


I. INTRODUCTION
Convolutional neural networks (CNNs) are a type of deep neural network (DNN) inspired by the human visual system. Recent advances in deep learning show that CNNs have led to major breakthroughs in computer vision [Reference LeCun, Bengio and Hinton1]. Impressively, the last ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2017 proved that the image classification accuracy has surpassed the level of human performance (i.e. error rate of 2.25%). There is no doubt that CNNs have dominated visual recognition systems in many different applications.
However, training successful CNNs is very expensive because it requires a huge amount of data and fast computing resources (e.g. GPU-accelerated computing). For example, the ImageNet dataset contains about 1.2 million images, and training on such a dataset takes days and weeks even on GPU-accelerated machines. In fact, collecting images and labeling them will also consume a massive amount of resources. Moreover, algorithms used in training a CNN model may be patented or have restricted licenses. Therefore, trained CNNs have great business value. Considering the expenses necessary for the expertise, money, and time taken to train a CNN model, a model should be regarded as a kind of intellectual property. While distributing a trained model, an illegal party may also obtain a model and use it for its own service.
To protect the copyrights of trained models, researchers have adopted digital watermarking technology to embed watermarks into the models [Reference Uchida, Nagai, Sakazawa and Satoh2–Reference Adi, Baum, Cissé, Pinkas and Keshet9]. These studies focus on identifying the ownership of a model in question. In reality, a stolen model can be directly used by an attacker without arousing suspicion. In addition, the stolen model can be exploited in many different ways such as through model inversion attacks [Reference Fredrikson, Jha and Ristenpart10] and adversarial attacks [Reference Szegedy, Zaremba, Sutskever, Bruna, Erhan, Goodfellow and Fergus11]. To the best of our knowledge, the consequences of a stolen model have not been considered before in model protection research except for ownership verification. In this paper, we focus on protecting a model from misuse when it has been stolen by taking inspiration from an adversarial defense.
Recently, a key-based adversarial defense was proposed to combat adversarial examples [Reference AprilPyone and Kiya12, Reference AprilPyone and Kiya13], which was in turn inspired by perceptual image encryption methods, which were proposed for privacy-preserving machine learning [Reference Kawamura, Kinoshita, Nakachi, Shiota and Kiya14] and encryption-then-compression systems [Reference Tanaka15–Reference Chuman, Kurihara and Kiya21]. The uniqueness of the key for the model in [Reference AprilPyone and Kiya12, Reference AprilPyone and Kiya13] motivated us to use a key-based transformation technique for model protection.
Therefore, for the first time, in this paper, we propose a model protection method with a secret key set in such a way that a stolen model cannot be used without a key set. Specifically, the proposed method preprocesses input images with a secret key set and trains a model by using such preprocessed images. The preprocessing technique used in the proposed method is a low-cost block-wise operation. In addition, the proposed method does not modify the network, and therefore, there is no overhead for both training and inference time. In an experiment, the performance of a model protected by the proposed method is demonstrated not only to be close to that of a non-protected one when the key set is correct but also to significantly drop upon using an incorrect key set. We make the following contributions in this paper.
• We demonstrate block-wise image transformation with a secret key to be effective for model protection.
• We conduct extensive experiments on different datasets including ImageNet and carry out key estimation attacks and fine-tuning attacks.
The rest of this paper is structured as follows. Section II presents related work on conventional model watermarking, its problems and learnable image encryption (LIE). Section III puts forward the proposed model protection method. Experiments and results are presented in Section IV. Section V includes discussion and analysis, and Section VI concludes this paper. This paper is an extension of the work in [Reference AprilPyone and Kiya22].
II. RELATED WORK
We review the existing model watermarking schemes of image classifiers and discuss problems with them. In addition, we also overview learnable encryption methods by which the proposed method has been inspired.
A) Model watermarking
Digital watermarking technology is widely used to combat copyright infringement for multimedia data [Reference Swanson, Kobayashi and Tewfik23]. An owner embeds a watermark into multimedia content (such as images, audio, etc.). When the protected content is stolen, the embedded watermark is extracted and used to verify ownership. In a similar fashion, to prevent the illegal distribution of DNN models, digital watermarking techniques are used to embed watermarks into proprietary DNN models. There are mainly two scenarios in DNN model watermarking: white-box and black-box.
A model watermarking scenario in white-box settings requires access to model weights for embedding and extracting a watermark. Uchida et al. first proposed a white-box model-watermarking method [Reference Uchida, Nagai, Sakazawa and Satoh2]. A watermark is embedded in one or more layers of model weights by using “an embedding regularizer,” which is an additional regularization term in the loss function during training. Similarly, there are other studies that follow the use of an additional regularization term as in [Reference Fan, Ng and Chan4, Reference Rouhani, Chen and Koushanfar6, Reference Chen, Rouhani and Koushanfar8].
Extracting watermarks in white-box settings requires access to the model weights. To overcome this limitation, another model watermarking scenario for black-box settings was proposed, where an inspector observes the input and output of a model in doubt to verify the ownership of the model. In the black-box scenario, adversarial examples are exploited as a backdoor trigger set [Reference Zhang, Gu, Jang, Wu, Stoecklin, Huang and Molloy7, Reference Adi, Baum, Cissé, Pinkas and Keshet9], or a set of training examples is utilized so that a watermark pattern can be extracted from the inference of a model by using a specific set of training examples [Reference Merrer, Pérez and Trédan3–Reference Sakazawa, Myodo, Tasaka and Yanagihara5]. Therefore, access to the model weights is not required to verify ownership in black-box settings.
The above-mentioned model-watermarking schemes focus on ownership verification. Thus, a stolen model can be directly used and exploited without arousing suspicion because the performance of a protected model (i.e. fidelity) is independent of the embedded watermark. In contrast, the proposed model protection is not a watermarking method, and it is more relevant to authorization or digital rights management because only the rightful user who has the correct key set can use a model to full capacity. Although frameworks for model watermarking and the proposed model protection are different, they are both necessary for dealing with digital rights management in different applications.
B) Model watermarking with passports
Fan et al. [Reference Fan, Ng and Chan4] pointed out that conventional ownership verification schemes are vulnerable against ambiguity attacks [Reference Craver, Memon, Yeo and Yeung24] where two watermarks can be extracted from the same protected model, causing confusion regarding ownership. Therefore, Fan et al. [Reference Fan, Ng and Chan4] introduced passports and passport layers, which allow us to verify ownership with the correct passports. However, the passport in [Reference Fan, Ng and Chan4] is a set of extracted features of a secret image/images or equivalent random patterns from a pre-trained model. In addition, a network has to be modified with additional passport layers to use passports. Therefore, there are significant overhead costs in both the training and inference phases, in addition to user-unfriendly management of lengthy passports in [Reference Fan, Ng and Chan4].
In this paper, we aim to protect a model by embedding a secret key with minimal impact on model performance. Similar to the study in [Reference Fan, Ng and Chan4], a correct key is required for correct inference. However, the proposed method does not introduce any overhead in training or inference. Ownership is automatically verified upon being given the correct key.
