


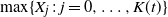
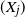
1. Introduction
In many real-life situations one encounters observations which tend to cluster when collected over time. This behaviour is commonly seen in various applied fields, including, for instance, non-life insurance, climatology, and hydrology (see e.g. [Reference Mikosch24], [Reference Vogel, Hauser and Seneviratne30], [Reference Towe, Tawn, Eastoe and Lamb29]). This article aims to describe the limiting distribution for the extremes of such observations over increasing time intervals.
In Section 2 we study a simpler question concerning the tail behaviour of the maximum in one random cluster of observations. More precisely, consider
 \begin{equation*} H = \bigvee_ {j=1}^K X_j,\end{equation*}
\begin{equation*} H = \bigvee_ {j=1}^K X_j,\end{equation*}
where we assume that the sequence
 $(X_j)$
of independent and identically distributed (i.i.d.) random variables belongs to the maximum domain of attraction of some extreme value distribution G, or
$(X_j)$
of independent and identically distributed (i.i.d.) random variables belongs to the maximum domain of attraction of some extreme value distribution G, or
 $\mathrm{MDA}(G)$
for short, and K is a positive random integer, possibly dependent on the observations themselves. For an introduction to MDAs and extreme value theory in general we refer to [Reference Resnick26], [Reference Embrechts, Klüppelberg and Mikosch14], or [Reference De Haan and Ferreira13]. In the case of non-random K, H belongs to the same MDA as
$\mathrm{MDA}(G)$
for short, and K is a positive random integer, possibly dependent on the observations themselves. For an introduction to MDAs and extreme value theory in general we refer to [Reference Resnick26], [Reference Embrechts, Klüppelberg and Mikosch14], or [Reference De Haan and Ferreira13]. In the case of non-random K, H belongs to the same MDA as
 $X_1$
by standard extreme value theory. The case of K independent of the sequence
$X_1$
by standard extreme value theory. The case of K independent of the sequence
 $(X_j)$
has been subject of several studies, including [Reference Jessen and Mikosch20] and [Reference Tillier and Wintenberger28]; see also [Reference Faÿ, González-Arévalo, Mikosch and Samorodnitsky15], where the tail behaviour of the randomly indexed sums is studied in a similar setting. The same problem in a multidimensional setting has recently been considered in [Reference Hashorva, Padoan and Rizzelli18]. In the sequel, we allow, for instance, for K to be a stopping time with respect to the sequence
$(X_j)$
has been subject of several studies, including [Reference Jessen and Mikosch20] and [Reference Tillier and Wintenberger28]; see also [Reference Faÿ, González-Arévalo, Mikosch and Samorodnitsky15], where the tail behaviour of the randomly indexed sums is studied in a similar setting. The same problem in a multidimensional setting has recently been considered in [Reference Hashorva, Padoan and Rizzelli18]. In the sequel, we allow, for instance, for K to be a stopping time with respect to the sequence
 $(X_j)$
, and we show that H remains in the same MDA as the observations as long as K has a finite mean. This is the content of our main theorem in Section 2. For this result we provide an original and relatively simple proof based on [Reference Basrak and Špoljarić5].
$(X_j)$
, and we show that H remains in the same MDA as the observations as long as K has a finite mean. This is the content of our main theorem in Section 2. For this result we provide an original and relatively simple proof based on [Reference Basrak and Špoljarić5].
In Section 3 we consider observations
 $(X_j)$
which are i.i.d. but arrive in possibly overlapping groups at times
$(X_j)$
which are i.i.d. but arrive in possibly overlapping groups at times
 $\tau_1,\tau_2,\ldots$
. We show how one can determine the asymptotic distribution of
$\tau_1,\tau_2,\ldots$
. We show how one can determine the asymptotic distribution of
 $ M(t) = \sup \!\left\lbrace X_k\,:\, \tau_{k} \leq t\right\rbrace$
under certain mild conditions on the clustering among the observations. Thanks to the results in Section 2, it turns out that the effects of clustering often remain relatively small in the limit; cf. Corollary 3.1. Processes of the form
$ M(t) = \sup \!\left\lbrace X_k\,:\, \tau_{k} \leq t\right\rbrace$
under certain mild conditions on the clustering among the observations. Thanks to the results in Section 2, it turns out that the effects of clustering often remain relatively small in the limit; cf. Corollary 3.1. Processes of the form
 $M(t) = \bigvee_ {j=0}^{K(t)} X_j$
, where K(t) is a stochastic process possibly dependent on the observations
$M(t) = \bigvee_ {j=0}^{K(t)} X_j$
, where K(t) is a stochastic process possibly dependent on the observations
 $X_j$
, have received considerable attention over the years. For some of the earliest contributions see [Reference Berman8] and [Reference Barndorff-Nielsen2]. More recently, [Reference Meerschaert and Stoev23] and [Reference Pancheva, Mitov and Mitov25] studied the convergence of the process (M(t)) towards an appropriate extremal process. For the study of all upper order statistics up to time K(t), see [Reference Basrak and Špoljarić5], and for the more general weak convergence of extremal processes with a random sample size, see [Reference Silvestrov and Teugels27].
$X_j$
, have received considerable attention over the years. For some of the earliest contributions see [Reference Berman8] and [Reference Barndorff-Nielsen2]. More recently, [Reference Meerschaert and Stoev23] and [Reference Pancheva, Mitov and Mitov25] studied the convergence of the process (M(t)) towards an appropriate extremal process. For the study of all upper order statistics up to time K(t), see [Reference Basrak and Špoljarić5], and for the more general weak convergence of extremal processes with a random sample size, see [Reference Silvestrov and Teugels27].
Section 4 is dedicated to the application of our main results to some frequently used stochastic models of clustering. In particular, we study variants of Neyman–Scott, Bartlett–Lewis, and randomly marked Hawkes processes. For each of the three clustering mechanisms we find sufficient conditions which imply that M(t) properly centred and normalized, roughly speaking, stays in
 $\mathrm{MDA}(G)$
.
$\mathrm{MDA}(G)$
.
Throughout, let
 $\mathbb{S}$
denote a general Polish space and
$\mathbb{S}$
denote a general Polish space and
 $\mathcal{B}(\mathbb{S})$
a Borel
$\mathcal{B}(\mathbb{S})$
a Borel
 $\sigma$
-algebra on
$\sigma$
-algebra on
 $\mathbb{S}$
. The space of boundedly finite point measures on
$\mathbb{S}$
. The space of boundedly finite point measures on
 $ \mathbb{S}$
is denoted by
$ \mathbb{S}$
is denoted by
 $M_p ( \mathbb{S})$
. For this purpose
$M_p ( \mathbb{S})$
. For this purpose
 $\mathbb{S}$
is endowed with a family of so-called bounded sets; see [Reference Basrak and Planinić3]. We use the standard vague topology on the space
$\mathbb{S}$
is endowed with a family of so-called bounded sets; see [Reference Basrak and Planinić3]. We use the standard vague topology on the space
 $M_p(\mathbb{S})$
(see [Reference Resnick26] or [Reference Kallenberg21]). Recall that
$M_p(\mathbb{S})$
(see [Reference Resnick26] or [Reference Kallenberg21]). Recall that
 $m_n \stackrel{v}{\longrightarrow} m$
in
$m_n \stackrel{v}{\longrightarrow} m$
in
 $M_p( \mathbb{S})$
simply means that
$M_p( \mathbb{S})$
simply means that
 $\int f dm_n \longrightarrow \int f dm$
for any bounded continuous function
$\int f dm_n \longrightarrow \int f dm$
for any bounded continuous function
 $f\,:\, \mathbb{S} \to \mathbb{R}$
whose support is bounded in the space
$f\,:\, \mathbb{S} \to \mathbb{R}$
whose support is bounded in the space
 $\mathbb{S}$
.
$\mathbb{S}$
.
The Lebesgue measure on
 $[0,\infty)$
will be denoted by Leb, whereas the Poisson random measure with mean measure
$[0,\infty)$
will be denoted by Leb, whereas the Poisson random measure with mean measure
 $\eta$
will be denoted by
$\eta$
will be denoted by
 $\mathrm{PRM}(\eta)$
. To simplify the notation, for a generic member of an identically distributed sequence or an array, say
$\mathrm{PRM}(\eta)$
. To simplify the notation, for a generic member of an identically distributed sequence or an array, say
 $(X_j)$
,
$(X_j)$
,
 $(A_{i,j})$
, throughout we write
$(A_{i,j})$
, throughout we write
 $X,\, A$
, etc. The set of natural numbers will be denoted by
$X,\, A$
, etc. The set of natural numbers will be denoted by
 $\mathbb{N} = \{1,2,\dots\}$
. The set of non-negative integers we denote by
$\mathbb{N} = \{1,2,\dots\}$
. The set of non-negative integers we denote by
 $\mathbb{Z}_+$
.
$\mathbb{Z}_+$
.
2. Random maxima
Let
 $(X_j)_{j\in \mathbb{N}}$
be an i.i.d. sequence with distribution belonging to
$(X_j)_{j\in \mathbb{N}}$
be an i.i.d. sequence with distribution belonging to
 $\mathrm{MDA}(G)$
where G is one of the three extreme value distributions, and let K denote a random non-negative integer. We are interested in the tail behaviour of
$\mathrm{MDA}(G)$
where G is one of the three extreme value distributions, and let K denote a random non-negative integer. We are interested in the tail behaviour of
 \begin{equation*} H = \bigvee_ {j=1}^K X_j.\end{equation*}
\begin{equation*} H = \bigvee_ {j=1}^K X_j.\end{equation*}
In the sequel we allow for K to depend on the values of the sequence
 $(X_j)_{j\in \mathbb{N}}$
together with some additional sources of randomness. Assume that
$(X_j)_{j\in \mathbb{N}}$
together with some additional sources of randomness. Assume that
 $((W_j, X_j))_{j\in \mathbb{N}}$
is a sequence of i.i.d. random elements in
$((W_j, X_j))_{j\in \mathbb{N}}$
is a sequence of i.i.d. random elements in
 $\mathbb{S}\times \mathbb{R}$
. For the filtration
$\mathbb{S}\times \mathbb{R}$
. For the filtration
 $(\mathcal{F}_n)_{n\in \mathbb{N}} = (\sigma\{(W_j, X_j)\,:\, j\leq n \})_{n\in \mathbb{N}}$
we assume that K is a stopping time with respect to
$(\mathcal{F}_n)_{n\in \mathbb{N}} = (\sigma\{(W_j, X_j)\,:\, j\leq n \})_{n\in \mathbb{N}}$
we assume that K is a stopping time with respect to
 $(\mathcal{F}_n)_{n\in \mathbb{N}}$
. Already in this case, H can be a rather complicated distribution, as one can see from the following.
$(\mathcal{F}_n)_{n\in \mathbb{N}}$
. Already in this case, H can be a rather complicated distribution, as one can see from the following.
Example 2.1.
-
(a) Assume
 $(W_j)_{j\in \mathbb{N}}$
is independent of
$(X_j)_{j\in \mathbb{N}}$
and integer-valued. When
$K=W_1$
, H has been studied already in the references mentioned in the introduction.
$(W_j)_{j\in \mathbb{N}}$
is independent of
$(X_j)_{j\in \mathbb{N}}$
and integer-valued. When
$K=W_1$
, H has been studied already in the references mentioned in the introduction. -
(b) Assume
$((W_j, X_j))_{j\in \mathbb{N}}$
is i.i.d. as before (note that some mutual dependence between
$W_j$
and
$X_j$
is allowed) and
$\mathbb{P}(X>W)>0$
. Let
$K=\inf\{k\in \mathbb{N}\,:\, X_k>W_k\}$
. Clearly K has geometric distribution, and we will show that this implies that H is in the same MDA as X. -
(c) Assume
$(W_j)_{j\in \mathbb{N}}$
and
$(X_j)_{j\in \mathbb{N}}$
are two independent i.i.d. sequences. Let
$K=\inf \{k\in \mathbb{N}\,:$
$X_k > W_1\}$
. Clearly
$H=X_{K}>W_1$
. Therefore, H has a tail at least as heavy as W.













