

I. INTRODUCTION
During recent years, digital images and videos have played more and more important roles in our work and life because of increasing availability and accessibility. Thanks to the rapid advancement of new technology, people can easily have an imaging device, such as a digital camera, camcorder, and cellular phone, to capture what they see and what happens in daily life. In addition, with the development of social network and mobile devices, photo and video sharing over the Internet becomes much more popular than before. Quality assessment and assurance for digital images and videos in an objective manner have become an increasingly useful and interesting topic in the research community.
In general, visual quality assessment can be divided into two categories. One is subjective visual quality assessment, and the other is objective visual quality assessment. As the name implies, the former is done by humans. It represents the most realistic opinion of humans toward an image or a video, and also the most reliable measure of visual quality among all available means (if the pool of subjects is sufficiently large and the nature of the circumstances allows such assessments).
For subjective evaluation of visual quality, the tests can be performed with the methods defined in [20,23]: (a) pair comparison (PC); (b) absolute category rating (ACR); (c) degradation category rating (DCR) (also called double-stimulus impairment scale (DSIS)); (d) double-stimulus continuous quality scale (DSCQS); (e) single-stimulus continuous quality evaluation (SSCQE); (f) simultaneous double-stimulus for continuous evaluation (SDSCE). We have presented these methods in the Appendix for easy reference.
In general, methods (a)–(c) above can be used in multimedia applications. Television pictures can be evaluated with methods (c)–(f). In all these test methods, visual quality ratings evaluated by test subjects are then averaged to obtain the mean opinion score (MOS). In some cases, difference mean opinion score (DMOS) is used to represent the mean of differential subjective score instead of MOS.
However, the subjective method is time-consuming, and not applicable for real-time processing because the test has to be performed carefully in order to obtain meaningful results. Moreover, it is not feasible to have human intervention with in-loop and on-service processes (such as video encoding, transmission, etc.). Thus, most research has been focused on automatic assessment of quality for an image or a video.
This paper aims at an overview and discussion of the latest research in the area of objective quality evaluation of visual signal (both image and video). There have been a few good survey papers in this area before, such as [Reference Engelke and Zepernick35, Reference Lin and Kuo56, Reference Winkler and Mohandas105]. Our current work has several new contributions. First, we put an equal emphasis on image and video quality assessment. Video quality assessment is a rapidly growing field and has progressed a lot in the last 3–4 years. The recent developments have not been well covered in the existing survey papers. Here, we provide the most updated results in this field. Second, we have an in-depth discussion on the application of visual quality assessment to perceptual image/video coding, which is one of the most researched areas in applications. Third, we benchmark the performance of several state-of-the-art quality metrics for both images and videos with appropriate databases and experiments. Finally, future trends in visual quality assessment are discussed.
The rest of the paper is organized as follows. In Section II, the classification of objective quality assessment methods will be presented. Recent developments, applications, and publicly available databases in image quality assessment (IQA) will be examined in Section III, whereas those in video quality assessment (VQA) are to be introduced in Section IV. We follow the similar format of writing for images and videos respectively, for readers' easy reading, reference and comparison. Section V will present performance comparison for some recent popular visual quality metrics. Then, we will point out several possible future trends for visual quality assessment in Section VI. Finally, the conclusion will be drawn in Section VII.
II. CLASSIFICATION OF OBJECTIVE VISUAL QUALITY ASSESSMENT METHODS
There are several popular ways to classify the visual quality assessment methods [Reference Engelke and Zepernick35, Reference Lin and Kuo56, Reference Winkler and Mohandas105]. In this section, we present two possibilities of classification to facilitate the presentation and understanding of the related problems, the existing solutions (taking into account the most recent developments), and future trends.
A) Classification based on the availability of reference
The classification depends on the availability of original (reference) image/video. If there is no reference signal available for the distorted (test) one to compare with, then a quality evaluation method is termed as a no-reference (NR) one [Reference Marziliano, Dufaux, Winkler and Ebrahimi64]. The current NR methods [Reference Ong, Lin, Lu, Yao, Yang and Jiang74,Reference Tong, Li, Zhang and Zhang90] do not perform well in general because they judge the quality solely based on the distorted medium and without any reference available.
If the information of the reference medium is partially available, e.g., in the form of a set of extracted features, then this is the so-called reduced-reference (RR) method [Reference Pinson and Wolf78]. Since the extracted partial reference information is much sparser than the whole reference, the RR approach can be used in a remote location (e.g., the relay site and receiving end of transmission) with reasonable bandwidth overheads to achieve better results than the NR method, or in a situation where the reference is available (such as a video encoder) to reduce the computational requirement (especially in repeated manipulation and optimization).
The last one is the full-reference (FR) method (e.g., [Reference Wang, Bovik, Sheikh and Simoncelli96]), as the opposite of the NR method. As the name suggests, an FR metric needs the complete reference medium to assess the distorted (test) medium. Since it has full information about the original medium, it is expected to have the best quality prediction performance. Most existing quality assessment schemes belong to this category, and can be usually used in image and video coding. We will discuss more in Sections III and IV.
B) Classification based upon methodology for assessment
The first type in this classification is image/video fidelity metrics, which operate based only on direct accumulation of errors and therefore are usually FR. Mean-squared error (MSE) and peak signal-to-noise ratio (PSNR) are two representatives in this category. Although being the simplest and still widely used, such a metric is often not a good reflection of perceived visual quality if the distortion is not additive.
The second type is human visual system (HVS) model-based metrics, which typically employ a frequency-based decomposition, and take into account various aspects of the HVS. This can include modeling of contrast and orientation sensitivity, spatial and temporal masking effects, frequency selectivity and color perception. Owing to the complexity of the HVS, these metrics can become very complex and computationally expensive. Examples of the work following this framework include the works in [Reference Daly32, Reference Jayant, Johnston and Safranek43, Reference Lubin62, Reference Teo and Heeger89], perceptual distortion metric (PDM) [Reference Winkler104], the continuous VQM in [Reference Masry and Hemami66], and the scalable wavelet-based video distortion index [Reference Masry, Hemami and Sermadevi65]. Recently, a new strategy to measure image quality, called most apparent distortion (MAD) [Reference Larson and Chandler48], also belongs to this category.
Signal structure (information or other feature)-based metrics are the third type of metrics. Some of them quantify visual fidelity based on the assumption that a high-quality image or video is the one whose structural content, such as object boundaries or regions of high entropy, most closely matches that of the original image or video [Reference Sheikh and Bovik84, Reference Sheikh, Bovik and De Veciana85, Reference Wang, Bovik, Sheikh and Simoncelli96]. Other metrics of this type are based on the assumption that the HVS understands an image mainly through its low-level features. Hence, image degradations can be perceived by comparing the low-level features between the distorted and the reference images. The latest work is called feature-similarity (FSIM) index [Reference Zhang, Zhang, Mou and Zhang108]. We will discuss in more detail on this type of metric in Section III.
The fourth type in the classification is packet-analysis-based metrics. This type of metric focuses on assessment of the impact caused by network impairments on visual quality. It is usually based on the parameters extracted from the transport stream to measure the quality loss. It also has the advantage of measuring the quality of several image/video streams in parallel. Lately, this type of metric has become more popular because of increasing video delivery service over networks, such as IPTV or Internet streaming. One example of such metrics is the V-Factor [Reference Winkler and Mohandas105]. The details about this metric will be introduced in Section IV.
The last type of metric is the emerging learning-oriented metrics. Some recent works are[Reference Liu, Lin and Kuo57–Reference Liu, Lin and Kuo59, Reference Luo63, Reference Narwaria and Lin68, Reference Narwaria and Lin70, Reference Suresh, Babu and Sundararajan87]. Basically, it extracts specific features from the image or video, and then uses the machine learning approach to obtain a trained model. Finally, the trained model is used to predict the perceived quality of images/videos. The obtained experimental results are quite promising, especially for multi-metric fusion (MMF) approach [Reference Liu, Lin and Kuo57, Reference Liu, Lin and Kuo59] that uses the major existing metrics as the components for the learnt model. The MMF is expected to outperform all the existing metrics as the fusion-based approach to allow the combination of merits from each metric.
III. RECENT DEVELOPMENTS IN IQA
A) Image quality databases
Databases with subjective data facilitate metric development and benchmarking, as the ground truth and source of inspiration. There are a number of publicly available image quality databases, including LIVE [9], TID2008 [15], CSIQ [2], IVC [7], IVC-LAR [8], Toyoma [16], WIQ [19], A57 [1], and MMSP 3D Image [12]. We will give a brief introduction for each database below.
LIVE Image Quality Database has 29 reference images (also called source reference circuits (SRC)) and 779 test images, including five distortion types – JPEG2000, JPEG, white noise in the RGB components, Gaussian blur, and transmission errors in the JPEG2000 bitstream using a fast-fading Rayleigh channel model. The subjective quality scores provided in this database are DMOS, ranging from 0 to 100.
