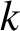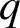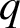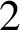
1 Introduction and main result
Automatic sequences can be defined via deterministic finite automata with output: feeding the base-q expansion (where
 $q\geq 2$
is an integer) of
$q\geq 2$
is an integer) of
 $0,1,2,\ldots $
into such an automaton, we obtain an automatic sequence as its output, and each automatic sequence is obtained in this way. One of the simplest automatic sequences (in terms of the size of the defining substitution) is the Thue–Morse sequence
$0,1,2,\ldots $
into such an automaton, we obtain an automatic sequence as its output, and each automatic sequence is obtained in this way. One of the simplest automatic sequences (in terms of the size of the defining substitution) is the Thue–Morse sequence
 ${\mathbf t}$
. It is the fixed point of the substitution
${\mathbf t}$
. It is the fixed point of the substitution
 $\tau $
given by
$\tau $
given by
 $$ \begin{align} \tau: {\mathtt 0}\mapsto{\mathtt 0}{\mathtt 1},\quad {\mathtt 1}\mapsto{\mathtt 1}{\mathtt 0}, \end{align} $$
$$ \begin{align} \tau: {\mathtt 0}\mapsto{\mathtt 0}{\mathtt 1},\quad {\mathtt 1}\mapsto{\mathtt 1}{\mathtt 0}, \end{align} $$
starting with
 ${\mathtt 0}$
:
${\mathtt 0}$
:
 $$ \begin{align} {\mathbf t}=\tau^{\omega}({\mathtt 0})= {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0} {\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1} \cdots. \end{align} $$
$$ \begin{align} {\mathbf t}=\tau^{\omega}({\mathtt 0})= {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0} {\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1} \cdots. \end{align} $$
(Here
 $\tau ^{\omega }({\mathtt 0})$
denotes the pointwise limit of the iterations
$\tau ^{\omega }({\mathtt 0})$
denotes the pointwise limit of the iterations
 $\tau ^k({\mathtt 0})$
, in symbols
$\tau ^k({\mathtt 0})$
, in symbols
 $\tau ^{\omega }({\mathtt 0})\rvert _j=\lim _{k\rightarrow \infty }\tau ^k({\mathtt 0})\rvert _j$
. We use analogous notation in other places too.) Occurrences of this sequence in different areas of mathematics can be found in the paper [Reference Allouche, Shallit, Ding, Helleseth and Niederreiter3] by Allouche and Shallit, which also offers a good bibliography. Another survey paper on the Thue–Morse sequence was written by Mauduit [Reference Mauduit23]. Much more information concerning automatic and general morphic sequences is presented in the book [Reference Allouche and Shallit4] by Allouche and Shallit.
$\tau ^{\omega }({\mathtt 0})\rvert _j=\lim _{k\rightarrow \infty }\tau ^k({\mathtt 0})\rvert _j$
. We use analogous notation in other places too.) Occurrences of this sequence in different areas of mathematics can be found in the paper [Reference Allouche, Shallit, Ding, Helleseth and Niederreiter3] by Allouche and Shallit, which also offers a good bibliography. Another survey paper on the Thue–Morse sequence was written by Mauduit [Reference Mauduit23]. Much more information concerning automatic and general morphic sequences is presented in the book [Reference Allouche and Shallit4] by Allouche and Shallit.
Terms
 $1$
–
$1$
–
 $12$
of the Thue–Morse sequence (the
$12$
of the Thue–Morse sequence (the
 $0\, $
th term is omitted) make a peculiar appearance in The Simpsons Movie [Reference Brooks12]:
$0\, $
th term is omitted) make a peculiar appearance in The Simpsons Movie [Reference Brooks12]:
Russ Cargill: I want 10,000 tough guys, and I want 10,000 soft guys to make the tough guys look tougher! And here’s how I want them arranged: tough, tough, soft, tough, soft, soft, tough, tough, soft, soft, tough, soft.
This could, of course, be a coincidence. A different, more sensible explanation of this appearance is along the lines of Brams and Taylor [Reference Brams and Taylor11, pages 36–44]. They rediscover the Thue–Morse sequence while seeking balanced alternation between two parties, ‘Ann’ and ‘Ben’. However, Brams and Taylor do not attribute the resulting sequence to Thue and Morse (nor to Prouhet).
We are interested in counting the number of times that a word occurs as a factor (a contiguous finite subsequence) of another word; a related concept is the binomial coefficient of two words, which counts the corresponding number concerning general subsequences. We wish to note the related paper by Rigo and Salimov [Reference Rigo and Salimov25], defining the m-binomial equivalence of two words, and the later paper by Lejeune et al. [Reference Lejeune, Leroy and Rigo21], where the Thue–Morse sequence is investigated with regard to this new concept.
It is well known that the sequence
 ${\mathbf t}$
is uniformly recurrent [Reference Lothaire22, Section 1.5.2]. That is, for each factor w of
${\mathbf t}$
is uniformly recurrent [Reference Lothaire22, Section 1.5.2]. That is, for each factor w of
 ${\mathbf t}$
there is a length n with the following property: every contiguous subsequence of
${\mathbf t}$
there is a length n with the following property: every contiguous subsequence of
 ${\mathbf t}$
of length n contains w as a factor. The factor
${\mathbf t}$
of length n contains w as a factor. The factor
 ${\mathtt 0}{\mathtt 1}$
therefore appears in
${\mathtt 0}{\mathtt 1}$
therefore appears in
 ${\mathbf t}$
with bounded distances. We are interested in the infinite word
${\mathbf t}$
with bounded distances. We are interested in the infinite word
 ${\mathbf B}$
(over a finite alphabet) describing these differences. We mark the occurrences of
${\mathbf B}$
(over a finite alphabet) describing these differences. We mark the occurrences of
 ${\mathtt 0}{\mathtt 1}$
in the first
${\mathtt 0}{\mathtt 1}$
in the first
 $64$
letters of
$64$
letters of
 ${\mathbf t}$
:
${\mathbf t}$
:

from which we see that
 $$ \begin{align*}{\mathbf B}=\mathtt{334233243342433233423}\cdots. \end{align*} $$
$$ \begin{align*}{\mathbf B}=\mathtt{334233243342433233423}\cdots. \end{align*} $$
The blocks
 ${\mathtt 0}{\mathtt 0}{\mathtt 0}$
and
${\mathtt 0}{\mathtt 0}{\mathtt 0}$
and
 ${\mathtt 1}{\mathtt 1}{\mathtt 1}$
do not appear as factors in
${\mathtt 1}{\mathtt 1}{\mathtt 1}$
do not appear as factors in
 ${\mathbf t}$
, since
${\mathbf t}$
, since
 ${\mathbf t}$
is a concatenation of the blocks
${\mathbf t}$
is a concatenation of the blocks
 ${\mathtt 0}{\mathtt 1}$
and
${\mathtt 0}{\mathtt 1}$
and
 ${\mathtt 1}{\mathtt 0}$
. Therefore the gaps between consecutive occurrences of
${\mathtt 1}{\mathtt 0}$
. Therefore the gaps between consecutive occurrences of
 ${\mathtt 0}{\mathtt 1}$
in
${\mathtt 0}{\mathtt 1}$
in
 ${\mathbf t}$
are in fact bounded by
${\mathbf t}$
are in fact bounded by
 $4$
, and clearly they are bounded below by
$4$
, and clearly they are bounded below by
 $2$
(since different occurrences of
$2$
(since different occurrences of
 ${\mathtt 0}{\mathtt 1}$
cannot overlap). It follows that we only need three letters,
${\mathtt 0}{\mathtt 1}$
cannot overlap). It follows that we only need three letters,
 $\mathtt 2$
,
$\mathtt 2$
,
 $\mathtt 3$
, and
$\mathtt 3$
, and
 $\mathtt 4$
, in order to capture the gap sequence.
$\mathtt 4$
, in order to capture the gap sequence.
The set of return words [Reference Durand16, Reference Justin and Vuillon20] of a factor w of
 ${\mathbf t}$
is the set of words x of the form
${\mathbf t}$
is the set of words x of the form
 $x=w\tilde x$
, where w is not a factor of
$x=w\tilde x$
, where w is not a factor of
 $\tilde x$
, and
$\tilde x$
, and
 $w\tilde xw$
is a factor of
$w\tilde xw$
is a factor of
 ${\mathbf t}$
. The gap sequence is the sequence of lengths of words in the decomposition
${\mathbf t}$
. The gap sequence is the sequence of lengths of words in the decomposition
 ${\mathbf t}=x_0x_1\cdots $
of the Thue–Morse sequence into return words of
${\mathbf t}=x_0x_1\cdots $
of the Thue–Morse sequence into return words of
 ${\mathtt 0}{\mathtt 1}$
, which are
${\mathtt 0}{\mathtt 1}$
, which are
 ${\mathtt 0}{\mathtt 1}{\mathtt 1}$
,
${\mathtt 0}{\mathtt 1}{\mathtt 1}$
,
 ${\mathtt 0}{\mathtt 1}{\mathtt 0}$
,
${\mathtt 0}{\mathtt 1}{\mathtt 0}$
,
 ${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, and
${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, and
 ${\mathtt 0}{\mathtt 1}$
in order of appearance.
${\mathtt 0}{\mathtt 1}$
in order of appearance.
An appearance of the factor
 ${\mathtt 0}{\mathtt 1}$
marks the beginning of a block of
${\mathtt 0}{\mathtt 1}$
marks the beginning of a block of
 ${\mathtt 1}$
s in
${\mathtt 1}$
s in
 ${\mathbf t}$
. Moreover, no other block of
${\mathbf t}$
. Moreover, no other block of
 ${\mathtt 1}$
s can appear before the next appearance of
${\mathtt 1}$
s can appear before the next appearance of
 ${\mathtt 0}{\mathtt 1}$
: between two blocks of
${\mathtt 0}{\mathtt 1}$
: between two blocks of
 ${\mathtt 1}$
s we can find a block of one or more
${\mathtt 1}$
s we can find a block of one or more
 ${\mathtt 0}$
s, and the last
${\mathtt 0}$
s, and the last
 ${\mathtt 0}$
in this block is followed by
${\mathtt 0}$
in this block is followed by
 ${\mathtt 1}$
. The assumption that we see a block of
${\mathtt 1}$
. The assumption that we see a block of
 ${\mathtt 1}$
s before the next appearance of
${\mathtt 1}$
s before the next appearance of
 ${\mathtt 0}{\mathtt 1}$
therefore leads to a contradiction. This argument is clearly visible in (1-3). The sequence
${\mathtt 0}{\mathtt 1}$
therefore leads to a contradiction. This argument is clearly visible in (1-3). The sequence
 ${\mathbf B}$
therefore gives the distances of consecutive blocks of
${\mathbf B}$
therefore gives the distances of consecutive blocks of
 ${\mathtt 1}$
s. We see in Lemma 2.3 that the sequence
${\mathtt 1}$
s. We see in Lemma 2.3 that the sequence
 ${\mathbf B}$
is morphic or substitutive. That is, it can be described as the coding of a fixed point of a substitution over a finite alphabet. Jeffrey Shallit (private communication, July 2019) proposed to prove the nonautomaticity of
${\mathbf B}$
is morphic or substitutive. That is, it can be described as the coding of a fixed point of a substitution over a finite alphabet. Jeffrey Shallit (private communication, July 2019) proposed to prove the nonautomaticity of
 ${\mathbf B}$
to the author. In the present paper, we investigate the sequence
${\mathbf B}$
to the author. In the present paper, we investigate the sequence
 ${\mathbf B}$
and the closely related, very well-known automatic sequence
${\mathbf B}$
and the closely related, very well-known automatic sequence
 ${\mathbf A}$
defined in Section 2.1. In particular, we prove the following theorem.
${\mathbf A}$
defined in Section 2.1. In particular, we prove the following theorem.
Theorem 1.1. Let w be a factor of the Thue–Morse word of length at least
 $2$
, and C the sequence of gaps between consecutive occurrences of w in
$2$
, and C the sequence of gaps between consecutive occurrences of w in
 ${\mathbf t}$
. Then C is morphic, but not automatic.
${\mathbf t}$
. Then C is morphic, but not automatic.
Note that the set of positions where a given factor w appears in
 ${\mathbf t}$
is
${\mathbf t}$
is
 $2$
-automatic; that is, its characteristic sequence is automatic. This follows from the following theorem by Brown et al. [Reference Brown, Rampersad, Shallit and Vasiga13, Theorem 2.1].
$2$
-automatic; that is, its characteristic sequence is automatic. This follows from the following theorem by Brown et al. [Reference Brown, Rampersad, Shallit and Vasiga13, Theorem 2.1].
Theorem A. Let
 $\mathbf a=a_0a_1a_2\cdots $
be a k-automatic sequence over the alphabet
$\mathbf a=a_0a_1a_2\cdots $
be a k-automatic sequence over the alphabet
 $\Delta $
, and let
$\Delta $
, and let
 $w\in \Delta ^{\ast }$
. Then the set of positions p such that w occurs beginning at position p is k-automatic.
$w\in \Delta ^{\ast }$
. Then the set of positions p such that w occurs beginning at position p is k-automatic.
Concerning factors of length
 $1$
, the corresponding gap sequence is automatic too; this follows from [Reference Blanchet-Sadri, Currie, Rampersad and Fox10].
$1$
, the corresponding gap sequence is automatic too; this follows from [Reference Blanchet-Sadri, Currie, Rampersad and Fox10].
The second part of our paper is concerned with the discrepancy of occurrences of
 ${\mathtt 0}{\mathtt 1}$
-blocks in
${\mathtt 0}{\mathtt 1}$
-blocks in
 ${\mathbf t}$
. More precisely, assume that N is a nonnegative integer. We count the number of times the factor
${\mathbf t}$
. More precisely, assume that N is a nonnegative integer. We count the number of times the factor
 ${\mathtt 0}{\mathtt 1}$
occurs in the first N terms of the Thue–Morse sequence, and compare it to
${\mathtt 0}{\mathtt 1}$
occurs in the first N terms of the Thue–Morse sequence, and compare it to
 $N/3$
:
$N/3$
:
 $$ \begin{align} D_N:=\#\{0\leq n<N:{\mathbf t}_n={\mathtt 0},{\mathbf t}_{n+1}={\mathtt 1}\}-\frac N3. \end{align} $$
$$ \begin{align} D_N:=\#\{0\leq n<N:{\mathbf t}_n={\mathtt 0},{\mathbf t}_{n+1}={\mathtt 1}\}-\frac N3. \end{align} $$
From Theorem A we can immediately derive that the sequence
 $(D_N)_{N\ge 0}$
is
$(D_N)_{N\ge 0}$
is
 $2$
-regular [Reference Allouche and Shallit2, Reference Allouche and Shallit5] as the sequence of partial sums of a
$2$
-regular [Reference Allouche and Shallit2, Reference Allouche and Shallit5] as the sequence of partial sums of a
 $2$
-automatic sequence: the sequence having
$2$
-automatic sequence: the sequence having
 $$ \begin{align*} \begin{cases} 2/3\quad&\mbox{if } \ {\mathbf t}_n{\mathbf t}_{n+1}={\mathtt 0}{\mathtt 1},\\ -1/3\quad&\mbox{otherwise}, \end{cases} \end{align*} $$
$$ \begin{align*} \begin{cases} 2/3\quad&\mbox{if } \ {\mathbf t}_n{\mathbf t}_{n+1}={\mathtt 0}{\mathtt 1},\\ -1/3\quad&\mbox{otherwise}, \end{cases} \end{align*} $$
as its
 $n\, $
th term is automatic as the sum of four
$n\, $
th term is automatic as the sum of four
 $2$
-automatic sequences, and
$2$
-automatic sequences, and
 $D_N$
is the sum of the first N terms of this sequence [Reference Allouche and Shallit2, Theorem 3.1]. Our second theorem shows, more specifically, that
$D_N$
is the sum of the first N terms of this sequence [Reference Allouche and Shallit2, Theorem 3.1]. Our second theorem shows, more specifically, that
 $D_N$
can be obtained as the output sum of a base-
$D_N$
can be obtained as the output sum of a base-
 $2$
transducer (see Heuberger et al. [Reference Heuberger, Kropf and Prodinger18], in particular Remark 3.10 in that paper).
$2$
transducer (see Heuberger et al. [Reference Heuberger, Kropf and Prodinger18], in particular Remark 3.10 in that paper).
Theorem 1.2. The sequence
 $(D_N)_{N\geq 0}$
is the sequence of output sums of a base-
$(D_N)_{N\geq 0}$
is the sequence of output sums of a base-
 $2$
transducer. In particular,
$2$
transducer. In particular,
 $D_N\leq C\log N$
for some absolute implied constant C. Moreover,
$D_N\leq C\log N$
for some absolute implied constant C. Moreover,
 $$ \begin{align*} \{D_N:N\geq 0\}=\tfrac 13\mathbb Z. \end{align*} $$
$$ \begin{align*} \{D_N:N\geq 0\}=\tfrac 13\mathbb Z. \end{align*} $$
Note that the unboundedness of
 $D_N$
follows from Corollary 4.10 in the paper by Berthé and Bernales [Reference Berthé and Bernales9] on balancedness in words.
$D_N$
follows from Corollary 4.10 in the paper by Berthé and Bernales [Reference Berthé and Bernales9] on balancedness in words.
1.1 Plan of the paper
In Section 2 we prove that the gap sequence for a factor w of
 ${\mathbf t}$
is not automatic. The central step of this proof is the case
${\mathbf t}$
is not automatic. The central step of this proof is the case
 $w={\mathtt 0}{\mathtt 1}$
, which is handled in the first three subsections. Section 2.4 reduces the general case to this special case. In Section 3 we study the automatic sequence
$w={\mathtt 0}{\mathtt 1}$
, which is handled in the first three subsections. Section 2.4 reduces the general case to this special case. In Section 3 we study the automatic sequence
 ${\mathbf A}$
on the three symbols
${\mathbf A}$
on the three symbols
 $\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
, closely related to the gap sequences. In particular, we lift this sequence to the seven-letter alphabet
$\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
, closely related to the gap sequences. In particular, we lift this sequence to the seven-letter alphabet
 . From this new sequence we can in particular read off the discrepancy
. From this new sequence we can in particular read off the discrepancy
 $D_N$
easily, which leads to a proof of Theorem 1.2.
$D_N$
easily, which leads to a proof of Theorem 1.2.
2 Proving the nonautomaticity of gap sequences
The main part of the proof of Theorem 1.1 concerns nonautomaticity of the gaps between occurrences of
 ${\mathtt 0}{\mathtt 1}$
. As a second step in our proof, the general case is reduced to this one.
${\mathtt 0}{\mathtt 1}$
. As a second step in our proof, the general case is reduced to this one.
2.1 An auxiliary automatic sequence
We start by defining a substitution
 $\varphi $
on three letters:
$\varphi $
on three letters:
 $$ \begin{align} \begin{array}{llll} \varphi:&{\mathtt a}\mapsto {\mathtt a}{\mathtt b}{\mathtt c},&{\mathtt b}\mapsto {\mathtt a}{\mathtt c},& {\mathtt c}\mapsto{\mathtt b}. \end{array} \end{align} $$
$$ \begin{align} \begin{array}{llll} \varphi:&{\mathtt a}\mapsto {\mathtt a}{\mathtt b}{\mathtt c},&{\mathtt b}\mapsto {\mathtt a}{\mathtt c},& {\mathtt c}\mapsto{\mathtt b}. \end{array} \end{align} $$
The morphism
 $\varphi $
can be extended to
$\varphi $
can be extended to
 $\{{\mathtt a},{\mathtt b},{\mathtt c}\}^{\mathbb N}$
by concatenation, and we denote this extension by
$\{{\mathtt a},{\mathtt b},{\mathtt c}\}^{\mathbb N}$
by concatenation, and we denote this extension by
 $\varphi $
again. The unique fixed point (of length greater than
$\varphi $
again. The unique fixed point (of length greater than
 $0$
) of
$0$
) of
 $\varphi $
is
$\varphi $
is
 $$ \begin{align*} {\mathbf A}={\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt c} {\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b} {\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt c} {\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt c}\cdots. \end{align*} $$
$$ \begin{align*} {\mathbf A}={\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt c} {\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b} {\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt c} {\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}{\mathtt a}{\mathtt c}\cdots. \end{align*} $$
This fixed point is a morphic, or substitutive, sequence [Reference Allouche and Shallit4, Ch. 7]. As a fixed point of
 $\varphi $
(without having to apply a coding of the fixed point) it is even pure morphic. The sequence
$\varphi $
(without having to apply a coding of the fixed point) it is even pure morphic. The sequence
 ${\mathbf A}$
is in fact
${\mathbf A}$
is in fact
 $2$
-automatic, which follows from Berstel [Reference Berstel7, Corollary 4]. It is a ‘hidden automatic sequence’, as treated very recently by Allouche et al. [Reference Allouche, Dekking and Queffélec1]. In fact, every automatic sequence can also be written as a coding of a fixed point of a nonuniform morphism [Reference Allouche, Shallit, Raigorodskii and Rassias6] and in this sense is a ‘hidden’ automatic sequence. We restate a corresponding
$2$
-automatic, which follows from Berstel [Reference Berstel7, Corollary 4]. It is a ‘hidden automatic sequence’, as treated very recently by Allouche et al. [Reference Allouche, Dekking and Queffélec1]. In fact, every automatic sequence can also be written as a coding of a fixed point of a nonuniform morphism [Reference Allouche, Shallit, Raigorodskii and Rassias6] and in this sense is a ‘hidden’ automatic sequence. We restate a corresponding
 $2$
-uniform substitution found by Berstel in due course. The sequence
$2$
-uniform substitution found by Berstel in due course. The sequence
 ${\mathbf A}$
, called the ternary Thue–Morse sequence (for example, in the On-Line Encyclopedia of Integer Sequences (OEIS) [Reference Sloane26, A036577]), Istrail squarefree sequence [Reference Allouche, Dekking and Queffélec1, Reference Istrail19], or vtm [Reference Blanchet-Sadri, Currie, Rampersad and Fox10], is well known. Citing Dekking [Reference Dekking14], we note that it appears in fact 12 times on the OEIS [Reference Sloane26], featuring all renamings of the letters corresponding to permutations of the sets
${\mathbf A}$
, called the ternary Thue–Morse sequence (for example, in the On-Line Encyclopedia of Integer Sequences (OEIS) [Reference Sloane26, A036577]), Istrail squarefree sequence [Reference Allouche, Dekking and Queffélec1, Reference Istrail19], or vtm [Reference Blanchet-Sadri, Currie, Rampersad and Fox10], is well known. Citing Dekking [Reference Dekking14], we note that it appears in fact 12 times on the OEIS [Reference Sloane26], featuring all renamings of the letters corresponding to permutations of the sets
 $\{0,1,2\}$
and
$\{0,1,2\}$
and
 $\{1,2,3\}$
. These 12 entries are A005679, A007413, and A036577–A036586. The sequence
$\{1,2,3\}$
. These 12 entries are A005679, A007413, and A036577–A036586. The sequence
 ${\mathbf A}$
encodes the gaps between consecutive
${\mathbf A}$
encodes the gaps between consecutive
 ${\mathtt 1}$
s in
${\mathtt 1}$
s in
 ${\mathbf t}$
[Reference Blanchet-Sadri, Currie, Rampersad and Fox10]. Thue [Reference Thue27] showed that
${\mathbf t}$
[Reference Blanchet-Sadri, Currie, Rampersad and Fox10]. Thue [Reference Thue27] showed that
 ${\mathbf A}$
is squarefree, while Rao et al. [Reference Rao, Rigo and Salimov24] later proved the stronger statement that
${\mathbf A}$
is squarefree, while Rao et al. [Reference Rao, Rigo and Salimov24] later proved the stronger statement that
 ${\mathbf A}$
even avoids
${\mathbf A}$
even avoids
 $2$
-binomial squares [Reference Rigo and Salimov25], thus settling in particular the question whether
$2$
-binomial squares [Reference Rigo and Salimov25], thus settling in particular the question whether
 $2$
-abelian squares are avoidable over a three-letter alphabet. We use the squarefreeness property in our proof of Theorem 1.1.
$2$
-abelian squares are avoidable over a three-letter alphabet. We use the squarefreeness property in our proof of Theorem 1.1.
Lemma 2.1 (Thue)
The sequence
 ${\mathbf A}$
is squarefree. That is, no factor of the form
${\mathbf A}$
is squarefree. That is, no factor of the form
 $CC$
, where C is a finite word over
$CC$
, where C is a finite word over
 $\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
of length at least
$\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
of length at least
 $1$
, appears in
$1$
, appears in
 ${\mathbf A}$
.
${\mathbf A}$
.
We have the following important relation between
 ${\mathbf A}$
and our problem.
${\mathbf A}$
and our problem.
Lemma 2.2. The Thue–Morse sequence
 ${\mathbf t}$
can be recovered from
${\mathbf t}$
can be recovered from
 ${\mathbf A}$
via the substitution
${\mathbf A}$
via the substitution
 $$ \begin{align} f:{\mathtt a}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0},\quad {\mathtt b}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0},\quad {\mathtt c}\mapsto {\mathtt 0}{\mathtt 1}, \end{align} $$
$$ \begin{align} f:{\mathtt a}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0},\quad {\mathtt b}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0},\quad {\mathtt c}\mapsto {\mathtt 0}{\mathtt 1}, \end{align} $$
by concatenation: we have
 $$ \begin{align} {\mathbf t}=f({\mathbf A}_0)f({\mathbf A}_1)\cdots. \end{align} $$
$$ \begin{align} {\mathbf t}=f({\mathbf A}_0)f({\mathbf A}_1)\cdots. \end{align} $$
We prove this in a moment. From this observation, noting also that each of the three words
 $f({\mathtt a})$
,
$f({\mathtt a})$
,
 $f({\mathtt b})$
, and
$f({\mathtt b})$
, and
 $f({\mathtt c})$
begins with
$f({\mathtt c})$
begins with
 ${\mathtt 0}{\mathtt 1}$
, we see that we can extract from
${\mathtt 0}{\mathtt 1}$
, we see that we can extract from
 ${\mathbf A}$
the sequence of gaps between occurrences of the factor
${\mathbf A}$
the sequence of gaps between occurrences of the factor
 ${\mathtt 0}{\mathtt 1}$
in
${\mathtt 0}{\mathtt 1}$
in
 $\mathbf t$
: each
$\mathbf t$
: each
 ${\mathtt a}$
yields two consecutive gaps of size
${\mathtt a}$
yields two consecutive gaps of size
 $3$
, each
$3$
, each
 ${\mathtt b}$
yields a gap of size
${\mathtt b}$
yields a gap of size
 $4$
, and each
$4$
, and each
 ${\mathtt c}$
a gap of size
${\mathtt c}$
a gap of size
 $2$
.
$2$
.
Proof of Lemma 2.2
We prove that for
 $k\geq 1$
,
$k\geq 1$
,
 $$ \begin{align} {\mathbf t}_{[0,6\cdot 2^k]}= f({\mathbf A}_0)f({\mathbf A}_1)\cdots f({\mathbf A}_{L_k}), \end{align} $$
$$ \begin{align} {\mathbf t}_{[0,6\cdot 2^k]}= f({\mathbf A}_0)f({\mathbf A}_1)\cdots f({\mathbf A}_{L_k}), \end{align} $$
where
 $L_k=3\cdot 2^{k-1}-1$
, by induction. The case
$L_k=3\cdot 2^{k-1}-1$
, by induction. The case
 $k=1$
is just the trivial identity
$k=1$
is just the trivial identity
 ${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}=f({\mathtt a})f({\mathtt b})f({\mathtt c})$
.
${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}=f({\mathtt a})f({\mathtt b})f({\mathtt c})$
.
Note that
 $\tau (f({\mathtt a}))=f({\mathtt a})f({\mathtt b})f({\mathtt c})$
,
$\tau (f({\mathtt a}))=f({\mathtt a})f({\mathtt b})f({\mathtt c})$
,
 $\tau (f({\mathtt b}))=f({\mathtt a})f({\mathtt c})$
, and
$\tau (f({\mathtt b}))=f({\mathtt a})f({\mathtt c})$
, and
 $\tau (f({\mathtt c}))=f({\mathtt b})$
. Extending f by concatenation, for convenience of notation, to words over
$\tau (f({\mathtt c}))=f({\mathtt b})$
. Extending f by concatenation, for convenience of notation, to words over
 $\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
, we obtain
$\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
, we obtain
 $\tau (f(x))=f(\varphi (x))$
for each
$\tau (f(x))=f(\varphi (x))$
for each
 $x\in \{{\mathtt a},{\mathtt b},{\mathtt c}\}$
. An application of the morphism
$x\in \{{\mathtt a},{\mathtt b},{\mathtt c}\}$
. An application of the morphism
 $\tau $
to both sides of (2-4) yields
$\tau $
to both sides of (2-4) yields
 $$ \begin{align*} \begin{aligned} {\mathbf t}_{[0,6\cdot 2^{k+1})} &=\tau(f({\mathbf A}_0))\cdots\tau(f({\mathbf A}_{L_k})) =f(\varphi({\mathbf A}_0))\cdots f(\varphi({\mathbf A}_{L_k})) \\&=f(\varphi({\mathbf A}_0\cdots{\mathbf A}_{L_k})) =f({\mathbf A}_1\cdots{\mathbf A}_{L_{k+1}}) =f({\mathbf A}_0)\cdots f({\mathbf A}_{L_{k+1}}). \end{aligned} \end{align*} $$
$$ \begin{align*} \begin{aligned} {\mathbf t}_{[0,6\cdot 2^{k+1})} &=\tau(f({\mathbf A}_0))\cdots\tau(f({\mathbf A}_{L_k})) =f(\varphi({\mathbf A}_0))\cdots f(\varphi({\mathbf A}_{L_k})) \\&=f(\varphi({\mathbf A}_0\cdots{\mathbf A}_{L_k})) =f({\mathbf A}_1\cdots{\mathbf A}_{L_{k+1}}) =f({\mathbf A}_0)\cdots f({\mathbf A}_{L_{k+1}}). \end{aligned} \end{align*} $$
Note that we see by induction that
 $\varphi ^k({\mathtt a}{\mathtt b}{\mathtt c})$
contains each of the three letters
$\varphi ^k({\mathtt a}{\mathtt b}{\mathtt c})$
contains each of the three letters
 $2^k$
times, hence the numbers
$2^k$
times, hence the numbers
 $L_k$
. This proves the lemma.
$L_k$
. This proves the lemma.
Since each of the words
 $f({\mathtt a})$
,
$f({\mathtt a})$
,
 $f({\mathtt b})$
, and
$f({\mathtt b})$
, and
 $f({\mathtt c})$
starts with
$f({\mathtt c})$
starts with
 ${\mathtt 0}{\mathtt 1}$
, the differences
${\mathtt 0}{\mathtt 1}$
, the differences
 $a_j=k_{j+1}-k_j$
between successive occurrences of
$a_j=k_{j+1}-k_j$
between successive occurrences of
 ${\mathtt 0}{\mathtt 1}$
in
${\mathtt 0}{\mathtt 1}$
in
 $\mathbf t$
are easily obtained from
$\mathbf t$
are easily obtained from
 ${\mathbf A}$
by the substitution
${\mathbf A}$
by the substitution
 $$ \begin{align} r:{\mathtt a}\mapsto {\mathtt 3}{\mathtt 3},\quad{\mathtt b}\mapsto {\mathtt 4},\quad{\mathtt c}\mapsto {\mathtt 2}. \end{align} $$
$$ \begin{align} r:{\mathtt a}\mapsto {\mathtt 3}{\mathtt 3},\quad{\mathtt b}\mapsto {\mathtt 4},\quad{\mathtt c}\mapsto {\mathtt 2}. \end{align} $$
Here each
 ${\mathtt a}$
yields two blocks
${\mathtt a}$
yields two blocks
 ${\mathtt 0}{\mathtt 1}$
, and each
${\mathtt 0}{\mathtt 1}$
, and each
 ${\mathtt b}$
or
${\mathtt b}$
or
 ${\mathtt c}$
one block.
${\mathtt c}$
one block.
Let
 ${\mathbf B}$
be the sequence of gaps between consecutive occurrences of
${\mathbf B}$
be the sequence of gaps between consecutive occurrences of
 ${\mathtt 0}{\mathtt 1}$
in the Thue–Morse sequence, and
${\mathtt 0}{\mathtt 1}$
in the Thue–Morse sequence, and
 $\check {{\mathbf B}}$
the corresponding sequence for
$\check {{\mathbf B}}$
the corresponding sequence for
 ${\mathtt 1}{\mathtt 0}$
.
${\mathtt 1}{\mathtt 0}$
.
Lemma 2.3. The sequence
 ${\mathbf B}$
is a morphic sequence, given by the substitution
${\mathbf B}$
is a morphic sequence, given by the substitution
 $\psi $
on the four letters
$\psi $
on the four letters
 ${\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}$
, together with the coding p, given by
${\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}$
, together with the coding p, given by
 $$ \begin{align} \begin{array}{lllll} \psi:&{\mathtt a}\mapsto{\mathtt a}{\bar{\mathtt a}},&{\bar{\mathtt a}}\mapsto{\mathtt b}{\mathtt c},&{\mathtt b}\mapsto{\mathtt a}{\bar{\mathtt a}}{\mathtt c},&{\mathtt c}\mapsto{\mathtt b},\\ p:&{\mathtt a}\mapsto{\mathtt 3},&{\bar{\mathtt a}}\mapsto{\mathtt 3},&{\mathtt b}\mapsto{\mathtt 4},&{\mathtt c}\mapsto{\mathtt 2}. \end{array} \end{align} $$
$$ \begin{align} \begin{array}{lllll} \psi:&{\mathtt a}\mapsto{\mathtt a}{\bar{\mathtt a}},&{\bar{\mathtt a}}\mapsto{\mathtt b}{\mathtt c},&{\mathtt b}\mapsto{\mathtt a}{\bar{\mathtt a}}{\mathtt c},&{\mathtt c}\mapsto{\mathtt b},\\ p:&{\mathtt a}\mapsto{\mathtt 3},&{\bar{\mathtt a}}\mapsto{\mathtt 3},&{\mathtt b}\mapsto{\mathtt 4},&{\mathtt c}\mapsto{\mathtt 2}. \end{array} \end{align} $$
Let
 ${\bar {\mathbf B}}$
denote the fixed point of
${\bar {\mathbf B}}$
denote the fixed point of
 $\psi $
starting with
$\psi $
starting with
 ${\mathtt a}$
.
${\mathtt a}$
.
The sequence
 $\check {\mathbf B}$
is morphic. More precisely, it is the image of
$\check {\mathbf B}$
is morphic. More precisely, it is the image of
 ${\bar {\mathbf B}}$
under the morphism
${\bar {\mathbf B}}$
under the morphism
 $$ \begin{align*} \check p:{\mathtt a}\mapsto {\mathtt 2}{\mathtt 4},\quad{\bar{\mathtt a}}\mapsto {\mathtt 3}{\mathtt 3},\quad {\mathtt b}\mapsto {\mathtt 2}{\mathtt 3}{\mathtt 3},\quad {\mathtt c}\mapsto {\mathtt 4}. \end{align*} $$
$$ \begin{align*} \check p:{\mathtt a}\mapsto {\mathtt 2}{\mathtt 4},\quad{\bar{\mathtt a}}\mapsto {\mathtt 3}{\mathtt 3},\quad {\mathtt b}\mapsto {\mathtt 2}{\mathtt 3}{\mathtt 3},\quad {\mathtt c}\mapsto {\mathtt 4}. \end{align*} $$
Note that
 ${\bar {\mathbf B}}$
is the pointwise limit of the finite words
${\bar {\mathbf B}}$
is the pointwise limit of the finite words
 $\psi ^k({\mathtt a})$
, and begins as follows:
$\psi ^k({\mathtt a})$
, and begins as follows:
 $$ \begin{align*} {\bar{\mathbf B}}={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c} {\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b} {\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c} \cdots. \end{align*} $$
$$ \begin{align*} {\bar{\mathbf B}}={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c} {\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b} {\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c} \cdots. \end{align*} $$
Proof. Let q be the morphism that replaces
 ${\mathtt a}$
by
${\mathtt a}$
by
 ${\mathtt a}{\bar {\mathtt a}}$
and leaves
${\mathtt a}{\bar {\mathtt a}}$
and leaves
 ${\mathtt b}$
and
${\mathtt b}$
and
 ${\mathtt c}$
unchanged. We show by induction on the length of a word C over
${\mathtt c}$
unchanged. We show by induction on the length of a word C over
 ${\mathtt a}{\mathtt b}{\mathtt c}$
that
${\mathtt a}{\mathtt b}{\mathtt c}$
that
 $$ \begin{align} q(\varphi(C))=\psi(q(C)). \end{align} $$
$$ \begin{align} q(\varphi(C))=\psi(q(C)). \end{align} $$
This is clear for words of length
 $1$
, since
$1$
, since
 $q(\varphi ({\mathtt a}))={\mathtt a}{\bar {\mathtt a}}{\mathtt b}{\mathtt c}=\psi (q({\mathtt a}))$
,
$q(\varphi ({\mathtt a}))={\mathtt a}{\bar {\mathtt a}}{\mathtt b}{\mathtt c}=\psi (q({\mathtt a}))$
,
 $q(\varphi ({\mathtt b}))={\mathtt a}{\bar {\mathtt a}}{\mathtt c}=\psi (q({\mathtt b}))$
, and
$q(\varphi ({\mathtt b}))={\mathtt a}{\bar {\mathtt a}}{\mathtt c}=\psi (q({\mathtt b}))$
, and
 $q(\varphi ({\mathtt c}))={\mathtt b}=\psi (q({\mathtt c}))$
. Appending a letter
$q(\varphi ({\mathtt c}))={\mathtt b}=\psi (q({\mathtt c}))$
. Appending a letter
 $x\in \{{\mathtt a},{\mathtt b},{\mathtt c}\}$
to a word C for which the identity (2-7) already holds, we obtain
$x\in \{{\mathtt a},{\mathtt b},{\mathtt c}\}$
to a word C for which the identity (2-7) already holds, we obtain
 $$ \begin{align*} \begin{aligned} q(\varphi(Cx))&=q(\varphi(C)\varphi(x))=q(\varphi(C))q(\varphi(x)) \\&=\psi(q(C))\psi(q(x))=\psi(q(C)q(x))=\psi(q(Cx)) \end{aligned} \end{align*} $$
$$ \begin{align*} \begin{aligned} q(\varphi(Cx))&=q(\varphi(C)\varphi(x))=q(\varphi(C))q(\varphi(x)) \\&=\psi(q(C))\psi(q(x))=\psi(q(C)q(x))=\psi(q(Cx)) \end{aligned} \end{align*} $$
and therefore (2-7) for C replaced by
 $Cx$
. Next, we prove by induction, using (2-7), that
$Cx$
. Next, we prove by induction, using (2-7), that
 $$ \begin{align*}q(\varphi^k({\mathtt a}))=\psi^k(q({\mathtt a})).\end{align*} $$
$$ \begin{align*}q(\varphi^k({\mathtt a}))=\psi^k(q({\mathtt a})).\end{align*} $$
Clearly, this holds for
 $k=1$
. For
$k=1$
. For
 $k\geq 2$
, we obtain
$k\geq 2$
, we obtain
 $$ \begin{align*}q(\varphi^k({\mathtt a}))= q(\varphi(\varphi^{k-1}({\mathtt a}))) =\psi(q(\varphi^{k-1}({\mathtt a}))) =\psi(\psi^{k-1}(q({\mathtt a}))) =\psi^k(q({\mathtt a})). \end{align*} $$
$$ \begin{align*}q(\varphi^k({\mathtt a}))= q(\varphi(\varphi^{k-1}({\mathtt a}))) =\psi(q(\varphi^{k-1}({\mathtt a}))) =\psi(\psi^{k-1}(q({\mathtt a}))) =\psi^k(q({\mathtt a})). \end{align*} $$
Noting that
 $q({\mathtt a})=\psi ({\mathtt a})$
and
$q({\mathtt a})=\psi ({\mathtt a})$
and
 $p\circ q=r$
, the proof of the first part of Lemma 2.3 is complete.
$p\circ q=r$
, the proof of the first part of Lemma 2.3 is complete.
We proceed to the second part, concerning
 $\check {\mathbf B}$
. Note that by Corollary 7.7.5 in [Reference Allouche and Shallit4] we only have to prove that
$\check {\mathbf B}$
. Note that by Corollary 7.7.5 in [Reference Allouche and Shallit4] we only have to prove that
 $\check {\mathbf B}=\check p({\bar {\mathbf B}})$
.
$\check {\mathbf B}=\check p({\bar {\mathbf B}})$
.
Let
 $$ \begin{align*} \check f: {\mathtt a}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0},\quad {\bar{\mathtt a}}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1},\quad {\mathtt b}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1},\quad {\mathtt c}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}, \end{align*} $$
$$ \begin{align*} \check f: {\mathtt a}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0},\quad {\bar{\mathtt a}}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1},\quad {\mathtt b}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1},\quad {\mathtt c}\mapsto {\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}, \end{align*} $$
and extend this function to words (finite or infinite) over
 $\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
by concatenation.
$\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
by concatenation.
Applying
 $\tau $
, we see by direct computation that
$\tau $
, we see by direct computation that
 $$ \begin{align*}\tau(\check f({\mathtt a}))={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1} = \check f({\mathtt a})\check f({\bar{\mathtt a}}) =\check f(\psi({\mathtt a})), \end{align*} $$
$$ \begin{align*}\tau(\check f({\mathtt a}))={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1} = \check f({\mathtt a})\check f({\bar{\mathtt a}}) =\check f(\psi({\mathtt a})), \end{align*} $$
and analogously, we get
 $\tau (\check f(x))=\check f(\psi (x))$
for each letter
$\tau (\check f(x))=\check f(\psi (x))$
for each letter
 $x\in \{{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
. Applying this letter by letter, we obtain
$x\in \{{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
. Applying this letter by letter, we obtain
 $$ \begin{align*} \tau(\check f(w))=\check f(\psi(w)) \end{align*} $$
$$ \begin{align*} \tau(\check f(w))=\check f(\psi(w)) \end{align*} $$
for every finite word over
 $\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
. By induction, we obtain
$\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
. By induction, we obtain
 $$ \begin{align*}\tau^k(\check f({\mathtt a}))=\check f(\psi^k({\mathtt a})),\end{align*} $$
$$ \begin{align*}\tau^k(\check f({\mathtt a}))=\check f(\psi^k({\mathtt a})),\end{align*} $$
using the step
 $$ \begin{align*}\tau^{k+1}(\check f({\mathtt a}))= \tau(\tau^k(\check f({\mathtt a}))) =\tau(\check f(\psi^k({\mathtt a}))) =\check f(\psi^{k+1}({\mathtt a})). \end{align*} $$
$$ \begin{align*}\tau^{k+1}(\check f({\mathtt a}))= \tau(\tau^k(\check f({\mathtt a}))) =\tau(\check f(\psi^k({\mathtt a}))) =\check f(\psi^{k+1}({\mathtt a})). \end{align*} $$
Noting that
 $\check f({\mathtt a})$
begins with
$\check f({\mathtt a})$
begins with
 ${\mathtt 0}$
, we obtain
${\mathtt 0}$
, we obtain
 ${\mathbf t}=\check f({\bar {\mathbf B}})$
. In other words, the sequence
${\mathbf t}=\check f({\bar {\mathbf B}})$
. In other words, the sequence
 ${\bar {\mathbf B}}$
yields the decomposition
${\bar {\mathbf B}}$
yields the decomposition
 ${\mathbf t}=x_0x_1\cdots $
of the Thue–Morse sequence into return words of
${\mathbf t}=x_0x_1\cdots $
of the Thue–Morse sequence into return words of
 ${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, where
${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, where
 $x_j=\check f({\bar {\mathbf B}}_j)$
. From this decomposition we can easily read off the sequence of gaps between occurrences of
$x_j=\check f({\bar {\mathbf B}}_j)$
. From this decomposition we can easily read off the sequence of gaps between occurrences of
 ${\mathtt 1}{\mathtt 0}$
, since this word appears in each of the four return words, and the first occurrence always takes place at the same position, which is
${\mathtt 1}{\mathtt 0}$
, since this word appears in each of the four return words, and the first occurrence always takes place at the same position, which is
 $2$
. In this way, we obtain the gaps
$2$
. In this way, we obtain the gaps
 $2$
and
$2$
and
 $3$
from the return word
$3$
from the return word
 $\check f({\mathtt a})$
each time
$\check f({\mathtt a})$
each time
 ${\mathtt a}$
appears in
${\mathtt a}$
appears in
 ${\bar {\mathbf B}}$
. Analogously,
${\bar {\mathbf B}}$
. Analogously,
 ${\bar {\mathtt a}}$
yields the gaps
${\bar {\mathtt a}}$
yields the gaps
 $3$
and
$3$
and
 $3$
, the letter
$3$
, the letter
 ${\mathtt b}$
the gaps
${\mathtt b}$
the gaps
 $2$
,
$2$
,
 $3$
, and
$3$
, and
 $3$
, and finally
$3$
, and finally
 ${\mathtt c}$
yields the gap
${\mathtt c}$
yields the gap
 $4$
. This proves the second part of Lemma 2.3.
$4$
. This proves the second part of Lemma 2.3.
Remark 2.4. A hint as to how to come up with the definition of
 $\psi $
can be found by combining the substitutions
$\psi $
can be found by combining the substitutions
 $\varphi $
and r, given in (2-1) and (2-5), respectively, and considering the first few words
$\varphi $
and r, given in (2-1) and (2-5), respectively, and considering the first few words
 $w_k=r(\varphi ^k({\mathtt a}))$
: we have
$w_k=r(\varphi ^k({\mathtt a}))$
: we have
 $w_1={\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}$
,
$w_1={\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}$
,
 $w_2={\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}{\mathtt 3}{\mathtt 3}{\mathtt 2}{\mathtt 4}$
,
$w_2={\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}{\mathtt 3}{\mathtt 3}{\mathtt 2}{\mathtt 4}$
,
 $w_3={\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}{\mathtt 3}{\mathtt 3}{\mathtt 2}{\mathtt 4}{\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}{\mathtt 4}{\mathtt 3}{\mathtt 3}{\mathtt 2}$
. We see that a first guess for a definition of
$w_3={\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}{\mathtt 3}{\mathtt 3}{\mathtt 2}{\mathtt 4}{\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}{\mathtt 4}{\mathtt 3}{\mathtt 3}{\mathtt 2}$
. We see that a first guess for a definition of
 $\psi $
, choosing
$\psi $
, choosing
 ${\mathtt 3}\mapsto {\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}$
, leads to the incorrect result
${\mathtt 3}\mapsto {\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}$
, leads to the incorrect result
 ${\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}{\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}\cdots $
after the next iteration; we are led to distinguishing between ‘the first letter “
${\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}{\mathtt 3}{\mathtt 3}{\mathtt 4}{\mathtt 2}\cdots $
after the next iteration; we are led to distinguishing between ‘the first letter “
 ${\mathtt 3}$
”’ and ‘the second letter “
${\mathtt 3}$
”’ and ‘the second letter “
 ${\mathtt 3}$
”’ in each occurrence of
${\mathtt 3}$
”’ in each occurrence of
 ${\mathtt 3}{\mathtt 3}$
, which is exactly what our definition of
${\mathtt 3}{\mathtt 3}$
, which is exactly what our definition of
 $\psi $
does. On the other hand, we directly obtain (2-6) by inspecting the decomposition of
$\psi $
does. On the other hand, we directly obtain (2-6) by inspecting the decomposition of
 ${\mathbf t}$
into return words of
${\mathbf t}$
into return words of
 ${\mathtt 0}{\mathtt 1}$
. (Equivalently, we can study return words of
${\mathtt 0}{\mathtt 1}$
. (Equivalently, we can study return words of
 ${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, as we did in the second part of the proof of Lemma 2.3.) We can write the image under
${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, as we did in the second part of the proof of Lemma 2.3.) We can write the image under
 $\tau $
of each return word as a concatenation of return words, which yields the desired morphism.
$\tau $
of each return word as a concatenation of return words, which yields the desired morphism.
2.2 Factors of
 ${\mathbf B}$
appearing at positions in a residue class
${\mathbf B}$
appearing at positions in a residue class