Recall (see Chapter 1 in [Reference Resnick26] by Resnick) that the assumption that X belongs to
 $\mathrm{MDA}(G)$
is equivalent to the existence of a sequence of positive real numbers
$\mathrm{MDA}(G)$
is equivalent to the existence of a sequence of positive real numbers
 $(a_n)_{n\in \mathbb{N}}$
and a sequence of real numbers
$(a_n)_{n\in \mathbb{N}}$
and a sequence of real numbers
 $(b_n)_{n\in \mathbb{N}}$
such that for every
$(b_n)_{n\in \mathbb{N}}$
such that for every
 $x\in \mathbb{E} = \{y\in \mathbb{R}\,:\, G(y)>0\}$
$x\in \mathbb{E} = \{y\in \mathbb{R}\,:\, G(y)>0\}$
 \begin{align} n \cdot \mathbb{P}(X> a_n \cdot x + b_n)\to -\log G(x) \quad \text{ as } n\to \infty,\end{align}
\begin{align} n \cdot \mathbb{P}(X> a_n \cdot x + b_n)\to -\log G(x) \quad \text{ as } n\to \infty,\end{align}
and it is further equivalent to
 \begin{equation*} \mathbb{P}\!\left(\frac{\bigvee_{i=1}^n X_i - b_n}{a_n}\leq x\right)\to G(x) \quad \text{ as } n\to\infty.\end{equation*}
\begin{equation*} \mathbb{P}\!\left(\frac{\bigvee_{i=1}^n X_i - b_n}{a_n}\leq x\right)\to G(x) \quad \text{ as } n\to\infty.\end{equation*}
We denote by
 $\mu_G$
the measure
$\mu_G$
the measure
 $\mu_G (x, \infty) = -\log G(x)$
,
$\mu_G (x, \infty) = -\log G(x)$
,
 $x\in \mathbb{E}$
. Consider point processes
$x\in \mathbb{E}$
. Consider point processes
 \begin{equation*} N_n = \sum_{i\in \mathbb{N}} \delta_{\left(\frac{i}{n}, \frac{X_i - b_n}{a_n} \right)}, \quad n \in \mathbb{N}.\end{equation*}
\begin{equation*} N_n = \sum_{i\in \mathbb{N}} \delta_{\left(\frac{i}{n}, \frac{X_i - b_n}{a_n} \right)}, \quad n \in \mathbb{N}.\end{equation*}
It is well known (again again [Reference Resnick26]) that
 $X\in\mathrm{MDA}(G)$
is both necessary and sufficient for weak convergence of
$X\in\mathrm{MDA}(G)$
is both necessary and sufficient for weak convergence of
 $N_n$
towards a limiting point process, N say, which is a
$N_n$
towards a limiting point process, N say, which is a
 $\mathrm{PRM}(\mathrm{Leb}\times \mu_G)$
in
$\mathrm{PRM}(\mathrm{Leb}\times \mu_G)$
in
 $M_p([0,\infty)\times \mathbb{E})$
, where both
$M_p([0,\infty)\times \mathbb{E})$
, where both
 $\mathbb{E}$
and the concept of boundedness depend on G. For instance, in the Gumbel MDA,
$\mathbb{E}$
and the concept of boundedness depend on G. For instance, in the Gumbel MDA,
 $\mathbb{E}=({-}\infty,\infty)$
, and sets are considered bounded in
$\mathbb{E}=({-}\infty,\infty)$
, and sets are considered bounded in
 $[0,\infty) \times \mathbb{E}$
if contained in some set of the type
$[0,\infty) \times \mathbb{E}$
if contained in some set of the type
 $[0,T] \times (a,\infty)$
,
$[0,T] \times (a,\infty)$
,
 $a \in \mathbb{R}$
,
$a \in \mathbb{R}$
,
 $T>0 $
; cf. [Reference Basrak and Planinić4].
$T>0 $
; cf. [Reference Basrak and Planinić4].
Denote by
 $m |_{A}$
the restriction of a point measure m to a set A, i.e.
$m |_{A}$
the restriction of a point measure m to a set A, i.e.
 $m |_{A}(B) = m(A \cap B).$
Denote by
$m |_{A}(B) = m(A \cap B).$
Denote by
 $\mathbb{E}^{\prime}$
an arbitrary measurable subset of
$\mathbb{E}^{\prime}$
an arbitrary measurable subset of
 $\mathbb{R}^d$
. The following simple lemma (see Lemma 1 in [Reference Basrak and Špoljarić5]) plays an important role in a couple of our proofs.
$\mathbb{R}^d$
. The following simple lemma (see Lemma 1 in [Reference Basrak and Špoljarić5]) plays an important role in a couple of our proofs.
Lemma 2.1. Assume that N,
 $(N_t)_{t \geq 0}$
are point processes with values in
$(N_t)_{t \geq 0}$
are point processes with values in
 $M_p([0, \infty)\times \mathbb{E}^{\prime})$
. Assume further that Z,
$M_p([0, \infty)\times \mathbb{E}^{\prime})$
. Assume further that Z,
 $(Z_t)_{t\geq 0}$
are
$(Z_t)_{t\geq 0}$
are
 $\mathbb{R}_+$
-valued random variables. If
$\mathbb{R}_+$
-valued random variables. If
 $P(N(\{Z\} \times \mathbb{E}^{\prime}) > 0) = 0$
and
$P(N(\{Z\} \times \mathbb{E}^{\prime}) > 0) = 0$
and
 $(N_t, Z_t) \stackrel{d}{\longrightarrow} (N, Z),$
in the product topology as
$(N_t, Z_t) \stackrel{d}{\longrightarrow} (N, Z),$
in the product topology as
 $t \to\infty,$
then
$t \to\infty,$
then
 \begin{align*} N_t |_{[0,Z_t] \times \mathbb{E}^{\prime}} \stackrel{d}{\longrightarrow} N |_{[0,Z] \times \mathbb{E}^{\prime}} \quad { as }\ t\to \infty. \end{align*}
\begin{align*} N_t |_{[0,Z_t] \times \mathbb{E}^{\prime}} \stackrel{d}{\longrightarrow} N |_{[0,Z] \times \mathbb{E}^{\prime}} \quad { as }\ t\to \infty. \end{align*}
Suppose that the stopping time K is almost surely finite. Our analysis of H depends on the following simple observation: since
 $((W_j, X_{j}))_{j\in \mathbb{N}}$
is an i.i.d. sequence, by the strong Markov property, after the stopping time
$((W_j, X_{j}))_{j\in \mathbb{N}}$
is an i.i.d. sequence, by the strong Markov property, after the stopping time
 $K_1 = K$
, the sequence
$K_1 = K$
, the sequence
 $((W_{K_1+j},$
$((W_{K_1+j},$
 $X_{K_1+j}))_{j\in \mathbb{N}}$
has the same distribution as the original sequence. Therefore it has its own stopping time
$X_{K_1+j}))_{j\in \mathbb{N}}$
has the same distribution as the original sequence. Therefore it has its own stopping time
 $K_2$
, distributed as
$K_2$
, distributed as
 $K_1$
, such that
$K_1$
, such that
 $((W_{K_1+K_2+j}, X_{K_1+K_2+j}))_{j\in \mathbb{N}}$
again has the same distribution. Using the shift operator
$((W_{K_1+K_2+j}, X_{K_1+K_2+j}))_{j\in \mathbb{N}}$
again has the same distribution. Using the shift operator
 $\vartheta$
, one can also write
$\vartheta$
, one can also write
 $K_2 = K \circ \vartheta^{K_1}(((W_j, X_{j}))_{j})$
. Applying this argument iteratively, we can break the original sequence into i.i.d. blocks
$K_2 = K \circ \vartheta^{K_1}(((W_j, X_{j}))_{j})$
. Applying this argument iteratively, we can break the original sequence into i.i.d. blocks
 \begin{gather*} ((W_{T(l-1)+1}, X_{T(l-1)+1}),\, (W_{T(l-1)+2}, X_{T(l-1)+2}),\, \dots,\, (W_{T(l)}, X_{T(l)}))_{l\in \mathbb{N}}, \nonumber\\\mbox{where} \quad T(0)=0, \quad T(n) = K_1+K_2+\dots+K_n.\end{gather*}
\begin{gather*} ((W_{T(l-1)+1}, X_{T(l-1)+1}),\, (W_{T(l-1)+2}, X_{T(l-1)+2}),\, \dots,\, (W_{T(l)}, X_{T(l)}))_{l\in \mathbb{N}}, \nonumber\\\mbox{where} \quad T(0)=0, \quad T(n) = K_1+K_2+\dots+K_n.\end{gather*}
Clearly,
 \begin{equation*} H_l = \bigvee_{j=T(l-1)+1}^{T(l)} X_j,\qquad l \in \mathbb{N},\end{equation*}
\begin{equation*} H_l = \bigvee_{j=T(l-1)+1}^{T(l)} X_j,\qquad l \in \mathbb{N},\end{equation*}
are i.i.d. with the same distribution as the original compound maximum H. Assume that
 $((W_{i,j}, X_{i,j}))_{i,j\in \mathbb{N}}$
is an i.i.d. array of elements as above, and let
$((W_{i,j}, X_{i,j}))_{i,j\in \mathbb{N}}$
is an i.i.d. array of elements as above, and let
 $(K^{\prime}_i)_{i\in \mathbb{N}}$
be an i.i.d. sequence of stopping times such that for each
$(K^{\prime}_i)_{i\in \mathbb{N}}$
be an i.i.d. sequence of stopping times such that for each
 $l\in \mathbb{N}$
,
$l\in \mathbb{N}$
,
 $(K^{\prime}_l, (W_{l,j}, X_{l,j})_{j\in \mathbb{N}})\stackrel{d}{=} (K, (W_j, X_j)_{j\in \mathbb{N}})$
. Then
$(K^{\prime}_l, (W_{l,j}, X_{l,j})_{j\in \mathbb{N}})\stackrel{d}{=} (K, (W_j, X_j)_{j\in \mathbb{N}})$
. Then
 \begin{equation*} H^{\prime}_l = \bigvee_{j=1}^{K^{\prime}_l} X_{l,j}\end{equation*}
\begin{equation*} H^{\prime}_l = \bigvee_{j=1}^{K^{\prime}_l} X_{l,j}\end{equation*}
are also i.i.d. with the same distribution as H. Before stating the main theorem, we prove a simple lemma.
