





1. Introduction
In a globalised and highly integrated world, the boundaries of languages have become fluid and seemingly continuous. Speakers are more likely to move across countries, transfer their homeland language to their offspring and acquire other languages, with bilingual proficiency reaching native-like language abilities well after childhood (Gallo et al., Reference Gallo, Ramanujan, Shtyrov and Myachykov2021; Hartshorne et al., Reference Hartshorne, Tenenbaum and Pinker2018; Köpke, Reference Köpke2021; Roncaglia-Denissen & Kotz, Reference Roncaglia-Denissen and Kotz2016; Steinhauer, Reference Steinhauer2014). However, bilingualism is known to substantially vary among individuals, as it is shaped by intra- and extralinguistic factors such as amount of exposure, social status and education (Bialystok, Reference Bialystok2016; Gullifer et al., Reference Gullifer, Chai, Whitford, Pivneva, Baum, Klein and Titone2018; Gullifer & Titone, Reference Gullifer and Titone2020; Hartanto & Yang, Reference Hartanto and Yang2016; Polinsky & Scontras, Reference Polinsky and Scontras2020; Rodina et al., Reference Rodina, Kupisch, Meir, Mitrofanova, Urek and Westergaard2020). Consequently, research in bilingualism has progressively abandoned strict categorical approaches in favour of more nuanced ones. In fact, the increased complexity of a “winner-take-all” definition of bilingualism has created a plethora of labels to classify speakers (see Surrain & Luk, Reference Surrain and Luk2019, for a systematic review), sometimes leading to the same speakers being labelled differently according to whether the classification is based on language dominance, learning history, age and so on, rendering it impractical to perform consistent comparisons across different studies. Moreover, strict classifications disregard that individuals can also change their “label” during their lifetime. The most notable examples are expatriates to foreign countries who exhibit quick changes in their native language after immersion in the dominant language of the host country (so-called attriters, with attrition phenomena starting just a few years of immersion, Ecke & Hall, Reference Ecke and Hall2013), or early bilinguals who experience expatriation to the family homeland (so-called returnees, Flores et al., Reference Flores, Zhou and Eira2022).
All above taken, the cogent question explored in the present study is how separate these categories truly are, especially given that they could overlap. The effects of cross-linguistic influence associated with the attrition on the first language by the second language (L2), for example, are hard to disentangle, with long-lasting effects attested bidirectionally, which implies that every bilingual may also be an attriter (Schmid & Köpke, Reference Schmid and Köpke2017a, Reference Schmid and Köpke2017b). Even the category of monolinguals, that may represent a gold standard, is now considered the exception rather than the norm, given the growing number of people immersed in multilingual and multidialectal societies (Davies, Reference Davies2013; Rothman et al., Reference Rothman, Bayram, DeLuca, Di Pisa, Duñabeitia, Gharibi, Hao, Kolb, Kubota, Kupisch, Laméris, Luque, van Osch, Soares, Prystauka, Tat, Tomić, Voits and Wulff2023). Critically, this debate about terminology and categorical labels in bilingualism has key implications for research practices. Most of the research on bilingualism has adopted a grouping model whereby individuals are assigned to a priori selected language groups with arbitrary cut-offs (Wagner et al., Reference Wagner, Bialystok and Grundy2022). These categories have typically been used to compare bilinguals, also articulated in different categorical subtypes, to a control group of monolinguals. However, even more nuanced categorical distinctions pose several challenges. First, any a priori classification is based on some enumerable inclusion criteria (e.g., age of acquisition) but may exclude others (e.g., quantity of exposure; Kremin & Byers-Heinlein, Reference Kremin and Byers-Heinlein2021; Marian & Hayakawa, Reference Marian and Hayakawa2021; Wagner et al., Reference Wagner, Bialystok and Grundy2022). Second, empirical evidence deriving from possible class comparisons, which feed hypothetical models aiming to explain them, circularly depend on the criteria adopted to define the groups at the outset. While this issue is inherent to most research comparing groups, it bears important consequences when such groups are highly variable at their core. This is the case, for example, in comparative research about autism spectrum disorder (ASD) which often employs selection criteria at the outset that are based on measures such as verbal and non-verbal intelligence. This is problematic because individuals with ASD widely vary on other cognitive abilities, so even if matched on standardised common measures, they may still be very different in their cognitive profiles (see Jarrold & Brock, Reference Jarrold and Brock2004, and references therein). As already hinted, this issue is of paramount importance for research into bilingualism too, as the variability in the criteria used to define bilingual classes could inevitably lead to results that are difficult to replicate.
