



Introduction
High-resolution transmission electron microscopy (HRTEM) is a very powerful technique for imaging atomic structure due to its extremely high spatial resolution. HRTEM has found wide application in studies of the local atomic structure of two-dimensional (2D) materials, such as graphene (Meyer et al., Reference Meyer, Geim, Katsnelson, Novoselov, Booth and Roth2007, Reference Meyer, Kurasch, Park, Skakalova, Künzel, Groß, Chuvilin, Algara-Siller, Roth, Iwasaki, Starke, Smet and Kaiser2011; Warner et al., Reference Warner, Rümmeli, Ge, Gemming, Montanari, Harrison, Büchner and Briggs2009; Mas-Balleste et al., Reference Mas-Balleste, Gomez-Navarro, Gomez-Herrero and Zamora2011; Rasool et al., Reference Rasool, Ophus, Klug, Zettl and Gimzewski2013, Reference Rasool, Ophus and Zettl2015; Robertson & Warner, Reference Robertson and Warner2013). Monolayer graphene is composed of a single 2D sheet of carbon atoms, with the same in-plane structure as the parent material graphite (Cooper et al., Reference Cooper, D'Anjou, Ghattamaneni, Harack, Hilke, Horth, Majlis, Massicotte, Vandsburger, Whiteway and Yu2012). Most synthesis methods that can produce monolayer graphene will also produce defect structures, including point defects (Hashimoto et al., Reference Hashimoto, Suenaga, Gloter, Urita and Iijima2004; Jeong et al., Reference Jeong, Ihm and Lee2008; Kotakoski et al., Reference Kotakoski, Mangler and Meyer2014), edges (Russo & Golovchenko, Reference Russo and Golovchenko2012; Wang et al., Reference Wang, Santos, Jiang, Cubuk, Ophus, Centeno, Pesquera, Zurutuza, Ciston, Westervelt and Kaxiras2014), and line defects, such as grain boundaries (Huang et al., Reference Huang, Ruiz-Vargas, Van Der Zande, Whitney, Levendorf, Kevek, Garg, Alden, Hustedt, Zhu, Park, McEuen and Muller2011; Yu et al., Reference Yu, Jauregui, Wu, Colby, Tian, Su, Cao, Liu, Pandey, Wei, Chung, Peng, Guisinger, Stach, Bao, Pei and Chen2011).
Grain boundaries in graphene are scientifically interesting because of their distinctive mechanical (Grantab et al., Reference Grantab, Shenoy and Ruoff2010; Lee et al., Reference Lee, Cooper, An, Lee, Van Der Zande, Petrone, Hammerberg, Lee, Crawford, Oliver, Kysar and Hone2013; Rasool et al., Reference Rasool, Ophus, Klug, Zettl and Gimzewski2013), electronic (Jauregui et al., Reference Jauregui, Cao, Wu, Yu and Chen2011; Tapasztó et al., Reference Tapasztó, Nemes-Incze, Dobrik, Jae Yoo, Hwang and Biró2012; Fei et al., Reference Fei, Rodin, Gannett, Dai, Regan, Wagner, Liu, McLeod, Dominguez, Thiemens, Castro Neto, Keilmann, Zettl, Hillenbrand, Fogler and Basov2013), optical (Duong et al., Reference Duong, Han, Lee, Gunes, Kim, Kim, Kim, Ta, So, Yoon, Chae, Jo, Park, Chae, Lim, Choi and Lee2012; Podila et al., Reference Podila, Anand, Spear, Puneet, Philip, Sai and Rao2012), and chemical properties (Kim et al., Reference Kim, Lee, Johnson, Tanskanen, Liu, Kim, Pang, Ahn, Bent and Bao2014; Yasaei et al., Reference Yasaei, Kumar, Hantehzadeh, Kayyalha, Baskin, Repnin, Wang, Klie, Chen, Král and Salehi-Khojin2014). In a previous study, Ophus et al. (Reference Ophus, Shekhawat, Rasool and Zettl2015) used experimental HRTEM imaging and numerical simulations to map out the parameter space of single-layer graphene grain boundaries as a function of misorientation and boundary tilt angle. This previous work used semi-automated analysis routines to map out the atomic positions of the boundaries. Once boundary regions were identified, the atomic position analysis was almost entirely automated. However, each of these boundaries had to be hand selected and individually masked due to the presence of surface contaminants. These contaminants are likely amorphous carbon (Zhang et al., Reference Zhang, Jia, Lin, Zhao, Quang, Sun, Li, Li, Liu, Zheng, Xue, Gao, Luo, Rummeli, Yuan, Peng and Liu2019), which tends to be attracted by the charging induced by the electron beam to the boundary regions. This previous work did not utilize a reliable fully automated computational method for segmenting between the desirable and undesirable atomic structures.
Recently, however, new image analysis methods have been developed under the umbrella of deep learning (Garcia-Garcia et al., Reference Garcia-Garcia, Orts-Escolano, Oprea, Villena-Martinez and Garcia-Rodriguez2017). Deep learning as an approach to data processing problems has substantially grown in popularity over the last decade. This can be attributed to increasing availability of large labeled datasets, such as Image-Net (Deng et al., Reference Deng, Dong, Socher, Li, Li and Fei-Fei2009), breakthrough research publications in the field (Krizhevsky et al., Reference Krizhevsky, Sutskever and Hinton2010), and availability of high performance deep learning frameworks, such as PyTorch (Paszke et al., Reference Paszke, Gross, Massa, Lerer, Bradbury, Chanan, Killeen, Lin, Gimelshein, Antiga, Desmaison, Köpf, Yang, DeVito, Raison, Tejani, Chilamkurthy, Steiner, Fang, Bai and Chintala2019) and TensorFlow (Abadi et al., Reference Abadi, Agarwal, Barham, Brevdo, Chen, Citro, Corrado, Davis, Dean, Devin, Ghemawat, Goodfellow, Harp, Irving, Isard, Jia, Jozefowicz, Kaiser, Kudlur, Levenberg, Mané, Monga, Moore, Murray, Olah, Schuster, Shlens, Steiner, Sutskever, Talwar, Tucker, Vanhoucke, Vasudevan, Viégas, Vinyals, Warden, Wattenberg, Wicke, Yu and Zheng2015). Convolutional neural networks (CNNs) have been used for various different image processing tasks, such as image classification (recognition of the object class within an image), object detection (classification and detection of objects in an image as well as generation of the bounding box around the object), and semantic segmentation (pixel-wise classification of an image).