Tampere Image Database 2008 (TID2008) has 25 reference images and 1700 distorted images, including 17 types of distortions and four different levels for each type of distortion. Hence, there are 68 test conditions (also called hypothetical reference circuits (HRC)). MOS is provided in this database, and the scores range from 0 to 9.
Categorical Image Quality (CSIQ) Database contains 30 reference images, and each image is distorted using six types of distortions – JPEG compression, JPEG2000 compression, global contrast decrements, additive Gaussian white noise, additive Gaussian pink noise, and Gaussian blurring – at 4–5 different levels, resulting in 866 distorted images. The score ratings (0–1) are reported in the form of DMOS.
IVC Database has 10 original images and 235 distorted images, including four types of distortions – JPEG, JPEG2000, locally adaptive resolution (LAR) coding, and blurring. The subjective quality scores provided in this database are MOS, ranging from 1 to 5.
IVC-LAR Database contains eight original images (four natural images and four art images) and 120 distorted images, including three distortion types – JPEG, JPEG2000, and LAR coding. The subjective quality scores provided in this database are MOS, ranging from 1 to 5.
Toyoma Database has 14 original images and 168 distorted images, including two types of distortions – JPEG and JPEG2000. The subjective scores in this database are MOS, ranging from 1 to 5.
Wireless Imaging Quality (WIQ) Database has seven reference images and 80 distorted images. The subjective quality scores used in this database are DMOS, ranging from 0 to 100.
A57 Database has three original images and 54 distorted images, including six distortion types – quantization of the LH subbands of a five-level DWT of the image using the 9/7 filters, additive Gaussian white noise, JPEG compression, JPEG2000 compression, JPEG2000 compression with Dynamic Contrast-Based Quantization (DCQ), and Gaussian blurring. The subjective quality scores used for this database are DOMS, ranging from 0 to 1.
MMSP 3D Image Quality Assessment Database contains stereoscopic images with a resolution of 1920 × 1080 pixels. Various indoor and outdoor scenes with a large variety of colors, textures, and depth structures have been captured. The database contains 10 scenes. Seventeen subjects participated in the test. For each of the scenes, six different stimuli have been considered corresponding to different camera distances (10, 20, 30, 40, 50, and 60 cm).
To make a clear comparison among these databases, we list important information for each database in Table 1.

B) Major IQA metrics
As mentioned earlier, the simplest and most widely used image quality metrics are MSE and PSNR because they are easy to calculate and are also mathematically convenient in the optimization sense. However, they often correlate poorly with subjective visual quality [Reference Wang and Bovik95].
Hence, researchers have done a lot of work to include the characteristics of the HVS to improve the performance of quality prediction. The noise quality measure (NQM) [Reference Damera-Venkata, Kite, Geisler, Evans and Bovik33], PSNR-HVS-M [Reference Ponomarenko, Silvestri, Egiazarian, Carli, Astola and Lukin79], and the visual signal-to-noise ratio (VSNR) [Reference Chandler and Hemami27] are several representatives in this category.
NQM (FR, HVS model-based metric), which is based on Peli's contrast pyramid [Reference Peli77], takes into account the following:
(1) variation in contrast sensitivity with distance, image dimensions, and spatial frequency;
(2) variation in the local luminance mean;
(3) contrast interaction between spatial frequencies; and
(4) contrast masking effects.
It has been demonstrated that the nonlinear NQM is a better measure of additive noise than PSNR and other linear quality measures [Reference Damera-Venkata, Kite, Geisler, Evans and Bovik33].
PSNR-HVS-M (FR, HVS model-based metric) is a still image quality metric that takes into account contrast sensitivity function (CSF) and between-coefficient contrast masking of DCT basis functions. It has been shown that PSNR-HVS-M outperforms other well-known reference-based quality metrics and demonstrated high correlation with the results of subjective experiments [Reference Ponomarenko, Silvestri, Egiazarian, Carli, Astola and Lukin79].
VSNR (FR, HVS model-based metric) is a metric computed by a two-stage approach [Reference Chandler and Hemami27]. In the first stage, contrast thresholds for detection of distortions in the presence of natural images are computed via wavelet-based models of visual masking and visual summation in order to determine whether distortions in the distorted image are visible. If the distortions are below the threshold of detection, the distorted image is claimed to be of perfect visual quality. If the distortions are higher than a threshold, a second stage is applied, which operates based on the visual property of perceived contrast and global precedence. These two properties are modeled as Euclidean distances in distortion-contrast space of a multi-scale wavelet decomposition, and the final VSNR is obtained by linearly summing these distances.
However, the HVS is a nonlinear and highly complicated system, and most models so far are only based on quasi-linear or linear operators. Hence, a different framework was introduced, based on the assumption that a measurement of structural information change should provide a good approximation to perceived image distortion. Structural similarity (SSIM) index (FR, signal structure-based metric) [Reference Wang, Bovik, Sheikh and Simoncelli96] is the most well-known one in this category.
Suppose two image signals x and y, and let μx, μy, σx2, σy2, and σxy be the mean of x, the mean of y, the variance of x, the variance of y, and the covariance of x and y respectively. Wang et al. [Reference Wang, Bovik, Sheikh and Simoncelli96] define the luminance, contrast, and structure comparison measures as follows:
 $$\eqalign{l\lpar {\bf x}\comma \; {\bf y}\rpar &=\displaystyle{2\mu_{x}\mu_{y} + C_{1} \over \mu_{x}^{2}+\mu_{y}^{2}+C_{1}}\comma \; \quad c\lpar {\bf x}\comma \; {\bf y}\rpar = \displaystyle{2 \sigma_{x}\sigma_{y}+C_{2} \over \sigma_{x}^{2}+\sigma_{y}^{2}+C_{2}}\comma \; \cr s\lpar {\bf x}\comma \; {\bf y}\rpar & = \displaystyle{\sigma_{xy} + C_{3} \over \sigma_{x}\sigma_{y}+C_{3}}\comma \; } $$
$$\eqalign{l\lpar {\bf x}\comma \; {\bf y}\rpar &=\displaystyle{2\mu_{x}\mu_{y} + C_{1} \over \mu_{x}^{2}+\mu_{y}^{2}+C_{1}}\comma \; \quad c\lpar {\bf x}\comma \; {\bf y}\rpar = \displaystyle{2 \sigma_{x}\sigma_{y}+C_{2} \over \sigma_{x}^{2}+\sigma_{y}^{2}+C_{2}}\comma \; \cr s\lpar {\bf x}\comma \; {\bf y}\rpar & = \displaystyle{\sigma_{xy} + C_{3} \over \sigma_{x}\sigma_{y}+C_{3}}\comma \; } $$where the constants C 1, C 2, and C 3 are included to avoid instabilities when μx2 + μy2, σx2 + σy2, and σxσy are very close to zeros. Finally, they combine these three comparison measures and name the resulting similarity measure between image signals x and y as
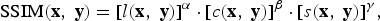 $$\hbox{SSIM}\lpar {\bf x}\comma \; {\bf y}\rpar =\lsqb l\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\alpha}\cdot \lsqb c\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\beta }\cdot \lsqb s\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\gamma }\comma \;$$
$$\hbox{SSIM}\lpar {\bf x}\comma \; {\bf y}\rpar =\lsqb l\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\alpha}\cdot \lsqb c\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\beta }\cdot \lsqb s\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\gamma }\comma \;$$where α > 0, β > 0, and γ > 0 are the parameters used to adjust the relative importance of these three components. In order to simplify the expression, set α = β= γ =1 and C 3 = C 2/2. This results in a specific form of the SSIM index between image signals x and y:
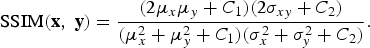 $$\hbox{SSIM}\lpar {\bf x}\comma \; {\bf y}\rpar =\displaystyle{\lpar 2\mu_{x}\mu_{y}+C_{1}\rpar \lpar 2\sigma_{xy}+C_{2}\rpar \over \lpar \mu_{x}^{2}+\mu_{y}^{2}+C_{1}\rpar \lpar \sigma_{x}^{2}+\sigma_{y}^{2}+C_{2}\rpar }.$$
$$\hbox{SSIM}\lpar {\bf x}\comma \; {\bf y}\rpar =\displaystyle{\lpar 2\mu_{x}\mu_{y}+C_{1}\rpar \lpar 2\sigma_{xy}+C_{2}\rpar \over \lpar \mu_{x}^{2}+\mu_{y}^{2}+C_{1}\rpar \lpar \sigma_{x}^{2}+\sigma_{y}^{2}+C_{2}\rpar }.$$However, the standard SSIM defined above is only a single-scale method. To be able to consider image details at different resolutions (we do not know the right object sizes in general), a multi-scale SSIM (MS-SSIM) (FR, signal structure-based metric) [Reference Wang, Simoncelli and Bovik101] is adopted. Taking the reference and distorted image signals as the input, the system iteratively applies a low-pass filter and down-samples the filtered image by a factor of two. The original image is labeled as scale 1, and the highest scale as M, which is obtained after M − 1 iterations; at the j-th scale, the contrast comparison and the structure comparison are calculated and denoted as c j(x, y) and s j(x, y), respectively. The luminance comparison is computed only at scale M and denoted as l M(x, y). The overall SSIM evaluation is obtained by combining the measurement at different scales using
 $$\hbox{MS-SSIM}\lpar {\bf x}\comma \; {\bf y}\rpar = \lsqb l_{M}\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\alpha_{M}}\prod_{j=1}^{M}\lsqb c_{j}\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\beta_{j}}\lsqb s_{j}\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\gamma_{j}}. $$
$$\hbox{MS-SSIM}\lpar {\bf x}\comma \; {\bf y}\rpar = \lsqb l_{M}\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\alpha_{M}}\prod_{j=1}^{M}\lsqb c_{j}\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\beta_{j}}\lsqb s_{j}\lpar {\bf x}\comma \; {\bf y}\rpar \rsqb ^{\gamma_{j}}. $$ Similarly, exponents αM, βj and γj are used to adjust the relative importance of different components. As the simplest parameter selection, αj = βj = γj for all j's. In addition, normalization is performed for the cross-scale settings such that 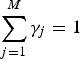 $\sum_{j=1}^{M}\gamma_{j}=1$.
