


Introduction
Reading a word is often described as a process of linking a presented letter string to the best matching lexical form and meaning representation in the reader's long-term memory store (also called the ‘mental lexicon’). Because average adult language users know at least 42,000 words in their native language (Brysbaert, Stevens, Mandera & Keuleers, Reference Brysbaert, Stevens, Mandera and Keuleers2016) and have a typical reading rate of about 240 words per minute (Brysbaert, Reference Brysbaert2019b), their usually flawless word retrieval process can be considered to be extremely efficient. When language users master a second language (L2) in addition to their first language (L1) and become bilinguals, their reading process becomes even more impressive. This is not only because the word recognition process must typically deal with a substantial influx of new words in the mental lexicon (often 10,000s of words), but also because these words may have forms and meanings that are similar or even identical to items that are already present. In light of this increased complexity, one wonders how exactly bilinguals manage to successfully derive the intended meaning from the visual scribbles that are presented to them on paper or on a screen.
Processing cognates (translation equivalents with form overlap)
To arrive at a better understanding of the mechanisms supporting bilingual visual word recognition, researchers in this domain have gratefully exploited the fact that, particularly for language combinations that make use of similar scripts, certain words have both orthographic and semantic overlap across languages. These so-called cognates can be defined as translation equivalents with considerable form overlap, such as the Dutch word ‘tomaat’ that translates into the English equivalent ‘tomato’. Studies involving individually presented cognates have shown that sharing form and meaning across languages has consequences for an item's representation and processing. Due to their cross-linguistic overlap in orthographic form, both members of a cognate pair are typically activated when one of them is presented (co-activation). The degree of activation of each cognate member has been found to depend on several factors, like language dominance (the relative strength of L1 vs L2), task language (L1 or L2), subjective item frequency (high or low), and cross-linguistic orthographic overlap with the input (high or low) (e.g., Duñabeitia, Perea & Carreiras, Reference Duñabeitia, Perea and Carreiras2010; Peeters, Dijkstra & Grainger, Reference Peeters, Dijkstra and Grainger2013). During recognition, activated orthographic representations activate their semantic counterparts and a process of orthographic-semantic resonance ensues. This resonance induces a facilitation effect for cognates relative to items without cross-linguistic overlap. Figure 1 (upper left panel) illustrates this account for a cognate presented to a Dutch–English reader in their L2 English (Dijkstra, Miwa, Brummelhuis, Sappelli & Baayen, Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Peeters et al., Reference Peeters, Dijkstra and Grainger2013).
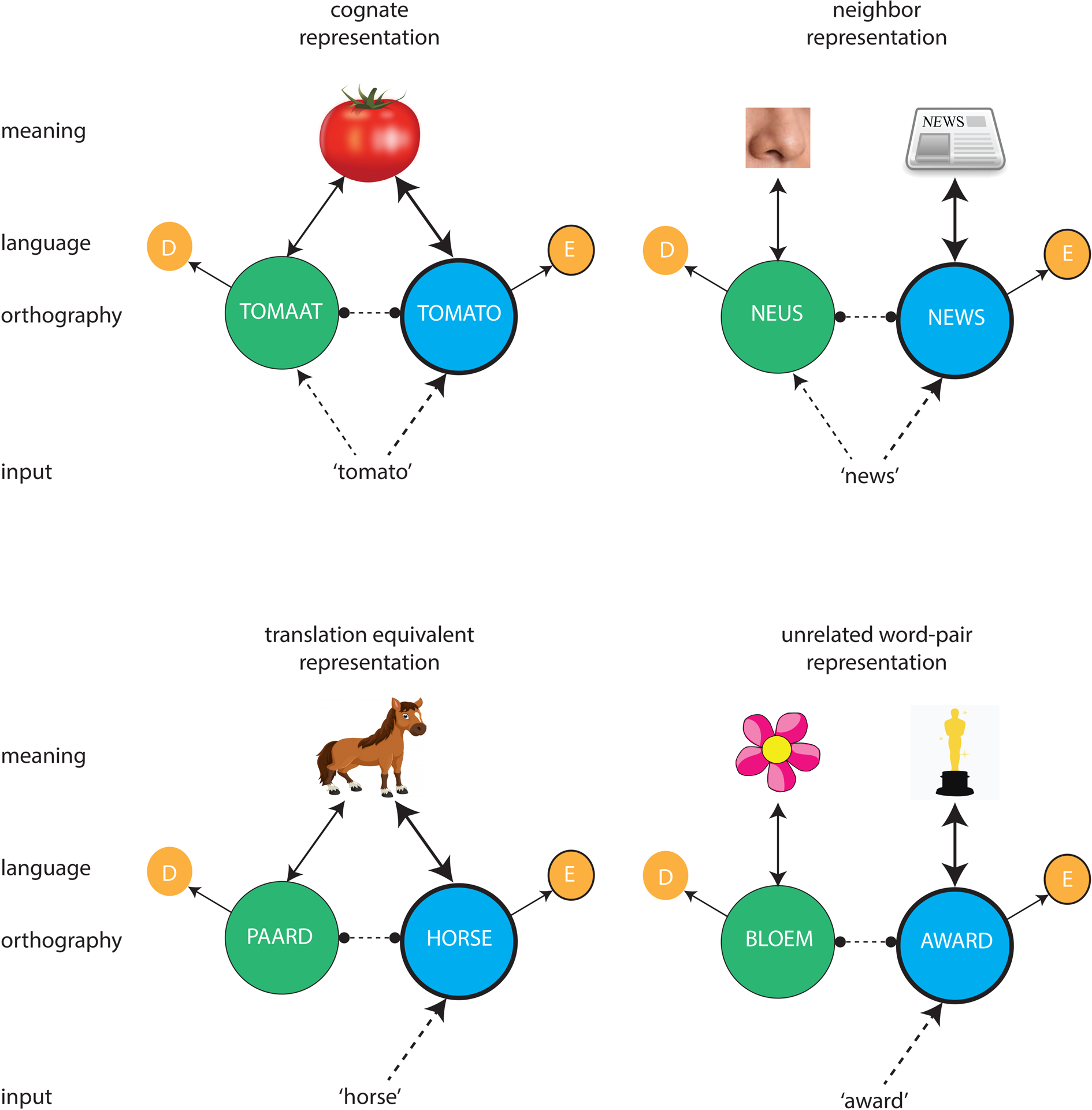
Figure 1. Proposed representation and processing of cognates, neighbors, translation equivalents, and unrelated items in the mental lexicon of a bilingual reader. When a Dutch-English bilingual encounters the L2 cognate ‘tomato’, both English (‘E’) and Dutch (‘D’) orthographic representations are activated, which converge on a shared meaning representation. Facilitatory resonance between orthographic and semantic codes (‘cognate facilitation’) trumps inhibitory effects caused by competition between the orthographically similar forms (‘lateral inhibition’). Such facilitatory resonance, but not lateral inhibition, is arguably absent for non-cognate neighbor words.
Processing neighbours (orthographically overlapping words with different meanings)
The cognate facilitation effect contrasts remarkably with findings for word pairs that are similar in orthography but do not share their meaning across languages, such as the English word ‘tail’ and the Dutch word ‘taal’ (meaning ‘language’). It is commonly assumed that such cross-linguistic orthographic neighbours are initially co-activated in word recognition as a function of their orthographic overlap with the visual input string (e.g., van Heuven, Dijkstra & Grainger, Reference van Heuven, Dijkstra and Grainger1998; Mulder, van Heuven & Dijkstra, Reference Mulder, van Heuven and Dijkstra2018). Neighbours are assumed to compete for selection through lateral inhibition, i.e., active word candidates inhibit competing alternatives until one viable word candidate remains. The degree of competition is thought to depend on their frequency-dependent resting-level activation and the degree of orthographic overlap with the stimulus word (e.g., McClelland & Rumelhart, Reference McClelland and Rumelhart1981). In this view, lateral inhibition can be considered as a structural property of the word recognition system.
