


When people consider intelligence, they will first tend to think of IQ, and scores that distinguish people, one from another. They will also tend to think of those scores as describing something as much part of individuals’ make-up as faces and fingerprints. Today, a psychologist who uses IQ tests and attempts to prove score differences are caused by genetic differences will be described as an ‘expert’ on intelligence. That indicates how influential IQ testing has become, and how much it has become part of society’s general conceptual furniture.
And yet, it’s never sat comfortably among us. Everyone – including experts – will agree that, whatever intelligence is, it’s bound to be complex, enigmatic, and difficult to describe: probably the most intricate function ever evolved. To this day, psychologists argue over what it actually is. So how has measuring it become so easy and apparently so convincing? Most IQ tests take around half an hour, though they vary a lot. Some researchers claim to do it in a few minutes, or over the telephone, or online. How do they get away with that?
Well, for three reasons, I think. First, differences readily match common social observations, much as a model of the universe once matched everyone’s experience of sun and stars going around the earth. In the case of intelligence, we sense it comes in grades, with people arranged on a kind of ladder. Second – and partly because of that – it’s been easy for scientists to propose a natural ladder; that is, intelligence based on our biological make-up. That makes differences real and immutable. Third, IQ testing became influential because it’s been so useful as a socially practical tool. Psychologists have boasted about that for a long time.
Indeed, there’s a long history behind all of that. Proving that the intelligence we ‘see’ socially is perceived accurately, and is biologically inevitable, was the task of polymath Herbert Spencer. Writing in utilitarian Victorian Britain of the 1850s, one biographer described him as ‘the single most famous European intellectual’ of his time. Spencer did try to create a theory of intelligence, but didn’t get far. He was sure, however, that individual and group differences must originate in the physiology of the brain, and due more ‘to the completion of the cerebral organization, than to the individual experiences’. ‘From this law’, he went on, ‘must be deducible all the phenomena of unfolding intelligence, from its lowest to its highest grades’.
Spencer’s method was still theoretical. He read Darwin, and coined the term ‘survival of the fittest’. That idea was later to inspire a wider eugenics movement favouring policies like selective breeding. From common observation he told us that ‘the minds of the inferior human races, cannot respond to relations of even moderate complexity’. By the same token, helping the poor and weak in British society flew in the face of nature, he said – they should be allowed to perish. That’s also practical, in a way, if rather blunt. But sharper tools were on the horizon.
An Unnatural Measure
Gentleman scientist Sir Francis Galton followed much of Spencer’s drift. He was, in addition, very practically minded. In possession of a fortune (inherited), Galton was able to indulge many interests. Travels in Africa in the 1850s had already convinced him of the mental inferiority of its natives. He had read Charles Darwin’s theory, conversed with Spencer, and became convinced that there is something he called ‘natural ability’. It varies substantially among people, he argued, just like height and weight, and is distributed like the bell-shaped curve. Later he observed that members of the British establishment were often related to each other. That convinced him that differences in intelligence must lie in biological inheritance, which also implied that society could be improved through eugenics, or selective breeding programmes. However, he realised, that would need some measure ‘for the indications of superior strains or races, and in so favouring them that their progeny shall outnumber and gradually replace that of the old one’.
Galton was amazingly energetic and inventive. He believed that differences in natural ability, being innate, must lie in neurological efficiency, or the ‘physiology of the mind’ – functions obviously hidden and unidentified. He reasoned, however, that responses to simple sensorimotor tests could provide a window on those hidden differences. He even set up a special laboratory and got people to pay for the fun: reaction times, speed of hand motions, strength of grip, judgements of length, weight, and many others, which all provided the data he sought.
Of course, individuals varied in their scores. But how could he convince people that they were really differences in the unseen intelligence? He already had an idea: ‘the sets of measures should be compared with an independent estimate of the man’s powers’, he said. The individuals’ social status and reputation were what he had in mind. As he put it in Hereditary Genius (1883), ‘my argument is to show that high reputation is a pretty accurate test of high ability’.
And that was it: a numerical surrogate of human worth, of ‘strains and races’, in a few quick tests of sensation, speed, and motion. If you’re thinking about it, though, you might see some suspicious circularity in the logic and want to ask Sir Francis a few questions, like:
How do you know that reputation is a good indication of natural ability (and not, for example, a consequence of social background)?
Possible answer: It’s the only one I can employ (he actually said that) – or, more honestly, we don’t really know.
If you know in advance who is more or less intelligent, why do you need the test?
Possible answer: For mass testing. Also, because numbers look objective and scientific.
If the tests are chosen to agree with what you already know, how can it possibly be more accurate?