$\sum_{j=1}^{M}\gamma_{j}=1$.
Since SSIM is sensitive to relative translations, rotations, and scalings of images [Reference Wang and Bovik95], complex-wavelet SSIM (CW-SSIM) [Reference Wang and Simoncelli100] has been developed. The CW-SSIM is locally computed from each subband, and then averaged over space and subbands, yielding an overall CW-SSIM index between the original and the distorted images. The CW-SSIM method is robust with respect to luminance changes, contrast changes, and translations [Reference Wang and Simoncelli100].
Afterward, some researchers have tried to propose a new metric by modifying SSIM, such as three-component weighted SSIM (3-SSIM) [Reference Li and Bovik51], and information content weighted SSIM (IW-SSIM) [Reference Wang and Li98]. They are all based on the similar strategy to assign different weightings to the SSIM scores.
Another metric based on the information theory to measure image fidelity is called information fidelity criterion (IFC) (FR, signal information-extracted metric) [Reference Sheikh, Bovik and De Veciana85]. It was later extended to visual information fidelity (VIF) metric (FR, signal information-extracted metric) [Reference Sheikh and Bovik84]. The VIF attempts to relate signal fidelity to the amount of information that is shared between two signals. The shared information is quantified using the concept of mutual information. The reference image is modeled by a wavelet domain Gaussian scale mixture (GSM), which has been shown to model the non-Gaussian marginal distributions of the wavelet coefficients of natural images effectively, and also capture the dependencies between the magnitudes of neighboring wavelet coefficients. Therefore, it brings good performance to the VIF index over a wide range of distortion types [Reference Sheikh, Sabir and Bovik86].
Reduced-reference image quality assessment (RRIQA) (RR, signal feature-extracted metric) is proposed in [Reference Li and Wang52]. The authors use GSM statistical model of image wavelet coefficients to compute a divisive normalization transform (DNT) for images. Then, they evaluate the image quality based on the comparison between features extracted from the DNT of reference and distorted images. The proposed RR approach has improved performance and even works better than FR PSNR in LIVE Image Quality Database.
In [Reference Gao, Lu, Tao and Li39], multi-scale geometric analysis (MGA) is used to decompose images and extract features to model the multi-channel structure of HVS. Moreover, several transforms (e.g., wavelet, curvelet, bandelet, and contourlet) are also utilized to capture different kinds of geometric information of images. CSF is used to weight the coefficients obtained by the MGA. Next, Just Noticeable Difference (JND) is applied to produce a noticeable variation. Finally, the quality of the distorted image is obtained by comparing the normalized histogram between the distorted image and reference one. In addition to the good consistency with human subjective evaluation, this MGA-based IQA (RR, signal feature-extracted metric) also has the advantage of using low data rate to represent features.
Ferzli et al. [Reference Ferzli and Karam36] proposed an objective image sharpness metric, called Just Noticeable Blur Metric (JNBM) (NR, HVS model-based metric). They claimed the just noticeable blur (JNB) is a function of local contrast and can be used to derive an edge-based sharpness metric with probability summation model over space. The experiment results showed this method can successfully predict the relative amount of sharpness/blurriness in images, even with different scenes.
In [Reference Choi, Jung and Jeon30], the authors presented a method for IQA by combining the features obtained from the computation of mean and ratio of edge blurriness and noise (MREBN). The proposed metric MREBN (NR, signal feature-extracted metric) has high correlation with subjective quality scores. They also claimed the low computational load of the model because of linear combination of the features obtained.
In [Reference Larson and Chandler48], Larson and Chandler suggested that a single strategy may not be sufficient to determine the image quality. They presented a quality assessment method, called most apparent distortion (MAD) (FR, HVS model-based metric), which can model two different strategies. First, they used local luminance and contrast masking to estimate detection-based perceived distortions in high-quality images. Then changes in the local statistics of spatial-frequency components are used to estimate the appearance-based perceived distortions in low quality images. In the end, the authors showed that combining these two strategies can predict subjective ratings of image quality well.
FSIM (FR, signal feature-extracted metric) [Reference Zhang, Zhang, Mou and Zhang108] is a recently developed image quality metric, which compares the low-level feature sets between the reference image and the distorted image based on the fact that the HVS understands an image mainly according to its low-level features. Phase congruency (PC) is the primary feature to be used in computing FSIM. Gradient magnitude (GM) is the second feature to be added in FSIM metric because PC is contrast invariant and contrast information also affects the HVS' perception of image quality. Actually, in the FSIM index, similarity measures for PC and GM all follow the same formula as in the SSIM metric.
More recently, we proposed a multi-metric fusion (MMF) (FR, learning-oriented metrics) approach for visual quality assessment [Reference Liu, Lin and Kuo57, Reference Liu, Lin and Kuo59]. This method is motivated by the observation that no single metric can give the best performance scores in all situations. To achieve MMF, a regression approach is adopted. First, we collected a large number of image samples, each of which has a score labeled by human observers and scores associated with different quality metrics. The new MMF score is set to be the nonlinear combination of scores obtained by multiple existing metrics (including SSIM [Reference Wang, Bovik, Sheikh and Simoncelli96], MS-SSIM [Reference Wang, Simoncelli and Bovik101], VSNR [Reference Chandler and Hemami27], IFC [Reference Sheikh, Bovik and De Veciana85], VIF [Reference Sheikh and Bovik84], PSNR, PSNR-HVS [Reference Egiazarian, Astola, Ponomarenko, Lukin, Battisti and Carli34], NQM [Reference Damera-Venkata, Kite, Geisler, Evans and Bovik33], FSIM [Reference Zhang, Zhang, Mou and Zhang108], and MAD [Reference Larson and Chandler48]) with suitable weights via a training process. We also term it as context-free MMF (CF-MMF) because it does not depend on image contexts. Furthermore, we divide image distortions into several groups and perform regression within each group, which is called context-dependent MMF (CD-MMF). One task in CD-MMF is to determine the context automatically, which is achieved by a machine learning approach. It is shown by experimental results that the proposed MMF metric outperforms all existing metrics by a significant margin.
Table 2 summarizes the IQA models that we have mentioned so far and the corresponding classifications based on reference availability and assessment methodology; we have also commented on the strength and weakness of the models under discussion in the table.
Table 2. Classification of IQA models based on reference availability and assessment methodology.

C) Application in perceptual image coding
IQA metrics are widely exploited for image coding. Different metrics, such as SSIM [Reference Channappayya, Bovik and Heath28, Reference Wang, Bovik, Sheikh and Simoncelli96] and VIF [Reference Sheikh and Bovik84] are used to improve the perceptual performance of JPEG and JPEG2000 compression and provide feedback to rate-control algorithms. In other words, the concept of perceptual image coding is to assess the quality of the target image by using IQAs and then apply the index to improve coding efficiency. Each IQA reflects specific{} features. Thus, choosing the perceptual model is based on the need of specific application or codec. Coding distortion can be approximated from the extracted perceptual features and used to guide an image coder.
Yim and Bovik [Reference Yim and Bovik107] analyzed the blockiness of compressed JPEG images. The proposed metric index focuses on discrete cosine transformed and quantized images. It has been shown that the blocking effect can be assessed by using the quality metric which detects differences of the neighborhoods of the target block. The blocking effect factor (BEF) is defined by the difference of the mean boundary pixel squared difference and the mean non-boundary pixel squared difference. The mean-squared error including the blocking effect (MSE-B) is calculated from the corresponded BEF and MSE and leads to peak signal-to-noise ratio including the blocking effect (PSNR-B). The PSNR-B can quantify the blocking effect in a boundary of macroblocks. Moreover, this can help to develop H.264/AVC de-blocking filters.
