



Scholars frequently use measures of representational diversity to assess the health of democracies and to understand the extent to which legislatures reflect the populations they govern (Cross, Reference Cross2011). In Canada, the Library of Parliament provides information on federal election candidates’ gender and occupation, and these data have recently been systematized for all elections since 1867 (Sevi, Reference Sevi2021).Footnote 1 We contribute to this effort by adding new data on candidates’ race, Indigenous background and age, alongside data on their gender, occupation, prior electoral experience and electoral outcome. The dataset includes the 4,516 candidates who ran for the major federal parties in the 2008, 2011, 2015 and 2019 Canadian elections. This research note describes the main features of the dataset, explains the procedures for collecting and coding the information within it, and outlines some of the potential applications.
The dataset's most significant contribution is its inclusion of information on candidate race and Indigenous background, a focus of study where Canadian political science has typically lagged behind (Ladner, Reference Ladner2017; Thompson, Reference Thompson2008). Idle No More, Black Lives Matter and the rise of white supremacy all suggest we ignore matters of identity at our peril (Andrew, Reference Andrew2017). Political parties typically do not collect (or at least opt not to publicly share) individual-level data on candidate demographics, and this has left gaps in the knowledge base. Our new dataset is therefore an important step forward, providing new information on the representation of identities in Canadian federal politics, which can be used to develop single-case studies as well as comparative benchmarking.
Other Canadian research tracks candidates’ gender and racial background but includes only aggregate numbers, such as the total number of women or racialized candidates, and this prevents researchers from linking these data to other variables (Black, Reference Black2017). Like others (Lucas et al., Reference Lucas, Merrill, Blidook, Breux, Conrad, Eidelman, Koop, Marciano, Taylor and Vallette2021; Sevi, Reference Sevi2021), we expand the possibilities by providing publicly accessible data at the district level for all candidates, and we add novel data on racial and Indigenous backgrounds. These data can be tracked as dependent variables across multiple elections or included as independent variables to understand the relationship between candidate background and other political phenomena.
Data Collection and Variables
Researchers have experimented with several methods for gathering data on candidate demographics, including surveys (Andrew et al., Reference Andrew, Biles, Siemiatycki and Tolley2008; Black and Hicks, Reference Black and Hicks2006), probability-based classifiers (Lucas et al., Reference Lucas, Merrill, Blidook, Breux, Conrad, Eidelman, Koop, Marciano, Taylor and Vallette2021; Sevi, Reference Sevi2021) and genealogical approaches based on publicly available biographical materials and surname and photographic analysis (Black, Reference Black, Andrew, Biles, Siemiatycki and Tolley2008). Many researchers combine two or more of these techniques. Surveys offer highly reliable information because they are based on self-identification, but they often have considerable missing data given low response rates. Non-responses are of particular concern because they may be systematically linked to candidate demographics (Walgrave and Joly, Reference Walgrave and Joly2018), and this is why we do not use a survey-based approach. Probability-based classifiers based on candidate name offer the advantage of automation and are most commonly applied to the study of gender using the R package genderizeR (Wais, Reference Wais2016), but they require sample data to train the classifier and generate reliable inferences. In the United States, researchers have extrapolated candidates’ racial identities using the Census Bureau's Surname List (Grumbach and Sahn, Reference Grumbach and Sahn2020), but this resource does not exist in Canada, so researchers must rely on other methods (Besco and Tolley, Reference Besco and Tolley2020). Given this situation, we developed a rigorous expert coding procedure based on genealogical methods, an approach that has been recognized as the “gold standard” in tracking candidate demographics (Shah and Davis, Reference Shah and Davis2017).
Although researchers in a number of contexts rely on genealogical methods to infer or ascribe a candidate's background, there is the potential for error and bias. To guard against these limitations, our coding procedure was based on the principle of triangulation: all demographic observations were cross-referenced across multiple sources. We required positive verification in at least two sources, such as a photograph and a biographical reference, prior to making a determination about a candidate's background. In cases where two positive verifications could not be obtained, the data are coded as missing.