Lemma 2.2. Assume that
 $\xi = \mathbb{E} [K]< \infty$
. Then
$\xi = \mathbb{E} [K]< \infty$
. Then
 \begin{align*} \sum_{i=1}^n \sum_{j=1}^{K^{\prime}_i} \delta_{\frac{X_{i,j}-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}} \stackrel{d}{\longrightarrow} \mathrm{PRM}(\mu_G) \quad { as }\ n\to \infty.\end{align*}
\begin{align*} \sum_{i=1}^n \sum_{j=1}^{K^{\prime}_i} \delta_{\frac{X_{i,j}-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}} \stackrel{d}{\longrightarrow} \mathrm{PRM}(\mu_G) \quad { as }\ n\to \infty.\end{align*}
Proof. First note that
 \begin{equation*} \sum_{i=1}^n \sum_{j=1}^{K^{\prime}_i} \delta_{\frac{X_{i,j}-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}} \stackrel{d}{=} \sum_{i=1}^{T(n)} \delta_{\frac{X_i-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}}.\end{equation*}
\begin{equation*} \sum_{i=1}^n \sum_{j=1}^{K^{\prime}_i} \delta_{\frac{X_{i,j}-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}} \stackrel{d}{=} \sum_{i=1}^{T(n)} \delta_{\frac{X_i-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}}.\end{equation*}
To use Lemma 2.1, let
 $Z=1$
,
$Z=1$
,
 $(Z_n)_{n\in \mathbb{N}} = (T(n)/(n\xi))_{n\in \mathbb{N}}$
be
$(Z_n)_{n\in \mathbb{N}} = (T(n)/(n\xi))_{n\in \mathbb{N}}$
be
 $\mathbb{R}_+$
-valued random variables,
$\mathbb{R}_+$
-valued random variables,
 $N=\mathrm{PRM}(\mathrm{Leb}\times \mu_G)$
as before, and define point processes
$N=\mathrm{PRM}(\mathrm{Leb}\times \mu_G)$
as before, and define point processes
 $(N^{\prime}_n)_{n\in \mathbb{N}}$
, where
$(N^{\prime}_n)_{n\in \mathbb{N}}$
, where
 \begin{equation*} N^{\prime}_n = \sum_{i\in \mathbb{N}} \delta_{\left(\frac{i}{n\xi}, \frac{X_{i}-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n \xi \rfloor}}\right)},\end{equation*}
\begin{equation*} N^{\prime}_n = \sum_{i\in \mathbb{N}} \delta_{\left(\frac{i}{n\xi}, \frac{X_{i}-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n \xi \rfloor}}\right)},\end{equation*}
with values in the space
 $[0, \infty)\times \mathbb{E}$
, where
$[0, \infty)\times \mathbb{E}$
, where
 $\mathbb{E}$
depends on G as before. By the weak law of large numbers and by Proposition 3.21 from [Reference Resnick26], since
$\mathbb{E}$
depends on G as before. By the weak law of large numbers and by Proposition 3.21 from [Reference Resnick26], since
 $X_1\in \mathrm{MDA}(G)$
, we have
$X_1\in \mathrm{MDA}(G)$
, we have
 \begin{equation*} Z_n \stackrel{P}{\longrightarrow} Z=1\quad \text{and} \quad N^{\prime}_n\stackrel{d}{\longrightarrow} N \quad \text{ as } n\to \infty.\end{equation*}
\begin{equation*} Z_n \stackrel{P}{\longrightarrow} Z=1\quad \text{and} \quad N^{\prime}_n\stackrel{d}{\longrightarrow} N \quad \text{ as } n\to \infty.\end{equation*}
Hence, by the standard Slutsky argument (Theorem 3.9 in [Reference Billingsley9]),
 \begin{equation*} (N^{\prime}_n,\, Z_n) \stackrel{d}{\longrightarrow} (N,\,Z) \quad \text{ as } n\to \infty.\end{equation*}
\begin{equation*} (N^{\prime}_n,\, Z_n) \stackrel{d}{\longrightarrow} (N,\,Z) \quad \text{ as } n\to \infty.\end{equation*}
Note that
 $ \mathbb{P}\!\left(N(\{Z\}\times \mathbb{E} ) >0\right) = 0$
, so by Lemma 2.1,
$ \mathbb{P}\!\left(N(\{Z\}\times \mathbb{E} ) >0\right) = 0$
, so by Lemma 2.1,
 \begin{align*} N^{\prime}_n\Big|_{[0, Z_n]\times \mathbb{E}} \stackrel{d}{\longrightarrow} N\Big|_{[0, Z]\times \mathbb{E}}\,. \end{align*}
\begin{align*} N^{\prime}_n\Big|_{[0, Z_n]\times \mathbb{E}} \stackrel{d}{\longrightarrow} N\Big|_{[0, Z]\times \mathbb{E}}\,. \end{align*}
We conclude that
 \begin{align*} N^{\prime}_n\Big|_{\left[0, \frac{T(n)}{n\xi}\right]\times\mathbb{E}} ([0,\infty)\times {\cdot}) &= \sum_{i=1}^{T(n)} \delta_{\frac{X_i-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}}({\cdot}) \stackrel{d}{\longrightarrow} N\Big|_{[0,1]\times \mathbb{E}}([0,\infty)\times {\cdot}) \quad \text{ as } n\to \infty, \end{align*}
\begin{align*} N^{\prime}_n\Big|_{\left[0, \frac{T(n)}{n\xi}\right]\times\mathbb{E}} ([0,\infty)\times {\cdot}) &= \sum_{i=1}^{T(n)} \delta_{\frac{X_i-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}}({\cdot}) \stackrel{d}{\longrightarrow} N\Big|_{[0,1]\times \mathbb{E}}([0,\infty)\times {\cdot}) \quad \text{ as } n\to \infty, \end{align*}
where the point process on the right is a
 $\mathrm{PRM}(\mu_G)$
; see Theorem 2 in [Reference Basrak and Špoljarić5] for details.
$\mathrm{PRM}(\mu_G)$
; see Theorem 2 in [Reference Basrak and Špoljarić5] for details.
Theorem 2.1. Assume that K is a stopping time with respect to the filtration
 $(\mathcal{F}_j)_{j\in \mathbb{N}}$
with a finite mean. If X belongs to
$(\mathcal{F}_j)_{j\in \mathbb{N}}$
with a finite mean. If X belongs to
 $\mathrm{MDA}(G)$
, then the same holds for
$\mathrm{MDA}(G)$
, then the same holds for
 $H=\bigvee_ {j=1}^K X_j$
.
$H=\bigvee_ {j=1}^K X_j$
.
Proof. For
 $(H_i)$
i.i.d. copies of H, using Lemma 2.2 and the notation therein,
$(H_i)$
i.i.d. copies of H, using Lemma 2.2 and the notation therein,
 \begin{align*} \mathbb{P}\!\left(\frac{\bigvee_{i=1}^n H_i - b_{\lfloor n \xi\rfloor}}{a_{\lfloor n\xi \rfloor}}\leq x\right) &= \mathbb{P} \!\left( \sum_{i=1}^n \sum_{j=1}^{K^{\prime}_i} \delta_{\frac{X_{i,j}-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}} (x, \infty) = 0 \right) \\ &\to \mathbb{P}\!\left(\mathrm{PRM}(\mu_G)(x,\infty)=0\right) = G(x).\end{align*}
\begin{align*} \mathbb{P}\!\left(\frac{\bigvee_{i=1}^n H_i - b_{\lfloor n \xi\rfloor}}{a_{\lfloor n\xi \rfloor}}\leq x\right) &= \mathbb{P} \!\left( \sum_{i=1}^n \sum_{j=1}^{K^{\prime}_i} \delta_{\frac{X_{i,j}-b_{\lfloor n\xi \rfloor}}{a_{\lfloor n\xi \rfloor}}} (x, \infty) = 0 \right) \\ &\to \mathbb{P}\!\left(\mathrm{PRM}(\mu_G)(x,\infty)=0\right) = G(x).\end{align*}
Example 2.2.
(Example 2.1 continued.) Provided
 $\mathbb{E} [W] < \infty$
, we recover known results for Example 2.1(a). Since
$\mathbb{E} [W] < \infty$
, we recover known results for Example 2.1(a). Since
 $\mathbb{E} [K]< \infty$
, in the case (b) H belongs to the same MDA as X. As we have seen, the case (c) is more involved, but the theorem implies that if
$\mathbb{E} [K]< \infty$
, in the case (b) H belongs to the same MDA as X. As we have seen, the case (c) is more involved, but the theorem implies that if
 $W_1$
has a heavier tail index than X, then
$W_1$
has a heavier tail index than X, then
 $\mathbb{E} [K] =\infty$
and
$\mathbb{E} [K] =\infty$
and
 $H \not \in \mathrm{MDA}(G)$
. On the other hand, for bounded or lighter-tailed W, we can still have
$H \not \in \mathrm{MDA}(G)$
. On the other hand, for bounded or lighter-tailed W, we can still have
 $H \in \mathrm{MDA}(G)$
.
$H \in \mathrm{MDA}(G)$
.
3. Limiting behaviour of the maximal claim size in the marked renewal cluster model
To describe the marked renewal cluster model, consider first an independently marked renewal process
 $N^0$
. Let
$N^0$
. Let
 $(Y_k)_{ k\in \mathbb{N} }$
be a sequence of i.i.d. non-negative inter-arrival times in
$(Y_k)_{ k\in \mathbb{N} }$
be a sequence of i.i.d. non-negative inter-arrival times in
 $N^0$
, and let
$N^0$
, and let
 $(A_k)_{ k\in \mathbb{N} }$
be i.i.d. marks independent of
$(A_k)_{ k\in \mathbb{N} }$
be i.i.d. marks independent of
 $(Y_k)_{ k\in \mathbb{N} }$
with distribution Q on
$(Y_k)_{ k\in \mathbb{N} }$
with distribution Q on
 $(\mathbb{S}, \mathcal{B}(\mathbb{S}))$
. Throughout we assume that
$(\mathbb{S}, \mathcal{B}(\mathbb{S}))$
. Throughout we assume that
 \begin{equation*}0<\mathbb{E} [Y] = \frac{1}{\nu} < \infty.\end{equation*}
\begin{equation*}0<\mathbb{E} [Y] = \frac{1}{\nu} < \infty.\end{equation*}
If we denote by
 $(\Gamma_i)_{i\in \mathbb{N}}$
the sequence of partial sums of
$(\Gamma_i)_{i\in \mathbb{N}}$
the sequence of partial sums of
 $(Y_k)_{ k\in \mathbb{N}}$
, the process
$(Y_k)_{ k\in \mathbb{N}}$
, the process
 $N^0$
on the space
$N^0$
on the space
 $[0,\infty) \times \mathbb{S}$
has the representation
$[0,\infty) \times \mathbb{S}$
has the representation
 \begin{equation*}N^0 = \displaystyle\sum_{i\in \mathbb{N}} \delta_{ \Gamma_i,A_i}.\end{equation*}
\begin{equation*}N^0 = \displaystyle\sum_{i\in \mathbb{N}} \delta_{ \Gamma_i,A_i}.\end{equation*}
Processes of this type appear in non-life insurance mathematics, where marks are often referred to as claims. They can represent the size of the claim, type of the claim, severity of the accident, etc.
Assume that at each time
 $\Gamma_i$
with mark
$\Gamma_i$
with mark
 $A_i$
another point process in
$A_i$
another point process in
 $M_p([0,\infty)\times \mathbb{S}) $
, denoted by
$M_p([0,\infty)\times \mathbb{S}) $
, denoted by
 $G_i$
, is generated. All
$G_i$
, is generated. All
 $G_i$
are mutually independent and intuitively represent clusters of points superimposed on
$G_i$
are mutually independent and intuitively represent clusters of points superimposed on
 $N^0$
after time
$N^0$
after time
 $ \Gamma_i$
. Formally, there exists a probability kernel K from
$ \Gamma_i$
. Formally, there exists a probability kernel K from
 $\mathbb{S}$
to
$\mathbb{S}$
to
 $M_p([0,\infty)\times \mathbb{S})$
such that, conditionally on
$M_p([0,\infty)\times \mathbb{S})$
such that, conditionally on
 $N^0$
, the point processes
$N^0$
, the point processes
 $G_i$
are independent, almost surely finite, and with distribution equal to
$G_i$
are independent, almost surely finite, and with distribution equal to
 $K(A_i,\cdot)$
. Note that this permits dependence between
$K(A_i,\cdot)$
. Note that this permits dependence between
 $G_i$
and
$G_i$
and
 $A_i$
.
