






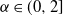



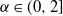
1. Introduction
Deep neural networks have brought remarkable progress in a wide range of applications, such as language translation and speech recognition, but a satisfactory mathematical answer on why they are so effective has yet to be found. One promising direction, which has been the subject of a large amount of recent research, is to analyze neural networks in an idealized setting where the networks have infinite widths and the so-called step size becomes infinitesimal. In this idealized setting, seemingly intractable questions can be answered. For instance, it has been shown that as the widths of deep neural networks tend to infinity, the networks converge to Gaussian processes, both before and after training, if their weights are initialized with independent and identically distributed (i.i.d.) samples from the Gaussian distribution [Reference Neal32, Reference Lee24, Reference Matthews30, Reference Novak33, Reference Yang43]. (The methods used in these works can easily be adapted to show convergence to Gaussian processes when the initial weights are i.i.d. with finite variance.) Furthermore, in this setting, the training of a deep neural network (under the standard mean-squared loss) is shown to achieve zero training error, and an analytic form of a fully-trained network with zero error has been identified [Reference Jacot, Hongler and Gabriel17, Reference Lee, Xiao, Schoenholz, Bahri, Novak, Sohl-Dickstein and Pennington26]. These results, in turn, enable the use of tools from stochastic processes and differential equations to analyze deep neural networks in a novel way. They have also led to new high-performing data-analysis algorithms based on Gaussian processes [Reference Lee25].
One direction extending this line of research is to consider neural networks with possibly heavy-tailed initializations. Although these are not common, their potential for modeling heavy-tailed data was recognized early on by [Reference Wainwright and Simoncelli41], and even the convergence of an infinitely wide yet shallow neural network under non-Gaussian
 $\alpha$
-stable initialization was shown in the 1990s [Reference Neal32]. Recently, Favaro, Fortini, and Peluchetti extended such convergence results from shallow to deep networks [Reference Favaro, Fortini and Peluchetti4].
$\alpha$
-stable initialization was shown in the 1990s [Reference Neal32]. Recently, Favaro, Fortini, and Peluchetti extended such convergence results from shallow to deep networks [Reference Favaro, Fortini and Peluchetti4].
Favaro et al. [Reference Favaro, Fortini and Peluchetti4] considered multi-layer perceptrons (MLPs) having large width n, and having i.i.d. weights with a symmetric
 $\alpha$
-stable (S
$\alpha$
-stable (S
 $\alpha$
S) distribution of scale parameter
$\alpha$
S) distribution of scale parameter
 $\sigma_w$
. A random variable X is said to have an S
$\sigma_w$
. A random variable X is said to have an S
 $\alpha$
S distribution if its characteristic function takes the form, for
$\alpha$
S distribution if its characteristic function takes the form, for
 $0<\alpha\le 2$
,
$0<\alpha\le 2$
,
 \begin{align*}\psi_X(t)\;:\!=\; \mathbb{E} e^{itX} = e^{-|\sigma t|^\alpha},\end{align*}
\begin{align*}\psi_X(t)\;:\!=\; \mathbb{E} e^{itX} = e^{-|\sigma t|^\alpha},\end{align*}
for some constant
 $\sigma>0$
called the scale parameter. In the special case
$\sigma>0$
called the scale parameter. In the special case
 $\alpha=2$
, X has a Gaussian distribution with variance
$\alpha=2$
, X has a Gaussian distribution with variance
 $2\sigma^2$
(which differs from standard notation in this case, by a factor of 2).
$2\sigma^2$
(which differs from standard notation in this case, by a factor of 2).
The results of Favaro et al. [Reference Favaro, Fortini and Peluchetti4] show that as n tends to
 $\infty$
, the arguments of the nonlinear activation function
$\infty$
, the arguments of the nonlinear activation function
 $\phi$
, in any given hidden layer, converge jointly in distribution to a product of S
$\phi$
, in any given hidden layer, converge jointly in distribution to a product of S
 $\alpha$
S(
$\alpha$
S(
 $\sigma_\ell$
) distributions with the same
$\sigma_\ell$
) distributions with the same
 $\alpha$
parameter. The scale parameter
$\alpha$
parameter. The scale parameter
 $\sigma_\ell$
differs for each layer
$\sigma_\ell$
differs for each layer
 $\ell$
; however, an explicit form is provided as a function of
$\ell$
; however, an explicit form is provided as a function of
 $\sigma_w$
, the input
$\sigma_w$
, the input
 $\mathbf{x} = (x_1,\ldots,x_I)$
, and the distribution of bias terms which have an S
$\mathbf{x} = (x_1,\ldots,x_I)$
, and the distribution of bias terms which have an S
 $\alpha$
S(
$\alpha$
S(
 $\sigma_{B}$
) distribution for some
$\sigma_{B}$
) distribution for some
 $\sigma_{B}>0$
. Favaro et al. also show that as a function of
$\sigma_{B}>0$
. Favaro et al. also show that as a function of
 $\mathbf{x}$
, the joint distribution described above is an
$\mathbf{x}$
, the joint distribution described above is an
 $\alpha$
-stable process, and they describe the spectral measure (see [Reference Samorodnitsky and Taqqu38, Section 2.3]) of this process at the points
$\alpha$
-stable process, and they describe the spectral measure (see [Reference Samorodnitsky and Taqqu38, Section 2.3]) of this process at the points
 $\mathbf{x}_1,\ldots,\mathbf{x}_n$
.
