



1. Introduction
In this article, we present a corpus graph-based computational approach to analysis of lexical similarity, lexical ambiguity and identification of semantic domain relatedness based on the cognitive linguistics assumption that coordination constructions instantiate conceptual relatedness (Langacker Reference Langacker2009). In contrast to methods based on the distributional semantic approach (Harris Reference Harris1954), which compute paradigmatic lexical similarity on the basis of pure word distribution and syntagmatic collocation (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013a; Mikolov, Yih, and Zweig 2013b; Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018), the underlying idea of this method is to use the conjunctions and disjunctions in coordinated lexical structures as markers of semantic relatedness (Progovac Reference Progovac1998; Widdows and Dorow Reference Widdows and Dorow2002; Haspelmath Reference Haspelmath2004; Langacker Reference Langacker2009; Perak Reference Perak2017; Van Oirsouw Reference Van Oirsouw2019) in constructing a corpus-based lexical network of collocations in coordination construction and implementing graph algorithms to represent semantic structure and measure lexical similarity.
The seemingly simple coordinated construction [lexeme
 $_{\textrm{A}}$
and/or lexeme
$_{\textrm{A}}$
and/or lexeme
 $_{\textrm{B}}$
] (Van Oirsouw Reference Van Oirsouw2019), marked with the logical connectives and and or, forms the backbone of this syntactic-based network approach, as it conventionally expresses the conceptual and categorical association between conjoining lexemes. For example, in sentences (1–2), the noun chair is conjoined with the concepts table and professor, respectively, using the connective and:
$_{\textrm{B}}$
] (Van Oirsouw Reference Van Oirsouw2019), marked with the logical connectives and and or, forms the backbone of this syntactic-based network approach, as it conventionally expresses the conceptual and categorical association between conjoining lexemes. For example, in sentences (1–2), the noun chair is conjoined with the concepts table and professor, respectively, using the connective and:
-
(1) There is a small table and some chairs.
-
(2) She is a professor and chair in the Department of the History of Art and Architecture.
The method begins with the extraction of coordination collostructions (Stefanowitsch and Gries Reference Stefanowitsch and Gries2003) from a grammatically tagged corpus and proceeds to the construction of a coordination lexical network that captures the emergent conceptual space of lexemes and semantic domains structured by the semantic features of the coordination relation. The lexical subgraph clusters and their prominent nodes reveal the polysemous nature of the source lexeme. From the perspective of language use (Ellis, O’Donnell, and Römer Reference Ellis, O’Donnell and Römer2013), the lexical network clusters represent the cognitively latent associative domains necessary for understanding the overall (poly)semantic structure of a source lexeme in a given language community.
The main contributions and features of this Construction Grammar Conceptual Network (ConGraCNet) coordination methodology include:
A computational method for constructing lexical networks from tagged corpora;
A syntactic-semantic approach that can be universally implemented in a language with expressed coordination construction;
A syntactic-semantic coordination dependency-based method for extracting conceptually associated nouns, adjectives or verbs from the selected tagged corpus that does not rely on external ontologies or dictionaries;
A pruning procedure to fine tune the granularity and salience of the associated lexical networks based on their centrality measures;
Implementation of graph-based community detection algorithms for identification of coherent lexical communities as associated semantic domains;
A method for representing prototypical conceptual distribution patterns from a cross-cultural framing perspective;
A web-based application demonstrating the ConGraCNet method, available at http://emocnet.uniri.hr, and the Python script used to store corpus data from the Sketch Engine API serviceFootnote a in the Neo4j graph database.Footnote b
The syntactic–semantic construction graph-based analysis methodology has been applied in our ongoing research that includes the tasks of identifying semantic similarity in: linguistic expression of emotions (Perak Reference Perak2020b; Perak and Ban Kirigin Reference Perak and Ban Kirigin2020), lexical communities labelling (Ban Kirigin, Bujačić Babić, and Perak Reference Ban Kirigin, Bujačić Babić and Perak2021; Perak and Ban Kirigin Reference Perak and Ban Kirigin2021), detection of swear words in Croatian (Perak, Damčević, and Milošević Reference Perak, Damčević and Milošević2018) and the cultural framing of the nation (Perak Reference Perak2019b; Perak Reference Perak2019a; Perak Reference Perak2020a). The method has shown promising results in identifying semantic domains and their sense clusters, which represent the global and local semantic similarity structures of nouns, adjectives and verbs in a specific corpus. Using this method as a basis for distinguishing word senses, we were able to enrich and propagate sentiment dictionaries and provide a sentiment potential based on the lexical sense structure (Ban Kirigin et al. Reference Ban Kirigin, Bujačić Babić and Perak2021). Moreover, in combination with other syntactic dependencies and lexical resources, it also proved valuable for lexical label assignment of polysemous lexemes using the best hypernym candidates (Perak and Ban Kirigin Reference Perak and Ban Kirigin2021).
The article is organized as follows. Related research and the theoretical foundations of the approach are presented in Section 2. Section 3 presents the design of the method. In Section 4, we demonstrate the results of the methodology using examples with different linguistic parameters. In Section 5, we discuss the effectiveness of the method and conclude with Section 6, where we also propose avenues for future research.
2. Theoretical foundations and related work
ConGraCNet is an interdisciplinary linguistic computational method that draws on the insights, tools and resources of computational linguistics, cognitive linguistics, logic and graph analysis. In this section, we provide an overview of the main theoretical foundations and related work.
2.1 Linguistic aspects
The ConGraCNet method is linguistically based on the theoretical perspective of Cognitive Linguistics (CL), which views language patterns as symbolic extensions of human conceptualizing abilities (Tomasello and Brooks Reference Tomasello and Brooks1999; Lakoff et al. Reference Lakoff and Johnson1999; Nazzi and Gopnik Reference Nazzi and Gopnik2001; Tummers, Heylen, and Geeraerts Reference Tummers, Heylen and Geeraerts2005; Langacker Reference Langacker2008; Gentner Reference Gentner2016). Language is a complex adaptive system (Ellis Reference Ellis2019) and a cognitive communication tool for inducing situated and embodied categorization (Bergen and Chang Reference Bergen and Chang2005).
Within the CL approach, the influential syntactic–semantic framework of Construction Grammars theories (CxG) asserts that grammar is not just a formal system consisting of stable but arbitrary rules for defining well-formed sequences, but a meaningful continuum of lexicon, morphology and syntax. They regard constructions, symbolic units that connect a morphosyntactic form to a meaning, as the primary objects of grammatical description (Langacker Reference Langacker1987; Goldberg Reference Goldberg1995; Croft Reference Croft2001; Goldberg Reference Goldberg2006; Croft Reference Croft2007; Langacker Reference Langacker2008).
A construction is defined as either a linguistic pattern that has some aspect of its form or function that is not strictly predictable from its component parts (Goldberg Reference Goldberg1995) or a pattern that occurs with sufficient frequency (Goldberg Reference Goldberg2006), a schema abstracted from expressions capable of being psychologically entrenched and conventionalized in a speech community (Langacker Reference Langacker2009; Ellis et al. Reference Ellis, O’Donnell and Römer2013). With this perspective in mind, we consider lexical co-occurrence and distribution in a construction as indicators of meaning, with the following implications relevant to the implementation of the ConGraCNet methodology:
A corpus represents a particular configuration of construction networks within a community of speakers. A corpus is a collection of texts that can be used to analyse linguistic patterns and abstract conceptualizations within a community of communicators. Corpus studies and corpus-based computational methods have been used to identify different types of construction networks (Perek Reference Perek2015; Dunn Reference Dunn2017; Perak Reference Perak2019b). The corpus-driven data lend themselves to various types of descriptive and inferential statistical techniques (Yoon and Gries Reference Yoon and Gries2016). In addition, very large corpora are essential for training vector representations of words that have been shown to store constructional information (Madabushi et al. Reference Madabushi, Romain, Divjak and Milin2020).
It should be noted, however, that a corpus does not represent the absolute value of lexical senses or conceptual relations. Rather, it is a set of linguistic utterances that can reveal cross-cultural and intra-cultural synchronic variations and diachronic changes (Höder Reference Höder2018; Sommerer and Smirnova Reference Sommerer and Smirnova2020). The corpus-based methods, such as ConGraCNet, can be used to identify usage-based lexical sense structures in a particular language community, as exemplified in Section 4.3.
Syntactic–semantic constructions are symbolic pairings of linguistic forms and conceptual frames that refer to a particular entity, property or relation. Constructions express the embodied categorization of perceived and conceptualized objects and construed relations, see Figure 1.
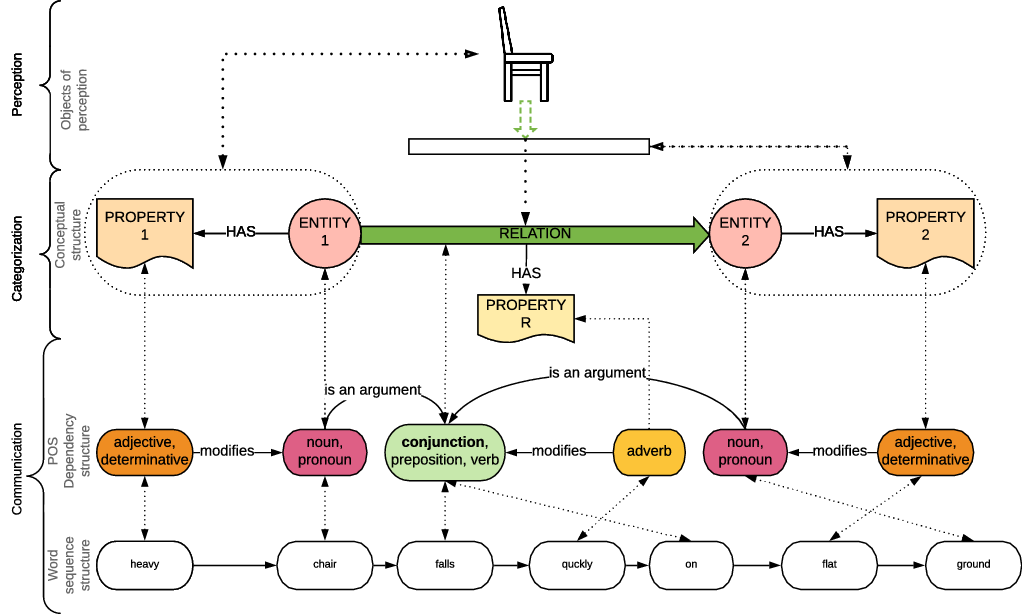
Figure 1. The emergence of the syntactic–semantic form function communication patterns from the categorization and perception.
Syntactic–semantic constructions categorize and impose the conceptualization patterns of:
entities,
properties of entities,
relations between entities, and
properties of relations
using the conventionalized morphosyntactic classes. For example, the linguistic utterance ‘the heavy chair falls quickly on the flat ground’ conceptualizes an event with two objects: chair, ground, and the relations to fall and on. The lexeme chair is classified as an entity E1 with property x1: heavy. The categorization profiles a processual relation Ry1: to fall and a spatial relation Ry2: on with the entity E2: ground with the properties E2x1: flat. The lexicalization to fall frames the dynamic process that entity E1 undergoes, while the lexical unit on captures the spatial relation between two entities. The processual relation has a set of properties Ry1 x1: fast.
