



1. Introduction
This paper is about social robots, the class of robots that are designed to interact with people. Many social robots resemble people or animals, but others look like novel creatures. Some of them talk and listen; others only talk; others communicate with sounds, lights, or movements. Some of them walk on two legs, some on four or more; some move on wheels; others don't travel at all. Social robots have been designed to serve as tutors, caretakers, interviewers, receptionists, personal assistants, companions, service workers, and even sexual partners.
Social robots are a puzzle. On the one hand, people interact with them as if they were humans or pets. They talk with them, show them things, and engage with them in joint activities. At the same time, people know that social robots are mechanical artifacts. They have metal and plastic parts, sensors for vision and hearing, and speech that sounds artificial. It seems self-contradictory, even irrational, for people to hold these two attitudes simultaneously: (a) a willingness to interact with social robots as real people or animals and (b) a recognition that they are mechanical artifacts. The puzzle is not only theoretical but practical. When a robot stops moving, people must decide “Did the social agent fall asleep, or did the artifact's battery die?” And when its finger breaks off, “Am I sad because the social agent is in pain, or because the artifact needs repairing.” Call this the social artifact puzzle.
Our proposal is that people construe social robots not as agents per se, but as depictions of agents. Briefly put, depictions are physical analogs of what they depict. As we spell out later, depictions of humans range from static depictions (paintings, sketches, and sculptures of people) through staged depictions (stage actors and cartoon characters that enact people) to interactive depictions (ventriloquist's dummies, children's dolls, and hand puppets that interact with people). Social robots, we argue, are a type of interactive depiction. Depictions in general consist of three physical scenes with part-by-part mappings between them: (a) a base scene (the raw physical artifact or actor simpliciter), (b) the depiction proper (those features of the artifact or actor that are taken as depictive), and (c) the scene depicted (what people are to imagine). People are able to think about depictions from each of these perspectives. This is also true of social robots.
Treating social robots as depictions of social agents, we argue, has distinct advantages over previous accounts. It also helps resolve the social artifact puzzle. We begin with a brief review of several previous approaches and hint at their shortcomings. We then characterize social robots as depictions and provide evidence that people interact with them consistent with this view. Finally, we conclude.
2. Previous approaches
For much of the past century, robots were only fictional. The term robot was introduced in a 1920 play by Karl Čapek (Reference Čapek1921) for artificial agents who worked as household servants, and it was later adopted in science fiction for other agents. The term has since been extended to industrial machines, surgical robots, military weapons, and other artifacts that are not social.
But what are social robots? How are they viewed, not in science fiction, but by the people who interact with them? We begin with three previous approaches – named the media equation, trait attributions, and social constructions – and argue that they are useful, but incomplete. The account we propose is intended to resolve issues they do not cover.
2.1 Media equation
The idea behind the media equation (Reeves & Nass, Reference Reeves and Nass1996; see also Nass & Moon, Reference Nass and Moon2000) is that people treat interactive devices as social actors: “All people automatically and unconsciously respond socially and naturally to media” (p. 7). The term media refers to computers, social robots, and other devices that people communicate with. The media equation is “media = real life.”
The main proposal is that people communicate with media using the same “social and natural rules” (p. 5) they would use in human-to-human communication. One study, for example, looked at gender stereotypes (Nass, Moon, & Green, Reference Nass, Moon and Green1997). People were brought into a lab, taught a body of facts by a computer, and later asked about the computer's knowledge. The computer had a male voice for half of the participants and a female voice for the other half. Later, participants claimed that the computer knew more about technology than romance when it had a male voice, but the reverse when it had a female voice.
The media equation has been influential because it predicts many features of social interactions with media – from gender stereotypes, politeness, and interpersonal distance to arousal, timing, and physical size (for a review, see Reeves & Nass, Reference Reeves and Nass1996). Still, the media equation leaves certain questions unanswered. Why, for example, do people “respond socially and naturally” to social robots when they know the robots are artifacts? And are their responses truly “automatic and unconscious”? These are just two issues we will return to.
2.2 Trait attributions
The trait attribution approach assumes that people are predisposed to attribute human traits to nonhuman artifacts (Epley, Waytz, & Cacioppo, Reference Epley, Waytz and Cacioppo2007; Ruijten, Reference Ruijten2015; Ruijten, Haans, Ham, & Midden, Reference Ruijten, Haans, Ham and Midden2019; Waytz et al., Reference Waytz, Morewedge, Epley, Monteleone, Gao and Cacioppo2010b, among others). People have this predisposition, it is argued, because they know more about human than nonhuman agents (Epley et al., Reference Epley, Waytz and Cacioppo2007), so they “commonly anthropomorphize nonhuman agents, imbuing everything from computers to pets to gods with humanlike capacities and mental experiences” (Waytz, Gray, Epley, & Wegner, Reference Waytz, Gray, Epley and Wegner2010a; Waytz et al., Reference Waytz, Morewedge, Epley, Monteleone, Gao and Cacioppo2010b, p. 410). They do so “to satisfy the basic motivation to make sense of an otherwise uncertain environment.” People therefore treat humanoid robots on a “continuum ranging from low to high humanlikeness” depending on “the ease with which [anthropomorphic characteristics] can be ascribed to robots” (Ruijten, Bouten, Rouschop, Ham, & Midden, Reference Ruijten, Bouten, Rouschop, Ham and Midden2014, p. 1).
Trait attributions have been studied in social robots by identifying the features that contribute their humanlikeness. The features investigated include not only physical properties such as eyes and fingers (e.g., Mieczkowski, Liu, Hancock, & Reeves, Reference Mieczkowski, Liu, Hancock and Reeves2019; Phillips, Ullman, de Graaf, & Malle, Reference Phillips, Ullman, de Graaf and Malle2017), but also psychological capacities such as speech and agency (e.g., Crowell, Deska, Villano, Zenk, & Roddy, Reference Crowell, Deska, Villano, Zenk and Roddy2019; Mohammadi & Vinciarelli, Reference Mohammadi and Vinciarelli2012). In several studies, people rated how well human traits apply to a variety of entities (Epley et al., Reference Epley, Waytz and Cacioppo2007; Gray, Gray, & Wegner, Reference Gray, Gray and Wegner2007; Reeves, Hancock, & Liu, Reference Reeves, Hancock and Liu2020; Weisman, Dweck, & Markman, Reference Weisman, Dweck and Markman2017). In Gray et al.'s study, the entities ranged from a baby, a fetus, a dead woman, and a frog to God, “you,” and a robot, and they were rated on dimensions of both “experience” (e.g., hunger, pain, fear) and “agency” (e.g., self-control, morality, memory). The robot was rated low in experience and moderate in agency.
It is one thing to attribute humanlike traits to an artifact and quite another to know how to engage, for example, with a being that is low in experience and moderate in agency. This is just one of the issues we will return to.
2.3 Social constructions
In the third approach, people treat social robots as human- or life-like beings – as social constructions – because of the way they are framed (e.g., Chang & Šabanović, Reference Chang and Šabanović2015). Whenever people speak about robots as humanlike, for example, they invite others to treat them as if they were humans (Coeckelbergh, Reference Coeckelbergh2011).
Social constructions depend on pretense. When people interact with social robots, in this view, they engage in the pretense that they are interacting with actual beings (Airenti, Reference Airenti2018). This is a social practice that children learn in make-believe play (Bretherton, Reference Bretherton1984, Reference Bretherton1989; Garvey, Reference Garvey1990; Piaget, Reference Piaget1962). And evidence suggests that the more children engage in role play, the more willing they are to attribute humanness to nonhuman animals and artifacts such as robots (Severson & Woodard, Reference Severson and Woodard2018).
But what precisely are these social constructions, and how do they account for the different perspectives people take on social robots? These are issues we will return to.
2.4 Unresolved issues
The previous approaches help characterize the social artifact puzzle, but they are hardly the whole story. Consider three issues that are raised by the conversation in Table 1 between an English-speaking robot (Smooth, see Fig. 1) and three Danish adults (whom we will call Arne, Beth, and Carl).

