





1. Introduction
Speakers know how to describe an event in the language they speak, using acceptable sentence structures (i.e., information that guides the assembly of words into sentences). For example, Korean speakers know that the canonical word order in Korean is subject-object-verb (SOV), so that they can describe an event of a dog chasing a cat by saying dog.NOM cat.ACC chase.PRES.DECL in KoreanFootnote 1. In contrast, English speakers know that the canonical word order in English is subject-verb-object (SVO), so that they can describe the same event of a dog chasing a cat by saying the dog chases the cat in English. This knowledge of which word orders speakers can use in their languages must be stable to communicate successfully with other speakers of the same languages. However, sometimes speakers learn a second language (L2) which can introduce different word orders, while (almost) always keeping their first language (L1). For example, for the same event that a Korean speaker describes using SOV word order in Korean, in English they should use SVO word order. How does adding structural knowledge of the L2 influence structural knowledge of the L1?
Although L1 might feel stable and resistant to change, the current bilingualism literature suggests that L1 might be subject to changes in response to acquiring an L2, and bilinguals are not identical to monolinguals even in their L1 (for reviews, see Kroll et al., Reference Kroll, Dussias and Bajo2018; Kroll & Gollan, Reference Kroll, Gollan, Goldrick, Ferreira and Miozzo2014). In particular, abundant evidence supports that bilinguals access linguistic information such as sounds and words from both of their languages even when speaking only one (for reviews, see Costa, Reference Costa2005; Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002; Kroll & Gollan, Reference Kroll, Gollan, Goldrick, Ferreira and Miozzo2014; Kroll et al., Reference Kroll, Gullifer and Rossi2017; Runnqvist et al., Reference Runnqvist, Strijkers and Costa2014). To modulate this co-activation, bilinguals use domain-general control mechanisms such as inhibitory control (for review, see Declerck, Reference Declerck2020; Goldrick & Gollan, Reference Goldrick and Gollan2023), and this inhibition helps to modulate language competition by inhibiting the dominant language (typically L1; e.g., Guo et al., Reference Guo, Liu, Misra and Kroll2011; Kroll et al., Reference Kroll, Bobb, Misra and Guo2008; Linck et al., Reference Linck, Kroll and Sunderman2009; Philipp et al., Reference Philipp, Gade and Koch2007). Furthermore, the dominant language seems to require more inhibition than the non-dominant language, as switching to the dominant language takes longer than switching to non-dominant language (e.g., Christoffels et al., Reference Christoffels, Firk and Schiller2007, Reference Christoffels, Ganushchak and La Heij2016; Costa & Santesteban, Reference Costa and Santesteban2004; Gollan & Ferreira, Reference Gollan and Ferreira2009; Heikoop et al., Reference Heikoop, Declerck, Los and Koch2016; Meuter & Allport, Reference Meuter and Allport1999; Verhoef et al., Reference Verhoef, Roelofs and Chwilla2009, Reference Verhoef, Roelofs and Chwilla2010). Thus, it seems that L1 goes through repetitive inhibition for bilinguals in a way that does not happen for monolinguals' L1. From this, it may be that bilinguals' L1 is subject to long-lasting consequences in which their L1 representations become different from that of monolinguals.
Studies of bilingual structural representations also point to possibilities of changes in L1 following L2 acquisition, particularly in bilinguals who know languages with similar word orders such as English and Spanish. In English, speakers can describe an event of a dog chasing a cat by using an active sentence structure (e.g., the dog chases the cat) or a passive sentence structure (e.g., the cat is chased by the dog). Similar active (el perro persigue al gato; the dog is boldfaced and the cat is underlined for the ease of interpretation) and passive (el gato es perseguido por el perro) sentence structures also exist in Spanish. These sentence structures could be organized in a bilingual's mind separately or together. For example, there could be two separate representations for English (the cat is chased by the dog) and Spanish (el gato es perseguido por el perro) passive sentence structures. Alternatively, there could be a single, shared abstract representation that applies to both English and Spanish passive structures, such as the cat or el gato comes first in the sentence, and the verb is modified differently from the active sentences (-ed for English; -ido for Spanish).
Several studies investigated whether bilinguals have shared or separate representations for sentence structures in the languages that they know by using a cross-language structural priming paradigm. In monolingual studies, structural priming refers to the phenomenon in which speakers are more likely to repeat the structure that they previously produced or comprehended (Bock, Reference Bock1986; Mahowald et al., Reference Mahowald, James, Futrell and Gibson2016; Pickering & Ferreira, Reference Pickering and Ferreira2008). For example, speakers are more likely to say the cat is chased by the dog (a passive) after hearing the truck is chased by the taxi (another passive) compared to after hearing the taxi chases the truck (an active). Critically, structural priming has also been observed across languages, such that bilinguals were more likely to say the cat is chased by the dog (a passive) after hearing el camión es perseguido por el taxi (‘the truck is chased by the taxi’; another passive) compared to after hearing el taxi persigue el camion (‘the taxi chases the truck’; an active). The idea is that if Spanish and English passive structures are completely separate, accessing a passive structure in one language should not influence the access of a passive structure in another language. Cross-language structural priming effects thus provide evidence for a shared structural representation between two languages for bilinguals (e.g., Gries & Kootstra, Reference Gries and Kootstra2017; Hartsuiker & Bernolet, Reference Hartsuiker and Bernolet2017; Hartsuiker & Pickering, Reference Hartsuiker and Pickering2008; Hartsuiker et al., Reference Hartsuiker, Pickering and Veltkamp2004; Kootstra & Muysken, Reference Kootstra and Muysken2017; Loebell & Bock, Reference Loebell and Bock2003; Van Gompel & Arai, Reference Van Gompel and Arai2018).
Such cross-language priming effects were also observed across languages that have different word orders, suggesting that the sharedness of structural representation is independent of word order (e.g., Bernolet et al., Reference Bernolet, Hartsuiker and Pickering2009; Chen et al., Reference Chen, Jia, Wang, Dunlap and Shin2013; Desmet & Declercq, Reference Desmet and Declercq2006; Hwang et al., Reference Hwang, Shin and Hartsuiker2018; Muylle et al., Reference Muylle, Bernolet and Hartsuiker2020, Reference Muylle, Bernolet and Hartsuiker2021; Shin & Christianson, Reference Shin and Christianson2009; Son, Reference Son2020; Weber & Indefrey, Reference Weber and Indefrey2009; but see Bernolet et al., Reference Bernolet, Hartsuiker and Pickering2007; Jacob et al., Reference Jacob, Katsika, Family and Allen2017; but see Ahn et al., Reference Ahn, Ferreira and Gollan2021; Ahn & Ferreira, Reference Ahn and Ferreira2023). For example, Shin and Christianson (Reference Shin and Christianson2009) examined cross-language structural priming in Korean L1 speakers who learned English as their L2. They used dative sentences, which have different linear word orders across English and Korean (e.g., for the prepositional dative, or PD, the knitter gave the sweater to her sister vs. knitter.NOM her sister.DAT sweater.ACC gave), but are argued to be analogous at the functional level (e.g., Baek & Lee, Reference Baek and Lee2004; O'Grady, Reference O'Grady1991; Urushibara, Reference Urushibara1991; although it is unclear to what extent these word-order variants in Korean are analogous to PD and DO forms in English, for simplicity, we adopt the PD and DO terminology here). Shin and Christianson asked participants to memorize English prepositional dative (PD; the lawyer handed the gift to the child) or double object dative (DO; The lawyer handed the child the gift) target sentences. Then, after listening to Korean PD (knitter.NOM her sister.DAT sweater.ACC gave) or DO (knitter.NOM her sister.ACC sweater.ACC gave) priming sentences, participants were asked to recall the English target sentences that they had memorized before listening to the Korean priming sentences. Despite the different linear word orders, participants were more likely to recall the English target sentences as PD sentence structures after listening to Korean PD sentences compared to after listening to Korean DO sentences. This suggested that word order differences do not limit the extent to which sentence structures can have shared representations across languages. Even though the word orders are different across languages, some structural information, such as the selection process between the two alternative choices (PD vs. DO), could be represented together in a bilingual's cognitive system (see also Son, Reference Son2020; but see Ahn & Ferreira, Reference Ahn and Ferreira2023 for a lack of strong cross-language structural priming effect between Korean and English using cumulative structural priming paradigm). If bilinguals have a single, shared representation for a sentence structure across languages, we might expect that some structural information from L2 could alter the representation of sentence structures in L1.
