Let  $X_1, X_2,\dots$
be a short-memory linear process of random variables. For
$X_1, X_2,\dots$
be a short-memory linear process of random variables. For 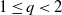 $1\leq q<2$
, let
$1\leq q<2$
, let 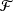 ${\mathcal{F}}$
be a bounded set of real-valued functions on [0, 1] with finite q-variation. It is proved that
${\mathcal{F}}$
be a bounded set of real-valued functions on [0, 1] with finite q-variation. It is proved that 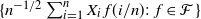 $\{n^{-1/2}\sum_{i=1}^nX_i\,f(i/n)\colon f\in{\mathcal{F}}\}$
converges in outer distribution in the Banach space of bounded functions on
$\{n^{-1/2}\sum_{i=1}^nX_i\,f(i/n)\colon f\in{\mathcal{F}}\}$
converges in outer distribution in the Banach space of bounded functions on 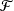 ${\mathcal{F}}$
as
${\mathcal{F}}$
as  $n\to\infty$
. Several applications to a regression model and a multiple change point model are given.
$n\to\infty$
. Several applications to a regression model and a multiple change point model are given.