Along with other researchers, therefore, we suggest that a more fruitful conceptualisation of bilingualism would be to place each individual on one point of a continuum according to certain linguistic characteristics (Baum & Titone, Reference Baum and Titone2014; de Bruin, Reference de Bruin2019; Marian & Hayakawa, Reference Marian and Hayakawa2021; Rothman et al., Reference Rothman, Bayram, DeLuca, Alonso, Kubota, Puig-Mayenco, Luk, Grundy and Anderson2023). A recent proposal in this direction comes from Kremin and Byers-Heinlein (Reference Kremin and Byers-Heinlein2021), who suggest factor-mixture and grade-of-membership models, which evaluate individuals' bilingualism according to their intrinsic variability in language experience along a continuum of fuzzy classes. Conceptually, these models assign to each individual a composite continuous score, based on specific measures (e.g., a bilingual questionnaire), which reflects how much they belong to a monolingual or bilingual (also of multiple types) class, therefore accounting for within-group heterogeneity. In essence, this approach proposes bilingual classes, but their boundaries are fuzzy so that individuals who deviating from the strict inclusion criteria could also be accommodated. The main advantage of this approach is to still investigate a diversity of factors contributing to the bilingual experience but without introducing biases that may arise when evaluations are strictly based on predetermined categories (DeLuca et al., Reference DeLuca, Rothman, Bialystok and Pliastikas2019, Reference DeLuca, Rothman, Bialystok and Pliatsikas2020; Kałamała et al., Reference Kałamała, Senderecka and Wodniecka2022; Li & Xu, Reference Li and Xu2022). Another useful, more continuous, approach to examine bilingualism is through machine learning, which has already shown promising results such as differentiating the degree of L2 proficiency (Yang et al., Reference Yang, Yu and Lim2016), qualifying its relationship to executive control (Gullifer & Titone, Reference Gullifer and Titone2021) or uncovering its longitudinal lifelong impact (Jones et al., Reference Jones, Davies-Thompson and Tree2021).
Yet, the concept of bilingual continuum still struggles to take off, despite its theoretical and methodological benefits, and it is still countered by attempts to establish better boundaries of bilingual categories through richer assessments or questionnaires (see Kašćelan et al., Reference Kašćelan, Prévost, Serratrice, Tuller, Unsworth and De Cat2022, for a review). The core objective of this study is to precisely provide an empirical and computational proof that that the adoption of a categorical approach can be fallacious in bilingual research; and that instead continuous approaches better describe the true nature of bilingualism and must be adopted whenever possible.
2. Current study
The key proposition of the current study is that bilingualism distributes along a continuum, which is difficult to frame within strictly defined classes. We provide empirical proof to this proposition with machine learning classifiers trained on psycholinguistics language production data from individuals who vary in their degree of bilingualism but are conventionally identified as belonging to three specific classes (i.e., monolinguals, attriters, heritage). We demonstrate that even if we can successfully identify the class an individual was a priori assigned to, based our classification performance widely varies as susceptible to inevitable overlaps in the language production profiles. So, individuals belonging to a class situated in the middle of two possible extremes (i.e., attriters) are identified much less accurately as their language profile is shared by other classes. We precisely take the uncertainty in the classification of bilingualism as the proof of concept about its continuous nature. In fact, if individuals of all classes were equally identifiable, then the existence of such classes would have been correctly assumed, but this is not what we find. Instead, the variability found in the language production profiles of these individuals, and consequently the inability to fully discriminate among them, is coherent with a continuous rather than categorical definition of their bilingual nature.
Here, we train a support vector machine (SVM) on the syntactic typology of utterances produced in a question-directed image description task to predict three classes of speakers on the monolingual–bilingual spectrum (i.e., homeland residents, long-term residents, heritage speakers).