Figure 1. Robot Smooth.
Table 1. Conversation between Smooth (a robot) and Arne, Beth, and Carl (from a corpus described in Langedijk & Fischer, Reference Langedijk and Fischer2023)

The first issue is willingness: Arne, Beth, and Carl differed in how willing they were to interact with the robot. Beth stepped in front of it, looked at its face, listened to it, and responded to its “Cheers” with English “Cheers,” but Arne and Carl did just the opposite. Arne looked behind the robot and then spoke to Beth and Carl in Danish, a language the robot hadn't used, while Carl stood back and looked at the robot out of the corner of his eye. In line with the media equation, Beth responded to the robot as if it were a person. Arne and Carl, however, did not. Why was Beth willing to interact with Smooth, but Arne and Carl were not?
The second issue is changes in perspective. Although Beth interacted with the robot in lines 7 through 10, she suddenly changed her perspective. She tilted her head toward Arne and spoke to him in Danish, something that would be very impolite in front of an actual person. That is, Beth treated the robot as a social agent one moment, but as an inanimate artifact the next. This behavior is at odds with all three previous approaches. How could she change perspectives so quickly, and why?
The final issue is selectivity. When the robot produced “Cheers!” Beth replied “Cheers,” lifted her glass, and laughed as if the robot was making a genuine toast. She did this even though the robot had no arms and couldn't raise a glass in a follow-up drink. Beth was selective in her interpretation of the robot's behavior. She took account of its speech but ignored its lack of arms. But how was she selective, and why?
The alternative account we take up addresses these three issues plus many others not covered in the earlier proposals. In sections 3, 4, and 5 we take up depictions in general – what they are, the perspectives they entail, and the types of agents they depict – and show how social robots align with these properties. In sections 6, 7, 8, and 9 we examine three types of agents associated with social robots and show how they arise from treating the robots as depictions. In section 10, we summarize what we have argued.
3. What are depictions?
Our proposal is that people take social robots to be depictions of social agents – artifacts created to look, move, and sound like social agents. Construing them as depictions is no different from thinking of Michelangelo's statue of David as a depiction of the biblical David, the puppet Kermit the frog as a depiction of a talking frog named Kermit, or a toy dog as a depiction of a dog. But what are depictions?
3.1 Depictions as physical analogs
Depictions represent physical scenes by the way they look, sound, or feel: They are physical analogs of those scenes (see Clark, Reference Clark2016, Reference Clark and Hagoort2019). By physical scene, we mean a configuration in space and time of people, objects, places, events, and any other physical elements.
Most depictions are intended to have particular interpretations. When Alice draws a circle on paper for Bert, for all he knows she could be depicting a bicycle wheel, an earring, or the trajectory of the earth around the sun. She needs to provide Bert not only with the perceptual display (the drawn circle) but also with an interpretive framework for construing the display (e.g., “this is a bicycle wheel”). A depiction consists of the display plus its interpretive framework. Social robots are just such artifacts – perceptual displays with interpretive frameworks.
Social robots are clearly intended by their makers to be construed as depictions. Many have humanlike names and depict humanlike creatures (e.g., Honda's Asimo [Fig. 2], SoftBank's Nao and Pepper, Hanson Robotics' Little Sophia and Professor Einstein). Others have pet-like names and depict pets. These include dogs (Sony's Aibo, ToyQuest's Tekno), cats (Phillips' iCat), frogs (ToyQuest's Rosco), turtles (ToyQuest's Flash), seals (AIST's Paro), and even scorpions (ToyQuest's Scorpion). Still others depict beings that people know little or nothing about (e.g., Breazeal's Jibo) or unknown “robotic” creatures (e.g., R2-D2 and BB8 from Star Wars).

Figure 2. Asimo.
3.2 Varieties of depictions
Depictions come in many types (see, e.g., Chatman, Reference Chatman1980; Clark, Reference Clark2016; Walton, Reference Walton1973, Reference Walton1978, Reference Walton1990, Reference Walton2008, Reference Walton2015). Table 2 lists 15 familiar ways of depicting people. Michelangelo's David, for example, depicts a warrior, the biblical David, about to do battle with Goliath. Manet's painting “Chez le père Lathuille” depicts an attentive young man chatting with a young woman in a Parisian restaurant. A Punch and Judy show depicts the activities of a quarrelsome husband and wife, Punch and Judy. The people depicted (David, the two Parisians, Punch and Judy) we will call characters.
Table 2. Fifteen types of depictions with examples (and dates created)

Depictions of people run the gamut from sketches to social robots. The depictions listed in Table 2 differ on five relevant dimensions:
(1) Static versus dynamic depictions. Types 1 through 5 are static depictions, and the rest are dynamic. Social robots like Asimo belong to the dynamic category.
(2) Staged versus interactive depictions. Dynamic depictions divide into staged and interactive depictions. Types 6 through 10 are depictions that people view from outside the scene proper. Types 11 through 15 are depictions of characters that people interact with from within the same scene. Social robots like Asimo belong to the interactive category.
(3) Actor versus prop depictions (see Clark, Reference Clark2016). Actor depictions are those in which the characters are enacted, or played, by actors within the scene. Types 6, 7, 8, and 13 are actor depictions. Prop depictions are those in which the characters are established or controlled by prop managers outside the scene. Types 1 through 5, 11, 14, and 15 are prop depictions. There are also hybrid depictions in which the characters are created by a combination of actors (for the voices) and props (for the bodies), as in types 9, 10, and 12. Social robots (e.g., Asimo) are prop depictions.
(4) Sensory modalities. Paintings, photographs, and sketches rely on vision alone, and radio plays and virtual assistants on audition alone. Animated cartoons, movies, and stage plays deploy both vision and audition, and dolls add touch. Most social robots rely on vision, audition, and touch.
(5) Displacement. The scenes depicted in statues, photographs, plays, and puppet shows are displaced from the here-and-now in both space and time. The scenes depicted in live broadcasts, Skype, and Zoom are displaced in space but not time. The scenes represented in interactive depictions, however, are displaced in neither space nor time. Social robots belong to this category.
On their very face, then, social robots such as Asimo are depictions of social agents. They are dynamic, interactive depictions that use vision, audition, and touch, and depict agents in the here-and-now. The category they belong to includes children's dolls, ventriloquist dummies, and hand puppets, so people should conceive of social robots in ways that are common to depictions like these. In what follows, we will use Asimo as our standard exemplar (see Fig. 2).
4. Perspectives on depictions
Social robots are usually treated as indivisible wholes. Asimo would be referred to simply as “the robot” or as “Asimo.” But people interacting with social robots often take other perspectives on them, such as “the robot's machinery,” “the robot's material presence,” and “the character voiced by the robot,” and they switch easily from one perspective to another, as Beth did in Table 1. But what are these perspectives, and how are they connected?
4.1 Depictions as multiple scenes
People interpret depictions in general as consisting of three physical scenes with mappings between them (Clark, Reference Clark2016; Nanay, Reference Nanay2018).Footnote 1 We will illustrate with Michelangelo's sculpture David.
(1) Base scene. In the Galleria dell'Accademia in Florence, there is a 5.17 m tall irregular piece of Carrara marble on top of a 2 m square block of white marble. This is the raw, uninterpreted material of Michelangelo's sculpture, the base scene for his depiction.
(2) Depictive scene (or depiction proper). Viewers are expected to construe a subset of features of the base scene as the depiction proper. They note that the upper half of Michelangelo's sculpture has the shape of a muscular man with something slung over his shoulder. This is the perceptual display. They also infer that the plinth is not part of the depiction proper. And they take a nearby sign that translates to “David by Michelangelo” as supplying an interpretive framework for the display: Michelangelo intended the display to depict the biblical David.
(3) Scene depicted. Viewers recognize that they are to use the depiction proper (the perceptual display plus its interpretive framework) as a guide in imagining the scene depicted – David preparing to attack Goliath with a slingshot.