Various works (Ziatdinov et al., Reference Ziatdinov, Dyck, Jesse and Kalinin2018; Lee et al., Reference Lee, Shi, Luo, Khan, Janicek, Kang, Zhu, Clark and Huang2019) have successfully applied deep learning methodologies to analyzing atomic defects in microscopic images of materials. In particular, Madsen et al. (Reference Madsen, Liu, Kling, Wagner, Hansen, Winther and Schiøtz2018) used a deep learning network trained on simulated TEM data to recognize local structures in graphene images.
Various studies have made use of neural networks for the segmentation of images of cells, such as Akram et al. (Reference Akram, Kannala, Eklund, Heikkilä, Carneiro, Mateus, Peter, Bradley, João Manuel, Belagiannis, Paulo, Nascimento, Loog, Lu, Cardoso and Cornebise2016), Al-Kofahi et al. (Reference Al-Kofahi, Zaltsman, Graves, Marshall and Rusu2018), as well as other biological datasets, such as vasculature stacks (Teikari et al., Reference Teikari, Santos, Poon and Hynynen2016), brain tumors (Dong et al., Reference Dong, Yang, Liu, Mo and Guo2017), and neuron structures (Dahmen et al., Reference Dahmen, Potocek, Trampert, Peemen and Schoenmakers2019). Many works have introduced application specific architectures for their studies, e.g., Kassim et al. (Reference Kassim, Glinskii, Glinsky, Huxley and Palaniappan2017) and Roberts et al. (Reference Roberts, Sainju, Hutchinson, Toloczko, Edwards and Zhu2019).
For the segmentation task considered in this paper, we utilize the U-Net architecture as described in Ronneberger et al. (Reference Ronneberger, Fischer and Brox2015) due to its proven ability to achieve high performance results on image segmentation tasks with limited training data. This aspect is crucial, as large databases of labeled data are typically not readily available for most scientific imaging applications. U-Net has been applied to various datasets, such as urine microscopic images (Aziz et al., Reference Aziz, Pande, Cheluvaraju and Rai Dastidar2018), ADF-STEM images (Ge & Xin, Reference Ge and Xin2018), corneal endothelial cell images (Daniel et al., Reference Daniel, Atzrodt, Bucher, Wacker, Böhringer, Reinhard and Böhringer2019), and fluorescently labeled cell nuclei images (Gudla et al., Reference Gudla, Zaki, Shachar, Misteli and Pegoraro2019). Many other works performed similar microscopy segmentation tasks on the nanoscale using modified versions of the U-Net Architecture such as EM-Net (Khadangi et al., Reference Khadangi, Boudier and Rajagopal2020), Fully Residual U-Net (Gómez-de Mariscal et al., Reference Gómez-de Mariscal, Maška, Kotrbová, Pospíchalová, Matula and Muñoz-Barrutia2019), Inception U-Net (Punn & Agarwal, Reference Punn and Agarwal2020), and the domain adaptive approach with two coupled U-Nets (Bermúdez-Chacón et al., Reference Bermúdez-Chacón, Márquez-Neila, Salzmann and Fua2018).
In this paper, we develop a deep learning-based image segmentation pipeline for detecting surface contaminants in HRTEM images of graphene and compare it to a conventional Bragg filtering approach (Hÿtch, Reference Hÿtch1997; Galindo et al., Reference Galindo, Kret, Sanchez, Laval, Yanez, Pizarro, Guerrero, Ben and Molina2007). The next section reviews materials and methods used in our study. First, we describe image acquisition and preprocessing methodologies as well as labeling training and test data for our modeling approach. We also review Bragg filtering as a classical image segmentation approach for detecting surface contaminants in graphene, which serves as a baseline model. We then introduce our new method that trains and evaluates a U-Net-based neural network architecture using k-fold cross-validation. We demonstrate that our neural network's automated feature learning capabilities outperform Bragg filtering for detecting material properties and discuss two potential applications of this segmentation model (section “Results and Discussion”). Furthermore, we show how it can be easily used to further automate software-based scientific image analysis pipelines. Finally, we summarize results and suggest future extensions and uses (section “Conclusion”).
Materials and Methods
We first describe the process through which we grow our graphene samples, how images are extracted, and the different classes of surface structures observed in the data. We then introduce the mathematical definitions for the preprocessing of this acquired data used in this study. We then describe the conventional Bragg filtering method for segmentation. Finally, we introduce our deep learning approach to the segmentation task.
HRTEM Imaging of Graphene Structures
The single-layer, polycrystalline graphene samples are grown on polycrystalline copper substrates at 135°C by chemical vapor deposition. The copper substrate is first held under 150 mTorr of pressure in hydrogen for 1.5 h, and then 400 mTorr pressure of methane is flowed at 5 standard cubic centimeters per minute (sccm) to form single-layer graphene. Further information of this sample preparation method are given by Li et al. (Reference Li, Cai, An, Kim, Nah, Yang, Piner, Velamakanni, Jung, Tutuc, Banerjee, Colombo and Ruoff2009) and Rasool et al. (Reference Rasool, Song, Allen, Wassei, Kaner, Wang, Weiller and Gimzewski2011, Reference Rasool, Ophus, Klug, Zettl and Gimzewski2013).
