

I. INTRODUCTION
Emotion plays an important role in social interaction, human intelligence, perception, etc. [Reference Picard1]. Since perception and experience of emotion are vital for communication in the social environment, understanding emotions becomes indispensable for the day-to-day function of humans. Technologies for processing daily activities, including facial expression, speech, and language have expanded the interaction modalities between humans and computer-supported communicational artifacts, such as robots, iPad, and mobile phones. With the growing and varied uses of human–computer interactions, emotion recognition technologies provide an opportunity to promote harmonious interactions or communication between computers and humans [Reference Cowie2, Reference Fragopanagos and Taylor3].
Basically, emotion could be expressed through several social behaviors, including facial expression, speech, text, gesture, etc. According to human judgment of affect, psychologists have various opinions about the importance of the cues from facial expression, vocal expression and linguistic message. Mehrabian stated that the facial expression of a message contribute 55% of the overall impression while the vocal part and the semantic contents contribute 38 and 7%, respectively [Reference Mehrabian4]. Among these modalities, facial expression is acknowledged as one of the most direct channels to transmit human emotions in non-verbal communication [Reference Ambady, Weisbuch, Fiske, Gilbert and Lindzey5, Reference Rule and Ambady6]. On the one hand, speech is another important and natural channel to transmit human affective states especially in verbal communication. Affective information in speech can be transmitted through explicit (linguistic) and implicit (paralinguistic) messages during communication [Reference Devillers and Vidrascu7]. The former can be understood and extracted from affective words, phrases, sentences, semantic contents, and more. The later may be explored from prosodic and acoustic information of speech. In the past years, analysis and recognition approaches of artificial affective expressions from a uni-modal input have been widely investigated [Reference Ayadi, Kamel and Karray8–Reference Pantic and Bartlett11]. However, the performance of emotion recognition based on only facial or vocal modality still has its limitation. To further improve emotion recognition performance, a promising research area is to explore the data fusion strategy for effectively integrating facial and vocal cues [Reference Zeng, Pantic, Roisman and Huang12–Reference Busso14]. In face-to-face communication, humans employ these communication paths alone or using one to complement and enhance another. But the roles of multiple modalities and their interplay remain to be quantified and scientifically understood. In the past 3 years, Audio/Visual Emotion Challenges (AVEC 2011–2013) [Reference Schuller, Valstar, Eyben, McKeown, Cowie and Pantic15–Reference Valstar17] aimed to compare audiovisual signal processing and machine learning methods to advance emotion recognition systems. Data fusion strategy effectively integrating the facial and vocal cues has become the most important issue.
This paper gives a survey on the existing audiovisual emotion databases and recent advances in the research on audiovisual bimodal data fusion strategies. This paper also introduces and surveys the recent emotion challenges which have been conducted in ACM Multimedia, ICMI, ACII, INTERSPEECH, and FG, specifically the AVEC 2011–2014 [Reference Schuller, Valstar, Eyben, McKeown, Cowie and Pantic15–Reference Valstar18], 2009 Emotion challenge [Reference Schuller, Steidl and Batliner19], 2010 Paralinguistic Challenge [Reference Schuller20], 2013 COMputational PARalinguistics challengE (ComParE) [Reference Schuller21], Facial Expression Recognition and Analysis (FERA) 2011 challenge [Reference Valstar, Jiang, Mehu, Pantic and Scherer22] and Emotion recognition in the Wild (EmotiW) 2013 challenge [Reference Dhall, Goecke, Joshi, Wagner and Gedeon23].
The rest of the paper is organized as follows. Section II describes the existing audio-visual emotion databases. Section III presents the state-of-the-art audiovisual bimodal data fusion strategies and introduces the utilized audio/ facial features and classifiers. Finally, Section IV offers the conclusion.
II. AUDIOVISUAL EMOTION DATABASES
Audiovisual emotion databases play a key role in emotion recognition for model training and evaluation. Numerous achievements have been reported on the collection of the emotion databases [Reference Zeng, Pantic, Roisman and Huang12, 24, Reference D'Mello and Kory25]. For instance, the Association for the Advancement of Affective Computing (AAAC), formerly the HUMAINE Association, provided several multimodal, speech, and facial expression databases for association members. Although rich emotion databases were collected for different application purposes, most of the databases were constructed between 1996 and 2005. Moreover, the modalities of the multimodal emotion databases include not only speech and facial expressions but also texts, bio-signals, and body poses. In this paper, we focused only on emotion databases for audiovisual processing. This paper also provided the detailed characteristics of the currently available benchmark databases between 2006 and 2014 which were commonly used in audiovisual emotion recognition studies and emotion challenges from facial and vocal expressions. Table 1 summarizes the databases and some of the noteworthy data resources for audiovisual emotion recognition task. This table describes the following information about each database:
-
(1) Name of database,
-
(2) Language of recordings,
-
(3) Affective state elicitation method (posed (acted), induced or spontaneous emotional expression) [Reference Zeng, Pantic, Roisman and Huang12, Reference D'Mello and Kory25–Reference Gunes and Schuller27],
-
(4) Number of subjects,
-
(5) Number of available data samples,
-
(6) Affective state description (category, dimension or event) [Reference Zeng, Pantic, Roisman and Huang12, Reference D'Mello and Kory25, Reference Gunes and Pantic28],
-
(7) Availability,
-
(8) Publication year, and
-
(9) Challenges used or references reported.
Table 1. Audiovisual databases for emotion recognition task.
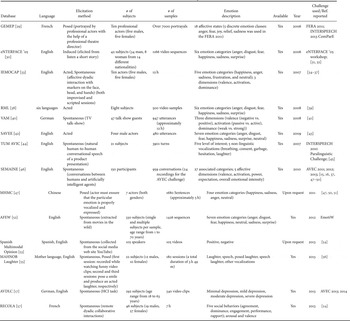
A) Elicitation method
The affective state elicitation methods for the collection of the audiovisual databases reported in the literature can be classified into three major categories: (a) posed (acted), (b) induced (via clips), and (c) spontaneous (occurring during an interaction) [Reference Zeng, Pantic, Roisman and Huang12, Reference D'Mello and Kory25–Reference Gunes and Schuller27]. With regard to the posed databases [Reference Bänziger, Pirker and Scherer29, Reference Lin, Wu and Wei47], every actor was asked to correctly express each emotion. For instance, the GEneva Multimodal Emotion Portrayal (GEMEP) database [Reference Bänziger, Pirker and Scherer29, Reference Bänziger and Scherer58, Reference Bänziger, Mortillaro and Scherer59] consists of more than 7000 audio-video emotion portrayals, which were portrayed by ten professional actors with the help of a professional theater director. The GEMEP was selected as the database for the emotion sub-challenge of the INTERSPEECH 2013 ComParE [Reference Schuller21]. A subset of the GEMEP database was also used as the dataset for facial Action Unit (AU) recognition sub-challenge of the FERA 2011 challenge [Reference Valstar, Jiang, Mehu, Pantic and Scherer22].