C) Learnable image encryption
LIE is to perceptually encrypt images to mainly protect visual information on plain images while maintaining the network ability to learn the encrypted ones for classification tasks. Conventional LIE methods are classified into two classes in terms of application: LIE for privacy-preserving deep learning [Reference Tanaka15, Reference Sirichotedumrong, Kinoshita and Kiya16, Reference Sirichotedumrong, Maekawa, Kinoshita and Kiya18, Reference Madono, Tanaka, Onishi and Ogawa25–Reference Ito, Kinoshita and Kiya28] and LIE for adversarial robustness [Reference AprilPyone and Kiya12, Reference AprilPyone and Kiya13].
LIE methods for privacy-preserving have two requirements: protecting visual information and maintaining a high classification accuracy under the use of encrypted images. In a block-wise manner, a color image is divided into blocks, and each block is processed by using a series of encryption with a common key to all blocks [Reference Tanaka15] or with different keys [Reference Madono, Tanaka, Onishi and Ogawa25]. In a pixel-wise manner, negative/positive transformation to each pixel and color shuffling across three channels are exploited to produce learnable encrypted images [Reference Sirichotedumrong, Kinoshita and Kiya16, Reference Sirichotedumrong, Maekawa, Kinoshita and Kiya18]. In contrast, a transformation network is trained in cooperation with a pre-trained classification model to generate images without visual information on plain images. One such study utilized a generative adversarial network [Reference Sirichotedumrong and Kiya26]. To improve classification accuracy and robustness against various attacks, transformation networks have been proposed that use U-Net as in [Reference Ito, Kinoshita and Kiya27, Reference Ito, Kinoshita and Kiya28].
LIE methods for adversarial defenses [Reference AprilPyone and Kiya12, Reference AprilPyone and Kiya13] have three requirements: a high classification accuracy, robustness against adversarial attacks, and resistance to key estimation attacks. The methods in this class do not aim to protect the visual information of plain images. Instead, a key is used to control the model's decision. In this paper, we do not propose a new encryption method. We adopt the methods in [Reference AprilPyone and Kiya12, Reference AprilPyone and Kiya13] for a new application, model protection, for the first time. The proposed model protection method is carried out on the basis of LIE methods for adversarial defenses [Reference AprilPyone and Kiya12, Reference AprilPyone and Kiya13], but hyperparameters are carefully tuned for model protection purposes. LIE methods have never been applied to model protection applications. The contribution in this paper is to introduce some conventional image encryption algorithms into a model protection task.
III. PROPOSED MODEL-PROTECTION METHOD
A) Notation
The following notations are utilized throughout this paper:
• $w$
 , $h$, and $c$ are used to denote the width, height, and number of channels of an image.
, $h$, and $c$ are used to denote the width, height, and number of channels of an image.• The tensor $x \in {[0, 1]}^{c \times h \times w}$
represents an input color image.• The tensor $x' \in {[0, 1]}^{c \times h \times w}$
represents a transformed image.• $M$
is the block size of an image.• Tensors $x_b, x_b' \in {[0, 1]}^{h_b \times w_b \times p_b}$
are a block image and a transformed block image, respectively, where $w_b = {w}/{M}$ is the number of blocks across width $w$, $h_b = {h}/{M}$ is the number of blocks across height $h$, and $p_b = M \times M \times c$ is the number of pixels in a block.• A pixel value in a block image ($x_b$
or $x_b'$) is denoted by $x_b(i, j, k)$ or $x_b'(i, j, k)$, where $i \in \{0, \dots , h_b - 1\}$, $j \in \{0, \dots , w_b - 1\}$, and $k \in \{0, \dots , p_b - 1\}$ are indices corresponding to the dimension of $x_b$ or $x_b'$.• $B$
is a block of an image, and its dimension is $M \times M \times c$.• $\hat {B}$
is a flattened version of block $B$, and its dimension is $1 \times 1 \times p_b$.• $K$
denotes a set of keys.• A password required for format-preserving encryption, which refers to encrypting in such a way that the output is in the same format as its input, is denoted as $password$
.• $\text {Enc}(n, password)$
denotes format-preserving Feistel-based encryption (FFX) [Reference Bellare, Rogaway and Spies29] with a length of $3$, where $n$ is an integer (used only in FFX encryption).• An image classifier is denoted as $f(\cdot )$
.
































B) Requirements of proposed scheme
We consider a model protection scenario that aims to fulfill the following requirements:
(i) Usability: A rightful user with key set $K$
can access a model without any noticeable overhead in both training and inference time, and performance degradation. The key management should be easy.(ii) Unusability: Ideally, stolen models should not be usable in any case without key set $K$
. In addition, even when the adversary retrains a stolen model with a forged key set, the performance of the model should heavily drop.


C) Overview
An overview of image classification with the proposed method is depicted in Fig. 1. In the proposed model protection, input images are transformed by using secret key set $K$ before training or testing a model. Model $f$
before training or testing a model. Model $f$ is trained by using the transformed images. To test a trained model, test images are also transformed with the same key set $K$
is trained by using the transformed images. To test a trained model, test images are also transformed with the same key set $K$ before testing.
before testing.
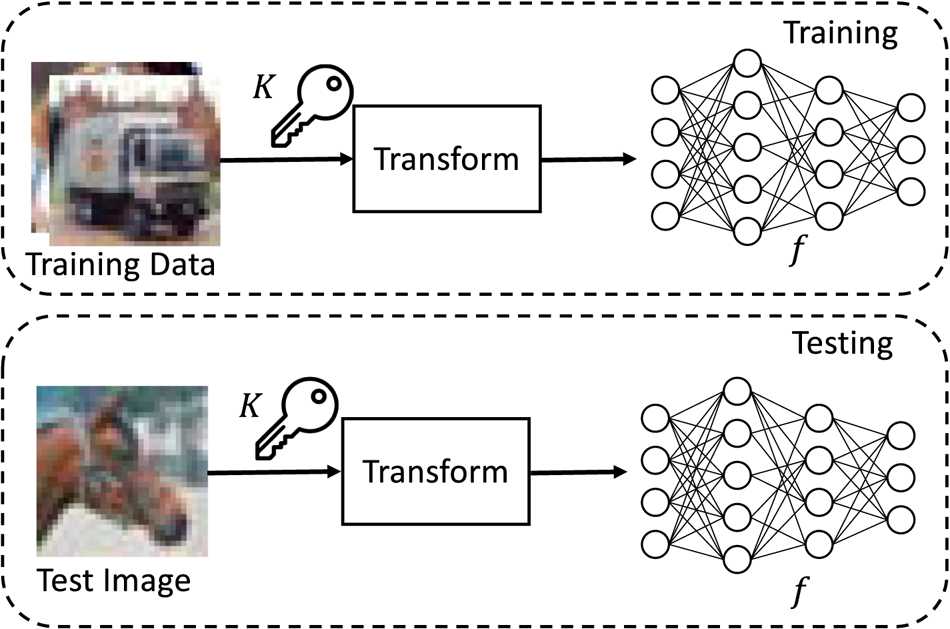
Fig. 1. Overview of image classification with proposed model protection method.
