


One of the most striking aspects of language is that it can be processed and learned as easily by eye-and-hand as by ear-and-mouth – in other words, language can be constructed out of manual signs or out of spoken words. Nowadays this is not a controversial statement, but 50 years ago there was little agreement about whether a language of signs could be a “real” language: that is, identical or even analogous to speech in its structure and function. But this acceptance has opened up a series of fundamental questions. Welcoming sign language into the fold of human languages could force us to rethink our view of what a human language is.
Our first goal in this article is to chart the three stages that research on sign language has gone through since the early 1960s. (1) Initially, sign was considered nothing more than pantomime or a language of gestures. (2) The pendulum then swung in the opposite direction – sign was shown to be like speech on many dimensions, a surprising result because it underscores the lack of impact that modality has on linguistic structure. During this period, sign was considered a language just like any other language. (3) The pendulum is currently taking another turn. Researchers are discovering that modality does influence the structure of language, and some have revived the claim that sign is (at least in part) gestural.
But in the meantime, gesture – the manual movements that speakers produce when they talk – has become a popular topic of study in its own right. Our second goal is to review this history. Researchers have discovered that gesture is an integral part of language – it forms a unified system with speech and, as such, plays a role in processing and learning language and other cognitive skills. So what, then, might it mean to claim that sign is gestural? Perhaps it is more accurate to say that signers gesture just as speakers do – that is, that the manual movements speakers produce when they talk are also found when signers sign.
Kendon (Reference Kendon2008) has written an excellent review of the history of sign and gesture research, focusing on the intellectual forces that led the two to be considered distinct categories. He has come to the conclusion that the word “gesture” is no longer an effective term, in part because it is often taken to refer to nonverbal communication, paralinguistic behaviors that are considered to be outside of language. He has consequently replaced the word with a superordinate term that encompasses both gesture and sign – visible action as utterance (Kendon Reference Kendon2004). By using a superordinate term, Kendon succeeds in unifying all phenomena that involve using the body for communication, but he also runs the risk of blurring distinctions among different uses of the body, or treating all distinctions as equally important.
We agree with Kendon's (Reference Kendon2008) characterization of the history and current state of the field, but we come to a different conclusion about the relationships among sign, gesture, and language or, at the least, to a different focus on what we take to be the best way to approach this question. Our third goal is to articulate why. We argue that there are strong empirical reasons to distinguish between linguistic forms (both signed and spoken) and gestural forms – that doing so allows us to make predictions about learning that we would not otherwise be able to make. We agree with Kendon that gesture is central to language and is not merely an add-on. This insight leads us (and Kendon) to suggest that we should not be comparing all of the movements signers make to speech, simply because some of these movements have the potential to be gestures. We should, instead, be comparing signers’ productions to speech-plus-gesture. However, unlike Kendon, whose focus is on the diversity of forms used by signers versus speakers, our focus is on the commonalities that can be found in signers’ and speakers’ gestural forms. The gestural elements that have recently been identified in sign may be just that – co-sign gestures that resemble co-speech gestures – making the natural alignment sign-plus-gesture versus speech-plus-gesture. Sign may be no more (and no less) gestural than speech is when speech is taken in its most natural form: that is, when it is produced along with gesture. We conclude that a full treatment of language needs to include both the more categorical (sign or speech) and the more imagistic (gestural) components regardless of modality (see also Kendon Reference Kendon2014) and that, in order to make predictions about learning, we need to recognize (and figure out how to make) a critical divide between the two.
Our target article is thus organized as follows. We first review the pendulum swings in sign language research (sects. 2, 3, 4), ending where the field currently is – considering the hypothesis that sign language is heavily gestural. We then review the contemporaneous research on gesture (sects. 5, 6); in so doing, we provide evidence for the claim that signers gesture, and that those gestures play some of the same roles played by speakers’ gestures. We end by considering the implications of the findings we review for the study of gesture, sign, and language (sect. 7). Before beginning our tour through research on sign and gesture, we consider two issues that are central to the study of both – modality and iconicity (sect. 1).
1. Modality and iconicity
Sign language is produced in the manual modality, and it is commonly claimed that the manual modality offers greater potential for iconicity than the oral modality (see Fay et al. Reference Fay, Lister, Ellison and Goldin-Meadow2014 for experimental evidence for this claim). For example, although it is possible to iconically represent a cat using either the hand (tracing the cat's whiskers at the nose) or the mouth (saying “meow,” the sound a cat makes), it is difficult to imagine how one would iconically represent more complex relations involving the cat in speech – for example, that the cat is sitting under a table. In contrast, a relation of this sort is relatively easy to convey in gesture – one could position the right hand, which has been identified as representing the cat, under the left hand, representing the table. Some form-to-world mappings may be relatively easy to represent iconically in the oral modality (e.g., representing events that vary in speed, rhythm, repetitiveness, duration; representing events that vary in arousal or tension; representing objects that vary in size; but see Fay et al. Reference Fay, Lister, Ellison and Goldin-Meadow2014). However, there seems to be a greater range of linguistically relevant meanings (e.g., representing the spatial relations between objects; the actions performed on objects) that can be captured iconically in the manual modality than in the oral modality.
Many researchers have rightly pointed out that iconicity runs throughout sign languages (Cuxac & Sallandre Reference Cuxac, Sallandre, Pizzuto, Pietandrea and Simone2007; Fusellier-Souza Reference Fusellier-Souza2006; Taub Reference Taub2001) and that this iconicity can play a role in processing (Thompson et al. Reference Thompson, Vinson and Vigliocco2009; Reference Thompson, Vinson and Vigliocco2010), acquisition (Casey Reference Casey2003; Slobin et al. Reference Slobin, Hoiting, Kuntze, Lindert, Weinberg, Pyers, Anthony, Biederman, Thumann and Emmorey2003), and metaphoric extension (Meir Reference Meir2010). But it is worth noting that there is also iconicity in the oral modality (Perniss et al. Reference Perniss, Thompson and Vigliocco2010; see also Haiman Reference Haiman1980; Nygaard et al. Reference Nygaard, Cook and Namy2009a; Reference Nygaard, Herold and Namy2009b; Shintel et al. Reference Shintel, Nusbaum and Okrent2006 – more on this point in sect. 7.2), and that having iconicity in a system does not preclude arbitrariness, which is often taken as a criterion for language (Hockett Reference Hockett1960; de Saussure Reference de Saussure and Baskin1916, who highlighted the importance of the arbitrary mapping between the signifier and the signified). Indeed, Waugh (Reference Waugh and Violo2000) argues that it is time to “slay the dragon of arbitrariness” (p. 45) and embrace the link between form and meaning in spoken language. According to Waugh, linguistic structure at many levels (lexicon, grammar, texts) is shaped by the balance between two dynamical forces centered on the relation between form and meaning – one force pushing structures toward iconicity, and the other pushing them toward non-iconicity. Under this view, iconicity is a natural part of all languages (spoken or signed). We therefore do not take the presence of iconicity in a system as an indicator that the system is not a language.
2. Sign language is not a language
In 1880, the International Congress of the Educators of the Deaf, which met in Milan, passed a resolution condemning the use of manualist methods to teach language to deaf children (Facchini Reference Facchini, Stokoe and Volterra1983). This resolution reflected the widespread belief that sign was not an adequate language, an attitude that educators of the deaf continued to hold for many years (see Baynton Reference Baynton, Armstrong, Karchmer and van Cleve2002 for a description of the cultural attitudes that prevailed during this period). As an example, in his book, The Psychology of Deafness, Myklebust (Reference Myklebust1960, p. 241) described sign language as “more pictorial, less symbolic” than spoken language, a language that “falls mainly at the level of imagery.” In comparison with verbal symbol systems, sign languages “lack precision, subtlety, and flexibility.” At the time, calling a language pictorial was tantamount to saying it was not adequate for abstract thinking.
At the same time as Myklebust was writing, discoveries in linguistics were leading to a view that speech is a special vehicle for language. For example, listeners do not accurately perceive sounds that vary continuously along a continuum like voice-onset-time (VOT). Rather, they perceive these sounds in categories – they can easily distinguish between two sounds on the VOT continuum that are on different sides of a categorical boundary, but they cannot easily distinguish between two sounds that are the same distance apart on the VOT continuum but fall within a single category. Importantly, these perceptual categories match the phonetic categories of the language the listeners speak (Liberman et al. Reference Liberman, Cooper, Shankweiler and Studdert-Kennedy1967). This phenomenon, called categorical perception (see Harnad Reference Harnad1987 for a thorough treatment), was at first believed to be restricted to speech, and indeed, early attempts to find categorical perception in sign were not successful (Newport Reference Newport, Wanner and Gleitman1982; but see Baker et al. Reference Baker, Idsardi, Michnick Golinkoff and Petitto2005, Reference Baker, Michnick Golinkoff and Petitto2006; Emmorey et al. Reference Emmorey, McCullough and Brentari2003). Subsequent work has shown that categorical perception is not unique to humans (Kuhl & Miller Reference Kuhl and Miller1975) nor to speech sounds (Cutting & Rosner Reference Cutting and Rosner1974). But, at the time, it seemed important to show that sign had the characteristics of speech that appeared to make it a good vehicle for language.Footnote 1
Even more damaging to the view that sign is a language was the list of 13 design features that Hockett (Reference Hockett1960) hypothesized could be found in all human languages. Hockett considered some of the features on the list to be so obvious that they almost went without saying. The first of these obvious features was the vocal-auditory channel, which, of course, rules out sign language. Along the same lines, Landar (Reference Landar1961, p. 271) maintained that “a signalling system that does not involve a vocal-auditory channel directly connecting addresser and addressee lacks a crucial design-feature of human language.” Interestingly, however, by 1978, Hockett had revised his list of design features so that it no longer contained the vocal-auditory channel, a reflection of his having been convinced by this time that sign language does indeed have linguistic structure.
One of the important steps on the way to recognizing sign as a language was Stokoe's linguistic analysis of American Sign Language (ASL) published in 1960. He argued that sign had the equivalent of a phonology, a morphology, and a syntax, although he did point out differences between sign and speech (e.g., that sub-morphemic components are more likely to be produced simultaneously in sign than in speech). Despite this impressive effort to apply the tools of linguistics to sign language, there remained great skepticism about whether these tools were appropriate for the job. For example, DeMatteo (Reference DeMatteo and Friedman1977) attempted to describe syntactic relationships, morphological processes, and sign semantics in ASL and concluded that the patterns cannot be characterized without calling upon visual imagery. The bottom-line – that “sign is a language of pictures” (DeMatteo Reference DeMatteo and Friedman1977, p. 111) – made sign language seem qualitatively different from spoken language, even though DeMatteo did not deny that sign language had linguistic structure (in fact, many of his analyses were predicated on that structure). Looking back on DeMatteo's work now, it is striking that many of the issues he raised are again coming to the fore, but with a new focus (see sect. 4). However, at the time, DeMatteo's concerns were seen by the field as evidence that sign language was different from spoken language and, as a result, not a “real” language.
3. Sign language is just like spoken language and therefore a language
One of the best ways to determine whether sign language is similar to, or different from, spoken language is to attempt to characterize sign language using the linguistic tools developed to characterize spoken language. Building on the fundamental work done by Stokoe (Reference Stokoe1960), Klima and Bellugi and their team of researchers (Reference Klima and Bellugi1979) did just that, and fundamentally changed the way sign language was viewed in linguistics, psychology, and deaf education.Footnote 2
For example, Lane et al. (Reference Lane, Boyes-Braem and Bellugi1976) conducted a study, modeled after Miller and Nicely's (Reference Miller and Nicely1955) classic study of English consonants, which was designed to identify features in ASL handshapes. Miller and Nicely began with theoretically driven ideas in linguistics about the phonetic and phonological structure of English consonants, and used their experiment to determine the perceptual reality of these units. The basic aim of the study was to examine the confusions listeners made when perceiving syllables in noise. Consonants hypothesized to share several features were, in fact, confused more often than consonants hypothesized to share few or no features, providing evidence for the perceptual reality of the features. Lane et al. (Reference Lane, Boyes-Braem and Bellugi1976) conducted a comparable study on features of ASL handshapes based on Stokoe's (Reference Stokoe1960) list of hand configurations. They presented hand configurations under visual masking to generate confusions and used the confusability patterns to formulate a set of features in ASL hand configurations. They then validated their findings by demonstrating that they were consistent with psycholinguistic studies of memory errors in ASL. Along similar lines, Frishberg (Reference Frishberg1975) showed that processes found in spoken language (e.g., processes that neutralize contrasts across forms, or that assimilate one form to another) can account for changes seen in ASL signs over historical time; and Battison (Reference Battison1978) showed that assimilation processes in spoken language can account for the changes seen in fingerspelled forms (words spelled out as handshape sequences representing English letters) as they are “borrowed” into ASL. Studies of this sort provided evidence for phonological structure in at least one sign language, ASL.
