We compared climatic relationships to insurance loss across the inland Pacific Northwest region of the United States, using a design matrix methodology, to identify optimum temporal windows for climate variables by county in relationship to wheat insurance loss due to drought. The results of our temporal window construction for water availability variables (precipitation, temperature, evapotranspiration, and the Palmer drought severity index [PDSI]) identified spatial patterns across the study area that aligned with regional climate patterns, particularly with regards to drought-prone counties of eastern Washington. Using these optimum time-lagged correlational relationships between insurance loss and individual climate variables, along with commodity pricing, we constructed a regression-based random forest model for insurance loss prediction and evaluation of climatic feature importance. Our cross-validated model results indicated that PDSI was the most important factor in predicting total seasonal wheat/drought insurance loss, with wheat pricing and potential evapotranspiration having noted contributions. Our overall regional model had a
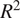 $ {R}^2 $
of 0.49, and a RMSE of $30.8 million. Model performance typically underestimated annual losses, with moderate spatial variability in terms of performance between counties.
$ {R}^2 $
of 0.49, and a RMSE of $30.8 million. Model performance typically underestimated annual losses, with moderate spatial variability in terms of performance between counties.