In terms of the induced databases [Reference Martin, Kotsia, Macq and Pitas30], a subject's emotional responses are commonly evoked by films, stories, music, etc. For example, the eNTERFACE'05 EMOTION Database [Reference Martin, Kotsia, Macq and Pitas30, 60] was designed and collected during the eNTERFACE'05 workshop. Each subject was asked to listen to six successive short stories, each eliciting a particular emotion. If two human experts judged the reaction expressing the emotion in an unambiguous way, then the sample was added to the database. However, in recent years the study of emotion recognition on the expressed stances has gradually moved from posed or induced expressions to more spontaneous expressions.
According to previous studies, the important issues for natural emotion database collection include spontaneous emotion and conversational elements. The audiovisual data with spontaneous emotion are difficult to collect because the emotion expressions are relatively rare, short-lived, and often associated with a complex contextual structure. In addition, the recorded data in most emotion databases were not produced in a conversational context, which limits the naturalness of temporal course of emotional expressions, and ignores the response to different situations. To deal with these problems, some of the existing databases were collected based on interactive scenarios including human–human (dyadic) conversation [Reference Busso33, Reference Schuller, Müller, Hörnler, Höthker, Konosu and Rigoll44, Reference Ringeval, Sonderegger, Sauer and Lalanne57] and human–computer interaction (HCI) [Reference Valstar17, Reference McKeown, Valstar, Pantic and Cowie46]. To this end, the Sensitive Artificial Listeners (SAL) scenario [Reference Douglas-Cowie, Cowie, Cox, Amier and Heylen61] was developed from the ELIZA concept introduced by Weizenbaum [Reference Weizenbaum62]. The SAL scenario can be used to build a spontaneous emotion database through machine agent–human conversation, which tries to elicit the subject's emotions. However, in previous SAL recordings, an operator navigated a complex script and decided what the “agent” should say next. These recordings were emotionally interesting, but the operator conducted a conversation with quite minimal understanding of the speech content. Therefore, the conversational elements were very limited. Then the “Solid SAL” scenario was recently developed to overcome this problem; that is, the operator was requested to be thoroughly familiar with the SAL characters, and spoke as they would without navigating a complex script. The most famous example is the public benchmark database “SEMAINE” [Reference McKeown, Valstar, Pantic and Cowie46, Reference Mckeown, Valstar, Cowie, Pantic and Schroe63, 64]. For data recording of the SEMAINE database, the participant selected one of four characters (i.e. Prudence, Poppy, Spike, and Obadiah) of the operator to interact with. In AVEC 2011 and 2012 [Reference Schuller, Valstar, Eyben, McKeown, Cowie and Pantic15, Reference Schuller, Valstar, Eyben, Cowie and Pantic16], part of the SEMAINE database was used as the benchmark database.
As mentioned above, toward robust automatic emotion recognition, collecting the data with spontaneous emotion and conversational element is valuable and important. However, current audiovisual expression databases have been recorded in laboratory conditions lacking available data with real-world or close-to-real-world conditions. Accordingly, in EmotiW 2013 challenge [Reference Dhall, Goecke, Joshi, Wagner and Gedeon23], the Acted Facial Expressions in the Wild (AFEW) database was collected from movies and formed the bases providing a platform for researchers to create, extend and verify their methods on real-world data. The AFEW database was collected by searching the closed caption keywords (e.g. [HAPPY], [SAD], [SURPRISED], [SHOUTS], [CRIES], [GROANS], [CHEERS], etc.) which were then validated by human annotators. In addition, Spanish Multimodal Opinion database [Reference Rosas, Mihalcea and Morency53] also collected a dataset consisting of 105 videos in Spanish from YouTube. The videos were found using the following keywords: mi opinion (my opinion), mis producto favoritos (my favorite products), me gusta (I like), no me gusta (I dislike), producto para bebe (baby products), mis perfumes favoritos (my favorite perfumes), peliculas recomendadas (recommended movies), opinion politica (politic opinion), video juegos (video games), and abuso animal (animal abuse).
B) Emotion categorization
In light of emotion characterization in the databases, emotions are categorized into three representations for emotion recognition: (a) discrete categorical representation, (b) continuous dimensional representation, and (c) event representation (affective behavior; e.g. level of interest, depression, laughter, etc.) [Reference Zeng, Pantic, Roisman and Huang12, Reference D'Mello and Kory25, Reference Gunes and Pantic28]. Many of the emotion recognition studies have attempted to recognize a small set of prototypical emotional states such as six prototypical emotions: anger, disgust, fear, happiness, sadness, and surprise proposed by Ekman [Reference Cowie2, Reference Ekman and Friesen65, Reference Ekman66]. Even though automatic facial/speech emotion recognition has been well studied, prototypical emotions cover only a subset of the total possible facial/speech expressions. For example, boredom, and interest cannot seem to fit well in any of the prototypical emotions. Moreover, the collection of audio or visual emotional signals in some categories such as fear or disgust is not easy. Accordingly, several studies [Reference Metallinou, Lee and Narayanan34, Reference Metallinou, Lee and Narayanan36, Reference Lin, Wu and Wei47, Reference Wu, Lin and Wei50, Reference Lin, Wu and Wei51] focused on recognition of more familiar emotion categories such as happy, sad, angry, and neutral which were comparatively easy to express. For example, the recognition work using the posed MHMC database [Reference Lin, Wu and Wei47] focused on these four emotional categories. Figure 1 shows some example images for the four emotional states in the MHMC database. However, these emotions only represent a small set of human affective states, and are unable to capture the subtle affective change that humans exhibit in everyday interactions.

Fig. 1. Examples for the posed expression with four emotional states: (a) Neutral, (b) Happy, (c) Angry, and (d) Sad.
