$ \alpha \gg 1 $) penalty contributions. Recalling Remark 2, we thus use again the proximal gradient descent algorithm for solving (Reference Goulart, Blanc-Féraud, Debreuve and Schaub20). The desired solution  $ \hat{\mathbf{b}} $ at each
$ \hat{\mathbf{b}} $ at each  $ k\ge 1 $ can thus be found by iterating:
$ k\ge 1 $ can thus be found by iterating:
 $$ {\mathbf{b}}^{n+1}={\mathbf{prox}}_{q,\delta}\left({\mathbf{b}}^n-\delta \nabla r\left({\mathbf{b}}^n\right)\right),\hskip1em n=1,2,\dots, $$
$$ {\mathbf{b}}^{n+1}={\mathbf{prox}}_{q,\delta}\left({\mathbf{b}}^n-\delta \nabla r\left({\mathbf{b}}^n\right)\right),\hskip1em n=1,2,\dots, $$for  $ \delta \hskip0.2em \in \left(0,\frac{1}{L_r}\right] $. The proximal operator
$ \delta \hskip0.2em \in \left(0,\frac{1}{L_r}\right] $. The proximal operator  $ {\mathbf{prox}}_{q,\delta}\left(\cdot \right) $, has an explicit expression and it is defined element-wise for
$ {\mathbf{prox}}_{q,\delta}\left(\cdot \right) $, has an explicit expression and it is defined element-wise for  $ i=1,\dots, {M}^2 $ as:
$ i=1,\dots, {M}^2 $ as:
 $$ {\left({\mathbf{prox}}_{q,\delta}\left(\mathbf{d}\right)\right)}_i={\mathrm{prox}}_{q,\delta}\left({\mathbf{d}}_i\right)=\left\{\begin{array}{cc}\hskip-2.5em {\mathbf{d}}_i& \mathrm{if}\;{\mathbf{d}}_i\ge 0,\\ {}\frac{{\mathbf{d}}_i}{1+\alpha \delta}& \hskip0.18em \mathrm{if}\;{\mathbf{d}}_i<0.\end{array}\right. $$
$$ {\left({\mathbf{prox}}_{q,\delta}\left(\mathbf{d}\right)\right)}_i={\mathrm{prox}}_{q,\delta}\left({\mathbf{d}}_i\right)=\left\{\begin{array}{cc}\hskip-2.5em {\mathbf{d}}_i& \mathrm{if}\;{\mathbf{d}}_i\ge 0,\\ {}\frac{{\mathbf{d}}_i}{1+\alpha \delta}& \hskip0.18em \mathrm{if}\;{\mathbf{d}}_i<0.\end{array}\right. $$4.3. Intensity and background estimation results
Intensity estimation results can be found in Figure 6 where (Reference Gustafsson, Culley, Ashdown, Owen, Pereira and Henriques13) is used for intensity/background estimation on the supports  $ {\Omega}_{\mathcal{R}} $ estimated from the first step of COL0RME using
$ {\Omega}_{\mathcal{R}} $ estimated from the first step of COL0RME using  $ \mathcal{R}= $CEL0,
$ \mathcal{R}= $CEL0,  $ \mathcal{R}={\mathrm{\ell}}_1 $, and
$ \mathcal{R}={\mathrm{\ell}}_1 $, and  $ \mathcal{R}= $TV. We are referring to them as COL0RME-CEL0, COL0RME-
$ \mathcal{R}= $TV. We are referring to them as COL0RME-CEL0, COL0RME- $ {\mathrm{\ell}}_1 $, and COL0RME-TV, respectively. The colormap ranges are different for the coarse-grid and fine-grid representations, as explained in Section 6.1 The result on
$ {\mathrm{\ell}}_1 $, and COL0RME-TV, respectively. The colormap ranges are different for the coarse-grid and fine-grid representations, as explained in Section 6.1 The result on  $ {\Omega}_{TV} $, even after the second step does not allow for the observation of a few significant details (e.g., the separation of the two filament on the bottom left corner) and that is, why it will not further discussed.
$ {\Omega}_{TV} $, even after the second step does not allow for the observation of a few significant details (e.g., the separation of the two filament on the bottom left corner) and that is, why it will not further discussed.

Figure 6. On top: Diffraction limited image  $ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_{\mathbf{t}} $, with T = 500 (4× zoom) for the low-background (LB) dataset and for the high-background (HB) dataset, ground truth (GT) intensity image. (a) Reconstructions for the noisy simulated dataset with LB. (b) Reconstruction for the noisy simulated dataset with HB. From left to right: intensity estimation result on estimated support using CEL0 regularization,
$ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_{\mathbf{t}} $, with T = 500 (4× zoom) for the low-background (LB) dataset and for the high-background (HB) dataset, ground truth (GT) intensity image. (a) Reconstructions for the noisy simulated dataset with LB. (b) Reconstruction for the noisy simulated dataset with HB. From left to right: intensity estimation result on estimated support using CEL0 regularization,  $ {\mathrm{\ell}}_1 $ regularization and TV regularization. For all COL0RME intensity estimations, the same colorbar, presented at the bottom of the figure, has been used.
$ {\mathrm{\ell}}_1 $ regularization and TV regularization. For all COL0RME intensity estimations, the same colorbar, presented at the bottom of the figure, has been used.
A quantitative assessment for the other two regularization penalty choices,  $ {\Omega}_{\mathrm{CEL}0} $ and
$ {\Omega}_{\mathrm{CEL}0} $ and  $ {\Omega}_{{\mathrm{\ell}}_1} $, is available in Figure 7. More precisely, we compute the peak-signal-to-noise-ratio (PSNR), given the following formula:
$ {\Omega}_{{\mathrm{\ell}}_1} $, is available in Figure 7. More precisely, we compute the peak-signal-to-noise-ratio (PSNR), given the following formula:
 $$ {\mathrm{PSNR}}_{\mathrm{dB}}=10{\log}_{10}\left(\frac{{\operatorname{MAX}}_{\mathbf{R}}^2}{\mathrm{MSE}}\right),\hskip2em \mathrm{MSE}=\frac{1}{L^2}\sum \limits_{i=1}^{L^2}{\left({\mathbf{R}}_i-{\mathbf{K}}_i\right)}^2, $$
$$ {\mathrm{PSNR}}_{\mathrm{dB}}=10{\log}_{10}\left(\frac{{\operatorname{MAX}}_{\mathbf{R}}^2}{\mathrm{MSE}}\right),\hskip2em \mathrm{MSE}=\frac{1}{L^2}\sum \limits_{i=1}^{L^2}{\left({\mathbf{R}}_i-{\mathbf{K}}_i\right)}^2, $$where  $ \mathbf{R}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ is the reference image,
$ \mathbf{R}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ is the reference image,  $ \mathbf{K}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ the image we want to evaluate using the PSNR metric and
$ \mathbf{K}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ the image we want to evaluate using the PSNR metric and  $ {\operatorname{MAX}}_{\mathbf{R}} $ the maximum value of the image
$ {\operatorname{MAX}}_{\mathbf{R}} $ the maximum value of the image  $ \mathbf{R} $. In our case, the reference image is the ground truth intensity image:
$ \mathbf{R} $. In our case, the reference image is the ground truth intensity image:  $ {\mathbf{x}}^{GT}\hskip0.2em \in {\unicode{x211D}}^{L^2} $. The higher the PSNR, the better the quality of the reconstructed image.
$ {\mathbf{x}}^{GT}\hskip0.2em \in {\unicode{x211D}}^{L^2} $. The higher the PSNR, the better the quality of the reconstructed image.

Figure 7. COL0RME peak-signal-to-noise-ratio (PSNR) values for two different datasets (low-background and high-background datasets), stack sizes and regularization penalty choices. The mean and the standard deviation of 20 different noise realizations are presented.
According to Figures 6 and 7, when only a few frames are considered (e.g.,  $ T=100 $ frames, high temporal resolution), the method performs better using the CEL0 penalty for the support estimation. However, when longer temporal sequences are available (e.g.,
$ T=100 $ frames, high temporal resolution), the method performs better using the CEL0 penalty for the support estimation. However, when longer temporal sequences are available (e.g.,  $ T=500 $ or
$ T=500 $ or  $ T=700 $ frames) the method performs better using the
$ T=700 $ frames) the method performs better using the  $ {\mathrm{\ell}}_1 $-norm instead. In addition to this, for both penalizations, PSNR improves as the number of temporal frames increases.
$ {\mathrm{\ell}}_1 $-norm instead. In addition to this, for both penalizations, PSNR improves as the number of temporal frames increases.
Background estimation results are available in Figure 8 where (Reference Gustafsson, Culley, Ashdown, Owen, Pereira and Henriques13) is used for intensity/background estimation on the supports  $ {\Omega}_{\mathcal{R}} $, with
$ {\Omega}_{\mathcal{R}} $, with  $ \mathcal{R}= $ CEL0 and
$ \mathcal{R}= $ CEL0 and  $ \mathcal{R}={\mathrm{\ell}}_1 $, that have been already estimated in the first step. In the figure, there is also the constant background generated by the SOFI Simulation Tool(Reference Girsault, Lukes and Sharipov31), the software we used to generate our simulated data (more details in Section 6.1). Although the results look different due to the considered space-variant regularisation on
$ \mathcal{R}={\mathrm{\ell}}_1 $, that have been already estimated in the first step. In the figure, there is also the constant background generated by the SOFI Simulation Tool(Reference Girsault, Lukes and Sharipov31), the software we used to generate our simulated data (more details in Section 6.1). Although the results look different due to the considered space-variant regularisation on  $ \mathbf{b} $, the variations are very little. The estimated background is smooth, as expected, while higher values are estimated near the simulated filaments and values closer to the true background are found away from them.
$ \mathbf{b} $, the variations are very little. The estimated background is smooth, as expected, while higher values are estimated near the simulated filaments and values closer to the true background are found away from them.

