


Self-paced reading (SPR) is an online computer-assisted research technique in which participants read sentences, broken into words or segments, at a pace they control by pressing a key. The time elapsed (reaction time; RT) between each keypress is recorded. Underlying this technique is an assumption that participant RTs indicate their knowledge of and/or sensitivity to linguistic phenomena relative to other linguistic phenomena. The technique was originally used to investigate first language (L1) reading mechanisms (Aaronson & Scarborough, Reference Aaronson and Scarborough1976), including word recognition in sentential contexts, meaning representation, and real-time parsing (building syntactic structures), among native speakers, often highly literate, monolingual adults. The method has been increasingly adopted by researchers interested in L2 phenomena, yet special challenges are presented when using SPR for L2 research. As the applicability and rigor of usage of this technique in L2 research has not been scoped systematically, one of the main purposes of the current study is to identify why and how L2 researchers have used this method. For example, although SPR is thought to offer a window into processes that are largely automatic (i.e., fast and without awareness), L2 learners are often of varying proficiencies, experiences, and ages. They also have a wide range of L2 reading skills and are more likely than many adult L1 participants to have explicit knowledge of the language due to formal L2 instruction. Thus, how the nature of knowledge and mechanisms elicited by SPRs, and the instruments used alongside them, are discussed and operationalized by L2 researchers is worthy of empirical and systematic investigation.
L2 learners are also unique in that they bring to the task of reading a complex set of phenomena due to their highly entrenched L1 representations and processing routines, along with varying degrees of L1 reading expertise. To illustrate, in L2 research an inverse relationship is generally expected between proficiency and the time needed to process words or segments in an SPR test (higher proficiency = faster). However, we might also expect more advanced users to process anomalies or disambiguations more slowly than less proficient users who may be less sensitive to the target structure. In addition, we might anticipate certain effects to obtain as a function of different L1s, depending on the particular theory about the role of the L1 in real-time processing, representation, and learning of an L2. Other questions specific to L2 research are whether L2 online processing is fundamentally different to L1 processing (e.g., more superficial or “shallower”; see below) and the extent to which it is different to offline knowledge in the L2 compared to the L1; investigations into these questions inform our understanding of differences between L1 and L2 learning. The extent to which all these issues and relevant participant characteristics have been investigated, operationalized, and reported is, therefore, of high importance, and can provide the field of L2 research with data about the purpose and nature of its own practices and on relations between data elicitation, analysis, and theorizing.
Our focus on SPR in L2 research had several motivations. First, as noted above, L2 populations present specific areas of interest and, therefore, entail particular methodological decisions and reporting requirements. Second, SPR is increasingly popular. Of course, other methods for investigating L2 knowledge and reading exist (e.g., rapid serial visual presentation; RSVP; Boo & Conklin, Reference Boo and Conklin2015; whereby the researcher, rather than the participant, controls the pace), but SPR is often thought to provide certain advantages, no doubt reflected by its increasing popularity. RSVP is much less commonly used perhaps because SPR, unlike RSVP, leaves control over exposure time to the participant (as in natural reading) and, as such, can concurrently measure processing time, thus reflecting online cognitive mechanisms (see Just, Carpenter, & Woolley, Reference Just, Carpenter and Woolley1982). Similarly, other methods exist for investigating online processing, such as eye tracking and event-related potentials, but, again, SPR presents some advantages, including: its relative ease of administration and cost; its elicitation of behavioral data rather than neurological data where links between constructs and their signatures are still relatively nascent and debated (Morgan-Short, Reference Morgan-Short2014); and its comparability to eye tracking in its capacity to tap into cognitive processes (Just et al., Reference Just, Carpenter and Woolley1982; see Keating & Jegerski, Reference Keating and Jegerski2015, for a narrative review of these three online techniques). Third, our focus on SPR allows us to drill down with a high level of detail, in the space available, into substantive and methodological issues that pertain to this particular technique and are specific to L2 research. These issues include comprehension measures, participant sampling and reporting practices, segmentation decisions in different languages, and the extent and nature of investigations such as patterns of L1-L2 combinations and different processing phenomena. Fourth, a systematic methodological review is already available for another online processing technique (see Lai et al., Reference Lai, Tsai, Yang, Hsu, Liu, Lee and Tsai2013, for eye tracking). Thus, given our interest in the context of L2 research, we limited the scope of inquiry for our synthesis accordingly, i.e., to studies employing SPR with L2 users as participants. Future studies could compare L1 to L2 SPR research, or SPR to RSVP. (See Bowles, Reference Bowles2010; Lai et al., Reference Lai, Tsai, Yang, Hsu, Liu, Lee and Tsai2013; Yan, Maeda, Lv, & Ginther, Reference Yan, Maeda, Lv and Ginther2016, for similar rationales underpinning systematic methodological reviews of think-alouds, eye-tracking, and elicited imitation, respectively).
With many of the issues and challenges described thus far in mind, Keating and Jegerski (Reference Keating and Jegerski2015) provide particularly useful guidance on SPR, addressing design, administration, data preparation, and analysis procedures (see also Jegerski & VanPatten, Reference Jegerski and VanPatten2013; Roberts, Reference Roberts, Mackey and Marsden2016, for methodological guidance and commentary on key studies). The present study complements these and other relevant discussions (e.g., Clahsen & Felser, Reference *Clahsen and Felser2006; Jiang, Reference Jiang2012; Juffs & Rodríguez, Reference Juffs and Rodríguez2015) to systematically examine the purpose and use of SPR in L2 research. More specifically, we apply a synthetic/meta-analytic technique, namely, systematic methodological synthesis, to understand the following:
1. The extent to which SPR has been used in L2 research and the research areas that such studies have addressed
2. The contexts, demographics, design features, and instrumentation used in L2 SPR research
3. The features of L2 SPR tests and corresponding analyses
4. The methodological transparency of L2 SPR research
By investigating these characteristics within a comprehensive body of research using SPR, we sought to better understand why and how this technique has been used in L2 research. It is not our intention to criticize the efforts of previous researchers but, rather, to highlight issues and practices that relate to construct validity, reliability, and reproducibility. We use our results to indicate where empirically grounded standard practices might be useful and also to indicate specific study and participant characteristics that would extend the agendas thus far investigated using SPRs. Our study thereby complements and builds on foundational discussions put forward by others (e.g., Keating & Jegerski, Reference Keating and Jegerski2015).
RESEARCH AIMS AND RATIONALES FOR USING SPR IN L2 RESEARCH
Methodological syntheses cover a wide range of issues that cannot all be justified in a background section of a journal article. As noted above, we refer the reader to several existing narrative reviews and guides, which do an excellent job of laying out the substantive and methodological considerations in the use of SPR. Those works were also highly influential in motivating the current study and in the development of our scheme for coding our studies. The majority of the background section that follows is, therefore, limited to issues that require further explanation, particularly those where greater inferencing was needed to code for features in our sample of primary studies. These issues are as follows: the reported rationales for using SPR; the broad research aims of studies; the processing phenomena and linguistic features investigated; the sentence regions analyzed; and the nature of processing/knowledge elicited.
Overarching rationales and research aims of SPR research
Two broad questions, both central to much of L2 research, have driven the use of SPR: the extent and nature of differences between native and nonnative language acquisition and knowledge, and the role of the L1 in L2 development (i.e., cross-linguistic influence). In the former, SPRs have been used to investigate the extent to which L1 (native) and L2 (nonnative) processing draw on fundamentally different mechanisms, such as access to and nature of linguistic representations. For example, there is evidence that L2 adult learners access superficial linguistic syntactic information as compared to adults processing their L1 (Clahsen & Felser, Reference *Clahsen and Felser2006; Marinis, Roberts, Felser, & Clahsen, Reference *Marinis, Roberts, Felser and Clahsen2005). SPR data have also been used to show, however, that nativelike syntactically based processing can occur (Dussias, Reference *Dussias2003; Juffs, Reference *Juffs1998; Williams, Mobius, & Kim, Reference *Williams, Mobius and Kim2001), and that this can depend on, for example, proficiency (Dekydtspotter & Outcalt, Reference *Dekydtspotter and Outcalt2005; Hopp, Reference *Hopp2006), the complexity of syntactic structures, the nature of the task (Havik, Roberts, van Hout, Schreuder, & Haverkort, Reference *Havik, Roberts, van Hout, Schreuder and Haverkort2009), and the type of learning experience (immersion vs. more form-focused, Pliatsikas & Marinis, Reference *Pliatsikas and Marinis2013a).
A closely related agenda investigates the extent to which the L1 influences L2 processing, learning, or representations. A key principle motivating this line of research is as follows: if the speed of processing is affected on words or structures that share some similarity with the L1 compared to others that do not, we might assume that L1 representations are activated, at some level, during reading (Koda, Reference Koda2005). Such findings have been used to suggest that the L1 influenced or continues to influence L2 learning or use, via the lexicon (Bultena, Dijkstra, & van Hell, Reference *Bultena, Dijkstra and van Hell2014; Ibáñez, Macizo, & Bajo, Reference *Ibáñez, Macizo and Bajo2010) or morphosyntax (Dussias, Reference *Dussias2003; Hopp, Reference *Hopp2009; Jiang, Novokshanova, Masuda, & Wang, Reference *Jiang, Novokshanova, Masuda and Wang2011; Marull, Reference Marull2015).
In the current study, we systematically review the designs of SPRs that have addressed these broad questions and the processing phenomena they target (e.g., ambiguity resolution or anomaly detection). We also systematically review the features that have served as the linguistic targets in this line of inquiry.
Sentence processing phenomena and the linguistic “critical regions”
A large part of L2 sentence processing research is based on the idea that initial parses can be erroneous and reanalysis is required (this reanalysis has been theorized in various ways; see Van-Gompel, Reference Van-Gompel2013, for a detailed overview). For example, in (1) the reader could interpret “the mistake” (an ambiguity) as a direct object that completes a subject–verb–object parse, and not as a reduced relative clause (i.e., “The ticket agent admitted that the mistake . . .”), until the disambiguation point “might” is reached. This could then result in a reinterpretation of the sentence by parsing the ellipsed “that,” observable in slower processing during or after the disambiguation point.