$\mathbf{x}_1,\ldots,\mathbf{x}_n$
.
Our work is a further extension of the work of [Reference Favaro, Fortini and Peluchetti4]. We consider deep networks whose weights in a given layer are allowed to be initialized with i.i.d. samples from either a light-tailed (finite-variance) or heavy-tailed distribution, not necessarily stable, but in the domain of attraction of an S
 $\alpha$
S distribution. We show that as the widths of the networks increase, the networks at initialization converge to S
$\alpha$
S distribution. We show that as the widths of the networks increase, the networks at initialization converge to S
 $\alpha$
S processes.
$\alpha$
S processes.
One of our aims is to show universality, in the sense that the results also hold when the weights are i.i.d. and heavy-tailed, and in the domain of attraction of an S
 $\alpha$
S distribution. Such heavy-tailed (and non-stable) weight distributions are important in the context of deep neural networks, since they have been empirically seen to emerge from trained deep neural networks such as the ResNet and VGG series [Reference Martin and Mahoney28, Reference Martin and Mahoney29] and have been shown to arise naturally via stochastic gradient descent [Reference Gurbuzbalaban, Simsekli and Zhu14, Reference Hodgkinson and Mahoney16]. Also, such heavy-tailed distributions cover a wide range of distributions, including for example some Pareto, inverse gamma, Fréchet, Student t, horseshoe, and beta-prime distributions. In particular, both Student t and horseshoe priors have been used for weights in Bayesian neural networks [Reference Fortuin8], since heavy tails can potentially improve the performance of priors [Reference Fortuin9]. Another of our goals is to fill a (minor) gap regarding one nontrivial step, and to clarify other details, of the proof in [Reference Favaro, Fortini and Peluchetti4] and its companion paper [Reference Favaro, Fortini and Peluchetti5] (see Lemma 3.1 below). Finally, we also generalize by considering a slightly more general case where the
$\alpha$
S distribution. Such heavy-tailed (and non-stable) weight distributions are important in the context of deep neural networks, since they have been empirically seen to emerge from trained deep neural networks such as the ResNet and VGG series [Reference Martin and Mahoney28, Reference Martin and Mahoney29] and have been shown to arise naturally via stochastic gradient descent [Reference Gurbuzbalaban, Simsekli and Zhu14, Reference Hodgkinson and Mahoney16]. Also, such heavy-tailed distributions cover a wide range of distributions, including for example some Pareto, inverse gamma, Fréchet, Student t, horseshoe, and beta-prime distributions. In particular, both Student t and horseshoe priors have been used for weights in Bayesian neural networks [Reference Fortuin8], since heavy tails can potentially improve the performance of priors [Reference Fortuin9]. Another of our goals is to fill a (minor) gap regarding one nontrivial step, and to clarify other details, of the proof in [Reference Favaro, Fortini and Peluchetti4] and its companion paper [Reference Favaro, Fortini and Peluchetti5] (see Lemma 3.1 below). Finally, we also generalize by considering a slightly more general case where the
 $\alpha$
parameter for the weights may depend on the layer it is in, including the case where it may be that
$\alpha$
parameter for the weights may depend on the layer it is in, including the case where it may be that
 $\alpha=2$
for some layers. This provides, for instance, a proof of universality in the Gaussian case. Such a result for the non-Gaussian finite-variance weights is known in the ‘folklore’, but we are unaware of a published proof of it.
$\alpha=2$
for some layers. This provides, for instance, a proof of universality in the Gaussian case. Such a result for the non-Gaussian finite-variance weights is known in the ‘folklore’, but we are unaware of a published proof of it.
Notation. Let
 $\Pr(\mathbb{R})$
be the set of probability distributions on
$\Pr(\mathbb{R})$
be the set of probability distributions on
 $\mathbb{R}$
. In the sequel, for
$\mathbb{R}$
. In the sequel, for
 $\alpha\in(0,2]$
, let
$\alpha\in(0,2]$
, let
 $\mu_{\alpha,\sigma}\in \Pr(\mathbb{R})$
denote an S
$\mu_{\alpha,\sigma}\in \Pr(\mathbb{R})$
denote an S
 $\alpha$
S(
$\alpha$
S(
 $\sigma$
) distribution. We will typically use capital letters to denote random variables in
$\sigma$
) distribution. We will typically use capital letters to denote random variables in
 $\mathbb{R}$
. For example, a random weight in our neural network from layer
$\mathbb{R}$
. For example, a random weight in our neural network from layer
 $\ell-1$
to layer
$\ell-1$
to layer
 $\ell$
is denoted by
$\ell$
is denoted by
 $W_{ij}^{(\ell)}$
and is henceforth assumed to be in the domain of attraction of
$W_{ij}^{(\ell)}$
and is henceforth assumed to be in the domain of attraction of
 $\mu_{\alpha,\sigma}$
, which may depend on
$\mu_{\alpha,\sigma}$
, which may depend on
 $\ell$
. One notable exception to this convention is our use of the capital letter L to denote a slowly varying function. We use the notation
$\ell$
. One notable exception to this convention is our use of the capital letter L to denote a slowly varying function. We use the notation
 $|\cdot|^{\alpha\pm\epsilon}$
to denote the maximum of
$|\cdot|^{\alpha\pm\epsilon}$
to denote the maximum of
 $|\cdot|^{\alpha +\epsilon}$
and
$|\cdot|^{\alpha +\epsilon}$
and
 $|\cdot|^{\alpha -\epsilon}$
.