Evidence for the role of competition and lateral inhibition between neighbours is found not only in single-word but also masked priming experiments. For instance, Bijeljac-babic, Biardeau, and Grainger (Reference Bijeljac-babic, Biardeau and Grainger1997) reported two cross-linguistic priming experiments with proficient French–English bilinguals. Following a forward mask of hash marks for 500 ms, primes were presented for 57 ms and were immediately replaced by targets. Lexical decisions were made on the targets. Orthographically related primes inhibited target word recognition by about 28 ms (relative to unrelated primes) when prime and target belonged to the same language (L1 French). When they were from different languages (L1 French and L2 English), the bilinguals displayed even larger inhibitory effects of 54 and 43 ms (given overall RTs of about 661 and 771 ms, respectively).
Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010) conducted another cross-linguistic priming study, in which orthographic primes were presented for 60 ms. Dutch–English bilinguals performed a Dutch (L1) lexical decision task on target words preceded by Dutch or English words or non-words. When the prime and target words were related (i.e., they were neighbours) and from the same language (Dutch), within-language priming inhibition effects arose of 11 ms. In a second experiment, related English–Dutch (L2-L1) prime-target pairs resulted in inhibition effects of 21 ms relative to unrelated item pairs. Word primes that orthographically overlapped with the targets induced small inhibition effects, whereas overlapping non-word primes generally resulted in facilitation. This general finding may be attributed to the effects of lateral inhibition in word-word priming conditions (see also Grainger & Ferrand, Reference Grainger and Ferrand1996).
An interesting question is to what extent lateral inhibition effects are independent of item properties (e.g., their error rates) and task instructions. In a monolingual lexical decision study, De Moor, Verguts, and Brysbaert (Reference De Moor, Verguts and Brysbaert2005) found that the size of neighbour inhibition effects in lexical decision depended on whether the task stressed accuracy or response speed. Stress on accuracy, especially through on-line feedback, led to stronger inhibition effects than stress on response speed. Thus, item properties and decision aspects possibly affect the size of inhibition effects in available studies.
In the light of this observation, one may wonder to what extent the recognition of cognates is influenced by lateral inhibition between their two readings. In particular, the widely replicated cognate facilitation effect indicates that any decelerating processing consequences of lateral inhibition between the two orthographic readings of a cognate are usually more than compensated for by the facilitatory resonance between orthographic and semantic codes (Dijkstra, Reference Dijkstra, Kroll and Groot2005).
Processing translation equivalents without form overlap
Based on Figure 1, the presence of lateral inhibition between the co-activated orthographic representations of ‘tomato’ (English) and ‘tomaat’ (Dutch) might be expected to reduce the size of the cognate facilitation effect (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Peeters et al., Reference Peeters, Dijkstra and Grainger2013). Indeed, given enough lateral inhibition, the facilitation effect due to the shared semantic component might even become smaller than that for translation equivalents without form overlap (e.g., English ‘horse’ and Dutch ‘paard’). This could be tested by comparing the processing of cognates to that of translation equivalents without orthographic overlap; the latter condition, henceforth called ‘(noncognate) translation’, should then result in larger facilitation effects relative to an unrelated condition.
However, the results of many available lexical decision studies involving isolated target words are not in line with this suggestion. For instance, in a study manipulating the degree of orthographic overlap in cognates and control words, Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010) observed facilitatory effects of orthographic overlap for all cognate types. Apparently, the facilitatory coactivation effect due to form overlap on cognate recognition consistently superseded any inhibitory effects of lexical competition.
At the same time, inhibitory effects in cognate processing do arise depending on stimulus list composition and task type, particularly when only non-identical cognates are considered (Arana, Oliveira, Fernandes, Soares & Comesaña, Reference Arana, Oliveira, Fernandes, Soares and Comesaña2022; Comesaña, Ferré, Romero, Guasch, Soares & García-Chico, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015; Comesaña, Haro, Macizo & Ferré, Reference Comesaña, Haro, Macizo and Ferré2021; Peeters, Vanlangendonck, Rueschemeyer & Dijkstra, Reference Peeters, Vanlangendonck, Rueschemeyer and Dijkstra2019; Poort & Rodd, Reference Poort and Rodd2017; Vanlangendonck, Peeters, Rüschemeyer & Dijkstra, Reference Vanlangendonck, Peeters, Rüschemeyer and Dijkstra2019). In a computational model like Multilink (Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte & Rekké, Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019), such inhibition effects are attributed to decision level processes that are sensitive to stimulus list composition and task demands, rather than to structural lateral inhibition effects (but see Arana et al., Reference Arana, Oliveira, Fernandes, Soares and Comesaña2022).
Another way to test the relative contribution of orthographic and semantic effects on the processing of cognates is to use a masked priming paradigm. The presentation of a form- or meaning related prime before the target word is known to enlarge the effects of overlap in lexical representations. As far as we know, a direct orthogonal comparison of the processing of non-identical cognates, noncognate translations, and orthographic neighbours in masked priming studies has not yet been made, possibly because it entails a combination of orthographic and semantic priming.
Relevant here is a masked priming study by Comesaña et al. (Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012) who reported that priming effects for cognates and noncognates were modulated by the relative degree of phonological vs orthographic overlap. In particular, when items had little orthographic overlap (O-) but considerable phonological (P+) overlap, the bilingual participants’ event-related potentials showed larger N400 amplitude than when both types of overlap were consistent. The authors explained these effects in terms of inhibitory connections between lexical representations. In the O-P+ condition, ‘the lower orthographic overlap hampers the recognition of cognate target words due to lateral inhibition’ (p. 79). Inhibitory effects of orthographic overlap might also be responsible for their finding of slower responses for non-identical cognate targets than for matched noncognates (571 ms vs 551 ms; p. 79).
Voga and Grainger (Reference Voga and Grainger2007) investigated the processing of cognates, translations, and word pairs overlapping in (phonological) form in a cross-script translation priming study. In two priming experiments, Greek–French bilinguals made lexical decisions on French targets that appeared after Greek primes with durations of 50 ms or 66 ms. Prime conditions with cognate pairs (e.g., κανόνι - CANON) were processed faster than prime conditions overlapping in phonology (κανόνας – CANON; with κανόνας meaning ‘rule’) or involving noncognate translations (δɛ́ντρο – ARBRE, where δɛ́ντρο is pronounced as /dentro/). Voga and Grainger argued that, relative to unrelated conditions, cognates resulted in stronger facilitation effects than translations, because cognate priming adds a form-priming component to the semantic priming component that both conditions share. The presentation of the prime and target in different scripts (Greek vs Latin/French) would explain the absence of lateral inhibition across languages (cf. their Figure 2 on p. 946).