Indeed, some evidence from bilingual language comprehension suggests that L1 comprehension is influenced by L2 structural information for sentences with the same word order across languages – namely, relative clauses in English and Spanish (Dussias, Reference Dussias2003, Reference Dussias2004; Dussias & Sagarra, Reference Dussias and Sagarra2007). Monolingual Spanish speakers and monolingual English speakers show different preferences for structural interpretations of sentences with relative clauses (e.g., Carreiras & Clifton, Reference Carreiras and Clifton1999; Cuetos & Mitchell, Reference Cuetos and Mitchell1988). For example, when reading an ambiguous sentence such as someone shot the servant of the actress [who was on the balcony], monolingual English speakers tend to interpret the sentence so that the actress was on the balcony (a low-attachment interpretation). In contrast, monolingual Spanish speakers tend to interpret the sentence so that the servant was on the balcony (a high-attachment interpretation).
Importantly, this interpretation preference seems to change for Spanish native speakers after learning English as an L2 (Dussias, Reference Dussias2003, Reference Dussias2004; Dussias & Sagarra, Reference Dussias and Sagarra2007). In a series of experiments, Spanish native speakers who were proficient in English preferred the relative clause attachment that is comparable to what English native speakers prefer. For example, eye movement recordings revealed that Spanish–English bilinguals took longer to read Spanish sentences in which their grammatical gender agreement forced high attachment (e.g., The police arrested the sister of the (male) servant who had been ill (female) for a while), compared to sentences that force low attachment (e.g., The police arrested the brother of the (female) baby-sitter who had been ill (female) for a while). In other words, Spanish native speakers who learned English as their second language showed faster reading times for L1 sentences that were biased towards interpretations preferred in their L2 rather than their L1. This result suggests that Spanish–English bilinguals might have developed a shared structural representation in their two languages such that their comprehension of L1 was influenced by structural information from their L2.
A similar influence of L2 might be found for languages with different word orders, such as Korean and English. (1) shows a Korean transitive sentence in six possible orders of constituents.

Korean is primarily categorized as a verb-final language, with a canonical sentence structure of subject-object-verb (SOV). While it allows flexibility in constituent order, encompassing all six logical word orders (Ko, Reference Ko2014), verb-initial structures like verb-subject-object (VSO) and verb-object-subject (VOS) are rare and considered highly marked (Namboodiripad et al., Reference Namboodiripad, Kim and Kim2019; Sohn, Reference Sohn2001; Song, Reference Song2006). Furthermore, as long as the verb retains the final position, subject and object positions can be freely interchanged without changing the overall interpretation (i.e., SOV and OSV are relatively interchangeable; Sohn, Reference Sohn2001; Song, Reference Song2006). Additionally, due to its discourse-oriented nature, Korean allows for the omission of contextually understood elements such as the subject and object (i.e., OV and SV are common and acceptable; Sohn, Reference Sohn2001). Finally, while SOV and object-subject-verb (OSV) are most common in both spoken and written language, verb-medial orders such as subject-verb-object (SVO; which is the canonical word order in English) or object-verb-subject (OVS) are also relatively common in spoken language (Namboodiripad et al., Reference Namboodiripad, Kim and Kim2019).
Because of these properties of Korean, examining Korean speakers allows us to test the change in the representation of L1 Korean sentence structures after L2 English immersion. In other words, because the English-canonical word order (SVO) is less common than SOV or OSV but still grammatical and not completely unused in Korean, we might observe that English immersion leads to an increase in acceptability and production of SVO word order in Korean (whereas, for instance, English native speakers are probably very unlikely to use SOV word order in English even after prolonged exposure to Korean). For example, the word order representation of a Korean native speaker (who grew up using SOV canonical word order in Korean) might adapt when exposed to English (which is a language with SVO canonical word order), such that Korean sentences in SVO word order become more natural. To test this, we compared Korean-immersed speakers with little exposure to English to English-immersed Korean speakers with extensive exposure to English. Experiment 1 tested their acceptability judgments of Korean sentences in Korean canonical word order (SOV), English canonical word order (SVO), and an alternative Korean word order (OSV; which is, as described above, roughly interchangeable in Korean with SOV without change in meaning). Experiments 2 and 3 tested the production of Korean sentences in these word orders. We selected English-immersed speakers who moved to the US after at least the age of 11, to investigate the change of representation of a well-established L1 after L2 exposure.
Korean-immersed speakers should rate Korean sentences in Korean-canonical word order as most acceptable, and Korean sentences in English-canonical word order as least acceptable. Given that Korean has a relatively flexible word order and OSV can be used, the acceptability rating of Korean sentences in OSV (a Korean-alternative) word order should be in between Korean sentences in Korean-canonical or English-canonical word orders. If English and Korean representations are shared for English-immersed speakers and English exposure influences the representation of Korean word orders to become more English-like, the acceptability rating and production of Korean sentences in English-canonical word order should be higher for English-immersed speakers compared to Korean-immersed speakers. Alternatively, if English and Korean representations are completely separate and English immersion does not influence the representation of Korean word order, Korean- and English-immersed speakers should show a similar acceptability rating for English-canonical word order. Given that our English-immersed speakers were late learners of English, the representation of L1 canonical word order should be intact and thus acceptability ratings and production for Korean-canonical and Korean-alternative word orders should not necessarily differ between English-immersed speakers and Korean-immersed speakers.
2. Experiment 1
2.1. Method
Participants
Forty-eight Korean-immersed speakers and forty-eight English-immersed speakers were recruited from Amazon's Mechanical Turk, the UC San Diego Psychology Department subject pool, and by word of mouth. All Korean-immersed speakers responded that they never lived in the US (or any other English-speaking country) for more than 2 years (M = 0.1 years; SD = 0.3 years). All English-immersed speakers indicated that they were born and raised in Korea, learned Korean as their first language, used only Korean until they moved to the United States after age eleven, and Korean was their dominant language. At the time of participation, English-immersed participants lived in the US for an average of 12.3 years (SD = 8.6). See Table 1 for detailed participant information.
Table 1. Participant characteristics and language proficiency based on self-report and modified MINT.

Note. Proficiency self-ratings were on the scale of 1-7 (1 = almost none, 2 = very poor, 3 = fair, 4 = functional, 5 = good, 6 = very good, 7 = like native speaker). All numbers represent means across participants. Standard deviations are indicated in parentheses. MINT refers to a Korean modified version of Multilingual Naming Test (Gollan, Weissberger, Runnqvist, Montoya, & Cera, Reference Gollan, Weissberger, Runnqvist, Montoya and Cera2012). To adapt the MINT for use in Korean, 7 items that are Korean-English cognates were excluded; thus, participants were tested on 61 items, first in English, and then in Korean. Measures in which there are statistical differences between the two groups based on Welch two sample t-tests are boldfaced.
Materials and design
Ninety-six Korean sentences were created. Each sentence was written in three word orders: the Korean-canonical word order (subject-object-verb; SOV; e.g., composer.NOM several notes.ACC evenly drew), the English-canonical word order (subject-verb-object; SVO; e.g., composer.NOM evenly drew several notes.ACC), or Korean-alternative – but grammatical – word order (object-subject-verb; OSV; e.g., several notes.ACC composer.NOM evenly drew), creating 288 sentences in total. To provide more context for sentences, an adverb (e.g., evenly) and an adjective (e.g., several) were included for each sentence. For more detailed examples with original Korean text, transliterations, and English translations, see (1) above.
Six lists were created using the following procedure. Each list included all ninety-six experimental sentences once. These sentences were divided into three groups of 32 sentences each. Then, each group was assigned with one of the three word orders, ensuring all possible combinations of word orders across the six lists (in List 1, Group 1 was assigned with SOV, Group 2 with OSV, and Group 3 with SVO; in List 2, Group 1 was still assigned with SOV but the assignments for Groups 2 and 3 were interchanged so that Group 2 was assigned with SVO and Group 3 with OSV). This procedure ensured that the acceptability judgement of one sentence was not dependent on the word order of another sentence in the same list. By having six fully counterbalanced lists, for example, we were able to present one sentence in SOV word order (e.g., composer.NOM several music notes.ACC evenly drew) with another sentence in OSV word order in one list (e.g., expensive fountain pen.ACC writer.NOM tightly held in List 1) and in SVO word order in another list (e.g., writer.NOM tightly held expensive fountain pen.ACC in List 2). All lists included equal numbers of Korean-canonical, Korean-alternative, and English-canonical word orders.
Procedure
The experiment was built, and responses were recorded using Qualtrics (Qualtrics, Provo, UT). Participants completed the survey on their personal computers or cellphones on their own time. Each participant was presented with 96 sentences from one list in random order, one sentence at a time. Participants were asked to judge each sentence on its grammatical acceptability and naturalness on a scale of 1-7, 1 being “very unnatural” and 7 being “very natural.” Participants were asked to complete a language history questionnaire at the end of the experiment.
