5 results
Human and animal behaviour in dairy buffalo at milking
-
- Journal:
- Animal Welfare / Volume 16 / Issue 2 / May 2007
- Published online by Cambridge University Press:
- 11 January 2023, pp. 139-142
-
- Article
-
- You have access
- Export citation
Genetic perspective of milk yield persistency in the first three lactations of Iranian buffaloes (Bubalus bubalis)
-
- Journal:
- Journal of Dairy Research / Volume 84 / Issue 4 / November 2017
- Published online by Cambridge University Press:
- 20 September 2017, pp. 434-439
- Print publication:
- November 2017
-
- Article
- Export citation
Modelling lactation curve for milk fat to protein ratio in Iranian buffaloes (Bubalus bubalis) using non-linear mixed models
-
- Journal:
- Journal of Dairy Research / Volume 83 / Issue 3 / August 2016
- Published online by Cambridge University Press:
- 07 September 2016, pp. 334-340
- Print publication:
- August 2016
-
- Article
- Export citation
Comparison of non-linear models to describe the lactation curves for milk yield and composition in buffaloes (Bubalus bubalis)
-
- Article
- Export citation
-
In order to describe the lactation curves of milk yield (MY) and composition in buffaloes, seven non-linear mathematical equations (Wood, Dhanoa, Sikka, Nelder, Brody, Dijkstra and Rook) were used. Data were 116 117 test-day records for MY, fat (FP) and protein (PP) percentages of milk from the first three lactations of buffaloes which were collected from 893 herds in the period from 1992 to 2012 by the Animal Breeding Center of Iran. Each model was fitted to monthly production records of dairy buffaloes using the NLIN and MODEL procedures in SAS and the parameters were estimated. The models were tested for goodness of fit using adjusted coefficient of determination (
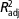 $$_{{{\rm adj}}}^{2} $$
), root means square error (RMSE), Durbin–Watson statistic and Akaike’s information criterion (AIC). The Dijkstra model provided the best fit of MY and PP of milk for the first three parities of buffaloes due to the lower values of RMSE and AIC than other models. For the first-parity buffaloes, Sikka and Brody models provided the best fit of FP, but for the second- and third-parity buffaloes, Sikka model and Brody equation provided the best fit of lactation curve for FP, respectively. The results of this study showed that the Wood and Dhanoa equations were able to estimate the time to the peak MY more accurately than the other equations. In addition, Nelder and Dijkstra equations were able to estimate the peak time at second and third parities more accurately than other equations, respectively. Brody function provided more accurate predictions of peak MY over the first three parities of buffaloes. There was generally a positive relationship between 305-day MY and persistency measures and also between peak yield and 305-day MY, calculated by different models, within each lactation in the current study. Overall, evaluation of the different equations used in the current study indicated the potential of the non-linear models for fitting monthly productive records of buffaloes.
$$_{{{\rm adj}}}^{2} $$
), root means square error (RMSE), Durbin–Watson statistic and Akaike’s information criterion (AIC). The Dijkstra model provided the best fit of MY and PP of milk for the first three parities of buffaloes due to the lower values of RMSE and AIC than other models. For the first-parity buffaloes, Sikka and Brody models provided the best fit of FP, but for the second- and third-parity buffaloes, Sikka model and Brody equation provided the best fit of lactation curve for FP, respectively. The results of this study showed that the Wood and Dhanoa equations were able to estimate the time to the peak MY more accurately than the other equations. In addition, Nelder and Dijkstra equations were able to estimate the peak time at second and third parities more accurately than other equations, respectively. Brody function provided more accurate predictions of peak MY over the first three parities of buffaloes. There was generally a positive relationship between 305-day MY and persistency measures and also between peak yield and 305-day MY, calculated by different models, within each lactation in the current study. Overall, evaluation of the different equations used in the current study indicated the potential of the non-linear models for fitting monthly productive records of buffaloes.