Existential rules form an expressive 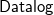 ${{\textsf{Datalog}}}$-based language to specify ontological knowledge. The presence of existential quantification in rule-heads, however, makes the main reasoning tasks undecidable. To overcome this limitation, in the last two decades, a number of classes of existential rules guaranteeing the decidability of query answering have been proposed. Unfortunately, only some of these classes fully encompass
${{\textsf{Datalog}}}$-based language to specify ontological knowledge. The presence of existential quantification in rule-heads, however, makes the main reasoning tasks undecidable. To overcome this limitation, in the last two decades, a number of classes of existential rules guaranteeing the decidability of query answering have been proposed. Unfortunately, only some of these classes fully encompass 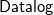 ${{\textsf{Datalog}}}$ and, often, this comes at the price of higher computational complexity. Moreover, expressive classes are typically unable to exploit tools developed for classes exhibiting lower expressiveness. To mitigate these shortcomings, this paper introduces a novel general syntactic condition that allows us to define, systematically and in a uniform way, from any decidable class
${{\textsf{Datalog}}}$ and, often, this comes at the price of higher computational complexity. Moreover, expressive classes are typically unable to exploit tools developed for classes exhibiting lower expressiveness. To mitigate these shortcomings, this paper introduces a novel general syntactic condition that allows us to define, systematically and in a uniform way, from any decidable class 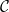 $\mathcal{C}$ of existential rules, a new class called
$\mathcal{C}$ of existential rules, a new class called 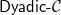 ${{\textsf{Dyadic-}\mathcal{C}}}$ enjoying the following properties: (i) it is decidable; (ii) it generalizes
${{\textsf{Dyadic-}\mathcal{C}}}$ enjoying the following properties: (i) it is decidable; (ii) it generalizes 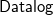 ${{\textsf{Datalog}}}$; (iii) it generalizes
${{\textsf{Datalog}}}$; (iii) it generalizes 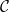 $\mathcal{C}$; (iv) it can effectively exploit any reasoner for query answering over
$\mathcal{C}$; (iv) it can effectively exploit any reasoner for query answering over 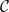 $\mathcal{C}$; and (v) its computational complexity does not exceed the highest between the one of
$\mathcal{C}$; and (v) its computational complexity does not exceed the highest between the one of 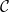 $\mathcal{C}$ and the one of
$\mathcal{C}$ and the one of 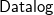 ${{\textsf{Datalog}}}$.
${{\textsf{Datalog}}}$.
This paper investigates the computational complexity of deciding if a given finite idempotent algebra has a ternary term operation  $m$ that satisfies the minority equations
$m$ that satisfies the minority equations 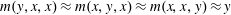 $m(y,x,x)\approx m(x,y,x)\approx m(x,x,y)\approx y$. We show that a common polynomial-time approach to testing for this type of condition will not work in this case and that this decision problem lies in the class
$m(y,x,x)\approx m(x,y,x)\approx m(x,x,y)\approx y$. We show that a common polynomial-time approach to testing for this type of condition will not work in this case and that this decision problem lies in the class
This article presents a proof that Buss’s 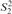 $S_2^2$ can prove the consistency of a fragment of Cook and Urquhart’s PV from which induction has been removed but substitution has been retained. This result improves Beckmann’s result, which proves the consistency of such a system without substitution in bounded arithmetic
$S_2^2$ can prove the consistency of a fragment of Cook and Urquhart’s PV from which induction has been removed but substitution has been retained. This result improves Beckmann’s result, which proves the consistency of such a system without substitution in bounded arithmetic 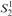 $S_2^1$.
$S_2^1$.
Our proof relies on the notion of “computation” of the terms of PV. In our work, we first prove that, in the system under consideration, if an equation is proved and either its left- or right-hand side is computed, then there is a corresponding computation for its right- or left-hand side, respectively. By carefully computing the bound of the size of the computation, the proof of this theorem inside a bounded arithmetic is obtained, from which the consistency of the system is readily proven.
This result apparently implies the separation of bounded arithmetic because Buss and Ignjatović stated that it is not possible to prove the consistency of a fragment of PV without induction but with substitution in Buss’s 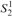 $S_2^1$. However, their proof actually shows that it is not possible to prove the consistency of the system, which is obtained by the addition of propositional logic and other axioms to a system such as ours. On the other hand, the system that we have considered is strictly equational, which is a property on which our proof relies.
$S_2^1$. However, their proof actually shows that it is not possible to prove the consistency of the system, which is obtained by the addition of propositional logic and other axioms to a system such as ours. On the other hand, the system that we have considered is strictly equational, which is a property on which our proof relies.
The paper introduces a graph theory variation of the general position problem: given a graph 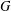 $G$, determine a largest set
$G$, determine a largest set 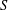 $S$ of vertices of
$S$ of vertices of 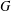 $G$ such that no three vertices of
$G$ such that no three vertices of 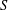 $S$ lie on a common geodesic. Such a set is a max-gp-set of
$S$ lie on a common geodesic. Such a set is a max-gp-set of 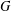 $G$ and its size is the gp-number
$G$ and its size is the gp-number 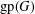 $\text{gp}(G)$ of
$\text{gp}(G)$ of 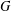 $G$. Upper bounds on
$G$. Upper bounds on 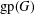 $\text{gp}(G)$ in terms of different isometric covers are given and used to determine the gp-number of several classes of graphs. Connections between general position sets and packings are investigated and used to give lower bounds on the gp-number. It is also proved that the general position problem is NP-complete.
$\text{gp}(G)$ in terms of different isometric covers are given and used to determine the gp-number of several classes of graphs. Connections between general position sets and packings are investigated and used to give lower bounds on the gp-number. It is also proved that the general position problem is NP-complete.
Fix a finite semigroup 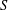 $S$ and let
$S$ and let 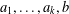 $a_{1},\ldots ,a_{k},b$ be tuples in a direct power
$a_{1},\ldots ,a_{k},b$ be tuples in a direct power 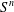 $S^{n}$. The subpower membership problem (SMP) for
$S^{n}$. The subpower membership problem (SMP) for 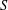 $S$ asks whether
$S$ asks whether 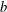 $b$ can be generated by
$b$ can be generated by 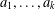 $a_{1},\ldots ,a_{k}$. For combinatorial Rees matrix semigroups we establish a dichotomy result: if the corresponding matrix is of a certain form, then the SMP is in P; otherwise it is NP-complete. For combinatorial Rees matrix semigroups with adjoined identity, we obtain a trichotomy: the SMP is either in P, NP-complete, or PSPACE-complete. This result yields various semigroups with PSPACE-complete SMP including the six-element Brandt monoid, the full transformation semigroup on three or more letters, and semigroups of all
$a_{1},\ldots ,a_{k}$. For combinatorial Rees matrix semigroups we establish a dichotomy result: if the corresponding matrix is of a certain form, then the SMP is in P; otherwise it is NP-complete. For combinatorial Rees matrix semigroups with adjoined identity, we obtain a trichotomy: the SMP is either in P, NP-complete, or PSPACE-complete. This result yields various semigroups with PSPACE-complete SMP including the six-element Brandt monoid, the full transformation semigroup on three or more letters, and semigroups of all  $n$ by
$n$ by  $n$ matrices over a field for
$n$ matrices over a field for 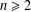 $n\geq 2$.
$n\geq 2$.