Analysis
Linear mixed effects models (LMMs; Baayen et al., Reference Baayen, Davidson and Bates2008) were constructed with participants’ ratings on the sentences as a continuous dependent variable. LMMs were fit using the lmer function from the lme4 package (Version 1.1-18-1; Bates et al., Reference Bates, Mächler, Bolker and Walker2015) in R: A Language and Environment for Statistical Computing (Version 3.5.1; R Core Team, 2014). We coded the categorical predictors using sum-to-zero contrasts (i.e., the intercept of the model was the grand mean of the dependent measure) for language background (Korean-immersed speakers vs. English-immersed speakers) and given sentence (Given Korean-canonical, Given Korean-alternative, or Given English-canonical).
LMMs were fit incorporating the maximal random effects structure given the experimental design (Barr et al., Reference Barr, Levy, Scheepers and Tily2013), with subject-specific intercepts and slopes for word order, as well as item-specific intercepts and slopes for both main effects and the interaction included. When the maximal model did not converge, random effects accounting for the least variance were gradually removed until a model successfully converged. For significance testing, Type III Wald chi-square tests were performed on fitted LMM models using the “Anova” function from the car package (Version 3.0-3 Fox & Weisberg, Reference Fox and Weisberg2011). Additionally, we computed estimated marginal means and standard errors using the emmeans package (Version 1.2.4; Lenth, Reference Lenth2019) to compare each treatment level. The final converged model, data, and R code are available at https://osf.io/mr9v5.
2.2. Results
Figure 1 illustrates acceptability judgments. Throughout the results, it is important to note that all sentences were given in Korean.

Figure 1. Acceptability judgments split by given word orders. The acceptability judgment was on a scale of 1-7, 1 being “very unnatural” and 7 being “very natural.” The boxes represent inter-quartile ranges, with the thick horizontal bars representing condition medians and edge of the boxes representing lower and upper quartiles. Dots represent outliers, which are defined as >1.5 times the inter-quartile range away from the edge of the box. Whiskers extend to the furthest non-outlier. Diamonds represent condition means.
Collapsed across given word orders, Korean- and English-immersed speakers were not different in their acceptability judgment of given sentences [4.3 (0.6) vs. 4.4 (0.6); χ 2 (1) < 1, p = .43].
Collapsed across Korean- and English-immersed speakers, participants rated the sentences differently based on the given word orders (χ 2 (2) = 1156.27, p < .001). In particular, participants rated sentences with Korean-canonical word order as more acceptable than sentences with Korean-alternative word order [6.2 (0.7) vs. 4.7 (1.1); b = 1.42, SE = .10, t = 14.41, p < .001], sentences with Korean-canonical word order as more acceptable than sentences with English-canonical word order [6.2 (0.7) vs. 2.1 (0.9); b = 4.00, SE = .12, t = 33.85, p < .001], and sentences with Korean-alternative word order as more acceptable than sentences with English-canonical word order [4.7 (1.1) vs. 2.1 (0.9); b = 2.58, SE = .13, t = 20.50, p < .001]. Given that all sentences were in Korean, these results were as predicted.
Korean- and English-immersed speakers rated the sentences differently based on the given word order (i.e., the 2-way interaction between group and given word order was significant; χ 2 (2) = 10.01, p = .007). That is, opposite to what we predicted, Korean-immersed speakers gave lower acceptability ratings compared to English-immersed speakers for sentences with Korean-canonical word order [6.0 (0.8) vs. 6.3 (0.6); b = -.36, SE = .14, t = -2.54, p = .01], whereas Korean-immersed speakers gave higher acceptability ratings than English-immersed speakers for sentences with English-canonical word order [2.3 (1.0) vs. 2.0 (0.8); b = .37, SE = .18, t = 2.07, p = .04]. Korean- and English-immersed speakers were not different in their acceptability rating for sentences with Korean-alternative word order [4.6 (1.1) vs. 4.9 (1.0); b = -.30, SE = .22, t = -1.39, p = .17].
2.3. Discussion
Based on the acceptability judgments of Korean sentences, as predicted, we found that Korean-immersed and English-immersed speakers are not different in their ratings of Korean sentences in Korean-alternative word order (OSV). However, for Korean sentences in Korean-canonical word order (SOV) and English-canonical word order (SVO), we found an opposite pattern from our prediction. Compared to how Korean-immersed speakers rated the sentences, English-immersed speakers rated Korean sentences in Korean-canonical word orders as more acceptable and Korean sentences in English-canonical word orders as less acceptable.
Given that acceptability judgment tasks allowed participants to spend as much time as they wanted, these results might be driven by the meta-linguistic knowledge that English-canonical (SVO) word order is non-canonical in Korean. Such use of meta-linguistic knowledge could be exaggerated in English-immersed speakers, as part of overcompensating for their L1 attrition (which late English learners who immigrate to English-immersed environments can experience; e.g., Schmid, Reference Schmid2010, Reference Schmid2013). Although an overcompensation for L1 attrition and the meta-linguistic knowledge that English-canonical (SVO) word order is non-canonical in Korean could drive acceptability judgments, more implicit language knowledge might drive the choice of word orders in Korean during production. To test this, we conducted Experiment 2 using a memory-recall paradigm adapted from Ferreira and Dell (Reference Ferreira and Dell2000). In their study, participants were asked to memorize temporarily ambiguous sentences such as the coach knew (that) you missed practice with or without the optional that. When asked to recall the sentences later, participants did not always exactly repeat the given sentence. Instead, participants did or did not include the optional “that” in a way that suggested that they produced the sentence structure that was most available to them as they spoke (i.e., even though participants were given the “that” in half of sentences, they produced it back in nearly three-quarters of sentences). Similarly, if bilinguals were asked to memorize and recall a sentence, they might produce the sentence using the sentence structure that is most available to them.
If English-immersed Korean native speakers who learned English as a second language develop a shared structural representation between Korean and English and their L1 Korean word order production becomes more like L2 English, we should observe that English-immersed speakers produce Korean (with a canonical word order of SOV) using English-canonical word order (SVO) more often than Korean-immersed speakers. Alternatively, if Korean and English representations are completely separate and English word order knowledge has no influence on Korean word order production even after English immersion, we should observe that the production of SVO word orders is similar between Korean- and English-immersed speakers
3. Experiment 2
3.1. Method
Participants: Korean-immersed speakers
Forty-eight Korean-immersed speakers from the Seoul National University (Seoul, Republic of Korea) community volunteered for monetary compensation. All participants were born and raised in Korea. Because the English language is a part of the school curriculum in Korea from third grade (about age 9; Ministry of Education - Republic of Korea, 1997), no participant was truly monolingual. However, all participants responded that they were functionally Korean monolinguals and never lived in the US (or any other English-speaking countries) for more than 12 months (M = 0.1 years; SD = 0.2 years).
Participants: English-immersed speakers
Forty-eight English-immersed speakers from the UC San Diego Psychology Department subject pool volunteered for course credit. All participants indicated that they were born and raised in Korea, learned Korean as their first language, moved to the United States after 11 years of age, and Korean is their dominant language. At the time of participation, participants had lived in the US for an average of 5.6 years (SD = 2.5).
Detailed participant characteristics are provided in Table 1.
Materials and design
Materials and Design were identical to Experiment 1, except the order of sentences was kept identical for all participants who were given the same list. Order of sentences in each list was randomized, with a restriction that a single word order never repeated more than twice.
Eight additional Korean sentences were included for instruction and training.
Procedure
The experiment was presented on a Macbook Air (13-inch, Mid 2013) for Korean-immersed speakers and an iMac (21.5-inch, Mid 2014) for English-immersed speakers using PsychoPy2 Version 1.81.03. Responses were recorded using the Voice Memos App on an iPhone 6 (Korean-immersed speakers) or a Marantz Solid State Recorder PMD661 (English-immersed speakers) for coding and analyses.
Each trial included three experimental sentences and involved an encoding phase and a recall phase. In the encoding phase, each sentence was shown in the middle of the screen for six seconds with one second of blank screen in between. Participants were asked to carefully read and memorize the given sentences, as they were to recall those sentences in the next phase. The instruction stated: “A short sentence will appear for 6 seconds. Please read and memorize the sentence.” In the recall phase, participants were given an adverb and verb as cues to recall the respective sentences. The instruction stated: “You will see two selected parts from the sentences you saw earlier. Say aloud the entire sentence that contains those parts to the best of your memory.” All instructions were given in Korean. The order of cues in the recall phase was different from the order of sentences in the encoding phase, with the restriction that the last memorized sentence was never the first recalled sentence. The recall cue stayed on the screen for two seconds, before the cues disappeared and participants were given three seconds to say the sentence out loud. The next recall cue appeared on the screen after one second of blank screen. Participants continued to the next trial by pressing the space bar at their own pace. Participants were encouraged to recall the sentences as much as possible and to guess if they did not remember the exact details of the memorized sentences. Example stimuli for two trials are shown in Table 2. As shown in Table 2, some trials (example trial 1) had only two of the three word orders because the only restriction for item order randomization was that the same word order did not appear more than twice in a row.