Viewing depictions as a conjunction of these scenes satisfies two principles of depictions (Clark, Reference Clark2016), namely:
-
Double-reality principle: Every depiction has two realities: its base, or raw execution; and its appearance, the features intended to be depictive.
-
Pas-une-pipe principle: A depiction is not what it depicts.
The first principle was proposed by Richard Gregory (Reference Gregory1968, Reference Gregory1970, Reference Gregory2005; see also Maynard, Reference Maynard1994). In paintings, he noted, the canvas, splotches of paint, and brush stokes constitute one reality, and their interpretation as a depiction of a scene constitutes a second. The first reality is our base scene, and the second is the depiction proper. The pas-une-pipe principle is named after René Magritte's painting of a briarwood pipe over the words “Ceci n'est pas une pipe” (“This is not a pipe.”), and it relates the depiction proper, Gregory's second reality, to the scene depicted. It is similar to a principle offered by Korzybski (Reference Korzybski1948; see also Bateson, Reference Bateson1972; Borges, Reference Borges1998; Carroll, Reference Carroll1894): “A map is not the territory it represents.”
4.2 Mapping between scenes
For people to represent depictions as three scenes plus mappings, they need to compartmentalize the scenes – to represent them as distinct but connected. By the double-reality principle, they must distinguish the base scene – the raw artifact – from its construal as a depiction. And for the pas-une-pipe principle, they must distinguish the depiction proper from what it depicts. They must also represent the mappings between scenes. How might they do that?
People recognize that the scenes are connected in part-by-part mappings. There is a part of the marble in the base scene for David that corresponds to David's right hand, a part we will designate handbase. The same portion of marble is construed in the depiction proper as a depictive prop for a man's right hand, a part we will designate handprop. That prop, in turn, maps into the actual right hand of the character David in the scene depicted, a part we will designate handchar. The part-by-part mapping is: handbase → handprop → handchar. There are similar mappings for other parts of the sculpture, such as the stone in David's hand, David's left eye, and, of course, David as a whole (see Clark, Reference Clark2016; Walton, Reference Walton1990).
The three scenes plus mappings form a package of constraints. Elements of Davidbase constrain what viewers take to be the depictive prop, Davidprop, and vice versa, and elements of Davidprop constrain what they take to be the scene depicted, Davidchar, and vice versa. If Michelangelo had added a belt of stones to Davidbase, that would have changed Davidprop and what viewers took to be Davidchar. If, instead, Michelangelo had labeled the sculpture “Apple picker,” that would have changed viewers' interpretation of Davidprop and its relation to Davidbase.
4.3 Language and perspective
If people can view depictions from three perspectives, they should be able to refer to each scene separately, and they can. When Emma and Sam are looking at Michelangelo's David, she could point at the sculpture and tell Sam:
(1) That is marble quarried in Carrara.
(2) That is a statue of the biblical David by Michelangelo.
(3) That is David preparing to slay Goliath.
Emma uses that to refer, respectively, to the base scene, the depiction proper, and the scene depicted – to Davidbase, Davidprop, and Davidchar. She could do the same for most parts of the sculpture. Pointing at David's right hand, she could tell Sam “That's Carrara marble,” “That's an exaggerated size for a hand,” or “Look – David is holding a stone.”
All depictions allow for these perspectives. One could hold up a photograph of Eleanor Roosevelt and say, “I bought this in a flea market,” or “This is a photograph of FDR's wife Eleanor,” or “This woman/She was the first U.S. delegate to the U.N.” And at a performance of Hamlet, one could nod at an actor on stage and whisper to a companion, “Didn't we see him at the pub the other night?” or “That guy is playing Hamlet,” or “He's the prince of Denmark.”
Part-by-part mappings in depictions are also reflected in language. In talking about David, viewers would use “hand” both for the sculpture's marble hand (handprop) and for David's flesh-and-blood hand (handchar). In the languages we know, individual parts of a depiction proper are generally denoted with the same terms as the corresponding parts of the scene depicted. As a result, references to parts (e.g., “David's left hand”) are often ambiguous.
4.4 Perspectives on social robots
If social robots are depictions, they, too, should consist of three scenes plus mappings. Asimo, our standard exemplar, consists of these scenes:
(1) Asimo base is the artifact or machine that constitutes Asimo's base. It is made of metal, plastic, sensors, and other material, and has parts that move and make sounds.
(2) Asimo prop is the depiction proper. Like a hand puppet, child's doll, or ventriloquist's dummy, it is a prop for the agent it represents. It depicts Asimo char in certain of its shapes, movements, and sounds.
(3) Asimo char is the character depicted by Asimo prop. He is a male, humanlike being named Asimo.
The mapping is Asimobase → Asimoprop → Asimochar, and there are similar mappings for many of Asimo's parts. As illustrated in Table 1, evidence shows that people can switch from one of these perspectives to another, often in quick succession (Fischer, Reference Fischer2021).
As with depictions in general, people can use “this robot” or “Asimo” to refer to Asimo's base, prop, or character. Examples: “This robot/Asimo/It was manufactured in Japan”; “This robot/Asimo/It looks quite like a human adult”; and “This robot/Asimo/He likes to kick soccer balls,” or “Asimo, please kick the ball over here.” So, when someone refers to “the robot” or “Asimo” or “Asimo's right leg,” it is crucial to determine which perspective they are taking.
And people understand at least some of the mappings between scenes. Aibo, a robot dog sold by Sony, can sit, stand, lie down, bark, wag its tail, recognize its name, obey commands, and respond to being petted. When owners play with their Aibo, they focus on Aibochar. Still, they are aware that Aibobase works from a battery and is turned on and off with a switch on the back of its neck. They realize that a cessation of Aibobase's power causes a cessation of Aibochar's behavior – a part-by-part mapping from Aibo's base to its character. We return to this point in section 9.2.
4.5 Language problems
It is one thing to tacitly distinguish the three perspectives on a robot (a matter of cognition) and quite another to answer questions about them (a matter of meta-cognition). Consider a study by Kahn et al. (Reference Kahn, Kanda, Ishiguro, Freier, Severson, Gill and Shen2012) that used a 120 cm tall humanoid robot called Robovie. In the study, 90 participants aged 9–15 interacted with the robot for 15 min and were then asked 40 questions about it. Participants had no problems with the interaction. Almost all reciprocated when Robovie offered to shake hands, asked them to point at something, and offered to hug them. But the participants did have trouble with the questions.
Two of the questions asked were: (1) “Does Robovie have feelings?” and (2) “Can a person sell Robovie?” If the participants thought of Robovie as a human – it had an adult male voice and spoke fluent English – they should have said “yes” to 1 and “no” to 2, but if they thought of Robovie as an artifact, they should have said the reverse. In fact, 60% of them said “yes” to 1, but 89% also said “yes” to 2. How is this possible?
One problem is that all 40 questions referred to the robot as “Robovie,” which has at least three interpretations:
(a) the raw artifact (“Robovie's battery lost power”),
(b) the artifact construed as a depiction (“Robovie has metal rods for arms”), and
(c) the character depicted (“Robovie just greeted me”).
Question 1 about feelings makes sense for (c), but not for (a) or (b), whereas question 2 about selling makes sense for (a) or (b), but not for (c) (at least not for an adult male English-speaking character). Although this pattern fits the participants who said “yes” to both 1 and 2, roughly 40% of those who said “no” to 1 said “yes” to 2.
Participants clearly struggled with their answers. When asked if they thought Robovie was a living being, 14% said “yes” and 48% said “no,” but 38% were unwilling to commit either way. The uncommitted “talked in various ways of Robovie being ‘in between’ living and not living or simply not fitting either category.” As one insightful participant said, “He's like, he's half living, half not” (Kahn et al. [Reference Kahn, Kanda, Ishiguro, Freier, Severson, Gill and Shen2012], p. 310). All these responses make sense if Robovie is an artifact construed as depicting a character of some kind.
To sum up, depictions represent physical scenes by the way they look, sound, and feel. People compartmentalize them into a base scene, depiction proper, and scene depicted, with part-by-part mappings between scenes. As a result, people can think about depictions from three perspectives. Social robots are just such depictions.