Syntactic–semantic constructions reflect the conceptualized structure of the world, while imposing conventionalized symbolic patterns on the word sequence structure (Ungerer Reference Ungerer2017). Each syntactic–semantic pattern expresses a particular conceptual and ontological relation. Of the many linguistic syntactic–semantic constructions identifiable by formal models (Beekhuizen and Bod Reference Beekhuizen and Bod2014; Dunn Reference Dunn2017; Dunn and Madabushi Reference Dunn and Madabushi2021) that are highly conventionalized and framed as universal (Universal Dependencies Project 2014; De Marneffe and Nivre Reference De Marneffe and Nivre2019) or less conventionalized and language-specific (Hilpert Reference Hilpert2014), we focus on a linguistic construction that instantiates the conceptualization of sense similarity between two or more identical part-of-speech lexemes: (a) entities lexicalized as nouns, (b) properties lexicalized as adjectives or (c) verb relations and extract their collocations, as shown in the Section 4.2.
Coordinated construction [lexeme A and/or lexeme B] reveals prototypical conceptualizations of entities that are ontologically related to the same domain.The syntactic–semantic pattern of conjoining, disjoining and sequencing of lexical items [lexeme A +and/or+ lexeme B] is also called coordination, since the arguments are syntactically non-dependent (Chantree et al. Reference Chantree, Kilgarriff, De Roeck and Willis2005; Van Oirsouw Reference Van Oirsouw2019). The nature of coordination construction has been described syntactically from the generative perspective (Progovac Reference Progovac1998) and analysed by the authors of functional typological linguistics (Haspelmath Reference Haspelmath2004), corpus linguistics (Chantree et al. Reference Chantree, Kilgarriff, De Roeck and Willis2005) and construction grammar (Langacker Reference Langacker2009). Langacker recognizes the parallelism and schematic co-equality of the conjuncts and disjuncts in coordination, not only because of their shared part of speech grammatical category, but also because of their ability to represent distinct and separate types whose emergent properties cannot be reduced to those of their components.
The lack of syntactic dependence between co-occurring lexemes in a coordinated construction indicates their semantic association: Words are grouped together because they are ontologically related with respect to an abstract semantic domain, or are part of the same semantic domain. Saliently related elements form a meronymically linked emergent set.
In terms of conventionalization, coordination is one of the most frequent type of constructions in any corpus. For example, in various large web corpora represented in the Sketch Engine service,Footnote c the lemma and is almost always among the first five most frequent words: in English Web 2013 (enTenTen13Footnote d : 19,685,733,337 words) the lemma and is third most frequent with 570,243,588 occurrences, in German Web 2018(deTenTen18Footnote e : 5,346,041,196 words) the lemma und is also third with 158,049,447 occurrences, in Italian Web 2020 (itTenTen20Footnote f : 12,451,734,885 words) the lemma e is also third with 352,470,372 occurrences, in French Web 2017 (frTenTen17Footnote g : 5,752,261,039 words) the lemma et is fourth with 135,489,621 occurrences, in Croatian Web (hrWaC 2.2Footnote h : 1,210,021,198 words) the lemma i is second with 44,774,568 occurrences, etc. Regardless of the size, language and domain of the corpus, the logical connectives themselves take a large proportion of the overall lexical occurrences, enabling the creation of a rich coordination lexical network from the large number of frequently collocated nouns, adjectives and verbs. The CQL query that identifies nouns conjoined with logical connectors: [tag=‘N.*’] [lemma=‘and’ | lemma=‘or’ | lemma=‘nor’ | lemma=‘neither’] [tag=‘N.*’] yields 10,573,955 collocations or 465.23 per million tokens in enTenTen13 and 13,083,035 collocations or 506.59 per million tokens in enTenTen18, which makes it one of the most frequent lexical patterns. In the case of nouns, we have analysed the Croatian hrWac 2.2. corpus of 1,210,021,198 words, in which 86,360 unique lemmas occur in conjunction. They can be considered as a subcategory of the total tagged nouns in the corpus. The proportion of nouns in conjunction in such a large corpus can be relevantly represented (as correctly tagged) if we filter at least the nouns that occur five or more times, that is 117,517 lemmas. This amounts to a ratio of 0.73 in coordination to relevant nouns in the corpus. If we raise the threshold to lemmas with a frequency of eight or more, we arrive at 87,842 nouns or a ratio 0.98. This means that the majority of the relevant lemmas will be represented in the lexical coordination network.
The conventional aspect of this construction is also represented by the fact that it is syntactically formalized in all major NLP syntactic parsing models (Nivre et al. Reference Nivre, De Marneffe, Ginter, Goldberg, Hajic, Manning, McDonald, Petrov, Pyysalo, Silveira, Tsarfaty and Zeman2016; Qi et al. Reference Qi, Zhang, Zhang, Bolton and Manning2020), although it is not always defined in the same way. For example, in Universal Dependencies it is defined as a class conjunction, an asymmetric dependency relation between two elements connected by a coordinating conjunction, such as and, or. In contrast, in the predefined grammatical relations in Sketch Engine grammars (Kilgarriff and Tugwell Reference Kilgarriff and Tugwell2001; Kilgarriff et al. Reference Kilgarriff, Baisa, Bušta, Jakubček, KováŘ, Michelfeit, Rychlý and Suchomel2014) for English corpora, coordination is usually referred to as and/or.
From the cross-linguistic perspective, it seems that the method based on the coordination can be universally implemented, because: ‘in English and other European languages, the coordinators “and” and “or” can link a variety of categories: noun phrases, verb phrases, clauses, adjective phrases, prepositional phrases, and others.’ (Haspelmath Reference Haspelmath2004). This feature is further methodologically explained in Section 4.3.
2.2 The computational linguistics aspects
In the last decade, there have been a number of approaches to computational identification of word similarity (Minkov and Cohen Reference Minkov and Cohen2008; Turney Reference Turney2008; Faruqui et al. Reference Faruqui, Tsvetkov, Rastogi and Dyer2016), word relatedness (Halawi et al. Reference Halawi, Dror, Gabrilovich and Koren2012; Yih and Qazvinian Reference Yih and Qazvinian2012), word sense disambiguation (Schütze Reference Schütze1998; Lin Reference Lin1998; Pantel and Lin Reference Pantel and Lin2002; Dorow and Widdows Reference Dorow and Widdows2003; Navigli and Velardi Reference Navigli and Velardi2005; Navigli Reference Navigli2009) and classification of related semantic domains (Gliozzo and Strapparava Reference Gliozzo and Strapparava2009; Turney Reference Turney2012; Velardi, Faralli, and Navigli Reference Velardi, Faralli and Navigli2013). Techniques for solving these problems are either combined or broadly classified into two main categories: top-down approaches, which rely on pre-existing knowledge resources such as thesauri, semantic networks, taxonomies or encyclopaedias and bottom-up (or unsupervised) approaches, which exploit the distributional properties of words from corpora.
Earlier approaches use linguistic experts to identify lexical relations and to label the type of lexical relations. One of the best-known approaches is the WordNet project (Miller Reference Miller1995, Reference Miller1998), in which nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. The WordNet and other manually created lexical resources, while highly representative, often do not adequately cover the different lexical domains and their relations due to semantic variability and ever-increasing ambiguity. Even the largest curated WordNet, the English WordNet, with 117 000 synsets, certainly does not represent the full range of concepts in the stylistic/genre/diachronic variations of sense that occur in temporal and cultural contexts. The problems of scarcity are even greater in the WordNets of less curated languages.
On the other hand, there is an increasing tendency to extract word similarities and meanings directly from the context of word occurrence, taking advantage of the paradigmatic idea that similar senses occur in similar contexts (Harris Reference Harris1954; Firth Reference Firth1957). This bottom-up approach to word distribution has gained prominence with the rise of computational capabilities for processing large corpora. One of the most prominent examples is the NLP method for creating word embeddings (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013a). Most word embeddings are modelled as a multi-class classification problem, with the aim of evaluating words in their sequential context (Zhou and Srikumar Reference Zhou and Srikumar2019). An important result of this method is a list of vector space measures of similarity between words based on the similar context in which these words occur (Landauer, Foltz, and Laham Reference Landauer, Foltz and Laham1998; Goldberg and Levy Reference Goldberg and Levy2014; Pennington, Socher, and Manning Reference Pennington, Socher and Manning2014). This empirical approach to capturing lexical patterns has overcome the knowledge acquisition bottleneck created by the lack of lexical resources. More importantly, it effectively stores valuable linguistic information from large corpora (Mikolov et al. 2013b), mainly due to the generalization power (Goldberg Reference Goldberg2016).
The recent rapid development of computational resources (e.g., GPU), the availability of large training data and the success of pattern recognition research with neural networks has given a boost to many machine learning tasks, especially those represented in Euclidean space. Natural language processing has been overwhelmed by deep neural networks (DNNs) such as Deep Bidirectional Transformers, which have shown significant improvements over traditional approaches on many tasks (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018). Despite their conceptually simple pre-training of representations on unlabelled text, they exhibit high prediction accuracy resulting from their ability to learn discriminative feature representations.
The main drawback of DNNs is related to the black-box learning representation in terms of the information leveraged by the models for prediction, the flow of information through the layers in the different models and the evolution of the models during training (Guan et al. Reference Guan, Wang, Zhang, Chen, He and Xie2019), which has led to research efforts to alleviate the lack of interpretability (Kovaleva et al. Reference Kovaleva, Romanov, Rogers and Rumshisky2019). Sequential embedding methods, moreover, are generally hampered by an important semantic limitation that Camacho-Collados and Pilehvar (Reference Camacho-Collados and Pilehvar2018) refers to as ‘the meaning conflation deficiency’. The conflation is caused by the ambiguous symbolic nature of a lexeme, which can have multiple meanings, referred to as word senses, each referring to an ontologically distinct thing, property or process. The motive for this referential divergence lies in the diachronic dimension of lexical usage, where frequent and conceptually more complex words tend to acquire additional references that meronymically and/or metaphorically extend the original etymological meaning. For example, chair as a social position attributed to a person is a meronymic extension of an object chair used for sitting in a conferential interaction. Nouns, adjectives and verbs can take on a range of senses depending on context of use, genre, style, etc. Since the context-based vectors do not represent the morphosyntactic properties of the words and their relations, the resulting model lacks relational interpretability. Even if the two words are closely related in the vector space, we cannot identify the type of the functional relation that brought them together. So, is chair close to professor in the vector space because he/she sits on it, or do they represent closely related/interchangeable social functions? Furthermore, representing a single lexeme without explicit grammatical information can lead to meaning conflation and poor discrimination between different senses, without extensive and robust computation of context. However, recent research has shown that contextualized word embeddings carry useful semantic information for sense disambiguation (Wang et al. Reference Wang, Pruksachatkun, Nangia, Singh, Michael, Hill, Levy and Bowman2019) and that this approach can be combined with structured sources of knowledge such as lexical knowledge bases (Scarlini, Pasini, and Navigli Reference Scarlini, Pasini and Navigli2020b) and in multilingual contexts (Scarlini et al. Reference Scarlini, Pasini and Navigli2020a) with significant improvements in semantic tasks.
