



1. Introduction
Statistics over the last few decades demonstrate an increase in life expectancy in many countries. For example, in Japan, the life expectancy in 2020 was 85 years, whereas it was 60 years in 1950. Such a rapid change in longevity is called the “Longevity Revolution”. This trend confers selectivity and value to human life for individuals. However, this gives rise to several medical, economic, and social welfare problems. For instance, the Japanese financial crisis involving the national pension system is a pressing matter. The prediction of mortality is becoming a critical social issue worldwide.
Since the early 20th century, numerous authors have studied mortality prediction, and a methodology has already been established. Most mortality models treat “death” as the first event of a time-inhomogeneous Poisson process. Let
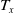 $T_x$
be the remaining lifetime of an individual of age x. It is assumed that
$T_x$
be the remaining lifetime of an individual of age x. It is assumed that
 \begin{align*}{\mathbb{P}}(T_x \gt t+1 \,|\,T_x>t) = \exp\left(\!- \int_t^{t+1} \mu(x,s)\,\textrm{d} s\right), \end{align*}
\begin{align*}{\mathbb{P}}(T_x \gt t+1 \,|\,T_x>t) = \exp\left(\!- \int_t^{t+1} \mu(x,s)\,\textrm{d} s\right), \end{align*}
where
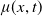 $\mu(x,t)$
is a (possibly stochastic) intensity function called the force of mortality in the insurance context. Previous studies have derived models for
$\mu(x,t)$
is a (possibly stochastic) intensity function called the force of mortality in the insurance context. Previous studies have derived models for
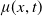 $\mu(x,t)$
. For instance, certain deterministic mortality models, such as the Gompertz, Makeham, and Heligman-Pollard laws, were introduced in earlier years; More recently, numerous stochastic mortality models have been proposed, such as those developed by Olivieri Olovieri (Reference Olovieri2001), Biffis (Reference Biffis2005), Cairns et al. (Reference Cairns, Blake and Dowd2006b), Hainaut and Devolder Hainaut and Devolder (Reference Hainaut and Devolder2008), Biffis et al. (Reference Biffis, Denuit and Devolder2010), Blackburn and Sherris (Reference Blackburn and Sherris2013). Moreover, by assuming that
$\mu(x,t)$
. For instance, certain deterministic mortality models, such as the Gompertz, Makeham, and Heligman-Pollard laws, were introduced in earlier years; More recently, numerous stochastic mortality models have been proposed, such as those developed by Olivieri Olovieri (Reference Olovieri2001), Biffis (Reference Biffis2005), Cairns et al. (Reference Cairns, Blake and Dowd2006b), Hainaut and Devolder Hainaut and Devolder (Reference Hainaut and Devolder2008), Biffis et al. (Reference Biffis, Denuit and Devolder2010), Blackburn and Sherris (Reference Blackburn and Sherris2013). Moreover, by assuming that
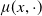 $\mu(x,\cdot)$
is constant between
$\mu(x,\cdot)$
is constant between
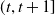 $(t,t+1]$
, say m(x, t), allows for modeling of the mortality m(x, t). This approach corresponds to many established classical models, such as the Lee-Carter (Reference Lee and Carter1992), Renshaw-Gaberman (2006), and CBD models (Cairns et al., Reference Cairns, Blake and Dowd2008, Reference Cairns, Blake, Dowd, Coughlan, Epstein, Ong and Balevich2009), among others. We refer to these approaches as reduced-form approaches, because they consider death just as a stochastic event.
$(t,t+1]$
, say m(x, t), allows for modeling of the mortality m(x, t). This approach corresponds to many established classical models, such as the Lee-Carter (Reference Lee and Carter1992), Renshaw-Gaberman (2006), and CBD models (Cairns et al., Reference Cairns, Blake and Dowd2008, Reference Cairns, Blake, Dowd, Coughlan, Epstein, Ong and Balevich2009), among others. We refer to these approaches as reduced-form approaches, because they consider death just as a stochastic event.
Shimizu et al. (Reference Shimizu, Minami and Ito2020) proposed a structural approach under the “survival energy hypothesis”, which assumes the existence of survival energy for human beings, and death occurs when the energy dissipates. Shimizu et al. (Reference Shimizu, Minami and Ito2020) used inhomogeneous diffusion (ID) processes as the cohort-wise survival energy model (SEM), such as
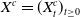 $X^c=(X^c_t)_{t\ge 0}$
with cohort c, called ID-SEM:
$X^c=(X^c_t)_{t\ge 0}$
with cohort c, called ID-SEM:
 \begin{align}X^c_t = x_c + \int_0^t U_c(s,\vartheta_c)\,\textrm{d} s + \int_0^t V_c(s,\vartheta_c)\,\textrm{d} W_s, \end{align}
\begin{align}X^c_t = x_c + \int_0^t U_c(s,\vartheta_c)\,\textrm{d} s + \int_0^t V_c(s,\vartheta_c)\,\textrm{d} W_s, \end{align}
where
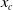 $x_c$
is a positive constant corresponding to the initial survival energy,
$x_c$
is a positive constant corresponding to the initial survival energy,
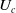 $U_c$
and
$U_c$
and
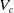 $V_c$
are deterministic functions on
$V_c$
are deterministic functions on
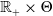 $\mathbb{R}_+\times \Theta$
with the parameter space given below, and W is the Wiener process:
$\mathbb{R}_+\times \Theta$
with the parameter space given below, and W is the Wiener process:
 \begin{align*}U_c(t,\vartheta_c) &= \alpha_c + \beta_c \exp\left( \gamma_c (t- T_c) \right)\mathbf{1}_{\{t \ge T_c\}};\\[3pt]V_c(t,\vartheta_c) &= \sqrt{\frac{2}{\kappa_c}U_c(t,\vartheta_c)},\end{align*}
\begin{align*}U_c(t,\vartheta_c) &= \alpha_c + \beta_c \exp\left( \gamma_c (t- T_c) \right)\mathbf{1}_{\{t \ge T_c\}};\\[3pt]V_c(t,\vartheta_c) &= \sqrt{\frac{2}{\kappa_c}U_c(t,\vartheta_c)},\end{align*}
where
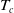 $T_c$
is a known parameter called change point, at which the trend of survival energy changes drastically.
$T_c$
is a known parameter called change point, at which the trend of survival energy changes drastically.
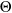 $\Theta$
of
$\Theta$
of
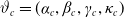 $\vartheta_c=(\alpha_c,\beta_c,\gamma_c,\kappa_c)$
is given by
$\vartheta_c=(\alpha_c,\beta_c,\gamma_c,\kappa_c)$
is given by
 \begin{align*}\Theta \subset \{(\alpha,\beta,\gamma,\kappa) \in \mathbb{R}^4\,|\, \alpha\lt 0,\, \beta<0,\, \gamma \gt 0,\, \kappa\lt 0 \}.\end{align*}
\begin{align*}\Theta \subset \{(\alpha,\beta,\gamma,\kappa) \in \mathbb{R}^4\,|\, \alpha\lt 0,\, \beta<0,\, \gamma \gt 0,\, \kappa\lt 0 \}.\end{align*}
Under this ID-SEM, they defined the time of death as the first hitting time for
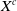 $X^c$
to reach zero:
$X^c$
to reach zero:
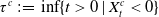 $\tau^c \,{:\!=}\, \inf\{t \gt 0\,|\, X^c_t \lt 0\}$
, and illustrated that the mortality function,
$\tau^c \,{:\!=}\, \inf\{t \gt 0\,|\, X^c_t \lt 0\}$
, and illustrated that the mortality function,
 \begin{align}q_c(t)\,{:\!=}\, {\mathbb{P}}(\tau^c \le t), \end{align}
\begin{align}q_c(t)\,{:\!=}\, {\mathbb{P}}(\tau^c \le t), \end{align}
or more practically, the following conditional mortality function:
 \begin{align}q_c(t|S)\,{:\!=}\, {\mathbb{P}}(\tau^c \le t|\tau^c \gt S) \end{align}
\begin{align}q_c(t|S)\,{:\!=}\, {\mathbb{P}}(\tau^c \le t|\tau^c \gt S) \end{align}
for a suitably chosen age S can fit their empirical version computed using data from the human mortality database (HMD) (Human Mortality Database); see also Remark 2.5. This indicates that the SEM can propose an excellent parametric family to predict future mortality functions; nevertheless, it is merely a fictitious assumption.