The majority of graphene HRTEM images utilized in the current study are published along with the measured atomic coordinates in a previous study (Ophus et al., Reference Ophus, Shekhawat, Rasool and Zettl2015). Some additional HRTEM images, including those from time- and focal-series are from various studies of the structure of graphene grain boundaries (Rasool et al., Reference Rasool, Ophus, Klug, Zettl and Gimzewski2013, Reference Rasool, Ophus, Zhang, Crommie, Yakobson and Zettl2014; Ophus et al., Reference Ophus, Rasool, Linck, Zettl and Ciston2017), were also included in the image dataset. All of our HRTEM images of graphene were recorded on the TEAM 0.5 microscope, a monochromated and aberration-corrected FEI/Thermo Fisher Titan microscope operated at 80 kV. The imaging conditions are optimized for fast data collection with a relatively low electron dose in order to record as many images as possible. The dose varied from approximately 1,000 to 10,000 electrons/Å2 across all images. Note that in these images, graphene atoms can appear as either local intensity maxima or minima (colloquially referred to as “white-atom” or “black-atom” contrast; Robertson & Warner, Reference Robertson and Warner2013). However, both families of filters used in this study (Fourier Bragg and U-Net) are not sensitive to the precise imaging condition, and both filters work with images showing either kind of contrast.
Figures 1a–1f show examples of these HRTEM images. Note that due to the monochromation of the electron beam, the intensity of all images varies across the field of view. The graphene samples used in this study contain four primary structural classes. The first class is the graphene lattice itself, which consists of a periodically repeating honeycomb structure. In this structure, each carbon atom is bonded to three neighbors with 120° between each bond, and six carbon atoms form closed hexagonal rings, which are tiled in a close-packed triangular lattice. Figures 1g–1l show these regions marked in white. Depending on the microscope defocus, the contrast is either white-atom or black-atom, meaning either increased or decreased intensity at the location of each carbon atom, respectively (O'Keefe, Reference O'Keefe2008). Figures 1b, 1c, 1d, and 1f show examples of white-atom contrast, while Figures 1a and 1e show black-atom contrast. These images show varying degrees of residual imaging aberrations; this is a consequence of the low-dose measurement protocol used where the sample is exposed to as little electron fluence as possible.
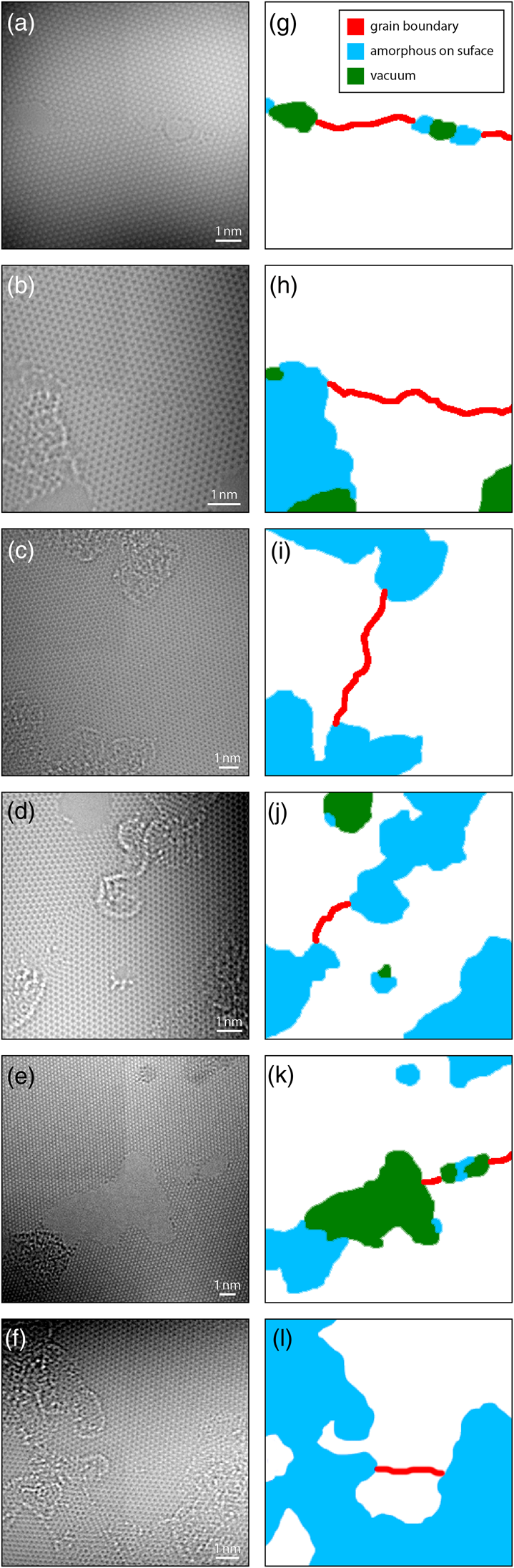
Fig. 1. (a–f) HRTEM image examples of polycrystalline, single-layer graphene, and (g–l) the corresponding labels.
We can define a simple order parameter calculated by using image convolution to measure the difference in signals between the atoms on a hexagonal ring (using the measured graphene lattice parameter) and the center of the ring. If we calculate this parameter for a range of hexagon orientations, the signal reaches a maximum when the measurement is oriented the same as the underlying lattice, giving an estimate for the lattice orientation. The regions where two different orientations meet in a discontinuity define the second class, the graphene grain boundaries. These boundaries are shown as red lines in Figures 1g–1l and were the focus of the previous study by Ophus et al. (Reference Ophus, Shekhawat, Rasool and Zettl2015).
The third class is the vacuum regions, marked as green areas in Figures 1g–1l. No structure is present in these regions, and the electron beam passes straight through with no modulation. Each of these first three classes is easy to detect with simple algorithms. Measuring the location of the vacuum regions is trivial after illumination flat-field correction (described below) since these regions have unit intensity everywhere.