5. Character types
To interact with a social robot, people need some idea of the character it represents. Is it a dog, a bear, or a human, and if it is a human, is it a child or an adult, a male or a female? What does it know, what can it do, how does it interact with people?
One source of information is a robot's perceptual display, but that is always incomplete. Picasso's sketch of Stravinsky depicts Stravinsky's shape and clothing, but not his size, behavior, or ability to speak Russian. Olivier's performance in Hamlet depicts Hamlet's overall shape, size, clothing, and behavior, but not his ability to speak Danish. Much the same holds for social robots. Asimoprop's display depicts Asimochar's overall shape, but not his eyes or ears. People cannot be certain what Asimochar is capable of from Asimoprop alone.
5.1 Selectivity of features
Observers of a depiction implicitly realize that only some of its features are depictive (see Clark & Gerrig, Reference Clark and Gerrig1990). By features, we mean aspects, parts, and capacities:
(1) An aspect is a property that applies to most or all of a depiction proper. Michelangelo's David has such base aspects as “shape,” “size,” “color,” “material,” “orientation,” “surface damage,” and “pigeon droppings.”
(2) A part is a continuous, identifiable portion of the depiction proper, such as David's left thumb.
(3) A capacity is a property that is dynamic. Kermit the puppet, for example, allows movement of its jaw and head. David has no such capacities. One can identify the static aspects and parts of a depiction from still photographs of the depiction, but it takes evidence over time to identify its capacities.
Observers implicitly register the status of each feature of a display. For Michelangelo's sculpture, they know that “overall shape” is depictive, but that other aspects are not. “Material” and “size,” for example, are supportive aspects. They are required in the perceptual display, but only as support for the aspect “shape.” And the aspects “surface damage” and “pigeon droppings” are neither depictive nor supportive. Parts and capacities can be classified on the same grounds.
If Asimo is a depiction, its perceptual display should divide in the same way. As with David, the aspect “overall shape” is depictive, “material” and “size” are supportive, and for Asimo at least “surface painting” is neither depictive nor supportive. Asimobase's head, torso, arms, fingers, and legs are depictive parts, but the hinges used for its finger joints, elbows, and knees are not. Asimobase's head is a mix of depictive and supportive parts: it has ears, but no eyes or mouth. Asimoprop has the capacity to walk, run, kick balls, climb stairs, grasp things, and look around, but not to smile.
Depictions are also selective in what they depict. Picasso's sketch of Stravinsky depicts the shape and location of Stravinsky's eyes, but not their color or movement. A color video of Stravinsky would depict all four attributes. So, for the sketch, eye location and shape are depicted attributes; eye color and movement are inferred attributes. For the video, all four attributes are depicted. People make analogous inferences for Asimo.
With depictions, then, people must take feature selectivity seriously or risk misinterpreting them. For the ventriloquist's dummy Charlie McCarthy, people probably infer that McCarthychar's eyes move even though McCarthyprop's eyes are static. For Asimo, they eventually infer that Asimochar can see and talk even though Asimoprop has no eyes or mouth. For social robots, the hardest features to infer are capacities: Can they speak and understand a language, and if so, what language and how well? What do they know and not know?
5.2 Nonstandard characters
Everyday depictions often represent nonstandard characters – beings that are not real. Many of these are near-humans, such as angels, pixies, zombies, and devils, and others are animals that talk, such as Mickey Mouse, Porky Pig, and Sesame Street's Big Bird. Still others are unlike any creatures we know. People can only guess at what the nonstandard characters can and cannot do.
All social robots represent nonstandard characters – and they are nonstandard in different ways. Asimo and Professor Einstein both represent humanlike creatures, but of quite different types. Asimochar can walk, run, climb stairs, kick balls, and grasp objects, but Professor Einsteinchar cannot. Professor Einsteinchar can make faces and answer scientific questions, but Asimochar cannot. Jibo, a personal assistant robot, has a spherical head, a single large eye, a short torso, and no limbs. Jibochar can speak, listen, and gesture with its head, but cannot locomote. And Ishiguro's robots (see Glas, Minato, Ishi, Kawahara, & Ishiguro, Reference Glas, Minato, Ishi, Kawahara and Ishiguro2016) look uncannily like real people, but do not speak or behave like real people.
Robot characters are therefore best viewed as composite characters – combinations of disparate physical and psychological attributes. Asimochar has a head, arms, hands, fingers, and other standard human features, but no mouth, jaw, or lips. He can walk, run, climb stairs, and kick soccer balls, but cannot smile or frown. He can speak even though he has no mouth. Professor Einsteinchar and Jibochar are composites of entirely different types.
How do people infer the content of these composites? They base some of their inferences on heuristics available for depictions of people. These include:
(1) Static features → physical attributes. Michelangelo's sculpture of David has two static eyesprop that point forward, so we infer that Davidchar has eyes that are directed at something in the distance.
(2) Static features → associated abilities. Although Davidprop has two static eyesprop, we infer that Davidchar has the standard abilities associated with eyes. He can focus on things, identify objects, distinguish colors, and so on.
(3) Dynamic features → physical attributes. The ventriloquist's dummy Charlie McCarthyprop produces fluent speech in interaction with Edgar and Candice Bergen, so we infer that McCarthychar has the standard anatomy for articulating speech.
(4) Dynamic features → associated abilities. McCarthyprop produces fluent English, so we infer that McCarthychar has the standard human skills for speaking and understanding English.
With social robots, for example, people tend to ascribe greater moral responsibility to a robot the more humanlike features it has (Arnold & Scheutz, Reference Arnold and Scheutz2017). And people expect a robot to understand more instructions that are grammatically complex the more types of grammatically complex instructions it produces (Fischer, Reference Fischer2016).
Heuristics like these, however, go only so far. Most social robots are introduced with interpretive frameworks such as “Here is your companion” or “your tutor” or “a receptionist,” but details of their characters can only be inferred over time, much as getting acquainted with a stranger takes place over time (see Fischer, Reference Fischer2016; Pitsch et al., Reference Pitsch, Kuzuoka, Suzuki, Sussenbach, Luff and Heath2009).
6. Interacting with characters
The characters represented in depictions are often agents. Think of Michelangelo's warrior, Shakespeare's King Lear, or Disney's Mickey Mouse. But depictions also involve intended recipients. They are the reason that sculptures are placed on plinths, paintings on walls, photographs in books, movies on screens, and plays on stage.
Depictions that are static or staged are designed to engage recipients in imagining the scenes depicted, scenes that are displaced in space, time, or both. But depictions that are interactive are designed to engage recipients in the current scene. Dolls are for children to play with, ventriloquist dummies are for people to talk to, virtual agents are for people to ask questions of, and social robots are for people to interact with. Still, the characters depicted are fictional, and people don't ordinarily interact with fictional characters. If so, how do people know what to do? Viewing social robots as depictions offers an answer.
6.1 Imagination in depictions
It takes imagination to interpret depictions of any kind (Clark, Reference Clark1996, Reference Clark2016, Reference Clark and Hagoort2019; Clark & Van Der Wege, Reference Clark, Van Der Wege, Tannen, Hamilton and Schiffrin2015; Walton, Reference Walton1990). But what we imagine depends on the type of depiction.
With depictions that are static or staged, we imagine ourselves transported into the world of the scene depicted (see, e.g., Chatman, Reference Chatman1980; Clark, Reference Clark1996; Clark & Van Der Wege, Reference Clark, Van Der Wege, Tannen, Hamilton and Schiffrin2015; Gerrig, Reference Gerrig1993; Oatley, Reference Oatley2011, Reference Oatley2016; Walton, Reference Walton1990). For Manet's painting “Chez le père Lathuille,” we imagine sitting in the sunny garden of a Parisian restaurant watching a young couple courting at a nearby table. At the movie Titanic, we imagine ourselves on the ship Titanic in 1912 watching Jack and Rose fall in love and seeing Jack go down with the ship. And at Hamlet, we imagine ourselves in medieval Denmark watching Hamlet and Ophelia talk.