As described in Shimizu et al. (Reference Shimizu, Minami and Ito2020), the term “structural approach” follows the structural approach in credit risk analysis. This approach is analogous to the structural approach to “default probability”, in which a stochastic process describes the asset price. Default time was defined as the first hitting time to a certain level. These two approaches are mathematically identical, but there is a significant difference from a statistical perspective: we can observe the asset process in a credit risk context unlike the “survival energy.” However, we can observe many deaths for many individuals’ data, although defaults are not directly observed in default risk calculations (because they are predetermined or assumed to occur before default). We estimated the parameters in the SEM family with careful attention to this point.
The main contribution of this paper is the proposal of a novel SEM in Section 2. The mortality function for ID-SEM is sensitive to the change-point parameter
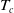 $T_c$
and is difficult to predict for a future cohort because it has no clear trend. To address this issue, we propose a new SEM, IG-SEM, which comprises a simple parametric family without such a threshold and is fully flexible enough to fit the training data without a change point. This is helpful because the mortality function can be written explicitly.
$T_c$
and is difficult to predict for a future cohort because it has no clear trend. To address this issue, we propose a new SEM, IG-SEM, which comprises a simple parametric family without such a threshold and is fully flexible enough to fit the training data without a change point. This is helpful because the mortality function can be written explicitly.
Another contribution is that we propose a methodology to improve long-term future predictions in Section 3. The prediction procedure proposed by Shimizu et al. (Reference Shimizu, Minami and Ito2020) is satisfactory for mid-term future (approximately 10–30 years future) but not for long-term future (e.g., 40 years future cohort). Occasionally, the predictive mortality function does not fit existing data. Therefore, we implement a two-step procedure: the first step is the same as in Shimizu et al. (Reference Shimizu, Minami and Ito2020), and in the second step, we refit the predicted mortality to the existing younger generation data using 95% prediction intervals for the parameters. We illustrate that this second step can drastically improve the long-term prediction.
Section 5 discusses some advantages of SEM over classical regression-type models in the reduced-form approach. Although this section only presents a theoretical discussion, there are some ongoing experimental studies. We refer to, for example, Shirai and Shimizu (Reference Shirai and Shimizu2022) for discussing the prediction of full life expectancy via SEM.
Finally, Section 6 introduces the SEM project. which explicitly provides cohort/countrywise mortality functions with parameter values on a website.
2. A new SEM: Inverse Gaussian SEM
Let us introduce some notations to provide a new SEM with an explicit mortality function.
Random variable Y follows an inverse Gaussian distribution, that is,
 \begin{align*}Y\sim IG(a,b),\end{align*}
\begin{align*}Y\sim IG(a,b),\end{align*}
with mean a and variance
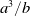 $a^3/b$
if the probability density is given by
$a^3/b$
if the probability density is given by
 \begin{align*}f_Y(y;\ a,b) = \sqrt{\frac{b}{2\pi y^3}} \exp\left(\!-\frac{b(y-a)^2}{2a^2y}\right),\quad y>0.\end{align*}
\begin{align*}f_Y(y;\ a,b) = \sqrt{\frac{b}{2\pi y^3}} \exp\left(\!-\frac{b(y-a)^2}{2a^2y}\right),\quad y>0.\end{align*}
Definition 2.1
(IG-SEM; Inverse Gaussian SEM). A survival energy process
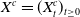 $X^c=(X_t^c)_{t\ge 0}$
follows the IG-SEM if
$X^c=(X_t^c)_{t\ge 0}$
follows the IG-SEM if
 \begin{align}X_t^c = x_c - Y^c_t,\quad t\ge 0,\end{align}
\begin{align}X_t^c = x_c - Y^c_t,\quad t\ge 0,\end{align}
where
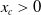 $x_c>0$
is the initial energy and
$x_c>0$
is the initial energy and
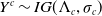 $Y^c\sim IG(\Lambda_c,\sigma_c)$
is an inverse Gaussian process with mean function
$Y^c\sim IG(\Lambda_c,\sigma_c)$
is an inverse Gaussian process with mean function
 $\Lambda_c$
and parameter
$\Lambda_c$
and parameter
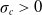 $\sigma_c>0$
; that is,
$\sigma_c>0$
; that is,
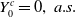 $Y_0^c=0,\ a.s.$
, and
$Y_0^c=0,\ a.s.$
, and
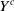 $Y^c$
have independent increments. Moreover, for any
$Y^c$
have independent increments. Moreover, for any
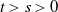 $t>s>0$
and an increasing function
$t>s>0$
and an increasing function
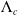 $\Lambda_c$
with
$\Lambda_c$
with
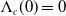 $\Lambda_c(0)=0$
, it follows that
$\Lambda_c(0)=0$
, it follows that
 \begin{align*}Y_t^c-Y_s^c\sim IG\left(\Lambda_c(t) - \Lambda_c(s), \sigma_c (\Lambda_c(t) - \Lambda_c(s))^2\right).\end{align*}
\begin{align*}Y_t^c-Y_s^c\sim IG\left(\Lambda_c(t) - \Lambda_c(s), \sigma_c (\Lambda_c(t) - \Lambda_c(s))^2\right).\end{align*}
Remark 2.2. If
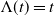 $\Lambda (t) = t$
, then Y is an inverse Gaussian Lévy process that is a spectrally positive pure-jump subordinator. Hence, IG-SEM can include a jump in the path of survival energy, although the path of ID-SEM is continuous.
$\Lambda (t) = t$
, then Y is an inverse Gaussian Lévy process that is a spectrally positive pure-jump subordinator. Hence, IG-SEM can include a jump in the path of survival energy, although the path of ID-SEM is continuous.
Such a process is used to model the time of system failure in engineering, where failure occurs at
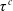 $\tau^c$
if the accumulated damage
$\tau^c$
if the accumulated damage
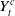 $Y^c_t$
exceeds a certain threshold
$Y^c_t$
exceeds a certain threshold
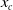 $x_c$
:
$x_c$
:
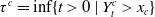 $\tau^c = \inf\{t>0\,|\,Y^c_t \gt x_c\}$
, which follows the same idea as our survival energy for human death; refer to Ye and Chen (Reference Ye and Chen2014). The following theorem provides the mortality function:
$\tau^c = \inf\{t>0\,|\,Y^c_t \gt x_c\}$
, which follows the same idea as our survival energy for human death; refer to Ye and Chen (Reference Ye and Chen2014). The following theorem provides the mortality function:
Theorem 2.3. The mortality function for IG-SEM is given by
 \begin{align*}q_c^{IG}(t,\vartheta_c) = \Phi\left(\sqrt{\frac{\sigma_c}{x_c}}(\Lambda_{\vartheta_c}(t) - x_c)\right)- e^{2\sigma_c\Lambda_{\vartheta_c}(t)}\Phi\left(\!- \sqrt{\frac{\sigma_c}{x_c}}(\Lambda_{\vartheta_c}(t) + x_c)\right),\end{align*}
\begin{align*}q_c^{IG}(t,\vartheta_c) = \Phi\left(\sqrt{\frac{\sigma_c}{x_c}}(\Lambda_{\vartheta_c}(t) - x_c)\right)- e^{2\sigma_c\Lambda_{\vartheta_c}(t)}\Phi\left(\!- \sqrt{\frac{\sigma_c}{x_c}}(\Lambda_{\vartheta_c}(t) + x_c)\right),\end{align*}
where
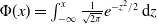 $\Phi(x) = \int_{-\infty}^x \frac{1}{\sqrt{2\pi}} e^{-z^2/2}\,\textrm{d} z$
,
$\Phi(x) = \int_{-\infty}^x \frac{1}{\sqrt{2\pi}} e^{-z^2/2}\,\textrm{d} z$
,
Subsequently, we consider the mean function
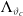 $\Lambda_{\vartheta_c}$
as follows:
$\Lambda_{\vartheta_c}$
as follows:
 \begin{align*}\Lambda_{\vartheta_c} (t) = e^{a_c t} + b_c t - 1,\quad \vartheta_c=(a_c,b_c,\sigma_c) \in \Theta,\end{align*}
\begin{align*}\Lambda_{\vartheta_c} (t) = e^{a_c t} + b_c t - 1,\quad \vartheta_c=(a_c,b_c,\sigma_c) \in \Theta,\end{align*}
where
 \begin{align*}\Theta \subset \{(a,b,\sigma) \in \mathbb{R}^3 \,|\, a>0,\ b>0,\ \sigma \gt 0\}.\end{align*}
\begin{align*}\Theta \subset \{(a,b,\sigma) \in \mathbb{R}^3 \,|\, a>0,\ b>0,\ \sigma \gt 0\}.\end{align*}
The parameters are estimated in a manner similar to those for ID-SEM, as shown in the data analysis in Section 4.