$A_i$
.
In this setting, the process
 $N^0$
is usually called the parent process, while the
$N^0$
is usually called the parent process, while the
 $G_i$
are called the descendant processes. We can write
$G_i$
are called the descendant processes. We can write
 \begin{equation*}G_i = \displaystyle\sum_{j= 1}^{K_i} \delta_{T_{i,j},A_{i,j}},\end{equation*}
\begin{equation*}G_i = \displaystyle\sum_{j= 1}^{K_i} \delta_{T_{i,j},A_{i,j}},\end{equation*}
where
 ${(T_{i,j})}_{j\in \mathbb{N}}$
is a sequence of non-negative random variables and
${(T_{i,j})}_{j\in \mathbb{N}}$
is a sequence of non-negative random variables and
 $K_i$
is a
$K_i$
is a
 $\mathbb{Z}_+ $
-valued random variable. If we count the original point arriving at time
$\mathbb{Z}_+ $
-valued random variable. If we count the original point arriving at time
 $\Gamma_i$
, the actual cluster size is
$\Gamma_i$
, the actual cluster size is
 $K_i+1$
.
$K_i+1$
.
Throughout, we also assume that the cluster processes
 $G_i$
are independently marked with the same mark distribution Q independent of
$G_i$
are independently marked with the same mark distribution Q independent of
 $A_i$
, so that all the marks
$A_i$
, so that all the marks
 $A_{i,j}$
are i.i.d. Note that
$A_{i,j}$
are i.i.d. Note that
 $K_i$
may possibly depend on
$K_i$
may possibly depend on
 $A_i$
. We assume throughout that
$A_i$
. We assume throughout that
 \begin{equation*} \mathbb{E} [K_i] <\infty.\end{equation*}
\begin{equation*} \mathbb{E} [K_i] <\infty.\end{equation*}
Finally, to describe the size and other characteristics of all the observations (claims) together with their arrival times, we use a marked point process N as a random element in
 $M_p([0,\infty)\times\mathbb{S})$
of the form
$M_p([0,\infty)\times\mathbb{S})$
of the form
 \begin{equation}N= \displaystyle\sum_{i=1}^\infty \displaystyle\sum_{j = 0}^{K_i} \delta_{ \Gamma_i+T_{i,j},A_{i,j}},\end{equation}
\begin{equation}N= \displaystyle\sum_{i=1}^\infty \displaystyle\sum_{j = 0}^{K_i} \delta_{ \Gamma_i+T_{i,j},A_{i,j}},\end{equation}
where we set
 $T_{i,0} = 0$
and
$T_{i,0} = 0$
and
 $A_{i,0} = A_i$
. In this representation, the claims arriving at time
$A_{i,0} = A_i$
. In this representation, the claims arriving at time
 $ \Gamma_i$
and corresponding to the index
$ \Gamma_i$
and corresponding to the index
 $j=0$
are called ancestral or immigrant claims, while the claims arriving at times
$j=0$
are called ancestral or immigrant claims, while the claims arriving at times
 $ \Gamma_i+T_{i,j},\ j \in \mathbb{N}$
, are referred to as progeny or offspring. Note that N is almost surely boundedly finite, because
$ \Gamma_i+T_{i,j},\ j \in \mathbb{N}$
, are referred to as progeny or offspring. Note that N is almost surely boundedly finite, because
 $\Gamma_i \to\infty$
as
$\Gamma_i \to\infty$
as
 $i \to\infty$
, and
$i \to\infty$
, and
 $K_i$
is almost surely finite for every i, so one could also write
$K_i$
is almost surely finite for every i, so one could also write
 \begin{equation}N = \displaystyle\sum_{k=1}^\infty \delta_{\tau_k,A^k} ,\end{equation}
\begin{equation}N = \displaystyle\sum_{k=1}^\infty \delta_{\tau_k,A^k} ,\end{equation}
with
 $\tau_k\leq \tau_{k+1}$
for all
$\tau_k\leq \tau_{k+1}$
for all
 $k \in \mathbb{N}$
and
$k \in \mathbb{N}$
and
 $A^k$
being i.i.d. marks which are in general not independent of the arrival times
$A^k$
being i.i.d. marks which are in general not independent of the arrival times
 $(\tau_k)$
. Observe that this representation ignores the information regarding the clusters of the point process. Note also that eventual ties turn out to be irrelevant asymptotically.
$(\tau_k)$
. Observe that this representation ignores the information regarding the clusters of the point process. Note also that eventual ties turn out to be irrelevant asymptotically.
In the special case, when the inter-arrival times are exponential with parameter
 $\nu,$
the renewal counting process which generates the arrival times in the parent process is a homogeneous Poisson process. The associated marked renewal cluster model is then called a marked Poisson cluster process (see [Reference Daley and Vere-Jones12]; cf. [Reference Basrak, Wintenberger and Žugec6]).
$\nu,$
the renewal counting process which generates the arrival times in the parent process is a homogeneous Poisson process. The associated marked renewal cluster model is then called a marked Poisson cluster process (see [Reference Daley and Vere-Jones12]; cf. [Reference Basrak, Wintenberger and Žugec6]).
Remark 3.1. In all our considerations we take into account the original immigrant claims arriving at times
 $\Gamma_i$
as well. One could of course ignore these claims and treat
$\Gamma_i$
as well. One could of course ignore these claims and treat
 $\Gamma_i$
as times of incidents that trigger, with a possible delay, a cluster of subsequent payments, as in the model of the so-called incurred but not reported (IBNR) claims; cf. [Reference Mikosch24].
$\Gamma_i$
as times of incidents that trigger, with a possible delay, a cluster of subsequent payments, as in the model of the so-called incurred but not reported (IBNR) claims; cf. [Reference Mikosch24].
The numerical observations, i.e. the sizes of the claims, are produced by the application of a measurable function on the marks, say
 $f\,:\,\mathbb{S} \to \mathbb{R}_+$
. The maximum of all claims due to the arrival of an immigrant claim at time
$f\,:\,\mathbb{S} \to \mathbb{R}_+$
. The maximum of all claims due to the arrival of an immigrant claim at time
 $ \Gamma_i$
equals
$ \Gamma_i$
equals
 \begin{equation} H_i = \bigvee_{j=0}^{K_i} X_{i,j},\end{equation}
\begin{equation} H_i = \bigvee_{j=0}^{K_i} X_{i,j},\end{equation}
where
 $X_{i,j} = f(A_{i,j})$
are i.i.d. random variables for all i and j. The random variable
$X_{i,j} = f(A_{i,j})$
are i.i.d. random variables for all i and j. The random variable
 $H_i$
has an interpretation as the maximal claim size coming from the ith immigrant and its progeny. If we denote
$H_i$
has an interpretation as the maximal claim size coming from the ith immigrant and its progeny. If we denote
 $f(A^k)$
by
$f(A^k)$
by
 $X^k$
, the maximal claim size in the period [0, t] can be represented as
$X^k$
, the maximal claim size in the period [0, t] can be represented as
 \begin{equation*}M(t) = \sup \big\lbrace X^k\,:\, \tau_{k} \leq t\big\rbrace .\end{equation*}
\begin{equation*}M(t) = \sup \big\lbrace X^k\,:\, \tau_{k} \leq t\big\rbrace .\end{equation*}
In order to bring the model into the context of Theorem 2.1, observe that one can let
 $W_k = A^k$
, for
$W_k = A^k$
, for
 $k\in \mathbb{N}$
. Introduce the first-passage-time process
$k\in \mathbb{N}$
. Introduce the first-passage-time process
 $(\tau(t))_{ t\geq 0 }$
defined by
$(\tau(t))_{ t\geq 0 }$
defined by
 \begin{equation*}\tau(t) = \inf \!\left\{ n \,:\, \Gamma_n > t \right\},\qquad t \geq 0.\end{equation*}
\begin{equation*}\tau(t) = \inf \!\left\{ n \,:\, \Gamma_n > t \right\},\qquad t \geq 0.\end{equation*}
This means that
 $\tau(t)$
is the renewal counting process generated by the sequence
$\tau(t)$
is the renewal counting process generated by the sequence
 $(Y_n)_{ n\in \mathbb{N}}.$
According to the strong law for counting processes (Theorem 5.1 in [Reference Gut16, Chapter 2]), for every
$(Y_n)_{ n\in \mathbb{N}}.$
According to the strong law for counting processes (Theorem 5.1 in [Reference Gut16, Chapter 2]), for every
 $c \geq 0,$
$c \geq 0,$
 \begin{align*}\frac{\tau (tc)}{\nu t} \stackrel{as}{\longrightarrow} c \quad \text{ as } t\to \infty.\end{align*}
\begin{align*}\frac{\tau (tc)}{\nu t} \stackrel{as}{\longrightarrow} c \quad \text{ as } t\to \infty.\end{align*}
Denote by
 \begin{equation*}M^{\tau}(t) = \bigvee_{i=1}^{\tau(t)} H_i \end{equation*}
\begin{equation*}M^{\tau}(t) = \bigvee_{i=1}^{\tau(t)} H_i \end{equation*}
the maximal claim size coming from the maximal claim sizes in the first
 $\tau(t)$
clusters. Now we can write
$\tau(t)$
clusters. Now we can write
 \begin{equation} M^{\tau}(t) = M(t) \bigvee H_{\tau(t)} \bigvee \varepsilon_t,\quad t \geq 0,\end{equation}
\begin{equation} M^{\tau}(t) = M(t) \bigvee H_{\tau(t)} \bigvee \varepsilon_t,\quad t \geq 0,\end{equation}
where the last error term represents the leftover effect at time t, i.e. the maximum of all claims arriving after t which correspond to the progeny of immigrants arriving before time t; more precisely,
 \begin{align*}\varepsilon_t = \max \{X_{i,j}\,:\, 0\leq \Gamma_i \leq t , \, t < \Gamma_i+T_{i,j}\}, \quad t \geq 0.\end{align*}
\begin{align*}\varepsilon_t = \max \{X_{i,j}\,:\, 0\leq \Gamma_i \leq t , \, t < \Gamma_i+T_{i,j}\}, \quad t \geq 0.\end{align*}
Denote the number of members in the set above by
 \begin{equation}J_t=\# \{(i,j)\,:\,0\le \Gamma_i \leq t , \, t < \Gamma_i + T_{i,j}\}.\end{equation}
\begin{equation}J_t=\# \{(i,j)\,:\,0\le \Gamma_i \leq t , \, t < \Gamma_i + T_{i,j}\}.\end{equation}
We study the limiting behaviour of the maximal claim size M(t) up to time t and aim to find sufficient conditions under which M(t) converges in distribution to a non-trivial limit after appropriate centring and normalization.
Recall that H belongs to
 $\mathrm{MDA}(G)$
if there exist constants
$\mathrm{MDA}(G)$
if there exist constants
 $c_n>0,$
$c_n>0,$
 $d_n \in \mathbb{R}$
such that for each
$d_n \in \mathbb{R}$
such that for each
 $x\in \mathbb{E}=\{y\in \mathbb{R}\,:\, G(y)>0\}$
,
$x\in \mathbb{E}=\{y\in \mathbb{R}\,:\, G(y)>0\}$
,
 \begin{equation}n \cdot \mathbb{P} \!\left( H > c_{n}x + d_{n} \right) \rightarrow - \log G(x) \quad \text{ as } n\to \infty.\end{equation}
\begin{equation}n \cdot \mathbb{P} \!\left( H > c_{n}x + d_{n} \right) \rightarrow - \log G(x) \quad \text{ as } n\to \infty.\end{equation}
An application of Lemma 2.1 yields the following result.