3. Methods
We train SVMs, which are suited to classification problems and often used in the cognitive sciences (see Cervantes et al., Reference Cervantes, Garcia-Lamont, Rodríguez-Mazahua and Lopez2020, for a review) on the syntactic typology of utterances produced in a question-directed image description task to predict three classes of speakers on the monolingual–bilingual spectrum (i.e., homeland monolingual residents, long-term residents or attriters and heritage speakers). Two different datasets, both including these three different classes of speakers, are used to train and test the SVMs. The first dataset, which we will refer to as “the original dataset”, that has been recently published by Smith et al. (Reference Smith, Spelorzi, Sorace and Garraffa2023) and a second dataset, which we will refer to as “the novel dataset”, that was purposely collected for the current study to ensure that our results are reliable and robust: if the SVM trained on the original dataset can predict well above chance the classes of speakers on a novel dataset, collected using the same stimuli, procedure and task, then results are highly replicable.
3.1. The datasets: participants
The original dataset comprises productions from a total of 86 adult speakers of Italian (26 homeland monolingual speakers, 30 attriters and 30 heritage speakers), while the novel dataset comprises a total of 15 adult speakers of Italian, 5 participants for each of the 3 classes of speakers considered in our study (see Table 1 for a description of the two datasets). At the time of testing, homeland speakers were living in Italy, attriters were living in Scotland, where they had been living for a minimum of 5 years and heritage speakers were living in Scotland, where they had lived all or most of their life but were highly proficient in Italian.Footnote 1
Table 1. Characteristics of study participants, for the original dataset and the novel dataset

3.2. The datasets: productions
All participants took part in a series of elicitation tasks, which are fully described in Smith et al. (Reference Smith, Spelorzi, Sorace and Garraffa2023). In the tasks, participants are prompted to answer a question about an image depicting two characters interacting with each other, and an object. The question is related to either one of the arguments (direct or indirect object, example in 1) or both (example in 2) and is designed to elicit an affirmative one-verb sentence with a bi- or tri-argumental verb.
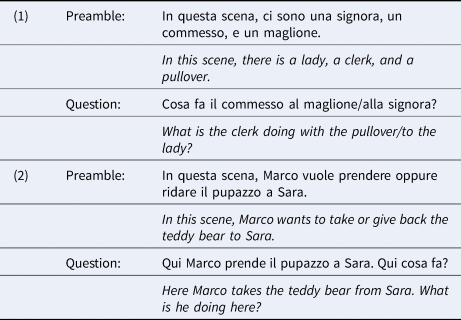
Although several answers are possible, the prompt question is designed to maximise the accessibility of the target object(s), consequently creating the pragmatic environment for the use of a weak form, which in Italian is realised through the clitic pronoun (gli in example 3). This design is widely used and is very effective in healthy native speakers of Italian in eliciting clitic pronouns (Arosio et al., Reference Arosio, Branchini, Barbieri and Guasti2014; Guasti et al., Reference Guasti, Palma, Genovese, Stagi, Saladini and Arosio2016; Tedeschi, Reference Tedeschi2008; Vender et al., Reference Vender, Garraffa, Sorace and Guasti2016, and more).

The production rates of this structure show significant differences between monolinguals and bilinguals as well as among bilinguals, particularly when the two languages spoken are a clitic and a non-clitic language (Belletti et al., Reference Belletti, Bennati and Sorace2007; Romano, Reference Romano2020, Reference Romano2021; Smith et al., Reference Smith, Spelorzi, Sorace and Garraffa2022). The study by Smith et al. (Reference Smith, Spelorzi, Sorace and Garraffa2023) provides the original dataset used also in the current study, found a differential pattern of clitic production across three groups (monolinguals, attriters, heritage speakers) where all types of clitics (one argument, as in 3 above, or clitic clusters) were significantly fewer in attriters compared to monolinguals, and in heritage speakers compared to attriters. This phenomenon was interpreted as a by-product of “inter-generational attrition”, where only monolinguals retain a strong preference for clitics over any other structure, attriters make use of single clitics but not of clusters and heritage speakers, whose input is provided by attriters, mostly prefer the use of lexical expressions.Footnote 2
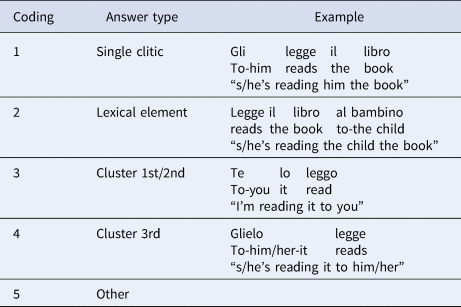
Building upon these insights, in the current study, we identified and coded for five types of answers according to how object(s) of the main verb was realised: “single clitic”, “lexical element”, “cluster 1st/2nd”, “cluster 3rd” and “other”. “Other” comprises all types of answers that did not fall under any of the remaining categories (e.g., irrelevant answers or answers containing either an omission or a strong pronoun). Examples of the coding are provided in Table 2.