Figure 8. (a) Low-background (LB) dataset: Diffraction limited image  $ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_{\mathbf{t}} $ with T = 500 (4× zoom), background estimation result on estimated support using CEL0 and
$ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_{\mathbf{t}} $ with T = 500 (4× zoom), background estimation result on estimated support using CEL0 and  $ {\mathrm{\ell}}_1 $ regularization, ground truth (GT) background image. (b) High-background (HB) dataset: Diffraction limited image
$ {\mathrm{\ell}}_1 $ regularization, ground truth (GT) background image. (b) High-background (HB) dataset: Diffraction limited image  $ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_{\mathbf{t}} $ with T = 500 (4× zoom), Background estimation result on estimated support using CEL0 and
$ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_{\mathbf{t}} $ with T = 500 (4× zoom), Background estimation result on estimated support using CEL0 and  $ {\mathrm{\ell}}_1 $ regularization, GT background image. Please note the different scales between the diffraction limited and background images for a better visualization of the results.
$ {\mathrm{\ell}}_1 $ regularization, GT background image. Please note the different scales between the diffraction limited and background images for a better visualization of the results.
5. Automatic Selection of Regularization Parameters
We describe in this section two parameter selection strategies addressing the problem of estimating the regularization parameters  $ \lambda $ and
$ \lambda $ and  $ \mu $ appearing in the COL0RME support estimation problem (Reference Gustafsson7) and intensity estimation one (Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12), respectively. The other two regularization parameters
$ \mu $ appearing in the COL0RME support estimation problem (Reference Gustafsson7) and intensity estimation one (Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12), respectively. The other two regularization parameters  $ \beta $ and
$ \beta $ and  $ \alpha $ do not need fine tuning. They are both chosen arbitrary high, so as with large enough
$ \alpha $ do not need fine tuning. They are both chosen arbitrary high, so as with large enough  $ \beta $ to allow for a very smooth background and with very high
$ \beta $ to allow for a very smooth background and with very high  $ \alpha $ to respect the required constraints (positivity for both intensity and background and restriction to the predefined support only for the intensity estimation).
$ \alpha $ to respect the required constraints (positivity for both intensity and background and restriction to the predefined support only for the intensity estimation).
5.1. Estimation of support regularization parameter λ
The selection of the regularization parameter value  $ \lambda $ in (Reference Gustafsson7) is critical, as it determines the sparsity level of the support of the emitters. For its estimation, we start by computing a reference value
$ \lambda $ in (Reference Gustafsson7) is critical, as it determines the sparsity level of the support of the emitters. For its estimation, we start by computing a reference value  $ {\lambda}_{max} $, defined as the smallest regularization parameter for which the identically zero solution is found. It is indeed possible to compute such a
$ {\lambda}_{max} $, defined as the smallest regularization parameter for which the identically zero solution is found. It is indeed possible to compute such a  $ {\lambda}_{max} $ for both regularization terms CEL0 and
$ {\lambda}_{max} $ for both regularization terms CEL0 and  $ {\mathrm{\ell}}_1 $ (see Refs. (Reference Soubies32) and (Reference Koulouri, Heins and Burger33)). Once such values are known, we thus need to find a fraction
$ {\mathrm{\ell}}_1 $ (see Refs. (Reference Soubies32) and (Reference Koulouri, Heins and Burger33)). Once such values are known, we thus need to find a fraction  $ \gamma \hskip0.2em \in \left(0,1\right) $ of
$ \gamma \hskip0.2em \in \left(0,1\right) $ of  $ {\lambda}_{max} $ corresponding to the choice
$ {\lambda}_{max} $ corresponding to the choice  $ \lambda ={\gamma \lambda}_{max} $. For the CEL0 regularizer the expression for
$ \lambda ={\gamma \lambda}_{max} $. For the CEL0 regularizer the expression for  $ {\lambda}_{max} $ (see Proposition 10.9 in Ref. (Reference Soubies32)) is:
$ {\lambda}_{max} $ (see Proposition 10.9 in Ref. (Reference Soubies32)) is:
 $$ {\lambda}_{max}^{CEL0}:= \underset{1\le i\le {L}^2}{\mathit{\max}}\frac{{\left\langle {\mathbf{a}}_i,{\mathbf{r}}_{\mathbf{y}}\right\rangle}^2}{2\parallel {\mathbf{a}}_i{\parallel}^2}, $$
$$ {\lambda}_{max}^{CEL0}:= \underset{1\le i\le {L}^2}{\mathit{\max}}\frac{{\left\langle {\mathbf{a}}_i,{\mathbf{r}}_{\mathbf{y}}\right\rangle}^2}{2\parallel {\mathbf{a}}_i{\parallel}^2}, $$where  $ {\mathbf{a}}_i={\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right)}_i $ denotes the
$ {\mathbf{a}}_i={\left(\boldsymbol{\Psi} \odot \boldsymbol{\Psi} \right)}_i $ denotes the  $ i $th column of the operator
$ i $th column of the operator  $ \mathbf{A}:= \boldsymbol{\Psi} \odot \boldsymbol{\Psi} $. Regarding the
$ \mathbf{A}:= \boldsymbol{\Psi} \odot \boldsymbol{\Psi} $. Regarding the  $ {\mathrm{\ell}}_1 $-norm regularization penalty,
$ {\mathrm{\ell}}_1 $-norm regularization penalty,  $ {\lambda}_{max} $ is given as follows:
$ {\lambda}_{max} $ is given as follows:
 $$ {\lambda}_{max}^{{\mathrm{\ell}}_1}:= \parallel {\mathbf{A}}^{\intercal }{\mathbf{r}}_{\mathbf{y}}{\parallel}_{\infty }=\underset{1\le i\le {L}^2}{\max}\left\langle {\mathbf{a}}_i,{\mathbf{r}}_{\mathbf{y}}\right\rangle . $$
$$ {\lambda}_{max}^{{\mathrm{\ell}}_1}:= \parallel {\mathbf{A}}^{\intercal }{\mathbf{r}}_{\mathbf{y}}{\parallel}_{\infty }=\underset{1\le i\le {L}^2}{\max}\left\langle {\mathbf{a}}_i,{\mathbf{r}}_{\mathbf{y}}\right\rangle . $$ As far as  $ {\mathrm{\ell}}_1 $ is used as regularization term in (Reference Gustafsson7), we report in Figure 9 a graph showing how the PSNR value of the final estimated intensity image (i.e., after the application of the second step of COL0RME) varies for the two datasets considered depending on
$ {\mathrm{\ell}}_1 $ is used as regularization term in (Reference Gustafsson7), we report in Figure 9 a graph showing how the PSNR value of the final estimated intensity image (i.e., after the application of the second step of COL0RME) varies for the two datasets considered depending on  $ \lambda $. It can be observed that for a large range of values
$ \lambda $. It can be observed that for a large range of values  $ \lambda $, the final PSNR remains almost the same. Although this may look a bit surprising at a first sight, we remark that such a robust result is due, essentially, to the second step of the algorithm where false localizations related to an underestimation of
$ \lambda $, the final PSNR remains almost the same. Although this may look a bit surprising at a first sight, we remark that such a robust result is due, essentially, to the second step of the algorithm where false localizations related to an underestimation of  $ \lambda $ can be corrected through the intensity estimation step. Note, however, that in the case of an overestimation of
$ \lambda $ can be corrected through the intensity estimation step. Note, however, that in the case of an overestimation of  $ \lambda $, points contained in the original support are definitively lost so no benefit is obtained from the intensity estimation step, hence the overall PSNR decreases.
$ \lambda $, points contained in the original support are definitively lost so no benefit is obtained from the intensity estimation step, hence the overall PSNR decreases.

Figure 9. The peak-signal-to-noise-ratio (PSNR) value of the final COL0RME image, using the  $ {\mathrm{\ell}}_1 $-norm regularizer for support estimation, for different
$ {\mathrm{\ell}}_1 $-norm regularizer for support estimation, for different  $ \gamma $ values, evaluating in both the low-background (LB) and high-background (HB) datasets. The mean and the standard deviation of 20 different noise realization are presented.
$ \gamma $ values, evaluating in both the low-background (LB) and high-background (HB) datasets. The mean and the standard deviation of 20 different noise realization are presented.
When the CEL0 penalty is used for support estimation, a heuristic parameter selection strategy can be used to improve the localization results, but also to avoid the fine parameter tuning. More specifically, the nonconvexity of the model can be used by considering an algorithmic restarting approach to improve the support reconstruction quality. In short, a value of  $ \lambda $ can be fixed, typically
$ \lambda $ can be fixed, typically  $ \lambda ={\gamma \lambda}_{\mathrm{max}}^{CEL0} $ with
$ \lambda ={\gamma \lambda}_{\mathrm{max}}^{CEL0} $ with  $ \gamma \approx 5\times {10}^{-4} $, so as to achieve a very sparse reconstruction. Then, the support estimation algorithm can be run and iteratively repeated with a new initialization (i.e., restarted) several times. While keeping
$ \gamma \approx 5\times {10}^{-4} $, so as to achieve a very sparse reconstruction. Then, the support estimation algorithm can be run and iteratively repeated with a new initialization (i.e., restarted) several times. While keeping  $ \lambda $ fixed along this procedure, a wise choice of the initialization depending, but not being equal to the previous output can be used to enrich the support, see Appendix C for more details. Nonconvexity is here exploited by changing, for a fixed
$ \lambda $ fixed along this procedure, a wise choice of the initialization depending, but not being equal to the previous output can be used to enrich the support, see Appendix C for more details. Nonconvexity is here exploited by changing, for a fixed  $ \lambda $, the initialization at each algorithmic restart, so that new local minimizers (corresponding to possible support points) can be computed. The final support image can thus be computed as the superposition of the different solutions computed at each restarting. In such a way, a good result for a not-finely-tuned value of
$ \lambda $, the initialization at each algorithmic restart, so that new local minimizers (corresponding to possible support points) can be computed. The final support image can thus be computed as the superposition of the different solutions computed at each restarting. In such a way, a good result for a not-finely-tuned value of  $ \lambda $ can be computed.
$ \lambda $ can be computed.
5.2. Estimation of intensity regularization parameter  $ \mu $ by discrepancy principle
$ \mu $ by discrepancy principle

