



1. Introduction
Arabic is one of the most widely spoken languages in the world (Eberhard, Simons, and Fennig Reference Eberhard, Simons and Fennig2020). It has specific characteristics that complicate the production of digital resources. In fact, its rich morphology associated with the semi-free order of words and the omission of diacritics (vowels) in most written Arabic texts make difficult its automatic processing. Today, Arabic morphological analysis has an effective set of programs and resources that provide reliable results. At the syntax level, different approaches (corpus-based or rule-based) have been realized. But to date, there is no large coverage grammar of Arabic, unlike other languages such as English and French. Resources are even rarer and underdeveloped for semantics. Thus, it is motivating to develop a grammar that reflects both the syntactic and the semantic phenomena in Arabic.
In this context, we set ourselves the goal of building a grammar with a semantic dimension for modern standard Arabic (MSA). This resource should be used for syntax-semantic analysis and other different NLP applications. We chose the formalism of tree-adjoining grammar (TAG) (Joshi, Levy, and Takahashi Reference Joshi, Levy and Takahashi1975) which has a rich expressivity. Moreover, this formalism allows the integration of semantic information straightforwardly.
The specificity of Arabic and the difficulty of designing a grammar in terms of cost time motivated us to use an extremely expressive description language such as so-called meta-grammatical languages. We have produced the grammar semi-automatically using the meta-grammatical formalism XMG (eXtensible MetaGrammar) (Crabbé et al. Reference Crabbé, Duchier, Gardent, Roux and Parmentier2013). From a compact description of the syntax (ArabicXMG meta-grammatical description), we generated ArabTAG V2.0 (XML file). Then, we extended this grammar by integrating semantic information using a very adapted format to the task of semantic composition, namely the semantic frames (Fillmore Reference Fillmore1982). The use of a meta-grammar allows us to further extend the generated grammar and also to consider extending our approach to other languages.
This paper is organized as follows. In Section 2, we focus on morphosyntactic specificities of Arabic language. In Section 3, we outline some relevant works related to the development of linguistic resources for processing Arabic. Section 4 explains the methodology we have adopted. We present the grammatical and the semantic formalism as well as the grammar construction approach that we used to define our own grammar. In Section 5, we introduce our approach by describing the syntax of Arabic using a meta-grammar. We also present a survey of different linguistic phenomena covered by the generated grammar as well as a testing environment, including a corpus of phenomena that was designed to facilitate our grammar development. It is followed by the semantic information integration process. Finally, in Section 6, we discuss the experiments we made and the obtained results of the evaluation of our grammar and the syntax-semantic analysis.
2. Impact of morphosyntactic properties on Arabic parsing
Morphology and syntax in Arabic are closely related because morphology can express syntactic relationships. For example, the subject of a verb has a nominative case, and the adjectival modifier of nouns must have the same case as the name they modify. In this section, we focus on the morphosyntactic characteristics that make parsing difficult to implement.
2.1 Vowellation
The majority of Arabic documents are non-voweled. Therefore, the absence of the vowels can generate many ambiguous cases during the analysis of a text. In this case, only the context will help to understand the meaning of a sentence. For example, the non-voweled form ![]() (write) can accept the following vowellations:
(write) can accept the following vowellations: ![]() (kataba/ he wrote);
(kataba/ he wrote); ![]() (katb/ writing) or
(katb/ writing) or ![]() (kutubun/ books).
(kutubun/ books).
2.2 Grammatical ambiguity
Words in Arabic are grammatically ambiguous. The grammatical ambiguity rate of lexical forms increases without vowel signs. According to Debili, Achour, and Souissi (Reference Debili, Achour and Souissi2002), the grammatical ambiguity rateFootnote a for a vocalized Arabic form is 5.63. It increases by the absence of vowels to reach the average of 8.71. For example, without vowels, the word ![]() (to write) can refer to the verb (to write) conjugated in the 3rd person singular
(to write) can refer to the verb (to write) conjugated in the 3rd person singular ![]() (kataba/ he wrote) or the noun
(kataba/ he wrote) or the noun ![]() (kutubun/ books).
(kutubun/ books).
2.3 Agglutination
The phenomenon of agglutination consists in joining proclitics (particles and/or articles) and/or enclitics (pronouns) to simple forms of words, which gives rise to more complex forms called agglutinated forms. The morphological analysis is confronted with the problem of ambiguity since a lexical form can have several possible segmentations. Moreover, it is difficult to distinguish between proclitic/enclitic and a character in a word. For example, the character ![]() is part of the word
is part of the word ![]() (wacada/to promise) but it’s a proclitic (and) in the word
(wacada/to promise) but it’s a proclitic (and) in the word ![]() (wa kataba/ and he wrote).
(wa kataba/ and he wrote).
2.4 Free word order
Order of words in Arabic is relatively free. Thus, we can change the order of words in a verbal sentence composed of Verb (V), Subject (S), and Object (O). However, the most used order in standard Arabic is VSO. Also, changing the order of the components of the sentence can also change its type to become a nominal sentence. In fact, nominal sentences begin with a noun or a pronoun, while verbal sentences begin with a verb.
Let us consider the following sentence with standard order VSO:
-
(1)