Table 2. Coding strategy, with examples from the data
In the original dataset (i.e., from Smith et al., Reference Smith, Spelorzi, Sorace and Garraffa2023) we have a total of 2,688 items, which are divided into 760 (single clitic), 757 (lexical element), 619 (cluster 1st/2nd), 444 (cluster 3rd) and 108 (other). In the novel dataset (i.e., collected specifically for the current study) we have a total of 480 items, divided into 126 (single clitic), 106 (lexical element), 128 (cluster 1st/2nd), 115 (cluster 3rd) and 5 (other).
4. Analyses
We performed three types of analyses all based on SVM classifiersFootnote 3 trained to predict the class of the speaker, i.e., a three-level categorical vector of class labels (monolingual, attriter, heritage) based on the type of answer produced (a categorical vector of five levels indicating the typology of the utterance). All data processing and analyses were conducted on R statistical software (v. 4.3.2, R Core Team, 2023) through the RStudio environment (v. 2023.09, RStudio Team, 2020) and using the package e1071 (v. 1.7-14, Chang & Lin, Reference Chang and Lin2011) to run the SVMs.
The first analysis only uses the original dataset, and we train the SVM classifier on a randomly selected 90% of such data and then test it on the remaining, unseen, 10%. This process was repeated 1,000 times to make sure that the classifier was not over-fitting the data while making full use of a relatively small data set.Footnote 4 To measure the prediction performance of the algorithm, we computed the F-score, which is the geometric mean of precision and recall defined as F = 2 × (P × R)/(P + R). Precision (P) is the number of correctly classified instances over the total number of instances labelled as belonging to the class, defined as tp/(tp + fp). Here, tp is the number of true positives (i.e., instances of the class correctly predicted), and fp is the number of false positives (i.e., instances wrongly labelled as members of the class). Recall (R) is the number of correctly classified instances over the total number of instances in that class, defined as tp/(tp + fn), where fn is the number of false negatives, i.e., the instances labelled as non-members of the class even though they were. As precision, recall and F-score are relative to the class being predicted, we report separate values for each of them. To explicitly quantify the differences in classification performance for the three different classes, we run a simple linear regression predicting F-scores as a function of the to-be-predicted class (monolingual, attriter, heritage, with heritage as the reference level). The purpose of this first analysis is to demonstrate that we can successfully classify the class an individual belongs to, based on a published dataset of which we already know the characteristics (i.e., the original dataset by Smith et al., Reference Smith, Spelorzi, Sorace and Garraffa2023), but not with the same accuracy, indicating a continuum of linguistic behaviours across classes.
In the second analysis, we train the SVM on the original dataset but test it only on the second novel and unseen dataset, which has collected at a different time (after the original dataset) on a different set of speakers but using exactly the same task, and report the same measures of F-score, precision and recall. As already said, the purpose of this analysis is to conceive a blind test that makes sure our classification results are fully replicable also on unseen data (i.e., a novel dataset). In fact, i.e., if we repeat the elicited production task with the same class of speakers, and we observe the same level of categorisation accuracy in our predictions, it means that our empirical results are highly replicable and consequently our theoretical claims are very solid (i.e., we can repeat the experiment and run the models on yet another unseen sample of the same populations and observe the same pattern).