$|\cdot|^{\alpha -\epsilon}$
.
2. The model: heavy-tailed multi-layer perceptrons
At a high level, a neural network is just a parameterized function Y from inputs in
 $\mathbb{R}^I$
to outputs in
$\mathbb{R}^I$
to outputs in
 $\mathbb{R}^O$
for some I and O. In this article, we consider the case that
$\mathbb{R}^O$
for some I and O. In this article, we consider the case that
 $O = 1$
. The parameters
$O = 1$
. The parameters
 $\Theta$
of the function consist of real-valued vectors
$\Theta$
of the function consist of real-valued vectors
 $\mathbf{W}$
and
$\mathbf{W}$
and
 $\mathbf{B}$
, called weights and biases. These parameters are initialized randomly, and get updated repeatedly during the training of the network. We adopt the common notation
$\mathbf{B}$
, called weights and biases. These parameters are initialized randomly, and get updated repeatedly during the training of the network. We adopt the common notation
 $Y_\Theta(\mathbf{x})$
, which expresses that the output of Y depends on both the input
$Y_\Theta(\mathbf{x})$
, which expresses that the output of Y depends on both the input
 $\mathbf{x}$
and the parameters
$\mathbf{x}$
and the parameters
 $\Theta=(\mathbf{W},\mathbf{B})$
.
$\Theta=(\mathbf{W},\mathbf{B})$
.
Note that since
 $\Theta$
is set randomly,
$\Theta$
is set randomly,
 $Y_\Theta$
is a random function. This random-function viewpoint is the basis of a large body of work on Bayesian neural networks [Reference Neal32], which studies the distribution of this random function or its posterior conditioned on input–output pairs in training data. Our article falls into this body of work. We analyze the distribution of the random function
$Y_\Theta$
is a random function. This random-function viewpoint is the basis of a large body of work on Bayesian neural networks [Reference Neal32], which studies the distribution of this random function or its posterior conditioned on input–output pairs in training data. Our article falls into this body of work. We analyze the distribution of the random function
 $Y_\Theta$
at the moment of initialization. Our analysis is in the situation where
$Y_\Theta$
at the moment of initialization. Our analysis is in the situation where
 $Y_\Theta$
is defined by an MLP, the width of the MLP is large (so the number of parameters in
$Y_\Theta$
is defined by an MLP, the width of the MLP is large (so the number of parameters in
 $\Theta$
is large), and the parameters
$\Theta$
is large), and the parameters
 $\Theta$
are initialized by possibly using heavy-tailed distributions. The precise description of the setup is given below.
$\Theta$
are initialized by possibly using heavy-tailed distributions. The precise description of the setup is given below.
-
2.1 (Layers.) We suppose that there are
 $\ell_{\text{lay}}$
layers, not including those for the input and output. Here, the subscript lay means ‘layers’. The 0th layer is for the input and consists of I nodes assigned with deterministic values from the input
$\mathbf{x}=(x_1,\ldots,x_I)$
. We assume for simplicity that
$x_i\in\mathbb{R}$
. (None of our methods would change if we instead let
$x_i\in\mathbb{R}^d$
for arbitrary finite d.) The layer
$\ell_{\text{lay}}+1$
is for the output. For layer
$\ell$
with
$1\le\ell\le\ell_{\text{lay}}$
, there are
$n_\ell$
nodes for some
$n_\ell \ge 2$
.
$\ell_{\text{lay}}$
layers, not including those for the input and output. Here, the subscript lay means ‘layers’. The 0th layer is for the input and consists of I nodes assigned with deterministic values from the input
$\mathbf{x}=(x_1,\ldots,x_I)$
. We assume for simplicity that
$x_i\in\mathbb{R}$
. (None of our methods would change if we instead let
$x_i\in\mathbb{R}^d$
for arbitrary finite d.) The layer
$\ell_{\text{lay}}+1$
is for the output. For layer
$\ell$
with
$1\le\ell\le\ell_{\text{lay}}$
, there are
$n_\ell$
nodes for some
$n_\ell \ge 2$
. -
2.2 (Weights and biases.) The MLP is fully connected, and the weights on the edges from layer
$\ell-1$
to
$\ell$
are given by
$ \mathbf{W}^{(\ell)} = (W^{(\ell)}_{ij})_{1\le i\le n_\ell, 1\le j\le n_{\ell-1}}$
. Assume that
$\mathbf{W}^{(\ell)}$
is a collection of i.i.d. symmetric random variables in each layer, such that for each layer
$\ell$
, -
(2.2.a) they are heavy-tailed, i.e. for all
$t>0$
, (2.1)where
\begin{align} \mathbb{P}(|W^{(\ell)}_{ij}| > t) = t^{-\alpha_\ell}L^{(\ell)}(t),\qquad {\text{for some }\alpha_\ell\in(0,2]}, \end{align}
$L^{(\ell)}$
is some slowly varying function, or
-
(2.2.b)
$\mathbb{E} |W^{(\ell)}_{ij}|^{2}<\infty$
. (In this case, we set
$ \alpha_{\ell} = 2 $
by default.)



