The main step in our proof of Theorem 1.1 is given by the following proposition. For completeness, we let
 $\psi ^0$
denote the identity, so that
$\psi ^0$
denote the identity, so that
 $\psi ^0(w)=w$
for all words w over
$\psi ^0(w)=w$
for all words w over
 $\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
.
$\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
.
Proposition 2.5. Let
 $\mu \ge 0$
be an integer. The sequence of indices where
$\mu \ge 0$
be an integer. The sequence of indices where
 $\psi ^{4\mu }({\mathtt a})$
appears as a factor in
$\psi ^{4\mu }({\mathtt a})$
appears as a factor in
 ${\bar {\mathbf B}}$
has nonempty intersection with every residue class
${\bar {\mathbf B}}$
has nonempty intersection with every residue class
 $a+m\mathbb Z$
, where
$a+m\mathbb Z$
, where
 $m\ge 1$
and a are integers.
$m\ge 1$
and a are integers.
In the remainder of this section, we prove this proposition. We work with the fourth iteration
 ${\sigma }=\psi ^4$
of the substitution
${\sigma }=\psi ^4$
of the substitution
 $\psi $
: we have
$\psi $
: we have
 $$ \begin{align} \begin{array}{l@{\hspace{0.4em}}l@{\hspace{1.5em}}l@{\hspace{0.4em}}l} {\sigma}({\mathtt a})&={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c},& {\sigma}({\bar{\mathtt a}})&={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b},\\ {\sigma}({\mathtt b})&={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b},& {\sigma}({\mathtt c})&={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}. \end{array} \end{align} $$
$$ \begin{align} \begin{array}{l@{\hspace{0.4em}}l@{\hspace{1.5em}}l@{\hspace{0.4em}}l} {\sigma}({\mathtt a})&={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c},& {\sigma}({\bar{\mathtt a}})&={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b},\\ {\sigma}({\mathtt b})&={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt b},& {\sigma}({\mathtt c})&={\mathtt a}{\bar{\mathtt a}}{\mathtt b}{\mathtt c}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}{\mathtt b}{\mathtt a}{\bar{\mathtt a}}{\mathtt c}. \end{array} \end{align} $$
We have the following explicit formulas for the lengths of
 ${\sigma }^k(x)$
, where
${\sigma }^k(x)$
, where
 $x\in \{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
:
$x\in \{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
:
 $$ \begin{align} \begin{aligned} a_k&:= \lvert{\sigma}^k({\mathtt a})\rvert=\lvert{\sigma}^k({\bar{\mathtt a}})\rvert=16^k,\\ b_k&:=\lvert{\sigma}^k({\mathtt b})\rvert=\frac{4\cdot16^k-1}3,\\ c_k&:=\lvert{\sigma}^k({\mathtt c})\rvert=\frac{2\cdot16^k+1}3. \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} a_k&:= \lvert{\sigma}^k({\mathtt a})\rvert=\lvert{\sigma}^k({\bar{\mathtt a}})\rvert=16^k,\\ b_k&:=\lvert{\sigma}^k({\mathtt b})\rvert=\frac{4\cdot16^k-1}3,\\ c_k&:=\lvert{\sigma}^k({\mathtt c})\rvert=\frac{2\cdot16^k+1}3. \end{aligned} \end{align} $$
The proof of this identity is based on the formula
 $$ \begin{align*} \left(\begin{matrix}4&4&4&4\\4&4&4&4\\5&5&6&5\\3&3&2&3\end{matrix}\right)^k \!\!=\left(\begin{matrix} 16^k/4&16^k/4&16^k/4&16^k/4\\ 16^k/4&16^k/4&16^k/4&16^k/4\\ (16^k-1)/3&(16^k-1)/3&(16^k+2)/3&(16^k-1)/3\\ (16^k+2)/6&(16^k+2)/6&(16^k-4)/6&(16^k+2)/6 \end{matrix}\right)\!, \end{align*} $$
$$ \begin{align*} \left(\begin{matrix}4&4&4&4\\4&4&4&4\\5&5&6&5\\3&3&2&3\end{matrix}\right)^k \!\!=\left(\begin{matrix} 16^k/4&16^k/4&16^k/4&16^k/4\\ 16^k/4&16^k/4&16^k/4&16^k/4\\ (16^k-1)/3&(16^k-1)/3&(16^k+2)/3&(16^k-1)/3\\ (16^k+2)/6&(16^k+2)/6&(16^k-4)/6&(16^k+2)/6 \end{matrix}\right)\!, \end{align*} $$
valid for
 $k\geq 1$
, which takes care of the numbers of the letters
$k\geq 1$
, which takes care of the numbers of the letters
 ${\mathtt a}$
,
${\mathtt a}$
,
 ${\bar {\mathtt a}}$
,
${\bar {\mathtt a}}$
,
 ${\mathtt b}$
, and
${\mathtt b}$
, and
 ${\mathtt c}$
in
${\mathtt c}$
in
 ${\sigma }^k({\mathtt a})$
,
${\sigma }^k({\mathtt a})$
,
 ${\sigma }^k({\bar {\mathtt a}})$
,
${\sigma }^k({\bar {\mathtt a}})$
,
 ${\sigma }^k({\mathtt b})$
, and
${\sigma }^k({\mathtt b})$
, and
 ${\sigma }^k({\mathtt c})$
. This formula can be proved easily by induction. Moreover, (2-9) also holds for
${\sigma }^k({\mathtt c})$
. This formula can be proved easily by induction. Moreover, (2-9) also holds for
 $k=0$
.
$k=0$
.
By applying
 ${\sigma }^k$
on the first line of (2-8), we see that each letter in
${\sigma }^k$
on the first line of (2-8), we see that each letter in
 $\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
is replaced by a word having the respective lengths
$\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
is replaced by a word having the respective lengths
 $a_k$
,
$a_k$
,
 $a_k$
,
$a_k$
,
 $b_k$
,
$b_k$
,
 $c_k$
. For each
$c_k$
. For each
 $\nu \geq 0$
, it follows that the factor
$\nu \geq 0$
, it follows that the factor
 $\sigma ^{\nu }({\mathtt a})$
, of length
$\sigma ^{\nu }({\mathtt a})$
, of length
 $a_{\nu }=16^{\nu }$
, can be found at the following positions in
$a_{\nu }=16^{\nu }$
, can be found at the following positions in
 ${\sigma }^{\nu +1}({\mathtt a})$
:
${\sigma }^{\nu +1}({\mathtt a})$
:
 $$ \begin{align} \begin{array}{ll} A^{(\nu,0)}:= 0,& A^{(\nu,1)}:= 4\cdot16^{\nu},\\ A^{(\nu,2)}:=8\cdot16^{\nu},& \displaystyle A^{(\nu,3)}:=12\cdot16^{\nu}+\frac{4\cdot16^{\nu}-1}3. \end{array} \end{align} $$
$$ \begin{align} \begin{array}{ll} A^{(\nu,0)}:= 0,& A^{(\nu,1)}:= 4\cdot16^{\nu},\\ A^{(\nu,2)}:=8\cdot16^{\nu},& \displaystyle A^{(\nu,3)}:=12\cdot16^{\nu}+\frac{4\cdot16^{\nu}-1}3. \end{array} \end{align} $$
We may repeat this for
 $\nu -1,\nu -2,\ldots ,\mu $
, where
$\nu -1,\nu -2,\ldots ,\mu $
, where
 $\mu \le \nu $
is a given natural number, from which we obtain the following statement. For all integers
$\mu \le \nu $
is a given natural number, from which we obtain the following statement. For all integers
 $0\leq \mu \leq \nu $
and all
$0\leq \mu \leq \nu $
and all
 $\boldsymbol \varepsilon =(\varepsilon _{\mu },\varepsilon _{\mu +1},\ldots ,\varepsilon _{\nu }) \in \{0,1,2,3\}^{\nu -\mu +1}$
, the factor
$\boldsymbol \varepsilon =(\varepsilon _{\mu },\varepsilon _{\mu +1},\ldots ,\varepsilon _{\nu }) \in \{0,1,2,3\}^{\nu -\mu +1}$
, the factor
 $\sigma ^{\mu }({\mathtt a})$
of length
$\sigma ^{\mu }({\mathtt a})$
of length
 $16^{\mu }$
can be found at the position
$16^{\mu }$
can be found at the position
 $$ \begin{align} N_{\boldsymbol\varepsilon}:= A^{(\mu,\varepsilon_{\mu})}+A^{(\mu+1,\varepsilon_{\mu+1})}+\cdots+A^{(\nu,\varepsilon_{\nu})} \end{align} $$
$$ \begin{align} N_{\boldsymbol\varepsilon}:= A^{(\mu,\varepsilon_{\mu})}+A^{(\mu+1,\varepsilon_{\mu+1})}+\cdots+A^{(\nu,\varepsilon_{\nu})} \end{align} $$
in
 ${\bar {\mathbf B}}$
. There are other positions where the factor
${\bar {\mathbf B}}$
. There are other positions where the factor
 $\sigma ^{\mu }({\mathtt a})$
appears, but for our proof it is sufficient to consider these special positions. We show that we can find one among these indices
$\sigma ^{\mu }({\mathtt a})$
appears, but for our proof it is sufficient to consider these special positions. We show that we can find one among these indices
 $N_{\boldsymbol \varepsilon }$
in a given residue class
$N_{\boldsymbol \varepsilon }$
in a given residue class
 $a+m\mathbb Z$
.
$a+m\mathbb Z$
.
Let us sketch the remainder of the proof. The case where m is even causes mild difficulties. We therefore write
 $m=2^kd$
, where d is odd, and proceed in two steps. As a first step, we find integers
$m=2^kd$
, where d is odd, and proceed in two steps. As a first step, we find integers
 $\mu $
,
$\mu $
,
 $\nu $
, and
$\nu $
, and
 $\varepsilon _{\mu },\varepsilon _{\mu +1},\ldots ,\varepsilon _{\lambda -1}\in \{0,1,2,3\}$
, such that
$\varepsilon _{\mu },\varepsilon _{\mu +1},\ldots ,\varepsilon _{\lambda -1}\in \{0,1,2,3\}$
, such that
 $N_{\varepsilon _{\mu },\varepsilon _{\mu +1},\ldots ,\varepsilon _{\lambda -1}}$
lies in any given residue class modulo
$N_{\varepsilon _{\mu },\varepsilon _{\mu +1},\ldots ,\varepsilon _{\lambda -1}}$
lies in any given residue class modulo
 $2^k$
. The second step involves refining the description by appending a sequence
$2^k$
. The second step involves refining the description by appending a sequence
 $(\varepsilon _{\lambda },\ldots ,\varepsilon _{\nu -1})\in \{0,1,2\}^{\nu -\lambda }$
. Since we exclude the digit
$(\varepsilon _{\lambda },\ldots ,\varepsilon _{\nu -1})\in \{0,1,2\}^{\nu -\lambda }$
. Since we exclude the digit
 $\varepsilon _i=3$
, and we take care that
$\varepsilon _i=3$
, and we take care that
 $16^{\mu }\geq 2^k$
, we have
$16^{\mu }\geq 2^k$
, we have
 $$ \begin{align*}N_{\varepsilon_{\mu},\ldots,\varepsilon_{\nu-1}}\equiv N_{\varepsilon_{\mu},\ldots,\varepsilon_{\lambda-1}}\bmod 2^k.\end{align*} $$
$$ \begin{align*}N_{\varepsilon_{\mu},\ldots,\varepsilon_{\nu-1}}\equiv N_{\varepsilon_{\mu},\ldots,\varepsilon_{\lambda-1}}\bmod 2^k.\end{align*} $$
We choose the integers
 $\varepsilon _j$
for
$\varepsilon _j$
for
 $\lambda \leq j<\mu $
in such a way that any given residue class modulo d (note that d is odd) is hit. Due to the excluded digit
$\lambda \leq j<\mu $
in such a way that any given residue class modulo d (note that d is odd) is hit. Due to the excluded digit
 $3$
, this is a missing digit problem, and a short argument including exponential sums finishes this step. Combining these two steps, we see that every residue class modulo
$3$
, this is a missing digit problem, and a short argument including exponential sums finishes this step. Combining these two steps, we see that every residue class modulo
 $2^kd$
is reached. We now go into the details.
$2^kd$
is reached. We now go into the details.
First step: hitting a residue class modulo
 $2^k$
$2^k$
We are interested in appearances of the initial segment
 $\sigma ^{\mu }({\mathtt a})$
in
$\sigma ^{\mu }({\mathtt a})$
in
 ${\bar {\mathbf B}}$
at positions lying in the residue class
${\bar {\mathbf B}}$
at positions lying in the residue class
 $a+2^k\mathbb Z$
. Let us assume in the following that
$a+2^k\mathbb Z$
. Let us assume in the following that
 $$ \begin{align} 16^{\mu}\geq 2^k. \end{align} $$
$$ \begin{align} 16^{\mu}\geq 2^k. \end{align} $$
This lower bound on
 $\mu $
does not cause any problems.
$\mu $
does not cause any problems.
We choose
 $\lambda>\mu $
in a moment, and we set
$\lambda>\mu $
in a moment, and we set
 $\varepsilon _{\mu }=\cdots =\varepsilon _{\lambda -1}=3$
. Let us consider the integers
$\varepsilon _{\mu }=\cdots =\varepsilon _{\lambda -1}=3$
. Let us consider the integers
 $\alpha _0:=0$
, and for
$\alpha _0:=0$
, and for
 $1\leq \ell \leq \lambda -\mu $
,
$1\leq \ell \leq \lambda -\mu $
,
 $$ \begin{align*}\alpha_{\ell}:= N_{\varepsilon_{\mu},\ldots,\varepsilon_{\mu+\ell-1}}.\end{align*} $$
$$ \begin{align*}\alpha_{\ell}:= N_{\varepsilon_{\mu},\ldots,\varepsilon_{\mu+\ell-1}}.\end{align*} $$
Assume that
 $0\leq \ell <\lambda -\mu $
. By (2-11) and (2-12), we have
$0\leq \ell <\lambda -\mu $
. By (2-11) and (2-12), we have
 $$ \begin{align*} \begin{aligned} \alpha_{\ell+1}-\alpha_{\ell} &=12\cdot 16^{\mu+\ell}+\frac{4\cdot 16^{\mu+\ell}-1}3 \equiv \frac{4\cdot 16^{\mu+\ell}-1}3\bmod 2^{\ell} \\[4pt]& \equiv \sum_{0\leq j\leq 2\mu+2\ell}4^j \bmod 2^{\ell} \equiv \sum_{0\leq j<2\mu}4^j \bmod 2^{\ell}. \end{aligned} \end{align*} $$
$$ \begin{align*} \begin{aligned} \alpha_{\ell+1}-\alpha_{\ell} &=12\cdot 16^{\mu+\ell}+\frac{4\cdot 16^{\mu+\ell}-1}3 \equiv \frac{4\cdot 16^{\mu+\ell}-1}3\bmod 2^{\ell} \\[4pt]& \equiv \sum_{0\leq j\leq 2\mu+2\ell}4^j \bmod 2^{\ell} \equiv \sum_{0\leq j<2\mu}4^j \bmod 2^{\ell}. \end{aligned} \end{align*} $$
The latter sum is an odd integer, and independent of
 $\ell $
. It follows that
$\ell $
. It follows that
 $(\alpha _{\ell })_{0\leq \ell \leq \lambda -\mu }$
is an arithmetic progression modulo
$(\alpha _{\ell })_{0\leq \ell \leq \lambda -\mu }$
is an arithmetic progression modulo
 $2^k$
, where the common difference is odd; choosing
$2^k$
, where the common difference is odd; choosing
 $\lambda \geq \mu +2^k$
, we see that
$\lambda \geq \mu +2^k$
, we see that
 $(\alpha _{\ell })_{0\leq \ell <\lambda -\mu }$
hits every residue class modulo
$(\alpha _{\ell })_{0\leq \ell <\lambda -\mu }$
hits every residue class modulo
 $2^k$
. We summarize the first step in the following lemma.
$2^k$
. We summarize the first step in the following lemma.
Lemma 2.6. Let
 $k\geq 0$
and
$k\geq 0$
and
 $\mu \geq k/4$
, and choose
$\mu \geq k/4$
, and choose
 $\varepsilon _{\mu +\ell }=3$
for
$\varepsilon _{\mu +\ell }=3$
for
 $\ell \ge 0$
. The integers
$\ell \ge 0$
. The integers
 $N_{\varepsilon _{\mu },\ldots ,\varepsilon _{\lambda -1}}$
hit every residue class modulo
$N_{\varepsilon _{\mu },\ldots ,\varepsilon _{\lambda -1}}$
hit every residue class modulo
 $2^k$
, as
$2^k$
, as
 $\lambda $
runs through the integers
$\lambda $
runs through the integers
 $\geq \mu $
.
$\geq \mu $
.
Second step: a discrete Cantor set–missing digits
We follow the paper [Reference Erdős, Mauduit and Sárközy17] by Erdős et al., who studied integers with missing digits in residue classes. Let
 ${\mathcal W}_{\lambda }$
be the set of nonnegative multiples of
${\mathcal W}_{\lambda }$
be the set of nonnegative multiples of
 $16^{\lambda }$
having only the digits
$16^{\lambda }$
having only the digits
 $0,4$
, and
$0,4$
, and
 $8$
in their base-
$8$
in their base-
 $16$
expansion. Set
$16$
expansion. Set
 $$ \begin{align*}U(\alpha)=\frac 13\sum_{0\leq k\leq 2}\operatorname{{\mathrm{e}}}(4k\alpha)\quad\mbox{and}\quad G(\alpha,\lambda,\nu)=\frac1{3^{\nu-\lambda}}\sum_{\substack{0\leq j<16^{\nu}\\ j\in {\mathcal W}}} \operatorname{{\mathrm{e}}}({\kern1.5pt}j\alpha), \end{align*} $$
$$ \begin{align*}U(\alpha)=\frac 13\sum_{0\leq k\leq 2}\operatorname{{\mathrm{e}}}(4k\alpha)\quad\mbox{and}\quad G(\alpha,\lambda,\nu)=\frac1{3^{\nu-\lambda}}\sum_{\substack{0\leq j<16^{\nu}\\ j\in {\mathcal W}}} \operatorname{{\mathrm{e}}}({\kern1.5pt}j\alpha), \end{align*} $$
where
 $\operatorname {{\mathrm {e}}}(x)=\exp (2\pi i x)$
. Note that the elements
$\operatorname {{\mathrm {e}}}(x)=\exp (2\pi i x)$
. Note that the elements
 $j\in {\mathcal W}_{\lambda }$
have the form
$j\in {\mathcal W}_{\lambda }$
have the form
 $j=\sum _{\lambda \leq k<\eta }4\,\varepsilon _k16^k$
, where
$j=\sum _{\lambda \leq k<\eta }4\,\varepsilon _k16^k$
, where
 $\eta \geq 0$
and
$\eta \geq 0$
and
 $\varepsilon _k\in \{0,1,2\}$
for
$\varepsilon _k\in \{0,1,2\}$
for
 $\lambda \leq k<\eta $
. In particular,
$\lambda \leq k<\eta $
. In particular,
 ${\mathcal W}_{\lambda }\cap [0,16^{\eta })$
has
${\mathcal W}_{\lambda }\cap [0,16^{\eta })$
has
 $3^{\eta -\lambda }$
elements for
$3^{\eta -\lambda }$
elements for
 $\eta \geq \lambda $
. We obtain
$\eta \geq \lambda $
. We obtain
 $$ \begin{align} G(\alpha,\lambda,\nu)&= \frac 1{3^{\nu-\lambda}} \hspace{-1em} \sum_{(\varepsilon_{\lambda},\ldots,\varepsilon_{\nu-1})\in\{1,2,3\}^{\nu-\lambda}} \hspace{-1em} \operatorname{{\mathrm{e}}}(4\,\varepsilon_{\lambda} 16^{\lambda}\alpha+\cdots+4\,\varepsilon_{\nu-1}16^{\nu-1}\alpha) \nonumber\\&= \prod_{\lambda\leq r<\nu} \tfrac 13(\operatorname{{\mathrm{e}}}(0\cdot 16^r\alpha)+\operatorname{{\mathrm{e}}}(4\cdot 16^r\alpha)+\operatorname{{\mathrm{e}}}(8\cdot 16^r\alpha)) \nonumber\\&= \prod_{\lambda\leq r<\nu} U(16^r\alpha). \end{align} $$
$$ \begin{align} G(\alpha,\lambda,\nu)&= \frac 1{3^{\nu-\lambda}} \hspace{-1em} \sum_{(\varepsilon_{\lambda},\ldots,\varepsilon_{\nu-1})\in\{1,2,3\}^{\nu-\lambda}} \hspace{-1em} \operatorname{{\mathrm{e}}}(4\,\varepsilon_{\lambda} 16^{\lambda}\alpha+\cdots+4\,\varepsilon_{\nu-1}16^{\nu-1}\alpha) \nonumber\\&= \prod_{\lambda\leq r<\nu} \tfrac 13(\operatorname{{\mathrm{e}}}(0\cdot 16^r\alpha)+\operatorname{{\mathrm{e}}}(4\cdot 16^r\alpha)+\operatorname{{\mathrm{e}}}(8\cdot 16^r\alpha)) \nonumber\\&= \prod_{\lambda\leq r<\nu} U(16^r\alpha). \end{align} $$
The purpose of this section is to prove the following lemma.
Lemma 2.7. Let
 $\lambda \geq 0$
be an integer, and
$\lambda \geq 0$
be an integer, and
 $a,d$
integers such that
$a,d$
integers such that
 $d\geq 1$
is odd. Then
$d\geq 1$
is odd. Then
 ${\mathcal W}_{\lambda }\cap (a+d\,\mathbb Z)$
contains infinitely many elements.
${\mathcal W}_{\lambda }\cap (a+d\,\mathbb Z)$
contains infinitely many elements.
In order to prove this, we first show that it is sufficient to prove the following auxiliary result (compare [Reference Erdős, Mauduit and Sárközy17, formula (4.3)]).
Lemma 2.8. Assume that
 $d\geq 1$
is an odd integer, and
$d\geq 1$
is an odd integer, and
 $\ell \in \{1,\ldots ,d-1\}$
. Let
$\ell \in \{1,\ldots ,d-1\}$
. Let
 $\lambda \geq 0$
be an integer. Then
$\lambda \geq 0$
be an integer. Then
 $$ \begin{align*}\lim_{\nu\rightarrow \infty}G\bigg(\frac \ell d,\lambda,\nu\bigg)=0.\end{align*} $$
$$ \begin{align*}\lim_{\nu\rightarrow \infty}G\bigg(\frac \ell d,\lambda,\nu\bigg)=0.\end{align*} $$
In fact, by the orthogonality relation
 $$ \begin{align*} \frac 1d\sum_{0\leq n<d}\operatorname{{\mathrm{e}}}(nk/d)=\left\{\!\begin{array}{l} \!1\quad\mbox{if }d\mid k,\\ \!0\quad\mbox{otherwise}, \end{array}\right. \end{align*} $$
$$ \begin{align*} \frac 1d\sum_{0\leq n<d}\operatorname{{\mathrm{e}}}(nk/d)=\left\{\!\begin{array}{l} \!1\quad\mbox{if }d\mid k,\\ \!0\quad\mbox{otherwise}, \end{array}\right. \end{align*} $$
we have
 $$ \begin{align} & \frac1{3^{\nu-\lambda}} \#\{ 0\leq j<16^{\nu}: j\in {\mathcal W}, j\equiv a\bmod d \} -\frac 1d \nonumber\\&\quad= \frac 1d \frac1{3^{\nu-\lambda}} \sum_{0\leq \ell<d} \sum_{\substack{0\leq j<16^{\nu}\\ j\in{\mathcal W}}} \operatorname{{\mathrm{e}}}(\ell({\kern1.5pt}j-a)/d) -\frac 1d\nonumber\\ &\quad= \frac 1d \sum_{1\leq \ell<d} \operatorname{{\mathrm{e}}}(-\ell a/d) \frac1{3^{\nu-\lambda}} \sum_{\substack{0\leq j<16^{\nu}\\ j\in{\mathcal W}}} \operatorname{{\mathrm{e}}}({\kern1.5pt}j\ell/d) \leq \sum_{1\leq \ell<d} \bigg\lvert G\bigg(\frac \ell d,\lambda,\nu\bigg) \bigg\rvert. \end{align} $$
$$ \begin{align} & \frac1{3^{\nu-\lambda}} \#\{ 0\leq j<16^{\nu}: j\in {\mathcal W}, j\equiv a\bmod d \} -\frac 1d \nonumber\\&\quad= \frac 1d \frac1{3^{\nu-\lambda}} \sum_{0\leq \ell<d} \sum_{\substack{0\leq j<16^{\nu}\\ j\in{\mathcal W}}} \operatorname{{\mathrm{e}}}(\ell({\kern1.5pt}j-a)/d) -\frac 1d\nonumber\\ &\quad= \frac 1d \sum_{1\leq \ell<d} \operatorname{{\mathrm{e}}}(-\ell a/d) \frac1{3^{\nu-\lambda}} \sum_{\substack{0\leq j<16^{\nu}\\ j\in{\mathcal W}}} \operatorname{{\mathrm{e}}}({\kern1.5pt}j\ell/d) \leq \sum_{1\leq \ell<d} \bigg\lvert G\bigg(\frac \ell d,\lambda,\nu\bigg) \bigg\rvert. \end{align} $$
If
 $G(\ell /d,\lambda ,\nu )$
converges to zero as
$G(\ell /d,\lambda ,\nu )$
converges to zero as
 $\nu \rightarrow \infty $
, for all
$\nu \rightarrow \infty $
, for all
 $\ell \in \{1,\ldots ,d-1\}$
, the last sum in (2-14) is eventually smaller than
$\ell \in \{1,\ldots ,d-1\}$
, the last sum in (2-14) is eventually smaller than
 $1/d$
. Consequently, the number of
$1/d$
. Consequently, the number of
 $j\in \{0,\ldots,16^\nu-1\}$
such that
$j\in \{0,\ldots,16^\nu-1\}$
such that
 $j\in\mathcal W_\lambda$
and
$j\in\mathcal W_\lambda$
and
 $j\equiv a\bmod d$
diverges to
$j\equiv a\bmod d$
diverges to
 $\infty$
as
$\infty$
as
 $\nu$
approaches
$\nu$
approaches
 $\infty$
.
$\infty$
.
Proof of Lemma 2.8
By (2-14), we have to show that the product
 $$ \begin{align} \prod_{\lambda\leq r<\nu}U(16^r\ell/d) = \prod_{\lambda\leq r<\nu}(1+\operatorname{{\mathrm{e}}}(4\cdot 16^r\ell/d)+\operatorname{{\mathrm{e}}}(8\cdot 16^r\ell/d)) \end{align} $$
$$ \begin{align} \prod_{\lambda\leq r<\nu}U(16^r\ell/d) = \prod_{\lambda\leq r<\nu}(1+\operatorname{{\mathrm{e}}}(4\cdot 16^r\ell/d)+\operatorname{{\mathrm{e}}}(8\cdot 16^r\ell/d)) \end{align} $$
converges to zero as
 $\nu \rightarrow \infty $
. To this end, we use the following lemma [Reference Delange15] by Delange.
$\nu \rightarrow \infty $
. To this end, we use the following lemma [Reference Delange15] by Delange.
Lemma 2.9 (Delange)
Assume that
 $q\geq 2$
is an integer and
$q\geq 2$
is an integer and
 $z_1,\ldots ,z_{q-1}$
are complex numbers such that
$z_1,\ldots ,z_{q-1}$
are complex numbers such that
 $\lvert z_j\rvert \leq 1$
for
$\lvert z_j\rvert \leq 1$
for
 $1\leq j<q$
. Then
$1\leq j<q$
. Then
 $$ \begin{align*}\bigg\lvert \frac1q(1+z_1+\cdots+z_{q-1})\bigg\rvert\leq 1-\frac1{2q}\max_{1\leq j<q}(1-{\operatorname{{\mathrm{Re}}}}\ z_j).\end{align*} $$
$$ \begin{align*}\bigg\lvert \frac1q(1+z_1+\cdots+z_{q-1})\bigg\rvert\leq 1-\frac1{2q}\max_{1\leq j<q}(1-{\operatorname{{\mathrm{Re}}}}\ z_j).\end{align*} $$
Since d is odd and
 $1\leq \ell <d$
, the integer
$1\leq \ell <d$
, the integer
 $4k16^r\ell $
is not a multiple of d for
$4k16^r\ell $
is not a multiple of d for
 $k\in \{1,2\}$
. It follows that
$k\in \{1,2\}$
. It follows that
 $\operatorname {{\mathrm {Re}}} \operatorname {{\mathrm {e}}}(4k16^r\ell /d) \leq 1-\tilde \varepsilon $
for some
$\operatorname {{\mathrm {Re}}} \operatorname {{\mathrm {e}}}(4k16^r\ell /d) \leq 1-\tilde \varepsilon $
for some
 $\tilde \varepsilon>0$
only depending on d.
$\tilde \varepsilon>0$
only depending on d.
Therefore each factor in (2-13) is smaller than
 $1-\varepsilon $
, where
$1-\varepsilon $
, where
 $\varepsilon>0$
does not depend on r. Consequently, by Lemma 2.9 the product (2-15) converges to zero. Lemma 2.8, and therefore Lemma 2.7, is proved.
$\varepsilon>0$
does not depend on r. Consequently, by Lemma 2.9 the product (2-15) converges to zero. Lemma 2.8, and therefore Lemma 2.7, is proved.
Now we combine the two steps, corresponding to the cases (i)
 $2^k$
and (ii) d odd.
$2^k$
and (ii) d odd.
Let
 $k\geq 0$
and
$k\geq 0$
and
 $d\geq 1$
be integers, and d odd. We are interested in a residue class
$d\geq 1$
be integers, and d odd. We are interested in a residue class
 $a+2^kd\,\mathbb Z$
, where
$a+2^kd\,\mathbb Z$
, where
 $a\in \mathbb Z$
. Choose
$a\in \mathbb Z$
. Choose
 $$ \begin{align*}a^{(1)}:= a\bmod 2^k\in\{0,\ldots,2^k-1\}.\end{align*} $$
$$ \begin{align*}a^{(1)}:= a\bmod 2^k\in\{0,\ldots,2^k-1\}.\end{align*} $$
Choose
 $\mu $
large enough such that
$\mu $
large enough such that
 $16^{\mu }\geq 2^k$
. By Lemma 2.6 there exists
$16^{\mu }\geq 2^k$
. By Lemma 2.6 there exists
 $\lambda \geq \mu $
such that
$\lambda \geq \mu $
such that
 $$ \begin{align*}\kappa^{(1)}\equiv a^{(1)}\bmod 2^k,\end{align*} $$
$$ \begin{align*}\kappa^{(1)}\equiv a^{(1)}\bmod 2^k,\end{align*} $$
where
 $\kappa ^{(1)}:= N_{\varepsilon _{\mu },\ldots ,\varepsilon _{\lambda -1}}$
and
$\kappa ^{(1)}:= N_{\varepsilon _{\mu },\ldots ,\varepsilon _{\lambda -1}}$
and
 $\varepsilon _{\ell }=3$
for
$\varepsilon _{\ell }=3$
for
 $\mu \leq \ell <\lambda $
. Next, choose
$\mu \leq \ell <\lambda $
. Next, choose
 $$ \begin{align*}a^{(2)}:= (a-\kappa^{(1)})\bmod d.\end{align*} $$
$$ \begin{align*}a^{(2)}:= (a-\kappa^{(1)})\bmod d.\end{align*} $$
By Lemma 2.7, the set
 ${\mathcal W}_{\lambda }\cap (a^{(2)}+d\,\mathbb Z)$
is not empty. Let
${\mathcal W}_{\lambda }\cap (a^{(2)}+d\,\mathbb Z)$
is not empty. Let
 $\sum _{\lambda \leq \ell <\nu }4\,\varepsilon _{\ell }16^{\ell }$
be an element, where
$\sum _{\lambda \leq \ell <\nu }4\,\varepsilon _{\ell }16^{\ell }$
be an element, where
 $\varepsilon _{\ell }\in \{0,1,2\}$
for
$\varepsilon _{\ell }\in \{0,1,2\}$
for
 $\lambda \leq \ell <\nu $
. By (2-11) we have
$\lambda \leq \ell <\nu $
. By (2-11) we have
 $$ \begin{align*} \kappa:= N_{\varepsilon_{\mu},\ldots,\varepsilon_{\lambda-1},\varepsilon_{\lambda},\ldots,\varepsilon_{\nu-1}} &= \kappa^{(1)}+\kappa^{(2)}, \end{align*} $$
$$ \begin{align*} \kappa:= N_{\varepsilon_{\mu},\ldots,\varepsilon_{\lambda-1},\varepsilon_{\lambda},\ldots,\varepsilon_{\nu-1}} &= \kappa^{(1)}+\kappa^{(2)}, \end{align*} $$
where
 $$ \begin{align*} \kappa^{(2)}:= N_{\varepsilon_{\lambda},\ldots,\varepsilon_{\nu-1}}. \end{align*} $$
$$ \begin{align*} \kappa^{(2)}:= N_{\varepsilon_{\lambda},\ldots,\varepsilon_{\nu-1}}. \end{align*} $$
The integer
 $\kappa ^{(1)}$
lies in the residue class
$\kappa ^{(1)}$
lies in the residue class
 $a^{(1)}+2^k\mathbb Z$
by construction, while
$a^{(1)}+2^k\mathbb Z$
by construction, while
 $\kappa ^{(2)}$
is divisible by
$\kappa ^{(2)}$
is divisible by
 $2^k$
, as no digit among
$2^k$
, as no digit among
 $\varepsilon _{\lambda },\ldots ,\varepsilon _{\nu -1}$
equals
$\varepsilon _{\lambda },\ldots ,\varepsilon _{\nu -1}$
equals
 $3$
. It follows that
$3$
. It follows that
 $\kappa \in a^{(1)}+2^k\mathbb Z=a+2^k\mathbb Z$
. Moreover, by (2-10),
$\kappa \in a^{(1)}+2^k\mathbb Z=a+2^k\mathbb Z$
. Moreover, by (2-10),
 $$ \begin{align*}\kappa^{(2)}=\sum_{\lambda\leq \ell<\nu}4\,\varepsilon_{\ell}16^{\ell}\in a^{(2)}+d\,\mathbb Z,\end{align*} $$
$$ \begin{align*}\kappa^{(2)}=\sum_{\lambda\leq \ell<\nu}4\,\varepsilon_{\ell}16^{\ell}\in a^{(2)}+d\,\mathbb Z,\end{align*} $$
hence
 $\kappa =\kappa ^{(1)}+\kappa ^{(2)} \equiv \kappa ^{(1)}+(a-\kappa ^{(1)})\equiv a\bmod d$
.
$\kappa =\kappa ^{(1)}+\kappa ^{(2)} \equiv \kappa ^{(1)}+(a-\kappa ^{(1)})\equiv a\bmod d$
.
Summarizing, we have
 $\kappa \in (a+2^k\mathbb Z)\cap (a+d\,\mathbb Z)$
. Since
$\kappa \in (a+2^k\mathbb Z)\cap (a+d\,\mathbb Z)$
. Since
 $2^k$
and d are coprime, which implies
$2^k$
and d are coprime, which implies
 $2^k\mathbb Z\cap d\,\mathbb Z=2^kd\,\mathbb Z$
, we have
$2^k\mathbb Z\cap d\,\mathbb Z=2^kd\,\mathbb Z$
, we have
 $(a+2^k\mathbb Z)\cap (a+d\,\mathbb Z)=a+2^kd\,\mathbb Z$
(applying a shift by a) and therefore
$(a+2^k\mathbb Z)\cap (a+d\,\mathbb Z)=a+2^kd\,\mathbb Z$
(applying a shift by a) and therefore
 $\kappa \in a+2^kd\,\mathbb Z$
. This finishes the proof of Proposition 2.5.
$\kappa \in a+2^kd\,\mathbb Z$
. This finishes the proof of Proposition 2.5.
2.3 Nonautomaticity of
$\mathbf B$