The block-wise transformation consists of three steps: block segmentation, block-wise transformation, and block integration (see Fig. 2). The process of the block-wise transformation is shown as follows.
(i) Block segmentation: The process of block segmentation is illustrated in Fig. 2.
• Step 1: An input image $x$
is divided into blocks such that $\{B_{11}, B_{12}, \dots , B_{h_{b}w_{b}}\}$.• Step 2: Each block in $x$
is flattened to obtain $\{\hat {B}_{11}, \hat {B}_{12}, \dots , \hat {B}_{h_{b}w_{b}}\}$.• Step 3: The flattened blocks are concatenated in such a way that the relative spatial location among blocks in $x_b$
is the same as that among blocks in $x$.
(ii) Block-wise transformation: Given a key set $K$
, $x_b$ is transformed by using a block-wise transformation algorithm, $t(x_b, K)$. The transformed block image is written as
(1)\begin{equation} x_b' = t(x_b, K). \end{equation}
(iii) Block Integration: The transformed blocks in $x_b'$
are integrated back to the original dimension (i.e. $c \times h \times w$) in the reverse order to the block segmentation process for obtaining a transformed image $x'$.













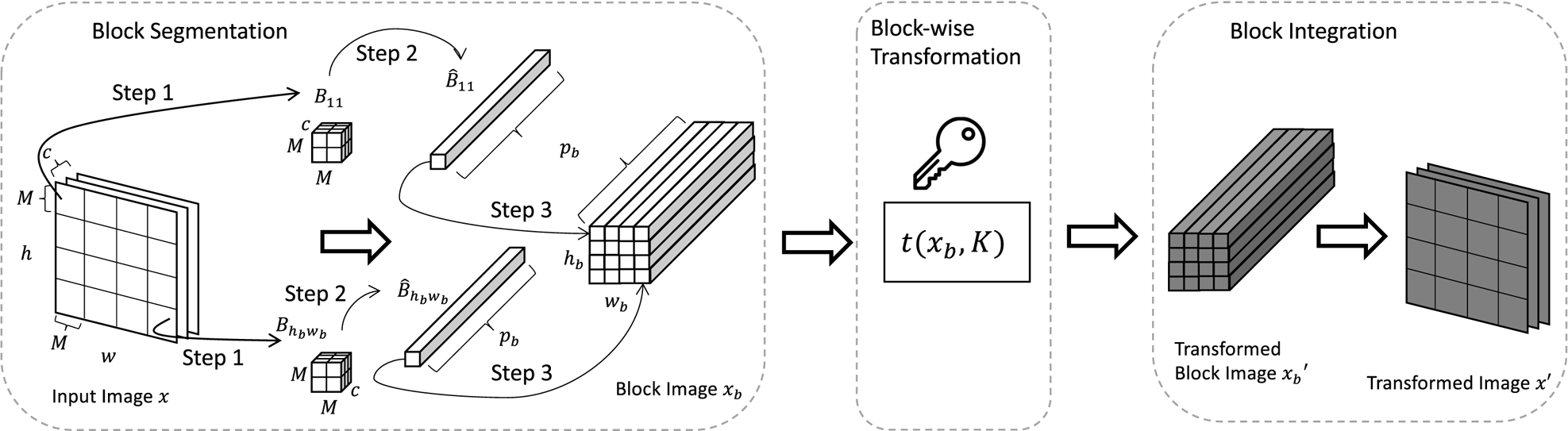
Fig. 2. Process of block-wise transformation.
D) Block-wise transformation with secret key
We introduce three block-wise transformations: pixel shuffling (SHF), negative/positive transformation (NP), and FFX for realizing $t(x_b, K)$ . We selected these three transformations from among LIE methods for model protection applications because the requirements of LIE methods for these applications are expected to be similar to those for adversarial defenses.
. We selected these three transformations from among LIE methods for model protection applications because the requirements of LIE methods for these applications are expected to be similar to those for adversarial defenses.
A set of keys $K$ consists of one or more keys depending on the desired number of transformations. For example, if one transformation (SHF) is used, $K = \{\alpha \}$
consists of one or more keys depending on the desired number of transformations. For example, if one transformation (SHF) is used, $K = \{\alpha \}$ , if two (SHF and NP) are used, $K = \{\alpha , \beta \}$
, if two (SHF and NP) are used, $K = \{\alpha , \beta \}$ , and if three (SHF, NP, and FFX) are used, $K = \{\alpha , \beta , \gamma \}$
, and if three (SHF, NP, and FFX) are used, $K = \{\alpha , \beta , \gamma \}$ , where $\alpha$
, where $\alpha$ is for SHF, $\beta$
is for SHF, $\beta$ is for NP, and $\gamma$
is for NP, and $\gamma$ is for FFX, respectively.
is for FFX, respectively.
Key $\alpha$ is a permutation vector, and it is defined as
is a permutation vector, and it is defined as
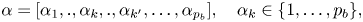
where $\alpha _k \neq \alpha _{k'}$ if $k \neq k'$
if $k \neq k'$ .
.
Key $\beta$ is a binary vector, and it is given by
is a binary vector, and it is given by
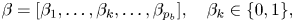
where the value of the occurrence probability $P(\beta _k)$ is $0.5$
is $0.5$ .
.
Key $\gamma$ is defined as
is defined as
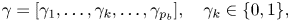
where the value of the occurrence probability $P(\gamma _k)$ is $0.5$
is $0.5$ .
.
When SHF is used, $x_b'$ is obtained as:
is obtained as:
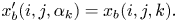
When NP is used, every pixel value in $x_b$ needs to be at $255$
needs to be at $255$ scale with 8 bits (i.e. multiply $x_b$
scale with 8 bits (i.e. multiply $x_b$ by $255$
by $255$ ), and $x_b'$
), and $x_b'$ is obtained as:
is obtained as:
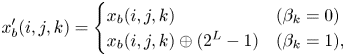
where $\oplus$ is an exclusive or (XOR) operation, $L$
is an exclusive or (XOR) operation, $L$ is the number of bits used in $x_b(i, j, k)$
is the number of bits used in $x_b(i, j, k)$ , and $L = 8$
, and $L = 8$ is used in this paper. After the transformation, every pixel value in $x_b'$
is used in this paper. After the transformation, every pixel value in $x_b'$ is converted back to $[0, 1]$
is converted back to $[0, 1]$ scale (i.e. divide $x'_b$
scale (i.e. divide $x'_b$ by $255$
by $255$ ).
).