Table 2. Example trials from Experiment 2.

Note. Case markers are indicated in capital letters (NOM, nominative; ACC, accusative). Items were randomized so that the same word order did not appear for more than twice. Note that all experimental trials were presented in Korean. Each sentence had one adjective and one adverb—music notes, fountain pen, and landscape painting in the example are single words in the original Korean items.
Participants completed a language history questionnaire at the end of the experiment.
Coding and Analysis
Participants’ responses were transcribed and coded by native speakers of Korean, into Korean-canonical (SOV), Korean-alternative (OSV), English-canonical (SVO), Other, or Forgot. Responses were coded only based on the word order, such that responses that deviated from the given sentences were coded following the same procedure as responses that repeated the given sentences verbatim. “Other” responses included responses that included any two of S, O, and V in any order, and responses that included all three parts but were not in the order of Korean-canonical (SOV), Korean-alternative (OSV), or English-canonical (SVO). See Table 3a for a numerical breakdown of “Other” responses. “Forgot” responses included instances where the participant explicitly said that they forgot the response or did not say anything, and responses that included only one of S, O, or V. We included “Other” and “Forgot” responses in our analysis because although our main hypotheses rely on the production of Korean- and English-canonical word orders, these responses could still reveal some aspects of how Korean production differs between Korean- and English-immersed speakers. Specifically, for example, we might observe that English-immersed speakers are less likely to provide “Forgot” responses compared to Korean-immersed speakers when given English-canonical word order. Such observations could provide additional insights into how English immersion can influence representation of word orders (for instance, a better memory retention) for Korean native speakers. Furthermore, because subject or object can be omitted in Korean, it is possible that differences in such responses across Korean- and English-immersed speakers also reflect some mechanisms on how Korean word orders are represented in English-immersed speakers, similarly to “Forgot” responses.
Table 3a. A numerical breakdown of “Other” responses in Experiment 2.

Note. The word orders are ordered from most to least commonly produced per given word order, summed across Korean-immersed and English-immersed speakers. OV and SV word orders (boldfaced) are acceptable and relatively common in Korean (Sohn, Reference Sohn2001). Word orders with verb before subject or object are uncommon and highly marked (Namboodiripad et al., Reference Namboodiripad, Kim and Kim2019; Sohn, Reference Sohn2001; Song, Reference Song2006).
GLMMs were fit using the glmer function from the lme4 package (Version 1.1-20; Bates et al., Reference Bates, Mächler, Bolker and Walker2015) in R: A Language and Environment for Statistical Computing (Version 3.5.1; R Core Team, 2014). GLMMs were fit incorporating the maximal random effects structure given the experimental design (Barr et al., Reference Barr, Levy, Scheepers and Tily2013), with subject-specific intercepts and slopes for given word order, as well as item-specific intercepts and slopes for both main effects and the interaction included. For maximal models that did not converge, random effects accounting for the least variance were gradually removed until a model successfully converged. We fit five separate binomial logistic regressions to predict proportions of utterances in Korean-canonical (SOV), Korean-alternative (OSV), English-canonical (SVO), Other, and Forgot by assigning each of the possible word order as 1 and all the rest of the word orders as 0 (e.g., for the analysis of Korean-canonical word order, SOV was assigned as 1 and OSV, SVO, Other, and Forgot were assigned as 0). Participant language background (Korean- vs. English-immersed) and given word order (Given Korean-canonical, Given Korean-alternative, or Given English-canonical) were entered as categorial predictors using sum–to–zero contrasts (i.e., the intercept of the model was the grand mean of the dependent measure). Using the “Anova” function from the car package (Version 3.0-2; Fox & Weisberg, Reference Fox and Weisberg2011), Type III Wald Chi square tests were conducted in order to calculate main effects and interactions. On the fitted GLMMs, the emmeans package (Version 1.3.2; Lenth, Reference Lenth2019) was used to compute estimated marginal means and standard errors for each treatment level. The final converged model, data, and R code are available at https://osf.io/mr9v5.
We fit five additional GLMMs with the word order of the previous sentence as an additional factor to ensure that the results are not modulated by language inhibition. None of the fitted models showed significant effects or higher order interactions related to the word orders of previous sentences. The final converged model, statistical results, and R code for these additional models are also available at https://osf.io/mr9v5.
3.2. Results
Figure 2 illustrates proportions of produced word orders, split by given word orders. Throughout the results, it is important to note that all sentences were given and produced in Korean.

Figure 2. Proportions of produced word orders in Experiment 2, split by given word orders. “Other” responses included responses that included any two of S, O, and V in any order, and responses that included all three parts but were not in the order of Korean-canonical (SOV), Korean-alternative (OSV), or English-canonical (SVO). “Forgot” responses included instances where the participant explicitly said that they forgot the response or did not say anything, and responses that included only one of S, O, or V. The means that were statistically different between Korean-immersed vs. English-immersed speakers are labeled with asterisk above English-immersed speakers (~ : <.10; * : < .05). Collapsed across given word orders, English-immersed speakers produced more “Other” responses compared to Korean-immersed speakers (although statistically marginal). The proportion of “Forgot” responses statistically did not differ between Korean- versus English-immersed speakers when collapsed across given word orders. Error bars represent standard errors.
Proportions of utterances with Korean-canonical word order (SOV)
Collapsed across given word orders, Korean- and English-immersed speakers were statistically equally likely to produce sentences using Korean-canonical word order [58% (17%) vs. 52% (22%); χ 2 (1) = 1.63, p = .20]. Collapsed across Korean- and English-immersed speakers, the proportions of utterances produced with Korean-canonical word order were influenced by given word order [χ 2 (2) = 114.46, p < .001]. Specifically, participants were more likely to produce Korean-canonical word order when given Korean-canonical compared to when given Korean-alternative word orders [73% (22%) vs. 47% (23%); b = 1.45, SE = .14, z = 10.23, p < .001] and when given Korean-canonical compared to when given English-canonical [73% (22%) vs. 45% (26%); b = 1.49, SE = 0.15, z = 9.76, p < .001], and statistically equally likely to produce Korean-canonical word order when given Korean-alternative compared to when given English-canonical word order [47% (23%) vs. 45% (26%); b = .04, SE = 0.10, z = .40, p = .92]. The interaction between participant language background and given sentence was significant [χ 2 (2) = 8.24, p = .02]. Specifically, Korean-immersed speakers were more likely to produce Korean-canonical word order than English-immersed speakers when given Korean-canonical [78% (17%) vs. 68% (25%); b = .56, SE = .29, z = 1.98, p = .048] and marginally more likely to produce Korean-canonical word order than English-immersed speakers when given Korean-alternative [51% (23%) vs. 42% (23%); b = .43, SE = .25, z = 1.76, p = .08], but not when given English-canonical word order [45% (25%) vs. 46% (28%); b = -.07, SE = .30, z = -.24, p = .81].
Proportions of utterances with Korean-alternative word order (OSV)
Collapsed across given word orders, Korean- and English-immersed speakers were statistically equally likely to produce sentences using Korean-alternative word order [10% (8%) vs. 10% (9%); χ 2 (1) = 1.59, p = .21]. Collapsed across Korean- and English-immersed speakers, the proportions of utterances produced with Korean-alternative word order were influenced by given word order [χ 2 (2) = 819.19, p < .001]. Specifically, participants were more likely to produce Korean-alternative word order when given Korean-alternative word-order compared to when given Korean-canonical word order [27% (23%) vs. 2% (4%); b = -3.47, SE = .16, z = -22.37, p < .001], when given Korean-alternative word order compared to when given English-canonical word order [27% (23%) vs. 1% (3%); b = 3.96, SE = .19, z = 20.03, p < .001], but not when given Korean-canonical word order compared to when given English-canonical word order [2% (4%) vs. 1% (3%); b = .39, SE = .24, z = 1.65, p = .22]. The interaction between participant language background and given sentence was significant [χ 2 (2) = 10.46, p = .005]. Specifically, Korean-immersed speakers were less likely to produce Korean-alternative word order than English-immersed speakers when given English-canonical [1% (2%) vs. 2% (4%); b = .56, SE = .29, z = 1.98, p = .048], but not when given Korean-canonical word order [1% (3%) vs. 2% (4%); b = -.36, SE = .41, z = -.88, p = .38] and when given Korean-alternative word order [28% (23%) vs. 27% (23%); b = .14, SE = .29, z = .50, p = .61]. However, note that it is likely that this interaction is driven by the very low number of Korean-alternative word order produced by both groups when given English-canonical word order, and thus it is more reasonable to infer that the Korean- and English-immersed groups were equally likely to produce Korean-alternative word order regardless of given word orders.