In this section, we provide some details on the estimation of the parameter  $ \mu $ in (Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12), which is crucial for an accurate intensity estimation. Recall that the problem we are looking at in this second step is
$ \mu $ in (Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12), which is crucial for an accurate intensity estimation. Recall that the problem we are looking at in this second step is
 $$ \mathrm{find}\hskip1em \mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}\hskip1em \mathrm{s}.\mathrm{t}.\hskip1em \overline{\mathbf{y}}=\boldsymbol{\Psi} \mathbf{x}+\mathbf{b}+\overline{\mathbf{n}}, $$
$$ \mathrm{find}\hskip1em \mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}\hskip1em \mathrm{s}.\mathrm{t}.\hskip1em \overline{\mathbf{y}}=\boldsymbol{\Psi} \mathbf{x}+\mathbf{b}+\overline{\mathbf{n}}, $$where the quantities correspond to the temporal averages of the vectorized model in (Reference Rust, Bates and Zhuang4), so that  $ \overline{\mathbf{n}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{n}}_{\mathbf{t}} $. The temporal realizations
$ \overline{\mathbf{n}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{n}}_{\mathbf{t}} $. The temporal realizations  $ {\mathbf{n}}_{\mathbf{t}} $ of the random vector
$ {\mathbf{n}}_{\mathbf{t}} $ of the random vector  $ \mathbf{n} $ follow a normal distribution with zero mean and covariance matrix
$ \mathbf{n} $ follow a normal distribution with zero mean and covariance matrix  $ s{\mathbf{I}}_{M^2} $, where
$ s{\mathbf{I}}_{M^2} $, where  $ s $ has been estimated in the first step of the algorithm, see Section 3.1. Consequently, the vector
$ s $ has been estimated in the first step of the algorithm, see Section 3.1. Consequently, the vector  $ \overline{\mathbf{n}} $ follows also a normal distribution with zero mean and covariance matrix equal to
$ \overline{\mathbf{n}} $ follows also a normal distribution with zero mean and covariance matrix equal to  $ \frac{s}{T}{\mathbf{I}}_{M^2} $. As both
$ \frac{s}{T}{\mathbf{I}}_{M^2} $. As both  $ s $ and
$ s $ and  $ T $ are known, we can use the discrepancy principle, a well-known a posteriori parameter-choice strategy (see, e.g., Refs. (Reference Hansen34) and (Reference Gfrerer35)), to efficiently estimate the hyper-parameter
$ T $ are known, we can use the discrepancy principle, a well-known a posteriori parameter-choice strategy (see, e.g., Refs. (Reference Hansen34) and (Reference Gfrerer35)), to efficiently estimate the hyper-parameter  $ \mu $. To detail how the procedure is applied to our problem, we write
$ \mu $. To detail how the procedure is applied to our problem, we write  $ {\mathbf{x}}_{\mu } $ in the following to highlight the dependence of
$ {\mathbf{x}}_{\mu } $ in the following to highlight the dependence of  $ \mathbf{x} $ on
$ \mathbf{x} $ on  $ \mu $. According to the discrepancy principle strategy, the regularization parameter
$ \mu $. According to the discrepancy principle strategy, the regularization parameter  $ \mu $ is chosen so that the residual norm of the regularized solution satisfies:
$ \mu $ is chosen so that the residual norm of the regularized solution satisfies:
 $$ \parallel \overline{\mathbf{y}}-\Psi {\hat{\mathbf{x}}}_{\mu }-\hat{\mathbf{b}}{\parallel}_2^2={\nu}_{DP}^2\parallel \overline{\mathbf{n}}{\parallel}_2^2, $$
$$ \parallel \overline{\mathbf{y}}-\Psi {\hat{\mathbf{x}}}_{\mu }-\hat{\mathbf{b}}{\parallel}_2^2={\nu}_{DP}^2\parallel \overline{\mathbf{n}}{\parallel}_2^2, $$where  $ {\hat{\mathbf{x}}}_{\mu}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ and
$ {\hat{\mathbf{x}}}_{\mu}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ and  $ \hat{\mathbf{b}}\hskip0.2em \in {\unicode{x211D}}^{M^2} $ are the solutions of (Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12). The expected value of
$ \hat{\mathbf{b}}\hskip0.2em \in {\unicode{x211D}}^{M^2} $ are the solutions of (Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12). The expected value of  $ \parallel \overline{\mathbf{n}}{\parallel}_2^2 $ is:
$ \parallel \overline{\mathbf{n}}{\parallel}_2^2 $ is:
 $$ \unicode{x1D53C}\left\{\parallel \overline{\mathbf{n}}{\parallel}_2^2\right\}={M}^2\frac{s}{T}, $$
$$ \unicode{x1D53C}\left\{\parallel \overline{\mathbf{n}}{\parallel}_2^2\right\}={M}^2\frac{s}{T}, $$which can be used as an approximation of  $ \parallel \overline{\mathbf{n}}{\parallel}_2^2 $ for
$ \parallel \overline{\mathbf{n}}{\parallel}_2^2 $ for  $ {M}^2 $ big enough. The scalar value
$ {M}^2 $ big enough. The scalar value  $ {\nu}_{DP}\approx 1 $ is a “safety factor” that plays an important role in the case when a good estimate of
$ {\nu}_{DP}\approx 1 $ is a “safety factor” that plays an important role in the case when a good estimate of  $ \parallel \overline{\mathbf{n}}{\parallel}_2 $ is not available. In such situations, a value
$ \parallel \overline{\mathbf{n}}{\parallel}_2 $ is not available. In such situations, a value  $ {\nu}_{DP} $ closer to
$ {\nu}_{DP} $ closer to  $ 2 $ is used. As detailed in Section 3.1, the estimation of
$ 2 $ is used. As detailed in Section 3.1, the estimation of  $ s $ is rather precise in this case, hence we fix
$ s $ is rather precise in this case, hence we fix  $ {\nu}_{DP}=1 $ in the following.
$ {\nu}_{DP}=1 $ in the following.
We can now define the function  $ f\left(\mu \right):{\unicode{x211D}}_{+}\to \unicode{x211D} $ as:
$ f\left(\mu \right):{\unicode{x211D}}_{+}\to \unicode{x211D} $ as:
 $$ f\left(\mu \right)=\frac{1}{2}\parallel \overline{\mathbf{y}}-\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\hat{\mathbf{b}}{\parallel}_2^2-\frac{\nu_{DP}^2}{2}\parallel \overline{\mathbf{n}}{\parallel}_2^2. $$
$$ f\left(\mu \right)=\frac{1}{2}\parallel \overline{\mathbf{y}}-\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\hat{\mathbf{b}}{\parallel}_2^2-\frac{\nu_{DP}^2}{2}\parallel \overline{\mathbf{n}}{\parallel}_2^2. $$We want to find the value  $ \hat{\mu} $ such that
$ \hat{\mu} $ such that  $ f\left(\hat{\mu}\right)=0 $. This can be done iteratively, using the Newton’s method whose iterations read:
$ f\left(\hat{\mu}\right)=0 $. This can be done iteratively, using the Newton’s method whose iterations read:
 $$ {\mu}_{n+1}={\mu}_n-\frac{f\left({\mu}_n\right)}{f^{\prime}\left({\mu}_n\right)},\hskip1em n=1,2,\dots . $$
$$ {\mu}_{n+1}={\mu}_n-\frac{f\left({\mu}_n\right)}{f^{\prime}\left({\mu}_n\right)},\hskip1em n=1,2,\dots . $$ In order to be able to compute easily the values  $ f\left(\mu \right) $ and
$ f\left(\mu \right) $ and  $ {f}^{\prime}\left(\mu \right) $, the values
$ {f}^{\prime}\left(\mu \right) $, the values  $ {\hat{\mathbf{x}}}_{\mu}\hskip0.2em \in {\unicode{x211D}}^{L^2} $,
$ {\hat{\mathbf{x}}}_{\mu}\hskip0.2em \in {\unicode{x211D}}^{L^2} $,  $ \hat{\mathbf{b}}\hskip0.2em \in {\unicode{x211D}}^{M^2} $, and
$ \hat{\mathbf{b}}\hskip0.2em \in {\unicode{x211D}}^{M^2} $, and  $ {\hat{\mathbf{x}}}_{\mu}^{\prime }=\frac{\partial }{\partial \mu }{\hat{\mathbf{x}}}_{\mu}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ need to be computed, as it can be easily noticed by writing the expression of
$ {\hat{\mathbf{x}}}_{\mu}^{\prime }=\frac{\partial }{\partial \mu }{\hat{\mathbf{x}}}_{\mu}\hskip0.2em \in {\unicode{x211D}}^{L^2} $ need to be computed, as it can be easily noticed by writing the expression of  $ {f}^{\prime}\left(\mu \right) $ which reads:
$ {f}^{\prime}\left(\mu \right) $ which reads:
 $$ {f}^{\prime}\left(\mu \right)=\frac{\partial }{\partial \mu}\left\{\frac{1}{2}\parallel \overline{\mathbf{y}}-\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\hat{\mathbf{b}}{\parallel}_2^2\right\}={\left({\hat{\mathbf{x}}}_{\mu}^{\prime}\right)}^{\intercal }{\boldsymbol{\Psi}}^{\intercal}\left(\overline{\mathbf{y}}-\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\hat{\mathbf{b}}\right). $$
$$ {f}^{\prime}\left(\mu \right)=\frac{\partial }{\partial \mu}\left\{\frac{1}{2}\parallel \overline{\mathbf{y}}-\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\hat{\mathbf{b}}{\parallel}_2^2\right\}={\left({\hat{\mathbf{x}}}_{\mu}^{\prime}\right)}^{\intercal }{\boldsymbol{\Psi}}^{\intercal}\left(\overline{\mathbf{y}}-\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\hat{\mathbf{b}}\right). $$ The values  $ {\hat{\mathbf{x}}}_{\mu } $ and
$ {\hat{\mathbf{x}}}_{\mu } $ and  $ \hat{\mathbf{b}} $ can be found by solving the minimization problem (Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12). As far as
$ \hat{\mathbf{b}} $ can be found by solving the minimization problem (Reference Geissbuehler, Bocchio, Dellagiacoma, Berclaz, Leutenegger and Lasser12). As far as  $ {\hat{\mathbf{x}}}_{\mu}^{\prime } $ is concerned, we report in Appendix B the steps necessary for its computation. We note here, however, that in order to compute such a quantity, the relaxation of the support/non-negativity constraints by means of the smooth quadratic terms discussed above is fundamental. One can show that
$ {\hat{\mathbf{x}}}_{\mu}^{\prime } $ is concerned, we report in Appendix B the steps necessary for its computation. We note here, however, that in order to compute such a quantity, the relaxation of the support/non-negativity constraints by means of the smooth quadratic terms discussed above is fundamental. One can show that  $ {\hat{\mathbf{x}}}_{\mu}^{\prime } $ is the solution of the following minimization problem:
$ {\hat{\mathbf{x}}}_{\mu}^{\prime } $ is the solution of the following minimization problem:
 $$ {\hat{\mathbf{x}}}_{\mu}^{\prime }=\underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}{\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}+\mathbf{c}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\mathbf{x}{\parallel}_2^2\right), $$
$$ {\hat{\mathbf{x}}}_{\mu}^{\prime }=\underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}}{\arg \hskip0.1em \min}\frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}{\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}+\mathbf{c}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\mathbf{x}{\parallel}_2^2\right), $$where  $ \mathbf{c} $ is a known quantity defined by
$ \mathbf{c} $ is a known quantity defined by  $ \mathbf{c}=\frac{1}{\mu}\nabla {\hat{\mathbf{x}}}_{\mu } $, and the diagonal matrix
$ \mathbf{c}=\frac{1}{\mu}\nabla {\hat{\mathbf{x}}}_{\mu } $, and the diagonal matrix  $ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\hskip0.2em \in {\unicode{x211D}}^{L^2\times {L}^2} $ identifies the support of
$ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\hskip0.2em \in {\unicode{x211D}}^{L^2\times {L}^2} $ identifies the support of  $ {\hat{\mathbf{x}}}_{\mu } $ by:
$ {\hat{\mathbf{x}}}_{\mu } $ by:
 $$ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\left(i,i\right)=\left\{\begin{array}{cc}0& \mathrm{if}\;{\left({\hat{\mathbf{x}}}_{\mu}\right)}_{\mathrm{i}}\ge 0,\\ {}1& \hskip0.2em \mathrm{if}\;{\left({\hat{\mathbf{x}}}_{\mu}\right)}_{\mathrm{i}}<0.\end{array}\right. $$
$$ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\left(i,i\right)=\left\{\begin{array}{cc}0& \mathrm{if}\;{\left({\hat{\mathbf{x}}}_{\mu}\right)}_{\mathrm{i}}\ge 0,\\ {}1& \hskip0.2em \mathrm{if}\;{\left({\hat{\mathbf{x}}}_{\mu}\right)}_{\mathrm{i}}<0.\end{array}\right. $$ We can find  $ {\hat{\mathbf{x}}}_{\mu}^{\prime } $ by iterating
$ {\hat{\mathbf{x}}}_{\mu}^{\prime } $ by iterating
 $$ {{\mathbf{x}}^{\prime}}_{\mu}^{n+1}={\mathbf{prox}}_{\overline{h},\tau}\left({{\mathbf{x}}^{\prime}}_{\mu}^n-\tau \nabla \overline{g}\left({{\mathbf{x}}^{\prime}}_{\mu}^n\right)\right),\hskip1em n=1,2,\dots, $$
$$ {{\mathbf{x}}^{\prime}}_{\mu}^{n+1}={\mathbf{prox}}_{\overline{h},\tau}\left({{\mathbf{x}}^{\prime}}_{\mu}^n-\tau \nabla \overline{g}\left({{\mathbf{x}}^{\prime}}_{\mu}^n\right)\right),\hskip1em n=1,2,\dots, $$where
 $$ \overline{g}\left(\mathbf{x}\right):= \frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}{\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}+\mathbf{c}{\parallel}_2^2,\hskip2em \overline{h}\left(\mathbf{x}\right):= \frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\mathbf{x}{\parallel}_2^2\right). $$
$$ \overline{g}\left(\mathbf{x}\right):= \frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}{\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}+\mathbf{c}{\parallel}_2^2,\hskip2em \overline{h}\left(\mathbf{x}\right):= \frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\mathbf{x}{\parallel}_2^2\right). $$ For  $ \mathbf{z}\hskip0.2em \in {\unicode{x211D}}^{L^2} $, the proximal operator
$ \mathbf{z}\hskip0.2em \in {\unicode{x211D}}^{L^2} $, the proximal operator  $ {\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right) $ can be obtained following the computations in Appendix A:
$ {\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right) $ can be obtained following the computations in Appendix A:
 $$ {\left({\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right)\right)}_i={\mathrm{prox}}_{\overline{h},\tau}\left({\mathbf{z}}_i\right)=\frac{{\mathbf{z}}_i}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+{\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\Big(i,i\Big)\right)}, $$
$$ {\left({\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right)\right)}_i={\mathrm{prox}}_{\overline{h},\tau}\left({\mathbf{z}}_i\right)=\frac{{\mathbf{z}}_i}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+{\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\Big(i,i\Big)\right)}, $$while
 $$ \nabla \overline{g}\left({\mathbf{x}}^{\prime}\right)=\left({\boldsymbol{\Psi}}^{\intercal}\boldsymbol{\Psi} +\mu {\nabla}^{\intercal}\nabla \right){\mathbf{x}}^{\prime }+{\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }, $$
$$ \nabla \overline{g}\left({\mathbf{x}}^{\prime}\right)=\left({\boldsymbol{\Psi}}^{\intercal}\boldsymbol{\Psi} +\mu {\nabla}^{\intercal}\nabla \right){\mathbf{x}}^{\prime }+{\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }, $$and the step  $ \tau \hskip0.2em \in \left(0,\frac{1}{L_{\overline{g}}}\right] $, with
$ \tau \hskip0.2em \in \left(0,\frac{1}{L_{\overline{g}}}\right] $, with  $ {L}_{\overline{g}}=\parallel {\boldsymbol{\Psi}}^{\intercal}\boldsymbol{\Psi} +\mu {\nabla}^{\intercal}\nabla {\parallel}_2 $ the Lipschitz constant of
$ {L}_{\overline{g}}=\parallel {\boldsymbol{\Psi}}^{\intercal}\boldsymbol{\Psi} +\mu {\nabla}^{\intercal}\nabla {\parallel}_2 $ the Lipschitz constant of  $ \nabla \overline{g} $. A pseudo-code explaining the procedure we follow to find the optimal
$ \nabla \overline{g} $. A pseudo-code explaining the procedure we follow to find the optimal  $ \hat{\mu} $ can be found in Algorithm 3. Finally, in Figure 10, a numerical example is available to show the good estimation of the parameter
$ \hat{\mu} $ can be found in Algorithm 3. Finally, in Figure 10, a numerical example is available to show the good estimation of the parameter  $ \hat{\mu} $.
$ \hat{\mu} $.
Algorithm 3 Discrepancy Principle.
Require:  $ \overline{\mathbf{y}}\hskip0.2em \in {\unicode{x211D}}^{M^2},{\mathbf{x}}^0\hskip0.2em \in {\unicode{x211D}}^{L^2},{\mathbf{b}}^0\hskip0.2em \in {\unicode{x211D}}^{M^2},{\mu}_0,\beta >0 $,
$ \overline{\mathbf{y}}\hskip0.2em \in {\unicode{x211D}}^{M^2},{\mathbf{x}}^0\hskip0.2em \in {\unicode{x211D}}^{L^2},{\mathbf{b}}^0\hskip0.2em \in {\unicode{x211D}}^{M^2},{\mu}_0,\beta >0 $, $ \alpha \gg 1 $.
$ \alpha \gg 1 $.
repeat.
Find  $ {\hat{\mathbf{x}}}_{\mu_n},\hat{\mathbf{b}} $ using Algorithm 2
$ {\hat{\mathbf{x}}}_{\mu_n},\hat{\mathbf{b}} $ using Algorithm 2
Find  $ {\hat{\mathbf{x}}}_{\mu_n}^{\prime } $ solving (Reference Soubies32)
$ {\hat{\mathbf{x}}}_{\mu_n}^{\prime } $ solving (Reference Soubies32)
Compute  $ f\left({\mu}_n\right),{f}^{\prime}\left({\mu}_n\right) $ from (Reference Gale and Shapley29) and (Reference Girsault, Lukes and Sharipov31)
$ f\left({\mu}_n\right),{f}^{\prime}\left({\mu}_n\right) $ from (Reference Gale and Shapley29) and (Reference Girsault, Lukes and Sharipov31)
 $ {\mu}_{n+1}\leftarrow {\mu}_n-\frac{f\left({\mu}_n\right)}{f^{\prime}\left({\mu}_n\right)} $
$ {\mu}_{n+1}\leftarrow {\mu}_n-\frac{f\left({\mu}_n\right)}{f^{\prime}\left({\mu}_n\right)} $
until convergence.
return  $ \hat{\mu} $.
$ \hat{\mu} $.