Remark 2.4. As described in Shimizu et al. (2020), we can interpret the parameters and coefficients of the SDE. For example, in ID-SEM, the drift term represents the intrinsic survival power of a human and the diffusion term is affected by the social environment. In IG-SEM,
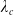 $\lambda_c$
may correspond to the drift term because it is the mean of the accumulating damage process
$\lambda_c$
may correspond to the drift term because it is the mean of the accumulating damage process
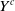 $Y^c$
, and
$Y^c$
, and
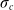 $\sigma_c$
may be an environmental parameter because it affects damage variance.
$\sigma_c$
may be an environmental parameter because it affects damage variance.
Remark 2.5. We estimate the parameters by least-squares fitting of the “conditional” mortality function
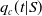 $q_c(t|S)$
given in (1.3) to the corresponding empirical version, which can be computed based on the data in the HMD (Human Mortality Database), as explained in Shimizu et al.(Reference Shimizu, Shirai, Kojima, Mitsuda and Inoue2023). We often recommend choosing a conditioning age S of approximately 20 years. This is because mortality at young ages is highly volatile and unstable, making it difficult to predict with simple models, such as ours. The value of S must be determined empirically by examining the abundance of the data and mortality rates at young ages, which depends on the country.
$q_c(t|S)$
given in (1.3) to the corresponding empirical version, which can be computed based on the data in the HMD (Human Mortality Database), as explained in Shimizu et al.(Reference Shimizu, Shirai, Kojima, Mitsuda and Inoue2023). We often recommend choosing a conditioning age S of approximately 20 years. This is because mortality at young ages is highly volatile and unstable, making it difficult to predict with simple models, such as ours. The value of S must be determined empirically by examining the abundance of the data and mortality rates at young ages, which depends on the country.
3. Modification of estimated mortality functions
Suppose we have estimated the values of
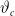 $\vartheta_c$
for some cohorts
$\vartheta_c$
for some cohorts
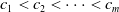 $c_1<c_2 \lt \dots <c_m$
, say,
$c_1<c_2 \lt \dots <c_m$
, say,
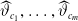 $\widehat{\vartheta}_{c_1},\dots,\widehat{\vartheta}_{c_m}$
via LSE, as in Shimizu et al. (Reference Shimizu, Minami and Ito2020). We assume that future parameter
$\widehat{\vartheta}_{c_1},\dots,\widehat{\vartheta}_{c_m}$
via LSE, as in Shimizu et al. (Reference Shimizu, Minami and Ito2020). We assume that future parameter
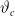 $\vartheta_c$
is determined as follows:
$\vartheta_c$
is determined as follows:
 \begin{align}\vartheta_c = h(c) + {\epsilon}_c,\quad {\epsilon}_c\sim N_p(0, { \Sigma_c}), \end{align}
\begin{align}\vartheta_c = h(c) + {\epsilon}_c,\quad {\epsilon}_c\sim N_p(0, { \Sigma_c}), \end{align}
for the deterministic (unknown) mean function h. Assuming that the estimated parameters
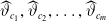 $\widehat{\vartheta}_{c_1},\widehat{\vartheta}_{c_2},\dots,\widehat{\vartheta}_{c_m}$
are the realisations of
$\widehat{\vartheta}_{c_1},\widehat{\vartheta}_{c_2},\dots,\widehat{\vartheta}_{c_m}$
are the realisations of
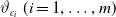 $\vartheta_{c_i}\ (i=1,\dots,m)$
, we estimate h, parameterized case-by-case, as described in Section 4. Once h is estimated, say
$\vartheta_{c_i}\ (i=1,\dots,m)$
, we estimate h, parameterized case-by-case, as described in Section 4. Once h is estimated, say
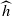 $\widehat{h}$
, we predict the parameter
$\widehat{h}$
, we predict the parameter
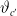 $\vartheta_{c^{\prime}}$
for a future cohort c’ by
$\vartheta_{c^{\prime}}$
for a future cohort c’ by
 \begin{align}\widehat{\vartheta}_{c'} = \widehat{h}(c'),\quad c'>c_m, \end{align}
\begin{align}\widehat{\vartheta}_{c'} = \widehat{h}(c'),\quad c'>c_m, \end{align}
and obtain a predicted mortality function (PMF)
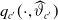 $q_{c'}(\cdot, \widehat{\vartheta}_{c'})$
, as in Shimizu et al. (Reference Shimizu, Minami and Ito2020). However, in this study, we propose further modifications to improve the prediction.
$q_{c'}(\cdot, \widehat{\vartheta}_{c'})$
, as in Shimizu et al. (Reference Shimizu, Minami and Ito2020). However, in this study, we propose further modifications to improve the prediction.
Based on assumption (3.1), we can construct the
 $\alpha$
-prediction interval for
$\alpha$
-prediction interval for
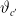 $\vartheta_{c'}$
:
$\vartheta_{c'}$
:
 \begin{align}\widehat{I}_{\alpha}^{c',m} \,{:\!=}\, \left[\widehat{\vartheta}_{c'}- z_{\alpha/2} { \mathrm{diag}(\widehat{\Sigma}_c^{1/2})},\ \widehat{\vartheta}_{c'} + z_{\alpha/2} { \mathrm{diag}(\widehat{\Sigma}_c^{1/2})}\right], \end{align}
\begin{align}\widehat{I}_{\alpha}^{c',m} \,{:\!=}\, \left[\widehat{\vartheta}_{c'}- z_{\alpha/2} { \mathrm{diag}(\widehat{\Sigma}_c^{1/2})},\ \widehat{\vartheta}_{c'} + z_{\alpha/2} { \mathrm{diag}(\widehat{\Sigma}_c^{1/2})}\right], \end{align}
where
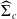 $\widehat{\Sigma}_c$
is an estimator of
$\widehat{\Sigma}_c$
is an estimator of
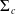 $\Sigma_c$
in (3.1), and
$\Sigma_c$
in (3.1), and
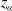 $z_\alpha$
is the
$z_\alpha$
is the
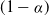 $(1-\alpha)$
-percentile of N(0,1); that is,
$(1-\alpha)$
-percentile of N(0,1); that is,
 \begin{align*}\lim_{m\to \infty} {\mathbb{P}}\left(\vartheta_{c'} \in \widehat{I}_\alpha^{c',m}\right) = \alpha.\end{align*}
\begin{align*}\lim_{m\to \infty} {\mathbb{P}}\left(\vartheta_{c'} \in \widehat{I}_\alpha^{c',m}\right) = \alpha.\end{align*}
(Numerical illustrations for these (95%-) prediction intervals are shown in Figures 1 and 2 in the real data analysis). Using prediction interval
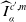 $\widehat{I}_\alpha^{c',m}$
, we readjust the parameters within the
$\widehat{I}_\alpha^{c',m}$
, we readjust the parameters within the
 $\alpha$
-prediction interval such that the mortality function can fit the existing (younger) data for cohort c
$\alpha$
-prediction interval such that the mortality function can fit the existing (younger) data for cohort c
 $^{\prime}$
as follows:
$^{\prime}$
as follows:

Figure 1. Estimation of parameters by nonlinear regressions in ID-SEM of Denmark, Female. The x-axis represents
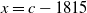 $x = c - 1815$
; The blue lines are the regression curves. The orange and green curves are upper and lower 95%-prediction bound (
$x = c - 1815$
; The blue lines are the regression curves. The orange and green curves are upper and lower 95%-prediction bound (
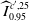 $\widehat{I}_{0.95}^{c',25}$
), respectively.