In order to prove that
 $\mathbf B$
is not automatic, we use the characterization by the k-kernel: a sequence
$\mathbf B$
is not automatic, we use the characterization by the k-kernel: a sequence
 $(a_n)_{n\geq 0}$
is k-automatic if and only if the set
$(a_n)_{n\geq 0}$
is k-automatic if and only if the set
 $$ \begin{align} \{(a_{\ell+k^jn})_{n\geq 0}: j\geq 0, 0\leq \ell<k^j\} \end{align} $$
$$ \begin{align} \{(a_{\ell+k^jn})_{n\geq 0}: j\geq 0, 0\leq \ell<k^j\} \end{align} $$
is finite.
We are now in a position to prove that any two arithmetic subsequences of
 ${\mathbf B}$
with the same modulus m and different shifts
${\mathbf B}$
with the same modulus m and different shifts
 $\ell _1$
,
$\ell _1$
,
 $\ell _2$
are different: the sequences
$\ell _2$
are different: the sequences
 $({\mathbf B}(\ell _1+nm))_{n\geq 0}$
and
$({\mathbf B}(\ell _1+nm))_{n\geq 0}$
and
 $({\mathbf B}(\ell _2+nm))_{n\geq 0}$
cannot be equal. This proves, in particular, that the k-kernel is infinite and thus nonautomaticity of the gap sequence for
$({\mathbf B}(\ell _2+nm))_{n\geq 0}$
cannot be equal. This proves, in particular, that the k-kernel is infinite and thus nonautomaticity of the gap sequence for
 ${\mathtt 0}{\mathtt 1}$
.
${\mathtt 0}{\mathtt 1}$
.
Let us assume, in order to obtain a contradiction, that the sequence
 ${\mathbf B}$
contains two identical arithmetic subsequences with common differences equal to m, indexed by
${\mathbf B}$
contains two identical arithmetic subsequences with common differences equal to m, indexed by
 $n\mapsto \ell _1+nm$
and
$n\mapsto \ell _1+nm$
and
 $n\mapsto \ell _2+nm$
respectively, where
$n\mapsto \ell _2+nm$
respectively, where
 $\ell _1<\ell _2$
. Let
$\ell _1<\ell _2$
. Let
 $r=\ell _2-\ell _1$
, and choose
$r=\ell _2-\ell _1$
, and choose
 $\mu $
large enough such that
$\mu $
large enough such that
 $16^{\mu }\geq 2r$
. By Proposition 2.5, the block
$16^{\mu }\geq 2r$
. By Proposition 2.5, the block
 $\sigma ^{\mu }({\mathtt a})$
appears in
$\sigma ^{\mu }({\mathtt a})$
appears in
 ${\bar {\mathbf B}}$
at positions that hit each residue class. In particular, for each
${\bar {\mathbf B}}$
at positions that hit each residue class. In particular, for each
 $s\in \{0,\ldots ,r-1\}$
, we choose the residue class
$s\in \{0,\ldots ,r-1\}$
, we choose the residue class
 $\ell _1-s+m\mathbb Z$
, and we can find an index n such that
$\ell _1-s+m\mathbb Z$
, and we can find an index n such that
 $\sigma ^{\mu }({\mathtt a})$
appears at position
$\sigma ^{\mu }({\mathtt a})$
appears at position
 $\ell _1-s+nm$
in
$\ell _1-s+nm$
in
 ${\bar {\mathbf B}}$
. Since
${\bar {\mathbf B}}$
. Since
 $16^m\geq 2r>s$
, this means that
$16^m\geq 2r>s$
, this means that
 $\ell _1+mn$
hits the
$\ell _1+mn$
hits the
 $s\, $
th letter in
$s\, $
th letter in
 $\sigma ^{\mu }({\mathtt a})$
, or in symbols,
$\sigma ^{\mu }({\mathtt a})$
, or in symbols,
 $$ \begin{align*}{\bar{\mathbf B}}_{\ell_1+nm}=\sigma^{\mu}({\mathtt a})\rvert_s.\end{align*} $$
$$ \begin{align*}{\bar{\mathbf B}}_{\ell_1+nm}=\sigma^{\mu}({\mathtt a})\rvert_s.\end{align*} $$
Since
 $s+r$
is still in the range
$s+r$
is still in the range
 $[0,16^{\mu })$
, we also have
$[0,16^{\mu })$
, we also have
 $$ \begin{align*}{\bar{\mathbf B}}_{\ell_2+nm}=\sigma^{\mu}({\mathtt a})\rvert_{s+r}\end{align*} $$
$$ \begin{align*}{\bar{\mathbf B}}_{\ell_2+nm}=\sigma^{\mu}({\mathtt a})\rvert_{s+r}\end{align*} $$
for the same index n. Applying the coding p defined in (2-6), and our equality assumption, we see that
 $$ \begin{align*} {\mathbf B}_s= p(\sigma^{\mu}({\mathtt a})\rvert_s)= {\mathbf B}_{\ell_1+nm}={\mathbf B}_{\ell_2+nm}= p(\sigma^{\mu}({\mathtt a})\rvert_{s+r})={\mathbf B}_{s+r}.\end{align*} $$
$$ \begin{align*} {\mathbf B}_s= p(\sigma^{\mu}({\mathtt a})\rvert_s)= {\mathbf B}_{\ell_1+nm}={\mathbf B}_{\ell_2+nm}= p(\sigma^{\mu}({\mathtt a})\rvert_{s+r})={\mathbf B}_{s+r}.\end{align*} $$
Carrying this out for all
 $s\in \{0,\ldots ,r-1\}$
, we see that the first
$s\in \{0,\ldots ,r-1\}$
, we see that the first
 $2r$
terms of
$2r$
terms of
 ${\mathbf B}$
form a square. Now there are two cases to consider.
${\mathbf B}$
form a square. Now there are two cases to consider.
The case
 $r=1$
. Assume that
$r=1$
. Assume that
 ${\mathbf B}_{\ell _1+nm}={\mathbf B}_{\ell _1+1+nm}$
for all
${\mathbf B}_{\ell _1+nm}={\mathbf B}_{\ell _1+1+nm}$
for all
 $n\geq 0$
. By Proposition 2.5, the positions where the prefix
$n\geq 0$
. By Proposition 2.5, the positions where the prefix
 $\mathtt {3342}={\mathbf B}_0{\mathbf B}_1{\mathbf B}_2{\mathbf B}_3$
appears as a factor in
$\mathtt {3342}={\mathbf B}_0{\mathbf B}_1{\mathbf B}_2{\mathbf B}_3$
appears as a factor in
 ${\mathbf B}$
hit every residue class. In particular, there is an index n such that the block
${\mathbf B}$
hit every residue class. In particular, there is an index n such that the block
 $\mathtt {3342}$
can be found at position
$\mathtt {3342}$
can be found at position
 $\ell _1-1+nm$
in
$\ell _1-1+nm$
in
 ${\mathbf B}$
. This implies
${\mathbf B}$
. This implies
 $\mathtt {3}={\mathbf B}_1={\mathbf B}_{\ell _1+nm}={\mathbf B}_{\ell _1+1+nm}={\mathbf B}_2=\mathtt {4}$
, a contradiction.
$\mathtt {3}={\mathbf B}_1={\mathbf B}_{\ell _1+nm}={\mathbf B}_{\ell _1+1+nm}={\mathbf B}_2=\mathtt {4}$
, a contradiction.
The case
 $r\ge 2$
. In this case we resort to the fact, proved below, that
$r\ge 2$
. In this case we resort to the fact, proved below, that
 ${\mathbf B}$
does not contain squares of length greater than
${\mathbf B}$
does not contain squares of length greater than
 $2$
. Therefore we get a contradiction also in this case. In order to complete the proof that
$2$
. Therefore we get a contradiction also in this case. In order to complete the proof that
 ${\mathbf B}$
is not automatic, it remains to prove (the second part of) the following result.
${\mathbf B}$
is not automatic, it remains to prove (the second part of) the following result.
Lemma 2.10. The infinite word
 ${\bar {\mathbf B}}$
is squarefree. The word
${\bar {\mathbf B}}$
is squarefree. The word
 ${\mathbf B}$
does not contain squares of length greater than
${\mathbf B}$
does not contain squares of length greater than
 $2$
.
$2$
.
Proof. We begin with the first statement. Note first that, by the morphism (2-5), letters ‘
 ${\mathtt 3}$
’ in
${\mathtt 3}$
’ in
 ${\mathbf B}$
appear in pairs; moreover, the squarefreeness of
${\mathbf B}$
appear in pairs; moreover, the squarefreeness of
 ${\mathbf A}$
implies that there are no runs of three or more
${\mathbf A}$
implies that there are no runs of three or more
 ${\mathtt 3}$
s. This implies that the morphism r defined in (2-5) can be ‘reversed’ in the sense that
${\mathtt 3}$
s. This implies that the morphism r defined in (2-5) can be ‘reversed’ in the sense that
 ${\mathbf A}$
can be restored from
${\mathbf A}$
can be restored from
 ${\mathbf B}$
by the (unambiguous) rule
${\mathbf B}$
by the (unambiguous) rule
 $\tilde r:{\mathtt 3}{\mathtt 3}\mapsto {\mathtt a}$
,
$\tilde r:{\mathtt 3}{\mathtt 3}\mapsto {\mathtt a}$
,
 ${\mathtt 4}\mapsto {\mathtt b}$
,
${\mathtt 4}\mapsto {\mathtt b}$
,
 ${\mathtt 2}\mapsto {\mathtt c}$
. Also,
${\mathtt 2}\mapsto {\mathtt c}$
. Also,
 ${\bar {\mathbf B}}$
can be restored from
${\bar {\mathbf B}}$
can be restored from
 ${\mathbf B}$
by the (unambiguous) rule
${\mathbf B}$
by the (unambiguous) rule
 ${\mathtt 3}{\mathtt 3}\mapsto {\mathtt a}{\bar {\mathtt a}}$
,
${\mathtt 3}{\mathtt 3}\mapsto {\mathtt a}{\bar {\mathtt a}}$
,
 ${\mathtt 4}\mapsto {\mathtt b}$
,
${\mathtt 4}\mapsto {\mathtt b}$
,
 ${\mathtt 2}\mapsto {\mathtt c}$
, thus reversing the effect on
${\mathtt 2}\mapsto {\mathtt c}$
, thus reversing the effect on
 ${\bar {\mathbf B}}$
of the morphism p defined in (2-6). In particular, since
${\bar {\mathbf B}}$
of the morphism p defined in (2-6). In particular, since
 ${\mathbf A}$
is squarefree, each occurrence of the factor
${\mathbf A}$
is squarefree, each occurrence of the factor
 ${\mathtt a}{\bar {\mathtt a}}$
in
${\mathtt a}{\bar {\mathtt a}}$
in
 ${\bar {\mathbf B}}$
is bordered by symbols from the set
${\bar {\mathbf B}}$
is bordered by symbols from the set
 $\{{\mathtt b},{\mathtt c}\}$
(where of course the first occurrence at
$\{{\mathtt b},{\mathtt c}\}$
(where of course the first occurrence at
 $0$
is not bordered on the left by another symbol).
$0$
is not bordered on the left by another symbol).
Assume, in order to obtain a contradiction, that the square
 $CC$
is a factor of
$CC$
is a factor of
 ${\bar {\mathbf B}}$
. We distinguish between two cases.
${\bar {\mathbf B}}$
. We distinguish between two cases.
The case
 $\lvert C\rvert =1$
. Let C consist of a single symbol
$\lvert C\rvert =1$
. Let C consist of a single symbol
 $x\in \{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
. The squarefreeness of
$x\in \{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
. The squarefreeness of
 ${\mathbf A}$
forbids
${\mathbf A}$
forbids
 $x\in \{{\mathtt b},{\mathtt c}\}$
; moreover, we saw a moment ago that
$x\in \{{\mathtt b},{\mathtt c}\}$
; moreover, we saw a moment ago that
 ${\mathtt a}$
and
${\mathtt a}$
and
 ${\bar {\mathtt a}}$
may only appear together, bordered by symbols
${\bar {\mathtt a}}$
may only appear together, bordered by symbols
 $\in \{{\mathtt b},{\mathtt c}\}$
. This excludes the possibility
$\in \{{\mathtt b},{\mathtt c}\}$
. This excludes the possibility
 $x\in \{{\mathtt a},{\bar {\mathtt a}}\}$
, therefore this case leads to a contradiction.
$x\in \{{\mathtt a},{\bar {\mathtt a}}\}$
, therefore this case leads to a contradiction.
The case
 $\lvert C\rvert \geq 2$
. There are two subcases to consider. (i) Assume that C begins with
$\lvert C\rvert \geq 2$
. There are two subcases to consider. (i) Assume that C begins with
 ${\bar {\mathtt a}}$
. In this case, C has to end with
${\bar {\mathtt a}}$
. In this case, C has to end with
 ${\mathtt a}$
: the concatenation
${\mathtt a}$
: the concatenation
 $CC$
has to be a factor of
$CC$
has to be a factor of
 ${\bar {\mathbf B}}$
, and therefore the symbol
${\bar {\mathbf B}}$
, and therefore the symbol
 ${\bar {\mathtt a}}$
at the start of the second ‘C’ has to be preceded by a symbol
${\bar {\mathtt a}}$
at the start of the second ‘C’ has to be preceded by a symbol
 ${\mathtt a}$
. Analogously, each occurrence of the word
${\mathtt a}$
. Analogously, each occurrence of the word
 $CC$
is immediately preceded by
$CC$
is immediately preceded by
 ${\mathtt a}$
, and followed by
${\mathtt a}$
, and followed by
 ${\bar {\mathtt a}}$
. That is,
${\bar {\mathtt a}}$
. That is,
 ${\mathtt a} CC{\bar {\mathtt a}}$
appears as a factor of
${\mathtt a} CC{\bar {\mathtt a}}$
appears as a factor of
 ${\bar {\mathbf B}}$
. Writing
${\bar {\mathbf B}}$
. Writing
 $C={\bar {\mathtt a}} y{\mathtt a}$
for a finite (possibly empty) word y over
$C={\bar {\mathtt a}} y{\mathtt a}$
for a finite (possibly empty) word y over
 $\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
, we see that
$\{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
, we see that
 ${\mathtt a}{\bar {\mathtt a}} y{\mathtt a}{\bar {\mathtt a}} y{\mathtt a}{\bar {\mathtt a}}$
is a factor of
${\mathtt a}{\bar {\mathtt a}} y{\mathtt a}{\bar {\mathtt a}} y{\mathtt a}{\bar {\mathtt a}}$
is a factor of
 ${\bar {\mathbf B}}$
. Applying the coding p, it follows that
${\bar {\mathbf B}}$
. Applying the coding p, it follows that
 $T={\mathtt a}{\mathtt a} y{\mathtt a}{\mathtt a} y{\mathtt a}{\mathtt a}$
appears in
$T={\mathtt a}{\mathtt a} y{\mathtt a}{\mathtt a} y{\mathtt a}{\mathtt a}$
appears in
 ${\mathbf B}$
, and it is a concatenation of the words
${\mathbf B}$
, and it is a concatenation of the words
 ${\mathtt 3}{\mathtt 3}$
,
${\mathtt 3}{\mathtt 3}$
,
 ${\mathtt 4}$
, and
${\mathtt 4}$
, and
 ${\mathtt 2}$
. Consequently, it makes sense to apply the ‘inverse morphism’
${\mathtt 2}$
. Consequently, it makes sense to apply the ‘inverse morphism’
 $\tilde r:{\mathtt 3}{\mathtt 3}\mapsto {\mathtt a}$
,
$\tilde r:{\mathtt 3}{\mathtt 3}\mapsto {\mathtt a}$
,
 ${\mathtt 4}\mapsto {\mathtt b}$
,
${\mathtt 4}\mapsto {\mathtt b}$
,
 ${\mathtt 2}\mapsto {\mathtt c}$
. Therefore
${\mathtt 2}\mapsto {\mathtt c}$
. Therefore
 $\tilde r(T)={\mathtt a} z{\mathtt a} z{\mathtt a}$
, for some finite word z over
$\tilde r(T)={\mathtt a} z{\mathtt a} z{\mathtt a}$
, for some finite word z over
 $\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
, appears in
$\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
, appears in
 ${\mathbf A}$
. This contradicts Lemma 2.1. (ii) Assume that C starts with a letter
${\mathbf A}$
. This contradicts Lemma 2.1. (ii) Assume that C starts with a letter
 $\in \{{\mathtt a},{\mathtt b},{\mathtt c}\}$
. In this case, C ends with a letter
$\in \{{\mathtt a},{\mathtt b},{\mathtt c}\}$
. In this case, C ends with a letter
 $\in \{{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
; otherwise, the concatenation
$\in \{{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
; otherwise, the concatenation
 $CC$
, and therefore
$CC$
, and therefore
 ${\bar {\mathbf B}}$
, would contain
${\bar {\mathbf B}}$
, would contain
 ${\mathtt a}{\mathtt a}$
, which we have already ruled out. We apply p, and in this case
${\mathtt a}{\mathtt a}$
, which we have already ruled out. We apply p, and in this case
 $p(C)$
is a concatenation of the words
$p(C)$
is a concatenation of the words
 ${\mathtt 3}{\mathtt 3}$
,
${\mathtt 3}{\mathtt 3}$
,
 ${\mathtt 4}$
, and
${\mathtt 4}$
, and
 ${\mathtt 2}$
. Therefore we can form
${\mathtt 2}$
. Therefore we can form
 $\tilde r(p(C))$
, revealing that the square
$\tilde r(p(C))$
, revealing that the square
 $\tilde r(p(C))\tilde r(p(C))$
is a factor of
$\tilde r(p(C))\tilde r(p(C))$
is a factor of
 ${\mathbf A}$
. This is a contradiction.
${\mathbf A}$
. This is a contradiction.
We have to prove the second statement. Assume that
 $CC$
is a factor of
$CC$
is a factor of
 ${\mathbf B}$
, where
${\mathbf B}$
, where
 $\lvert C\rvert \geq 2$
. This proof is analogous to the corresponding case for
$\lvert C\rvert \geq 2$
. This proof is analogous to the corresponding case for
 ${\bar {\mathbf B}}$
, and we skip some of the details that we have already seen there. (i) Assume that C begins with exactly one
${\bar {\mathbf B}}$
, and we skip some of the details that we have already seen there. (i) Assume that C begins with exactly one
 ${\mathtt a}$
. In this case, C has to end with exactly one
${\mathtt a}$
. In this case, C has to end with exactly one
 ${\mathtt a}$
, and therefore
${\mathtt a}$
, and therefore
 $C={\mathtt a} y {\mathtt a}$
for a finite word y over
$C={\mathtt a} y {\mathtt a}$
for a finite word y over
 $\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
. It follows that
$\{{\mathtt a},{\mathtt b},{\mathtt c}\}$
. It follows that
 ${\mathtt a}{\mathtt a} y{\mathtt a}{\mathtt a} y{\mathtt a}{\mathtt a}$
is a factor of
${\mathtt a}{\mathtt a} y{\mathtt a}{\mathtt a} y{\mathtt a}{\mathtt a}$
is a factor of
 ${\mathbf B}$
. Applying
${\mathbf B}$
. Applying
 $\tilde r$
, we obtain a contradiction to Lemma 2.1.
$\tilde r$
, we obtain a contradiction to Lemma 2.1.
(ii) Assume that C starts with
 ${\mathtt a}{\mathtt a}$
,
${\mathtt a}{\mathtt a}$
,
 ${\mathtt b}$
, or
${\mathtt b}$
, or
 ${\mathtt c}$
. In this case, C ends with
${\mathtt c}$
. In this case, C ends with
 ${\mathtt a}{\mathtt a}$
,
${\mathtt a}{\mathtt a}$
,
 ${\mathtt b}$
, or
${\mathtt b}$
, or
 ${\mathtt c}$
, otherwise
${\mathtt c}$
, otherwise
 $CC$
, and therefore
$CC$
, and therefore
 ${\bar {\mathbf B}}$
, would contain a block of
${\bar {\mathbf B}}$
, would contain a block of
 ${\mathtt a}$
s of length not equal to
${\mathtt a}$
s of length not equal to
 $2$
. We apply p on the word
$2$
. We apply p on the word
 $CC$
, followed by
$CC$
, followed by
 $\tilde r$
, which yields the square
$\tilde r$
, which yields the square
 $\tilde r(p(C))\tilde r(p(C))$
. Again, this contradicts Lemma 2.1.
$\tilde r(p(C))\tilde r(p(C))$
. Again, this contradicts Lemma 2.1.
Summarizing, arithmetic subsequences of
 ${\mathbf B}$
with common difference m are distinct as soon as their offsets differ. In particular, for each integer
${\mathbf B}$
with common difference m are distinct as soon as their offsets differ. In particular, for each integer
 $k\ge 2$
, the k-kernel of
$k\ge 2$
, the k-kernel of
 ${\mathbf B}$
is infinite. Therefore
${\mathbf B}$
is infinite. Therefore
 ${\mathbf B}$
is not automatic, which proves the case
${\mathbf B}$
is not automatic, which proves the case
 $w={\mathtt 0}{\mathtt 1}$
of Theorem 1.1.
$w={\mathtt 0}{\mathtt 1}$
of Theorem 1.1.
2.4 Occurrences of general factors in
${\mathbf t}$