Figure 10. The solid blue line shows the peak-signal-to-noise-ratio (PSNR) values computed by solving (Reference Gustafsson, Culley, Ashdown, Owen, Pereira and Henriques13) for several values of  $ \mu $ within a specific range. Tha data used are the high-background (HB) dataset with
$ \mu $ within a specific range. Tha data used are the high-background (HB) dataset with  $ T=500 $ frames (Figure 12c) and the
$ T=500 $ frames (Figure 12c) and the  $ {\mathrm{\ell}}_1 $-norm regularization penalty. The red cross shows the PSNR value
$ {\mathrm{\ell}}_1 $-norm regularization penalty. The red cross shows the PSNR value  $ \hat{\mu} $ obtained by applying the Discrepancy Principle. We note that such value is very close to one maximizing the PSNR metric.
$ \hat{\mu} $ obtained by applying the Discrepancy Principle. We note that such value is very close to one maximizing the PSNR metric.
6. Results
In this section, we compare the method COL0RME with state-of-the-art methods that exploit the temporal fluctuations/blinking of fluorophores, while applying them to simulated and real data. More precisely, we compare: COL0RME-CEL0 (using the CEL0 regularization in the support estimation), COL0RME- $ {\mathrm{\ell}}_1 $ (using the
$ {\mathrm{\ell}}_1 $ (using the  $ {\mathrm{\ell}}_1 $-norm regularization in the support estimation), SRRF(Reference Gustafsson, Culley, Ashdown, Owen, Pereira and Henriques13), SPARCOM(Reference Solomon, Eldar, Mutzafi and Segev18), and LSPARCOM(Reference Dardikman-Yoffe and Eldar19). We further performed preliminary comparisons also with the ESI, 3B, and bSOFI approaches using available codes provided by the authors on the web,Footnote 1 but we did not successfully obtain satisfactory results, so we omit them in the following.
$ {\mathrm{\ell}}_1 $-norm regularization in the support estimation), SRRF(Reference Gustafsson, Culley, Ashdown, Owen, Pereira and Henriques13), SPARCOM(Reference Solomon, Eldar, Mutzafi and Segev18), and LSPARCOM(Reference Dardikman-Yoffe and Eldar19). We further performed preliminary comparisons also with the ESI, 3B, and bSOFI approaches using available codes provided by the authors on the web,Footnote 1 but we did not successfully obtain satisfactory results, so we omit them in the following.
6.1. Simulated data
To evaluate the method COL0RME we choose images of tubular structures that simulate standard microscope acquisitions with standard fluorescent dyes. In particular, the spatial pattern (see Figure 12a) is taken from the MT0 microtubules training dataset uploaded for the SMLM Challenge of 2016.Footnote 2 The temporal fluctuations are obtained using the SOFI simulation tool(Reference Girsault, Lukes and Sharipov31). This simulation software, implemented in Matlab, generates realistic stacks of images, similar to the ones obtained from real microscopes, as it makes use of parameters of the microscope setup and some of the sample’s main properties. However, differently from the fluctuatingFootnote 3 microscopic data presented in Section 6.2, the blinking generated by the SOFI Simulation Tool have a more distinctive “on–off” behavior.

Figure 11. One frame of the high-background (HB) dataset, before and after the addition of background and the simulated noise degradation. (a) A convoluted and down-sampled image  $ \mathtt{\varPsi}{\mathbf{x}}_t^{GT} $ obtained from a ground truth frame
$ \mathtt{\varPsi}{\mathbf{x}}_t^{GT} $ obtained from a ground truth frame  $ {\mathbf{x}}_t^{GT} $, (b) a frame of the final noisy sequence:
$ {\mathbf{x}}_t^{GT} $, (b) a frame of the final noisy sequence:  $ {\mathbf{y}}_t $. Note the different colormaps to better capture the presence of noise and background.
$ {\mathbf{y}}_t $. Note the different colormaps to better capture the presence of noise and background.