$\widehat{I}_{0.95}^{c',25}$
), respectively.

Figure 2. Estimation of parameters by nonlinear regressions in IG-SEM of Denmark, Female. The x-axis represents
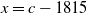 $x = c - 1815$
.
$x = c - 1815$
.
Definition 3.1
(Modified PMF). When empirical data
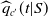 $\widehat{q}_{c'}(t|S)$
for
$\widehat{q}_{c'}(t|S)$
for
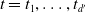 $ t= t_1,\dots,t_{d'}$
exist, we reselect the predictor such that
$ t= t_1,\dots,t_{d'}$
exist, we reselect the predictor such that
 \begin{align}\widetilde{\vartheta}_{c'} = \arg\min_{\vartheta \in \widehat{I}_\alpha^{c',m}}\sum_{i=1}^{d'} |q_{c'}(t_i,\vartheta|S) - \widehat{q}_{c'}(t_i|S)|^2, \end{align}
\begin{align}\widetilde{\vartheta}_{c'} = \arg\min_{\vartheta \in \widehat{I}_\alpha^{c',m}}\sum_{i=1}^{d'} |q_{c'}(t_i,\vartheta|S) - \widehat{q}_{c'}(t_i|S)|^2, \end{align}
where
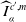 $ \widehat{I}_\alpha^{c',m}$
is given by (3.3). We used
$ \widehat{I}_\alpha^{c',m}$
is given by (3.3). We used
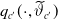 $q_{c'}(\cdot, \widetilde{\vartheta}_{c'})$
as the final predictive mortality function. We refer to it as the modified predicted mortality function (MPMF).
$q_{c'}(\cdot, \widetilde{\vartheta}_{c'})$
as the final predictive mortality function. We refer to it as the modified predicted mortality function (MPMF).
Later, in certain examples, we compare the direct prediction (3.2) with the above modification (3.4).
4. Data analysis: ID-SEM versus IG-SEM
In this section, we compare ID-SEM and IG-SEM using actual data from the HMD (Human Mortality Database) and illustrate that the MPMF with (3.4) can predict future mortality significantly better than the PMF without modification.
Remark 4.1. Determining the change-point parameter
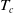 $T_c$
in ID-SEM is difficult. In principle, it should be estimated from data, but this is challenging because the estimated mortality function is susceptible to this parameter. In the following examples, we fix
$T_c$
in ID-SEM is difficult. In principle, it should be estimated from data, but this is challenging because the estimated mortality function is susceptible to this parameter. In the following examples, we fix
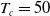 $T_c=50$
, for which ID-SEM can fit the training data relatively well.
$T_c=50$
, for which ID-SEM can fit the training data relatively well.
4.1 Denmark
The first example is Denmark. We use the following mortality data from the
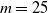 $m=25$
cohorts:
$m=25$
cohorts:
 \begin{align*}\begin{array}{c@{\quad}c} {c_1}=1816\ \textrm{birth cohort:} & {20}\ \textrm{years old} - 110\ \textrm{years old;}\\[2pt]{c_2}=1817\ \textrm{birth cohort:} & {20}\ \textrm{years old} - 110\ \textrm{years old;}\\[2pt]\vdots & \vdots \\[2pt]{c_{25}}=1840\ \textrm{birth cohort:} & {20}\ \textrm{years old} - 110\ \textrm{years old,}\end{array}\end{align*}
\begin{align*}\begin{array}{c@{\quad}c} {c_1}=1816\ \textrm{birth cohort:} & {20}\ \textrm{years old} - 110\ \textrm{years old;}\\[2pt]{c_2}=1817\ \textrm{birth cohort:} & {20}\ \textrm{years old} - 110\ \textrm{years old;}\\[2pt]\vdots & \vdots \\[2pt]{c_{25}}=1840\ \textrm{birth cohort:} & {20}\ \textrm{years old} - 110\ \textrm{years old,}\end{array}\end{align*}
and suppose that we are in 1951 (because we already have the data of 110 years old of the 1840 birth cohort). Based on this data, we predicted the mortality functions of 20 years old in the future cohorts
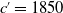 $c'=1850$
, 1870, and 1890 for females and males, respectively. The predicted age groups for
$c'=1850$
, 1870, and 1890 for females and males, respectively. The predicted age groups for
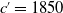 $c'=1850$
,
$c'=1850$
,
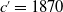 $c'=1870$
, and
$c'=1870$
, and
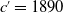 $c'=1890$
will be 101 years old, 81 years old, and 61 years old, respectively, based on the assumption that the current year is 1951.
$c'=1890$
will be 101 years old, 81 years old, and 61 years old, respectively, based on the assumption that the current year is 1951.
Data analysis was performed using the following procedure.
-
1. We estimate the parameters in
 $q_c^{ID}(t,\vartheta_c)$
and
$q_c^{IG}(t,\vartheta_c)$
for the data
$c=$
1816 – 1840 and obtain the values of the parameters in the future cohorts
$c=1850,1870$
and 1890 as in Section 3; also refer to Shimizu et al. (Reference Shimizu, Minami and Ito2020).
$q_c^{ID}(t,\vartheta_c)$
and
$q_c^{IG}(t,\vartheta_c)$
for the data
$c=$
1816 – 1840 and obtain the values of the parameters in the future cohorts
$c=1850,1870$
and 1890 as in Section 3; also refer to Shimizu et al. (Reference Shimizu, Minami and Ito2020).The results for ID-SEM and IG-SEM with the (adjusted) coefficient of determination
$R^2, (\overline{R}^2)$
and 95. We will show the tables for
$R^2\, (\overline{R}^2)$
and the regression curves with the amplitude of the 95%-PI for males, but not the corresponding figures.
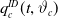
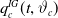
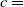

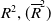
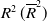
-
2. To obtain the MPMF, we split the data into training and test data. For example, in
$c'=1890$
, we split the mortality data into two parts: 20–60 years (training data: red dots) and 61–110 years (test data: black dots), and use the training data for modification (3.4). -
3. In Figure 3, we will visually compare the two mortality curves with test data (black dots) for males and females, but only for
$c'=1890$
. For other cohorts (
$c'=1850$
and 1870), we will only show the MSE between the predicted mortality function and the actual empirical mortality function in Table 3.
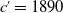
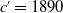
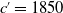

Figure 3. Mortality functions by ID-SEM (left) and IG-SEM (right) for 1890 birth cohort in Denmark; females (top) and males (bottom). The magenta curve is before modification, and the blue one is the modified version. The prediction part is more than 60 years old.
Table 1. The (adjusted) coefficient of determination
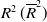 $R^2\, (\overline{R}^2)$
for nonliner regression of each parameter with the 95%-prediction intervals (95%-PI). For nonlinear exponential regression, we computed the
$R^2\, (\overline{R}^2)$
for nonliner regression of each parameter with the 95%-prediction intervals (95%-PI). For nonlinear exponential regression, we computed the
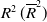 $R^2\,(\overline{R}^2)$
by transforming it to the linear regression after taking the logarithm on both sides.
$R^2\,(\overline{R}^2)$
by transforming it to the linear regression after taking the logarithm on both sides.

Table 2. The (adjusted) coefficient of determination
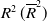 $R^2\, (\overline{R}^2)$
for nonlinear regression of each parameter with the 95%-prediction intervals (95%-PI). Although
$R^2\, (\overline{R}^2)$
for nonlinear regression of each parameter with the 95%-prediction intervals (95%-PI). Although
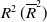 $R^2\,(\overline{R}^2)$
for Males is extremely small (the regression may not fit well), the MSE (Table 3) is not so bad. This is one of the advantages of our “modification”.
$R^2\,(\overline{R}^2)$
for Males is extremely small (the regression may not fit well), the MSE (Table 3) is not so bad. This is one of the advantages of our “modification”.

Table 3. MSE between MPMF and the empirical MF (test data) from Denmark data. Predictions for
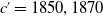 $c'=1850, 1870$
are very good, and
$c'=1850, 1870$
are very good, and
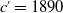 $c'=1890$
is also admissible.
$c'=1890$
is also admissible.