Hontzsch and Karam [Reference Hontzsch and Karam41] presented a locally adaptive perceptual image coder, which optimizes the bit allocation of the targeted distortion type. The algorithm starts from extracting visual properties adaptively based on the local image features. It decomposes data into discrete cosine transform (DCT) coefficients, which are fed to the perceptual model to generate perceptual properties. These properties are used to compute the local distortion adaptively and result in local distortion sensitivity profiles. The thresholds, which are derived from the profiles, reflect the characteristics of local image data. Two visual phenomena, contrast sensitivity dependent on background luminance and contrast masking, are modeled to generate the thresholds. For contrast sensitivity, the threshold is defined related to the luminance of the background to verify the sensitivity of the eye under the condition of the background. For contrast masking adjustment, contrast masking pertains to the visual change. The masker signal is in the form of the DCT subband coefficients of the input image comparing to the quantization error. Thus, the quantization step size is calculated from the threshold in order to achieve the target bitrate.
Rehman and Wang [Reference Rehman and Wang80] addressed the practical use of SSIM. Instead of fully accessing the original image, reduced reference technique only uses partial information. The first step of the algorithm is the multi-scale multi-orientation DNT which extracts the neural features of the biological HVS. DNT coefficient distribution is parameterized and provides needed partial information of the reference image. This information can be used to define the distortion of the compressed image and reflect the SSIM value of the images. The proposed reduced reference version of SSIM shows linear relationship to the full reference version in specific circumstances. The application of the algorithm does not only measure the SSIM but also repair some distortions.
Besides VIF, other approaches are taken to JPEG2000. Tan et al. [Reference Tan, Tan and Wu88] proposed an image coder based on the just-noticeable distortion model which considers a variety of perceptual aspects. The algorithm is developed from a monochromatic vision model to a color image one. The monochromatic contrast gain control (CGC) model includes spatial masking, orientation masking and contrast sensitivity. The luminance and chromatic parts are modeled by the CGC. The distortion metric is designed to estimate perceptual error and applied to replace MSE which is used in the cost function in embedded block coding with optimal truncation (EBCOT). The 14 parameters in the metric are optimized with a two tiered approach. One calculates the parameter set recursively; the other fine-tunes the parameter set via algorithmic optimization.
SSIM is also exploited in JPEG2000. Richter et al. [Reference Richter and Kim81] proposed a JPEG encoder based on optimal Multi-scale SSIM (MS-SSIM) [Reference Wang, Simoncelli and Bovik101]. Efforts are made to modify MS-SSIM in order to be embedded to the encoder. The first step of the algorithm is trying to modify MS-SSIM to the logarithmic form. The contrast and the structure part of the index can be expressed by the reconstruction error; the luminance part is ignored due to its minor effect. The final term of the index can be computed by utilizing the results from EBCOT and wavelet decomposition process. Thus, the implementation integrates MS-SSIM into a JPEG2000 encoder.
IV. RECENT DEVELOPMENTS IN VQA
A) Video quality databases
To our knowledge, there are nine public video quality databases available, including VQEG FRTV-I [17], IRCCyN/IVC 1080i [5], IRCCyN/IVC SD RoI [6], EPFL-PoliMI [4], LIVE [10], LIVE Wireless [11], MMSP 3D Video [13], MMSP SVD [14], and VQEG HDTV [18]. We will briefly introduce them below.
VQEG FR-TV Phase I Database is the oldest public database on video quality applied to MPEG-2 and H.263 video with two formats: 525@60 Hz and 625@50 Hz in this database. The resolution for video sequence 525@60 Hz is 720 × 486 pixels and 720 × 576 pixels for 625@50 Hz. The video format is 4:2:2. The subjective quality scores provided are DMOS, ranging from 0 to 100.
IRCCyN/IVC 1080i Database contains 24 contents. For each content, there is one reference and seven different compression rates on H.264 video. The resolution is 1920 × 1080 pixels, the display mode is interleaving and the field display frequency is 50 Hz. The provided subjective quality scores are MOS, ranging from 1 to 5.
IRCCyN/IVC SD RoI Database contains six reference videos and 14 HRCs (i.e., 84 videos in total). The HRCs are H.264 coding with or without error transmission simulations. The contents of this database are SD videos. The resolution is 720 × 576 pixels, the display mode is interleaving, and the field display frequency is 50 Hz with MOS from 1 to 5.
EPFL-PoliMI Video Quality Assessment Database contains 12 reference videos (6 in CIF, and 6 in 4CIF), and 144 distorted videos, which are encoded with H.264/AVC and corrupted by simulating the packet loss due to transmission over an error-prone network. For CIF, the resolution is 352 × 288 pixels, and frame rate is 30 fps. For 4CIF, the resolution is 704 × 576 pixels, and frame rates are 30 fps and 25 fps. For each of the 12 original H.264/AVC videos, they have generated a number of corrupted ones by dropping packets according to a given error pattern. To simulate burst errors, patterns have been generated at six different packet-loss rates (PLR) and two channel realizations have been selected for each PLR.
LIVE Video Quality Database [Reference Seshadrinathan, Soundararajan, Bovik and Cormack83] includes 10 reference videos. All videos are 10 s long, except for Blue Sky. The Blue Sky sequence is 8.68 s long. The first seven sequences have a frame rate of 25 fps, while the remaining three (Mobile & Calendar, Park Run, and Shields) have a frame rate of 50 fps. There are 15 test sequences from each of the reference sequences using four different distortion processes – simulated transmission of H.264 compressed videos through error-prone wireless networks and through error-prone IP networks, H.264 compression, and MPEG-2 compression. All video files have planar YUV 4:2:0 formats and do not contain any headers. The spatial resolution of all videos is 768 × 432 pixels.
LIVE Wireless Video Quality Assessment Database has 10 reference videos, and 160 distorted videos, which focus on H.264/AVC compressed video transmission over wireless networks. The video is YUV 4:2:0 formats with a resolution of 768 × 480 and a frame rate of 30 fps. Four bit-rates and four packet-loss rates are performed. However, this database has been taken offline temporarily because it has limited video level contents and a tendency to cluster at 0.95–0.96 correlation for most objective metrics.
MMSP 3D Video Quality Assessment Database contains stereoscopic videos with a resolution of 1920 × 1080 pixels and a frame rate of 25 fps. Various indoor and outdoor scenes with a large variety of color, texture, motion, and depth structure have been captured. The database contains 6 scenes, and 20 subjects participated in the test. For each of the scenes, 5 different stimuli have been considered corresponding to different camera distances (10, 20, 30, 40, and 50 cm).
MMSP Scalable Video Database is related to two scalable video codecs (SVC and wavelet-based codec), three HD contents, and bit rates ranging between 300 kbps and 4 Mbps. There are three spatial resolutions (320 × 180, 640 × 360, and 1280 × 720), and four temporal resolutions (6.25 fps, 12.5 fps, 25 fps, and 50 fps). In total, 28 and 44 video sequences were considered for each codec, respectively. The video data are in the YUV 4:2:0 formats.
VQEG HDTV Database has four different video formats – 1080p at 25 and 29.97 fps, 1080i at 50 and 59.94 fps. The impairments are restricted to MPEG-2 and H.264, with both coding-only error and coding-plus-transmission error. The video sequences are released progressively via the Consumer Digital Video Library (CDVL) [3].
We summarize and compare these video quality databases in Table 3 for the convenience of readers.
Table 3. Comparison of video quality databases.

B) Major VQA metrics
One obvious way to implement VQMs is to apply a still IQA metric on a frame-by-frame basis. The quality of each frame is evaluated independently, and the global quality of the video sequence can be obtained by a simple time average.
SSIM has been applied in VQA as reported in [Reference Wang, Lu and Bovik99]. The quality of the distorted video is measured in three levels: the local region level, the frame level, and the sequence level. First, the SSIM indexing approach is applied to the Y, Cb, and Cr color components independently and combined into a local quality measure using a weighted summation. In the second level of quality evaluation, the local quality values are weighted to obtain a frame level quality index. Finally, in the third level, overall quality of the video sequence is given by weighted summation of the frame level quality index. This approach is often called V-SSIM (FR, signal structure-based metric), and has been demonstrated to perform better than KPN/Swisscom CT [91] (the best metric for the Video Quality Experts Group (VQEG) Phase I test dataset [17]) in [Reference Wang, Lu and Bovik99].
Wang and Li [Reference Wang and Li97] proposed Speed-SSIM (FR, signal structure based metric) that incorporated a model of the human visual speed perception by formulating the visual perception process in an information communication framework. Consistent improvement over existing VQA algorithms has been observed in the validation with the VQEG Phase I test dataset [17].