Apart from this contextualized approach, the complementary way to deal with the problems of semantic conflation is to go beyond merely processing the sequential nature of a text and focus on the grammatical features of the linguistic structures. The emergence of improved Part of Speech Taggers and Dependency Parser models (Manning et al. Reference Manning, Surdeanu, Bauer, Finkel, Bethard and McClosky2014; Honnibal Reference Honnibal2015; Nivre et al. Reference Nivre, De Marneffe, Ginter, Goldberg, Hajic, Manning, McDonald, Petrov, Pyysalo, Silveira, Tsarfaty and Zeman2016) enabled large-scale dependency-based lexical representation and its computational use (Lin Reference Lin1998; Pantel and Lin Reference Pantel and Lin2002; Widdows and Dorow Reference Widdows and Dorow2002; Dorow and Widdows Reference Dorow and Widdows2003; Navigli and Velardi Reference Navigli and Velardi2005; Minkov and Cohen Reference Minkov and Cohen2008).
Dependency-based word2vec embeddings (Levy and Goldberg Reference Levy and Goldberg2014) compute the context of words based on dependency relations. Compared to sequence-based skip-gram embeddings, which tend to yield broad topical similarities, dependency-based word embeddings exhibit more functional similarities of a cohyponymous nature (Levy and Goldberg Reference Levy and Goldberg2014). In the study evaluating the cognitive plausibility of eight different word embedding models in terms of their usefulness for predicting neural activation patterns associated with concrete nouns, the syntactically informed, dependency-based word2vec model achieved the best overall performance (Abnar et al. Reference Abnar, Ahmed, Mijnheer and Zuidema2017).
The ConGraCNet method shares similarities with the dependency-based word embeddings methods in that they all derive their network structure from automatically generated dependency parse-trees. Overall, the syntactic dependency network representations are cognitively more plausible, interpretable and concise than the skip-gram word embeddings type of the bottom-up approach of lexical representation due to the inherent storage of semantic information, but still provide rich, cognitively reliable and comprehensive data.
The ConGraCNet coordination dependency graph analysis shares methodological similarities with the semantic disambiguation methods described in Widdows and Dorow (Reference Widdows and Dorow2002), Dorow and Widdows (Reference Dorow and Widdows2003) or graph methods for collocation representation such as GraphColl (Brezina et al. Reference Brezina, McEnery and Wattam2015), LancsBox (Brezina, Weill-Tessier, and McEnery Reference Brezina, Weill-Tessier and McEnery2020) or AntConc (Anthony Reference Anthony2019; Zih, El Biadi, and Chatri Reference Zih, El Biadi and Chatri2021). The ConGraCNet method, not only enables the exploration of syntactic constructions with different part-of-speech classification and collocation measures, but also offers graph-based extraction capabilities in terms of tuning the particular lexical network granularity and size based on several centrality and clustering algorithms. The method also allows the practical application and theoretical explanation of the use of other dependencies to explore bottom-up label propagation and other linguistic phenomena such as metonymy, antonymy, analogy and metaphor, which is however beyond the scope of this article. The results of the ConGraCNet graph computation can be combined with other lexical resources such as the WordNet synsets, sentiment dictionaries (Ban Kirigin et al. Reference Ban Kirigin, Bujačić Babić and Perak2021), natural language understanding systems and language generation systems to create a range of possible downstream applications.
2.3 Logical grounding of semantic aspects
Semantic aspects of the coordinated construction [lexeme
A and/or lexeme
B] have their corresponding formalization in logic. In mathematical logic (van Dalen Reference van Dalen2004; Partee, ter Meulen, and Wall Reference Partee, ter Meulen and Wall2012), connectives such as and (also known as conjunction and written
 $\land$
) and or (also known as disjunction and written
$\land$
) and or (also known as disjunction and written
 $\lor$
), called logical connectives, have specific syntactic and semantic aspects. They assign a semantic value to syntax, that is, they associate truth values with logical formulae (Humberstone Reference Humberstone2011).
$\lor$
), called logical connectives, have specific syntactic and semantic aspects. They assign a semantic value to syntax, that is, they associate truth values with logical formulae (Humberstone Reference Humberstone2011).
Formulas are normally associated with declarative sentences called propositions. However, due to naturally occurring elliptical cohesion, which reduces redundancy in communication, it is possible to map formulas with logical connectives
 $\land$
and
$\land$
and
 $\lor$
onto smaller lexical structures such as single lexemes. Namely, we relate the logical connectives
$\lor$
onto smaller lexical structures such as single lexemes. Namely, we relate the logical connectives
 $\land$
and
$\land$
and
 $\lor$
with the lexical connectives and and or, and associate formulas of the form
$\lor$
with the lexical connectives and and or, and associate formulas of the form
 $A \land B$
and
$A \land B$
and
 $A \lor B$
with the constructions [lexeme
A+and+lexeme
B] and [lexeme
A+or+lexeme
B], respectively.
$A \lor B$
with the constructions [lexeme
A+and+lexeme
B] and [lexeme
A+or+lexeme
B], respectively.
Logical connectives are used syntactically in the construction of more complex formulae from the composition of atomic formulae. For example, if A and B are formulas, then
 $A \land B$
and
$A \land B$
and
 $A \lor B$
are also formulas. The semantics of a formula follows directly and unambiguously from its syntax. Logical connectives are considered semantically as functions, often called logical operators. Logical operators provide the semantic value of a formula, which is either true or false in a given interpretation. The interpretation of more complex formulae is derived from the interpretation of the atomic constituent formulae. Each interpretation represents a ‘state of affairs’, that is, a view of truth in a world that is logically consistent with respect to the logical operators.
$A \lor B$
are also formulas. The semantics of a formula follows directly and unambiguously from its syntax. Logical connectives are considered semantically as functions, often called logical operators. Logical operators provide the semantic value of a formula, which is either true or false in a given interpretation. The interpretation of more complex formulae is derived from the interpretation of the atomic constituent formulae. Each interpretation represents a ‘state of affairs’, that is, a view of truth in a world that is logically consistent with respect to the logical operators.
In the case of conjunction, the truth value of formulae of the form
 $A \land B$
is derived from the interpretation of the less complex formulae A and B in the following way:
$A \land B$
is derived from the interpretation of the less complex formulae A and B in the following way:
 $A \land B$
is true if and only if A is true and B is true. The lexical connective and is prototypically used to express associating relations between lexemes. In naturally occurring communication, conjoined lexemes tend to form a coherent conceptual set, typically referring to an abstract category or semantic domain. For example, the expression ‘table and chair’ refers to the abstract category furniture, ‘bread and butter’ refers to food, etc.
$A \land B$
is true if and only if A is true and B is true. The lexical connective and is prototypically used to express associating relations between lexemes. In naturally occurring communication, conjoined lexemes tend to form a coherent conceptual set, typically referring to an abstract category or semantic domain. For example, the expression ‘table and chair’ refers to the abstract category furniture, ‘bread and butter’ refers to food, etc.
In the case of disjunction, the semantic value of the formula
 $A \lor B$
is true if and only if A is true or B is true, possibly both. Accordingly,
$A \lor B$
is true if and only if A is true or B is true, possibly both. Accordingly,
 $A \lor B$
is false if and only if A is false and B is false, representing the inclusive or. In the case of a somewhat similar type of exclusive or (denoted by Xor,
$A \lor B$
is false if and only if A is false and B is false, representing the inclusive or. In the case of a somewhat similar type of exclusive or (denoted by Xor,
 $\oplus$
or
$\oplus$
or
 $ \mathbin{ \underline{\vee} }$
), the semantic value of a formula of the form
$ \mathbin{ \underline{\vee} }$
), the semantic value of a formula of the form
 $A \mathbin{ \underline{\vee} } B$
is the following:
$A \mathbin{ \underline{\vee} } B$
is the following:
 $A \mathbin{ \underline{\vee} } B$
is true if and only if A is true or if B is true, but not both.
$A \mathbin{ \underline{\vee} } B$
is true if and only if A is true or if B is true, but not both.
Both inclusive and exclusive disjunctions can be expressed in linguistic communication. The connective or typically frames exclusive options, choices or alternatives. Although the disjunction in the exclusive sense obviously implies a conceptual difference, the concepts frequently collocated with or tend to refer to opposite features of a radially distributed abstract category or semantic domain (Lakoff Reference Lakoff2008), such as ‘dead or alive’ for the domain living beings, ‘black or white’ for colour.
The commutative nature of the logical connectives and and or, with the same semantics of
 $A \land B$
and
$A \land B$
and
 $B \land A$
, and, respectively, of
$B \land A$
, and, respectively, of
 $A \lor B$
and
$A \lor B$
and
 $B \lor A$
, is reflected in the undirected nature of the lexical network construction, as explained in more detail in Sections 3.1 and 3.2. The logical function of the lexical connectives and and or is further reinforced by the second-order friend-of-a-friend (FoF) pattern relation, as demonstrated in Section 3.2. Namely, the FoF relation expresses the transitivity of the and/or connectives:
$B \lor A$
, is reflected in the undirected nature of the lexical network construction, as explained in more detail in Sections 3.1 and 3.2. The logical function of the lexical connectives and and or is further reinforced by the second-order friend-of-a-friend (FoF) pattern relation, as demonstrated in Section 3.2. Namely, the FoF relation expresses the transitivity of the and/or connectives:
 $xRy \land yRz \implies xRz$
, that is, if lexeme
A and lexeme
B are connected and lexeme
B and lexeme
C are connected, then lexeme
A and lexeme
C are also connected. Therefore, we rely on the FoF networks and graph theoretic analysis to reveal the structure of semantically related concepts and domains. In our approach, we use this feature to identify semantically coherent lexical domains, as implemented in Section 3.5.
$xRy \land yRz \implies xRz$
, that is, if lexeme
A and lexeme
B are connected and lexeme
B and lexeme
C are connected, then lexeme
A and lexeme
C are also connected. Therefore, we rely on the FoF networks and graph theoretic analysis to reveal the structure of semantically related concepts and domains. In our approach, we use this feature to identify semantically coherent lexical domains, as implemented in Section 3.5.
Other traditional logical connectives, such as the negation (
 $\neg$
, not), the conditional (
$\neg$
, not), the conditional (
 $\rightarrow$
, if then) and the biconditional (
$\rightarrow$
, if then) and the biconditional (
 $\leftrightarrow$
, if and only if), which are most commonly used to express mathematical statements, are not prototypically expressed in natural languages by dependency structures or syntactic collocations. For example, the conditional is usually expressed by more complex lexical structures, which may relate entire phrases or even more complex parts of sentences. For example, statements like: If you try, you might succeed. and You might succeed if you try. Also, phrases expressing a biconditional are quite rare in non-mathematical texts.
$\leftrightarrow$
, if and only if), which are most commonly used to express mathematical statements, are not prototypically expressed in natural languages by dependency structures or syntactic collocations. For example, the conditional is usually expressed by more complex lexical structures, which may relate entire phrases or even more complex parts of sentences. For example, statements like: If you try, you might succeed. and You might succeed if you try. Also, phrases expressing a biconditional are quite rare in non-mathematical texts.
Similarly, there are several ways of expressing negation in natural language. For example, the negation of the statement: This T-shirt is white. can be expressed by This T-shirt is not white, It is not true that this T-shirt is white or even This T-shirt is colourful. The Sketch Engine extraction of coordination dependencies that we use in the ConGraCNet application, captures some forms of negation in language, such as the ‘… neither … nor’ collocation, as in the EnTenTen13 corpus utterance she has neither feelings nor consciousness. However, due to the general dominance of the and connective, the contribution of these instances involving negation is not very significant. It is the syntactic simplicity of the use of and/or connectives that we resort to, and together with the statistical summarization we obtain noticeable results in terms of the suppositional semantic aspect.
2.4 Graph-theoretic foundation
The method presented in this article generates undirected weighted lexical networks of lexemes from coordination co-occurrences that exhibit the semantic properties of association, relatedness and similarity.
