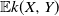1. Introduction
In the context of Lévy-driven queues [Reference DĘbicki and Mandjes8] and Lévy storage processes [Reference Kyprianou18], it was recently shown [Reference Berkelmans, Cichocka and Mandjes3] that, whenever the stationary distribution exists and has a finite second moment, the correlation function associated with the stationary version of the reflected process is nonnegative, nonincreasing, and convex. Here, a Lévy-driven queue is to be interpreted as the one-sided (Skorokhod) reflection map applied to a Lévy process. Notably, the results in [Reference Berkelmans, Cichocka and Mandjes3] show that the mentioned structural properties carry over to the finite-buffer Lévy-driven queue, i.e., the two-sided (Skorokhod) reflection map. One could regard [Reference Berkelmans, Cichocka and Mandjes3] as the endpoint of a long-lasting research effort which began over four decades ago. The nonnegativity, nonincreasingness, and convexity of the correlation function of the stationary process was proven in [Reference Ott19] for the case where the Lévy process under consideration is compound Poisson. The more recent contributions [Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11] deal with the spectrally positive and negative cases, respectively. Finally, [Reference Berkelmans, Cichocka and Mandjes3] removed the spectral restrictions on the Lévy process assumed in [Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11]. Whereas [Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11, Reference Ott19] rely on the machinery of completely monotone functions, [Reference Berkelmans, Cichocka and Mandjes3] uses a direct conditioning argument in combination of elementary properties of the reflection map.
A second strand of research that we would like to mention concerns structural properties of the mean value (and related quantities) of the reflected process. It was found [Reference Kella and Sverchkov14] that for a one-sided Skorokhod reflection, when the driving process has stationary increments and starts from zero, the mean of the reflected process (as a function of time) is nondecreasing and concave. In particular this holds when the driving process also has independent increments (i.e., the Lévy case), which for the spectrally-positive case had been discovered earlier [Reference Kella12]; we refer to [Reference Kella and Whitt15, Theorem 11] for a multivariate analogue. The nondecreasingness and concavity of the mean was proven to extend to the two-sided reflection case in [Reference Andersen and Mandjes1], where it was also shown that for the one- and two-sided reflection cases the variance is nondecreasing.
The main objective of this paper is to explore to what level of generality the results from the above two branches of the literature can be extended, and whether they could be somehow brought under a common umbrella. Importantly, in our attempt to understand the above-mentioned structural properties better, we discovered that they are covered by a substantially broader framework. We have done so by considering stochastically monotone Markov processes (in both discrete and continuous time), and deriving properties of the expected value of bivariate supermodular functions of coordinates of the process.
Importantly, we discovered a neat and quite simple approach to extend a broad range of existing results to a substantially broader class of processes and more general functional setups. We strongly feel that this particular approach gets to the heart of the matter, and also helps in giving a much clearer understanding of earlier results. More specifically, our findings directly imply the type of monotonicity results for the covariance that were found in [Reference Berkelmans, Cichocka and Mandjes3, Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11] and [Reference Kella12, Reference Kella and Sverchkov14]. For the convexity results of [Reference Berkelmans, Cichocka and Mandjes3, Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11] and the concavity results of [Reference Kella and Sverchkov14] (restricted to Lévy processes) and [Reference Kella12], a further, rather natural, condition needs to be imposed on the underlying Markov transition kernel; this is Condition 1, to follow. However, notably, the monotonicity of the variance established in [Reference Andersen and Mandjes1] is not valid under the conditions imposed in the current paper, as we will show by means of a counterexample.
The area of stochastically monotone Markov processes is vast. Without aiming at giving a full overview, we would like to mention [Reference Daley7, Reference Keilson and Kester16, Reference Rüschendorf22, Reference Siegmund23]. In particular, in [Reference Daley7] a main result is Theorem 4, which states that if
 $\{X_n\,|\,n\ge 0\}$
is a stationary stochastically monotone time-homogeneous Markov chain (on a real-valued state space) and f is nondecreasing, then
$\{X_n\,|\,n\ge 0\}$
is a stationary stochastically monotone time-homogeneous Markov chain (on a real-valued state space) and f is nondecreasing, then
 $\text{Cov}(f(X_0),f(X_n))$
(whenever it exists and is finite) is nonnegative and nonincreasing in n. As it turns out, this result also is a special case of the results established in our current paper. Importantly, quite a few frequently used stochastic processes are stochastically monotone Markov processes, including for example birth–death processes and diffusions [Reference Keilson and Kester16], as well as certain Lévy dams and (state-dependent) random walks, besides the above-mentioned reflected processes.
$\text{Cov}(f(X_0),f(X_n))$
(whenever it exists and is finite) is nonnegative and nonincreasing in n. As it turns out, this result also is a special case of the results established in our current paper. Importantly, quite a few frequently used stochastic processes are stochastically monotone Markov processes, including for example birth–death processes and diffusions [Reference Keilson and Kester16], as well as certain Lévy dams and (state-dependent) random walks, besides the above-mentioned reflected processes.
In our proofs we use the notion of a generalized inverse of a distribution function and some of its properties, conditioning arguments, and the application of the concept of supermodularity and its relationship to comonotonicity. More concretely, it will be important to study the properties of
 $h(X_s,X_t)$
or
$h(X_s,X_t)$
or
 $h(X_s,X_t-X_{t+\delta})$
(and others) for
$h(X_s,X_t-X_{t+\delta})$
(and others) for
 $0\le s\le t$
and
$0\le s\le t$
and
 $\delta>0$
, where h is a supermodular function. This will be done for both the stationary case and the transient case (under various conditions). For background on results associated with supermodular functions, and in particular the relationship with comonotone random variables, which we will need several times, we refer to [Reference Cambanis, Simons and Stout5, Reference Puccetti and Scarsini20, Reference Puccetti and Wang21].
$\delta>0$
, where h is a supermodular function. This will be done for both the stationary case and the transient case (under various conditions). For background on results associated with supermodular functions, and in particular the relationship with comonotone random variables, which we will need several times, we refer to [Reference Cambanis, Simons and Stout5, Reference Puccetti and Scarsini20, Reference Puccetti and Wang21].
As so often in mathematics, once we are in the right framework, proofs can be highly compact and seemingly straightforward. It is, however, typically far from trivial to identify this best ‘lens’ through which one should look at the problem. This phenomenon also applies in the context of the properties derived in the present paper. Indeed, in previous works the focus has been on specific models and specific properties, with proofs that tend to be ad hoc, lengthy, and involved, reflecting the lack of an overarching framework. With the general approach that we develop in this paper, we manage to bring a wide class of existing results under a common denominator, with the underlying proofs becoming clean and insightful. In addition, because we have found the right angle to study this class of problems, we succeed in shedding light on the question of the extent to which these results can be further generalized. Our objective was to present the framework as cleanly as possible; our paper is self-contained in the sense that it does not require any previous knowledge of stochastically monotone Markov processes.
The paper is organized as follows. In Section 2 the formal setup (including Condition 1), the main results, and their proofs will be given. In Section 3 we provide a series of appealing examples of frequently used stochastically monotone Markov processes that satisfy Condition 1. Section 4 concludes.
Throughout we write
 $a\wedge b=\min\!(a,b)$
,
$a\wedge b=\min\!(a,b)$
,
 $a\vee b=\max\!(a,b)$
,
$a\vee b=\max\!(a,b)$
,
 $a^+=a\vee 0$
,
$a^+=a\vee 0$
,
 $a^-=-a\wedge 0=({-}a)^+$
. In addition, a.s. stands for almost surely (i.e., with probability one), and CDF stands for cumulative distribution function. Also,
$a^-=-a\wedge 0=({-}a)^+$
. In addition, a.s. stands for almost surely (i.e., with probability one), and CDF stands for cumulative distribution function. Also,
 $=_{\rm d}$
means ‘distributed’ or ‘distributed like’, and
$=_{\rm d}$
means ‘distributed’ or ‘distributed like’, and
 $X\le_{\text{st}}Y$
means
$X\le_{\text{st}}Y$
means
 ${\mathbb P}(X>t)\le {\mathbb P}(Y>t)$
for all t (stochastic order).
${\mathbb P}(X>t)\le {\mathbb P}(Y>t)$
for all t (stochastic order).
2. General theory
This section presents our main results. Section 2.1 treats our general theory, whereas Section 2.2 further reflects on general questions that can be dealt with relying on our results, as well as the connection with supermodular functions.
2.1. Main results
For
 $x\in\mathbb{R}$
and A Borel (one-dimensional), we let p(x, A) be a Markov transition kernel. By this we mean that for every Borel A,
$x\in\mathbb{R}$
and A Borel (one-dimensional), we let p(x, A) be a Markov transition kernel. By this we mean that for every Borel A,
 $p(\cdot,A)$
is a Borel function and for each
$p(\cdot,A)$
is a Borel function and for each
 $x\in\mathbb{R}$
,
$x\in\mathbb{R}$
,
 $p(x,\cdot)$
is a probability measure. We will say that p is stochastically monotone if
$p(x,\cdot)$
is a probability measure. We will say that p is stochastically monotone if
 $p(x,(y,\infty))$
is nondecreasing in x for each
$p(x,(y,\infty))$
is nondecreasing in x for each
 $y\in\mathbb{R}$
, which, as was discussed earlier and will be demonstrated later, is a natural property across a broad range of frequently used stochastic models.
$y\in\mathbb{R}$
, which, as was discussed earlier and will be demonstrated later, is a natural property across a broad range of frequently used stochastic models.
The following condition plays a crucial role in our results. Whenever it is satisfied, it allows us to establish highly general results. The condition is natural in the context of, e.g., queues and other storage systems, as will be pointed out in Section 3.
Condition 1. For each y,
 $p(x,(x+y,\infty))$
is nonincreasing in x.
$p(x,(x+y,\infty))$
is nonincreasing in x.
Now, for
 $n\ge 1$
, let p and
$n\ge 1$
, let p and
 $p_n$
, for
$p_n$
, for
 $n\ge 1$
, be transition kernels. Define
$n\ge 1$
, be transition kernels. Define
 \begin{equation}G(x,u)=\inf\{y\,|\, p(x,({-}\infty,y])\ge u\}\end{equation}
\begin{equation}G(x,u)=\inf\{y\,|\, p(x,({-}\infty,y])\ge u\}\end{equation}
to be the generalized inverse function associated with the CDF
 $F_x(y)=p(x,({-}\infty,y])$
, and similarly let
$F_x(y)=p(x,({-}\infty,y])$
, and similarly let
 $G_n(x,u)$
be the generalized inverse function associated with
$G_n(x,u)$
be the generalized inverse function associated with
 $p_n$
. We recall (see e.g. the paper [Reference Embrechts and Hofert9], among many others) that G(x, u) is nondecreasing and left-continuous in u (on (0, 1)), and that
$p_n$
. We recall (see e.g. the paper [Reference Embrechts and Hofert9], among many others) that G(x, u) is nondecreasing and left-continuous in u (on (0, 1)), and that
 $G(x,u)\le y$
if and only if
$G(x,u)\le y$
if and only if
 $u\le p(x,({-}\infty,y])$
. Thus, if
$u\le p(x,({-}\infty,y])$
. Thus, if
 $U=_{\rm d}\text{U}(0, 1)$
, where
$U=_{\rm d}\text{U}(0, 1)$
, where
 $\text{U}(0, 1)$
is the uniform distribution on (0, 1), then
$\text{U}(0, 1)$
is the uniform distribution on (0, 1), then
 ${\mathbb P}(G(x,U)\le y)=p(x,({-}\infty,y])$
and thus
${\mathbb P}(G(x,U)\le y)=p(x,({-}\infty,y])$
and thus
 ${\mathbb P}(G(x,U)\in A)=p(x,A)$
. Similar reasoning applies to
${\mathbb P}(G(x,U)\in A)=p(x,A)$
. Similar reasoning applies to
 $G_n(x,u)$
for every
$G_n(x,u)$
for every
 $n\ge 1$
.
$n\ge 1$
.
Lemma 1. The transition kernel p is stochastically monotone if and only if, for each
 $u\in(0, 1)$
, G(x, u) is nondecreasing in x. Furthermore, Condition 1 is satisfied if and only if, for each u,
$u\in(0, 1)$
, G(x, u) is nondecreasing in x. Furthermore, Condition 1 is satisfied if and only if, for each u,
 $G(x,u)-x$
is nonincreasing in x.
$G(x,u)-x$
is nonincreasing in x.
Proof. It follows from the facts (i) that for
 $x_1<x_2$
$x_1<x_2$
 \begin{equation}\{y\,|\,p(x_1,({-}\infty,y])\ge u\}\supset \{y\,|\,p(x_2,({-}\infty,y])\ge u\},\end{equation}
\begin{equation}\{y\,|\,p(x_1,({-}\infty,y])\ge u\}\supset \{y\,|\,p(x_2,({-}\infty,y])\ge u\},\end{equation}
(ii) that under Condition 1 for
 $x_1<x_2$
$x_1<x_2$
 \begin{equation}\{y\,|\,p(x_1,({-}\infty,x_1+y])\ge u\}\subset \{y\,|\,p(x_2,({-}\infty,x_2+y])\ge u\},\end{equation}
\begin{equation}\{y\,|\,p(x_1,({-}\infty,x_1+y])\ge u\}\subset \{y\,|\,p(x_2,({-}\infty,x_2+y])\ge u\},\end{equation}
and (iii) that
 $G(x,u)-x=\inf\{y\,|\,p(x,({-}\infty,x+y]\ge u\}$
.