However, the fourth class, which corresponds to surface contaminants such as amorphous carbon, is more difficult to accurately segment. These regions are shown as blue areas in Figures 1g–1l. The regions often show strong lattice contrast of ideal or near-ideal graphene structure, overlaid with random modulations. These modulations can be strong or weak and consist of a complex mix of white-atom and black-atom contrast. Amorphous contaminants also tend to be attracted to the structures we would like to analyze, e.g., the grain boundaries. This is likely due to the surface topology induced by these boundaries (Ni et al., Reference Ni, Zhang, Li, Li and Gao2019). In the study of graphene grain boundaries by Ophus et al. (Reference Ophus, Shekhawat, Rasool and Zettl2015), most of the analysis steps were automated, but avoiding these surface contaminant regions was done manually. In this work, we tackle the segmentation of these regions, as it represents the most difficult step to automate.
Image Preprocessing
For both the U-Net and Bragg filtering image segmentation, we have applied the same preprocessing and normalization steps, based on the image processing described in Ophus et al. (Reference Ophus, Shekhawat, Rasool and Zettl2015). To normalize the intensity variation due to the monochromation, we have fit the average local intensity I 0(r) for each image with a 2x2 Bézier surface (Farin, Reference Farin2001) given by the following equation:
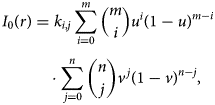 $$\eqalign{I_0( {r}) & = k_{i, j} \sum_{i = 0}^{m} {m \choose i} u^{i} ( 1-u) ^{m-i} \cr & \quad \cdot\sum_{\,j = 0}^{n}{n \choose j} v^{\,j} ( 1-v) ^{n-j},\; }$$
$$\eqalign{I_0( {r}) & = k_{i, j} \sum_{i = 0}^{m} {m \choose i} u^{i} ( 1-u) ^{m-i} \cr & \quad \cdot\sum_{\,j = 0}^{n}{n \choose j} v^{\,j} ( 1-v) ^{n-j},\; }$$where (u, v) are the image coordinates normalized to range from 0 to 1, and k i,j are the Bézier surface coefficients. After fitting these coefficients, the normalized intensity I(r) is given by the following equation:
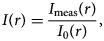 $$I( {r}) = {I_{{\rm meas}}( {r}) \over I_0( {r}) },\; $$
$$I( {r}) = {I_{{\rm meas}}( {r}) \over I_0( {r}) },\; $$where r = (x, y) are the real space coordinates, and I meas(r) is the measured image intensity. After this step, the mean intensity is equal to one.
Next, we scale the intensity range by calculating the image standard deviation σ, which is equal to the root mean square of the intensity  $\sigma = \sqrt {\langle ( I( {r}) -1) ^{2} \rangle }$. We then normalize the image by subtracting the mean μ and dividing by the standard deviation σ as described by the following equation:
$\sigma = \sqrt {\langle ( I( {r}) -1) ^{2} \rangle }$. We then normalize the image by subtracting the mean μ and dividing by the standard deviation σ as described by the following equation:
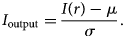 $$I_{\rm {output}} = {I( {r}) - \mu\over \sigma}.$$
$$I_{\rm {output}} = {I( {r}) - \mu\over \sigma}.$$The images in this dataset were originally 1024 × 1024 or 2048 × 2048 images. We resize these images down to the size of 256 × 256 pixels. Training/test labels were generated by hand using the Paint S software application for macOS.
Segmentation by Fourier Filtering
The defining feature for crystalline samples is their high degree of ordering and long-range translation symmetry. When crystalline samples are imaged along a low-index zone axis, the resulting images display local periodicity inside each crystalline grain. These periodic regions create sharply peaked maxima in the image's 2D Fourier transform amplitude that are closely related to Bragg diffraction from a periodic crystal. These peaks are not strictly speaking due to true Bragg diffraction, but are nevertheless often referred to as “Bragg spots” (Hÿtch, Reference Hÿtch1997; Galindo et al., Reference Galindo, Kret, Sanchez, Laval, Yanez, Pizarro, Guerrero, Ben and Molina2007). By applying numerical masks around a given Bragg spot, we measure the degree of local ordering over the image coordinates that corresponds to the associated crystal planes (Pan et al., Reference Pan, Kaplan, Rühle and Newnham1998). We have developed a “Bragg Filtering” procedure to segment the images into two classes, corresponding to clean atomically resolved graphene, and the amorphous surface contaminants. Bragg filtering is a standard procedure in many image processing routines for atomic-resolution micrographs such as lattice strain deformation mapping (Hÿtch, Reference Hÿtch1997). Our segmentation procedure is shown schematically in Figure 2.

Fig. 2. Segmenting surface contaminants and graphene lattices using Bragg filtering. (a) Input image data and (b) its Fourier transform amplitude. (c) Inverse Fourier transform after applying Bragg mask and (d) difference from input image data. (e) Absolute difference smoothed and then (f) threshold segmentation image. (g) Corresponding training data.
After preprocessing the initial image and padding the boundaries, we calculate a weighted Fourier transform G(q) of the image I(r), as shown in Figure 2a, given by the following equation:
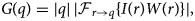 $$G( {q}) = \vert {q}\vert \, \vert {\cal F}_{{r} \to {q}} \{ I( {r}) W( {r}) \} \vert ,\; $$
$$G( {q}) = \vert {q}\vert \, \vert {\cal F}_{{r} \to {q}} \{ I( {r}) W( {r}) \} \vert ,\; $$where r = (x, y) and q = (q x, q y) are the real space and Fourier space coordinates, respectively,  ${\cal F}_{{r} \to {q}}$ is a 2D Fourier transform from real to Fourier space, and W(r) is a window function. Next, we find the local maxima of this image that are above a threshold value G thresh, as shown in Figure 2b.
${\cal F}_{{r} \to {q}}$ is a 2D Fourier transform from real to Fourier space, and W(r) is a window function. Next, we find the local maxima of this image that are above a threshold value G thresh, as shown in Figure 2b.