Note that both (2.2.a) and (2.2.b) can hold at the same time. Even when this happens, there is no ambiguity about
 $\alpha_{\ell}$
, which is set to be 2 in both cases. Our proof deals with the cases when
$\alpha_{\ell}$
, which is set to be 2 in both cases. Our proof deals with the cases when
 $ \alpha_{\ell} <2 $
and
$ \alpha_{\ell} <2 $
and
 $\alpha_{\ell} =2 $
separately. (See below, in the definition of
$\alpha_{\ell} =2 $
separately. (See below, in the definition of
 $ L_{0}$
.) We permit both the conditions (2.2.a) and (2.2.b) to emphasize that our result covers a mixture of both heavy-tailed and finite-variance (light-tailed) initializations.
$ L_{0}$
.) We permit both the conditions (2.2.a) and (2.2.b) to emphasize that our result covers a mixture of both heavy-tailed and finite-variance (light-tailed) initializations.
Let
 $B^{(\ell)}_{i}$
be i.i.d. random variables with distribution
$B^{(\ell)}_{i}$
be i.i.d. random variables with distribution
 $\mu_{\alpha_\ell,\sigma_{B^{(\ell)}}}.$
Note that the distribution of
$\mu_{\alpha_\ell,\sigma_{B^{(\ell)}}}.$
Note that the distribution of
 $B^{(\ell)}_i$
is more constrained than that of
$B^{(\ell)}_i$
is more constrained than that of
 $W^{(\ell)}_{ij}$
. This is because the biases are not part of the normalized sum, and normalization is, of course, a crucial part of the stable limit theorem.
$W^{(\ell)}_{ij}$
. This is because the biases are not part of the normalized sum, and normalization is, of course, a crucial part of the stable limit theorem.
For later use in the
 $ \alpha=2 $
case, we define a function
$ \alpha=2 $
case, we define a function
 $ \widetilde{L}^{(\ell)} $
by
$ \widetilde{L}^{(\ell)} $
by
 \begin{align*} \widetilde{L}^{(\ell)}(x) \;:\!=\; \int_{0}^{x} y \mathbb{P}(|W_{ij}^{(\ell)}|>y) \, dy. \end{align*}
\begin{align*} \widetilde{L}^{(\ell)}(x) \;:\!=\; \int_{0}^{x} y \mathbb{P}(|W_{ij}^{(\ell)}|>y) \, dy. \end{align*}
Note that
 $ \widetilde{L}^{(\ell)} $
is increasing. For the case (2.2.b),
$ \widetilde{L}^{(\ell)} $
is increasing. For the case (2.2.b),
 $\int_{0}^{x} y \mathbb{P}(|W_{ij}^{(\ell)}|>y) \, dy$
converges to a constant, namely to
$\int_{0}^{x} y \mathbb{P}(|W_{ij}^{(\ell)}|>y) \, dy$
converges to a constant, namely to
 $1/2$
of the variance, and thus it is slowly varying. For the case (2.2.a), it is seen in Lemma A.1 that
$1/2$
of the variance, and thus it is slowly varying. For the case (2.2.a), it is seen in Lemma A.1 that
 $ \widetilde{L}^{(\ell)} $
is slowly varying as well.
$ \widetilde{L}^{(\ell)} $
is slowly varying as well.
For convenience, let
 \begin{align*} L_{0} \;:\!=\; \begin{cases} L^{(\ell)} \quad &\text{if } \alpha_{\ell} < 2, \\ \widetilde{L}^{(\ell)} &\text{if } \alpha_{\ell} = 2. \end{cases} \end{align*}
\begin{align*} L_{0} \;:\!=\; \begin{cases} L^{(\ell)} \quad &\text{if } \alpha_{\ell} < 2, \\ \widetilde{L}^{(\ell)} &\text{if } \alpha_{\ell} = 2. \end{cases} \end{align*}
We have dropped the superscript
 $ \ell $
from
$ \ell $
from
 $L_0$
as the dependence on
$L_0$
as the dependence on
 $ \ell $
will be assumed.
$ \ell $
will be assumed.