When FFX is used, every pixel value in $x_b$ also needs to be at $255$
also needs to be at $255$ scale with 8 bits (i.e. multiply $x_b$
scale with 8 bits (i.e. multiply $x_b$ by $255$
by $255$ ). In addition, FFX also requires a $password$
). In addition, FFX also requires a $password$ for FFX [Reference Bellare, Rogaway and Spies29], and $x_b'$
for FFX [Reference Bellare, Rogaway and Spies29], and $x_b'$ is obtained as:
is obtained as:
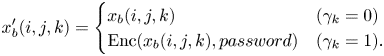
Note that FFX [Reference Bellare, Rogaway and Spies29] takes an integer value and outputs an integer; therefore, pixel values should be at $[0,255]$ scale. The pixel value $x_b(i,j,k) \in \{0, 1, \dots , 254, 255\}$
scale. The pixel value $x_b(i,j,k) \in \{0, 1, \dots , 254, 255\}$ is encrypted by FFX with a length of $3$
is encrypted by FFX with a length of $3$ digits to cover the whole range from $0$
digits to cover the whole range from $0$ to $255$
to $255$ . Therefore, FFX transforms each pixel with an integer value of ($[0,255]$
. Therefore, FFX transforms each pixel with an integer value of ($[0,255]$ scale) into a pixel with an integer value of ($[0,999]$
scale) into a pixel with an integer value of ($[0,999]$ scale), preserving the integer format. Another notable thing is that a $password$
scale), preserving the integer format. Another notable thing is that a $password$ for FFX can be arbitrary, and the only important thing is the location of the encrypted pixels that are determined by the key $\gamma$
for FFX can be arbitrary, and the only important thing is the location of the encrypted pixels that are determined by the key $\gamma$ .
.
The overall block-wise transformation is detailed in Algorithm 1. An example of images transformed by different transformations is shown in Fig. 3. The three transformations (SHF, NP, and FFX) were confirmed to have different performances in terms of classification accuracy and key estimation attack in [Reference AprilPyone and Kiya12, Reference AprilPyone and Kiya13], so these transformations are compared again under model protection in this paper. In particular, parameter $M$ affects the classification accuracy and resistance to key estimation attacks.
affects the classification accuracy and resistance to key estimation attacks.

Fig. 3. Example of block-wise transformed images ($M = 4$ ) with key set $K$
) with key set $K$ . (a) Original. (b) SHF. (c) NP. (d) FFX. (e) SHF + NP. (f) SHF + FFX. (g) SHF + NP + FFX.
. (a) Original. (b) SHF. (c) NP. (d) FFX. (e) SHF + NP. (f) SHF + FFX. (g) SHF + NP + FFX.

E) Robustness against attacks
A threat model includes a set of assumptions such as an attacker's goals, knowledge, and capabilities. An attacker may steal a model to achieve different goals. In this paper, we consider the attacker's goal to be to make use of a stolen model by estimating a key set or fine-tuning the stolen model for different purposes. In this regard, we assume that the attacker knows the transformation details such as the block size and type of transformation, and a small subset of the training dataset. Therefore, the attacker may observe the accuracy of his or her test dataset to estimate a key set or fine-tune the stolen model. We carry out the following possible attacks with the intent of stealing a model to evaluate the robustness of the proposed method. In experiments, the proposed method will be demonstrated to be robust against attacks.
1) Key estimation attack
We consider a scenario where a model is stolen and transformation details are known except the secret key. The key may be estimated by brute-force checking possible keys. The key space $\mathcal {K}$ of each transformation is given by
of each transformation is given by
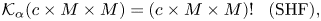
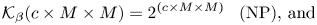

Therefore, the key space will vary with respect to block size $M$ and the type of block-wise transformation used for protecting a model.
and the type of block-wise transformation used for protecting a model.
The attacker may estimate the key heuristically by observing the accuracy over a batch of images. Algorithm 2 describes the process of estimating key set $K$ . First, we randomly initialize key set $K' = \{\alpha ', \beta ', \gamma '\}$
. First, we randomly initialize key set $K' = \{\alpha ', \beta ', \gamma '\}$ in accordance with the transformation. Next, we also initialize a set of index pairs $\mathcal {P}$
in accordance with the transformation. Next, we also initialize a set of index pairs $\mathcal {P}$ as $\mathcal {P} = \{(1, 2), (1, 3), \ldots , (c \times M \times M - 1, c \times M \times M)\}$
as $\mathcal {P} = \{(1, 2), (1, 3), \ldots , (c \times M \times M - 1, c \times M \times M)\}$ for keys $\alpha '$
for keys $\alpha '$ , $\beta '$
, $\beta '$ , or $\gamma '$
, or $\gamma '$ . The number of all possible combinations of pairs for each key can be computed as a binomial coefficient given by
. The number of all possible combinations of pairs for each key can be computed as a binomial coefficient given by
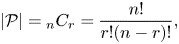
where $n = c \times M \times M$ , and $r = 2$
, and $r = 2$ . For each index pair, we swap the pair in $\alpha '$
. For each index pair, we swap the pair in $\alpha '$ , $\beta '$
, $\beta '$ , or $\gamma '$
, or $\gamma '$ if the swap improves the accuracy as shown in Algorithm 2.
if the swap improves the accuracy as shown in Algorithm 2.

Key estimation attacks do not guarantee that the attacker will find the correct key because the attacker does not know the actual performance of the correct key. However, the attacker may perform fine-tuning attacks to exploit a stolen model as below.
2) Fine-tuning attack with incorrect key set and small dataset
Fine-tuning (transfer learning) [Reference Simonyan and Zisserman30] is to train a model on top of pre-trained weights. Since fine-tuning alters the weights of the model, an attacker may use fine-tuning as an attack to overwrite a protected model with the intent of forging keys. The goal of this attack is to replace the key set with a different key set by retraining a protected model with a small subset of a dataset. We can consider such an attack scenario where the adversary has a subset of dataset $D'$ and retrains the model with a forged key set ($K'$
and retrains the model with a forged key set ($K'$ ).
).
3) Fine-tuning attack with new dataset
We assume an attacker may steal a protected model and fine-tune the model with a new dataset. The goal of this attack is to replace a protected model with an unprotected one without any key by using transfer learning.
In practice, CNNs are not trained from the beginning with random weights because creating a large dataset like ImageNet is difficult and expensive. Therefore, CNNs are usually pre-trained with a larger dataset (e.g. ImageNet), known as transfer learning [Reference Simonyan and Zisserman30]. There are two major transfer-learning scenarios:
• Fixed CNN: A pre-trained CNN model is used as a fixed feature extractor, and the last fully connected layer is replaced with a targeted number of classes. In other words, convolutional layers are frozen, and only the last fully connected layer is trained with random initialization from scratch.
• Fine-tuned CNN: In this scenario, the CNN is fine-tuned from a pre-trained model. Here, it is possible that some convolutional layers can be fixed or the whole CNN is fine-tuned.
IV. EXPERIMENTS AND RESULTS
To verify the effectiveness of the proposed model protection method, we ran a number of experiments on different datasets. All the experiments were carried out in PyTorch [Reference Paszke, Gross, Massa, Lerer, Bradbury, Chanan, Killeen, Lin, Gimelshein, Antiga, Desmaison, Kopf, Yang, DeVito, Raison, Tejani, Chilamkurthy, Steiner, Fang, Bai and Chintala31] platform.
A) Datasets
We conducted image classification experiments on datasets with different scales, namely, the CIFAR (both 10 and 100 classes) [Reference Krizhevsky and Hinton32] and ImageNet [Reference Russakovsky, Deng, Su, Krause, Satheesh, Ma, Huang, Karpathy, Khosla, Bernstein, Berg and Fei-Fei33] datasets.