We begin with the case
 $w={\mathtt 1}{\mathtt 0}$
. We work with the Thue–Morse morphism
$w={\mathtt 1}{\mathtt 0}$
. We work with the Thue–Morse morphism
 $\tau :{\mathtt 0}\mapsto {\mathtt 0}{\mathtt 1}$
,
$\tau :{\mathtt 0}\mapsto {\mathtt 0}{\mathtt 1}$
,
 ${\mathtt 1}\mapsto {\mathtt 1}{\mathtt 0}$
, defined in (1-1). First of all, we recall the well-known fact that
${\mathtt 1}\mapsto {\mathtt 1}{\mathtt 0}$
, defined in (1-1). First of all, we recall the well-known fact that
 $a_{k+1}=\tau ^{k+1}({\mathtt 0})$
can be constructed from
$a_{k+1}=\tau ^{k+1}({\mathtt 0})$
can be constructed from
 $a_k=\tau ^k({\mathtt 0})$
by concatenating
$a_k=\tau ^k({\mathtt 0})$
by concatenating
 $a_k$
and its Boolean complement
$a_k$
and its Boolean complement
 $\overline {a_k}$
(which replaces each
$\overline {a_k}$
(which replaces each
 ${\mathtt 0}$
by
${\mathtt 0}$
by
 ${\mathtt 1}$
and each
${\mathtt 1}$
and each
 ${\mathtt 1}$
by
${\mathtt 1}$
by
 ${\mathtt 0}$
). The proof of this little fact is by an easy induction. For
${\mathtt 0}$
). The proof of this little fact is by an easy induction. For
 $k=0$
we have
$k=0$
we have
 $a_1={\mathtt 0}{\mathtt 1}={\mathtt 0}\overline {{\mathtt 0}}$
. The case
$a_1={\mathtt 0}{\mathtt 1}={\mathtt 0}\overline {{\mathtt 0}}$
. The case
 $k\geq 1$
makes use of the identity
$k\geq 1$
makes use of the identity
 $\tau (\overline w)=\overline {\tau (w)}$
, valid for each word w over
$\tau (\overline w)=\overline {\tau (w)}$
, valid for each word w over
 $\{{\mathtt 0},{\mathtt 1}\}$
, which follows from the special structure of the morphism
$\{{\mathtt 0},{\mathtt 1}\}$
, which follows from the special structure of the morphism
 $\tau $
. Applying this identity and the induction hypothesis, we obtain
$\tau $
. Applying this identity and the induction hypothesis, we obtain
 $$ \begin{align*} a_{k+1}&=\tau(\tau^k({\mathtt 0}))=\tau(a_{k-1}\overline{a_{k-1}}) \\&=\tau(a_{k-1})\tau(\overline{a_{k-1}}) =\tau(a_{k-1})\overline{\tau(a_{k-1})} =a_k\overline{a_k}. \end{align*} $$
$$ \begin{align*} a_{k+1}&=\tau(\tau^k({\mathtt 0}))=\tau(a_{k-1}\overline{a_{k-1}}) \\&=\tau(a_{k-1})\tau(\overline{a_{k-1}}) =\tau(a_{k-1})\overline{\tau(a_{k-1})} =a_k\overline{a_k}. \end{align*} $$
Using this, we show that for even
 $k\geq 0$
, the word
$k\geq 0$
, the word
 $\tau ^k({\mathtt 0})$
is a palindrome. The case
$\tau ^k({\mathtt 0})$
is a palindrome. The case
 ${k=0}$
is trivial. If
${k=0}$
is trivial. If
 $a_k=\tau ^k({\mathtt 0})$
is a palindrome, then
$a_k=\tau ^k({\mathtt 0})$
is a palindrome, then
 $a_{k+2}=\tau (\tau (a_k))=\tau (a_k\overline {a_k})=a_k\overline {a_k}\overline {a_k}a_k$
is clearly a palindrome too, and the statement follows by induction. In particular, we see from the above that
$a_{k+2}=\tau (\tau (a_k))=\tau (a_k\overline {a_k})=a_k\overline {a_k}\overline {a_k}a_k$
is clearly a palindrome too, and the statement follows by induction. In particular, we see from the above that
 $$ \begin{align} \tau^k({\mathtt 0})=\tau^{k-1}({\mathtt 0})\tau^{k-1}({\mathtt 1}),\quad \tau^k({\mathtt 1})=\tau^{k-1}({\mathtt 1})\tau^{k-1}({\mathtt 0}), \quad\mbox{for all }k\geq 0. \end{align} $$
$$ \begin{align} \tau^k({\mathtt 0})=\tau^{k-1}({\mathtt 0})\tau^{k-1}({\mathtt 1}),\quad \tau^k({\mathtt 1})=\tau^{k-1}({\mathtt 1})\tau^{k-1}({\mathtt 0}), \quad\mbox{for all }k\geq 0. \end{align} $$
Note that, by applying
 $\tau ^k$
on
$\tau ^k$
on
 ${\mathbf t}$
, every
${\mathbf t}$
, every
 ${\mathtt 0}$
gets replaced by
${\mathtt 0}$
gets replaced by
 $\tau ^k({\mathtt 0})$
and every
$\tau ^k({\mathtt 0})$
and every
 ${\mathtt 1}$
by
${\mathtt 1}$
by
 $\tau ^k({\mathtt 1})$
, and the result is again
$\tau ^k({\mathtt 1})$
, and the result is again
 ${\mathbf t}$
since it is a fixed point of
${\mathbf t}$
since it is a fixed point of
 $\tau $
. It follows that
$\tau $
. It follows that
 $$ \begin{align} \begin{array}{rl} \mbox{for all }k\geq 0,&\mbox{ we have } {\mathbf t}=A_{{\mathbf t}_0}A_{{\mathbf t}_1}A_{{\mathbf t}_2}\cdots,\\ &\mbox{ where } A_x=\tau^k(x)\mbox{ for }x\in\{{\mathtt 0},{\mathtt 1}\}. \end{array} \end{align} $$
$$ \begin{align} \begin{array}{rl} \mbox{for all }k\geq 0,&\mbox{ we have } {\mathbf t}=A_{{\mathbf t}_0}A_{{\mathbf t}_1}A_{{\mathbf t}_2}\cdots,\\ &\mbox{ where } A_x=\tau^k(x)\mbox{ for }x\in\{{\mathtt 0},{\mathtt 1}\}. \end{array} \end{align} $$
Let
 $(r_j)_{j\geq 0}$
be the increasing sequence of indices where
$(r_j)_{j\geq 0}$
be the increasing sequence of indices where
 ${\mathtt 1}{\mathtt 0}$
occurs in
${\mathtt 1}{\mathtt 0}$
occurs in
 ${\mathbf t}$
. For k even, let
${\mathbf t}$
. For k even, let
 $J=J(k)$
be the number of occurrences of
$J=J(k)$
be the number of occurrences of
 ${\mathtt 1}{\mathtt 0}$
with indices less than or equal to
${\mathtt 1}{\mathtt 0}$
with indices less than or equal to
 $2^k-2$
. Note that
$2^k-2$
. Note that
 $r_{J-1}=2^k-2$
. We read the (palindromic) sequence
$r_{J-1}=2^k-2$
. We read the (palindromic) sequence
 $a_k$
, of length
$a_k$
, of length
 $2^k$
, backwards; it follows that
$2^k$
, backwards; it follows that
 $(2^k-1-r_{J-1-j})_{0\leq j<J}$
is the increasing sequence of indices pointing to the letter
$(2^k-1-r_{J-1-j})_{0\leq j<J}$
is the increasing sequence of indices pointing to the letter
 ${\mathtt 1}$
in an occurrence of
${\mathtt 1}$
in an occurrence of
 ${\mathtt 0}{\mathtt 1}$
in
${\mathtt 0}{\mathtt 1}$
in
 $a_k$
. Therefore,
$a_k$
. Therefore,
 $$ \begin{align*}(2^k-2-r_{J-1-j})_{0\leq j<J}\end{align*} $$
$$ \begin{align*}(2^k-2-r_{J-1-j})_{0\leq j<J}\end{align*} $$
is the increasing sequence of indices where
 ${\mathtt 0}{\mathtt 1}$
occurs in
${\mathtt 0}{\mathtt 1}$
occurs in
 $a_k$
. Consequently, by the definition of
$a_k$
. Consequently, by the definition of
 ${\mathbf B}$
as the differences of these indices, we obtain
${\mathbf B}$
as the differences of these indices, we obtain
 ${\mathbf B}_j=-r_{J-1-({\kern1.5pt}j+1)}+r_{J-1-j}$
for
${\mathbf B}_j=-r_{J-1-({\kern1.5pt}j+1)}+r_{J-1-j}$
for
 $0\leq j<J-1$
, and thus
$0\leq j<J-1$
, and thus
 $$ \begin{align} r_{j+1}-r_j={\mathbf B}_{J-2-j,}\quad\mbox{for }0\leq j\le J-2. \end{align} $$
$$ \begin{align} r_{j+1}-r_j={\mathbf B}_{J-2-j,}\quad\mbox{for }0\leq j\le J-2. \end{align} $$
We have to prove that the sequence
 $$ \begin{align*} \check{{\mathbf B}}=(r_{j+1}-r_j)_{j\geq 0} \end{align*} $$
$$ \begin{align*} \check{{\mathbf B}}=(r_{j+1}-r_j)_{j\geq 0} \end{align*} $$
is not automatic. More generally, we prove that any two arithmetic subsequences
 $$ \begin{align*}L^{(1)}=(\check{{\mathbf B}}(\ell_1+nd))_{n\geq 0},\quad L^{(2)}=(\check{{\mathbf B}}(\ell_2+nd))_{n\geq 0},\end{align*} $$
$$ \begin{align*}L^{(1)}=(\check{{\mathbf B}}(\ell_1+nd))_{n\geq 0},\quad L^{(2)}=(\check{{\mathbf B}}(\ell_2+nd))_{n\geq 0},\end{align*} $$
where
 $d\geq 1$
and
$d\geq 1$
and
 $\ell _1\neq \ell _2$
, are different. In order to obtain a contradiction, let us assume that
$\ell _1\neq \ell _2$
, are different. In order to obtain a contradiction, let us assume that
 $L^{(1)}=L^{(2)}$
, and let
$L^{(1)}=L^{(2)}$
, and let
 $k\geq 0$
be even. By (2-19), we get arithmetic subsequences
$k\geq 0$
be even. By (2-19), we get arithmetic subsequences
 $M_1$
,
$M_1$
,
 $M_2$
of
$M_2$
of
 ${\mathbf B}$
with common difference d, different offsets
${\mathbf B}$
with common difference d, different offsets
 $m_1(k),m_2(k)\in \{0,\ldots ,d-1\}$
and length equal to
$m_1(k),m_2(k)\in \{0,\ldots ,d-1\}$
and length equal to
 $J(k)-1$
, such that
$J(k)-1$
, such that
 $$ \begin{align*}{\mathbf B}_{m_1(k)+nd}=M^{(1)}_j=M^{(2)}_j={\mathbf B}_{m_2(k)+nd},\quad\mbox{for }0\leq n\le J(k)-2.\end{align*} $$
$$ \begin{align*}{\mathbf B}_{m_1(k)+nd}=M^{(1)}_j=M^{(2)}_j={\mathbf B}_{m_2(k)+nd},\quad\mbox{for }0\leq n\le J(k)-2.\end{align*} $$
Note the important fact that the offsets
 $m_j(k)$
are bounded by d. Since there are only
$m_j(k)$
are bounded by d. Since there are only
 $d(d-1)/2$
pairs
$d(d-1)/2$
pairs
 $(a,b)\in \{0,\ldots ,d-1\}^2$
with
$(a,b)\in \{0,\ldots ,d-1\}^2$
with
 $a\neq b$
, it follows that there are two different offsets
$a\neq b$
, it follows that there are two different offsets
 $0\le \overline {m_1},\overline {m_2}<d$
with the following property: there are arbitrarily long arithmetic subsequences of
$0\le \overline {m_1},\overline {m_2}<d$
with the following property: there are arbitrarily long arithmetic subsequences of
 ${\mathbf B}$
with indices of the form
${\mathbf B}$
with indices of the form
 $\overline {m_1}+nd$
and
$\overline {m_1}+nd$
and
 $\overline {m_2}+nd$
respectively, taking the same values. This is just the statement that the infinite sequences
$\overline {m_2}+nd$
respectively, taking the same values. This is just the statement that the infinite sequences
 $({\mathbf B}_{\overline {m_1}+nd})_{n\geq 0}$
and
$({\mathbf B}_{\overline {m_1}+nd})_{n\geq 0}$
and
 $({\mathbf B}_{\overline {m_2}+nd})_{n\geq 0}$
are equal. In the course of proving that
$({\mathbf B}_{\overline {m_2}+nd})_{n\geq 0}$
are equal. In the course of proving that
 ${\mathbf B}$
is not automatic (which is the case
${\mathbf B}$
is not automatic (which is the case
 $w={\mathtt 0}{\mathtt 1}$
of Theorem 1.1) we proved that this is impossible, and we obtain a contradiction. The sequence
$w={\mathtt 0}{\mathtt 1}$
of Theorem 1.1) we proved that this is impossible, and we obtain a contradiction. The sequence
 $\check {{\mathbf B}}$
is therefore not automatic either, which finishes the case
$\check {{\mathbf B}}$
is therefore not automatic either, which finishes the case
 $w={\mathtt 1}{\mathtt 0}$
.
$w={\mathtt 1}{\mathtt 0}$
.
We proceed to the case
 $w={\mathtt 0}{\mathtt 0}$
. Let
$w={\mathtt 0}{\mathtt 0}$
. Let
 $(a_i)_{i\geq 0}$
be the increasing sequence of indices j such that
$(a_i)_{i\geq 0}$
be the increasing sequence of indices j such that
 ${\mathbf t}_j{\mathbf t}_{j+1}={\mathtt 0}{\mathtt 0}$
. Assume that
${\mathbf t}_j{\mathbf t}_{j+1}={\mathtt 0}{\mathtt 0}$
. Assume that
 $i\geq 0$
, and set
$i\geq 0$
, and set
 $j:= a_i$
. We have
$j:= a_i$
. We have
 $j\equiv 1\bmod 2$
, since
$j\equiv 1\bmod 2$
, since
 ${\mathbf t}_{2j'}=\overline {{\mathbf t}_{2j'+1}}$
for all
${\mathbf t}_{2j'}=\overline {{\mathbf t}_{2j'+1}}$
for all
 $j'\geq 0$
(where the overline denotes the Boolean complement,
$j'\geq 0$
(where the overline denotes the Boolean complement,
 ${\mathtt 0}\mapsto {\mathtt 1}$
,
${\mathtt 0}\mapsto {\mathtt 1}$
,
 ${\mathtt 1}\mapsto {\mathtt 0}$
). Equality
${\mathtt 1}\mapsto {\mathtt 0}$
). Equality
 ${\mathbf t}_j={\mathbf t}_{j+1}$
(as needed) can therefore only occur at odd indices j, and we choose
${\mathbf t}_j={\mathbf t}_{j+1}$
(as needed) can therefore only occur at odd indices j, and we choose
 $j'\ge 0$
such that
$j'\ge 0$
such that
 $j=2j'+1$
. Necessarily,
$j=2j'+1$
. Necessarily,
 ${\mathbf t}_{j'}={\mathtt 1}$
and
${\mathbf t}_{j'}={\mathtt 1}$
and
 ${\mathbf t}_{j'+1}={\mathtt 0}$
, since the identities
${\mathbf t}_{j'+1}={\mathtt 0}$
, since the identities
 ${\mathbf t}_{2j'+1}=\overline {{\mathbf t}_{j'}}$
and
${\mathbf t}_{2j'+1}=\overline {{\mathbf t}_{j'}}$
and
 ${\mathbf t}_{2j'+2}={\mathbf t}_{j'+1}$
would produce an output
${\mathbf t}_{2j'+2}={\mathbf t}_{j'+1}$
would produce an output
 ${\mathbf t}_{2j'+1}{\mathbf t}_{2j'+2}\neq {\mathtt 0}{\mathtt 0}$
in the other case. On the other hand,
${\mathbf t}_{2j'+1}{\mathbf t}_{2j'+2}\neq {\mathtt 0}{\mathtt 0}$
in the other case. On the other hand,
 ${\mathbf t}_{j'}{\mathbf t}_{j'+1}={\mathtt 1}{\mathtt 0}$
indeed implies
${\mathbf t}_{j'}{\mathbf t}_{j'+1}={\mathtt 1}{\mathtt 0}$
indeed implies
 ${\mathbf t}_{2j'+1}{\mathbf t}_{2j'+2}={\mathtt 0}{\mathtt 0}$
. Each occurrence of
${\mathbf t}_{2j'+1}{\mathbf t}_{2j'+2}={\mathtt 0}{\mathtt 0}$
. Each occurrence of
 ${\mathtt 0}{\mathtt 0}$
in
${\mathtt 0}{\mathtt 0}$
in
 ${\mathbf t}$
, at position j, therefore corresponds in a bijective manner to an occurrence of
${\mathbf t}$
, at position j, therefore corresponds in a bijective manner to an occurrence of
 ${\mathtt 1}{\mathtt 0}$
at position
${\mathtt 1}{\mathtt 0}$
at position
 $({\kern1.5pt}j-1)/2$
(which is an integer). It follows that the corresponding gap sequence equals
$({\kern1.5pt}j-1)/2$
(which is an integer). It follows that the corresponding gap sequence equals
 $2\check {\mathbf B}$
, which is not automatic by the already proved case
$2\check {\mathbf B}$
, which is not automatic by the already proved case
 $w={\mathtt 1}{\mathtt 0}$
.
$w={\mathtt 1}{\mathtt 0}$
.
In a completely analogous manner, we can reduce the case
 $w={\mathtt 1}{\mathtt 1}$
to the case
$w={\mathtt 1}{\mathtt 1}$
to the case
 ${\mathtt 0}{\mathtt 1}$
, and the gap sequence equals
${\mathtt 0}{\mathtt 1}$
, and the gap sequence equals
 $2{\mathbf B}$
, which is not automatic either.
$2{\mathbf B}$
, which is not automatic either.
We now reduce the case of general factors w of
 ${\mathbf t}$
of length at least
${\mathbf t}$
of length at least
 $3$
to these four cases.
$3$
to these four cases.
Lemma 2.11. For
 $x,y\in \{{\mathtt 0},{\mathtt 1}\}$
, let
$x,y\in \{{\mathtt 0},{\mathtt 1}\}$
, let
 $(a^{xy}_k)_{k\ge 0}$
be the increasing sequence of indices j such that
$(a^{xy}_k)_{k\ge 0}$
be the increasing sequence of indices j such that
 ${\mathbf t}_j{\mathbf t}_{j+1}=xy$
. We have
${\mathbf t}_j{\mathbf t}_{j+1}=xy$
. We have
 $$ \begin{align} \begin{aligned} &a^{{\mathtt 0}{\mathtt 1}}_0<a^{{\mathtt 1}{\mathtt 0}}_0<a^{{\mathtt 0}{\mathtt 1}}_1<a^{{\mathtt 1}{\mathtt 0}}_1<a^{{\mathtt 0}{\mathtt 1}}_2<a^{{\mathtt 1}{\mathtt 0}}_2< \cdots\quad\mbox{and}\\ &a^{{\mathtt 1}{\mathtt 1}}_0<a^{{\mathtt 0}{\mathtt 0}}_0<a^{{\mathtt 1}{\mathtt 1}}_1<a^{{\mathtt 0}{\mathtt 0}}_1<a^{{\mathtt 1}{\mathtt 1}}_2<a^{{\mathtt 0}{\mathtt 0}}_2<\cdots. \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} &a^{{\mathtt 0}{\mathtt 1}}_0<a^{{\mathtt 1}{\mathtt 0}}_0<a^{{\mathtt 0}{\mathtt 1}}_1<a^{{\mathtt 1}{\mathtt 0}}_1<a^{{\mathtt 0}{\mathtt 1}}_2<a^{{\mathtt 1}{\mathtt 0}}_2< \cdots\quad\mbox{and}\\ &a^{{\mathtt 1}{\mathtt 1}}_0<a^{{\mathtt 0}{\mathtt 0}}_0<a^{{\mathtt 1}{\mathtt 1}}_1<a^{{\mathtt 0}{\mathtt 0}}_1<a^{{\mathtt 1}{\mathtt 1}}_2<a^{{\mathtt 0}{\mathtt 0}}_2<\cdots. \end{aligned} \end{align} $$
Proof. First of all,
 ${\mathbf t}$
begins with
${\mathbf t}$
begins with
 ${\mathtt 0}{\mathtt 1}{\mathtt 1}$
, which explains the first item in each of the two displayed chains of inequalities. The first chain is almost trivial since after each block of consecutive
${\mathtt 0}{\mathtt 1}{\mathtt 1}$
, which explains the first item in each of the two displayed chains of inequalities. The first chain is almost trivial since after each block of consecutive
 ${\mathtt 0}$
s, a letter
${\mathtt 0}$
s, a letter
 ${\mathtt 1}$
follows, and vice versa.
${\mathtt 1}$
follows, and vice versa.
Let us prove the second series of inequalities by induction. Assume that
 $a^{({\mathtt 1}{\mathtt 1})}_0<a^{({\mathtt 0}{\mathtt 0})}_0<\cdots <a^{({\mathtt 0}{\mathtt 0})}_{i-1}<a^{({\mathtt 1}{\mathtt 1})}_i=j$
. Then
$a^{({\mathtt 1}{\mathtt 1})}_0<a^{({\mathtt 0}{\mathtt 0})}_0<\cdots <a^{({\mathtt 0}{\mathtt 0})}_{i-1}<a^{({\mathtt 1}{\mathtt 1})}_i=j$
. Then
 ${\mathbf t}_j{\mathbf t}_{j+1}={\mathtt 1}{\mathtt 1}$
, and it follows that
${\mathbf t}_j{\mathbf t}_{j+1}={\mathtt 1}{\mathtt 1}$
, and it follows that
 ${\mathbf t}_{j+2}={\mathtt 0}$
, since
${\mathbf t}_{j+2}={\mathtt 0}$
, since
 ${\mathtt 1}{\mathtt 1}{\mathtt 1}$
is not a factor of
${\mathtt 1}{\mathtt 1}{\mathtt 1}$
is not a factor of
 ${\mathbf t}$
. Two cases can occur. (i) If
${\mathbf t}$
. Two cases can occur. (i) If
 ${\mathbf t}_{j+3}={\mathtt 0}$
, then clearly
${\mathbf t}_{j+3}={\mathtt 0}$
, then clearly
 $a^{({\mathtt 1}{\mathtt 1})}_i<a^{({\mathtt 0}{\mathtt 0})}_i=j+2$
by our hypothesis. (ii) Otherwise, we have
$a^{({\mathtt 1}{\mathtt 1})}_i<a^{({\mathtt 0}{\mathtt 0})}_i=j+2$
by our hypothesis. (ii) Otherwise, we have
 ${\mathbf t}_j{\mathbf t}_{j+1}{\mathbf t}_{j+2}{\mathbf t}_{j+3}={\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}$
. Necessarily, j is odd: if
${\mathbf t}_j{\mathbf t}_{j+1}{\mathbf t}_{j+2}{\mathbf t}_{j+3}={\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}$
. Necessarily, j is odd: if
 $j=2j'$
, it would follow that
$j=2j'$
, it would follow that
 ${\mathbf t}_j{\mathbf t}_{j+1}\in \{{\mathtt 0}{\mathtt 1},{\mathtt 1}{\mathtt 0}\}$
, but we need
${\mathbf t}_j{\mathbf t}_{j+1}\in \{{\mathtt 0}{\mathtt 1},{\mathtt 1}{\mathtt 0}\}$
, but we need
 ${\mathtt 1}{\mathtt 1}$
. Moreover,
${\mathtt 1}{\mathtt 1}$
. Moreover,
 $j\equiv 3\bmod 4$
is also not possible. Let
$j\equiv 3\bmod 4$
is also not possible. Let
 $j+1=4j'$
. Then
$j+1=4j'$
. Then
 ${\mathbf t}_{j+1}{\mathbf t}_{j+2}{\mathbf t}_{j+3}\in \{{\mathtt 0}{\mathtt 1}{\mathtt 1},{\mathtt 1}{\mathtt 0}{\mathtt 0}\}$
, but we need
${\mathbf t}_{j+1}{\mathbf t}_{j+2}{\mathbf t}_{j+3}\in \{{\mathtt 0}{\mathtt 1}{\mathtt 1},{\mathtt 1}{\mathtt 0}{\mathtt 0}\}$
, but we need
 ${\mathtt 1}{\mathtt 0}{\mathtt 1}$
. It follows that
${\mathtt 1}{\mathtt 0}{\mathtt 1}$
. It follows that
 $j\equiv 1\bmod 4$
, and therefore
$j\equiv 1\bmod 4$
, and therefore
 ${\mathbf t}_{j+4}{\mathbf t}_{j+5}={\mathtt 0}{\mathtt 0}$
, which implies
${\mathbf t}_{j+4}{\mathbf t}_{j+5}={\mathtt 0}{\mathtt 0}$
, which implies
 $a^{({\mathtt 0}{\mathtt 0})}_i=j+4$
. By a completely analogous argument (reversing the roles of
$a^{({\mathtt 0}{\mathtt 0})}_i=j+4$
. By a completely analogous argument (reversing the roles of
 ${\mathtt 1}$
and
${\mathtt 1}$
and
 ${\mathtt 0}$
), we may finish the proof of Lemma 2.11 by induction.
${\mathtt 0}$
), we may finish the proof of Lemma 2.11 by induction.
Let w be a factor of
 ${\mathbf t}$
, of length at least
${\mathbf t}$
, of length at least
 $3$
. Choose
$3$
. Choose
 $k\geq 0$
minimal such that w is a factor of some
$k\geq 0$
minimal such that w is a factor of some
 $a^{xy}_k=\tau ^k(x)\tau ^k(y)$
, where
$a^{xy}_k=\tau ^k(x)\tau ^k(y)$
, where
 $x,y\in \{{\mathtt 0},{\mathtt 1}\}$
. By minimality, w is not a factor of
$x,y\in \{{\mathtt 0},{\mathtt 1}\}$
. By minimality, w is not a factor of
 $\tau ^k({\mathtt 0})$
or
$\tau ^k({\mathtt 0})$
or
 $\tau ^k({\mathtt 1})$
, using (2-17). Consequently, w appears at most once in each
$\tau ^k({\mathtt 1})$
, using (2-17). Consequently, w appears at most once in each
 $a^{xy}_k$
. Next, we need the fact that
$a^{xy}_k$
. Next, we need the fact that
 ${\mathbf t}$
is overlap-free [Reference Berstel8, Reference Brown, Rampersad, Shallit and Vasiga13, Reference Thue27], meaning that it does not contain a factor of the form
${\mathbf t}$
is overlap-free [Reference Berstel8, Reference Brown, Rampersad, Shallit and Vasiga13, Reference Thue27], meaning that it does not contain a factor of the form
 $axaxa$
, where
$axaxa$
, where
 $a\in \{{\mathtt 0},{\mathtt 1}\}$
and
$a\in \{{\mathtt 0},{\mathtt 1}\}$
and
 $x\in \{{\mathtt 0},{\mathtt 1}\}^{\ast }$
. We derive from this property that w cannot occur simultaneously in both members of any of the pairs
$x\in \{{\mathtt 0},{\mathtt 1}\}^{\ast }$
. We derive from this property that w cannot occur simultaneously in both members of any of the pairs
 $$ \begin{align} (a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 0}{\mathtt 1}}_k),\quad(a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 0}}_k),\quad (a^{{\mathtt 1}{\mathtt 1}}_k,a^{{\mathtt 0}{\mathtt 1}}_k),\quad(a^{{\mathtt 1}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k). \end{align} $$
$$ \begin{align} (a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 0}{\mathtt 1}}_k),\quad(a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 0}}_k),\quad (a^{{\mathtt 1}{\mathtt 1}}_k,a^{{\mathtt 0}{\mathtt 1}}_k),\quad(a^{{\mathtt 1}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k). \end{align} $$
For example, assume that w is a factor of both
 $a^{{\mathtt 0}{\mathtt 0}}_k$
and
$a^{{\mathtt 0}{\mathtt 0}}_k$
and
 $a^{{\mathtt 0}{\mathtt 1}}_k$
. By minimality, as we had before,
$a^{{\mathtt 0}{\mathtt 1}}_k$
. By minimality, as we had before,
 $$ \begin{align*} \tau^k({\mathtt 0})\tau^k({\mathtt 0})=AwB,\quad \tau^k({\mathtt 0})\tau^k({\mathtt 1})=A'wB', \end{align*} $$
$$ \begin{align*} \tau^k({\mathtt 0})\tau^k({\mathtt 0})=AwB,\quad \tau^k({\mathtt 0})\tau^k({\mathtt 1})=A'wB', \end{align*} $$
where A and
 $A'$
are initial segments of
$A'$
are initial segments of
 $\tau ^k({\mathtt 0})$
, and B (respectively,
$\tau ^k({\mathtt 0})$
, and B (respectively,
 $B'$
) are final segments of
$B'$
) are final segments of
 $\tau ^k({\mathtt 0})$
(respectively,
$\tau ^k({\mathtt 0})$
(respectively,
 $\tau ^k({\mathtt 1})$
), and all of these segments are proper subwords of the respective words. We have
$\tau ^k({\mathtt 1})$
), and all of these segments are proper subwords of the respective words. We have
 $A\neq A'$
, since otherwise
$A\neq A'$
, since otherwise
 $\tau ^k({\mathtt 0})=\tilde wB=\tilde wB'=\tau ^k({\mathtt 1})$
for some
$\tau ^k({\mathtt 0})=\tilde wB=\tilde wB'=\tau ^k({\mathtt 1})$
for some
 $\tilde w$
that is not the empty word. This contradicts the fact that
$\tilde w$
that is not the empty word. This contradicts the fact that
 $\tau ^k({\mathtt 0})=\overline {\tau ^k({\mathtt 1})}$
. Let us, without loss of generality, assume that
$\tau ^k({\mathtt 0})=\overline {\tau ^k({\mathtt 1})}$
. Let us, without loss of generality, assume that
 $\lvert A\rvert <\lvert A'\rvert $
. The first
$\lvert A\rvert <\lvert A'\rvert $
. The first
 $2^k$
letters of
$2^k$
letters of
 $Aw$
and
$Aw$
and
 $A'w$
are equal, or in symbols,
$A'w$
are equal, or in symbols,
 $$ \begin{align} (Aw)\rvert_{[0,2^k)}=(A'w)\rvert_{[0,2^k)}. \end{align} $$
$$ \begin{align} (Aw)\rvert_{[0,2^k)}=(A'w)\rvert_{[0,2^k)}. \end{align} $$
We can therefore choose
 $a\in \{{\mathtt 0},{\mathtt 1}\}$
and
$a\in \{{\mathtt 0},{\mathtt 1}\}$
and
 $w_1,w_2\in \{{\mathtt 0},{\mathtt 1}\}^{\ast }$
in such a way that
$w_1,w_2\in \{{\mathtt 0},{\mathtt 1}\}^{\ast }$
in such a way that
 ${aw_1w_2=w}$
and
${aw_1w_2=w}$
and
 $Aaw_1=A'$
. Then trivially
$Aaw_1=A'$
. Then trivially
 $Aw=Aaw_1w_2=A'w_2$
, and since
$Aw=Aaw_1w_2=A'w_2$
, and since
 $\lvert A\rvert <2^k$
,
$\lvert A\rvert <2^k$
,
 $\lvert A'\rvert <2^k$
, it follows from (2-22) that
$\lvert A'\rvert <2^k$
, it follows from (2-22) that
 $w_2=aw_3$
for some
$w_2=aw_3$
for some
 $w_3\in \{{\mathtt 0},{\mathtt 1}\}^{\ast }$
. Finally, the factor
$w_3\in \{{\mathtt 0},{\mathtt 1}\}^{\ast }$
. Finally, the factor
 $A'w$
of
$A'w$
of
 ${\mathbf t}$
can be written as
${\mathbf t}$
can be written as
 $A'w=Aaw_1w=Aaw_1aw_1w_2=Aaw_1aw_1aw_3$
, which contradicts the overlap-freeness of
$A'w=Aaw_1w=Aaw_1aw_1w_2=Aaw_1aw_1aw_3$
, which contradicts the overlap-freeness of
 ${\mathbf t}$
. The other three cases, corresponding to the second, third and fourth pairs in (2-21), are analogous. We have therefore shown that the set of
${\mathbf t}$
. The other three cases, corresponding to the second, third and fourth pairs in (2-21), are analogous. We have therefore shown that the set of
 $A\in \{a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k\}$
such that w is a factor of A is a subset of either
$A\in \{a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k\}$
such that w is a factor of A is a subset of either
 $\{a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k\}$
or
$\{a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k\}$
or
 $\{a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k\}$
.
$\{a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k\}$
.
First case. Let w be a factor of
 $a^{{\mathtt 0}{\mathtt 1}}_k$
, or of
$a^{{\mathtt 0}{\mathtt 1}}_k$
, or of
 $a^{{\mathtt 1}{\mathtt 0}}_k$
. Assume first that w is a factor of
$a^{{\mathtt 1}{\mathtt 0}}_k$
. Assume first that w is a factor of
 $a^{{\mathtt 0}{\mathtt 1}}_k$
, but not of
$a^{{\mathtt 0}{\mathtt 1}}_k$
, but not of
 $a^{{\mathtt 1}{\mathtt 0}}_k$
. In this case, we show that the gap sequence for w is given by the gap sequence for
$a^{{\mathtt 1}{\mathtt 0}}_k$
. In this case, we show that the gap sequence for w is given by the gap sequence for
 $a^{{\mathtt 0}{\mathtt 1}}_k$
: (i) each occurrence of
$a^{{\mathtt 0}{\mathtt 1}}_k$
: (i) each occurrence of
 $a^{{\mathtt 0}{\mathtt 1}}_k$
yields exactly one occurrence of w (involving a constant shift); (ii) by (2-18), every occurrence of w takes place within a block of the form
$a^{{\mathtt 0}{\mathtt 1}}_k$