Figure 12. The ground truth (GT) intensity image, as well as, the diffraction limited images  $ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_{\mathbf{t}} $ for the two datasets with a 4× zoom, for a sequence of T = 500 frames.
$ \overline{\mathbf{y}}=\frac{1}{T}{\sum}_{t=1}^T{\mathbf{y}}_{\mathbf{t}} $ for the two datasets with a 4× zoom, for a sequence of T = 500 frames.
For the experiments presented in this paper, we generate initially a video of  $ 700 $ frames, however we evaluate the methods using the first
$ 700 $ frames, however we evaluate the methods using the first  $ T=100 $,
$ T=100 $,  $ T=300 $,
$ T=300 $,  $ T=500 $, and
$ T=500 $, and  $ T=700 $ frames, so as to examine further the trade-off between temporal and spatial resolution. The frame rate is fixed at 100 frames per second (fps) and the pixel size is
$ T=700 $ frames, so as to examine further the trade-off between temporal and spatial resolution. The frame rate is fixed at 100 frames per second (fps) and the pixel size is  $ 100 $ nm. Regarding the optical parameters, we set the numerical aperture equal to 1.4 and the emission wavelength to 525 nm, while the FWHM of the PSF is equal to
$ 100 $ nm. Regarding the optical parameters, we set the numerical aperture equal to 1.4 and the emission wavelength to 525 nm, while the FWHM of the PSF is equal to  $ 228.75 $ nm. The fluorophore parameters are set as follows:
$ 228.75 $ nm. The fluorophore parameters are set as follows:  $ 20 $ ms for on-state average lifetime,
$ 20 $ ms for on-state average lifetime,  $ 40 $ ms for off-state average lifetime and
$ 40 $ ms for off-state average lifetime and  $ 20 $ s for average time until bleaching. The emitter density is equal to 10.7 emitters/pixel/frame, while 500 photons are emitted, on average, by a single fluorescent molecule in every frame.
$ 20 $ s for average time until bleaching. The emitter density is equal to 10.7 emitters/pixel/frame, while 500 photons are emitted, on average, by a single fluorescent molecule in every frame.
We create two datasets with the main difference between them being the background level, as in real scenarios the background is usually present. More precisely we create: the LB dataset, where the background is equal to  $ 50 $ photons/pixel/frame and, the most realistic of the two, the HB dataset, where the background is equal to 2,500 photons/pixel/frame. In both datasets, we proceed as follows: initially, Poisson noise is added to simulate the photon noise (see (2)); subsequently, the number of photons recorded by each camera pixel is converted into an electric charge in accordance with the quantum efficiency and gain of the camera that have been set to 0.7 and 6, respectively (thus resulting in an overall gain of 4.2); finally, Gaussian noise is added. In order to give a visual inspection of the background and noise, in Figure 11, one frame of the HB dataset is presented before and after the background/noise addition. As we want, also, to provide a quantitative assessment, we measure the quality of the reconstruction of the final sequence of
$ 50 $ photons/pixel/frame and, the most realistic of the two, the HB dataset, where the background is equal to 2,500 photons/pixel/frame. In both datasets, we proceed as follows: initially, Poisson noise is added to simulate the photon noise (see (2)); subsequently, the number of photons recorded by each camera pixel is converted into an electric charge in accordance with the quantum efficiency and gain of the camera that have been set to 0.7 and 6, respectively (thus resulting in an overall gain of 4.2); finally, Gaussian noise is added. In order to give a visual inspection of the background and noise, in Figure 11, one frame of the HB dataset is presented before and after the background/noise addition. As we want, also, to provide a quantitative assessment, we measure the quality of the reconstruction of the final sequence of  $ T $ frames (
$ T $ frames ( $ {\mathbf{y}}_t,t=1,2,\dots, T $) using the signal-to-noise-ration (SNR) metric, given by the following formula:
$ {\mathbf{y}}_t,t=1,2,\dots, T $) using the signal-to-noise-ration (SNR) metric, given by the following formula:
 $$ {\mathrm{SNR}}_{\mathrm{dB}}=10{\log}_{10}\left(\frac{\frac{1}{{\mathrm{TM}}^2}\sum \limits_{i=1}^{{\mathrm{TM}}^2}{\left({\mathbf{R}}_i\right)}^2}{\frac{1}{{\mathrm{TM}}^2}\sum \limits_{i=1}^{{\mathrm{TM}}^2}{\left({\mathbf{R}}_i-{\mathbf{K}}_i\right)}^2}\right), $$
$$ {\mathrm{SNR}}_{\mathrm{dB}}=10{\log}_{10}\left(\frac{\frac{1}{{\mathrm{TM}}^2}\sum \limits_{i=1}^{{\mathrm{TM}}^2}{\left({\mathbf{R}}_i\right)}^2}{\frac{1}{{\mathrm{TM}}^2}\sum \limits_{i=1}^{{\mathrm{TM}}^2}{\left({\mathbf{R}}_i-{\mathbf{K}}_i\right)}^2}\right), $$where  $ \mathbf{R}\hskip0.2em \in {\unicode{x211D}}^{TM^2} $ is the reference image and
$ \mathbf{R}\hskip0.2em \in {\unicode{x211D}}^{TM^2} $ is the reference image and  $ \mathbf{K}\hskip0.2em \in {\unicode{x211D}}^{TM^2} $ the image we want to evaluate, both of them in a vectorized form. As reference, we choose the sequence of convoluted and down-sampled ground truth frames (see one frame of the reference sequence in Figure 11a). The SNR values for a sequence of
$ \mathbf{K}\hskip0.2em \in {\unicode{x211D}}^{TM^2} $ the image we want to evaluate, both of them in a vectorized form. As reference, we choose the sequence of convoluted and down-sampled ground truth frames (see one frame of the reference sequence in Figure 11a). The SNR values for a sequence of  $ T=500 $ frames for the LB and HB dataset are
$ T=500 $ frames for the LB and HB dataset are  $ 15.57 $ dB and
$ 15.57 $ dB and  $ -6.07 $ dB, respectively. A negative value is computed for the HB dataset due to the very high background used in this case.
$ -6.07 $ dB, respectively. A negative value is computed for the HB dataset due to the very high background used in this case.
The diffraction limited image (the average image of the stack) of each dataset as well as the ground truth intensity image are available in Figure 12. In the LB dataset, due to the high signal values, the background is not visible. Further, as the observed microscopic images and the reconstructed ones belong to different grids, coarse and fine grid respectively, their intensity values are not comparable and we can not use the same colorbar to represent them. The intensity of one pixel in the coarse grid is the summation of the intensities of  $ q\times q $ pixels in the fine grid, where
$ q\times q $ pixels in the fine grid, where  $ q $ is the super-resolution factor. For this reason, we use two different colorbars.
$ q $ is the super-resolution factor. For this reason, we use two different colorbars.
The comparison of the method COL0RME with other state-of-the-art methods that take advantage of the blinking fluorophores is available below. Regarding the method COL0RME-CEL0 and COL0RME- $ {\mathrm{\ell}}_1 $, a regularization parameter equal to
$ {\mathrm{\ell}}_1 $, a regularization parameter equal to  $ \lambda =5\times {10}^{-4}\times {\lambda}_{max}^{CEL0} $ and
$ \lambda =5\times {10}^{-4}\times {\lambda}_{max}^{CEL0} $ and  $ \lambda =5\times {10}^{-4}\times {\lambda}_{max}^{{\mathrm{\ell}}_1} $, respectively, is used in the support estimation. The hyper-parameters
$ \lambda =5\times {10}^{-4}\times {\lambda}_{max}^{{\mathrm{\ell}}_1} $, respectively, is used in the support estimation. The hyper-parameters  $ \alpha $ and
$ \alpha $ and  $ \beta $ are set as follows:
$ \beta $ are set as follows:  $ \alpha ={10}^6 $,
$ \alpha ={10}^6 $,  $ \beta =20 $. For the method COL0RME-CEL0 the algorithmic restarting approach is used for a better support estimation. It stops when there are not additional pixels added to the estimated support or if a maximum number of
$ \beta =20 $. For the method COL0RME-CEL0 the algorithmic restarting approach is used for a better support estimation. It stops when there are not additional pixels added to the estimated support or if a maximum number of  $ 10 $ restarts is reached. Such number was empirically determined by preliminary simulations. For the method SRRF, we are using the NanoJ SRRF plugin for ImageJ.Footnote 4 Concerning the method SPARCOM, we make use of the Matlab code available online.Footnote 5 As regularization penalty we choose the
$ 10 $ restarts is reached. Such number was empirically determined by preliminary simulations. For the method SRRF, we are using the NanoJ SRRF plugin for ImageJ.Footnote 4 Concerning the method SPARCOM, we make use of the Matlab code available online.Footnote 5 As regularization penalty we choose the  $ {\mathrm{\ell}}_1 $-norm with a regularization parameter equal to
$ {\mathrm{\ell}}_1 $-norm with a regularization parameter equal to  $ {10}^{-10} $ and we avoid the postprocessing step (the convolution with a small Gaussian function) for most precise localization. Finally, we test the method LSPARCOM, using the code that is, available onlineFootnote 6 and the tubulin (TU) training set that is provided.
$ {10}^{-10} $ and we avoid the postprocessing step (the convolution with a small Gaussian function) for most precise localization. Finally, we test the method LSPARCOM, using the code that is, available onlineFootnote 6 and the tubulin (TU) training set that is provided.
In Figure 13, we compare the reconstructions of the methods COL0RME-CEL0, COL0RME- $ {\mathrm{\ell}}_1 $, SRRF, SPARCOM, and LSPARCOM for the LB dataset and in Figure 14 for the HB dataset, for a sequence of T =
$ {\mathrm{\ell}}_1 $, SRRF, SPARCOM, and LSPARCOM for the LB dataset and in Figure 14 for the HB dataset, for a sequence of T = $ 500 $ frames. Results for different stack sizes, are available in the Supplementary Figures S1–S3. Quantitative metrics like the JI for the localization precision and the PSNR for the evaluation of the estimated intensities, are only available for the methods COL0RME-CEL0 and COL0RME-
$ 500 $ frames. Results for different stack sizes, are available in the Supplementary Figures S1–S3. Quantitative metrics like the JI for the localization precision and the PSNR for the evaluation of the estimated intensities, are only available for the methods COL0RME-CEL0 and COL0RME- $ {\mathrm{\ell}}_1 $ (see Figures 4 and 7). For the rest of the methods, the JI values are very small due to background and noise artifacts in the reconstructions that lead to the appearance of many false positives, while the PSNR metric is not possible to be computed as the methods SRRF, SPARCOM, and LSPARCOM do not reconstruct the intensity level. In both datasets, LB and HB datasets, and for a sequence of T =
$ {\mathrm{\ell}}_1 $ (see Figures 4 and 7). For the rest of the methods, the JI values are very small due to background and noise artifacts in the reconstructions that lead to the appearance of many false positives, while the PSNR metric is not possible to be computed as the methods SRRF, SPARCOM, and LSPARCOM do not reconstruct the intensity level. In both datasets, LB and HB datasets, and for a sequence of T =  $ 500 $ frames, the better reconstruction, visually, is the one of the method COL0RME-
$ 500 $ frames, the better reconstruction, visually, is the one of the method COL0RME- $ {\mathrm{\ell}}_1 $, as it is able to achieve a more clear separation of the filaments in the critical regions (yellow and green zoom boxes). The method COL0RME-CEL0 achieves also a good result, eventhough the separation of the filaments, that are magnified in the green box, is not so obvious. The same happens also when the method SPARCOM is being used. Finally, the reconstruction of the methods SRRF and LSPARCOM, is slightly misleading.
$ {\mathrm{\ell}}_1 $, as it is able to achieve a more clear separation of the filaments in the critical regions (yellow and green zoom boxes). The method COL0RME-CEL0 achieves also a good result, eventhough the separation of the filaments, that are magnified in the green box, is not so obvious. The same happens also when the method SPARCOM is being used. Finally, the reconstruction of the methods SRRF and LSPARCOM, is slightly misleading.