The third analysis instead examines the impact of each type of production on the classification performance to provide a rough idea about the importance of each elicited structure in distinguishing the class each speaker may belong to. First, we aggregate both the original and the novel datasets and recode all different productions into binary vectors (0, 1), indicating whether a certain structure (e.g., cluster 1st/2nd) was used for that particular item. This re-coding generates five different binary feature vectors, one for each production observed (refer to Section 3 for a description of the coding). Then, we used a stepwise forward model-building procedure, where at each step we evaluated whether the model with the added feature was significantly better, i.e., it has a higher F-score, than the one without it. If there was no significant improvement in the F-score, we retained the model without that feature. We repeated this procedure over 1,000 iterations (randomly sampling 90% of the data for training and the remaining 10% for testing) and calculated the frequency of observing a certain feature in the final feature set according to the position it was selected to. For example, if the first feature selected, because it produced a higher F-score compared to the rest, is cluster 3rd, then it ranks first. If the F-score then significantly improved on F-score by adding cluster 1st/2nd, then this feature will be ranked as second (refer to Coco & Keller, Reference Coco and Keller2014, for a similar approach but based on eye-movement features).
All these analyses were run on an SVM whose parameters were tuned to achieve optimal performance. There are two parameters in SVM models: Gamma, which shapes the decision boundaries by assembling similar data points into the same cluster, and Cost, which attributes a penalty to misclassification. These parameters are used to adapt the prediction plane to potentially non-linear data patterns. We extracted optimal values for the gamma and cost parameters across the original dataset using the tune.svm() function also available in the e1071 package. We examined a range of gamma values going from .005 to .1 in steps of .005. The optimal parameters obtained to model our dataset were .01 for gamma and .5 for the cost.
Finally, we visually inspect and evaluate more in-depth the performance of the SVM classifiers through confusion matrices, which reveal how much the model may erroneously predict one class for another. A confusion matrix is, in fact, a contingency table, where expected and predicted values are cross-tabulated, i.e., the number of correct and incorrect predictions is counted for each of the expected classes. In practice, confusion matrices provide insights about the type of errors that are made, e.g., whether a monolingual is more often confused with an attriter or with a heritage. In the context of our study, it is interesting to examine whether classes are univocally represented, and in case of errors, what are the most prominent switches. So, if for example, monolinguals are more confused with attriters, we can infer that these two classes share a closer production strategy than say between monolinguals and heritage.
The data and R script to illustrate the analysis supporting the findings of this study can be found in the Open Science Framework (https://osf.io/w24p3/?view_only=48f70ddee34e44a1b4ba2dd766ff9a34).
5. Results
In Table 3, we report the descriptives for F-score, precision and recall, regarding the classification performance of the SVM models trained and tested only on the original dataset (first analysis); and trained on the original dataset but tested on the novel dataset (second analysis, refer to Section 4 for details about their purposes). Across the board, we can predict the class of the speaker based on their typology of linguistics production with an accuracy above chance, which is 33% in our data (i.e., the SVM is trying to predict one class out of three possible classes). In particular, when training and testing were conducted using the original dataset, we found that the classes most accurately classified are monolingual (~72%) followed by heritage (~58%) and finally attriters (~42%). These results are fully confirmed, if not improved when training was done on the original dataset but testing performed on the novel dataset (monolingual = 79%; heritage = 64% and attriters = 47%).
Table 3. Descriptive statistics of the SVM classification performances
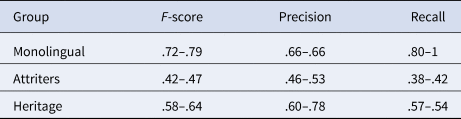
We report the mean of F-score, precision and recall on 1,000 iterations of training SVMs on 90% of the data, and testing on the remaining unseen 10%. The N-dash separates the first classifier (trained and tested on the original dataset) from the second classifier (trained on the original dataset but tested on the novel dataset).
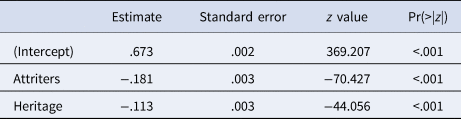
This finding is corroborated by the linear regression on the original dataset, which confirms that heritage and especially attriters are predicted with a significantly smaller accuracy than monolinguals (refer to Table 4 for the model coefficientsFootnote 5).