-
Wulida al-bāḥithu fī tūnis
-
Tunisia in the-researcher was-born
-
“The researcher was born in Tunisia.”
We can change the order of words to have the two combinations, SVO (2) and OVS (3) with the same meaning:
-
(2)
-
Al-bāḥithu wulida fī tūnis
-
Tunisia in was-born the-researcher
-
“The researcher was born in Tunisia.”
-
(3)
-
Fī tūnis wulida al-bāḥithu
-
the-researcher was-born Tunisia in
-
“The researcher was born in Tunisia.”
The semi-free order does not concern only the basic components of the sentence, but also its complements (circumstantial of time, of place, complements of manner, etc). As a result, it will be necessary to provide, within a grammar, all the rules of possible combinations and inversion of words in the sentence.
2.5 Embedded structures
Embedded structures, commonly known as relative and subordinate clauses, are very common in Arabic. This kind of structures can be illustrated by the following example:
-
(4)
-
Al-mudīru huwa alladhī salaama al-jāizata liltilmīdhi
-
to-the-student the-prize awarded who is the-director
-
“It is the director [who awarded the prize] to the student.”
-
(5)
-
Al-mudīru huwa alladhī salaama al-jāizata liltilmīdhi alladhī ḥaqqaqa al-nnajāḥ
-
success has-achieved who to-the-student the-prize awarded who is the-director
-
“The director awarded the prize to the student [who passed].”
Furthermore, there are no commas or other punctuation as markers of embedded clauses and even segmentation into micro-sentences are not allowed in this case.
3. Related work
There have been several generations of grammars in the NLP field, including unification grammars that was developed in the late seventies with the purpose of correcting some formal limitations of transformational grammar and its implementation deficiencies. Unification grammar is based on feature structures and highlights the interfacing of syntax with lexicon and semantics. Thus, different formalisms and grammatical models have been established to represent syntactic and semantic data. Each formalism has its own characteristics, its strengths but also its weaknesses.
Four formalisms of unification grammars with large coverage retained our attention: the Tree-adjoining Grammar (TAG) (Joshi et al. Reference Joshi, Levy and Takahashi1975) and its extensions (Schabes and Joshi Reference Schabes and Joshi1990), the Lexical Functional Grammar (LFG) (Bresnan and Kaplan Reference Bresnan and Kaplan1982), the Generalized Phrase Structure Grammar (GPSG) (Gerald et al. Reference Gerald, Ewan, Geoffrey and Ivan1985) and the Head-driven Phrase Structure Grammar (HPSG) (Pollard and Sag Reference Pollard and Sag1994). Sentence in LFG grammar is described by means of two distinct levels: the representation of grammatical functions (f-structure) and the structure of syntactic constituents (c-structure). As for GPSG grammar, syntactic constituents are recognized using enriched and more complex syntagmatic rules than simple rewriting rules. HPSG is a direct extension of GPSG; nevertheless, it incorporates innovations from other theories, including LFG grammar and categorial grammars (CG). It uses the notion of signFootnote b in order to organize lexical or syntagmatic categories in a modular way.
TAG grammar, with which we are concerned here, constitutes a tree generating system. This formalism has been extended to several extensions; among them, we can cite the Lexicalized Tree Adjoining Grammar (LTAG) (Schabes and Joshi Reference Schabes and Joshi1990) which considers the specificities of each word in the lexicon by associating it with a tree. Each tree represents the use of a word in the different sentences of the language. LTAG is made of thousands of trees which leads to significant structural redundancy. Moreover, the process of its development as well as its maintenance are very difficult to achieve since its size continues to increase considerably. For instance, the development of the first large coverage TAG for French took more than 10 person-years (Abeillé Reference Abeillé1993). Therefore, many efforts have been deployed to produce such grammar semi-automatically by using description languages to capture generalizations among grammar rules. This compact description of grammatical information is called meta-grammar. There have been several seminal works of designing and implementing description languages for grammar specification such as DATR (Evans and Gazdar Reference Evans and Gazdar1996), Metagrammar compiler (Candito Reference Candito1996), LexOrg (Xia Reference Xia2001), MGCompiler (Gaiffe et al. Reference Gaiffe, Crabbé and Roussanaly2002), DyALog (Villemonte De la Clergerie Reference Villemonte De la Clergerie2005), or more recently XMG (Crabbé et al. Reference Crabbé, Duchier, Gardent, Roux and Parmentier2013). These languages differ among others, in the way variables are handled (local versus global scopes) and how structure sharing is represented (inheritance versus transformations).
XMG (eXtensible MetaGrammar) is a formalism based on the combination of tree fragments. With recent advances in its implementation, it was extended to XMG2 (Petitjean Reference Petitjean2014). The latter can be seen as a meta-interpreter which takes as an input a compiler specification and produces as an output a compiler for a description language. It is used by linguists to describe grammatical resources. This grammar production technique has been used to develop several electronic grammars for French (Crabbé Reference Crabbé2005; Gardent Reference Gardent2008), English (Alahverdzhieva Reference Alahverdzhieva2008), and German (Kallmeyer et al. Reference Kallmeyer, Lichte, Maier, Parmentier and Dellert2008).
For Arabic, such meta-grammar has never been used. Nonetheless, several methods of Arabic parsing have adopted rule-based approach and used well-defined formal grammars to represent Arabic syntax. Among them, the parser MASPAR (Belguith, Aloulou, and Hamadou Reference Belguith, Aloulou and Hamadou2007), the PHARAS platform (Loukam and Laskri Reference Loukam and Laskri2008), and the parser of Haddar, Zalila, and Boukedi (Reference Haddar, Zalila and Boukedi2009) who propose a syntactic analysis based on the HPSG formalism. Haddar, Boukedi, and Zalila (Reference Haddar, Boukedi and Zalila2010) and Boukedi and Haddar (Reference Boukedi and Haddar2014) constructed manually their HPSG. Others, such as Attia (Reference Attia2008), have developed manually a LFG grammar to analyze Arabic. As for Al-Bataineh and Bataineh (Reference Al-Bataineh and Bataineh2009) and Al-Taani, Msallam, and Wedian (Reference Al-Taani, Msallam and Wedian2012), they used a context-free grammar (CFG) and Othman, Shaalan, and Rafea (Reference Othman, Shaalan and Rafea2003) a unification-based grammar (UBG). Most recently, Hammouda and Haddar (Reference Hammouda and Haddar2017) have established a method for parsing noun sentences based on a set of lexical and syntactic rules. The proposed parser integrates a process of disambiguation and automatically annotates Arabic corpora.
To our knowledge, there are only two TAG-based descriptions of Arabic. The first grammar is based on a corpus. In fact, Habash and Rambow (Reference Habash and Rambow2004) constructed a TAG for Arabic by extracting elementary trees from Part 1 of PATB Version 2.0 (Maamouri et al. Reference Maamouri, Bies, Jin and Buckwalter2003). This extraction involves a reinterpretation of the corpus into dependency structures. However, the obtained structures are limited to those included in the used corpus. This is the main problem of corpus-based approaches, as they remain limited to the information defined in corpora. The second grammar is a semi-lexicalized Tree-Adjoining Grammar called ArabTAG (Ben Fraj Reference Ben Fraj2010). We particularly studied this grammar which was built also manually. It includes a set of elementary trees representing the basic syntactic structures of Arabic. The construction of these structures was based on school grammar books and books of Arabic grammar such as Kouloughli (Reference Kouloughli1992). More precisely, ArabTAG contains two sets of elementary trees: 24 lexicalized trees (i.e., having at least one lexical item as a leaf node) which are reserved to prepositions, modifiers, conjunctions, demonstratives, etc and 241 patterns trees represent verbs, nouns, adjectives, and any kind of simple phrases (active, passive, interrogative). The elementary trees are enriched by different information organized in feature structures. However, this grammar has some limitations. First of all, enriched syntactic structures with supplements such as circumstantial complements of time, place are not described. Moreover, agglutinated forms are not well represented. These forms should be extended to improve the coverage of this grammar. Furthermore, ArabTAG consists of a flat set of elementary trees without any structure sharing. It is not organized in a hierarchical way, which does not facilitate its extension and maintenance.
All of these grammars deal only with the syntax of Arabic and do not include the semantic dimension. Indeed, approaches dealing with semantic of Arabic are rare. For example, Haddad and Yaseen (2005) proposed a semantic construction model of Arabic sentences. Their approach is based on the use of
 $\lambda$
-calculus. It considers the structured syntactical categories of the sentence as a guideline for constructing semantic representations in the form of logical formulas. In this context, applying semi-automatic grammar production techniques should be useful and even indispensable to build a wide-coverage formal grammar of the Arabic language that integrates semantic dimension.
$\lambda$
-calculus. It considers the structured syntactical categories of the sentence as a guideline for constructing semantic representations in the form of logical formulas. In this context, applying semi-automatic grammar production techniques should be useful and even indispensable to build a wide-coverage formal grammar of the Arabic language that integrates semantic dimension.
4. Methodology
Our aim is to build an electronic grammar describing the syntax and semantics of Arabic. The construction of such grammar can be achieved in different ways. We have studied various grammar construction approaches in order to define our own method of construction. In this section, we introduce the formalisms that we used to build our grammar.
4.1. Presentation of TAG formalism
Tree Adjoining Grammar (TAG) (Joshi Reference Joshi1987) is a syntactic formalism which handles the links between the constituents of the sentence to build grammatical representations. It consists of a set of elementary trees divided in initial treesFootnote c and auxiliary trees.Footnote d Derived trees are generated as a result of the application of substitutionFootnote e and adjunctionFootnote f operations.
TAG integrates feature structures and the notion of unification which leads to the emergence of the Unified-Based Tree Adjoining Grammar (UTAG) (Vijay-Shanker and Joshi Reference Vijay-Shanker and Joshi1991). Each node of an elementary tree is associated to two feature structures “top” and “bottom” on which constraints can be defined. They are used during the unification of the structures following a substitution operation or an adjunction operation. Unification between two feature structures produces a resulting feature structure unless these two structures carry incompatible information. In the latter case, the unification fails. TAG is distinguished by its rich power of representation (e.g., simple, complex, combined, and shared structures) and its strong generative power, which includes long-distance and cross-dependencies (Lecomte Reference Lecomte2004). This type of grammar has enough constraints to avoid the problems of undecidability and treatment complexity. Thus, it permits parsing in polynomial time proportional to the length of the input sentence.
We have therefore chosen TAG to represent Arabic. We cannot assert that this formalism is undoubtedly the best to represent Arabic. Nevertheless, its characteristics make it possible to represent specific phenomena in Arabic such as embedded structures and some types of crossed dependencies. In addition, it allows interfacing between the syntactic and the semantic level.
4.2. Presentation of semantic frames
Fillmore (Reference Fillmore1982) defines frames as cognitive structures representing any relational system of concepts in which the understanding of the concept requires the comprehension of the full system. A frame can be defined by a data structure representing a concept. The name of this concept is associated with a set of elements describing its situational roles (attributes) or relational roles (semantic roles). There are various semantic roles in the language (e.g. actor, agent, source, destination).
Unlike flat (i.e., non-recursive) semantics representations (Bos Reference Bos1995), semantic frames provide a hierarchically structured representation. Figure 1 illustrates an example of a semantic representation of the phrase “Sam travels from Paris to Orleans.” The verb “to travel” has three arguments which will be assigned their roles. These roles are as follows: Traveler (the traveler), Source (the starting point), and Goal (the arrival). The last two roles form the path. Correspondence between the syntactic arguments of the sentence and the semantic roles of the frame is done as follows: The Traveler is Sam. The direction is described through the path. The latter is also represented by semantic frames specifying that the source (the city of departure) is “Paris” towards the final destination (goal) the city “Orleans.”

Figure 1. Semantic frame of the sentence “Sam travels from Paris to Orleans.”
Semantic frames offer a rich and structured semantic representation. However, with this formalism, it is difficult to integrate logical operators such as quantifiers. Frames are more appropriate to capture structured lexical meaning and subtle meaning differences. They ensure the diversity of combinations of the frames elements. In addition, they deal with more complex scenarios such as relations between distinct events that occur in the same domain. Finally, this semantic formalism allows linking lexical entries with conceptual representations.
Using frames to represent semantics is coherent with the Montague theory. Moreover, we can benefit from existing lexical resources such as ArabicVerbNet (Mousser Reference Mousser2010, Reference Mousser2011), the Arabic version of VerbNet (Kipper et al. Reference Kipper, Korhonen, Ryant and Palmer2008), to extract the needed information to define semantic frames.
4.3. Choice of the grammar construction method
The construction of a grammar can be addressed in two ways: the automatic extraction from a corpus or the manual construction. The manual method offers more coverage control than the second one. In fact, automatic extraction generates a grammar that is limited to the coverage of the corpus. However, manual construction is very expensive in terms of implementation, time, and maintenance. Moreover, it is difficult to have a grammar that covers all syntactic structures of a language. Consequently, we opted for an intermediate solution: using a meta-grammar to generate semi-automatically a grammar.
Meta-grammatical approaches were introduced by Marie Candito in late nineties (Candito Reference Candito1996). She proposed a new process for generating semi-automatically a TAG from a reduced description which offers a high level of abstraction in descriptions of grammatical structures. It captures the linguistic generalizations appearing among grammar trees and offers a detailed decomposition of syntactic building blocks called elementary fragments. These fragments, described as classes, are combined and structured within an inheritance hierarchy based on linguistic motivations. This reduced description is called a meta-grammar. A meta-grammar provides an excellent way for sharing information to avoid redundancy and inconsistencies between rules by providing a generalization of the information contained in these rules.
Generating a grammar using a meta-grammar requires a meta-grammatical compiler. Several approaches have been based on the use of meta-grammatical descriptions: Gaiffe et al. (Reference Gaiffe, Crabbé and Roussanaly2002), Xia (Reference Xia2001), Thomasset and De La Clergerie (Reference Thomasset and De La Clergerie2005), Crabbé et al. (Reference Crabbé, Duchier, Gardent, Roux and Parmentier2013).
Here, we propose to use the XMG description language (Crabbé et al. Reference Crabbé, Duchier, Gardent, Roux and Parmentier2013) to describe Arabic. This language is particularly adapted to the description of tree grammars. It makes possible to define highly factorized grammar descriptions. This can be used to deal with semi-free word order in Arabic. Moreover, XMG can be configured to describe various levels of language, such as semantics or morphology.
5. Proposition: A Grammar with a semantic dimension
As mentioned above, we are interested in developing a formal grammar to use in various applications of Arabic language processing. Unlike other grammars, which mainly deal with syntax and are, in most cases, built manually, we propose a meta-grammatical description. It allows a syntactically and semantically rich representation of this language.
Within this meta-grammar, a correspondence between the syntactic structures of a sentence and its semantic representations is performed. Link between semantic and syntax is established using a syntax-semantic interface which supervises the construction of the meaning of the sentence by unifying the semantic information of its constituents.
We can cite several examples of syntax-semantic interface, within a TAG for English, that used various semantic representations. These latter can be a formula in predicate logic such as the work of Joshi and Vijay-Shanker (Reference Joshi and Vijay-Shanker2001), an underspecified logic using labels holes and range constraints (Kallmeyer and Joshi Reference Kallmeyer and Joshi2003), a glue part (Frank and Van Genabith Reference Frank and Van Genabith2001), or a flat semantic (Kallmeyer and Romero Reference Kallmeyer and Romero2008). More recently, Kallmeyer and Osswald (Reference Kallmeyer and Osswald2013) introduced semantic representation based on semantic frames. To our knowledge, such work has not been conducted in Arabic.
5.1. Describing the syntax of Arabic using a meta-grammar
The new version of ArabTAG, called ArabTAG V2.0, is generated semi-automatically using XMG. First, we defined our meta-grammar manually by specifying the linguistic phenomena of Arabic. Then, this meta-grammatical descriptionFootnote g was compiled automatically (with the XMG compiler) into tree-adjoining grammar giving rise to ArabTAG V2.0 (XML format).
5.1.1 Fragment hierarchies
In XMG, elementary trees are made of common reusable tree fragments, which can be combined conjunctivelyFootnote h and/or disjunctively.Footnote i Each of these fragments are specified and encapsulated within classes (also called abstractions). These latter are defined by means of dominance and precedence constraints (Rogers and Vijay-Shanker Reference Rogers and Vijay-Shanker1994) which have the function of ensuring that the solutions generated are well-formed trees. Furthermore, XMG allows inheritance between classes. Thus, unlike its first version, ArabTAG V2.0 (Ben Khelil et al. Reference Ben Khelil, Duchier, Parmentier, Ben Othmane Zribi and Ben Fraj2016) is organized into hierarchically factorized structures. In fact, the first version consists of a set of elementary trees that are not interconnected. We have thus prioritized the hierarchical organization because it facilitates the extension of the grammar. Indeed, it is important to structure the grammar by involving various phenomena such as the inheritance structures or the hierarchy of tree patterns.
Verbal sentences . We described the syntax of verbal predicates in Arabic in a concise and modular way. We used the transitivity of the verb as a fundamental criterion to create a hierarchical organization between tree fragments. Then, we have combined these fragments together in order to obtain the three basic verb families (intransitive, transitive, and ditransitive). This organization is shown in Figure 2.