We began by compiling candidate lists using official returns from Elections Canada. These returns also include election year, province, and electoral district name and number; these are all included in the dataset. To this, we added variables on incumbency, gender, racial and Indigenous background, occupation, office-holding at other levels of government, age and electoral outcome. Data for variables not included in official returns were gathered from the Library of Parliament, Elections Canada, official party and candidate websites, social media and news media. Coders collected the data, which were then cleaned, verified and standardized by one of the authors. Coding took place in several rounds and at different timepoints, with the procedures adjusted and improved as new sources of candidate information were discovered. At least two separate coders examined each individual data point, and the approach to data generation was team-based and iterative. For this reason, we do not report conventional measures of intercoder reliability but instead provide a transparent account of the procedures and decision rules we used. We conservatively estimate that the data collection and coding took more than 1,200 hours. The supplementary appendix includes additional details on the coding procedures and sources we consulted; in this research note, we highlight the main features of the substantive variables.
Party. From 2008 through 2015, the dataset includes candidates for the Bloc Québécois, Conservative, Liberal and New Democratic parties. In 2019, we added candidates for the Green party.
Incumbency. Candidates who held a seat in the House of Commons immediately preceding the election were coded as incumbents; all others were coded as non-incumbents.
Gender. Candidates’ gender identity or expression at the time of their candidacy was coded using biographical information, news reports, photographs and first names. In 2008, 2011 and 2015, candidates were coded as either male/man or female/woman. In 2019, when nine candidates publicly identified as non-binary—meaning they do not identify strictly as a man or a woman—we added a third code to this variable.
Racial or Indigenous background. Candidates were classified as racialized, Indigenous or white. We based these constructs on the definitions of “visible minority” and “Aboriginal” that are included in Canada's Census Dictionary (Statistics Canada, Reference Canada2017). While we retain the content of these definitions, the labels themselves have been criticized and are often not the ones used by the communities to which they refer (Hennig, Reference Hennig2019; United Nations, 2007; Vowel, Reference Vowel2016). The categorizing and labelling of demographic characteristics are not without contention, but consistent with best practices in the relevant scholarship; we use “racialized” and “Indigenous” rather than “visible minority” and “Aboriginal” (see, for example, Gonzalez-Sobrino and Goss, Reference Gonzalez-Sobrino and Goss2019; Thompson, Reference Thompson2016; Vowel, Reference Vowel2016).
Racialized candidates are those who are not Indigenous and are “non-Caucasian in race or non-white in colour” (Statistics Canada, Reference Canada2017). This category includes those who are South Asian, Chinese, Black, Filipino, Latin American, Arab, Southeast Asian, West Asian, Korean or Japanese and those who have mixed racialized backgrounds. Indigenous candidates are those who are First Nations (for example, Status Indian, Cree, Ojibway), Métis or Inuit. Candidates who are neither racialized nor Indigenous were coded as white. These classifications rely on both self-identification and ascription. Some candidates self-identify as racialized or Indigenous in their personal biographies or in media interviews, and we would code their background accordingly. In instances where existing sources provided no identification of a candidate's racial or Indigenous background, this variable was treated ascriptively and coded based on photographs and surnames, using the principle of triangulation outlined above.Footnote 2 Although higher levels of disaggregation are desirable, this goal is impeded by a lack of data on subcategories of candidate identification (for example, whether a candidate identified as Indigenous is Métis or First Nations), as well as the near impossibility of reliably inferring a candidate's specific racial background; to achieve this aim, expert coding using genealogical methods is generally not appropriate. Thus, with some reservations, we use macro-level categories (“racialized” and “Indigenous”).
Occupation. We coded candidates’ primary occupation prior to their entrance into politics. We relied extensively on the Library of Parliament's list of elections and candidates, which provides every federal candidate's occupation following each election. Elected representatives sometimes report “Parliamentarian” or “politician” as their primary occupation. To better reflect candidates’ occupational background at the time they were first elected, we therefore sought information from other sources, including candidate and party websites, interviews and media reports. Occupational data are reported in nine broad categories: agriculture; business; education; government and politics; physicians and doctors; other health care; journalism; law; and other.