The emerging ConGraCNet graph of lexemes as nodes and syntactic dependencies as relations is weighted by mapping collocation measures to edge weights. There are two main measures: frequency and logDice score. Co-occurrence frequency gives a value for the actual instances of co-occurrence of lexemes, while logDice score (Rychlý Reference Rychlý2008) expresses the relative degree of lexical association. Since logDice is a logarithmic measure of the relative frequencies of lexemes and their co-occurrences, it is neither corpus-specific nor lexeme-specific in the sense that it scales well to different corpus sizes and lexeme frequencies, and is furthermore stable across subcorpora. For a comparison of the ranking with two co-occurrence measures, see Figure 2, where the logDice score is compared with a logarithmic cFreq co-occurrence. The zigzag deviations result from the relative frequency used in the definition of logDice compared to the logarithmic cFreq.
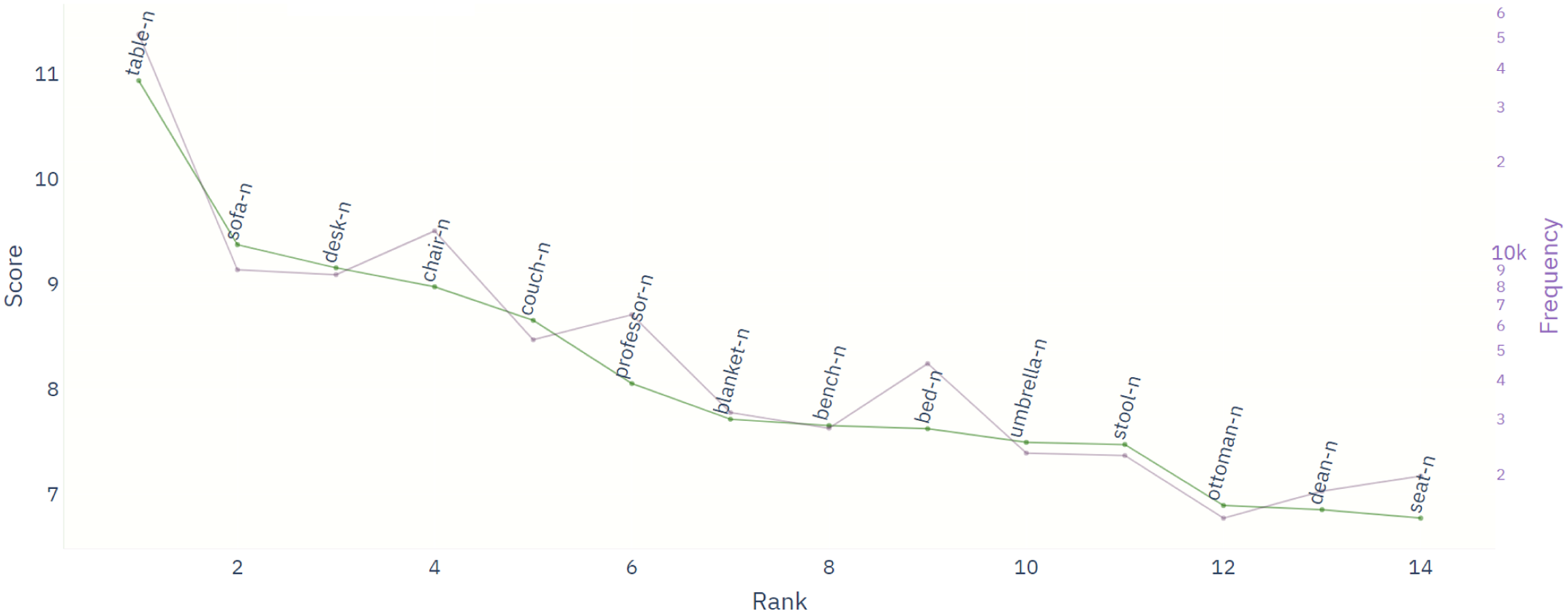
Figure 2. Co-occurrence measures of the [CHAIR+and/or+NOUN] constructions extracted from the enTenTen13 corpus.
The type of relation in the graph is obtained by filtering the specific dependency type (Perak Reference Perak2017), which indicates the specific semantic representation of a given dependency type. For example, the coordination dependency network constructed from the weighted and/or collocations provides insight into the associative properties of the collocated nodes. Furthermore, the noun-subject dependency can be used to construct the network representing what an entity does, etc. Graph representation allows the computation of dependency-related linguistic phenomena using various graph measures and algorithms, and provides the summarization of weighted networks (Zhou, Qu, and Toivonen Reference Zhou, Qu and Toivonen2017).
Sets of strongly interconnected lexemes in a network or the lexical subgraphs can be identified using community detection algorithms, such as Label Propagation (Raghavan, Albert, and Kumara Reference Raghavan, Albert and Kumara2007), Connected Components (Tarjan Reference Tarjan1972), Triangle Counting/Clustering Coefficient (Latapy Reference Latapy2008), Louvain algorithm (Blondel et al. Reference Blondel, Guillaume, Lambiotte and Lefebvre2008), Leiden (Traag, Waltman, and van Eck Reference Traag, Waltman and van Eck2018), etc. Clustering in the network structure is based on a quality function, for example, modularity (Clauset, Newman, and Moore Reference Clauset, Newman and Moore2004; Newman and Girvan Reference Newman and Girvan2004) or Constant Potts Model (CPM) (Traag, Van Dooren, and Nesterov Reference Traag, Van Dooren and Nesterov2011), defined with respect to a resolution parameter (Reichardt and Bornholdt Reference Reichardt and Bornholdt2006), which indicates the internal density of the emerging communities in the network. The higher the resolution, the greater the number of communities identified.
The cda algorithms are applied to the lexical coordination-type graph to identify associated lexemes that exhibit the feature of semantic relatedness and refer to a common semantic domain. The structure of semantic relatedness is constructed in the previous steps where we (1) use the first-degree F
 $_{\mathrm{S}}$
network to find the most related collocates of the source lexeme, (2) use the second-degree FoF
$_{\mathrm{S}}$
network to find the most related collocates of the source lexeme, (2) use the second-degree FoF
 $_{\mathrm{S}}$
network to construct the structure between nodes and (3) prune the nodes to keep the most influential nodes in the local source network. The community detection algorithms are then used to identify the clusters of lexical nodes with the strongest mutual connections. The degree of semantic relatedness is determined based on weighted syntactic connectedness, and the clustering algorithm identifies the group of nodes that are syntactically semantically related. Subgraph communities in a dependency-based network identify semantically related lexemes according to the functional dependency properties. For example, subgraph communities in a coordination dependency network conjoined with and/or connectives represent the domains of semantically related lexemes. The subnetworks obtained by our method could be interpreted for further analysis in the multilayer language network formalism (Ban Kirigin, Meštrović, and Martinčić-Ipšić Reference Ban Kirigin, Meštrović and Martinčić-Ipšić2015).
$_{\mathrm{S}}$
network to construct the structure between nodes and (3) prune the nodes to keep the most influential nodes in the local source network. The community detection algorithms are then used to identify the clusters of lexical nodes with the strongest mutual connections. The degree of semantic relatedness is determined based on weighted syntactic connectedness, and the clustering algorithm identifies the group of nodes that are syntactically semantically related. Subgraph communities in a dependency-based network identify semantically related lexemes according to the functional dependency properties. For example, subgraph communities in a coordination dependency network conjoined with and/or connectives represent the domains of semantically related lexemes. The subnetworks obtained by our method could be interpreted for further analysis in the multilayer language network formalism (Ban Kirigin, Meštrović, and Martinčić-Ipšić Reference Ban Kirigin, Meštrović and Martinčić-Ipšić2015).
Graph centrality measures, such as degree, weighted degree, PageRank (Brin and Page Reference Brin and Page1998) or betweenness centrality, can be selected to identify salient nodes in the network that reflect the relatedness of a lexeme in the coordinated conceptual network. The higher the centrality of a node, the more central the lexeme is in the semantic domain. Lexemes with the highest centrality are the main representatives of the semantic (sub)domains.
The directionality of the relations in the graph depends on the semantic features of the dependency type. Coordination-dependency graphs are modelled as bidirectional because, unlike other dependencies, coordination does not express a directed dependency between two conjoined lexemes. We store the lexical data in the Neo4jFootnote i (Needham and Hodler Reference Needham and Hodler2018) graph database and use the Python Igraph (Csardi et al. Reference Csardi and Nepusz2006) implementation of the graph algorithms.

Figure 3. Schema of the ConGraCNet pipeline.
3. Methodology and results
In language representation and analysis (Biemann Reference Biemann2011; Nastase, Mihalcea, and Radev Reference Nastase, Mihalcea and Radev2015), graph-based methods are particularly useful due to the highly complex and discrete nature of lexical relations. The network generated by the ConGraCNet method is a weighted graph structure with the lexemes as vertices/nodes and their dependency relations as edges/links.
The procedure for constructing the network relies on a corpus tagged with syntactic dependencies, see Figure 3. The syntactic tagging can be produced by using one of the available syntactic parsers (Honnibal Reference Honnibal2015; Straka, Hajic, and Straková Reference Straka, Hajic and Straková2016; Qi et al. Reference Qi, Zhang, Zhang, Bolton and Manning2020; Ljubešić and Štefanec Reference Ljubešić and Štefanec2020) and various frameworks (Bird Reference Bird2006; Nivre et al. Reference Nivre, De Marneffe, Ginter, Goldberg, Hajic, Manning, McDonald, Petrov, Pyysalo, Silveira, Tsarfaty and Zeman2016; Mrini et al. Reference Mrini, Dernoncourt, Tran, Bui, Chang and Nakashole2019; He and Choi Reference He and Choi2020) for consistent annotation of the corpus, or by extracting the dependency types within an already preprocessed text. In this work, we have used large morphosyntactically tagged English corpora enTenTen13Footnote j with
 $19\times 10^9$
words and a corpus of European debates EuroParl7Footnote k with 60 million words, available through the Sketch Engine serviceFootnote l (Kilgarriff et al. Reference Kilgarriff, Baisa, Bušta, Jakubček, KováŘ, Michelfeit, Rychlý and Suchomel2014). These are electronically stored, morphosyntactically tagged corpora with high frequency of lexical occurrence and grammatical relation structures, which can be accessed via the Sketch Engine Word sketch API. The syntactically tagged corpora are processed to represent the summary of the various syntactic dependency data for each lexeme. These syntactic dependency co-occurrences are abstracted to the lemmatized types of inflected word forms, which is important for a more coherent representation of conceptual collocations in morpho-grammatically rich languages. In Slavic languages, for instance, the same collocated items in the coordination construction may have different word forms, posing a data sparsity problem for the construction of a conceptual coordination network. Moreover, the parallelism of different word forms in the coordination does not necessarily break the schematic co-equality, as mentioned in Section 2.1 and can therefore be semantically abstracted in this task. This data is used as input for the construction of lexical dependency networks in the ConGraCNet method.