Figure 2. Organization of the meta-grammatical description of verbal sentences.
The starting point of this organization is the abstraction “VerbalSpine.” It contributes to a fragment of a tree for the verbal spine. VerbalSpine is instantiated into two classes: The “MorphActive” class for the active form of the verbs and the “MorphPassive” class for the passive form.
We also represented two other forms of verbs with clitics. The first one describes verbs preceded by a verbal proclitic. As for the second one, it represents a verb attached with enclitic (for example an anaphor representing the object of the verb).
We introduced “ArgSpine” in order to attach the verbal spine to the tree descriptions of its arguments (the subject and the object(s)). A subject can be in elliptical, canonical, or relative form. Each of these forms is represented by a specific class.
Likewise, an object can be realized in different forms: noun phrase, prepositional phrase, verbal phrase, subordinate phrase (relative object), or an enclitic. Each of these variants is represented by a specific class.
We combined these fragments to obtain the three families of verbs (intransitive, transitive, ditransitive). Each of these classes captures the possible syntactic realizations between the different structures of the sentence. They are organized as follows: Morphactive class defines the elementary tree fragment that constitutes the verbal spine of the sentence. The Intransitive family is obtained as a result of a conjunction between Morphactive and the subject’s classes. The Transitive family is obtained by combining the Intransitive class and the Object class.
The latter represents a disjunction between the direct object (in canonical, relative, or clitic form) and the indirect object. Finally, we get the DiTransitive family by combining Transitive and the second object.
Nominal sentences . Tree fragments specific to nominal sentences are defined in the second part of our meta-grammatical description. The organization of these fragments is illustrated by Figure 3.

Figure 3. Organization of the meta-grammatical description of nominal sentences.
In the same way as the verbal sentence, we defined the abstraction NominalSpine (parameterized by a color) that contributes to a tree fragment for the subject of nominal sentence. However, the subject is instantiated by two different classes SubjectSpine and SubjectVSpine. Indeed, we chose to distinguish these two classes in order to allow the representation of modified noun sentences (sentences that begin with a verb of existence or a verb of certainty).
“Subject” groups the set of possible realizations of themes for simple and modified nominal sentences. As a result, this class is parameterized by a variable of the case thus making it possible to define the nominative or accusative subject as well as its corresponding verbal spine.
“Predicate” has three parameters: the case of the subject, the case of the predicate, and the spine of the verb. This class includes all the possible realizations of the predicateFootnote j: adjective, noun phrase, etc.
Therefore, the family of nominal sentences corresponds to the combination of the verbal spine SubjectSpine, the nominative predicate and the nominative subject. While the modified nominal sentences are distinguished into two families: (1) family of nominal sentences modified by a verb of existence. The theme spine of the modified sentence is combined with “Subject” (nominative) and “Predicate” (accusative). As for (2), the family of nominal sentences modified by a “certainty” verb is defined by the conjunction of the subject spine of the modified sentences, “Subject” (accusative) and “Predicate” (nominative).
Phrases
. Our meta-grammar defines different types of Arabic phrases, namely noun phrases
 $\big($
$\big($
![]() / al-murakabāt al-ismiyah
/ al-murakabāt al-ismiyah
 $\big)$
, prepositional phrases
$\big)$
, prepositional phrases
 $\big($
$\big($
![]() /al-murakabāt al-ḥarfīyah
/al-murakabāt al-ḥarfīyah
 $\big)$
, and subordinate phrases
$\big)$
, and subordinate phrases
 $\big($
$\big($
![]() / al-murakabāt al-maūṣūliyah
/ al-murakabāt al-maūṣūliyah
 $\big)$
. Each category of these phrases is described by at least one elementary fragment.
$\big)$
. Each category of these phrases is described by at least one elementary fragment.
5.1.2 Syntactic phenomena addressed by ArabTAG V2.0
In this section, we focus on linguistic phenomena specific to Arabic language which are represented in ArabTAG V2.0 (Ben Khelil et al. Reference Ben Khelil, Ben Othmane Zribi, Duchier and Parmentier2018). We cite the variation of the position of the syntactic components of the sentence, the optional complements, the agreement rules, the agglutinated forms, and the complex structures such as embedded structures.
Free word order . TAG is suitable to analyze natural language free word order such as Arabic. Through to its adjunction and/or substitution operations, we can combine tree structures without taking into consideration the order of combinations. Indeed, these two operations can be performed in a free order and consequently form sentences with multiple syntactic structures.
Moreover, by using XMG, we were able to represent this phenomenon within our meta-grammatical description. To ensure this, we avoided imposing priority constraints between nodes whose order change does not affect the consistency of the sentence. The generated combinations, following the conjunctions and/or disjunction of the defined tree fragments, will cover all the tree structures corresponding to all the possible positions of the nodes without precedence constraint.

Figure 4. Tree fragments for adverbs management.
By these changes, our grammar provided the tree models. However, when checking these models, we found a problem of over-generating verbal sentences with two objects (ditransitive verbs). In order to prevent the redundancy of models and respect the order of precedence, we defined and integrated two new principles in XMG: “precedes” and “requires.” The first principle “precedes” controls the order of precedence between two nodes X and Y. While “requires” imposes the presence of a node X so that the node Y exists. Combinations of elementary fragments were more controlled with these two principles. The obtained tree models at the end of the compilation are those that fulfill both conditions, that is: the first object (object 1) always precedes the second one (object 2) and the latter (object 2) exists only if the first object (object 1) already present in the sentence.
Adjunction of adverbs and optional complements . Adjunction in TAG allows the insertion of a complete structure at an inner node of another complete structure. It is a very natural way of managing adverbs in natural language. In Arabic, adverbs and optional complement (circumstantial of time, circumstantial of place, cause, etc) can be freely placed between the constituents of the sentence.
We decided to provide, within our meta-grammatical description, two appropriate adjunction points for these complements: ADVG (left adverb) and ADVD (right adverb). The ADVG node of the model (C) of Figure 4 is an adjunction point allowing an adverb (conforming to model (A)) or an optional complement at the front of the clause, while ADVD (model (B) of Figure 4) allows the insertion of an adverb or an optional complement after a verb or an argument.
For example, we can add the adverb ![]() (kathīrān/ a lot) in the sentence (6)
(kathīrān/ a lot) in the sentence (6)
-
(6)
-
Yanāmu
-
Ali sleeps
-
“Ali sleeps”.
before the subject:
-
(7)
-
Yanāmu kathīrān
-
Ali a-lot sleeps
-
“Ali sleeps a lot”.
or after the subject:
-
(8)
-
Yanāmu
kathīrān -
a-lot Ali sleeps
-
“Ali sleeps a lot.”
Insertion is performed at the adjunction node of the right adverb ADVD. In the same way, this adverb can be placed at the beginning of the sentence.
Through the adjunction node of the left adverb ADVG, ![]() (kathīrān/ a lot) is inserted before the verb
(kathīrān/ a lot) is inserted before the verb ![]() (Yanāmu/ sleep). Thus, we obtain the sentence (9).
(Yanāmu/ sleep). Thus, we obtain the sentence (9).
-
(9)
-
Kathīrān yanāmu
-
Ali sleeps a-lot
-
“Ali sleeps a lot”.
The syntactic trees of ArabTAG V2.0 corresponding to these three sentences are illustrated in Figure 5.Footnote k

Figure 5. Inserting the adverb ![]() (kathīrān/ a lot) in the sentence
(kathīrān/ a lot) in the sentence ![]() (yanāmu
(yanāmu ![]() / Ali sleeps).
/ Ali sleeps).
Representation of agglutinated forms . TAG allows to manage the agglutination phenomenon thanks to its power of control. Indeed, the defined features within elementary trees can contain morphological and syntactic information. These features make it possible to assist the parsing process and remove ambiguities that may arise.
Figure 6 illustrates the agglutinated form of the sentence (10). We can define in one feature structure that the proclitic ![]() (sa/ will) is a particle of the future (Specified by the feature cat: proc_v). This kind of particles can only be attached to a verb in the indicative mode, which is indeed the case of the word
(sa/ will) is a particle of the future (Specified by the feature cat: proc_v). This kind of particles can only be attached to a verb in the indicative mode, which is indeed the case of the word ![]() (yaktubu/ he writes). The latter represents the indicative mode of the verb
(yaktubu/ he writes). The latter represents the indicative mode of the verb ![]() (ktb/ to write). Finally, the enclitic attached to the end of the verb
(ktb/ to write). Finally, the enclitic attached to the end of the verb ![]() (hu/it) represents the object of the verb (Specified by the feature fg: objet) whose case is accusative (Specified by the feature cas: acc).
(hu/it) represents the object of the verb (Specified by the feature fg: objet) whose case is accusative (Specified by the feature cas: acc).
-
(10)
-
sayaktubuhu
-
it-write-will
-
“he will write it”.