-
2.3 (Scaling.) Fix a layer
$\ell$
with
$2\le \ell\le\ell_{\text{lay}}+1$
, and let
$n=n_{\ell-1}$
be the number of nodes at the layer
$\ell-1$
. We will scale the random values at the nodes (pre-activation) by Then
\begin{align*} a_{n}(\ell)\;:\!=\; \inf\{ t > 0 \colon t^{-\alpha_\ell}L_{0}(t) \le n^{-1} \}. \end{align*}
$ a_{n}(\ell)$
tends to
$\infty$
as n increases. One can check that
$ a_{n}(\ell) = n^{1/\alpha_{\ell}} G(n) $
for some slowly varying function G. If we consider, for example, power-law weights where
$ \mathbb{P}(|W^{(\ell)}_{ij}| > t) = t^{-\alpha_\ell}$
for
$ t \ge 1 $
, then
$ a_{n}(\ell) = n^{1/\alpha_{\ell}} $
. For future purposes we record the well-known fact that, for
$a_n=a_n(\ell)$
, (2.2)Let us quickly show (2.2). For the case (2.2.b),
\begin{align} \lim_{n\to\infty}n a_{n}^{-\alpha_\ell} L_0(a_{n}) = 1 . \end{align}
$t^2 L_0(t)$
becomes continuous and so
$n a_n^{-\alpha_{\ell}}L_0(a_n)$
is simply 1. To see the convergence in the case (2.2.a), first note that as
$ \mathbb{P}(|W^{(\ell)}_{ij}|>t) = t^{-\alpha_{\ell}}L^{(\ell)}(t) $
is right-continuous,
$ n a_{n}^{-\alpha_{\ell}} L^{(\ell)}(a_{n}) \le 1 $
. For the reverse inequality, note that by (2.1) and the definition of
$a_n$
, for n large enough we have
$\mathbb{P}\left(|W^{(\ell)}_{ij}| > \frac{1}{1+\epsilon}a_{n}\right) \geq 1/n$
, and by the definition of a slowly varying function we have that
\begin{align*} (1+2\epsilon)^{-\alpha_{\ell}} = \lim_{n\to \infty} \frac{\mathbb{P}\left(|W^{(\ell)}_{ij}| > \frac{1+2\epsilon}{1+\epsilon}a_{n}\right)}{\mathbb{P}\left(|W^{(\ell)}_{ij}| > \frac{1}{1+\epsilon}a_{n}\right)} \le \liminf_{n\to\infty} \frac{\mathbb{P}\left(|W^{(\ell)}_{ij}| > a_{n}\right)}{1/n} . \end{align*}
-
2.4 (Activation.) The MLP uses a nonlinear activation function
$\phi(y)$
. We assume that
$ \phi $
is continuous and bounded. The boundedness assumption simplifies our presentation; in Section 4 we relax this assumption so that for particular initializations (such as Gaussian or stable), more general activation functions such as ReLU are allowed. -
2.5 (Limits.) We consider one MLP for each
$(n_1,\ldots, n_{\ell_{\text{lay}}})\in\mathbb{N}^{\ell_{\text{lay}}}$
. We take the limit of the collection of these MLPs in such a way that (2.3)(Our methods can also handle the case where limits are taken from left to right, i.e.,
\begin{align} \min(n_1,\ldots,n_{\ell_{\text{lay}}})\to\infty.\end{align}
$\lim_{n_{\ell_{\text{lay}}}\to\infty}\cdots\lim_{n_1\to\infty}$
, but since this order of limits is easier to prove, we will focus on the former.)
-
2.6 (Hidden layers.) We write
$\mathbf{n}=(n_1,\ldots, n_{\ell_{\text{lay}}})\in\mathbb{N}^{\ell_{\text{lay}}}$
. For
$ \ell $
with
$ 1\le\ell\le\ell_{\text{lay}}+1 $
, the pre-activation values at these nodes are given, for an input
$ \mathbf{x} \in \mathbb{R}^{I} $
, recursively by for each
\begin{align*} &Y^{(1)}_{i}(\mathbf{x};\,\,\mathbf{n}) \;:\!=\; Y^{(1)}_{i}(\mathbf{x}) \;:\!=\; \sum_{j=1}^{I}W^{(1)}_{ij} x_{j} + B^{(1)}_{i}, \\ &Y^{(\ell)}_{i}(\mathbf{x};\;\;\mathbf{n}) \;:\!=\; \frac{1}{a_{n_{\ell-1}}(\ell)} \sum_{j=1}^{n_{\ell-1}} W^{(\ell)}_{ij} \phi(Y^{(\ell-1)}_{j}(\mathbf{x};\;\;\mathbf{n})) + B^{(\ell)}_{i} , \quad \ell \ge 2, \end{align*}
$ n_{\ell-1} \in \mathbb{N} $
and
$ i \in \mathbb{N} $
. Note that
$Y^{(\ell)}_{i}(\mathbf{x};\;\;\mathbf{n})$
depends on only the coordinates
$n_1,\ldots,n_{\ell-1}$
, but we may simply let it be constant in the coordinates
$n_\ell,\ldots,n_{\ell_{\text{lay}}}$
. This will often be the case when we have functions of
$\mathbf{n}$
in the sequel.




