Figure 13. Results for the low-background (LB) dataset with  $ T=500 $. Note that the methods super-resolution radial fluctuations (SRRF), SPARCOM, and LSPARCOM do not estimate real intensity values. Between the compared methods only COL0RME is capable of estimating them, while the other methods estimate the mean of a radiality image sequence (SRRF) and normalized autocovariances (SPARCOM, LSPARCOM).
$ T=500 $. Note that the methods super-resolution radial fluctuations (SRRF), SPARCOM, and LSPARCOM do not estimate real intensity values. Between the compared methods only COL0RME is capable of estimating them, while the other methods estimate the mean of a radiality image sequence (SRRF) and normalized autocovariances (SPARCOM, LSPARCOM).

Figure 14. Results for the high-background (HB) dataset with  $ T=500 $.
$ T=500 $.
6.2. Real data
To show the effectiveness of our method for handling real-world data, we apply COL0RME to an image sequence acquired from a TIRF microscope. The TIRF microscope offers a good observation of the activities happening next to the cell membrane, as it uses an evanescent wave to illuminate and excite fluorescent molecules only in this restricted region of the specimen(Reference Axelrod36). Further, the TIRF microscope does not require specific fluorescent dyes, allows live cell imaging using a low illumination laser, with really low out-of-focus contribution and produces images with a relatively good, in comparison with other fluorescence microscopy techniques, SNR. To enhance the resolution of the images acquired from a TIRF microscope, super-resolution approaches that exploit the temporal fluctuations of blinking/fluctuating fluorophores, like COL0RME, can be applied.
The data we are using have been obtained from a multiangle TIRF microscope, with a fixed angle close to the critical one. A sequence of  $ 500 $ frames has been acquired, with an acquisition time equal to
$ 500 $ frames has been acquired, with an acquisition time equal to  $ 25 $ s. Tubulins in endothelial cells are being imaged, while they are colored with the Alexa Fluor 488. The variance of fluctuations over time for a typical pixel is measured and is belonging to the range
$ 25 $ s. Tubulins in endothelial cells are being imaged, while they are colored with the Alexa Fluor 488. The variance of fluctuations over time for a typical pixel is measured and is belonging to the range  $ 5\times {10}^5-7\times {10}^5 $. The diffraction limited image, or with other words the mean stack image
$ 5\times {10}^5-7\times {10}^5 $. The diffraction limited image, or with other words the mean stack image  $ \overline{\mathbf{y}} $ is shown in Figure 15, together with one frame
$ \overline{\mathbf{y}} $ is shown in Figure 15, together with one frame  $ {\mathbf{y}}_t $ extracted from the entire stack. The FWHM of the PSF has been measured experimentally and is equal to
$ {\mathbf{y}}_t $ extracted from the entire stack. The FWHM of the PSF has been measured experimentally and is equal to  $ 292.03 $ nm, while the CCD camera has a pixel of size
$ 292.03 $ nm, while the CCD camera has a pixel of size  $ 106 $ nm.
$ 106 $ nm.

Figure 15. Real total internal reflection fluorescence (TIRF) data,  $ T=500 $ frames. Diffraction limited image or the mean of the stack
$ T=500 $ frames. Diffraction limited image or the mean of the stack  $ \overline{\mathbf{y}} $ (4× zoom), a frame
$ \overline{\mathbf{y}} $ (4× zoom), a frame  $ {\mathbf{y}}_t $ from the stack (4× zoom), the intensity and background estimation of the methods COL0RME-CEL0 and COL0RME-
$ {\mathbf{y}}_t $ from the stack (4× zoom), the intensity and background estimation of the methods COL0RME-CEL0 and COL0RME- $ {\mathrm{\ell}}_1 $.
$ {\mathrm{\ell}}_1 $.
The results of the method COL0RME-CEL0 and COL0RME- $ {\mathrm{\ell}}_1 $ and more precisely the intensity and the background estimation, can be found in Figure 15. Experiments using different stack sizes have been done showing that the more frames we use (up to a point that we do not have many molecules bleached), the more continuous filaments we find. However, by acquiring only 500 frames we have a good balance between temporal and spatial resolution. For this reason we present here only results using a stack of 500 frames. For the method COL0RME-CEL0 the regularization parameter
$ {\mathrm{\ell}}_1 $ and more precisely the intensity and the background estimation, can be found in Figure 15. Experiments using different stack sizes have been done showing that the more frames we use (up to a point that we do not have many molecules bleached), the more continuous filaments we find. However, by acquiring only 500 frames we have a good balance between temporal and spatial resolution. For this reason we present here only results using a stack of 500 frames. For the method COL0RME-CEL0 the regularization parameter  $ \lambda $ is equal to
$ \lambda $ is equal to  $ \lambda =5\times {10}^{-4}\times {\lambda}_{max}^{CEL0} $ and the algorithmic restarting approach has been used (stopping criteria: when, in a certain restarting, there are not additional pixels added to the global support, but with maximum 10 restarts). Regarding the method COL0RME-
$ \lambda =5\times {10}^{-4}\times {\lambda}_{max}^{CEL0} $ and the algorithmic restarting approach has been used (stopping criteria: when, in a certain restarting, there are not additional pixels added to the global support, but with maximum 10 restarts). Regarding the method COL0RME- $ {\mathrm{\ell}}_1 $ the regularization parameter
$ {\mathrm{\ell}}_1 $ the regularization parameter  $ \lambda $ is equal to
$ \lambda $ is equal to  $ \lambda =5\times {10}^{-6}\times {\lambda}_{max}^{{\mathrm{\ell}}_1} $, a relatively small value so as to be sure that we will include all the pixels that contain fluorescent molecules. Even if we underestimate
$ \lambda =5\times {10}^{-6}\times {\lambda}_{max}^{{\mathrm{\ell}}_1} $, a relatively small value so as to be sure that we will include all the pixels that contain fluorescent molecules. Even if we underestimate  $ \lambda $ and find more false positives in the support estimation, after the second step of the algorithm, the final reconstruction is corrected, as explained in 5.1. The hyper-parameters
$ \lambda $ and find more false positives in the support estimation, after the second step of the algorithm, the final reconstruction is corrected, as explained in 5.1. The hyper-parameters  $ \alpha $ and
$ \alpha $ and  $ \beta $ are equal to:
$ \beta $ are equal to:  $ \alpha ={10}^6 $,
$ \alpha ={10}^6 $,  $ \beta =20 $. Using any of the two regularizers the spatial resolution is enhanced, as it can be also observed from the yellow zoom boxes. However, the reconstruction obtained by both COL0RME-CEL0 and COL0RME-
$ \beta =20 $. Using any of the two regularizers the spatial resolution is enhanced, as it can be also observed from the yellow zoom boxes. However, the reconstruction obtained by both COL0RME-CEL0 and COL0RME- $ {\mathrm{\ell}}_1 $ is to some degree punctuated due to mainly limitations arising from experimental difficulties to get a staining sufficiently homogeneous for this imaging resolution. Furthermore, there are a few filaments that do not seem to be well reconstructed, especially using the COL0RME-CEL0 method, for example, the one inside the green box.
$ {\mathrm{\ell}}_1 $ is to some degree punctuated due to mainly limitations arising from experimental difficulties to get a staining sufficiently homogeneous for this imaging resolution. Furthermore, there are a few filaments that do not seem to be well reconstructed, especially using the COL0RME-CEL0 method, for example, the one inside the green box.
Finally, the comparison of the methods COL0RME-CEL0 and COL0RME- $ {\mathrm{\ell}}_1 $ with the other state-of-the-art methods is available in Figure 16. The parameters used for the methods SRRF, SPARCOM, and LSPARCOM, are explained in the Section 6.1. Here, we further use the postprocessing step (convolution with a small Gaussian function) in the method SPARCOM, as the result was dotted. The methods COL0RME-CEL0 and COL0RME-
$ {\mathrm{\ell}}_1 $ with the other state-of-the-art methods is available in Figure 16. The parameters used for the methods SRRF, SPARCOM, and LSPARCOM, are explained in the Section 6.1. Here, we further use the postprocessing step (convolution with a small Gaussian function) in the method SPARCOM, as the result was dotted. The methods COL0RME-CEL0 and COL0RME- $ {\mathrm{\ell}}_1 $ seem to have the most precise localization, by reconstructing thin filaments, as shown in the cross-section plotted in Figure 16, although a bit punctuated. The most appealing visually is the result of the method SRRF, where the filaments have a more continuous structure, however from the cross-section, we can see that the resolution is not so much improved compared to the other methods. SPARCOM and LSPARCOM do not perform very well in this real image sequence due to, mainly, background artifacts.
$ {\mathrm{\ell}}_1 $ seem to have the most precise localization, by reconstructing thin filaments, as shown in the cross-section plotted in Figure 16, although a bit punctuated. The most appealing visually is the result of the method SRRF, where the filaments have a more continuous structure, however from the cross-section, we can see that the resolution is not so much improved compared to the other methods. SPARCOM and LSPARCOM do not perform very well in this real image sequence due to, mainly, background artifacts.

Figure 16. Real total internal reflection fluorescence (TIRF) data,  $ T=500 $ frames. Diffraction limited image
$ T=500 $ frames. Diffraction limited image  $ \overline{\mathbf{y}} $ (4× zoom), comparisons between the method that exploit the temporal fluctuations, normalized cross-section along the green line presented in the diffraction limited and reconstructed images, but also in the blue zoom-boxes. Discription of colorbars: real intensity values for
$ \overline{\mathbf{y}} $ (4× zoom), comparisons between the method that exploit the temporal fluctuations, normalized cross-section along the green line presented in the diffraction limited and reconstructed images, but also in the blue zoom-boxes. Discription of colorbars: real intensity values for  $ \overline{\mathbf{y}} $ and COL0RME in two different grids, mean of the radiality image sequence for super-resolution radial fluctuations (SRRF), normalized autocovariances for SPARCOM and LSPARCOM.
$ \overline{\mathbf{y}} $ and COL0RME in two different grids, mean of the radiality image sequence for super-resolution radial fluctuations (SRRF), normalized autocovariances for SPARCOM and LSPARCOM.