With depictions that are interactive, on the other hand, we imagine characters imported into our world. On television in 1964, ventriloquist Edgar Bergen and his dummy Charlie McCarthy chatted with several people, including Bergen's daughter Candice. The recipients who were there all interacted with McCarthychar as if they were talking to him in the here-and-now. The same holds for people conversing with hand puppets, Apple's Siri, and Snow White at Disneyland.
Importation is different from transportation. With paintings, movies, and stage plays, recipients engage in the pretense that they are covert observers in the scenes depicted, where a covert observer is present in a scene, but invisible, mute, and unable to intervene (see Clark, Reference Clark2016). With importation, recipients engage instead in the pretense that they are co-participants with the characters depicted.
6.2 Frames of reference
Every physical scene, real or fictional, has a place- and a time-frame – a spatial and a temporal frame of reference. Suppose Emma visited Florence in 2020 to see Michelangelo's David. The place and time for her was Florence in 2020, but the place and time of the scene she imagined was the Valley of Elah in 700 BCE – if she knew her history (see Table 3). The scene depicted was displaced from the depiction proper in both space and time (placeprop ≠ placechar, and timeprop ≠ timechar). Telephone conversations, chatting on Skype, and live TV broadcasts are displaced in space but not time (placeprop ≠ placechar, and timeprop = timechar).
Table 3. Frames of reference when observing Michelangelo's David in 2020

Interactive depictions are displaced in neither space nor time (placeprop = placechar, and timeprop = timechar). This we will call auto-presence. We will speak of the characters depicted (e.g., McCarthychar) as auto-present with the props that depict them (McCarthyprop). On the set of Sesame Street, adults and children interact with the characters Bert, Ernie, and Big Bird, who are auto-present with the puppets. And at Disneyland, visitors talk extemporaneously with the characters Snow White, Mickey Mouse, and Grumpy, who are auto-present with the actors playing them.
If social robots are interactive depictions, they, too, should require auto-presence. Indeed, when people interact with Asimo, they construe Asimochar as occupying precisely the same location and behaving at precisely the same time as Asimoprop. They imagine Asimochar as auto-present with Asimoprop.
6.3 Layers of activity
With dynamic depictions, observers keep track of two layers of activity – the depiction proper (e.g., Hamlet performed on stage), and the scene depicted (activities taking place in medieval Denmark). We will call these layer 1 and layer 2 (Clark, Reference Clark1996, Ch. 12; Clark, Reference Clark1999). For the audience at Hamlet in 1937, the scene they actually watched was layer 1, and the scene they imagined watching was layer 2:
-
Layer 1: On stage here and now, Olivier turns his head and body toward Leigh and produces “Get thee to a nunnery.”
-
Layer 2: In Denmark centuries ago, Hamlet turns to Ophelia and says, “Get thee to a nunnery.”
The audience used the actions they perceived in layer 1 as a guide to the actions they imagined perceiving in layer 2. Layer 2 mirrored layer 1 moment-by-moment and part-by-part.
Observers of depictions are expected to execute two classes of processes – engagement and appreciation (Bloom, Reference Bloom2010; Clark, Reference Clark1996). The audience at Hamlet was to engage in – focus their imagination on or get engrossed in – layer 2, Hamlet and Ophelia's actions in medieval Denmark. Those who did were horrified when in Act III Hamlet drew his sword and killed Polonius, and when in Act IV they learned that Ophelia had drowned. These processes are all part of engaging in a depiction.
Observers must also appreciate the content of layer 1 and its relation to layer 2. At Hamlet the audience knew that Olivier's sword was fake, the actor playing Polonius didn't die, and Leigh didn't drown. In Act III they knew they shouldn't rush onstage to hold Olivier for the police or call an ambulance for the actor playing Polonius. They could also reflect on such aspects of layer 1 as Shakespeare's language, Olivier's and Leigh's acting, and the Old Vic's stage sets. All these processes are part of appreciating a depiction.
Interactive depictions have the same two layers. At one point, the ventriloquist's dummy Charlie McCarthy faced Candice Bergen and produced “How about you and me going dancing?” For Candice, the two layers were:
-
Layer 1. Here and now, the ventriloquist rotates McCarthyprop's head toward Candice and produces “How about you and me going dancing?”
-
Layer 2. Here and now, McCarthychar asks Candice to go dancing.
It took the ventriloquist, Candice, and McCarthyprop together to create layer 1 (the depiction proper), and they did that to guide Candice and others in imagining layer 2 (the scene depicted). Candice engaged in the pretense that McCarthychar was asking her to go dancing when she replied “Great idea! We can do the watusi.” At the same time, she clearly appreciated, among other things, that in layer 1 McCarthyprop was under the control of the ventriloquist, her father.
Interacting with social robots works the same way. Suppose Ben is kicking a soccer ball back and forth with Asimo.
-
Layer 1: Here and now, Asimoprop moves its footprop and propels the ball to Ben.
-
Layer 2: Here and now, Asimochar kicks the ball toward Ben.
Asimoprop and Ben produce the events in layer 1 for Ben and others to use in imagining the events in layer 2. That is, Ben is to engage with Asimochar in layer 2 while appreciating Asimoprop's function as a depiction in layer 1.
Imported characters have a curious property. Even though they themselves are not real, many of the activities they create in the here-and-now are real. When Asimochar and Ben are kicking the ball back and forth, the ball and kicking are real (cf. Seibt, Reference Seibt, Hakli and Seibt2017). If Asimochar were skillful enough, he could play in a real soccer game, running, passing, and scoring along with the real players. Imported characters can do real things when the objects, people, and activities they are auto-present with are also real.
6.4 Acquisition of pretense
How do children interpret social robots? The short answer is as interactive toys – as props in make-believe social play. By age 2, children use dolls and stuffed animals as props for pretend characters, and by 3–4, they can alternate in their play between giving stage directions (such as “I a daddy” or “Pretend I'm a witch”) and enacting characters (“I want my mommy”) (Clark, Reference Clark1997, Reference Clark2009, Reference Clark2020; Garvey, Reference Garvey1990). So, at an early age, they are fully prepared to assimilate robots into their play, and that is what they appear to do (see, e.g., Turkle, Breazeal, Dasté, & Scassellati, Reference Turkle, Breazeal, Dasté, Scassellati, Messaris and Humphreys2006).
At the same time, research on depictions suggests that it should take children years to fully understand the dual layers of social robots. Children recognize that drawings of objects map into actual objects by 12–18 months of age (DeLoache, Pierroutsakos, Uttal, Rosengren, & Gottlieb, Reference DeLoache, Pierroutsakos, Uttal, Rosengren and Gottlieb1998; Hochberg & Brooks, Reference Hochberg and Brooks1962), but they do not understand how maps and models map into physical layouts until they are 3–4 (DeLoache, Reference DeLoache1991). Nor do they understand how television represents physical objects until they are 4 (Flavell, Flavell, Green, & Korfmacher, Reference Flavell, Flavell, Green and Korfmacher1990). Children recognize that movies represent fictional worlds by age 4, but they do not differentiate fictional worlds in an adult-like way until they are 7 or older (Choe, Keil, & Bloom, Reference Choe, Keil and Bloom2005; Goldstein & Bloom, Reference Goldstein and Bloom2015; Skolnick & Bloom, Reference Skolnick and Bloom2006). It is an open question what children understand about social robots at each age.
7. Communicating with characters
It takes coordination for two individuals to interact with each other, and they cannot do that without communicating (Clark, Reference Clark1996). But what if one of them is a person, say Margaret, and the other is a fictional character, say Kermit the frog? Margaret must engage in the pretense that she can communicate with Kermit as if Kermit speaks and understands English like an adult human. She must also appreciate that Kermit's handler, the puppeteer, is the person immediately responsible for Kermit's speech and actions. People need the same two layers in communicating with social robots.