$19\times 10^9$
words and a corpus of European debates EuroParl7Footnote k with 60 million words, available through the Sketch Engine serviceFootnote l (Kilgarriff et al. Reference Kilgarriff, Baisa, Bušta, Jakubček, KováŘ, Michelfeit, Rychlý and Suchomel2014). These are electronically stored, morphosyntactically tagged corpora with high frequency of lexical occurrence and grammatical relation structures, which can be accessed via the Sketch Engine Word sketch API. The syntactically tagged corpora are processed to represent the summary of the various syntactic dependency data for each lexeme. These syntactic dependency co-occurrences are abstracted to the lemmatized types of inflected word forms, which is important for a more coherent representation of conceptual collocations in morpho-grammatically rich languages. In Slavic languages, for instance, the same collocated items in the coordination construction may have different word forms, posing a data sparsity problem for the construction of a conceptual coordination network. Moreover, the parallelism of different word forms in the coordination does not necessarily break the schematic co-equality, as mentioned in Section 2.1 and can therefore be semantically abstracted in this task. This data is used as input for the construction of lexical dependency networks in the ConGraCNet method.
The various syntactic dependency co-occurrences for a lexeme are stored in the Neo4j graph database using a Py2Neo client libraryFootnote m and schema, where the nodes represent the lemmas with their linguistic metadata properties, while the syntactic dependencies are stored as links with dependency types and collocation summarization data as properties. The properties of the lexical nodes are the frequency and relative frequency measures from the corpus, while the weight of the edges is determined by a collocation measure from the corpus, such as the co-occurrence frequency (cFreq) or the co-occurrence logDice (Rychlý Reference Rychlý2008) score. This database organization leads to a simple scheme that can be described in the Cypher graph query language as follows:
(node
 $_x$
:Lemma)-[relation:Dependency]-(node
$_y$
:Lemma)
$_x$
:Lemma)-[relation:Dependency]-(node
$_y$
:Lemma)


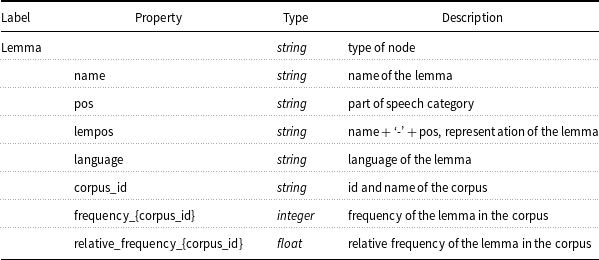
Nodes labelled Lemma have the following properties: name, pos, lempos, language, corpus_id, frequency_corpus_id, relative_frequency_corpus_id, as described in Table 1. Each node within a database is uniquely identified by the lempos + language property. Lempos is a combination of the lemma, the hyphen and a one-letter abbreviation of the part-of-speech (pos) tag. In this way, we can store unique lexical concepts from multiple languages as nodes and also retain information about different sources of corpus data within a single language.
Table 1. Node labels and properties
Similarly, relations are labelled with their respective dependency tag and have the following properties: language, frequency_{corpus_id}, frequency_score_{corpus_id}, as described in Table 2. Each relation stores the relation frequency as well as the computed relation score between lexical nodes in a given corpus. In this way, we can analyse the behaviour of a single lexical item in different corpora. The code for initializing the graph database and the Sketch Engine APIFootnote n is available in the GitHub repository.Footnote o
Table 2. Relation labels and properties

This lexical data structure is used to construct a local weighted coordination dependency-based graph using a selected source lexeme
 $_{\mathrm{S}}$
, a syntactic dependency (dep
x) and a ranking of n collocated lexemes ordered by relation frequency or score measures.
$_{\mathrm{S}}$
, a syntactic dependency (dep
x) and a ranking of n collocated lexemes ordered by relation frequency or score measures.
The construction of the coordination-type ConGraCNet network consists of the following steps:
-
(1) Construction of a friend network with the collocated lexemes in the coordination syntactic–semantic construction;
-
(2) Construction of a friend-of-a-friend network from the collocated lexemes in the coordination syntactic–semantic construction;
-
(3) Identification of prominent nodes using a centrality detection algorithm;
-
(4) Centrality-based pruning of the network;
-
(5) Identification of subgraph communities of collocated lexemes using a community detection algorithm.
3.1 Construction of the first-order coordination dependency-based network
The choice of language (L), corpus (C), source concept (lexeme
 $_{\mathrm{S}}$
), part-of-speech classification (POS) and type of syntactic-semantic dependency (dep
x) (Universal Dependencies Project 2014) are part of the linguistic parameters. The corpus selection determines the language, while the selection of the source lexeme and its POS determines the list of possible syntactic dependencies. For example, an adjective cannot have a noun subject dependency, etc. These parameters are the starting point for the construction of a [lexeme
$_{\mathrm{S}}$
), part-of-speech classification (POS) and type of syntactic-semantic dependency (dep
x) (Universal Dependencies Project 2014) are part of the linguistic parameters. The corpus selection determines the language, while the selection of the source lexeme and its POS determines the list of possible syntactic dependencies. For example, an adjective cannot have a noun subject dependency, etc. These parameters are the starting point for the construction of a [lexeme
 $_{\mathrm{S}}$
-dep
$_{\mathrm{S}}$
-dep
 $_{\mathrm{x}}$
-lexeme
$_{\mathrm{x}}$
-lexeme
 $_{\mathrm{X}}$
] syntactic construction. Of the many possible syntactic–semantic dependencies, coordination dependency [lexeme
A +and/or+ lexeme
B], which can occur between nouns, adjectives and verbs, is used to identify conceptually associated lexemes.
$_{\mathrm{X}}$
] syntactic construction. Of the many possible syntactic–semantic dependencies, coordination dependency [lexeme
A +and/or+ lexeme
B], which can occur between nouns, adjectives and verbs, is used to identify conceptually associated lexemes.
The lexical network of the highest ranking co-occurrences is called the friend network. We use
 ${\mathrm{F}^{\mathrm{n}}}_{\mathrm{S}}$
to denote the friend network of the lexeme S with n collocated nodes. For a source concept (lexeme
${\mathrm{F}^{\mathrm{n}}}_{\mathrm{S}}$
to denote the friend network of the lexeme S with n collocated nodes. For a source concept (lexeme
 $_{\mathrm{S}}$
), an arbitrary number (n) of the strongest collocation lexemes (lexeme
$_{\mathrm{S}}$
), an arbitrary number (n) of the strongest collocation lexemes (lexeme
 $_{\mathrm{X}}$
) is extracted according to a collocation measure (c) in a syntactic construction (dep
x) to create the weighted undirected first-order friend network.
$_{\mathrm{X}}$
) is extracted according to a collocation measure (c) in a syntactic construction (dep
x) to create the weighted undirected first-order friend network.
The nodes of the friend network can be extracted as the highest ranked lexemes according to one of the collocation measures or their combination through additional filters, for example, by setting the minimum frequency to
 $>50$
or the logDice score to
$>50$
or the logDice score to
 $>5$
. Changing these parameters can result in a different set of lexemes in the friend network. In the ConGraCNet application, the default co-occurrence measure is set to the logDice score due to its more informative global stability properties, as explained in Section 2.4.
$>5$
. Changing these parameters can result in a different set of lexemes in the friend network. In the ConGraCNet application, the default co-occurrence measure is set to the logDice score due to its more informative global stability properties, as explained in Section 2.4.
In coordination dependency, the n best-ranked list represents semantically related lexemes that share a semantic domain with the source lexeme. A too small n may result in an underrepresented list of semantically related concepts, while a too large n may attract slightly less related concepts and burden the further computational steps. In the ConGraCNet application, the default value n is set to 15.
The influence of the parameter n can be observed in Figure 4, which shows two friend networks of the same noun source lexeme chair in the English enTenTen13 corpus with a different number of collocations. The friend network F4
CHAIR-n with
 $n=4$
(Figure 4a) captures only the semantically related collocations referring to the semantic domain furniture. The collocations that refer to the social function domain, such as professor and dean, appear only in the larger friend network F13
CHAIR-n (Figure 4b) with 13 collocations: table, sofa, desk, couch, professor, blanket, bench, bed, umbrella, stool, ottoman, dean, seat.
$n=4$
(Figure 4a) captures only the semantically related collocations referring to the semantic domain furniture. The collocations that refer to the social function domain, such as professor and dean, appear only in the larger friend network F13
CHAIR-n (Figure 4b) with 13 collocations: table, sofa, desk, couch, professor, blanket, bench, bed, umbrella, stool, ottoman, dean, seat.

Figure 4. First-order coordination-type networks: (a) F4
CHAIR-n network and (b) F13
CHAIR-n network with collocation measure
 $c=logDice$
.
$c=logDice$
.
The major shortcoming of the first-order and/or friend network is its linear structure. Each lexeme is ordered according to a certain measure, but there is no way to distinguish between potential semantic clusters in the list of collocated lexemes. The low relational complexity (source - collocation) of the friend network provides no differentiation between multiple senses or polysemous domains expressed by the collocated lexemes, regardless of the number of co-occurrences extracted. To overcome this lack of differentiation of the domain structure, we introduce the second-order friend of a friend network, as described in the following section.
3.2 Construction of the second-order coordination dependency-based network
The second iteration of the coordination dependency-based network, called the friend-of-a-friend (FoF) network, is introduced to enrich the linear first-order source lexeme network
 $\mathrm{F^{n}}_{\mathrm{S}}$
with the interrelational structure. The second-order coordination-based network of the source lexeme S is constructed by extracting the [lexeme
A - dep
x - lexeme
B] collocations and selecting n top-ranked dep
x-collocates of each of the nodes from the first-order network
$\mathrm{F^{n}}_{\mathrm{S}}$
with the interrelational structure. The second-order coordination-based network of the source lexeme S is constructed by extracting the [lexeme
A - dep
x - lexeme
B] collocations and selecting n top-ranked dep
x-collocates of each of the nodes from the first-order network
 $\mathrm{F^{n}}_{\mathrm{S}}$
. By
$\mathrm{F^{n}}_{\mathrm{S}}$
. By
 $\mathrm{FoF^{n}}_{\mathrm{S}}$
we denote the weighted undirected FoF network of the source lexeme S and n number of collocated nodes.
$\mathrm{FoF^{n}}_{\mathrm{S}}$
we denote the weighted undirected FoF network of the source lexeme S and n number of collocated nodes.
More precisely,
 $\mathrm{FoF^{n}}_{\mathrm{S}}$
is obtained by merging the friend network of the source lexeme S,
$\mathrm{FoF^{n}}_{\mathrm{S}}$
is obtained by merging the friend network of the source lexeme S,
 $\mathrm{F^{n}}_{\mathrm{S}}$
, with the friend networks
$\mathrm{F^{n}}_{\mathrm{S}}$
, with the friend networks
 $\mathrm{F^{n}}_{\mathrm{A_{i}}}$
of all n nodes
$\mathrm{F^{n}}_{\mathrm{A_{i}}}$
of all n nodes
 $\rm{A_{1}}$
, …,
$\rm{A_{1}}$
, …,
 $\rm{A_{n}}$
of
$\rm{A_{n}}$
of
 $\mathrm{F^{n}}_{\mathrm{S}}$
. The nodes and the edges of the
$\mathrm{F^{n}}_{\mathrm{S}}$
. The nodes and the edges of the
 $\mathrm{FoF^{n}}_{\mathrm{S}}$
network are all nodes and all edges from the above friend networks
$\mathrm{FoF^{n}}_{\mathrm{S}}$
network are all nodes and all edges from the above friend networks
 $\mathrm{F^{n}}_{\mathrm{S}}$
,
$\mathrm{F^{n}}_{\mathrm{S}}$
,
 $\mathrm{F^{n}}_{\mathrm{A_{1}}}$
, …,
$\mathrm{F^{n}}_{\mathrm{A_{1}}}$
, …,
 $\mathrm{F^{n}}_{\mathrm{A_{n}}}$
. The weight of an edge in the
$\mathrm{F^{n}}_{\mathrm{A_{n}}}$
. The weight of an edge in the
 $\mathrm{FoF^{n}}_{\mathrm{S}}$
network is the same as its weight in the friend network in which it occurs. The number of nodes (vs) in the
$\mathrm{FoF^{n}}_{\mathrm{S}}$
network is the same as its weight in the friend network in which it occurs. The number of nodes (vs) in the
 $\mathrm{FoF^{n}}_{\mathrm{S}}$
network is bounded by
$\mathrm{FoF^{n}}_{\mathrm{S}}$
network is bounded by
 $n(n-1)$
, where n is the assigned number of edges. However, vs is usually lower because some nodes denoting the same lexeme may be listed among the collocates in multiple friend networks
$n(n-1)$
, where n is the assigned number of edges. However, vs is usually lower because some nodes denoting the same lexeme may be listed among the collocates in multiple friend networks
 $\mathrm{F^{n}}_{\mathrm{A_{i}}}$
and
$\mathrm{F^{n}}_{\mathrm{A_{i}}}$
and
 $\mathrm{F^{n}}_{\mathrm{S}}$
.