$G(x,u)-x=\inf\{y\,|\,p(x,({-}\infty,x+y]\ge u\}$
.
Now, let
 $g_k^{k}(x,u)=G_k(x,u)$
, and for
$g_k^{k}(x,u)=G_k(x,u)$
, and for
 $n\ge k+1$
let
$n\ge k+1$
let
 \begin{equation}g_k^n(x,u_1,\ldots,u_{n-k+1})=G_n(g_k^{n-1}(x,u_1,\ldots,u_{n-k}),u_{n-k+1}).\end{equation}
\begin{equation}g_k^n(x,u_1,\ldots,u_{n-k+1})=G_n(g_k^{n-1}(x,u_1,\ldots,u_{n-k}),u_{n-k+1}).\end{equation}
It immediately follows by induction that if
 $p_k,\ldots,p_n$
are stochastically monotone, then
$p_k,\ldots,p_n$
are stochastically monotone, then
 $g_k^n(x,u_1,\ldots,u_{n-k+1})$
is nondecreasing in x. Assume that
$g_k^n(x,u_1,\ldots,u_{n-k+1})$
is nondecreasing in x. Assume that
 $U_1,U_2,\ldots$
are independent and identically distributed (i.i.d.) with distribution
$U_1,U_2,\ldots$
are independent and identically distributed (i.i.d.) with distribution
 $\text{U}(0, 1)$
; then with
$\text{U}(0, 1)$
; then with
 $X^{\prime}_0=x$
and
$X^{\prime}_0=x$
and
 \begin{equation}X^{\prime}_n=g_1^n(x,U_1,\ldots,U_n)\end{equation}
\begin{equation}X^{\prime}_n=g_1^n(x,U_1,\ldots,U_n)\end{equation}
for
 $n\ge 1$
,
$n\ge 1$
,
 $\{X^{\prime}_n\,|\, n\ge 0\}$
is a real-valued (possibly time-inhomogeneous) Markov chain with possibly time-dependent transition kernels
$\{X^{\prime}_n\,|\, n\ge 0\}$
is a real-valued (possibly time-inhomogeneous) Markov chain with possibly time-dependent transition kernels
 $p_1,p_2,\ldots$
. Let us now set
$p_1,p_2,\ldots$
. Let us now set
 $p^{k-1}_k(x,A)=1_A(x)$
and, for
$p^{k-1}_k(x,A)=1_A(x)$
and, for
 $n\ge k$
,
$n\ge k$
,
 \begin{equation}p^n_k(x,A)=\int_{\mathbb{R}}p_n(y,A)p_k^{n-1}(x,\text{d}y).\end{equation}
\begin{equation}p^n_k(x,A)=\int_{\mathbb{R}}p_n(y,A)p_k^{n-1}(x,\text{d}y).\end{equation}
Lemma 2. If, for
 $1\le k\le n$
,
$1\le k\le n$
,
 $p_k,\ldots,p_n$
are stochastically monotone Markov kernels (resp., and in addition satisfy Condition 1), then
$p_k,\ldots,p_n$
are stochastically monotone Markov kernels (resp., and in addition satisfy Condition 1), then
 $p_k^n$
is stochastically monotone (resp., and in addition satisfies Condition 1).
$p_k^n$
is stochastically monotone (resp., and in addition satisfies Condition 1).
Proof. By induction, it suffices to show this for the case
 $n=k+1$
. If
$n=k+1$
. If
 $p_k$
and
$p_k$
and
 $p_{k+1}$
are stochastically monotone, then
$p_{k+1}$
are stochastically monotone, then
 $g_k^{k+1}(x,U_1,U_2)$
is a random variable having the distribution
$g_k^{k+1}(x,U_1,U_2)$
is a random variable having the distribution
 $p_k^{k+1}(x,\cdot)$
. Therefore, the stochastic monotonicity of
$p_k^{k+1}(x,\cdot)$
. Therefore, the stochastic monotonicity of
 $p_k^{k+1}$
is a consequence of the fact that
$p_k^{k+1}$
is a consequence of the fact that
 $g_k^{k+1}(x,U_1,U_2)$
is nondecreasing in x. Now, if stochastic monotonicity and Condition 1 hold, then
$g_k^{k+1}(x,U_1,U_2)$
is nondecreasing in x. Now, if stochastic monotonicity and Condition 1 hold, then
 $G_k(x,U_1)-x$
and
$G_k(x,U_1)-x$
and
 $G_{k+1}(G_k(x,U_1),U_2)-G_k(x,U_1)$
are nonincreasing in x, and thus so is their sum. This implies that
$G_{k+1}(G_k(x,U_1),U_2)-G_k(x,U_1)$
are nonincreasing in x, and thus so is their sum. This implies that
 $g_k^{k+1}(x,U_1,U_2)-x$
is nonincreasing in x, which implies that
$g_k^{k+1}(x,U_1,U_2)-x$
is nonincreasing in x, which implies that
 $p_k^{k+1}$
satisfies Condition 1.
$p_k^{k+1}$
satisfies Condition 1.
A (possibly time-inhomogeneous) Markov chain with stochastically monotone transition kernels will be called a stochastically monotone Markov chain (see, e.g., [Reference Daley7] for the time-homogeneous case). Lemma 2 immediately implies the following.
Corollary 1. Any subsequence of a stochastically monotone Markov chain (resp., in addition satisfying Condition 1) is also a stochastically monotone Markov chain (resp., in addition satisfying Condition 1).
Therefore, a subsequence of a time-homogeneous stochastically monotone Markov chain (resp., in addition satisfying Condition 1) may no longer be time-homogeneous, but is always a stochastically monotone Markov chain (resp., in addition satisfying Condition 1).
Recall that
 $h\,:\,\mathbb{R}^2\to\mathbb{R}$
is called supermodular if whenever
$h\,:\,\mathbb{R}^2\to\mathbb{R}$
is called supermodular if whenever
 $x_1\le x_2$
and
$x_1\le x_2$
and
 $y_1\le y_2$
we have that
$y_1\le y_2$
we have that
 \begin{equation}h(x_1,y_2)+h(x_2,y_1)\le h(x_1,y_1)+h(x_2,y_2).\end{equation}
\begin{equation}h(x_1,y_2)+h(x_2,y_1)\le h(x_1,y_1)+h(x_2,y_2).\end{equation}
If X and Y have CDFs
 $F_X$
and
$F_X$
and
 $F_Y$
, then (X, Y) will be called comonotone if
$F_Y$
, then (X, Y) will be called comonotone if
 $\mathbb{P}(X\le x,Y\le y)=\mathbb{P}(X\le x)\wedge \mathbb{P}(Y\le y)$
for all x, y. There are various equivalent definitions for comonotonicity. In particular it is worth mentioning that when X and Y are identically distributed, they are comonotone if and only if
$\mathbb{P}(X\le x,Y\le y)=\mathbb{P}(X\le x)\wedge \mathbb{P}(Y\le y)$
for all x, y. There are various equivalent definitions for comonotonicity. In particular it is worth mentioning that when X and Y are identically distributed, they are comonotone if and only if
 $\mathbb{P}(X=Y)=1$
. It is well known that if (X
′, Y
′) is comonotone and has the same marginals as (X, Y), then for any Borel supermodular h for which
$\mathbb{P}(X=Y)=1$
. It is well known that if (X
′, Y
′) is comonotone and has the same marginals as (X, Y), then for any Borel supermodular h for which
 $\mathbb{E} h(X,Y)$
and
$\mathbb{E} h(X,Y)$
and
 $\mathbb{E} h(X^{\prime},Y^{\prime})$
exist and are finite, we have that
$\mathbb{E} h(X^{\prime},Y^{\prime})$
exist and are finite, we have that
 $\mathbb{E} h(X,Y)\le \mathbb{E} h(X^{\prime},Y^{\prime})$
. In particular, if X, Y are identically distributed, then
$\mathbb{E} h(X,Y)\le \mathbb{E} h(X^{\prime},Y^{\prime})$
. In particular, if X, Y are identically distributed, then
 $\mathbb{E} h(X,Y)\le \mathbb{E} h(Y,Y)$
, which is a property that we will need later in this paper. For such results and much more, see e.g. [Reference Puccetti and Wang21] and references therein, where the Borel assumption is not made but is actually needed, as there are non-Borel supermodular functions for which h(X, Y) is not necessarily a random variable. We write down what we will need later as a lemma. Everything in this lemma is well known.
$\mathbb{E} h(X,Y)\le \mathbb{E} h(Y,Y)$
, which is a property that we will need later in this paper. For such results and much more, see e.g. [Reference Puccetti and Wang21] and references therein, where the Borel assumption is not made but is actually needed, as there are non-Borel supermodular functions for which h(X, Y) is not necessarily a random variable. We write down what we will need later as a lemma. Everything in this lemma is well known.
Lemma 3. Let (X,Y) be a random pair such that
 $X=_{\rm d} Y$
. Then for every Borel supermodular function
$X=_{\rm d} Y$
. Then for every Borel supermodular function
 $h\,:\,\mathbb{R}^2\to\mathbb{R}$
for which
$h\,:\,\mathbb{R}^2\to\mathbb{R}$
for which
 $\mathbb{E} h(X,Y)$
and
$\mathbb{E} h(X,Y)$
and
 $\mathbb{E} h(Y,Y)$
exist and are finite, we have that
$\mathbb{E} h(Y,Y)$
exist and are finite, we have that
 \begin{equation}\mathbb{E} h(X,Y)\le \mathbb{E} h(Y,Y).\end{equation}
\begin{equation}\mathbb{E} h(X,Y)\le \mathbb{E} h(Y,Y).\end{equation}
Moreover, if h is supermodular and
 $f_1,f_2$
are nondecreasing, then
$f_1,f_2$
are nondecreasing, then
 $h(f_1(x),f_2(y))$
is supermodular, and in particular, since
$h(f_1(x),f_2(y))$
is supermodular, and in particular, since
 $h(x,y)=xy$
is supermodular,
$h(x,y)=xy$
is supermodular,
 $f_1(x)f_2(y)$
is supermodular as well.
$f_1(x)f_2(y)$
is supermodular as well.
As usual, we call
 $\pi$
invariant for a Markov kernel p if, for every Borel A,
$\pi$
invariant for a Markov kernel p if, for every Borel A,
 $\int_{\mathbb{R}}p(x,A)\pi(\text{d}x)=\pi(A)$
. We proceed by stating and proving our first main result.
$\int_{\mathbb{R}}p(x,A)\pi(\text{d}x)=\pi(A)$
. We proceed by stating and proving our first main result.
Theorem 1. Assume that
 $X_0,X_1,X_2$
is a stochastically monotone Markov chain where
$X_0,X_1,X_2$
is a stochastically monotone Markov chain where
 $p_1$
has an invariant distribution
$p_1$
has an invariant distribution
 $\pi_1$
and
$\pi_1$
and
 $X_0$
is
$X_0$
is
 $\pi_1$
-distributed. Then for every Borel supermodular
$\pi_1$
-distributed. Then for every Borel supermodular
 $h\,:\,\mathbb{R}^2\to\mathbb{R}$
,
$h\,:\,\mathbb{R}^2\to\mathbb{R}$
,
 \begin{equation}\mathbb{E} h(X_0,X_2)\le \mathbb{E} h(X_1,X_2)\end{equation}
\begin{equation}\mathbb{E} h(X_0,X_2)\le \mathbb{E} h(X_1,X_2)\end{equation}
whenever the means exist and are finite. In particular, for any nondecreasing
 $f_1,f_2$
for which the means of
$f_1,f_2$
for which the means of
 $f_1(X_0)$
,
$f_1(X_0)$
,
 $f_2(X_2)$
,
$f_2(X_2)$
,
 $f_1(X_0)f_2(X_2)$
, and
$f_1(X_0)f_2(X_2)$
, and
 $f_1(X_1)f_2(X_2)$
exist and are finite, we have that
$f_1(X_1)f_2(X_2)$
exist and are finite, we have that
 \begin{equation}0\le\text{ Cov}(f_1(X_0),f_2(X_2))\le \text{Cov}(f_1(X_1),f_2(X_2)).\end{equation}
\begin{equation}0\le\text{ Cov}(f_1(X_0),f_2(X_2))\le \text{Cov}(f_1(X_1),f_2(X_2)).\end{equation}
Proof. Let
 $X^{\prime}_0,U_1,U_2$
be independent with
$X^{\prime}_0,U_1,U_2$
be independent with
 $U_1,U_2=_{\rm d}\text{U}(0, 1)$
and
$U_1,U_2=_{\rm d}\text{U}(0, 1)$
and
 $X^{\prime}_0= X_0$
. Then with
$X^{\prime}_0= X_0$
. Then with
 $X^{\prime}_1=G_1(X^{\prime}_0,U_1)$
and
$X^{\prime}_1=G_1(X^{\prime}_0,U_1)$
and
 $X^{\prime}_2=G_2(X^{\prime}_1,U_2)$
we have that
$X^{\prime}_2=G_2(X^{\prime}_1,U_2)$
we have that
 $(X^{\prime}_0,X^{\prime}_1,X^{\prime}_2)=_{\rm d} (X_0,X_1,X_2)$
. Now we note that since
$(X^{\prime}_0,X^{\prime}_1,X^{\prime}_2)=_{\rm d} (X_0,X_1,X_2)$
. Now we note that since
 $G_2(y,u_2)$
is nondecreasing in y, we have (by Lemma 3) that
$G_2(y,u_2)$
is nondecreasing in y, we have (by Lemma 3) that
 $h(x,G_2(y,u_2))$
is supermodular in x, y for every fixed
$h(x,G_2(y,u_2))$
is supermodular in x, y for every fixed
 $u_2$
. Since
$u_2$
. Since
 $X^{\prime}_0=_{\rm d} X^{\prime}_1$
, it follows from Lemma 3 that
$X^{\prime}_0=_{\rm d} X^{\prime}_1$
, it follows from Lemma 3 that
 \begin{equation}\mathbb{E} (h(X^{\prime}_0,G_2(X^{\prime}_1,U_2))\,|\,U_2)\le \mathbb{E} (h(X^{\prime}_1,G_2(X^{\prime}_1,U_2))\,|\,U_2).\end{equation}
\begin{equation}\mathbb{E} (h(X^{\prime}_0,G_2(X^{\prime}_1,U_2))\,|\,U_2)\le \mathbb{E} (h(X^{\prime}_1,G_2(X^{\prime}_1,U_2))\,|\,U_2).\end{equation}
Taking expected values on both sides gives (9). Noting that
 $\mathbb{E} f_1(X_0)\mathbb{E} f_2(X_2)=\mathbb{E} f_1(X_1)\mathbb{E} f_2(X_2)$
and that
$\mathbb{E} f_1(X_0)\mathbb{E} f_2(X_2)=\mathbb{E} f_1(X_1)\mathbb{E} f_2(X_2)$
and that
 $f_1(x)f_2(y)$
is supermodular gives the right inequality in (10). To show the left inequality, note that
$f_1(x)f_2(y)$
is supermodular gives the right inequality in (10). To show the left inequality, note that
 $G_2(G_1(x,u_1),u_2)$
is a nondecreasing function of x, and thus, so is
$G_2(G_1(x,u_1),u_2)$
is a nondecreasing function of x, and thus, so is
 $\gamma(x)=\mathbb{E} f_2(G_2(G_1(x,U_1,U_2)))$
. Now,
$\gamma(x)=\mathbb{E} f_2(G_2(G_1(x,U_1,U_2)))$
. Now,
 \begin{equation}\text{Cov}(f_1(X_0),f_2(X_2))=\text{Cov}(f_1(X_0),\mathbb{E} [f_2(X_2)|X_0])=\text{Cov}(f_1(X_0),\gamma(X_0)),\end{equation}
\begin{equation}\text{Cov}(f_1(X_0),f_2(X_2))=\text{Cov}(f_1(X_0),\mathbb{E} [f_2(X_2)|X_0])=\text{Cov}(f_1(X_0),\gamma(X_0)),\end{equation}
and it is well known that the covariance of comonotone random variables (whenever well defined and finite) must be nonnegative.