7.1 Forms of communication
People communicate using both speech and gestures, where gestures include “any visible act of communication” (Kendon, Reference Kendon2004). Most robots are able to use gestures. Some use gaze for indexing addressees and nearby objects (e.g., Mutlu, Shiwa, Kanda, Ishiguro, & Hagita, Reference Mutlu, Shiwa, Kanda, Ishiguro and Hagita2009). Some point at things with their hands and arms, and some position themselves in relation to people and objects (e.g., Mead & Matarić, Reference Mead, Matarić, Hsieh, Khatib and Kumar2016). And some robots (e.g., Kismet, Erica, and Emys) make facial gestures (Breazeal, Reference Breazeal2002; Glas et al., Reference Glas, Minato, Ishi, Kawahara and Ishiguro2016; Paiva, Leite, Boukricha, & Wachsmuth, Reference Paiva, Leite, Boukricha and Wachsmuth2017). In one study (Chidambaram, Chiang, & Mutlu, Reference Chidambaram, Chiang and Mutlu2012), a robot was fitted out with one or more of these cues: (a) facial expressions; (b) body postures; (c) eye gaze; (d) hand movements; (e) self-placement; and (f) vocal expressions. In general, the more of these cues the robot used, the more competent it was judged to be and the more often its advice was followed. It is in this process that social cues have the effects predicted by the media equation.
Most robots, however, do not make full use of language. Paro the seal blinks, coos, and moves its body, but doesn't speak. Leonardo, an animal-like creature, moves its eyes, ears, arms, and head, but also doesn't speak. Some robots, like Paro and Leonardo, understand some speech but do not speak. Others both speak and understand language but in ways that are severely limited (Moore, Reference Moore, Jokinen and Wilcock2017). One limitation is in taking turns. In extemporaneous human-to-human conversations, listeners collaborate with the current speaker in locating the end of his or her turn so they can initiate the next turn with a minimum gap or overlap (Holler, Kendrick, Casillas, & Levinson, Reference Holler, Kendrick, Casillas and Levinson2016; Sacks, Schegloff, & Jefferson, Reference Sacks, Schegloff and Jefferson1974; Schegloff, Jefferson, & Sacks, Reference Schegloff, Jefferson and Sacks1977). The challenge is to design social robots that collaborate on turns the way humans do.
7.2 Communication as pretense
When people talk with the puppet Kermit the frog, as we noted, they must engage in the pretense that Kermitchar is real and understands what they are saying. Not everyone is willing to do that, and the same holds for social robots.
In one study, participants were instructed to guide Aibo, the robot dog, along a complicated route by telling it where to go. Although Aibo opened the conversation with a greeting, only some people reciprocated (Fischer, Reference Fischer2016). Here is Aibo's greeting and the responses of four participants:
-
Aibo: Yes, hello. How are you?
-
(a) A042: I I'm good, and you? (laughter)
-
(b) A044: Hello Aibo. – I want you to go, straight ahead.
-
(c) A047: Okay, good, and how are you?
-
(d) A030: (2 sec pause) Go straight.
-
Participants A042, A044, and A047 each accepted Aibo's greeting and reciprocated with greetings of their own. But A030 was unwilling to play along. He ignored Aibo's greeting and launched right in on the first instruction. And A042's laughter suggests that she was self-conscious about the pretense even though she played along. In Fischer's terminology, A042, A044, and A047 were players, and A030 was a non-player.
Players contrast with non-players in the perspectives they adopt with robots (Fischer, Reference Fischer2006, Reference Fischer2011). With Aibo, the players were more likely than the non-players to use complete sentences and personal pronouns (such as “he” and “she”). In a follow-up study by Lee, Kiesler, and Forlizzi (Reference Lee, Kiesler and Forlizzi2010), members of the public exchanged typed messages with a robot receptionist at the entrance of a university building. About half of the users opened their session with a greeting (such as “Hi” or “What's up?” or “Hello”); the rest started right in on their queries. The greeters were more likely to use politeness expressions, engage in small talk, disclose personal information, and avoid rude or intrusive language. In the authors' words, the greeters “treated the robot more like a person” (p. 36). The non-greeters treated it more like an “information kiosk,” a mere source of information.
To be a player is to engage in the second, imagined layer of activity. When A047 heard Aiboprop depict the greeting “Hello. How are you?” she imagined, and became engaged in, the auto-present scene in layer 2:
-
Layer 1: Here and now, Aiboprop produces the sounds “Yes, hello. How are you?” and then I produce the sounds “Okay, good, and how are you?”
-
Layer 2: Here and now, Aibochar greets me with “Yes, hello. How are you?” and I politely reciprocate “Okay, good, and how are you?”
Although A030 heard the same greeting, he did not engage in layer 2.
People can appreciate what a depiction is and still not engage with it. When the robot greeted the Danes in Table 1, Beth engaged in layer 2 and reciprocated the robot's greeting, but Arne and Carl chose not to do so even though they recognized what Beth was doing. Appreciation doesn't require engagement, although engagement requires some level of appreciation.
So, not everyone is willing to play along with a robot – or to do so all the time. In the study by Kahn et al. (Reference Kahn, Kanda, Ishiguro, Freier, Severson, Gill and Shen2012), 97% of the participants reciprocated when the robot greeted them and offered to shake their hand. But when Smooth greeted people with “Hello!” “Hi there!” or “Sorry to bother you, but…” in the lobby of a Danish concert hall, the percentage reciprocating was 78% (Fischer et al., Reference Fischer2021). And when a robotic wheelchair greeted people during one lab study, the percentage was only 40% (Fischer, Reference Fischer2016). A person's willingness to play along with a robot probably has several origins.
7.3 Processes in communication
People's responses to social robots, according to the media equation, should be automatic and unconscious (Nass & Moon, Reference Nass and Moon2000; Reeves & Nass, Reference Reeves and Nass1996), but this is clearly too simple. People's responses cannot be automatic if, as just noted, people vary in their willingness to respond. And even when people do respond, only some of their processes are automatic and unconscious.
Social robots communicate with people via several media: print alone (e.g., the robot receptionist), speech alone (e.g., Professor Einstein), gestures but no speech (e.g., Aibo), and composites of speech and gestures (e.g., Asimo and Smooth). As a result, people responding to the robots require different processes, some automatic and some not, depending on the media:
(1) Skill-based processes. It takes years of guided practice, or formal instruction, for people to speak, understand, or read a language. But once fully proficient in these skills, people process speech and print automatically (see, e.g., Nieuwland & Van Berkum, Reference Nieuwland and Van Berkum2006; Van Berkum, Reference Van Berkum2008, Reference Van Berkum, Sauerland and Yatsushiro2009).
(2) Self-paced processes. People read printed works at their own variable pace, a process they have some control over and is not automatic (Just & Carpenter, Reference Just and Carpenter1980).
(3) Concept-based processes. When people read a passage (as with the robot receptionist), most try to imagine the scene described (Zwaan, Reference Zwaan1999, Reference Zwaan2014). They do so, however, one portion of the scene at a time and base their imagination on successive phrases of the passage (see Miller, Reference Miller and Ortony1993). This process is neither automatic nor unconscious.
(4) Percept-based processes. When people examine a visual depiction (such as Michelangelo's David or Asimo), they try to imagine a character that is physically analogous to the display they are examining. The process of examining the display is generally piecemeal and self-paced even though what people imagine is a holistic character.
(5) Time-locked processes. Speech and gestures (as in plays, movies, Siri, or Asimo) are evanescent – they fade instantly – so they must be processed instantly, or all is lost. Consider the moment in Hamlet when Olivier turned to Leigh and uttered the line “Get thee to a nunnery.” Olivier intended the audience to imagine Hamlet turning to, gesturing for, and speaking to Ophelia at precisely the same time that he, Olivier, was turning to, gesturing for, and speaking to Leigh. The audience had to synchronize, or time-lock, the process of imagining to what they were seeing and hearing. This process must be instantaneous and largely automatic.
So, people's interpretation of a robot's speech is skill-based, but their interpretation of its actions is concept- and percept-based and time-locked to those actions. Some of these processes are automatic and unconscious, but others are not.