To accommodate such subtle affective expressions, researchers have begun adopting a dimensional description of human emotion where an emotional state is characterized in numerous latent dimensions [Reference Russell67, Reference Fontaine, Scherer, Roesch and Ellsworth68]. Examples of the affective dimensions, such as Activation/Arousal (passive/active), Expectation (anticipation), Power/Dominance (sense of control, i.e. weak/strong), and Valence (negative/ positive), have been well established in the psychological literature. The problem of dimensional emotion recognition can thus be posed as a regression problem or reduced into a binary-class classification problem [Reference Gunes and Pantic28] (active versus passive, positive vs. negative, etc.) or even as a four-class classification problem (classification into quadrants of an arousal-valence two-dimensional (2D) space as shown in Fig. 2 [Reference Thayer69–Reference Zeng, Zhang, Pianfetti, Tu and Huang71]). An example of this category is the Vera-Am-Mittag (VAM) German audiovisual spontaneous database [Reference Grimm, Kroschel and Narayanan40]. The VAM database consists of audio-visual recordings taken from a German TV talk show and was annotated along three emotional dimensions: valence, arousal, and dominance. In order to label the dimensions in continuous time and continuous value in AVEC 2011 and 2012 challenges, a tool called FeelTrace [Reference Cowie, Douglas-Cowie, Savvidou, McMahon, Sawey and Schröder72] was used to annotate the SEMAINE database.
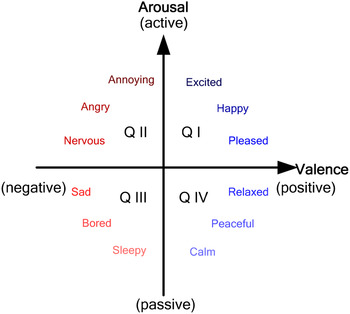
Fig. 2. Valence-activation 2D emotion plane [Reference Thayer69, Reference Yang, Lin, Su and Chen70].
In addition, in the INTERSPEECH 2010 Paralinguistic Challenge, AVEC 2013, and 2014, and LREC Workshop on Corpora for Research on Emotion Sentiment and Social Signals (ES3) 2012, event recognition has also been an object of study. Since emotion, social signals, and sentiment from text are part of social communication, recognition of events, including signals such as laugh, smile, sigh, hesitation, consent, etc. are highly relevant in helping better understand affective behavior and its context. For instance, understanding a subject's personality is needed to make better sense of observed emotional patterns and non-linguistic behavior, that is, laughter and depression analysis can give further insight into the personality trait of the subject. Different from discrete categorical and continuous dimensional emotion prediction, event-based recognition, such as level of depression, has given us new opportunities and challenges. In the INTERSPEECH 2010 Paralinguistic Challenge [Reference Schuller20], audio part of TUM Audio-Visual Interest Corpus (TUM AVIC) [Reference Schuller, Müller, Hörnler, Höthker, Konosu and Rigoll44, Reference Schuller73] was used and labeled in three levels of interest from boredom (level of interest 1 (loi1)), over neutral (loi2) to joyful (loi3) interaction. In AVEC 2013 and 2014 [Reference Valstar17, Reference Valstar18, 74], a subset of Audio-Visual Depressive Language Corpus (AVDLC) labeled with the level of self-reported depression was used for the depression recognition subchallenge. On the one hand, since both laughter and speech are also naturally audiovisual events, the MAHNOB Laughter audiovisual database [Reference Petridis, Martinez and Pantic55] containing laughter, speech, posed laughs, speech-laughs, and other vocalizations was also created.
III. AUDIOVISUAL BIMODAL FUSION FOR EMOTION RECOGNITION
As it is difficult to include all of these studies, this paper introduces and surveys these advances for the recent research on audiovisual bimodal data fusion strategies for emotion recognition. Table 2 lists the existing popular data fusion strategies for facial–vocal expression-based emotion recognition with respect to the utilized database, type of emotion categorization, audio, and facial features, recognition methods (i.e. audio classifier (A), visual classifier (V), and audiovisual bimodal fusion approach (AV)), classifier fusion modality, recognition performance, and publication year.
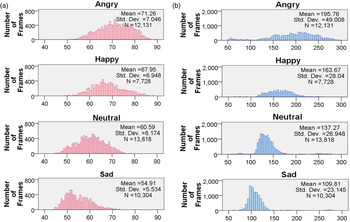
Fig. 3. The distributions of (a) energy and (b) pitch (Hz) for four emotional states in the posed MHMC database; N denotes the total number of frames.
Table 2. Literature review on facial–vocal expression-based emotion recognition.
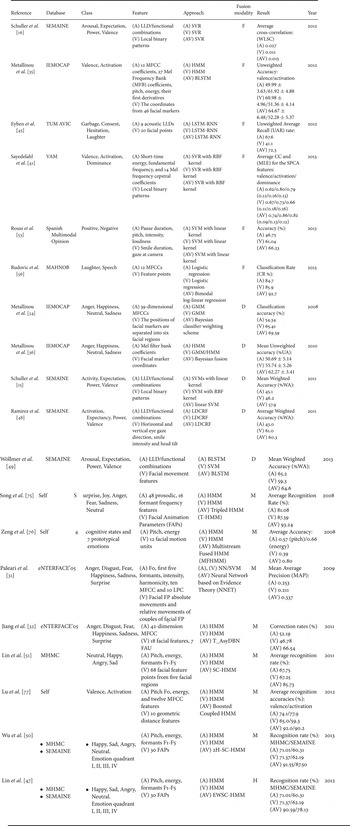
Feature: LLD: Low-Level Descriptors, MFCC: Mel-Frequency Cepstral Coefficients, FAPs: Facial Animation Parameters, LPC: Linear Predictive Coefficients, FP: Feature Points, FAU: Facial Animation Unit. Approach: SVR: Support Vector Machine for regression, LSTM-RNN: Long Short-Term Memory Recurrent Neural Networks, HMM: Hidden Markov Model, BLSTM: Bidirectional Long Short-Term Memory neural network, SVM: Support Vector Machine, GMM: Gaussian Mixture Model. LDCRF: Latent-Dynamic Conditional Random Field, NN: Neural Network, T_AsyDBN: Triple stream Asynchronous Dynamic Bayesian Network. SC-HMM: Semi-Coupled HMM, 2H-SC-HMM: Two-level Hierarchical alignment-based SC-HMM, EWSC-HMM: Error Weighted SC-HMM. Fusion Modality: Feature/Decision/Model/Hybrid-level. Result: WLSC: Word-Level Sub-Challenge, CC: Correlation Coefficient, MLE: Mean Linear Error, SPCA: Supervised Principal Component Analysis.