Proposition 3.1. Assume that H belongs to
 $\mathrm{MDA}(G)$
, so that (3.6) holds, and that the error term in (3.5) satisfies
$\mathrm{MDA}(G)$
, so that (3.6) holds, and that the error term in (3.5) satisfies
 \begin{equation*} J_t = o_P(t). \end{equation*}
\begin{equation*} J_t = o_P(t). \end{equation*}
Then
 \begin{equation} \frac{M(t) - d_{\lfloor \nu t \rfloor} }{ c_{\lfloor \nu t \rfloor} } \stackrel{d}{\longrightarrow} G \quad { as }\ t\to \infty. \end{equation}
\begin{equation} \frac{M(t) - d_{\lfloor \nu t \rfloor} }{ c_{\lfloor \nu t \rfloor} } \stackrel{d}{\longrightarrow} G \quad { as }\ t\to \infty. \end{equation}
Proof. Using the equation (3.4),
 \begin{equation*}\frac{M^{\tau}(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} = \frac{M(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} \bigvee \frac{H_{\tau(t)} - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} \bigvee \frac{\varepsilon_t - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}}.\end{equation*}
\begin{equation*}\frac{M^{\tau}(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} = \frac{M(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} \bigvee \frac{H_{\tau(t)} - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} \bigvee \frac{\varepsilon_t - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}}.\end{equation*}
Since for
 $x\in \mathbb{E}$
$x\in \mathbb{E}$
 \begin{align*} 0 &\leq \mathbb{P} \!\left( \frac{M^{\tau}(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right) - \mathbb{P} \!\left( \frac{M(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right)\\ &\leq \mathbb{P} \!\left( \frac{H_{\tau(t)} - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right) + \mathbb{P} \!\left( \frac{\varepsilon_t - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x\right), \end{align*}
\begin{align*} 0 &\leq \mathbb{P} \!\left( \frac{M^{\tau}(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right) - \mathbb{P} \!\left( \frac{M(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right)\\ &\leq \mathbb{P} \!\left( \frac{H_{\tau(t)} - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right) + \mathbb{P} \!\left( \frac{\varepsilon_t - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x\right), \end{align*}
it suffices to show that
 \begin{align} \frac{M^{\tau}(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} \stackrel{d}{\longrightarrow} G \quad \text{ as } t\to \infty, \end{align}
\begin{align} \frac{M^{\tau}(t) - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} \stackrel{d}{\longrightarrow} G \quad \text{ as } t\to \infty, \end{align}
 \begin{align} \lim_{t \to\infty} \mathbb{P} \!\left( \frac{H_{\tau(t)} - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right) = 0, \quad \text{and} \quad \lim_{t \to\infty} \mathbb{P} \!\left( \frac{\varepsilon_t - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x\right) = 0. \end{align}
\begin{align} \lim_{t \to\infty} \mathbb{P} \!\left( \frac{H_{\tau(t)} - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right) = 0, \quad \text{and} \quad \lim_{t \to\infty} \mathbb{P} \!\left( \frac{\varepsilon_t - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x\right) = 0. \end{align}
Recall that
 $H_i$
represents the maximum of all claims due to the arrival of an immigrant claim at time
$H_i$
represents the maximum of all claims due to the arrival of an immigrant claim at time
 $ \Gamma_i$
, and by (3.3) it equals
$ \Gamma_i$
, and by (3.3) it equals
 \begin{equation*} H_i =\bigvee_{j=0}^{K_i} X_{i,j} . \end{equation*}
\begin{equation*} H_i =\bigvee_{j=0}^{K_i} X_{i,j} . \end{equation*}
Note that
 $(H_i)$
is an i.i.d. sequence, because the ancestral mark in every cluster comes from an independently marked renewal point process. As in the proofs of Lemma 2.2 and Theorem 2.1,
$(H_i)$
is an i.i.d. sequence, because the ancestral mark in every cluster comes from an independently marked renewal point process. As in the proofs of Lemma 2.2 and Theorem 2.1,
 \begin{align*} \mathbb{P}\!\left(\frac{M^{\tau}(t) - d_{\lfloor \nu t\rfloor}}{c_{\lfloor \nu t \rfloor}}\leq x\right) &= \mathbb{P} \!\left( \sum_{i=1}^{\tau(t)} \delta_{\frac{H_{i}-d_{\lfloor \nu t\rfloor}}{c_{\lfloor \nu t \rfloor}}} (x, \infty) = 0 \right) \\ &\to \mathbb{P}\!\left(\mathrm{PRM}(\mu_G)(x,\infty)=0\right) = G(x), \end{align*}
\begin{align*} \mathbb{P}\!\left(\frac{M^{\tau}(t) - d_{\lfloor \nu t\rfloor}}{c_{\lfloor \nu t \rfloor}}\leq x\right) &= \mathbb{P} \!\left( \sum_{i=1}^{\tau(t)} \delta_{\frac{H_{i}-d_{\lfloor \nu t\rfloor}}{c_{\lfloor \nu t \rfloor}}} (x, \infty) = 0 \right) \\ &\to \mathbb{P}\!\left(\mathrm{PRM}(\mu_G)(x,\infty)=0\right) = G(x), \end{align*}
as
 $t\to\infty$
, which shows (3.8). To show (3.9), note that
$t\to\infty$
, which shows (3.8). To show (3.9), note that
 $\left\lbrace \tau(t) = k \right\rbrace \in \sigma(Y_1, \dots Y_k)$
and by assumption
$\left\lbrace \tau(t) = k \right\rbrace \in \sigma(Y_1, \dots Y_k)$
and by assumption
 $\left\lbrace H_{k} \in A \right\rbrace$
is independent of
$\left\lbrace H_{k} \in A \right\rbrace$
is independent of
 $\sigma(Y_1, \dots Y_k)$
for every k. Therefore,
$\sigma(Y_1, \dots Y_k)$
for every k. Therefore,
 $ H_{\tau(t)} \stackrel{d}{=} H_1\in \mathrm{MDA}(G)$
, so the first part of (3.9) easily follows from (3.6). For the second part of (3.9), observe that the leftover effect
$ H_{\tau(t)} \stackrel{d}{=} H_1\in \mathrm{MDA}(G)$
, so the first part of (3.9) easily follows from (3.6). For the second part of (3.9), observe that the leftover effect
 $\varepsilon _t$
admits the representation
$\varepsilon _t$
admits the representation
 \begin{equation*}\varepsilon_t \stackrel{d}{=} \bigvee_{i=1}^{J_t}X_i,\end{equation*}
\begin{equation*}\varepsilon_t \stackrel{d}{=} \bigvee_{i=1}^{J_t}X_i,\end{equation*}
for
 $(X_i)_{i\in \mathbb{N}}$
i.i.d. copies of
$(X_i)_{i\in \mathbb{N}}$
i.i.d. copies of
 $X=f(A)$
. Hence,
$X=f(A)$
. Hence,
 \begin{equation*}\frac{\varepsilon _t - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} \stackrel{d}{=} \frac{\bigvee_{i=1}^{J_t}X_i - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}}.\end{equation*}
\begin{equation*}\frac{\varepsilon _t - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} \stackrel{d}{=} \frac{\bigvee_{i=1}^{J_t}X_i - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}}.\end{equation*}
Since
 $J_t = o_P(t)$
, for every fixed
$J_t = o_P(t)$
, for every fixed
 $\delta>0$
and t large enough,
$\delta>0$
and t large enough,
 $\mathbb{P}(J_t>\delta t)< \delta.$
For measurable
$\mathbb{P}(J_t>\delta t)< \delta.$
For measurable
 $A=\{J_t>\delta t\}$
we have
$A=\{J_t>\delta t\}$
we have
 \begin{align*} \mathbb{P}\!\left(\dfrac{\bigvee_{i=1}^{J_t}X_i - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x\right) &\leq \mathbb{P}(A) + \mathbb{P} \!\left( \left\lbrace \dfrac{\bigvee_{i=1}^{J_t}X_i - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right\rbrace \cap A^C \right)\\ &< \delta + \mathbb{P}\!\left(\dfrac{\bigvee_{i=1}^{\lfloor \delta t\rfloor}X_i - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x\right), \end{align*}
\begin{align*} \mathbb{P}\!\left(\dfrac{\bigvee_{i=1}^{J_t}X_i - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x\right) &\leq \mathbb{P}(A) + \mathbb{P} \!\left( \left\lbrace \dfrac{\bigvee_{i=1}^{J_t}X_i - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x \right\rbrace \cap A^C \right)\\ &< \delta + \mathbb{P}\!\left(\dfrac{\bigvee_{i=1}^{\lfloor \delta t\rfloor}X_i - d_{\lfloor \nu t \rfloor}}{c_{\lfloor \nu t \rfloor}} > x\right), \end{align*}
which converges to 0 as
 $\delta\to 0$
.
$\delta\to 0$
.
As we have seen above, it is relatively easy to determine the asymptotic behaviour of the maximal claim size M(t) as long as one can determine the tail properties of the random variables
 $H_i$
and the number of points in the leftover effect at time t,
$H_i$
and the number of points in the leftover effect at time t,
 $J_t$
in (3.5). An application of Theorem 2.1 immediately yields the following corollary.
$J_t$
in (3.5). An application of Theorem 2.1 immediately yields the following corollary.
Corollary 3.1. Let
 $J_t = o_P(t)$
, and let
$J_t = o_P(t)$
, and let
 $(X_{i,j})$
satisfy (2.1) and the assumptions from the proof of Theorem 2.1. Then (3.7) holds with
$(X_{i,j})$
satisfy (2.1) and the assumptions from the proof of Theorem 2.1. Then (3.7) holds with
 $(c_n)$
and
$(c_n)$
and
 $(d_n)$
defined by
$(d_n)$
defined by
 \begin{equation} (c_n) = (a_{\lfloor (\mathbb{E} [K] +1) \cdot n \rfloor}), \quad (d_n) = (b_{\lfloor (\mathbb{E} [K]+1) \cdot n \rfloor}) . \end{equation}
\begin{equation} (c_n) = (a_{\lfloor (\mathbb{E} [K] +1) \cdot n \rfloor}), \quad (d_n) = (b_{\lfloor (\mathbb{E} [K]+1) \cdot n \rfloor}) . \end{equation}
As we shall see in the following section, showing that
 $J_t = o_P(t)$
holds remains a rather technical task. However, this can be done for several frequently used cluster models.
$J_t = o_P(t)$
holds remains a rather technical task. However, this can be done for several frequently used cluster models.
4. Maximal claim size for three special models
In this section we present three special models belonging to the general marked renewal cluster model introduced in Section 3. We try to find sufficient conditions for these models in order to apply Proposition 3.1.
Remark 4.1. In any of the three examples below, the point process N can be made stationary if we start the construction in (3.1) on the state space
 $\mathbb{R} \times \mathbb{S}$
with a renewal process
$\mathbb{R} \times \mathbb{S}$
with a renewal process
 $ \sum_i \delta_{\Gamma_i}$
on the whole real line. For the resulting stationary cluster process we use the notation
$ \sum_i \delta_{\Gamma_i}$
on the whole real line. For the resulting stationary cluster process we use the notation
 $N^*$
. Still, from the applied perspective, it seems more interesting to study the nonstationary version, where both the parent process
$N^*$
. Still, from the applied perspective, it seems more interesting to study the nonstationary version, where both the parent process
 $N^0$
and the cluster process itself have arrivals only from some point onwards, e.g. in the interval
$N^0$
and the cluster process itself have arrivals only from some point onwards, e.g. in the interval
 $[0,\infty)$
.
$[0,\infty)$
.