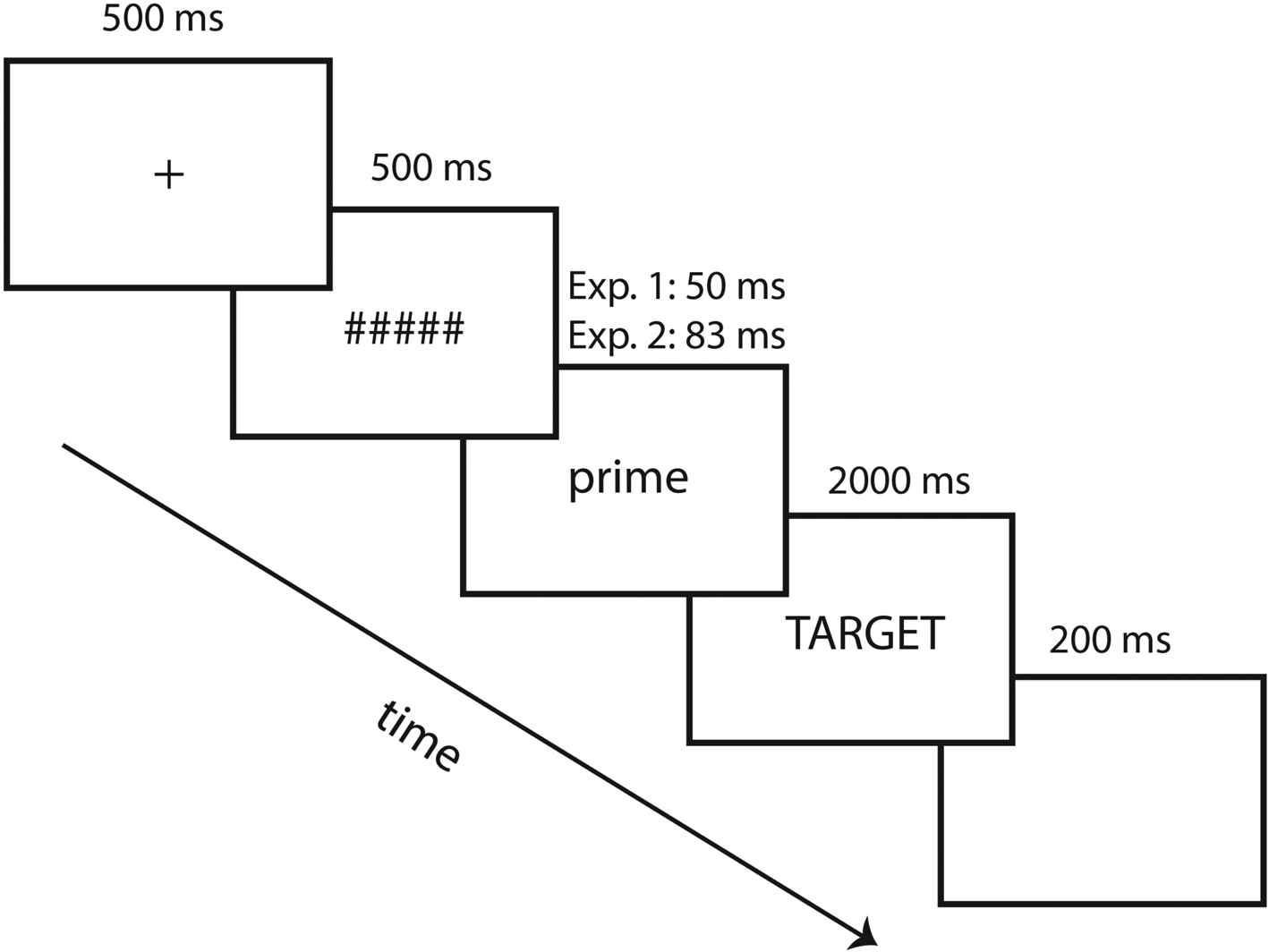
Figure 2. Trial structure used in the masked priming lexical decision experiments.
A meta-analysis of a considerable number of masked priming studies by Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2010) argues in favor of cognate facilitation effects that are generally larger for cognate than for noncognate translation pairs (see Wen & van Heuven, Reference Wen and van Heuven2017, for a meta-analysis of noncognate translation priming). Across the studies reviewed, Duñabeitia et al. report an average priming effect of 62 ms for cognate translations and of 39 ms for noncognate translations in forward (L1-to-L2) direction. In many of those studies, prime and target belonged to the same script. Nevertheless, as far as we know, none of these studies have differentiated the relative contribution of lateral inhibition with respect to the orthographic and semantic components of the cognate priming effect by comparing the processing of matched cognates, orthographic neighbours, and translations. This is an important issue, because the assumption of lateral inhibition is important to both bilingual and monolingual word recognition models (for instance, the IA model by McClelland & Rumelhart, Reference McClelland and Rumelhart1981; Rumelhart & McClelland, Reference Rumelhart and McClelland1982; the BIA+ model by Dijkstra & Van Heuven, Reference Dijkstra and Heuven2002; and the Multilink model by Dijkstra et al., Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019).
The present study
In order to disentangle the contribution of orthographic inhibition and semantic facilitation to bilingual visual word recognition under same-script conditions, we conducted a Dutch–English masked priming study with four test conditions, summarized in Table 1. As in earlier studies, our experiments included cognate and noncognate translation conditions, and an unrelated control condition. However, to disentangle the orthographic and semantic components contributing to the cognate effect, we also included a condition with cross-linguistic orthographic neighbours (see Table 1 for examples). In sum, the first goal of our primed lexical decision study was to investigate how inhibitory orthographic competition effects and semantic facilitation effects combine when prime and target are (a) both orthographically and semantically related (i.e., they are non-identical cognates); (b) only semantically related (translations); (c) only orthographically related (neighbours); or (d) unrelated.
Table 1. Orthogonal manipulation of semantic and orthographic relatedness of the Dutch prime and the English target word with example word pairs.

In line with the meta-analysis by Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2010), it was predicted that non-identical cognate pairs would lead to a larger facilitation effect than noncognate translation pairs, while both should be facilitated relative to unrelated word pairs. Based on the available studies on orthographic priming and the assumption of lateral inhibition, orthographically related primes may be expected to result in an inhibition effect on the target relative to orthographically unrelated primes (cf. Forster, Davis, Schoknecht & Carter, Reference Forster, Davis, Schoknecht and Carter1987; Lam & Dijkstra, Reference Lam and Dijkstra2010).
The processing account underlying Figure 1 would lead us to expect non-additive effects of orthographic and semantic overlap on cognates. In an orthographically unrelated prime-target condition, the prime should not activate the non-overlapping target at all. However, the recognition process of a (non-identical) cognate in the priming task begins with full activation of prime orthography and partial activation of the target orthography. This coactivation will arguably lead to cross-linguistic competition due to lateral inhibition (indicated by the dashed horizontal lines in Figure 1). Thus, in order to obtain a cognate facilitation effect, the positive effect of target coactivation must still win out over the negative lateral inhibition effect at the moment the prime is replaced in the input by the target; otherwise, the target would not be facilitated by the prime, but inhibited. In this reasoning, the lateral inhibition exerted by the prime could only start to play a negative differential role when the prime becomes sufficiently more active than the target; however, this moment might never arrive, because the prime is replaced by the target after a short time (i.e., prime duration). This account explains why cognates can still show a semantic facilitation effect in (masked) priming studies, even when the presence of lateral inhibition is assumed.
This processing account also has its consequences for the orthographic neighbour condition. In this priming condition, there is no effect of shared semantics that could possibly reduce the simultaneous effect of lateral inhibition by the prime on the target. Thus, we considered this condition optimal for assessing the pure contribution of lateral inhibition due to orthographic overlap to the cognate priming effect.
Importantly, the account also leads us to expect that the observed result patterns will depend on the relative duration of the prime and target. As a second goal of our study, we therefore decided to manipulate the relative duration of the prime at hand. More specifically, we replicated our Experiment 1, in which prime duration was 50 ms, with a longer prime duration of 83 ms in Experiment 2. This new experiment further allowed us to assess the stability of the results obtained in Experiment 1.