We often omit
 $\mathbf{n}$
and write
$\mathbf{n}$
and write
 $Y^{(\ell)}_{i}(\mathbf{x})$
. When computing the output of the MLP with widths
$Y^{(\ell)}_{i}(\mathbf{x})$
. When computing the output of the MLP with widths
 $\mathbf{n}$
, one only needs to consider
$\mathbf{n}$
, one only needs to consider
 $i\le n_{\ell}$
for each layer
$i\le n_{\ell}$
for each layer
 $\ell$
. However, it is always possible to assign values to an extended MLP beyond
$\ell$
. However, it is always possible to assign values to an extended MLP beyond
 $\mathbf{n}$
, which is why we have assumed more generally that
$\mathbf{n}$
, which is why we have assumed more generally that
 $ i \in \mathbb{N} $
. This will be important for the proofs, as we explain in the next paragraph.
$ i \in \mathbb{N} $
. This will be important for the proofs, as we explain in the next paragraph.
Extending finite neural networks to infinite neural networks
Let us describe a useful construct for the proofs which allows us to leverage the natural exchangeability present in the model. For each
 $\mathbf{n}=(n_1,\ldots,n_{\ell_{\text{lay}}})$
, the MLP is finite and each layer has finite width. A key part of the proof is the application of de Finetti’s theorem at each layer, which applies only in the case where one has an infinite sequence of random variables. As in [Reference Favaro, Fortini and Peluchetti4], a crucial observation is that for each
$\mathbf{n}=(n_1,\ldots,n_{\ell_{\text{lay}}})$
, the MLP is finite and each layer has finite width. A key part of the proof is the application of de Finetti’s theorem at each layer, which applies only in the case where one has an infinite sequence of random variables. As in [Reference Favaro, Fortini and Peluchetti4], a crucial observation is that for each
 $\mathbf{n}=(n_1,\ldots,n_{\ell_{\text{lay}}})$
, we can extend the MLP to an infinite-width MLP by adding an infinite number of nodes at each layer that compute values in the same manner as nodes of the original MLP, but are ignored by nodes at the next layer. Thus, the finite-width MLP is embedded in an infinite-width MLP. This allows us to use de Finetti’s theorem. With this in mind we will henceforth consider an infinite collection of weights
$\mathbf{n}=(n_1,\ldots,n_{\ell_{\text{lay}}})$
, we can extend the MLP to an infinite-width MLP by adding an infinite number of nodes at each layer that compute values in the same manner as nodes of the original MLP, but are ignored by nodes at the next layer. Thus, the finite-width MLP is embedded in an infinite-width MLP. This allows us to use de Finetti’s theorem. With this in mind we will henceforth consider an infinite collection of weights
 $(W_{ij}^{(\ell)})_{ij\in\mathbb{N}^2}$
, for any finite neural network.
$(W_{ij}^{(\ell)})_{ij\in\mathbb{N}^2}$
, for any finite neural network.
3. Convergence to
$\alpha$
-stable distributions

Our main results are summarized in the next theorem and its extension to the situation of multiple inputs in Theorem 5.1 in Section 5. They show that as the width of an MLP tends to infinity, the MLP becomes a relatively simple random object: the outputs of its
 $\ell$
th layer become merely i.i.d. random variables drawn from a stable distribution, and the parameters of the distribution have explicit inductive characterizations.
$\ell$
th layer become merely i.i.d. random variables drawn from a stable distribution, and the parameters of the distribution have explicit inductive characterizations.
Let
 \begin{align*} c_\alpha \;:\!=\; \lim_{M \to \infty} \int_{0}^{M} \frac{\sin u}{u^{\alpha}} \, du \quad \text{for } \alpha < 2 \quad \text{and} \quad c_{2}=1, \end{align*}
\begin{align*} c_\alpha \;:\!=\; \lim_{M \to \infty} \int_{0}^{M} \frac{\sin u}{u^{\alpha}} \, du \quad \text{for } \alpha < 2 \quad \text{and} \quad c_{2}=1, \end{align*}
and let
 \begin{align} \sigma_{2}^{\alpha_2} &\;:\!=\; (\sigma_{2}(\mathbf{x}))^{\alpha_2} \;:\!=\; \sigma_{B^{(2)}}^{\alpha_2} + c_{\alpha_2} \int |\phi(y)|^{\alpha_2} \, \nu^{(1)}(dy), \quad \ell = 2, \\ \sigma_{\ell}^{\alpha_\ell} &\;:\!=\; (\sigma_{\ell}(\mathbf{x}))^{\alpha_\ell} \;:\!=\; \sigma_{B^{(\ell)}}^{\alpha_\ell} + c_{\alpha_\ell} \int |\phi(y)|^{\alpha_\ell} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy), \quad \ell = 3,\ldots,\ell_{\text{lay}}+1 \notag, \end{align}
\begin{align} \sigma_{2}^{\alpha_2} &\;:\!=\; (\sigma_{2}(\mathbf{x}))^{\alpha_2} \;:\!=\; \sigma_{B^{(2)}}^{\alpha_2} + c_{\alpha_2} \int |\phi(y)|^{\alpha_2} \, \nu^{(1)}(dy), \quad \ell = 2, \\ \sigma_{\ell}^{\alpha_\ell} &\;:\!=\; (\sigma_{\ell}(\mathbf{x}))^{\alpha_\ell} \;:\!=\; \sigma_{B^{(\ell)}}^{\alpha_\ell} + c_{\alpha_\ell} \int |\phi(y)|^{\alpha_\ell} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy), \quad \ell = 3,\ldots,\ell_{\text{lay}}+1 \notag, \end{align}
where
 $\nu^{(1)} \;:\!=\; \nu^{(1)}(\mathbf{x})$
is the distribution of
$\nu^{(1)} \;:\!=\; \nu^{(1)}(\mathbf{x})$
is the distribution of
 $Y^{(1)}_{1}(\mathbf{x})$
.