A) Audio features
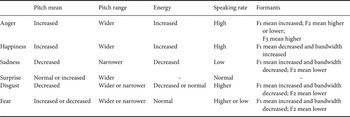
An important issue for emotion recognition from speech is the selection of salient features. Numerous features such as prosodic and acoustic features of emotional speech signals have been discussed over the years [Reference Wu, Yeh and Chuang78–Reference Scherer82]. Among these features, prosodic features have been found to represent the most significant characteristics of emotional content in verbal communication and were widely and successfully used for speech emotion recognition [Reference Zeng, Pantic, Roisman and Huang12, Reference Luengo, Navas, Hernáez and Sánchez83, Reference Kooladugi, Kumar and Rao84]. Several studies have shown that pitch- and energy-related features are useful to determine emotion in speech [Reference Zeng, Pantic, Roisman and Huang12, Reference Lin, Wu and Wei47, Reference Wu, Lin and Wei50, Reference Kwon, Chan, Hao and Lee85]. Morrison et al. [Reference Morrison, Wang and De Silva80] further summarized the correlations between prosodic features and emotions as shown in Table 3. In this survey, feature statistics in the MHMC database [Reference Wu, Lin and Wei50] are explored and used to illustrate the difference of the energy and pitch features among four emotional states (happy, angry, sad, and neutral). The distributions of the energy and pitch values for the four emotional states are shown in Fig. 3. According to our observations from the mean value of the energy feature, happy, and angry emotional states have higher intensities compared to sad and neutral states as shown in Fig. 3(a). In pitch features, the pitch levels and pitch ranges of sad emotion are lower and narrower than those of other emotional states; the mean and standard deviation of pitch in sad emotion are smaller than those of other emotions in Fig. 3(b). For energy feature, an ANOVA test [Reference Freedman86] was applied to test the difference of the extracted energy values from speech frames among the four emotions. The ANOVA test results show that the difference of energy feature among the four emotional states is statistically significant (F(3, 43 977) = 14 196.709, p < 0.0001). Similarly, the ANOVA test was also applied to pitch features and demonstrated the statistical significance (F(3, 43 977) = 13 173.271, p < 0.0001). The results indicate that using pitch and energy is beneficial to emotion recognition for the posed MHMC database [Reference Wu, Lin and Wei50]. Even though these properties are obtained from the posed database, the findings are somewhat in accordance with the results of the previous studies based on natural emotion databases [Reference Morrison, Wang and De Silva80].
Table 3. Correlations among prosodic features and emotions [Reference Morrison, Wang and De Silva80].
Besides energy and pitch features, voice quality features such as Harmonics-to-Noise Ratio (HNR), jitter, or shimmer, and spectral and cepstral features such as formants and Mel-Frequency Cepstral Coefficients (MFCCs) were also frequently used and discussed for emotion recognition [Reference Ayadi, Kamel and Karray8, Reference Schuller, Batliner, Steidl and Seppi9, Reference Schuller, Valstar, Eyben, McKeown, Cowie and Pantic15–Reference Valstar17, Reference Schuller, Steidl and Batliner19–Reference Schuller21]. Referring to Table 2, Lin et al. [Reference Lin, Wu and Wei47, Reference Lin, Wu and Wei51] and Wu et al. [Reference Wu, Lin and Wei50] used “Praat” [Reference Boersma and Weenink87] to extract three types of prosodic features, pitch, energy, and formants F1–F5 in each speech frame for emotion recognition. In [Reference Jiang, Cui, Zhang, Fan, Gonzalez and Sahli32, Reference Metallinou, Lee and Narayanan34, Reference Rudovic, Petridis and Pantic56], the MFCCs were used as audio features, which capture some local temporal characteristics. For instance, Metallinou et al. [Reference Metallinou, Lee and Narayanan34] used a 39D feature vector consisting of 12 MFCCs and energy, and their first and second derivations. In AVEC, 2011–2014 and 2009–2013 INTERSPEECH challenges, Schuller et al. utilized the open source software openSMILE [Reference Eyben, Wöllmer and Schuller88] to extract Low-Level Descriptors (LLDs) features as the baseline feature set. The set of LLDs covers a standard range of commonly used features in audio signal analysis and emotion recognition. For example, in INTERSPEECH 2009 Emotion challenge [Reference Schuller, Steidl and Batliner19], the 16 LLDs are zero crossing rate (ZCR) from time signal, root-mean-squared (RMS) frame energy, pitch frequency, HNR by autocorrelation function, and MFCCs 1–12. The corresponding delta coefficients of the above features were also considered. Then 12 functionals, consisting of mean, standard deviation, kurtosis, skewness, minimum and maximum value, relative position, and range as well as two linear regression coefficients with their mean-squared error (MSE), were applied. In addition, openEAR [Reference Eyben, Wöllmer and Schuller89] has been widely used as an affect and emotion recognition toolkit for audio and speech affect recognition [Reference Schuller, Valstar, Eyben, Cowie and Pantic16, Reference Rosas, Mihalcea and Morency53].
For speech emotion recognition, speech features can be classified into two major categories including local (frame-level) and global (utterance-level) features according to the model properties [Reference Ayadi, Kamel and Karray8, Reference Huang, Zhang, Li and Da90]. The local features represent the speech features extracted based on the unit of speech “frame”. On the one hand, the global features are calculated from the statistics of all speech features extracted from the entire “utterance” [Reference Ayadi, Kamel and Karray8]. For example, local features include spectral LLDs (e.g. MFCCs and Mel Filter Bank (MFB)), energy LLDs (e.g. loudness, energy), and voice LLDs (e.g. F0, jitter and shimmer); global features include the set of functionals extracted from the LLDs, such as max, min, mean, standard deviation, duration, linear predictive coefficients (LPC) [Reference Schuller, Steidl, Batliner, Schiel and Krajewski91]. Based on the extracted speech features (i.e. local or global features), traditional pattern recognition engines such as Hidden Markov Model (HMM), Gaussian Mixture Model (GMM), support vector machine (SVM), etc. have been used in speech emotion recognition systems to decide the underlying emotion of the speech utterance. For instance, the dynamic modeling approach (e.g. HMM) was applied to capture the temporal characteristics of affective speech and the detailed feature fluctuations for local feature vectors; the static modeling approach (e.g. GMM) was employed as the classifier for the global features.