The motivation to increase the duration of the prime word is the following. When the prime is presented for a longer duration, the relative activation advantage of the prime word over its neighbour, the target, should increase, because the prime input has a complete overlap with the prime word but not with the target word in memory. As a consequence, a larger orthographic competition effect of the prime on the target might arise through lateral inhibition. We did not opt for a prime duration beyond 83 ms, because this may result in conscious awareness of the prime's identity and subsequent strategic effects in the reading participant (e.g., Kinoshita & Lupker, Reference Kinoshita and Lupker2004; Wernicke & Mattler, Reference Wernicke and Mattler2019). With respect to semantic facilitation effects, a longer prime duration (and/or SOA) might modulate effects for cognate and translation conditions, because both prime and target here map onto the same, shared semantic representation (see Ferré, Sánchez-Casas, Comesaña & Demestre, Reference Ferré, Sánchez-Casas, Comesaña and Demestre2017; Wen & van Heuven, Reference Wen and van Heuven2017).
This line of argumentation treats the effects of increasing prime duration as qualitative (verbal, as in ‘larger’ or ‘smaller’) rather than quantitative (numerical) in nature. In fact, all predictions made in the literature on cognate, translation, and neighbour pairs have so far been qualitative, rather than quantitative. As a third goal of this paper, we therefore aimed to simulate our results numerically by means of a recent computational model for word retrieval, called Multilink (Dijkstra et al., Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019). In this model, the proposed representations for cognates, translations, and neighbours discussed above are all implemented in a combined orthographic and semantic network. Simulations in the last part of this paper will show to what extent the model is able to capture the word recognition process in our orthographic-semantic priming experiments. In particular, such simulations may inform us about the importance of lateral inhibition for lexical processing. We note that this is the first time the model is applied to orthographic and semantic priming studies. In addition, the simulations will allow us to assess the effect of the difference in prime duration between Experiments 1 and 2 on Multilink performance. A further description of the model will be given later in the section called ‘Simulation Study’ (following Experiment 2).
Experiment 1 (50 ms prime duration)
Method
Participants
Forty participants (30 female; 19-29 years of age; mean age 22.9) took part in the experiment. The participants were students at Radboud University Nijmegen. All were native speakers of Dutch who started learning their second language English in school between the ages of 8 and 12. As such, they were unbalanced bilinguals with native proficiency in Dutch and a high, non-native proficiency in English, as confirmed by a relatively high score (M = 78.2/100, SD = 10.1) on the English LexTale vocabulary test (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012). All participants had normal or corrected-to-normal vision. They received monetary compensation for their participation.
Stimuli
The critical stimuli used in the masked priming lexical decision task consisted of 112 Dutch–English word-pairs. All words consisted of either four or five letters. Word length was identical between the Dutch (L1) word and the English (L2) word in each word pair. Each word pair belonged to one of four conditions in a 2 x 2 within-subject design that crossed orthographic relatedness (related vs unrelated) with semantic relatedness (related vs unrelated). Twenty-eight word pairs were non-identical cognates that had a similar meaning, but differed orthographically in one letter between Dutch and English (e.g., magie-MAGIC). Twenty-eight word pairs were neighbours that differed orthographically in one letter between Dutch and English, but had different, unrelated meanings (e.g., griep-GRIEF, where the Dutch word griep means flu in English). Twenty-eight word pairs were Dutch–English translations that had no orthographic overlap (e.g., paard-HORSE, where the Dutch word paard means horse in English), but had similar meanings. Twenty-eight word pairs had no semantic overlap and no orthographic overlap across the two languages (e.g., doos-CHIN, where the Dutch word doos means box in English). These served as unrelated controls.
Dutch and English words were matched within and across languages and conditions based on lexical characteristics taken from the SUBTLEX-US database (Brysbaert & New, Reference Brysbaert and New2009) for the English words and the SUBTLEX-NL database (Keuleers, Brysbaert & New, Reference Keuleers, Brysbaert and New2010) for the Dutch words (see Table 2). All word stimuli are included as online Supplementary Materials on the Open Science Framework entry for this paper (see link below). This file not only presents the words’ log10 frequencies in occurrences per million, but also their Zipf-values (see van Heuven, Mandera, Keuleers & Brysbaert, Reference van Heuven, Mandera, Keuleers and Brysbaert2014), the concreteness value of each word, and the number of orthographic neighbours of the target words on the basis of the British Lexicon Project (Keuleers, Lacey, Rastle & Brysbaert, Reference Keuleers, Lacey, Rastle and Brysbaert2012). For each dimension, corrected t-tests on prime and target items revealed no significant differences between any of the four conditions (all p's > 0.05).
Table 2. Mean English and Dutch prime and target log word frequencies (SUBTLEX-US in opm), and mean word length in letters for the different stimulus categories in the experiment. Standard deviations are presented within parentheses.

Note: The Zipf-values of items can be found in Supplementary Materials.
The word pair stimuli were further matched with 112 pseudoword pairs (e.g., bruim-LOUND) with a length of four or five letters per pseudoword. Pseudowords complied with Dutch’ (for the first item in each pair – the prime) and English’ (for the second item in each pair – the target) orthotactics and phonotactics, but did not exist as a word in English or Dutch. Finally, 16 additional item pairs (8 word pairs; 8 pseudoword pairs) were selected that served as practice trials in the experiment.
Procedure
The experiment took place in English. After providing informed consent, participants were individually seated in a quiet room at approximately 45 cm in front of a 22-inch computer monitor (120 Hz). They performed a masked priming lexical decision task in English. Participants pressed one button on a dedicated response box on the side of their dominant hand when they judged that the target item was an existing English word and the other button on the side of their non-dominant hand when they considered it a pseudoword. They were instructed to respond as quickly and as accurately as possible.
All letter strings were presented in black Arial letters (font size 32) against a white background. On each trial, a fixation cross in the middle of the screen (500 ms) was followed by a row of four (for subsequent four letter items) or five (for five letter items) hash marks (#) that served as a forward mask for a duration of 500 ms. This was followed by the presentation of a Dutch (L1) word or pseudoword lowercase prime (three frames: 50 ms) in the same position, immediately followed by the English target word (L2) in uppercase. The target item remained on the screen until the participant gave a response (2000 ms time-out). Immediately after the participant's response or when the time-out limit was reached, the target word disappeared and the screen stayed blank for 2000 ms before the next trial started. Figure 2 visually depicts the trial structure.
The experiment was preceded by 16 practice trials during which feedback (the word ‘correct’ in green or the word ‘incorrect’ in red as a function of whether a response was correct or not) was automatically presented on the screen after the participant's lexical decision for each target item. Twenty-four different pseudorandomized stimulus lists were used in the experiment. After the main experiment, participants performed the LexTALE vocabulary task in their L2 English (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012), which confirmed that participants were unbalanced bilinguals with a relatively high proficiency in their L2 English.
Presentation software (Neurobehavioral Systems Inc.) was used to present the experiment to the participants. We used a digital oscilloscope (Tektronix) with a light-to-voltage optical sensor (TSL250) to confirm, prior to data collection, that primes were indeed presented for an exact duration of 50 ms.
In total, the full experimental session took approximately 40 minutes.