$\mathrm{F^{n}}_{\mathrm{S}}$
.
The coordination-based lexical FoF network reveals the extended structure of ontologically associated lexemes. In the coordination-based undirected graph, the weight of an edge between two overlapping nodes is the same in all friendship networks in which it occurs, and this is the weight assigned to it in the
 $\mathrm{FoF^{n}}_{\mathrm{S}}$
network.
$\mathrm{FoF^{n}}_{\mathrm{S}}$
network.
The parameter n is important in determining the semantic richness of the representation, that is, the sense structure. The
 $\rm{FoF^{n}}$
graph with a low number n gives a prominent but sparse representation of the ontological associations of
$\rm{FoF^{n}}$
graph with a low number n gives a prominent but sparse representation of the ontological associations of
 $\rm{F^{n}}$
. This is illustrated in the Figure 5 with second-order
$\rm{F^{n}}$
. This is illustrated in the Figure 5 with second-order
 ${\rm{FoF^{n}}}_{\rm{CHAIR-n}}$
networks constructed with parameters
${\rm{FoF^{n}}}_{\rm{CHAIR-n}}$
networks constructed with parameters
 $n=4$
and
$n=4$
and
 $n=13$
. The
$n=13$
. The
 ${\rm{FoF^{n}}}_{\rm{CHAIR-n}}$
with
${\rm{FoF^{n}}}_{\rm{CHAIR-n}}$
with
 $n=4$
contains ontologically associated lexemes referring to the semantic domain furniture: chair, table, sofa, desk, couch, bench, chart, armchair, loveseat, bed, cabinet, dresser, recliner (Figure 5a). Increasing n leads to an overall richer representation with references to other related semantic domains. This can be seen in the
$n=4$
contains ontologically associated lexemes referring to the semantic domain furniture: chair, table, sofa, desk, couch, bench, chart, armchair, loveseat, bed, cabinet, dresser, recliner (Figure 5a). Increasing n leads to an overall richer representation with references to other related semantic domains. This can be seen in the
 ${\rm{FoF^{n}}}_{\rm{CHAIR-n}}$
network with lexemes that also refer to the domain social position: professor, blanket, umbrella, stool, ottoman, dean, seat, graph, figure, seating, grill, lamp, recliner, fireplace, cushion, mattress, rug, carpet, shelf, bookcase, wardrobe, drawer, computer, counter, workstation, tv, phd, ph.d., md, student, m.d., researcher, director, teacher, author, lecturer, department (Figure 5b).
${\rm{FoF^{n}}}_{\rm{CHAIR-n}}$
network with lexemes that also refer to the domain social position: professor, blanket, umbrella, stool, ottoman, dean, seat, graph, figure, seating, grill, lamp, recliner, fireplace, cushion, mattress, rug, carpet, shelf, bookcase, wardrobe, drawer, computer, counter, workstation, tv, phd, ph.d., md, student, m.d., researcher, director, teacher, author, lecturer, department (Figure 5b).

Figure 5. Second-order coordination-type networks: (a) FoF4
CHAIR-n and (b) FoF15
CHAIR-n, corpus = enTenTen13,
 $c=logDice$
.
$c=logDice$
.
The FoF network enables structural analysis of network prominence using centrality measures and lexical clustering using community detection algorithms.
3.3 Identification of the most prominent nodes in the network
Statistical corpus measures such as word frequency, relative word frequency, etc. indicate the extent of lexical usage in a corpus, conceptual conventionality and familiarity. However, this does not necessarily translate to the prominence of the lexeme in an associative lexical cluster structure of the coordination-based FoF network. The graph structure of the second-degree coordination-based network allows us to analyse the semantic aspects of lexical prominence using graph centrality measures, such as degree, weighted degree, PageRank (Brin and Page Reference Brin and Page1998), and betweenness centrality.
Table 3 lists the most prominent nodes of the lexeme chair w with respect to various centrality measures. Degree and weighted degree represent the embedding of a node in the FoF network and indicate the associative strength of a node in the network. For example, Figure 5b illustrates the label size to represent the most prominent nodes based on the weighted degree in the FoF network of the lexeme chair. PageRank highlights the connectedness with other important well-connected nodes. This can highlight the conceptual relatedness of a node in a network. Betweenness centrality, as the computation of the shortest (weighted) path between each pair of nodes in a connected graph, also indicates the rank of associativity. All measures are computed using the Igraph package (Csardi et al. Reference Csardi and Nepusz2006). The ConGraCNet application allows visualization of the centrality measures via node size and label size.
Table 3. The most prominent nodes in FoF20 CHAIR-n w.r.t. various centrality measures

3.4 Centrality-based pruning of the second-degree network
In order to: (a) maximize the semantic richness obtained with the higher n in the first-degree network, (b) preserve the syntactic-semantic structure created with the second-degree associations and (c) reduce the information noise, we apply the centrality-based pruning of the second-degree network. The pruning procedure allows us to create a concise representation of the structural semantic distribution of FoF with a larger number n of coordination type associated lexemes without compromising the underlying lexical complexity. Theoretically, n can be set to a value that includes the maximum scope for all interconnected lexemes in the
 $\mathrm{FoF^{n}}_{\mathrm{S}}$
network, and prune out an arbitrary number of the more relevant associations for the source lexeme network using node centrality or relation weight scores.
$\mathrm{FoF^{n}}_{\mathrm{S}}$
network, and prune out an arbitrary number of the more relevant associations for the source lexeme network using node centrality or relation weight scores.
 $\mathrm{FoF^{n}}_{\mathrm{S}}$
pruning is performed by filtering out lexemes with a low centrality value, in terms of graph measures such as degree, weighted degree, betweenness or PageRank.
$\mathrm{FoF^{n}}_{\mathrm{S}}$
pruning is performed by filtering out lexemes with a low centrality value, in terms of graph measures such as degree, weighted degree, betweenness or PageRank.
For example, the coordination-based
 ${\rm{FoF^{50}}}_{\rm{CHAIR-n}}$
network of 876 lexemes can be reduced to the 84 most prominent lexemes by filtering out the nodes with a degree value of 5 or less, see Figure 6. Both representations show two large clusters, one related to the concepts of the semantic domain furniture and the other related to the domain social position. However, the second graph represents the lexical associations more optimally, without losing the semantic information that can occur at low n, and without introducing additional noise that results from applying a large n.
${\rm{FoF^{50}}}_{\rm{CHAIR-n}}$
network of 876 lexemes can be reduced to the 84 most prominent lexemes by filtering out the nodes with a degree value of 5 or less, see Figure 6. Both representations show two large clusters, one related to the concepts of the semantic domain furniture and the other related to the domain social position. However, the second graph represents the lexical associations more optimally, without losing the semantic information that can occur at low n, and without introducing additional noise that results from applying a large n.

Figure 6. Coordination-type FoF50
CHAIR-n networks, corpus = enTenTen13,
 $c=logDice$
, constructed: (a) without pruning and (b) with pruning
$c=logDice$
, constructed: (a) without pruning and (b) with pruning
 $degree\geq5$
.
$degree\geq5$
.
3.5 Identification of subgraph communities
The structure of the FoF network can be analysed using graph community detection algorithms (cda), for example, Louvain (Blondel et al. Reference Blondel, Guillaume, Lambiotte and Lefebvre2008) or Leiden algorithm (Traag et al. Reference Traag, Waltman and van Eck2018). Community detection algorithms generally evaluate how to partition a graph into clusters of densely interconnected nodes that have much weaker connections with the nodes of other subgraphs.
The specific and/or coordination relations between lexemes filtered from the corpus and mapped onto the structure of the weighted FoF graphs are further analysed using community detection algorithms. The identified subgraphs with strongly associated nodes reflect the emerging semantic properties of coordination dependency. The members within the identified lexical communities of FoF
 $_{\mathrm{S}}$
exhibit the features of coherent conceptual relatedness. The greater the syntactic interconnectivity, the stronger the semantic interrelatedness or domain coherence. These emerging communities are interpreted as semantic domains related to the expressed senses of the source lexeme.
$_{\mathrm{S}}$
exhibit the features of coherent conceptual relatedness. The greater the syntactic interconnectivity, the stronger the semantic interrelatedness or domain coherence. These emerging communities are interpreted as semantic domains related to the expressed senses of the source lexeme.
The level of clustering resolution of the cda algorithm can be modified to reveal subgraph communities with different levels of granularity, so that the abstraction of lexical communities can be represented at different scales. Indeed, a larger modularity resolution parameter leads to a more granular, less abstract and more coherent classification of related semantic domains. This identifies subcategories within a more abstract category of related semantic domains. For example, the Leiden algorithm, applied to the
 $\rm{FoF^{50}}_{{\rm{CHAIR-n}}}$
network, identifies subgraph communities as shown in Figure 7 and listed in Table 4.
$\rm{FoF^{50}}_{{\rm{CHAIR-n}}}$
network, identifies subgraph communities as shown in Figure 7 and listed in Table 4.
Table 4. Communities in FoF50
CHAIR-n network, corpus = enTenTen13,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 8$
,
$ degree\geq 8$
,
 $cda=\text{Leiden}$
,
$cda=\text{Leiden}$
,
 $cpm=0.5$
$cpm=0.5$


Figure 7. Coordination-type FoF50
CHAIR-n network, corpus = enTenTen13,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 8$
,
$ degree\geq 8$
,
 $cda=\text{Leiden}$
with (a) 2 communities with clustering resolution
$cda=\text{Leiden}$
with (a) 2 communities with clustering resolution
 $cpm=0.1$
(b) 11 communities with clustering resolution
$cpm=0.1$
(b) 11 communities with clustering resolution
 $cpm=0.5$
.
$cpm=0.5$
.
Using a low clustering resolution
 $cpm=0.1$
, the Leiden algorithm identifies two communities of lexical concepts that refer to two main senses of the lexeme chair: furniture and social position, as shown in Figure 7a. Setting the clustering resolution to
$cpm=0.1$
, the Leiden algorithm identifies two communities of lexical concepts that refer to two main senses of the lexeme chair: furniture and social position, as shown in Figure 7a. Setting the clustering resolution to
 $cpm=0.5$
further refines the granularity of the semantic domains, as shown in Figure 6b.