(1) “The ticket agent admitted the mistake might not have been caught” (Dussias & Cramer Scaltz, Reference *Dussias and Cramer Scaltz2008, p. 505).
Some studies have manipulated the plausibility of the noun following the first verb to investigate temporary ambiguity resolution (known as “garden-pathing”). For example, in the version of example (2) with “milk,” an initial parse of “milk” as a direct object, rather than as the subject of a new clause, would require reanalysis on encountering “disappeared” (the disambiguation point) to reach the correct interpretation.
(2) “As the girl drank the milk /dog disappeared from the kitchen” (Roberts & Felser, Reference *Roberts and Felser2011, p. 328).
In this example, the parser encounters an optionally transitive verb (drink) and so can expect an object. However, in the version with “dog,” the parser might slow down because this object does not fit with the semantics of “drink” (especially in the absence of punctuation and prosody). However, because it is an implausible direct object of “drink,” it is more likely than “milk” to receive a correct initial parse, that is, as the subject of an upcoming coordinating clause. Thus, sentences containing nouns that are implausible as objects may result in quicker recovery in the disambiguating region (“disappeared”) compared to nouns that initially seemed plausible objects.Footnote 1 That is, patterns of RTs indicate sensitivity to verb semantics and arguments, and this sensitivity may vary as a function of similarity/difference between features in the L1 versus L2, or native/nonnativeness.
The relevant point for the current methodological review is that decisions about which words or segments to manipulate and analyze should be reported explicitly and be broadly systematic across studies investigating related phenomena. Thus, the choice and reporting of which region to analyze is critical to construct validity in SPR research and, as such, is one of the features we examine in our review.
Underlying constructs: Processing and knowledge types
Another more common technique used to elicit sensitivity to morphosyntax in the input is the grammaticality (or acceptability) judgment test (JT). Compared to JTs, SPRs allow researchers to determine with more precision the moment where difficulty (or processing cost) or facilitation (processing ease) arises, without seeking an explicit and offline judgment. Researchers use this information to infer that a representation (of, e.g., morphosyntax or lexicon) is sufficiently well established in a participant's mind for them to demonstrate sensitivity to it, without intentionally drawing on awareness or explicit knowledge (see Vafaee, Suzuki, & Kachisnke, Reference *Vafaee, Suzuki and Kachisnke2016). Thus, one reason that researchers turn to SPRs is that they are thought to provide a window into implicit processing and, possibly, into learners’ implicit underlying linguistic knowledge representations. However, many L2 researchers recognize a distinction between processing and knowledge. Within this position, investigating online processing per se does not predetermine a particular assumption about the type of knowledge or the nature of linguistic representations that processing mechanisms draw on. Consequently, SPRs can and have been used by researchers with a range of theoretical perspectives (e.g., generative and cognitive).
Related to the issue of the knowledge constructs being elicited is the fact that SPR, by definition, is both in the written modality (in contrast to self-paced listening; see Padapdopoulou, Tsimpli, & Amvrazis, Reference Papadopoulou, Tsimpli, Amvrazis, Jegerski and VanPatten2013) and is not time constrained by the researcher (i.e., untimed, in contrast to RSVP). There is evidence that these test characteristics are more likely to allow access to awareness and even explicit knowledge (Ellis, Reference Ellis2005; Kim & Nam, Reference Kim and Nam2016; Spada, Reference Spada2017; Vafaee et al., Reference *Vafaee, Suzuki and Kachisnke2016). In addition, the early stages of reading itself begin as conscious processes, and can be accounted for by skill acquisition theories (DeKeyser, Reference DeKeyser, VanPatten and Williams2015; Laberge & Samuels, Reference Laberge and Samuels1974; Tunmer & Nicholson, Reference Tunmer, Nicholson, Kamil, Pearson, Moje and Afflerbach2010).
Although not a full account of these issues, we have touched upon them as they informed our decision to code certain features: (a) the rationales discussed for using an SPR and (b) the extent to which authors discussed the nature of knowledge and processing (e.g., implicit, explicit, or automatized). They also informed our decision to examine design features that can affect participants’ attentional focus and awareness of the target of the test: (c) the use of other instruments (e.g., JTs) in the same study and (d) the focus of comprehension questions (if used) on particular words in the sentences in relation to the target feature.
METHODOLOGICAL SYNTHESIS IN SECOND LANGUAGE RESEARCH
A number of useful narrative discussions of different online data collection techniques exist. These include Frenck-Mestre (Reference Frenck-Mestre2005) and Roberts and Siyanova-Chanturia (Reference Roberts and Siyanova-Chanturia2013) on eye-movement techniques; Kotz (Reference Kotz2009) on event-related potentials and functional magnetic resonance imaging; and Bowles (Reference Bowles2010) and Leow, Grey, Marijuan, and Moorman (Reference Leow, Grey, Marijuan and Moorman2014) on concurrent think-alouds. Several publications also focus on online sentence processing techniques (Jegerski & VanPatten, Reference Jegerski and VanPatten2013; Keating & Jegerski, Reference Keating and Jegerski2015; Marinis, Reference Marinis, Unsworth and Blom2010; Roberts, Reference Roberts2012; Witzel, Witzel, & Forster, Reference Witzel, Witzel and Forster2012), with one that focusses uniquely on SPR (Roberts, Reference Roberts, Mackey and Marsden2016). The present study differs from these in its exclusive focus on SPR and, critically, the comprehensive and systematic nature of our approach: methodological synthesis.
In methodological synthesis, unlike other types of synthetic and meta-analytic research, the focus is not so much on aggregating substantive findings but, rather, on the methods that have produced them. In doing so, this approach draws heavily on the synthetic ethic developing in applied linguistics (Norris & Ortega, Reference Norris and Ortega2006); it is also closely tied to the methodological reform movement taking place in the field and efforts to understand and investigate “study quality” (Plonsky, Reference Plonsky2013).
Methodological synthesis involves collecting a representative or exhaustive sample of studies with a common interest, which are then coded systematically for different study features, research practices, and so forth. This procedure has been used to examine methodologies within large substantive domains, such as interaction in second language acquisition (SLA; Plonsky & Gass, Reference Plonsky and Gass2011), written corrective feedback (Liu & Brown, Reference Liu and Brown2015), and task-based learner production (Plonsky & Kim, Reference Plonsky and Kim2016). Methodological syntheses have also looked across domains focusing on a particular technique, procedure, or set of practices, such as: designs, analyses, and reporting practices in quantitative research (Plonsky, Reference Plonsky2013); classroom experiment designs (Marsden & Torgerson, Reference Marsden and Torgerson2012); factor analysis (Plonsky & Gonulal, Reference Plonsky and Gonulal2015); and instrument reporting practices (Derrick, Reference Derrick2016).
The methodological syntheses carried out to date in applied linguistics have provided a number of insights derived from describing and evaluating their domains of inquiry. Findings include underpowered samples, a lack of demographic diversity, and, in terms of analyses, an overreliance on techniques that are not always appropriate to the data or research questions (Plonsky & Oswald, Reference Plonsky and Oswald2017). Of additional concern is the lack of transparency about both instrumentation (e.g., Derrick, Reference Derrick2016: Marsden, Mackey, & Plonsky, Reference Marsden, Mackey, Plonsky, Mackey and Marsden2016) and data and analysis reporting practices, which are critical to enable consumers and synthesists to capitalize on reports (Norris & Ortega, Reference Norris and Ortega2000).
To our knowledge, only two systematic reviews of individual data elicitation techniques in applied linguistics have been conducted to date: Bowles's (Reference Bowles2010) meta-analysis of reactivity in think-alouds, and Yan et al.’s (Reference Yan, Maeda, Lv and Ginther2016) meta-analysis on the validity of elicited imitation tests (see also Lai et al.’s Reference Lai, Tsai, Yang, Hsu, Liu, Lee and Tsai2013 review of eye-tracking in the wider domain of education research). These studies provide comprehensive data on the methods they target. No reviews of this nature exist for SPR. The current synthesis aimed to produce such a review by providing a comprehensive examination of the amount, purpose, scope, nature of usage, reporting, and transparency of SPRs.
RESEARCH QUESTIONS
The ultimate goal of the study was to provide an empirical evidence base regarding the use of SPR in L2 research that could help to improve the rigor and scope of future research. Within the domain of L2 research that is reported in journal articles, the following research questions guided the study:
RQ1: How much L2 research using SPR is there, and what are its stated aims and rationales?
RQ2: What are the study and participant characteristics in L2 SPR research?
RQ3: What are the L2 SPR instrument design characteristics?
RQ4: How are L2 SPR data cleaning and statistical procedures carried out and reported?
RQ5: What is the extent of L2 SPR instrument transparency?
METHOD
The present study adheres to best practices in research synthesis at all stages, including searching for studies, clarifying inclusion/exclusion criteria, piloting the coding scheme, and analyzing synthetic data.
Study selection
We aimed to find all peer-reviewed journal articles reporting the use of one or more SPRs in a study investigating second language, foreign language, or bilingual (but not child bilingual) participants. Following Plonsky and Brown (Reference Plonsky and Brown2015), we searched a variety of sources: Linguistics and Language Behaviour Abstracts (LLBA), PsycInfo, IRIS (Marsden, et al., Reference Marsden, Mackey, Plonsky, Mackey and Marsden2016), and the L2 Research Corpus (a collection of around 8,000 articles from 16 journals from 1980 until the present day held by Plonsky). There was no a priori start date; the search concluded in March 2016 (this did not include studies that were only in online format by this date as LLBA and PsycInfo do not index them). Any studies published in journals were eligible for inclusion. We recognize that this may render our syntheses susceptible to a certain type of publication bias. A number of book chapters (e.g., Bannai, Reference Bannai2011; Fernández & Souza, Reference Fernández, Souza, Heredia, Altarriba and Cieślicka2016; Suda, Reference Suda2015; White & Juffs, Reference White, Juffs, Flynn, Martohardjono and Neil1998) and eight doctoral dissertations were excluded. However, we believe that our journal-based sample is representative of the population of research employing SPR. Further, this approach provides for enhanced systematicity and replicability (Plonsky & Derrick, Reference Plonsky and Derrick2016; Plonsky & Gass, Reference Plonsky and Gass2011). In any case, publication bias was less of a concern in our study as we were not aggregating substantive effects as in a meta-analysis. In addition, we wished to focus on usage and reporting of SPRs that have been approved through the journal peer review system.