Possible answer: It logically cannot be; but it looks as if it is.
These questions refer to the ‘validity’ of a test. Does it measure what it claims to measure? Or do we really know what score differences are differences in? Those questions have hung over intelligence testing like a dark cloud ever since. In this chapter, I hope to show you how IQ testers have dealt with it, and how that has entailed a very special understanding of intelligence. To get a better idea of validity, though, let’s briefly compare the strategy with real tests of physiology, as in biomedical tests.
Physiological Testing
Like psychologists, real physiologists need to describe hidden causes of observed differences, especially in disease conditions. So they have long pored over whatever fluids, excretions, secretions, or expectorants they could coax from the insides to compare with outer symptoms.
Urinalysis was practised even in Ancient Greece, in the time of Hippocrates. In the Middle Ages, flasks and charts were carried by all respectable physicians, duly called ‘pisse prophets’, to assist diagnosis. Colour charts, used well into the nineteenth century, as well as notes on smell (and sometimes taste!) were the first attempts at standardised tests of physiology. Diabetic urine was noted for its ‘exceeding sweetness’. It’s thought that this is where the expression ‘taking the piss’ stems from.
Of course, the tests were rough and ready. But validity improved for a simple reason. Scientific research painstakingly revealed the true nature of the internal functions, including the many detailed steps in urine production, where they can go wrong, and how that is reflected in the chosen markers. So today we have a formidable array of valid tests of physiological functions. We can reliably rate differences in the measure on the ‘outside’ – even the colour of urine – to the unseen functional differences on the ‘inside’. We can understand what variations in cholesterol measures mean. Likewise with blood pressure readings; why a white blood cell count is an index of levels of internal infection; and why a roadside breathalyser reading corresponds fairly accurately with level of alcohol consumption.
‘We Classify’
It turned out that Galton’s test didn’t work, anyway. Differences between upper class and tradesmen, having experienced contrasting conditions in development, would have been unsurprising. But they turned out to be tiny. For example, reaction time to sound was 0.147 versus 0.152 seconds. For ‘highest audible sound’, Galton recorded 17,530 versus 17,257 vibrations per second. But what about intellectual differences? In the USA, doctoral student Clark Wissler tried to correlate results from Galton’s tests with academic grades of university students. There was virtually no correlation between them. And the test scores did not even appear to correlate with each other. It is not possible, Wissler said, they could be valid measures of intelligence. The physiologists of the mind needed another approach.
It so happened that, around that time, the early 1900s, a psychologist in Paris was also devising psychological tests, though of a different kind and for a different purpose. Parisian schools were now admitting more children from poorer backgrounds, and some might struggle with unfamiliar demands. Alfred Binet was charged by the local school board to help identify those who might need help.
Like Galton, Binet devised series of quick questions and mental tasks. But he was looking for ones related to school learning rather than physiology. He got them, quite sensibly, from close observation of classroom activities, by devising short questions and tasks to reflect those activities, and then trying them out. Each item was deemed suitable, or not, according to two criteria: (1) whether the number of correct answers increased with age; and (2) whether a given child’s performances matched teachers’ judgements of his or her progress.
Binet and his colleague Henri Simon produced their first Metrical Scale of Intelligence in 1905. It contained 30 items, designed for children aged 3–12 years, arranged in order of difficulty. By 1911 the collection had expanded to 54 items. Here are some examples expected to be passable by two age groups:
Five-year olds:
compare two weights;
copy a square;
repeat a sentence of 10 syllables;
count four pennies;
join the halves of a divided rectangle.
Ten-year olds:
arrange five blocks in order of weight;
copy drawings from memory;
criticise an absurd statement;
answer sentence-comprehension questions;
use three given words into a sentence.
Average scores for each age group were calculated. The ‘mental age’ of individuals could then be worked out from how many items they could do. If a child achieved a score expected of six-year-olds, they would be said to have a mental age of six. A child passing them all would have a mental age of 12. Binet suggested that a deficit of two years or more between mental age and chronological age indicated that help was needed. Finally, in 1912, the German psychologist William Stern proposed the use of the ratio of mental age to chronological age to yield the now familiar intelligence quotient, or IQ:

So IQ was born. But it is important to stress the narrow, practical, purpose of Binet’s test: ‘Psychologists do not measure … we classify’, he said. However, it had an unintended, but hugely portentous, quality. By its nature it produced different scores for different social classes and ‘races’. Galton’s followers soon claimed Binet’s to be the test of innate intelligence they had been looking for. Translations appeared in many parts of the world, especially in the USA. Binet himself condemned the perversion of his tests as ‘brutal pessimism’.