B) Facial features
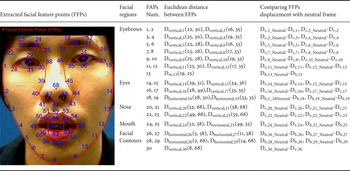
The commonly used facial feature types can be divided into appearance and geometric features [Reference Sumathi, Santhanam and Mahadevi10, Reference Pantic and Bartlett11]. The appearance features depict the facial texture such as wrinkles, bulges, and furrows. The geometric features represent the shape or location of facial components (e.g. eyebrows, eyes, mouth, etc.). As the studies listed in Table 2, the IEMOCAP database [Reference Busso33] contains detailed facial marker information. Metallinou et al. [Reference Metallinou, Wollmer, Katsamanis, Eyben, Schuller and Narayanan35, Reference Metallinou, Lee and Narayanan36] used the (x,y,z) coordinates of 46 facial markers as the facial features. To capture face movements in an input video, in [Reference Eyben, Petridis, Schuller and Pantic45, Reference Rudovic, Petridis and Pantic56], the Patras-Pantic particle filtering tracking scheme [Reference Patras and Pantic92] was used to track 20 facial points. The 20 facial points consist of the corners/extremities of the eyebrows (4 points), eyes (8 points), nose (3 points), mouth (4 points), and chin (1 point). In addition, the features of shape and location can be estimated based on the results of facial component alignments through the classical approach, active appearance model (AAM) [Reference Cootes, Edwards and Taylor93]. From previous research, the AAM achieved successful human face alignment, even for the human faces having non-rigid deformations. In [Reference Lin, Wu and Wei47, Reference Wu, Lin and Wei50], the AAM was thus employed to extract the 68 labeled facial feature points (FFPs) from five facial regions, including eyebrows, eyes, nose, mouth, and facial contours, as shown in Table 4. For the purpose of normalization among different people, the facial animation parameters (FAPs) were expressed in terms of FAP units; each FAP unit represents a fraction of a key distance on the face. Then 30 FAPs were estimated from the vertical and horizontal distances from 24 out of 68 extracted FFPs as shown in Table 4. For example, the inner raised eyebrow FAPs were calculated as the distances by projecting vertically from the inner eyebrow feature points to the inner eye corners feature points, that is, from points 25 and 19 to points 30 and 35, which are further compared to their corresponding distances in the neutral frame. Similarly, Song et al. [Reference Song, You, Li and Chen75] used a set of 56 tracked FFPs to compute the 18 FAPs based on the displacement from the initial neutral face configuration. Jiang et al. [Reference Jiang, Cui, Zhang, Fan, Gonzalez and Sahli32] chose seven facial animation units (FAUs) features including AUV6-eyes closed, AUV3-brow lower, AUV5-outer brow raiser, AUV0-upper lip raiser, AUV11-jaw drop, AUV2-lip stretcher, and AUV14-lip corner depressor. For each image frame, the concatenation of 18 2D facial features and 7 FAU features, together with their first-order derivatives, results in a 50D feature vector as the facial features.
Table 4. The example of 68 facial feature points extracted using AAM alignment and related facial animation parameters.
Being the dense local appearance descriptors, local binary patterns (LBPs) have been used extensively for facial expression recognition in recent years [Reference Shan, Gong and Mcowan94, Reference Ahonen, Hadid and Pietikäinen95]. LBPs were also used as the baseline features for the recent challenges in AVEC 2011–2014 challenges [Reference Schuller, Valstar, Eyben, McKeown, Cowie and Pantic15–Reference Valstar18] and FERA 2011 challenge [Reference Valstar, Jiang, Mehu, Pantic and Scherer22]. For example, Schuller et al. [Reference Schuller, Valstar, Eyben, McKeown, Cowie and Pantic15, Reference Schuller, Valstar, Eyben, Cowie and Pantic16] used LBP appearance descriptors as the facial features. After face and eye detection, the resulting face region was normalized based on eye locations. Then face region was divided into small blocks to extract LBP histograms through eight neighbors using binary comparisons. Finally, the LBP features extracted from each sub-region were concatenated into a feature vector (histogram) to represent a facial image. Furthermore, Rosas et al. [Reference Rosas, Mihalcea and Morency53] and Ramirez et al. [Reference Ramirez, Baltrušaitis and Morency48] processed each video sequence with the Omron OKAO Vision software library [96]. The software automatically extracted the higher-level facial features from a subset of communicative signals such as horizontal and vertical eye gaze direction (degrees), smile intensity (from 0 to 100), and head tilt (degrees). This approach was shown to be useful when analyzing dyadic interactions for more naturalistic databases.
For audiovisual data fusion, to deal with the problem of mismatched frame rates between audio and visual features, the linear interpolation technique has been widely applied, which interpolates the video features to match the frame rate of audio features [Reference Jiang, Cui, Zhang, Fan, Gonzalez and Sahli32, Reference Chen, Jiang, Ravyse and Sahli97]. In addition, some studies were based on reducing the frame rate of audio features in order to match the video features [Reference Lin, Wu and Wei47, Reference Wu, Lin and Wei50].