After various trials, our ultimate search terms for LLBA and PsycInfo were (self-paced reading OR subject-paced reading OR moving window) AND (learning OR acquisition OR biling* OR language OR multiling*), with “peer-reviewed” checked. This resulted in 384 hits in LLBA and 250 hits in PsycInfo. The L2 Research Corpus yielded an additional 14 studies that had not been found by LLBA or PsycInfo because those databases do not search the full texts (just the title, abstract, and keywords). After eliminating duplicates and excluding any studies that focused only on L1 acquisition or child bilinguals, the final sample consisted of 64 studies, reporting a total of 74 SPR tests. Included studies are marked in the references with*.
Coding
Our data collection instrument, a coding scheme, can be found in full in Appendix A (online supplementary material) and on the IRIS database (iris-database.org). Most items were categorical (e.g., absent/present; English/French/Spanish etc.; gender/tense etc.), although a few allowed for open-ended text (e.g., rationales for SPR use).
The scheme was developed through a process of rigorous piloting by the authors, involving 10 iterations, with additions and refinements of categories, definitions, and values within coding parameters at each stage. The initial scheme was informed by previous literature (Jegerski & VanPatten, Reference Jegerski and VanPatten2013; Keating & Jegerski, Reference Keating and Jegerski2015; Roberts, Reference Roberts, Mackey and Marsden2016) and was used by the three authors to independently code two randomly selected studies (Amato & MacDonald, Reference *Amato and MacDonald2010; Roberts & Liszka, Reference *Roberts and Liszka2013). Disagreements were resolved and unclear codes amended. The revised scheme was then used by the second author to code nine studies, and further refinements were discussed with the first author. Each study was then coded by the second author.
To check coding reliability, a second coder, who was not involved in the development of the coding scheme but who had considerable training and experience in meta-analytic research, was trained to use the scheme. He then independently coded 15 (20%) of the 74 SPRs. These SPRs were chosen quasi-randomly, ensuring they came from different studies. For just 6 of the 121 coding categories agreement fell below 75%; for these, the first coder either amended her coding or requested the second coder reconsider. We then recalculated agreement, and all categories reached at least 80%. In terms of Cohen's kappa (κ), out of 121 coding parameters (113 of which allowed κ to be calculated) all κ ≥ 0.63, with just 6 exceptions exhibiting κ of 0.48, 0.31, 0.52, 0.55, 0.44, and 0.36, but high agreement rates of 93%, 80%, 93%, 87%, 87%, and 80% respectively. We attribute these apparent discrepancies between percentage agreement and κs to the very high consistency of values within those items (e.g., almost all “zeros”), which leads to overly conservative κ estimates. The final overall mean agreement was 94%, with a mean interrater reliability of κ = 0.86. See Appendix A (in online Supplementary Materials) and www.iris-database.org for % agreement and κ on each coding category. To benchmark this against other methodological syntheses, Plonsky (Reference Plonsky2013) reported an interrater reliability agreement rate of 82%, κ = 0.56, Plonsky and Derrick (Reference Plonsky and Derrick2016) κ = 0.74, and Marsden, Morgan-Short, Thompson, and Abugaber (Reference Marsden, Morgan-Short, Thompson and Abugaber2018) 89% agreement and mean κ = 0.80.
FINDINGS AND DISCUSSION
We present our findings below organized according to our research questions. Given the wide range of issues covered by methodological syntheses and space constraints, we also include most of our discussion in this section. This approach, though somewhat nontraditional, allows us to present interpretations of our findings in closer proximity to their associated data. Given the number of unique quantitative results, we felt that this style of presentation would be helpful and more efficient than the standard approach.
RQ1: How much L2 research using SPR is there, and what are its stated aims and rationales?
Our search revealed a total of 74 SPRs in 64 individual articles (7 of which used multiple SPRs) used in L2 research. The majority of these studies (k = 42) were published since 2010, illustrating the increasing popularity of this technique (Figure 1). The earliest example of L2 SPR appears in Juffs and Harrington (Reference *Juffs and Harrington1995), approximately 20 years after the early L1 SPR studies. Our sample spans 21 journals, with most published in Applied Psycholinguistics (14), Bilingualism: Language and Cognition (9), Studies in Second Language Acquisition (9), Language Learning (8), Second Language Research (8), and a small number in other journals.
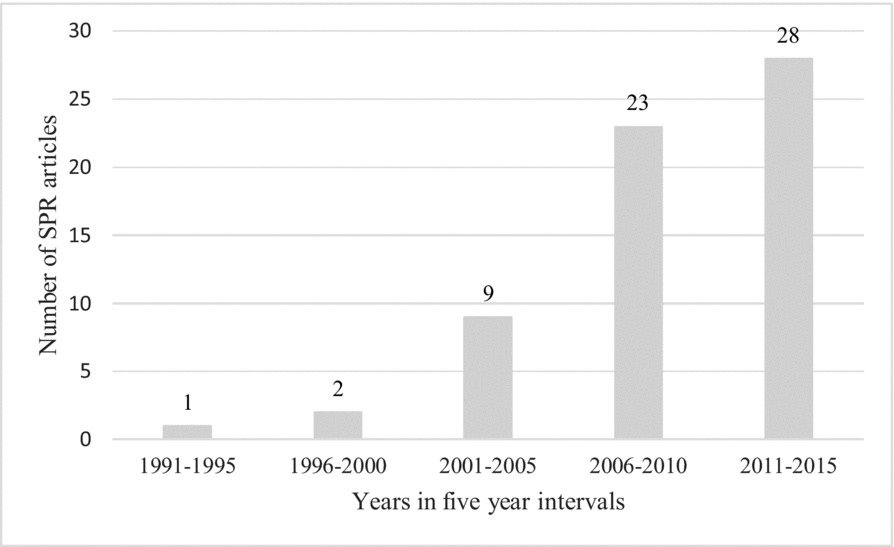
Figure 1. Number of journal articles reporting SPRs over time. The year 2016 is excluded because this review only went up to the first quarter of 2016 (three articles).
Rationales given for using SPR: Knowledge and processing
A total of 52 studies included some rationale for using an SPR (beyond a general interest in examining online processing). We found a total of 129 individual (tokens of) rationales. These were first coded “bottom-up” to extract keywords, and we then searched for these keywords across all articles. This produced the seven main themes, shown in Table 1. Two broad types of rationales emerged: one relating to learner knowledge (40 tokens across 26 articles) and one relating to processing mechanisms or phenomena (89 tokens across 57 articles). Twenty-six articles referred to both knowledge and processing. Twenty-three articles used the word “processing” alone to explain their use of the technique.
Table 1. Rationales provided for using an SPR
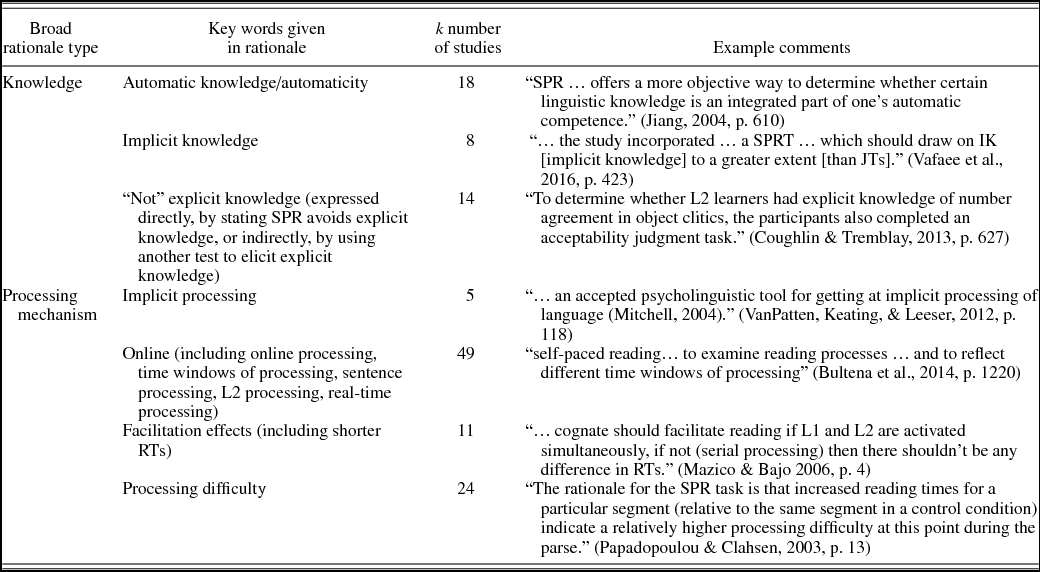
Although many rationales were given related to implicit knowledge and processing, we found little in-depth discussion of the nature of knowledge or processing. We found no challenges to the notion that SPRs in L2 research are a measure of implicit knowledge, and no discussion of a potential role for awareness or attention. When explicit knowledge was mentioned, it was in relation to SPR reducing access to it or in relation to other measures being used in the same study to elicit a different type of knowledge to the SPR. This perhaps reflects a consensus that reactions in SPRs are deemed to operate below the level of consciousness, though empirical validation of this would be useful. For example, some have argued that conscious thought can occur 300 ms after registration of a stimulus (Dehaene, Reference Dehaene2014). SPR has clearly been used to investigate relations between offline knowledge and online processing, as reflected in the 29 studies mentioning both in their rationales, and this was often manifested in studies that incorporated other measures alongside an SPR. However, we did not find any studies looking at the concurrent development of processing and L2 knowledge over time (discussed below).