Next, we perform Bragg filtering by applying a 2D Gaussian distribution aperture to N Bragg peaks at positions q n, given by the following equation, where  ${\cal F}_{{q} \to {r}}$ is the inverse Fourier transform, and σ is the aperture size of the Bragg filter.
${\cal F}_{{q} \to {r}}$ is the inverse Fourier transform, and σ is the aperture size of the Bragg filter.
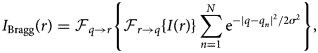 $$I_{{\rm Bragg}}( {r}) = {\cal F}_{{q} \to {r}} \left\{{\cal F}_{{r} \to {q}}\{ I( {r}) \} \sum_{n = 1}^{N} {\rm e}^{-\vert {q} - {q}_n\vert ^{2} / 2 \sigma^{2}} \right\},\; $$
$$I_{{\rm Bragg}}( {r}) = {\cal F}_{{q} \to {r}} \left\{{\cal F}_{{r} \to {q}}\{ I( {r}) \} \sum_{n = 1}^{N} {\rm e}^{-\vert {q} - {q}_n\vert ^{2} / 2 \sigma^{2}} \right\},\; $$Note that if symmetric pairs of Bragg diffraction peaks are used, the output image will be real-valued for all pixels. The resulting image is shown in Figure 2c. By subtracting the Bragg filtered image and the mean intensity from the original image, we generate an image consisting of the nonperiodic components, as shown in Figure 2d. Since we consider both negative and positive deviations to be signals from the surface contaminants, we take the absolute value and then low pass filter F LP(…) the output, giving an image like Figure 2e. In this figure, we see weak signals in the aperiodic boundary between the two graphene grains and a strong signal from the contaminants.
Finally, by choosing an appropriate mask threshold M thresh, we compute the desired segmentation output I seg(r) by Equation (3). The output is shown in Figure 2f.
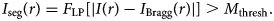 $$I_{{\rm seg}}( {r}) = F_{{\rm LP}} [ \vert I( {r}) - I_{{\rm Bragg}}( {r}) \vert ] > M_{\rm {thresh}}.$$
$$I_{{\rm seg}}( {r}) = F_{{\rm LP}} [ \vert I( {r}) - I_{{\rm Bragg}}( {r}) \vert ] > M_{\rm {thresh}}.$$This image compares favorably with the training dataset in Figure 2g. We accurately mask the contaminant region while not producing a “false postive” signal at the grain boundary. There are some false positives (FP) at the image boundary due to the breakdown of the lattice periodicity at the image boundaries. We use padding and normalization of the filter output to reduce the magnitude of these effects, but they are still present in some images. In practice, however, these edge artifacts are insignificant, since we cannot perform accurate measurements of the local atomic neighborhood at the image boundaries.
In this study, we have optimized the parameters σ, G thresh, and M thresh by using gradient descent to minimize the error between the segmentation maps generated and the training data. The Bragg filter parameters and performance were measured using fivefold cross-validation, giving values of σ = 0.0156 ± 0.0005 1/pixels, G thresh = 12.5 ± 0.1, and M thresh = 0.054 ± 0.000. The maximum number of Bragg peaks included was coarsely tuned but does not strongly affect the results (as long as it is high enough) and is therefore fixed at 24. The degree of low pass filtering both of the initial Fourier transform for Bragg peak detection and of the output difference image does not strongly affect the results. These two steps were performed by convolution with a 2D Gaussian function with 2 and 5 pixels standard deviation, respectively. The cross-validation ensures that the segmentation map accuracy was measured only on the validation subset of the data using parameters optimized from the other 80% of the training images. This procedure prevents over-fitting of the parameters to the training data. The accuracy of the resulting segmentation images is summarized in Table 1.
Table 1. Table of Performance Metrics.
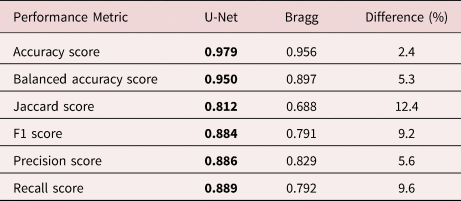
The bold values refer to the cases where the metrics are higher.
Deep Learning Segmentation
The U-Net architecture (Ronneberger et al., Reference Ronneberger, Fischer and Brox2015) is a CNN architecture based on a fully convolutional neural network, modified and extended to improve segmentation performance for medical and scientific (microscopy) segmentation tasks with limited training data. A fully convolutional neural network (FCN) is a common baseline deep learning architecture for semantic segmentation. It is formed using convolutional layers, pooling layers, nonlinear activation layers, and transposed convolution or upconvolution layers. It generates a network output equal in dimensions to the input, offering a classification for each input pixel. U-Net, which is a network based on the FCN, consists of a down-sampling path and an up-sampling path. Features from the down-sampling path are combined with features generated by the up-sampling path.
Each U-Net block in the down-sampling path consists of two 3 × 3 kernel convolution layers, a Rectified Linear Unit (ReLU) layer, and a 2 × 2 Maximum Pooling operation (MaxPool) layer. Each block in this path doubles the number of features in the previous block. Each block in the up-sampling path starts with an up-convolution operation that doubles the size of the feature maps but also reduces the number of feature by a factor of two. The features from this up-convolution operation are concatenated with the feature maps of the corresponding layer of the down-sampling path, bridged across the network. This is followed by two convolution layers and a single ReLU layer. The final layer in each U-Net block is a single 1 × 1 convolution layer that translates the final feature maps to two separate output classes, foreground and background.