Figure 17. The yellow pixels belong to the support estimated in the previous restarting, while the red pixels belong to the initialization that is, used in the current restarting.
7. Discussion and Conclusions
In this paper, we propose and discuss the model and the performance of COL0RME, a method for super-resolution microscopy imaging based on the sparse analysis of the stochastic fluctuations of molecules’ intensities. Similarly to other methods exploiting temporal fluctuations, COL0RME relaxes all the requirements for special equipment (microscope and fluorescent dyes) and allows for live-cell imaging, due to the good temporal resolution and the low power lasers employed. In comparison with competing methods, COL0RME achieves higher spatial resolution than other methods exploiting fluctuations while having a sufficient temporal resolution. COL0RME is based on two different steps: a former one where accurate molecule localization and noise estimation are achieved by solving nonsmooth convex/nonconvex optimization problems in the covariance domain and the latter where intensity information is retrieved in correspondence with the estimated support only. Our numerical results show that COL0RME outperforms competing approaches in terms of localization precision. To the best of our knowledge, COL0RME is the only super-resolution method exploiting temporal fluctuations which is capable of retrieving intensity-type information, signal and spatially varying background, which are of fundamental interest in biological data analysis. For both steps, automatic parameter selection strategies are detailed. Let us remark that such strategy of intensity estimation could be applied to the other competing super-resolution methods in the literature. Several results obtained on both simulated and real data are discussed, showing the superior performance of COL0RME in comparison with analogous methods such as SPARCOM, LSPARCOM and SRRF. Possible extensions of this work shall address the use of intensity information estimated by COL0RME for 3D reconstruction in, for example, MA-TIRF acquisitions. Furthermore, a systematic study to assess quantitatively the spatial resolution achieved by COL0RME under different scenarios (different background levels, different PSNRs, and number of frames) is envisaged.
Acknowledgments
The authors would like to thank E. van Obberghen-Shilling and D. Grall from the Institut de Biologie Valrose (iBV) who kindly prepared and provided the experimental samples. Furthermore, the authors would like to thank the anonymous reviewers for their valuable comments and suggestions.
Competing Interests
The authors declare no competing interests exist.
Authorship Contributions
V.S., L.C., J.H.M.G., and L.B.-F. conceived and designed the study. S.S. conducted data gathering. V.S. and J.H.M.G. implemented the software. V.S. carried out the experiments. L.C. and L.B.-F. supervised the work. V.S., L.C., J.H.M.G., and L.B.-F. wrote the article. All authors approved the final submission.
Funding Statement
The work of V.S. and L.B.-F. has been supported by the French government, through the 3IA Côte d’Azur Investments in the Future project managed by the National Research Agency (ANR) with the reference number ANR-19-P3IA-0002. L.C. acknowledges the support received by the academy on complex systems of UCA JEDI, the one received by the EU H2020 RISE program NoMADS, GA 777826, and the one received by the GdR ISIS grant SPLIN. The work of J.H.M.G was supported by the French Agence Nationale de la Recherche in the context of the project Investissements d’Avenir UCAJEDI (ANR-15-IDEX-01). Support for development of the microscope was received from IBiSA (Infrastructures en Biologie Santé et Agronomie) to the MICA microscopy platform.
Data Availability Statement
Replication data and code can be found in: https://github.com/VStergiop/COL0RME.
Supplementary Materials
To view supplementary material for this article, please visit http://doi.org/10.1017/S2633903X22000010.
A. Appendix. Proximal Computations
Given the function  $ h:{\unicode{x211D}}^{L^2}\to \unicode{x211D} $, defined in (Reference Solomon, Mutzafi, Segev and Eldar17), the proximal mapping of
$ h:{\unicode{x211D}}^{L^2}\to \unicode{x211D} $, defined in (Reference Solomon, Mutzafi, Segev and Eldar17), the proximal mapping of  $ h $ is a an operator given by:
$ h $ is a an operator given by:
 $$ {\displaystyle \begin{array}{c}{\mathbf{prox}}_{h,\tau}\left(\mathbf{w}\right)=\underset{\mathbf{u}}{\arg \hskip0.1em \min}\left(\frac{1}{2\tau}\parallel \mathbf{u}-\mathbf{w}{\parallel}_2^2+h\left(\mathbf{w}\right)\right)\\ {}=\underset{\mathbf{u}}{\arg \hskip0.1em \min}\left(\frac{1}{2\tau}\parallel \mathbf{u}-\mathbf{w}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{u}{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\mathbf{u}}_i\right)\right]}^2\right)\right).\end{array}} $$
$$ {\displaystyle \begin{array}{c}{\mathbf{prox}}_{h,\tau}\left(\mathbf{w}\right)=\underset{\mathbf{u}}{\arg \hskip0.1em \min}\left(\frac{1}{2\tau}\parallel \mathbf{u}-\mathbf{w}{\parallel}_2^2+h\left(\mathbf{w}\right)\right)\\ {}=\underset{\mathbf{u}}{\arg \hskip0.1em \min}\left(\frac{1}{2\tau}\parallel \mathbf{u}-\mathbf{w}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{u}{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\mathbf{u}}_i\right)\right]}^2\right)\right).\end{array}} $$ The optimal solution  $ \hat{\mathbf{u}} $ (
$ \hat{\mathbf{u}} $ ( $ \hat{\mathbf{u}}={\mathrm{prox}}_{h,\tau}\left(\mathbf{w}\right) $), as the problem (A.1) is convex, is attained when:
$ \hat{\mathbf{u}}={\mathrm{prox}}_{h,\tau}\left(\mathbf{w}\right) $), as the problem (A.1) is convex, is attained when:
 $$ {\displaystyle \begin{array}{l}\mathbf{0}\hskip0.2em \in \nabla \left(\frac{1}{2\tau}\parallel \hat{\mathbf{u}}-\mathbf{w}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\hat{\mathbf{u}}}_i\right)\right]}^2\right)\right),\\ {}\mathbf{0}\hskip0.2em \in \frac{1}{\tau}\left(\hat{\mathbf{u}}-\mathbf{w}\right)+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}+{\left[\phi \left({\hat{\mathbf{u}}}_i\right){\phi}^{\prime}\left({\hat{\mathbf{u}}}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right).\end{array}} $$
$$ {\displaystyle \begin{array}{l}\mathbf{0}\hskip0.2em \in \nabla \left(\frac{1}{2\tau}\parallel \hat{\mathbf{u}}-\mathbf{w}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\hat{\mathbf{u}}}_i\right)\right]}^2\right)\right),\\ {}\mathbf{0}\hskip0.2em \in \frac{1}{\tau}\left(\hat{\mathbf{u}}-\mathbf{w}\right)+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}+{\left[\phi \left({\hat{\mathbf{u}}}_i\right){\phi}^{\prime}\left({\hat{\mathbf{u}}}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right).\end{array}} $$ Starting from (Reference Cox, Rosten and Monypenny14), we can compute  $ {\phi}^{\prime }:\unicode{x211D}\to {\unicode{x211D}}_{+} $, as:
$ {\phi}^{\prime }:\unicode{x211D}\to {\unicode{x211D}}_{+} $, as:
 $$ {\phi}^{\prime }(z):= \left\{\begin{array}{cc}0& \mathrm{if}\;z\ge 0,\\ {}1& \mathrm{if}\;z<0,\end{array}\right.\hskip2em \forall z\hskip0.2em \in \unicode{x211D}. $$
$$ {\phi}^{\prime }(z):= \left\{\begin{array}{cc}0& \mathrm{if}\;z\ge 0,\\ {}1& \mathrm{if}\;z<0,\end{array}\right.\hskip2em \forall z\hskip0.2em \in \unicode{x211D}. $$Given (A.3), we can write:
 $$ \mathbf{0}\hskip0.2em \in \frac{1}{\tau}\left(\hat{\mathbf{u}}-\mathbf{w}\right)+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}+{\left[\phi \left({\hat{\mathbf{u}}}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right). $$
$$ \mathbf{0}\hskip0.2em \in \frac{1}{\tau}\left(\hat{\mathbf{u}}-\mathbf{w}\right)+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}+{\left[\phi \left({\hat{\mathbf{u}}}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right). $$ Exploiting component-wise, as problem (A.1) is separable with respect to both  $ \mathbf{x} $ and
$ \mathbf{x} $ and  $ \mathbf{w} $, and assuming
$ \mathbf{w} $, and assuming  $ {\hat{\mathbf{u}}}_i\ge 0 $, the derivative computed at (A.4) vanishes for:
$ {\hat{\mathbf{u}}}_i\ge 0 $, the derivative computed at (A.4) vanishes for:
 $$ {\hat{\mathbf{u}}}_i=\frac{1}{1+\alpha \tau {\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)}{\mathbf{w}}_i, $$
$$ {\hat{\mathbf{u}}}_i=\frac{1}{1+\alpha \tau {\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)}{\mathbf{w}}_i, $$and it holds for  $ {\mathbf{w}}_i\ge 0 $. Similarly, for the case
$ {\mathbf{w}}_i\ge 0 $. Similarly, for the case  $ {\hat{\mathbf{u}}}_i<0 $, this analysis yields:
$ {\hat{\mathbf{u}}}_i<0 $, this analysis yields:
 $$ {\hat{\mathbf{u}}}_i=\frac{1}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+1\right)}{\mathbf{w}}_i, $$
$$ {\hat{\mathbf{u}}}_i=\frac{1}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+1\right)}{\mathbf{w}}_i, $$for  $ {\mathbf{w}}_i<0 $.
$ {\mathbf{w}}_i<0 $.
So finally, the proximal operator is given by:
 $$ {\left({\mathbf{prox}}_{h,\tau}\left(\mathbf{w}\right)\right)}_i={\mathrm{prox}}_{h,\tau}\left({\mathbf{w}}_i\right)=\left(\begin{array}{cc}\hskip-3.8em \frac{{\mathbf{w}}_i}{1+\alpha \tau {\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)}& \mathrm{if}\;{\mathbf{w}}_i\ge 0,\\ {}\frac{{\mathbf{w}}_i}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+1\right)}& \mathrm{if}\;{\mathbf{w}}_i<0.\end{array}\right. $$
$$ {\left({\mathbf{prox}}_{h,\tau}\left(\mathbf{w}\right)\right)}_i={\mathrm{prox}}_{h,\tau}\left({\mathbf{w}}_i\right)=\left(\begin{array}{cc}\hskip-3.8em \frac{{\mathbf{w}}_i}{1+\alpha \tau {\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)}& \mathrm{if}\;{\mathbf{w}}_i\ge 0,\\ {}\frac{{\mathbf{w}}_i}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+1\right)}& \mathrm{if}\;{\mathbf{w}}_i<0.\end{array}\right. $$ In a similar way, we compute the proximal mapping of the function  $ \overline{h}:{\unicode{x211D}}^{L^2}\to \unicode{x211D} $, defined in (Reference Hansen34), as follows:
$ \overline{h}:{\unicode{x211D}}^{L^2}\to \unicode{x211D} $, defined in (Reference Hansen34), as follows:
 $$ {\displaystyle \begin{array}{c}{\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right)=\underset{\mathbf{u}}{\arg \hskip0.1em \min}\left(\frac{1}{2\tau}\parallel \mathbf{u}-\mathbf{z}{\parallel}_2^2+\overline{h}\left(\mathbf{u}\right)\right)\\ {}=\underset{\mathbf{u}}{\arg \hskip0.1em \min}\left(\frac{1}{2\tau}\parallel \mathbf{u}-\mathbf{z}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{u}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\mathbf{u}{\parallel}_2^2\right)\right).\end{array}} $$
$$ {\displaystyle \begin{array}{c}{\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right)=\underset{\mathbf{u}}{\arg \hskip0.1em \min}\left(\frac{1}{2\tau}\parallel \mathbf{u}-\mathbf{z}{\parallel}_2^2+\overline{h}\left(\mathbf{u}\right)\right)\\ {}=\underset{\mathbf{u}}{\arg \hskip0.1em \min}\left(\frac{1}{2\tau}\parallel \mathbf{u}-\mathbf{z}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{u}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\mathbf{u}{\parallel}_2^2\right)\right).\end{array}} $$ The optimal solution  $ \hat{\mathbf{u}} $ of (A.8)
$ \hat{\mathbf{u}} $ of (A.8)  $ \left(\hat{\mathbf{u}}={\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right)\right) $ is attained when:
$ \left(\hat{\mathbf{u}}={\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right)\right) $ is attained when:
 $$ {\displaystyle \begin{array}{l}\mathbf{0}\hskip0.2em \in \nabla \left(\frac{1}{2\tau}\parallel \hat{\mathbf{u}}-\mathbf{z}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\hat{\mathbf{u}}{\parallel}_2^2\right)\right),\\ {}\mathbf{0}\hskip0.2em \in \frac{1}{\tau}\left(\hat{\mathbf{u}}-\mathbf{z}\right)+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}+{\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\hat{\mathbf{u}}\right).\end{array}} $$
$$ {\displaystyle \begin{array}{l}\mathbf{0}\hskip0.2em \in \nabla \left(\frac{1}{2\tau}\parallel \hat{\mathbf{u}}-\mathbf{z}{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\hat{\mathbf{u}}{\parallel}_2^2\right)\right),\\ {}\mathbf{0}\hskip0.2em \in \frac{1}{\tau}\left(\hat{\mathbf{u}}-\mathbf{z}\right)+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}\hat{\mathbf{u}}+{\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\hat{\mathbf{u}}\right).\end{array}} $$ By eliminating  $ \hat{\mathbf{u}} $ in the expression (A.9), we compute element-wise the proximal operator:
$ \hat{\mathbf{u}} $ in the expression (A.9), we compute element-wise the proximal operator:
 $$ {\left({\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right)\right)}_i={\mathrm{prox}}_{\overline{h},\tau}\left({\mathbf{z}}_i\right)=\frac{{\mathbf{z}}_i}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+{\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\Big(i,i\Big)\right)}. $$
$$ {\left({\mathbf{prox}}_{\overline{h},\tau}\left(\mathbf{z}\right)\right)}_i={\mathrm{prox}}_{\overline{h},\tau}\left({\mathbf{z}}_i\right)=\frac{{\mathbf{z}}_i}{1+\alpha \tau \left({\mathbf{I}}_{\boldsymbol{\Omega}}\left(i,i\right)+{\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\Big(i,i\Big)\right)}. $$B. Appendix. The Minimization Problem to Estimate $ {\hat{x}}_{\boldsymbol{\mu}}^{\prime } $