Original Mental Endowment
In the USA, Henry H. Goddard translated the Binet–Simon test into English in 1908, and found it useful for assessing the ‘feebleminded’. As a eugenicist, Goddard worried about the degeneration of the ‘race’ (and nation) by the mentally handicapped, and also by the waves of new immigrants from Southern and Eastern Europe. He was commissioned to administer the test to arrivals at the immigration reception centre on Ellis Island. Test scores famously suggested that 87 per cent of the Russians, 83 per cent of the Jews, 80 per cent of the Hungarians, and 79 per cent of the Italians were feebleminded. Demands for immigration laws soon followed.
Lewis Terman, a professor at Stanford University, developed another translation of Binet’s test in 1916. He enthused over the way it could help clear ‘high-grade defectives’ off the streets, curtail ‘the production of feeblemindedness’, and eliminate crime, pauperism, and industrial inefficiency. By using his IQ test, he said, we could ‘preserve our state for a class of people worthy to possess it’. Binet’s screen for a specific category thus became scores of the genetic worth of people in general. ‘People do not fall into two well defined groups, the “feeble minded” and the “normal”’, Terman said. ‘Among those classed as normal vast individual differences exist in original mental endowment.’ He, too, called for eugenic reproduction controls, which soon followed. Galton’s programme had found its measure.
Mass Testing
Terman’s test was applied to individuals, one at a time. During World War I, however, the US Army wanted to test recruits in large numbers from many different backgrounds. A group led by Robert Yerkes constructed two pencil-and-paper tests: one for those who could read and write English; the other for those who could not. These were quite ingenious, including tasks like tracing through a maze, completing a picture with a part missing, and comparing geometrical shapes. Up to 60 recruits could be tested at a time, taking 40–50 minutes. In Army Mental Tests, published in 1920, Clarence Yokum and Robert Yerkes claimed that the test was ‘definitely known … to measure native intellectual ability’.
These group tests set the scene for mass IQ testing in populations generally, and for the spread of the ideology underlying it. Up to the early 1930s the IQ message became useful in the USA in the passing of compulsory sterilisation laws, immigration laws, and the banning of ‘inter-racial’ marriage. Hitler’s ministers in Nazi Germany were impressed by America’s IQ testing regimes, and its eugenics policies. They took the message away with even more deadly consequences, as we all know.
And in Britain
In Britain, the new intelligence tests were just as energetically promoted. Eugenics movements were popular, and, in 1911, a report to the Board of Education recommended their use for the identification of ‘mental defectives’. By the late 1930s psychologists like Cyril Burt were urging their use in the British 11+ exam. ‘It is possible at a very early age’, they advised, ‘to predict with accuracy the ultimate level of a child’s intellectual power’, and that ‘different children … require (different) types of education’.
Since then, IQ testing has developed rapidly into the huge enterprise it is today. But constant controversy has hinged on the same burning question. Do IQ tests really measure what they claim to measure – even if we aren’t sure what that is? It’s important to see how IQ testers have dealt with the question, and how they have dodged it.
Validity Vacuum
In his book IQ and Human Intelligence, Nicholas Macintosh stated: ‘If you are trying to devise a test that will measure a particular trait … it will surely help to have a psychological theory specifying the defining features of the trait, to ensure that the test maps on to them.’ That means being clear about what differences on the ‘outside’ (the measure) really mean in terms of differences on the ‘inside’. That’s what we expect of modern physiological and biomedical tests, after all. Such mapping is called ‘construct validity’. As mentioned earlier, simple definitions do not do that.
Lewis Terman used previously translated items from Binet’s test, but added many more of similar types: memory span, vocabulary, word definition, general knowledge, and so on. Now called the Stanford–Binet, the test soon became the standard on both sides of the Atlantic. Like Binet’s test items, they obviously tended to reflect school learning and a literary/numerical mindset, itself related to social background. But there is no systematic attempt at construct validity.
As regards the Army Mental Tests, mentioned above, Yokum and Yerkes duly emphasised (on page 2!) that the test ‘should have a high degree of validity as a test of intelligence’. But little more was said about it. Instead, correlations of scores with those on Terman’s test, and with teachers’ ratings, as well as social class, are given.
David Wechsler devised the Adult Intelligence Scale in 1939, and then the Wechsler Scale for Children in 1949. Wechsler had worked on the Army tests and used similar items. Through a number of revisions, these tests have rivalled the Stanford–Binet in popularity. As for validity, as psychologist Nicholas Mackintosh noted, ‘Wechsler had little evidence [of] the validity of his tests’, except their correlation with Stanford–Binet scores and teachers’ ratings. He quotes Wechsler to say, ‘How do we know that our tests are “good” measure of intelligence? The honest answer we can reply is that our own experience has shown them to be so.’ As apology, Wechsler mentions only that the same applies ‘to every other intelligence test’.