$Y^{(1)}_{1}(\mathbf{x})$
.
Theorem 3.1.
For each
 $ \ell = 2,\ldots,\ell_{\text{lay}}+1 $
, the joint distribution of
$ \ell = 2,\ldots,\ell_{\text{lay}}+1 $
, the joint distribution of
 $ (Y^{(\ell)}_{i}(\mathbf{x};\;\;\mathbf{n}))_{i \ge 1}$
converges weakly to
$ (Y^{(\ell)}_{i}(\mathbf{x};\;\;\mathbf{n}))_{i \ge 1}$
converges weakly to
 $\bigotimes_{i \ge 1} \mu_{\alpha_\ell,\sigma_\ell} $
as
$\bigotimes_{i \ge 1} \mu_{\alpha_\ell,\sigma_\ell} $
as
 $\min(n_1,\ldots,n_{\ell_{\text{lay}}})\to\infty$
, with
$\min(n_1,\ldots,n_{\ell_{\text{lay}}})\to\infty$
, with
 $ \sigma_{\ell} $
inductively defined by (3.1). That is, the characteristic function of the limiting distribution is, for any finite subset
$ \sigma_{\ell} $
inductively defined by (3.1). That is, the characteristic function of the limiting distribution is, for any finite subset
 $ \mathcal{L} \subset \mathbb{N} $
,
$ \mathcal{L} \subset \mathbb{N} $
,
 \begin{align*} &\prod_{i\in\mathcal{L}} \psi_{B^{(2)}}(t_i)\exp\left( -c_{\alpha_2} |t_{i}|^{\alpha_2} \int |\phi(y)|^{\alpha_2} \, \nu^{(1)}(dy) \right) , \quad \ell = 2, \\ &\prod_{i\in\mathcal{L}} \psi_{B^{(\ell)}}(t_i)\exp\left( -c_{\alpha_\ell} |t_{i}|^{\alpha_\ell} \int |\phi(y)|^{\alpha_\ell} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right) , \quad \ell = 3,\ldots,\ell_{\text{lay}}+1 . \end{align*}
\begin{align*} &\prod_{i\in\mathcal{L}} \psi_{B^{(2)}}(t_i)\exp\left( -c_{\alpha_2} |t_{i}|^{\alpha_2} \int |\phi(y)|^{\alpha_2} \, \nu^{(1)}(dy) \right) , \quad \ell = 2, \\ &\prod_{i\in\mathcal{L}} \psi_{B^{(\ell)}}(t_i)\exp\left( -c_{\alpha_\ell} |t_{i}|^{\alpha_\ell} \int |\phi(y)|^{\alpha_\ell} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right) , \quad \ell = 3,\ldots,\ell_{\text{lay}}+1 . \end{align*}
Remark 3.1. The integrals in Theorem 3.1 are well-defined since
 $ \phi $
is bounded. For (possibly) unbounded
$ \phi $
is bounded. For (possibly) unbounded
 $ \phi $
, these integrals are well-defined as well under suitable assumptions on
$ \phi $
, these integrals are well-defined as well under suitable assumptions on
 $ \phi $
. See Section 4.
$ \phi $
. See Section 4.
This theorem shows that, for a given data point
 $\mathbf{x}$
, the individual layers of our MLP converge in distribution to a collection of i.i.d. stable random variables. The result is a universality counterpart to a similar result in [Reference Favaro, Fortini and Peluchetti4] where, instead of general heavy-tailed weights on edges, one initializes precisely with stable weights. As already mentioned in the introduction, heavy-tailed initializations other than
$\mathbf{x}$
, the individual layers of our MLP converge in distribution to a collection of i.i.d. stable random variables. The result is a universality counterpart to a similar result in [Reference Favaro, Fortini and Peluchetti4] where, instead of general heavy-tailed weights on edges, one initializes precisely with stable weights. As already mentioned in the introduction, heavy-tailed initializations other than
 $\alpha$
-stable have been considered and discussed in previous literature. Later, in Theorem 5.1, we generalize this result to consider multiple data points
$\alpha$
-stable have been considered and discussed in previous literature. Later, in Theorem 5.1, we generalize this result to consider multiple data points
 $\mathbf{x}_1, \mathbf{x}_2, \ldots,\mathbf{x}_k.$
$\mathbf{x}_1, \mathbf{x}_2, \ldots,\mathbf{x}_k.$
Heuristic of the proof. The random variables
 $(Y_i^{(\ell)}(\mathbf{x};\;\;\mathbf{n}))_{i \in \mathbb{N}}$
are dependent only through the randomness of the former layer’s outputs
$(Y_i^{(\ell)}(\mathbf{x};\;\;\mathbf{n}))_{i \in \mathbb{N}}$
are dependent only through the randomness of the former layer’s outputs
 $(Y_j^{(\ell-1)}(\mathbf{x};\;\;\mathbf{n}))_{j \in \mathbb{N}}$
. Just as in proofs in the literature for similar models, as the width grows to infinity, this dependence vanishes via an averaging effect.