Data analysis
R (R Core Team, 2017), lme4 (Bates, Maechler, Bolker & Walker, Reference Bates, Maechler, Bolker and Walker2015), and lmerTest (Kuznetsova, Brockhoff & Christensen, Reference Kuznetsova, Brockhoff and Christensen2017) were used to test for main effects of orthographic relatedness (related vs unrelated), semantic relatedness (related vs unrelated), and their interaction in the reaction time (RT) and accuracy data, using linear mixed effects regression models (lmer) for the RT data and logistic mixed effects models (glmer, binomial) for the accuracy data. To facilitate interpretation of the regression coefficients, orthographic relatedness (1 related; -1 unrelated) and semantic relatedness (1 related; -1 unrelated) were sum-coded. The total raw dataset consisted of 8,960 data points (40 participants, 224 trials per participant), half of which concerned word targets. Ten word pairs were excluded from the RT analysis because > 35% of participants made an incorrect lexical decision on the target word (see Table 7 for their respective conditions). Also outliers, defined as trials that elicited an RT that was more than 2.5SD removed from a participant's average RT on correct trials, and trials that elicited an incorrect lexical decision, were removed from the RT analyses. This left a dataset of 7,811 data points for the RT analysis. We used an inverse transform (-1000/RT) in these analyses, to correct for the observed (typical) skewedness of the RT distribution, which successfully reduced non-normality. The random effects structure of the statistical models is provided in Table 4. More complex models failed to converge. We present the RT analyses below, and the error rate analyses in the Supplementary Material.
Table 4. Outcome of the linear mixed effects analysis performed on the RT data from Experiment 1.

* p < .05; ** p < .01; *** p < .001; OrthRel = orthographic relatedness; SemRel = semantic relatedness
Table 7. Pearson correlations between RTs and CTs for items in each test condition of Experiments 1 and 2. All correlations significant at p < .001. The number of items included for each condition in the two experiments is given in parentheses.

Results
Table 3 presents average RTs for correct responses and error rates per condition in Experiment 1, while the outcome of the linear mixed effects analysis on the RT data is provided in Table 4. As Table 4 shows, semantically related word pairs (with cognates and translations as targets) were, overall, responded to significantly faster (p < 0.001) than semantically unrelated word pairs (with neighbours and unrelated controls as targets). Table 3 indicates that non-identical cognate targets (M = 577 ms) were responded to faster than unrelated control targets (M = 625 ms), amounting to an overall cognate facilitation effect of 48 ms. Translations (M = 608 ms) were responded to 17 ms faster than unrelated control words (M = 625 ms).
Table 3. Mean reaction times in milliseconds and mean error rates in percentages for cognates, neighbors, translations, unrelated control words, and pseudowords in Experiment 1. Only correct responses were included in the RT averages. Standard deviations are presented within parentheses.

In contrast, orthographically related word pairs (with cognates and neighbours as targets) were, combined, not processed significantly faster than orthographically unrelated word pairs (with translations and unrelated controls as targets) (p = 0.0781). Table 3 shows that neighbours (M = 628 ms) were responded to minimally slower than unrelated controls (M = 625 ms), displaying a numeric inhibitory difference of only 3 ms.
The interaction between orthographic relatedness and semantic relatedness also did not reach significance (p = 0.077). However, in this case we had formulated theoretical predictions for the specific contrast with respect to cognates vs translations, and therefore carried out a follow-up analysis. This analysis indicated that orthographic overlap was a significant predictor (Est. = −0.05, SE = 0.02, t = −2.32, p = 0.02) of RT in the comparison of semantically related stimuli (cognates vs translations). In other words, cognate targets (M = 577 ms) were processed significantly faster than translation targets (M = 608 ms). In contrast, semantic overlap was not a significant predictor (Est. = −0.03, SE = 0.02, t = −1.60, p = 0.12) of RT in the comparison of the orthographically unrelated stimuli (translations vs control words). Thus, there was no statistical difference in RT between translations (M = 608 ms) and unrelated control words (M = 625 ms).
Discussion Experiment 1
The results of Experiment 1 were only to some extent in line with our predictions and partially consistent with the available literature on orthographic and semantic priming in bilinguals. As expected, a strong facilitatory cognate priming effect of 48 ms was obtained relative to the unrelated priming condition. Note that priming an identical cognate by a prime with a duration of 50 ms would not be expected to result in a larger priming effect than this (because in this condition the target duration would actually be prolonged by 50 ms). Furthermore, this cognate facilitation effect was significantly larger than the non-significant ‘semantic’ difference of 17 ms for the noncognate translation condition compared to the unrelated (control) condition. However, the absence of a significant translation priming effect from Dutch (L1) to English (L2) was unexpected (cf. for instance, Table 1 in Schoonbaert, Duyck, Brysbaert & Hartsuiker, Reference Schoonbaert, Duyck, Brysbaert and Hartsuiker2009). One possible explanation is that at a prime duration of 50 ms, the prime (e.g., Dutch ‘kooi’) was not activated enough to induce sufficient semantic pre-activation of its meaning shared with the orthographically fully different target (e.g., English ‘CAGE’). Another contributing factor here may be that the overall RTs for this participant group were quite fast. The possibility that there was a lack of statistical power (given 23–27 items per condition in 40 participants) will be considered in the Discussion of Experiment 2.
If indeed the prime word in our noncognate translation priming condition was not activated enough to affect its meaning, this might be ascribed in part to an effect of lateral inhibition. However, although we did obtain a numerical inhibitory difference of 3 ms for the neighbour relative to the unrelated condition, this difference was clearly statistically non-significant in both RTs and error rates. Theoretically, one might expect a significant inhibitory priming effect of an orthographically overlapping prime from the native language (L1) on the foreign language (L2) target, due to the lateral inhibition by the relatively higher-frequency L1 competitor. Unfortunately, empirically, there are not many studies that have documented this effect. An exception is the study by Bijeljac-babic et al. (Reference Bijeljac-babic, Biardeau and Grainger1997), who reported large cross-linguistic (L1-to-L2) inhibition effects for orthographic neighbours.
Given the partially unexpected pattern of results, especially for the translation and neighbour conditions, we decided to replicate Experiment 1 with a somewhat longer prime duration. The replication was both theoretically and methodologically motivated. From a theoretical perspective, prime duration affects the relative prominence of orthographic and semantic activation of prime and target. The longer the prime duration is, the more the prime representation can win out over that of the target. Thus, an increase of the potential effects of orthographic lateral inhibition might be expected at longer prime durations. In addition, semantics might become activated, resulting in facilitatory semantic-orthographic resonance. For the present study, these effects are particularly important for both the neighbour and the cognate conditions. However, in order to avoid the prime from becoming visible at all times, which could elicit unwanted conscious strategies, we limited the prime duration to 83 ms.
From a methodological perspective, the replication allowed us to assess the stability of the results across participant groups and computer equipment. We note that Experiment 1 resulted in 40 participants * 28 items = 1120 measurements per condition, suggesting that power problems should not have been severe (Brysbaert, Reference Brysbaert2019a). Following Experiment 2, we will therefore also present a joint analysis of both experiments.
Experiment 2 (83 ms prime duration)
Method
Participants
Forty-one participants (35 female; 17–34 years of age; mean age 21.5) took part in the experiment. The participants were students at Radboud University Nijmegen. All were native speakers of Dutch who started learning their second language English in school between the ages of 8 and 12. As such, they were unbalanced bilinguals with native proficiency in Dutch and a high, non-native proficiency in English, as confirmed by a relatively high score (M = 4198/5000, SD = 544) on the English XLex vocabulary test (Meara & Milton, Reference Meara and Milton2005). All participants had normal or corrected-to-normal vision. They received course credits or monetary compensation for their participation.
Stimuli, Procedure, and Data Analysis
Stimuli were identical to those used in Experiment 1. The only procedural difference between the two experiments was that prime duration was longer (five frames: 83 ms) in Experiment 2 than in Experiment 1 (three frames: 50 ms).