yields exactly one occurrence of w (involving a constant shift); (ii) by (2-18), every occurrence of w takes place within a block of the form
 $a^{xy}_k$
; (iii) only the block
$a^{xy}_k$
; (iii) only the block
 $a^{{\mathtt 0}{\mathtt 1}}_k$
is eligible. We prove that
$a^{{\mathtt 0}{\mathtt 1}}_k$
is eligible. We prove that
 $a^{{\mathtt 0}{\mathtt 1}}_k$
appears exactly at positions
$a^{{\mathtt 0}{\mathtt 1}}_k$
appears exactly at positions
 $2^kj$
in
$2^kj$
in
 ${\mathbf t}$
, where
${\mathbf t}$
, where
 ${\mathbf t}_j{\mathbf t}_{j+1}={\mathtt 0}{\mathtt 1}$
. The easy direction follows from (2-18): each occurrence of
${\mathbf t}_j{\mathbf t}_{j+1}={\mathtt 0}{\mathtt 1}$
. The easy direction follows from (2-18): each occurrence of
 ${\mathtt 0}{\mathtt 1}$
yields an occurrence of
${\mathtt 0}{\mathtt 1}$
yields an occurrence of
 $a^{{\mathtt 0}{\mathtt 1}}_k$
, where the index has to be multiplied by
$a^{{\mathtt 0}{\mathtt 1}}_k$
, where the index has to be multiplied by
 $2^k$
. On the other hand, it is sufficient to show that
$2^k$
. On the other hand, it is sufficient to show that
 $a^{{\mathtt 0}{\mathtt 1}}_k$
can only appear in positions
$a^{{\mathtt 0}{\mathtt 1}}_k$
can only appear in positions
 $2^kj$
. Given this, there is no admissible choice for
$2^kj$
. Given this, there is no admissible choice for
 $({\mathbf t}_j,{\mathbf t}_{j+1})$
different from
$({\mathbf t}_j,{\mathbf t}_{j+1})$
different from
 $({\mathtt 0},{\mathtt 1})$
, by (2-18). Suppose that we already know this for some
$({\mathtt 0},{\mathtt 1})$
, by (2-18). Suppose that we already know this for some
 $k\ge 0$
(the case
$k\ge 0$
(the case
 $k=0$
being trivial). Assume that
$k=0$
being trivial). Assume that
 $$ \begin{align} a^{{\mathtt 0}{\mathtt 1}}_{k+1}=\tau^k({\mathtt 0})\tau^k({\mathtt 1})\tau^k({\mathtt 1})\tau^k({\mathtt 0}) \mbox{ appears on some position }\ell. \end{align} $$
$$ \begin{align} a^{{\mathtt 0}{\mathtt 1}}_{k+1}=\tau^k({\mathtt 0})\tau^k({\mathtt 1})\tau^k({\mathtt 1})\tau^k({\mathtt 0}) \mbox{ appears on some position }\ell. \end{align} $$
Since
 $\tau ^k({\mathtt 0})\tau ^k({\mathtt 1})=a^{{\mathtt 0}{\mathtt 1}}_k$
, we know by hypothesis that
$\tau ^k({\mathtt 0})\tau ^k({\mathtt 1})=a^{{\mathtt 0}{\mathtt 1}}_k$
, we know by hypothesis that
 $\ell \equiv 0\bmod 2^k$
. Assume that the case
$\ell \equiv 0\bmod 2^k$
. Assume that the case
 $\ell \equiv 2^k\bmod 2^{k+1}$
occurs. We set
$\ell \equiv 2^k\bmod 2^{k+1}$
occurs. We set
 $\ell =(2j+1)2^k$
for some
$\ell =(2j+1)2^k$
for some
 $j\geq 0$
. Our assumption (2-23) implies
$j\geq 0$
. Our assumption (2-23) implies
 $\tau ^k({\mathtt 1})=\tau ^k({\mathbf t}_{2j+2})=\tau ^k({\mathbf t}_{j+1})$
and therefore
$\tau ^k({\mathtt 1})=\tau ^k({\mathbf t}_{2j+2})=\tau ^k({\mathbf t}_{j+1})$
and therefore
 ${\mathbf t}_{j+1}={\mathtt 1}$
, which implies that
${\mathbf t}_{j+1}={\mathtt 1}$
, which implies that
 $\tau ^{k+1}({\mathbf t}_{j+1})=\tau ^k({\mathtt 1})\tau ^k({\mathtt 0})$
appears in position
$\tau ^{k+1}({\mathbf t}_{j+1})=\tau ^k({\mathtt 1})\tau ^k({\mathtt 0})$
appears in position
 $\ell +2^k=(2j+2)2^k$
in
$\ell +2^k=(2j+2)2^k$
in
 ${\mathbf t}$
. This is incompatible with (2-23). In particular, the gap sequence for w, which is identical to the gap sequence for
${\mathbf t}$
. This is incompatible with (2-23). In particular, the gap sequence for w, which is identical to the gap sequence for
 $a^{{\mathtt 0}{\mathtt 1}}_k$
, is given by
$a^{{\mathtt 0}{\mathtt 1}}_k$
, is given by
 $2^k{\mathbf B}$
, and therefore not automatic. Switching the roles of
$2^k{\mathbf B}$
, and therefore not automatic. Switching the roles of
 ${\mathtt 0}$
and
${\mathtt 0}$
and
 ${\mathtt 1}$
in this proof, we also obtain nonautomaticity for the case where w is a factor of
${\mathtt 1}$
in this proof, we also obtain nonautomaticity for the case where w is a factor of
 $a_k^{{\mathtt 1}{\mathtt 0}}$
, but not of
$a_k^{{\mathtt 1}{\mathtt 0}}$
, but not of
 $a_k^{{\mathtt 0}{\mathtt 1}}$
, with the sequence
$a_k^{{\mathtt 0}{\mathtt 1}}$
, with the sequence
 $2^k\check {\mathbf B}$
as the corresponding gap sequence.
$2^k\check {\mathbf B}$
as the corresponding gap sequence.
Let w be a factor of both
 $a^{{\mathtt 0}{\mathtt 1}}_k$
and
$a^{{\mathtt 0}{\mathtt 1}}_k$
and
 $a^{{\mathtt 1}{\mathtt 0}}_k$
. In this case, each occurrence of w in
$a^{{\mathtt 1}{\mathtt 0}}_k$
. In this case, each occurrence of w in
 ${\mathbf t}$
takes place within a subblock of
${\mathbf t}$
takes place within a subblock of
 ${\mathbf t}$
of one of these two forms. By Lemma 2.11, combined with the above argument that occurrences of
${\mathbf t}$
of one of these two forms. By Lemma 2.11, combined with the above argument that occurrences of
 $a^{{\mathtt 0}{\mathtt 1}}_k$
(respectively,
$a^{{\mathtt 0}{\mathtt 1}}_k$
(respectively,
 $a^{{\mathtt 1}{\mathtt 0}}_k$
) in
$a^{{\mathtt 1}{\mathtt 0}}_k$
) in
 ${\mathbf t}$
take place at indices obtained from occurrences of
${\mathbf t}$
take place at indices obtained from occurrences of
 ${\mathtt 0}{\mathtt 1}$
(respectively,
${\mathtt 0}{\mathtt 1}$
(respectively,
 ${\mathtt 1}{\mathtt 0}$
), multiplied by
${\mathtt 1}{\mathtt 0}$
), multiplied by
 $2^k$
, these blocks occur alternatingly. Assuming, in order to obtain a contradiction, that the gap sequence
$2^k$
, these blocks occur alternatingly. Assuming, in order to obtain a contradiction, that the gap sequence
 $(g_j)_{j\geq 0}$
for w is automatic, we obtain a new automatic sequence
$(g_j)_{j\geq 0}$
for w is automatic, we obtain a new automatic sequence
 $(g_{2j}+g_{2j+1})_{j\geq 0}$
as the sum of two automatic sequences (note that the characterization involving the
$(g_{2j}+g_{2j+1})_{j\geq 0}$
as the sum of two automatic sequences (note that the characterization involving the
 $2$
-kernel (2-16) immediately implies that
$2$
-kernel (2-16) immediately implies that
 $(g_{2j+\varepsilon })_{j\ge 0}$
, for
$(g_{2j+\varepsilon })_{j\ge 0}$
, for
 $\varepsilon \in \{0,1\}$
, is automatic). By the alternating property, this is the gap sequence for
$\varepsilon \in \{0,1\}$
, is automatic). By the alternating property, this is the gap sequence for
 $a^{{\mathtt 0}{\mathtt 1}}_k$
, which is not automatic, as we have just seen. A contradiction!
$a^{{\mathtt 0}{\mathtt 1}}_k$
, which is not automatic, as we have just seen. A contradiction!
Second case. Let w be a factor of
 $a^{{\mathtt 0}{\mathtt 0}}_k$
or of
$a^{{\mathtt 0}{\mathtt 0}}_k$
or of
 $a^{{\mathtt 1}{\mathtt 1}}_k$
. This case is largely analogous. Assume that w is not a factor of
$a^{{\mathtt 1}{\mathtt 1}}_k$
. This case is largely analogous. Assume that w is not a factor of
 $a^{{\mathtt 1}{\mathtt 1}}_k$
. As in the case
$a^{{\mathtt 1}{\mathtt 1}}_k$
. As in the case
 $a^{{\mathtt 0}{\mathtt 1}}_k$
, the gap sequence for w in this case is identical to the gap sequence for
$a^{{\mathtt 0}{\mathtt 1}}_k$
, the gap sequence for w in this case is identical to the gap sequence for
 $a^{{\mathtt 0}{\mathtt 0}}_k$
, and we only have to show that this sequence is not automatic. We know already that the gap sequence for
$a^{{\mathtt 0}{\mathtt 0}}_k$
, and we only have to show that this sequence is not automatic. We know already that the gap sequence for
 ${\mathtt 0}{\mathtt 0}$
is not automatic. Therefore it suffices to prove that
${\mathtt 0}{\mathtt 0}$
is not automatic. Therefore it suffices to prove that
 $\tau ^k({\mathtt 0})\tau ^k({\mathtt 0})$
can only appear at positions in
$\tau ^k({\mathtt 0})\tau ^k({\mathtt 0})$
can only appear at positions in
 ${\mathbf t}$
divisible by
${\mathbf t}$
divisible by
 $2^k$
. Suppose that we already know this for some
$2^k$
. Suppose that we already know this for some
 $k\ge 0$
(the case
$k\ge 0$
(the case
 $k=0$
again being trivial). Assume that
$k=0$
again being trivial). Assume that
 $$ \begin{align} a^{{\mathtt 0}{\mathtt 0}}_{k+1}=\tau^k({\mathtt 0})\tau^k({\mathtt 1})\tau^k({\mathtt 0})\tau^k({\mathtt 1}) \mbox{ appears on some position }\ell. \end{align} $$
$$ \begin{align} a^{{\mathtt 0}{\mathtt 0}}_{k+1}=\tau^k({\mathtt 0})\tau^k({\mathtt 1})\tau^k({\mathtt 0})\tau^k({\mathtt 1}) \mbox{ appears on some position }\ell. \end{align} $$
Since
 $\tau ^k({\mathtt 0})\tau ^k({\mathtt 1})=a^{{\mathtt 0}{\mathtt 1}}_k$
, we know by hypothesis that
$\tau ^k({\mathtt 0})\tau ^k({\mathtt 1})=a^{{\mathtt 0}{\mathtt 1}}_k$
, we know by hypothesis that
 $\ell \equiv 0\bmod 2^k$
. Assume that the case
$\ell \equiv 0\bmod 2^k$
. Assume that the case
 $\ell \equiv 2^k\bmod 2^{k+1}$
occurs. We set
$\ell \equiv 2^k\bmod 2^{k+1}$
occurs. We set
 $\ell =(2j+1)2^k$
for some
$\ell =(2j+1)2^k$
for some
 $j\geq 0$
. Our assumption (2-24) implies
$j\geq 0$
. Our assumption (2-24) implies
 $\tau ^k({\mathtt 1})=\tau ^k({\mathbf t}_{2j+4})=\tau ^k({\mathbf t}_{j+2})$
and therefore
$\tau ^k({\mathtt 1})=\tau ^k({\mathbf t}_{2j+4})=\tau ^k({\mathbf t}_{j+2})$
and therefore
 ${\mathbf t}_{j+2}={\mathtt 1}$
, which implies that
${\mathbf t}_{j+2}={\mathtt 1}$
, which implies that
 $\tau ^{k+1}({\mathbf t}_{j+2})=\tau ^k({\mathtt 1})\tau ^k({\mathtt 0})$
appears in position
$\tau ^{k+1}({\mathbf t}_{j+2})=\tau ^k({\mathtt 1})\tau ^k({\mathtt 0})$
appears in position
 $\ell +3\cdot 2^k=(2j+4)2^k$
in
$\ell +3\cdot 2^k=(2j+4)2^k$
in
 ${\mathbf t}$
. In position
${\mathbf t}$
. In position
 $\ell $
, we therefore see the factor
$\ell $
, we therefore see the factor
 $$ \begin{align*}\tau^k({\mathtt 0})\tau^k({\mathtt 1})\tau^k({\mathtt 0})\tau^k({\mathtt 1})\tau^k({\mathtt 0}),\end{align*} $$
$$ \begin{align*}\tau^k({\mathtt 0})\tau^k({\mathtt 1})\tau^k({\mathtt 0})\tau^k({\mathtt 1})\tau^k({\mathtt 0}),\end{align*} $$
which contradicts the overlap-freeness of
 ${\mathbf t}$
.
${\mathbf t}$
.
Again, the case where w is a factor of
 $a^{{\mathtt 1}{\mathtt 1}}_k$
, but not of
$a^{{\mathtt 1}{\mathtt 1}}_k$
, but not of
 $a^{{\mathtt 0}{\mathtt 0}}_k$
, is analogous; the case that it is a factor of both words can be handled as in the case
$a^{{\mathtt 0}{\mathtt 0}}_k$
, is analogous; the case that it is a factor of both words can be handled as in the case
 $\{a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k\}$
, this time with the help of the second chain of inequalities in (2-20).
$\{a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k\}$
, this time with the help of the second chain of inequalities in (2-20).
Summarizing, we have shown nonautomaticity for all gap sequences for factors w of
 ${\mathbf t}$
of length at least
${\mathbf t}$
of length at least
 $2$
.
$2$
.
In order to finish the proof of Theorem 1.1, we still have to prove that the gap sequence is morphic for the ‘mixed cases’. That is, assume that w is a factor of two words of the form
 $a^{xy}_k$
, where
$a^{xy}_k$
, where
 $x,y\in \{{\mathtt 0},{\mathtt 1}\}$
, and where k is chosen minimal such that w is a factor of at least one of
$x,y\in \{{\mathtt 0},{\mathtt 1}\}$
, and where k is chosen minimal such that w is a factor of at least one of
 $a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k$
. Let us begin with the case
$a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k$
. Let us begin with the case
 $\{a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k\}$
. The positions where w appears in
$\{a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k\}$
. The positions where w appears in
 ${\mathbf t}$
are given by
${\mathbf t}$
are given by
 $2^kj+\sigma _0$
, where
$2^kj+\sigma _0$
, where
 ${\mathtt b}_j{\mathtt b}_{j+1}={\mathtt 0}{\mathtt 1}$
, and
${\mathtt b}_j{\mathtt b}_{j+1}={\mathtt 0}{\mathtt 1}$
, and
 $2^kj+\sigma _1$
, where
$2^kj+\sigma _1$
, where
 ${\mathtt b}_j{\mathtt b}_{j+1}={\mathtt 1}{\mathtt 0}$
. Here
${\mathtt b}_j{\mathtt b}_{j+1}={\mathtt 1}{\mathtt 0}$
. Here
 $\sigma _0,\sigma _1$
are the positions where the word w appears in
$\sigma _0,\sigma _1$
are the positions where the word w appears in
 $a^{{\mathtt 0}{\mathtt 1}}_k$
and
$a^{{\mathtt 0}{\mathtt 1}}_k$
and
 $a^{{\mathtt 1}{\mathtt 0}}_k$
, respectively. As before, this follows since
$a^{{\mathtt 1}{\mathtt 0}}_k$
, respectively. As before, this follows since
 ${\mathbf t}_j{\mathbf t}_{j+1}={\mathtt 0}{\mathtt 1}$
is equivalent to
${\mathbf t}_j{\mathbf t}_{j+1}={\mathtt 0}{\mathtt 1}$
is equivalent to
 $({\mathbf t}_{\ell },\ldots ,{\mathbf t}_{\ell +2^{k+1}-1})=a^{{\mathtt 0}{\mathtt 1}}_k$
, and from the corresponding statement for
$({\mathbf t}_{\ell },\ldots ,{\mathbf t}_{\ell +2^{k+1}-1})=a^{{\mathtt 0}{\mathtt 1}}_k$
, and from the corresponding statement for
 ${\mathtt 1}{\mathtt 0}$
. We see that it is sufficient to write
${\mathtt 1}{\mathtt 0}$
. We see that it is sufficient to write
 ${\mathbf t}$
as a concatenation of the words
${\mathbf t}$
as a concatenation of the words
 $$ \begin{align} w_{{\mathtt a}}:={\mathtt 0}{\mathtt 1}{\mathtt 1},\quad w_{{\bar{\mathtt a}}}:={\mathtt 0}{\mathtt 1}{\mathtt 0},\quad w_{{\mathtt b}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0},\quad\mbox{and}\quad w_{{\mathtt c}}:={\mathtt 0}{\mathtt 1}, \end{align} $$
$$ \begin{align} w_{{\mathtt a}}:={\mathtt 0}{\mathtt 1}{\mathtt 1},\quad w_{{\bar{\mathtt a}}}:={\mathtt 0}{\mathtt 1}{\mathtt 0},\quad w_{{\mathtt b}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0},\quad\mbox{and}\quad w_{{\mathtt c}}:={\mathtt 0}{\mathtt 1}, \end{align} $$
since each word
 $w_x$
takes care of one
$w_x$
takes care of one
 ${\mathtt 0}{\mathtt 1}$
-block, followed by one
${\mathtt 0}{\mathtt 1}$
-block, followed by one
 ${\mathtt 1}{\mathtt 0}$
-block, and the gap sequence for w is obtained by replacing each
${\mathtt 1}{\mathtt 0}$
-block, and the gap sequence for w is obtained by replacing each
 $w_x$
by a succession of two gaps. Applying the morphism
$w_x$
by a succession of two gaps. Applying the morphism
 $\tau $
, we obtain
$\tau $
, we obtain
 $\tau (w_{{\mathtt a}})=w_{{\mathtt a}}w_{{\bar {\mathtt a}}}$
,
$\tau (w_{{\mathtt a}})=w_{{\mathtt a}}w_{{\bar {\mathtt a}}}$
,
 $\tau (w_{{\bar {\mathtt a}}})=w_{{\mathtt b}}w_{{\mathtt c}}$
,
$\tau (w_{{\bar {\mathtt a}}})=w_{{\mathtt b}}w_{{\mathtt c}}$
,
 $\tau (w_{{\mathtt b}})=w_{{\mathtt a}}w_{{\bar {\mathtt a}}}w_{{\mathtt c}}$
,
$\tau (w_{{\mathtt b}})=w_{{\mathtt a}}w_{{\bar {\mathtt a}}}w_{{\mathtt c}}$
,
 $\tau (w_{{\mathtt c}})=w_{{\mathtt b}}$
. This mimics the morphism
$\tau (w_{{\mathtt c}})=w_{{\mathtt b}}$
. This mimics the morphism
 $\psi $
; proceeding as in the proof of Lemma 2.2 (alternatively, as in the proof of Lemma 2.3), we obtain
$\psi $
; proceeding as in the proof of Lemma 2.2 (alternatively, as in the proof of Lemma 2.3), we obtain
 $$ \begin{align} {\mathbf t}=w_{{\bar{\mathbf B}}_0}w_{{\bar{\mathbf B}}_1}w_{{\bar{\mathbf B}}_2}\cdots. \end{align} $$
$$ \begin{align} {\mathbf t}=w_{{\bar{\mathbf B}}_0}w_{{\bar{\mathbf B}}_1}w_{{\bar{\mathbf B}}_2}\cdots. \end{align} $$
Since
 ${\bar {\mathbf B}}$
is morphic, the succession of gaps with which w occurs in
${\bar {\mathbf B}}$
is morphic, the succession of gaps with which w occurs in
 ${\mathbf t}$
is morphic by [Reference Allouche and Shallit4, Corollary 7.7.5] (that is, ‘morphic images of morphic sequences are morphic’).
${\mathbf t}$
is morphic by [Reference Allouche and Shallit4, Corollary 7.7.5] (that is, ‘morphic images of morphic sequences are morphic’).
The case
 $\{a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k\}$
is similar. Defining
$\{a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k\}$
is similar. Defining
 $$ \begin{align*} \tilde w_{{\mathtt a}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0},\quad \tilde w_{{\bar{\mathtt a}}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1},\quad \tilde w_{{\mathtt b}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1},\quad\mbox{and}\quad \tilde w_{{\mathtt c}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}, \end{align*} $$
$$ \begin{align*} \tilde w_{{\mathtt a}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0},\quad \tilde w_{{\bar{\mathtt a}}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1},\quad \tilde w_{{\mathtt b}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1},\quad\mbox{and}\quad \tilde w_{{\mathtt c}}:={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}, \end{align*} $$
it is straightforward to verify that
 $\tau (\tilde w_{{\mathtt a}})=\tilde w_{{\mathtt a}}\tilde w_{{\bar {\mathtt a}}}$
,
$\tau (\tilde w_{{\mathtt a}})=\tilde w_{{\mathtt a}}\tilde w_{{\bar {\mathtt a}}}$
,
 $\tau (\tilde w_{{\bar {\mathtt a}}})=\tilde w_{{\mathtt b}}\tilde w_{{\mathtt c}}$
,
$\tau (\tilde w_{{\bar {\mathtt a}}})=\tilde w_{{\mathtt b}}\tilde w_{{\mathtt c}}$
,
 $\tau (\tilde w_{{\mathtt b}})=\tilde w_{{\mathtt a}}\tilde w_{{\bar {\mathtt a}}}\tilde w_{{\mathtt c}}$
, and
$\tau (\tilde w_{{\mathtt b}})=\tilde w_{{\mathtt a}}\tilde w_{{\bar {\mathtt a}}}\tilde w_{{\mathtt c}}$
, and
 $\tau (\tilde w_{{\mathtt c}})=\tilde w_{{\mathtt b}}$
. Again, we can spot the morphism
$\tau (\tilde w_{{\mathtt c}})=\tilde w_{{\mathtt b}}$
. Again, we can spot the morphism
 $\psi $
, and we obtain
$\psi $
, and we obtain
 $$ \begin{align*} {\mathbf t}=\tilde w_{{\bar{\mathbf B}}_0}\tilde w_{{\bar{\mathbf B}}_1}\tilde w_{{\bar{\mathbf B}}_2}\cdots \end{align*} $$
$$ \begin{align*} {\mathbf t}=\tilde w_{{\bar{\mathbf B}}_0}\tilde w_{{\bar{\mathbf B}}_1}\tilde w_{{\bar{\mathbf B}}_2}\cdots \end{align*} $$
in exactly the same way as before. Each of the words
 $w_x$
in this representation yields a block
$w_x$
in this representation yields a block
 ${\mathtt 1}{\mathtt 1}$
in
${\mathtt 1}{\mathtt 1}$
in
 ${\mathbf t}$
, followed by a block
${\mathbf t}$
, followed by a block
 ${\mathtt 0}{\mathtt 0}$
. Therefore, also in this case, the gap sequence for w is a morphic image of a morphic sequence. This finishes the proof of Theorem 1.1.
${\mathtt 0}{\mathtt 0}$
. Therefore, also in this case, the gap sequence for w is a morphic image of a morphic sequence. This finishes the proof of Theorem 1.1.
Remark 2.12. Let us have a closer look at the gaps in the ‘mixed case’
 $\{a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k\}$
. Let
$\{a^{{\mathtt 0}{\mathtt 1}}_k,a^{{\mathtt 1}{\mathtt 0}}_k\}$
. Let
 $\sigma _0$
be the index at which w appears in
$\sigma _0$
be the index at which w appears in
 $a^{{\mathtt 0}{\mathtt 1}}_k$
, and
$a^{{\mathtt 0}{\mathtt 1}}_k$
, and
 $\sigma _1$
the index at which w appears in
$\sigma _1$
the index at which w appears in
 $a^{{\mathtt 1}{\mathtt 0}}_k$
. By (2-26) and the choice (2-25), each letter
$a^{{\mathtt 1}{\mathtt 0}}_k$
. By (2-26) and the choice (2-25), each letter
 $x\in \{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
in
$x\in \{{\mathtt a},{\bar {\mathtt a}},{\mathtt b},{\mathtt c}\}$
in
 ${\bar {\mathbf B}}$
corresponds to two gaps, as follows.
${\bar {\mathbf B}}$
corresponds to two gaps, as follows.
 $$ \begin{align*} \begin{array}{l@{\hspace{2em}}l@{\hspace{2em}}l} \mbox{Letter in } {\bar{\mathbf B}} &\mbox{Gap } 1&\mbox{Gap } 2\\ {\mathtt a}&\sigma_1-\sigma_0+2^{k+1}&\sigma_0-\sigma_1+2^k\\ {\bar{\mathtt a}}& \sigma_1-\sigma_0+2^k&\sigma_0-\sigma_1+2^{k+1}\\ {\mathtt b}& \sigma_1-\sigma_0+2^{k+1}&\sigma_0-\sigma_1+2^{k+1}\\ {\mathtt c}& \sigma_1-\sigma_0+2^k&\sigma_0-\sigma_1+2^k\\ \end{array} \end{align*} $$
$$ \begin{align*} \begin{array}{l@{\hspace{2em}}l@{\hspace{2em}}l} \mbox{Letter in } {\bar{\mathbf B}} &\mbox{Gap } 1&\mbox{Gap } 2\\ {\mathtt a}&\sigma_1-\sigma_0+2^{k+1}&\sigma_0-\sigma_1+2^k\\ {\bar{\mathtt a}}& \sigma_1-\sigma_0+2^k&\sigma_0-\sigma_1+2^{k+1}\\ {\mathtt b}& \sigma_1-\sigma_0+2^{k+1}&\sigma_0-\sigma_1+2^{k+1}\\ {\mathtt c}& \sigma_1-\sigma_0+2^k&\sigma_0-\sigma_1+2^k\\ \end{array} \end{align*} $$
It follows that there are at most four gaps that can occur in this case. For example, consider the gap sequence for the factor
 $w={\mathtt 0}{\mathtt 1}{\mathtt 0}$
. In this case
$w={\mathtt 0}{\mathtt 1}{\mathtt 0}$
. In this case
 $k=2$
, and we have
$k=2$
, and we have
 $a^{{\mathtt 0}{\mathtt 1}}_2={\mathtt 0}{\mathtt 1}{\mathtt 1}\underline {{\mathtt 0}{\mathtt 1}{\mathtt 0}}{\mathtt 0}{\mathtt 1}$
and
$a^{{\mathtt 0}{\mathtt 1}}_2={\mathtt 0}{\mathtt 1}{\mathtt 1}\underline {{\mathtt 0}{\mathtt 1}{\mathtt 0}}{\mathtt 0}{\mathtt 1}$
and
 $a^{{\mathtt 1}{\mathtt 0}}_2={\mathtt 1}{\mathtt 0}\underline {{\mathtt 0}{\mathtt 1}{\mathtt 0}}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, where the occurrences of w are underlined. We have
$a^{{\mathtt 1}{\mathtt 0}}_2={\mathtt 1}{\mathtt 0}\underline {{\mathtt 0}{\mathtt 1}{\mathtt 0}}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, where the occurrences of w are underlined. We have
 $\sigma _0=3$
and
$\sigma _0=3$
and
 $\sigma _1=2$
. This yields the gaps
$\sigma _1=2$
. This yields the gaps
 $3$
,
$3$
,
 $5$
,
$5$
,
 $7$
, and
$7$
, and
 $9$
, occurring only in the combinations
$9$
, occurring only in the combinations
 $(7,5)$
,
$(7,5)$
,
 $(3,9)$
,
$(3,9)$
,
 $(7,9)$
, and
$(7,9)$
, and
 $(3,5)$
. Noting also the first occurrence
$(3,5)$
. Noting also the first occurrence
 ${\mathbf t}_3{\mathbf t}_4{\mathbf t}_5={\mathtt 0}{\mathtt 1}{\mathtt 0}$
, the first few occurrences of
${\mathbf t}_3{\mathbf t}_4{\mathbf t}_5={\mathtt 0}{\mathtt 1}{\mathtt 0}$
, the first few occurrences of
 ${\mathtt 0}{\mathtt 1}{\mathtt 0}$
in
${\mathtt 0}{\mathtt 1}{\mathtt 0}$
in
 ${\mathbf t}$
are at positions
${\mathbf t}$
are at positions
 $3$
,
$3$
,
 $10$
,
$10$
,
 $15$
,
$15$
,
 $18$
, and
$18$
, and
 $27$
; compare (1-2). In particular, the gap sequence is not of the form
$27$
; compare (1-2). In particular, the gap sequence is not of the form
 $2^{\ell }{\mathbf B}$
or
$2^{\ell }{\mathbf B}$
or
 $2^{\ell }\check {\mathbf B}$
for some
$2^{\ell }\check {\mathbf B}$
for some
 $\ell \geq 0$
, each of which has only three different values.
$\ell \geq 0$
, each of which has only three different values.
Similar considerations hold for the case
 $\{a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k\}$
. More precisely, let
$\{a^{{\mathtt 0}{\mathtt 0}}_k,a^{{\mathtt 1}{\mathtt 1}}_k\}$
. More precisely, let
 $\sigma _0$
be the index at which w appears in
$\sigma _0$
be the index at which w appears in
 $a^{{\mathtt 1}{\mathtt 1}}_k$
and
$a^{{\mathtt 1}{\mathtt 1}}_k$
and
 $\sigma _1$
the index at which w appears in
$\sigma _1$
the index at which w appears in
 $a^{{\mathtt 0}{\mathtt 0}}_k$
. Each letter occurring in
$a^{{\mathtt 0}{\mathtt 0}}_k$
. Each letter occurring in
 ${\bar {\mathbf B}}$
corresponds to two gaps for w, as follows.
${\bar {\mathbf B}}$
corresponds to two gaps for w, as follows.
 $$ \begin{align*} \begin{array}{l@{\hspace{2em}}l@{\hspace{2em}}l} \mbox{Letter in } {\bar{\mathbf B}}&\mbox{Gap } 1&\mbox{Gap } 2\\ {\mathtt a}&\sigma_1-\sigma_0+4\cdot 2^k&\sigma_0-\sigma_1+2\cdot 2^k\\ {\bar{\mathtt a}}& \sigma_1-\sigma_0+2\cdot 2^k&\sigma_0-\sigma_1+4\cdot 2^k\\ {\mathtt b}& \sigma_1-\sigma_0+4\cdot 2^k&\sigma_0-\sigma_1+4\cdot 2^k\\ {\mathtt c}& \sigma_1-\sigma_0+2\cdot 2^k&\sigma_0-\sigma_1+2\cdot 2^k. \end{array} \end{align*} $$
$$ \begin{align*} \begin{array}{l@{\hspace{2em}}l@{\hspace{2em}}l} \mbox{Letter in } {\bar{\mathbf B}}&\mbox{Gap } 1&\mbox{Gap } 2\\ {\mathtt a}&\sigma_1-\sigma_0+4\cdot 2^k&\sigma_0-\sigma_1+2\cdot 2^k\\ {\bar{\mathtt a}}& \sigma_1-\sigma_0+2\cdot 2^k&\sigma_0-\sigma_1+4\cdot 2^k\\ {\mathtt b}& \sigma_1-\sigma_0+4\cdot 2^k&\sigma_0-\sigma_1+4\cdot 2^k\\ {\mathtt c}& \sigma_1-\sigma_0+2\cdot 2^k&\sigma_0-\sigma_1+2\cdot 2^k. \end{array} \end{align*} $$
An example for this case is given by the word
 ${\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, which is a factor of
${\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
, which is a factor of
 $a^{{\mathtt 0}{\mathtt 0}}_2={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
and of
$a^{{\mathtt 0}{\mathtt 0}}_2={\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
and of
 $a^{{\mathtt 1}{\mathtt 1}}_2={\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}$
. We have
$a^{{\mathtt 1}{\mathtt 1}}_2={\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 0}{\mathtt 1}$
. We have
 $\sigma _0=1$
and
$\sigma _0=1$
and
 $\sigma _1=3$
, and therefore the gaps
$\sigma _1=3$
, and therefore the gaps
 $6$
,
$6$
,
 $10$
,
$10$
,
 $14$
, and
$14$
, and
 $18$
, which appear as pairs
$18$
, which appear as pairs
 $(18,6)$
,
$(18,6)$
,
 $(10,14)$
,
$(10,14)$
,
 $(18,14)$
, and
$(18,14)$
, and
 $(10,6)$
.
$(10,6)$
.
3 The structure of the sequence
$\mathbf A$