Proportions of utterances with English-canonical word order (SVO)
Collapsed across given word orders, Korean-immersed were statistically marginally more likely to produce sentences using English-canonical word order [14% (11%) vs. 10% (11%); χ 2 (1) = 2.93, p = .09]. Collapsed across Korean- and English-immersed speakers, the proportions of utterances produced with English-canonical word order were influenced by given word order [χ 2 (2) = 333.40, p < .001]. Specifically, participants were equally very unlikely to produce English-canonical word order when given Korean-canonical or Korean-alternative word orders [3% (6%) vs. 2% (4%); b = .02, SE = .18, z = .10, p = 1.00], but more likely to produce English-canonical word orders when given English-canonical compared to when given Korean-canonical [31% (27%) vs. 3% (6%); b = -3.32, SE = .20, z = -16.35, p < .001], and compared to when given Korean-alternative [31% (27%) vs. 2% (4%); b = -3.33, SE = .20, z = -16.33, p < .001]. The interaction between participant language background and given sentence was not significant based on the chi square test [χ 2 (2) = .48, p = .79]. However, comparisons of estimated marginal means revealed that although Korean- and English-immersed speakers were equally unlikely to produce English-canonical word order when given Korean-canonical [3% (6%) vs. 2% (7%); b = .59, SE = .50, z = 1.18, p = .24] and when given Korean-alternative word orders [2% (4%) vs. 2% (4%); b = .63, SE = .46, z = 1.37, p = .17], contrary to what we predicted, Korean-immersed speakers were significantly more likely to produce English-canonical word orders compared to English-immersed speakers when given English-canonical word order [36% (28%) vs. 25% (26%); b = .86, SE = .43, z = 2.99, p = .04].
Proportions of utterances in “Other” word orders
On average, English-immersed speakers were marginally more likely to produce “Other” word orders compared to Korean-immersed speakers [19% (22%) vs. 12% (14%); χ 2 (1) = 3.05, p = .08], and this was not different depending on the given word order [i.e., the interaction between language background and given word order was not significant; χ 2 (2) < 1, p = .62]. Furthermore, speakers’ production of “Other” word orders was not statistically different depending on given word orders [χ 2 (2) = 3.11, p = .21].
Proportions of “Forgot” responses
On average, English-immersed and Korean-immersed speakers were equally likely to provide “Forgot” responses [9% (11%) vs. 7% (6%); χ 2 (1) < 1, p = .32], and this was not different depending on the given word order [i.e., the interaction between language background and given word order was not significant; χ 2 (2) = 3.57, p = .17]. Furthermore, speakers’ production of “Forgot” responses was not statistically different depending on given word orders [χ 2 (2) = 1.65, p = .44].
Post-hoc analysis of English-immersed speakers
To test whether the results are modulated by the length of L2 immersion, we fit additional GLMMs for each of the five responses on only the English-immersed speakers with given word order as categorical fixed factor and length of living in the US as continuous factor. Subject-specific intercepts and slopes for given word order, as well as item-specific intercepts and slopes for both main effects and the interaction were included. We observed no significant main effect of the length of living in the US and interactions. Thus, it seems that even a short period of English immersion is still associated with the difference we observed between English- versus Korean-immersed speakers. The final converged model, statistical results, and R code for these additional models are available at https://osf.io/mr9v5.
3.3. Discussion
Contrary to our prediction, collapsed across given word orders, we found that Korean- and English-immersed speakers were not different in their production of Korean sentences using Korean-canonical (SOV) word order, and Korean- and English-immersed speakers were only marginally different in their production of Korean sentences using English-canonical (SVO) word order. If anything, although the higher order interactions were statistically non-significant, comparing estimated marginal means suggested that Korean-immersed speakers were more likely to produce English-canonical word order when given English-canonical word order. Moreover, unlike what we would predict from Experiment 1 where English-immersed speakers rated the Korean canonical word order higher than Korean-immersed speakers did, Korean-immersed speakers were more likely to produce Korean-canonical word orders when given Korean-canonical word order (and marginally more likely to produce Korean-canonical word order when given Korean-alternative) compared to English-immersed speakers. In other words, it seemed that English-immersed speakers’ Korean (L1) production did not resemble English (L2) structures. This might suggest that English-immersed speakers represent L1 and L2 structural information separately for L1-canonical vs. L2-canonical word orders.
Interestingly, however, it seemed that English-immersed speakers produced more “Other” word orders compared to Korean-immersed speakers. This is unlikely to be driven by English-immersed speakers being more forgetful, given that the two groups were equivalent in their “Forgot” responses. Instead, the higher proportion of “Other” responses from English-immersed speakers might suggest that the selection and retrieval of L1 word orders are more difficult for English-immersed speakers than Korean-immersed speakers. Incorporated with our main analysis, these results might still support the hypothesis of shared structural representations across L1 and L2. Our task was to memorize sentences and recall them, and participants were likely to try also to remember the word order that the given sentences were in (although the instructions were not explicit that they should remember the given word orders). If speakers develop shared representations between L1 and L2 after L2 immersion, because SOV from L1 and SVO from L2 are the canonical word orders in their respective languages, the distinction between these word orders might become murkier for English-immersed speakers – on the assumption that structural representations are somehow shared. Thus, trying to remember Korean-canonical and English-canonical word orders separately might be more difficult for English-immersed speakers. To compensate for this difficulty, English-immersed speakers might adopt an implicit strategy that they drop the subject or object, which is common in Korean (Sohn, Reference Sohn2001) and still conforms with the experimental task of recalling Korean sentences to the best of their memory. In contrast, for Korean-immersed speakers, Korean-canonical and English-canonical word orders are so distinctive that it is easier for them to remember the sentences in given word orders than for English-immersed speakers. This might lead to the production pattern that we observed, in which Korean-immersed speakers can memorize and produce more English-canonical word orders than English-immersed speakers can.
If English-immersed speakers produce fewer English-canonical word orders and more “Other” word orders because of a murkier distinction between Korean-canonical and English-canonical word orders from their shared representation of L1 and L2, then we should again observe a similar production pattern when speakers are given word orders that are non-canonical and rare in Korean and ungrammatical English, such as VSO. Recall that verb-initial word orders are rare and highly marked in Korean (Namboodiripad et al., Reference Namboodiripad, Kim and Kim2019; Sohn, Reference Sohn2001; Song, Reference Song2006), making VSO word order effectively “ungrammatical” in Korean. Thus, if learning English can influence the L1 Korean production, Korean-immersed speakers should produce more VSO word order and less “Other” word orders compared to English-immersed speakers showing a similar pattern as observed in Experiment 2. That is, because VSO word order is rare in Korean and ungrammatical in English, English-immersed speakers might develop “double evidence” from Korean and English that such word order is not preferable in speech. Moreover, although rare, even the rare exposure to VSO word orders in Korean would enable Korean-immersed speakers to have more exposure to VSO word order compared to English-immersed speakers, allowing Korean-immersed speakers to produce more VSO word orders than English-immersed speakers. Alternatively, if Korean and English representations are completely separate for English-immersed speakers, we should observe a similar production pattern between Korean- and English-immersed speakers because learning English should have no influence on the production of VSO word order that is ungrammatical in English. To test this, we conducted Experiment 3 with an identical design as Experiment 2, except the word orders given were Korean-canonical (SOV), Korean-alternative (OSV), and English-ungrammatical (VSO) word orders.
4. Experiment 3
4.1. Method
Participants: Korean-immersed speakers
Forty-eight Korean-immersed speakers from the Seoul National University (Seoul, Republic of Korea) community volunteered for monetary compensation. All participants responded that they were born and raised in Korea, were functionally Korean monolinguals, and never lived in the US (or any other English-speaking countries) for more than 24 months (M = 0.1 years; SD = 0.3 years).
Participants: English-immersed speakers
Forty-eight English-immersed speakers from the UC San Diego Psychology Department subject pool volunteered for course credit. All participants indicated that they were born and raised in Korea, learned Korean as their first language, moved to the United States after eleven years of age, and that Korean is their dominant language. At the time of participation, participants lived in the US for an average of 6.5 years (SD = 3.3).
Materials and design
The materials and design were identical to Experiment 2, except English-canonical (SVO) sentences from Experiment 2 were presented in English-ungrammatical (VSO) order.
Detailed participant characteristics are provided in Table 1.
Procedure
The procedure was identical to Experiment 2, except participants were additionally asked to complete an adapted version of Multilingual Naming Test (MINT; Gollan et al., Reference Gollan, Weissberger, Runnqvist, Montoya and Cera2012) at the end of the experiment (see Table 1 for more information). This additional measure of language proficiency was added to account for the possibility that internal reference frames of language proficiency self-ratings might vary between groups (Tomoschuk et al., Reference Tomoschuk, Ferreira and Gollan2019).