Other studies of ASL followed at different levels of analysis. For example, Supalla (Reference Supalla1982) proposed a morphological model of verbs of motion and location in which verb stems contain morphemes for the motion's path, manner, and orientation, as well as classifier morphemes marking the semantic category or size and shape of the moving object (although see discussions in Emmorey Reference Emmorey2003); he then validated this linguistic analysis using acquisition data on deaf children acquiring ASL from their deaf parents. Fischer (Reference Fischer1973) showed that typical verbs in ASL are marked morphologically for agreement in person and number with both subject and object (see also Padden Reference Padden1988), as well as for temporal aspect (Klima & Bellugi Reference Klima and Bellugi1979); in other words, ASL has inflectional morphology. Supalla and Newport (Reference Supalla, Newport and Siple1978) showed that ASL has noun–verb pairs that differ systematically in form, suggesting that ASL also has derivational morphology. In a syntactic analysis of ASL, Liddell (Reference Liddell1980) showed that word order is SVO in unmarked situations, and, when altered (e.g., in topicalization), the moved constituent is marked by grammatical facial expressions; ASL thus has syntactic structure.
These early studies of ASL make it clear that sign language can be described using tools developed to describe spoken languages. In subsequent years, the number of scholars studying the structure of sign language has grown, as has the number and variety of sign languages that have been analyzed. We now know quite a lot about the phonological, morphological, and syntactic structure of sign languages. In the following sections, we present examples of structures that are similar in sign and speech at each of these levels.
3.1. Phonology
Sign languages have features and segmental structure (Brentari Reference Brentari1998; Liddell & Johnson Reference Liddell and Johnson1989; Sandler 1989), as well as syllabic and prosodic structure (Brentari Reference Brentari and Lucas1990a; Reference Brentari1990b; 1990c; Perlmutter Reference Perlmutter1992; Sandler Reference Sandler2010; Reference Sandler, Pfau, Steinbach and Woll2012b), akin to those found in spoken languages. A clear example of a feature that applies in a parallel way in spoken and signed language phonology is aperture. Spoken language segments can be placed on a scale from fully closed (i.e., stops /p, t, k, b, d, g/, which have a point of full closure), to fully open (i.e., vowels /a, i, u/), with fricatives /s, z/, approximates /l, r/, and glides /w, j/ falling in between. Handshapes in sign languages can be placed along a similar scale, from fully closed (the closed fist handshape) to fully open (the open palm handshape), with flat, bent, and curved handshapes in between. In spoken languages, there are phonotactics (phonological rules) that regulate the sequence of open and closed sounds; similarly, in ASL, phonotactics regulate the alternations between open and closed handshapes (Brentari Reference Brentari1998; Friedman Reference Friedman and Friedman1977; Sandler 1989).
Sub-lexical phonological features are used in both spoken and signed languages to identify minimal pairs or minimal triples – sets of words that differ in only one feature (
p
at vs.
b
at vs.
f
at in English; APPLE vs. CANDY vs. NERVE in ASL, see Fig. 1). The three sounds in bold are all bilabial and all obstruent, but /b/ differs from /p/ in that it is [+voice] and /f/ differs from /p/ in that it is [+continuant]; [voice] and [continuant] can vary independently. The three signs differ in handshape features (the number of fingers that are “selected,” and whether the fingers are straight or bent): The handshape in CANDY ![]() differs from the handshape in APPLE
differs from the handshape in APPLE ![]() in that the index finger is straight instead of bent (a feature of joint configuration, in this case aperture, as just described), and the handshape in NERVE
in that the index finger is straight instead of bent (a feature of joint configuration, in this case aperture, as just described), and the handshape in NERVE ![]() differs from the handshape in APPLE
differs from the handshape in APPLE ![]() in that there are two fingers bent instead of one (a feature of selected finger group). These features, like their spoken language counterparts, can also vary independently.
in that there are two fingers bent instead of one (a feature of selected finger group). These features, like their spoken language counterparts, can also vary independently.

Figure 1. A set of three signs in ASL that differ from each other in only one handshape feature and thus form minimal pairs (Brentari Reference Brentari1998, reprinted with permission of MIT Press).
Liddell (Reference Liddell1984) pointed out the functional similarities between vowels in spoken languages and movements in sign. Syllables in sign languages are based on number of movements (Brentari Reference Brentari1998), just as syllables in spoken language are based on number of vowels.
3.2. Morphology
We also see similarities between spoken and signed languages at the morphological level (Meir Reference Meir, Pfau, Steinbach and Woll2012). Reduplication is a morpho-phonological process that both signed and spoken languages undergo, and recent work has shown that native users of both types of languages treat reduplication as a rule in their grammars. Reduplication takes many forms in spoken languages, but one common form is consonant reduplication at the right edge of a word in Semitic languages. For example, the Hebrew word simem (English: to drug, to poison) is formed from a diconsonantal root (sm, or AB), which has undergone reduplication (smm, or ABB) (Bat-El Reference Bat-el2006; McCarthy Reference McCarthy1981); words with reduplication at the left edge (ssm, or AAB) are unattested in Hebrew. Berent et al. (Reference Berent, Shimron and Vaknin2001) showed that Hebrew speakers take longer to decide whether a non-word is an actual word if the non-word has the ABB pattern (i.e., if it behaves like a real word) than if it has the AAB pattern, suggesting that speakers have a rule that interferes with their judgments about novel non-words.
The same process takes place in reduplication in ASL (Supalla & Newport Reference Supalla, Newport and Siple1978). For example, one-movement stems can surface as single movements when used as a verb but as reduplicated restrained movements when used as a noun; CLOSE-WINDOW vs. WINDOW (Fig. 2, top). Berent et al. (Reference Berent, Dupuis and Brentari2014) hypothesized that if reduplication is a core word-formational rule for ASL signers as it is for Hebrew speakers, then signers should have slower reaction times when deciding whether a disyllabic, reduplicated non-sign is an actual sign than if the non-sign is disyllabic but not reduplicated. Disyllabic signs in which the movement was reduplicated according to a derivational process in ASL (see Fig. 2, bottom left) were, in fact, more difficult for signers to reject (i.e., had longer reaction times) than disyllabic signs in which the movement was not reduplicated (Fig. 2, bottom right). Reduplication appears to be a core word-formational strategy for signers as well as speakers.

Figure 2. The top pictures display a noun-verb pair in ASL (Brentari Reference Brentari1998, reprinted with permission of MIT Press); the movement is reduplicated (two identical syllables) in the noun, WINDOW (top left), but not in the verb, CLOSE-WINDOW (top right). The bottom pictures display nonsense signs, both of which are disyllabic (i.e., they both contain two movements). The movement is reduplicated in the sign on the left, following a derivational process in ASL, but not in the sign on the right. Signers had more difficulty rejecting nonsense forms that followed the reduplication process characteristic of actual ASL signs (the left sign) than signs that violated the process (the right sign) (Berent et al. Reference Berent, Dupuis and Brentari2014).
3.3. Syntax
In syntax, many of the constituent structures found in spoken languages are the same as those found in sign languages. Consider, for example, relative clauses in Italian, English, Italian Sign Language (LIS), and ASL (see example 1). All four languages have complex sentences containing relative clauses, although each language has a different way of marking that clause. Italian (1a) and English (1b) both use complementizers to introduce the relative clause. Both LIS (1c) and ASL (1d) also use complementizers, along with raised eyebrows over the relative clause. LIS puts the complementizer, the sign PE, at the right edge of the relative clause, whereas ASL puts the complementizer, the sign WHO, at the left edge.
-
(1) Relative clause structures in Italian, English, Italian Sign Language (LIS), and ASL.
-
a. l'uomo [ che lavora di sotto] è un amico. [Italian]
-
b. The man [who works downstairs] is my friend. [English]
____brow raise_________________
-
c. UOMO [LAVORA DI SOTTO PE ] AMICO MIO. [LIS]
brow raise_________________________
-
d. MAN [WHO WORKS DOWNSTAIRS ] MY FRIEND. [ASL]
-
As another example, pro-drop is a common phenomenon found in both spoken languages (e.g., Spanish and Italian) and sign languages (e.g., ASL, Brazilian Sign Language, and German Sign Language, Glück & Pfau Reference Glück, Pfau, Cambier-Langeveld, Lipták, Redford and van derTorre1999; Lillo-Martin Reference Lillo-Martin1986; Quadros Reference de Quadros1999). Pro-drop occurs when a verb contains morphology that refers to its arguments, permitting those arguments to be dropped in speech (e.g., Italian, see example 2a) and sign (e.g., ASL, see example 2b). The subscript a's and b's in the ASL example indicate that the sign for Mary was placed in location b, the sign for John was placed in location a, and the verb sign ASK was moved from a to b, thereby indicating that John asked Mary. Because the argument signs had been set up in space in the initial question (i), the response (ii) could contain only the verb ASK, which incorporated markers for its arguments, that is, a ASK b . In the Italian example, note that the initial question contains nouns for both the subject Maria and the indirect object Gianni; the subject (she) is also marked on the auxiliary verb ha, as is the direct object clitic l’ (it, standing in for the question). The response (ii) contains no nouns at all, and the subject (she), indirect object (to-him), and direct object (it) are all marked on the auxiliary verb gliel'ha. The argument information is therefore indicated in the verb in Italian, just as it is in ASL.Footnote 3
-
(2) Null arguments in Italian (a) and ASL (b).
-
a. i. Maria l'ha domandata a Gianni?[Italian]
Maria it-has-she asked to Gianni“Has Maria asked it [the question] to Gianni?”
ii. Sí, gliel'ha domandata.
Yes, to-him-it-has-she asked
“Yes, she has asked him it.”
-
b. i. MARYb JOHNa aASKb? [ASL]
Mary John he-asked-her
“Did John ask Mary?”
ii. YES, aASKb.
Yes, he-asked-her
“Yes, he asked her.”
-
4. Sign language is not like spoken language in all respects – could the differences be gestural?
Despite evidence that many of the same formal mechanisms used for spoken languages also apply to sign languages, there are striking grammatical differences between the two kinds of languages. Some of these differences are differences in degree. In other words, the difference between sign and speech can be accounted for by the same mechanisms that account for differences between two spoken languages. Other differences are more qualitative and do not fit neatly into a grammatical framework. We provide examples of each type of difference in the next two sections.
4.1. Differences between sign language and spoken language that can be explained within a grammatical framework
We return to the minimal pairs displayed in Figure 1 to illustrate a difference between sign and speech that can be explained using linguistic tools. The English word pat contains three timing slots (segments) corresponding to /p/, /a/, and /t/. Note that the feature difference creating the minimal pairs is on the first slot only. In contrast, the feature difference creating the minimal pairs in the three signs, CANDY, APPLE, and NERVE, is found throughout the sign.
At one time, this difference in minimal pairs was attributed to the fact that English is a spoken language and ASL is a sign language. However, advances in phonological theory brought about by autosegmental phonology (Goldsmith Reference Goldsmith1976) uncovered the fact that some spoken languages (languages with vowel harmony, e.g., Turkish, Finnish, and languages with lexical tones, e.g., the Chadic language Margi, the Bantu language Shona) have “ASL type” minimal pairs. When the plural suffix –lar is added to the Turkish word dal (English “branch”), the [-high] vowel in the suffix is [+back], matching the [+back] vowel [a] in the stem. But when the same plural suffix is added to the word yel (English “wind”), the [-high] vowel in the suffix is [-back], matching the [-back] vowel [e] in the stem. The important point is that the vowel feature [±back] has one value that spreads throughout the entire word, just as the features of the selected fingers in ASL have one value that spreads throughout the entire sign (Sandler Reference Sandler1986). Minimal pairs in sign and speech can thus be described using the same devices, although the distribution of these devices appears to differ across the two types of languages – vowel harmony and lexical tone patterns are not as widespread in spoken languages as the selected finger patterns of handshape are in sign languages.