Watson et al. [Reference Watson, Hu and McGowan102] developed a VQM, which they call digital video quality (DVQ) (FR, HVS model-based metric). The DVQ accepts a pair of video sequences and computes a measure of the magnitude of the visible difference between them. The first step consists of various sampling, cropping, and color transformations that serve to restrict processing to a region of interest (ROI) and to express the sequence in a perceptual color space. This stage also deals with de-interlacing and de-gamma-correcting the input video. The sequence is then subjected to a blocking and a discrete cosine transform (DCT), and the results are transformed to local contrast. Then, the next steps are temporal, spatial filtering, and a contrast masking operation. Finally, the masked differences are pooled over spatial, temporal and chromatic dimensions to compute a quality measure.
Video Quality Metric (VQM) (RR, HVS model-based metric) [Reference Pinson and Wolf78] is developed by National Telecommunications and Information Administration (NTIA) to provide an objective measurement for perceived video quality. The NTIA VQM provides several quality models, such as the Television Model, the General Model, and the Video Conferencing Model, based on the video sequence under consideration and with several calibration options prior to feature extraction in order to produce efficient quality ratings. The General Model contains seven independent parameters. Four parameters (si_loss, hv_loss, hv_gain, and si_gain) are based on the features extracted from spatial gradients of Y luminance component, two parameters (chroma_spread, chroma_extreme) are based on the features extracted from the vector formed by the two chrominance components (Cb, Cr), and one parameter (ct_ati_gain) is based on the product of features that measure contrast and motion, both of which are extracted from Y luminance component. The VQM takes the original video and the processed video as inputs and is computed using the linear combination of these seven parameters. Owing to its good performance in the VQEG Phase II validation tests, the VQM method was adopted as a national standard by the American National Standards Institute (ANSI) and as International Telecommunications Union Recommendations [,2122].
By analyzing subjective scores of various video sequences, Lee et al. [Reference Lee, Cho, Choe, Jeong, Ahn and Lee49] found out that the HVS is sensitive to degradation around edges. In other words, when edge areas of a video sequence are degraded, human evaluators tend to give low-quality scores to the video, even though the overall MSE is not large. Based on this observation, they proposed an objective video quality measurement method based on degradation around edges. In the proposed method, they first applied an edge detection algorithm to videos and located edge areas. Then, they measured degradation of those edge areas by computing MSEs and used it as a VQM after some post-processing. Experiments show that this proposed method EPSNR (FR, video fidelity metric) outperforms the conventional PSNR. This method was also evaluated by independent laboratory groups in the VQEG Phase II test. As a result, it was included in international recommendations for objective video quality measurement.
Kawayoke et al. [Reference Kawayoke and Horita46] suggested a new objective VQA method, called continuous video quality (CVQ) (NR, learning-oriented metric). The metric can provide quality values at a rate of two scores per second according to the data obtained from subjective assessment tests under a SSCQE method. It is based on the concept that frame quality value needs to be adjusted by spatial and temporal information. As a result, the objective quality scores computed by this approach have a higher estimation accuracy than frame quality scores.
More recently, an approach integrates both spatial and temporal aspects of distortion assessment, known as MOtion-based Video Integrity Evaluation (MOVIE) index (FR, HVS model based metric) [Reference Seshadrinathan and Bovik82]. The MOVIE uses optical flow estimation to adaptively guide spatial–temporal filtering using three-dimensional (3D) Gabor filterbanks. The key differentiation of this method is that a subset of filters is selected adaptively at each location based on the direction and speed of motion, such that the major axis of the filter set is oriented along the direction of motion in the frequency domain. The video quality evaluation process is carried out with coefficients computed from these selected filters only. One component of the MOVIE framework, known as the Spatial MOVIE index, uses the output of the multi-scale decomposition of reference and test videos to measure spatial distortions in the video. The second component of the MOVIE index, known as the Temporal MOVIE index, captures temporal degradations in the video. The Temporal MOVIE index computes and uses motion information from the reference video, and evaluates the quality of the test video along the motion trajectories of the reference video. Finally, the Spatial MOVIE index and the Temporal MOVIE index are combined to obtain a single measure of video quality known as the MOVIE index. The performance of MOVIE on the VQEG FRTV Phase I dataset is summarized in [Reference Seshadrinathan and Bovik82].
In addition, TetraVQM (FR, HVS model-based metric) [Reference Barkowsky, Bialkowski, Eskofier, Bitto and Kaup25] has been proposed to utilize motion estimation within a VQA framework, where motion-compensated errors are computed between reference and distorted images. Based on the motion vectors and the motion prediction error, the appearance of new image areas and the display time of objects are evaluated. In addition, degradations on moving objects can be judged more exactly. In [Reference Ninassi, Le Meur, Le Callet and Barba72], Ninassi et al. tried to utilize models of visual attention (VA) and human eye movements to improve VQA performance. The temporal variations of the spatial distortions are evaluated both at eye fixation level and on the whole video sequence. These two kinds of temporal variations are assimilated into a short-term temporal pooling and a long-term temporal pooling, respectively.
V-Factor (NR, packet-analysis-based metric) [Reference Winkler and Mohandas105] is a real-time, packet-based VQM, which works without the need of references. In [Reference Winkler and Mohandas105], this metric is primarily used in MPEG-2 and H.264 video streamings over IP networks. First, it inspects several parts of the video stream, including the transport stream (TS) headers, the packetized elementary stream (PES) headers, the video coding layer (VCL), and the decoded video signal. Then, it analyzes the bitstream to obtain static parameters, such as the frame rate and the image size. The dynamic parameters (e.g., variation of quantization steps) are also obtained along with the analysis. The final video quality is estimated based upon the content characteristics, compression methods, bandwidth constraints, delays, jitter, and packet loss. Among these six factors, the first three are affected by video impairments and the last three are caused by network impairments. In addition, this metric also analyzes real-time network impairments to calculate the packet loss probability ratio by using hidden Markov models. The final V-Factor value (i.e., the estimate of MOS) is obtained by using a codec-specific curve fit equation and inputs from the following three models: the bandwidth model, the VCL complexity model, and the loss model.
Li et al. [Reference Li, Ma, Zhang and Ngan54] proposed to use temporal inconsistency measure (TIM) to describe visual disparity of the same object in consecutive distortion frames. First, they performed block-based motion estimation on the reference video to obtain the motion vectors. Then, the motion vectors can be used to create motion-compensated frames for reference and distorted videos, respectively. The difference between motion compensated and real frames of the reference video (DoR) is called inherent difference. Similarly, there is also a difference between motion compensated and real frames of the distorted video (DoD). However, DoD consists of two components, including inherent difference and temporal inconsistency. Hence, the TIM can be computed by subtracting DoR from DoD. In the end, they incorporated TIM into MSE, called MSE_TIM (FR, video fidelity metrics) and introduced a weighting parameter to adjust the importance between spatial impairment and TIM in quality prediction. The experiment results show that TIM improves the performance of MSE. Moreover, the performance becomes even better when using TIM alone.
In [Reference Amirshahi and Larabi24], the authors proposed a new VQM, named spatial–temporal assessment of quality (STAQ) (RR, HVS model-based metric). As the name suggests, it includes both spatial and temporal parts. In the first step, they used a temporal approach to find the matching regions in adjacent frames. One important change from existing motion estimation methods during this step is to use CW-SSIM instead of the mean absolute difference to compute the motion vectors. This will increase the precision of finding the matching regions. In the second step, a spatial method is used to compute the quality of the matching regions extracted via the temporal approach. The visual attention map (VAM) is used to weight each sub-block in the luminance channel based on the importance. In the final step, the video quality is estimated according to the values obtained from both the spatial and temporal domains, and quality of experience (QoE) is introduced as a function related to the motion activity density group of the video to control the pooling function. The results are quite promising in H.264 distorted video case, but are less competitive than MOVIE in either MPEG-2 or IP case.
There is also another approach integrating both spatial and temporal domains, called spatiotemporal MAD (ST-MAD) (FR, HVS model-based metric) [Reference Vu, Vu and Chandler93], which is extended from the image quality metric MAD [Reference Larson and Chandler48]. First, a spatiotemporal slice (STS) image is constructed from the time-based slices of the reference and distorted videos. The detailed procedure is as follows: a single column or row of the frame is extracted for each video frame, and these columns (or rows) are stacked from left to right (or top to bottom) to become a STS image. Then ST-MAD estimates motion-based distortions by using MAD's appearance-based model to STS images. Next, it gives larger weights to the fast-moving regions by applying optical-flow algorithm. Finally, it employs a combination rule to add spatial and temporal distortions together. Experimental results show that ST-MAD performs better than other state-of-the-art quality metrics in LIVE Video Quality Database, especially on H.264 and MPEG-2 distorted videos. However, MOVIE only outperforms ST-MAD for wireless distorted videos.
To summarize these VQA models, we present a simple comparison based on reference availability and assessment methodology in Table 4, as well as providing comments on strength and weakness of each metric.
Table 4. Classification of VQA models based on reference availability and assessment methodology.