All instructions were kept identical between Experiment 2 and 3, although we recognized the possibility that participants from Experiment 2 were explicitly attempting to memorize the exact given word orders. By doing so, any difference in results should reflect the difference introduced by the English-canonical (SVO in Experiment 2) and English-ungrammatical (VSO in Experiment 3) word orders.
Coding and Analysis
Coding and Analysis were identical to Experiment 2, except English-ungrammatical (VSO) word order replaced the English-canonical (SVO) word order from Experiment 2. See Table 3b for a numerical breakdown of “Other” responses. The final converged model, data, and R code are available at https://osf.io/mr9v5.
Table 3b. A numerical breakdown of “Other” responses in Experiment 3.
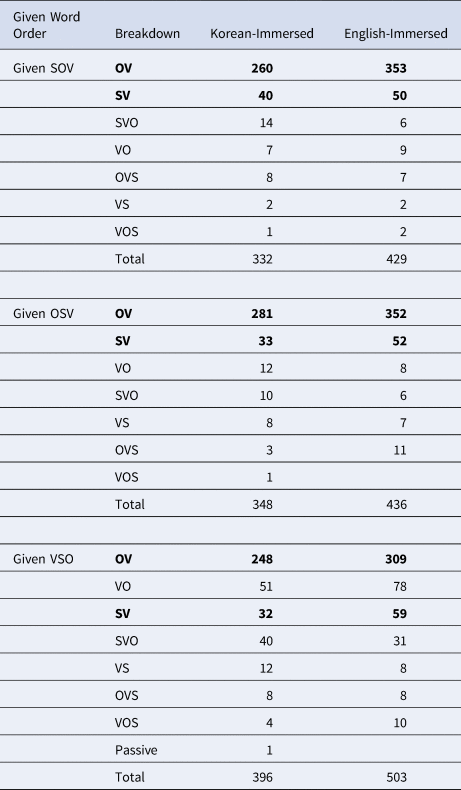
Note. The word orders are ordered from most to least commonly produced per given word order, summed across Korean-immersed and English-immersed speakers. OV and SV word orders (boldfaced) are acceptable and relatively common in Korean (Sohn, Reference Sohn2001). Word orders with verb before subject or object are uncommon and highly marked (Namboodiripad et al., Reference Namboodiripad, Kim and Kim2019; Sohn, Reference Sohn2001; Song, Reference Song2006).
As we did for Experiment 2, we have fitted five additional GLMMs with word order of previous sentence as an additional factor to ensure that the results are not modulated by language inhibition. Again, none of the fitted models showed significant effect or higher order interactions related to word orders of previous sentences. The final converged model, statistical results, and R code for these additional models are also available at https://osf.io/mr9v5.
4.2. Results
Figure 3 illustrates proportions of produced word orders, split by given word orders. Throughout the results, it is important to note that all sentences were given in Korean.

Figure 3. Proportions of produced word orders in Experiment 3, split by given word orders. Note that unlike participants in Experiment 2 who were given SVO, an English-canonical word order, participants in Experiment 3 were given VSO, which is rare in Korean and ungrammatical in English. “Other” responses included responses that included any two of S, O, and V in any order, and responses that included all three parts but were not in the order of Korean-canonical (SOV), Korean-alternative (OSV), or English-ungrammatical (VSO). “Forgot” responses included instances where the participant explicitly said that they forgot the response or did not say anything, and responses that included only one of S, O, or V. The means that were statistically different between Korean-immersed vs. English-immersed speakers are labeled with asterisk above English-immersed speakers (~ : <.10; * : <.05; *** : <.001). The proportion of “Other” responses were significantly different between Korean- versus English-immersed speakers, when collapsed across given word orders. Error bars represent standard errors.
Proportions of utterances with Korean-canonical word order (SOV)
Unlike in Experiment 2 where Korean- and English-immersed speakers were not statistically different in their production of Korean-canonical word order, collapsed across given word orders, Korean-immersed speakers were more likely to produce sentences using Korean-canonical word order [48% (18%) vs. 35% (18%); χ 2 (1) = 11.25, p < .001]. Collapsed across Korean- and English-immersed speakers, the proportions of utterances in Korean-canonical word order were influenced by given word order [χ 2 (2) = 67.43, p < .001]. Specifically, participants were statistically more likely to produce Korean-canonical word order when given Korean-canonical compared to when given Korean-alternative word orders [55% (22%) vs. 38% (21%); b = .84, SE = .11, z = 7.76, p < .001], when given Korean-canonical compared to when given English-ungrammatical [55% (22%) vs. 33% (24%); b = 1.16, SE = .15, z = 7.52, p < .001], and when given Korean-alternative compared to when given English-ungrammatical [38% (21%) vs. 33% (24%); b = .32, SE = .10, z = 3.06, p = .006]. The interaction between participant language background and given sentence was not significant [χ 2 (2) = 2.98, p = .23]. That is, Korean-immersed speakers were more likely to produce Korean-canonical word orders compared to English-immersed speakers regardless of given word orders – when given Korean-canonical [63% (19%) vs. 46% (21%); b = .86, SE = .22, z = 3.98, p < .001], when given Korean-alternative [43% (21%) vs. 32% (20%); b = .55, SE = .22, z = 2.46, p = .01], and when given English-ungrammatical [39% (24%) vs. 27% (23%); b = .69, SE = .30, z = 2.29, p = .02].
Proportions of utterances in Korean-alternative word order (OSV)
Collapsed across given word orders, Korean-immersed speakers were marginally more likely to produce sentences using Korean-alternative word order compared to English-immersed speakers [9% (8%) vs. 6% (6%); χ 2 (1) = 3.26, p = .07], and this was not different depending on given word orders [i.e., the interaction between language background and given word order was not significant; χ 2 (2) < 1, p = .89]. Collapsed across Korean- and English-immersed speakers, the proportions of utterances with Korean-alternative word order were influenced by given word order [χ 2 (2) = 198.48, p < .001]. Specifically, participants were more likely to produce Korean-alternative word order when given Korean-alternative word-order compared to when given Korean-canonical word order [18% (16%) vs. 2% (4%); b = -2.85, SE = .23, z = -12.40, p < .001], when given Korean-alternative word order compared to when given English-ungrammatical word order [18% (16%) vs. 3% (5%); b = 2.18, SE = .19, z = 11.69, p < .001], and when given English-ungrammatical word order compared to when given Korean-canonical word order [3% (5%) vs. 2% (4%); b = -.67, SE = .22, z = -3.05, p < .007].
Proportions of utterances in English-ungrammatical word order (VSO)
Collapsed across given word orders, Korean-immersed speakers were not more likely to produce sentences using English-ungrammatical word order [7% (9%) vs. 5% (7%); χ 2 (1) = 2.69, p =.10]. Collapsed across Korean- and English-immersed speakers, the proportions of utterances in English-ungrammatical word order were influenced by given word order [χ 2 (2) = 419.46, p < .001]. Specifically, participants were less likely to produce English-ungrammatical word order when given Korean-canonical compared to when given Korean-alternative [0% (2%) vs. 2% (3%); b = -1.67, SE = .42, z = -3.97, p < .001], when given Korean-canonical compared to when given English-ungrammatical [0% (2%) vs. 17% (22%); b = -4.56, SE = .39, z = -11.64, p < .001], and when given Korean-alternative compared to when given English-ungrammatical word order [2% (3%) vs. 17% (22%); b = -2.89, SE = .17, z = -17.23, p < .001]. However, it should be noted that the statistically significant difference between when given Korean-canonical vs. Korean-alternative word orders arises from extremely unlikely English-ungrammatical sentence production. Thus, it is reasonable to argue that collapsed across Korean- and English-immersed speakers, participants nearly only produced English-ungrammatical word order when given English-ungrammatical word order.
The interaction between participant language background and given sentence was significant [χ 2 (2) = 10.21, p = .006]. That is, Korean-immersed speakers were more likely to produce English-ungrammatical word order compared to English-immersed speakers when given Korean-canonical [1% (3%) vs. 0% (1%); b = 2.66, SE = 1.00, z = 2.68, p = .007], but not when given Korean-alternative [2% (3%) vs. 2% (3%); b = .04, SE = .67, z = .01, p = .95] or when given English-ungrammatical [20% (24%) vs. 14% (19%); b = .54, SE = .60, z = .91, p = .36]. Similar to the comparisons collapsed across Korean- and English-immersed speakers, this statistically significant difference between Korean- and English-immersed speakers when given Korean-canonical word order arises from the extremely unlikely production of English-ungrammatical word orders. Thus, it is reasonable to assume that Korean- and English-immersed speakers were equally likely to produce English-ungrammatical word order, regardless of given word orders, although there were some conditions that showed statistical tendencies for Korean-immersed speakers to produce more English-ungrammatical word orders compared to English-immersed speakers.
