Models of mortality often require constraints in order that parameters may be estimated uniquely. It is not difficult to find references in the literature to the “identifiability problem”, and papers often give arguments to justify the choice of particular constraint systems designed to deal with this problem. Many of these models are generalised linear models, and it is known that the fitted values (of mortality) in such models are identifiable, i.e., invariant with respect to the choice of constraint systems. We show that for a wide class of forecasting models, namely ARIMA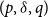 $(p,\delta, q)$
models with a fitted mean and
$(p,\delta, q)$
models with a fitted mean and 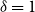 $\delta = 1$
or 2, identifiability extends to the forecast values of mortality; this extended identifiability continues to hold when some model terms are smoothed. The results are illustrated with data on UK males from the Office for National Statistics for the age-period model, the age-period-cohort model, the age-period-cohort-improvements model of the Continuous Mortality Investigation and the Lee–Carter model.
$\delta = 1$
or 2, identifiability extends to the forecast values of mortality; this extended identifiability continues to hold when some model terms are smoothed. The results are illustrated with data on UK males from the Office for National Statistics for the age-period model, the age-period-cohort model, the age-period-cohort-improvements model of the Continuous Mortality Investigation and the Lee–Carter model.
Let the function 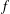 $f$ be analytic in
$f$ be analytic in 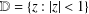 $\mathbb{D}=\{z:|z|<1\}$ and given by
$\mathbb{D}=\{z:|z|<1\}$ and given by 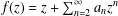 $f(z)=z+\sum _{n=2}^{\infty }a_{n}z^{n}$. For
$f(z)=z+\sum _{n=2}^{\infty }a_{n}z^{n}$. For 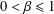 $0<\unicode[STIX]{x1D6FD}\leq 1$, denote by
$0<\unicode[STIX]{x1D6FD}\leq 1$, denote by 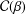 ${\mathcal{C}}(\unicode[STIX]{x1D6FD})$ the class of strongly convex functions. We give sharp bounds for the initial coefficients of the inverse function of
${\mathcal{C}}(\unicode[STIX]{x1D6FD})$ the class of strongly convex functions. We give sharp bounds for the initial coefficients of the inverse function of 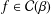 $f\in {\mathcal{C}}(\unicode[STIX]{x1D6FD})$, showing that these estimates are the same as those for functions in
$f\in {\mathcal{C}}(\unicode[STIX]{x1D6FD})$, showing that these estimates are the same as those for functions in 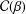 ${\mathcal{C}}(\unicode[STIX]{x1D6FD})$, thus extending a classical result for convex functions. We also give invariance results for the second Hankel determinant
${\mathcal{C}}(\unicode[STIX]{x1D6FD})$, thus extending a classical result for convex functions. We also give invariance results for the second Hankel determinant 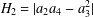 $H_{2}=|a_{2}a_{4}-a_{3}^{2}|$, the first three coefficients of
$H_{2}=|a_{2}a_{4}-a_{3}^{2}|$, the first three coefficients of 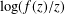 $\log (f(z)/z)$ and Fekete–Szegö theorems.
$\log (f(z)/z)$ and Fekete–Szegö theorems.