As a second example, we see differences between signed and spoken languages in the typical number of morphemes and the number of syllables that are contained within a word (Brentari Reference Brentari and Goldsmith1995; Reference Brentari1998; Reference Brentari, Goldsmith, Riggle and Yu2011; Reference Brentari, Pfau, Steinbach and Woll2012). Morphemes are the meaningful, discrete, and productive parts of words – stems (morphemes that can stand alone as words) and affixes (prefixes and suffixes that attach to existing words and change either the part of speech or the meaning of the word). In English, character–istic–ally has three morphemes: the noun stem character, defined as “the distinctive nature of something” (Oxford English Dictionary, originally from Greek kharakter), followed by two suffixes that change it into first an adjective (-istic) and then an adverb (-ally). Morphemic units in sign languages meet the same criteria used for spoken language (meaningful, discrete, productive), and can assume any one of the five parameters of a sign – for example, a non-manual movement – pressing the lips together with a squint – can be added to many activity verbs (e.g., fish, cook, plan, read, write, look-for) and is produced across the entire sign; the resulting meaning is to-x-carefully. In contrast, syllables are meaningless parts of words, based on vowels in speech – for example, the stem character [kæ.ɹək.tɝ] has three syllables, each marked here by a period. Recall that syllables in sign languages are determined by the number of movements – for example, close-window in Figure 2 has one movement and is therefore one syllable; window has two movements and is therefore disyllabic (Brentari Reference Brentari1998).
Importantly, morphemes and syllables are independent levels of structure. Figure 3 presents examples of each of the four types of languages that result from crossing these two dimensions (number of syllables, number of morphemes) – a 2 × 2 typological grid. Surveying the languages of the world, we know that some have an abundance of words that contain only one morpheme (e.g., Hmong, English), whereas others have an abundance of words that are polymorphemic (e.g., ASL, Hopi). Some languages have many words that contain only one syllable (e.g., Hmong, ASL); others have many words that are polysyllabic (e.g., English, Hopi).

Figure 3. The top of the figure presents examples of word structure in the four types of languages that result from crossing the number of syllables with the number of morphemes. A period indicates a syllable boundary; a dash indicates a morpheme boundary; and a hash mark (#) indicates a word boundary. The bottom of the figure presents a depiction of the polymorphemic, monosyllabic ASL form “people-goforward-carefully” (Brentari Reference Brentari1998, reprinted with permission of MIT Press).
English (Fig. 3, top right) tends to have words composed of several syllables (polysyllabic) and one morpheme (monomorphemic); character [kæ.ɹək.tɝ] with three syllables and one morpheme is such a word. Hmong (top left) tends to have words composed of a single syllable and a single morpheme (Ratliff Reference Ratliff1992; Golston & Yang Reference Golston, Yang, Féry, Green and van de Vijver2001). Each of the meaningful units in the Hmong sentence Kuv. noj. mov. lawm. (English: “I ate rice”) is a separate monomorphemic word, even the perfective marker lawm, and each word contains a single syllable (each marked here by a period). Hopi (bottom right) tends to have words composed of many morphemes, each composed of more than one syllable; the verb phrase pa.kiw.–maq.to.–ni. (English: “will go fish-hunting”) is a single word with three morphemes, and the first two of these morphemes each contains two syllables (Mithun Reference Mithun1984). Finally, ASL (bottom left) has many words/signs composed of several morphemes packaged into a single syllable (i.e., one movement). Here we see a classifier form that means people–goforward–carefully, which is composed of three single-syllable morphemes: (i) the index finger handshapes (![]() = person); (ii) the path movement (linear path = goforward); and (iii) the non-manual expression (pressed together lips and squinted eyes = carefully).
= person); (ii) the path movement (linear path = goforward); and (iii) the non-manual expression (pressed together lips and squinted eyes = carefully).
Spoken languages have been identified that fall into three of the four cells in this typology. No spoken language has been found that falls into the fourth cell; that is, no spoken language has been found that is polymorphemic and monosyllabic. Interestingly, however, most of the signed languages analyzed to date have been found to be both polymorphemic and monosyllabic, and thus fall into the fourth cell. Although sign languages are different in kind from spoken languages, they fit neatly into the grid displayed in Figure 3 and, in this sense, can be characterized by the linguistic tools developed to describe spoken languages.
Note that the ASL sign in Figure 3 (bottom) contains three additional meaningful elements: (1) the two hands indicating that two people go forward; (2) the bent knuckle indicating that the people are hunched-over; and (3) the orientation of the hands with respect to one another indicating that the two people are side by side. Each of these aspects of the sign is likely to have been analyzed as a morpheme in the 1990s (see Brentari Reference Brentari and Goldsmith1995; Reference Brentari, Meier, Quinto and Cormier2002). However, more recent analyses consider non-productive, potentially non-discrete, forms of this sort to be gestural (not a listable or finite set) rather than linguistic. This is precisely the issue that is raised by the examples described in the next section, to which we now turn.
4.2. Differences between sign language and spoken language that cannot be explained within a grammatical framework
We turn to syntax to explore differences between sign and speech that are not easily handled using traditional linguistic tools. Like spoken languages, sign languages realize person and number features of the arguments of a verb through agreement. For example, the ASL verb ask (a crooked index finger), when moved in a straight path away from the signer (with the palm facing out), means I ask you; when the same verb is moved toward the signer (with the palm facing in), it means you ask me (see Fig. 4). This phenomenon is found in many sign languages (see Mathur & Rathmann Reference Mathur, Rathmann, Napoli and Mathur2010a; Reference Mathur, Rathmann and Brentari2010b; Rathmann & Mathur Reference Rathmann, Mathur, Pfau, Steinbach and Woll2012, p. 137) and is comparable to verb agreement in spoken language in that the difference between the two sign forms corresponds to a difference in meaning marked in spoken language by person agreement with the subject and/or object.
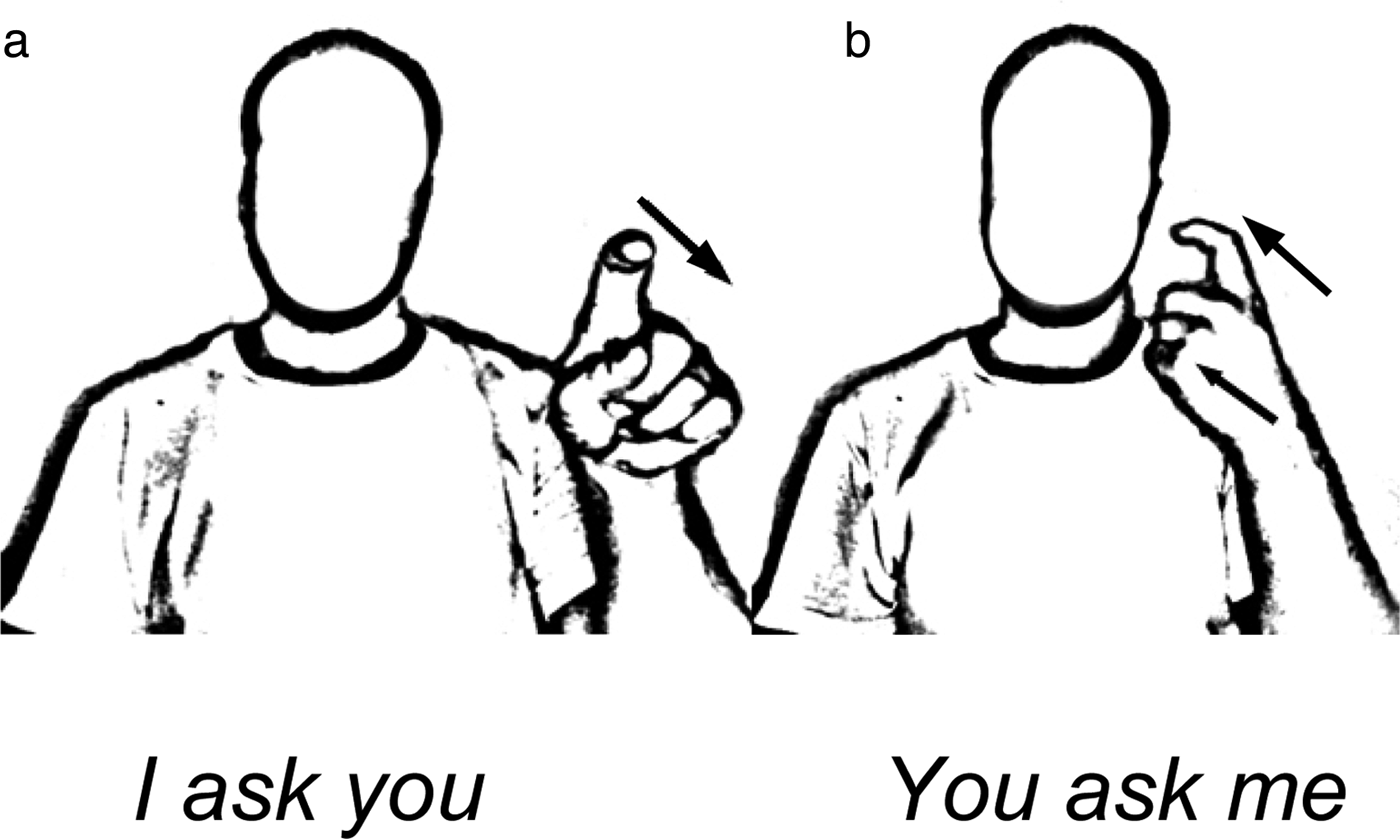
Figure 4. Examples of verb agreement in an ASL verb, ASK. When the verb is moved away from the signer (a), it means I ask you; when it is moved toward the signer (b), it means you ask me (Mathur & Rathmann Reference Mathur, Rathmann and Brentari2010b, reprinted with permission of Cambridge University Press).
But these agreeing verbs in sign differ from their counterparts in speech in that the number of locations toward which the verbs can be directed is not a discrete (finite or listable) set, as agreement morphemes are in spoken languages. Liddell (Reference Liddell2003) prefers to call verbs of this sort “indicating” verbs (rather than “agreeing” verbs), because they indicate, or point to, referents just as a speaker might gesture toward a person when saying I asked him. In addition to the fact that it is not possible to list all of the loci that could serve as possible morphemes for these verb signs, the signs differ from words in another respect – their forms vary as a function of the referents they identify or with which they agree (Liddell Reference Liddell2003; Liddell & Metzger Reference Liddell and Metzger1998). For example, if the signer is directing his question to a tall person, the ask verb will be moved higher in the signing space than it would be if the signer were directing his question to a child (as first noted by Fischer & Gough Reference Fischer and Gough1978).
These characteristics have raised doubts about whether agreement in sign should be analyzed entirely using the same linguistic tools as agreement in spoken language. The alternative is that some of these phenomena could be analyzed using tools developed to code the co-speech gestures that hearing speakers produce. Liddell (Reference Liddell2003, see also Dudis Reference Dudis2004; Liddell & Metzger Reference Liddell and Metzger1998) argues that the analog and gradient components of these signs makes them more gestural than linguistic. This debate hints at the underlying problem inherent in deciding whether a particular form that a signer produces is a gesture or a sign. The same form can be generated by either a categorical (sign) or a gradient (gestural) system, and, indeed, a single form can contain both categorical and gradient components (see examples in Duncan Reference Duncan2005, described in sect. 6); it is only by understanding how a particular form relates to other forms within a signer's repertoire that we can get a handle on this question (see Goldin-Meadow et al. Reference Goldin-Meadow, McNeill and Singleton1996 for discussion).
If a form is part of a categorical linguistic system, that is, if it is a sign, it must adhere to standards of form. Signers who use the same sign language should all produce a particular form in the same way if that form is a sign (i.e., there should be some invariance across signers). But we might not necessarily expect the same consistency across signers if the form is a gesture (see Sandler Reference Sandler2009, who uses this criterion to good effect to divide mouth movements that are grammatical from mouth movements that are gestural in signers of Israeli Sign Language). Since standards of form operate within a linguistic system, signers of different sign languages might be expected to use different forms to convey the same meaning – but there should be consistency across signers who all use the same sign language.
