
The 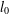 $l_{0}$-minimisation problem has attracted much attention in recent years with the development of compressive sensing. The spark of a matrix is an important measure that can determine whether a given sparse vector is the solution of an
$l_{0}$-minimisation problem has attracted much attention in recent years with the development of compressive sensing. The spark of a matrix is an important measure that can determine whether a given sparse vector is the solution of an 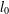 $l_{0}$-minimisation problem. However, its calculation involves a combinatorial search over all possible subsets of columns of the matrix, which is an NP-hard problem. We use Weyl’s theorem to give two new lower bounds for the spark of a matrix. One is based on the mutual coherence and the other on the coherence function. Numerical examples are given to show that the new bounds can be significantly better than existing ones.
$l_{0}$-minimisation problem. However, its calculation involves a combinatorial search over all possible subsets of columns of the matrix, which is an NP-hard problem. We use Weyl’s theorem to give two new lower bounds for the spark of a matrix. One is based on the mutual coherence and the other on the coherence function. Numerical examples are given to show that the new bounds can be significantly better than existing ones.