4.1. Mixed binomial cluster model
Assume that the renewal counting process which generates the arrival times in the parent process
 ${(\Gamma_i)}_{i\in \mathbb{N}}$
is a homogeneous Poisson process with mean measure (
${(\Gamma_i)}_{i\in \mathbb{N}}$
is a homogeneous Poisson process with mean measure (
 $\nu\mathrm{Leb}$
) on the state space
$\nu\mathrm{Leb}$
) on the state space
 $[ 0,\infty) $
for
$[ 0,\infty) $
for
 $\nu >0$
, and that the individual clusters have the form
$\nu >0$
, and that the individual clusters have the form
 \begin{equation*}G_i = \displaystyle\sum_{j=1}^{K_i} \delta_{V_{i,j}, A_{i,j}}.\end{equation*}
\begin{equation*}G_i = \displaystyle\sum_{j=1}^{K_i} \delta_{V_{i,j}, A_{i,j}}.\end{equation*}
Assume that
 $(K_i,(V_{i,j})_{j\in \mathbb{N}},(A_{i,j})_{j\in \mathbb{Z}_+})_{i\in \mathbb{N}}$
constitutes an i.i.d. sequence with the following properties for fixed
$(K_i,(V_{i,j})_{j\in \mathbb{N}},(A_{i,j})_{j\in \mathbb{Z}_+})_{i\in \mathbb{N}}$
constitutes an i.i.d. sequence with the following properties for fixed
 $i\in \mathbb{N}$
:
$i\in \mathbb{N}$
:
-
$(A_{i,j})_{j\in \mathbb{Z}_+}$
are i.i.d.;
-
$(V_{i,j})_{j\in \mathbb{N}}$
are conditionally i.i.d. given
$A_{i,0}$
;
-
$(A_{i,j})_{j\in \mathbb{N}}$
are independent of
$(V_{i,j})_{j\in \mathbb{N}}$
;
-
$K_i$
is a stopping time with respect to the filtration generated by the
$(A_{i,j})_{j\in \mathbb{Z}_+},$
i.e. for every
$k \in \mathbb{Z}_+$
,
$\{ K_i = k\} \in \sigma (A_{i,0}, \dots A_{i,k}).$









Notice that we do allow possible dependence between
 $K_i$
and
$K_i$
and
 ${(A_{i,j})}_{j\in \mathbb{Z}_+}$
. Also, we do not exclude the possibility of dependence between
${(A_{i,j})}_{j\in \mathbb{Z}_+}$
. Also, we do not exclude the possibility of dependence between
 $(V_{i,j})_{j\in \mathbb{N}}$
and the ancestral mark
$(V_{i,j})_{j\in \mathbb{N}}$
and the ancestral mark
 $A_{i,0}$
(and consequently
$A_{i,0}$
(and consequently
 $K_i$
). Recall that K is an integer-valued random variable representing the size of a cluster, such that
$K_i$
). Recall that K is an integer-valued random variable representing the size of a cluster, such that
 $\mathbb{E}[K]<\infty$
. Observe that we use the notation
$\mathbb{E}[K]<\infty$
. Observe that we use the notation
 $V_{i,j}$
instead of
$V_{i,j}$
instead of
 $T_{i,j}$
to emphasize the relatively simple structure of clusters in this model, in contrast with the other two models in this section. Such a process N is a marked version of the so-called Neyman–Scott process; e.g. see [Reference Daley and Vere-Jones12, Example 6.3(a)].
$T_{i,j}$
to emphasize the relatively simple structure of clusters in this model, in contrast with the other two models in this section. Such a process N is a marked version of the so-called Neyman–Scott process; e.g. see [Reference Daley and Vere-Jones12, Example 6.3(a)].
Corollary 4.1. Assume that
 $f(A)=X$
belongs to
$f(A)=X$
belongs to
 $\mathrm{MDA}(G)$
, so that (2.1) holds. Then (3.7) holds for
$\mathrm{MDA}(G)$
, so that (2.1) holds. Then (3.7) holds for
 $(c_n)$
and
$(c_n)$
and
 $(d_n)$
defined in (3.10).
$(d_n)$
defined in (3.10).
Proof. Using Theorem 2.1 we conclude that the maximum H of all claims in a cluster belongs to the MDA of the same distribution as X. Apply Proposition 3.1 after observing that
 $J_t=o_P(t)$
. Using Markov’s inequality, it is enough to check that
$J_t=o_P(t)$
. Using Markov’s inequality, it is enough to check that
 $\mathbb{E}[J_t]=o(t)$
,
$\mathbb{E}[J_t]=o(t)$
,
 \begin{align*} \mathbb{E} [J_t]&=\mathbb{E} [\# \{(i,j)\,:\,0\le \Gamma_i \leq t ,\, t< \Gamma_i + V_{i,j}\}] \\ &= \mathbb{E}\!\left[\sum_{0\le \Gamma_i \leq t }\sum_{j=1}^{K_i}\mathbb{I}_{t\le \Gamma_i +V_{i,j}}\right]. \end{align*}
\begin{align*} \mathbb{E} [J_t]&=\mathbb{E} [\# \{(i,j)\,:\,0\le \Gamma_i \leq t ,\, t< \Gamma_i + V_{i,j}\}] \\ &= \mathbb{E}\!\left[\sum_{0\le \Gamma_i \leq t }\sum_{j=1}^{K_i}\mathbb{I}_{t\le \Gamma_i +V_{i,j}}\right]. \end{align*}
Using Lemma 7.2.12 in [Reference Mikosch24] and calculations similar to those in the proofs of Corollaries 5.1 and 5.3 in [Reference Basrak, Wintenberger and Žugec6], we have
 \begin{align*} \mathbb{E}\!\left[\sum_{0\le \Gamma_i\le t}\sum_{j=1}^{K_i}\mathbb{I}_{t< \Gamma_i+V_{i,j}}\right] &= \int_0^t\mathbb{E}\!\left[\sum_{j=1}^{K_i}\mathbb{I}_{V_{i,j}> t-s} \right]\nu ds = \int_0^t\mathbb{E}\!\left[\sum_{j=1}^{K_i}\mathbb{I}_{V_{i,j}> x} \right]\nu dx. \end{align*}
\begin{align*} \mathbb{E}\!\left[\sum_{0\le \Gamma_i\le t}\sum_{j=1}^{K_i}\mathbb{I}_{t< \Gamma_i+V_{i,j}}\right] &= \int_0^t\mathbb{E}\!\left[\sum_{j=1}^{K_i}\mathbb{I}_{V_{i,j}> t-s} \right]\nu ds = \int_0^t\mathbb{E}\!\left[\sum_{j=1}^{K_i}\mathbb{I}_{V_{i,j}> x} \right]\nu dx. \end{align*}
Now note that as
 $x \to\infty$
, by the dominated convergence theorem,
$x \to\infty$
, by the dominated convergence theorem,
 \begin{equation*}\mathbb{E}\!\left[\sum_{j=1}^{K_i}\mathbb{I}_{V_{i,j}> x} \right] \to 0 .\end{equation*}
\begin{equation*}\mathbb{E}\!\left[\sum_{j=1}^{K_i}\mathbb{I}_{V_{i,j}> x} \right] \to 0 .\end{equation*}
An application of a Cesàro argument now yields that
 $\mathbb{E}[J_t]/t \to 0$
.
$\mathbb{E}[J_t]/t \to 0$
.
4.2. Renewal cluster model
Assume next that the clusters
 $G_i$
have the following distribution:
$G_i$
have the following distribution:
 \begin{equation*}G_i = \displaystyle\sum_{j=1}^{K_i} \delta_{T_{i,j}, A_{i,j}},\end{equation*}
\begin{equation*}G_i = \displaystyle\sum_{j=1}^{K_i} \delta_{T_{i,j}, A_{i,j}},\end{equation*}
where
 $(T_{i,j})$
represents the sequence such that
$(T_{i,j})$
represents the sequence such that
 \begin{equation*}T_{i,j} = V_{i,1} + \cdots + V_{i,j},\quad 1\leq j\leq K_i.\end{equation*}
\begin{equation*}T_{i,j} = V_{i,1} + \cdots + V_{i,j},\quad 1\leq j\leq K_i.\end{equation*}
We keep all the other assumptions from the model in the previous subsection.
A general unmarked model of a similar type, called the Bartlett–Lewis model, is analysed in [Reference Daley and Vere-Jones12]; see Example 6.3(b). See also [Reference Faÿ, González-Arévalo, Mikosch and Samorodnitsky15] for an application of a similar point process to modelling of teletraffic data. By adapting the arguments from Corollary 4.1 we can easily obtain the next corollary.




4.3. Marked Hawkes processes
Another example in our analysis is the so-called (linear) marked Hawkes process. These processes are typically introduced through their stochastic intensity (see, for example, [Reference Karabash and Zhu22] or [Reference Daley and Vere-Jones12]). More precisely, a point process
 $N = \sum_{k} \delta_{\tau_k,A^k}$
represents a Hawkes process of this type if the random marks
$N = \sum_{k} \delta_{\tau_k,A^k}$
represents a Hawkes process of this type if the random marks
 $(A^k)$
are i.i.d. with distribution Q on the space
$(A^k)$
are i.i.d. with distribution Q on the space
 $\mathbb{S}$
, while the arrivals
$\mathbb{S}$
, while the arrivals
 $(\tau_k)$
have stochastic intensity of the form
$(\tau_k)$
have stochastic intensity of the form
 \begin{equation*}\lambda(t) = \nu + \sum_{\tau_i< t} h(t-\tau_i,A^i),\end{equation*}
\begin{equation*}\lambda(t) = \nu + \sum_{\tau_i< t} h(t-\tau_i,A^i),\end{equation*}
where
 $\nu > 0$
is a constant and
$\nu > 0$
is a constant and
 $h\,:\,[0,\infty)\times \mathbb{S}\to \mathbb{R}_+$
is assumed to be integrable in the sense that
$h\,:\,[0,\infty)\times \mathbb{S}\to \mathbb{R}_+$
is assumed to be integrable in the sense that
 $\int_0^\infty \mathbb{E} [h(s,A)] ds < \infty$
. On the other hand, Hawkes processes of this type have a neat Poisson cluster representation due to [Reference Hawkes and Oakes19]. For this model, the clusters
$\int_0^\infty \mathbb{E} [h(s,A)] ds < \infty$
. On the other hand, Hawkes processes of this type have a neat Poisson cluster representation due to [Reference Hawkes and Oakes19]. For this model, the clusters
 $G_{i}$
are recursive aggregations of Cox processes, i.e. Poisson processes with random mean measure
$G_{i}$
are recursive aggregations of Cox processes, i.e. Poisson processes with random mean measure
 $ \tilde{\mu}_{A_i} \times Q$
where
$ \tilde{\mu}_{A_i} \times Q$
where
 $ \tilde{\mu}_{A_i} $
has the form
$ \tilde{\mu}_{A_i} $
has the form
 \begin{align*}\tilde{\mu}_{A_i} (B) = \displaystyle\int_B h(s, A_i) ds,\end{align*}
\begin{align*}\tilde{\mu}_{A_i} (B) = \displaystyle\int_B h(s, A_i) ds,\end{align*}
for some fertility (or self-exciting) function h; cf. Example 6.4(c) of [Reference Daley and Vere-Jones12]. It is useful to introduce a time shift operator
 $\theta_t$
, by defining
$\theta_t$
, by defining
 \begin{equation*}\theta _t m = \sum_j \delta_{t_j+t,a_j},\end{equation*}
\begin{equation*}\theta _t m = \sum_j \delta_{t_j+t,a_j},\end{equation*}
for an arbitrary point measure
 $m = \sum_j \delta_{t_j,a_j} \in M_p([0,\infty)\times \mathbb{S})$
and
$m = \sum_j \delta_{t_j,a_j} \in M_p([0,\infty)\times \mathbb{S})$
and
 $t\geq 0$
. Now, for the parent process
$t\geq 0$
. Now, for the parent process
 $N^0 = \sum_{i\in \mathbb{N}} \delta_{ \Gamma_i,A_i}$
, which is a Poisson point process with mean measure
$N^0 = \sum_{i\in \mathbb{N}} \delta_{ \Gamma_i,A_i}$
, which is a Poisson point process with mean measure
 $\nu \times Q$
on the space
$\nu \times Q$
on the space
 $[0,\infty) \times \mathbb{S}$
, the cluster process corresponding to a point
$[0,\infty) \times \mathbb{S}$
, the cluster process corresponding to a point
 $( \Gamma_i,A_i)$
satisfies the following recursive relation:
$( \Gamma_i,A_i)$
satisfies the following recursive relation:
 \begin{equation} G_i = \displaystyle\sum_{l=1}^{{L_{A_i}}} \left( {\delta_{\tau^1_l,A^1_l}} + \theta_{\tau^1_l} G^1_l \right),\end{equation}
\begin{equation} G_i = \displaystyle\sum_{l=1}^{{L_{A_i}}} \left( {\delta_{\tau^1_l,A^1_l}} + \theta_{\tau^1_l} G^1_l \right),\end{equation}
where, given
 $A_i,$
$A_i,$
 \begin{equation*}{\tilde{N}}_i = \sum_{l=1}^{L_{A_i}} \delta_{\tau^1_l,A^1_l}\end{equation*}
\begin{equation*}{\tilde{N}}_i = \sum_{l=1}^{L_{A_i}} \delta_{\tau^1_l,A^1_l}\end{equation*}
is a Poisson process with mean measure
 $ \tilde{\mu}_{A_i} \times Q,$
and the sequence
$ \tilde{\mu}_{A_i} \times Q,$
and the sequence
 $(G^1_l)_l$
is i.i.d., distributed as
$(G^1_l)_l$
is i.i.d., distributed as
 $G_i$
and independent of
$G_i$
and independent of
 ${\tilde{N}}_i$
.