For the CIFAR-10 and CIFAR-100 datasets, we used a batch size of 128 and live augmentation (random cropping with padding of 4 and random horizontal flip) on training sets. Both datasets consist of 60 000 color images (dimensions of $32 \times 32 \times 3$ ) where 50 000 images are for training and 10 000 for testing. There are 10 classes (6000 images for each class) for the CIFAR-10 dataset and 100 classes (600 images for each class) for the CIFAR-100 dataset.
) where 50 000 images are for training and 10 000 for testing. There are 10 classes (6000 images for each class) for the CIFAR-10 dataset and 100 classes (600 images for each class) for the CIFAR-100 dataset.
ImageNet comprises 1.28 million color images for training and 50 000 color images for validation. We progressively resized images during training, starting with larger batches of smaller images to smaller batches of larger images. We adapted three phases of training from the DAWNBench top submissions as mentioned in [Reference Wong, Rice and Kolter34]. Phases 1 and 2 resized images to 160 and 352 pixels, respectively, and phase 3 used the entire image size from the training set. The augmentation methods used in the experiment were random resizing, cropping (sizes of $128$ , $224$
, $224$ , and $288$
, and $288$ , respectively, for each phase), and random horizontal flip.
, respectively, for each phase), and random horizontal flip.
B) Networks
We utilized deep residual networks [Reference He, Zhang, Ren and Sun35] with 18 layers (ResNet18) and trained for $200$ epochs with cyclic learning rates [Reference Smith and Topin36] and mixed precision training [Reference Micikevicius, Narang, Alben, Diamos, Elsen, García, Ginsburg, Houston, Kuchaiev, Venkatesh and Wu37] for the CIFAR datasets. The parameters of the stochastic gradient descent (SGD) optimizer were a momentum of $0.9$
epochs with cyclic learning rates [Reference Smith and Topin36] and mixed precision training [Reference Micikevicius, Narang, Alben, Diamos, Elsen, García, Ginsburg, Houston, Kuchaiev, Venkatesh and Wu37] for the CIFAR datasets. The parameters of the stochastic gradient descent (SGD) optimizer were a momentum of $0.9$ , weight decay of $0.0005$
, weight decay of $0.0005$ , and maximum learning rate of $0.2$
, and maximum learning rate of $0.2$ . For the ImageNet dataset, we used ResNet50 with pre-trained weights. We adapted the training settings from [Reference Wong, Rice and Kolter34] with the removal of weight decay regularization from batch normalization layers. The network was trained for 15 epochs in total for the ImageNet dataset.
. For the ImageNet dataset, we used ResNet50 with pre-trained weights. We adapted the training settings from [Reference Wong, Rice and Kolter34] with the removal of weight decay regularization from batch normalization layers. The network was trained for 15 epochs in total for the ImageNet dataset.
C) Classification performance
We trained protected models by using images transformed by various transformations (both single and combined transformations) with different block sizes (i.e. $M \in \{2, 4, 8, 16\}$ ) on three different datasets (CIFAR-10, CIFAR-100, and ImageNet). The models are named after the shorthand of the respective transformations. For example, the model trained by using images transformed by SHF transformation is denoted as SHF, that by NP transformation as NP, and so on. We tested the protected models under three conditions: with correct key set $K$
) on three different datasets (CIFAR-10, CIFAR-100, and ImageNet). The models are named after the shorthand of the respective transformations. For example, the model trained by using images transformed by SHF transformation is denoted as SHF, that by NP transformation as NP, and so on. We tested the protected models under three conditions: with correct key set $K$ , with incorrect key set $K'$
, with incorrect key set $K'$ , and with plain images (without any transformation).
, and with plain images (without any transformation).
In the experiments, the correct keys were generated by using a random number generator from the PyTorch platform [Reference Paszke, Gross, Massa, Lerer, Bradbury, Chanan, Killeen, Lin, Gimelshein, Antiga, Desmaison, Kopf, Yang, DeVito, Raison, Tejani, Chilamkurthy, Steiner, Fang, Bai and Chintala31] with a seed value of 42 (64-bit integer), and we used a publicly available library for FFX (pyffx [Reference Dollinger38]) with the password string “password.” The incorrect keys were also generated by using the same random number generator from the PyTorch platform [Reference Paszke, Gross, Massa, Lerer, Bradbury, Chanan, Killeen, Lin, Gimelshein, Antiga, Desmaison, Kopf, Yang, DeVito, Raison, Tejani, Chilamkurthy, Steiner, Fang, Bai and Chintala31] with 1000 random seed values (64-bit integer).
Table 1 summarizes the simulation results for all three datasets, where the classification accuracy for incorrect key set $K'$ was averaged over 1000 random key sets.
was averaged over 1000 random key sets.
Table 1. Accuracy (%) of protected models and baseline model for three datasets
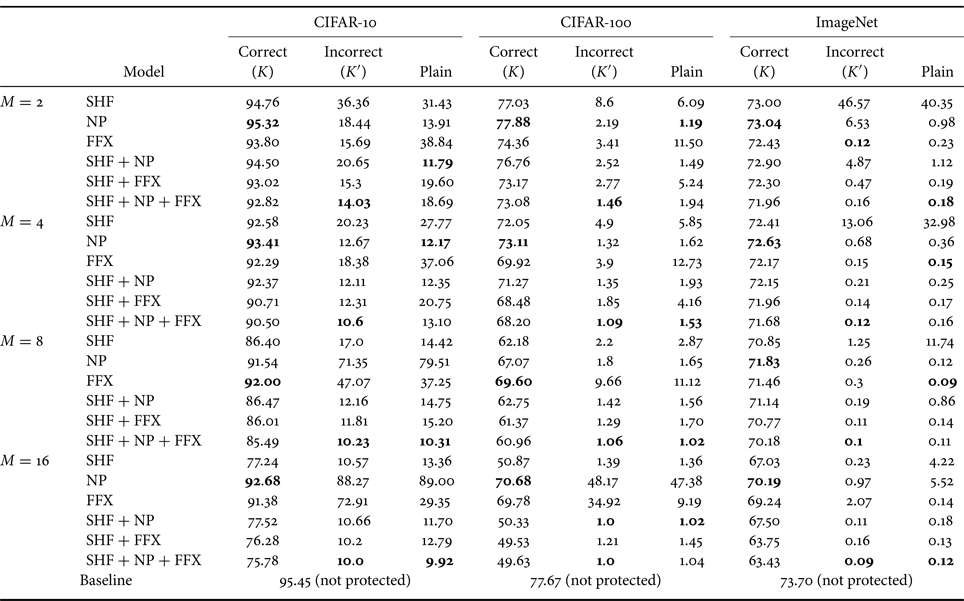
Best results are given in bold.
SHF: for SHF, as block size $M$ was increased, the classification accuracy decreased when using correct key set $K$
was increased, the classification accuracy decreased when using correct key set $K$ . Under the use of incorrect key set $K'$
. Under the use of incorrect key set $K'$ or plain images, the accuracy significantly dropped as block size $M$
or plain images, the accuracy significantly dropped as block size $M$ was increased, suggesting resistance against unauthorized access. Therefore, the selection of $M$
was increased, suggesting resistance against unauthorized access. Therefore, the selection of $M$ controls the trade-off between classification accuracy and resistance against illegal usage.
controls the trade-off between classification accuracy and resistance against illegal usage.