C) Application in perceptual video coding
Since perceptual quality assessment is a hot topic in video coding, we use this as an example for applications. Currently, there are two main approaches of perceptual video coding. One is to use different IQA or VQA metrics to measure distortions and develop the perceptual rate-distortion model to achieve better performance in a perceptual sense. The other one is to utilize human visual features to develop a just noticeable distortion (JND) model for quantization step (QP) selection, or a visual attention (VA) model in order to find the ROI in the target video and optimize the bit allocation corresponding to ROI information. A JND model may be combined with a VA one for a more comprehensive evaluation (to become a foveated JND model).
For the former approach, not all applications are developed to the whole codec. Some efforts [Reference Cui and Zhu31,Reference Yang, Leung, Po and Mai106] are made to tune the performance of encoding intra frames or made to optimize the coding efficiency of inter frames. The others target overall rate-distortion optimization of video coding. The algorithms are strongly bound to the codec type because the measurement of distortion is replaced in a perceptual fashion.
For the latter approach, the JND model is used to analyze the image features. Compared to the former method, it is more independent of the codec type.
Use of IQA or VQA metrics
Chen et al. [Reference Huang, Ou, Su and Chen42,Reference Ou, Huang and Chen75] proposed rate-distortion framework based on the SSIM index. In [Reference Huang, Ou, Su and Chen42], the mode decision of H.264 intra-frame and inter-frame coding is optimized perceptually by using SSIM index. The SSIM index is applied to replace the SSD to measure the difference between the reference block and the reconstructed block. Since it is hard to determine rate-distortion optimization by the SSIM index, the proposed approach to rate-distortion modeling provides a way to determine the Lagrange multiplier which is related to SSIM in the cost function. The rate-distortion curve fitting is defined by two parameters α and β which can be computed from two data points of the key frame. By using the data, the rate-distortion curves of subsequent frames can be estimated. For the given rate-distortion curve, the Lagrange multiplier can be calculated by the gradient or slope of the curve. In [Reference Ou, Huang and Chen75], the perceptual encoding scheme is based on the rate control algorithm in [Reference Huang, Ou, Su and Chen42] and extended to bit allocation. The proposed rate-control scheme separates the coding methods of key frames and other frames. The algorithm adopts extra quantization parameters for key frames to update the rate-distortion model. More precisely, the Lagrange multiplier is selected adaptively according to the input data from key frames.
The perceptual cost function determines the target bit budget in the frame level and the QP sizes. By combining [Reference Huang, Ou, Su and Chen42] and [Reference Ou, Huang and Chen75], the proposed technique is thoroughly implemented to improve perceptual rate control optimization of H.264/AVC.
In [Reference Wang, Rehman, Wang, Ma and Gao94], a model related to the reduced reference SSIM is developed to improve rate-distortion optimization. Instead of DNT, the proposed algorithm extracts the frame features from discrete cosine transform (DCT). With less computing complexity than DNT, the DCT coefficients provide required partial information of the reference image and lead to the estimated reduced reference SSIM index, which is an important parameter of the proposed rate-distortion model. The SSIM index is generated by the local SSIM index via sliding windows. The SSIM is provided by overlapped blocks, but the macroblocks are processed individually in the encoder. Also, the boundaries of the macroblocks are not continuous. To solve these issues, the macroblocks are extended to 22 × 22 and a sliding 4 × 4 window is applied to get the SSIM index. The reference-reduced SSIM index is derived from the DCT coefficients. At first, the DCT coefficients of 4 × 4 non-overlap blocks are calculated and then grouped into 16 subbands. The reduced reference distortion can be defined from the DCT subbands and MSE to the reference frame. Since the measured distortion is linearly equivalent to the SSIM index, the reduced reference SSIM index can be written in the form of the distortion. The proposed algorithm tends to update the parameters of the model in frame level and adjust the Lagrange multiplier in macro-block level.
The SSIM index is introduced to video coding to model the perceived distortion. Since SSIM is not a traditional block-based distortion measurement, current video compression standard can be optimized perceptually by introducing SSIM as a distortion measurement. In [Reference Huang, Ou, Su and Chen42,Reference Ou, Huang and Chen75], the RD curve is parameterized to fit the SSIM RD curve; the complexity of SSIM can be reduced and a more practical method is proposed in [Reference Wang, Rehman, Wang, Ma and Gao94].
Use of JND and VA models
Besides SSIM, JND is also applied to video coding algorithms. The JND is measured based on sensitivity of the HVS. With the JND, priority bit-allocation can be determined. In [Reference Chen and Guillemot29], a foveated JND model is proposed to measure distortion. This model combines the spatial JND model and the temporal JND model. For spatial JND, the measurement is based on the luminance of the background. If the luminance of the background is not high enough for human observers to recognize the targeted objects, then a larger QP is used to encode the frame. The threshold of background luminance is not only defined by spatial features but also considered temporal features. In the temporal model, change of luminance across frames is the key point. In the proposed model, inter-frame luminance change is considered as larger visibility threshold and separated in two cases, which are high-to-low and low-to-high. The former change results in more significant VA. The foveated JND is integrated to the H.264/AVC encoder. The QP is adjusted by weighting the macroblocks. If the macroblocks are perceived in higher priority, they can tolerate less distortion and preserve more bit budgets.
Itti et al. [Reference Li, Qin and Itti55] developed a VA model to detect the ROI in the video. The model is based on human visual characteristics including color information, contrast, shape, motion, etc. The model prediction generates the saliency map which is used in the bit allocation strategy. To improve the saliency map, frame to frame information is considered to update the salient locations of the objects. The relationships of the object across frames are determined by the four criteria: the Euclidean distance between the location in different frames, the Euclidean distance between feature vectors corresponding to the locations, a penalty term of the differences between frames to depress permuting pairings, and a tracking priority according to the intensity of the saliency to encourage track of the salient objects. With the criteria, the proposed algorithm can identify the salient objects and track their locations in the map. Combing in the information, the more significant object is assigned to higher priority for bit allocation.
More consideration of temporal and textural features
Motion and texture are significant features to the HVS for videos. Video coding by considering texture and motion can achieve good performance in a perceptual way. The approach in [Reference Bosch, Zhu and Delp26] is based on texture and motion modeling. The texture model employed in the algorithm is to separate perceptually relevant and non-relevant regions. The relevant region needs more bits to encode. The temporal (motion) model tries to improve consistency in textural regions across frames. Texture analysis provides information of textural regions to the encoder; the texture synthesis is applied to the decoder to reconstruct the scene. In texture analysis, frames are divided into groups with the same textures and the boundaries of the regions are detected. The features extracted in this stage include gray-level co-occurrence matrix, angular second moment, dissimilarity, correlation, entropy, sum of squares, and coefficients of Gabor filters. The employed segmentation techniques are split-and-merge method and K-means clustering. In order to track the region from frame to frame, motion vectors are bound to the textural regions. The temporal model is parameterized by the motion vectors to obtain the location of the regions in the consequent frames. In the encoder side, only key frames and non-synthesizable parts are coded by H.264/AVC. At the decoder, texture synthesis is designed to construct the other parts. With the temporal information, textures of the synthesizable frames are derived from the key frames and segmentation information is also passed from the encoder via the channel as side information to reconstruct the frame at the decoder.
To guarantee temporal consistency of texture-based video coding, a different approach was taken in [Reference Oh, Su, Segall and Kuo73]. The framework is established on cube-based texture growing method [Reference Ndjiki-Nya, Stuber and Wiegand71]. The proposed algorithm utilizes side information, which is a coded bitstream with a larger QP of the source video for two advantages. One is that the side information can be generated by any coding tool hence it can be associated to any video coding system. The other one is that the amount of side information can be adjusted by the QP with the result that the algorithm is flexible. To achieve the goal, an area-adaptive side information selection scheme that can decide the proper amount of side information is devised. The scheme determines rate-distortion optimization of the output coded data and side information bitrate. The results show that the gap between the analyzed and synthesized texture regions can be fulfilled and the perceptual quality of the regions is similar. In [Reference Bosch, Zhu and Delp26], the algorithm can significantly help to save more bits used in the side information. For intra coding, the proposed algorithm in [Reference Oh, Su, Segall and Kuo73] reconstructs the texture by the texture seed from a low-quality video, so the side information can be reduced by controlling the mechanism.
Naccari and Pereira [Reference Naccari and Pereira67] designed a complete perceptual video coding algorithm covering decoding, encoding, and testing tools. The JND model generates a threshold for each DCT subband coefficient. The adopted JND model contains spatial masking and temporal masking components. The spatial masking model is related to three properties: frequency band masking, luminance variations masking, and image pattern masking. Frequency band masking reflects the visual sensitivity of the noise introduced in DCT coefficients. Luminance variations masking reflects the change of the luminance part in different image regions. The JND threshold of image pattern masking varies with the threshold of frequency band masking and luminance variations masking.