Figure 6. Derived tree of the sentence ![]() (sayaktubuhu/ he will write it).
(sayaktubuhu/ he will write it).
Subject Omission . ArabTAG V2.0 covers sentences with an elliptical subject and proposes the corresponding models to represent them. Figure 7 illustrates two sentences with different structures, but the same meaning: “he sleeps.”

Figure 7. Derived trees of ![]() (yanāmu/ sleeps)/
(yanāmu/ sleeps)/![]() (huwa yanāmu/ he sleeps).
(huwa yanāmu/ he sleeps).
The model (A) represents the derived tree of the sentence ![]() (yanāmu) composed of a verb and an elliptical subject, whereas, the model (B) represents the derived tree of the sentence
(yanāmu) composed of a verb and an elliptical subject, whereas, the model (B) represents the derived tree of the sentence ![]() (huwa yanāmu) composed of a pronoun
(huwa yanāmu) composed of a pronoun ![]() (huwa/ he) and a verb
(huwa/ he) and a verb ![]() (yanāmu/ sleeps).
(yanāmu/ sleeps).
Embedded structures . The representation of embedded structures is one of TAG’s strengths. It is possible thanks to the adjunction operation which allows to insert a complete structure into another structure. Let us consider the sentence (11) illustrated by Figure 8.
-
(11)
-
al-tilmīdhu tasalama al-jāizata
-
the-prize received the-student
-
“The student received the prize.”

Figure 8. Example of handling embedded structures with TAG.
We can insert a subordinate phrase (13) between the subject ![]() (al-tilmīdhu/ the student) and his verb
(al-tilmīdhu/ the student) and his verb ![]() (tasalama/ received).
(tasalama/ received).
-
(12)
-
alladhī ḥaqqaqa al-nnajāḥ
-
success achieved who
-
“Who achieved success.”
The resulting sentence is:
-
(13)
-
al-tilmīdhu alladhī ḥaqqaqa al-nnajāḥ tasalama al-jāizata
-
the-prize received success achieved who the-student
-
“The student who achieved success received the prize.”
Crossed dependencies . TAG represents grammar rules (by elementary trees) of any depth, higher or equal to one.
Thus, it is possible to define an extended locality domain. This locality domain offers the possibility of describing local representation of syntactic dependencies. Thanks to the adjunction operation, we can represent some complex sentence structures such as sentences with cross dependencies.Footnote l This phenomenon occurs when dependency relationships between two sets of words cross each other.
Figure 9 illustrates the following example:
-
(14)
-
al-qalamu alladhī yaktubu bihi al-ṭālibu
-
the-student with-it writes that the-pen
-
“The pen that the student uses to write.”

Figure 9. Example of handling crossed dependencies with TAG.
The management of cross dependencies is achieved by performing two adjunction operations in the structure “VS.” The requirement that at the end of these operations, the features of all nodes in the derived tree are unified.
Agreement rules . ArabTAG V2.0 deals with agreement rules of Arabic: the adjective-noun agreement (in definiteness, gender, number, and case), the subject-verb agreement in verbal sentence, and the agreement between elements of nominal sentences. These rules are handled in the grammar through morphosyntactic features specific to the involved nodes. By using these features, we were able to define the appropriate constraints to ensure all the agreement rules in our meta-grammatical description.
For example (Figure 10), the subject-verb agreement is ensured as follows: We define the equations of agreement within subject trees. These equations link the feature between the verb node and its subject. When a verb precedes the subject, the verb is singular, but agrees with its subject in gender. This is represented in ArabTAG V2.0 as follows: The gender agreement is realized with the equality between the gender features of the node of the verb, and the node of the subject (?V_gen =?NP_gen) and the verb is always singular with the feature ?V_num = sg.

Figure 10. Agreement between the verb and the subject when the verb precedes the subject.
However, when the subject precedes the verb, the two distinguished cases are represented as follows (Figure 11):
(1) If the subject is non-human (?Hum = h_0) and plural (?NP_num = plr), the verb is in the feminine singular form with the following equations ?V_num = sg and ?V_gen = f. Otherwise, like in (2) and (3), the verb agrees in gender and number with these equations between features of the verb and its subject: ?V_gen =?NP_gen (for gender) and ?V_num = ?NP_num (for number).

Figure 11. Agreement between the verb and the subject when subject precedes the verb.
5.1.3 Distribution of tree models in ArabTAG V2.0
The current version of ArabTAG V2.0 consists of 1074 generated trees from a description made of 29 classes (29 tree fragments or combination rules). The distribution of these models, that is the number of trees corresponding to each family of trees, is shown in Figure 12.

Figure 12. Distribution of tree models in ArabTAG V2.0.
Thanks to a corpus of phenomena containing different types of Arabic sentences, we were able to verify that our grammar covers the structures already treated in the first version of ArabTAG, namely verbal sentences (active and passive form), noun sentences, subordinate phrases, prepositional phrases, and noun phrases. These latter have several categories: annexation phrase
 $\big($
$\big($
![]() / murakab idhāfī
/ murakab idhāfī
 $\big)$
, adjectival phrase
$\big)$
, adjectival phrase
 $\big($
$\big($
![]() / murakab nactī
/ murakab nactī
 $\big)$
, corroborative phrase
$\big)$
, corroborative phrase
 $\big($
$\big($
![]() / murakab tawkīdī
/ murakab tawkīdī
 $\big)$
, approbative phrase
$\big)$
, approbative phrase
 $\big($
$\big($
![]() / murakab badalī
/ murakab badalī
 $\big)$
, state phrase
$\big)$
, state phrase
 $\big($
$\big($
![]() / murakab biḥāli al-mufradat
/ murakab biḥāli al-mufradat
 $\big)$
, conjunctive phrase
$\big)$
, conjunctive phrase
 $\big($
$\big($
![]() / murakab al-caṭf
/ murakab al-caṭf
 $\big)$
, and the semi-propositional phrase
$\big)$
, and the semi-propositional phrase
 $\big($
$\big($
![]() / murakab shibh īsnādī
/ murakab shibh īsnādī
 $\big)$
. The coverage of the grammar has also been extended, compared to the first version by adding elementary trees for the representation of an elliptical subject as well as additional complements such as circumstantial complements of time, circumstantial complements of place and adverbs.
$\big)$
. The coverage of the grammar has also been extended, compared to the first version by adding elementary trees for the representation of an elliptical subject as well as additional complements such as circumstantial complements of time, circumstantial complements of place and adverbs.
Moreover, ArabTAG V2.0 deals with more complex forms of sentences and different phenomena of the Arabic language, such as the semi-free order of words, agglutinated forms, embedded structures, and crossed dependencies and agreement rules.
However, these results are insufficient to conclude on the grammar’s quality. The manually defined corpus of phenomena is limited, that’s why we evaluated our grammar using a larger corpus of real texts (ref. Section 6).
5.1.4 Grammar validation process
In order to verify the grammar coverage, we set up a development environment (as a python script) while designing ArabTAG V2.0 with XMG. Besides our grammar, we defined manually syntactic and morphological lexicons following the 3-layer architecture of the XTAG project (XTAG 2001). The XTAG system consists of three sub-modules:
-
A basis of tree schemas classified into families of elementary trees
-
A lemma basis where each lemma is associated at least to a family tree
-
A morphological basis in which each surface form is associated with a lemma and its appropriate morphosyntactic information.
The aim of this validation process (Figure 13) is to evaluate both under-generation and over-generation of the elementary trees of our grammar. The generated grammar must be able (1) to recognize valid sentences covering linguistic phenomena in Arabic (sentences in Arabic textbooks, newspapers, etc) and (2) to reject ungrammatical sentences. For this reason, we built a test corpus called: corpus of phenomena. It covers the most prominent and frequent syntactic phenomena in MSA.

Figure 13. Validation architecture of ArabTAG V2.0.
The corpus of phenomena is enriched manually with grammatical and ungrammatical sentences whenever we introduce new syntactic phenomena within the meta-grammar. Ungrammatical examples have been added to check if the grammar can return incorrect syntactic trees. Each sentence of this corpus is associated with the number of expected syntagmatic analyzes (0, 1, or more).
The corpus of phenomena contains 212 examples of sentences (150 grammatical sentences and 62 ungrammatical ones). It is composed with 134 verbal sentences, 45 noun sentences, 32 noun phrases, and one prepositional phrase. Table 1 summarizes the different phenomena covered by ArabTAG V2.0.
Table 1. Phenomena corpus

5.2. Integrating semantic dimension into the ArabTAG-XMG Meta-grammar
To produce TAG with semantic scope, we chose to extend the meta-grammar by associating semantic frames to the described families trees. For this, we were inspired by the “linking” theory (Levin Reference Levin1993; Kasper Reference Kasper2008). According to this theory, in most cases, the verb expresses the semantics of an event as well as the relation between its participants. For example, when the actor of the verb is present in a sentence, he is often the subject (with nominative case). This component can have the role of “AGENT.” Thus, the grammatical function can indicate the role to be attributed. In other words, we can consider that the verbal predicate helps to constitute a semantic frame by selecting the set of semantic roles of its participants.
However, we have not restricted our approach to the labeling of semantic roles. Indeed, our idea consists in using XMG2 to describe the different models of semantic frames (frames for predicates and elementary frames) compatible with the families of the syntactic tree in ArabTAG V2.0. The unification of these frames is controlled by a hierarchy of types and constraints that we have implemented within our meta-grammar. As for the semantic roles, they will be specified at the level of the predicate (which is the verb). The frame of the sentence is then built up as syntactic analysis progresses by unifying the elementary semantic frames of its syntactic components via a syntax-semantic interface.
The following steps (Figure 14) were followed to complete our approach:
-
At the syntactic level of the meta-grammar (SynArabTAG), we defined the arguments of the predicate (verb). We remind that each verbal tree is anchored by a verb and a node (of substitution) for each argument of the predicate.
-
At the semantic level (SemArabTAG), we defined the semantic frame models corresponding to each tree family defined in the syntactic level. The dimension <frame> is used to describe a semantic frame using typed feature structures.
-
Within SemArabTAG, we implemented a hierarchy of semantic roles as well as hierarchy of constraints on frame types.
-
We established the link between semantic frame elements and syntactic constituents with the syntax-semantic interface using the
$<$
iface
$>$
dimension. -
The compiler of XMG2 “synframe” generated the new version of ArabTAG V2.0 (from ArabTAG-XMG which combines the two meta-grammatical descriptions) with a corresponding file of the hierarchy of constraints implemented previously.