These are the most popular, and almost the ‘gold standard’, tests. A huge number of other IQ-type tests have been constructed, and I will refer to some below. But they are almost all collections of items closely related to school learning and literacy and numeracy. Testers almost always imply that they’re measuring learning ability, not simply learning. What that is has not been made clear. If you get the chance, have a look at the test manuals and search for any claims about test validity. What you will almost always get is reference to one or other of four substitutes for it. Let us look at these in turn.
Score Patterns
IQ test items are devised by individual psychologists introspectively, according to the cognitive processes they imagine will be invoked. They are then included or rejected in a test after exhaustive trial-and-error procedures known as item analysis. The aim is to end up with a pattern of average scores that match expectations of individual differences in intelligence. An item is included if, as seen in trials, it more or less contributes to such a pattern. Otherwise it is rejected. Although the pattern is thus ‘built in’, it is then taken to confirm test validity.
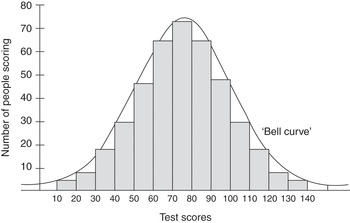
For example, test constructors have assumed that intelligence, as a ‘biological’ trait, should be distributed like physical traits, according to the bell-shaped curve (Figure 1.1). The pattern was achieved by Lewis Terman, after preliminary trials, by a simple device: rejecting items that proved to be either too easy or too difficult for most people. The practise has continued, and the results have been taken to confirm test validity, instead of being an artefact of test construction. In fact, many physiological variables, including many in the brain, are not distributed like that (see Chapter 6).
Test items are also selected such that progressively more of each age group respond correctly. That makes scores resemble those of a simple physical trait such as height or foot size. However, the school-related content of many items ensures that average test scores indeed increase with age – as desired – and then steadily decline thereafter (Figure 1.2). Even today, researchers worry about the declining average intelligence of adults, and are looking (unsuccessfully) for the neural bases of it. But it’s only a side-effect of the method of test construction.

The problem could, of course, be solved, by introducing items that older people are better at. In such ways, sex differences evident in the original Stanford–Binet test were equalised by introducing, in later revisions, new items on which boys did better than girls, or vice versa. Other psychologists have shown how social class and ‘racial’ differences could be eliminated (or even reversed) in exactly the same way. In all these ways we find ‘test validity’ inferred from score patterns that are actually consequences of test construction.
Scores Agree – It Must Be ‘g’
We all appreciate how entities that change (i.e. variables) can sometimes change together, or co-vary: for example, season and daytime temperature, or shoe size and hand size. In the late nineteenth century, Karl Pearson devised a statistical measure of such co-variation. His ‘correlation coefficient’, widely used ever since, ranges from 0 to 1 (0.0–1.0) according to the degree of co-variation. Psychologists often warn about inferring causes from correlations: the price of coffee correlates with global warming but does not cause it. But they also have a habit of ignoring it. That has been an issue running throughout the history of IQ.
People who do well on one kind of mental test (such as an intelligence test or school test) tend to do well on others, and vice versa. British psychologist Charles Spearman had noted that in the early 1900s. He suggested that the correlations must be caused by the single underlying factor proposed by Galton: a ‘General Intelligence’ that he also called ‘g’. The correlations were not perfect (around 0.6 for school subjects). So Spearman suggested that individual differences were also partly due to differences in ‘special’ factors, meaning ability at some particular cognitive tasks (such as maths or writing).
Such correlations are taken by leading IQ testers as proof of test validity – that the tests are really invoking a real and common intelligence factor. But that is a causal inference from the correlations, not a fact. It might be due to something else, and there have been big disagreements about that. As just described, test items are selected according to the designer’s preconceptions and ingenuity. So, some tests are constructed to emphasise the unitary factor g as causing most individual differences; others emphasise the special or ‘group’ factors, such as ‘verbal’ or ‘visuo-spatial’ abilities. That has caused much debate about the ‘structure’ of intelligence, as if the different score patterns are saying something about internal processes rather than test construction.
Behind it all is a tacit model of the mind as a kind of machine. Even today, Spearman’s g is said to reflect individual differences in some kind of ‘energy’, ‘power’, ‘capacity’, or even ‘speed of processing’. The special or group factors are treated as if they are components in the machine. People vary, that is, according to the ‘strengths’ of their components. Again, we don’t know what they are or how they work. The names they are given – such as memory, verbal, mathematical – simply describe the ‘look’ of respective items, not real cognitive functions. Yet correlation patterns in a test are frequently presented as evidence of test validity. We should not be fooled by them.