In this section we investigate the infinite word
 ${\mathbf A}$
, in particular by extending it to a word over a seven-letter alphabet. This extension allows us to better understand the structure of
${\mathbf A}$
, in particular by extending it to a word over a seven-letter alphabet. This extension allows us to better understand the structure of
 ${\mathbf A}$
, and gives us a tool to handle the discrepancy
${\mathbf A}$
, and gives us a tool to handle the discrepancy
 $D_N$
. In particular, we prove Theorem 1.2.
$D_N$
. In particular, we prove Theorem 1.2.
3.1
$\mathbf A$
is automatic

It has been known since Berstel [Reference Berstel7] that
 ${\mathbf A}$
is
${\mathbf A}$
is
 $2$
-automatic. In this section we re-prove this statement using slightly different notation. Note that we give similar proofs (of Lemmas 2.2 and 2.3) in the first part of this paper. First of all, we recapture Berstel’s
$2$
-automatic. In this section we re-prove this statement using slightly different notation. Note that we give similar proofs (of Lemmas 2.2 and 2.3) in the first part of this paper. First of all, we recapture Berstel’s
 $2$
-uniform morphism. Introducing an auxiliary letter
$2$
-uniform morphism. Introducing an auxiliary letter
 ${\bar {\mathtt b}}$
, we have the morphism
${\bar {\mathtt b}}$
, we have the morphism
 $\overline \varphi $
as well as the coding
$\overline \varphi $
as well as the coding
 $\pi $
:
$\pi $
:
 $$ \begin{align*} \begin{array}{lllll} \overline\varphi:& {\mathtt a}\mapsto {\mathtt a}{\mathtt b},& {\mathtt b}\mapsto{\mathtt c}{\mathtt a},& {\bar{\mathtt b}}\mapsto{\mathtt a}{\mathtt c},& {\mathtt c}\mapsto{\mathtt c}{\bar{\mathtt b}}, \\ \pi:&{\mathtt a}\mapsto{\mathtt a},&{\mathtt b}\mapsto{\mathtt b},&{\bar{\mathtt b}}\mapsto{\mathtt b},&{\mathtt c}\mapsto{\mathtt c}. \end{array} \end{align*} $$
$$ \begin{align*} \begin{array}{lllll} \overline\varphi:& {\mathtt a}\mapsto {\mathtt a}{\mathtt b},& {\mathtt b}\mapsto{\mathtt c}{\mathtt a},& {\bar{\mathtt b}}\mapsto{\mathtt a}{\mathtt c},& {\mathtt c}\mapsto{\mathtt c}{\bar{\mathtt b}}, \\ \pi:&{\mathtt a}\mapsto{\mathtt a},&{\mathtt b}\mapsto{\mathtt b},&{\bar{\mathtt b}}\mapsto{\mathtt b},&{\mathtt c}\mapsto{\mathtt c}. \end{array} \end{align*} $$
We wish to prove that
 $$ \begin{align} \pi({\overline{\mathbf A}})={\mathbf A}, \end{align} $$
$$ \begin{align} \pi({\overline{\mathbf A}})={\mathbf A}, \end{align} $$
where
 ${\overline {\mathbf A}}$
is the fixed point of
${\overline {\mathbf A}}$
is the fixed point of
 $\overline \varphi $
starting with
$\overline \varphi $
starting with
 ${\mathtt a}$
. For this purpose, we show, by induction on
${\mathtt a}$
. For this purpose, we show, by induction on
 $k\geq 0$
, that the initial segment
$k\geq 0$
, that the initial segment
 $$ \begin{align*}s_k:=\overline\varphi^k({\mathtt a}{\mathtt b}{\mathtt c})\end{align*} $$
$$ \begin{align*}s_k:=\overline\varphi^k({\mathtt a}{\mathtt b}{\mathtt c})\end{align*} $$
of
 ${\overline {\mathbf A}}$
, of length
${\overline {\mathbf A}}$
, of length
 $3\cdot 2^k$
, is a concatenation of the three words
$3\cdot 2^k$
, is a concatenation of the three words
 $w_0={\mathtt a}{\mathtt b}{\mathtt c}$
,
$w_0={\mathtt a}{\mathtt b}{\mathtt c}$
,
 $w_1={\mathtt a}{\mathtt c}$
, and
$w_1={\mathtt a}{\mathtt c}$
, and
 $w_2={\bar {\mathtt b}}$
. We also call the words
$w_2={\bar {\mathtt b}}$
. We also call the words
 $w_j$
‘base words’ in this context, and the latter statement the ‘concatenation property’. Having proved this property, we use (recall the morphism
$w_j$
‘base words’ in this context, and the latter statement the ‘concatenation property’. Having proved this property, we use (recall the morphism
 $\varphi $
defined in (2-1))
$\varphi $
defined in (2-1))
 $$ \begin{align*} \begin{array}{lll} \pi(\overline\varphi(w_1)) &={\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}&=\varphi(\pi(w_1)),\\ \pi(\overline\varphi(w_2)) &={\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b}&=\varphi(\pi(w_1)),\\ \pi(\overline\varphi(w_3)) &={\mathtt a}{\mathtt c}&=\varphi(\pi(w_3)), \end{array} \end{align*} $$
$$ \begin{align*} \begin{array}{lll} \pi(\overline\varphi(w_1)) &={\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\mathtt b}&=\varphi(\pi(w_1)),\\ \pi(\overline\varphi(w_2)) &={\mathtt a}{\mathtt b}{\mathtt c}{\mathtt b}&=\varphi(\pi(w_1)),\\ \pi(\overline\varphi(w_3)) &={\mathtt a}{\mathtt c}&=\varphi(\pi(w_3)), \end{array} \end{align*} $$
in order to obtain
 $$ \begin{align} \varphi(\pi(s_k)) =\pi(\overline\varphi(s_k)) \end{align} $$
$$ \begin{align} \varphi(\pi(s_k)) =\pi(\overline\varphi(s_k)) \end{align} $$
for all
 $k\geq 0$
, by concatenation. In other words,
$k\geq 0$
, by concatenation. In other words,
 $\varphi $
and
$\varphi $
and
 $\overline {\varphi }$
act in the same way on an initial segment of
$\overline {\varphi }$
act in the same way on an initial segment of
 ${\overline {\mathbf A}}$
of length
${\overline {\mathbf A}}$
of length
 $3\cdot 2^k$
.
$3\cdot 2^k$
.
We may also display the relation (3-2) graphically. Define
 $S=\{s_k:k\geq 0\}\subseteq \{{\mathtt a},{\mathtt b},{\bar {\mathtt b}},{\mathtt c}\}^{\mathbb N}$
and
$S=\{s_k:k\geq 0\}\subseteq \{{\mathtt a},{\mathtt b},{\bar {\mathtt b}},{\mathtt c}\}^{\mathbb N}$
and
 $\Omega =\{{\mathtt a},{\mathtt b},{\mathtt c}\}^{\mathbb N}$
. Then the following diagram is commutative:
$\Omega =\{{\mathtt a},{\mathtt b},{\mathtt c}\}^{\mathbb N}$
. Then the following diagram is commutative:

Gluing together copies of this diagram, we obtain, for all
 $\ell \geq 1$
,
$\ell \geq 1$
,
 $$ \begin{align*} \varphi^{\ell}(s_0)&=\varphi^{\ell}(\pi(s_0)) = \varphi^{\ell-1}(\pi(\overline\varphi(s_0))) \\&= \varphi^{\ell-2}(\varphi(\pi(\overline\varphi(s_0)))) = \varphi^{\ell-2}(\pi(\overline\varphi^2(s_0))) =\cdots=\pi(\overline\varphi^{\ell}(s_0)). \end{align*} $$
$$ \begin{align*} \varphi^{\ell}(s_0)&=\varphi^{\ell}(\pi(s_0)) = \varphi^{\ell-1}(\pi(\overline\varphi(s_0))) \\&= \varphi^{\ell-2}(\varphi(\pi(\overline\varphi(s_0)))) = \varphi^{\ell-2}(\pi(\overline\varphi^2(s_0))) =\cdots=\pi(\overline\varphi^{\ell}(s_0)). \end{align*} $$
For each index
 $j\geq 0$
, choose
$j\geq 0$
, choose
 $\ell $
so large that
$\ell $
so large that
 $3\cdot 2^{\ell }\geq j$
. Then
$3\cdot 2^{\ell }\geq j$
. Then
 $$ \begin{align*}{\mathbf A}_i=\varphi^{\ell}(s_0)\rvert_i=\pi(\overline\varphi^{\ell}(s_0))\rvert_i= \pi(\overline\varphi^{\ell}(s_0)\rvert_i)= \pi({\overline{\mathbf A}}_i)\end{align*} $$
$$ \begin{align*}{\mathbf A}_i=\varphi^{\ell}(s_0)\rvert_i=\pi(\overline\varphi^{\ell}(s_0))\rvert_i= \pi(\overline\varphi^{\ell}(s_0)\rvert_i)= \pi({\overline{\mathbf A}}_i)\end{align*} $$
for
 $0\leq i<j$
. Therefore the infinite word
$0\leq i<j$
. Therefore the infinite word
 ${\mathbf A}$
is
${\mathbf A}$
is
 $2$
-automatic, being the coding under
$2$
-automatic, being the coding under
 $\pi $
of the
$\pi $
of the
 $2$
-automatic sequence
$2$
-automatic sequence
 ${\overline {\mathbf A}}$
, and thus we have derived (3-1) from the concatenation property.
${\overline {\mathbf A}}$
, and thus we have derived (3-1) from the concatenation property.
We still have to prove that
 $s_k$
is a concatenation of the base words. Clearly, this holds for
$s_k$
is a concatenation of the base words. Clearly, this holds for
 $s_0={\mathtt a}{\mathtt b}{\mathtt c}=w_0$
. Assume that we have already established that
$s_0={\mathtt a}{\mathtt b}{\mathtt c}=w_0$
. Assume that we have already established that
 $s_k=w_{\varepsilon _0}w_{\varepsilon _1}\cdots $
for some
$s_k=w_{\varepsilon _0}w_{\varepsilon _1}\cdots $
for some
 $\varepsilon _j\in \{0,1,2\}$
. We have
$\varepsilon _j\in \{0,1,2\}$
. We have
 $$ \begin{align*} \overline\varphi(w_1)&={\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}=w_0w_1w_2,\\ \overline\varphi(w_2)&={\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}=w_0w_2,\\ \overline\varphi(w_3)&={\mathtt a}{\mathtt c}=w_1, \end{align*} $$
$$ \begin{align*} \overline\varphi(w_1)&={\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}=w_0w_1w_2,\\ \overline\varphi(w_2)&={\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}=w_0w_2,\\ \overline\varphi(w_3)&={\mathtt a}{\mathtt c}=w_1, \end{align*} $$
and thus
 $$ \begin{align*}s_{k+1}=\overline\varphi(s_k) =\overline\varphi(w_{\varepsilon_0})\overline\varphi(w_{\varepsilon_1})\cdots\end{align*} $$
$$ \begin{align*}s_{k+1}=\overline\varphi(s_k) =\overline\varphi(w_{\varepsilon_0})\overline\varphi(w_{\varepsilon_1})\cdots\end{align*} $$
is a concatenation of the
 $w_j$
too. This proves (3-1).
$w_j$
too. This proves (3-1).
Complementing this result, we note that Berstel [Reference Berstel7, Corollary 7] also proved that
 ${\mathbf A}$
itself is not a fixed point of (the extension of) a uniform morphism.
${\mathbf A}$
itself is not a fixed point of (the extension of) a uniform morphism.
3.2 Transforming
$\mathbf A$

We identify circular shifts, or rotations, of factors of length
 $L\geq 2$
appearing in the sequence
$L\geq 2$
appearing in the sequence
 ${\mathbf A}$
. Such a rotation of a word
${\mathbf A}$
. Such a rotation of a word
 $(a_i)_{i\geq 0}$
replaces the subword
$(a_i)_{i\geq 0}$
replaces the subword
 $a_j\,a_{j+1}\cdots a_{j+L-2}\,a_{j+L-1}$
by
$a_j\,a_{j+1}\cdots a_{j+L-2}\,a_{j+L-1}$
by
 $a_{j+1}\cdots a_{j+L-2}\,a_{j+L-1}\,a_j$
(rotation to the left), or
$a_{j+1}\cdots a_{j+L-2}\,a_{j+L-1}\,a_j$
(rotation to the left), or
 $a_{j+L-1}\,a_j\,a_{j+1}\cdots a_{j+L-2}$
(rotation to the right).
$a_{j+L-1}\,a_j\,a_{j+1}\cdots a_{j+L-2}$
(rotation to the right).
Carrying out a certain number of such rotations, we see that the sequence
 $\mathbf A$
is reduced to the periodic word
$\mathbf A$
is reduced to the periodic word
 $({\mathtt a}{\mathtt b}{\mathtt c})^{\omega }$
. Of course, this is possible for any word containing an infinite number of each of
$({\mathtt a}{\mathtt b}{\mathtt c})^{\omega }$
. Of course, this is possible for any word containing an infinite number of each of
 ${\mathtt a}$
,
${\mathtt a}$
,
 ${\mathtt b}$
, and
${\mathtt b}$
, and
 ${\mathtt c}$
, and it can be achieved in uncountably many ways. In our case, however, an admissible sequence of rotations can be made very explicit, by defining a new morphism
${\mathtt c}$
, and it can be achieved in uncountably many ways. In our case, however, an admissible sequence of rotations can be made very explicit, by defining a new morphism
 $\varphi ^+$
. This morphism has the fixed point
$\varphi ^+$
. This morphism has the fixed point
 ${\overline {\mathbf A}}$
, which maps to
${\overline {\mathbf A}}$
, which maps to
 ${\mathbf A}$
under a coding. From this augmented sequence, we see very clearly the ‘nested structure’ of the above-mentioned rotations. In particular, we can find a certain noncrossing matching, defined in (3-8), describing the intervals that we perform rotations on, and the direction of each rotation. Moreover, in the process we learn something about the discrepancy of
${\mathbf A}$
under a coding. From this augmented sequence, we see very clearly the ‘nested structure’ of the above-mentioned rotations. In particular, we can find a certain noncrossing matching, defined in (3-8), describing the intervals that we perform rotations on, and the direction of each rotation. Moreover, in the process we learn something about the discrepancy of
 ${\mathtt 0}{\mathtt 1}$
-blocks in
${\mathtt 0}{\mathtt 1}$
-blocks in
 ${\mathbf t}$
, which was defined in (1-4). Let us consider the iteration
${\mathbf t}$
, which was defined in (1-4). Let us consider the iteration
 $\overline \varphi ^2$
of Berstel’s morphism:
$\overline \varphi ^2$
of Berstel’s morphism:
 $$ \begin{align*} \begin{array}{lllll} \overline\varphi^2:& {\mathtt a}\mapsto {\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a},& {\mathtt b}\mapsto{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b},& {\bar{\mathtt b}}\mapsto{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}},& {\mathtt c}\mapsto{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}. \end{array} \end{align*} $$
$$ \begin{align*} \begin{array}{lllll} \overline\varphi^2:& {\mathtt a}\mapsto {\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a},& {\mathtt b}\mapsto{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b},& {\bar{\mathtt b}}\mapsto{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}},& {\mathtt c}\mapsto{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}. \end{array} \end{align*} $$
We introduce certain decorations (connectors) of the letters. Their meaning becomes clear in a moment. Based on the morphism
 $\overline \varphi ^2$
, we define the following decorated version, which is a morphism on the seven-letter alphabet
$\overline \varphi ^2$
, we define the following decorated version, which is a morphism on the seven-letter alphabet


This morphism has a unique fixed point
 ${{\mathbf A}^{\!+}}$
starting with
${{\mathbf A}^{\!+}}$
starting with
 ${\mathtt a}$
. The image of
${\mathtt a}$
. The image of
 ${{\mathbf A}^{\!+}}$
under the obvious coding
${{\mathbf A}^{\!+}}$
under the obvious coding
 $\gamma $
given by
$\gamma $
given by

yields the sequence
 ${\mathbf A}$
. Based on this, we speak of letters of types
${\mathbf A}$
. Based on this, we speak of letters of types
 ${\mathtt a}$
,
${\mathtt a}$
,
 ${\mathtt b}$
, and
${\mathtt b}$
, and
 ${\mathtt c}$
, thus referring to letters from
${\mathtt c}$
, thus referring to letters from
 $\{{\mathtt a}\}$
,
$\{{\mathtt a}\}$
,
 , and
, and
![]() , respectively.
, respectively.
From substitution (3-3), we can immediately derive the following lemma.
Lemma 3.1. Let
 $j\geq 1$
, and
$j\geq 1$
, and
 $(x,y,z)=({{\mathbf A}^{\!+}}_{j-1},{{\mathbf A}^{\!+}}_j,{{\mathbf A}^{\!+}}_{j+1})$
. Then
$(x,y,z)=({{\mathbf A}^{\!+}}_{j-1},{{\mathbf A}^{\!+}}_j,{{\mathbf A}^{\!+}}_{j+1})$
. Then

We wish to connect the ‘loose ends’ of the connectors; we say that two connectors at indices
 $i<j$
match if the connector at i points to the right and the connector at j points to the left. The very simple algorithm FindMatching joins matching connectors, beginning with shortest connections. Only pairs of free connectors are connected, that is, each letter may be the starting point of only one link.
$i<j$
match if the connector at i points to the right and the connector at j points to the left. The very simple algorithm FindMatching joins matching connectors, beginning with shortest connections. Only pairs of free connectors are connected, that is, each letter may be the starting point of only one link.

Note that we have to pay attention that previously selected indices are not chosen again. This explains the introduction of SelectedIndices. A connection between the two letters at indices i and j is just a different name for the pair
 $(i,j)$
. For any finite word w over the alphabet K this procedure yields a (possibly empty) set
$(i,j)$
. For any finite word w over the alphabet K this procedure yields a (possibly empty) set
 $M(w)$
of pairs
$M(w)$
of pairs
 $(i,j)$
of indices.
$(i,j)$
of indices.
We wish to prove that the algorithm is monotone.
Lemma 3.2. Let w and
 $w'$
be finite words over the alphabet K, and assume that w is an initial segment of
$w'$
be finite words over the alphabet K, and assume that w is an initial segment of
 $w'$
. Let
$w'$
. Let
 $M(w)$
(respectively,
$M(w)$
(respectively,
 $M(w')$
) be the sets of pairs found by the FindMatching algorithm. Then
$M(w')$
) be the sets of pairs found by the FindMatching algorithm. Then
 $$ \begin{align*} M(w)\subseteq M(w'). \end{align*} $$
$$ \begin{align*} M(w)\subseteq M(w'). \end{align*} $$
Proof. We show this by induction on the length j of w. Clearly, it holds for
 $j=0$
. Let us append a symbol
$j=0$
. Let us append a symbol
 $x\in K$
to w (at position j). Define
$x\in K$
to w (at position j). Define
 $M_{\ell }(w)$
as the set of connections
$M_{\ell }(w)$
as the set of connections
 $(a,b)$
for w of length strictly smaller than
$(a,b)$
for w of length strictly smaller than
 $\ell $
, found by the algorithm. Define
$\ell $
, found by the algorithm. Define
 $M_{\ell }(wx)$
analogously. We prove by induction on
$M_{\ell }(wx)$
analogously. We prove by induction on
 $\ell $
that
$\ell $
that
 $M_{\ell }(w)\subseteq M_{\ell }(wx)$
, and that, if the inclusion is strict, we have
$M_{\ell }(w)\subseteq M_{\ell }(wx)$
, and that, if the inclusion is strict, we have
 $M_{\ell }(wx)=M_{\ell }(w)\cup \{(i,j)\}$
for some
$M_{\ell }(wx)=M_{\ell }(w)\cup \{(i,j)\}$
for some
 $i<j$
. Suppose that this is true for some
$i<j$
. Suppose that this is true for some
 $\ell $
(clearly, it holds for
$\ell $
(clearly, it holds for
 $\ell =0$
). We distinguish between two cases. (i) If
$\ell =0$
). We distinguish between two cases. (i) If
 $(i,j)\not \in M_{\ell }(wx)$
for all i, we have
$(i,j)\not \in M_{\ell }(wx)$
for all i, we have
 $M_{\ell }(w)=M_{\ell }(wx)$
by hypothesis; we add each pair
$M_{\ell }(w)=M_{\ell }(wx)$
by hypothesis; we add each pair
 $(a,b)$
with
$(a,b)$
with
 $b<j$
having matching connectors and such that
$b<j$
having matching connectors and such that
 $b-a=\ell $
to the sets
$b-a=\ell $
to the sets
 $M_{\ell }(w)$
and
$M_{\ell }(w)$
and
 $M_{\ell }(wx)$
, and possibly one more pair
$M_{\ell }(wx)$
, and possibly one more pair
 $(i,j)$
, for some
$(i,j)$
, for some
 $i<j$
, to
$i<j$
, to
 $M_{\ell }(wx)$
. (ii) If
$M_{\ell }(wx)$
. (ii) If
 $(i,j)\in M_{\ell }(wx)$
for some i, we have
$(i,j)\in M_{\ell }(wx)$
for some i, we have
 $\ell>j-i$
by the definition of
$\ell>j-i$
by the definition of
 $M_{\ell }(wx)$
; we add the pairs
$M_{\ell }(wx)$
; we add the pairs
 $(a,b)$
, with
$(a,b)$
, with
 $b<j$
, having matching connectors and such that
$b<j$
, having matching connectors and such that
 $a\neq i$
and
$a\neq i$
and
 $b-a=\ell $
to both sets
$b-a=\ell $
to both sets
 $M_{\ell }(w)$
and
$M_{\ell }(w)$
and
 $M_{\ell }(wx)$
. There are clearly no more pairs added to
$M_{\ell }(wx)$
. There are clearly no more pairs added to
 $M_{\ell }(wx)$
, since i and j are already taken; moreover, the condition that
$M_{\ell }(wx)$
, since i and j are already taken; moreover, the condition that
 $\ell>j-i$
renders impossible the chance of another connection
$\ell>j-i$
renders impossible the chance of another connection
 $(i,b)$
, where
$(i,b)$
, where
 $b<j$
, being added to
$b<j$
, being added to
 $M_{\ell }(w)$
.
$M_{\ell }(w)$
.
We extend M to a function on all (finite or infinite) words w over K, in the following obvious way: for each
 $\ell $
, form the set
$\ell $
, form the set
 $\tilde M_{\ell }(w)$
of all pairs
$\tilde M_{\ell }(w)$
of all pairs
 $(a,b)$
satisfying
$(a,b)$
satisfying
 $b-a=\ell $
, having matching connectors, such that neither a nor b is a component of any
$b-a=\ell $
, having matching connectors, such that neither a nor b is a component of any
 $\tilde M_{\ell '}(w)$
, where
$\tilde M_{\ell '}(w)$
, where
 $\ell '<\ell $
. Set
$\ell '<\ell $
. Set
 $\tilde M(w)=\bigcup _{\ell \geq 1}\tilde M_{\ell }(w)$
. The following lemma gives us a method to compute a matching for an infinite word by only looking at finite segments.
$\tilde M(w)=\bigcup _{\ell \geq 1}\tilde M_{\ell }(w)$
. The following lemma gives us a method to compute a matching for an infinite word by only looking at finite segments.
Lemma 3.3. Let w be an infinite word over K. Then
 $$ \begin{align} \bigcup_{j\geq 0}M(w\rvert_{[0,j)})=\tilde M(w). \end{align} $$
$$ \begin{align} \bigcup_{j\geq 0}M(w\rvert_{[0,j)})=\tilde M(w). \end{align} $$
Proof. Let
 $M_{\ell }(w)$
be the set of connections added in step
$M_{\ell }(w)$
be the set of connections added in step
 $\ell $
of the FindMatching algorithm. We prove, more generally, that
$\ell $
of the FindMatching algorithm. We prove, more generally, that
 $$ \begin{align} \bigcup_{j\geq 0}M_{\ell}(w\rvert_{[0,j)})=\tilde M_{\ell}(w). \end{align} $$
$$ \begin{align} \bigcup_{j\geq 0}M_{\ell}(w\rvert_{[0,j)})=\tilde M_{\ell}(w). \end{align} $$
We prove this by induction on
 $\ell $
, and we start at connections of length
$\ell $
, and we start at connections of length
 $\ell =1$
. Let
$\ell =1$
. Let
 $(i,i+1)\in M_{\ell }(w\rvert _{[0,j)})$
. Then there is a pair of matching connectors at indices i and
$(i,i+1)\in M_{\ell }(w\rvert _{[0,j)})$
. Then there is a pair of matching connectors at indices i and
 $i+1$
(where
$i+1$
(where
 $i+1<j$
), and therefore this pair is also contained in
$i+1<j$
), and therefore this pair is also contained in
 $\tilde M_1(w)$
. This proves the inclusion ‘
$\tilde M_1(w)$
. This proves the inclusion ‘
 $\subseteq $
’. On the other hand, if
$\subseteq $
’. On the other hand, if
 $(i,i+1)$
is a link connecting matching connectors in w, this link is also to be found in the sequence
$(i,i+1)$
is a link connecting matching connectors in w, this link is also to be found in the sequence
 $w\rvert _{[0,i+2)}$
, hence the inclusion ‘
$w\rvert _{[0,i+2)}$
, hence the inclusion ‘
 $\supseteq $
’. Assume that (3-7) holds for some
$\supseteq $
’. Assume that (3-7) holds for some
 $\ell \geq 1$
. If the algorithm finds a pair
$\ell \geq 1$
. If the algorithm finds a pair
 $(i,i+\ell )$
of matching connectors in
$(i,i+\ell )$
of matching connectors in
 $w\rvert _{[0,j)}$
, where
$w\rvert _{[0,j)}$
, where
 $(i,i+\ell )\not \in M_{\ell }(w\rvert _{[0,j)})$
, this pair trivially also matches in the (unrestricted) word w. By hypothesis, the connectors at i and
$(i,i+\ell )\not \in M_{\ell }(w\rvert _{[0,j)})$
, this pair trivially also matches in the (unrestricted) word w. By hypothesis, the connectors at i and
 $i+\ell $
are not used by
$i+\ell $
are not used by
 $\tilde M_{\ell }(w)$
, hence the inclusion ‘
$\tilde M_{\ell }(w)$
, hence the inclusion ‘
 $\subseteq $
’. On the other hand, a link
$\subseteq $
’. On the other hand, a link
 $(i,i+\ell )$
of matching connectors in w that is still free in step
$(i,i+\ell )$
of matching connectors in w that is still free in step
 $\ell $
is also free in
$\ell $
is also free in
 $w\rvert _{[0,i+\ell +1)}$
by hypothesis, which proves (3-7) and hence the lemma.
$w\rvert _{[0,i+\ell +1)}$
by hypothesis, which proves (3-7) and hence the lemma.
Our algorithm avoids crossing connections: if
 $i<j<k<\ell $
are indices such that
$i<j<k<\ell $
are indices such that
 $(i,k)\in M(w)$
and
$(i,k)\in M(w)$
and
 $({\kern1.5pt}j,\ell )\in M(w)$
, then the connector at index j is pointing to the right, and the one at k to the left, so the shorter connection
$({\kern1.5pt}j,\ell )\in M(w)$
, then the connector at index j is pointing to the right, and the one at k to the left, so the shorter connection
 $({\kern1.5pt}j,k)$
would have been chosen earlier. This contradicts the construction rule that indices may only be chosen once.
$({\kern1.5pt}j,k)$
would have been chosen earlier. This contradicts the construction rule that indices may only be chosen once.
More generally, a noncrossing matching for a word w over K (finite or infinite) is a set M of pairs
 $(i,j)$
such that
$(i,j)$
such that