Age. We include a variable on candidate age, reported by year of birth. The Library of Parliament does not include age in its candidate database. Year of birth is available for elected members of Parliament, as well as for some candidates who previously served in a provincial legislature, and some candidates report their age in their official biographies or in media interviews. However, many do not disclose this information, and we are missing data on age for approximately one-third of the candidates in the database.
Other levels. To capture electoral experience at other levels of government, we include a dichotomous variable indicating whether candidates previously held office at the provincial or municipal level, or if they have not.
Electoral outcome and competitiveness. In each election, the candidate who won the district is coded as elected; all others are coded as having been defeated. We also include a measure of competitiveness, which is the difference between a candidate's percentage of the vote and that of the victor. The information for both variables was derived from Elections Canada's official electoral returns.Footnote 3
Applications
The dataset can be used, first, to understand and track diversity among electoral candidates. Figure 1 shows that since 2008, the proportion of candidates who are women, racialized or Indigenous has increased. The increase in women candidates between 2015 and 2019 is particularly notable and in contrast to the relative stagnation in this category in the preceding three election cycles. Other researchers can extend this analysis intersectionally to look at, for example, the presence of racialized women candidates in Canadian politics. Such an application would help to reveal whether racialized women are “doubly burdened” on account of their race and gender or, alternatively, whether they are “doubly advantaged,” with their race and gender providing party elites with an opportunity to tick two diversity boxes at once (Black and Erickson, Reference Black and Erickson2006; Celis et al., Reference Celis, Erzeel, Mügge and Damstra2014; Hughes, Reference Hughes2011). These questions have been posed in the comparative literature, but they have been less studied in Canada.
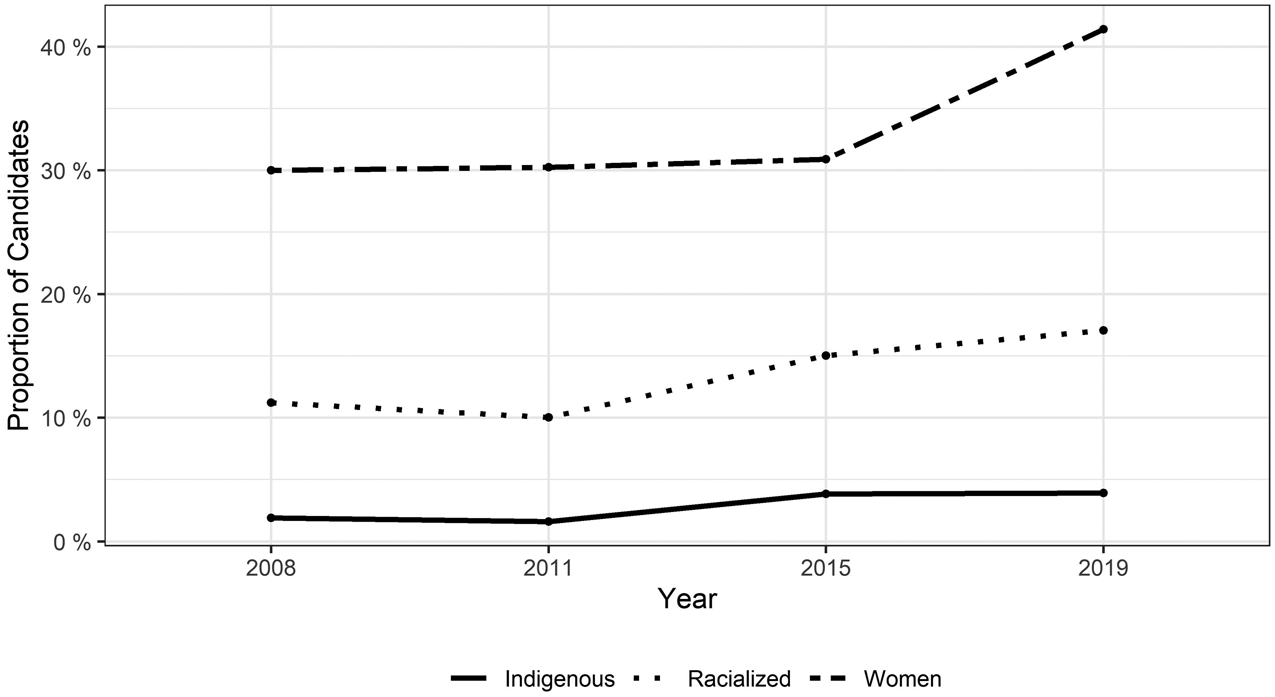
Figure 1 Women, Racialized and Indigenous Candidates in Canadian Elections
Note: For all elections, data capture information on candidates who ran for the Bloc Québécois, Conservative, Liberal and New Democratic parties, in addition to the Green party in 2019.