NP, FFX: for NP, the highest accuracy values were achieved for all transformations on all the datasets for each block size with correct key set $K$ . When using $M = 8$
. When using $M = 8$ or $16$
or $16$ on the CIFAR-10 and CIFAR-100 datasets, NP had the highest accuracy, and FFX had the second highest accuracy under the use of incorrect key set $K'$
on the CIFAR-10 and CIFAR-100 datasets, NP had the highest accuracy, and FFX had the second highest accuracy under the use of incorrect key set $K'$ or plain images except for $M = 8$
or plain images except for $M = 8$ on the CIFAR-100 dataset. In contrast, on ImageNet, the accuracy was significantly low for both NP and FFX under the use of incorrect key set $K'$
on the CIFAR-100 dataset. In contrast, on ImageNet, the accuracy was significantly low for both NP and FFX under the use of incorrect key set $K'$ or plain images because the size of the images in the ImageNet dataset is larger than that of CIFAR-10 and CIFAR-100.
or plain images because the size of the images in the ImageNet dataset is larger than that of CIFAR-10 and CIFAR-100.
Combined: the models with combined transformations such as SHF + NP and SHF + FFX decreased the classification accuracy, compared with those with NP and FFX, when using $M = 8$ or $16$
or $16$ . Under the use of incorrect key set $K'$
. Under the use of incorrect key set $K'$ or plain images, the accuracy severely dropped for all block sizes. The advantage of a combined transformation is that it can increase the key space, but it slightly reduces the classification accuracy.
or plain images, the accuracy severely dropped for all block sizes. The advantage of a combined transformation is that it can increase the key space, but it slightly reduces the classification accuracy.
From the empirical results, generally, the performance of an incorrect key set depends on the number of classes in a dataset. When using a dataset with a large number of classes such as CIFAR-100 and ImageNet, the accuracy of the incorrect key set was low due to difficulty in classifying images transformed by using an incorrect key set or plain images. In summary, the proposed method had a high classification accuracy (i.e. close to baseline accuracy) when correct key set $K$ was given. In contrast, the accuracy deteriorated significantly when using incorrect key set $K'$
was given. In contrast, the accuracy deteriorated significantly when using incorrect key set $K'$ or plain images. Since models with $M = 4$
or plain images. Since models with $M = 4$ provided a good trade-off between classification accuracy and resistance against unauthorized access, we focused on $M = 4$
provided a good trade-off between classification accuracy and resistance against unauthorized access, we focused on $M = 4$ in the following sections to further evaluate against attacks on the CIFAR-10 and CIFAR-100 datasets.
in the following sections to further evaluate against attacks on the CIFAR-10 and CIFAR-100 datasets.
D) Robustness against key estimation attack
The proposed method was evaluated in a scenario involving a key estimation attack in accordance with Algorithm 2. As described in Section III-E)-1), elements in each key were rearranged in accordance with the improvement in accuracy, and the resulting estimated key set $K'$ was used to evaluate the performance of the protected models.
was used to evaluate the performance of the protected models.
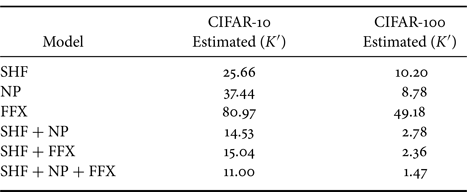
Table 2 captures the classification performance of the models under the use of estimated key set $K'$ on the CIFAR-10 and CIFAR-100 datasets. The estimated keys were not good enough to provide a reasonable accuracy except for FFX, which replaces a pixel value with a random value by using a password, so the encrypted pixel value contains almost no information. Therefore, the location of the un-encrypted pixel values plays an important role in the model's decision-making process, as the encrypted pixel values are not important. This property helps an attacker to effectively find a good key when performing key estimation attacks (Algorithm 2). In contrast, in the other two transformations (SHF and NP), transformed pixel values have some information, and both positions of un-encrypted pixels and pixel values are important. Therefore, the indication to search for a good key was difficult for SHF and NP compared to FFX.
on the CIFAR-10 and CIFAR-100 datasets. The estimated keys were not good enough to provide a reasonable accuracy except for FFX, which replaces a pixel value with a random value by using a password, so the encrypted pixel value contains almost no information. Therefore, the location of the un-encrypted pixel values plays an important role in the model's decision-making process, as the encrypted pixel values are not important. This property helps an attacker to effectively find a good key when performing key estimation attacks (Algorithm 2). In contrast, in the other two transformations (SHF and NP), transformed pixel values have some information, and both positions of un-encrypted pixels and pixel values are important. Therefore, the indication to search for a good key was difficult for SHF and NP compared to FFX.
Table 2. Accuracy (%) of protected models ($M = 4$ ) under use of estimated key set $K'$
) under use of estimated key set $K'$
E) Robustness against fine-tuning attack with incorrect key and small dataset
We ran an experiment with different sizes for the adversary's dataset (i.e. $\left | D' \right | \in \{100, 500, 1000, 10\,000\}$ ) for the CIFAR-10 and CIFAR-100 datasets. We retrained the models with $D'$
) for the CIFAR-10 and CIFAR-100 datasets. We retrained the models with $D'$ for 30 epochs. Table 3 shows the results of fine-tuning attacks for both datasets. Table 1 shows the performance of the incorrect key set before the model weights were modified. In contrast, fine-tuning with $\left | D' \right | = 100$
for 30 epochs. Table 3 shows the results of fine-tuning attacks for both datasets. Table 1 shows the performance of the incorrect key set before the model weights were modified. In contrast, fine-tuning with $\left | D' \right | = 100$ modified the weights. Therefore, the models in Table 1 are different from those in Table 3, so the accuracy was not equal to that of the incorrect key set in Table 1.
modified the weights. Therefore, the models in Table 1 are different from those in Table 3, so the accuracy was not equal to that of the incorrect key set in Table 1.
Table 3. Accuracy (%) of protected models under fine-tuning attacks with incorrect key and small dataset
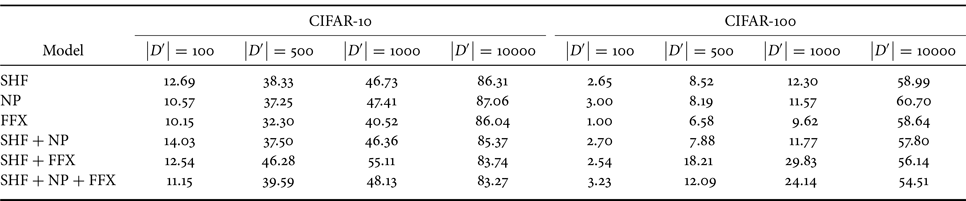
Although the accuracy improved with respect to the size of the adversary's dataset, it was still lower than the performance of the correct key set $K$ as presented in Table 1. Therefore, the results show that the compromised models were not as good as the original models, even when fine-tuning with a small subset of a dataset. As a result, the attacker is not able to use the model to full capacity, suggesting robustness against this type of attack.
as presented in Table 1. Therefore, the results show that the compromised models were not as good as the original models, even when fine-tuning with a small subset of a dataset. As a result, the attacker is not able to use the model to full capacity, suggesting robustness against this type of attack.