I will be reminding readers frequently of this ‘mechanical’ model of the human mind. It underlies much of what is wrong in research and ideas about intelligence.
Predictive Validity
By far the most quoted source of test validity consists of associations with other aspects of achievement. ‘[T]he measurement of intelligence … is a reasonably good predictor of grades at school, performance at work, and many other aspects of success in life.’ So said a report for the American Psychological Association in 2012. It is a well-rehearsed mantra, and IQ testers readily join the chorus line.
Does that really tell us what is being measured? Things are not so simple. There are correlations between individuals’ IQs and their school performances. But IQ test items tend to be selected because they are related to school knowledge and learning. They are, to a large extent, measuring the same learning. A correlation between the two is self-fulfilling, and hardly an independent index of test validity.
Another problem with the argument is that the associations diminish over time, outside the narrow confines of early school learning. In the UK, IQ predicts GCSE (General Certificate of Secondary Education) performances in tests taken at around 16 years old. But the latter only moderately predict A-level performances two years later, which, in turn, only very moderately predict university performance (see Chapter 9). That doesn’t suggest we’re measuring a very robust ‘intelligence’.
IQ scores are also statistically associated with occupational level, salary, and so on. But level of entry to the job market is largely determined by school attainment. That’s another self-fulfilling pseudo-validity. But what about job performance? For nearly a century, in fact, hundreds of studies have tried to assess how much IQ predicts job performance. But only very weak correlations (around 0.2) could be found. IQ testers, however, tend to appeal to the remarkable ‘corrections’ hammered out of the originals by the complex statistical manoeuvres of industrial psychologists Frank Schmidt, John Hunter, and their associates in the 1980s. The corrections involved ‘pooling’ all the available results and have attracted many criticisms – for very good reasons.
The original studies tended to be old, some from the 1920s, and related to particular jobs, companies, and locations, mainly in the USA. Many were performed in rough-and-ready circumstances, with only small samples. And many of the tests were not even IQ tests: reading tests, memory tests, simple vocabulary or English tests, judgement of speed, and other ‘aptitude’ tests – in fact, dozens of anything looking remotely like a mental test. It seems a travesty to call these ‘general ability tests’ as Schmidt and others do. Moreover, the statistical corrections required crucial information about test reliabilities, measurement errors, score ranges, and so on. In many cases that information was not available, so had to be estimated using more assumptions. Yet these corrections have been extremely influential in backing up supposed test validity. Those who continue to rely on them really should look at the datasets more closely.
In fact, job performance is difficult to assess objectively, and has almost always been based on supervisor ratings. Those tend to be subjective, and based on inconsistent criteria. Age, height, ethnic group, and facial attractiveness have all been shown to sway judgements. And – as we surely all know – performance can vary drastically from time to time, in different contexts, work environments, and how long individuals have spent on the job. In sum, the idea that IQ tests are valid measures of intelligence because they predict educational and job performance is debatable. The bottom line, anyway, is that none of these so-called test validities are clear about what the measures are measuring. So let’s have a closer look at that.
Differences in What?
It is not difficult to find examples of IQ test items in magazines and online. To the general public they can seem impressive and convincing. They can look as if they definitely need complex mental processing. The variety, hatched through the ingenuity of item designers, is itself impressive: word meanings, synonyms, block puzzles, identifying shapes; there’s hundreds of them. So only a few examples can be considered here.
Many require general knowledge, such as: What is the boiling point of water? Who wrote Hamlet? In what continent is Egypt? These fall under the category of ‘verbal intelligence’. But they surely demand little more than factual knowledge obviously learned, and, as such, related to background opportunities for doing so.
Most items require some use of words and numbers, such as recall of a short string of digits like 5, 2, 4, 9, 6, or of words like dog, camera, train, animal, job. They are read out to be recalled five minutes later as a measure of memory. Others are classified as ‘verbal comprehension’, such as:
Which single letter completes the following words? CA*; *US; RU*Y; *OTH.
‘Verbal reasoning’ items are deemed to be particularly important, and usually include verbal analogies such as:
Horse is to foal as Cow is to (calf; to be chosen from the given options).
These also come in nonverbal forms, as shown in Figure 1.3.

Indeed, whole tests have been based on such ‘analogical reasoning items’, and it’s instructive to take a special look at them. In his book Innate (2018), Kevin Mitchell describes analogical reasoning as ‘at the very heart of intelligence’. That argument, too, seems convincing until we consider the way that so much of everyday human communication and activity utilises analogical reasoning:
‘His bark is worse than his bite.’
