1 results
Is your document novel? Let attention guide you. An attention-based model for document-level novelty detection
-
- Journal:
- Natural Language Engineering / Volume 27 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 24 April 2020, pp. 427-454
-
- Article
- Export citation
-
Detecting, whether a document contains sufficient new information to be deemed as novel, is of immense significance in this age of data duplication. Existing techniques for document-level novelty detection mostly perform at the lexical level and are unable to address the semantic-level redundancy. These techniques usually rely on handcrafted features extracted from the documents in a rule-based or traditional feature-based machine learning setup. Here, we present an effective approach based on neural attention mechanism to detect document-level novelty without any manual feature engineering. We contend that the simple alignment of texts between the source and target document(s) could identify the state of novelty of a target document. Our deep neural architecture elicits inference knowledge from a large-scale natural language inference dataset, which proves crucial to the novelty detection task. Our approach is effective and outperforms the standard baselines and recent work on document-level novelty detection by a margin of
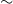 $\sim$
3% in terms of accuracy.
$\sim$
3% in terms of accuracy.