F) Robustness against fine-tuning attack with new dataset
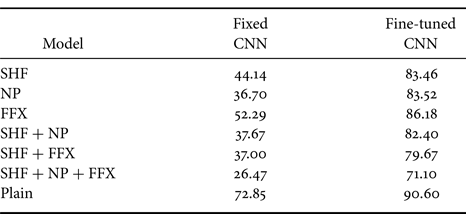
We simulated this attack scenario by fine-tuning the CIFAR-100 to the CIFAR-10 under both conditions (fixed CNN and fine-tuned CNN). We fine-tuned the CIFAR-100 model for 25 epochs. The parameters of the SGD optimizer were a learning rate of 0.001 and a momentum of 0.9, and a StepLR scheduler was used with a step size of 7 and a gamma value of 0.1.
Table 4 shows the results of fine-tuning the CIFAR-100 dataset to the CIFAR-10 dataset. Training only the last layer (fixed CNN) did not provide good accuracy even for the non-protected models (plain). However, for “fine-tuned CNN,” the non-protected (plain) model was fine-tuned to an accuracy of 90.60%, which was closer to the baseline accuracy (i.e. 95.45%). In contrast, the fine-tuned accuracies of the protected models were lower (83.46% for SHF, 83.52% for NP, and 86.18% for FFX) than that of the plain model. For the fine-tuned CNN, the results show that the protected models were still transferable, although this was not as good as fine-tuning from the non-protected models.
Table 4. Accuracy (%) of protected models under fine-tuning attacks with new dataset (CIFAR-100 to CIFAR-10) for fixed CNN and fine-tuned CNN
G) Comparison with state-of-the-art methods
Both watermarking and encryption algorithms can be used to protect the copyright of digital products, but the former is imperceptible, while the latter is a means of direct encryption. It is difficult to compare both approaches in terms of their aims and robustness against attacks. In particular, in conventional model watermarking methods, the embedded watermark is independent of model performance. Therefore, we compared the proposed protected model (NP) with the state-of-the-art passport protected model, Scheme $\mathcal {V}_1$ [Reference Fan, Ng and Chan4] in terms of classification accuracy with/without correct key/passports, overheads, network modification and key management, for both the CIFAR-10 and CIFAR-100 datasets. Scheme $\mathcal {V}_1$
[Reference Fan, Ng and Chan4] in terms of classification accuracy with/without correct key/passports, overheads, network modification and key management, for both the CIFAR-10 and CIFAR-100 datasets. Scheme $\mathcal {V}_1$ [Reference Fan, Ng and Chan4] was not trained and tested using the same settings as the proposed method because the network in $\mathcal {V}_1$
[Reference Fan, Ng and Chan4] was not trained and tested using the same settings as the proposed method because the network in $\mathcal {V}_1$ was modified with passport layers and the hyperparameters were based on the modified network. In contrast, the proposed method used a standard ResNet18 and was trained with cyclic learning rates [Reference Smith and Topin36] and mixed precision training [Reference Micikevicius, Narang, Alben, Diamos, Elsen, García, Ginsburg, Houston, Kuchaiev, Venkatesh and Wu37].
was modified with passport layers and the hyperparameters were based on the modified network. In contrast, the proposed method used a standard ResNet18 and was trained with cyclic learning rates [Reference Smith and Topin36] and mixed precision training [Reference Micikevicius, Narang, Alben, Diamos, Elsen, García, Ginsburg, Houston, Kuchaiev, Venkatesh and Wu37].
CIFAR-10: In terms of accuracy when the correct key/passport was given, the accuracy of $\mathcal {V}_1$ was slightly higher than that of NP at 1.21%. However, it was confirmed that if block size $M = 2$
was slightly higher than that of NP at 1.21%. However, it was confirmed that if block size $M = 2$ was used, NP achieved higher accuracy than $\mathcal {V}_1$
was used, NP achieved higher accuracy than $\mathcal {V}_1$ (i.e. 95.32%). When estimated incorrect key set was given, the accuracy of NP significantly dropped. In contrast, when reverse-engineered (i.e. estimated) passports were used, the accuracy of $\mathcal {V}_1$
(i.e. 95.32%). When estimated incorrect key set was given, the accuracy of NP significantly dropped. In contrast, when reverse-engineered (i.e. estimated) passports were used, the accuracy of $\mathcal {V}_1$ was high (70%).
was high (70%).
CIFAR-100: Similarly, for CIFAR-100, the accuracy of $\mathcal {V}_1$ was also slightly higher. However, when an estimated key was given, the proposed method was more resistant than $\mathcal {V}_1$
was also slightly higher. However, when an estimated key was given, the proposed method was more resistant than $\mathcal {V}_1$ .
.
In terms of overhead, $\mathcal {V}_1$ modifies a network with additional passport layers; therefore, it introduces a training and inference overhead for both datasets. The overheads in [Reference Fan, Ng and Chan4] are based on the relative recorded time taken as mentioned in the paper by the original authors. In contrast, the proposed model NP does not have any noticeable overhead, and there is no modification in the network for both datasets [Reference Fan, Ng and Chan4]. Moreover, the block-wise transformation in the proposed model protection can be efficiently implemented with vectorized operations; therefore, pre-processing with the block-wise transformation does not cause any noticeable overheads in both training and testing. From a key management perspective, $\mathcal {V}_1$
modifies a network with additional passport layers; therefore, it introduces a training and inference overhead for both datasets. The overheads in [Reference Fan, Ng and Chan4] are based on the relative recorded time taken as mentioned in the paper by the original authors. In contrast, the proposed model NP does not have any noticeable overhead, and there is no modification in the network for both datasets [Reference Fan, Ng and Chan4]. Moreover, the block-wise transformation in the proposed model protection can be efficiently implemented with vectorized operations; therefore, pre-processing with the block-wise transformation does not cause any noticeable overheads in both training and testing. From a key management perspective, $\mathcal {V}_1$ requires a trained model to generate passports, and the proposed model NP does not need any model to generate keys. Therefore, the key management of the proposed method is simple and straightforward (Table 5).
requires a trained model to generate passports, and the proposed model NP does not need any model to generate keys. Therefore, the key management of the proposed method is simple and straightforward (Table 5).
Table 5. Comparison of proposed protected model NP and state-of-the-art passport-protected model in terms of classification accuracy (%) for CIFAR datasets

V. ANALYSIS AND DISCUSSION
In this section, we analyze the block-wise transformations utilized in the proposed model-protection method in terms of pixel correlation and key sensitivity. Then, we discuss possible key improvement, the selection of transformations, and the application range of the proposed scheme.
A) Image correlation analysis
To gain insights into the classification performance of block-wise transformed images, we carried out adjacent pixel correlation tests on a test image, “dog,” in the horizontal, vertical, and diagonal directions as shown in Fig. 4. From the figure, all transformations were confirmed to maintain some correlation between pixels differently. The pixel correlation distribution of the image transformed by SHF was similar to that of the plain image. For NP and FFX, the pixel correlation distributions were different from that of the plain image. In addition, the pixel correlation of FFX was slightly weak due to the use of FFX, compared with the other ones, so this property might have caused a lower accuracy than those of the other transformations in Table 1. Accordingly, there is some correlation between pixels in the transformed images, so block-wise transformations can achieve a high classification accuracy.