Table 4. Output of a linear model predicting F-score as a function of the three classes of speakers in our study (attriters, heritage and monolinguals, as the reference level)
Our examination of the confusion matrix (third analysis) shows that the class predicted most often was monolinguals, followed by heritage and attriters. The same result holds when using only the original dataset (Figure 1A), and when instead testing is performed on the novel dataset (Figure 1B). In these figures, the diagonals of the confusion matrices display all percentages of expected cases (Target, organised as columns) that were correctly predicted (Prediction, organised as a row) by the classifier. Most interesting perhaps are the misclassification errors, namely the percentages of mismatches between targets and predictions which can be read in the off-diagonal cells of the matrix. Here, we find that attriters are misclassified as monolinguals more often than as heritage, whereas heritages are misclassified as attriters more often than as monolinguals. This is again true for both analyses.

Figure 1. Visualisation of the confusion matrices about the classification performance of our models (A: trained and tested using the original dataset; B: trained on the original dataset tested on the novel dataset). Predictions of the model are organised over the rows while the target, i.e., expected outcome, is organised over the columns. The percentages indicate how many cases, per class, matched or not, between predictions and targets. The colours of the tiles go from white (few cases) to orange (most cases). (C) Percentages of times a certain type of production was selected as a key feature, i.e., it significantly improved performance, by the classifier. The type of productions is depicted as colours and organised as stacked bars. Cluster glie-lo in the image refers to cluster 3rd, and cluster me-lo to cluster 1st/2nd. The x-axis indicates instead whether the feature was selected as the first or second feature.
Note: All models contained a maximum of two types of production, hence, there are no further ranks.
Finally, the feature selection analysis showed that the best classifiers needed an average of 1.88 (±.31) types of productions to achieve the maximum F-score. Moreover, if we inspect the relative importance of each feature for the classification, we found that cluster 3rd was the feature most frequently selected as first, followed by cluster 1st/2nd. The lexical element was instead the third most selected feature, and when it happened, it was usually the only one selected, i.e., adding any other would not significantly improve the F-score (refer to Figure 1C for a visualisation).
6. Discussion
In the present study, we tested the hypothesis that linguistic performance can be used as a proxy for bilingual categories and that their boundaries are fuzzy. By applying machine learning to a dataset of utterances, speakers were assigned to their class, out of three possible (monolingual, heritage and attriter), with an accuracy well above chance (47–79%, where chance is 33%). This shows that specific linguistic patterns are to some extent coherent with bilingual classes created a priori, also lending empirical support to our modelling approach. However, the classification accuracy varied greatly between classes, showing that the boundaries of these classes have a degree of fuzziness, with some linguistic profiles characterising one class more strongly compared to the others. These results confirm that even if speakers can be identified to some extent as belonging to a possible category in the monolingual–bilingual spectrum based on their language production profiles, the classes consistently overlap. Critically, this is especially the case for those Italian speakers (i.e., the attriters) in the middle between a linguistic environment which was fully Italian-dominant (i.e., where they grew up) and the other which is fully English-dominant (i.e., where they now live).
Specifically, the confusion matrix and associated analysis of errors show that the monolinguals are closer to those of attriters, which are in turn closer to heritage. We take this uncertainty in the classification of bilingualism as a proof of concept about its continuous nature. Classification accuracy was higher for monolinguals and heritage, while lower for attriters. This is in line with predictions made by a continuous approach to bilingualism, where, considering different definitions of classes in the spectrum, we have monolinguals and heritage speakers at opposite ends (e.g., monolinguals are at the “least bilingual” end). Since the language investigated is Italian, it is theoretically expected that monolinguals will be very productive of a specific syntactic element (i.e., the clitic pronoun) that is frequently adopted in the homeland. At the other end of the spectrum are heritage speakers, who are the most dominant speakers of the L2, in this case English and, while highly proficient, the least exposed to Italian. It seems to be the case that their language, sometimes referred to as the heritage language, is quite identifiable. This is consistent with accounts of heritage languages as being stand-alone varieties of the homeland language (Kupisch & Polinsky, Reference Kupisch and Polinsky2022; Nagy, Reference Nagy, Jones, Smith and Brown2016; Polinsky & Scontras, Reference Polinsky and Scontras2020).