‘Letting the tail wag the dog.’
‘The harder you shake the pack the easier it will be for some cornflakes to get to the top.’
Biblical proverbs, sermons, and parables use them a lot (I seem to remember something about rich folk, heaven, a camel, and the eye of a needle). So does much of everyday humour. As I will explain in other parts of this book, analogy formation and recognition are aspects of the general pattern abstraction that takes place even in simple organisms. Indeed, Mitchell himself uses analogies to get across certain points:
Sexual selection [e.g. females being choosy about partners] can act [on males] like an escalating arms race.
The [resting] brain is like a car sitting with its engine running, just idling.
When authors use analogies in that way, they do so with an obvious assumption: that the analogy will be understandable through familiarity, from experience. So, it seems reasonable to ask why we would assume the opposite with IQ tests: that they reveal something other than familiarity? That’s like swallowing camels and straining at gnats. (And there’s another one.)
In fact, many studies have now shown, even in young children, how ability to do specific analogical reasoning items does depend on familiarity with the relations bound up in them, rather than a hypothetical mental ‘strength’ or ‘power’. They seem to be so widely included in IQ tests for no other reason than that they reliably discriminate between social classes – which, of course, gives the whole game away. Such black box, mechanical thinking also exposes the point made by Linda Gottfredson in 1997, that ‘We lack systematic task analyses of IQ tests.’
It’s worth applying that caution to other nonverbal items, which are very popular. These include identifying missing parts of pictures (e.g. a face with its nose missing); tracing routes through mazes; counting boxes in a stack (with some of them hidden behind others); and so on. By far the favourites, however, are matrix items (Figure 1.4). Raven’s Matrices tests are made up entirely of such items. Again, it is instructive to give them further consideration.

In order to solve a matrix, test-takers need to work out the rules dictating changes across rows and down columns. These are mostly changes to size, position, or number of elements. The difficulty seems to depend on the number of rules to be identified and the dissimilarity of elements to be compared. A tremendous mystique has developed around them. Their appearance suggests that they really are getting at basic differences in cognitive ability, free from any cultural or other background influence.
In fact, a little further analysis shows that ‘Raven IQ’ is just as dependent on familiarity, itself varying with social background, as the analogies items. The manipulation of elements (e.g. words, numbers) in two-dimensional arrays on paper or computer screens is very common in many jobs and family backgrounds, and less so in others. It figures prominently in record sheets, tables with rows and columns giving totals and subtotals, spreadsheets, timetables, and so on, as well as ordinary reading material. These nearly all require the reading of symbols from top left to bottom right, and additions, subtractions, and substitutions across columns and down rows. Familiarity with such relations and procedures varies significantly across cultures and social classes. For example, Asian cultures that read from right to left have difficulty with them. That suggests what is really being tested.
Real-Life Complexity
We can’t be sure what cognitive processes are really being compared in IQ tests. On the other hand, it can be claimed that typical IQ test items are remarkably un-complex in comparison to the complexity of cognitive processing nearly all of us use every day. Ordinary, everyday, social life is more complex than we think. As Linda Gottfredson also explained, ‘other individuals are among the most complex, novel, changing, active, demanding, and unpredictable objects in our environments’. The mental activity needed to deal with real life tends to be a great deal more complex than that required by IQ test items, including those in the Raven.
Some studies have set up simulated factories, tailor’s shops, or public services, where participants have to control several variables at once (staff numbers, input costs, and so on) to maximise production. Reported associations with IQ have tended to be weak. In 1986 psychologists Stephen Ceci and Jeffrey Liker reported their famous study of betting at a racecourse. They found gamblers’ predictions of odds to be a sophisticated cognitive process. It involved taking account of up to 11 variables, with complex interactions between them. Individuals’ accuracy at such predictions was unrelated to their IQ test scores.
Highly complex cognition is already evident in pre-school children. Developmental psychologist Erno Téglás and colleagues argue, as I will do many times later, that ‘many organisms can predict future events from the statistics of past experience’. That means integrating many sources of information ‘to form rational expectations about novel situations, never directly experienced’. We do this all the time in ordinary social situations (think about driving in a strange town). But what Téglás and colleagues found is that ‘this reasoning is surprisingly rich, powerful, and coherent even in preverbal infants’.
Much other evidence shows how different people, in different circumstances, develop different ways of thinking and feeling. These are even reflected in brain networks, as we shall see in Chapter 6. Being cognitively intelligent means different things for different people in many different places. As the European Human Behaviour and Evolution Association warned in a statement in 2020, ‘Even those IQ tests which claim to be culture-neutral … rely on modes of thinking which are routinely embedded in Western education systems (e.g. analysing 2-dimensional stimuli), but not reflective of skills and learning experiences of a large proportion of the global population.’