The temporal masking model uses an existing model [Reference Wei and Ngan103] because of its performance compared to other solutions. The model is established by using motion vector information. To apply this model, the issues of B-frame and intra frame are considered. Two motion vectors are used in the B-frame, and only the past vector is adopted in the model. For intra, skip motion vector is introduced to the JND computation. In decoder side, the JND model is employed to estimate average block luminance, integer DCT coefficients, and JND thresholds. In encoder side, the model is integrated into quantization, motion estimation, and rate-distortion optimization. The QP for each DCT band of a given macroblock is adjusted by the respective JND threshold. The motion estimation andthe rate-distortion optimization processes are weighted by the JND thresholds. The weighting process tends to weight the estimation error to provide the error in a perceptual fashion. Perceptual distortion is employed to motion estimation and rate-distortion optimization. Thus, the cost function of rate-distortion optimization is converted to perceptual cost function and the Lagrange multiplier is also changed in the flavor. The proposed testing procedure is to assess rate-distortion performance. The algorithm is to compare the performance of a codec and another one based on a quality metric.
Other attempts
Besides visual quality metrics and perceptual models, audio information can be used to improve coding efficiency. In practical cases, audio is bound to video, hence the audio is also perceived by human observers synchronously. Lee et al. [Reference Lee and Ebrahimi50] proposed the video coding algorithm combined with audio information. The proposed scheme utilized the relation of the sound source and corresponding spatial location to gain the efficient coding with the scene that contains multiple moving objects. The work is to find the sound source and its region. Based on the assumption that human observers tends to recognize the sound object as the ROI, the corresponding region is encoded with more bits. The implementation encoded the ROI blocks with smaller QP relative to the non-ROI ones.
V. PERFORMANCE COMPARISON
We use the following three indexes to measure metric performance [91, 92]. The first index is the Pearson linear correlation coefficient (PLCC) between objective/subjective scores after non-linear regression analysis. It provides an evaluation of prediction accuracy. The second index is the Spearman rank order correlation coefficient (SROCC) between the objective/subjective scores. It is considered as a measure of prediction monotonicity. The third index is the root-mean-squared error (RMSE). Before computing the first and second indexes, we need to use the logistic function and the procedure outlined in [91] to fit the objective model scores to the MOS (or DMOS) in order to account for quality rating compression at the extremes of the test range and prevent the overfitting problem. The monotonic logistic function used to fit the objective prediction scores to the subjective quality scores [91] is:
 $$f\lpar x\rpar = \displaystyle{\beta_1-\beta_2 \over 1+\exp^{-\lpar {x-\beta_3}\rpar /{\vert \beta_4\vert }}}+\beta_2\comma \; $$
$$f\lpar x\rpar = \displaystyle{\beta_1-\beta_2 \over 1+\exp^{-\lpar {x-\beta_3}\rpar /{\vert \beta_4\vert }}}+\beta_2\comma \; $$where x is the objective prediction score, f(x) is the fitted objective score, and the parameters βj (j = 1, 2, 3, 4) are chosen to minimize the least squares error between the subjective score and the fitted objective score. Initial estimates of the parameters were chosen based on the recommendation in [91]. For an ideal match between the objective prediction scores and the subjective quality scores, PLCC = 1, SROCC = 1, and RMSE = 0.
A) Image quality metric benchmarking
To examine the performance of existing popular image quality metrics in this work, we choose CSIQ, LIVE, and TID2008 to test image quality metrics since they include the largest number of distorted images and also span more distortion types; these three databases cover most image distortion types that other publicly available image quality databases can provide. The performance results are listed in Tables 5–7 with the three indexes given above. The two best performing metrics are highlighted in bold. Clearly, MMF (both CF-MMF and CD-MMF) [Reference Liu, Lin and Kuo57, Reference Liu, Lin and Kuo59] have the highest PLCCs, SROCCs, and the smallest RMSEs among the 13 image quality metrics under comparison.
Table 5. Performance comparison among IQA models in CSIQ database.

Table 6. Performance comparison among IQA models in database.

Table 7. Performance comparison among IQA models in TID2008 database.

B) Video quality metric benchmarking
For the comparison of the state-of-the-art VQMs, LIVE Video Quality Database, and EPFL-PoliMI Video Quality Assessment Database are adopted.
Although most people use VQEG-FRTV Phase I Database (built in 2000) to test their video metric performance previously [Reference Seshadrinathan and Bovik82, Reference Wang, Lu and Bovik99], we use LIVE Video Quality Database (released in 2009) as our test database because it is new and contains distortion types in more processes, such as H.264 compression, simulated transmission of H.264 packetized streams through error-prone wireless networks and error-prone IP networks, and MPEG-2 compression. The comparison results are summarized in Table 8. Here, the image quality metrics (i.e., PSNR, VSNR, and SSIM) are used on a frame-by-frame basis for the video sequence, and then time-averaging the frame scores to obtain the video quality score.
Table 8. Performance comparison of VQA models in database.

In Table 8, the results of ST-MAD are extracted from [Reference Vu, Vu and Chandler93]. From Table 8, we can see that ST-MAD and MOVIE are the best metrics (which are both highlighted in bold) for LIVE Video Quality Database; VQM ranks the third. It means that MOVIE and ST-MAD correlate better with subjective results than other approaches under comparison. The reason why ST-MAD and MOVIE perform well is that they both consider the spatial and temporal features. In general, consideration of temporal information as well as interaction of spatial and temporal features [Reference Narwaria and Lin69] can improve the video quality prediction performance.
In addition, we also summarize the performance results in Table 9 from [Reference Park, Seshadrinathan, Lee and Bovik76] to see if the existing quality metrics can predict the quality well for videos distorted with different PLRs. We can observe that MOVIE still works the best compared to other metrics in Table 9 with packet loss.
Table 9. Performance comparison of VQA models in EPFL-POLIMI database [Reference Park, Seshadrinathan, Lee and Bovik76].

VI. DISCUSSION ON FUTURE TRENDS
Although many visual quality assessment metrics have been developed for both image and video during the past decade, there are still great technological challenges ahead and much space for improvement, toward effective, reliable, efficient, and widely accepted replacement for MSE/PSNR, for both standalone and embedded applications. We will discuss the possible directions in this section.
A) PSNR or SSIM-modified metrics
PSNR has always been criticized for poor correlation with human subjective evaluations. However, according to our observations [Reference Liu, Lin and Kuo57, Reference Liu, Lin and Kuo59], PSNR sometimes still can work very well on some specific distortion types, such as additive and quantization noise. Hence, a lot of metrics have been developed or derived from PSNR, such as PSNR-HVS [Reference Egiazarian, Astola, Ponomarenko, Lukin, Battisti and Carli34], EPSNR [Reference Lee, Cho, Choe, Jeong, Ahn and Lee49], and SPHVSM [Reference Jin, Ponomarenko and Egiazarian45]. They either incorporate some related HVS characteristics into PSNR or include some experimental observations to modify PSNR to improve the correlation. Promising results can be achieved in this way of modification. Among the quality metrics we just mentioned above, only the EPSNR is developed to use on VQA.
As a single metric, the SSIM is considered the well-performed metric among all visual quality evaluation metrics, in terms of consistency. Thus, researchers in the field have managed to transform it by changing its pooling method or using other image features. Several examples of the former are V-SSIM [Reference Wang, Lu and Bovik99], Speed-SSIM [Reference Wang and Li97], 3-SSIM [Reference Li and Bovik51], and IW-SSIM [Reference Wang and Li98], while FSIM index [Reference Zhang, Zhang, Mou and Zhang108] is an example of the latter. They are all proven quite useful in improving the quality prediction performance, especially FSIM, which shows superior performance in several image quality databases, including TID2008, CSIQ, LIVE, and IVC.
Building new metrics based upon more mature metrics (like PSNR and SSIM) is expected to continue, especially in new application scenarios (e.g., for 3D scenes, mobile media, medical imaging, image/video retargeting, computer graphics, and so on).
B) Multiple strategies or MMF approaches
MAD [Reference Larson and Chandler48] and MMF [Reference Liu, Lin and Kuo57, Reference Liu, Lin and Kuo59] are representatives for multiple strategies and MMF, respectively. Especially for the latter one, appropriate fusion of existing metrics opens the chances to build on the strength of each participating metric and the resultant framework can be even used when new, good metrics emerge. More careful and in-depth investigation is needed for this topic.
Most recently, a block-based MMF (BMMF) [Reference Jin, Egiazarian and Kuo44] approach is proposed on coping with IQA. The authors first decomposed images into smaller block size. Then they classify the blocks into three types (smooth, edge, and texture). And they also divided all the images into five different distortion groups, like in [Reference Liu, Lin and Kuo57, Reference Liu, Lin and Kuo59]. Finally, only one appropriate quality metric is selected for each block based on the distortion groups and the block types. Fusion through all the blocks leads to the final quality score for each image. Performing MMF this way helps to reduce the high complexity caused by using multiple metrics.