Figure 14. Semi-automatic generation of ArabTAG V2.0 with semantic dimension.
5.2.1 Type constraint hierarchy implemented in the meta-grammar
To build the hierarchy of constraints, we exploited the lexical resource “ArabicVerbNet” (Mousser Reference Mousser2010) It has 334 classes that contain 7672 verbs and 1393 frames. We reviewed all verb classes of ArabicVerbNet, and we gathered information about the described frames and the roles of their participants. For example, for a verb “to chase,” its semantic frame can have several lexical units such as “to pursue,” “to conduct,” “to run”. Its mandatory semantic roles are as follows: AGENT and THEME, and it can have the following descriptive roles: LOCATION, MODE, DURATION, etc. With this information, we created two hierarchies: the hierarchy of semantic roles and the hierarchy of frames types.
Hierarchy of semantic roles . The implemented hierarchy of semantic roles is illustrated by Figure 15. We were guided by the organization of the proposed roles within ArabicVerbNet. Verbs with similar syntax and semantic behavior are assigned to the same class group. A class group represents a hierarchy established by the semantic relations between its classes. This hierarchy is also inspired by VerbNet for English (Kipper et al. Reference Kipper, Korhonen, Ryant and Palmer2008).

Figure 15. Hierarchy of semantic roles implemented in SemArabTAG.
This hierarchy makes it easier to assign the general roles for participants of different types of events (such as an actor who is the instigator of the event), to specify them (such as AGENT and CAUSE) or to distinguish them. Also, this distinction permits to differentiate the verb classes. For example, the roles “CAUSE” and “AGENT” are two actors who initiate an event, but the first one does it without intention contrary to the second one.
Hierarchy of types of frames . A verb may impose a set of restrictions on its argument roles. For example, it can require that a role must be a human and/or animated, etc.
Let us consider the following two sentences with their semantic interpretations:
-
(15)
-
yuḥibu calīyun fāṭimah
-
Fatima Ali loves
-
“Ali loves Fatima.”
-
EXPERIENCER
/ calīyun/ Ali+ PATIENT / fāṭimah/ Fatima. -
(16)
-
yuḥibu al-kitābu fāṭimah
-
Fatima the-book loves
-
“The book loves Fatima.”
-
EXPERIENCER
/ al-kitābu/ the book+ PATIENT / fāṭimah/ Fatima.
The verb ![]() (āḥaba/ to love) is the predicate. Although both sentences are syntactically correct, the second one is semantically incorrect. The subject, who is the EXPERIENCER
(āḥaba/ to love) is the predicate. Although both sentences are syntactically correct, the second one is semantically incorrect. The subject, who is the EXPERIENCER ![]() (al-kitābu/ book), cannot express feelings towards a human. Therefore, it is important to use the constraints specified for semantic roles to filter out sentences that are semantically incorrect. After examining the verbal class of
(al-kitābu/ book), cannot express feelings towards a human. Therefore, it is important to use the constraints specified for semantic roles to filter out sentences that are semantically incorrect. After examining the verbal class of ![]() (āḥaba/ loving), we noticed that the restrictions imposed by this class on the “EXPERIENCER” are “animated” and “human.” We further exploited the ArabicVerbNet classes, and we established a second hierarchy (Figure 16) that relates to the basic types of semantic frames. These types can also be used to impose restrictions on semantic roles.
(āḥaba/ loving), we noticed that the restrictions imposed by this class on the “EXPERIENCER” are “animated” and “human.” We further exploited the ArabicVerbNet classes, and we established a second hierarchy (Figure 16) that relates to the basic types of semantic frames. These types can also be used to impose restrictions on semantic roles.

Figure 16. Hierarchy of frame types implemented in SemArabTAG.
During semantic analysis, this hierarchy will optimize the task of semantic role labeling and handle type constraints when unifying frames.
5.2.2 Meta-grammatical description of semantic frames
Kallmeyer and Osswald (Reference Kallmeyer and Osswald2013) formally define a semantic frame as base-labeled, typed feature structures. Elementary trees are paired with frames by using unification variables. Semantic roles and types are defined as attributes and values within frame description. We took another approach and defined different patterns of frames.
Using XMG2, we described within our meta-grammar (SemArabTAG) 27 semantic frames in typed feature structure format. These models of semantic frames are divided into two categories: the semantic frames of the predicate and the elementary frames. The lexicon of trees and frames are given separately, but paired during parsing. Semantic information (roles, types, and constraints) is provided by the lexicon. Thus, the syntactic tree(s) and semantic frames pair(s) are built during parsing according to information provided by the lexicon and the implemented hierarchy.
Semantic frame of the predicate . In accordance with the hierarchical modeling of the family trees of verbs (intransitive, transitive, and ditransitive), we have adopted a hierarchical organization between the descriptions of the semantic frames of the predicate (the verb). This organization is shown in Figure 17.

Figure 17. Hierarchy of semantic frames of the predicate in SemArabTAG.
We can specify the event type of the predicate with the variable
 $<$
FrameType
$<$
FrameType
 $>$
. The semantic roles corresponding to the participants of the event are defined by the FE attributes. The latter receives as value the variable
$>$
. The semantic roles corresponding to the participants of the event are defined by the FE attributes. The latter receives as value the variable
 $<$
FEType
$<$
FEType
 $>$
which designates the semantic role and its elementary frame
$>$
which designates the semantic role and its elementary frame
 $<$
sub-Frame
$<$
sub-Frame
 $>$
. This elementary frame must fulfill the possible restrictions on the type of the semantic role (
$>$
. This elementary frame must fulfill the possible restrictions on the type of the semantic role (
 $<$
constraint
$<$
constraint
 $>$
). Thus, an event expressed by a verbal predicate, for example
$>$
). Thus, an event expressed by a verbal predicate, for example ![]() (nāma/ to sleep), belonging to the family of intransitive verbs requires a single participant designated by the attribute FE1. This attribute will receive as value the frame representing the semantic role “AGENT” which must have as a participant an animated entity. In the same way, an event expressed by a verbal predicate belonging to a family of transitive verbs (respectively ditransitive) requires two participants designated by the attributes FE1 and FE2 (respectively three participants: FE1, FE2, and FE3). For example, the semantic frame of the transitive verb
(nāma/ to sleep), belonging to the family of intransitive verbs requires a single participant designated by the attribute FE1. This attribute will receive as value the frame representing the semantic role “AGENT” which must have as a participant an animated entity. In the same way, an event expressed by a verbal predicate belonging to a family of transitive verbs (respectively ditransitive) requires two participants designated by the attributes FE1 and FE2 (respectively three participants: FE1, FE2, and FE3). For example, the semantic frame of the transitive verb ![]() (āḥaba/ to love) is composed of two participants. The first corresponds to the semantic role “EXPERIENCER” (the one who feels the event and which must be a human) while the second corresponds to the role “PATIENT” (the one who undergoes the event). Finally, the semantic frame of the ditransitive verb
(āḥaba/ to love) is composed of two participants. The first corresponds to the semantic role “EXPERIENCER” (the one who feels the event and which must be a human) while the second corresponds to the role “PATIENT” (the one who undergoes the event). Finally, the semantic frame of the ditransitive verb ![]() (ācṭá/ to give) is described by three participants: the animated “AGENT” who initiates the event, the “THEME” which is the center of the event and finally the “DESTINATION” which designates the animated physical location to which the “THEME” is directed.
(ācṭá/ to give) is described by three participants: the animated “AGENT” who initiates the event, the “THEME” which is the center of the event and finally the “DESTINATION” which designates the animated physical location to which the “THEME” is directed.
Elementary frame . Within the meta-grammar, we described elementary frames corresponding to the frames of noun phrases. During the semantic analysis, these frames will be unifiedFootnote m with the frame of the predicate (and possibly with other elementary frames) to build the whole meaning of the sentence. For example, an elementary frame of a simple noun phrase is described in the FrameCommonName class. The described frame specifies the type of the phrase as well as the value of its lemma.
Figure 18 shows the syntactic tree of the noun phrase ![]() (al-shurṭīyu/ the policeman) and its corresponding elementary frame.
(al-shurṭīyu/ the policeman) and its corresponding elementary frame.