C) Bimodal fusion approaches
Many data fusion strategies have been developed in recent years. The fusion operations in previous studies can be classified into feature-level (early) fusion, decision-level (late) fusion, model-level fusion, and hybrid approaches for audiovisual emotion recognition [Reference Zeng, Pantic, Roisman and Huang12, Reference D'Mello and Kory25, Reference Lin, Wu and Wei47, Reference Ramirez, Baltrušaitis and Morency48, Reference Wu, Lin and Wei50]. For the integration of various modalities, the most intuitive way is the fusion at the feature level. In feature-level fusion [Reference Schuller, Valstar, Eyben, Cowie and Pantic16, Reference Metallinou, Wollmer, Katsamanis, Eyben, Schuller and Narayanan35, Reference Sayedelahl, Araujo and Kamel41, Reference Eyben, Petridis, Schuller and Pantic45, Reference Rosas, Mihalcea and Morency53, Reference Rudovic, Petridis and Pantic56], facial and vocal features are concatenated to construct a joint feature vector, and are then modeled by a single classifier for emotion recognition as shown in Fig. 4. For instance, Rosas et al. [Reference Rosas, Mihalcea and Morency53] used the SVMs with a linear kernel as the early fusion technique for binary classification. The experiments performed on the Spanish Multimodal Opinion database show that the integration of audio and visual features can improve significantly over the use of one modality at a time. To recognize continuously valued affective dimensions, Schuller et al. [Reference Schuller, Valstar, Eyben, Cowie and Pantic16] concatenated the audio and video features into a single feature vector and used the support vector regression (SVR) as the baseline in the AVEC 2012 challenge. Eyben et al. [Reference Eyben, Petridis, Schuller and Pantic45] investigated an audiovisual fusion approach to classification of vocal outbursts (non-linguistic vocalizations) in noisy conditions. The visual features are complementary information, which is useful when the audio channel is noisy. Then the audio and visual modalities are fused at the feature level and classification is performed using Long Short-Term Memory Recurrent Neural Networks (LSTM-RNNs). Sayedelahl et al. [Reference Sayedelahl, Araujo and Kamel41] also proposed a fusion approach to enhance the recognition performance of continuous-valued emotion in spontaneous conversations. First, the audio features extracted from the whole utterance was concatenated with the visual features extracted from each of the individual visual frames with respect to the sentence, and the Supervised Principal Component Analysis (SPCA) was used to reduce the dimensions of the prosodic, spectral, and the facial features. Then a frame-level regression model was developed to estimate the continuous values of the three emotional dimensions (valence, activation, and dominance). Finally, a simple decision aggregation rule was used by averaging the resulting estimates of all image frames for final emotion recognition. Although fusion at feature level using simple concatenation of the audiovisual features has been successfully used in several applications, high-dimensional feature set may easily suffer from the problem of data sparseness, and does not take into account the interactions between features. Hence, the advantages of combining audio and visual cues at the feature level will be limited.
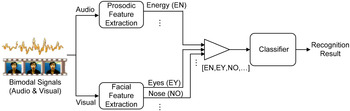
Fig. 4. Illustration of feature-level fusion strategy for audiovisual emotion recognition.
To eliminate the disadvantage of feature-level fusion strategy, a vast majority of research on data fusion strategies was explored toward the decision-level fusion. In decision-level fusion [Reference Schuller, Valstar, Eyben, McKeown, Cowie and Pantic15, Reference Metallinou, Lee and Narayanan34, Reference Metallinou, Lee and Narayanan36, Reference Ramirez, Baltrušaitis and Morency48, Reference Wöllmer, Kaiser, Eyben, Schuller and Rigoll49], multiple signals can be modeled by the corresponding classifier first, and then the recognition results from each classifier are fused in the end, as shown in Fig. 5. The fusion-based method at the decision level, without increasing the dimensionality, can combine various modalities by exploring the contributions of different emotional expressions. In the AVEC 2011 challenge [Reference Schuller, Valstar, Eyben, McKeown, Cowie and Pantic15], Schuller et al. first obtained predictions of the audio and video classifiers separately, then fused the two modalities by concatenating the two posterior probabilities and used a linear SVM as the audiovisual challenge baseline. Ramirez et al. [Reference Ramirez, Baltrušaitis and Morency48] presented the late fusion using Latent-Dynamic Conditional Random Field (LDCRF) as a model to fuse the outputs of uni-modal classifiers. Error Weighted Classifier (EWC) combination [Reference Metallinou, Lee and Narayanan34, Reference Metallinou, Lee and Narayanan36] is another well-known example. For EWC, Metallinou et al. [Reference Metallinou, Lee and Narayanan36] applied a Bayesian framework to combine empirical evidences with prior beliefs to fuse multiple cues. For voice modality, an HMM was trained for each emotional phonetic category. For face modality, the upper face is modeled by GMMs trained for each emotion with no viseme information, and the lower face is modeled by HMMs trained for each emotional viseme. Then the weighted sum of the individual decisions was combined to effectively combine various modalities by exploring their contributions estimated from the confusion matrices of each classifier for final decision. However, as facial and vocal features have been confirmed complementary to each other in emotional expression [Reference Picard1], the assumption of conditional independence among multiple modalities at the decision level is inappropriate. The correlations between audio and visual modalities should be considered.
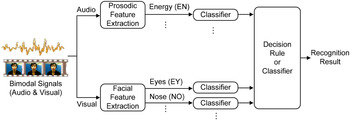
Fig. 5. Illustration of decision-level fusion strategy for audiovisual emotion recognition.
To deal with this problem, a model-level fusion strategy [Reference Paleari, Benmokhtar and Huet31, Reference Jiang, Cui, Zhang, Fan, Gonzalez and Sahli32, Reference Wu, Lin and Wei50, Reference Lin, Wu and Wei51, Reference Song, You, Li and Chen75–Reference Lu and Jia77] was proposed to emphasize the information of correlation among multiple modalities, and explore the temporal relationship between audio and visual signal streams (as shown in Fig. 6). There are several distinctive examples such as Coupled HMM (C-HMM) [Reference Lu and Jia77, Reference Nicolaou, Gunes and Pantic98], Tripled HMM (T-HMM) [Reference Song, You, Li and Chen75], Multistream Fused HMM (MFHMM) [Reference Zeng, Tu, Pianfetti and Huang76], and Semi-Coupled HMM (SC-HMM) [Reference Lin, Wu and Wei51]. In C-HMM, which is a traditional example, two component HMMs are linked through cross-time and cross-chain conditional probabilities. This structure models the asynchrony of audio and visual modalities and preserves their natural correlations over time. Although cross-time and cross-chain causal modeling in C-HMM may better capture the inter-process influences between audio and visual modalities in real-world scenarios, a complex model structure and rigorous parameter estimation method of the statistical dependencies in C-HMM may lead to the overfitting effect in sparse data conditions. Further, Lu et al. [Reference Lu and Jia77] designed an AdaBoost-CHMM strategy which boosts the performance of component C-HMM classifiers with the modified expectation maximization (EM) training algorithm to generate a strong ensemble classifier. Song et al. [Reference Song, You, Li and Chen75] extended C-HMM to T-HMM to collect three HMMs for two visual input sequences and one audio sequence. Similarly, Jiang et al. [Reference Jiang, Cui, Zhang, Fan, Gonzalez and Sahli32] proposed a Triple stream audio visual Asynchronous Dynamic Bayesian Network (T_AsyDBN) to combine the MFCC features, local prosodic features and visual emotion features in a reasonable manner. Different from C-HMM and T-HMM, Zeng et al. [Reference Zeng, Tu, Pianfetti and Huang76] proposed the Multistream Fused HMM (MFHMM) which constructed a new structure linking the multiple component HMMs to detect 11 affective states. The MFHMM allows the building of an optimal connection among multiple streams according to the maximum entropy principle and the maximum mutual information criterion. To obtain a better statistical dependency among various modalities and diminish the overfitting effect, Lin et al. [Reference Lin, Wu and Wei51] proposed a novel connection criterion of model structures, which is a simplified state-based bi-modal alignment strategy in SC-HMM to align the temporal relation of the states between audio and visual streams.