In total, the full experimental session took approximately 40 minutes. Data analysis and specification of statistical models were identical to Experiment 1. Data from one participant were excluded from the analyses due to an overall error proportion that exceeded 25%, leaving a total raw dataset of 8,960 data points (40 participants, 224 trials per participant), as in Experiment 1. After removal of errors and outliers as in Experiment 1, a total of 7,951 trials entered the RT analyses. We again present the RT analyses below, and the error rate analyses in the Supplementary Material (Supplementary Materials).
Results
Table 5 presents the average RTs and error rates per condition in Experiment 2. It can be seen that non-identical cognate targets (M = 595 ms) were again responded to substantially faster than control words (M = 645 ms), which amounted to an overall cognate facilitation effect of 50 ms. Translations (M = 618 ms) were also responded to faster than control words, amounting to a translation facilitation effect of 27 ms. Neighbours (M = 654 ms) were responded to slower than control words, displaying an inhibitory difference of 9 ms.
Table 5. Mean reaction times in milliseconds and mean error rates in percentages for cognates, neighbors, translations, unrelated control words, and pseudowords in Experiment 2. Only correct responses were included in the RT averages. Standard deviations are presented within parentheses.

The outcome of the linear mixed effects analysis on the RT data (correct responses only) is provided in Table 6. It was found that, overall, orthographically related words (cognates and neighbours) were responded to not significantly (p = 0.13) faster than orthographically unrelated words (translations and control words). Furthermore, semantically related words (cognates and translations) were again, overall, responded to significantly faster than semantically unrelated words (p < 0.001; neighbours and control words). Most importantly, however, we observed a significant interaction between orthographic relatedness and semantic relatedness (p < 0.05; see Table 6).
Table 6. Outcome of the linear mixed effects analysis performed on the RT data from Experiment 2.

* p < .05; ** p < .01; *** p < .001; OrthRel = orthographic relatedness; SemRel = semantic relatedness
Follow-up analyses indicated that orthographic overlap was a significant predictor (Est. = −0.04, SE = 0.02, t = −2.50, p = 0.02) of RT in the comparison of semantically related stimuli (cognates vs translations). This means that cognates (M = 595 ms) were processed significantly faster than translations (M = 618 ms). No such effect of orthographic overlap (Est. = 0.006, SE = 0.02, t = 0.36, p = 0.72) was observed in the comparison of the two stimulus conditions that were semantically unrelated (neighbours vs unrelated controls). Thus, the RTs for neighbours (M = 654 ms) did not statistically differ from those for unrelated words (M = 645 ms). Note that, numerically, the RTs for neighbours were again longer than the RTs for unrelated words. Finally, follow-up analyses indicated that semantic overlap was a significant predictor (Est. = −0.03, SE = 0.02, t = −2.11, p = 0.04) of RT in the comparison of the orthographically unrelated stimuli (translations vs unrelated words). Translations (M = 618 ms) yielded therefore significantly faster RTs than unrelated control words (M = 645 ms).
Discussion Experiment 2
Experiment 2 (prime duration = 83 ms) yielded a result pattern similar to that of Experiment 1 (prime duration = 50 ms). The participants of Experiment 2 were overall somewhat slower to respond than those in Experiment 1 and made fewer errors. Nevertheless, relatively similar result patterns for the orthographic and semantic manipulations arose in both experiments. From a methodological perspective, this is reassuring.
As can be seen in Tables 5 and 6, Experiment 2 yielded a significant facilitation priming effect of 50 ms for cognates and a significant advantage of 27 ms for translations. These results for a prime duration of 83 ms are remarkably similar to those reported by Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2010) for a prime duration of 50 ms. In their study, balanced Spanish–Basque bilinguals made lexical decisions on Spanish or Basque target words following masked primes. In two sessions, the presented target words were Basque or Spanish, respectively. Like in our study, larger priming effects were obtained for cognates than for noncognate translation equivalents. For cognate targets, similarly-sized facilitation effects were obtained relative to unrelated prime-target conditions of 44 ms for Spanish and 62 ms for Basque. Translation conditions involving noncognate pairs led to smaller facilitation effects of 16 ms for Spanish targets and 20 ms for Basque targets.
Their and our cognate and translation effects are somewhat smaller than the effects they themselves reported in their meta-analysis of a considerable number of masked priming studies. Across the reviewed studies (in their Tables 1 and 2), they report an average priming effect of 62 ms for forward (L1-to-L2) cognate translations compared to 39 ms for masked noncognate translations. As the authors indicate, the size of priming effects observed in a study may be dependent on the response times obtained and on other factors (e.g., the actual rather than the intended duration of the prime). In the current study, we used a digital oscilloscope with a light-to-voltage optical sensor to confirm that the primes were consistently presented for exactly the intended prime durations.
With respect to cognate translation pairs, an earlier, comparable, study by de Groot and Nas (Reference de Groot and Nas1991) obtained forward priming effects varying between 48 and 64 ms for highly overlapping Dutch–English cognates relative to unrelated conditions in a Dutch–English masked priming study at a prime duration of 40 ms followed by a 20 ms blank. Gollan, Forster, and Frost (Reference Gollan, Forster and Frost1997, Exp. 2) reported a cognate effect of 53 ms in a Hebrew–English primed lexical-decision study at a prime duration of 50 ms. Note that, like the study by Voga and Grainger (Reference Voga and Grainger2007), this study involved different scripts for prime and target. As a final example, Ferré et al. (Reference Ferré, Sánchez-Casas, Comesaña and Demestre2017) tested proficient unbalanced Spanish–English bilinguals in a masked L1-to-L2 translation priming task. Cognate facilitation effects of 34 and 44 ms were found for a prime duration of 50 ms and SOAs of 50 or 100 ms.
With respect to noncognate translation pairs, our priming differences are comparable in size to those found by Voga and Grainger (Reference Voga and Grainger2007; 22 ms and 23 ms) and Dimitropoulou, Duñabeitia, and Carreiras (Reference Dimitropoulou, Duñabeitia and Carreiras2011; 24 ms). Both these studies involved different script bilinguals (Greek–French and Greek–Spanish, respectively) processing noncognate translations at a prime duration of 50 ms. However, the effects were somewhat smaller than in the earlier mentioned Dutch–English study by de Groot and Nas (Reference de Groot and Nas1991) with same script bilinguals, who reported noncognate translation effects of 35 ms and 40 ms.
In sum, as in the available literature, our cognate pairs led to larger facilitation effects than our translation pairs, while translation pairs themselves led to faster RTs than unrelated conditions. When we consider the contribution of lateral inhibition to the data patterns, the result patterns are less clear. In Experiment 2, orthographic neighbour primes led to a small and non-significant (p = 0.72) difference of 9 ms inhibition for the targets relative to unrelated primes. In Experiment 1, a similar inhibitory difference was also clearly statistically non-significant (3 ms, p = 0.99). A statistical analysis combining all data from both experiments indicated that the absence of an inhibition effect was not due to a lack of statistical power (see Appendix A; also see Peeters et al., Reference Peeters, Loermans, Thorin and Dijkstra2022).
Simulation Study
As a final goal of our study, we aimed to simulate our results quantitatively in a computational model for word retrieval that implements both this general framework and the proposed cognate representation. This model, called Multilink (Dijkstra et al., Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019), implements the mental lexicon of monolinguals and bilinguals as an orthographic, semantic, and phonological network. Multilink is a symbolic connectionist network model that applies the standard activation function of this paradigm in order to regulate the flow of activation between representations in the network. The priming effects for cognates, neighbours, and translations, in our lexical decision task can all be understood in terms of co-activation and resonance of their representations in this network, exactly as shown in a simplified way in Figure 1 of this paper. We note that, at present, the model has been tested on the recognition of individual words (see Dijkstra et al., Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019, for simulations of lexical decision, word naming, and translation production). Until now, it has not been assessed whether the model can also account for the results of orthographic and translation priming experiments. We will call the model variant used here Multilink+, because it makes a number of additional assumptions (mostly semantic in nature) due to its application to priming studies. We refer the reader to Dijkstra et al. (Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019) for basic aspects of the modeling framework, but will reiterate major characteristics and extensions that are relevant to the present study.