The original U-Net architecture consists of a total of nine U-Net blocks. The modified U-Net architecture used in our work is illustrated in Figure 3. First, we use padded convolution, allowing us to produce a segmentation map with the same size as the input image. In order to build a model optimized to our data, we need to select the best hyperparameters. In the context of deep learning, hyperparameters are configurations set by the developer for a given data modeling problem. These are typically factors such as the learning rate, number of features, and depth of the network. The optimal hyperparameters for a given data modeling problem are not known from the start and are usually optimized through trial and error. In this study, we used the grid search method for hyperparameter tuning. Grid search involves exhaustive trial and error of all combinations of possible hyperparameters in a search space defined by the programmer. Once each version of the network was trained for 150 epochs, the model with the best performance based on the accuracy score was selected. The selected model was then retrained for an additional 300 epochs for two trials to generate accuracy metrics in order to verify full convergence. We optimized across three hyperparameters: number of features in the first block (with each subsequent block having an adjusted number of features to maintain network symmetry), number of blocks, and learning rate. We found that a U-Net with seven blocks and 32 features in the first block with a learning rate of 0.0001 achieved the highest accuracy of 0.9792 and a Jaccard score of 0.8125. For reference, the original U-Net model achieved an accuracy score of 0.9775 and a Jaccard score of 0.8015 using a 0.0001 learning rate, which yielded the best results for this network architecture as well. An additional advantage of a smaller network is achieving higher throughput which is essential for speed-dependent applications such as compression of real-time tracking.

Fig. 3. Our neural network architecture based on a scaled down version of U-Net. Each color arrow corresponds to different operations: 2D Convolution (Conv) with the kernel size of 3 × 3, Rectified Linear Unit (ReLU), Maximum Pooling (MaxPool) with the window size of 2 × 2, feature map Copying (Copy), and 2 × 2 Up (Up-conv). Each dark grey box represents a multichannel feature map resulting from the previous convolution operation where light grey boxes represent features copied from the down path to the up path. The number of feature maps between each convolution layer is labeled at that top of the box.
We train this network using an Adam optimizer (Kingma & Ba, Reference Kingma and Ba2014) to estimate parameters and pixel-wise cross-entropy as a loss function. We train for 300 epochs/approximately 41 min on an Nvidia GeForce GTX TITAN Black GPU using a learning rate of 0.0001. We use fivefold cross-validation for training. In this scheme, the dataset is split into five different groups. For each unique group, the data in that group are excluded, and the model is fit (from scratch) to the remaining four groups. Then this model is evaluated for accuracy metrics on the excluded fold in order to have a separate test set from the training set. At the end, the accuracy metrics from the fivefolds are averaged together. We repeat this experiment twice over the different folds, randomizing the dataset each trial, and then average the performance results for evaluation. We train our model using the PyTorch Deep Learning Framework (Paszke et al., Reference Paszke, Gross, Massa, Lerer, Bradbury, Chanan, Killeen, Lin, Gimelshein, Antiga, Desmaison, Köpf, Yang, DeVito, Raison, Tejani, Chilamkurthy, Steiner, Fang, Bai and Chintala2019).
Results and Discussion
In this section, we describe the results of our experiments. We first qualitatively compare the two methods in terms of the types of errors perceived via two separate cases. We then define several key performance metrics that are commonly used for evaluating segmentation models and report the performance of each model across these different metrics. We also describe how these networks can be used in atomic position workflows and discuss the different results of using each model. Finally, we offer an additional usage of the segmentation model for data reduction and sorting.
Qualitative Comparison
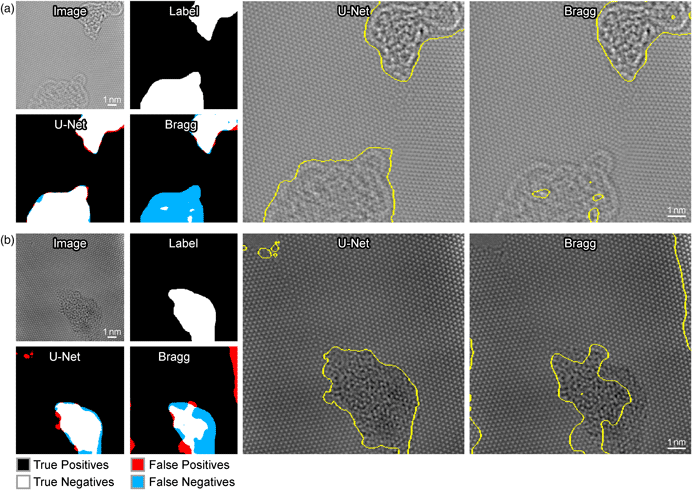
Figure 4 shows the performance of each method on two different example input images. Figure 4a shows an example of a critical failure by the Bragg filter to detect amorphous carbon. The Bragg filter produces incomplete segmentation results ignoring the bottom section of amorphous carbon, possibly due to its low contrast with respect to the other region of amorphous carbon at the top of the image. On the other hand, U-Net successfully identifies both of these regions as amorphous with precision. The resolution of our segmented boundaries (positional uncertainty of the edges) is roughly given by the feature size of the structures being imaged, which is approximately equal to the graphene lattice parameter.

Fig. 4. Comparison of the performance of the Bragg filter method and the U-Net method for segmentation. Detected errors are visualized on the left. True positives are shown in white, true negatives in black, FP in red, and false negatives in blue. The sectioning generated by U-Net is shown on the original image in the middle column, and the sectioning generated by the Bragg filter is shown in the right column.
Figure 4b shows an example where both the U-Net and Bragg Filter methods produce precise results; however, the results of the Bragg filter produce a substantial amount of false negatives (FN), whereas the U-Net method produces visibly superior results. Furthermore, the bright spot at the right side of the image is incorrectly identified as deformed graphene. U-Net, in contrast, has a much higher coverage of the main defect present in the image and does not incorrectly classify the bright spot as amorphous. Moreover, the U-Net segmentation detects FP of amorphous graphene in the upper left-hand corner. However, if one inspects the raw image, one will observe that there is, in fact, a small amount of amorphous graphene present in this part of the image that is overlooked during the labeling process. This demonstrates that the capabilities of deep learning surpass human performance on some tasks and effectively avoid over-fitting to human labels in certain cases.