Figure 18. Example of an elementary frame for a noun phrase defined in SemArabTAG.
5.2.3 Construction of the syntax-semantic interface
The syntax-semantic interface corresponds to the definition of a matrix of features for each class using the
 $<$
iface
$<$
iface
 $>$
dimension. This matrix associates a global name (the feature) with a unification variable (the feature value) which syntactic feature is bound to where semantic feature.
$>$
dimension. This matrix associates a global name (the feature) with a unification variable (the feature value) which syntactic feature is bound to where semantic feature.
Figure 19 provides an example of the syntax-semantic interface between a syntactic structure of a verbal sentence and its corresponding semantic frame. The link between these two dimensions is ensured by the feature E (for the event of the predicate) arg0 (for the first argument) and arg1 (for the second argument). The last two features receive, in the semantic dimension, the values of the semantic roles corresponding to the arguments of the predicate. Let us consider the following sentence:
-
(17)
-
ṭārada al-shurṭīyu al-liṣa
-
the-thief the-policeman pursues
-
“The policeman pursues the thief.”
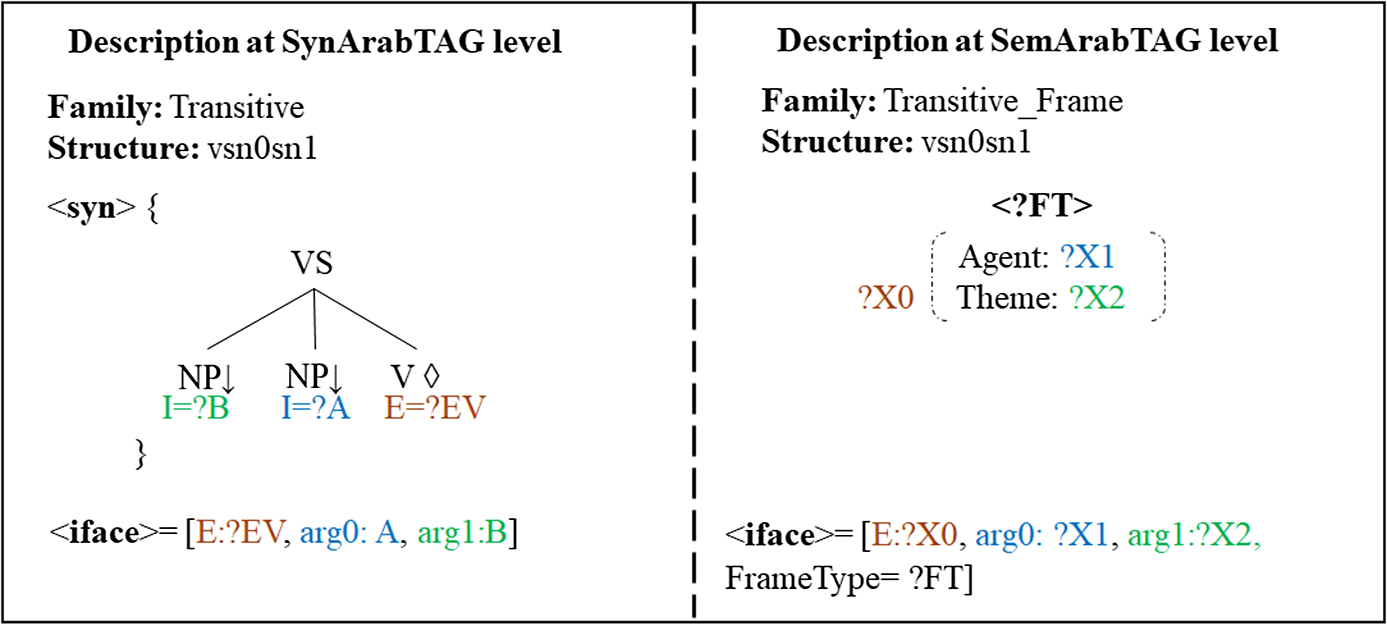
Figure 19. Description of the syntax-semantic interface within the meta-grammar.
Applying our approach, the process of constructing the meaning of this sentence is carried out as follows:
-
(1) At the lexical level, each element of the sentence is associated with its semantic frame and its syntactic tree family as follow: The elementary frames (Figure 20) are attributed to the phrases:
(al-shurṭīyu/ the policeman) and (al-liṣa/ the thief). At the level of the predicate frame, the semantic roles and their constraints are defined by matching the verb (ṭārada/ to pursue) and ArabicVerbNet classes. At the end of this correspondence, the two roles attributed to the predicate are AGENT and THEME. Each of these roles admits type constraints. The “AGENT” can be “human” or “animal,” and the “THEME” must be “animate”. Thus, the verb (ṭārada/ to pursue) is given two possible combinations of semantic frames illustrated by Figure 21. -
(2) The element “I” of Figure 22 represents the syntax-semantic interface. It allows sharing between the features of the nodes and the variables from the semantic frames.
-
(3) Substitution operations trigger the unification equations between these variables: [X1 = A] and [X2 = B] (Figure 23).
-
(4) During unification process, illustrated by Figure 24, the syntax-semantic parser has to deal with ambiguity in the semantic frames of the predicate. Thanks to the hierarchy of the constraints on the frame types, the parser checks if the imposed constraints by the roles “AGENT” (?X1) and “THEME” (?X2) are compatible with the type “human” of the two elementary frames [A] and [B].
The implemented hierarchy distinguishes the “human” type from the “animal” type, which are both subtypes of “animate.” In other words, the “human” type of the
(al-liṣa/ the thief) can be unified with the “animate” type of the role “THEME” of the two semantic frames of the verb ‘ (ṭārada/ to pursue). On the other hand, the type of the frame (al-shurṭīyu/ the policeman) is unified with a single frame of the verb (ṭārada/ to pursue). Indeed, the unification between “human” and “animal” fails, thus leading to the resolution of the ambiguity. As a result, only the first semantic frame of the predicate is selected. -
(5) At the end of the unification, the elementary frames of
(al-shurṭīyu/ the policeman) and (al-liṣa/ the thief) are inserted in the semantic frame of the verb (ṭārada/ to pursue). Thus, the final frame representing the meaning of the sentence is formed. The result of syntax-semantic analysis, namely the syntactic tree and its corresponding semantic frame, is illustrated by Figure 25.

Figure 20. Elementary frames assigned to (the policeman) and (the thief).

Figure 21. Semantic frames attributed to the verb (to pursue).

Figure 22. The process of the syntax-semantic analysis of the sentence.

Figure 23. Triggering the unification process of semantic frames.

Figure 24. Unification of semantic frames.

Figure 25. Result of the syntax-semantic analysis.
6. Experiments and results
Before beginning the evaluation, we specify what our grammar needs to meet. Since it describes the syntax and the semantic of MSA, it should be able to (1) identify grammatically valid sentences as described in MSA (school books, Arabic novels), (2) cover the major syntactic phenomena of Arabic, (3) recognize ungrammatical sentences, and (4) provide a syntax-semantic description of valid sentences. Nevertheless, during this task, we faced a major difficulty regarding the resources needed for the evaluation. Indeed, the availability of digital resources differs from one language to another. We explored the three most famous corpora for MSA: Penn Arabic Tree Bank (PATB) (Maamouri and Bies Reference Maamouri and Bies2004), Prague Arabic Dependency Treebank (PADT) (Hajič et al. Reference Hajič, Smrž, Petr, Snaidauf and Beška2004), and Columbia Arabic Treebank (CATiB) (Habash and Roth Reference Habash and Roth2009). The texts in these three corpora are journalistic, while we want to exploit literary texts containing richer and more representative structures of Arabic and its syntactic phenomena. In addition, all these corpora are not free resources. Faced with these constraints, we chose to build our own test corpus.
6.1. Syntactic evaluation
We begin this section by outlining the test corpus used for the syntactic evaluation. Then, we will detail each step of this evaluation, before finishing with a discussion about the obtained results.
6.1.1 Test corpus
The test corpus (i.e., Grammatical Dataset) construction was done manually by extracting 1000 sentences from the Tunisian Basic Education reading textbook (grade 8). This textbook brings together a rich set of texts of Arabic literature. It describes the majority of the syntactic structure of sentences in MSA. So, we have selected 650 verbal sentences and 350 nominal sentences that are syntactically correct. The number of words in these sentences varies between 1 and 20 words. This selection has been made while considering the following phenomena: Negation, exclamation, interrogation, optional complements, types of phrases, active form, passive form, agreement, tense and aspect of verbs, coordination, and embedding. Unlike the corpus used during the validation process of ArabTAG V2.0 (ref. Section 5.1.4), this test corpus is composed of a wide variety of sentences and more complex structures.
In order to evaluate the capacity of our grammar to recognize ungrammatical sentences, we transformed a few sentences of this test corpus and created 250 grammatically incorrect sentences. This Ungrammatical Dataset consists of 167 verbal sentences and 83 nominal sentences. They cover the following errors:
-
False agreement between the verb and the subject,
-
False agreement in nominal sentences,
-
False agreement between the verb of existence or certitude and its theme or subject,
-
Incomplete agreement,
-
Incorrect order within the phrase,
-
Incorrect order of the words of the sentence.
6.1.2 Process of syntactic evaluation
We have developed a new tool dedicated to ensuring the analysis process (Figure 26). It allows to:
-
(1) Perform the morphosyntactic tagging of the input sentence.
-
(2) Generate the lemma basis and morphological basis of labeled words.
-
(3) Run the TuLiPA parser (Parmentier et al. Reference Parmentier, Kallmeyer, Lichte, Maier and Dellert2008).
-
(4) Store the result of the analysis (labeled tree(s)) in a new file in order to build a tree labeled corpus (in xml format).

Figure 26. Parsing process.
In what follows, we detail each step.
The morphosyntactic tagging . We used a tool that we have developed, based on the POS-Tagger of Ben Othmane Zribi, Ben Fraj, and Limam (Reference Ben Othmane Zribi, Ben Fraj and Limam2017), to ensure and facilitate the morphosyntactic labeling. Each input sentence is divided into words. Each word is assigned its lemma, its corresponding morphosyntactic features and eventually its semantic frame.
Let us consider the following example:
-
(18)
-
calīyun yuḥibu fāṭimah
-
Fatima loves Ali
-
“Ali loves Fatima.”
This sentence is divided into three words: : ![]() (calīyun/ Ali),
(calīyun/ Ali), ![]() (yuḥibu/ loves), and
(yuḥibu/ loves), and ![]() (fāṭimah/ Fatima). Then, each word receives its corresponding features. The validation of these data leads to the expansion of the lexicon database.
(fāṭimah/ Fatima). Then, each word receives its corresponding features. The validation of these data leads to the expansion of the lexicon database.
The lexical database consists of two well-defined files:
-
The morphological basis: in which each line corresponds to a morphological item. The latter consists of the flexed form associated with a lemma and its appropriate morphosyntactic information. Figure 27 shows an extract from the morphological lexicon following the morphosyntactic labeling of the sentence (18).
-
The lemma basis: analogous to the morphological lexicon. The lemma of each item is associated with its category, one (or more) family trees (e.g. NomPropre for Proper noun and TransitifActif for active-transitive verbs) and its semantic frame (FrameNomPropre for Proper noun and FrameTransitif for active-transitive verbs) defined in Arab TAG V2.0. An extract from this database is illustrated in Figure 28.

Figure 27. Extract from the morphological lexicon: ![]() (calīyun/ Ali),
(calīyun/ Ali), ![]() (fāṭimah/ Fatima) and
(fāṭimah/ Fatima) and ![]() (yuḥibu/loves).
(yuḥibu/loves).