Given the centrality of political parties to candidate selection in Canada, the dataset also allows for comparisons across parties (Cross and Pruysers, Reference Cross and Pruysers2019; Thomas and Bodet, Reference Thomas and Bodet2013; Tolley, Reference Tolley2019). Figure 2 compares candidate diversity across the federal parties, with panels for the proportion of women, racialized and Indigenous candidates across the previous four federal elections. It shows the Bloc and Conservatives have consistently advanced the least racially diverse candidate slates and that they have generally nominated fewer women than the other parties. The uptick in racialized and Indigenous candidates in the 2019 election appears to have been led by the Liberals and the New Democrats, with both parties making large gains here, and the New Democratic party showing substantial increases on both measures. Future research could use these data to probe parties’ strategies to recruit more diverse candidate slates and, in addition, advance new research on the competitive placement and outcome of these new recruits.
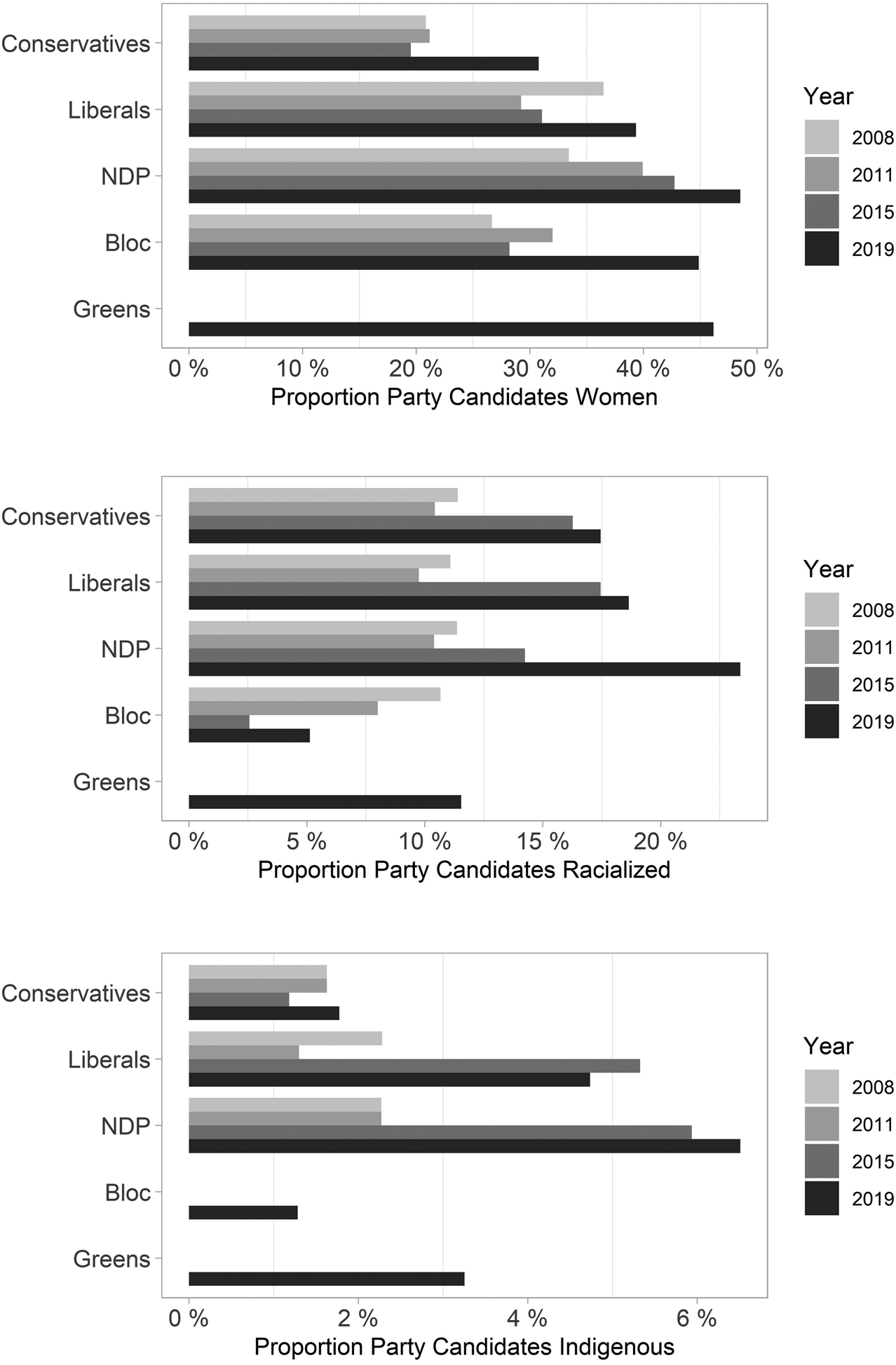
Figure 2 Candidate Diversity by Party
Note: For all elections, data capture information on candidates who ran for the Bloc Québécois, Conservative, Liberal and New Democratic parties, in addition to the Green party in 2019.
In addition to these descriptive possibilities, the dataset offers significant analytical leverage on a range of questions related to electoral dynamics, political donations, vote choice and media coverage. For example, by merging the candidate data with voter data from the Canadian Election Study, researchers could answer new questions on the relationship between candidate demographics, attitudinal measures and vote intention. What voter or district features are correlated with the election of more diverse candidates? Are more urban districts or those with more progressively minded voters more open to candidates who break the demographic mould? Researchers could also merge our candidate data with Elections Canada's district-level data on voter turnout, financial contributions and vote totals, in order to understand the relationship between these dependent variables and candidate demographics. Is voter turnout higher in districts with more diverse candidate slates? Do candidates with historically underrepresented backgrounds attract fewer donations? Candidate data could be merged with textual data, such as candidate mentions on Twitter or in election coverage, to track candidates’ portrayal and self-presentation, or with a new digital record of Hansard to track demographic patterns in parliamentary communication (Beelen et al., Reference Beelen, Thijm, Cochrane, Halvemaan, Hirst, Kimmins, Lijbrink, Marx, Naderi, Rheault, Polyanovsky and Whyte2017).
