
Wiggle matching is an important and powerful technique in radiocarbon dating that can be used to improve the precision of calendar age estimates. All radiocarbon determinations require calibration to provide calendar age estimates. This calibration is achieved by comparing the determinations against a calibration curve 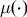 $\mu ( \cdot )$ to calculate the probability the sample arises from any particular calendar age t. Wiggle matching involves the calibration of a set of radiocarbon determinations taken from samples with known separations between their calendar ages. Since the calendar age separations between samples are known, all the calendar ages are known functions of one particular age,
$\mu ( \cdot )$ to calculate the probability the sample arises from any particular calendar age t. Wiggle matching involves the calibration of a set of radiocarbon determinations taken from samples with known separations between their calendar ages. Since the calendar age separations between samples are known, all the calendar ages are known functions of one particular age, 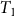 ${T_1}$ — commonly the most recent calendar age. Dating the sequence then reduces to considering
${T_1}$ — commonly the most recent calendar age. Dating the sequence then reduces to considering 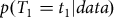 $p({T_1} = {t_1}|data)$, the probability of the calendar age
$p({T_1} = {t_1}|data)$, the probability of the calendar age 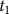 ${t_1}$ given the set of radiocarbon determinations. In previous work, a Bayesian approach has been used to derive a nice formula for this quantity under the assumption we have independent pointwise estimates of the calibration curve
${t_1}$ given the set of radiocarbon determinations. In previous work, a Bayesian approach has been used to derive a nice formula for this quantity under the assumption we have independent pointwise estimates of the calibration curve 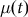 $\mu (t)$. In this paper, we derive a generalization of this formula showing how to incorporate covariance information from the calibration curve under an assumption of multivariate normality.
$\mu (t)$. In this paper, we derive a generalization of this formula showing how to incorporate covariance information from the calibration curve under an assumption of multivariate normality.