It is perfectly reasonable to ask, then, are IQ tests testing for mental ‘strength’ or familiarity? The latter will vary for many reasons other than innate endowments. Indeed, I will be presenting much evidence that those we label as intelligent – or bright or smart or whatever – tend to be those culturally ‘like us’. In speaking the same language, they are using the same cognitive rules of engagement, and similar conceptual models of the world. Engagement with ease and confidence also creates the illusion of underlying mental strength or power.
Familiarity and Class
Familiarity with items, as in analogies and matrices, will mostly vary with social background. As a 2017 review by psychologist Natalie Brito found, the specific language and numerical skills needed for IQ tests are closely related to social class background. So it’s not so much individual strength, power, or capacity that is being described in IQ differences as the demographics of the society in which they have lived.
That explains why average IQ scores have increased enormously across generations in all societies where records are available: about 15 points per generation. It has been called the ‘Flynn effect’, after James Flynn, one of the researchers first reporting it. IQ theorists are still puzzled about it. It could not be due to hypothetical genetic changes over such a short time. Nor is it likely to be due to general improvements in simple speed, capacity, or strength. The effect does correspond, however, with massive expansion of middle-class occupational roles, and reduction of working class roles. More and more people have simply become more familiar with the acquired numerical and literary skills of the middle class.
Not Intelligence
IQ test performances will also vary for reasons that have little to do with cognition or learning ability. Some children will be motivated or ‘pushed’ by parents to acquire the knowledge, and the skills of numeracy and literacy, that figure in IQ tests. So it is not surprising that IQ also varies with degrees of parental support and encouragement. That will also tend to affect performance on all tests – which may be the real basis of the mysterious ‘general intelligence’, or ‘g’, mentioned above. Also, as anyone might expect, levels of self-confidence, stress, motivation, and anxiety, and general physical and mental vigour, all affect education, job, and cognitive test performances. Such factors are not spread randomly across a population. They will be closely associated with social class, and I will explore them further in Chapter 8.
Finally, although we are led to believe that IQ is a fixed attribute of an individual, that’s far from the case. Of course, if individuals’ social status and test-relevant experiences don’t change, neither will their proficiency on IQ tests, even over many years or even decades. That simply reflects continuity of social class membership. On the other hand, IQ test performance is demonstrably boosted by practice. Testing of the same individual at different times can show variations of as much as 30 points (over an average score of 100). IQs can improve with schooling, as just mentioned. Also, children adopted into middle-class homes from an early age have IQs, on average, 15 points higher than those not adopted. Other test-related experiences, such as computer games or even music training, can also boost IQ scores.
Other Ideas
The IQ view of intelligence continues to dominate biology and psychology. But some psychologists, conscious of its problems, have tried to present alternatives. An entertaining account of some of these is given in science journalist David Robson’s The Intelligence Trap, mostly based on the shortcomings of IQ testing (though without further analysis).
In Multiple Intelligences (1984) and Extraordinary Minds (1997), Howard Gardner has debunked the concept of g. Instead, he suggests there are ‘specialised intelligences’ such as linguistic intelligence, logico-mathematical intelligence, spatial intelligence, musical intelligence, and so on. In his more recent work, Gardner has extended his original list of 7 to 11, and suggests the list will grow. He doesn’t give details of cognitive processes, but speculates that each ‘intelligence’ has its own peculiar computational mechanisms, based on a distinct neural architecture. Intelligences, he says, also differ in strength from person to person. That explains, he suggests, why all children excel in one or two domains, while remaining mediocre or downright backward in others.
All that aligns with those who intuitively sense individual ‘talents’ in children. The problem is, where do they come from? Gardner also passes the question over to biology. He says that they are predetermined through genetic programmes. The specified structures will develop even in widely varying circumstances or environmental experiences, but individuals will vary in their ‘intelligences’ through inherited differences in those programmes. Thus, while appealing for its broader view, Gardner’s theoretical foundations remain tentative and undeveloped. Some see his ‘theory’ as just a ‘naming’ exercise – identifying areas of expertise in individuals without describing what any one actually is, or how it works or develops.
Psychologist Robert Sternberg has, for many years, expressed dismay at the narrowness of the concept of g. On his website in 2020 he says that ‘we no longer can afford to define intelligence merely as gor IQ. Doing so has been a disaster – literally, not merely figuratively.’ He has been developing a ‘tri-archic’ theory of intelligence, based on three wider attributes:
1. analytical thinking is that ability assumed in traditional IQ tests;
2. creative ability, which forms the basis of imagination and innovation; and
3. practical intelligence, which is the ability to plan and execute decisions.