Fig. 4. Horizontal, vertical, and diagonal correlation test results for plain image and images transformed by SHF, NP, and FFX ($M = 4$ ). (a) represents horizontal, vertical, and diagonal correlation distribution of plain image, (b) represents that of image transformed by SHF, (c) represents that of image transformed by NP, and (d) represents that of image transformed by FFX.
). (a) represents horizontal, vertical, and diagonal correlation distribution of plain image, (b) represents that of image transformed by SHF, (c) represents that of image transformed by NP, and (d) represents that of image transformed by FFX.
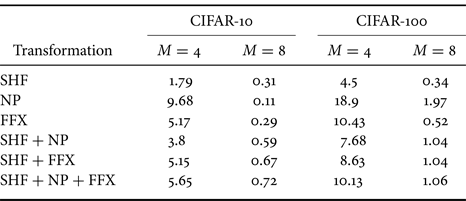
B) Key sensitivity test
We carried out key sensitivity tests for models with $M = 4$ and $8$
and $8$ on the CIFAR-10 and CIFAR-100 datasets. We define key sensitivity as the difference in accuracy between the correct key set and the modified key set (i.e. the correct key set with a small change), which is given by
on the CIFAR-10 and CIFAR-100 datasets. We define key sensitivity as the difference in accuracy between the correct key set and the modified key set (i.e. the correct key set with a small change), which is given by

where ACC is the classification accuracy with a correct key set, and ACC$'$ is that with a key set that has a small change from the correct key set.
is that with a key set that has a small change from the correct key set.
To make a small change, we swapped two random elements in the correct key for SHF, and one element in the correct key was flipped for NP and FFX (i.e. “0” to “1” and “1” to “0”). Table 6 shows the result of the key sensitivity tests, where the values in the table were averaged over $c \times M \times M$ times to cover changes in the different positions of the keys. From the results, we observed that low key sensitivity values reflected a higher accuracy for the incorrect keys, and high ones corresponded to a lower accuracy for the incorrect ones, as shown in Table 1. The key sensitivity in the table gives some insights into the difference among transformations.
times to cover changes in the different positions of the keys. From the results, we observed that low key sensitivity values reflected a higher accuracy for the incorrect keys, and high ones corresponded to a lower accuracy for the incorrect ones, as shown in Table 1. The key sensitivity in the table gives some insights into the difference among transformations.
Table 6. Key sensitivity of various transformations with $M = 4$ and $8$
and $8$
C) Discussion
Key improvement: When $M = 2$ , the key space for the block-wise transformations is relatively small, so brute force attacks are possible. To improve the key space, there are two ways: (1) to use a larger block size such as $8 \times 8$
, the key space for the block-wise transformations is relatively small, so brute force attacks are possible. To improve the key space, there are two ways: (1) to use a larger block size such as $8 \times 8$ , $8 \times 4$
, $8 \times 4$ , etc. and (2) to use a combined transformation such as SHF + NP or SHF + FFX. Note that a value of $M$
, etc. and (2) to use a combined transformation such as SHF + NP or SHF + FFX. Note that a value of $M$ affects not only the key space but also the classification accuracy and key sensitivity. Accordingly, users are requested to find a good trade-off among them.
affects not only the key space but also the classification accuracy and key sensitivity. Accordingly, users are requested to find a good trade-off among them.
Selection of transformations: Classification accuracy and model protection performance depend on the type of transformation and block size $M$ . We recommend the following selection of transformations accordingly. When a higher classification accuracy is required, NP or a combined transformation such as SHF + NP or SHF + FFX with a small block size $M$
. We recommend the following selection of transformations accordingly. When a higher classification accuracy is required, NP or a combined transformation such as SHF + NP or SHF + FFX with a small block size $M$ is recommended. When higher protection performance is preferred, a larger $M$
is recommended. When higher protection performance is preferred, a larger $M$ with SHF or a combined transformation is suitable.
with SHF or a combined transformation is suitable.
Application range: In this paper, the proposed model-protection method focuses on image classification tasks because the three encryption methods used in this paper are designed for image classification tasks. When these encryption methods are applied to other tasks such as image segmentation and image retrieval, the performance may drop compared with that of using plain images. Therefore, the proposed model protection is limited to image classification tasks, and novel image transformations are expected to be designed for applying other tasks.
VI. CONCLUSION
We proposed a model protection method that utilizes block-wise transformations with a secret key set to transform input images. Specifically, the transformation methods are pixel shuffling, negative/positive transformation, and FFX. The performance accuracy of a protected model was closer to that of a non-protected model when the key set was correct, and it dropped drastically when an incorrect key set was given, suggesting that a protected model is not usable even when the model is stolen. The proposed method is also applicable to large datasets like the ImageNet dataset, which has never been tested by previous model-protection methods. Moreover, the proposed model-protection method does not introduce any overhead in both training and inference time. It is also robust against fine-tuning attacks in which the adversary has a small subset of a training dataset to adapt a new forged key set and key estimation attacks.
FINANCIAL SUPPORT
This study was partially supported by JSPS KAKENHI (Grant Number JP21H01327) and JST CREST (Grant Number JPMJCR20D3).
AprilPyone MaungMaung received a BCS degree from the International Islamic University Malaysia in 2013 under an Albukhary Foundation Scholarship and an MCS degree from the University of Malaya in 2018 under the International Graduate Research Assistantship Scheme. Since 2019, he has been a Ph.D. student under the Tokyo Human Resources Fund for City Diplomacy Scholarship at Tokyo Metropolitan University. He received an IEEE ICCE-TW Best Paper Award in 2016. His research interests are in the area of information security. He is a student member of IEEE.
Hitoshi Kiya received his B.E. and M.E. degrees from the Nagaoka University of Technology, Japan, in 1980 and 1982, respectively, and his Dr.Eng. degree from Tokyo Metropolitan University in 1987. In 1982, he joined Tokyo Metropolitan University, where he became a Full Professor in 2000. From 1995 to 1996, he attended The University of Sydney, Australia, as a Visiting Fellow. He is a fellow of IEEE, IEICE, and ITE. He was a recipient of numerous awards, including 10 best paper awards. He served as the President of APSIPA from 2019 to 2020, and the Regional Director-at-Large for Region 10 of the IEEE Signal Processing Society from 2016 to 2017. He was also the President of the IEICE Engineering Sciences Society from 2011 to 2012. He has been an editorial board member of eight journals, including IEEE Transactions on Signal Processing, IEEE Transactions on Image Processing, and IEEE Transactions on Information Forensics and Security, and a member of nine technical committees, including the APSIPA Image, Video, and Multimedia Technical Committee (TC), and IEEE Information Forensics and Security TC. He has organized a lot of international conferences in such roles as the TPC Chair of IEEE ICASSP 2012 and as the General Co-Chair of IEEE ISCAS 2019.


















 Open access
Open access