8. Authorities
Most depictions have intended interpretations, but intended by whom? We assume that Michelangelo was responsible not only for carving David, but for its interpretation as the biblical David. We also assume that Edgar Bergen was responsible for the interpretation of his dummy as Charlie McCarthy. Most of us appreciate, on reflection, that Michelangelo and Bergen were the authorities responsible for these interpretations.
Other depictions entail a system of authorities. At the 1937 performance of Hamlet, the audience took Shakespeare to be responsible for the script, the actors for their acting, and the Old Vic Company for the staging. They surely appreciated all this and judged Shakespeare for the script, the actors for their acting, and the Old Vic Company for the staging. If social robots are depictions, people should assume an authority, or system of authorities, that is responsible for their interpretation, and evidence suggests they do.
8.1 Principals and rep-agents
Certain types of agents act on the authority of third parties – other individuals or groups. Suppose Goldberg's Bakery hires Susan as a server. At home, Susan can do whatever she wants, but at work, she is responsible for actions within the limits set by her contract with the bakery. If she cheats or insults a customer, the customer would blame her but hold the bakery legally responsible. In Anglo-American law, Goldberg's Bakery is called the principal, and Susan is called an agent of the principal (see Coleman, Reference Coleman1994). For clarity, we will call Susan a rep-agent (for “agent representing a principal”). That gives us a three-way distinction:
(a) Self-agents act on their own authority and are fully responsible for their actions.
(b) Principals are individuals, or groups of individuals, on whose authority others act as rep-agents.
(c) Rep-agents act on the authority of specified principals.
We are all familiar with rep-agents. Table 4 lists examples of specialists whose responsibilities are regulated by principals. Teachers, for example, have contracts with school officials to carry out certain instructional activities with students, so they are rep-agents for those officials.
Table 4. Examples of rep-agents, their settings, and third-party principals
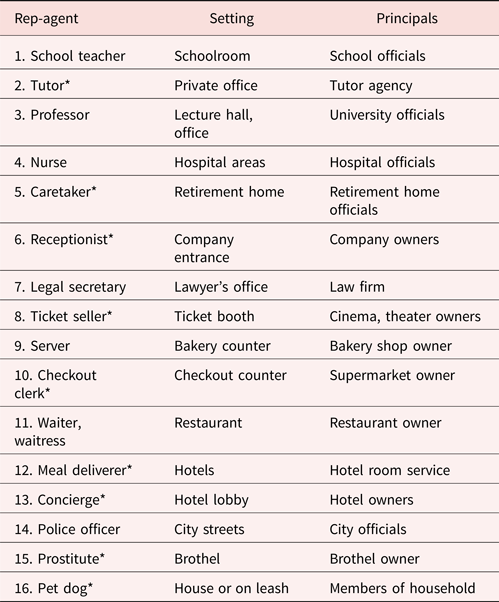
There are commercial robots for each of the starred rep-agents.
Most social robots, we suggest, are construed as rep-agents. People assume that robot math tutors know math and not history, that robot receptionists know schedules and not chemistry, and that sex robots engage in sex and not discussions. Many people are also aware, to some degree, of who the rep-agents are responsible to. If a robot math tutor makes errors, the student may blame the tutor but hold the tutor's principals responsible – the school or robotics company (for evidence, see Belanche, Casaló Luis, Flavián, & Schepers, Reference Belanche, Casaló Luis, Flavián and Schepers2020).
Most people realize that all social robots are limited in what they can do. And when Ben interacts with Asimo, he would assume that there are authorities responsible for what Asimochar actually does. If Asimo accidentally dented Ben's car, Ben would seek damages from those authorities.
Human rep-agents are not always on duty, and even when they are, they can break off and act as self-agents. Here is an example:
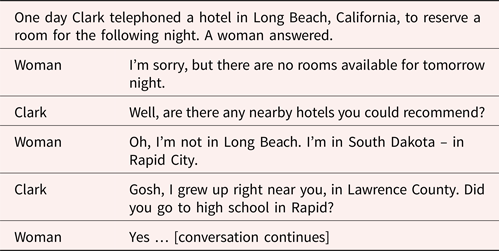
In the third turn the woman interrupted her official duties to engage in small talk with Clark, and after several turns, she returned to her official duties. Few robots have the capacity to engage in small talk (Moore, Reference Moore, Jokinen and Wilcock2017).
8.2 Agent control
Social robots are usually framed as autonomous agents – as agents that act on their own authority – even though they are ultimately controlled by principals. The same holds for other interactive depictions. When people engage with Kermit, Charlie McCarthy, Snow White at Disneyland, and Chatty Cathy, they act as if these characters, too, are autonomous agents, and they improvise what they say and do in talking with them. People take this tack even though the characters are obviously controlled by a puppeteer, a ventriloquist, an actress, and children engaged in make-believe play.
What is different about social robots is that their controls are hidden, making the principals harder to identify. Sophisticated users may assume that robots are controlled by computer programs written by specialists for hardware that was designed by the manufacturers – two sets of responsible authorities – but others may have no idea. Indeed, people sometimes suspect that the robots they encounter are teleoperated by people hidden nearby (e.g., Kahn et al., Reference Kahn, Kanda, Ishiguro, Freier, Severson, Gill and Shen2012; Yang, Mok, Sirkin, & Ju, Reference Yang, Mok, Sirkin and Ju2015), and they are often right. Many experiments use a so-called Wizard-of-Oz technique in which a teleoperator produces the robot's speech and controls its actions.
In fiction, the real Wizard-of-Oz was a ventriloquist (Baum, Reference Baum1900). The Wizard built “an enormous Head” with eyes and a mouth that moved, and from behind a screen, the Wizard produced “I am Oz, the Great and Terrible.” After the Wizard was unmasked by Dorothy the heroine, he told her:
“This [Head] I hung from the ceiling by a wire. I stood behind the screen and pulled a thread, to make the eyes move and the mouth open.”
“But how about the voice?” she enquired.
“Oh, I am a ventriloquist,” said the little man, “and I can throw the sound of my voice wherever you wish, so that you thought it was coming out of the Head.”
So, to use the Wizard-of-Oz technique is literally to treat the robot as a ventriloquist's dummy. Ventriloquist dummies, of course, are interactive depictions – just like robots.
9. Emotions
With social robots, emotions are experienced both by viewers and by the characters depicted. But what emotions, about what, and for whom? Here again, depictions offer a useful analysis.
9.1 Emotions and depictions
Emotions are essential to many depictions. When we look at Dorothea Lange's 1936 photograph, “Migrant mother,” we feel pity for the hungry, desperate woman it depicts. In Act III of Hamlet, we experience horror when Hamlet stabs Polonius. And in watching ventriloquist Edgar Bergen chat with his dummy, we laugh when the dummy makes fun of Bergen. The photograph, play, and ventriloquist show would be pointless without the emotions.
We experience some of our most vivid emotions at the movies (see, e.g., Rottenberg, Ray, & Gross, Reference Rottenberg, Ray, Gross, Coan and Allen2007; Walton, Reference Walton1978). A study by Gross and Levenson (Reference Gross and Levenson1995) identified 16 film clips that elicited emotions ranging from amusement, anger, and contentment to disgust, fear, and sadness, and did so consistently and vividly. In a related study (Gross, Fredrickson, & Levenson, Reference Gross, Fredrickson and Levenson1994), 150 undergraduate women were shown a 5 min film clip from the movie Steel Magnolias while they were monitored physiologically. About 20% of the students cried, and the rest showed physiological changes consistent with being sad.
What were the students sad about? In our analysis, they engaged in the pretense that they were watching the scene in layer 2 while tacitly appreciating its relation to the scene they were watching in layer 1:
-
Layer 1: Here and now, a 2D color movie is showing actress Sally Field in a cemetery delivering lines to other actresses.
-
Layer 2: At some fictional place and time, M'Lynn Eatenton is speaking to friends at a funeral about the death of her daughter.
The students were sad, not about Sally Field in layer 1, but about M'Lynn Eatenton in layer 2. And they attributed grief, not to Sally Field, but to M'Lynn Eatenton. Still, movie critics were so moved by Sally Field's acting that they nominated her for a Golden Globes Award. The students were sad about M'Lynn Eatenton (a depicted character), but the critics – and surely some students – were in awe of Sally Field (a responsible authority).