C) Migration from IQA to VQA
Up to now, more research has been performed for IQA. As mentioned before, video quality evaluation can be done by using image quality metrics on a frame-by-frame basis, and then averaging to obtain a final video quality score. However, this only works well when video contents do not have large motion in temporal domain. When there exists a large motion, we need to find the temporal structure and temporal features.
The most common method is to use motion estimation to find out the motion vectors and measure the variations in the temporal domain. One simple realization of this idea is in [Reference Liu, Liu and Liu60]. The authors extended one existing IQA metric to a VQM by considering temporal information and converted it into a compensation factor to correct the video quality score obtained in the spatial domain. There are also other VQMs that utilize motion estimation to detect temporal variations, such as Speed-SSIM [Reference Wang and Li97], MOVIE [Reference Seshadrinathan and Bovik82], TetraVQM [Reference Barkowsky, Bialkowski, Eskofier, Bitto and Kaup25], MSE_TIM [Reference Li, Ma, Zhang and Ngan54], STAQ [Reference Amirshahi and Larabi24], and ST-MAD [Reference Vu, Vu and Chandler93]. All of the above approaches improve the correlation between predictions and subjective quality scores more or less. This demonstrates that the temporal variation is indeed an important factor that we need to consider for VQA.
Another feasible method is to extend original image quality metric into a VQM by considering three additional processing steps: temporal channel decomposition, temporal masking, and temporal pooling. One example of this is recently proposed in [Reference Li, Ma and Ngan53]. Their resultant VQM shows a quite good performance in matching subjective scores for LIVE Video Quality Database.
Similarly, we can also use the MMF strategy on VQA, via fusing the scores obtained from all available VQMs. A possible problem of this approach is the high complexity because multiple metrics and video data are involved. One solution to realize efficient MMF for video is to pick up the best features used in all metrics, including both spatial and temporal features, instead of using all participating metrics as they are. Moreover, this solution gives a chance to eliminate the repetition in feature detection among different metrics, and proper machine learning techniques will be customized for this purpose. In addition, VA modeling [Reference Lu, Lin, Yang, Ong and Yao61] may play a more active role in VQA than IQA.
D) Audiovisual quality assessment for 4G networks
During recent years, the term quality of experience (QoE) has been used and defined as the users' perceived quality of service (QoS). More often than not in multimedia applications, quality assessment has to be performed with audio and video (images) being presented together. It is an important but less investigated research topic, in spite of some early work in this area [Reference Frater, Arnold and Vahedian37, Reference Furini and Ghini38, Reference Ghinea and Thomas40].
It has been proposed that a better QoE can be achieved when the QoS is considered both in the network and application layers as a whole [Reference Khan, Li, Sun and Ifeachor47]. In the application layer, QoS is affected by the factors such as resolution, frame rate, sampling rate, number of channels, color, video codec type, audio codec type, and layering strategy. The network layer introduces impairment parameters such as packet loss, jitter, network delay, burstiness, decreased throughput, etc. These are all the key factors that affect the overall audiovisual QoE. Hence, the investigation into the quality assessment methods for both audio and video is also important and meaningful because video chats and video conferences over 4G networks may be frequently used by the general public in the near future. We believe this is a significant extension of the current research work and very meaningful in total multimedia experience evaluation.
Currently, there is no public database for joint audiovisual quality and experience evaluation. The establishment of such databases will facilitate research and promote advancement in this field.
E) Perceptual image/video coding
The accuracy of IQA is becoming better and better. The performance of perceptual image coding could be further improved under some specific conditions. Perceptual considerations can help the performance to be enhanced compared to the traditional image coding. As the introduced applications above, IQA metrics have been associated to video coding for some time. More and more related research is in progress.
In general, VQA-related video compression is less investigated. Seshadrinathan and Bovik [Reference Seshadrinathan and Bovik82] addressed motion-based video integrity evaluation (MOVIE) index to evaluate video quality. The MOVIE index based on Gabor decomposition is calculated from two components, which are Spatial MOVIE map and Temporal MOVIE map. The spatial part is established as a combination of SSIM and VIF; the temporal part is brought by using motion information. The performance of MOVIE shows the potential to be employed to video coding. Nevertheless, it is challenging to be handled in video coding because it needs to parse the whole video to give the index. Hence, modifying VQA to low complexity and real-time processing would be a possible goal to integrate VQA to video coding. These are issues to apply VQA to perceptual video coding.
F) No-Reference (NR) quality metrics
As we know, the NR method does not perform as well as the FR one in general because it judges the quality solely based on the distorted medium and without any reference available. However, it can be used in wider scope of applications because of its suitability in both situations with and without reference information. Moreover, the computational requirement is usually less because there is no need to process the reference. In addition to the traditional NR cases (like the relay site and receiving end of transmission), there are emerging NR applications (e.g., super-resolution construction, image, and video retargeting/adaption, and computer graphics/animation). That is the reason why several NR quality metrics have been proposed recently, including MREBN [Reference Choi, Jung and Jeon30] and JNBM [Reference Ferzli and Karam36] in images, and CVQ [Reference Kawayoke and Horita46] and V-Factor [Reference Winkler and Mohandas105] in videos. We believe that there will be more quality metrics developing along this direction.
VII. CONCLUSION
In this paper, we have first reviewed the existing visual quality assessment methods and their classifications in a comprehensive perspective. Then, we introduced recent developments in IQA, including the popular public image quality databases that play important roles in facilitating relevant research activities in this field and several well-performed image quality metrics. In a similar format, we also discussed recent developments for VQA in general, the publicly available video quality databases and several state-of-the-art VQA metrics. In addition, we have presented and discussed several possible directions for future visual signal quality assessment, i.e., PSNR or SSIM-modified metrics, multiple strategy and MMF approaches, migration of IQA to VQA, joint audiovisual assessment, perceptual image/video coding, and NR quality assessment, with reasoning based upon our experience and understanding of the related research. In the end, we have compared the major existing IQA and VQA metrics, and given some discussion, by using the most comprehensive image and video quality databases, respectively.
One important class of applications of visual quality assessment is perceptual image and video coding. The perceptually driven coding methods have demonstrated their merits, compared to the traditional MSE-based coding techniques. Such research takes a different path (i.e., removing perceptual signal redundancy apart from the statistical one) to further improve coding performance and makes it more use-oriented because humans are the ultimate appreciators of almost all processed visual signals. Existing and interesting methods include: utilizing a perceptual quality index to measure distortion; utilizing JND and VA models in coding; integrating motion or texture information to improve coding efficiency in a perceptual sense. We believe that there are still a lot of possibilities for perceptual coding and beyond, which wait to be discovered.
Appendix. STANDARD SUBJECTIVE TESTING METHODS [20, 23]
a) Pair Comparison (PC)
The method of PCs implies that the test sequences are presented in pairs, consisting of the same sequence being presented first through one system under test and then through another system.
b) Absolute Category Rating (ACR)
The ACR method is a category judgment where the test sequences are presented one at a time and are rated independently on a discrete five-level scale from “bad” to “excellent”. This method is also called Single Stimulus Method.
c) Degradation Category Rating (DCR) (also called the Double-Stimulus Impairment Scale (DSIS))
The reference picture (sequence) and the test picture (sequence) are presented only once or twice. The reference is always shown before the test sequence, and neither is repeated. Subjects rate the amount of impairment in the test sequence on a discrete five-level scale from “very annoying” to “imperceptible”.
d) Double-Stimulus Continuous Quality Scale (DSCQS)
The reference and test sequences are presented twice in alternating fashion, in the order of the two chosen randomly for each trial. Subjects are not informed which one is the reference and which one is the test sequence. They rate each of the two separately on a continuous quality scale ranging from “bad” to “excellent”. Analysis is based on the difference in rating for each pair, which is calculated from an equivalent numerical scale from 0 to 100.
e) Single-Stimulus Continuous Quality Evaluation (SSCQE)
Instead of seeing separate short sequence pairs, subjects watch a program of 20–30 minutes duration which has been processed by the system under test. The reference is not shown. The subjects continuously rate the perceived quality on the continuous scale from “bad” to “excellent” using a slider.
f) Simultaneous Double-Stimulus for Continuous Evaluation (SDSCE)
The subjects watch two sequences at the same time. One is the reference sequence, and the other one is the test sequence. If the format of the sequences is the standard image format (SIF) or smaller, the two sequences can be displayed side by side on the same monitor; otherwise two aligned monitors should be used. Subjects are requested to check the differences between the two sequences and to judge the fidelity of the video by moving the slider. When the fidelity is perfect, the slider should be at the top of the scale range (coded 100); when the fidelity is the worst, the slider should be at the bottom of the scale (coded 0). Subjects are aware of which one is the reference and they are requested to express their opinion while they view the sequences throughout the whole duration.










 Open access
Open access