A time-homogeneous continuous-time Markov process
 $\{X_t\,|\,t\ge 0\}$
will be called stochastically monotone whenever
$\{X_t\,|\,t\ge 0\}$
will be called stochastically monotone whenever
 $p^t(x,A)=\mathbb{P}_x(X_t\in A)$
is a stochastically monotone kernel for each
$p^t(x,A)=\mathbb{P}_x(X_t\in A)$
is a stochastically monotone kernel for each
 $t>0$
. We will say that it satisfies Condition 1 whenever
$t>0$
. We will say that it satisfies Condition 1 whenever
 $p^t$
satisfies this condition for every
$p^t$
satisfies this condition for every
 $t>0$
. Note that by Corollary 1 this is equivalent to the assumption that these conditions are satisfied for
$t>0$
. Note that by Corollary 1 this is equivalent to the assumption that these conditions are satisfied for
 $0<t\le \epsilon$
for some
$0<t\le \epsilon$
for some
 $\epsilon>0$
.
$\epsilon>0$
.
Theorem 2. Consider a stationary stochastically monotone discrete-time or continuous-time time-homogeneous Markov process
 $\{X_t\,|\,t\ge0\}$
. Then for every supermodular h for which the following expectations exist and are finite,
$\{X_t\,|\,t\ge0\}$
. Then for every supermodular h for which the following expectations exist and are finite,
 $\mathbb{E} h(X_0,X_t)$
is nonincreasing in
$\mathbb{E} h(X_0,X_t)$
is nonincreasing in
 $t\ge 0$
, where t is either nonnegative integer- or nonnegative real-valued. In particular, when
$t\ge 0$
, where t is either nonnegative integer- or nonnegative real-valued. In particular, when
 $f_1,f_2$
are nondecreasing and the appropriate expectations exist,
$f_1,f_2$
are nondecreasing and the appropriate expectations exist,
 $\text{Cov}(f_1(X_0),f_2(X_t))$
is nonnegative and nonincreasing in
$\text{Cov}(f_1(X_0),f_2(X_t))$
is nonnegative and nonincreasing in
 $t\ge0$
.
$t\ge0$
.
Proof. For every
 $0<t_1<t_2$
we have that
$0<t_1<t_2$
we have that
 $X_0,X_{t_2-t_1},X_{t_2}$
satisfy the conditions and hence the conclusions of Theorem 1 (for the discrete-time case, recall Corollary 1). By stationarity we have that
$X_0,X_{t_2-t_1},X_{t_2}$
satisfy the conditions and hence the conclusions of Theorem 1 (for the discrete-time case, recall Corollary 1). By stationarity we have that
 $(X_{t_2-t_1},X_{t_2})=_{\rm d} (X_0,X_{t_1})$
. Therefore
$(X_{t_2-t_1},X_{t_2})=_{\rm d} (X_0,X_{t_1})$
. Therefore
 \begin{equation}\mathbb{E} h(X_0,X_{t_2})\le \mathbb{E} h(X_{t_2-t_1},X_{t_2})=\mathbb{E} h(X_0,X_{t_1}).\end{equation}
\begin{equation}\mathbb{E} h(X_0,X_{t_2})\le \mathbb{E} h(X_{t_2-t_1},X_{t_2})=\mathbb{E} h(X_0,X_{t_1}).\end{equation}
Note that, since
 $X_t=_{\rm d} X_0$
, Lemma 3 implies that
$X_t=_{\rm d} X_0$
, Lemma 3 implies that
 \begin{equation}\mathbb{E} h(X_0,X_t)\le \mathbb{E} h(X_0,X_0),\end{equation}
\begin{equation}\mathbb{E} h(X_0,X_t)\le \mathbb{E} h(X_0,X_0),\end{equation}
so that
 $\mathbb{E} h(X_0,X_t)$
is nonincreasing on
$\mathbb{E} h(X_0,X_t)$
is nonincreasing on
 $[0,\infty)$
and not just on
$[0,\infty)$
and not just on
 $(0,\infty)$
. Since
$(0,\infty)$
. Since
 \begin{equation*}\mathbb{E} f_1(X_0)\mathbb{E} f_2(X_t)=\mathbb{E} f_1(X_0)\mathbb{E} f_2(X_0),\end{equation*}
\begin{equation*}\mathbb{E} f_1(X_0)\mathbb{E} f_2(X_t)=\mathbb{E} f_1(X_0)\mathbb{E} f_2(X_0),\end{equation*}
the result for the covariance follows by taking
 $h(x,y)=f_1(x)f_2(y)$
.
$h(x,y)=f_1(x)f_2(y)$
.
Remark 1. The following is a standard and very simple exercise in ergodic theory. Let T be a measure-preserving transformation on
 $(\Omega,\mathcal{F},\mu)$
, where
$(\Omega,\mathcal{F},\mu)$
, where
 $\mu$
is a
$\mu$
is a
 $\sigma$
-finite measure. This means that
$\sigma$
-finite measure. This means that
 $\mu(T^{-1}(A))=\mu(A)$
for every
$\mu(T^{-1}(A))=\mu(A)$
for every
 $A\in\mathcal{F}$
, where
$A\in\mathcal{F}$
, where
 $T^{-1}(A)=\{\omega\in \Omega\,|\,T(\omega)\in A\}$
. Then T is mixing (in the sense that
$T^{-1}(A)=\{\omega\in \Omega\,|\,T(\omega)\in A\}$
. Then T is mixing (in the sense that
 $\mu(A\cap T^{-n}B)\to \mu(A)\mu(B)$
as
$\mu(A\cap T^{-n}B)\to \mu(A)\mu(B)$
as
 $n\to\infty$
, for every
$n\to\infty$
, for every
 $A,B\in\mathcal{F}$
) if and only if, for every
$A,B\in\mathcal{F}$
) if and only if, for every
 $f_1,f_2\,:\,\Omega\to\mathbb{R}$
such that
$f_1,f_2\,:\,\Omega\to\mathbb{R}$
such that
 $\int f_i^2\text{d}\mu<\infty$
for
$\int f_i^2\text{d}\mu<\infty$
for
 $i=1,2$
, we have that
$i=1,2$
, we have that
 $\int f_1\cdot T^nf_2\text{d}\mu \to \int f_1\text{d}\mu\cdot \int f_2\text{d}\mu$
, where
$\int f_1\cdot T^nf_2\text{d}\mu \to \int f_1\text{d}\mu\cdot \int f_2\text{d}\mu$
, where
 $T^nf_2(\omega)=f_2(T^n\omega)$
.
$T^nf_2(\omega)=f_2(T^n\omega)$
.
The implication of this, under the assumptions of Theorem 2, is that with such mixing conditions,
 $\text{Cov}(f_1(X_0),f_2(X_n))\to 0$
for every Borel
$\text{Cov}(f_1(X_0),f_2(X_n))\to 0$
for every Borel
 $f_1,f_2$
such that
$f_1,f_2$
such that
 $\mathbb{E} f_i^2(X_0)<\infty$
for
$\mathbb{E} f_i^2(X_0)<\infty$
for
 $i=1,2$
. This in particular holds when in addition
$i=1,2$
. This in particular holds when in addition
 $f_i$
,
$f_i$
,
 $i=1,2$
, are nondecreasing. This also implies that the same would hold in the continuous-time case as the covariance is nonincreasing (when
$i=1,2$
, are nondecreasing. This also implies that the same would hold in the continuous-time case as the covariance is nonincreasing (when
 $f_i$
are nondecreasing), and thus it suffices that it vanishes along any subsequence (such as
$f_i$
are nondecreasing), and thus it suffices that it vanishes along any subsequence (such as
 $t_n=n$
). In particular this will hold for any Harris-recurrent Markov process for which there exists a stationary distribution. In this case an even stronger form of mixing is known to hold (called strong mixing or
$t_n=n$
). In particular this will hold for any Harris-recurrent Markov process for which there exists a stationary distribution. In this case an even stronger form of mixing is known to hold (called strong mixing or
 $\alpha$
-mixing; see e.g. [Reference Athreya and Pantula2]). All the examples discussed in Section 3 for which a stationary distribution exists are in fact Harris-recurrent and even have a natural regenerative state. Alternatively, the same holds whenever the stationary distribution is unique and
$\alpha$
-mixing; see e.g. [Reference Athreya and Pantula2]). All the examples discussed in Section 3 for which a stationary distribution exists are in fact Harris-recurrent and even have a natural regenerative state. Alternatively, the same holds whenever the stationary distribution is unique and
 $f_1,f_2$
are nondecreasing with
$f_1,f_2$
are nondecreasing with
 $\mathbb{E} f_i(X_0)^2<\infty$
for
$\mathbb{E} f_i(X_0)^2<\infty$
for
 $i=1,2$
. This may be shown by adapting the proof of [Reference Daley7, Theorem 4], in which
$i=1,2$
. This may be shown by adapting the proof of [Reference Daley7, Theorem 4], in which
 $f_1=f_2$
. For all of our examples in which a stationary distribution exists, it is also unique.
$f_1=f_2$
. For all of our examples in which a stationary distribution exists, it is also unique.
Of course, we cannot expect that the covariance will vanish without such mixing conditions or uniqueness of the stationary distribution. For example, if
 $\xi$
is some random variable having a finite second moment and variance
$\xi$
is some random variable having a finite second moment and variance
 $\sigma^2>0$
, set
$\sigma^2>0$
, set
 $X_t=\xi$
for all
$X_t=\xi$
for all
 $t\ge 0$
. Then
$t\ge 0$
. Then
 $\{X_t\,|\, t\ge 0\}$
is trivially a stochastically monotone, stationary Markov process (and also trivially satisfies Condition 1), but (taking
$\{X_t\,|\, t\ge 0\}$
is trivially a stochastically monotone, stationary Markov process (and also trivially satisfies Condition 1), but (taking
 $f_1(x)=f_2(x)=x$
)
$f_1(x)=f_2(x)=x$
)
 $\text{Cov}(X_0,X_t)=\sigma^2$
clearly does not vanish as
$\text{Cov}(X_0,X_t)=\sigma^2$
clearly does not vanish as
 $t\to\infty$
.
$t\to\infty$
.
 $\diamond$
$\diamond$
We continue with two theorems in which Condition 1 is imposed.