Schembri et al. (Reference Schembri, Jones and Burnham2005) examined adherence to standards of form in event descriptions by studying signers of three historically unrelated sign languages (Australian Sign Language, Taiwan Sign Language, and ASL). They looked, in particular, at the three linguistic dimensions Stokoe (Reference Stokoe1960) had established in sign languages – handshape, motion, and location (place of articulation) – and found that signers of the same sign language used the same handshape forms to describe the events (e.g., the ASL signers used a 3-handshape [thumb, index and middle fingers extended] to represent vehicles), but did not necessarily use the same handshape forms as signers of the other sign languages (the Australian Sign Language signers used a B handshape [a flat palm] to represent vehicles). In contrast, signers of all three languages used the same motion forms and the same location forms to describe the events (e.g., signers of all three languages used a linear path to represent motion forward along a path). In other words, there was variability across signers of different languages in handshape, but not in motion and location. The findings suggest that handshape functions like a linguistic category in sign language, but leave open the possibility that motion and location may not.
Schembri & colleagues (Reference Schembri, Jones and Burnham2005) also entertained the hypothesis that motion and location (but not handshape) reflect influences from gesture, and tested the hypothesis by asking English-speakers who knew no sign language to use their hands rather than their voices to describe the same events. To the extent that the forms generated by signers share properties with gesture, there should be measurable similarities between the forms used by signers of unrelated languages and the forms generated by the “silent gesturers” (as these hearing participants have come to be known, Goldin-Meadow Reference Goldin-Meadow2015). Schembri & colleagues (Reference Schembri, Jones and Burnham2005) found, in fact, that the handshape forms used by the silent gesturers differed from those used by the signers, but that their motion and location forms did not. Singleton et al. (Reference Singleton, Morford and Goldin-Meadow1993) similarly found that English-speakers, asked to use only their hands to describe a series of events, produced different handshape forms from ASL signers who described the same events, but produced the same motion and location forms. In other words, hearing non-signers, when asked to use only their hands to communicate information, invent gestures that resemble signs with respect to motion and location, but not with respect to handshape.
Consistent with these findings, Emmorey et al. (Reference Emmorey, McCullough and Brentari2003) explored categorical perception (the finding that speech stimuli are perceived categorically rather than continuously despite the fact that they vary continuously in form) for two parameters – hand configuration and place of articulation – in ASL signers and in hearing non-signers. In a discrimination task, they found that the ASL signers displayed categorical perception for hand configuration, but not for place of articulation. The hearing non-signers perceived neither parameter categorically.
A recent neuroimaging study by Emmorey et al. (Reference Emmorey, McCullough, Mehta, Ponto and Grabowski2013) also bears on whether handshape, motion, and location function as linguistic categories in signers. Deaf native ASL signers were asked to perform a picture description task in which they produced lexical signs for different objects, or classifier constructions for events that varied in type of object, location, or movement. Production of both lexical signs and classifier constructions that required different handshapes (e.g., descriptions of a bottle, lamp, or hammer, all in the same location) engaged left-hemisphere language regions; production of classifier constructions that required different locations (e.g., descriptions of a clock in different places relative to a table) or different motions (e.g., descriptions of a ball rolling off a table along different trajectories) did not.
Taken together, the findings from signers and silent gesturers suggest that handshape has many of the attributes found in linguistic categories in spoken language, but motion and location may not. It is important to note, however, that the silent gestures studied by Schembri et al. (Reference Schembri, Jones and Burnham2005) and Singleton et al. (Reference Singleton, Morford and Goldin-Meadow1993) are not the spontaneous gestures that hearing speakers produce when they talk – they are gestures created on the spot to replace speech rather than to work with speech to communicate. But it is the spontaneous co-speech gestures that we need to compare the gradient aspects of sign to, not silent gestures. Before turning to developments in the literature on co-speech gesture that took place during the time these debates about sign languages were surfacing, we assess what we can learn about the relation between sign and gesture from silent gestures produced by hearing individuals.
4.3. Silent gesture in hearing speakers is really spontaneous sign
We begin by noting that the term “silent gesture” is, in some sense, a contradiction in terms given that we have defined gesture as co-occurring with talk. Consistent with this contradiction, Singleton et al. (Reference Singleton, Goldin-Meadow, McNeill, Emmorey and Reilly1995; see also Goldin-Meadow et al. Reference Goldin-Meadow, McNeill and Singleton1996) found that silent gestures not only fail to meet the “produced-with-speech” criterion for a gesture, but they also fail to take on the other characteristics associated with co-speech gesture. Singleton et al. asked hearing speakers who knew no sign language to describe a set of scenes using speech, and analyzed the gestures that the participants spontaneously produced along with that speech. They then asked the participants to describe the scenes again, this time using only their hands and not their mouths. They found a dramatic change in gesture form when it was produced with speech (i.e., when it was real gesture), compared with when it was produced without speech. The gestures without speech immediately took on sign-like properties – they were discrete in form, with gestures forming segmented word-like units that were concatenated into strings characterized by consistent (non-English) order.
These findings have two implications: (1) There is a qualitative difference between hand movements when they are produced along with speech (i.e., when they are gestures) and when they are required to carry the full burden of communication without speech (when they begin to take on linguistic properties and thus resemble signs); and (2) this change can take place instantly in a hearing individual. Taken together, the findings provide support for a categorical divide between these two forms of manual communication (i.e., between gesture and sign), and suggest that when gesture is silent, it crosses the divide (see also Kendon Reference Kendon and Poyatos1988a). In this sense, silent gesture might be more appropriately called “spontaneous sign.”
Importantly, silent gestures crop up not only in experimental situations, but also in naturalistic circumstances where speech is not permitted but communication is required (see Pfau Reference Pfau, Pfau, Steinbach and Woll2013 for an excellent review of these “secondary sign languages,” as they are called). For example, in sawmills where noise prevents the use of speech, workers create silent gestures that they use not only to talk about the task at hand, but also to converse about personal matters (Meissner & Philpott Reference Meissner and Philpott1975). Similarly, Christian monastic orders impose a law of silence on their members, but when communication is essential, silent gestures are permitted and used (Barakat Reference Barakat, Umiker-Sebeok and Sebeok1975). As a final example, Aboriginal sign languages have evolved in Australia in response to a taboo on speaking during mourning; since mourning is done primarily by women in this culture, Walpiri Sign Language tends to be confined to middle-aged and older women (Kendon Reference Kendon1984; Reference Kendon1988b; Reference Kendon1988c). In all of these situations, the manual systems that develop look more like silent gestures than like the gestures that co-occur with speech. Although the gesture forms initially are transparent depictions of their referents, over time they become less motivated, and as a result, more conventionalized, just as signs do in sign languages evolving in deaf communities (Burling Reference Burling and King1999; Frishberg Reference Frishberg1975). In many cases, the structure underlying the silent gestures is borrowed from the user's spoken language (e.g., compound signs are generated on the basis of compound words in Walpiri Sign Language; the order in which signs are produced follows the word order in the monks’ spoken language). Interestingly, however, the gesture strings used by the silent gesturers in the experimental studies (Goldin-Meadow et al. Reference Goldin-Meadow, McNeill and Singleton1996; Singleton et al. Reference Singleton, Goldin-Meadow, McNeill, Emmorey and Reilly1995) did not adhere to English word order (although the strings did follow a consistent order; see also Goldin-Meadow et al. Reference Goldin-Meadow, So, Özyürek and Mylander2008). At the moment, we do not know which conditions are likely to encourage silent gesturers to model their gestures after their own spoken language, and which are likely to encourage them to develop new structures. But this would be an interesting area of research for the future. And now, on to co-speech gesture.
5. Gesture forms an integrated system with speech
In 1969, Ekman and Friesen proposed a scheme for classifying nonverbal behavior and identified five types. (1) Affect displays, whose primary site is the face, convey the speaker's emotions, or at least those emotions that the speaker does not wish to mask (Ekman et al. Reference Ekman, Friesen and Ellsworth1972). (2) Regulators, which typically involve head movements or slight changes in body position, maintain the give-and-take between speaker and listener and help pace the exchange. (3) Adaptors are fragments or reductions of previously learned adaptive hand movements that are maintained by habit – for example, smoothing the hair, pushing glasses up the nose even when they are perfectly positioned, holding or rubbing the chin. Adaptors are performed with little awareness and no intent to communicate. (4) Emblems are hand movements that have conventional forms and meanings – for example, the thumbs up, the okay, the shush. Speakers are typically aware of having produced an emblem and produce them, with speech or without it, to communicate with others, often to control their behavior. (5) Illustrators are hand movements that are part of an intentional speech act, although speakers are typically unaware of these movements. The movements are, for the most part, produced along with speech and often illustrate that speech – for example, a speaker says that the way to get to the study is to go upstairs and, at the same time, bounces his hand upward. Our focus is on illustrators – called gesticulation by Kendon (Reference Kendon and Key1980b) and plain old gesture by McNeill (Reference McNeill1992), the term we use here.
Communication has traditionally been divided into content-filled verbal and affect-filled nonverbal components. Under this view, nonverbal behavior expresses emotion, conveys interpersonal attitudes, presents one's personality, and helps manage turn-taking, feedback, and attention (Argyle Reference Argyle1975; see also Wundt Reference Wundt1900) – it conveys the speaker's attitude toward the message and/or the listener, but not the message itself. Kendon (Reference Kendon and Key1980b) was among the first to challenge this traditional view, arguing that at least one form of nonverbal behavior – gesture – cannot be separated from the content of the conversation. As McNeill (Reference McNeill1992) has shown in his groundbreaking studies of co-speech gesture, speech and gesture work together to convey meaning.
But speech and gesture convey meaning differently – whereas speech uses primarily categorical devices, gesture relies on devices that are primarily imagistic and analog. Unlike spoken sentences in which lower constituents combine into higher constituents, each gesture is a complete holistic expression of meaning unto itself (McNeill Reference McNeill1992). For example, in describing an individual running, a speaker might move his hand forward while wiggling his index and middle fingers. The parts of the gesture gain meaning because of the meaning of the whole. The wiggling fingers mean “running” only because we know that the gesture, as a whole, depicts someone running and not because this speaker consistently uses wiggling fingers to mean running. Indeed, in other gestures produced by this same speaker, wiggling fingers may well have a very different meaning (e.g., offering someone two options). To argue that the wiggling-fingers gesture is composed of separately meaningful parts, one would have to show that the three components that comprise the gesture – the V handshape, the wiggling motion, and the forward motion –are each used for a stable meaning across the speaker's gestural repertoire. The data (e.g., Goldin-Meadow et al. Reference Goldin-Meadow, Mylander and Butcher1995; Reference Goldin-Meadow, Mylander and Franklin2007b; McNeill Reference McNeill1992) provide no evidence for this type of stability in the gestures that accompany speech. Moreover, since the speaker does not consistently use the forms that comprise the wiggling-fingers gesture for stable meanings, the gesture cannot easily stand on its own without speech – which is consistent with the principle that speech and gesture form an integrated system.
Several types of evidence lend support to the view that gesture and speech form a single, unified system. First, gestures and speech are semantically and pragmatically co-expressive. When people speak, they produce a variety of spontaneous gesture types in conjunction with speech (e.g., deictic gestures, iconic gestures, metaphoric gestures; McNeill Reference McNeill1992), and each type of spontaneous gesture has a characteristic type of speech with which it occurs. For example, iconic gestures accompany utterances that depict concrete objects and events, and fulfill a narrative function – they accompany the speech that “tells the story.” A social worker describes the father of a patient and says, “… and he just sits in his chair at night smokin’ a big cigar …” while moving her hand back and forth in front of her mouth as though holding a long fat object and taking it in and out of her mouth (Kendon Reference Kendon and Poyatos1988a; Reference Kendon1988b, pp. 131–2). The cigar-smoking gesture is a concrete depiction of an event in the story and is a good example of an iconic gesture co-occurring with the narrative part of the discourse.Footnote 4 In contrast, other types of gestures (called metaphoric by McNeill [1992]) accompany utterances that refer to the structure of the discourse rather than to a particular event in the narrative.Footnote 5 For example, a speaker is describing a person who suffers from the neuropathological problem known as “neglect” and produces three open-hand palm-up gestures (with the hand shaped as though presenting something to the listener) at three different points in her speech (the placement of each gesture is indicated by brackets): “So there's [this woman], she's in the [doctor's office] and she can't, she doesn't recognize half of her body. She's neglecting half of her body and the doctor walks over an’ picks up her arm and says ‘whose arm is this?’ and she goes, ‘Well that's your arm’ and he's an [Indian doctor].” The speaker used her first two open-palm gestures to set up conditions for the narrative, and then used the third when she explained that the doctor was Indian (which was notable because the woman was unable to recognize her own arm even when the skin color of the doctor who picked up her arm was distinctly different from her own; Kendon Reference Kendon2004, p. 267). Gesture works together with speech to convey meaning.