Remark 4.2. We employed the simplest regression functions feasible to facilitate ease of use. For
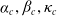 $\alpha_c,\beta_c,\kappa_c$
, we used a negative increasing function of the form
$\alpha_c,\beta_c,\kappa_c$
, we used a negative increasing function of the form
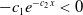 $-c_1 e^{-c_2x} \lt 0$
because these values should be negative. Although
$-c_1 e^{-c_2x} \lt 0$
because these values should be negative. Although
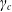 $\gamma_c$
should be positive, it may be justifiable to model it using a linear function, among other possible forms, given the available data. Occasionally, one can use the information criteria, for example, AIC or BIC, to select a regression function; it is also possible to use a time-series model to predict future parameters. However, any model has merits and demerits; therefore, we attempted it as simply as possible.
$\gamma_c$
should be positive, it may be justifiable to model it using a linear function, among other possible forms, given the available data. Occasionally, one can use the information criteria, for example, AIC or BIC, to select a regression function; it is also possible to use a time-series model to predict future parameters. However, any model has merits and demerits; therefore, we attempted it as simply as possible.
In this cohort (relatively long future prediction), the difference between ID-SEM and IG-SEM is more significant. Even a modified version in IG-SEM cannot predict well in males because of the parameter prediction for
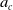 $a_c$
and
$a_c$
and
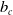 $b_c$
. This is a successful example of ID-SEM with a change point T and more parameters than IG-SEM.
$b_c$
. This is a successful example of ID-SEM with a change point T and more parameters than IG-SEM.
4.2 Norway
The second example is that of Norway. Similar to Denmark, we use the following mortality data from the
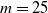 $m=25$
cohorts:
$m=25$
cohorts:
 \begin{align*}\begin{array}{c@{\quad}c}{c_1}=1826\ \textrm{birth cohort:}& {20}\ \textrm{years old} - 110\ \textrm{years old;}\\[2pt]{c_2}={1827}\ \textrm{birth cohort:}& {20}\ \textrm{years old}- {110}\ \textrm{years old;}\\[2pt]\vdots & \vdots \\[2pt]{c_{25}}=1850\ \textrm{birth cohort:} &{20}\ \textrm{years old} - {110}\ \textrm{years old.}\end{array}\end{align*}
\begin{align*}\begin{array}{c@{\quad}c}{c_1}=1826\ \textrm{birth cohort:}& {20}\ \textrm{years old} - 110\ \textrm{years old;}\\[2pt]{c_2}={1827}\ \textrm{birth cohort:}& {20}\ \textrm{years old}- {110}\ \textrm{years old;}\\[2pt]\vdots & \vdots \\[2pt]{c_{25}}=1850\ \textrm{birth cohort:} &{20}\ \textrm{years old} - {110}\ \textrm{years old.}\end{array}\end{align*}
and assume that we are in 1961 (because we already have data for the 110-year-old in the 1840 cohort). Based on these data, we predicted the mortality functions of the 20-year-old for future cohorts
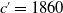 $c'=1860$
, 1880, and 1900 for males and females. The prediction is after the 101 years for
$c'=1860$
, 1880, and 1900 for males and females. The prediction is after the 101 years for
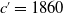 $c'=1860$
, 81 years for
$c'=1860$
, 81 years for
 $c'=1880$
, and 61 years for
$c'=1880$
, and 61 years for
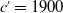 $c'=1900$
. The results only for
$c'=1900$
. The results only for
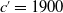 $ c'=1900$
are given in Figure 4.
$ c'=1900$
are given in Figure 4.

Figure 4. Mortality functions by ID-SEM (left) and IG-SEM (right) for 1900 birth cohort in Norway; females (top) and males (bottom). The magenta curve is before modification, and the blue one is the modified version. The prediction part is more than 60 years old.
All other procedures were identical to those used in Denmark. We estimate parameters using nonlinear regression and obtain PMFs before/after the modification. For these results, we only show the figures of PMF before/after changes for
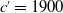 $c'=1900$
. For the others, we only show the noninear regression curves with the values of
$c'=1900$
. For the others, we only show the noninear regression curves with the values of
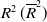 $R^2\,(\overline{R}^2)$
and their 95%-PI in Tables 4 and 5. Moreover, Table 6 lists the MSE of MPMFs.
$R^2\,(\overline{R}^2)$
and their 95%-PI in Tables 4 and 5. Moreover, Table 6 lists the MSE of MPMFs.
Table 4. The (adjusted) coefficient of determination
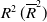 $R^2\, (\overline{R}^2)$
for nonlinear regression of each parameter with the 95%-prediction intervals (95%-PI). For nonlinear exponential regression, we computed the
$R^2\, (\overline{R}^2)$
for nonlinear regression of each parameter with the 95%-prediction intervals (95%-PI). For nonlinear exponential regression, we computed the
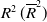 $R^2\,(\overline{R}^2)$
by transforming it to the linear regression after taking the logarithm on both sides.
$R^2\,(\overline{R}^2)$
by transforming it to the linear regression after taking the logarithm on both sides.

Table 5. The (adjusted) coefficient of determination
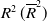 $R^2\, (\overline{R}^2)$
for nonliner regression of each parameter with the 95%-prediction intervals (95%-PI).
$R^2\, (\overline{R}^2)$
for nonliner regression of each parameter with the 95%-prediction intervals (95%-PI).

Table 6. MSE between MPMF and the empirical MF (test data) for Norway data. After our modification, the predictions become very good in any case.

Remark 4.3. In Denmark, ID-SEM is superior to IG-SEM. However, IG-SEM is effective in this example and occasionally outperforms ID-SEM. Because it is challenging to determine a suitable change-point parameter T in ID-SEM, IG-SEM, which has fewer parameters than ID-SEM, is also a good candidate for the prediction model of the mortality function.
In this example, IG-SEM is superior to ID-SEM in females but not males. Accordingly, it would be challenging to determine the SEM to predict and compute some quantities of interest. We should compute them both by ID-SEM and IG-SEM and compare the values objectively to make a decision
5. Advantages of SEM
5.1 Comparison with the classical model with cohort-effects
Shimizu et al. (Reference Shimizu, Minami and Ito2020) demonstrated that ID-SEM is superior to the classical Lee–Carter model. This section compares our SEM with the Renshaw–Haberman model (RHM), extending the Lee–Carter model, including cohort effects.
For comparison, we use the same data as in the previous section for Denmark and Norway. Moreover, for RHM, we used 20–110 years old of the 1911–1950 calendar years in Denmark and the same ages of 1921–1960 in Norway. We compared the modified mortality functions of the 1870 and 1890 birth cohorts using ID- and IG-SEM and the mortality functions of the RHM. The results are shown in Figure 5 along with their MSEs. The results demonstrate that the differences in prediction errors are similar, but ID-SEM is often superior to RHM at senior ages.

Figure 5. Modified mortality functions by IG-SEM (blue); ID-SEM (magenta), and RHM (red dots) with a table of their MSEs for 1890 cohort of Denmark (top) and 1900 cohort of Norway (bottom). The black dots are the actual data that should be predicted. The results for males suggest that ID-SEM is superior, whereas those for females suggest that IG-SEM and RH may be better, depending on the case. Ultimately, which model is most suitable depends heavily on the data.
Remark 5.1. Although we used the CBD model, for example, Cairns et al. (2006a, 2008), as a candidate cohort model, it was unsuitable for long-term prediction. Therefore, these results were excluded from this study.