$cpm=0.5$
further refines the granularity of the semantic domains, as shown in Figure 6b.
The example shows the structure of the senses of the lexeme chair and the classification of conceptually similar lexemes into their respective communities. The conjoining function of the and/or semantic–syntactic construction facilitates the grouping of lexical members into defined conceptual domains or lexical senses.
4 Examples of coordination-type networks with different linguistic parameters
In this section, we demonstrate the results of coordination-based graph analysis with different linguistic parameters: lexemes, part of speech and corpus.
4.1 Source lexeme selection
The source lexeme is the basic unit of network construction. The selected lexeme becomes the source of the locally constructed associative network.
For example, a coordination dependency network of the lexeme bass shown in Figure 8 and Table 5 shows the two main semantic domains related to the senses 1. bass as an instrument and 2. bass as a kind of fish. Similarly, the ConGraCNet method can provide a graph representation of the associated semantic domains for each lexeme in a corpus that occurs in a coordinated dependency.
Table 5. Communities in FoF15
BASS-n network, corpus = enTenTen13,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 2$
,
$ degree\geq 2$
,
 $cda=\text{Leiden}$
,
$cda=\text{Leiden}$
,
 $cpm=0.1$
$cpm=0.1$


Figure 8. Coordination-type FoF15
BASS-n network, corpus = enTenTen13,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 2$
,
$ degree\geq 2$
,
 $cda=\text{Leiden}$
,
$cda=\text{Leiden}$
,
 $cpm=0.1$
with vs=40,
$cpm=0.1$
with vs=40,
 $es=99$
.
$es=99$
.
4.2 Part-of-speech selection
In addition to representing the sense structure of nouns, the coordinated dependency graph can also be used to identify conceptually associated adjectives and verbs.
While nouns express the conceptualized entities, adjectives can be considered as the conceptualization of entity properties. Adjectives conjoined by logical connectives form a network of properties, where a set of nodes can be classified as properties belonging to a semantic domain.
Figure 9 shows the resulting semantic network of the adjective lexeme rational with the classified subnetwork lexemes listed in Table 6, referring to rational as a feature of a mental property and associated dispositions, as an emotional property and the property from the mathematical domain.
Table 6. Communities in FoF50
RATIONAL-j network, corpus = enTenTen13,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 5$
,
$ degree\geq 5$
,
 $cda=\text{Leiden}$
,
$cda=\text{Leiden}$
,
 $cpm=0.1$
with vs=27,
$cpm=0.1$
with vs=27,
 $es=76$
$es=76$


Figure 9. Coordination-type FoF50
RATIONAL-j network, corpus = enTenTen13,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 5$
,
$ degree\geq 5$
,
 $cda=\text{Leiden}$
,
$cda=\text{Leiden}$
,
 $cpm=0.1$
with vs=27,
$cpm=0.1$
with vs=27,
 $es=76$
.
$es=76$
.

Figure 10. Coordination-type FoF15
CHAIR-v network, corpus = enTenTen13,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 2$
,
$ degree\geq 2$
,
 $cda=\text{Leiden}$
,
$cda=\text{Leiden}$
,
 $cpm=0.1$
with vs=27,
$cpm=0.1$
with vs=27,
 $es=62$
.
$es=62$
.
The relations between two conceptualized entities are typically categorized by linguistic constructions, where words are grammatically classified as prepositions and verbs. Verbs represent the complex processes that take place between the arguments of the verb. Coordination dependency can be used to classify verbs with conceptually commensurable semantic complexity. For example, the verb to chair shown in Figure 10 and Table 7 refers to the highly complex process of organizing a social interaction, which has relations to the processes of founding, serving and leading in a social interaction, as well as to the more physical aspects of stooling and couching something.
Table 7. Communities in FoF15
CHAIR-v network, corpus = enTenTen13,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 2$
,
$ degree\geq 2$
,
 $cda=\text{Leiden}$
,
$cda=\text{Leiden}$
,
 $cpm=0.1$
with vs=27,
$cpm=0.1$
with vs=27,
 $es=62$
$es=62$

4.3 Corpus selection
The corpus represents the particular nature of conceptualization within a community of communicators. The different collections of texts naturally change the lexical instances and the subsequent structure of the lexical networks. A more extensive and diverse corpus will yield a more robust structure of collocations and more general uses of the lexeme. A less extensive corpus, on the other hand, will yield a set of leaner relations and conceptual structures. Different genres focus on different conceptual structures and frame lexical usage in different ways. This feature can be used to uncover specific senses of a lexical concept in different specific socio-cultural domains, for example, in legal, historical or medical corpora, or to extract the use of a concept in different time periods.
One of the additional features that influence the whole process of dependency network construction is the quality of the underlying syntactic annotation and the biases that certain annotation strategies may introduce. In this work, we have relied on the predefined Sketch grammar, a collection of definitions that allow the system to automatically identify possible relations of words to the source word in a particular corpus.Footnote p In order to maximize the quality of the results, we excluded coordination collocates with mixed part-of-speech, which we considered noise in the tagging procedure.
The ConGraCNet data processing pipeline can be modified to take any NLP tagged corpus as input. In this approach, the network is constructed from the tagged lempos collocated with the conjunct relation. The formalism for tagging conjunct relation is found in all contemporary trained pipelines with dependency taggers based on the Universal Dependency grammar (Universal Dependencies Project 2014), such as, the Stanford parser (Manning et al. Reference Manning, Surdeanu, Bauer, Finkel, Bethard and McClosky2014), Stanza language toolkit supporting 66 languages (Qi et al. Reference Qi, Zhang, Zhang, Bolton and Manning2020), the Classla package for Slavic languages (Slovenian, Croatian, Serbian, Macedonian and Bulgarian) (Ljubešić and Dobrovoljc Reference Ljubešić and Dobrovoljc2019), the Spacy NLP package with models for more than 18 languages (Vasiliev Reference Vasiliev2020) and so on. These frameworks with language-specific dependency tree-banks offer the advantage of being able to handle languages that are morphologically rich and have relatively free word order (Jurafsky and Martin Reference Jurafsky and Martin2018), which in turn can improve the quality of dependency network construction. The procedure for constructing a coordinated dependency-based network layer from a corpus includes:
-
(1) Corpus collection from a set of texts;
-
(2) Corpus processing with NLP pipeline (tokenization, lemmatization, POS tagging, dependency tagging);
-
(3) Extraction of lempos with the same POS, which are collocated in a coordination dependency (conj, coord, etc.);
-
(4) Lexical-graph creation with lempos as graph vertices and dependency relations as graph edges;
-
(5) Database storage of corpus-specific node (lempos) and relation (coordination dependency) properties and calculation of collocation measures.
This coordinated dependency-based lexical network layer can be further processed with the ConGraCNet methods described in this article.
We illustrate the domain-specific contextual use of the same lexeme, chair in English, by comparing its lexical networks obtained with two different corpora using the Sketch grammar type of data input. Table 8 and Figure 11 illustrate the semantic network of the lexeme chair in the EuroParl7Footnote q corpus. The EuroParl7 corpus was created from the European Parliament Proceedings in English from 2010 to 2012 and contains around 60 million English words from the legal and political domains.
Table 8. Community detection in FoF20
CHAIR-n network, corpus = Europarl7,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 2$
,
$ degree\geq 2$
,
 $cda=\text{Leiden}$
,
$cda=\text{Leiden}$
,
 $cpm=0.15$
with vs=20,
$cpm=0.15$
with vs=20,
 $es=32$
$es=32$


Figure 11. Coordination-type FoF20
CHAIR-n network, corpus = Europarl7,
 $c=logDice$
,
$c=logDice$
,
 $m= \text{weighted degree}$
,
$m= \text{weighted degree}$
,
 $ degree\geq 2$
,
$ degree\geq 2$
,
 $cda=\text{Leiden}$
,
$cda=\text{Leiden}$
,
 $cpm=0.15$
with vs=20,
$cpm=0.15$
with vs=20,
 $es=32$
.
$es=32$
.
The specific subgraphs in Figure 11 express the idiomatic senses of the lexeme chair in the EuroParl7 corpus. These semantic domains differ in structure and lexical instances from the network of the same lexeme obtained with the robust 13-billion web corpus enTenTen (see Figure 7 and Table 4). For ex ample, one community is clustered around the lexeme rapporteur (‘a person who reports (as at a meeting of a learned society)’Footnote r), a lexeme specific to the underlying parliamentary aspect of the sense title/person. Like most of the identified communities, the rapporteur community also contains personal name lexemes denoting persons associated with the role of rapporteur, for example, a person who submits a report to the European Parliament, such as Klaus-Heiner Lehne, who was rapporteur during the period covered by the corpus.Footnote s
Another example obtained with ConGraCNet on corpora of different languages is showcased in a comparative analysis of the lexemes feeling and osjećaj (Perak and Ban Kirigin Reference Perak and Ban Kirigin2020). In order to adapt the method to a new language, it is necessary to apply syntactic parsing using a language-specific parsing model and construct the and/or collocates with their collocation measures, and then proceed with the computation of FoF graph measures. We currently have several corpora in English, German, Italian and Croatian integrated into our web application.
Comparison of a lexeme in culturally different corpora reveals clear differences in sense structure and related conceptual domains. The differences are the result of different lexical usage by participants in the act of communication. This usage-based approach assumes that the lexical patterns represent the emerging system of distributed conceptualizations of the community involved in the act of communication (Sharifian Reference Sharifian2008, Reference Sharifian2017).
Corpus selection can therefore be used as a parameter for the study of lexical usage and sense distribution in a corpus-specific context, whether in relation to cross/intra-cultural features, a literary genre or an era. In addition to dependency-tagged corpora, other natural language processing models and corpus storage systems can also be used, provided they offer access to the lexical and syntactic level of tagging. This bottom-up approach can be used to describe the lexical senses in a particular social domain, subject area or expert domain, or to extract the structure of topics within a corpus, diachronic changes in lexical usage, etc.
5. Evaluation
In order to validate the results, we compared the identified coordination clusters of coherent conceptual domains for a number of nouns, adjectives and verbs in enTenTen13 with the lexical senses listed in reference dictionaries. The comparison with the Cambridge DictionaryFootnote t shows that the ConGraCNet coherent local lexical clusters in the enTenTen13 corpus for a source lexeme are highly consistent with the senses listed in the Cambridge Dictionary. For example, according to the Cambridge Dictionary, the lexeme chair has the following senses: (a) furniture, (b) person in charge/title. All the senses listed have corresponding lexical clusters in the EnTenTen13 source coordination subgraph.
The WordNet dictionaryFootnote u provides a slightly more refined version of the sense classification:
-
(a) chair (a seat for one person, with a support for the back),
-
(b) professorship, chair (the position of professor),
-
(c) president, chairman, chairwoman, chair, chairperson (the officer who presides at the meetings of an organization),
-
(d) electric chair, chair, death chair, hot seat (an instrument of execution by electrocution; resembles an ordinary seat for one person),
-
(e) chair (a particular seat in an orchestra).
However, senses (b) and (c) could be seen as an elaboration of the sense listed in the Cambridge Dictionary: person in charge/title. Sense (d) electric chair, can be classified as a subcategory of furniture with the special function of electrocution. The subcategory is encoded with a particular modifier construction [adjective + noun] that is not identifiable with the coordinated construction of the ConGraCNet approach. But if we take this adjective modifier construction, the question arises, how many kinds of chairs should we distinguish besides the electric chair? Should we then also classify wooden, metal, plastic chair, etc. as a highly relevant subset of meanings?