The broad aims and processing phenomena investigated
The key aim for 34 out of the 64 studies was to investigate differences between native and nonnative online processing. The vast majority of these (30/34) used a native comparison group within the same study (the remaining 4 compared their findings to previous studies that used different SPRs or other measures).
Twenty-one studies investigated both cross-linguistic influence and also differences between native and nonnative online processing. Nineteen of these used a native-speaker group for comparison, and 11 used different L1 groups for comparison.
Five studies had the sole key aim of investigating cross-linguistic influence: one of these had more than one L1 group as a between-subject factor, whereas four addressed this question without an L1 comparison group (three used SPRs in the participants’ L1 and L2, and one manipulated the similarity of L2 verbs to those in the L1). One (of these five) also had a native comparison group.
Four studies had other aims: one used an artificial language to investigate the early stages of acquisition, one used novel words to investigate vocabulary learning, one investigated the effect of translation and repetition, and another validated measures of implicit and explicit knowledge.
Of the 74 SPR tests, the majority (40) were used to investigate the processing and resolution of ambiguities (13 global and 27 local/temporary/garden path ambiguities). Global ambiguities remain after the reader has processed the entire sentence (e.g., “Peter fell in love with the daughter of the psychologist who studied in California”; Dussias, Reference *Dussias2003, p. 541), whereas local/garden path ambiguities result in an initial syntactic misanalysis and are then disambiguated at later a point in the sentence (e.g., “After Bill drank the water proved to be poisoned”; Roberts, Reference Roberts, Mackey and Marsden2016, p. 59).
Twenty-two SPRs were used to investigate the processing of and sensitivity to anomalies, seven of which investigated multiple features (e.g., gender and number; Sagarra & Herschensohn, Reference *Sagarra and Herschensohn2010, Reference *Sagarra and Herschensohn2011). Of those investigating just one feature, the most common was gender (k = 6), then number (k = 4). Other commonly investigated features (some combined with other features) included tense (3), aspect (2), person (4), and number (7).
Twelve other SPR tests did not clearly fall into any of those three categories (global ambiguity, local ambiguity, or anomaly). Three investigated syntactic distance dependency (Amato & MacDonald, Reference *Amato and MacDonald2010; Coughlin & Tremblay, Reference *Coughlin and Tremblay2013; Marinis et al., Reference *Marinis, Roberts, Felser and Clahsen2005). Others investigated how cognates affect processing (Bultena et al., Reference *Bultena, Dijkstra and van Hell2014; Ibáñez et al., Reference *Ibáñez, Macizo and Bajo2010), the effect of text type on reading speed (Lazarte & Barry, Reference *Lazarte and Barry2008; Yamashita & Ichikawa, Reference *Yamashita and Ichikawa2010), the plausibility of collocations (Lim & Christianson, Reference *Lim and Christianson2013), and novel word learning (Bordag, Kirschenbaum, Tschirner, & Opitz, Reference *Bordag, Kirschenbaum, Tschirner and Opitz2015).
Other instrumentation used alongside SPRs
Of the 74 SPRs, 57 (77%) were used in coordination with other instruments (Table 2). Almost half of the studies (31) used a JT, enabling researchers to investigate relationships between online processing and offline performance. Of the 31, 14 did so in an “integrated” fashion. That is, a JT item was provided after each SPR trial, prompting participants to indicate acceptability or plausibility of some morphosyntactic feature. This is a critical design decision, as orienting attention on particular features, in ways that participants might anticipate across trials, may affect response times and raise awareness of the target feature being tested. For example, Havik et al. (Reference *Havik, Roberts, van Hout, Schreuder and Haverkort2009) found that when L2 learners (particularly those with a higher working memory capacity) made judgments after trials, they manifested similar patterns of RTs to native speakers.
Table 2. Number of SPRs used with another instrument

JTs were also administered after SPR tests in 15 studies, and in just 2 studies a JT preceded an SPR. Study design in this respect seemed largely in line with Keating and Jegerski's (Reference Keating and Jegerski2015) observation that explicit JTs should be administered after SPRs. The rationale behind this is that JTs that precede or are integrated within SPRs may raise the participants' awareness about a study's target.
However, none of the studies used a measure to determine the nature or magnitude of awareness during the SPR tests, such as retrospective subjective measures or knowledge source judgments (Rebuschat, Reference Rebuschat2013). Thus, despite SPRs being untimed and written, and tapping into a process (reading) that is explicit in its early stages, it remains for future research to investigate the extent to which participants are aware during SPR of the linguistic focus of the study. Collecting such information will be especially important if SPRs are to be considered measures of implicit processing or knowledge (see Vafaee et al., Reference *Vafaee, Suzuki and Kachisnke2016).
RQ2: What are the study and participant characteristics in L2 SPR research?
Contexts and languages
Thirty-four of the 74 SPRs were used in second language and 33 in foreign language contexts, and 6 were used in both contexts (i.e., in two or more sites). One study used an artificial language. The vast majority of participants were university students (59/74 SPRs). Fifty-four studies included instructed language learners and at least 2 were students from education or applied linguistics departments. Such participants likely possess a specific nature of language competence (Hulstijn, Reference Hulstijn2015) and above average meta-linguistic knowledge (Roehr, Reference Roehr2008), which may affect the nature and speed of reading processes (as suggested by Keating & Jegerski, Reference Keating and Jegerski2015, p. 27).
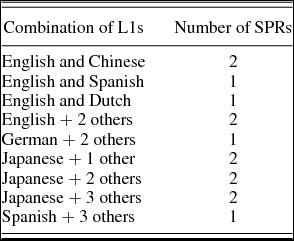
Table 3 shows the range and frequency of L1 and target languages investigated. Fourteen of the 20 studies using learners with different L1s used the L1 as a between-subject variable (Table 4). The other 6 studies grouped learners into a single group, regardless of their L1.
Table 3. Languages used in SPRs

Table 4. Types and numbers of comparisons between different L1s
Participant sample sizes
Whole-study sample sizes ranged from 12 (Macizo & Bajo, Reference *Macizo and Bajo2006) to 133 (Sagarra & Herschensohn, Reference *Sagarra and Herschensohn2010), with a mean of 46.58 (SD = 26.12, median = 43.5). Subgroup sample sizes ranged from 10 to 69, with a mean of 26.91 (SD = 11.15, median = 24). This is somewhat higher than Plonsky's (Reference Plonsky2013) finding, from 606 primary studies, of a median subgroup sample size of 19, and yet lower than his median whole study sample size of 60.Footnote 2 This difference might be due in part to the fact that administering SPRs can be done relatively easily in groups in labs. None of the studies reported an a priori power analysis, and very few reported effect sizes, which, among other benefits, would facilitate subsequent power analyses.
Of the 36 SPRs used to compare multiple groups, 14 had the same sample size across groups. However the mean difference between group (subsample) sizes was 8.9 (SD = 10.4, range 1–50). Such sample size differences may require specific statistical techniques (e.g., Games Howell post hoc paired comparison tests for nonequal sample sizes, or nonparametric tests). We did not find any studies that explicitly addressed unequal sample sizes in their analyses.
Participant proficiencies and study design
Participant groups were labeled by the studies’ authors as beginner (6), intermediate (18), advanced (53), near native (6), and bilingual (10).Footnote 3 This is not typical of the general propensity for L2 research to oversample intermediate learners (see Plonsky, Reference Plonsky2013) and shows the relative neglect of online processing research among lower proficiency levels. As well as ease of participant recruitment, this might be for several reasons. One might be the underpinning assumption that SPRs tap into comprehension processes, and successful comprehension is more likely among higher proficiencies. Another might be that one of the research aims that drove the use of SPR among L2 researchers (i.e., fundamental differences between native and nonnative processing) is thought to require high proficiency/high exposure to have given the SLA process maximum opportunity to reach an “end state.” However, it is of course possible, and of theoretical and pedagogical interest, to investigate online processing among less proficient learners (e.g., manipulating the comprehensibility of the stimuli). In our study sample, a relatively low number (16/64 studies) used a cross-sectional design using proficiency as a between-group factor. The majority of these compared what the authors referred to as “intermediate” and “advanced” learners (12 studies).
We found no examples of longitudinal research using SPR, defined as within-subject comparisons over time on the same SPR.Footnote 4 However, the number (16) of cross-sectional studies may reflect a growing interest in the developmental trajectory of online processing. Nevertheless, this number is surprisingly low, given the interest in the role of processing as a driver in the acquisition process (Chang, Dell, & Bock, Reference Chang, Dell and Bock2006; O'Grady Reference O'Grady2005; Philips & Ehrenhofer, Reference Philips and Ehrenhofer2015; Seidenberg & MacDonald, Reference Seidenberg and MacDonald1999). In our studies, we found little discussion of interfaces between processing/learning/knowledge, perhaps a reflection of SPRs being initially employed in L2 research under the premise that offline knowledge (such as access to a Universal Grammar, often elicited via JTs) was distinct from online behaviors. Thus, it remains to be explored the extent to which SPR has potential for investigating whether processing or anticipatory effects have a causal role in driving and constraining acquisition, or are more of a “symptom/product” of other acquisition mechanisms (e.g., Foucart, Reference Foucart2015; Huettig & Mani, Reference Huettig and Mani2016; Kaan, Reference Kaan2015).
We add a note of caution to our findings about proficiency levels. In terms of the measurement of proficiency, it was reassuring to find only three studies that just used educational level to assume proficiency and none that just used self-rating (i.e., the vast majority of studies used a measure to select or group participants). Thirty-four studies reported one proficiency indicator, detailed in Table 5, and the remaining studies used more than one.
Table 5. Studies using a single indicator of proficiency (k = 34)

A good number of studies used standardized proficiency tests, though there was a wide range, even within one language: for English: TOEFL (3), IELTS (3), The MELAB (3), and Cambridge Proficiency Test (2). Across all articles, 36% did not report using a standardized test. Thirty-three percent used a measure adapted or designed specifically for the study, though did not report native speaker scores or whether it was a single test or a battery of tests, which can be indicators of measurement validity and reliability (Hulstijn, Reference Hulstijn, Unsworth and Blom2010). Determining proficiency level remains an important endeavor to help comparability and replicability across primary studies (as noted by Bowden, Reference Bowden2016; Norris & Ortega, 2012).