5.2 Reducing statistical errors
One of the advantages of the proposed SEM approach is the statistical estimation of the actuarial quantities. Consider, for example, the single premium of all life insurance at age x, say
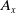 $A_x$
. It is written as follows:
$A_x$
. It is written as follows:
 \begin{align*}A_x &\,{:\!=}\, \sum_{k=1}^\infty v^{k} {}_{k-1|}q_{x+k-1} \quad \mbox{(Actuarial notation)}\\[3pt]&= \sum_{k=1}^\infty v^{k} \frac{q_c(x+k) - q_c(x+k-1)}{1-q_c(x)}\quad \mbox{(SEM notation)} \\[3pt] &= \sum_{k=1}^\infty v^{k} [q_c(k|x) - q_c(k-1|x)]\quad \mbox{(Conditional version)},\end{align*}
\begin{align*}A_x &\,{:\!=}\, \sum_{k=1}^\infty v^{k} {}_{k-1|}q_{x+k-1} \quad \mbox{(Actuarial notation)}\\[3pt]&= \sum_{k=1}^\infty v^{k} \frac{q_c(x+k) - q_c(x+k-1)}{1-q_c(x)}\quad \mbox{(SEM notation)} \\[3pt] &= \sum_{k=1}^\infty v^{k} [q_c(k|x) - q_c(k-1|x)]\quad \mbox{(Conditional version)},\end{align*}
where
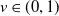 $v \in (0,1)$
is the discount factor. If we use the Lee–Carter model, then it is written as
$v \in (0,1)$
is the discount factor. If we use the Lee–Carter model, then it is written as
 \begin{align*}A_x = \sum_{k=1}^{\infty} v^{k} \left[1 - \exp\left( - m_{x + k-1,t}(\alpha_{x+k},\beta_{x+k}) \right)\right],\end{align*}
\begin{align*}A_x = \sum_{k=1}^{\infty} v^{k} \left[1 - \exp\left( - m_{x + k-1,t}(\alpha_{x+k},\beta_{x+k}) \right)\right],\end{align*}
where
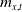 $m_{x,t}$
is the (crude) mortality parameterized by
$m_{x,t}$
is the (crude) mortality parameterized by
 \begin{align*}m_{x,t}(\alpha_x,\beta_x) = \exp\left(\alpha_x + \beta_x \kappa_t + {\epsilon}_{x,t}\right),\end{align*}
\begin{align*}m_{x,t}(\alpha_x,\beta_x) = \exp\left(\alpha_x + \beta_x \kappa_t + {\epsilon}_{x,t}\right),\end{align*}
with parameters
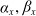 $\alpha_x,\beta_x$
estimated based on the predicted values of
$\alpha_x,\beta_x$
estimated based on the predicted values of
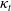 $\kappa_t$
, which are generated using a time series model that includes some unknown parameters, and
$\kappa_t$
, which are generated using a time series model that includes some unknown parameters, and
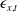 ${\epsilon}_{x,t}$
is a noise process. Here, we must estimate numerous parameters
${\epsilon}_{x,t}$
is a noise process. Here, we must estimate numerous parameters
 $\{(\alpha_y,\beta_y)\}_{y=x,x+1,\dots}$
and those in
$\{(\alpha_y,\beta_y)\}_{y=x,x+1,\dots}$
and those in
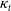 $\kappa_t$
, which can increase the statistical error of
$\kappa_t$
, which can increase the statistical error of
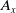 $A_x$
. However, if we use SEM, cohort-wise computation
$A_x$
. However, if we use SEM, cohort-wise computation
 \begin{align*}A_x = \sum_{k=1}^{\infty} v^{k} [q_c(k,\vartheta_c|x) - q_c(k-1,\vartheta_c|x)],\end{align*}
\begin{align*}A_x = \sum_{k=1}^{\infty} v^{k} [q_c(k,\vartheta_c|x) - q_c(k-1,\vartheta_c|x)],\end{align*}
requires only one parameter estimation for
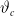 $\vartheta_c$
because
$\vartheta_c$
because
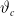 $\vartheta_c$
is independent of
$\vartheta_c$
is independent of
 $k=1,2,\dots$
. This can make the statistical error less than that of classical mortality models.
$k=1,2,\dots$
. This can make the statistical error less than that of classical mortality models.
5.3 Sensitivity analysis
As shown in the previous section, most actuarial quantities are written in the functionals of the mortality function
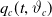 $q_c(t,\vartheta_c)$
, which are often rewritten in terms of the conditional mortality function
$q_c(t,\vartheta_c)$
, which are often rewritten in terms of the conditional mortality function
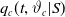 $q_c(t,\vartheta_c|S)$
, with a few unknown parameters
$q_c(t,\vartheta_c|S)$
, with a few unknown parameters
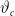 $\vartheta_c$
. This situation is suitable for sensitivity analysis concerning parameter changes.
$\vartheta_c$
. This situation is suitable for sensitivity analysis concerning parameter changes.
Consider an actuarial quantity for age x and cohort c represented by a Stieljes-type integral form such as
 \begin{align*}H(\vartheta) \,{:\!=}\,\int_0^\infty q_c(t,\vartheta|x)\,\textrm{d} h(t), \quad \vartheta \in \Theta,\end{align*}
\begin{align*}H(\vartheta) \,{:\!=}\,\int_0^\infty q_c(t,\vartheta|x)\,\textrm{d} h(t), \quad \vartheta \in \Theta,\end{align*}
where h denotes a measurable function of
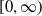 $[0,\infty)$
, The integral sign implies that
$[0,\infty)$
, The integral sign implies that
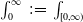 $\int_0^\infty \,{:\!=}\, \int_{[0,\infty)}$
. We suppose the exchangeability of
$\int_0^\infty \,{:\!=}\, \int_{[0,\infty)}$
. We suppose the exchangeability of
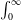 $\int_0^\infty$
and differentiation
$\int_0^\infty$
and differentiation
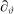 $\partial_{\vartheta}$
as far as we need
$\partial_{\vartheta}$
as far as we need
 \begin{align*}\partial_{\vartheta} H(\vartheta) = \int_0^\infty \partial_{\vartheta} q_c(t,\vartheta|x)\,\textrm{d} h(t) \lt \infty,\quad \vartheta\in \Theta,\end{align*}
\begin{align*}\partial_{\vartheta} H(\vartheta) = \int_0^\infty \partial_{\vartheta} q_c(t,\vartheta|x)\,\textrm{d} h(t) \lt \infty,\quad \vartheta\in \Theta,\end{align*}
which is continuous in
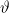 $\vartheta$
.
$\vartheta$
.