Here
 $\bigcup M=\{i:(i,j)\in M\mbox { for some }j\ \mbox {or }({\kern1.5pt}j,i)\in M\mbox { for some }j\}$
.
$\bigcup M=\{i:(i,j)\in M\mbox { for some }j\ \mbox {or }({\kern1.5pt}j,i)\in M\mbox { for some }j\}$
.
We call a word w closed if there exists a noncrossing matching for w.
Lemma 3.4. Let w be a word over K. There is at most one noncrossing matching for w. If there exists one, FindMatching generates it by virtue of (3-6).
Proof. Let m be a noncrossing matching of w. Since all connectors have to connect to something and the connecting lines must not cross, we see that all pairs
 $(i,i+1)$
of indices where matching connectors appear have to be contained in m. It follows that
$(i,i+1)$
of indices where matching connectors appear have to be contained in m. It follows that
 $M_1(w\rvert _{[0,j)})\subseteq m$
for all j, and therefore
$M_1(w\rvert _{[0,j)})\subseteq m$
for all j, and therefore
 $\tilde M_1(w)\subseteq m$
by (3-7). On the other hand, the definition of a noncrossing matching only allows matching connectors, therefore each connection
$\tilde M_1(w)\subseteq m$
by (3-7). On the other hand, the definition of a noncrossing matching only allows matching connectors, therefore each connection
 $(i,i+1)$
in m is found by FindMatching, for
$(i,i+1)$
in m is found by FindMatching, for
 $j=i+2$
.
$j=i+2$
.
Similar reasoning applies for longer connections too. Let us assume that the set of connections of length less than
 $\ell $
coming from FindMatching is the same as the set of connections of length less than
$\ell $
coming from FindMatching is the same as the set of connections of length less than
 $\ell $
contained in m. Assume that i is an index such that the connectors at indices i and
$\ell $
contained in m. Assume that i is an index such that the connectors at indices i and
 $i+\ell $
match, and neither i nor
$i+\ell $
match, and neither i nor
 $i+\ell $
appears in a connection of length less than
$i+\ell $
appears in a connection of length less than
 $\ell $
in m. Since m is a matching, the connector at index i has to be linked to a connector at an index
$\ell $
in m. Since m is a matching, the connector at index i has to be linked to a connector at an index
 $j>i$
. Indices
$j>i$
. Indices
 $j\in \{i+1,\ldots ,i+\ell -1\}$
are excluded by our hypothesis, and indices
$j\in \{i+1,\ldots ,i+\ell -1\}$
are excluded by our hypothesis, and indices
 $j>i+\ell $
are impossible by the noncrossing property, therefore
$j>i+\ell $
are impossible by the noncrossing property, therefore
 $(i,i+\ell )\in m$
. Again, other connections of length
$(i,i+\ell )\in m$
. Again, other connections of length
 $\ell $
cannot appear in m, therefore FindMatching finds all pairs
$\ell $
cannot appear in m, therefore FindMatching finds all pairs
 $(i,i+\ell )$
contained in m. This completes our argument by induction. Therefore,
$(i,i+\ell )$
contained in m. This completes our argument by induction. Therefore,
 $m=\tilde M(w)$
, and both statements of Lemma 3.4 follow.
$m=\tilde M(w)$
, and both statements of Lemma 3.4 follow.
Lemma 3.5. The sequence
 ${{\mathbf A}^{\!+}}$
is closed.
${{\mathbf A}^{\!+}}$
is closed.
Proof. First of all, we note that it is sufficient to prove that
 $\varphi ^+$
maps closed words w to closed words. If this is established, we obtain, by induction, that the initial segments
$\varphi ^+$
maps closed words w to closed words. If this is established, we obtain, by induction, that the initial segments
 $(\varphi ^+)^k({\mathtt a})$
of
$(\varphi ^+)^k({\mathtt a})$
of
 ${{\mathbf A}^{\!+}}$
are closed. Since noncrossing matchings are unique, the corresponding sequence
${{\mathbf A}^{\!+}}$
are closed. Since noncrossing matchings are unique, the corresponding sequence
 $(m_k)_{k\geq 0}$
of noncrossing matchings satisfies
$(m_k)_{k\geq 0}$
of noncrossing matchings satisfies
 $m_k\subseteq m_{k+1}$
, and
$m_k\subseteq m_{k+1}$
, and
 $\bigcup _{k\geq 0}m_k$
is easily seen to be the desired matching for
$\bigcup _{k\geq 0}m_k$
is easily seen to be the desired matching for
 ${{\mathbf A}^{\!+}}$
.
${{\mathbf A}^{\!+}}$
.
We prove by induction on the length n of a closed word w that
 $\varphi ^+(w)$
is closed. This is obvious for the closed words of length
$\varphi ^+(w)$
is closed. This is obvious for the closed words of length
 $n\le 2$
: the word
$n\le 2$
: the word
 is closed, and the cases
is closed, and the cases
![]() ,
,
 ,
,
![]() , and
, and
 are also easy. Moreover, a concatenation of two closed words is also closed: one of the matchings has to be shifted (both components of each entry have to be shifted), and we only have to form the union of the matchings.
are also easy. Moreover, a concatenation of two closed words is also closed: one of the matchings has to be shifted (both components of each entry have to be shifted), and we only have to form the union of the matchings.
If w is of the form
 for some nonempty word C over K, we obtain a noncrossing matching for C by stripping the pair
for some nonempty word C over K, we obtain a noncrossing matching for C by stripping the pair
 $(1,n)$
from a corresponding matching for w. Therefore, C is closed. Applying
$(1,n)$
from a corresponding matching for w. Therefore, C is closed. Applying
 $\varphi ^+$
, we see that
$\varphi ^+$
, we see that

This is closed by our hypothesis, since C is shorter than w. The other case
![]() is analogous (note that there are no more cases by (3-5)), and the proof is complete.
is analogous (note that there are no more cases by (3-5)), and the proof is complete.
Remark 3.6. We note that this proof can also be used to show that the substitution
 $\varphi ^+$
respects noncrossing matchings, in the following sense. If m is a noncrossing matching for w, then there exists a (unique) noncrossing matching
$\varphi ^+$
respects noncrossing matchings, in the following sense. If m is a noncrossing matching for w, then there exists a (unique) noncrossing matching
 $m'$
for
$m'$
for
 $\varphi ^+(w)$
; the matching m can be recovered from
$\varphi ^+(w)$
; the matching m can be recovered from
 $m'$
by omitting certain links, and applying a renaming
$m'$
by omitting certain links, and applying a renaming
 $(i,j)\mapsto (\mu (i),\mu ({\kern1.5pt}j))$
to the remaining links, where
$(i,j)\mapsto (\mu (i),\mu ({\kern1.5pt}j))$
to the remaining links, where
 $\mu :\mathbb N\rightarrow \mathbb N$
is nonincreasing. The proof is not difficult: if this procedure works for the closed word C, we can also carry this out for
$\mu :\mathbb N\rightarrow \mathbb N$
is nonincreasing. The proof is not difficult: if this procedure works for the closed word C, we can also carry this out for
 by (3-9); we see that the additional link
by (3-9); we see that the additional link
 is still present in
is still present in
 . Also, the procedure of recovering
. Also, the procedure of recovering
 $m'$
from m is compatible with concatenations of closed words C and D, as a matching for
$m'$
from m is compatible with concatenations of closed words C and D, as a matching for
 $\varphi ^+(CD)=\varphi ^+(C)\,\varphi ^+(D)$
does not connect letters in
$\varphi ^+(CD)=\varphi ^+(C)\,\varphi ^+(D)$
does not connect letters in
 $\varphi ^+(C)$
and
$\varphi ^+(C)$
and
 $\varphi ^+(D)$
.
$\varphi ^+(D)$
.
The construction of the matching in the proof of Lemma 3.5 also shows the following result.
Corollary 3.7. Let m be the noncrossing matching for
 ${{\mathbf A}^{\!+}}$
. By virtue of m, each letter of type
${{\mathbf A}^{\!+}}$
. By virtue of m, each letter of type
 ${\mathtt c}$
is connected to exactly one letter, which is of type
${\mathtt c}$
is connected to exactly one letter, which is of type
 ${\mathtt b}$
, and each letter of type
${\mathtt b}$
, and each letter of type
 ${\mathtt b}$
is connected to exactly one letter, which is of type
${\mathtt b}$
is connected to exactly one letter, which is of type
 ${\mathtt c}$
.
${\mathtt c}$
.
Our interest in the link structure of
 ${{\mathbf A}^{\!+}}$
stems from the fact that we may transform the sequence
${{\mathbf A}^{\!+}}$
stems from the fact that we may transform the sequence
 ${\mathbf A}$
into a periodic one, using the following transparent mechanism. Let m be the noncrossing matching for
${\mathbf A}$
into a periodic one, using the following transparent mechanism. Let m be the noncrossing matching for
 ${{\mathbf A}^{\!+}}$
, and let
${{\mathbf A}^{\!+}}$
, and let
 $((i_k,j_k))_{k\geq 0}$
be an enumeration of m such that
$((i_k,j_k))_{k\geq 0}$
be an enumeration of m such that
 $({\kern1.5pt}j_k-i_k)_{k\geq 0}$
is nondecreasing. We define a sequence
$({\kern1.5pt}j_k-i_k)_{k\geq 0}$
is nondecreasing. We define a sequence
 $(A^{(k)})_{k\geq 0}$
as follows.
$(A^{(k)})_{k\geq 0}$
as follows.
• Set
$A^{(0)}={{\mathbf A}^{\!+}}$
.• Let
$k\geq 0$
. If
, we rotate the letters in
$A^{(k)}$
with indices
$i_k,i_k+1,\ldots ,j_k$
to the right by one place, yielding
$A^{(k+1)}$
. Otherwise, we necessarily have
and we rotate the letters with indices
$i_k,i_k+1,\ldots ,j_k-1$
to the left by one place.








In more colourful language, in each step some letter of type
 ${\mathtt b}$
is moved along its connecting link and inserted just before the letter of type
${\mathtt b}$
is moved along its connecting link and inserted just before the letter of type
 ${\mathtt c}$
it is connected to. Note that due to the monotonicity requirement and the noncrossing property, the
${\mathtt c}$
it is connected to. Note that due to the monotonicity requirement and the noncrossing property, the
 $k\, $
th rotation does not change the indices at which the subsequent rotations are carried out. Therefore, the sequence
$k\, $
th rotation does not change the indices at which the subsequent rotations are carried out. Therefore, the sequence
 $(A^{(k)})_{k\ge 0}$
is well defined. Moreover, the result does not depend on the particular nondecreasing enumeration of m for the same reasons. Since the first N indices eventually remain unchanged, the limit
$(A^{(k)})_{k\ge 0}$
is well defined. Moreover, the result does not depend on the particular nondecreasing enumeration of m for the same reasons. Since the first N indices eventually remain unchanged, the limit
 $$ \begin{align*} \rho({{\mathbf A}^{\!+}}):=\gamma\big(\lim_{k\rightarrow\infty}A^{(k)}\big) \end{align*} $$
$$ \begin{align*} \rho({{\mathbf A}^{\!+}}):=\gamma\big(\lim_{k\rightarrow\infty}A^{(k)}\big) \end{align*} $$
exists (note that
 $\gamma $
, defined in (3-4), replaces each letter of type x by x). The definition of
$\gamma $
, defined in (3-4), replaces each letter of type x by x). The definition of
 $A^{(k)}$
is summarized in the RotateAlongLinks algorithm. As in the case of the FindMatching algorithm, we require a finite word w (and a finite set
$A^{(k)}$
is summarized in the RotateAlongLinks algorithm. As in the case of the FindMatching algorithm, we require a finite word w (and a finite set
 $m\subset \mathbb N^2$
) as input in order to guarantee finite running time.
$m\subset \mathbb N^2$
) as input in order to guarantee finite running time.

By the above remarks, the words RotateAlongLinks
 $(w_k,M(w_k))$
converge to
$(w_k,M(w_k))$
converge to
 $\rho ({{\mathbf A}^{\!+}})$
as
$\rho ({{\mathbf A}^{\!+}})$
as
 $k\rightarrow \infty $
, where
$k\rightarrow \infty $
, where
 $w=(\varphi ^+)^k({\mathtt a})$
. We have the following central proposition.
$w=(\varphi ^+)^k({\mathtt a})$
. We have the following central proposition.
Proposition 3.8. Let m be the noncrossing matching for
 ${{\mathbf A}^{\!+}}$
. Then
${{\mathbf A}^{\!+}}$
. Then
 $$ \begin{align*} \rho({{\mathbf A}^{\!+}})=({\mathtt a}{\mathtt b}{\mathtt c})^{\omega}. \end{align*} $$
$$ \begin{align*} \rho({{\mathbf A}^{\!+}})=({\mathtt a}{\mathtt b}{\mathtt c})^{\omega}. \end{align*} $$
Proof. Let us first note that the limit itself can be obtained in a simpler way. For any closed word C over K, (1) apply
 $\gamma $
, (2) remove all occurrences of
$\gamma $
, (2) remove all occurrences of
 ${\mathtt b}$
, and (3) reinsert
${\mathtt b}$
, and (3) reinsert
 ${\mathtt b}$
before each
${\mathtt b}$
before each
 ${\mathtt c}$
. The resulting word equals
${\mathtt c}$
. The resulting word equals
 $\rho (C)$
. This statement simply follows from the facts that (i) both procedures do not change the order in which the underlying letters
$\rho (C)$
. This statement simply follows from the facts that (i) both procedures do not change the order in which the underlying letters
 ${\mathtt a}$
and
${\mathtt a}$
and
 ${\mathtt c}$
appear, that (ii) each occurrence of
${\mathtt c}$
appear, that (ii) each occurrence of
 ${\mathtt c}$
in both results is preceded by
${\mathtt c}$
in both results is preceded by
 ${\mathtt b}$
, and that (iii) in both results,
${\mathtt b}$
, and that (iii) in both results,
 ${\mathtt b}$
does not appear at other places. We therefore see that Proposition 3.8 is equivalent to the following. Let
${\mathtt b}$
does not appear at other places. We therefore see that Proposition 3.8 is equivalent to the following. Let
 $\mathbf C$
be the sequence obtained from
$\mathbf C$
be the sequence obtained from
 ${{\mathbf A}^{\!+}}$
by deleting all decorations, and all occurrences of
${{\mathbf A}^{\!+}}$
by deleting all decorations, and all occurrences of
 ${\mathtt b}$
and
${\mathtt b}$
and
 ${\bar {\mathtt b}}$
. Then
${\bar {\mathtt b}}$
. Then
 $\mathbf C=({\mathtt a}{\mathtt c})^{\omega }$
. In other words, we only have to show that
$\mathbf C=({\mathtt a}{\mathtt c})^{\omega }$
. In other words, we only have to show that
 ${\mathtt a}$
and
${\mathtt a}$
and
 ${\mathtt c}$
occur alternatingly in
${\mathtt c}$
occur alternatingly in
 ${\mathbf A}$
, with the empty word or one occurrence of
${\mathbf A}$
, with the empty word or one occurrence of
 ${\mathtt b}$
in between. We prove a stronger statement concerning the sequence
${\mathtt b}$
in between. We prove a stronger statement concerning the sequence
 ${\overline {\mathbf A}}$
, which completes the proof of Proposition 3.8.
${\overline {\mathbf A}}$
, which completes the proof of Proposition 3.8.
Lemma 3.9. There are sequences
 $(\varepsilon _k)_{k\geq 0}$
and
$(\varepsilon _k)_{k\geq 0}$
and
 $(\varepsilon ^{\prime }_k)_{k\geq 0}$
in
$(\varepsilon ^{\prime }_k)_{k\geq 0}$
in
 $\{0,1\}$
such that
$\{0,1\}$
such that
 $$ \begin{align*}{\overline{\mathbf A}}={\mathtt a} ({\mathtt b}{\mathtt c}({\mathtt a}{\mathtt c})^{\varepsilon_0}{\bar{\mathtt b}}{\mathtt a}({\mathtt c}{\mathtt a})^{\varepsilon^{\prime}_0}) ({\mathtt b}{\mathtt c}({\mathtt a}{\mathtt c})^{\varepsilon_1}{\bar{\mathtt b}}{\mathtt a}({\mathtt c}{\mathtt a})^{\varepsilon^{\prime}_1}) \cdots. \end{align*} $$
$$ \begin{align*}{\overline{\mathbf A}}={\mathtt a} ({\mathtt b}{\mathtt c}({\mathtt a}{\mathtt c})^{\varepsilon_0}{\bar{\mathtt b}}{\mathtt a}({\mathtt c}{\mathtt a})^{\varepsilon^{\prime}_0}) ({\mathtt b}{\mathtt c}({\mathtt a}{\mathtt c})^{\varepsilon_1}{\bar{\mathtt b}}{\mathtt a}({\mathtt c}{\mathtt a})^{\varepsilon^{\prime}_1}) \cdots. \end{align*} $$
In order to prove this, we apply the second iteration
 $\overline \varphi ^2$
of Berstel’s morphism to one of the expressions in brackets. We use the abbreviation
$\overline \varphi ^2$
of Berstel’s morphism to one of the expressions in brackets. We use the abbreviation
 $$ \begin{align*}b(\varepsilon,\varepsilon')={\mathtt b}{\mathtt c}({\mathtt a}{\mathtt c})^{\varepsilon}{\bar{\mathtt b}}{\mathtt a}({\mathtt c}{\mathtt a})^{\varepsilon'}.\end{align*} $$
$$ \begin{align*}b(\varepsilon,\varepsilon')={\mathtt b}{\mathtt c}({\mathtt a}{\mathtt c})^{\varepsilon}{\bar{\mathtt b}}{\mathtt a}({\mathtt c}{\mathtt a})^{\varepsilon'}.\end{align*} $$
Direct computation yields
 $$ \begin{align*} \begin{aligned} \overline\varphi^2(b(0,0)) &={\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a} ={\mathtt c}{\bar{\mathtt b}}{\mathtt a}\,b(0,1)b(0,0){\mathtt b}{\mathtt c}{\mathtt a},\\ \overline\varphi^2(b(0,1)) &={\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a} ={\mathtt c}{\bar{\mathtt b}}{\mathtt a}\,b(0,1)b(0,0)b(1,1){\mathtt b}{\mathtt c}{\mathtt a},\\ \overline\varphi^2(b(1,0)) &={\mathtt c}{\bar{\mathtt b}}{\mathtt a} {\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a} ={\mathtt c}{\bar{\mathtt b}}{\mathtt a}\,b(0,1)b(1,1)b(0,0){\mathtt b}{\mathtt c}{\mathtt a},\\ \overline\varphi^2(b(1,1)) &={\mathtt c}{\bar{\mathtt b}}{\mathtt a} {\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a} \end{aligned}\\ ={\mathtt c}{\bar{\mathtt b}}{\mathtt a}\,b(0,1)b(1,1)b(0,0)b(1,1){\mathtt b}{\mathtt c}{\mathtt a}. \end{align*} $$
$$ \begin{align*} \begin{aligned} \overline\varphi^2(b(0,0)) &={\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a} ={\mathtt c}{\bar{\mathtt b}}{\mathtt a}\,b(0,1)b(0,0){\mathtt b}{\mathtt c}{\mathtt a},\\ \overline\varphi^2(b(0,1)) &={\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a} ={\mathtt c}{\bar{\mathtt b}}{\mathtt a}\,b(0,1)b(0,0)b(1,1){\mathtt b}{\mathtt c}{\mathtt a},\\ \overline\varphi^2(b(1,0)) &={\mathtt c}{\bar{\mathtt b}}{\mathtt a} {\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a} ={\mathtt c}{\bar{\mathtt b}}{\mathtt a}\,b(0,1)b(1,1)b(0,0){\mathtt b}{\mathtt c}{\mathtt a},\\ \overline\varphi^2(b(1,1)) &={\mathtt c}{\bar{\mathtt b}}{\mathtt a} {\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a}{\mathtt c}{\bar{\mathtt b}}{\mathtt a}{\mathtt c}{\mathtt a}{\mathtt b}{\mathtt c}{\mathtt a} \end{aligned}\\ ={\mathtt c}{\bar{\mathtt b}}{\mathtt a}\,b(0,1)b(1,1)b(0,0)b(1,1){\mathtt b}{\mathtt c}{\mathtt a}. \end{align*} $$
Arbitrary concatenations of these expressions are again of the form
 ${\mathtt c}{\bar {\mathtt b}}{\mathtt a} R\,{\mathtt b}{\mathtt c}{\mathtt a}$
, where R is a concatenation of words
${\mathtt c}{\bar {\mathtt b}}{\mathtt a} R\,{\mathtt b}{\mathtt c}{\mathtt a}$
, where R is a concatenation of words
 $b(\varepsilon ,\varepsilon ')$
. Assuming that w is of the form
$b(\varepsilon ,\varepsilon ')$
. Assuming that w is of the form
 ${\mathtt a}\prod _{j<r}b(\varepsilon _j,\varepsilon ^{\prime }_j){\mathtt b}{\mathtt c}{\mathtt a}$
, we obtain
${\mathtt a}\prod _{j<r}b(\varepsilon _j,\varepsilon ^{\prime }_j){\mathtt b}{\mathtt c}{\mathtt a}$
, we obtain
 $\overline \varphi ^2(w)={\mathtt a}\,b(1,0)R\,{\mathtt b}{\mathtt c}{\mathtt a}$
. Since the words
$\overline \varphi ^2(w)={\mathtt a}\,b(1,0)R\,{\mathtt b}{\mathtt c}{\mathtt a}$
. Since the words
 $(\overline \varphi ^2)^k({\mathtt a})$
approach a fixed point, and
$(\overline \varphi ^2)^k({\mathtt a})$
approach a fixed point, and
 $$ \begin{align*}\overline\varphi^4({\mathtt a})={\mathtt a}\,b(1,0)b(0,1){\mathtt b}{\mathtt c}{\mathtt a},\end{align*} $$
$$ \begin{align*}\overline\varphi^4({\mathtt a})={\mathtt a}\,b(1,0)b(0,1){\mathtt b}{\mathtt c}{\mathtt a},\end{align*} $$
it follows by induction that
 ${\overline {\mathbf A}}$
is indeed of the form stated in the lemma, and we have, in particular, proved Proposition 3.8.
${\overline {\mathbf A}}$
is indeed of the form stated in the lemma, and we have, in particular, proved Proposition 3.8.
From this algorithm, we can clearly see that a given letter
 ${\mathtt a}$
is shifted, one place at a time, for each link that is passing over this letter. The direction in which
${\mathtt a}$
is shifted, one place at a time, for each link that is passing over this letter. The direction in which
 ${\mathtt a}$
is shifted depends on whether
${\mathtt a}$
is shifted depends on whether
![]() or
or
![]() appears in the link we are dealing with. We use considerations of this kind in the following section, together with Proposition 3.8, in order to determine the discrepancy of
appears in the link we are dealing with. We use considerations of this kind in the following section, together with Proposition 3.8, in order to determine the discrepancy of
 ${\mathtt 0}{\mathtt 1}$
-occurrences in
${\mathtt 0}{\mathtt 1}$
-occurrences in
 ${\mathbf t}$
.
${\mathbf t}$
.
3.3 The discrepancy of
${\mathtt 0}{\mathtt 1}$
-blocks

For an integer
 $j\geq 0$
let us define the degree of j as follows. Let m be the noncrossing matching for
$j\geq 0$
let us define the degree of j as follows. Let m be the noncrossing matching for
 ${{\mathbf A}^{\!+}}$
and set
${{\mathbf A}^{\!+}}$
and set

We also talk about the degree of a letter in
 ${{\mathbf A}^{\!+}}$
, where the position in question will always be clear from the context.
${{\mathbf A}^{\!+}}$
, where the position in question will always be clear from the context.
We display the first
 $192$
letters of
$192$
letters of
 ${{\mathbf A}^{\!+}}$
, obtained by applying the third iteration of
${{\mathbf A}^{\!+}}$
, obtained by applying the third iteration of
 $\varphi ^+$
to the word
$\varphi ^+$
to the word

, and we connect associated connectors by actual lines for better readability. In position
 $10=({\mathtt 2}{\mathtt 2})_4$
in
$10=({\mathtt 2}{\mathtt 2})_4$
in
 ${{\mathbf A}^{\!+}}$
, we have a letter
${{\mathbf A}^{\!+}}$
, we have a letter
 ${\mathtt a}$
of degree
${\mathtt a}$
of degree
 $-1$
, and in position
$-1$
, and in position
 $170=({\mathtt 2}{\mathtt 2}{\mathtt 2}{\mathtt 2})_4$
, a letter
$170=({\mathtt 2}{\mathtt 2}{\mathtt 2}{\mathtt 2})_4$
, a letter
 ${\mathtt a}$
of degree
${\mathtt a}$
of degree
 $-2$
. These positions are marked with an arrow.
$-2$
. These positions are marked with an arrow.

From this initial segment we see that the sequence
 $(\deg ({\kern1.5pt}j))_{j\geq 0}$
starts with the
$(\deg ({\kern1.5pt}j))_{j\geq 0}$
starts with the
 $48$
integers
$48$
integers
 $$ \begin{align*}\begin{aligned} &0,0,0,0,0,0,0,0,0,0,-1,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0, \\&-1,0,0,0,0,0,-1,-1,-1,-1,0,0,-1,0,\ldots, \end{aligned} \end{align*} $$
$$ \begin{align*}\begin{aligned} &0,0,0,0,0,0,0,0,0,0,-1,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0, \\&-1,0,0,0,0,0,-1,-1,-1,-1,0,0,-1,0,\ldots, \end{aligned} \end{align*} $$
corresponding to the first line of (3-10). Applying the substitution
 $(\varphi ^+)^2$
to
$(\varphi ^+)^2$
to

appearing in positions
 $169$
–
$169$
–
 $171$
, we obtain the following
$171$
, we obtain the following
 $48$
letters. The marked letter
$48$
letters. The marked letter
 ${\mathtt a}$
has degree
${\mathtt a}$
has degree
 $-3$
, and it corresponds to the position
$-3$
, and it corresponds to the position
 $({\mathtt 2}{\mathtt 2}{\mathtt 2}{\mathtt 2}{\mathtt 2}{\mathtt 2})_4$
.
$({\mathtt 2}{\mathtt 2}{\mathtt 2}{\mathtt 2}{\mathtt 2}{\mathtt 2})_4$
.

In general, in position
 $({\mathtt 2}^{2k})_4$
, a letter
$({\mathtt 2}^{2k})_4$
, a letter
 ${\mathtt a}$
of degree
${\mathtt a}$
of degree
 $-k$
appears. This can be seen by considering the images of
$-k$
appears. This can be seen by considering the images of
 ${\mathtt a}$
and
${\mathtt a}$
and
under
 $\varphi ^+$
.
$\varphi ^+$
.
By Proposition 3.8,
 $\deg ({\kern1.5pt}j)$
has the following meaning in the case where
$\deg ({\kern1.5pt}j)$
has the following meaning in the case where
 ${{\mathbf A}^{\!+}}_j={\mathtt a}$
. A number of letters
${{\mathbf A}^{\!+}}_j={\mathtt a}$
. A number of letters
![]() (of which there are
(of which there are
 $\mathrm{deg}^+({\kern1.5pt}j)$
) are transferred from the right of the letter
$\mathrm{deg}^+({\kern1.5pt}j)$
) are transferred from the right of the letter
 ${\mathtt a}$
to the left of it; note that the letter
${\mathtt a}$
to the left of it; note that the letter
 ${\mathtt a}$
is shifted to the right
${\mathtt a}$
is shifted to the right
 $\deg ^+({\kern1.5pt}j)$
places. Analogously,
$\deg ^+({\kern1.5pt}j)$
places. Analogously,
 $\deg ^-({\kern1.5pt}j)$
letters
$\deg ^-({\kern1.5pt}j)$
letters
![]() are transferred from the left of
are transferred from the left of
 ${\mathtt a}$
to the right, and the letter
${\mathtt a}$
to the right, and the letter
 ${\mathtt a}$
is shifted to the left
${\mathtt a}$
is shifted to the left
 $\deg ^-({\kern1.5pt}j)$
places. In total, the letter
$\deg ^-({\kern1.5pt}j)$
places. In total, the letter
 ${\mathtt a}$
(among other letters) is shifted by
${\mathtt a}$
(among other letters) is shifted by
 $\deg ({\kern1.5pt}j)$
places, and
$\deg ({\kern1.5pt}j)$
places, and
 ${\mathtt b}$
s or
${\mathtt b}$
s or
 ${\bar {\mathtt b}}$
s are moved to account for the generated trailing space. The proposition states that the letters to the left of
${\bar {\mathtt b}}$
s are moved to account for the generated trailing space. The proposition states that the letters to the left of
 ${\mathtt a}$
’s new position
${\mathtt a}$
’s new position
 $j+\deg ^+({\kern1.5pt}j)$
are balanced: after removing decorations and replacing
$j+\deg ^+({\kern1.5pt}j)$
are balanced: after removing decorations and replacing
 ${\bar {\mathtt b}}$
by
${\bar {\mathtt b}}$
by
 ${\mathtt b}$
, the letters
${\mathtt b}$
, the letters
 ${\mathtt a}$
,
${\mathtt a}$
,
 ${\mathtt b}$
, and
${\mathtt b}$
, and
 ${\mathtt c}$
occur the same number of times. If
${\mathtt c}$
occur the same number of times. If
 , similar considerations hold. The case of letters of type
, similar considerations hold. The case of letters of type
 ${\mathtt b}$
is different, since a single rotation may shift such a letter to a remote place.
${\mathtt b}$
is different, since a single rotation may shift such a letter to a remote place.
The transducer
 $\mathcal T_1$
displayed in Figure 1 allows us to compute the degree of an arbitrary position j: starting from the centre node, we traverse the graph, guided by the base-
$\mathcal T_1$
displayed in Figure 1 allows us to compute the degree of an arbitrary position j: starting from the centre node, we traverse the graph, guided by the base-
 $4$
expansion
$4$
expansion
 $\delta _{\nu -1}\cdots \delta _0$
of j (read from left to right). Along the way, we sum up the numbers k whenever a vertex
$\delta _{\nu -1}\cdots \delta _0$
of j (read from left to right). Along the way, we sum up the numbers k whenever a vertex
 $\delta _i\mid k$
is taken. The sum over these numbers is the degree of j, multiplied by
$\delta _i\mid k$
is taken. The sum over these numbers is the degree of j, multiplied by
 $3$
. The transducer
$3$
. The transducer
 $\mathcal T_1$
is derived directly from the decorated,
$\mathcal T_1$
is derived directly from the decorated,
 $4$
-uniform morphism
$4$
-uniform morphism
 $\varphi ^+$
given in (3-3). Note that a change of degree takes place whenever new letters are inserted, by virtue of the morphism
$\varphi ^+$
given in (3-3). Note that a change of degree takes place whenever new letters are inserted, by virtue of the morphism
 $\varphi ^+$
, into the range of already existing links, which happens for
$\varphi ^+$
, into the range of already existing links, which happens for
![]() and
and
![]() ; or if a new link together with a letter
; or if a new link together with a letter
 ${\mathtt a}$
in its range is created, which happens for
${\mathtt a}$
in its range is created, which happens for
![]() .
.