Theorem 3. Assume that
 $X_0,X_1,X_2,X_3$
is a stochastically monotone Markov chain satisfying Condition 1, where
$X_0,X_1,X_2,X_3$
is a stochastically monotone Markov chain satisfying Condition 1, where
 $p_1$
has an invariant distribution
$p_1$
has an invariant distribution
 $\pi_1$
and
$\pi_1$
and
 $X_0$
is
$X_0$
is
 $\pi_1$
-distributed. Then for every Borel supermodular
$\pi_1$
-distributed. Then for every Borel supermodular
 $h\,:\,\mathbb{R}^2\to\mathbb{R}$
,
$h\,:\,\mathbb{R}^2\to\mathbb{R}$
,
 \begin{equation}\mathbb{E} h(X_0,X_2-X_3)\le \mathbb{E} h(X_1, X_2-X_3)\end{equation}
\begin{equation}\mathbb{E} h(X_0,X_2-X_3)\le \mathbb{E} h(X_1, X_2-X_3)\end{equation}
whenever the expectations exist and are finite. In particular, if f is nondecreasing and the appropriate expectations exist and are finite, then
 \begin{equation}0\le \text{ Cov}(f(X_0),X_2)-\text{ Cov}(f(X_0),X_3)\le \text{ Cov}(f(X_1),X_2)-\text{ Cov}(f(X_1),X_3).\end{equation}
\begin{equation}0\le \text{ Cov}(f(X_0),X_2)-\text{ Cov}(f(X_0),X_3)\le \text{ Cov}(f(X_1),X_2)-\text{ Cov}(f(X_1),X_3).\end{equation}
Proof. The proof is very similar to the proof of Theorem 1. That is, we let
 $X^{\prime}_0=X_0$
,
$X^{\prime}_0=X_0$
,
 $X^{\prime}_n=G_n(X^{\prime}_{n-1},U_n)$
for
$X^{\prime}_n=G_n(X^{\prime}_{n-1},U_n)$
for
 $n=1,2,3$
, where
$n=1,2,3$
, where
 $X^{\prime}_0,U_1,U_2,U_3$
are independent and
$X^{\prime}_0,U_1,U_2,U_3$
are independent and
 $U_1,U_2,U_3=_{\rm d} \text{U}(0, 1)$
. From the stochastic monotonicity and Condition 1 it follows that
$U_1,U_2,U_3=_{\rm d} \text{U}(0, 1)$
. From the stochastic monotonicity and Condition 1 it follows that
 $G_2(x,u_2)-G_3(G_2(x,u_2),u_3)$
is nondecreasing in x. Therefore, by Lemma 3 we have that, since
$G_2(x,u_2)-G_3(G_2(x,u_2),u_3)$
is nondecreasing in x. Therefore, by Lemma 3 we have that, since
 $h(x,G_2(y,u_2)-G_3(G_2(y,u_2),u_3))$
is supermodular in x, y and
$h(x,G_2(y,u_2)-G_3(G_2(y,u_2),u_3))$
is supermodular in x, y and
 $X^{\prime}_1=_{\rm d} X^{\prime}_0$
,
$X^{\prime}_1=_{\rm d} X^{\prime}_0$
,
 \begin{align}\mathbb{E} [h(X^{\prime}_0,X^{\prime}_2-X^{\prime}_3)|U_2,U_3]&=\mathbb{E} [h(X^{\prime}_0,G_2(X^{\prime}_1,U_2)-G_3(G_2(X^{\prime}_1,U_2),U_3))|U_2,U_3]\nonumber\\&\le \mathbb{E} [h(X^{\prime}_1,G_2(X^{\prime}_1,U_2)-G_3(G_2(X^{\prime}_1,U_2),U_3))|U_2,U_3]\\&=\mathbb{E} [h(X^{\prime}_1,X^{\prime}_2-X^{\prime}_3)|U_2,U_3],\nonumber\end{align}
\begin{align}\mathbb{E} [h(X^{\prime}_0,X^{\prime}_2-X^{\prime}_3)|U_2,U_3]&=\mathbb{E} [h(X^{\prime}_0,G_2(X^{\prime}_1,U_2)-G_3(G_2(X^{\prime}_1,U_2),U_3))|U_2,U_3]\nonumber\\&\le \mathbb{E} [h(X^{\prime}_1,G_2(X^{\prime}_1,U_2)-G_3(G_2(X^{\prime}_1,U_2),U_3))|U_2,U_3]\\&=\mathbb{E} [h(X^{\prime}_1,X^{\prime}_2-X^{\prime}_3)|U_2,U_3],\nonumber\end{align}
and taking expected values establishes (15). Taking
 $h(x,y)=f(x)y$
gives the right inequality of (16). The left inequality is obtained via comonotonicity, by observing that since
$h(x,y)=f(x)y$
gives the right inequality of (16). The left inequality is obtained via comonotonicity, by observing that since
 $G_2(G_1(x,u_1),u_2)-G_3(G_2(G_1(x,u_1),u_2),u_3)$
is nondecreasing in x,
$G_2(G_1(x,u_1),u_2)-G_3(G_2(G_1(x,u_1),u_2),u_3)$
is nondecreasing in x,
 $\mathbb{E} [X_2-X_3|X_0]$
is a nondecreasing function of
$\mathbb{E} [X_2-X_3|X_0]$
is a nondecreasing function of
 $X_0$
, so that this inequality follows from the comonotonicity of
$X_0$
, so that this inequality follows from the comonotonicity of
 $f(X_0)$
and
$f(X_0)$
and
 $\mathbb{E} [X_2-X_3|X_0]$
as in the proof of the left inequality of (10).
$\mathbb{E} [X_2-X_3|X_0]$
as in the proof of the left inequality of (10).
Theorem 4. Consider a stationary stochastically monotone discrete-time or continuous-time time-homogeneous Markov process
 $\{X_t\,|\,t\ge0\}$
, satisfying Condition 1. Then for every
$\{X_t\,|\,t\ge0\}$
, satisfying Condition 1. Then for every
 $s>0$
and every supermodular h for which the following expectations exist and are finite,
$s>0$
and every supermodular h for which the following expectations exist and are finite,
 $\mathbb{E} h(X_0,X_t-X_{t+s})$
is nonincreasing in t, where t is either nonnegative integer- or nonnegative real-valued. In particular, when f is nondecreasing and the appropriate expectations exist,
$\mathbb{E} h(X_0,X_t-X_{t+s})$
is nonincreasing in t, where t is either nonnegative integer- or nonnegative real-valued. In particular, when f is nondecreasing and the appropriate expectations exist,
 $\text{Cov}(f(X_0),X_t)$
is nonnegative, nonincreasing, and convex in t.
$\text{Cov}(f(X_0),X_t)$
is nonnegative, nonincreasing, and convex in t.
In particular, note that when choosing
 $f(x)=x$
and assuming that
$f(x)=x$
and assuming that
 $\mathbb{E} X_0^2<\infty$
, we see that, under the conditions of Theorem 4, the auto-covariance
$\mathbb{E} X_0^2<\infty$
, we see that, under the conditions of Theorem 4, the auto-covariance
 $R(t)=\text{Cov}(X_s,X_{s+t})$
(or auto-correlation
$R(t)=\text{Cov}(X_s,X_{s+t})$
(or auto-correlation
 $R(t)/R(0)$
when
$R(t)/R(0)$
when
 $X_0$
is not a.s. constant) is nonnegative, nonincreasing, and convex in t.
$X_0$
is not a.s. constant) is nonnegative, nonincreasing, and convex in t.
Proof. Let
 $t_1<t_2$
; then
$t_1<t_2$
; then
 $X_0,\, X_{t_2-t_1},\, X_{t_2-t_1+s},\, X_{t_2+s}$
satisfy the conditions and hence the conclusion of Theorem 3. Therefore,
$X_0,\, X_{t_2-t_1},\, X_{t_2-t_1+s},\, X_{t_2+s}$
satisfy the conditions and hence the conclusion of Theorem 3. Therefore,
 \begin{equation}\mathbb{E} h(X_0,X_{t_2}-X_{t_2+s})\le \mathbb{E} h(X_{t_2-t_1},X_{t_2}-X_{t_2+s})=\mathbb{E} h(X_0,X_{t_1}-X_{t_1+s}),\end{equation}
\begin{equation}\mathbb{E} h(X_0,X_{t_2}-X_{t_2+s})\le \mathbb{E} h(X_{t_2-t_1},X_{t_2}-X_{t_2+s})=\mathbb{E} h(X_0,X_{t_1}-X_{t_1+s}),\end{equation}
where the right equality follows from stationarity. If f is nondecreasing, then
 $h(x,y)=f(x)y$
is supermodular and thus
$h(x,y)=f(x)y$
is supermodular and thus
 $\mathbb{E} f(X_0)X_{t+s}-\mathbb{E} f(X_0) X_t$
is nonincreasing in t for every
$\mathbb{E} f(X_0)X_{t+s}-\mathbb{E} f(X_0) X_t$
is nonincreasing in t for every
 $s>0$
. Therefore
$s>0$
. Therefore
 $\mathbb{E} f(X_0)X_t$
is midpoint-convex, and since by Theorem 2 it is nonnegative and nonincreasing (hence Borel), it must be convex (see [Reference Blumberg4, Reference Sierpinski24]).
$\mathbb{E} f(X_0)X_t$
is midpoint-convex, and since by Theorem 2 it is nonnegative and nonincreasing (hence Borel), it must be convex (see [Reference Blumberg4, Reference Sierpinski24]).
Can anything be said for the case where the initial distribution is not invariant? Here is one possible answer.
Theorem 5. Let
 $\{X_t\,|\,t\ge0\}$
be a stochastically monotone discrete-time or continuous-time time-homogeneous Markov process. Assume that the initial distribution can be chosen so that
$\{X_t\,|\,t\ge0\}$
be a stochastically monotone discrete-time or continuous-time time-homogeneous Markov process. Assume that the initial distribution can be chosen so that
 $X_0\le X_t$
a.s. for every
$X_0\le X_t$
a.s. for every
 $t\ge 0$
. Then the following hold:
$t\ge 0$
. Then the following hold:
-
(i)
 $X_t$
is stochastically increasing in t.
$X_t$
is stochastically increasing in t. -
(ii) For every Borel supermodular function which is nondecreasing in its first variable and for which the expectations exist and are finite,
$\mathbb{E} h(X_s,X_t)$
is nondecreasing in s on
$[0, t]$
. When in addition Condition 1 is satisfied, the same is true for
$\mathbb{E} h(X_s,X_t-X_{t+\delta})$
for every
$\delta>0$
(whenever the expectations exist and are finite). -
(iii) If h is nondecreasing in both variables (not necessarily supermodular) and expected values exist and are finite, then
$\mathbb{E} h(X_s,X_{t+s})$
is nondecreasing in s. When Condition 1 is satisfied, the same is true for
$\mathbb{E} h(X_s,X_{s+t}-X_{s+t+\delta})$
for
$\delta>0$
. -
(iv) If
$\mathbb{E} X_t$
exists and is finite, then it is nondecreasing, and under Condition 1 it is also concave.









We note that it would suffice to assume that
 $X_0\le X_t$
for
$X_0\le X_t$
for
 $t\in(0,\epsilon]$
for some
$t\in(0,\epsilon]$
for some
 $\epsilon>0$
, or in discrete time for
$\epsilon>0$
, or in discrete time for
 $t=1$
. Also, we note that for (i) we can replace
$t=1$
. Also, we note that for (i) we can replace
 $X_0\le X_t$
by
$X_0\le X_t$
by
 $X_0\le_{\text{st}}X_t$
.
$X_0\le_{\text{st}}X_t$
.
Proof. For any
 $s<t$
take
$s<t$
take
 $\epsilon\in(0,t-s]$
and let
$\epsilon\in(0,t-s]$
and let
 $G_v(x,u)$
be the generalized inverse with respect to the kernel
$G_v(x,u)$
be the generalized inverse with respect to the kernel
 $p^v$
. Let
$p^v$
. Let
 $U_0,U_1,\ldots$
be i.i.d. with
$U_0,U_1,\ldots$
be i.i.d. with
 $U_i=_{\rm d}\text{U}(0, 1)$
. Since
$U_i=_{\rm d}\text{U}(0, 1)$
. Since
 $X_0\le X_\epsilon$
we have with
$X_0\le X_\epsilon$
we have with
 $X^{\prime}_0=X_0$
that
$X^{\prime}_0=X_0$
that
 $X^{\prime}_0\le G_\epsilon(X^{\prime}_0,U_0)$
, and thus
$X^{\prime}_0\le G_\epsilon(X^{\prime}_0,U_0)$
, and thus
 \begin{equation}X^{\prime}_s\equiv G_s(X^{\prime}_0,U_1)\le G_s(G_\epsilon(X^{\prime}_0,U_0),U_1)\equiv X^{\prime\prime}_{s+\epsilon}=_{\rm d} X^{\prime}_{s+\epsilon}\equiv G_\epsilon(X^{\prime}_s,U_2),\end{equation}
\begin{equation}X^{\prime}_s\equiv G_s(X^{\prime}_0,U_1)\le G_s(G_\epsilon(X^{\prime}_0,U_0),U_1)\equiv X^{\prime\prime}_{s+\epsilon}=_{\rm d} X^{\prime}_{s+\epsilon}\equiv G_\epsilon(X^{\prime}_s,U_2),\end{equation}
implying stochastic monotonicity.