This issue of the adjective modifier of a head noun is also related to other lexicalized entities in noun phrases with more than one lexeme and longer dependencies. This poses a problem in entity resolution, since coordination in noun phrases is often expressed with elliptical parts, which can lead to ambiguous reconstruction alternatives (Buyko and Hahn Reference Buyko and Hahn2008). We have not addressed this problem in this article, but the additional use of dependencies, such as syntactic relations classified as flat or nmod noun modifier or adjective modifier amod for noun phrase and named-entity tagging, could play an important role in disambiguating resolution alternatives.
The presented ConGraCNet method mimics the emergent structure of cognitive categorization by analysing the logical connectives that people use in everyday communication to associate two or more concepts of the same grammatical class. The analysis procedure is similar to classification in the real-world, where the features of an observed object are always processed in relation to a specific pragmatic context and function. The linguistic parameters determine the structure of the concepts associated with the source lexeme, while the network parameters make the classification finer or coarser.
When evaluating the method, the flexibility of the linguistic and network parameters mentioned above must be taken into account. Moreover, the results depend on the accuracy of morphosyntactic tagging of constructions in a selected corpus and the parameters and filters of the applied graph algorithms. However, this modular approach allows the methodology to evolve by selecting the most appropriate and up-to-date network and data algorithms and automated tools. The sense structure is also corpus-specific and highly parametrizable, with options to scale lexical collocation networks and fine-grained conceptual domains. This was demonstrated in the previous sections by comparing the different networks of English corpora.
In the study, we compared different lexeme senses displayed by the ConGraCNet method with the senses listed in the Cambridge Dictionary, WordNet, Wikidata,Footnote v BabelNetFootnote w and Croatian Lexical Portal (HJP).Footnote x The aim of the comparison was to identify differences and similarities between the available open Linked Data dictionary resources. We implemented the WordNet synset representation in the EmoCNet application and integrated the WordNet hypernym classification for the cluster labelling task (Ban Kirigin et al. Reference Ban Kirigin, Bujačić Babić and Perak2021). In addition, we compared the displayed lexeme senses with the list of concepts and named-entities available through the Wikidata API endpoint and shared with the BabelNet API. Wikidata provides a richer list of senses by including a number of named-entity items that expand the actual conceptual senses to numerous works of art, films, etc. In our future work, we plan to integrate the extensive knowledge of lexical senses for advanced conceptual resolution and named-entity referencing.
In addition, we analysed and evaluated the sense distribution of a number of English lexemes and compared them with the senses obtained from the Cambridge Dictionary. The lexemes for evaluation were selected with respect to their polysemy and part-of-speech tags. The list of selected lexemes included nouns, adjectives and verbs. The vast majority of the selected lexemes displayed high polysemous potential, which was determined in the previous step using Linked Data dictionary resources. For a balanced representation and control of results, some lexemes with low polysemous potential were also included.
Due to the difficulty of psychological evaluation, the selection was limited to a set of 30 English lexemes. Namely, the set of 30 selected lexemes already required an extensive semantic comparison of about 100 sense clusters from the dictionary with well over 100 lexical clusters provided by our method. Each of these clusters was populated with about 10 lexemes. In this way, the feasibility and accuracy of the psychological evaluation was maintained. In our future work, we plan to extend the evaluation method to a more significant number of lexemes related to specific domains of knowledge.
The evaluation was performed by eight annotators, including three linguists, three computer scientists, one sociologist and one humanities student. They evaluated the associated ConGraCNet lexical clusters of the source lexemes with respect to three dimensions: (a) coherence of the identified conceptual domains within the clusters, (b) correlation of the senses listed in the Cambridge Dictionary with the ConGraCNet lexical clusters and (c) identification of senses not listed in the Dictionary.
For 30 words (‘pride-n’, ‘joy-n’, ‘lust-n’, ‘passion-n’, ‘car-n’, ‘picture-n’, ‘shape-n’, ‘book-n’, ‘drama-n’, ‘politics-n’, ‘nation-n’, ‘heart-n’, ‘table-n’, ‘grass-n’, ‘neck-n’, ‘family-n’, ‘run-v’, ‘vehicle-n’, ‘nice-adj’, ‘smooth-adj’, ‘shelter-n’, ‘food-n’, ‘cure-n’, ‘justice-n’, ‘Christianity-n’, ‘democracy-n’, ‘swim-v’, ‘chair-n’, ‘gut-n’, ‘nationality-n’) ConGraCNet method identified 126 lexical clusters, while Cambridge Dictionary listed 86 word-clusters semantic domains. Annotators were asked to choose as many senses as they saw corresponding to identified ConGraCNet word-clusters.
In total, 83 of the 86 senses listed in the Cambridge Dictionary were identified by at least one annotator, which is 96.51%. The senses not indicated by the ConGraCNet lexical clusters refer to less conventional, domain-specific use or slang, such as the sense of lexeme ‘grass-n’: a person, usually a criminal, who tells the police about other criminals’ activities or a metaphorical extension of the lexeme ‘run-v’: to compete as a candidate in an election.
The score for the identification of all 86 senses listed in the Cambridge Dictionary by all annotators was 72.26% with the inter-annotation agreement of 77.41%. As expected, the score for the identification of the primary sense listed in the Cambridge Dictionary for all 30 lexemes was higher, 97.08%, with the inter-annotation agreement of 94.88%. The results show a very high correlation with the prototypical senses listed in the dictionary.
The coherence dimension of the lexical clusters was assessed using a five-point Likert scale (1-no coherent communities, 2- few coherent communities, 3- half of the communities, 4- most, 5- all coherent communities). The mean score for the coherence dimension was 4.34 (std 0.3). This result indicates a high level of perceived sense coherence between the lexemes in the communities identified by the method.
In addition, annotators indicated whether the representation of a perceived sense relevant to the source lexeme but not listed in the dictionary occurs in one of the corresponding ConGraCNet lexical communities. The identification of additional senses was scored with a Boolean value: 0-not found, 1-found. On average, for a lexeme 42.38% (std 21.70), the annotators perceived the existence of a relevant lexical community in the ConGraCnet graph that was underrepresented in the dictionary’s sense list. Similarly, evaluators indicated the presence of a lexical cluster that was not relevant to the sense representation of the source lexeme. For one lexeme, 10.47% (std 11.82) of the annotators perceived the existence of an irrelevant lexical cluster in the ConGraCnet graph. The identification of sense clusters not listed in the dictionary indicates the potential of the ConGraCNet method in identifying corpus-specific senses.
Although the ConGraCNet method was not designed to act as a thesaurus, the evaluation shows a high commensurability with the senses listed in dictionaries. These results become more robust the larger the amount of tagged texts. Besides the dictionary-like representation of a typical list of senses, the method also reveals the quantitative and qualitative structure of lexical networks. The identified prominent nodes and communities reveal related conceptual domains and lexical concepts that are not represented in dictionaries. The sense structures represented by ConGraCNet networks are intuitive, coherent, cognitively grounded and easy to interpret.
6. Conclusions and future work
This article presents a computational linguistic method to describe the sense structure and reveal the polysemy of lexical concepts in a linguistic community based on the analysis of conceptual relatedness in coordination construction.
The proposed ConGraCNet method relies on the premise that natural languages serve to communicate human conceptualization of the world, and reflects the cognitive classification of conceptual domains, their complex relations and the assumption that a corpus stores particular conceptualization patterns within a language community. Based on the construction grammar approach, which projects semantic values onto syntactic dependency structure, the method extracts concepts in a coordinated dependency expressed by the connectives and and or.
The conjoined collocated entities, properties and processes form prototypical semantic domains that are ontologically related. This feature is used to reveal the polysemous nature of lexemes. A lexeme is associated with other related lexemes, friends related to an abstracted sense. To identify different associated semantic domains, or senses, we iteratively identify their friends and the friends of their friends (FoF) to construct a local FoF network. By looking locally from the point of view of a source lexeme, the (sub)networks can reveal the prominence of the lexical concept in different semantic domains.
The method is applicable to most languages due to the almost universal use of coordinated constructions and logical connectives. The structure of the network can be used to show the semantic differences between lexemes within the same corpus or to compare them with different corpora, regardless of the size of the corpus or its domain.
As for the graph procedures, the method provides a number of parameters to control graph construction, pruning and cluster granularity. In this way, specific corpus-related word senses and semantic associations can be identified, and their structure made interpretable by machines and humans. The modular and parametrizable nature of the methodology can be tailored to the goals of the analysis. We leave the investigation of the appropriateness of the various measures and algorithms to future work.
The ConGraCNet methodology has already been applied to the task of lexical sense labelling, that is, determining a sense label for a set of lexical items in the community. For a number of languages, WordNet knowledge-based synset data structures have been integrated to abstract a lexicalized generalization of the semantic features of communities that refer to a source word. ConGraCNet’s semantic clustering method was also applied in the research area of sentiment analysis to provide a more comprehensive representation of the emotional score and to reveal the sentiment potential of polysemous lexemes with respect to a specific corpus and each identified sense (Ban Kirigin et al. Reference Ban Kirigin, Bujačić Babić and Perak2021).
The method has potential for downstream applications in identifying semantic similarity (Harispe et al. Reference Harispe, Ranwez, Janaqi and Montmain2015), word sense structures in different types of discourse, information extraction, knowledge engineering, comparison and enrichment of knowledge-based dictionaries, building custom thesauri, in identifying the conceptual distance between lexical items of the same grammatical category, in providing inferences about the meronymic, hierarchical and ontological structures of concepts within a corpus, and in improving antonym description procedures (Čulig Suknaić 2020).
In our future work, we intend to explore the applications of the ConGraCNet methodology for comparing lexical concepts of the same language that refer to ontologically distant domains, as well as for comparing results for lexical concepts in structurally and culturally different corpora. We are implementing various syntactic dependencies for further semantic enrichment and more general extraction of common-sense knowledge, such as semantic domain labelling, prototypical object and agency detection, ontological congruence and metonymy and metaphor detection. In addition, the method allows the comparison of systematic sense structure between different languages, and we intend to formalize the methods for cross-linguistic analysis. It would be interesting to combine other lexical approaches to syntactic-semantic analysis, for example, Buyko and Hahn (Reference Buyko and Hahn2008), Wilson, Wiebe, and Hoffmann Reference Wilson, Wiebe and Hoffmann2009, Taboada et al. (Reference Taboada, Brooke, Tofiloski, Voll and Stede2011) taking into account lexeme annotations of polarity and intensity, as well as logical negation, to obtain even more specific conceptual subdomains. Finally, the new neural graph network approaches (Mohammadshahi and Henderson Reference Mohammadshahi and Henderson2019; Wu et al. Reference Wu, Pan, Chen, Long, Zhang and Philip2020; Dwivedi and Bresson Reference Dwivedi and Bresson2020) offer a promising avenue for research involving the incorporation of dependency networks as well as extra-linguistic sentiment features into the more complex tasks of natural language processing.
The implementation of the ConGraCNet method is available as an applicationFootnote y, which complements the article.
Acknowledgements
This work has been supported in part by the Croatian Science Foundation under the project UIP-05-2017-9219 and the University of Rijeka under the project UNIRI-human-18-243.
Conflicts of interest
The authors declare none.

















































