Lexical representations in the network are initially set at a negative activation level that depends on their frequency of usage (in occurrences per million, taken from the SUBTLEX-UK dataset, but thus independent of its size). This Resting Level Activation (RLA) lies between 0 for very high frequency words and -.20, for very low frequency words. When an input letter string is presented to Multilink, these lexical orthographic representations are activated depending on their overlap with the letter string (measured in Levenshtein Distance). As soon as the activation of a representation surpasses a 0-threshold, it starts to compete with other such active representations; this is called lexical competition or lateral inhibition. Active orthographic representations also begin to activate semantic and phonological representations they are associated with. These, in turn, then interact with their own linked representations in the network. After a certain period of time (measured in cycles rather than milliseconds), one target word, usually the input item, transcends a recognition activation threshold (set at .72 of the maximal activation possible) and is recognized.
Depending on the task at hand, a task / decision system considers the activation of one or more representations in the network to arrive at a decision and response in correspondence with the task at hand (cf. Peeters et al., Reference Peeters, Vanlangendonck, Rueschemeyer and Dijkstra2019; Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rüschemeyer and Dijkstra2019). For instance, in lexical decision, an item will be recognized if its orthographic representation surpasses the activation threshold of .72. In contrast, in word naming, the pronunciation of a word can be determined after a lexical-phonological representation becomes active enough; and in semantic categorization, the initialization of a response requires the sufficient activation of a lexical concept.
An interesting possibility of this type of connectionist model that was already shown for the Interactive Activation model (McClelland & Rumelhart, Reference McClelland and Rumelhart1981), one of its predecessors, is to simulate the performance of a task combining primes and targets. Both orthographic and semantic priming can be simulated by the model by presenting, first, a prime word (e.g., for two time steps), and then replacing it by a target (indefinitely). The task/decision process is applied in the same way as before (e.g., the first orthographic word candidate that surpasses the recognition threshold is identified).
In the present simulation study, we simulated each and all conditions of the priming experiments in the following way. First, we tested to what extent the overall result pattern across the four conditions for each experiment was replicated by the Multilink+ model in terms of an overall correlation between RTs and Cycle Times (CTs). With respect to semantics, we incorporated whole-concept representations that were assumed to be sensitive to (orthographic) frequency of usage in occurrences per million, as taken from SUBTLEX_UK. We conducted simulations both with and without semantic lateral inhibition. Next, we computed the fit of the model for each of the individual conditions in the same way. We note that simulations for unprimed conditions involving the four item types were already presented by Dijkstra et al. (Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019). However, here the model is applied to primed items of these types.
To set the scene for all simulations, we will briefly discuss Multilink+'s lexicon and the method in which the simulations were set up. For more extensive descriptions of the Multilink framework, we refer to Dijkstra et al. (Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019) and Reference Dijkstra, van Geffen and HieselaarDijkstra et al. (in preparation). A task-sensitive account of masked L2-to-L1 translation priming for noncognates with inspirations from Multilink is found in McPhedran and Lupker (Reference McPhedran and Lupker2021).
Multilink+'s lexicon and input materials
All stimulus words of Experiments 1 and 2 were included in the standard large Multilink+ lexicon (Dijkstra et al., in preparation). For the simulation series at hand, this Dutch–English lexicon consisted of 2,690 word pairs of 3–8 letters in length. Word frequencies were obtained from SUBTLEX-US (Brysbaert, New & Keuleers, Reference Brysbaert, New and Keuleers2012) and SUBTLEX-NL (Keuleers et al., Reference Keuleers, Brysbaert and New2010). Phonological representations were obtained from the CELEX database (Baayen, Piepenbrock & Gulikers, Reference Baayen, Piepenbrock and Gulikers1996). Word translations were either obtained from Reference Dijkstra, van Geffen and HieselaarDijkstra et al. (in preparation) for stimuli in the near-cognate and translation equivalent conditions or from a translation program (Euroglot Professional 8.3.0, 2014) for stimuli in the neighbour and unrelated control conditions. Two Dutch prime words, when translated by Euroglot, resulted in English adjective-noun combinations (stift / felt-tip pen and pech / bad luck). For this reason, they were not included in Multilink+'s lexicon. Thus, in total, 110 out of 112 prime-target stimulus pairs were suitable as input materials for simulations.
Method and Results
Primes were presented to Multilink+ at time step 0 (the first time step) and target words at time step 2. Thus, primes were presented for a total of two time steps (step 0 and step 1). When one time cycle of model processing is assumed to correspond to 25 ms of human processing time, this amounts to a priming duration of 50 ms. Simulations suggested that this SOA of 2 time steps best approximated the masked priming situation of the experimental studies. The results of simulations including and excluding lateral inhibition with prime durations of 3 and 4 time cycles showed very similar correlational patterns and are available on request. Masks cannot be given as input to Multilink+ and were not used. Targets were provided as input until recognition took place or until a maximum number of 40 time steps was reached. The task/decision parameter of Multilink+ was set to perform a lexical decision task on English target words, i.e., an input word was assumed to be identified if its orthographic activation surpassed a recognition threshold of .72. For the simulations, all parameters of Multilink+ were set at their standard values (see Appendix B). Semantic activation was set at a frequency-dependent resting level activation (analogous to orthographic and phonological RLAs). With lateral inhibition in orthography, phonology, and semantics set at the standard value of −0.0001, an overall Pearson correlation was obtained between the simulation results and the RTs of Experiment 1 of r = .68 (N = 100), and between simulations and Experiment 2 of r = .67 (N = 101; both correlations significant at p < .001). Without lateral inhibition, the overall correlations were r = .67 (N = 100) and r = .66 (N = 101), respectively (p < .001). Using both settings, all words were correctly recognized.
Next, correlations based on the items in individual test conditions of Experiments 1 and 2 were also computed. These are presented in Table 7.
Discussion Simulation Study
This is the first time that the Multilink+ model is applied to the primed lexical decision task. The high overall correlations between simulation and empirical results indicate that Multilink+ does indeed capture the processing of different types of items across the board using one and the same representational network, task specification, and parameter settings. Moreover, separate correlations for each of the four categories of items indicate that the processing of cognates, neighbours, translations, and unrelated prime-target pairs are all well-accounted for by the Multilink+ model.
In addition, the correlations are relatively high for each of the two experiments. This observation, that the model fits both datasets about equally well, is in line with the finding that the result patterns in the two studies are directly comparable from a statistical perspective. The good fit for simulations of the results in both experiments and the absence of a statistical difference in their result patterns suggest that we should not pay too much attention to inter-experimental differences like the numerically smaller or larger translation effect. We will now theoretically assess the results of both the empirical and computational findings in the General Discussion.
General Discussion
Using a bilingual priming paradigm combined with a lexical decision task, we set out to investigate whether and how semantic facilitation effects and orthographic competition effects arise in neighbour cognates, translations, and orthographic neighbours, relative to unrelated prime-target pairs.