Taking
 $X^{\prime}_t=G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3)$
, we have that
$X^{\prime}_t=G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3)$
, we have that
 $(X^{\prime}_0,X^{\prime}_s,X^{\prime}_{s+\epsilon},X^{\prime}_t)$
is distributed like
$(X^{\prime}_0,X^{\prime}_s,X^{\prime}_{s+\epsilon},X^{\prime}_t)$
is distributed like
 $(X_0,X_s,X_{s+\epsilon},X_t)$
. Since h is nondecreasing in its first variable and
$(X_0,X_s,X_{s+\epsilon},X_t)$
. Since h is nondecreasing in its first variable and
 $X^{\prime}_s\le X^{\prime\prime}_{s+\epsilon}$
, it follows that
$X^{\prime}_s\le X^{\prime\prime}_{s+\epsilon}$
, it follows that
 \begin{equation}\mathbb{E} h(X^{\prime}_s,X^{\prime}_t)\le \mathbb{E} h(X^{\prime\prime}_{s+\epsilon},X^{\prime}_t).\end{equation}
\begin{equation}\mathbb{E} h(X^{\prime}_s,X^{\prime}_t)\le \mathbb{E} h(X^{\prime\prime}_{s+\epsilon},X^{\prime}_t).\end{equation}
The (by now repetitive) fact that
 \begin{align}\mathbb{E} [h(X^{\prime\prime}_{s+\epsilon},X^{\prime}_t)|U_3]&=\mathbb{E}[h(X^{\prime\prime}_{s+\epsilon},G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3)|U_3]\nonumber \\ &\le \mathbb{E}[h(X^{\prime}_{s+\epsilon},G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3)|U_3]=\mathbb{E}[h(X^{\prime}_{s+\epsilon},X^{\prime}_t)|U_3]\end{align}
\begin{align}\mathbb{E} [h(X^{\prime\prime}_{s+\epsilon},X^{\prime}_t)|U_3]&=\mathbb{E}[h(X^{\prime\prime}_{s+\epsilon},G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3)|U_3]\nonumber \\ &\le \mathbb{E}[h(X^{\prime}_{s+\epsilon},G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3)|U_3]=\mathbb{E}[h(X^{\prime}_{s+\epsilon},X^{\prime}_t)|U_3]\end{align}
follows from the supermodularity of
 $h(x,G_{t-s-\epsilon}(y,u_3))$
in x, y. Taking expected values, together with (20), implies that
$h(x,G_{t-s-\epsilon}(y,u_3))$
in x, y. Taking expected values, together with (20), implies that
 $\mathbb{E} h(X_s,X_t)$
is nondecreasing in s on [0, t]. The proof of the fact that, under Condition 1,
$\mathbb{E} h(X_s,X_t)$
is nondecreasing in s on [0, t]. The proof of the fact that, under Condition 1,
 $\mathbb{E} h(X_s,X_t-X_{t+\delta})$
is nondecreasing in s on [0, t] is similar, once we define
$\mathbb{E} h(X_s,X_t-X_{t+\delta})$
is nondecreasing in s on [0, t] is similar, once we define
 $X^{\prime}_{t+\delta}=G_\delta(X^{\prime}_t,U_4)$
and observe that
$X^{\prime}_{t+\delta}=G_\delta(X^{\prime}_t,U_4)$
and observe that
 $X^{\prime}_t-X^{\prime}_{t+\delta}=G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3)-G_\delta(G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3),U_4)$
is nondecreasing in
$X^{\prime}_t-X^{\prime}_{t+\delta}=G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3)-G_\delta(G_{t-s-\epsilon}(X^{\prime}_{s+\epsilon},U_3),U_4)$
is nondecreasing in
 $X^{\prime}_{s+\epsilon}$
.
$X^{\prime}_{s+\epsilon}$
.
When h is nondecreasing in both variables we have that
 \begin{equation*}h(X_s,X_{s+t})=_{\rm d} h(X_s,G_t(X_s,U_0)),\end{equation*}
\begin{equation*}h(X_s,X_{s+t})=_{\rm d} h(X_s,G_t(X_s,U_0)),\end{equation*}
so that by stochastic monotonicity
 $\mathbb{E} (h(X_s,G_t(X_s,U_0))|U_0)$
is nondecreasing in s and hence also
$\mathbb{E} (h(X_s,G_t(X_s,U_0))|U_0)$
is nondecreasing in s and hence also
 $\mathbb{E} h(X_s,X_{s+t})$
. The proof for
$\mathbb{E} h(X_s,X_{s+t})$
. The proof for
 $\mathbb{E} h(X_s,X_{s+t}-X_{s+t+\delta})$
, under Condition 1, is similar.
$\mathbb{E} h(X_s,X_{s+t}-X_{s+t+\delta})$
, under Condition 1, is similar.
Finally, since
 $X_t$
is stochastically increasing, it clearly follows that
$X_t$
is stochastically increasing, it clearly follows that
 $\mathbb{E} X_t$
is nondecreasing. When Condition 1 is met, taking
$\mathbb{E} X_t$
is nondecreasing. When Condition 1 is met, taking
 $h(x,y)=y$
(nondecreasing in both variables) we have that
$h(x,y)=y$
(nondecreasing in both variables) we have that
 $\mathbb{E} X_{s+t}-\mathbb{E} X_{s+t+\delta}$
is nondecreasing. This implies midpoint-concavity, so that since
$\mathbb{E} X_{s+t}-\mathbb{E} X_{s+t+\delta}$
is nondecreasing. This implies midpoint-concavity, so that since
 $\mathbb{E} X_t$
is monotone (hence Borel) it follows that it is concave (again, see [Reference Blumberg4, Reference Sierpinski24]).
$\mathbb{E} X_t$
is monotone (hence Borel) it follows that it is concave (again, see [Reference Blumberg4, Reference Sierpinski24]).
We complete this section by noting that although, for the sake of convenience, all the results are written for the case where the state space is
 $\mathbb{R}$
, they hold whenever the state space is any Borel subset of
$\mathbb{R}$
, they hold whenever the state space is any Borel subset of
 $\mathbb{R}$
, as was assumed in [Reference Daley7]; for instance, for the examples discussed in Section 3, the state space is either
$\mathbb{R}$
, as was assumed in [Reference Daley7]; for instance, for the examples discussed in Section 3, the state space is either
 $[0,\infty)$
or
$[0,\infty)$
or
 $\mathbb{Z}_+$
.
$\mathbb{Z}_+$
.
2.2. Role of stochastic monotone Markov processes and supermodularity
To put our work into perspective, we conclude this section by explaining the train of thought that led us to this research. One result that sparked this line of research was that for a stationary reflected (both one- and two-sided) Lévy process X with
 $\mathbb{E} X_0^2<\infty$
,
$\mathbb{E} X_0^2<\infty$
,
 $R(t)=\text{Cov}(X_0,X_t)$
is nonnegative, nonincreasing, and convex [Reference Berkelmans, Cichocka and Mandjes3, Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11]. Since in this case
$R(t)=\text{Cov}(X_0,X_t)$
is nonnegative, nonincreasing, and convex [Reference Berkelmans, Cichocka and Mandjes3, Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11]. Since in this case
 $\mathbb{E} X_t=\mathbb{E} X_0$
, this is equivalent to
$\mathbb{E} X_t=\mathbb{E} X_0$
, this is equivalent to
 $\mathbb{E} X_0X_t$
being nonnegative, nonincreasing, and convex. Another result is that for a stationary discrete-time stochastically monotone Markov process and a nondecreasing function g with
$\mathbb{E} X_0X_t$
being nonnegative, nonincreasing, and convex. Another result is that for a stationary discrete-time stochastically monotone Markov process and a nondecreasing function g with
 $\mathbb{E} g^2(X_0)<\infty$
,
$\mathbb{E} g^2(X_0)<\infty$
,
 $\text{Cov}(g(X_0),g(X_n))$
is nonincreasing [Reference Daley7]. This is equivalent to
$\text{Cov}(g(X_0),g(X_n))$
is nonincreasing [Reference Daley7]. This is equivalent to
 $\mathbb{E} g(X_0)g(X_n)$
being nonincreasing. We observed that xy, g(x)g(y) (when g is nondecreasing) are supermodular functions of x, y. Also, we knew that the one- and two-sided Skorokhod reflection of a process of the form
$\mathbb{E} g(X_0)g(X_n)$
being nonincreasing. We observed that xy, g(x)g(y) (when g is nondecreasing) are supermodular functions of x, y. Also, we knew that the one- and two-sided Skorokhod reflection of a process of the form
 $x+X_t$
is monotone in x. When X is a Lévy process, the reflected process is Markovian, and from the monotonicity in x it must be stochastically monotone.
$x+X_t$
is monotone in x. When X is a Lévy process, the reflected process is Markovian, and from the monotonicity in x it must be stochastically monotone.
Therefore, a natural question arose: is it true that for any stationary stochastically monotone Markov process (in discrete or continuous time) and for any supermodular h we have that
 $\mathbb{E} h(X_0,X_t)$
is nonincreasing? If yes, then this would make the abovementioned results from [Reference Berkelmans, Cichocka and Mandjes3, Reference Daley7, Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11], each of which uses a totally different (often quite involved) approach, simple special cases. We were happy to see that the answer to this question was ‘yes’.
$\mathbb{E} h(X_0,X_t)$
is nonincreasing? If yes, then this would make the abovementioned results from [Reference Berkelmans, Cichocka and Mandjes3, Reference Daley7, Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11], each of which uses a totally different (often quite involved) approach, simple special cases. We were happy to see that the answer to this question was ‘yes’.
The next step was to try to identify what condition ensures convexity of the correlation or even more general function. As seen in Section 2, the condition that ensures convexity of
 $\mathbb{E} g(X_0)X_t$
for a nondecreasing function g (in particular
$\mathbb{E} g(X_0)X_t$
for a nondecreasing function g (in particular
 $g(x)=x$
) is Condition 1. We lack a full intuitive understanding of why it is this precise condition that makes it work. As will be seen in Section 3, various natural Markovian models satisfy stochastic monotonicity and Condition 1.
$g(x)=x$
) is Condition 1. We lack a full intuitive understanding of why it is this precise condition that makes it work. As will be seen in Section 3, various natural Markovian models satisfy stochastic monotonicity and Condition 1.
Finally, we also knew that for a (one- and two-sided) reflected Lévy process X starting from the origin (and actually also for more general processes),
 $\mathbb{E} X_t$
is nonincreasing and concave [Reference Andersen and Mandjes1, Reference Kella12, Reference Kella and Sverchkov14, Reference Kella and Whitt15]. We asked ourselves whether this too might be seen as a special case of the more general theory we had discovered, and, as it turned out, the answer to this question was affirmative as well.
$\mathbb{E} X_t$
is nonincreasing and concave [Reference Andersen and Mandjes1, Reference Kella12, Reference Kella and Sverchkov14, Reference Kella and Whitt15]. We asked ourselves whether this too might be seen as a special case of the more general theory we had discovered, and, as it turned out, the answer to this question was affirmative as well.
3. Examples
The purpose of this section is to give a number of motivating examples for the kinds of processes to which our theory applies. We chose these examples to illustrate the huge potential of the methodology developed in this paper: it can serve to make proofs of existing results significantly more transparent and compact (as in the examples with reflected Lévy processes), and it can serve in the derivation of entirely new structural properties (as in the examples with the Lévy dam, the state-dependent random walk, and the birth-and-death processes).
3.1. Lévy process reflected at the origin
Consider a càdlàg Lévy process
 $Y=\{Y_t\,|\,t\ge 0\}$
with
$Y=\{Y_t\,|\,t\ge 0\}$
with
 $\mathbb{P}(Y_0=0)=1$
(not necessarily spectrally one-sided). For every x, the one-sided (Skorokhod) reflection map, with reflection taking place at level 0, is defined through
$\mathbb{P}(Y_0=0)=1$
(not necessarily spectrally one-sided). For every x, the one-sided (Skorokhod) reflection map, with reflection taking place at level 0, is defined through
 \begin{equation}X_t(x)=x+Y_t-\inf_{0\le s\le t}(x+Y_s)\wedge0=Y_t+L_t\wedge x,\end{equation}
\begin{equation}X_t(x)=x+Y_t-\inf_{0\le s\le t}(x+Y_s)\wedge0=Y_t+L_t\wedge x,\end{equation}
where
 $L_t=-\inf_{0\le s\le t}Y_s\wedge 0$
with
$L_t=-\inf_{0\le s\le t}Y_s\wedge 0$
with
 $L_t(x)=(L_t-x)^+$
(so, in particular,
$L_t(x)=(L_t-x)^+$
(so, in particular,
 $L_t=L_t(0)$
). The pair
$L_t=L_t(0)$
). The pair
 $(L_t(x),X_t(x))$
is known to be the unique process satisfying the following conditions:
$(L_t(x),X_t(x))$
is known to be the unique process satisfying the following conditions:
-
(i)
$L_t(x)$
is right-continuous and nondecreasing in t, with
$L_0=0$
. -
(ii)
$X_t(x)$
is nonnegative for every
$t\ge 0$
. -
(iii) For every
$t>0$
such that
$L_s(x)<L_t(x)$
for every
$s<t$
, we have that
$X_t(x)=0$
.








It is known [Reference Kella13] that (iii) is equivalent to the condition that
 \begin{equation}\int_{[0,\infty)}X_s(x)L_{\text{d}s}(x)=0,\end{equation}
\begin{equation}\int_{[0,\infty)}X_s(x)L_{\text{d}s}(x)=0,\end{equation}
or alternatively to the condition that
 $L_t(x)$
is the minimal process satisfying (i) and (ii). Special cases of such processes are the workload process in an M/G/1 queue and the (one-dimensional) reflected Brownian motion (where the reflection takes place at 0).
$L_t(x)$
is the minimal process satisfying (i) and (ii). Special cases of such processes are the workload process in an M/G/1 queue and the (one-dimensional) reflected Brownian motion (where the reflection takes place at 0).