Second, gesture and speech are temporally organized as a single system. The prosodic organization of speech and the phrasal structure of the co-occurring gestures are coordinated so that they appear to both be produced under the guidance of a unified plan or program of action (Kendon Reference Kendon, Siegman and Pope1972; Reference Kendon and Key1980b; Reference Kendon2004, Ch. 7; McNeill Reference McNeill1992). For example, the gesture and the linguistic segment representing the same information as that gesture are aligned temporally. More specifically, the gesture movement – the “stroke” – lines up in time with the tonic syllable of the word with which it is semantically linked (if there is one in the sentence).Footnote 6 For example, a speaker in one of McNeill's (Reference McNeill1992, p. 12) studies said “and he bends it way back” while his hand appears to grip something and pull it from a space high in front of him back and down to his shoulder (an iconic gesture representing bending a tree back to the ground); the speaker produced the stroke of the gesture just as he said, “bends it way back” (see Kita Reference Kita1993, for more subtle examples of how speech and gesture adjust to each other in timing, and Nobe Reference Nobe and McNeill2000). Typically, the stroke of a gesture tends to precede or coincide with (but rarely follow) the tonic syllable of its related word, and the amount of time between the onset of the gesture stroke and the onset of the tonic syllable of the word is quite systematic – the timing gap between gesture and word is larger for unfamiliar words than for familiar words (Morrell-Samuels & Krauss Reference Morrell-Samuels and Krauss1992). The systematicity of the relation suggests that gesture and speech are part of a single production process. Gesture and speech are systematically related in time even when the speech production process goes awry. For example, gesture production is halted during bouts of stuttering (Mayberry & Jaques Reference Mayberry, Jaques and McNeill2000; Mayberry et al. Reference Mayberry, Jaques, DeDe, Iverson and Goldin-Meadow1998). Synchrony of this sort underscores that gesture and speech form a single system.
Third, the view that gesture and speech form a unified system gains further support from the hand (right or left) with which gesture is produced. Gestures are more often produced with the right hand, whereas self-touching adaptors (e.g., scratching, pushing back the hair) are produced with both hands. This pattern suggests a link to the left-hemisphere-speech system for gesture, but not for self-touching adaptors (Kimura Reference Kimura1973).
Fourth, gestures have an effect on how speech is perceived and thus suggest that the two form a unified system. Listeners perceive prominent syllables as more prominent when they are accompanied by a gesture than when they are not (Krahmer & Swerts Reference Krahmer and Swerts2007). In addition, gesture can clarify the speaker's intended meaning in an ambiguous sentence and, in incongruent cases where gesture and prosody are at odds (e.g., a facial expression for incredulity paired with a neutral prosodic contour), gesture can make it more difficult to perceive the speaker's intended meaning (Sendra et al. Reference Sendra, Kaland, Swerts and Prieto2013).
Finally, the information conveyed in gesture, when considered in relation to the information conveyed in speech, argues for an integrated gesture–speech system. Often, a speaker intends the information conveyed in her gestures to be part of the message; for example, when she says, “Can you please give me that one,” while pointing at the desired object. In this case, the message received by the listener, and intended by the speaker, crucially depends on integrating information across the two modalities. But speakers can also convey information in gesture that they may not be aware of having expressed. For example, a speaker says, “I ran up the stairs,” while producing a spiral gesture – the listener can guess from this gesture that the speaker mounted a spiral staircase, but the speaker may not have intended to reveal this information. Under these circumstances, can we still assume that gesture forms an integrated system with speech for the speaker? The answer is “yes,” and the evidence comes from studies of learning (Goldin-Meadow Reference Goldin-Meadow2003a).
Consider, for example, a child participating in a Piagetian conservation task in which water from a tall glass is poured into a flat dish; young children are convinced that the pouring transformation has changed the amount of water. When asked why, one child said that the amount of water changed “‘cause this one's lower than this one” and thus focused on the height of the containers in speech. However, at the same time, she indicated the widths of the containers in her gestures, thus introducing completely new information in gesture that could not be found in her speech. The child produced what has been called a gesture–speech mismatch (Church & Goldin-Meadow Reference Church and Goldin-Meadow1986) – a response in which the information conveyed in gesture is different from, but relevant to, the information conveyed in speech. Although there is no evidence that this child was aware of having conveyed different information in gesture and speech, the fact that she did so had cognitive significance – she was more likely to profit from instruction in conservation than a child who conveyed the same information in gesture and speech, that is, a gesture–speech match; in this case, saying “‘cause that's down lower than that one,” while pointing at the water levels in the two containers and thus conveying height information in both modalities.
In general, learners who produce gesture–speech mismatches on the conservation task are more likely to profit from instruction in that task than learners whose gestures convey the same information as speech (Church & Goldin-Meadow Reference Church and Goldin-Meadow1986; Ping & Goldin-Meadow Reference Ping and Goldin-Meadow2008). The relation between a child's gestures and speech when explaining conservation thus indexes that child's readiness-to-learn conservation, suggesting that the information conveyed in speech and the information conveyed in gesture are part of the same system – if gesture and speech were two independent systems, the match or mismatch between the information conveyed in these systems should have no bearing on the child's cognitive state. The fact that gesture–speech mismatch does predict learning therefore suggests that the two modalities are not independent. Importantly, it is not merely the amount of information conveyed in a mismatch that gives it its power to predict learning – conveying the information across gesture and speech appears to be key. Church (Reference Church1999) found that the number of responses in which a child expressed two different ideas in gesture and speech (i.e., mismatch) on a conservation task was a better predictor of that child's ability to learn the task than the number of responses in which the child expressed two different ideas all in speech. In other words, it was not just expressing different pieces of information that mattered, but rather the fact that those pieces of information were conveyed in gesture and speech.Footnote 7
This phenomenon – that learners who convey information in gesture that is different from the information they convey in the accompanying speech are on the verge of learning – is not unique to 5- to 8-year old children participating in conservation tasks, but has also been found in 9- to 10-year-old children solving mathematical equivalence problems. For example, a child asked to solve the problem, 6+3+4=__+4, says that she “added the 6, the 3, and the 4 to get 13 and then put 13 in the blank” (an add-to-equal-sign strategy). At the same time, the child points at all four numbers in the problem, the 6, the 3, the 4 on the left side of the equal sign, and the 4 on the right side of the equal sign (an add-all-numbers strategy). The child has thus produced a gesture–speech mismatch. Here again, children who produce gesture–speech mismatches, this time on the mathematical equivalence task, are more likely to profit from instruction in the task than children whose gestures always match their speech – a child who, for example, produces the add-to-equal-sign strategy in both speech and gesture, that is, he gives the same response as the first child in speech but points at the 6, the 3, and the 4 on the left side of the equal sign (Alibali & Goldin-Meadow Reference Alibali and Goldin-Meadow1993; Perry et al. Reference Perry, Church and Goldin-Meadow1988; Reference Perry, Church and Goldin-Meadow1992).
The relation between gesture and speech has been found to predict progress in a variety of tasks at many ages: toddlers on the verge of producing their first sentences (Capirci et al. Reference Capirci, Iverson, Pizzuto and Volterra1996; Goldin-Meadow & Butcher Reference Goldin-Meadow, Butcher and Kita2003; Iverson & Goldin-Meadow Reference Iverson and Goldin-Meadow2005) and a number of different sentence constructions (Cartmill et al. Reference Cartmill, Hunsicker and Goldin-Meadow2014; Özçalişkan & Goldin-Meadow Reference Özçalişkan and Goldin-Meadow2005); 5-year-olds learning to produce narratives (Demir et al. Reference Demir, Levine and Goldin-Meadow2015); 5- to 6-year-olds learning to mentally rotate objects (Ehrlich et al. Reference Ehrlich and Goldin-Meadow2006); 5- to 9-year-olds learning to balance blocks on a beam (Pine et al. Reference Pine, Lufkin and Messer2004); and adults learning how gears work (Perry & Elder Reference Perry and Elder1997) or how to identify a stereoisomer in chemistry (Ping et al., Reference Ping, Larson, Decatur, Zinchenko and Goldin-Meadowunder review). When gesture and speech are taken together, they predict what a learner's next step will be, providing further evidence that gesture and speech are intimately connected and form an integrated cognitive system. It is important to note that this insight would be lost if gesture and speech were not analyzed as separate components of a single, integrated system; in other words, if they are not seen as contributing different types of information to a single, communicative act.
Further evidence that mismatch is generated by a single gesture–speech system comes from Alibali and Goldin-Meadow (Reference Alibali and Goldin-Meadow1993), who contrasted two models designed to predict the number of gesture–speech matches and mismatches children might be expected to produce when explaining their answers to mathematical equivalence problems. They then tested these models against the actual numbers of gesture–speech matches and mismatches that the children produced. The first model assumed that gesture and speech are sampled from a single set of representations, some of which are accessible to both gesture and speech (and thus result in gesture–speech matches) and some of which are accessible to gesture but not speech (and thus result in gesture–speech mismatches). The second model assumed that gesture and speech are sampled from two distinct sets of representations; when producing a gesture–speech combination, the speaker samples from one set of representations for speech, and independently samples from a second set of representations for gesture. Model 1 was found to fit the data significantly better than model 2. Gesture and speech can thus be said to form an integrated system in the sense that they do not draw upon two distinct sets of representations, but rather draw on a single set of representations, some of which are accessible only to gesture. Interestingly, the model implies that when new representations are acquired, they are first accessible only to gesture, which turns out to be true for the acquisition of mathematical equivalence (Perry et al. Reference Perry, Church and Goldin-Meadow1988).
In summary, communicative acts are often critically dependent on combining information that is expressed uniquely in one modality or the other. Gesture and speech together can achieve speakers’ communicative goals in ways that would otherwise not be accomplished by either channel alone.
6. Does gesture form an integrated system with sign?
McNeill (Reference McNeill1992) has hypothesized that human communication contains both categorical and imagistic forms; categorical forms are typically found in speech, imagistic forms in gesture (see also Goldin-Meadow & McNeill Reference Goldin-Meadow, McNeill, Corballis and Lea1999). If this view is correct, then sign, which for the most part is categorical in form, should also be accompanied by imagistic forms – in other words, signers should gesture just as speakers do.
Emmorey (Reference Emmorey, Messing and Campbell1999) was among the first to acknowledge that signers gesture, but she argued that signers do not gesture in the same way that speakers do. According to Emmorey, signers do not produce idiosyncratic hand gestures concurrently with their signs. But they do produce gestures with their face or other parts of the body that co-occur with their signs – for example, holding the tongue out with a fearful expression while signing dog runs; or swaying as if to music while signing, decide dance (Emmorey Reference Emmorey, Messing and Campbell1999). The gestures that signers produce as separate units with their hands tend to be conventional (i.e., they are emblems, such as shh, come-on, stop), and they tend to alternate with signs rather than being produced concurrently with them. Note that an emblem can be produced in a correct or an incorrect way (i.e., emblems have standards of form), and they can also occur without speech; they thus do not fit the definition of gesture that we are working with here.
Sandler (Reference Sandler2009), too, has found that signers can use their mouths to gesture. She asked four native signers of Israeli Sign Language to describe a Tweety Bird cartoon, and found that all four used mouth gestures to embellish the linguistic descriptions they gave with their hands. For example, while using his hands to convey a cat's journey up a drainpipe (a small-animal classifier moved upward), one signer produced the following mouth movements (Sandler Reference Sandler2009, p. 257, Fig. 8): a tightened mouth to convey the narrowness and tight fit of the cat's climb; and a zigzag mouth to convey a bend in the drainpipe. The signers’ mouth movements had all of the features identified by McNeill (Reference McNeill1992) for hand gestures in hearing speakers – they are global (i.e., not composed of discrete meaningless parts as words or signs are); they are context-sensitive (e.g., the mouth gesture used to mean “narrow” was identical to a mouth gesture used to indicate the “whoosh” generated by flying through the air); and they are idiosyncratic (i.e., different signers produced different mouth gestures for the same event). Signers can use their mouths to convey imagistic information typically conveyed by the hands in speakers.