RQ3: What are the L2 SPR instrument design characteristics?
Development of stimuli
Twenty-five SPRs reported using or adapting materials that had been used in previous published studies, perhaps reflecting a relatively strong systematicity within research agendas using SPR and/or a healthy collaborative ethic within the SPR community (though see section on transparency below).
Thirty of the 74 SPRs were reported as having been checked for plausibility, acceptability, or grammaticality before the main study, as part of stimuli development. We found inconsistencies in nomenclature of this stage of stimuli design. For example, 3/30 referred to these procedures as “norming,” 2 as “piloting,” and 1 as “base-line” tests. Of the 22 studies investigating anomalies, just 3 reported checking stimuli prior to testing, 1 of these altering the stimuli to be “more natural” or “unambiguously grammatical or ungrammatical” after native speaker feedback (Vafaee et al., Reference *Vafaee, Suzuki and Kachisnke2016, p. 17). Checking perceived naturalness with native speakers could be particularly important if using this population as a comparison: native speaker sensitivity to unnatural (though grammatical) language may affect RTs.
Frequency of lexical items across conditions (such as grammatical/ungrammatical, ambiguous/unambiguous, plausible/implausible, high/low attachment) can also affect RTs (as discussed by Keating & Jegerski, Reference Keating and Jegerski2015). In 26/64 studies, lexical frequency was addressed in some way, either by design, descriptively, or statistically. For example, 16 studies in the sample consulted corpora to select words from specific frequency bands.
Noncritical items
Keating and Jegerski (Reference Keating and Jegerski2015) define distractors as “intentionally designed to contain a specific linguistic form or structure [. . .] to counterbalance some characteristic of the critical stimuli that might otherwise make them stand out to the participant” (p. 16). Fillers are defined as “unrelated sentences that are not intended to elicit any specific type of processing effects” (p. 16). In our sample, nomenclature varied, with the terms “filler” and “distractor” being used interchangeably across studies and sometimes within studies. In Table 6 we report the frequency of terms as used by the authors.
Table 6. Balance of critical and noncritical items

Across all studies, the mean number of critical items was 43.26 (SD = 32.26), of fillers and/or distractors 50.55 (SD = 43.45), and practice items 5.01 (SD = 5.20).
Using too few noncritical compared to critical items may raise awareness of the experimental target. Fifty-seven out of the 62 SPRs that had noncritical items included 50% or more noncritical items (fillers and/or distractors) compared to critical items, which falls in line with Keating and Jegerski's suggestion of the minimum ratio of noncritical to critical items, though by no means always met their recommendation of 75% noncritical sentences. Furthermore, the mean difference between numbers of critical and noncritical items (fillers or distractors) was –0.30 (SD = 56.92), ranging from –224 to 148. This range indicates a need for research to investigate the effects that this ratio has on results, with a view to providing an evidence base for more standardization in this design decision.
Length of conditions and stimuli
In addition to overall instrument length, which may cause participant fatigue and thereby threaten a study's internal validity, other design characteristics that can affect construct validity include the number of items and lists in relation to the number of conditions, and the length of sentences, segments, words, and critical regions.
The recommended ratio of 8 to 12 items per condition (Keating & Jegerski Reference Keating and Jegerski2015) is thought to address the fact that too many items per condition can fatigue participants or make them accustomed to structures or features and thus show less sensitivity to the manipulations.Footnote 5 In contrast, too few items per condition does not provide sufficient data for many statistical procedures. According to this recommendation, a study with four conditions requires 32–48 items; this was met by 15 of the 44 studies that used four conditions. The other studies with four conditions used either between 6 and 31 or between 49 and 114. The range of items per condition is presented in Table 7, and again demonstrates that an evidence base for standardization would be helpful.
Table 7. Numbers of items, lists, and conditions
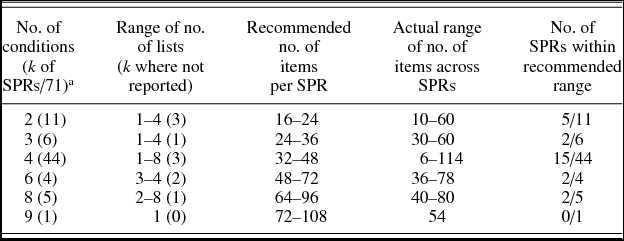
Note: aThree studies were excluded due to the design not requiring conditions or because the number of conditions was unclear.
Sentence length
Sentence length can affect processing ease as the start and end of sentences are thought to place the least burden on working memory (Pienemann & Kessler, Reference Pienemann and Kessler2011). However, sentence length was not reported in almost half the studies (30/64), so it was not always possible to ascertain whether the analyzed words occurred at the same point in each sentence, particularly problematic for 22 of these 30 studies that did not provide the full stimuli. In studies that reported sentence length, lengths were not always uniform across trials within a study (e.g., 1 study reported sentences ranging from 9 to 15 words).
Length of presented segments (including single words)
The most common presentation length was word-by-word (46/74). Out of the 28 SPRs that used multiword segments, 5 stated that individual segment length had been controlled, and 6 that the number of segments had been controlled. The other 17 did not report the length or number of segments, again particularly problematic when full stimuli are not provided.
Word length
Five out of 74 (7%) reported controlling for the number of syllables in each word. Four of these 5 gave a range of syllables per word, such as 2–4 (Sagarra & Herschensohn, Reference *Sagarra and Herschensohn2010). One used a t test to compare syllable length (Macizo & Bajo, Reference *Macizo and Bajo2006).
Comprehension questions: Attentional focus during sentence processing
A central tenet of SPR tests is that participants try to comprehend what they are reading. This is perhaps particularly important if the intention is to elicit implicit processing and knowledge, so participants may be conscious of extracting meaning but not structure or form. The majority of the SPRs included comprehension questions (CQs; k = 57, 77%), with various rationales: 18 gave a rationale of ‘checking understanding,’ 17 of ‘ensuring that participants were paying attention/on task,’ 5 gave both reasons, and 17 gave no (clear) reason. Keating and Jegerski also suggest analysing RTs on responses to CQs. Two in our sample of studies analyzed RTs on all CQs and 3 on CQs following fillers only.
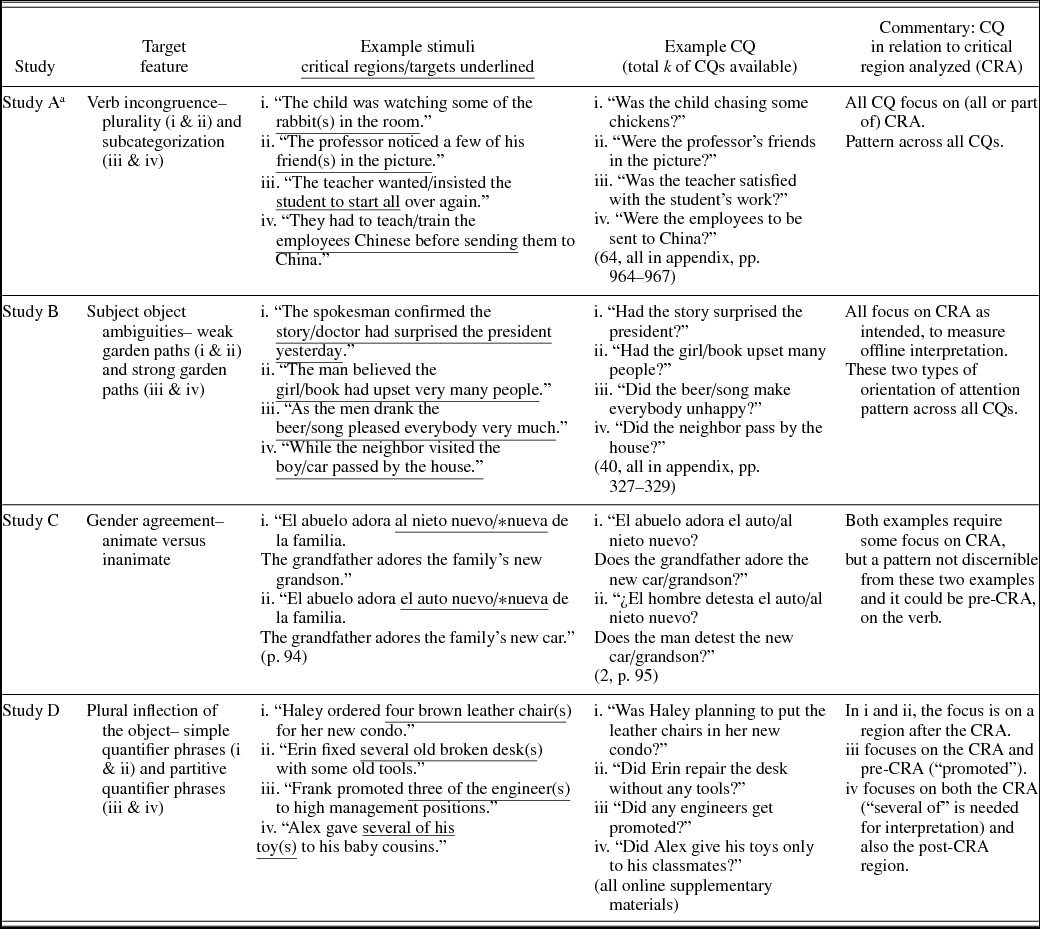
CQs can repeatedly focus participants’ attention on specific regions of sentences by repetitively, over many trials, asking about the meaning of the same region of the sentences. Thus, the region that CQs focus participants’ attention on is critical for construct validity (as raised awareness about specific regions can affect RTs and claims about implicitness or orientation to sentential meaning). A few researchers have intentionally aimed to focus participants’ attention on and check interpretation of the region that is analyzed for RTs. Others aim to do the opposite. That is, the CQ is not intended to draw (repeated) attention to the regions that are analyzed, so that slower RTs cannot be ascribed to paying special attention for the purpose of answering the CQ. To investigate these features, we set out to examine the CQs in relation to the analyzed regions. Twenty-five of the 50 studies using CQs provided no example of the CQs (7 of these described them as yes/no questions). Of the other 25 studies, 21 provided one example of a CQ that followed a critical trial. However, one isolated example (or even two) does not enable the reader to determine the nature of the CQs across the critical trials or whole test. Four studies provided multiple examples. These are given in Appendix B, alongside the SPR trial that the CQ followed, as well as the critical region analyzed (CRA), and a commentary is provided on the relation between the focus of the CQ and the CRA. This small subset of studies showed a mixed picture of design choices. One set of CQs focused on words within the CRA, as intended in the study, because interpretation of the CRA was central to the research questions; another set of CQs also focused on words within the CRA though it was not clear whether this was intentional; one set sometimes focused on words in the analyzed region and sometimes not; and for one set, the focus of the CQ was not discernible.