Sternberg says people vary in these different domains, and they influence decision-making and success in life. He has also attempted to develop tests for them. For example, in regard to ‘practical intelligence’, individuals are presented with problems relevant to their work context. He argues that those tests offer better predictions of university grades and occupational success than basic IQ tests. The theory has been lauded in some quarters for identifying intelligent individuals otherwise missed. But that does not really tell us what individuals have got and how they got it. However, we must look forward to Sternberg’s forthcoming Adaptive Intelligence (due 2021). Forward notices say it involves ‘dramatic reappraisal and reframing of … a fatally-flawed, outdated conception of intelligence’. It may be that what I have to say in Chapters 8 and 9, in particular, will be in some agreement with that.
There have been many other alternative views. In my view, they are adjuncts to the mechanical IQ view of intelligence differences. Some are refreshing, but do not get to the root of the matter of what intelligence is, how it evolved, and how it develops in individuals. What intelligence ‘is’ remains implicit (or, as Sternberg says, ‘tacit’) rather than explicit. That requires the more radical approach attempted in most of this book.
Use of IQ Tests
No one can criticise the medieval ‘pisse prophets’ for trying to help the physically distressed. The same applies to attempts to identify individuals in need of psychological help today. That was the intention of Binet through his original test: a purely pragmatic tool, without prejudgment of future intelligence, or even a theory of it. Today, many clinicians and other psychologists claim to find some IQ-type test items useful in helping children and adults in just that way. For example, some ‘visuo-spatial’ tests may help diagnose early Alzheimer’s disease. Some ‘verbal’ tests might identify specific problems with reading, and so on. And you may have read that the Wechsler Digit Symbol test is a ‘neuropsychological test’ sensitive to brain damage, dementia, and so on. But we must also be aware of their limitations.
We can describe an item by appearance, but we don’t really know what is happening ‘in’ the brain or cognitive system. That may lead users astray sometimes, as happened with medieval physicians. For example, as with all cognitive testing, performance is subject to the multitude of contextual and social background factors mentioned above. Test-takers who are illiterate, have little education, or lack cognitive confidence will show significantly lower performance on all cognitive assessment tests without lacking in learning ability at all.
Nevertheless, such specific uses may also be helpful in very complex circumstances, and they may well be useful in the long-term research needed to construct better theories of intelligence (which is what much of the rest of this book is about). What we cannot do is what happened as soon as the Binet–Simon tests were translated and used in Anglo-American contexts: that is, claim to have a measure of general intelligence – and genetic worth – in whole populations. Alas, that is a mistake being widely repeated today.
Back to Physiology
Galton’s followers have always tried to identify differences in intelligence with physiology. As educational psychologist Arthur Jensen put it in the 1980s, ‘the g factor is so thoroughly enmeshed in brain physiology’ as to really be ‘a property of the brain as a whole’. Much of the rest of this book will show that real biological systems are nothing like the ‘physiology’ those psychologists imagine. Here’s a glimpse of why.
Today, there are thousands of physiological tests, all external ‘biomarkers’ of clearly modelled internal differences. One of the most striking things about them, though, is the extremely wide ranges of variation within which normal, adequate function seems to operate. The following list presents what are ‘normal’ measures of physiological functions in a standard full blood count. Only deviations outside these wide limits suggest abnormality:
red blood cells: 4.5–6.5 trillion cells per litre;
white cells (for immunity): 4.0–11.0 billion cells per litre;
platelets (for clotting): 140–400 billion per litre;
lymphocytes (guiding immune response): 1.5–4.0 billion per litre;
vitamin B12 (for a wide range of processes): 150–1,000 nanograms per litre;
serum ferritin (levels of stored iron): 12.0–250 micrograms per litre;
serum folate (involved in DNA and red blood cell production): 2.0–18.8 micrograms per litre;
serum urea (indicates kidney function): 2.5–7.8 micromoles per litre;
alkaline phosphatase (indicates liver function): 30–130 units per litre.
These are very wide, yet normal, variations. Within them the system functions well enough. In a different context, the biophysicist Nicolas Rashevsky introduced the term ‘the principle of adequate design’. I think it fits very well in this context, too. Real physiology is nothing like the simplistic bell-curve model. It is a dynamic, interactive system of processes that tend to mutually compensate for each other. Indeed, I will show in Chapter 4 that physiology is, itself, an intelligent system. Huge variation observed is little guide to what lies beneath – which is what most of this book is about.