It turns out that when
 $x=0$
,
$x=0$
,
 $\mathbb{E} X_t$
is nondecreasing and concave in t [Reference Kella12, Reference Kella and Sverchkov14]. When
$\mathbb{E} X_t$
is nondecreasing and concave in t [Reference Kella12, Reference Kella and Sverchkov14]. When
 $\mathbb{E} Y_1<0$
, this process, which is well known to be Markovian, has a stationary distribution. If W has this stationary distribution and is independent of the process Y, then
$\mathbb{E} Y_1<0$
, this process, which is well known to be Markovian, has a stationary distribution. If W has this stationary distribution and is independent of the process Y, then
 $X^*_t=X_t(W)$
is a stationary process, and it has been established [Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11, Reference Ott19] that when
$X^*_t=X_t(W)$
is a stationary process, and it has been established [Reference Es-Saghouani and Mandjes10, Reference Glynn and Mandjes11, Reference Ott19] that when
 $\mathbb{E} W^2<\infty$
, the autocovariance
$\mathbb{E} W^2<\infty$
, the autocovariance
 $R(t)=\text{Cov}(X_s^*,X_{s+t}^*)$
(or autocorrelation
$R(t)=\text{Cov}(X_s^*,X_{s+t}^*)$
(or autocorrelation
 $R(t)/R(0)$
) is nonnegative, nonincreasing, and convex in t. Where earlier proofs tended to be ad hoc (e.g. dealing only with spectrally one-sided processes, i.e., assuming that the Lévy process has jumps in one direction) and involved (e.g. requiring delicate manipulations with completely monotone functions), with the techniques developed in the present paper this property now follows virtually immediately. The remainder of this subsection illustrates this.
$R(t)/R(0)$
) is nonnegative, nonincreasing, and convex in t. Where earlier proofs tended to be ad hoc (e.g. dealing only with spectrally one-sided processes, i.e., assuming that the Lévy process has jumps in one direction) and involved (e.g. requiring delicate manipulations with completely monotone functions), with the techniques developed in the present paper this property now follows virtually immediately. The remainder of this subsection illustrates this.
Let us define
 $p^t(x,A)=\mathbb{P}(X_t(x)\in A)$
, so that
$p^t(x,A)=\mathbb{P}(X_t(x)\in A)$
, so that
 $p^t(\cdot,\cdot)$
is the transition kernel of the associated Markov process. Since
$p^t(\cdot,\cdot)$
is the transition kernel of the associated Markov process. Since
 $X_t(x)=Y_t+L_t\wedge x$
is nondecreasing in x and
$X_t(x)=Y_t+L_t\wedge x$
is nondecreasing in x and
 $X_t(x)-x=Y_t-(x-L_t)^+$
is nonincreasing in x (for each
$X_t(x)-x=Y_t-(x-L_t)^+$
is nonincreasing in x (for each
 $t>0$
), we clearly have that
$t>0$
), we clearly have that
 \begin{equation}p^t(x,(y,\infty))=\mathbb{P}(X_t(x)>y)\end{equation}
\begin{equation}p^t(x,(y,\infty))=\mathbb{P}(X_t(x)>y)\end{equation}
is nondecreasing in x and
 \begin{equation}p^t(x,(x+y,\infty))=\mathbb{P}(X_t(x)>x+y)=\mathbb{P}(Y_t-(x-L_t)^+>y)\end{equation}
\begin{equation}p^t(x,(x+y,\infty))=\mathbb{P}(X_t(x)>x+y)=\mathbb{P}(Y_t-(x-L_t)^+>y)\end{equation}
is nonincreasing in x. Therefore stochastic monotonicity and Condition 1 are satisfied.
Remark 2. We note that for the same reasons, a (general) random walk reflected at the origin is a discrete-time version of the process featuring in the above setup. As a consequence, it is also stochastically monotone and satisfies Condition 1. In particular, this applies to the consecutive waiting times upon arrivals of customers in a GI/GI/1 queue.
3.2. Lévy process with a two-sided reflection
In this subsection we argue that the structural properties discussed in the previous subsection carry over to the case of a two-sided reflection. With Y as defined in Section 3.1, a two-sided (Skorokhod) reflection in [0, b] for
 $b>0$
(and similarly in [a, b] for any
$b>0$
(and similarly in [a, b] for any
 $a<b$
) is defined as the unique process
$a<b$
) is defined as the unique process
 $(X_t(x),L_t(x),U_t(x))$
, with
$(X_t(x),L_t(x),U_t(x))$
, with
 $X_t(x)=x+Y_t+L_t(x)-U_t(x)$
, satisfying the following:
$X_t(x)=x+Y_t+L_t(x)-U_t(x)$
, satisfying the following:
-
(i)
$L_t(x),\,U_t(x)$
are right-continuous and nondecreasing with
$L_0(x)=U_0(x)=0$
. -
(ii)
$X_t(x)\in [0,b]$
for all
$t\ge 0$
. -
(iii) For every
$t>0$
such that
$L_s(x)<L_t(x)$
(resp.,
$U_s(x)<U_t(x)$
) for every
$s<t$
,
$X_t(x)=0$
(resp.,
$X_t(x)=b$
).










Also here, (iii) is equivalent to
 \begin{equation}\int_{[0,\infty)}X_t(x)L_{\text{d}t}(x)=\int_{[0,\infty)}(b-X_t(x))U_{\text{d}t}(x)=0.\end{equation}
\begin{equation}\int_{[0,\infty)}X_t(x)L_{\text{d}t}(x)=\int_{[0,\infty)}(b-X_t(x))U_{\text{d}t}(x)=0.\end{equation}
For this case it is also known that
 $\mathbb{E} X_t(0)$
is nondecreasing and concave [Reference Andersen and Mandjes1] as well as that for the stationary version the autocovariance R(t) is nonnegative, nondecreasing, and convex [Reference Berkelmans, Cichocka and Mandjes3]. As in the one-sided case, we can apply our newly developed results to establish these facts in a very compact manner provided we verify that the process under consideration is a stochastically monotone Markov process that fulfills Condition 1.
$\mathbb{E} X_t(0)$
is nondecreasing and concave [Reference Andersen and Mandjes1] as well as that for the stationary version the autocovariance R(t) is nonnegative, nondecreasing, and convex [Reference Berkelmans, Cichocka and Mandjes3]. As in the one-sided case, we can apply our newly developed results to establish these facts in a very compact manner provided we verify that the process under consideration is a stochastically monotone Markov process that fulfills Condition 1.
Since Y is a Lévy process, we have that
 $X_t(x)$
is a time-homogeneous Markov process starting at x. The driving process Y being the same for both
$X_t(x)$
is a time-homogeneous Markov process starting at x. The driving process Y being the same for both
 $X_t(x)$
and
$X_t(x)$
and
 $X_t(y)$
, we find that choosing
$X_t(y)$
, we find that choosing
 $x<y$
means that
$x<y$
means that
 $X_t(x)$
can never overtake
$X_t(x)$
can never overtake
 $X_t(y)$
. Consequently,
$X_t(y)$
. Consequently,
 $X_t(x)$
is nondecreasing in x and thus the Markov chain is stochastically monotone (with some effort, this can also be shown directly from representation (27) to follow).
$X_t(x)$
is nondecreasing in x and thus the Markov chain is stochastically monotone (with some effort, this can also be shown directly from representation (27) to follow).
In order to verify that it satisfies Condition 1, we recall from [Reference Kruk, Lehoczky, Ramanan and Shreve17], upon re-denoting by
 $X^0_t(x)$
the one-sided reflected process described in Section 3.1, that
$X^0_t(x)$
the one-sided reflected process described in Section 3.1, that
 \begin{equation}X_t(x)=X^0_t(x)-\sup_{0\le s\le t}\left[\left(X_s^0(x)-b\right)^+\wedge\inf_{s\le u\le t}X_t^0(x)\right].\end{equation}
\begin{equation}X_t(x)=X^0_t(x)-\sup_{0\le s\le t}\left[\left(X_s^0(x)-b\right)^+\wedge\inf_{s\le u\le t}X_t^0(x)\right].\end{equation}
Since
 $X_t^0(x)$
is nondecreasing and
$X_t^0(x)$
is nondecreasing and
 $X_t^0(x)-x$
is nonincreasing in x (as explained in Section 3.1), it immediately follows that
$X_t^0(x)-x$
is nonincreasing in x (as explained in Section 3.1), it immediately follows that
 $X_t(x)-x$
is nonincreasing in x, which implies Condition 1.
$X_t(x)-x$
is nonincreasing in x, which implies Condition 1.
Regarding the results for R(t) that hold under stationarity, observe that in this two-sided reflected case a stationary distribution always exists and has a bounded support. Therefore, we do not need to impose any additional requirements on Y. This is in contrast to the one-sided case, where it was necessary to assume that
 $\mathbb{E} Y_1<0$
and that the stationary distribution has a finite second moment. As in the case with one-sided reflection, the findings carry over to the discrete-time counterpart: the two-sided reflected random walk.
$\mathbb{E} Y_1<0$
and that the stationary distribution has a finite second moment. As in the case with one-sided reflection, the findings carry over to the discrete-time counterpart: the two-sided reflected random walk.
3.3. Lévy dams with a nondecreasing release rule
In the previous two subsections, dealing with the one- and two-sided reflected Lévy process, we mentioned that existing (and also some previously nonexistent) results may be instantly concluded from the theory that we develop in this paper. The present subsection gives an illustration of our theory’s potential to produce similar results for dam processes which, to the best of our knowledge, are completely new for these kinds of processes and were not known earlier. More concretely, it shows that, with the general theory that we developed, the structural results discussed above carry over to more than just reflected Lévy processes.
Let the process
 $J=\{J_t\,|\,t\ge 0\}$
be a right-continuous subordinator (nondecreasing Lévy process) with
$J=\{J_t\,|\,t\ge 0\}$
be a right-continuous subordinator (nondecreasing Lévy process) with
 $\mathbb{P}(J_0=0)=1$
, and let
$\mathbb{P}(J_0=0)=1$
, and let
 $r\,:\,[0,\infty)\to [0,\infty)$
be nondecreasing and left-continuous on
$r\,:\,[0,\infty)\to [0,\infty)$
be nondecreasing and left-continuous on
 $(0,\infty)$
, with
$(0,\infty)$
, with
 $r(0)=0$
. Consider the following dam process:
$r(0)=0$
. Consider the following dam process:
 \begin{equation}X_t(x)=x+J_t-\int_0^tr(X_s(x))\text{d}s.\end{equation}
\begin{equation}X_t(x)=x+J_t-\int_0^tr(X_s(x))\text{d}s.\end{equation}
It is well known [Reference Çinlar and Pinsky6] that, under the stated assumptions, the solution to (28) is unique (pathwise) and belongs to the class of time-homogeneous Markov processes.
As before, we need to check that the process under consideration is stochastically monotone and fulfills Condition 1. For
 $x<y$
we have that
$x<y$
we have that
 \begin{equation}X_t(y)-X_t(x)=y-x-\int_0^t(r(X_s(y)-r(X_s(x))\text{d}s.\end{equation}
\begin{equation}X_t(y)-X_t(x)=y-x-\int_0^t(r(X_s(y)-r(X_s(x))\text{d}s.\end{equation}
Denote by
 $\tau$
the first time (if it exists) for which the right side is zero. Because
$\tau$
the first time (if it exists) for which the right side is zero. Because
 $x<y$
, for every
$x<y$
, for every
 $t<\tau$
we have that
$t<\tau$
we have that
 $X_t(x)<X_t(y)$
. On
$X_t(x)<X_t(y)$
. On
 $\tau<\infty$
we clearly have that
$\tau<\infty$
we clearly have that
 $X_\tau(x)=X_\tau(y)$
, and therefore we also have that for any
$X_\tau(x)=X_\tau(y)$
, and therefore we also have that for any
 $h\ge 0$
,
$h\ge 0$
,
 \begin{align}X_{\tau+h}(x)&=X_\tau(x)+J_{\tau+h}-J_\tau+\int_0^h r(X_{\tau+s}(x))\text{d}s\nonumber\\&=X_\tau(y)+J_{\tau+h}-J_\tau+\int_0^h r(X_{\tau+s}(x))\text{d}s=X_{\tau+h}(y),\end{align}
\begin{align}X_{\tau+h}(x)&=X_\tau(x)+J_{\tau+h}-J_\tau+\int_0^h r(X_{\tau+s}(x))\text{d}s\nonumber\\&=X_\tau(y)+J_{\tau+h}-J_\tau+\int_0^h r(X_{\tau+s}(x))\text{d}s=X_{\tau+h}(y),\end{align}
where the right equality follows from the uniqueness of the solution Z to the equation
 \begin{equation}Z_h=z+J_{\tau+h}-J_\tau-\int_0^hr(Z_s)\text{d}s.\end{equation}
\begin{equation}Z_h=z+J_{\tau+h}-J_\tau-\int_0^hr(Z_s)\text{d}s.\end{equation}
Therefore, we have that
 $X_t(x)\le X_t(y)$
for every
$X_t(x)\le X_t(y)$
for every
 $t\ge 0$
. Moreover, note that
$t\ge 0$
. Moreover, note that
 \begin{equation}(X_t(x)-x)-(Y_t(y)-y)=\int_0^t(r(X_s(y))-r(X_s(x))\text{d}s,\end{equation}
\begin{equation}(X_t(x)-x)-(Y_t(y)-y)=\int_0^t(r(X_s(y))-r(X_s(x))\text{d}s,\end{equation}
and thus, since r is assumed to be nondecreasing, we also have that
 $X_t(x)-x\ge X_t(y)-y$
. The conclusion is that
$X_t(x)-x\ge X_t(y)-y$
. The conclusion is that
 $X_t(x)$
is nondecreasing in x and
$X_t(x)$
is nondecreasing in x and
 $X_t(x)-x$
is nonincreasing in x. In other words, the process considered is a stochastically monotone Markov process satisfying Condition 1. As a consequence, the structural properties on
$X_t(x)-x$
is nonincreasing in x. In other words, the process considered is a stochastically monotone Markov process satisfying Condition 1. As a consequence, the structural properties on
 $\mathbb{E} X_t$
and R(t), as we discussed above, apply to this process as well. Regarding R(t), we note that here a stationary distribution exists whenever
$\mathbb{E} X_t$
and R(t), as we discussed above, apply to this process as well. Regarding R(t), we note that here a stationary distribution exists whenever
 $\mathbb{E} J_1<r(x)$
for some
$\mathbb{E} J_1<r(x)$
for some
 $x>0$
(recalling that
$x>0$
(recalling that
 $r({\cdot})$
is nondecreasing).