To summarize, although there were some statistical effects due to extremely unlikely English-ungrammatical sentence production, both Korean- and English-immersed speakers only produced English-ungrammatical sentences when given English-ungrammatical sentences and they were not different in the proportion of English-ungrammatical sentences produced.
Proportions of utterances in “Other” word orders
Replicating Experiment 2, English-immersed speakers were more likely to produce “Other” word orders compared to Korean-immersed speakers [30% (17%) vs. 23% (14%); χ 2 (1) = 3.90, p = .048], and this was not different depending on the given word order [i.e., the interaction between language background and given word order was not significant; χ 2 (2) < 1, p = .87]. Furthermore, speakers’ production of “Other” word orders differed depending on given word orders [χ 2 (2) = 20.35, p < .001]. That is, participants were less likely to produce “Other” word order when given Korean-canonical compared to when given English-ungrammatical [25% (17%) vs. 29% (18%); b = -.29, SE = .07, z = -4.24, p < .001], and when given Korean-alternative compared to when given English-ungrammatical word order [25% (17%) vs. 29% (18%); b = -.21, SE = .07, z = -3.16, p = .004], but did not show a statistical difference between when given Korean-canonical compared to when given Korean-alternative word order [25% (17%) vs. 26% (17%); b = -.08, SE = .07, z = -1.15, p = .49].
Proportions of “Forgot” responses
On average, English-immersed were more likely to provide “Forgot” responses compared to Korean-immersed speakers [24% (17%) vs. 12% (8%); χ 2 (1) = 20.00, p < .001], and this was not different depending on the given word order [i.e., the interaction between language background and given word order was not significant; χ 2 (2) < 1, p = .54]. Furthermore, speakers’ production of “Forgot” responses was not statistically different depending on given word orders [χ 2 (2) < 1, p = .86].
Post-hoc analysis of English-immersed speakers
To test whether the results are modulated by the length of L2 immersion, we fit additional GLMMs for each of the five responses on only the English-immersed speakers with given word order as categorical fixed factor and length of living in the US as continuous factor. Subject-specific intercepts and slopes for given word order, as well as item-specific intercepts and slopes for both main effects and the interaction were included. We observed no significant main effect of the length of living in the US or interaction. The final converged model, statistical results, and R code for these additional models are available at https://osf.io/mr9v5.
4.3. Discussion
Experiment 3 was designed to test whether the effect we found in Experiment 2 was associated with a shared representation across English and Korean in English-immersed speakers. Namely, we hypothesized that English-immersed speakers in Experiment 2 might have produced more “Other” word orders compared to Korean-immersed speakers because English-canonical word order (SVO) is less distinctive due to the (hypothetical) shared representation of canonical word orders across Korean and English. This predicts that when given a word order that is rare in Korean and ungrammatical in English, Korean-immersed speakers should produce more VSO word order and less “Other” word orders compared to English-immersed speakers. Supporting this prediction, we found that English-immersed speakers were still more likely to produce “Other” word orders compared to Korean-immersed speakers even when given English-ungrammatical (Experiment 3) instead of English-canonical (Experiment 2) word order. However, contrary to our prediction, Korean-immersed speakers were not necessarily more likely to produce English-ungrammatical word order. Thus, it seems that the higher proportion of “Other” word orders for English-immersed speakers is not driven by the difference in English-ungrammatical word order production, but rather, overall more random production in English-immersed speakers. Finally, the proportion of “Forgot” responses was higher in Experiment 3 compared to in Experiment 2 in both groups, and English-immersed speakers were more likely to provide “Forgot” responses compared to Korean-immersed speakers only in Experiment 3. It is possible that the overall increase of “Forgot” responses reflect a general task difficulty of memorizing a word order that is ungrammatical in both Korean and English. In other words, the participants in Experiment 3 might have found it more challenging to remember and reproduce word orders that deviated from the grammatical norms of both languages. However, the higher proportion of “Forgot” responses in English-immersed compared to Korean-immersed speakers in Experiment 3 might reflect that Korean-speakers are better at distinguishing ungrammatical sentences from grammatical ones. In other words, despite the increased task difficulty for all participants in Experiment 3, Korean-immersed speakers seemed to have an advantage in accurately identifying and differentiating ungrammatical sentences (VSO) from grammatical ones (SOV and OSV). This finding implies that Korean-immersed speakers’ knowledge of Korean grammar may have provided them with a stronger foundation for recognizing and retaining the correct word order patterns, even when faced with sentences that were ungrammatical in both languages.
Thus, to summarize, while Korean-immersed speakers were sensitive to the given word orders, English-immersed speakers were overall more random with which word orders they use and were more impacted by the given English-ungrammatical word order in their ability to recall given sentences compared to Korean-immersed speakers. From this, we might infer that instead of developing shared representations for different word orders leading speakers to produce their L1 in a way that its sentence structures resemble L2, English-immersed speakers develop more general difficulties in the selection and retrieval of word orders when using their L1 after L2 immersion.
5. General discussion
Three experiments tested whether Korean (L1) sentence processing and production can be influenced by English (L2) structural information for Korean speakers in an English-immersive environment. Experiment 1, where we tested acceptability judgment of Korean sentences in different word orders, showed an opposite pattern of what we predicted if L2 straightforwardly influences L1 sentence processing. That is, while Korean-immersed speakers rated Korean sentences in English canonical word order (SVO) higher than English-immersed speakers, English-immersed speakers rated Korean sentences in Korean-canonical word order (SOV) higher than Korean-immersed speakers did. Experiment 2 also did not show a pattern that we would expect if L2 straightforwardly influences L1 production. Namely, Korean- and English-immersed speakers were not statistically different in their production of Korean- or English-canonical word orders. If anything, although the higher-order interactions were not statistically significant, Korean-immersed speakers produced both Korean- and English-canonical word orders more than English-immersed speakers did. Interestingly, instead of producing more English canonical word orders as we predicted, English-immersed speakers tended to produce more “Other” word orders than Korean-immersed speakers even though they were not necessarily different in their “Forgot” responses. Experiment 3 tested whether the effects we found in Experiment 2 were associated with the increased perceived naturalness of English-canonical word orders for English-immersed speakers, which might have made our task more difficult and leading to production of more “Other” word orders. Testing a word order that is rare in Korean and ungrammatical in English (VSO), Experiment 3 revealed that Korean-immersed speakers were again more likely to produce Korean-canonical word order, while English-immersed speakers were more likely to produce “Other” word orders. Moreover, English-immersed speakers seemed to be overall more impacted by the given English-ungrammatical word orders than Korean-immersed speakers and exhibited more “Forgot” responses. Together, it appears that Korean-immersed speakers can recall and produce Korean sentences in given word orders more systematically than English-immersed speakers can. Thus, instead of resembling L2 structures, the L1 representation of English-immersed speakers might become more difficult to access and use in a systematical way.
These results contradict what we would predict if Korean native speakers’ representations of Korean word orders become more English-like after acquiring English. Instead, our results partially resemble the word order acceptability patterns that were reported by Namboodiripad et al. (Reference Namboodiripad, Kim and Kim2019), who tested English-dominant Korean–English bilinguals. In their study, Namboodiripad et al. compared Korean-immersed speakers and English-dominant Korean bilinguals in their acceptability judgment of Korean sentences in all possible word orders (SOV, OSV, SVO, OVS, VSO, VOS; SOV is the Korean-canonical word order; SVO is the English-canonical word order). Unlike the participants in our study (who grew up in Korea only using Korean until at least the age of 11 and were Korean-dominant), English-dominant speakers in Namboodiripad et al. were Korean heritage speakers who grew up in the US and learned Korean primarily through informal exposure at home. They found that although the two groups were not different in their preference of English-canonical word order and other word orders that are neither Korean- nor English-canonical word orders), English-dominant speakers were more likely to rate the Korean-canonical word order higher than the other word orders that are non-canonical in Korean. From this, they suggested that English contact reduces word order flexibility in Korean. Alternatively, they suggested that the frequency of input for English-dominant speakers led to their higher preference for Korean canonical word order. That is, in a corpus study, Cho (Reference Cho1982) found that the Korean canonical word order is predominant in Korean-speaking mothers’ infant-directed speech. Because Korean input for the English-dominant speakers in Namboodiripad et al. mainly was from home, it was possible that their early exposure to Korean mainly consisted of Korean canonical word order, which might have led to a higher preference of Korean canonical word order.