While we limit the learned parameters of the Bragg filtering method to certain tunable parameters for the purposes of this work, it is important to note that in general Bragg filtering tends to perform poorly when using any set of global parameters on all images. While adding more learnable global parameters for the Bragg filtering approach might slightly improve results, it would still not generalize well to all images. The only way to significantly improve the Bragg filtering approach would be to hand tune the parameters for each individual image. This is one of the main strengths of the U-Net approach for this application and its ability to create a general objective function that performs well on images with varying structures and complexities.
Quantitative Comparison
Multiple metrics for evaluating segmentations and comparing models exist (Udupa et al., Reference Udupa, LaBlanc, Schmidt, Imielinska, Saha, Grevera, Zhuge, Currie, Molholt and Jin2002; Taha & Hanbury, Reference Taha and Hanbury2015), where the choice of a particular metric depends on the problem scope and goals. In the following, we consider and define several metrics, discuss their typical usage as well as limitations, and use them to compare our U-Net-based approach to Bragg filtering. Table 1 summarizes all results, which were computed using SciKit-Learn (Pedregosa et al., Reference Pedregosa, Varoquaux, Gramfort, Michel, Thirion, Grisel, Blondel, Prettenhofer, Weiss, Dubourg, Vanderplas, Passos, Cournapeau, Brucher, Perrot and Duchesnay2011). All metrics are defined in terms of true positives (TP), true negatives (TN), FP, and FN (see Table 2).
Table 2. Definitions of TP, FP, TN, and FN, Where Y is the Ground Truth and Y′ is the Value Predicted by a Model.

One typical score for evaluating a segmentation is pixel-wise accuracy, which is calculated as the total number of correctly classified pixels (TP, TF) divided by the number of predictions (i.e., total number of pixels)
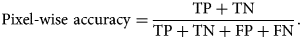 $$\hbox{Pixel-wise accuracy} = {{\rm TP} + {\rm TN}\over {\rm TP} + {\rm TN} + {\rm FP} + {\rm FN}}.$$
$$\hbox{Pixel-wise accuracy} = {{\rm TP} + {\rm TN}\over {\rm TP} + {\rm TN} + {\rm FP} + {\rm FN}}.$$Both segmentation methods achieve a pixel-wise accuracy above 95%, with U-Net performing roughly 2% better. While this metric is easy to interpret, it fails to properly take large class imbalances into account. In our case, segmentations are dominated by the background class, making the results of this metric potentially skewed. To avoid performance metric inflation due to class imbalance, balanced accuracy weighs samples by the inverse prevalence of their true classes. For the binary case, balanced accuracy is computed as follows:
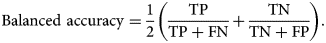 $$\hbox{Balanced accuracy} = {1\over 2} \left({{\rm TP}\over {\rm TP} + {\rm FN}} + {{\rm TN}\over {\rm TN} + {\rm FP}} \right).$$
$$\hbox{Balanced accuracy} = {1\over 2} \left({{\rm TP}\over {\rm TP} + {\rm FN}} + {{\rm TN}\over {\rm TN} + {\rm FP}} \right).$$Using this metric, we start to see the performance of our models to diverge numerically, with a difference of around 5% in favor of U-Net.
The Jaccard score and the F1 score are two of the most common metrics used for evaluating semantic segmentation models or in the presence of class imbalances. Mathematically, both metrics evaluate the same aspects of model performance (Taha & Hanbury, Reference Taha and Hanbury2015). The Jaccard score is computed as follows:
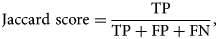 $$\hbox{Jaccard score} = {{\rm TP}\over {\rm TP} + {\rm FP} + {\rm FN}},\;$$
$$\hbox{Jaccard score} = {{\rm TP}\over {\rm TP} + {\rm FP} + {\rm FN}},\;$$and the F1 score is computed as follows:
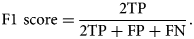 $$\hbox{F1 score} = {2{\rm TP}\over 2{\rm TP} + {\rm FP} + {\rm FN}}.$$
$$\hbox{F1 score} = {2{\rm TP}\over 2{\rm TP} + {\rm FP} + {\rm FN}}.$$Our U-Net model shows Jaccard and F1 improvements over the Bragg filtering method of approximately 12 and 9%, respectively. This further shows that for our class imbalanced dataset, U-Net holds significant advantages over Bragg filtering that are not as clear when using other metrics like accuracy.
To analyze performance differences more specifically in terms of FP and FN, we compare the precision and recall scores. Precision represents the ratio of correctly predicted positives to total predicted positives, i.e.,
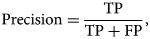 $${\rm Precision} = {{\rm TP}\over {\rm TP} + {\rm FP}},\;$$
$${\rm Precision} = {{\rm TP}\over {\rm TP} + {\rm FP}},\;$$while recall is the ratio of correctly predicted positives to the total number of positives in the ground truth, i.e.,
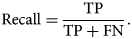 $${\rm Recall} = {{\rm TP}\over {\rm TP} + {\rm FN}} .$$
$${\rm Recall} = {{\rm TP}\over {\rm TP} + {\rm FN}} .$$High precision corresponds to a low FP rate, whereas high recall indicates to a low FN rate. Our study shows that U-Net achieves around 4 and 10% improvement over the Bragg filtering method in precision and recall scores, respectively.
It is clear from these results that deep learning outperforms the conventional Bragg filtering method across all quantitative metrics discussed here. An important consideration in deep learning approaches in general is that the limitations of the network performance depends on the problem being solved. In some cases where more diverse and complex features are being modeled, there may be need for a larger more memory intensive network and more training data. This depends entirely on the application and scope of the work.