Most actuarial quantities are written in this form (see Shimizu et al. (Reference Shimizu, Minami and Ito2020)). For example,
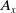 $A_x$
, the single premium of all life insurance at age x, is given by
$A_x$
, the single premium of all life insurance at age x, is given by
 \begin{align*}h(t)= \sum_{k=1}^\infty v^k \left(\mathbf{1}_{\{t\ge k\}} - \mathbf{1}_{\{t\ge k-1\}}\right), \quad t\ge 0,\end{align*}
\begin{align*}h(t)= \sum_{k=1}^\infty v^k \left(\mathbf{1}_{\{t\ge k\}} - \mathbf{1}_{\{t\ge k-1\}}\right), \quad t\ge 0,\end{align*}
where
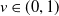 $v\in (0,1)$
, Moreover, for the immediate payment version:
$v\in (0,1)$
, Moreover, for the immediate payment version:
 \begin{align*}\bar{A} = \int_{0}^{\infty} v^{t} \frac{\partial_t q_c(x+t)}{1-q_c(x)} \,\textrm{d} t,\end{align*}
\begin{align*}\bar{A} = \int_{0}^{\infty} v^{t} \frac{\partial_t q_c(x+t)}{1-q_c(x)} \,\textrm{d} t,\end{align*}
is given by
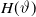 $H(\vartheta)$
with
$H(\vartheta)$
with
 \begin{align*}h(t) = -v^t.\end{align*}
\begin{align*}h(t) = -v^t.\end{align*}
It follows from integration by parts that
 \begin{align*}H(\vartheta) & = \int_0^\infty \frac{q_c(x+t, \vartheta)-q(x,\vartheta)}{1 - q_c(x,\vartheta)}\,(\!-\!v^t)' \textrm{d} t \\[3pt] &= \left[-v^t \frac{q_c(x+t, \vartheta) - q_c(x,\vartheta)}{1 - q_c(x,\vartheta)}\right]_{t=0}^\infty + \int_0^\infty v^t \frac{\partial_t q_c(x + t, \vartheta)}{1 - q_c(x,\vartheta)} \,\textrm{d} t \\[3pt] &= \int_0^\infty v^t \frac{\partial_t q_c(x + t, \vartheta)}{1 - q_c(x,\vartheta)} \,\textrm{d} t = \bar{A}_{x}.\end{align*}
\begin{align*}H(\vartheta) & = \int_0^\infty \frac{q_c(x+t, \vartheta)-q(x,\vartheta)}{1 - q_c(x,\vartheta)}\,(\!-\!v^t)' \textrm{d} t \\[3pt] &= \left[-v^t \frac{q_c(x+t, \vartheta) - q_c(x,\vartheta)}{1 - q_c(x,\vartheta)}\right]_{t=0}^\infty + \int_0^\infty v^t \frac{\partial_t q_c(x + t, \vartheta)}{1 - q_c(x,\vartheta)} \,\textrm{d} t \\[3pt] &= \int_0^\infty v^t \frac{\partial_t q_c(x + t, \vartheta)}{1 - q_c(x,\vartheta)} \,\textrm{d} t = \bar{A}_{x}.\end{align*}
We are interested in the difference
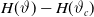 $H(\vartheta) - H(\vartheta_c)$
for different values of parameters
$H(\vartheta) - H(\vartheta_c)$
for different values of parameters
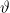 $\vartheta$
and
$\vartheta$
and
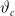 $\vartheta_c$
. By Taylor’s formula,
$\vartheta_c$
. By Taylor’s formula,
 \begin{align*}H(\vartheta) - H(\vartheta_c) = \int_0^\infty \partial_{\vartheta} q_c(t,\vartheta_c|x)\,\textrm{d} h(t)\cdot (\vartheta - \vartheta_c) + o(\vartheta - \vartheta_c).\end{align*}
\begin{align*}H(\vartheta) - H(\vartheta_c) = \int_0^\infty \partial_{\vartheta} q_c(t,\vartheta_c|x)\,\textrm{d} h(t)\cdot (\vartheta - \vartheta_c) + o(\vartheta - \vartheta_c).\end{align*}
Integral
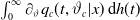 $\int_0^\infty \partial_{\vartheta} q_c(t,\vartheta_c|x)\,\textrm{d} h(t)$
can be evaluated via direct computation. For instance, we have the following inequality:
$\int_0^\infty \partial_{\vartheta} q_c(t,\vartheta_c|x)\,\textrm{d} h(t)$
can be evaluated via direct computation. For instance, we have the following inequality:
Lemma 5.2. For the mortality function of IG-SEM,
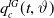 $q_c^{IG}(t,\vartheta)$
with
$q_c^{IG}(t,\vartheta)$
with
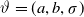 $\vartheta=(a,b,\sigma)$
, we obtain the following estimates:
$\vartheta=(a,b,\sigma)$
, we obtain the following estimates:
 \begin{align*}\left|\partial_a q_c^{IG}(t,\vartheta)\right| &\le 2t e^{at}\left( 1 + \frac{\sigma}{\Lambda_{\vartheta}(t) + x_c} \right)\phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)); \\\left|\partial_b q_c^{IG}(t,\vartheta)\right| &\le 2t \left( 1 + \frac{\sigma}{\Lambda_{\vartheta}(t) + x_c} \right)\phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)); \\\left|\partial_\sigma q_c^{IG}(t,\vartheta)\right| &\le \Lambda_{\vartheta}(t) \left(\frac{1}{\sigma} + \frac{2}{\Lambda_{\vartheta}(t) + x_c}\right) \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)),\end{align*}
\begin{align*}\left|\partial_a q_c^{IG}(t,\vartheta)\right| &\le 2t e^{at}\left( 1 + \frac{\sigma}{\Lambda_{\vartheta}(t) + x_c} \right)\phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)); \\\left|\partial_b q_c^{IG}(t,\vartheta)\right| &\le 2t \left( 1 + \frac{\sigma}{\Lambda_{\vartheta}(t) + x_c} \right)\phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)); \\\left|\partial_\sigma q_c^{IG}(t,\vartheta)\right| &\le \Lambda_{\vartheta}(t) \left(\frac{1}{\sigma} + \frac{2}{\Lambda_{\vartheta}(t) + x_c}\right) \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)),\end{align*}
where
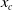 $x_c$
is the initial survival energy for cohort c and
$x_c$
is the initial survival energy for cohort c and
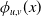 $\phi_{u,v}(x)$
is the probability density function of the normal distribution with mean u and variance v.
$\phi_{u,v}(x)$
is the probability density function of the normal distribution with mean u and variance v.
Proof. Note that
 \begin{align*}q_c^{IG}(t,\vartheta) = \Phi\left(\sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) - x_c)\right)- e^{2\sigma \Lambda_{\vartheta}(t)}\Phi\left(\!- \sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) + x_c)\right),\end{align*}
\begin{align*}q_c^{IG}(t,\vartheta) = \Phi\left(\sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) - x_c)\right)- e^{2\sigma \Lambda_{\vartheta}(t)}\Phi\left(\!- \sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) + x_c)\right),\end{align*}
where
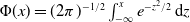 $\Phi(x) = (2\pi)^{-1/2}\int_{-\infty}^x e^{-z^2/2}\,\textrm{d} z$
.
$\Phi(x) = (2\pi)^{-1/2}\int_{-\infty}^x e^{-z^2/2}\,\textrm{d} z$
.
 \begin{align*}\partial_a q_c^{IG}(t,\vartheta) &= t e^{at} \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) - 2\sigma t e^{at} e^{2\sigma \Lambda_{\vartheta}(t)} \Phi\left(\!- \sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) + x_c)\right) \\ &\quad + e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) te^{at} \\ &= 2 t e^{at}\left[ \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) - \sigma e^{2\sigma \Lambda_{\vartheta}(t)} \Phi\left(\!- \sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) + x_c)\right)\right].\end{align*}
\begin{align*}\partial_a q_c^{IG}(t,\vartheta) &= t e^{at} \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) - 2\sigma t e^{at} e^{2\sigma \Lambda_{\vartheta}(t)} \Phi\left(\!- \sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) + x_c)\right) \\ &\quad + e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) te^{at} \\ &= 2 t e^{at}\left[ \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) - \sigma e^{2\sigma \Lambda_{\vartheta}(t)} \Phi\left(\!- \sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) + x_c)\right)\right].\end{align*}
In the final equality, we used
 \begin{align}e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) = \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)). \end{align}
\begin{align}e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) = \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)). \end{align}
We use an inequality for the “error function” such that for
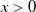 $x>0$
,
$x>0$
,
 \begin{align*}\Phi(\!-\!x) = \int_x^\infty \frac{1}{\sqrt{2\pi}}e^{-\frac{z^2}{2}}\,\textrm{d} z \le \frac{1}{\sqrt{2\pi}x} e^{-\frac{x^2}{2}},\end{align*}
\begin{align*}\Phi(\!-\!x) = \int_x^\infty \frac{1}{\sqrt{2\pi}}e^{-\frac{z^2}{2}}\,\textrm{d} z \le \frac{1}{\sqrt{2\pi}x} e^{-\frac{x^2}{2}},\end{align*}
to obtain
 \begin{align*}\left|\partial_a q_c^{IG}(t,\vartheta) \right| &\le 2 t e^{at}\left[ \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) + \sigma e^{2\sigma \Lambda_{\vartheta}(t)} \Phi\left(\!- \sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) + x_c)\right)\right] \\[3pt]&\le 2 t e^{at}\left[ \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) + \frac{\sigma}{\Lambda_{\vartheta}(t) + x_c} e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) \right] \\[3pt] &= 2te^{at} \left( 1 + \frac{\sigma}{\Lambda_{\vartheta}(t) + x_c}\right)\phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)).\end{align*}
\begin{align*}\left|\partial_a q_c^{IG}(t,\vartheta) \right| &\le 2 t e^{at}\left[ \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) + \sigma e^{2\sigma \Lambda_{\vartheta}(t)} \Phi\left(\!- \sqrt{\frac{\sigma}{x_c}}(\Lambda_{\vartheta}(t) + x_c)\right)\right] \\[3pt]&\le 2 t e^{at}\left[ \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) + \frac{\sigma}{\Lambda_{\vartheta}(t) + x_c} e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) \right] \\[3pt] &= 2te^{at} \left( 1 + \frac{\sigma}{\Lambda_{\vartheta}(t) + x_c}\right)\phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)).\end{align*}
We used equality (5.1) in the last equality. The estimate of the partial derivative
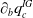 $\partial_bq_c^{IG}$
is slightly similar and omitted.