The frequency of input during early exposure cannot explain our results. Given that our English-immersed speakers moved to the US after the age of 11 at the youngest, their early Korean exposure should have been very similar to Korean-immersed speakers. Reduced L1 flexibility could explain part of our results in which English-immersed speakers rated the Korean canonical word orders higher than Korean-immersed speakers, but this does not explain why Korean-immersed speakers produced more Korean canonical word order sentences than English-immersed speakers did in some conditions. Moreover, it is unclear why we observed that English-immersed speakers both rated the English canonical word orders lower and produced the English canonical word order less frequently in some conditions than Korean-immersed speakers, which is a pattern that was not observed in Namboodiripad et al. We might speculate that our participants, who were late learners of English, were more likely to overcompensate than speakers who grew up speaking both English and Korean during the acceptability judgment task. Unlike Korean heritage speakers who are English dominant (and likely to be English dominant throughout their language learning experience), late English learners who immigrate to English-immersed environments can undergo L1 attrition (e.g., Schmid, Reference Schmid2010, Reference Schmid2013). Consequently, these late English learners might become more likely to give high ratings on canonical Korean sentences and low ratings on non-canonical Korean sentences as part of overcompensating for the L1 attrition.
This possible overcompensation might not be evident during the fast-paced online sentence production paradigm we used in Experiments 2 and 3, thereby contributing to the observed difficulties in the recalling of word orders in L1. Because the memory-recall paradigm in Experiments 2 and 3 did not allow for sufficient time to carefully consider each sentence (as one might during acceptability judgment) and produce more Korean-canonical sentences, English-immersed speakers might generate more “Other” sentence structures by dropping subjects and objects. Similarly, due to L1 attrition, English-immersed speakers might encounter more difficulty than Korean-immersed speakers when attempting to memorize VSO sentences that are (essentially) ungrammatical in both Korean and English. The introduction of such ungrammatical sentences could have imposed a heavier memory burden on English-immersed speakers compared to Korean-immersed speakers, who possess a firmer grasp of Korean (and thus a better ability to ignore the ungrammatical sentence stimuli).
Future research should consider incorporating working memory measures to better assess the differences between the groups and investigate the mechanisms underlying the production of “Other” sentence structures with subject and object drops. Introducing working memory measures would also be beneficial for addressing the potential memory burden inherent in the memory-recall paradigm and for disentangling the effects of memory from linguistic abilities. Similarly, it would be valuable to assess special bilingual populations, such as those with mild traumatic brain injuries (mTBI) or Alzheimer's disease. By studying these groups, we could gain insight into the mechanisms underlying why English-immersed bilinguals produce more “Other” sentence structures. This assessment would allow us to explore the interplay between cognitive factors and language acquisition, providing valuable insights into the intricate processes that contribute to the observed differences in sentence production patterns between Korean-immersed and English-immersed bilinguals.
Our results also contrast with what we would predict from the previous literature that showed structural priming across Korean and English dative sentences, despite the different word orders across Korean and English (e.g., Hwang et al., Reference Hwang, Shin and Hartsuiker2018; Shin & Christianson, Reference Shin and Christianson2009). Cross-language structural priming across Korean and English suggested that dative constructions could have a shared representation across Korean and English. Relevant to our hypotheses, this cross-language structural priming raised a possibility that Korean-canonical vs. English-canonical representations could also be shared for English-immersed speakers, and thus sentences that could be represented only using Korean-canonical word order for Korean-immersed speakers could also be represented using English-canonical word order for English-immersed speakers. Our results opposing the prediction might have been driven by the difference between the representation of dative constructions and Korean- vs. English-canonical constructions. That is, producing dative sentences involves selecting between two alternative choices that are comparable in meaning (e.g., the knitter gave the sweater to her sister vs. the knitter gave her sister the sweater). In contrast, Korean- vs. English-canonical constructions may not involve such a selection process between the two alternative constructions. If such a selection process is necessary for developing a shared representation across languages, representation for Korean- vs. English-canonical constructions might not develop a shared representation even after extensive L2 immersion.
Another possibility is that Korean–English bilinguals may not develop a shared structural representation between Korean and English in the same way that bilinguals of other languages (e.g., Dutch–English or Spanish–English bilinguals) have shown to do. For instance, Ahn et al. (Reference Ahn, Ferreira and Gollan2021) used an extended picture-word interference paradigm to investigate whether Korean–English bilinguals, with extended exposure to English, access structures from both languages while speaking in one language. Their findings revealed that Korean–English bilinguals only access the language they are currently using, even during tasks that involved frequent language switches. Similarly, Ahn and Ferreira (Reference Ahn and Ferreira2023) used cumulative cross-language structural priming to examine the sharedness of structural information between Korean and English. Their results provided evidence against a completely shared structural representation, underlining the need for more studies employing alternative methods beyond standard structural priming, particularly within understudied bilingual populations like Korean–English bilinguals. The findings from our current study align with this possibility that Korean–English bilinguals may not develop a shared structural representation. Consequently, it is not surprising that L1 Korean representations can still undergo changes due to factors such as L1 attrition, but not necessarily in a way that would cause Korean to resemble the L2 English.
Furthermore, our results also contrast with studies that suggested an L2 influence on L1 sentence parsing (Dussias, Reference Dussias2003, Reference Dussias2004; Dussias & Sagarra, Reference Dussias and Sagarra2007). This discrepancy might be due to the difference between comprehension and production. Given that language control mechanisms are not necessarily shared across production and comprehension (e.g., Ahn et al., Reference Ahn, Abbott, Rayner, Ferreira and Gollan2020; Blanco-Elorrieta & Pylkkänen, Reference Blanco-Elorrieta and Pylkkänen2016, Reference Blanco-Elorrieta and Pylkkänen2017; Mosca & de Bot, Reference Mosca and de Bot2017; but see Dussias, Reference Dussias2001; Gambi & Hartsuiker, Reference Gambi and Hartsuiker2016; Guzzardo Tamargo et al., Reference Guzzardo Tamargo, Valdés Kroff and Dussias2016; Peeters et al., Reference Peeters, Runnqvist, Bertrand and Grainger2014), it is correspondingly possible that the influence of L2 on L1 is different for comprehension versus production.
However, not only did we not observe an L2 influence on L1 in production, but we also did not observe an L2 influence on L1 acceptability judgments. We might suggest a few reasons for this discrepancy between our results and studies that suggested an L2 influence on L1 sentence parsing (e.g., Chen et al., Reference Chen, Jia, Wang, Dunlap and Shin2013; Hwang et al., Reference Hwang, Shin and Hartsuiker2018; Shin & Christianson, Reference Shin and Christianson2009). First, the greater typological difference between Korean and English, compared to Spanish and English, might hinder the influence of L2 on L1. Although there are studies that found cross-language structural priming across more typologically different languages (e.g., Chen et al., Reference Chen, Jia, Wang, Dunlap and Shin2013; Hwang et al., Reference Hwang, Shin and Hartsuiker2018; Shin & Christianson, Reference Shin and Christianson2009), a stronger connection from closer typological proximity might be necessary for the influence of L2 on L1 representation to occur. Second, similarly to our speculations on why we found different results from what we would expect from reported cross-language priming in Korean and English dative sentences, the relative clause attachment representations from Dussias and colleagues’ studies might be fundamentally different from SOV vs. SVO representation from our studies. That is, relative clause attachments are represented mostly covertly, such that sentences with different relative clause attachments are still indistinguishable on the surface (e.g., for both the interpretation of the servant or the actress who is on the balcony, the sentence is the same i.e., someone shot the servant of the actress [who was on the balcony]). In contrast, Korean- vs. English-canonical constructions differ from the surface (e.g., dog-NOM cat-ACC chase vs. the dog chases the cat). Perhaps an influence of L2 information on L1 structural representation is subtle and only can arise in sentence structures such as relative clause attachments. Future research should test more different sentence structures and diverse language pairs to investigate the L2 influence on L1 representation.
In sum, we did not find evidence that native Korean speakers’ L1 structural processing and production fully resemble their L2 English after English immersion. Instead, we suggest that L2 immersion is associated with increased selection and retrieval difficulties of word orders while using L1. These difficulties may be influenced by various factors, including L1 attrition, the extent of typological similarity between L1 and L2, and immersion, but further research is needed to gain a more comprehensive understanding of the complex interplay between memory and language acquisition.
Acknowledgments
This research was supported by grants from the National Science Foundation (BCS 1923065), National Institute on Deafness and Other Communication Disorders (NIDCD 011492), and the National Institute of Child Health and Human Development (HD051030, HD079426). Part of the results were presented at the 58th Annual Meeting of the Psychonomic Society, Vancouver, Canada, and 1st California Meeting of Psycholinguistics, Los Angeles, CA. We thank Wonsun (Jessie) Park, Heeju (Joy) Ryu, and Heesun (Jenny) Jung for assistance with data collection and data coding, and Hyeree Choo and Koh Eyetacking lab at Seoul National University for participant recruitment and providing laboratory space for Korean-immersed speakers in Experiments 2 and 3.








 Open access
Open access