Figure 28. Extract from the lemma basis corresponding to: ![]() (calīyun/ Ali),
(calīyun/ Ali), ![]() (fāṭimah/ Fatima) and
(fāṭimah/ Fatima) and ![]() (yuḥibu/loves).
(yuḥibu/loves).
Parsing . The TuLiPA parser (Parmentier et al. Reference Parmentier, Kallmeyer, Lichte, Maier and Dellert2008) receives as input, the sentence, the XML files of our grammar, the morphological basis, and the lemma basis.Footnote n Then, lexicalizationFootnote o is carried out as follows:
-
Each word of the input sentence is associated with its morphological lexicon.
-
The parser retrieves the corresponding lemmas from the morphological lexicon of the sentence.
-
The parser tries to associate every lemma and its flexed form with the corresponding trees by means of feature unification.
-
If the unification is done successfully, the parser attaches the flexed form to the lexical anchor of the tree template.
-
The selected trees are combined to provide a valid derived tree.
-
The result of the analysis is represented by the derived tree of the sentence and its derivation tree. We can have more than one syntax tree as a result. In this case, we talk about syntactic ambiguity of the sentence.
Let’s consider the previous example of the sentence (18). Initially, TuLiPA gets all the elementary trees associated with the following pairs of (lemma, flexed form):
 $\Big($
$\Big($
![]()
 $\Big)$
/ (calīyun, caly) for Ali,
$\Big)$
/ (calīyun, caly) for Ali,
 $\Big($
$\Big($
![]()
 $\Big)$
/ (yuḥibu,āḥabba) for loves, and
$\Big)$
/ (yuḥibu,āḥabba) for loves, and
 $\big($
$\big($
![]()
 $\big)$
/ (fāṭimah,faṭmah) for Fatima. Then, the parser tries to associate these lexical units to their corresponding trees. The resulted trees (Figure 29) can be obtained once the feature of the tree nodes and the lexical units are unified. After checking manually whether the final result is correct, the derived tree of the sentence and its derivation tree are saved into an XML file: the Parsed-Corpus.
$\big)$
/ (fāṭimah,faṭmah) for Fatima. Then, the parser tries to associate these lexical units to their corresponding trees. The resulted trees (Figure 29) can be obtained once the feature of the tree nodes and the lexical units are unified. After checking manually whether the final result is correct, the derived tree of the sentence and its derivation tree are saved into an XML file: the Parsed-Corpus.

Figure 29. Graphical output after parsing the sentence ![]() (calīyun yuḥibu fāṭimah/ Ali loves Fatima).
(calīyun yuḥibu fāṭimah/ Ali loves Fatima).
6.1.3 Parsing results
Table 2 shows the parsing results of the Grammatical and Ungrammatical Datasets. The sentence is considered successfully parsed if the parser has succeeded in finding the correct result, that is the expected syntactic tree for the grammatical sentence or no tree for ungrammatical sentence. We used a manual reference to verify the parser output.Footnote p
Table 2. Parsing results of the Grammatical (1000 sentences) and Ungrammatical Dataset (250 sentences)

As shown in Table 2, 90.22% of the sentences in these Datasets were correctly parsed. However, we measured 12.03% of the ambiguity rate (i.e., grammatical sentences having more than one correct resulting analysis). Figure 30 displays the number of resulting trees, according to the length of the 106 sentences.

Figure 30. Performance in terms of ambiguities in relation with sentence length.
Most of the these sentences have two syntactic trees as a result. This is explained by (1) the ambiguity at the lexical level since a word can be associated with several families of trees and (2) the syntactic ambiguity of some sentences. Indeed, the component of a sentence can be a nominal or verbal phrase which is itself composed of several types of phrases. Consequently, the parser provided all matching result trees with the possible syntactic interpretations of this component. Let us consider, for example, the following sentence (19):
-
(19)
-
waddaca al-mudarrisa cadadun kabīrun min ṭalabati al-madrasati wa mudarisīhā
-
its-teachers and the-school students of number the-teachers bade-farewell
-
“A large number of students of the school and its teachers bade farewell to the teacher”.
The parser provided two matching trees. This ambiguousness is due to the semantic interpretations of the noun phrase (21):
-
(20)
-
ṭalabati al-madrasati wa mudarisīhā
-
its-teachers and the-school students
-
“students of the school and its teachers.”
The phrase, in the first tree (Figure 31), is considered as a conjunction between ![]() (ṭalabati al-madrasati/ students of the school) and
(ṭalabati al-madrasati/ students of the school) and ![]() (mudarisīhā/ its teachers). The semantic interpretation is different from the second tree. It is represented by an annexation phrase among
(mudarisīhā/ its teachers). The semantic interpretation is different from the second tree. It is represented by an annexation phrase among ![]() (ṭalabati/ students) and
(ṭalabati/ students) and ![]() (al-madrasati wa mudarisīhā/ the school and its teachers). Although these two interpretations are plausible, the first remains the most adequate. In certain cases, using semantic information can resolve syntactic ambiguities.
(al-madrasati wa mudarisīhā/ the school and its teachers). Although these two interpretations are plausible, the first remains the most adequate. In certain cases, using semantic information can resolve syntactic ambiguities.

Figure 31. Syntactic trees of the noun phrase ![]() (ṭalabati al-madrasati wa mudarisīhā/ students of the school and its teachers).
(ṭalabati al-madrasati wa mudarisīhā/ students of the school and its teachers).
On the other hand, we obtained a 11.9% failure rate in parsing grammatical sentences. It represents 80 nominal sentences and 39 verbal sentences for which the parser did not find their corresponding syntactic trees. The majority of these cases are due to the non-recognition of some structures that are more complex than those described in our grammar such as the sentence:
-
(21)
-
ānā alladhī carafa mā fī al-īnsāni likathrati
lahu -
of-him my-observations because-of-multitude man in what knew who I-am-the-one
-
“I am the one who knew what man has because of my multitude observations of him.”
We have also underlined some unrecognized examples because of the imposed constraints of the structures which caused the under-generation of some models. For example, the parsing of sentence (22), which is grammatically correct, failed because we restricted the possibility of having a predicate that starts with an “existence” verb within the meta-grammar.
-
(22)
-
al-sururu al-khashabīyatu al-manqūshatu kānat min fanin mughriyī
-
alluring art of were the-carved the-woody the-beds
-
“The wood carved beds were alluring art.”
This finding was confirmed by the analysis of the Ungrammatical Dataset. In this instance, we check if the parser can correctly recognize the ungrammatical sentences. Since these input sentences are ungrammatical, none of them were wrongly declared by the parser to be grammatically incorrect. On the other hand, the parser did not detect the error and wrongly provided resulting trees for 33 sentences (16 sentences with incorrect agreement rules and 17 sentences with invalid structures).
This outcome can be explained by the insufficiency of the imposed constraints within the elementary trees descriptions. In addition, we have noted that it will be more relevant to refine the descriptions of some structures such as interrogative sentences or even nominal sentences.
6.2. Evaluation of semantic analysis
We begin this section with a presentation of the test corpus used to evaluate the semantic coverage of our grammar. Subsequently, we retrace the steps of this evaluation before concluding with a discussion of the measured results.
6.2.1 Test corpus
In order to ensure a relevant comparison between our results (of the semantic analysis) with examples of semantically labeled sentences, we chose to build a corpus composed of verbal sentences extracted from ArabicVerbNet. Within this lexical resource, each type of semantic frame is associated with at least one example of sentence labeled by its semantic roles. Our aim is to ensure that the obtained results of our syntax-semantic analysis matches with those of ArabicVerbNet.
We have therefore extracted an example of sentence of each type of semantic frames described in ArabicVerbNet, and we have obtained a corpus of 460 sentences (Semantic Dataset): 30 sentences with intransitive verb (require a single argument), 201 with transitive verb (requires two arguments), and 229 with ditransitive verbs (requires three arguments). The length of these sentences varies between 2 and 14 words.
6.2.2 Process of semantic evaluation
Sentences of the Semantic Dataset undergo the phase of the morphosyntactic and semantic tagging as well as the syntax-semantic analysis (Figure 32). After the analysis, we compare the resulting semantic representations with those of ArabicVerbNet.

Figure 32. Syntax-semantic analysis process.
First, each word of the input sentence is tagged and the semantic correspondence with the defined families of semantic frames (within the meta-grammar) is done. Following this step, the lemma and morphological basis are generated. Then, the syntax-semantic analysis is performed using a new version of the TuLiPA parser namely TuLiPA-frames (Arps and Petitjean Reference Arps and Petitjean2018). Finally, the resulted frame of the semantic analysis is compared to the semantic representation of the sentence within ArabicVerbNet.
Syntax-semantic analysis is performed using the TuLiPA-frames which provides the resulted syntactic trees and their corresponding semantic frame(s). TuLiPA-frames requires as input: the description of the syntax (SynArabTAG), the description of the semantic dimension (SemArabTAG), the hierarchy of semantic role constraints and semantic frame types, the lemma basis, the morphological basis, and finally the sentence (cut out). If the unification of the semantic frames succeeds, the parser provides one (or more) result(s) consisting of the derived tree(s) of the sentence, its derivation tree(s), and its final semantic frame(s).
Let’s take again the example of the sentence (18). Following the phase of semantic tagging (Figure 28), elementary semantic frames with type “human” are associated to ![]() (caly/ Ali) and
(caly/ Ali) and ![]() (faṭmah/ Fatima). The corresponding frame of the predicate
(faṭmah/ Fatima). The corresponding frame of the predicate ![]() (āḥabba/ to love) has two semantic roles: the “EXPERIENCER” and the “PATIENT.” These roles must be animated. During unification, the type of elementary semantic frames of
(āḥabba/ to love) has two semantic roles: the “EXPERIENCER” and the “PATIENT.” These roles must be animated. During unification, the type of elementary semantic frames of ![]() (caly/ Ali) and
(caly/ Ali) and ![]() (faṭmah/ Fatima) must be compatible with the constraint “animate” otherwise unification fails. The implemented hierarchy of constraints allows the unification of a human with an animate. Thus, the final semantic representation of the sentence corresponds to the semantic frame shown in Figure 33.
(faṭmah/ Fatima) must be compatible with the constraint “animate” otherwise unification fails. The implemented hierarchy of constraints allows the unification of a human with an animate. Thus, the final semantic representation of the sentence corresponds to the semantic frame shown in Figure 33.

