We study the average nearest-neighbour degree a(k) of vertices with degree k. In many real-world networks with power-law degree distribution, a(k) falls off with k, a property ascribed to the constraint that any two vertices are connected by at most one edge. We show that a(k) indeed decays with k in three simple random graph models with power-law degrees: the erased configuration model, the rank-1 inhomogeneous random graph, and the hyperbolic random graph. We find that in the large-network limit for all three null models, a(k) starts to decay beyond 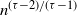 $n^{(\tau-2)/(\tau-1)}$ and then settles on a power law
$n^{(\tau-2)/(\tau-1)}$ and then settles on a power law 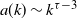 $a(k)\sim k^{\tau-3}$, with
$a(k)\sim k^{\tau-3}$, with  $\tau$ the degree exponent.
$\tau$ the degree exponent.