Starting from the penalized optimization problem (Reference Gustafsson, Culley, Ashdown, Owen, Pereira and Henriques13) and having  $ \mathbf{b} $ fixed, we aim to find a relation that contains the optimal
$ \mathbf{b} $ fixed, we aim to find a relation that contains the optimal  $ {\hat{\mathbf{x}}}_{\mu } $. While there are only quadratic terms, we proceed as following:
$ {\hat{\mathbf{x}}}_{\mu } $. While there are only quadratic terms, we proceed as following:
 $$ {\displaystyle \begin{array}{l}\mathbf{0}\hskip0.2em \in \nabla \left(\frac{1}{2}\parallel \boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\left(\overline{\mathbf{y}}-\mathbf{b}\right){\parallel}_2^2+\frac{\mu }{2}\parallel \nabla {\hat{\mathbf{x}}}_{\mu }{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu }{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right)\right]}^2\right)\right),\\ {}\mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\left(\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\left(\overline{\mathbf{y}}-\mathbf{b}\right)\right)+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu }+{\left[\phi \left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right){\phi}^{\prime}\left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right).\end{array}} $$
$$ {\displaystyle \begin{array}{l}\mathbf{0}\hskip0.2em \in \nabla \left(\frac{1}{2}\parallel \boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\left(\overline{\mathbf{y}}-\mathbf{b}\right){\parallel}_2^2+\frac{\mu }{2}\parallel \nabla {\hat{\mathbf{x}}}_{\mu }{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu }{\parallel}_2^2+\sum \limits_{i=1}^{L^2}\;{\left[\phi \left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right)\right]}^2\right)\right),\\ {}\mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\left(\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\left(\overline{\mathbf{y}}-\mathbf{b}\right)\right)+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu }+{\left[\phi \left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right){\phi}^{\prime}\left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right).\end{array}} $$Given (A.3), we can write:
 $$ \mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\left(\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\overline{\mathbf{y}}-\mathbf{b}\right)+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu }+{\left[\phi \left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right). $$
$$ \mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\left(\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\overline{\mathbf{y}}-\mathbf{b}\right)+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu }+{\left[\phi \left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right). $$ Our goal is to compute  $ {\hat{\mathbf{x}}}_{\mu}^{\prime } $, the partial derivative of
$ {\hat{\mathbf{x}}}_{\mu}^{\prime } $, the partial derivative of  $ {\hat{\mathbf{x}}}_{\mu } $ w.r.t.
$ {\hat{\mathbf{x}}}_{\mu } $ w.r.t.  $ \mu $. So, we derive as follows:
$ \mu $. So, we derive as follows:
 $$ {\displaystyle \begin{array}{l}\frac{\partial }{\partial \mu}\left(\mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\left(\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\overline{\mathbf{y}}-\mathbf{b}\right)+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu }+{\left[\phi \left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right)\right),\\ {}\mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu}^{\prime }+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu}^{\prime }+{\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu}^{\prime }+{\left[{\phi}^{\prime}\left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right){\left({\hat{\mathbf{x}}}_{\mu}^{\prime}\right)}_i\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right).\end{array}} $$
$$ {\displaystyle \begin{array}{l}\frac{\partial }{\partial \mu}\left(\mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\left(\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu }-\overline{\mathbf{y}}-\mathbf{b}\right)+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu }+{\left[\phi \left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right)\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right)\right),\\ {}\mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu}^{\prime }+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu}^{\prime }+{\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu}^{\prime }+{\left[{\phi}^{\prime}\left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right){\left({\hat{\mathbf{x}}}_{\mu}^{\prime}\right)}_i\right]}_{\left\{i=1,\dots, {L}^2\right\}}\right).\end{array}} $$ We define the matrix  $ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }} $ such as:
$ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }} $ such as:
 $$ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\left(i,i\right)=\left\{\begin{array}{ll}0& \mathrm{if}\;{\left({\hat{\mathbf{x}}}_{\mu}\right)}_{\mathrm{i}}\ge 0,\\ {}1& \mathrm{if}\;{\left({\hat{\mathbf{x}}}_{\mu}\right)}_{\mathrm{i}}<0.\end{array}\right. $$
$$ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\left(i,i\right)=\left\{\begin{array}{ll}0& \mathrm{if}\;{\left({\hat{\mathbf{x}}}_{\mu}\right)}_{\mathrm{i}}\ge 0,\\ {}1& \mathrm{if}\;{\left({\hat{\mathbf{x}}}_{\mu}\right)}_{\mathrm{i}}<0.\end{array}\right. $$ Now the vector  $ {\left[{\phi}^{\prime}\left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right){\left({\hat{\mathbf{x}}}_{\mu}^{\prime}\right)}_i\right]}_{\left\{i=1,\dots, {L}^2\right\}} $, using further the equation (A.3), can be simply written as:
$ {\left[{\phi}^{\prime}\left({\left({\hat{\mathbf{x}}}_{\mu}\right)}_i\right){\left({\hat{\mathbf{x}}}_{\mu}^{\prime}\right)}_i\right]}_{\left\{i=1,\dots, {L}^2\right\}} $, using further the equation (A.3), can be simply written as:  $ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}{\hat{\mathbf{x}}}_{\mu}^{\prime } $ and then (A.13) becomes:
$ {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}{\hat{\mathbf{x}}}_{\mu}^{\prime } $ and then (A.13) becomes:
 $$ \mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu}^{\prime }+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu}^{\prime }+{\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu}^{\prime }+{\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}{\hat{\mathbf{x}}}_{\mu}^{\prime}\right). $$
$$ \mathbf{0}\hskip0.2em \in {\boldsymbol{\Psi}}^{\intercal}\boldsymbol{\Psi} {\hat{\mathbf{x}}}_{\mu}^{\prime }+\mu {\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu}^{\prime }+{\nabla}^{\intercal}\nabla {\hat{\mathbf{x}}}_{\mu }+\alpha \left({\mathbf{I}}_{\boldsymbol{\Omega}}{\hat{\mathbf{x}}}_{\mu}^{\prime }+{\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}{\hat{\mathbf{x}}}_{\mu}^{\prime}\right). $$ The minimization problem we should solve in order to find  $ {\hat{\mathbf{x}}}_{\mu}^{\prime } $ thus is:
$ {\hat{\mathbf{x}}}_{\mu}^{\prime } $ thus is:
 $$ {\hat{\mathbf{x}}}_{\mu}^{\prime }=\underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}}{\arg \min}\frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}{\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}+\frac{1}{\mu}\nabla {\hat{\mathbf{x}}}_{\mu }{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\mathbf{x}{\parallel}_2^2\right). $$
$$ {\hat{\mathbf{x}}}_{\mu}^{\prime }=\underset{\mathbf{x}\hskip0.2em \in {\unicode{x211D}}^{L^2}}{\arg \min}\frac{1}{2}\parallel \boldsymbol{\Psi} \mathbf{x}{\parallel}_2^2+\frac{\mu }{2}\parallel \nabla \mathbf{x}+\frac{1}{\mu}\nabla {\hat{\mathbf{x}}}_{\mu }{\parallel}_2^2+\frac{\alpha }{2}\left(\parallel {\mathbf{I}}_{\boldsymbol{\Omega}}\mathbf{x}{\parallel}_2^2+\parallel {\mathbf{I}}_{{\hat{\mathbf{x}}}_{\mu }}\mathbf{x}{\parallel}_2^2\right). $$C. Appendix. Algorithmic Restart
Every initialization is based on the solution obtained at the previous restarting. There are many ways to choose the new initialization, deterministic, and stochastic ones. In this paper, we chose a deterministic way based on the following idea: for every pixel belonging to the solution of the previous restarting we find its closest neighbor. Then, we define the middle point between the two and we include it in the initialization of the current restarting. A small example is given in the Figure 17. The yellow points belong to the support estimation of the previous restarting. Starting from them we define the red points, used for the initialization of the current restarting.


























































 Open access
Open access