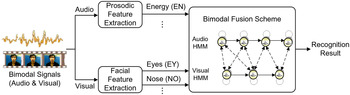
Fig. 6. Illustration of model-level fusion strategy for audiovisual emotion recognition.
On the one hand, a more sophisticated fusion strategy called hybrid approach was recently proposed to integrate different fusion approaches to obtain a better emotion recognition result. The Error Weighted SC-HMM (EWSC-HMM) [Reference Lin, Wu and Wei47], as an example of the hybrid approach, consists of model-level and decision-level fusion strategies and concurrently combines both advantages. First, the state-based bimodal alignment strategy in SC-HMM (model-level fusion) was proposed to align the temporal relation between audio and visual streams. Then the Bayesian classifier weighting scheme (decision-level fusion) was adopted to explore the contributions of the SC-HMM-based classifiers for different audio-visual feature pairs to obtain the optimal emotion recognition result.
D) A few related issues
Another important issue in audiovisual data fusion is related to the problem of asynchrony between audio and visual signals. From the speech production point of view, it has been proven that visual signal activity usually precedes the audio signal by as much as 120 ms [Reference Grant and Greenberg99, Reference Xie and Liu100]. When people speak something happily, smile expression normally shows on faces earlier than the happy sound [Reference Chen, Jiang, Ravyse and Sahli97]. Hence, data fusion strategy will face the problem related to how to deal with asynchronous signals for audiovisual emotion recognition. For audiovisual data fusion, the current feature-level fusion methods dealt with the asynchrony problem based on a strict constraint on time synchrony between modalities or using the static features from each input utterance (i.e. ignoring the temporal information). Hence, with the assumption of strict time synchrony, feature-level fusion is unable to work well if the input features of the vocal and facial expressions differ in the temporal characteristics [Reference Zeng, Pantic, Roisman and Huang12]. In addition, since decision-level fusion method focused on exploring how to effectively combine the recognition outputs from individual audio and visual classifiers, which model audio and visual signal streams independently, synchronization issue can be ignored in decision-level fusion. On the one hand, the model-level fusion methods (e.g. C-HMM, T-HMM, SC-HMM, T_AsyDBN, etc. [Reference Jiang, Cui, Zhang, Fan, Gonzalez and Sahli32, Reference Lin, Wu and Wei51, Reference Song, You, Li and Chen75, Reference Lu and Jia77]) were recently proposed and applied for audiovisual emotion recognition, trying to model asynchronous vocal and facial expressions, and preserving their natural correlation over time. Different from the dynamic programming algorithms (Viterbi and forward–backward analysis) used in conventional HMMs to handle temporal variations, the current model-level fusion methods [Reference Jiang, Cui, Zhang, Fan, Gonzalez and Sahli32, Reference Lin, Wu and Wei51, Reference Song, You, Li and Chen75, Reference Lu and Jia77] were extended to deal with the synchronization problem by de-synchronizing the audio and visual streams and aligning the audiovisual signals at the state level. Thus the current model-level fusion methods such as C-HMM can achieve good performance for the audiovisual signals with large deviations in synchrony. In other distinctive examples, Song et al. [Reference Song, You, Li and Chen75] proposed a T-HMM-based emotion recognition system to model the correlations of three component HMMs, allowing unconstrained state asynchrony between these streams. Chen et al. [Reference Chen, Jiang, Ravyse and Sahli97] proposed an audiovisual DBN model with constrained asynchrony for emotion recognition, which allows asynchrony between the audio and visual emotional states within a constraint. Based on the mentioned studies, the most current model-level fusion methods tried to model the natural correlations between asynchronous vocal and facial expressions over time by exploring the relationships at “state” level.
Besides, toward naturalistic emotion recognition, several existing fusion strategies explored the evolution patterns of emotional expression in a conversational environment [Reference Metallinou, Wollmer, Katsamanis, Eyben, Schuller and Narayanan35, Reference Wu, Lin and Wei50]. These approaches considered the emotional substate or emotional state transitions within/between sentences in a conversation, which not only employed the correlation between audio and visual streams but also explored emotional sub-state or emotional state evolution patterns. Previous research has demonstrated that a complete emotional expression can be divided into three sequential temporal phases, onset (application), apex (release), and offset (relaxation), which consider the manner and intensity of an expression [Reference Valstar and Pantic101–Reference Lin, Wu and Wei104]. An example of the temporal phases of onset, apex, and offset of facial expression is shown in Fig. 7. In the onset phase of the example, the muscles contract and the appearance of the face changes as the facial action grows stronger. The apex phase represents that the facial action is at its peak and there are no more changes in facial appearance. In the offset phase, the muscles relax and the face returns to its neutral appearance. To this end, a bimodal HMM-based emotion recognition scheme, constructed in terms of emotional substates defined to represent temporal phases of onset, apex, and offset, was proposed to model the temporal course of an emotional expression for audio and visual signal streams. Wu et al. [Reference Wu, Lin and Wei50] proposed a Two-level Hierarchical alignment-based SC-HMM (2H-SC-HMM) fusion method to align the relationship within and between the temporal phases in the audio and visual HMM sequences at the state and model levels. Each HMM in the 2H-SC-HMM was used to characterize one emotional substate, instead of the entire emotional state. Figure 8 illustrates model- and state-level alignments between audio and visual HMM sequences in the happy emotional state. Furthermore, by integrating an emotional sub-state language model, which considers the temporal transition between emotional substates, the 2H-SC-HMM can provide a constraint on allowable temporal structures to determine the final emotional state. In addition, Metallinou et al. [Reference Metallinou, Wollmer, Katsamanis, Eyben, Schuller and Narayanan35, Reference Wöllmer, Metallinou, Eyben, Schuller and Narayanan105] explored toward the evolution patterns of emotional expression in a conversational environment that considers the emotional state transitions between utterances in a dialog. For example, anger to anger are more probable than anger to happiness. To model emotion evolution within an utterance and between utterances over the course of a dialog, the Bidirectional Long Short-Term Memory (BLSTM) networks was proposed for incorporating the past and future contextual information in audio-visual emotion recognition system. On the one hand, Mariooryad et al. [Reference Mariooryad and Busso37] explored new directions to understand the emotional entrainment effect during dyadic spontaneous interactions. The relationship between acoustic features of the speaker and facial expressions of the interlocutor (i.e. cross-modality entrainment) was analyzed using mutual information framework. In IEMOCAP and SEMAINE databases, the results demonstrated the cross-modality and cross-speaker emotion recognition mechanism (i.e. recognizes the listener's emotions using facial features; recognizes the speaker's emotions using acoustic features) can improve the performance.