${\tilde{N}}_i$
.
Thus, at any ancestral point
 $(\Gamma_i,A_i)$
, a cluster of points appears as a whole cascade of points to the right in time generated recursively according to (4.1). Note that
$(\Gamma_i,A_i)$
, a cluster of points appears as a whole cascade of points to the right in time generated recursively according to (4.1). Note that
 $L_{A_i}$
has Poisson distribution conditionally on
$L_{A_i}$
has Poisson distribution conditionally on
 $A_i$
, with mean
$A_i$
, with mean
 $\kappa_{A_i}=\int_0^\infty h(s,A_i) ds$
. It corresponds to the number of first-generation progeny
$\kappa_{A_i}=\int_0^\infty h(s,A_i) ds$
. It corresponds to the number of first-generation progeny
 $(A^1_l)$
in the cascade. Note also that the point processes forming the second generation are again Poisson conditionally on the corresponding first-generation mark
$(A^1_l)$
in the cascade. Note also that the point processes forming the second generation are again Poisson conditionally on the corresponding first-generation mark
 $A_l^1$
. The cascade
$A_l^1$
. The cascade
 $G_i$
corresponds to the process formed by the successive generations, drawn recursively as Poisson processes given the former generation. The marked Hawkes process is obtained by attaching to the ancestors
$G_i$
corresponds to the process formed by the successive generations, drawn recursively as Poisson processes given the former generation. The marked Hawkes process is obtained by attaching to the ancestors
 $(\Gamma_i,A_{i})$
of the marked Poisson process
$(\Gamma_i,A_{i})$
of the marked Poisson process
 $N^0 = \sum_{i\in \mathbb{N}} \delta_{ \Gamma_i,A_i}$
a cluster of points, denoted by
$N^0 = \sum_{i\in \mathbb{N}} \delta_{ \Gamma_i,A_i}$
a cluster of points, denoted by
 $C_i$
, which contains the point
$C_i$
, which contains the point
 $(0,A_{i})$
and a whole cascade
$(0,A_{i})$
and a whole cascade
 $G_i$
of points to the right in time generated recursively according to (4.1) given
$G_i$
of points to the right in time generated recursively according to (4.1) given
 $A_i$
. Under the assumption
$A_i$
. Under the assumption
 \begin{equation} \kappa = \mathbb{E} \!\left[\displaystyle\int h(s,A) ds\right] < 1,\end{equation}
\begin{equation} \kappa = \mathbb{E} \!\left[\displaystyle\int h(s,A) ds\right] < 1,\end{equation}
the total number of points in a cluster is generated by a subcritical branching process. Therefore, the clusters are finite almost surely. Denote their size by
 $K_i {+1}$
. It is known (see Example 6.3(c) in [Reference Daley and Vere-Jones12]) that under (4.2) the clusters always satisfy
$K_i {+1}$
. It is known (see Example 6.3(c) in [Reference Daley and Vere-Jones12]) that under (4.2) the clusters always satisfy
 \begin{equation}\mathbb{E} [K_i] {+1} = \frac{1}{1-\kappa}.\end{equation}
\begin{equation}\mathbb{E} [K_i] {+1} = \frac{1}{1-\kappa}.\end{equation}
Note that the clusters
 $C_i$
, i.e. point processes which represent a cluster together with the mark
$C_i$
, i.e. point processes which represent a cluster together with the mark
 $A_i$
, are independent by construction. They can be represented as
$A_i$
, are independent by construction. They can be represented as
 \begin{align*}C_i= \displaystyle\sum_{j = 0}^{K_i} \delta_{\Gamma_i+T_{i,j},A_{i,j}},\end{align*}
\begin{align*}C_i= \displaystyle\sum_{j = 0}^{K_i} \delta_{\Gamma_i+T_{i,j},A_{i,j}},\end{align*}
with
 $A_{i,j}$
being i.i.d.,
$A_{i,j}$
being i.i.d.,
 $A_{i,0}=A_i$
,
$A_{i,0}=A_i$
,
 $T_{i,0} = 0$
, and
$T_{i,0} = 0$
, and
 $T_{i,j},$
$T_{i,j},$
 $j\in \mathbb{N}$
, representing arrival times of progeny claims in the cluster
$j\in \mathbb{N}$
, representing arrival times of progeny claims in the cluster
 $C_i$
. Observe that in the case when marks do not influence conditional density, i.e. when
$C_i$
. Observe that in the case when marks do not influence conditional density, i.e. when
 $h(s,a) = h(s)$
, the random variable
$h(s,a) = h(s)$
, the random variable
 $K_i{+1}$
has a so-called Borel distribution with parameter
$K_i{+1}$
has a so-called Borel distribution with parameter
 $\kappa$
; see [Reference Haight and Breuer17]. Notice also that in general, marks and arrival times of the final Hawkes process N are not independent of each other; rather, in the terminology of [Reference Daley and Vere-Jones12], the marks in the process N are only unpredictable.
$\kappa$
; see [Reference Haight and Breuer17]. Notice also that in general, marks and arrival times of the final Hawkes process N are not independent of each other; rather, in the terminology of [Reference Daley and Vere-Jones12], the marks in the process N are only unpredictable.
As before, the maximal claim size in one cluster is of the form
 \begin{equation*}H \stackrel{d}{=} \bigvee_{j=0}^K X_j .\end{equation*}
\begin{equation*}H \stackrel{d}{=} \bigvee_{j=0}^K X_j .\end{equation*}
Note that K and
 $(X_j)$
are not independent. In this case, thanks to the representation of Hawkes processes as the recursive aggregation of Cox processes (4.1), the maximal claim size can also be written as
$(X_j)$
are not independent. In this case, thanks to the representation of Hawkes processes as the recursive aggregation of Cox processes (4.1), the maximal claim size can also be written as
 \begin{equation*}H \stackrel{d}{=} X \vee \bigvee_{j=1}^{L_A} H_j.\end{equation*}
\begin{equation*}H \stackrel{d}{=} X \vee \bigvee_{j=1}^{L_A} H_j.\end{equation*}
Recall from (4.2) that
 $\kappa = \mathbb{E} [\kappa_A] < 1.$
The
$\kappa = \mathbb{E} [\kappa_A] < 1.$
The
 $H_j$
on the right-hand side are independent of
$H_j$
on the right-hand side are independent of
 $\kappa_A$
and i.i.d. with the same distribution as H. Conditionally on A, the waiting times are i.i.d. with common density
$\kappa_A$
and i.i.d. with the same distribution as H. Conditionally on A, the waiting times are i.i.d. with common density
 \begin{equation} \frac{h(t,A)}{\kappa_A}, \quad t\ge0; \end{equation}
\begin{equation} \frac{h(t,A)}{\kappa_A}, \quad t\ge0; \end{equation}
see [Reference Karabash and Zhu22] or [Reference Basrak, Wintenberger and Žugec6]. In order to apply Proposition 3.1, first we show that H is in
 $\mathrm{MDA}(G)$
, using the well-known connection between branching processes and random walks; see for instance [Reference Asmussen and Foss1], [Reference Bennies and Kersting7], or the quite recent [Reference Costa, Graham, Marsalle and Tran11]. This is the subject of the next lemma.
$\mathrm{MDA}(G)$
, using the well-known connection between branching processes and random walks; see for instance [Reference Asmussen and Foss1], [Reference Bennies and Kersting7], or the quite recent [Reference Costa, Graham, Marsalle and Tran11]. This is the subject of the next lemma.
Lemma 4.1. Let X belong to
 $\mathrm{MDA}(G)$
in the marked Hawkes model. Then H also belongs to the same
$\mathrm{MDA}(G)$
in the marked Hawkes model. Then H also belongs to the same
 $\mathrm{MDA}(G).$
$\mathrm{MDA}(G).$
Proof. By the recursive relation (4.1), each cluster can be associated with a subcritical branching process (Bienaymé–Galton–Watson tree) where the total number of points in a cascade (cluster) corresponds to the total number of vertices in such a tree. It has the same distribution as the first hitting time of level 0,
 \begin{equation*}\zeta = \inf \!\left\lbrace k\,:\, S_k = 0 \right\rbrace, \end{equation*}
\begin{equation*}\zeta = \inf \!\left\lbrace k\,:\, S_k = 0 \right\rbrace, \end{equation*}
by a random walk
 $(S_n)$
defined as
$(S_n)$
defined as
 \begin{align*}S_0 = 1,\quad S_n = S_{n-1} + L_n - 1,\end{align*}
\begin{align*}S_0 = 1,\quad S_n = S_{n-1} + L_n - 1,\end{align*}
with i.i.d.