$r({\cdot})$
is nondecreasing).
To perform a sanity check, we note that if we choose
 $r(x)=rx$
, then the resulting process is a (generalized) shot-noise process. In this case it is well known that we can explicitly write
$r(x)=rx$
, then the resulting process is a (generalized) shot-noise process. In this case it is well known that we can explicitly write
 \begin{equation}X_t(x)=xe^{-rt}+\int_{(0,t]}e^{-r(t-s)}J_{\text{d}s}.\end{equation}
\begin{equation}X_t(x)=xe^{-rt}+\int_{(0,t]}e^{-r(t-s)}J_{\text{d}s}.\end{equation}
In this setting it is immediately clear that
 $X_t(x)$
is nondecreasing and
$X_t(x)$
is nondecreasing and
 $X_t(x)-x$
is nonincreasing in x. We observe that here, if
$X_t(x)-x$
is nonincreasing in x. We observe that here, if
 $\mathbb{E} X_0^2<\infty$
, then
$\mathbb{E} X_0^2<\infty$
, then
 $R(t)=\text{Cov}(X_0,X_t)=\text{Var}(X_0)e^{-rt}$
, so that
$R(t)=\text{Cov}(X_0,X_t)=\text{Var}(X_0)e^{-rt}$
, so that
 $R(t)/R(0)=e^{-rt}$
, which is, as expected, nonnegative, nonincreasing, and convex in t (for any distribution of
$R(t)/R(0)=e^{-rt}$
, which is, as expected, nonnegative, nonincreasing, and convex in t (for any distribution of
 $X_0$
having a finite second moment), and which converges to zero as
$X_0$
having a finite second moment), and which converges to zero as
 $t\to\infty$
. It is well known that in this particular case, the stationary distribution has a finite second moment if and only if
$t\to\infty$
. It is well known that in this particular case, the stationary distribution has a finite second moment if and only if
 $J_1$
has a finite second moment. This is equivalent to requiring that
$J_1$
has a finite second moment. This is equivalent to requiring that
 $\int_{(1,\infty)}x^2\nu(\text{d}x)<\infty$
, where
$\int_{(1,\infty)}x^2\nu(\text{d}x)<\infty$
, where
 $\nu$
is the associated Lévy measure.
$\nu$
is the associated Lévy measure.
Remark 3. We note that if we replace J by any Lévy process and
 $-r({\cdot})$
by
$-r({\cdot})$
by
 $\mu({\cdot})$
where
$\mu({\cdot})$
where
 $\mu$
is nonincreasing (not necessarily negative), then whenever the process described by (28) is well defined, we have (for the same reasons as for the dam process) stochastic monotonicity and the validity of Condition 1. In particular, this is the case when
$\mu$
is nonincreasing (not necessarily negative), then whenever the process described by (28) is well defined, we have (for the same reasons as for the dam process) stochastic monotonicity and the validity of Condition 1. In particular, this is the case when
 $J_t=\sigma B_t$
and B is a Wiener process, resulting in a diffusion with constant diffusion coefficient and a nonincreasing drift.
$J_t=\sigma B_t$
and B is a Wiener process, resulting in a diffusion with constant diffusion coefficient and a nonincreasing drift.
3.4. Discrete-time (state-dependent) random walks
Consider a discrete-time random walk on
 $\mathbb{Z}_+$
with the following transition probabilities:
$\mathbb{Z}_+$
with the following transition probabilities:
 \begin{equation}p_{ij}=\begin{cases}q_i, &i\ge 1,\ j=i-1,\\r_i,&i\ge 0,\ j=i,\\p_i,&i\ge 0,\ j=i+1,\\0&\text{otherwise,}\end{cases}\end{equation}
\begin{equation}p_{ij}=\begin{cases}q_i, &i\ge 1,\ j=i-1,\\r_i,&i\ge 0,\ j=i,\\p_i,&i\ge 0,\ j=i+1,\\0&\text{otherwise,}\end{cases}\end{equation}
where
 $q_i+r_i+p_i=1$
for
$q_i+r_i+p_i=1$
for
 $i\ge 1$
and
$i\ge 1$
and
 $r_0+p_0=1$
. It is a trivial exercise to check that
$r_0+p_0=1$
. It is a trivial exercise to check that
 $p(i,A)=\sum_{j\in A}p_{ij}$
is stochastically monotone if and only if
$p(i,A)=\sum_{j\in A}p_{ij}$
is stochastically monotone if and only if
 $p_{i-1}\le 1-q_i$
for
$p_{i-1}\le 1-q_i$
for
 $i\ge 1$
, and that it satisfies Condition 1 if and only if
$i\ge 1$
, and that it satisfies Condition 1 if and only if
 $q_i$
is nondecreasing in i and
$q_i$
is nondecreasing in i and
 $p_i$
is nonincreasing in i. From Lemma 2 it may be concluded that these are also the respective conditions for this Markov chain to be stochastically monotone and to satisfy Condition 1. Therefore, the condition that both are satisfied is that for each
$p_i$
is nonincreasing in i. From Lemma 2 it may be concluded that these are also the respective conditions for this Markov chain to be stochastically monotone and to satisfy Condition 1. Therefore, the condition that both are satisfied is that for each
 $i\ge 1$
$i\ge 1$
 \begin{equation}p_i\le p_{i-1}\le 1-q_i\le 1-q_{i-1},\end{equation}
\begin{equation}p_i\le p_{i-1}\le 1-q_i\le 1-q_{i-1},\end{equation}
where
 $q_0\equiv 0$
.
$q_0\equiv 0$
.
From this it immediately follows that if
 $r_i=0$
for all
$r_i=0$
for all
 $i\ge 1$
, then the stochastic monotonicity together with Condition 1 is equivalent to the assumption that
$i\ge 1$
, then the stochastic monotonicity together with Condition 1 is equivalent to the assumption that
 $p_i=p$
for
$p_i=p$
for
 $i\ge 0$
and
$i\ge 0$
and
 $r_0=q_i=1-p$
for
$r_0=q_i=1-p$
for
 $i\ge 1$
. This is precisely the reflected process associated with
$i\ge 1$
. This is precisely the reflected process associated with
 $\sum_{k=1}^n Y_k$
(zero for
$\sum_{k=1}^n Y_k$
(zero for
 $n=0$
) where the
$n=0$
) where the
 $Y_k$
are i.i.d. with
$Y_k$
are i.i.d. with
 ${\mathbb P}(Y=1)=1-{\mathbb P}(Y=-1)=p$
, which is a simple special case of Remark 2.
${\mathbb P}(Y=1)=1-{\mathbb P}(Y=-1)=p$
, which is a simple special case of Remark 2.
3.5. Birth-and-death processes
Consider a right-continuous birth-and-death process on
 $\mathbb{Z}_+$
with birth rates
$\mathbb{Z}_+$
with birth rates
 $\lambda_i$
,
$\lambda_i$
,
 $i\ge 0$
, and death rates
$i\ge 0$
, and death rates
 $\mu_i\ge 1$
. If the process is explosive we assume that the ‘cemetery’ state is
$\mu_i\ge 1$
. If the process is explosive we assume that the ‘cemetery’ state is
 $+\infty$
and that from a possible time of explosion the process remains there forever (a minimal construction, that is).
$+\infty$
and that from a possible time of explosion the process remains there forever (a minimal construction, that is).
As observed in [Reference Keilson and Kester16], this Markov process is stochastically monotone. To see this (for the sake of ease of reference), simply start two such independent processes from different initial states. By independence they do not jump at the same time (a.s.), and thus as long as they do not meet in a given state one remains strictly above the other. If and when they do meet (stopping time + strong Markov property) we let them continue together. If the higher process explodes then it remains at infinity forever and thus the bottom process never overtakes the top one. This coupling immediately implies stochastic monotonicity.
Therefore it remains to identify when Condition 1 holds. For the random walk of Subsection 3.4 the condition was that
 $p_i$
is nonincreasing and
$p_i$
is nonincreasing and
 $q_i$
is nondecreasing in i. Therefore it is conceivable that the condition here should be that
$q_i$
is nondecreasing in i. Therefore it is conceivable that the condition here should be that
 $\lambda_i$
is nonincreasing and
$\lambda_i$
is nonincreasing and
 $\mu_i$
is nondecreasing in i. This indeed turns out to be correct. In order to see this we will first need the following lemma.
$\mu_i$
is nondecreasing in i. This indeed turns out to be correct. In order to see this we will first need the following lemma.
Lemma 4. For
 $k=1,2$
, let
$k=1,2$
, let
 $X^k=\{X_t^k|\,t\ge 0\}$
be a right-continuous birth-and-death process on
$X^k=\{X_t^k|\,t\ge 0\}$
be a right-continuous birth-and-death process on
 $\mathbb{Z}_+$
with birth rates
$\mathbb{Z}_+$
with birth rates
 $\lambda_i^k$
for
$\lambda_i^k$
for
 $i\ge 0$
and death rates
$i\ge 0$
and death rates
 $\mu_i^k$
for
$\mu_i^k$
for
 $i\ge 1$
. Assume that when the process is explosive, the ‘cemetery’ is
$i\ge 1$
. Assume that when the process is explosive, the ‘cemetery’ is
 $+\infty$
, and that the process remains there from the possible point of explosion onward. Then the following two conditions are equivalent:
$+\infty$
, and that the process remains there from the possible point of explosion onward. Then the following two conditions are equivalent:
-
(i)
$X^1_t\le_{{\rm st}}X^2_t$
for every
$t\ge 0$
for any choice of initial distributions such that
$X^1_0\le_{{\rm st}} X^2_0$
. -
(ii)
$\lambda_i^1\le \lambda_i^2$
for every
$i\ge 0$
and
$\mu_i^1\ge \mu_i^2$
for every
$i\ge 1$
.







Proof. We use the standard notation
 ${\mathbb P}_i$
to indicate the probability measure when the initial state is i. Also recall that a right-continuous birth-and-death process is orderly, in the sense that the probability that there are two or more jumps in the interval [0, t] starting from any initial state is o(t). This implies that
${\mathbb P}_i$
to indicate the probability measure when the initial state is i. Also recall that a right-continuous birth-and-death process is orderly, in the sense that the probability that there are two or more jumps in the interval [0, t] starting from any initial state is o(t). This implies that
 $\lim_{t\downarrow 0}t^{-1}{\mathbb P}_i(|X^k_t-i|\ge 2)=0$
and thus
$\lim_{t\downarrow 0}t^{-1}{\mathbb P}_i(|X^k_t-i|\ge 2)=0$
and thus
 \begin{equation}\lim_{t\downarrow0}\frac{1}{t}{\mathbb P}_i(X^k_t\ge i+1)=\lim_{t\downarrow0}\frac{1}{t}{\mathbb P}_i(X_t^k=i+1)=\lambda_i\end{equation}
\begin{equation}\lim_{t\downarrow0}\frac{1}{t}{\mathbb P}_i(X^k_t\ge i+1)=\lim_{t\downarrow0}\frac{1}{t}{\mathbb P}_i(X_t^k=i+1)=\lambda_i\end{equation}
for
 $i\ge 0$
. Similarly,
$i\ge 0$
. Similarly,
 $\lim_{t\downarrow0}t^{-1}{\mathbb P}_i(X^k_t\le i-1)=\mu_i$
for
$\lim_{t\downarrow0}t^{-1}{\mathbb P}_i(X^k_t\le i-1)=\mu_i$
for
 $i\ge 1$
.
$i\ge 1$
.
To show (i)
 $\Rightarrow$
(ii), suppose that
$\Rightarrow$
(ii), suppose that
 $X_0^1=X_0^2=i$
a.s. (clearly
$X_0^1=X_0^2=i$
a.s. (clearly
 $X^1_0\le_{\text{st}} X^2_0$
). From
$X^1_0\le_{\text{st}} X^2_0$
). From
 $X^1_t\le_{\text{st}}X^2_t$
we have that
$X^1_t\le_{\text{st}}X^2_t$
we have that
 ${\mathbb P}_i(X_t^1\ge i+1)\le {\mathbb P}_i(X_t^2\ge i+1)$
for
${\mathbb P}_i(X_t^1\ge i+1)\le {\mathbb P}_i(X_t^2\ge i+1)$
for
 $i\ge 0$
and
$i\ge 0$
and
 $t>0$
. Dividing by t and letting
$t>0$
. Dividing by t and letting
 $t\downarrow 0$
gives
$t\downarrow 0$
gives
 $\lambda^1_i\le \lambda^2_i$
. Similarly, since
$\lambda^1_i\le \lambda^2_i$
. Similarly, since
 ${\mathbb P}_i(X_t^1\ge i)\le {\mathbb P}_i(X_t^2\ge i)$
we have that
${\mathbb P}_i(X_t^1\ge i)\le {\mathbb P}_i(X_t^2\ge i)$
we have that
 ${\mathbb P}_i(X_t^1\le i-1)\le {\mathbb P}_i(X_t^2\ge i-1)$
for
${\mathbb P}_i(X_t^1\le i-1)\le {\mathbb P}_i(X_t^2\ge i-1)$
for
 $i\ge 1$
and
$i\ge 1$
and
 $t>0$
. Dividing by t and letting
$t>0$
. Dividing by t and letting
 $t\downarrow 0$
gives
$t\downarrow 0$
gives
 $\mu_i^1\ge \mu_i^2$
.