The present results attest to the importance of orthographic-semantic resonance as a mechanism underlying the processing of cognates and translation equivalents in bilinguals. For prime durations of both 50 ms (Experiment 1) and 83 ms (Experiment 2), large facilitation effects were obtained for (non-identical) cognates, in which there is substantial form and meaning overlap between prime and target. This effect was correctly mimicked by the Multilink+ computational model of word retrieval (both r > .70). This model assumes that neighbour cognates are coactivated upon the presentation of an input item (due to their substantial orthographic overlap), which is followed by a resonance process mediated by a shared semantic representation (see Figure 1; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Peeters et al., Reference Peeters, Dijkstra and Grainger2013). The cognate facilitation effect indicates that any inhibition effects due to lateral inhibition between the co-activated orthographic cognate representations are overridden by such semantic resonance.
The important role of semantic convergence is underscored by the finding of a non-significant translation priming difference of 17 ms in Experiment 1 and a significant translation priming effect of 27 ms in Experiment 2. This finding implies that the target item's meaning was activated by the prime. Thus, a prime duration of 83 ms was apparently sufficient to activate the meaning of the prime, which largely overlaps with or is identical to that of the target. Again, this effect was captured by Multilink+, as shown by substantial correlations between Cycle Times and RTs (correlations around .60).
Importantly, as in earlier studies (Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2010), the cognate effect was substantially larger than the translation effect. This indicates that primed cognate processing profited from the orthographic overlap between the two cognate members, which was absent in translations. As such, it again shows that at present prime durations, facilitatory co-activation won out on inhibitory lexical competition (e.g., lateral inhibition).
With respect to semantic priming, in the present study and in the Multilink+ model, no assumptions needed to be made concerning the nature of the semantic representations, in terms of features, vector dimensions, or other characteristics (cf. Mandera, Keuleers & Brysbaert, Reference Mandera, Keuleers and Brysbaert2017). The only assumption required was that in cognate and translation prime-target conditions, prime and target ended up activating a common (largely) shared semantic representation. The obtained empirical and simulation data suggest that this assumption is sufficient to account for translation and cognate priming effects.
With respect to orthographic priming, we obtained clearly different results. No significant effect of orthographic relatedness for neighbours and cognates together occurred in either experiment, and there were neither significant differences between neighbours and unrelated word pairs nor any significant interaction of orthographic and semantic overlap. In other words, in spite of clear semantic overlap effects, orthographic competition effects in our experiments can at best be called weak.
Note that orthographic overlap between neighbours could cause both co-activation of lexical candidates as well as lateral inhibition. In fact, lateral inhibition can only arise after a competitor of the target word (neighbour) becomes active enough itself. Thus, inhibition effects exerted by the neighbour on the target may be reduced because the prime also facilitates the activation of the target by co-activation.
Furthermore, Kinoshita et al. (Reference Kinoshita, Gayed and Norris2018) suggest that for prime and targets of the same script, mismatching letters in the prime provide wrong evidence for the orthographic representation of the target (although the effect may co-depend on the position of the deviant letter and the task at hand, e.g., whether the task is more or less perceptual in nature; see Comesaña et al., Reference Comesaña, Haro, Macizo and Ferré2021). The resulting competition might not be present if prime and target are presented in different scripts, possibly because of different degrees of form overlap.
Comparing the processing of cognates, translation equivalents, and neighbours, all empirical and simulation results together support the representational view on cognates proposed by Voga and Grainger (Reference Voga and Grainger2007) and Dijkstra, Miwa, Brummelhuis, Sappelli, and Baayen (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; see Figure 1). The priming effects in cognates and translations are primarily due to resonance of the shared semantic representation with linked orthographic codes. More specifically, in the case of a neighbour cognate, target activation benefits from the co-activation of the orthographic and semantic representation of the prime; in the case of a translation, target activation benefits from the co-activation of the semantic representation by the temporarily activated prime only. In the words of Voga and Grainger (Reference Voga and Grainger2007, p. 946): “… cognate translation primes show stronger effects than do noncognate translation primes because they combine both a semantic priming component that is common to all types of translation primes and a form priming component that is specific to cognate translations.”
However, according to Voga and Grainger (Reference Voga and Grainger2007, p. 947), same-script cognates should suffer from lexical inhibition, a process that was assumed to be absent in their study due to the use of Greek–French prime-target combinations. Nevertheless, in our same-script study, this lateral inhibition was, at best, quite small, as both the empirical evidence and the simulations (with their low setting of the lateral inhibition parameter) suggest.
Note that the prime is presented for only a very short duration in masked priming studies. As a consequence, the prime cannot be activated to a large extent and would not have time to exert a lot of lateral inhibition on the following target item. In this view, lateral inhibition requires the previous activation of the competitor, so it can kick in only later. This problem, that the prime requires time to be activated and start inhibiting the target, will not exist in non-masked priming with long primes. However, because correlations remain relatively high, the simulations with longer primes suggest that the pattern (ordering) of RTs remains about the same even when the prime is presented for a longer duration. Apparently, the activation gain of the prime relative to the neighbouring target during the longer presentation time is limited and quickly neutralized as soon as the target item appears.
The relative effects of orthographic and semantic overlap could further be investigated by incorporating the stimulus materials used here in a perceptual identification task (e.g., progressive demasking). An increased effect of prime-target form overlap, including phonological effects, on the present results would be expected. Studies suggest that the effect of phonology in priming paradigms may be greater the lower the orthographic similarity between prime and target is (see Comesaña et al., Reference Comesaña, Sánchez-Casas, Soares, Pinheiro, Rauber, Frade and Fraga2012).
Interestingly, the presented Multilink+ simulations without lateral inhibition are quite good relative to those with (some) lateral inhibition. The same was true for earlier simulations of empirical studies involving isolated items (see Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte & Rekké, Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019; Dijkstra, van Geffen & Reference Dijkstra, van Geffen and HieselaarHieselaar, in preparation). This suggests that lateral inhibition has played a marginal role in the present study. Given the strong cross-linguistic inhibition effects reported by Bijeljac-babic et al. (Reference Bijeljac-babic, Biardeau and Grainger1997), the size, origin, and nature of cross-linguistic inhibitory orthographic effects merits further investigation. As suggested by De Moor et al. (Reference De Moor, Verguts and Brysbaert2005) and Brysbaert (personal communication), varying degrees of lexical competition might apply to different item types under different task conditions (see Goertz et al., in preparation, who reported stronger inhibition effects for false friends in mixed list context). As such, lexical competition effects, due to lateral inhibition or decision level mechanisms, would be sensitive to stimulus list composition and task/decision strategies. Future research could aim at collecting data that allow the Multilink+ model to fine-tune the degree of lexical competition for different item types.
Conclusion
The experiments and simulations of this orthographic-semantic priming study support the representational and processing account of cognates by Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010) and Voga and Grainger (Reference Voga and Grainger2007), although they suggest that the role of lateral inhibition applying to cognates may be more limited or context-sensitive than presumed. The Multilink+ model for word retrieval, implementing the cognate account, already assigned a relatively restricted role to this marker of lexical competition. We have shown that the model can quantitatively and qualitatively account for the processing of prime-target combinations that involve neighbour cognates, orthographic neighbours, translations, and unrelated item pairs.
Data availability statement
The raw data and analysis script used can be found on this project's entry on the Open Science Framework (link: https://osf.io/pxrqd/?view_only=52e6eb7edb8244f88033107377e9297e) under a CC-By Attribution 4.0 International license.
Supplementary Material
For supplementary material accompanying this paper, visit https://doi.org/10.1017/S1366728922000591
Acknowledgments
We thank Annemijn Loermans and Jana Thorin for their collaboration in Experiment 2, and Kimberley Mulder and Pascal de Water for their support. The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.












 Open access
Open access