Fig. 7. An example of the temporal phases of happy facial expression from onset, over apex to offset phase.
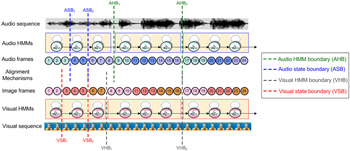
Fig. 8. An example illustrating model- and state-level alignments between audio and visual HMM sequences in the happy emotional state. The green and gray dotted lines represent the audio and visual HMM boundaries respectively and are used for model-level alignment estimation; the blue and red dotted lines represent the state boundaries under audio and visual HMMs respectively and are used for the state-level alignment estimation. The audio and image frames are represented by the numbered circles [50].
IV. CONCLUSION
This paper provides a survey on the latest research and challenges focusing on the theoretical background, databases, features, and data fusion strategies in audiovisual emotion recognition. First, the importance of integrating the facial and vocal cues is introduced. Second, we list the audiovisual emotion databases between 2006 and 2014 which were commonly used in audiovisual emotion recognition studies and emotion challenges from facial and vocal expressions. The content of the elicitation method and emotion categorization of the audiovisual emotion databases are also described. Third, the studies of data fusion strategies for facial–vocal expression-based emotion recognition in recent years are summarized, where the content of audio features, facial features, audiovisual bimodal fusion approach, and a few related issues are explained. Although a number of promising studies have been proposed and successfully applied to various applications, there are still some important issues, outlined in the following, needed to be addressed.
-
1. Unlike traditional emotion recognition performed on laboratory controlled data, EmotiW 2013 challenge provided a new direction to explore the performance of emotion recognition methods that work in real-world conditions.
-
2. A comprehensive and accessible database covering various social signals such as laughs [Reference Petridis, Martinez and Pantic55], smiles, depression [Reference Valstar17], etc. is desirable to help better understand affective behaviors.
-
3. For effective emotion recognition, more emotion-related information should be considered, such as textual (i.e. speech content) or body gesture information.
-
4. For features normalization, most studies assumed that the speaker ID was known, and the neutral example was often manually selected from the video sequences at the beginning. This assumption results in a limit to real-life applications and could be relaxed by automatically detecting the neutral segments [Reference Busso, Metallinou and Narayanan106] from the test data through a universal neutral model and a speaker identification system. The automatic feature normalization approach is a critical issue and should be considered in the future.
-
5. Compared with the unimodal methods, combining audio and visual cues can improve the performance of emotion recognition. Developing better data fusion approaches such as considering the various model properties, temporal expression, and asynchrony issue is desirable for multimodal emotion recognition to achieve better performance.
-
6. Exploring the expression styles from different users is an essential topic for effective emotion recognition, which is not only related to the expression intensity, but also related to the expression manner and significantly associated with personality trait.
-
7. Building a general emotion recognition system that performs equally well for every user could be insufficient for real applications. In contrast, it would be more desirable for personalized emotion recognition using personal computer/devices. Toward personalized emotion recognition, model adaptation based on a small-sized adaptation database should be considered in the future.
-
8. To increase the system's value in real-life applications, several existing methods tried to explore the issues on variations in spontaneous emotion expressions, including head pose variations, speaking-influenced facial expression, and partial facial occlusion in facial emotion recognition [Reference Rudovic, Pantic and Patras107–Reference Lin, Wu and Wei109]. Investigations on these effects are essential for achieving robust emotion recognition.
Acknowledgement
This work was supported in part by the Ministry of Science and Technology, Taiwan, under Contract NSC102-2221-E-006-094-MY3 and the Headquarters of University Advancement at the National Cheng Kung University, which is sponsored by the Ministry of Education, Taiwan.
Supplementary Methods and Materials
The supplementary material for this article can be found at http://www.journals.cambridge.org/SIP
Chung-Hsien Wu received the Ph.D. degree in Electrical Engineering from National Cheng Kung University, Taiwan, in 1991. Since 1991, he has been with the Department of Computer Science and Information Engineering, National Cheng Kung University. He became the professor and distinguished professor in 1997 and 2004, respectively. He received the Outstanding Research Award of National Science Council in 2010 and the Distinguished Electrical Engineering Professor Award of the Chinese Institute of Electrical Engineering in 2011, Taiwan. He is currently the associate editor of IEEE Trans. Audio, Speech and Language Processing, IEEE Trans. Affective Computing, and ACM Trans. Asian Language Information Processing. Dr. Wu serves as the Asia Pacific Signal and Information Processing Association (APSIPA) Distinguished Lecturer and Speech, Language and Audio (SLA) Technical Committee Chair in 2013–2014. His research interests include multimodal emotion recognition, speech recognition/synthesis, and spoken language processing.
Jen-Chun Lin received the Ph.D. degree in Computer Science and Information Engineering from National Cheng Kung University, Tainan, Taiwan, Republic of China, in 2014. Currently, he is a postdoctoral fellow of the Institute of Information Science, Academia Sinica, Taiwan. He is a student member of IEEE and also a student member of HUMAINE Association (emotion-research.net). His research interests include multimedia signal processing, pattern analysis and recognition, and affective computing.
Wen-Li Wei received the B.S. and M.S. degrees in Information Engineering from I-Shou University, Kaohsiung, Taiwan, Republic of China, in 2006 and 2008, respectively. She is currently working toward the Ph.D. degree in Computer Science and Information Engineering, National Cheng Kung University, Tainan, Taiwan, Republic of China She is a student member of IEEE. Her research interests include multimedia signal processing, pattern analysis and recognition, and affective computing.














 Open access
Open access