Figure 33. Semantic frame of the sentence ![]() (calīyun yuḥibu fāṭimah/ Ali loves Fatima).
(calīyun yuḥibu fāṭimah/ Ali loves Fatima).
The semantic representation consists of a frame that has a type desire-event and two attributes FE1 and FE2. The first attribute is of type patient-undergoer-experiencer and is unified with the subframe of the subject (type concrete-natural-animate-human-selRestr) through the variable ?B0. The second attribute is of type patient-undergoer and corresponds to the subframe of the object (type concrete-natural-animate-human-selRestr) unified by the variable ?D0. Unification is triggered by substitution, and the insertion of the lexicon into the frame is triggered by lexical anchoring.
6.2.3 Result of the semantic analysis
As shown in Table 3, we were able to correctly analyze 95.43% of the Semantic Dataset.
Table 3. Results of the semantic analysis (460 sentences)

In other words, semantic representations of 439 sentences matched with those of ArabicVerbNet. Among these analyzed sentences, 33 sentences have more than one semantic representation. This result can be explained by the lack of restriction defined in verb classes of ArabicVerbNet. Consequently, it is possible that a verb is assigned to several semantic frames without the possibility of filtering. The number of entries increases. Therefore, it increases the parsing ambiguity and generates several results that may be incorrect.
For instance, the analysis of the sentence (23) resulted in two semantic representations.
-
(23)
-
al-muṣallī calá al-masjidi
-
the-mosque to the-faithful perseveres
-
“The faithful perseveres in going to the mosque”.
The first, illustrated by Figure 34, corresponds to the unification of the elementary frames of ![]() (al-muṣallī/ the faithful) and
(al-muṣallī/ the faithful) and ![]() (calá al-masjidi/ to the mosque) with the frame of the predicate
(calá al-masjidi/ to the mosque) with the frame of the predicate ![]() (
(![]() / to persevere) that requires the roles “AGENT” (animate) and “PREDICATE.”
/ to persevere) that requires the roles “AGENT” (animate) and “PREDICATE.”

Figure 34. First semantic frame from the analysis of the sentence ![]() (
(![]() al-muṣallī calá al-masjidi/ The faithful perseveres in going to the mosque).
al-muṣallī calá al-masjidi/ The faithful perseveres in going to the mosque).
The second final semantic frame, represented by Figure 35, corresponds to the unification of the same elementary frames with another frame of the predicate ![]() (
(![]() / to persevere) that requires the roles “THEME” and “CAUSE.”
/ to persevere) that requires the roles “THEME” and “CAUSE.”
After a comparison between these results and the labeling of the example within ArabicVerbNet, we conclude that the first semantic frame is the correct one. However, the non-existence of restriction within the second semantic frame of the predicate, allowed obtaining an additional wrong result. The failure rate is 4.56%. The majority of the cases of failures are obtained at the level of parsing. The parsing failed for 17 sentences because their structures were not defined in ArabTAG V2.0. In contrast, semantic analysis failed only for four sentences. This result is due to the failure of the unification between the elementary frames defined for some phrases (approbative and corroborative phrases). These latter must be redefined in order to allow their unification.

Figure 35. Second semantic frame from the analysis of the sentence ![]() (
(![]() al-muṣallī calá al-masjidi/ The faithful perseveres in going to the mosque).
al-muṣallī calá al-masjidi/ The faithful perseveres in going to the mosque).
6.3. Discussion and comparison
The evaluation shows that ArabTAG V2.0 can produce precise results. It confirms grammar coverage of basic syntactic structures of Arabic sentences, the different phrasal structures as well as agglutinative forms and more complex structures with additional complements. The grammar allowed us to carry out a syntax-semantic analysis after which we were able to obtain 439 correct semantic frames. These latter, compared to the semantic representations in ArabicVerbNet, offer a more relevant information. Indeed, frames in ArabicVerbNet define only the correspondence between semantic roles and syntactic arguments. Moreover, the annotations of semantic roles in ArabicVerbNet lack precision and constraint. On the other hand, semantic frames provided by ArabTAG V2.0 are structured and include additional information such as the type of event, the type hierarchy of semantic role, and the type hierarchy of a constituent of the sentence (elementary frame).
At the end of the evaluation, we were able to built a new lexical resourcesFootnote q for Arabic. It incorporates the parsing results of successfully parsed sentences from Grammatical and Semantic Dataset as an annotated corpus (Parsed-Corpus) in addition to a lemma basis (17,740 entries, including 996 entries with semantic information) and a morphological basis (4057 inflected forms). It is possible to use such resources to accelerate the development of meta-grammars (e.g., structure extraction, search for examples) and to evaluate them. Corpus annotated in syntactic constructions would allow the focus on specific phenomena. Analysis results of 1320 sentences, namely derivation trees, derived trees, and possibly semantic representations, were exported as XML files. Figure 36 illustrates the structure of xml output following the analysis of the sentence (18).

Figure 36. Structure of the exported XML file of the sentence ![]() (calīyun yuḥibu fāṭimah/ Ali loves Fatima).
(calīyun yuḥibu fāṭimah/ Ali loves Fatima).
Derivation tree consists of a trace containing the names of the meta-grammar classes that were combined during parsing. Each entry represents an elementary tree of the grammar: TansitifAtctif for the verb ![]() (yuḥibu/ loves), and NomPropre for proper names
(yuḥibu/ loves), and NomPropre for proper names ![]() (calīyun/ Ali) and
(calīyun/ Ali) and ![]() (fāṭimah/ Fatima).
(fāṭimah/ Fatima).
Syntactic description, giving the structure of the derived tree, indicates data about the morphological entries and their features values used for anchoring. Graphical representation of the encoded derived tree (with features) and its derivation tree is shown in Figure 29. Lastly, semantic frame is expressed in a set of literalsFootnote r describing its structure and features. Figure 37 shows the encoded frame of the sentence (18). In accordance with Figure 33, information about the types of semantic roles as well as the subframes and their values (lexicon) is organized within the frame tag.

Figure 37. Encoded semantic frame of the exported XML file of the sentence ![]() (calīyun yuḥibu fāṭimah/ Ali loves Fatima).
(calīyun yuḥibu fāṭimah/ Ali loves Fatima).
In order to confront our approach with annotated Arabic Treebank, we lead off a comparison between syntactic models defined in ArabTAG V2.0 and syntactic structures in the Arabic Treebank Part 2 v 3.1 (ATB2) (Maamouri and Linguistic Data Consortium 2011). The latter consists of 501 Newswire stories from Ummah Press, and its syntactic Treebank annotation is based on the PATB Guidelines. First, we extracted all trees within ATB2, which corresponds to a number of 2591 syntactic trees representing 4183 sentences. Then, we compared its syntactic structures to model trees of our grammar.
The evaluation showed that our grammar ensures a coverage of 2050 syntactic trees that is, 79.12% of the total number of ATB2 v 3.1 trees (equivalent to 3043 sentences). We clarify that we had to add some constraints during this evaluation. In fact, ATB2 takes punctuation into account. We noted that trees of this corpus can correspond to a set of sentences separated by punctuation marks (period, comma, colon, double quotes, question mark, exclamation mark, etc). We also identified 922 syntactic trees starting with a linking word. However, unlike ATB, ArabTAG V2.0 does not include punctuation and conjunction should joins two syntactic structures (adjective, phrases, or sentences). Therefore, for the sake of consistency, punctuation and conjunction starting a sentence have been excluded.
On the other hands, we failed to cover 541 syntactic trees of ATB2 v 3.1 equals to 20.87% (i.e., 1140 sentences). This is mainly due to the absence, within our grammar, of the syntactic structures dealing with some forms of adverbs, particles (emphatic, focus, restriction) interjection as well as structures for the dialect, foreign and Latin nouns.
The purpose of this comparison is to check the syntactic coverage not the accuracy. Further study will be carried out in order to investigate the effectiveness of the defined features within our meta-grammar (phrasal and functional tags) as well as the relevance of the choices we made to represent certain phenomena such as managing adverbs, optional complements, and agglutinated forms.
Although these first results are encouraging, the current version of ArabTAG V2.0 has some problems of coverage and disambiguation that we aim to resolve. We noticed that some constituents were incorrectly analyzed. Despite the fact that these structures are defined within the meta-grammar, their attachment was not handled correctly due to the imposed constraints on the features occurring during the parsing. While in the semantic side, it is more complicated to assert the relevance of the obtained results since the evaluation was done on a small size set of sentences. In order to achieve better results, we consider redefining some of our frame models. We also intend to improve the annotation consistency in the lexicon to better manage verb categories.
7. Conclusion
In this paper, we presented a new method of generating semi-automatically an Arabic TAG called ArabTAG V2.0. It covers verbal sentences (active and passive form), nominal sentences, different types of noun phrases and prepositional phrases. It also deals with the different linguistic phenomena of Arabic such as the variation of the positions of the elements within the syntactic components, the additional complements, the agreement rules and the agglutinated forms. Unlike other developed grammars for Arabic, ArabTAG V2.0 provides both the syntactic and semantic representation of the sentence. Indeed, through the syntax-semantic analysis, we obtain one or more syntactic representations of the sentence and its resulted semantic frame(s). The evaluation gave us the primary estimation on the quality and the coverage of ArabTAG V2.0. We obtained 88.76% of the precision rate for parsing and 95.63% for semantic analysis. These results are very encouraging to ensure the continuity and the extension of our research work.
We are considering extending our meta-grammar to more general insights on language and possibly in a multilingual setting. Having meta-grammar that can be adapted to new languages within a few months to a year will be useful to linguists since they wish to have a dedicated model. This can be done by extracting structures (from our meta-grammar) representing the syntactic phenomena of Arabic. These structures can be reused, modified, or even enhanced to conform with another language (e.g. free word order, dealing with an adverbial object, agreement rules, agglutinated forms, etc).
Our approach is innovative. It separates the syntactic description from the semantic description while maintaining an interfacing link between these two levels. Thanks to this organization, we can extend our meta-grammar by adding another format of semantic description (e.g. flat semantics). It will be sufficient to define a new meta-grammatical description for the new semantic dimension and then link it to the syntactic dimension using the syntax-semantic interface. This might lead to a promising avenue of research regarding semantic computation for TAGs.
In the Future, we aspire to set up a TAG with a large-scale semantic representation for Arabic language and to automatically create a large tree corpus rich in syntactic and semantic information. Such resources will be very useful for NLP applications such as learning-based applications, for parsing evaluations or even for grammar evaluations.
Acknowledgments
I would like to thank all the members of the “Graduate Program StoRE The Structure of Representations“ at Heinrich Heine University Düsseldorf with whom I spent 4 months internship. By joining this program, I was able to significantly advance on the semantic part of my research. In particular, I like to thank Laura Kallmeyer and Simon PetitJean. With the very relevant remarks of ¨Professor Laura Kallmeyer and the valuable help of Doctor Simon PetitJean, I was able to define a suitable representation of semantic frames for my grammar and implement the constraint hierarchy to control the unification of frames during the semantic analysis.










