Despite the lack of attention and clarity on this issue, it is central to the construct validity of SPR tests, affecting claims about whether the critical region was understood, and whether participants became aware of the target feature or (de)sensitized to a particular anomaly. The nature of the CQ also determines decisions about which trials to analyze, such as only those where the CQ was answered correctly (see below). Of most relevance here is that we were only able to discern relevant details from those studies that provided sufficient examples of their stimuli.
To sum up findings related to RQ3, it seems that having full sets of stimuli and CQs available would allow researchers, reviewers, editors, and would-be replicators to better evaluate study and instrument quality, compare across studies, and design future SPRs.
RQ4: How are L2 SPR data cleaning and statistical procedures carried out and reported?
Data cleaning
SPR data must be examined for statistical outliers as outliers can heavily influence subsequent analyses, especially for null hypothesis significance tests, such as analyses of variance (ANOVAs), commonly applied to SPR data. We therefore coded for any discernible patterns or norms of practice. Of the 48 studies that reported removing outliers, in order to identify those outliers 20 studies used participant RTs, 11 used item RTs, and the other 17 used both participant and item RTs. Twenty of these 48 studies reported using SDs above or below the mean to identify outliers, with a mode 2.5 SD (k = 8/20), 17 studies used predetermined millisecond cutoff ranges, and 11 studies used both SD and cutoffs. The smallest lower cutoff was for RTs <100 ms and the largest upper limit was RTs >25000 ms (for total trials). The modal range was 200 ms to 2000 ms (4 studies), and the modal lower cutoff was <200 ms (3 studies). The mean reading speed of a native speaker has been found to be around 250 ms/word (Milton & Fitzpatrick, Reference Milton and Fitzpatrick2013), and such information might inform future empirical investigations into principled elimination of unnaturally fast key presses (as suggested by Conroy & Cupples, Reference *Conroy and Cupples2010). The upper cutoff ranged from >2000 ms to 20000 ms, with wide variability across studies, with a mode of >2000 ms (7 studies). As proficiency affects reading speed, it might be that cutoffs vary between studies using participants of different proficiencies, although no such discernible pattern emerged from our study sample: 5 of the 7 studies using RTs >2000 ms tested advanced learners; in the 6 studies with intermediate participants that used RTs to trim data, the upper cutoff ranged from >2000 ms to >20000 ms; in the 3 studies testing beginners, the upper cutoff ranged from >2000 to >3500.
In sum, research with SPRs would benefit from empirically based norms for the identification of outliers, as variation in this respect could affect the comparability of results between studies.
Incorrect responses to CQs were also used to remove trials or participants. Twenty-two out of the 50 studies using CQs analyzed only the items with correct responses, whereas 14 studies gave a specific accuracy rate (e.g., over 80%) for a participant's data to be included. Nine studies analyzed all data regardless of the correctness of responses. Some studies that included data for trials followed by incorrect responses provided reasons such as (a) the L2 participants’ responses did not differ significantly from NSs (Hopp, Reference *Hopp2016); (b) to avoid a high number of missing values (Jegerski, Reference *Jegerski2016); and (c) not all items were followed by CQs (Rah & Adone, Reference *Rah and Adone2010).
Although two studies have investigated the relationship between CQ error rate and RTs (Keating, Jegerski, & VanPatten, Reference *Keating, Jegerski and Vanpatten2016; Xu, Reference *Xu2014), in general, the practice of eliminating trials with incorrect responses probably relates to the tendency, observed earlier, to investigate online processing where comprehension is high. Investigating processing where there are comprehension difficulties (a frequent phenomenon for L2 learners) remains a relatively neglected area of research.
Statistics used
RT data from 58 SPRs were analyzed using ANOVA to identify within-subject effects (e.g., low vs. high attachment, anomalous vs. correct, or L1 vs. L2) and between-group effects (e.g., proficiencies, L1s, or learning contexts). This practice aligns with findings that point to the widespread dominance of ANOVA and its variants when other choices might be more appropriate (Plonsky & Oswald, Reference Plonsky and Oswald2017). Other analyses of RT data included general linear mixed effects models (k = 7 SPRs); t tests (k = 7), and correlations with confirmatory factor analysis (k = 1). Note that if using mixed effects models, the routine removal of outliers is not always necessary (Baayen & Milin, Reference Baayen and Milin2010).
Statistical reporting for the majority of SPRs (57/74) did not include effect sizes. Eleven provided eta squared (η2) or partial η2 (the often flawed default provided by SPSS) following the ANOVA, and just two studies reported Cohen's d (Kato, Reference *Kato2009; Vafaee et al., Reference *Vafaee, Suzuki and Kachisnke2016). Although η2 and partial η2 provide information about the amount of variance accounted for by the omnibus test (e.g., ANOVA; how much group membership explains the dependent variable), there are complications surrounding the use and interpretation of η2 (Larson-Hall, Reference Larson-Hall2016, p. 149; see also Norouzian & Plonsky, Reference Norouzian and Plonsky2018). Most important, the d family of effect sizes provides information about the paired comparisons that are usually of most theoretical interest (and omnibus effects are usually broken down into paired comparisons anyway). While not currently standard practice in SPR research, effect sizes of mean differences between groups or conditions determines the magnitude of difference. This is especially informative where comparisons should receive a nuanced rather than a dichotomous interpretation, given the multitude of factors we know to affect SLA. Rather than an “absence versus presence” of L1 influence on L2 processing, or “difference versus no difference” between native and nonnative processing, effect sizes such as d enable us to interpret the relative size of differences in one study (with one set of learners, on one linguistic feature) compared to another study. Thus far, very few meta-analyses have been done on studies using RTs (and those that have included effect sizes for RT data needed to extract information from primary studies in order to calculate them; e.g., Adesope, Lanvin, Thompson, & Ungerleider, Reference Adesope, Lavin, Thompson and Ungerleider2010).
Providing effect sizes in future studies based on SPR data would greatly facilitate meta-analyses, power analyses, cross-study comparisons, and more nuanced interpretations. Another concern is that we do not yet have a feel for interpreting effect sizes in studies using RTs from SPRs, for example, whether they are “small,” “medium,” or “large” (relative to the general tendencies presented by Cohen, Reference Cohen1988, or L2 field-specific ones by Plonsky & Oswald, Reference Plonsky and Oswald2014). As we know that different types of instrument tend to yield different effect sizes, this is an important consideration for future research.
Segments analyzed
Decisions about which parts of a sentence are predicted to reveal effects directly relate to the construct validity of the elicitation technique. Analyses are carried out on different segments depending on which regions are deemed critical and whether researchers consider effects may be observed pre-, during, or postcritical regions (e.g., spillover effects). We documented the nature of these choices, as a function of the processing and linguistic phenomena under investigation, to determine the level of consistency across similar studies. Nomenclature was not always consistent. For instance, the term “spillover” was used to refer to a “critical region,” as by Omaki and Schulz (Reference *Omaki and Schulz2011, p. 577) and to a “postcritical region,” as by Coughlin and Tremblay (Reference *Coughlin and Tremblay2013, p. 629).
In order to better understand the use of such terms and the phenomena they represent, we extracted the examples of regions analyzed from a subset of articles. We selected studies that investigated the same processing phenomena with the same (or similar) linguistic feature.Footnote 6 Again, we emphasize we do not aim to criticize any individual study, but rather to draw together different analysis choices with a view to illustrating potential benefits of methodological transparency and replication.