 $L_n \stackrel{d}{=} L.$
Notice that
$L_n \stackrel{d}{=} L.$
Notice that
 $(S_n)$
has negative drift, which leads to the conclusion that
$(S_n)$
has negative drift, which leads to the conclusion that
 $\zeta$
is a proper random variable. Moreover, since
$\zeta$
is a proper random variable. Moreover, since
 $\mathbb{E} [L] < 1$
, an application of Theorem 3 from [Reference Gut16] gives
$\mathbb{E} [L] < 1$
, an application of Theorem 3 from [Reference Gut16] gives
 $\mathbb{E} [\zeta] < \infty$
and implies that we can use (4.3) since
$\mathbb{E} [\zeta] < \infty$
and implies that we can use (4.3) since
 $\zeta = K+1.$
$\zeta = K+1.$
If we write, for arbitrary
 $k\in \mathbb{N}$
,
$k\in \mathbb{N}$
,
 \begin{align*}\left\lbrace \zeta = k \right\rbrace &= \left\lbrace S_0 >0, S_1 >0, \dots, S_{k-1} >0, S_k=0 \right\rbrace \\&=\left\lbrace 1>0, L_1>0, \dots, \displaystyle\sum_{i=1}^{k-1} L_i - (k-2) >0, \displaystyle\sum_{i=1}^{k} L_i - (k-1) =0 \right\rbrace \\&\in \sigma \!\left( L,A_0,A_1,\dots, A_k \right),\end{align*}
\begin{align*}\left\lbrace \zeta = k \right\rbrace &= \left\lbrace S_0 >0, S_1 >0, \dots, S_{k-1} >0, S_k=0 \right\rbrace \\&=\left\lbrace 1>0, L_1>0, \dots, \displaystyle\sum_{i=1}^{k-1} L_i - (k-2) >0, \displaystyle\sum_{i=1}^{k} L_i - (k-1) =0 \right\rbrace \\&\in \sigma \!\left( L,A_0,A_1,\dots, A_k \right),\end{align*}
we see that
 $\zeta$
is a stopping time with respect to
$\zeta$
is a stopping time with respect to
 $(\mathcal{F}^{\prime}_j)_{j\in \mathbb{Z}_+},$
where
$(\mathcal{F}^{\prime}_j)_{j\in \mathbb{Z}_+},$
where
 $\mathcal{F}^{\prime}_j = \sigma(L, A_0, A_1, \dots, A_j),$
and where L has conditionally Poisson distribution with random parameter
$\mathcal{F}^{\prime}_j = \sigma(L, A_0, A_1, \dots, A_j),$
and where L has conditionally Poisson distribution with random parameter
 $\kappa_A$
and is independent of the sequence
$\kappa_A$
and is independent of the sequence
 $(A_j)_{j\in \mathbb{Z}_+}.$
By Theorem 2.1 we conclude that H is also in
$(A_j)_{j\in \mathbb{Z}_+}.$
By Theorem 2.1 we conclude that H is also in
 $\mathrm{MDA}(G)$
.
$\mathrm{MDA}(G)$
.
Remark 4.2. The equation (4.3) implies that the sequences
 $(c_n)$
and
$(c_n)$
and
 $(d_n)$
in the following corollary have the representations
$(d_n)$
in the following corollary have the representations
 \begin{equation*}(c_n) = \left(a_{\lfloor \frac{1}{1-\kappa} n \rfloor} \right), \qquad (d_n) = \left(b_{\lfloor \frac{1}{1-\kappa} n \rfloor} \right).\end{equation*}
\begin{equation*}(c_n) = \left(a_{\lfloor \frac{1}{1-\kappa} n \rfloor} \right), \qquad (d_n) = \left(b_{\lfloor \frac{1}{1-\kappa} n \rfloor} \right).\end{equation*}
Corollary 4.3. Assume that X belongs to
 $\mathrm{MDA}(G)$
, so that (2.1) holds, and
$\mathrm{MDA}(G)$
, so that (2.1) holds, and
 \begin{align*} \mathbb{E}\!\left[ \tilde{\mu}_A(t,\infty)\right] \to 0 \quad \text{ as } t\to \infty. \end{align*}
\begin{align*} \mathbb{E}\!\left[ \tilde{\mu}_A(t,\infty)\right] \to 0 \quad \text{ as } t\to \infty. \end{align*}


Proof. Recall from (3.2) that one can write
 \begin{equation*} N= \displaystyle\sum_{i=1}^\infty \displaystyle\sum_{j = 0}^{K_i} \delta_{ \Gamma_i+T_{i,j},A_{i,j}} = \displaystyle\sum_{k=1}^\infty \delta_{\tau_k,A^{k}} , \end{equation*}
\begin{equation*} N= \displaystyle\sum_{i=1}^\infty \displaystyle\sum_{j = 0}^{K_i} \delta_{ \Gamma_i+T_{i,j},A_{i,j}} = \displaystyle\sum_{k=1}^\infty \delta_{\tau_k,A^{k}} , \end{equation*}
without loss of generality assuming that
 $0\leq \tau_1\leq \tau_2\leq \ldots$
. At each time
$0\leq \tau_1\leq \tau_2\leq \ldots$
. At each time
 $\tau_j$
, a claim arrives generated by one of the previous claims, or an entirely new (immigrant) claim appears. In the former case, if
$\tau_j$
, a claim arrives generated by one of the previous claims, or an entirely new (immigrant) claim appears. In the former case, if
 $\tau_j$
is the direct offspring of a claim at time
$\tau_j$
is the direct offspring of a claim at time
 $\tau_i$
, we will write
$\tau_i$
, we will write
 $\tau_i\to \tau_j$
. The progeny
$\tau_i\to \tau_j$
. The progeny
 $\tau_j$
then potentially creates further claims. Notice that
$\tau_j$
then potentially creates further claims. Notice that
 $\tau_i\to \tau_j$
is equivalent to
$\tau_i\to \tau_j$
is equivalent to
 $\tau_j=\tau_i+V_{i,k}$
,
$\tau_j=\tau_i+V_{i,k}$
,
 $k\le L^i = L_{A^i}$
, where
$k\le L^i = L_{A^i}$
, where
 $V_{i,k}$
are waiting times which, according to the discussion above (4.4), are i.i.d. with common density
$V_{i,k}$
are waiting times which, according to the discussion above (4.4), are i.i.d. with common density
 $h(t,A^i)/ \kappa_{A^i}$
,
$h(t,A^i)/ \kappa_{A^i}$
,
 $t\ge0$
, and independent of
$t\ge0$
, and independent of
 $L^{i}$
conditionally on the mark
$L^{i}$
conditionally on the mark
 $A^i$
of the claim at
$A^i$
of the claim at
 $\tau_i$
. Moreover, conditionally on
$\tau_i$
. Moreover, conditionally on
 $A^i$
, the number of direct progeny of the claim at
$A^i$
, the number of direct progeny of the claim at
 $\tau_i$
, denoted by
$\tau_i$
, denoted by
 $L^{i}$
, has Poisson distribution with parameter
$L^{i}$
, has Poisson distribution with parameter
 $\tilde{\mu}_{A^i}$
. We denote by
$\tilde{\mu}_{A^i}$
. We denote by
 $K_{\tau_j}$
the total number of points generated by the arrival at
$K_{\tau_j}$
the total number of points generated by the arrival at
 $\tau_j$
. Clearly, the
$\tau_j$
. Clearly, the
 $K_{\tau_j}$
are identically distributed as K and even mutually independent if we consider only points which are not offspring of one another.
$K_{\tau_j}$
are identically distributed as K and even mutually independent if we consider only points which are not offspring of one another.
It is enough to check
 $\mathbb{E}[J_t]/t=o(1)$
and see that
$\mathbb{E}[J_t]/t=o(1)$
and see that
 \begin{align*} \mathbb{E} [J_t] &= \mathbb{E}\Big[ \displaystyle\sum_{\Gamma_i \leq t}\displaystyle\sum_j \mathbb{I}_{\Gamma_i + T_{i,j} >t} \Big]= \mathbb{E}\Big[\displaystyle\sum_{\tau_i \leq t} \displaystyle\sum_{\tau_j > t} (K_{\tau_j}+1) \, \mathbb{I}_{\tau_i\to \tau_j}\Big]\\ &=\mathbb{E}\Big[\displaystyle\sum_{\tau_i \leq t} \mathbb{E}\Big[\displaystyle\sum_{k=1}^{L^{i}} (K_{\tau_i+V_{i,k}}+1) \mathbb{I}_{\tau_i+V_{i,k} > t} \mid (\tau_i,A^i)_{i\ge 0}; \tau_i \le t\Big]\Big]\\ &=\frac{1}{1-\kappa} \mathbb{E} \!\left[ \displaystyle\int_{0}^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) N(ds,da) \right], \end{align*}
\begin{align*} \mathbb{E} [J_t] &= \mathbb{E}\Big[ \displaystyle\sum_{\Gamma_i \leq t}\displaystyle\sum_j \mathbb{I}_{\Gamma_i + T_{i,j} >t} \Big]= \mathbb{E}\Big[\displaystyle\sum_{\tau_i \leq t} \displaystyle\sum_{\tau_j > t} (K_{\tau_j}+1) \, \mathbb{I}_{\tau_i\to \tau_j}\Big]\\ &=\mathbb{E}\Big[\displaystyle\sum_{\tau_i \leq t} \mathbb{E}\Big[\displaystyle\sum_{k=1}^{L^{i}} (K_{\tau_i+V_{i,k}}+1) \mathbb{I}_{\tau_i+V_{i,k} > t} \mid (\tau_i,A^i)_{i\ge 0}; \tau_i \le t\Big]\Big]\\ &=\frac{1}{1-\kappa} \mathbb{E} \!\left[ \displaystyle\int_{0}^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) N(ds,da) \right], \end{align*}
where
 $ \tilde{\mu}_{a} ((u,\infty)) = \int_u^\infty h(s, a) ds$
. Observe that from the projection theorem (see Theorem 3 in [Reference Bremaud10, Chapter 8]), the last expression equals
$ \tilde{\mu}_{a} ((u,\infty)) = \int_u^\infty h(s, a) ds$
. Observe that from the projection theorem (see Theorem 3 in [Reference Bremaud10, Chapter 8]), the last expression equals
 \begin{equation*} \frac{1}{1-\kappa} \mathbb{E}\!\left[\displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da) \lambda(s)ds \right]. \end{equation*}
\begin{equation*} \frac{1}{1-\kappa} \mathbb{E}\!\left[\displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da) \lambda(s)ds \right]. \end{equation*}
Recall from Remark 4.1 that N has a stationary version,
 $N^*$
, such that the expression
$N^*$
, such that the expression
 $\mathbb{E} \!\left[ \lambda^*(s) \right]$
is a constant equal to
$\mathbb{E} \!\left[ \lambda^*(s) \right]$
is a constant equal to
 $ \nu/(1-\kappa)$
. Using Fubini’s theorem, one can further bound the last expectation from above by
$ \nu/(1-\kappa)$
. Using Fubini’s theorem, one can further bound the last expectation from above by
 \begin{align*} \mathbb{E}\!\left[\displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da) \lambda^*(s)ds\right]&=\displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da) \mathbb{E}[\lambda^*(s)]ds\\ &=\frac{\nu}{1-\kappa}\displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da) ds. \end{align*}
\begin{align*} \mathbb{E}\!\left[\displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da) \lambda^*(s)ds\right]&=\displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da) \mathbb{E}[\lambda^*(s)]ds\\ &=\frac{\nu}{1-\kappa}\displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da) ds. \end{align*}
Now we have
 \begin{align*} \mathbb{E} {J_t} \leq \dfrac{\nu }{(1-\kappa)^{2}} \displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da)ds = \dfrac{\nu }{(1-\kappa)^{2}} \displaystyle\int_0^t \int_s^\infty \mathbb{E}[h(u,A)]du ds . \end{align*}
\begin{align*} \mathbb{E} {J_t} \leq \dfrac{\nu }{(1-\kappa)^{2}} \displaystyle\int_0^t \displaystyle\int_{\mathbb{S}} \tilde{\mu}_a((t-s,\infty)) Q(da)ds = \dfrac{\nu }{(1-\kappa)^{2}} \displaystyle\int_0^t \int_s^\infty \mathbb{E}[h(u,A)]du ds . \end{align*}
Dividing the last expression by t and applying L’Hôpital’s rule proves the theorem for the nonstationary or pure Hawkes process.
Acknowledgements
We sincerely thank the anonymous reviewers for suggestions which led to simplified proofs and improved layout of the article.
Funding information
The work of Bojan Basrak and Nikolina Milinčević was supported by the Swiss Enlargement Contribution in the framework of the Croatian-Swiss Research Programme (project number IZHRZ0_180549).
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.