Duncan (Reference Duncan2005) agrees that signers gesture, but believes that they can use their hands (as well as their mouths) to gesture just like speakers do. Her approach was to ask signers to describe the events of a cartoon that has been described by speakers of many different languages (again, Tweety Bird). Since Duncan knows a great deal about the gestures that speakers produce when describing this cartoon, she could assess the productions of her signers with this knowledge as a backdrop. Duncan studied nine adult signers of Taiwan Sign Language and found that all nine gestured with their hands. They produced hand gestures interleaved with signs (as found by Emmorey Reference Emmorey, Messing and Campbell1999), but the gestures were iconic rather than codified emblems. As an example, one signer enacted the cat's climb up the outside of the drainpipe (looking just like a hearing gesturer), and interspersed this gesture with the sign for climb-up (a thumb-and-pinky classifier, used for animals in Taiwanese Sign Language, moved upward; see Fig. 5 in Duncan Reference Duncan2005, p. 301).
The signers also produced idiosyncratic hand gestures concurrently with their signs – they modified some features of the handshapes of their signs, reflecting the spatial–imagistic properties of the cartoon. For example, Duncan (Reference Duncan2005) described how the signers modified another classifier for animals in Taiwan Sign Language, a three-fingered handshape, to capture the fact that the animal under discussion, a cat, was climbing up the inside of a drainpipe. One signer held the three fingers straight while contracting them to represent the fact that the cat squeezed inside the drainpipe; another signer curved two fingers in while leaving the third finger straight; a third signer bent all three fingers slightly inward. Duncan argues that the variability in how the three signers captured the cat's squeeze during his ascent is evidence that the modifications of these hand configurations are gestural – if all three signers had modified the handshape in the same way, the commonality among them would have argued for describing the modification as morphemic rather than gestural. The imagistic properties of the scene provide a source for gesture's meaning but do not dictate its form. Importantly, the variations across the three signers are reminiscent of the variations we find when we look at the gestures speakers produce as they describe this event; the difference is that hearing speakers can use whatever basic handshape they want (their linguistic categories are coming out of their mouths) – the signers all used the same three-fingered animal classifier.
What the signers are doing is idiosyncratically modifying their categorical linguistic morphemes to create a depictive representation of the event. We can see the same process in speakers who modify their spoken words to achieve a comparable effect. For example, Okrent (Reference Okrent, Meier, Quinto-Pozos and Cormier2002) notes that English speakers can extend the vowel of a word to convey duration or length, It took s-o-o-o l-o-o-o-ng. Both Okrent (Reference Okrent, Meier, Quinto-Pozos and Cormier2002) and Emmorey and Herzig (Reference Emmorey, Herzig and Emmorey2003) argue that all language users (speakers and signers) instinctively know which part of their words can be manipulated to convey analog information. Speakers know to say l-o-o-o-ng, and not *l-l-l-ong or *lo-ng-ng-ng, and signers know which parts of the classifier handshape can be manipulated to convey the iconic properties of the scene while retaining the essential characteristics of the classifier handshape.
Signers can thus manipulate handshape in gesture-like ways. What about the other parameters that constitute signs – for example, location? As mentioned earlier, some verb signs can be directed toward one or more locations in signing space that have been previously linked with the verb's arguments. Although there is controversy over how this phenomenon is best described (e.g., Lillo-Martin & Meier Reference Lillo-Martin and Meier2011, and the commentaries that follow), at this moment, there is little disagreement that these verbs have a linguistic and a gestural component – that they either “agree” with arguments associated with different locations pointed out in the signing space (Lillo-Martin Reference Lillo-Martin, Meier, Cormier and Quinto-Pozos2002; Rathmann & Mathur Reference Rathmann, Mathur, Meier, Cormier and Quinto-Pozos2002), or that they “indicate” present referents or locations associated with absent referents pointed out in the signing space (Liddell Reference Liddell, Emmorey and Lane2000). The signs tell us what grammatical role the referent is playing; gesture tells us who the referent is.
As Kendon (Reference Kendon2004) points out, speakers also use gesture to establish spatial locations that stand in for persons or objects being talked about. For example, in a conversation among psychiatrists discussing a case (Kendon Reference Kendon2004, p. 314), one speaker gesturally established two locations, one for the patient and one for the patient's mother. He said, “She [the patient] feels that this is not the case at times,” while thrusting his hand forward as he said “she,” and then said, “It's mother that has told her that she's been this way,” while thrusting his hand to his left as he said “mother.” Rathmann & Mathur (Reference Rathmann, Mathur, Meier, Cormier and Quinto-Pozos2002) suggest that gestures of this sort are more obligatory with (agreeing) verbs in sign languages than they are in spoken languages. This is an empirical question, but it is possible that this difference between sign and speech may be no different from the variations in gesture that we see across different spoken languages – co-speech gestures vary as a function of the structure of the particular language that they accompany (Gullberg Reference Gullberg, Bohnemeyer and Pederson2011; Kita & Özyürek Reference Kita and Özyürek2003). There are, in fact, circumstances in which gesture is obligatory for speakers (e.g., “the fish was this big,” produced along with a gesture indicating the length of the fish). Perhaps this is a difference of degree, rather than a qualitative difference between signed and spoken languages (a difference comparable to the fact that sign is found in only 1 of the 4 cells generated by the 2 × 2 typology illustrated in Fig. 3).
Thus far, we have seen that gesture forms an integrated system with sign in that gestures co-occur with signs and are semantically co-expressive with those signs. The detailed timing analyses that Kita (Reference Kita1993) and Nobe (Reference Nobe and McNeill2000) have conducted on gesture and speech have not yet been done on gesture and sign. However, the fifth and, in some ways, most compelling argument for integration has been examined in gesture and sign. We have evidence that the information conveyed in gesture, when considered in relation to the information conveyed in sign, predicts learning (Goldin-Meadow et al. Reference Goldin-Meadow, Shield, Lenzen, Herzog and Padden2012).
Following the approach that Duncan (Reference Duncan2005) took in her analyses of gesture in adult signers, Goldin-Meadow et al. (Reference Goldin-Meadow, Shield, Lenzen, Herzog and Padden2012) studied the manual gestures that deaf children produce when explaining their answers to math problems, and compared them to gestures produced by hearing children on the same task (Perry et al. Reference Perry, Church and Goldin-Meadow1988). They asked whether these gestures, when taken in relation to the sign or speech they accompany, predict which children will profit from instruction in those problems. Forty ASL-signing deaf children explained their solutions to math problems on a pre-test; they were then given instruction in those problems; finally, they were given a post-test to evaluate how much they had learned from the instruction.
The first question was whether deaf children gesture on the task – they did, and about as often as hearing children (80% of the deaf children's explanations contained gestures, as did 73% of the hearing children's explanations). The next question was whether deaf children produce gesture-sign mismatches – and again they did, and as often as the hearing children (42% of the deaf children produced 3 or more mismatches across six explanations, as did 35% of the hearing children). The final and crucially important question was whether mismatch predicts learning in deaf children as it does in hearing children – again it did, and at comparable rates (65% of the deaf children who produced 3 or more mismatches before instruction succeeded on the math task after instruction, compared with 22% who produced 0, 1, or 2 mismatches; comparable numbers for the hearing children were 62% vs. 25%). In fact, the number of pre-test mismatches that the children produced prior to instruction continuously predicted their success after instruction – each additional mismatch that a child produced before instruction was associated with greater success after instruction (see Fig. 2 in Goldin-Meadow et al. Reference Goldin-Meadow, Shield, Lenzen, Herzog and Padden2012; footnote 5 in Perry et al. Reference Perry, Church and Goldin-Meadow1988).
Examples of the gesture-sign mismatches that the children produced are instructive, because they underscore how intertwined gesture and sign are. In the first problem, 2 + 5 + 9 = 2 + __, a child puts 16 in the blank and explains how he got this answer by producing the (incorrect) add-to-equal sign strategy in sign (he signs fourteen, add, two, answer, sixteen); before beginning his signs, he produces a gesture highlighting the two unique numbers on the left side of the equation (5+9), thus conveying a different strategy with his gestures, the (correct) grouping strategy (i.e., group and add 5 and 9). In the second problem, 7 + 4 + 2 = 7 +__, a child puts 13 in the blank and explains how she got this answer by producing the (incorrect) add-to-equal-sign strategy in sign (add7+4+2, put13 ), and producing gestures conveying the (correct) add-subtract strategy – she covers the 7 on the right side of the problem while signing add over the 7, 4, and 2. Because the add sign is produced on the board over three numbers, we consider the sign to have gestural elements that point out the three numbers on the left side of the problem. In other words, the gesture string conveys adding 7 + 4 + 2 (via the placement of the add sign) and subtracting 7 (via the cover gesture). Gesture is thus incorporated into sign (the indexical components of the add sign) and is also produced as a separate unit that occurs simultaneously with sign (the covering gesture produced at the same time as the add sign).
The findings from this study have several implications. First, we now know that signers can produce gestures along with their signs that convey different information from those signs – that is, mismatches can occur within a single modality (the manual modality) and not just across two modalities (the manual and oral modality).
Second, the fact that gesture-sign mismatch (which involves one modality only) predicts learning as well as gesture–speech mismatch (which involves two modalities) implies that mismatch's ability to predict learning comes not from the juxtaposition of different information conveyed in distinct modalities (manual vs. oral), but rather from the juxtaposition of different information conveyed in distinct representational formats – a mimetic, imagistic format underlying gesture versus a discrete, categorical format underlying language, be it sign or speech. Thus, mismatch can predict learning whether the categorical information is conveyed in the manual (sign) or oral (speech) modality. However, the data leave open the possibility that the imagistic information in a mismatch needs to be conveyed in the manual modality. The manual modality may be privileged when it comes to expressing emergent or mimetic ideas, perhaps because our hands are an important vehicle for discovering properties of the world (Goldin-Meadow & Beilock Reference Goldin-Meadow and Beilock2010; Sommerville et al. Reference Sommerville, Woodward and Needham2005; Streeck Reference Streeck2009, Ch. 9).
Finally, the findings provide further evidence that gesture and sign form an integrated system, just as gesture and speech do – taking a learner's gesture and sign, or a learner's gesture and speech, together allows us to predict the next steps that the learner will take.
7. Implications for the study of gesture, sign, and language
7.1. Sign should be compared with speech-plus-gesture, not speech alone
The bottom line of our tour through the history of the sign and gesture literatures is that sign should not be compared with speech – it should be compared with speech-plus-gesture. If it were possible to easily separate sign into sign and its gestural components, it might then be reasonable to compare sign on its own to speech on its own. But there are problems with this strategy.
First, looking at speech or sign on its own means that we will miss generalizations that involve imagistic forms. We would not be able to see how sign and gesture collaborate to accomplish communicative goals – which may turn out to be the same type of collaboration that takes place between speech and gesture. Indeed, some (Kendon Reference Kendon2004; Reference Kendon2008; McNeill Reference McNeill1992) would argue that we miss the important generalizations about language if we ignore gesture. However, there is reason to want to take a look at the categorical components of language, be it sign or speech (knowing, of course, that we are setting aside its imagistic components).
Second, even if our goal is to examine the categorical components of sign on their own, it is currently difficult to separate them from sign's gestural components. Articulating criteria for gesture in sign is difficult, and we are still, for the most part, using hearing speakers’ gestures as a guide – which means that sign transcribers must be well-trained in coding gesture as well as sign language. As in the Duncan (Reference Duncan2005) and Goldin-Meadow et al. (Reference Goldin-Meadow, Shield, Lenzen, Herzog and Padden2012) studies, it helps to know a great deal about the gestures that hearing speakers produce on a task when trying to code a signer's gestures on that task.