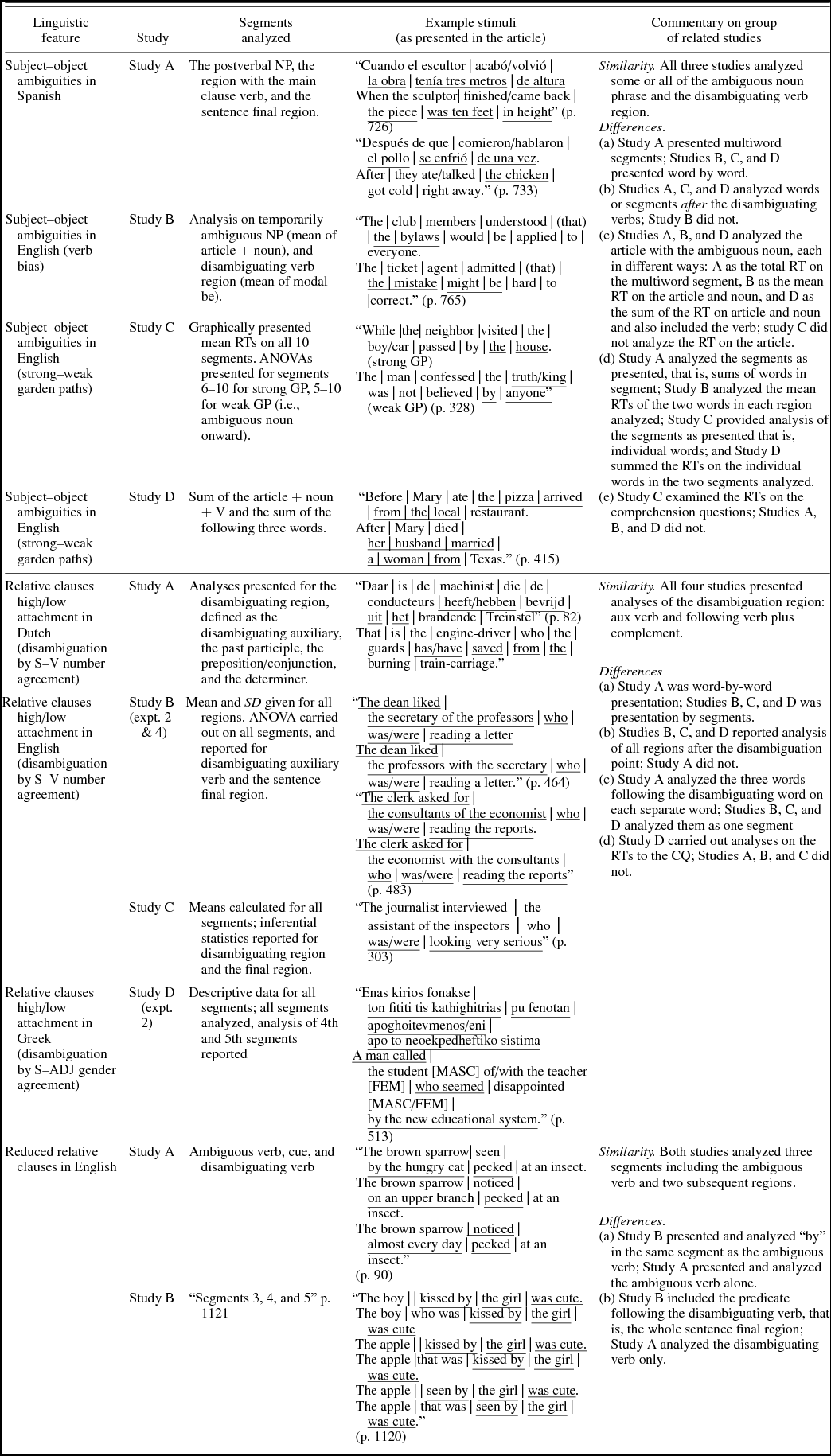
Local ambiguity
Twenty-seven SPRs investigated local ambiguity resolution (or garden path), in which the stimuli have an ambiguous region followed by a disambiguating region.Footnote 7 Out of these, we found three groups of comparable studies: four focused on subject/object ambiguity, four on antecedent attachment preferences in relative clauses, and two on reduced relative clauses. See Appendix C for the segments that were presented and analyzed in each of these groups, with detailed commentary comparing presentation and analysis decisions within each group of related studies. A few studies (e.g., Felser, Roberts, Marinis, & Gross Reference *Fesler, Roberts, Marinis and Gross2003; Papadopolou & Clahsen, Reference *Papadopoulou and Clahsen2003) reported having carried out analyses on all regions and, finding no statistical significance (as predicted) prior to the ambiguous region, reported the inferential statistics only from the ambiguous region onward. Some studies (e.g., Roberts & Felser, Reference *Roberts and Felser2011; Marinis et al., Reference *Marinis, Roberts, Felser and Clahsen2005) provided descriptive statistics (numerically or graphically, respectively) for all regions and carried out inferential statistics only for particular regions, for example, the ambiguity onward. Others presented data and analyses only for the regions that were either predetermined or selected after data collection on the basis of descriptive statistics.
Our close examination of groups of comparable studies (Appendix C) revealed some key similarities but also a number of important differences in analysis regions: five differences between the four studies focusing on subject/object ambiguity; four differences between the three studies on attachment preferences; and two differences between the two studies on reduced relative clauses.
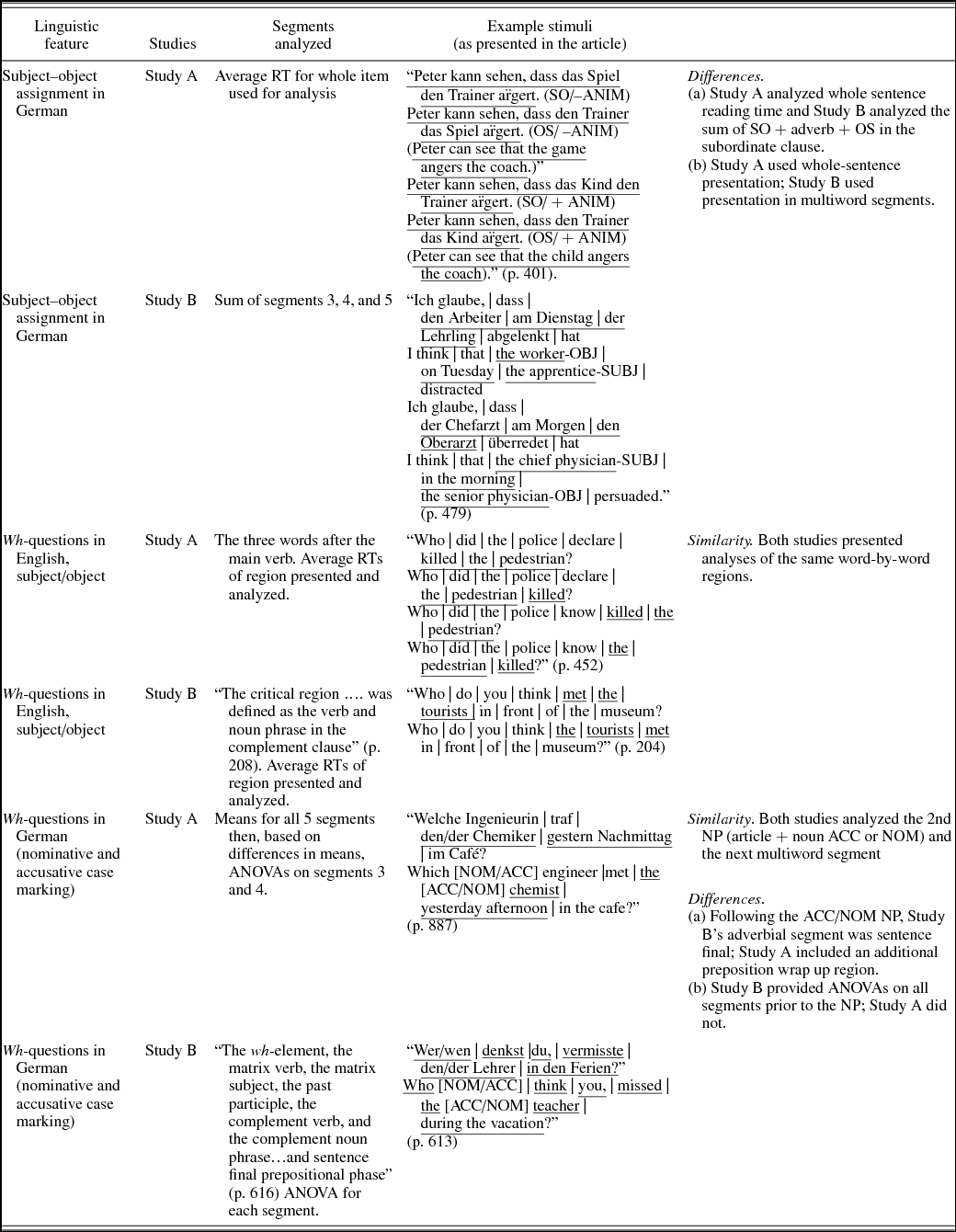
Global ambiguity
Out of 13 SPRs used to investigate global ambiguity resolution, we were able to compare three pairs of studies: one pair focusing on subject–object assignment in German, one pair on subject–object wh-questions in English, and one pair on subject–object wh-questions in German. See Appendix D for the segments presented and analyzed, with detailed commentary. The pair of studies focussing on wh-questions in English analyzed directly comparable regions, whereas the other two pairs each had two differences in their presentation and analysis decisions.
While analysis decisions will inevitably vary to some extent between studies, more similarities might be hoped for so as to allow better cross-study comparisons and future meta-analyses. We found comparability to be threatened for a number of reasons. For example, when the presentation format varied (word by word vs. multiword segments, or different multiword segments), then in one study RTs were the sum (or mean) for one group of words whereas in another study RTs were for different or individual words. These are critical design decisions that can affect parsing behaviors (for discussion, see De Vincenzi & Job, Reference De Vincenzi and Job1995; Gilboy & Sopena, Reference Gilboy, Sopena, Carreiras, García-Albea and Sebastian-Gallés1996; MacDonald, Reference MacDonald1994). Another problem is that where one study found effects in one region, another study did not analyze the equivalent region. One possible way forward to both enhance comparability and not stifle exploratory analyses is, when reporting results, to clearly separate confirmatory analyses, which allow comparison with previous studies, from exploratory analyses, which present new analyses (see Chambers, Reference Chambers2013; Marsden, Morgan-Short, Trofimovich, & Ellis, Reference Marsden, Morgan-Short, Trofimovich and Ellis2018).
RQ5: What is the extent of L2 SPR instrument transparency?
One of several aspects of transparency that we coded for is the provision of stimuli. The majority of studies (49/64) had only a brief example of stimuli available (e.g., one or two items). Between 2000 and 2009 27% of SPRs were available in full in the article, and the remaining 73% gave just examples in the article (i.e., accessible with journal subscription). Since 2010 the proportion of articles providing full stimuli rose to 46%, though for 54% of articles only example items were available. Table 8 illustrates the transparency of materials.
Table 8. Availability of SPR stimuli

Note: a“in full” means all the critical SPR items, but not necessarily distractors, fillers, comprehension questions, etc. bThis is including journal supplementary materials, i.e., behind the journal paywall.
As yet, no clear relationship between publication outlet and instrument availability is observable. However, this may change as more major journalsFootnote 8 begin to recognize authors for fully open methodological transparency, by, for example, adopting the Centre for Open Science badge scheme (Blohowiak et al., Reference Blohowiak, Cohoon, de-Wit, Farach, Hasselman and DeHaven2016), which has been shown to increase the long-term availability of materials and data (Kidwell et al., Reference Kidwell, Lazarević, Baranski, Hardwicke, Piechowski, Falkenberg, -S. and Nosek2016).