$\partial_bq_c^{IG}$
is slightly similar and omitted.
For
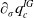 $\partial_\sigma q_c^{IG}$
, it follows from (5.1) that:
$\partial_\sigma q_c^{IG}$
, it follows from (5.1) that:
 \begin{align*}\partial_\sigma q_c^{IG}(t,\vartheta) &= \frac{1}{2\sqrt{\sigma x_c}}(\Lambda_{\vartheta}(t) - x)\cdot \sqrt{\frac{x_c}{\sigma}} \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) - 2\Lambda_{\vartheta}(t) e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) \\[3pt]&\quad + \frac{1}{2\sqrt{\sigma x_c}}(\Lambda_{\vartheta}(t) + x)\cdot \sqrt{\frac{x_c}{\sigma}} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) \\[3pt] &= \frac{1}{\sigma} \Lambda_{\vartheta}(t) \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) - 2\Lambda_{\vartheta}(t) e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)).\end{align*}
\begin{align*}\partial_\sigma q_c^{IG}(t,\vartheta) &= \frac{1}{2\sqrt{\sigma x_c}}(\Lambda_{\vartheta}(t) - x)\cdot \sqrt{\frac{x_c}{\sigma}} \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) - 2\Lambda_{\vartheta}(t) e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) \\[3pt]&\quad + \frac{1}{2\sqrt{\sigma x_c}}(\Lambda_{\vartheta}(t) + x)\cdot \sqrt{\frac{x_c}{\sigma}} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) \\[3pt] &= \frac{1}{\sigma} \Lambda_{\vartheta}(t) \phi_{x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)) - 2\Lambda_{\vartheta}(t) e^{2\sigma \Lambda_{\vartheta}(t)} \phi_{-x_c,x_c/\sigma}(\Lambda_{\vartheta}(t)).\end{align*}
Hence, the same argument as above is available and the proof ends. □
Corollary 5.3. Under the same model as in Lemma 5.2, assume that:
 \begin{align*}\sup_{\vartheta\in \Theta}\left| \int_0^\infty te^{a t} \phi_{0,1}(\Lambda_{\vartheta} (t))\,\mathrm{d} h(t) \right|\lt \infty. \end{align*}
\begin{align*}\sup_{\vartheta\in \Theta}\left| \int_0^\infty te^{a t} \phi_{0,1}(\Lambda_{\vartheta} (t))\,\mathrm{d} h(t) \right|\lt \infty. \end{align*}
Subsequently, it follows that
 \begin{align*} \sup_{\vartheta\in \Theta} \left|\int_0^\infty \partial_{\vartheta} q_c(t,\vartheta|x)\,\mathrm{d} h(t) \right| \lt \infty.\end{align*}
\begin{align*} \sup_{\vartheta\in \Theta} \left|\int_0^\infty \partial_{\vartheta} q_c(t,\vartheta|x)\,\mathrm{d} h(t) \right| \lt \infty.\end{align*}
For our LSE
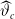 $\widehat{\vartheta}_c$
of
$\widehat{\vartheta}_c$
of
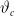 $\vartheta_c$
given in Theorem 3.2 in Shimizu et al. (Reference Shimizu, Minami and Ito2020) (see also the erratum Shimizu, Reference Shimizu2022) and the sample size
$\vartheta_c$
given in Theorem 3.2 in Shimizu et al. (Reference Shimizu, Minami and Ito2020) (see also the erratum Shimizu, Reference Shimizu2022) and the sample size
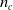 $n_c$
required to obtain the estimator, we have, by the delta method in statistics, that
$n_c$
required to obtain the estimator, we have, by the delta method in statistics, that
 \begin{align*}\sqrt{n_c}\left(H(\widehat{\vartheta}_c) - H(\vartheta_c)\right) &= \int_0^\infty \partial_{\vartheta} q_c(t,\vartheta_c|x)\,\textrm{d} h(t) \cdot\sqrt{n_c}(\widehat{\vartheta}_c - \vartheta_c) + o_p(1) \\ &\to^d N_p(0,\Sigma_{c,x}), \quad n_c\to \infty,\end{align*}
\begin{align*}\sqrt{n_c}\left(H(\widehat{\vartheta}_c) - H(\vartheta_c)\right) &= \int_0^\infty \partial_{\vartheta} q_c(t,\vartheta_c|x)\,\textrm{d} h(t) \cdot\sqrt{n_c}(\widehat{\vartheta}_c - \vartheta_c) + o_p(1) \\ &\to^d N_p(0,\Sigma_{c,x}), \quad n_c\to \infty,\end{align*}
where the asymptotic variance
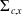 $\Sigma_{c,x}$
can be estimated using the estimators of
$\Sigma_{c,x}$
can be estimated using the estimators of
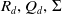 $R_d, Q_d, \Sigma$
in Theorem 3.2 in Shimizu et al. (Reference Shimizu, Minami and Ito2020) (with Shimizu, Reference Shimizu2022), and the plug-in estimator
$R_d, Q_d, \Sigma$
in Theorem 3.2 in Shimizu et al. (Reference Shimizu, Minami and Ito2020) (with Shimizu, Reference Shimizu2022), and the plug-in estimator
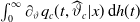 $\int_0^\infty \partial_{\vartheta} q_c(t,\widehat{\vartheta}_c|x)\,\textrm{d} h(t) $
. This yields the confidence interval
$\int_0^\infty \partial_{\vartheta} q_c(t,\widehat{\vartheta}_c|x)\,\textrm{d} h(t) $
. This yields the confidence interval
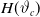 $H(\vartheta_c)$
:
$H(\vartheta_c)$
:
 \begin{align*}{\mathbb{P}}\left(H(\vartheta_c) \in \left[H(\widehat{\vartheta}_c) - z_{\alpha/2}\frac{\widehat{\Sigma}_{x,c}}{\sqrt{n_c}}, \ H(\widehat{\vartheta}_c) + z_{\alpha/2}\frac{\widehat{\Sigma}_{x,c}}{\sqrt{n_c}}\right]\right) \approx 1-\alpha,\end{align*}
\begin{align*}{\mathbb{P}}\left(H(\vartheta_c) \in \left[H(\widehat{\vartheta}_c) - z_{\alpha/2}\frac{\widehat{\Sigma}_{x,c}}{\sqrt{n_c}}, \ H(\widehat{\vartheta}_c) + z_{\alpha/2}\frac{\widehat{\Sigma}_{x,c}}{\sqrt{n_c}}\right]\right) \approx 1-\alpha,\end{align*}
where
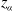 $z_\alpha$
is the upper
$z_\alpha$
is the upper
 $\alpha$
-percentile of the standard normal distribution and
$\alpha$
-percentile of the standard normal distribution and
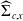 $\widehat{\Sigma}_{c,x}$
is an estimator of the asymptotic variance
$\widehat{\Sigma}_{c,x}$
is an estimator of the asymptotic variance
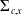 $\Sigma_{c,x}$
.
$\Sigma_{c,x}$
.
6. Conclusions
We proposed two types of parametric families for SEMs: ID-SEM and IG-SEM, which provide accurate cohort-wise PMFs. Using the (prediction) confidence intervals for unknown parameters, we can modify the MPMF to fit existing data in a manner consistent with LSE (refer to Remark 3.1).
SEM is a viable candidate for alternative modeling of mortality prediction. We illustrated that both SEMs had high potential for long-term mortality prediction and were superior to the classical model, possibly with cohort effects, for example, LC, RH, and CBD models. Moreover, SEM has numerous theoretical advantages: notational understanding for nonactuarial people, reduced estimation error owing to fewer parameters, and usefulness for sensitivity analysis.
For further information regarding SEM, such as graphs and other topics, please refer to the supplementary article by Shimizu et al. (Reference Shimizu, Shirai, Kojima, Mitsuda and Inoue2023).
Acknowledgments
The author thanks the anonymous referees for their detailed suggestions and proposals, which have improved the paper extensively. This research was partially supported by the JSPS KAKENHI Grant-in-Aid for Scientific Research (C) #21K03358.
























 Open access
Open access