Memory Usage and Speed
Using a workstation running an Intel Xeon 6138 CPU, the Bragg filtering routine requires 0.0203 s to process each 256 × 256 image. The RAM requirements for this routine are approximately 10 times those required for a single image, equal to 5 MB for a 256 × 256 pixel image. The U-Net implementation requires 0.0294 s per image, and uses 710MiB GPU RAM using an NVIDIA Titan Black GPU, for 256 × 256 size images.
Segmentation in Atomic Position Workflows
First, we demonstrate the use of Bragg and U-Net segmentation as part of an automated atom and bond-finding routine (Figure 5). After an initial illumination correction step, we determine candidate atom positions using the method described by Ophus et al. (Reference Ophus, Shekhawat, Rasool and Zettl2015). Subsequently, we discard all atom positions that fall inside contamination regions, which is determined either by using the mask output of the Bragg filtering routine or the U-Net segmentation routines, and remove them from the list of candidates. Finally, we connect neighboring atoms within a given distance threshold by candidate atomic bonds. Figure 5 shows candidate atom positions as white dots and candidate bonds colored by the bond angle modulo 60°, which is overlaid on the masks generated by the two segmentation filters. For this paper, we do not perform further any refinement of the atom positions and bonds and focus on segmentation quality.

Fig. 5. Three examples comparing Bragg and U-net filtering. (a) Output masks where both filters performed well, (b) masks where Bragg filter produced FP regions, and (c) masks where Bragg filter produced FN regions. In both (b) and (c), the U-Net filter produced a more accurate result.
Figure 5a shows scenario where both the Bragg filter and U-Net produce suitable results. In both cases, two surface contamination regions are correctly identified and masked, in agreement with the training data. In contrast, Figure 5b shows an example where the Bragg filter produces a series of FP regions (type I errors) at the boundary between the two graphene grains. This error can be addressed by decreasing the masking threshold M thresh, but this change would overall increase the error across the full dataset. Figure 5c shows an example of the kind of errors introduced into the Bragg filter segmentation when M thresh is set too low. In this example, the Bragg filter failed to mask off a region of surface contamination, which in turn leads to many erroneous atom positions and bonds. These two examples illustrate one weakness of the conventional Bragg filtering routine, which is that it relies on a small number of hyperparameters that cannot be set to values that will successfully perform the segmentation across the full dataset.
In comparison, the U-Net segmentation shown in Figures 5b and 5c outperforms the Bragg filter and produces successful results. These examples show that the deep learning approaches can be both more accurate and more robust than simpler, conventional imaging filters, i.e., Bragg filter. Both segmentation methods produce a FP at the left edge of Figure 5c, due to the correction of the low initial intensity value in that region causing boosting of the noise. However, edge pixels are significantly less valuable in analysis of the atomic structure, because the neighboring atomic environment is not visible at image boundaries.
Data Reduction and sorting
Lastly, we demonstrate how our segmentation methods can be applied to a data reduction and image sorting problem. Scientific experiments can yield tens thousands of images which can often have a high variance in terms of information that is useful for the particular experiment being practiced. To be able to sort images by the content ratio could be very useful to scientists. In the case of graphene images, a scientist may want to sort images by the ratio of graphene to amorphous carbon. We demonstrate the capability of our segmentation models to perform this task in Figure 6. Images are sorted based on what percentage is dominated by graphene rather than amorphous carbon. In some cases where frame rates of the data acquisition instrument are too high for the transference of the data to be done in a reasonable amount of time, it might be useful to compress certain parts of the image data. One way approach to this is the implementation of a run length compression on the content class that may be less important to that specific experiment being carried out.

Fig. 6. A subset of the images from our dataset sorted by the percentage of pixels that contain potentially useful information as computed by U-Net in decreasing order from left to right. Regions classified as amorphous carbon are highlighted in red.
It must be noted that such applications must be handled with caution. This use case of data compression comes with the risk of unintentionally removing valuable data from the original image. There is the possibility of biases existing in the curated training and test data that causes the U-net to incorrectly segment images in structures not represented in the training data. This would, in turn, cause incorrect segmentation and network outputs in real-world usage of the network. There is also the potential for adversarial attacks which involve the intentional crafting of modified input samples that result in incorrect outputs. The risks and concepts of adversarial attacks have been explored in various studies such as Finlayson et al. (Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane2019). It is vital to carefully inspect results in this use case and consider the risks associated in mission critical use cases of neural networks.
Conclusion
In this study, we have compared two methods to perform the segmentation of complex features in phase-contrast HRTEM images of monolayer graphene. The two methods we used were a conventional Bragg filtering algorithm and a deep learning method utilizing the U-Net architecture. The U-Net filter outperformed the conventional method in every performance metric tested and was very robust against incorrect determination of structurally important regions. The U-Net method has the additional advantage of being adaptable to many different pixel-wise classification problems and only requires a labeled dataset with a sufficient number of images that contain the desired segmentation features to perform the training. In the future, it may be possible to randomly generate structures and perform image simulation to automatically generate labeled training datasets, removing even this relatively minor barrier. Because of their generality and robustness, deep learning methods such as U-Net segmentation are extremely valuable for fully automated image processing in TEM.
Availability of data and materials
The adapted U-Net source code, HRTEM images, and the amorphous region-labeled images for training are all available at our graphene-u-net GitHub repository.
Acknowledgments
This work was supported by the Office of Advanced Scientific Computing Research for the Computational Research Division of the U.S. Department of Energy under Contract No. DE-AC02-05CH11231. Work at the Molecular Foundry was supported by the Office of Science, Office of Basic Energy Sciences, of the U.S. Department of Energy under Contract No. DE-AC02-05CH11231. R.S., A.B., and G.H.W. acknowledge additional support of the Laboratory-Directed Research and Development project “Network Computing for Experimental and Observational Data Management.” C.O. acknowledges additional support from the Department of Energy Early Career Research Program award. We thank NVIDIA for donation of GPU resources.









 Open access
Open access