The attriter class, which displays the lowest classification accuracy, is particularly relevant for the debate of a bilingual continuum. These speakers are confused as heritage almost as frequently as they are correctly categorised, confirming there is an important degree of overlap between classes that manifests in speakers' use of language. The linguistic production of attriters is closer to heritage who were born outside of the homeland and have lower exposure to Italian than monolinguals, who like them were born in Italy.
As was stated in Section 3, the way the dataset was coded (i.e., in relation to the stimuli and the chosen answer strategy for the production of the direct and/or indirect object) would maximise the emergence of potential differences given that the task was designed to promote the use of a pronominal element, which is a known area of differences between monolinguals, bilinguals and different classes of bilinguals. Despite this, overlap between classes is still present, as is demonstrated by the high confusability rates.
Results from the present study are consistent with accounts of bilingualism as a continuous rather than categorical variable (Bonfieni, Reference Bonfieni2018; Luk & Bialystok, Reference Luk and Bialystok2013), as the individual profiles of speakers are not univocally describable through strict boundaries, but rather behave as a continuum of discrete linguistic behaviours. The continuity of bilingual profiles also fits in well with the fact that some differences between speakers may always remain the same (e.g., whether they received inputs in a specific language as children or not), while others may change over time influenced by speakers' linguistic experience. Changes in linguistic boundaries across generations of speakers are to be expected and predictable because the language spoken by a speaker is constantly influenced by concurrent factors such as exposure, language dominance, environment during acquisition and so on (Anderson et al., Reference Anderson, Hawrylewicz and Bialystok2020; Luk & Bialystok, Reference Luk and Bialystok2013).
Classes in bilingual research are often determined based on a close set of a priori defined linguistic and extralinguistic factors such as the age of first exposure, country of residence and so on, or based on self-assessment questionnaires. The latter are often reported to be subjected to enhancement bias, particularly in the case of heritage speakers (Gollan et al., Reference Gollan, Weissberger, Runnqvist, Montoya and Cera2012; Macbeth et al., Reference Macbeth, Atagi, Montag, Bruni and Chiarello2022; MacIntyre et al., Reference MacIntyre, Noels and Clément1997; Marchman et al., Reference Marchman, Martinez, Hurtado, Gruter and Fernald2017); the former do not fully mirror linguistic performance (de Bruin, Reference de Bruin2019). Our study precisely confirms that there is a degree of overlap between the patterns of linguistic productions of speakers that would be assigned instead to different classes in the monolingual–bilingual spectrum. The major theoretical contribution of our novel findings is therefore the confirmation of a need to shift, whenever possible, from a priori grouping towards methodologies that either eliminate discrete groups or can exploit explicitly such intergroup variability to better model language experience (Kremin & Byers-Heinlein, Reference Kremin and Byers-Heinlein2021) in bilingual research.
7. Conclusions
In this study, a machine learning model (SVM) trained on the typology of linguistic productions was used to predict the bilingual class a speaker may have belonged to. We did this aiming to demonstrate that class boundaries are not as clear cut and overlaps exist. Results show that classes are predicted above chance, but with a varying degree of accuracy, which depended on the a priori bilingual class a speaker was assigned to. The typology of utterances speakers produced makes it clear that (mono- and) bilingualism does not have sharp categorical boundaries, but rather it distributes on a continuum of linguistic behaviours that are shared by different classes of speakers. Heritage speakers and monolinguals seem to speak rather different varieties of Italian, while attriters seem to sit somewhere in the middle. Future research may explore how the classification behaves with larger chunks of production, for example examining the outcomes of narrative tasks.
These results strongly suggest fostering more innovative research that exploits the true linguistic environment each speaker carries to derive a continuum rather than a class-based approach to bilingual research. Further studies that examine the reliability of classification are needed in other areas of linguistic research, for example in the classification of linguistic competence in neurodevelopmental disorders.
Data availability statement
The data and script to illustrate the analysis supporting the findings of this study are available in Open Science Framework at https://osf.io/w24p3/.
Ethical standards
The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008.
Competing interests
The authors declare that they have no conflict of interest.






 Open access
Open access