9.2 Emotions and social robots
Emotions should be just as essential to many social robots. Consider an online forum maintained by owners of Sony's robot dog Aibo (Friedman, Kahn, & Hagman, Reference Friedman, Kahn and Hagman2003). According to their postings, Aibo “liked” to do things, got “angry,” got “very sad and distressed,” and showed “happy eyes” and a “wagging tail.” (Aibo's eyes turned green to signal happiness and red to signal sadness.) These emotions belonged to Aibochar, but the owners experienced emotions as well. “I feel I care about him as a pal.” “He always makes me feel better when things aren't so great.” “My emotional attachment to him … is strong enough that I consider him to be part of my family, that he's not just a ‘toy.’” Aibo's owners reported these emotions even though they recognized that Aibo was an artifact. Fully 75% of their postings included such terms as “toy,” “battery,” “microphone,” “camera,” and “computer.” Owners not only distinguished Aibochar (“he” and “him”) from Aibobase (with a battery and computer) but saw Aibochar as a source of their emotions.
Emotions have been elicited by a wide range of social robots (see, e.g., Broadbent, Reference Broadbent2017; Paiva et al., Reference Paiva, Leite, Boukricha and Wachsmuth2017; Seo, Geiskkovitch, Nakane, King, & Young, Reference Seo, Geiskkovitch, Nakane, King and Young2015). To take one example (Logan et al., Reference Logan, Breazeal, Goodwin, Jeong, O'Connell, Smith-Freedman and Weinstock2019), children aged 3–10 in a pediatric hospital interacted with one of three versions of a bear-like robot named Huggable: (a) the animated robot itself, (b) a video version of the animated robot, or (c) the same robot but without animation. Using a Wizard-of-Oz technique, a child-life-specialist got the children to chat, sing, and play games with one of the three depictions. In their language, the children expressed more joy and less sadness with the animated versions of the robot (in person and on video) than with the unanimated robot. Children's emotions were elicited not by Huggable as an artifact or prop, but by the animated character it depicted.
Some emotions with robots have been validated physiologically. In a study by Rosenthal-von der Pütten, Krämer, Hoffmann, Sobieraj, and Eimler (Reference Rosenthal-von der Pütten, Krämer, Hoffmann, Sobieraj and Eimler2013), adults were monitored while they watched one of two videos about a small dinosaur robot named Pleo. In the normal video, a human handler fed, caressed, and stroked the robot, but in the so-called torture video, he punched it, choked it, and banged its head on a table. Compared to viewers of the normal video, viewers of the torture video were more aroused and, later, rated themselves as having more pity for Pleo and more anger for the handler. Whenever people experience “pity” and “anger,” it is not for inert objects but for sentient beings. If so, the viewers' pity was not for the Pleobase or Pleoprop, but for Pleochar, and their anger was not for the actor playing the handler, but for the handler as a character (see also Menne & Schwab, Reference Menne and Schwab2018; Suzuki, Galli, Ikeda, Itakura, & Kitazaki, Reference Suzuki, Galli, Ikeda, Itakura and Kitazaki2015). This is as it should be if they see Pleo as a depiction.
Compartmentalization of emotions is easy to demonstrate in invented scenarios. Suppose Amy sees a forklift operator run into Ben and severely injure his arm. She would surely fear for Ben's health, rush to his aid, and call for an ambulance. If she saw the same happen to Asimo, she would do none of that. She would take her time in contacting Asimo's principal about the damage, and although she might advise Ben to sue the forklift operator, that is advice she would give, not to Asimochar, but to Asimo's owner (see Belanche et al., Reference Belanche, Casaló Luis, Flavián and Schepers2020).
10. Conclusions
People conceive of social robots, we have argued, not as social agents per se, but as depictions of social agents. Depictions in general can be static, like paintings and sculptures; they can be staged, like plays and movies; or they can be interactive, like hand puppets and ventriloquist dummies. The argument here is that people construe social robots as interactive depictions.
Depictions, such as Michelangelo's David, Shakespeare's Hamlet, and Kermit the frog, are physical analogs of what they depict – the biblical David, events in medieval Denmark, and a ranarian creature named Kermit. Each consists of three scenes – three perspectives – with mappings between them. The claim here is that people view social robots the same way. They see Asimo as an artifact (its base scene), which maps into a physical scene (the depiction proper), which maps into a humanlike character (the scene depicted). When people look at Asimoprop, they are to imagine Asimochar, the character depicted.
People anticipate doing more than look at social robots: They expect to interact with them. To do that, they must engage in the pretense that they are interacting with the characters depicted (layer 2) and, at the same time, appreciate the depictions (layer 1) in relation to the characters depicted. It takes both processes to interpret robots properly. As we noted at the beginning, when a robot stops moving, viewers must decide, “Did the character fall asleep, or did the robot's battery die?” And when a robot's finger breaks off, “Am I sad because the character is in pain, or because the artifact needs repairing?”
Depictions of social agents encompass three classes of agents – the characters depicted (e.g., David, Hamlet and Ophelia, and Kermit the frog), the intended recipients (the viewers), and the authorities responsible for them (e.g., Michelangelo, Shakespeare, the actors, and the Old Vic, and Kermit's puppeteer). Social robots entail the same three classes. For Asimo, they are Asimochar, the people who interact with Asimochar, and the authorities responsible for Asimo – the designers, makers, and owners.
Still, people differ in their understanding of social robots. Children aged 2 have only the most basic understanding of pretense and depictions, and it takes them years to grasp these in depth. And just as adults vary in their appreciation of the fake blood, stunt doubles, and mock fighting in movies, they surely also vary in their appreciation of how robots work. People also differ in their willingness to engage with the characters depicted.
To return to the social artifact puzzle, how is it that people are willing to interact with a robot as if it was a social agent when they know it is a mechanical artifact? Do we need a “new ontological category” for “artifacts that appear to think and feel, can be friends, and at least potentially lay some moral claims for kind, fair and just treatment” (Melson, Kahn, Beck, & Friedman, Reference Melson, Kahn, Beck and Friedman2006, p. 4)? The answer is no. All of us have spent much of our lifetime – thousands of hours – engaging with depictions. We have all the experience we need to construe social robots as depictions of social agents.
Acknowledgments
We thank many friends and colleagues for their discussions on the issues we take up in this paper.
Financial support
Kerstin Fischer was funded in part by Carlsberg Foundation grant CF18-0166.
Competing interest
None.







Target article
Social robots as depictions of social agents
Related commentaries (29)
A more ecological perspective on human–robot interactions
A neurocognitive view on the depiction of social robots
Anthropomorphism, not depiction, explains interaction with social robots
Autonomous social robots are real in the mind's eye of many
Binding paradox in artificial social realities
Children's interactions with virtual assistants: Moving beyond depictions of social agents
Cues trigger depiction schemas for robots, as they do for human identities
Dancing robots: Social interactions are performed, not depicted
Depiction as possible phase in the dynamics of sociomorphing
Fictional emotions and emotional reactions to social robots as depictions of social agents
How cultural framing can bias our beliefs about robots and artificial intelligence
How deep is AI's love? Understanding relational AI
How puzzling is the social artifact puzzle?
Interacting with characters redux
Meta-cognition about social robots could be difficult, making self-reports about some cognitive processes less useful
Of children and social robots
On the potentials of interaction breakdowns for HRI
People treat social robots as real social agents
Social robots and the intentional stance
Social robots as social learning partners: Exploring children's early understanding and learning from social robots
Taking a strong interactional stance
The Dorian Gray Refutation
The now and future of social robots as depictions
The second-order problem of other minds
Trait attribution explains human–robot interactions
Unpredictable robots elicit responsibility attributions
Virtual and real: Symbolic and natural experiences with social robots
When Pinocchio becomes a real boy: Capability and felicity in AI and interactive depictions
“Who's there?”: Depicting identity in interaction
Author response
On depicting social agents