Figure 1 A base-
 $4$
transducer that generates the degree sequence.
$4$
transducer that generates the degree sequence.
We now apply Proposition 3.8 to the discrepancy
 $D_N$
of occurrences of
$D_N$
of occurrences of
 ${\mathtt 0}{\mathtt 1}$
in
${\mathtt 0}{\mathtt 1}$
in
 ${\mathbf t}$
.
${\mathbf t}$
.
Proposition 3.10. Let
 $j\in \mathbb N$
and set
$j\in \mathbb N$
and set
 $d=\deg ({\kern1.5pt}j)$
. Then
$d=\deg ({\kern1.5pt}j)$
. Then

In each of these cases, the subscript of D is the position in
 ${\mathbf t}$
that corresponds to the
${\mathbf t}$
that corresponds to the
 $j\, $
th letter in
$j\, $
th letter in
 ${\mathbf A}$
via (2-3).
${\mathbf A}$
via (2-3).
Proof. Choose
 $\varepsilon \in \{0,1,2\}$
and
$\varepsilon \in \{0,1,2\}$
and
 $n\in \mathbb N$
such that
$n\in \mathbb N$
such that
 $j=3n+\varepsilon $
. Let us consider each of the seven cases corresponding to letters from K.
$j=3n+\varepsilon $
. Let us consider each of the seven cases corresponding to letters from K.
First case. Assume that
 ${{\mathbf A}^{\!+}}_j={\mathtt a}$
. By the RotateAlongLinks algorithm and Proposition 3.8, a total of d letters of type
${{\mathbf A}^{\!+}}_j={\mathtt a}$
. By the RotateAlongLinks algorithm and Proposition 3.8, a total of d letters of type
 ${\mathtt b}$
have to be shifted from the right of our
${\mathtt b}$
have to be shifted from the right of our
 ${\mathtt a}$
in question to the left (if
${\mathtt a}$
in question to the left (if
 $d>0$
), or the other way round (if
$d>0$
), or the other way round (if
 $d<0$
). After this procedure, the numbers of letters of types
$d<0$
). After this procedure, the numbers of letters of types
 ${\mathtt a}$
,
${\mathtt a}$
,
 ${\mathtt b}$
, and
${\mathtt b}$
, and
 ${\mathtt c}$
to the left are equal. It follows that
${\mathtt c}$
to the left are equal. It follows that
 $\varepsilon \equiv -d\bmod 3$
; moreover,
$\varepsilon \equiv -d\bmod 3$
; moreover,
 $m=n+(\varepsilon +d)/3$
is the number of letters
$m=n+(\varepsilon +d)/3$
is the number of letters
 ${\mathtt a}$
(and also the number of letters of type
${\mathtt a}$
(and also the number of letters of type
 ${\mathtt c}$
) strictly to the left of j. The number of letters of type
${\mathtt c}$
) strictly to the left of j. The number of letters of type
 ${\mathtt b}$
to the left of j is
${\mathtt b}$
to the left of j is
 $m'=n+(\varepsilon -2d)/3$
. Symbols of type
$m'=n+(\varepsilon -2d)/3$
. Symbols of type
 ${\mathtt a}$
contribute two blocks
${\mathtt a}$
contribute two blocks
 ${\mathtt 0}{\mathtt 1}$
and correspond to a factor of length
${\mathtt 0}{\mathtt 1}$
and correspond to a factor of length
 $6$
in
$6$
in
 ${\mathbf t}$
, by (2-2); letters of type
${\mathbf t}$
, by (2-2); letters of type
 ${\mathtt b}$
contribute one block and correspond to a factor of length
${\mathtt b}$
contribute one block and correspond to a factor of length
 $4$
; letters of type
$4$
; letters of type
 ${\mathtt c}$
contribute one block and correspond to a factor of length
${\mathtt c}$
contribute one block and correspond to a factor of length
 $2$
. It follows that below position
$2$
. It follows that below position
 $$ \begin{align*} N=(6+2)\bigg(n+\frac{\varepsilon+d}3\bigg)+4 \bigg(n+\frac{\varepsilon-2d}{3}\bigg) =12n+4\,\varepsilon=4j \end{align*} $$
$$ \begin{align*} N=(6+2)\bigg(n+\frac{\varepsilon+d}3\bigg)+4 \bigg(n+\frac{\varepsilon-2d}{3}\bigg) =12n+4\,\varepsilon=4j \end{align*} $$
we find
 $$ \begin{align*}(2+1)\bigg(n+\frac{\varepsilon+d}3\bigg)+\bigg(n+\frac{\varepsilon-2d}3\bigg) =4n+4\,\varepsilon/3+d/3 \end{align*} $$
$$ \begin{align*}(2+1)\bigg(n+\frac{\varepsilon+d}3\bigg)+\bigg(n+\frac{\varepsilon-2d}3\bigg) =4n+4\,\varepsilon/3+d/3 \end{align*} $$
 ${\mathtt 0}{\mathtt 1}$
-blocks. This proves the case
${\mathtt 0}{\mathtt 1}$
-blocks. This proves the case
 ${{\mathbf A}^{\!+}}_j=a$
.
${{\mathbf A}^{\!+}}_j=a$
.
Second case. If
 , we note that necessarily
, we note that necessarily
 ${{\mathbf A}^{\!+}}_{j+1}={\mathtt a}$
, by Lemma 3.1. We apply the first case in position
${{\mathbf A}^{\!+}}_{j+1}={\mathtt a}$
, by Lemma 3.1. We apply the first case in position
 $j+1$
, which has degree d. Noting that a letter of type
$j+1$
, which has degree d. Noting that a letter of type
 ${\mathtt b}$
in
${\mathtt b}$
in
 ${{\mathbf A}^{\!+}}$
corresponds to
${{\mathbf A}^{\!+}}$
corresponds to
 ${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
in Thue–Morse, we obtain
${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}$
in Thue–Morse, we obtain
 $D_{4j}=D_{4j+4}+1/3=d/3+1/3$
, where
$D_{4j}=D_{4j+4}+1/3=d/3+1/3$
, where
 $4j$
(respectively,
$4j$
(respectively,
 $4j+2$
) corresponds to the
$4j+2$
) corresponds to the
 $j\, $
th (respectively,
$j\, $
th (respectively,
 $({\kern1.5pt}j+1)\, $
th) position in
$({\kern1.5pt}j+1)\, $
th) position in
 ${{\mathbf A}^{\!+}}$
.
${{\mathbf A}^{\!+}}$
.
Third case. Assume that
 . In this case, the letter at
. In this case, the letter at
 $j+1$
is
$j+1$
is
 ${\mathtt a}$
by Lemma 3.1 and
${\mathtt a}$
by Lemma 3.1 and
 $j+1$
has degree
$j+1$
has degree
 $d-1$
. It follows that
$d-1$
. It follows that
 $D_{4j}=D_{4j+4}+1/3=d/3-1/3+1/3=d/3$
.
$D_{4j}=D_{4j+4}+1/3=d/3-1/3+1/3=d/3$
.
Fourth case. If
 , we note that necessarily
, we note that necessarily
 ${{\mathbf A}^{\!+}}_{j-1}={\mathtt a}$
; we apply the first case in position
${{\mathbf A}^{\!+}}_{j-1}={\mathtt a}$
; we apply the first case in position
 $j-1$
, which has degree
$j-1$
, which has degree
 $d+1$
. Since
$d+1$
. Since
 ${\mathtt a}$
corresponds to
${\mathtt a}$
corresponds to
 ${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}$
in Thue–Morse, we have
${\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0}{\mathtt 1}{\mathtt 0}$
in Thue–Morse, we have
 $D_{4j+2}=D_{4j-4}=d/3+1/3$
, where
$D_{4j+2}=D_{4j-4}=d/3+1/3$
, where
 $4j-4$
(respectively,
$4j-4$
(respectively,
 $4j+2$
) corresponds to the
$4j+2$
) corresponds to the
 $({\kern1.5pt}j-1)\, $
th (respectively,
$({\kern1.5pt}j-1)\, $
th (respectively,
 $j\, $
th) positions in
$j\, $
th) positions in
 ${{\mathbf A}^{\!+}}$
.
${{\mathbf A}^{\!+}}$
.
Fifth case. Assume that
 . Then
. Then
 ${{\mathbf A}^{\!+}}_{j-1}={\mathtt a}$
, and
${{\mathbf A}^{\!+}}_{j-1}={\mathtt a}$
, and
 $j-1$
has degree d. Analogously to the fourth case, we obtain
$j-1$
has degree d. Analogously to the fourth case, we obtain
 $D_{4j+2}=D_{4j-4}=d/3$
.
$D_{4j+2}=D_{4j-4}=d/3$
.
Sixth case. If
 , this letter is connected to a letter of type
, this letter is connected to a letter of type
 ${\mathtt b}$
to the left, which stays on the left of
${\mathtt b}$
to the left, which stays on the left of
![]() after applying the rotations. Therefore, the number of letters of type
after applying the rotations. Therefore, the number of letters of type
 ${\mathtt b}$
to the left is changed by d, and the numbers of letters of types
${\mathtt b}$
to the left is changed by d, and the numbers of letters of types
 ${\mathtt a}$
or
${\mathtt a}$
or
 ${\mathtt c}$
to the left stay the same. Similarly to the first case, it follows that
${\mathtt c}$
to the left stay the same. Similarly to the first case, it follows that
 $\varepsilon \equiv 2-d\bmod 3$
. The numbers of letters, of type
$\varepsilon \equiv 2-d\bmod 3$
. The numbers of letters, of type
 ${\mathtt a}$
,
${\mathtt a}$
,
 ${\mathtt b}$
, and
${\mathtt b}$
, and
 ${\mathtt c}$
, to the left of j, are therefore
${\mathtt c}$
, to the left of j, are therefore
 $m=n+(\varepsilon +d+1)/3$
,
$m=n+(\varepsilon +d+1)/3$
,
 $m-d$
, and
$m-d$
, and
 $m-1$
, respectively. It follows that, below position
$m-1$
, respectively. It follows that, below position
 $$ \begin{align*} N&=6\bigg(n+\frac{\varepsilon+d+1}3\bigg) +4\bigg(n+\frac{\varepsilon-2d+1}3\bigg) +2\bigg(n+\frac{\varepsilon+d-2}3\bigg) \\&=12n+4\,\varepsilon+2=4j+2 , \end{align*} $$
$$ \begin{align*} N&=6\bigg(n+\frac{\varepsilon+d+1}3\bigg) +4\bigg(n+\frac{\varepsilon-2d+1}3\bigg) +2\bigg(n+\frac{\varepsilon+d-2}3\bigg) \\&=12n+4\,\varepsilon+2=4j+2 , \end{align*} $$
there are
 $$ \begin{align*}2\bigg(n+\frac{\varepsilon+d+1}3\bigg) +\bigg(n+\frac{\varepsilon-2d+1}3\bigg) +\bigg(n+\frac{\varepsilon+d-2}3\bigg) \!=4n+\frac{4\,\varepsilon}3+\frac d3+\frac13 \end{align*} $$
$$ \begin{align*}2\bigg(n+\frac{\varepsilon+d+1}3\bigg) +\bigg(n+\frac{\varepsilon-2d+1}3\bigg) +\bigg(n+\frac{\varepsilon+d-2}3\bigg) \!=4n+\frac{4\,\varepsilon}3+\frac d3+\frac13 \end{align*} $$
 ${\mathtt 0}{\mathtt 1}$
-blocks.
${\mathtt 0}{\mathtt 1}$
-blocks.
Seventh case. If
 , a letter of type
, a letter of type
 ${\mathtt b}$
takes its place after one rotation. In this case, we have
${\mathtt b}$
takes its place after one rotation. In this case, we have
 $\varepsilon \equiv 1-d\bmod 3$
; the numbers of letters to the left of j, of types
$\varepsilon \equiv 1-d\bmod 3$
; the numbers of letters to the left of j, of types
 ${\mathtt a}$
,
${\mathtt a}$
,
 ${\mathtt b}$
, and
${\mathtt b}$
, and
 ${\mathtt c}$
, are therefore
${\mathtt c}$
, are therefore
 $m=n+(\varepsilon +d+2)/3$
,
$m=n+(\varepsilon +d+2)/3$
,
 $m-d-1$
, and
$m-d-1$
, and
 $m-1$
, respectively. Therefore, below position
$m-1$
, respectively. Therefore, below position
 $$ \begin{align*} N&=6\bigg(n+\frac{\varepsilon+d+2}3\bigg) +4\bigg(n+\frac{\varepsilon-2d-1}3\bigg) +2\bigg(n+\frac{\varepsilon+d-1}3\bigg) \\&=12n+4\,\varepsilon+2=4j+2 , \end{align*} $$
$$ \begin{align*} N&=6\bigg(n+\frac{\varepsilon+d+2}3\bigg) +4\bigg(n+\frac{\varepsilon-2d-1}3\bigg) +2\bigg(n+\frac{\varepsilon+d-1}3\bigg) \\&=12n+4\,\varepsilon+2=4j+2 , \end{align*} $$
there are
 $$ \begin{align*}2\bigg(n+\frac{\varepsilon+d+2}3\bigg) +\bigg(n+\frac{\varepsilon-2d-1}3\bigg) +\bigg(n+\frac{\varepsilon+d-1}3\bigg) \!=4n+\frac{4\,\varepsilon}3+\frac d3+\frac23 \end{align*} $$
$$ \begin{align*}2\bigg(n+\frac{\varepsilon+d+2}3\bigg) +\bigg(n+\frac{\varepsilon-2d-1}3\bigg) +\bigg(n+\frac{\varepsilon+d-1}3\bigg) \!=4n+\frac{4\,\varepsilon}3+\frac d3+\frac23 \end{align*} $$
 ${\mathtt 0}{\mathtt 1}$
-blocks, which proves the last case.
${\mathtt 0}{\mathtt 1}$
-blocks, which proves the last case.
Since
 $\deg ({\kern1.5pt}j)$
is easy to obtain, Proposition 3.10 gives us a simple method to compute the discrepancy
$\deg ({\kern1.5pt}j)$
is easy to obtain, Proposition 3.10 gives us a simple method to compute the discrepancy
 $D_N$
for any given N.
$D_N$
for any given N.
Proposition 3.11. Let
 $N\geq 0$
be an integer and
$N\geq 0$
be an integer and
 $j=\lfloor N/4\rfloor $
.
$j=\lfloor N/4\rfloor $
.
(1) If
, choose
$\delta =D_{4j}/3=\deg ({\kern1.5pt}j)/3+\varepsilon $
, where
$\varepsilon \in \{0,1/3\}$
is given by the first block of (3-11). Then (3-12)
$$ \begin{align} (D_{4j},D_{4j+1},D_{4j+2},D_{4j+3})= (\delta,\delta+2/3,\delta+1/3,\delta). \end{align} $$
(2) If
, choose
$\delta =D_{4j+2}/3=\deg ({\kern1.5pt}j)/3+\varepsilon $
, where the variable
$\varepsilon \in \{-1/3,0, 1/3\}$
is given by the second block of (3-11). Then (3-13)
$$ \begin{align} (D_{4j},D_{4j+1},D_{4j+2},D_{4j+3})= (\delta+2/3,\delta+1/3,\delta,\delta+2/3). \end{align} $$








The scaled sequence of discrepancies (multiplied by
 $3$
) therefore begins with the
$3$
) therefore begins with the
 $48$
integers
$48$
integers
 $$ \begin{align*} \begin{array}{llllll} 0,2,1,0, &2,1,0,2, &1,0,-1,1, &0,2,1,0, &2,1,0,2, &1,3,2,1, \\0,2,1,0, &2,1,0,2, &1,0,-1,1, &0,2,1,0, &-1,1,0,-1, &1,0,-1,1. \end{array} \end{align*} $$
$$ \begin{align*} \begin{array}{llllll} 0,2,1,0, &2,1,0,2, &1,0,-1,1, &0,2,1,0, &2,1,0,2, &1,3,2,1, \\0,2,1,0, &2,1,0,2, &1,0,-1,1, &0,2,1,0, &-1,1,0,-1, &1,0,-1,1. \end{array} \end{align*} $$
The partition into segments of length
 $4$
is for better readability. Each segment corresponds to one symbol in
$4$
is for better readability. Each segment corresponds to one symbol in
 ${{\mathbf A}^{\!+}}$
.
${{\mathbf A}^{\!+}}$
.
Proof of Proposition 3.11
For the first sentence of each of the two cases, there is nothing to show, by Proposition 3.10. Let us begin with the first case. By the proposition, the position
 $4j$
in the Thue–Morse sequence corresponds to a letter
$4j$
in the Thue–Morse sequence corresponds to a letter
 ${\mathtt a}$
or
${\mathtt a}$
or
 ${\mathtt b}$
in
${\mathtt b}$
in
 ${\mathbf A}$
(in position j), and by (2-2) we have
${\mathbf A}$
(in position j), and by (2-2) we have
 $({\mathbf t}_{4j},{\mathbf t}_{4j+1},{\mathbf t}_{4j+2},{\mathbf t}_{4j+3})=({\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0})$
. Therefore, (3-12) follows. Concerning the second case, Proposition 3.10 gives us an expression for
$({\mathbf t}_{4j},{\mathbf t}_{4j+1},{\mathbf t}_{4j+2},{\mathbf t}_{4j+3})=({\mathtt 0}{\mathtt 1}{\mathtt 1}{\mathtt 0})$
. Therefore, (3-12) follows. Concerning the second case, Proposition 3.10 gives us an expression for
 $D_{4j+2}$
in terms of
$D_{4j+2}$
in terms of
 $\deg ({\kern1.5pt}j)$
, and the position
$\deg ({\kern1.5pt}j)$
, and the position
 $4j+2$
corresponds to the index j in
$4j+2$
corresponds to the index j in
 ${\mathbf A}$
. By (2-2), we have
${\mathbf A}$
. By (2-2), we have
 $({\mathbf t}_{4j+2},{\mathbf t}_{4j+3})=({\mathtt 0},{\mathtt 1})$
. Therefore,
$({\mathbf t}_{4j+2},{\mathbf t}_{4j+3})=({\mathtt 0},{\mathtt 1})$
. Therefore,
 $$ \begin{align*}(D_{4j+2},D_{4j+3})= (\delta,\delta+2/3).\end{align*} $$
$$ \begin{align*}(D_{4j+2},D_{4j+3})= (\delta,\delta+2/3).\end{align*} $$
In order to compute
 $D_{4j}$
and
$D_{4j}$
and
 $D_{4j+1}$
in this case, we note that
$D_{4j+1}$
in this case, we note that
![]() and
and
![]() are always preceded by
are always preceded by
 ${\mathtt a}$
or a letter of type
${\mathtt a}$
or a letter of type
 ${\mathtt b}$
(as we noted in the proof of Proposition 3.10), and
${\mathtt b}$
(as we noted in the proof of Proposition 3.10), and
![]() and
and
![]() are always preceded by a letter equal to
are always preceded by a letter equal to
 ${\mathtt a}$
or of type
${\mathtt a}$
or of type
 ${\mathtt b}$
, since
${\mathtt b}$
, since
 ${\mathbf A}$
is squarefree. It follows that the letter at index
${\mathbf A}$
is squarefree. It follows that the letter at index
 $j-1$
is of type
$j-1$
is of type
 ${\mathtt a}$
or
${\mathtt a}$
or
 ${\mathtt b}$
, and therefore
${\mathtt b}$
, and therefore
 $({\mathbf t}_{4j},{\mathbf t}_{4j+1})=({\mathtt 1}{\mathtt 0})$
. Consequently, we have
$({\mathbf t}_{4j},{\mathbf t}_{4j+1})=({\mathtt 1}{\mathtt 0})$
. Consequently, we have
 $$ \begin{align*}(D_{4j},D_{4j+1})= (\delta+2/3,\delta+1/3), \end{align*} $$
$$ \begin{align*}(D_{4j},D_{4j+1})= (\delta+2/3,\delta+1/3), \end{align*} $$
and (3-13) follows.
3.4 Proof of Theorem 1.2
We may now show that the sequence
 $(D_N)_{N\geq 0}$
of discrepancies is given by a base-
$(D_N)_{N\geq 0}$
of discrepancies is given by a base-
 $2$
transducer. The transducer in Figure 1 may be described by eight
$2$
transducer. The transducer in Figure 1 may be described by eight
 $7\times 7$
matrices
$7\times 7$
matrices
 $A^{(\ell )}, W^{(\ell )}$
, for
$A^{(\ell )}, W^{(\ell )}$
, for
 $0\leq \ell <4$
, where rows and columns are indexed by the letters of K, in the order
$0\leq \ell <4$
, where rows and columns are indexed by the letters of K, in the order
 .
.
The entry
 $A^{(\ell )}_{i,j}$
equals
$A^{(\ell )}_{i,j}$
equals
 $1$
if there is an arrow with first component equal to
$1$
if there is an arrow with first component equal to
 $\ell $
from the
$\ell $
from the
 $j\, $
th node to the
$j\, $
th node to the
 $i\, $
th node in Figure 1, and it is zero otherwise. The matrices
$i\, $
th node in Figure 1, and it is zero otherwise. The matrices
 $A^{(\ell )}$
are permutation matrices. The entry
$A^{(\ell )}$
are permutation matrices. The entry
 $W^{(\ell )}_{i,j}$
is the second component of the arrow from j to i with first component
$W^{(\ell )}_{i,j}$
is the second component of the arrow from j to i with first component
 $\ell $
, if there is one, and equal to zero otherwise.
$\ell $
, if there is one, and equal to zero otherwise.
The final modification given by (3-12) and (3-13) is dealt with by four more matrices
 $Z^{(\ell )}$
, where
$Z^{(\ell )}$
, where
 $0\leq \ell <4$
. The first three columns of these matrices are given by (3-12), as follows. Define the quadruple
$0\leq \ell <4$
. The first three columns of these matrices are given by (3-12), as follows. Define the quadruple
 $(q_0,q_1,q_2,q_3)=(0,2/3,1/3,0)$
(containing the shifts in (3-12)), and the triple
$(q_0,q_1,q_2,q_3)=(0,2/3,1/3,0)$
(containing the shifts in (3-12)), and the triple
 $(r_1,r_2,r_3)=(0,1/3,0)$
(taking care of the shifts present in the first block of (3-11)). Let
$(r_1,r_2,r_3)=(0,1/3,0)$
(taking care of the shifts present in the first block of (3-11)). Let
 $1\leq j\leq 3$
(corresponding to the letter at which an arrow starts), and
$1\leq j\leq 3$
(corresponding to the letter at which an arrow starts), and
 $0\leq \ell <4$
(a base-
$0\leq \ell <4$
(a base-
 $4$
digit, the first component of the label of the arrow). There is a unique
$4$
digit, the first component of the label of the arrow). There is a unique
 $i\in \{1,\ldots ,7\}$
such that
$i\in \{1,\ldots ,7\}$
such that
 $A^{(\ell )}_{i,j}=1$
, and we set
$A^{(\ell )}_{i,j}=1$
, and we set
 $Z^{(\ell )}_{i,j}=q_{\ell }+r_j$
, and
$Z^{(\ell )}_{i,j}=q_{\ell }+r_j$
, and
 $Z^{(\ell )}_{i',j}=0$
for
$Z^{(\ell )}_{i',j}=0$
for
 $i'\neq i$
. The remaining four columns are filled with the help of (3-13) as follows. Define
$i'\neq i$
. The remaining four columns are filled with the help of (3-13) as follows. Define
 $(\tilde q_0,\tilde q_1,\tilde q_2,\tilde q_3)=(2/3,1/3,0,2/3)$
and
$(\tilde q_0,\tilde q_1,\tilde q_2,\tilde q_3)=(2/3,1/3,0,2/3)$
and
 $(r_4,r_5,r_6,r_7)=(1/3,0,-1/3,0)$
. Let
$(r_4,r_5,r_6,r_7)=(1/3,0,-1/3,0)$
. Let
 $4\leq j\leq 7$
and
$4\leq j\leq 7$
and
 $0\leq \ell <4$
. There is a unique
$0\leq \ell <4$
. There is a unique
 $i\in \{1,\ldots ,7\}$
such that
$i\in \{1,\ldots ,7\}$
such that
 $A^{(\ell )}_{i,j}=1$
, and we set
$A^{(\ell )}_{i,j}=1$
, and we set
 $Z^{(\ell )}_{i,j}=\tilde q_{\ell }+r_j$
, and
$Z^{(\ell )}_{i,j}=\tilde q_{\ell }+r_j$
, and
 $Z^{(\ell )}_{i',j}=0$
for
$Z^{(\ell )}_{i',j}=0$
for
 $i'\neq i$
.
$i'\neq i$
.
In order to generate the discrepancy, we blow up the transducer by a factor of
 $28$
, in order to keep track of the arrow that led to the current node (that is, we need to save the previously read digit
$28$
, in order to keep track of the arrow that led to the current node (that is, we need to save the previously read digit
 $\ell '\in \{0,1,2,3\}$
and the node in
$\ell '\in \{0,1,2,3\}$
and the node in
 $\mathcal T_1$
that was last visited).
$\mathcal T_1$
that was last visited).
In each step, the contribution of
 $Z^{(\ell ')}$
is cancelled out, and the contributions of
$Z^{(\ell ')}$
is cancelled out, and the contributions of
 $A^{(\ell ')}$
and
$A^{(\ell ')}$
and
 $Z^{(\ell )}$
are added (where
$Z^{(\ell )}$
are added (where
 $\ell $
is the currently read digit). More precisely, let
$\ell $
is the currently read digit). More precisely, let
 $(i,\ell ',j)$
, for
$(i,\ell ',j)$
, for
 $1\leq i,j\leq 7$
and
$1\leq i,j\leq 7$
and
 $0\leq \ell '<4$
, be the
$0\leq \ell '<4$
, be the
 $196$
nodes of our new transducer
$196$
nodes of our new transducer
 $\mathcal T_2$
. There is an arrow from
$\mathcal T_2$
. There is an arrow from
 $({\kern1.5pt}j,\ell ',k)$
to
$({\kern1.5pt}j,\ell ',k)$
to
 $(i,\ell ,j')$
if and only if
$(i,\ell ,j')$
if and only if
 $j=j'$
and
$j=j'$
and
 $A^{(\ell )}_{j,i}=1$
, that is, if there is an arrow from j to i in
$A^{(\ell )}_{j,i}=1$
, that is, if there is an arrow from j to i in
 $\mathcal T_1$
whose label has
$\mathcal T_1$
whose label has
 $\ell $
as its first component. We may now define the weight of an arrow
$\ell $
as its first component. We may now define the weight of an arrow
 $({\kern1.5pt}j,\ell ',k)\rightarrow (i,\ell ,j)$
as
$({\kern1.5pt}j,\ell ',k)\rightarrow (i,\ell ,j)$
as
 $$ \begin{align*}Z^{(\ell)}_{i,j}-Z^{(\ell')}_{j,k}+W^{(\ell')}_{j,k}.\end{align*} $$
$$ \begin{align*}Z^{(\ell)}_{i,j}-Z^{(\ell')}_{j,k}+W^{(\ell')}_{j,k}.\end{align*} $$
The initial node is
 $(1,0,1)$
, which corresponds to the fact that leading zeros do not make a difference. Let us illustrate, by a short but representative example, the easy proof that the transducer
$(1,0,1)$
, which corresponds to the fact that leading zeros do not make a difference. Let us illustrate, by a short but representative example, the easy proof that the transducer
 $\mathcal T_2$
generates the discrepancy sequence. We wish to compute the discrepancy
$\mathcal T_2$
generates the discrepancy sequence. We wish to compute the discrepancy
 $D_{41}=D_{({\mathtt 2}{\mathtt 2}{\mathtt 1})_4}$
. The corresponding path in
$D_{41}=D_{({\mathtt 2}{\mathtt 2}{\mathtt 1})_4}$
. The corresponding path in
 $\mathcal T_2$
is given by
$\mathcal T_2$
is given by
 $$ \begin{align*}(1,0,1)\longrightarrow (5,2,1)\longrightarrow (1,2,5)\longrightarrow (4,1,1).\end{align*} $$
$$ \begin{align*}(1,0,1)\longrightarrow (5,2,1)\longrightarrow (1,2,5)\longrightarrow (4,1,1).\end{align*} $$
Note that the first and third components correspond to letters in K, that is, to nodes in
 $\mathcal T_1$
, via
$\mathcal T_1$
, via
 $1\rightleftharpoons {\mathtt a}$
,
$1\rightleftharpoons {\mathtt a}$
,
![]() , and
, and
![]() . The sum of the weights simplifies, due to a telescoping sum and since
. The sum of the weights simplifies, due to a telescoping sum and since
 $W^{(0)}_{1,1}=Z^{(0)}_{1,1}=0$
, to
$W^{(0)}_{1,1}=Z^{(0)}_{1,1}=0$
, to
 $$ \begin{align*}W^{(2)}_{5,1}+W^{(2)}_{1,5}+ Z^{(1)}_{4,1}. \end{align*} $$
$$ \begin{align*}W^{(2)}_{5,1}+W^{(2)}_{1,5}+ Z^{(1)}_{4,1}. \end{align*} $$
The first two summands sum to
 $\deg (({\mathtt 2}{\mathtt 2})_4)=-1/3$
by the construction of our transducer, while the last summand consists of two parts: the shift in the first line of the first block of (3-11) (which is
$\deg (({\mathtt 2}{\mathtt 2})_4)=-1/3$
by the construction of our transducer, while the last summand consists of two parts: the shift in the first line of the first block of (3-11) (which is
 $0$
), and the shift in the second component of (3-12) (which is
$0$
), and the shift in the second component of (3-12) (which is
 $2/3$
). Summing up, we obtain
$2/3$
). Summing up, we obtain
 $D_{41}=1/3$
. It is clear that the proof of the general case is not more complicated this example.
$D_{41}=1/3$
. It is clear that the proof of the general case is not more complicated this example.
Since the integers
 $2$
and
$2$
and
 $4$
are multiplicatively dependent, in symbols,
$4$
are multiplicatively dependent, in symbols,
 $2^m=4^n$
for
$2^m=4^n$
for
 $(m,n)=(2,1)$
, the sequence D is also generated by a base-
$(m,n)=(2,1)$
, the sequence D is also generated by a base-
 $2$
transducer. In order to carry out this reduction to base
$2$
transducer. In order to carry out this reduction to base
 $2$
, the four arrows starting from a given node in our base-
$2$
, the four arrows starting from a given node in our base-
 $4$
transducer have to be replaced by a complete binary tree of depth
$4$
transducer have to be replaced by a complete binary tree of depth
 $2$
, where two auxiliary nodes have to be inserted. This completes the proof of the proposition and thus the proof of the first part of Theorem 1.2.
$2$
, where two auxiliary nodes have to be inserted. This completes the proof of the proposition and thus the proof of the first part of Theorem 1.2.
The output sum of a base-q transducer is clearly bounded by a constant times the length of the base-q expansion we feed into the transducer. This immediately yields
 $D_N\ll \log N$
.
$D_N\ll \log N$
.
We easily see from Figure 1 that the integers
 $$ \begin{align*} ({\mathtt 2}^{2k})_4=2\,\frac{16^k-1}{3} \quad\mbox{and}\quad (({\mathtt 1}{\mathtt 1}{\mathtt 0})^k)_4 =20\,\frac{64^k-1}{63} \end{align*} $$
$$ \begin{align*} ({\mathtt 2}^{2k})_4=2\,\frac{16^k-1}{3} \quad\mbox{and}\quad (({\mathtt 1}{\mathtt 1}{\mathtt 0})^k)_4 =20\,\frac{64^k-1}{63} \end{align*} $$
have degrees
 $-k$
and k, respectively, for
$-k$
and k, respectively, for
 $k\geq 1$
, and that the letter
$k\geq 1$
, and that the letter
 ${\mathtt a}$
is attained at these positions. Therefore, Proposition 3.10 implies
${\mathtt a}$
is attained at these positions. Therefore, Proposition 3.10 implies
 $$ \begin{align*} D_{8\hspace{0.5pt}(16^k-1)/3}=-k/3\quad\mbox{and}\quad D_{80\hspace{0.5pt}(64^k-1)/63}=k/3 \end{align*} $$
$$ \begin{align*} D_{8\hspace{0.5pt}(16^k-1)/3}=-k/3\quad\mbox{and}\quad D_{80\hspace{0.5pt}(64^k-1)/63}=k/3 \end{align*} $$
for
 $k\geq 1$
, and clearly
$k\geq 1$
, and clearly
 $D_0=0$
. In particular,
$D_0=0$
. In particular,
 $\{D_N:N\geq 0\}=(1/3)\mathbb Z$
, which finishes the proof of Theorem 1.2.
$\{D_N:N\geq 0\}=(1/3)\mathbb Z$
, which finishes the proof of Theorem 1.2.
 $\square $
$\square $
By considering the path given by
 $n'=({\mathtt 2}^{2k-1})_4$
instead, we end up in the node
$n'=({\mathtt 2}^{2k-1})_4$
instead, we end up in the node
![]() , and the position
, and the position
 $n'$
has degree
$n'$
has degree
 $-k+1$
. Proposition 3.11 implies
$-k+1$
. Proposition 3.11 implies
 $D_n=-k/3$
, where
$D_n=-k/3$
, where
 $n=4n'+2=(({\mathtt 1}{\mathtt 0})^{4k})_2$
. This was observed by Jeffrey Shallit (private communication, 2021), but such an unboundedness result does not seem to be stated in the literature.
$n=4n'+2=(({\mathtt 1}{\mathtt 0})^{4k})_2$
. This was observed by Jeffrey Shallit (private communication, 2021), but such an unboundedness result does not seem to be stated in the literature.
Acknowledgements
The author thanks Jeff Shallit for sharing with him the research question treated in this paper, for constant interest in his research, and for quick and informative answers to e-mails. The question was presented to the author during the workshop ‘Numeration and Substitution’ at the ESI Vienna (Austria) in July 2019. We express our thanks to the ESI for providing optimal working conditions at the workshop, including offices for participants and blackboards in unconventional places. Finally, we thank Michel Rigo for fruitful discussions on the topic and Clemens Müllner for pointing out that the case of arbitrary factors can be reduced to the case
 $\mathtt 0\mathtt 1$
.
$\mathtt 0\mathtt 1$
.