There is, however, a caveat to this coding strategy. Many of the studies comparing sign to gesture have focused on what we have called “silent gesture” – the gestures hearing speakers produce when they are told not to use their mouths and use only their hands to communicate. These gestures are qualitatively different from co-speech gesture and cannot be used as a guide in trying to identify co-sign gestures, although they can provide insight into whether particular structures in current-day sign languages have iconic roots (see, e.g., Brentari et al. Reference Brentari, Coppola, Mazzoni and Goldin-Meadow2012). Silent gesture is produced to replace speech, not to work with it to express meaning (see sect. 4.3). The most relevant finding is that, when told to use only their hands to communicate, hearing speakers immediately adopt a more discrete and categorical format in their silent gestures, abandoning the more imagistic format of their co-speech gestures (Goldin-Meadow et al. Reference Goldin-Meadow, McNeill and Singleton1996; Singleton et al. Reference Singleton, Goldin-Meadow, McNeill, Emmorey and Reilly1995). As a result, we see some, but not all (more on this point later), of the properties found in language in silent gesture: for example, systematic use of location to establish co-reference (So et al. Reference So, Coppola, Licciardello and Goldin-Meadow2005) and consistent word order (Gershkoff-Stowe & Goldin-Meadow Reference Gershkoff-Stowe and Goldin-Meadow2000; Gibson et al. Reference Gibson, Piantadosi, Brink, Bergen, Lim and Saxe2013; Goldin-Meadow et al. Reference Goldin-Meadow, So, Özyürek and Mylander2008; Hall et al. Reference Hall, Ferreira and Mayberry2013; Langus & Nespor Reference Langus and Nespor2010; Meir et al. Reference Meir, Lifshitz, Ilkbasaran, Padden, Smith, Schouwstra, de Boer and Smith2010).
7.2 Speech can take on the properties of gesture; gesture can take on the properties of sign
Why is it important to make a distinction between gesture and sign? Although there may be descriptive phenomena that do not require a categorical division between gesture and sign, there are also phenomena that depend on the distinction; for example, predicting who is ready to profit from instruction on the math task depends on our ability to examine information conveyed in gesture in relation to information conveyed in sign language (Goldin-Meadow et al. Reference Goldin-Meadow, Shield, Lenzen, Herzog and Padden2012).Footnote 8 In addition, making a distinction between gesture and sign language allows us to recognize the conditions under which the manual modality can take on categorical properties and the oral modality can take on imagistic properties.
For example, there is now good evidence that speech can take on the properties of gesture; in other words, that there is gesture in the oral modality. Shintel and her colleagues (Shintel et al. Reference Shintel, Nusbaum and Okrent2006; Shintel & Nusbaum Reference Shintel and Nusbaum2007; Reference Shintel and Nusbaum2008; see also Grenoble et al. Reference Grenoble, Martinović, Baglini, Kramer, Zsiga and Boyer2015; Okrent Reference Okrent, Meier, Quinto-Pozos and Cormier2002) have found that speakers can continuously vary the acoustic properties of their speech to describe continuously varying events in the world. Faster events are described with faster speech, slower events with slower speech. This kind of analog expression can be used to describe a wide range of situations (e.g., raising or lowering pitch to indicate the height of an object). Moreover, not only do speakers spontaneously produce analog information of this sort, but also listeners pay attention to this information and use it to make judgments about the meaning of an utterance and who is expressing it. Speech then is not exclusively categorical, as many linguists have previously suggested (e.g., Bolinger Reference Bolinger1946; Trager Reference Trager1958). The gradient properties of language are important for expressing who we are, as seen in the burgeoning field of sociophonetics (Thomas Reference Thomas2011), in our affiliations with others (Sonderegger Reference Sonderegger2012), and in the future directions of historical change (Yu Reference Yu2013).
In addition, there is evidence that gesture can take on properties of sign. We have already described the silent gestures that hearing speakers produce when told to use only their hands to communicate (sect. 4.3). These gestures take on linguistic properties as soon as the hearing speaker stops talking and, in this sense, are categorical (Goldin-Meadow et al. Reference Goldin-Meadow, McNeill and Singleton1996). In addition, deaf children whose hearing losses prevent them from acquiring the spoken language that surrounds them, and whose hearing parents have not exposed them to a conventional sign language, invent gesture systems, called homesigns, that contain many of the properties of natural language (Goldin-Meadow Reference Goldin-Meadow2003b). Homesign has been studied in American (Goldin-Meadow & Mylander Reference Goldin-Meadow and Mylander1984), Chinese (Goldin-Meadow & Mylander 1998), Turkish (Goldin-Meadow et al. Reference Goldin-Meadow, Namboodiripad, Mylander, Özyürek and Sancar2015b), Brazilian (Fusellier-Souza Reference Fusellier-Souza2006), and Nicaraguan (Coppola & Newport Reference Coppola and Newport2005) individuals, and has been found to contain many, but not all, of the properties that characterize natural language – for example, structure within the word (morphology, Goldin-Meadow et al. Reference Goldin-Meadow, Mylander and Butcher1995; Reference Goldin-Meadow, Mylander and Franklin2007b), structure within basic components of the sentence (markers of thematic roles, Goldin-Meadow & Feldman Reference Goldin-Meadow and Feldman1977; nominal constituents, Hunsicker & Goldin-Meadow Reference Hunsicker and Goldin-Meadow2012; recursion, Goldin-Meadow Reference Goldin-Meadow, Wanner and Gleitman1982; the grammatical category of subject, Coppola & Newport Reference Coppola and Newport2005), structure in how sentences are modulated (negations and questions, Franklin et al. Reference Franklin, Giannakidou and Goldin-Meadow2011), and prosodic structure (Applebaum et al. Reference Applebaum, Coppola and Goldin-Meadow2014). The gestures that homesigners create, although iconic, are thus also categorical.
It is likely that all conventional sign languages, shared within a community of deaf (and sometimes hearing) individuals, have their roots in homesign (Coppola & Senghas Reference Coppola, Senghas and Brentari2010; Cuxac Reference Cuxac2005; Fusellier-Souza Reference Fusellier-Souza2006; Goldin-Meadow Reference Goldin-Meadow2010) and perhaps also in the co-speech gestures produced by hearing individuals within the community (Nyst Reference Nyst, Pfau, Steinbach and Woll2012). Language in the manual modality may therefore go through several steps as it develops (Brentari & Coppola Reference Brentari and Coppola2013; Goldin-Meadow et al. Reference Goldin-Meadow, Brentari, Coppola, Horton and Senghas2015a; Horton et al. Reference Horton, Goldin-Meadow, Coppola, Senghas and Brentari2016). The first and perhaps the biggest step is the distance between the manual modality when it is used along with speech (co-speech gesture) and the manual modality when it is used in place of speech (silent gesture, homesign, and sign language). Gesture used along with speech looks very different from gesture used as a primary language (Goldin-Meadow et al. Reference Goldin-Meadow, McNeill and Singleton1996; Singleton et al. Reference Singleton, Goldin-Meadow, McNeill, Emmorey and Reilly1995). The question is why.
As we have discussed, the gestures produced along with speech (or sign) form an integrated system with that speech (or sign). As part of this integrated system, co-speech gestures (and presumably co-sign gestures) are frequently called on to serve multiple functions – for example, they not only convey propositional information (e.g., describing the height and width of a container in the conservation of liquid quantity task, Church & Goldin-Meadow Reference Church and Goldin-Meadow1986), but also they coordinate social interaction (Bavelas et al. Reference Bavelas, Chovil, Lawrie and Wade1992; Haviland Reference Haviland and McNeill2000) and break discourse into chunks (Kendon Reference Kendon, Siegman and Pope1972; McNeill Reference McNeill and McNeill2000). As a result, the form of a co-speech (or co-sign) gesture reflects a variety of pressures, pressures that may compete with using those gestures in the way that a silent gesturer, homesigner, or signer does.
As described earlier, when asked to use gesture on its own, silent gesturers transform their co-speech gestures so that those gestures take on linguistic properties (e.g., word order). But, not surprisingly, silent gesturers do not display all of the properties found in natural language in their gestures, because they are invented on the spot. In fact, silent gestures do not even contain all of the linguistic properties found in homesign. For example, silent gesturers do not break their gestures for motion events into path and manner components, whereas homesigners do (Goldin-Meadow Reference Goldin-Meadow2015; Özyürek et al. Reference Özyürek, Furman and Goldin-Meadow2015). As another example, silent gesturers do not display the finger complexity patterns found in many conventional sign languages (i.e., that classifier handshapes representing objects display more finger complexity than those representing how objects are handled), whereas homesigners do show at least the beginning of this morpho-phonological pattern (Brentari et al. Reference Brentari, Coppola, Mazzoni and Goldin-Meadow2012). The interesting observation is that silent gesture, which is produced by individuals who already possess a language (albeit a spoken one), contains fewer linguistic properties than homesign, which is produced by children who do not have any model for language (Goldin-Meadow Reference Goldin-Meadow2015). The properties that are found in homesign, but not in silent gesture, may reflect properties that define a linguistic system. A linguistic system is likely to be difficult for a silent gesturer to construct on the spot, but it can be constructed over time by a homesigner (and perhaps by silent gesturers if given adequate time; see sect. 4.3).
By distinguishing between gesture and sign, we can identify the conditions under which gesture takes on the categorical properties of sign. One open question is whether homesigners (or silent gesturers) ever use their hands to convey the imagistic information captured in co-sign gesture and, if so, when in the developmental process this new function appears. The initial pressure on both homesigners and silent gesturers seems to be to convey information categorically (Goldin-Meadow et al. Reference Goldin-Meadow, McNeill and Singleton1996; Singleton et al. Reference Singleton, Goldin-Meadow, McNeill, Emmorey and Reilly1995), but the need to convey information imagistically may arise, perhaps at a particular point in the formation of a linguistic system.
7.3. Which aspects of sign are categorical? Why technology might be needed to study motion and location
It is generally accepted that handshape, motion, and location constitute the three parameters that characterize a manual sign (orientation may be a minor parameter, and non-manuals are relevant as well). Sign languages have two types of signs – a set of frozen signs whose forms do not vary as a function of the event being described, and a set of productive signs whose forms do vary. There is good evidence that handshape functions categorically in both sign types. For example, handshape is treated categorically in both the productive lexicon (Emmorey & Herzig Reference Emmorey, Herzig and Emmorey2003) and frozen lexicon (Emmorey et al. Reference Emmorey, McCullough and Brentari2003), despite the fact that the forms vary continuously. However, using the same paradigm, we find no evidence that place of articulation is treated categorically in either the frozen (Emmorey et al. Reference Emmorey, McCullough and Brentari2003) or productive (Emmorey & Herzig Reference Emmorey, Herzig and Emmorey2003) lexicon (motion has not been tested in this paradigm). Moreover, as noted earlier, when hearing that individuals are asked to describe scenes with their hands, the motions and locations that they use in their gestural descriptions resemble the motions and locations that signers use in their descriptions of the task (Schembri et al. Reference Schembri, Jones and Burnham2005; Singleton et al. Reference Singleton, Morford and Goldin-Meadow1993), suggesting that at least some of these forms may be gestural not only for hearing gesturers, but also for signers. In contrast, the handshapes gesturers use differ from the handshapes signers use, a finding that is consistent with evidence, suggesting that handshape is categorical in sign languages.
However, it is possible that motion and location forms may be less continuous than they appear if seen through an appropriate lens. Some evidence for this possibility comes from the fact that different areas of the brain are activated when hearing gesturers pantomime handling an object and when signers produce a sign for the same event – even when the sign resembles the pantomime (Emmorey et al. Reference Emmorey, McCullough, Mehta, Ponto and Grabowski2011). Different (linguistic) processes appear to be involved when signers create these forms than when gesturers create what appear to be the same forms. We have good methods for classifying (Eccarius & Brentari Reference Eccarius and Brentari2008; Prillwitz et al. Reference Prillwitz, Leven, Zienert, Hanke and Henning1989) and measuring (Keane Reference Keane2014; Liddell & Johnson Reference Liddell and Johnson2011) handshape, but the techniques currently available for capturing motion are less well developed. For example, linguistic descriptions of motion in sign typically do not include measures of acceleration or velocity (although see Wilbur Reference Wilbur2003; Reference Wilbur and Quer2008; Reference Wilbur and Brentari2010).