As can be seen in Table 8, as a follow-up to the current study, we sought to establish a “special collection” of SPR materials on IRIS (Marsden et al., Reference Marsden, Mackey, Plonsky, Mackey and Marsden2016) in order to improve materials transparency in this domain. The positive response we had is testimony to the willingness of researchers to engage in collaborative effort. We hope that this collection will serve as a reference corpus for future syntheses and substantive meta-analyses and as a research methods training tool, as well as serve to stimulate and facilitate replication.
Another important feature of transparent reporting about instrumentation is that of measurement reliability. We found two studies that reported reliability coefficients for the RTs, using Cronbach α. Improved reporting of reliability would help our understanding of measurements taken with SPRs, the error in the data, the psychometric properties of SPRs, and future instrument development.
FURTHER DISCUSSION AND FUTURE DIRECTIONS
Our review identified a good deal of coherence in terms of research aims and systematicity of agendas (across languages, processing phenomena, participant proficiencies and ages, and linguistic features). By contrast, this review also found massive variability in the SPRs used to investigate and advance those agendas. To name just a few: theoretical positions and assumptions to motivate the use of SPRs were occasionally, but certainly not uniformly, detailed explicitly. Reporting of some participant characteristics could also be patchy. SPRs were found to be used both with and without JTs and with or without CQs, not always with a clear or consistent rationale to justify these choices. Features of the instruments employed (e.g., number of items, sentence length, segment length, and item:condition ratios) were highly variable or regularly omitted from the report, as were critical data such as measures of internal consistency (i.e., reliability) and effect sizes. Data cleaning procedures varied widely, and regions of analysis in some related studies were also disparate; both of these issues can directly affect the outcomes of an analysis. Equally concerning as the inconsistency and opaqueness that we observed is our poor understanding of how these and many other aspects of SPR design might actually impact study results. We note that Keating and Jegerski (Reference Keating and Jegerski2015) had warned of a number of these issues. The current study goes beyond those comments, providing quantitative data based on a systematic synthesis of published empirical work to illustrate their pervasiveness and severity.
In concluding the paper, we indicate several directions for future use of this technique that, we believe, will lead to more informative SPR-based findings and interpretations. In doing so, we hasten to note again that we are building on some of the work of Keating and Jegerski but with the empirical support of the current review to motivate our comments.
Enhancing the scope of research agendas using SPR
Our data on study design and participant characteristics suggest several avenues that are currently largely neglected.
Sample demographics of SPR studies are skewed in line with L2 research in general, with a propensity to investigate English as an L1 or L2 (Norris & Ortega, Reference Norris and Ortega2000), and we found no evidence to suggest that trends in this respect are changing over time. Similarly, participants tended to be university students, often from language, linguistics, psychology, or education departments, thus limiting our understanding of L2 online reading processes from SPR data to the more highly educated and possibly meta-linguistically aware sections of society.
Perhaps due to the fact that SPRs were initially used in adult L1 research, successful comprehension of every sentence has been assumed to be necessary or at least desirable in most L2 SPR studies, with many researchers removing trials with incorrect responses to CQs. The extent to which sensitivity to morphosyntax changes with comprehension difficulty (e.g., less familiar lexical items) or individual differences (e.g., working memory capacity) seems worthy of future empirical effort (Hopp, Reference *Hopp2016; Sagarra, Reference Sagarra, Han and Park2008; VanPatten, Reference VanPatten2015). One consequence of this is that we found insufficient numbers of studies that would enable a meta-analysis of the relationship between proficiency and processing phenomena. This was partly because there were only 17 studies that compared different proficiencies, with a limited range of proficiencies (advanced/near native vs. native) and with little homogeneity of measures (as noted by Norris & Ortega, Reference Norris, Ortega, Doughty and Long2003; Wu & Ortega, Reference Wu and Ortega2013); for example, only 5 of the studies that investigated proficiency used a standardized proficiency test to provide a reliable benchmark for comparisons.
Nevertheless, a bright spot in our findings was relatively high consistency in terms of the two main research agendas addressed using SPRs to date: we found 52 studies that investigated differences between native and nonnative online reading; and 26 studies that investigated cross-linguistic influence. This body of research may be ripe, at least in the not too distant future, for meta-analyses of these two major questions. Despite the challenges that we have raised (e.g., of comparability and transparency), such a meta-analysis would have a very important advantage: it would draw on data from a single elicitation technique, thus avoiding the oft-cited problem of meta-analyses collapsing data from different outcome measures that may tap into different phenomena (i.e., the “apples and oranges” problem). Though requiring additional effort, effect sizes could be extracted from data in the primary studies, as most provided means, standard deviations, and n.
Methodological rigor
It was a positive indication of collaboration that 25 SPRs reported drawing on previously used stimuli. However, full scrutiny of the design of most stimuli was not possible in most cases due to the lack of availability (either in appendices or elsewhere), and reporting did not compensate for this. For example, a comprehensive synthesis of how lexical items are selected was not possible, an important consideration for future research as there is evidence that word length and lexical and collocational frequency (both L1 and L2) can affect reading times (Bultena et al., Reference *Bultena, Dijkstra and van Hell2014; Hopp, Reference *Hopp2016; Ibáñez et al., Reference *Ibáñez, Macizo and Bajo2010). Two ways of addressing such issues are by using letter-length corrected residual reading times (Ferreira & Clifton, Reference Ferreira and Clifton1986; Lee, Lu, & Garnsey, Reference *Lee, Lu and Garnsey2013) and/or mixed effects models with item as a random factor (Barr, Levy, Scheeper, & Tily, 2016; Cunnings, Reference Cunnings2012). We found 11/64 of L2 studies to date reported using residual reading times and 7 using mixed effects models, indicating there is some way to go to integrate these into our methodological toolkit.
Reporting and transparency
Other issues we observed relate to the reporting and consistency of data cleaning procedures, nomenclature (e.g., piloting and norming), and analysis. We hope to have illustrated the inseparability of methodological transparency and construct validity and reliability.
With respect to the data resulting from SPR tests, reporting the means, standard deviations, and results of all statistical analyses carried out, ideally on segments that are comparable across studies and on posttrial CQs, would facilitate comparisons and future meta-analyses. Reporting of effect sizes in primary studies and comparing these to others (Plonsky & Oswald, Reference Plonsky and Oswald2014) will provide a more accurate and informative depiction of the magnitude of the relationships being investigated.
In addition to more comprehensive reporting, providing the field with access to materials including stimuli (critical, distractors, and fillers), CQs, software scripts, and data cleaning and analysis procedures, would inspire more confidence among reviewers and readers. Improved reporting alone would rarely, if ever, capture all aspects of instrument design (Derrick, Reference Derrick2016), partly because conceptual and methodological innovation usually occur before reporting conventions become established. Greater materials transparency also reduces reinvention of the wheel and, in many cases, helps to build on previous efforts (Marsden et al., Reference Marsden, Mackey, Plonsky, Mackey and Marsden2016). We are a community of researchers, and we owe it to each other to behave like one. Provision of materials also facilitates replications with different sample demographics, target features, contexts, and so forth. While not complete, the special collection of SPRs on the IRIS database has now increased the open availability of full SPR stimuli from 2 to 46.Footnote 9 We hope this will stimulate an expansion of the scope and practice of replicating SPR research.
In terms of analysis, in some cases it was unclear whether the choice of segments for which to present analyses was made a priori (hypothesis testing), or postanalysis (exploratory). Of course, both approaches have their merits. We hope that this review and greater transparency of stimuli and analyses will inform and improve the consistency of future decisions about word/segment presentation and analysis.
Conclusion
One of the most basic findings of this study concerns, very simply, the extent to which L2 researchers have used SPRs. Although not as frequent as, for instance, JTs or cloze tests, SPR is part of the methodological repertoire of a growing number of L2 scholars. The motivation behind this project was to inform these efforts, and although providing a largely retrospective account, we hope to have highlighted some of the many choices inherent in utilizing SPRs. Perhaps most critical, we also hope to have stimulated future empirical examination of the impact of these methodological choices on findings and, consequently, on our ability to account for the findings. Finally, our approach of subjecting the research process to empirical scrutiny at the primary and synthetic levels can certainly be applied to other procedures. Doing so can only serve to promote a greater understanding of and confidence in our methods and findings.
APPENDIX B Examples of comprehension questions (CQs) with analyzed segments, in studies providing more than one example of a comprehension question on critical trials
Table B.1. Examples of CQs with analyzed segments, in studies providing more than one example of a CQ on critical trials
APPENDIX C Segments analyzed in studies investigating temporary (local) ambiguity
Table C.1. Segments analyzed in studies investigating temporary (local) ambiguityz
APPENDIX D Segments analyzed in studies investigating global ambiguity
Table D.1. Studies investigating global ambiguity and the segments analyzed
ACKNOWLEDGMENTS
An earlier version of part of this study contributed to the second author's dissertation for a masters in applied linguistics and ESRC funded PhD at the University of York. The project was also partially funded by the British Academy (Academy Research Project AN110002 and AN110003) and the Economic and Social Research Council (RES-062-23-2946). We are grateful to Yasser Teimouri (Georgetown University) for his help in second coding some of the data, and to Leah Roberts (University of York) for her useful comments on an earlier version of this manuscript. The coding scheme for the synthesis is available on IRIS (www.iris-database.org). We are very grateful to the researchers who have made their self-paced reading tests openly available in a special collection on IRIS. The current systematic review was presented at the Second Language Research Forum (Columbus, Ohio, 2017), and we thank the attendees for their helpful questions. We are grateful to three anonymous reviewers for their insightful feedback.
SUPPLEMENTARY MATERIAL
To view supplementary material for this article, please visit https://doi.org/10.1017/S0142716418000036















 Open access
Open access