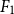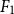1 results
Automatic classification of participant roles in cyberbullying: Can we detect victims, bullies, and bystanders in social media text?
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 18 November 2020, pp. 141-166
-
- Article
- Export citation
-
Successful prevention of cyberbullying depends on the adequate detection of harmful messages. Given the impossibility of human moderation on the Social Web, intelligent systems are required to identify clues of cyberbullying automatically. Much work on cyberbullying detection focuses on detecting abusive language without analyzing the severity of the event nor the participants involved. Automatic analysis of participant roles in cyberbullying traces enables targeted bullying prevention strategies. In this paper, we aim to automatically detect different participant roles involved in textual cyberbullying traces, including bullies, victims, and bystanders. We describe the construction of two cyberbullying corpora (a Dutch and English corpus) that were both manually annotated with bullying types and participant roles and we perform a series of multiclass classification experiments to determine the feasibility of text-based cyberbullying participant role detection. The representative datasets present a data imbalance problem for which we investigate feature filtering and data resampling as skew mitigation techniques. We investigate the performance of feature-engineered single and ensemble classifier setups as well as transformer-based pretrained language models (PLMs). Cross-validation experiments revealed promising results for the detection of cyberbullying roles using PLM fine-tuning techniques, with the best classifier for English (RoBERTa) yielding a macro-averaged
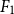 ${F_1}$-score of 55.84%, and the best one for Dutch (RobBERT) yielding an
${F_1}$-score of 55.84%, and the best one for Dutch (RobBERT) yielding an 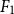 ${F_1}$-score of 56.73%. Experiment replication data and source code are available at https://osf.io/nb2r3.
${F_1}$-score of 56.73%. Experiment replication data and source code are available at https://osf.io/nb2r3.