We suggest that it may be time to develop such tools for describing motion and location. Just as the analysis of speech took a great leap forward with the development of tools that allowed us to discover patterns not easily found by just listening – for example, the spectrograph, which paved the way for progress in understanding the acoustic properties of speech segments (Potter et al. Reference Potter, Kopp and Green1947), and techniques for normalizing fundamental frequency across speakers, which led to progress in understanding prosody (’t Hart & Collier Reference ’t Hart and Collier1975) – we suspect that progress in the analysis of motion and location in sign is going to require new tools.
For example, we can use motion analysis to compare the co-speech gestures that a hearing speaker produces with a signer's description of precisely the same event (taking care to make sure that the two are describing the same aspects of the event). If the variability in the hearing speakers’ movements is comparable to the variability in the signers’ movements, we would have good evidence that these movements are gestural in signers. If, however, the variability in signers’ movements is significantly reduced relative to the variability in speakers’ movements, we would have evidence that the signers’ movements are generated by a different (perhaps more linguistic) system than the speakers’ gestures. This analysis could be conducted on any number of parameters (shape of trajectory, acceleration, velocity, duration, etc.).
Motion analysis is already being used in analyses of signers’ movements, which is an important step needed to determine which parameters are most useful to explore. For example, Malaia and Wilbur (Reference Malaia and Wilbur2011) used motion capture data to investigate the kinematics of verb sign production in ASL and found more deceleration in verbs for telic events (i.e., events with an end-point, e.g., throw, hit) than in verbs for atelic events. The interesting question from our point of view is whether the co-speech gestures that hearing speakers produce when describing a throwing or hitting event also display these same deceleration patterns. More generally, does motion in sign display a characteristic signature that distinguishes it from motion in gesture? If so, there may be more categorical structure in motion (and perhaps locationFootnote 9 ) than meets the eye.
At the same time, there may also be more grammatical structure in gesture than we currently recognize. For example, elements thought to be gestural in sign have been shown to contribute to the grammaticality of an utterance. Take the height of the ask sign described earlier, which is considered gestural in Liddell's (Reference Liddell2003) analysis. Schlenker (Reference Schlenkerforthcoming; see also Schlenker et al. Reference Schlenker, Lamberton and Santoro2013) have found that the height of a sign can provide information relevant to the set of logical semantic variables known as phi-features, which introduce presuppositions into an utterance and contribute to their truth-value. If a signer first signs that his cousin knows his brother is tall, and then that the cousin wrongfully thinks the brother (indicated by a point) is a basketball player, the height of the point for the brother can have either a neutral locus or a high locus. However, if the signer signs that his cousin wrongfully thinks his brother is tall, and then signs that the cousin thinks the brother (indicated by a point) is tall, the height of the point for the brother can only have a neutral locus; the high locus is ungrammatical. In other words, the high point is grammatical only if the cousin knows that the brother is tall, not if the cousin incorrectly thinks the brother is tall. The height of the point is thus constrained by semantic properties of the sentence. The interesting question then is whether the pointing gesture that hearing speakers produce to accompany a spoken reference to the brother is similarly constrained. If not, we can conclude that signers’ pointing gestures are more grammatical than speakers’ pointing gestures. However, if speakers’ gestures are also constrained, we would have evidence that grammatical structure (semantic presuppositions) can play a role in conditioning gesture in speakers just as it does in signers.
A final strategy that can help us discover similarities and differences between gestures produced by signers versus speakers is to watch the behaviors as they change. For example, it is commonly thought that speakers gesture less with talk that is becoming rote. If so, we can compare speakers and signers as they continue to repeat the same discourse to the same communication partner. If gesture does indeed decrease in speakers, we can then examine the changes that take place in speech over time (which information is lost, which transferred from gesture to speech) and look for comparable changes in sign over time. Whether sign language can be stripped of its gestural elements and still be as effective as speech is when it is delivered without its gestural elements (e.g., over the radio or the phone) is an open question. Comparing speakers and signers in situations that are more, or less, likely to elicit gesture could give us an experimental handle on which aspects of sign are, in fact, gestural, and how those gestural aspects are comparable.
8. Conclusion
In sum, we believe that it is too early to say whether our view of what human language is must be altered to accommodate sign languages. We suggest that the field may be ignoring categorical structure that underlies motion in sign language simply because our current tools are insufficient to capture this structure (much as we were unable to adequately describe the structure of spoken language before the spectrograph). At the same time, recent work in speech analysis has emphasized the crucial importance of gradient properties in speech for language change (Yu Reference Yu2013) and sociophonetics (Thomas Reference Thomas2011); in other words, there appears to be more gradient structure in spoken language than previously thought (whether gradient properties play the same role in language as imagistic properties is an open and important question). Taken together, these observations lead us to suggest that the study of language is undergoing a paradigm shift – the full communicative act includes, at the least, both categorical (speech or sign) and imagistic (gesture) components, and our comparisons should be between speech-plus-gesture and sign-plus-gesture.
Our tour through the recent history of sign language and gesture studies has brought us to the conclusion that the two fields need to be talking to one another. Sign language, at times, has been viewed as a language of gestures and is therefore very different from spoken language and, at other times, as a language characterized by structures just like those found in spoken language. More recently, researchers have recognized that sign language has gestural components just as spoken language does. The fact that sign's gestural components are produced in the same (manual) modality as its linguistic structures makes it more difficult to separate the two than in spoken language. We believe, nevertheless, that separation is a useful goal. Although there are undoubtedly phenomena that can be captured by not making a categorical divide between gesture and sign, there are also phenomena that depend on the divide; for example, predicting who is ready to learn a particular task (Goldin-Meadow Reference Goldin-Meadow2003a; Goldin-Meadow et al. Reference Goldin-Meadow, Shield, Lenzen, Herzog and Padden2012) – in order to predict who is ready to learn, we need to be able to distinguish information that is conveyed in an imagistic (gestural) format from information that is conveyed in a categorical (linguistic, be it sign or speech) format. The two formats together form the whole of a communicative act. However, by acknowledging the gestural components in sign, and comparing them to the gestural components in speech (cf. Okrent Reference Okrent, Meier, Quinto-Pozos and Cormier2002), we can discover how the imagistic properties of language work together with its categorical properties to make human communication what it is.
ACKNOWLEDGMENTS
Supported by NICHD (R01-HD47450), NIDCD (R01-DC00491; P01-HD 40605), NSF (BCS-0925595; BNS-8497941; SBE-0541957 supporting the Spatial Intelligence and Learning Center) to Goldin-Meadow; NSF (BCS-0547554BCS; BCS-1227908) to Brentari; and funding from the Neubauer Collegium to Goldin-Meadow and Brentari as codirectors of the Center for Gesture, Sign, and Language at the University of Chicago. We thank Nick Enfield for suggesting that we write this article, Daniel Casasanto for helpful comments on an earlier draft, the Franke Institute for the Humanities at the University of Chicago for sponsoring our Center for Disciplinary Innovation course on Gesture, Sign, and Language in 2012 where we first explored many of these ideas, and the graduate and undergraduate students in the course whose input was invaluable.



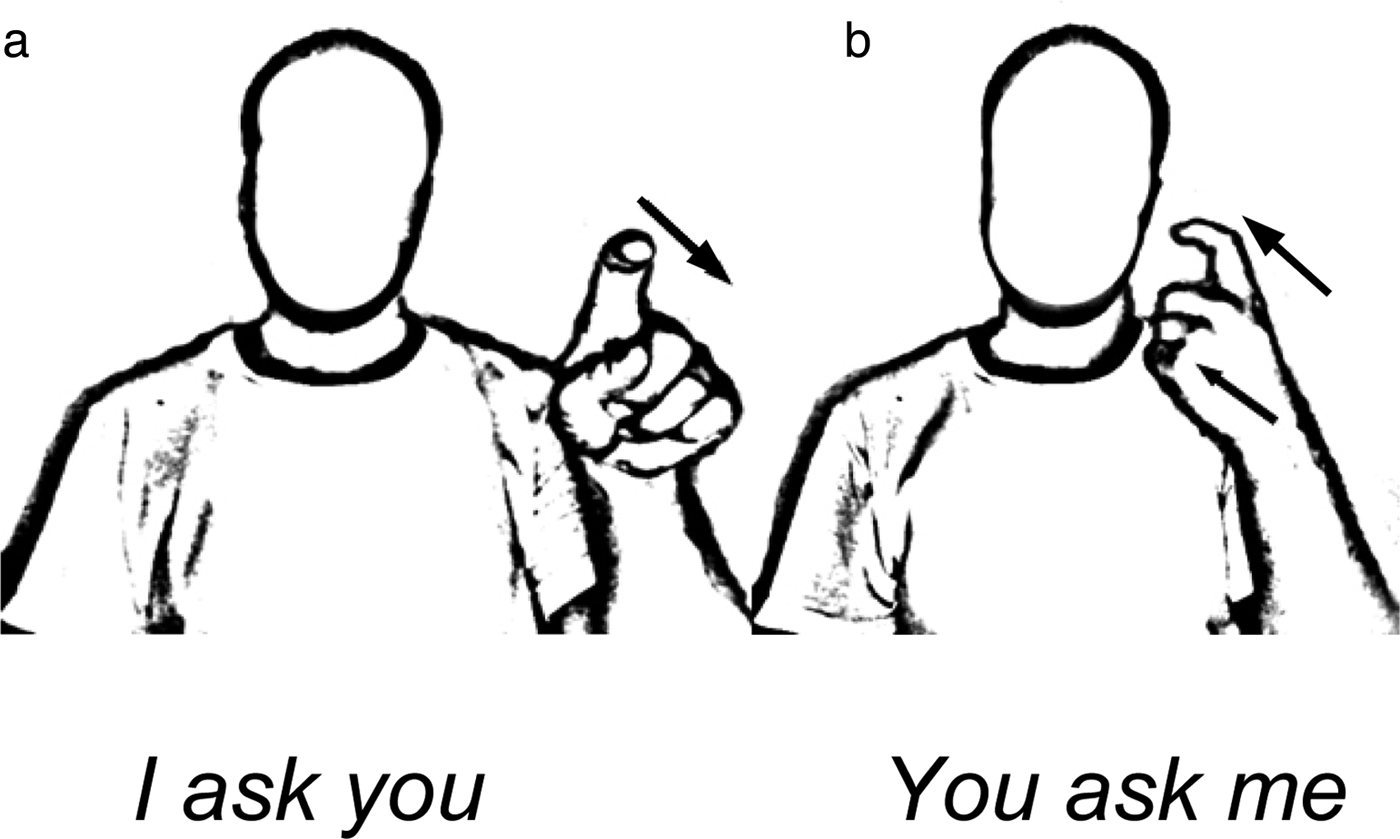

Target article
Gesture, sign, and language: The coming of age of sign language and gesture studies
Related commentaries (27)
An evolutionary approach to sign language emergence: From state to process
Are gesture and speech mismatches produced by an integrated gesture-speech system? A more dynamically embodied perspective is needed for understanding gesture-related learning
Building a single proposition from imagistic and categorical components
Current and future methodologies for quantitative analysis of information transfer in sign language and gesture data
Emoticons in text may function like gestures in spoken or signed communication
Gesture or sign? A categorization problem
Gestures can create diagrams (that are neither imagistic nor analog)
Good things come in threes: Communicative acts comprise linguistic, imagistic, and modifying components
How to distinguish gesture from sign: New technology is not the answer
Iconic enrichments: Signs vs. gestures
Is it language (yet)? The allure of the gesture-language binary
Language readiness and learning among deaf children
Languages as semiotically heterogenous systems
Perspectives on gesture from autism spectrum disorder: Alterations in timing and function
Pros and cons of blurring gesture-language lines: An evolutionary linguistic perspective
Same or different: Common pathways of behavioral biomarkers in infants and children with neurodevelopmental disorders?
Sign, language, and gesture in the brain: Some comments
The categorical role of structurally iconic signs
The influence of communication mode on written language processing and beyond
The physiognomic unity of sign, word, and gesture
Toward true integration
Understanding gesture in sign and speech: Perspectives from theory of mind, bilingualism, and acting
Vocal laughter punctuates speech and manual signing: Novel evidence for similar linguistic and neurological mechanisms
What is a gesture? A lesson from comparative gesture research
Where does (sign) language begin?
Why space is not one-dimensional: Location may be categorical and imagistic
Why would the discovery of gestures produced by signers jeopardize the experimental finding of gesture-speech mismatch?
Author response
Gesture and language: Distinct subsystem of an integrated whole