$\mu_i^1\ge \mu_i^2$
.
It remains to show (ii)
 $\Rightarrow$
(i). If we can find a coupling such that
$\Rightarrow$
(i). If we can find a coupling such that
 $X^1_t\le X^2_t$
a.s. for each
$X^1_t\le X^2_t$
a.s. for each
 $t\ge 0$
, then the lemma instantly follows. It is well known that if
$t\ge 0$
, then the lemma instantly follows. It is well known that if
 $X_0^1\le_{\text{st}}X_0^2$
, then there are
$X_0^1\le_{\text{st}}X_0^2$
, then there are
 $(\tilde X^1_0,\tilde X^2_0)$
such that
$(\tilde X^1_0,\tilde X^2_0)$
such that
 $\tilde X^k_0=_{\rm d} X^k_0$
and
$\tilde X^k_0=_{\rm d} X^k_0$
and
 $\tilde X^1_0\le \tilde X^2_0$
a.s. Now assume that
$\tilde X^1_0\le \tilde X^2_0$
a.s. Now assume that
 $(X^1,X^2)$
is a right-continuous Markov process on
$(X^1,X^2)$
is a right-continuous Markov process on
 $\{(i,j)|\,0\le i\le j\}$
with the following transition rates (with
$\{(i,j)|\,0\le i\le j\}$
with the following transition rates (with
 $\mu^1_0=\mu^2_0=0$
): for
$\mu^1_0=\mu^2_0=0$
): for
 $i<j$
we have
$i<j$
we have
 \begin{equation}\begin{array}{c@{\quad}c@{\quad}c@{\quad}c@{\quad}c}&&(i,j+1)\\ \\&&{\scriptstyle\lambda^2_j}\Big\uparrow\\ \\(i-1,j)&\stackrel{\mu^1_i}{\longleftarrow}&(i,j)&\stackrel{\lambda^1_i}{\longrightarrow}&(i+1,j)\\ \\&&{\scriptstyle\mu^2_j}\Big\downarrow\\ \\&&(i,j-1)\end{array}\end{equation}
\begin{equation}\begin{array}{c@{\quad}c@{\quad}c@{\quad}c@{\quad}c}&&(i,j+1)\\ \\&&{\scriptstyle\lambda^2_j}\Big\uparrow\\ \\(i-1,j)&\stackrel{\mu^1_i}{\longleftarrow}&(i,j)&\stackrel{\lambda^1_i}{\longrightarrow}&(i+1,j)\\ \\&&{\scriptstyle\mu^2_j}\Big\downarrow\\ \\&&(i,j-1)\end{array}\end{equation}
whereas for
 $i=j$
$i=j$
 \begin{equation}\begin{array}{c@{\quad}c@{\quad}c@{\quad}c@{\quad}c}&&(i,i+1)&&(i+1,i+1)\\ \\&&{\scriptstyle\lambda^2_i-\lambda^1_i}\Big\uparrow&{\scriptstyle\lambda^1_i}\nearrow\\ \\(i-1,i)&\stackrel{\mu^1_i-\mu^2_i}{\longleftarrow}&(i,i)\\ \\&{\scriptstyle\mu^2_i}\swarrow\\ \\(i-1,i-1)\end{array}\end{equation}
\begin{equation}\begin{array}{c@{\quad}c@{\quad}c@{\quad}c@{\quad}c}&&(i,i+1)&&(i+1,i+1)\\ \\&&{\scriptstyle\lambda^2_i-\lambda^1_i}\Big\uparrow&{\scriptstyle\lambda^1_i}\nearrow\\ \\(i-1,i)&\stackrel{\mu^1_i-\mu^2_i}{\longleftarrow}&(i,i)\\ \\&{\scriptstyle\mu^2_i}\swarrow\\ \\(i-1,i-1)\end{array}\end{equation}
All other transition rates are zero. Since the process lives on
 $\{(i,j)|\,0\le i\le j\}$
, it is clear that
$\{(i,j)|\,0\le i\le j\}$
, it is clear that
 $X^1_t\le X^2_t$
a.s. for each t. It is easy to check that for each
$X^1_t\le X^2_t$
a.s. for each t. It is easy to check that for each
 $k=1,2$
,
$k=1,2$
,
 $X^k$
is a birth-and-death process with birth rates
$X^k$
is a birth-and-death process with birth rates
 $\lambda^k_i$
and death rates
$\lambda^k_i$
and death rates
 $\mu^k_i$
.
$\mu^k_i$
.
Note that the processes suggested in the proof run independently as long as they do not meet, and only if and when they meet does something else happen that ensures that the bottom process does not overtake the top one.
Theorem 6. Assume that
 $X=\{X_t|\,t\ge 0\}$
is a right-continuous birth-and-death process with birth rates
$X=\{X_t|\,t\ge 0\}$
is a right-continuous birth-and-death process with birth rates
 $\lambda_i$
for
$\lambda_i$
for
 $i\ge 0$
and death rates
$i\ge 0$
and death rates
 $\mu_i$
for
$\mu_i$
for
 $i\ge 1$
. Also assume that the ‘cemetery’ (when explosive) is
$i\ge 1$
. Also assume that the ‘cemetery’ (when explosive) is
 $+\infty$
and that the process remains there forever from such an epoch onward. Then X satisfies Condition 1 if and only if
$+\infty$
and that the process remains there forever from such an epoch onward. Then X satisfies Condition 1 if and only if
 $\lambda_i$
is nonincreasing in i and
$\lambda_i$
is nonincreasing in i and
 $\mu_i$
is nondecreasing in i.
$\mu_i$
is nondecreasing in i.
Proof. Let us define X(i) to be a birth-and-death process with the above parameters which starts from i. We need to show that
 $X_t(i+1)-(i+1)\le_{\text{st}} X_t(i)-i$
, or, equivalently, that
$X_t(i+1)-(i+1)\le_{\text{st}} X_t(i)-i$
, or, equivalently, that
 $X_t(i+1)\le_{\text{st}} X_t(i)+1$
. Now
$X_t(i+1)\le_{\text{st}} X_t(i)+1$
. Now
 $X_t(i)+1$
is a birth-and-death process on
$X_t(i)+1$
is a birth-and-death process on
 $\mathbb{Z}_+$
starting from
$\mathbb{Z}_+$
starting from
 $i+1$
, with arrival rates
$i+1$
, with arrival rates
 $\tilde \lambda_i=\lambda_{i-1}$
for
$\tilde \lambda_i=\lambda_{i-1}$
for
 $i\ge 1$
, and
$i\ge 1$
, and
 $\tilde \lambda_0$
may be chosen arbitrarily in
$\tilde \lambda_0$
may be chosen arbitrarily in
 $[\lambda_0,\infty)$
. The departure rates of
$[\lambda_0,\infty)$
. The departure rates of
 $X_t(i)+1$
are
$X_t(i)+1$
are
 $\tilde\mu_i=\mu_{i-1}$
for
$\tilde\mu_i=\mu_{i-1}$
for
 $i\ge 2$
and
$i\ge 2$
and
 $\tilde\mu_1=0$
.
$\tilde\mu_1=0$
.
From Lemma 4 it follows that the necessary and sufficient condition that we seek is
 $\tilde \lambda_i\ge \lambda_i$
for
$\tilde \lambda_i\ge \lambda_i$
for
 $i\ge 0$
and
$i\ge 0$
and
 $\tilde\mu_i\le \mu_i$
, which is equivalent to the condition that
$\tilde\mu_i\le \mu_i$
, which is equivalent to the condition that
 $\lambda_i$
is nonincreasing and
$\lambda_i$
is nonincreasing and
 $\mu_i$
is nondecreasing (in i).
$\mu_i$
is nondecreasing (in i).
Remark 4. Note that pure birth and pure death processes are special cases of birth-and-death processes, and thus Theorem 4 and Corollary 6 hold for these processes as well. Also note that the state space does not need to be
 $\mathbb{Z}_+$
, but can also be any finite or infinite subinterval of
$\mathbb{Z}_+$
, but can also be any finite or infinite subinterval of
 $\mathbb{Z}$
.
$\mathbb{Z}$
.
4. Some concluding remarks
In this paper have focused on techniques to prove structural properties of Markov processes. We have developed a framework that succeeds in bringing various branches of the literature under a common umbrella. As indicated earlier, we strongly believe that the results presented in this paper open up the opportunity to produce compact proofs of existing results, as well as to efficiently derive new properties. We conclude this paper with a couple of remarks.
Recalling Remark 1, when there exists a stationary distribution, for all of the examples discussed in Section 3 we have that
 $\text{Cov}(f_1(X_0),f_2(X_t))$
vanishes as
$\text{Cov}(f_1(X_0),f_2(X_t))$
vanishes as
 $t\to\infty$
whenever
$t\to\infty$
whenever
 $f_1,f_2$
are nondecreasing with
$f_1,f_2$
are nondecreasing with
 $\mathbb{E} f_i^2(X_0)<\infty$
for
$\mathbb{E} f_i^2(X_0)<\infty$
for
 $i=1,2$
. We note that in light of the findings of Sections 3.1 and 3.2, [Reference Berkelmans, Cichocka and Mandjes3, Theorems 1 and 2] (as well as the earlier [Reference Es-Saghouani and Mandjes10, Theoremm 3.1] and [Reference Glynn and Mandjes11, Theorem 2.2]) are special cases of our Theorems 2 and 4. In addition, [Reference Kella and Sverchkov14, Theorem 3.1] restricted to the Lévy case (and the earlier [Reference Kella12, Theorem 3.3]), as well as the mean (not variance) parts of [Reference Andersen and Mandjes1, Theorems 4.6 and 7.5], are special cases of (iv) in our Theorem 5 (upon taking
$i=1,2$
. We note that in light of the findings of Sections 3.1 and 3.2, [Reference Berkelmans, Cichocka and Mandjes3, Theorems 1 and 2] (as well as the earlier [Reference Es-Saghouani and Mandjes10, Theoremm 3.1] and [Reference Glynn and Mandjes11, Theorem 2.2]) are special cases of our Theorems 2 and 4. In addition, [Reference Kella and Sverchkov14, Theorem 3.1] restricted to the Lévy case (and the earlier [Reference Kella12, Theorem 3.3]), as well as the mean (not variance) parts of [Reference Andersen and Mandjes1, Theorems 4.6 and 7.5], are special cases of (iv) in our Theorem 5 (upon taking
 $X_0=0$
in [Reference Andersen and Mandjes1], that is).
$X_0=0$
in [Reference Andersen and Mandjes1], that is).
One could wonder whether the monotonicity of the variance, as was discovered in [Reference Andersen and Mandjes1] in a reflected Lévy context, would carry over to any stochastically monotone Markov process satisfying Condition 1. However, as it turns out, this particular result from [Reference Andersen and Mandjes1] essentially follows from the specific properties of reflected Lévy processes (or, in the discrete-time case, reflected random walks) and is not true in general. One elementary counterexample is the following. Let
 $\{N_t\,|\,t\ge 0\}$
be a Poisson process (starting at 0) and take
$\{N_t\,|\,t\ge 0\}$
be a Poisson process (starting at 0) and take
 $X_t=(k+N_t)\wedge m$
. Then
$X_t=(k+N_t)\wedge m$
. Then
 $\{X_t\,|\,t\ge 0\}$
is a Markov process with state space
$\{X_t\,|\,t\ge 0\}$
is a Markov process with state space
 $\{i\,|\,i\le m\}$
, with an initial value k and an absorbing barrier m. On
$\{i\,|\,i\le m\}$
, with an initial value k and an absorbing barrier m. On
 $k\le m$
we have that
$k\le m$
we have that
 $(k+N_t)\wedge m$
is nondecreasing in k and
$(k+N_t)\wedge m$
is nondecreasing in k and
 $X_t-X_0=N_t\wedge(m-k)$
is nonincreasing in k, and thus this is a stochastically monotone Markov process satisfying Condition 1. Clearly,
$X_t-X_0=N_t\wedge(m-k)$
is nonincreasing in k, and thus this is a stochastically monotone Markov process satisfying Condition 1. Clearly,
 $\text{Var}(X_0)=0$
, and since
$\text{Var}(X_0)=0$
, and since
 $X_t\to m$
(a.s.) as
$X_t\to m$
(a.s.) as
 $t\to \infty$
, by bounded convergence (
$t\to \infty$
, by bounded convergence (
 $k\le X_t\le m$
) the variance vanishes as
$k\le X_t\le m$
) the variance vanishes as
 $t\to\infty$
. Since the variance is strictly positive for all
$t\to\infty$
. Since the variance is strictly positive for all
 $0<t<\infty$
, it cannot be monotone in t.
$0<t<\infty$
, it cannot be monotone in t.
Funding information
O. K. is supported in part by Grant No. 1647/17 from the Israel Science Foundation and the Vigevani Chair in Statistics. M. M. is partly funded by the Dutch Research Council (NWO) Gravitation Programme Networks (Grant No. 024.002.003) and an NWO Top Grant (Grant No. 613.001.352).
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.