This journal utilises an Online Peer Review Service (OPRS) for submissions. By clicking "Continue" you will be taken to our partner site https://mc.manuscriptcentral.com/apjournals. Please be aware that your Cambridge account is not valid for this OPRS and registration is required. We strongly advise you to read all "Author instructions" in the "Journal information" area prior to submitting.
In this paper we obtain an upper bound for the maximum of random fields of the form 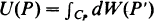 , where CP denotes circles of fixed radius and dW(P′) is a plane white noise field.
, where CP denotes circles of fixed radius and dW(P′) is a plane white noise field.
The results presented are obtained by means of successive steps involving Slepian's lemma for random fields, inequalities on Brownian fields and planar stochastic integrals.
A continuum structure function γ is a non-decreasing mapping from the unit hypercube to the unit interval. Block and Savits (1984) use the sets  and
and  to determine bounds on the distribution of γ (X) when X is a vector of associated random variables. It is shown that, if γ admits of a modular decomposition, improved bounds may be obtained.
to determine bounds on the distribution of γ (X) when X is a vector of associated random variables. It is shown that, if γ admits of a modular decomposition, improved bounds may be obtained.
We consider the relative error of a tail function  when this is approximated by y–α using an estimator of Hill's for α. The results combine recent work of Davis and Resnick on tail estimation with Anderson's work on large deviations in extreme-value theory. Treating separately the domains of attraction of Φα and Λ, we obtain general conditions for the relative error to tend to 0 as u →∞, y → ∞ simultaneously. The results serve as warning against the automatic extrapolation of estimates based on extreme-value approximations.
when this is approximated by y–α using an estimator of Hill's for α. The results combine recent work of Davis and Resnick on tail estimation with Anderson's work on large deviations in extreme-value theory. Treating separately the domains of attraction of Φα and Λ, we obtain general conditions for the relative error to tend to 0 as u →∞, y → ∞ simultaneously. The results serve as warning against the automatic extrapolation of estimates based on extreme-value approximations.
Let  where {Zn, ℱn} is a non-negative submartingale satisfying Ei(Zn log Zn) →∞. It is shown that
where {Zn, ℱn} is a non-negative submartingale satisfying Ei(Zn log Zn) →∞. It is shown that
 When {Zn} is a simple critical Galton–Watson process and
When {Zn} is a simple critical Galton–Watson process and  is slowly varying at∞, conditions are given ensuring that
is slowly varying at∞, conditions are given ensuring that
 This gives an alternative proof of a result recently established by Kammerle and Schuh.
This gives an alternative proof of a result recently established by Kammerle and Schuh.
A continuum structure function is a non-decreasing mapping from the unit hypercube to the unit interval. A definition of the reliability importance, ℛi(α) say, of component i at system level α(0 < α ≦ 1) is proposed. Some properties of this function are deduced, in particular conditions under which  and conditions under which ℛi(α) is positive (0 < α < 1).
and conditions under which ℛi(α) is positive (0 < α < 1).