Finally, the dataset offers possibilities for comparative analysis. It could be used alongside candidate data collected in other countries (for example, Center for American Women and Politics, 2020) or with data on the gender of office-holders worldwide (for example, Inter-Parliamentary Union, 2019) to better understand the relationship between representational diversity, political institutions and public attitudes.
Contribution
Candidates are at the centre of Canadian electoral politics. Despite diversity being a key feature of the country's composition, researchers to date have had limited access to data on candidate demographics, and the time required to gather such data may have deterred additional inferential analysis. This dataset remedies the problem, providing a rigorous, reliable and comprehensive source of information on candidate race, Indigenous background and age, alongside data on gender, occupation, electoral experience and outcomes. On their own, these data provide a benchmark for understanding representational diversity in Canada, but they also open up avenues for better understanding the political salience of identities on questions that are key to the study of electoral politics. Finally, by detailing the range of sources that were consulted, the coding procedures we used and the principles adopted to make decisions about contentious categories, this research note helps to “pull back the curtain” on the creation of new sources of data. The methods we describe here could be applied to the collection of other candidate data, including at other levels of government. By documenting the data collection, this research note provides a basis for replication and, we hope, a move toward more institutionalized data collection on candidate diversity.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0008423921000391.
Data Availability Statement
The full dataset is available at: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/MI5XQ6.
Acknowledgments
Funding for this project was provided by the University of Toronto and the Social Sciences and Humanities Research Council (grant #430-2017-00504). Kamille Leclair and Samuel Moir capably assisted with the collection and coding of candidate data.