$(Y_j^{(\ell-1)}(\mathbf{x};\;\;\mathbf{n}))_{j \in \mathbb{N}}$
. Just as in proofs in the literature for similar models, as the width grows to infinity, this dependence vanishes via an averaging effect.
Here, we briefly summarize the overarching technical points, from a bird’s-eye view, in establishing this vanishing dependence; we also highlight what we believe are new technical contributions in relation to models with general heavy-tailed initializations.
By de Finetti’s theorem, for each
 $\mathbf{n}$
there exists a random distribution
$\mathbf{n}$
there exists a random distribution
 $\xi^{(\ell-1)}(dy {;\;\;\mathbf{n}})$
such that the sequence
$\xi^{(\ell-1)}(dy {;\;\;\mathbf{n}})$
such that the sequence
 $(Y_j^{(\ell-1)}(\mathbf{x}))_j$
is conditionally i.i.d. with common random distribution
$(Y_j^{(\ell-1)}(\mathbf{x}))_j$
is conditionally i.i.d. with common random distribution
 $\xi^{(\ell-1)}$
. By first conditioning on
$\xi^{(\ell-1)}$
. By first conditioning on
 $(Y^{(\ell-1)}_{j}(\mathbf{x}))_{j}$
, we obtain independence among the summands of
$(Y^{(\ell-1)}_{j}(\mathbf{x}))_{j}$
, we obtain independence among the summands of
 \begin{align*}Y^{(\ell)}_i(\mathbf{x}) = \frac{1}{a_{n_{\ell-1}}(\ell)} \sum_{j=1}^{n_{\ell-1}} W^{(\ell)}_{ij} \phi(Y^{(\ell-1)}_{j}(\mathbf{x})) + B^{(\ell)}_{i}\end{align*}
\begin{align*}Y^{(\ell)}_i(\mathbf{x}) = \frac{1}{a_{n_{\ell-1}}(\ell)} \sum_{j=1}^{n_{\ell-1}} W^{(\ell)}_{ij} \phi(Y^{(\ell-1)}_{j}(\mathbf{x})) + B^{(\ell)}_{i}\end{align*}
as well as independence among the family
 $(Y_i^{(\ell)}(\mathbf{x}))_i$
. Let
$(Y_i^{(\ell)}(\mathbf{x}))_i$
. Let
 $\alpha \;:\!=\; \alpha_\ell$
,
$\alpha \;:\!=\; \alpha_\ell$
,
 $n \;:\!=\; n_{\ell - 1}$
, and
$n \;:\!=\; n_{\ell - 1}$
, and
 $a_n \;:\!=\; a_{n_{\ell - 1}}(\ell)$
. Then, with the help of Lemma A.2, the conditional characteristic function of
$a_n \;:\!=\; a_{n_{\ell - 1}}(\ell)$
. Then, with the help of Lemma A.2, the conditional characteristic function of
 $Y_1^{(\ell)}(\mathbf{x})$
given
$Y_1^{(\ell)}(\mathbf{x})$
given
 $\xi^{(\ell-1)}$
is asymptotically equal to
$\xi^{(\ell-1)}$
is asymptotically equal to
 \begin{align} e^{-\sigma_{B}^{\alpha} |t|^{\alpha}} \Bigg( 1 - \frac{b_n }{n} c_\alpha |t|^\alpha \int |\phi(y)|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy {;\;\;\mathbf{n}}) \Bigg)^n,\end{align}
\begin{align} e^{-\sigma_{B}^{\alpha} |t|^{\alpha}} \Bigg( 1 - \frac{b_n }{n} c_\alpha |t|^\alpha \int |\phi(y)|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy {;\;\;\mathbf{n}}) \Bigg)^n,\end{align}
where
 $b_n$
is a deterministic constant that tends to 1. Assuming the inductive hypothesis, the random distribution
$b_n$
is a deterministic constant that tends to 1. Assuming the inductive hypothesis, the random distribution
 $\xi^{(\ell-1)}$
converges weakly to
$\xi^{(\ell-1)}$
converges weakly to
 $\mu_{\alpha_{\ell-1}, \sigma_{\ell-1}}$
as
$\mu_{\alpha_{\ell-1}, \sigma_{\ell-1}}$
as
 $\mathbf{n}\to\infty$
in the sense of (2.3), by Lemma 3.1 below. This lemma is intuitively obvious, but we have not seen it proved in any previous literature.
$\mathbf{n}\to\infty$
in the sense of (2.3), by Lemma 3.1 below. This lemma is intuitively obvious, but we have not seen it proved in any previous literature.
Next, since
 $L_0$
is slowly varying, one can surmise that the conditional characteristic function tends to
$L_0$
is slowly varying, one can surmise that the conditional characteristic function tends to
 \begin{align*} \exp \left( -\sigma_{B}^{\alpha} |t|^{\alpha} -c_\alpha |t|^\alpha \int |\phi(y)|^\alpha \mu_{\alpha_{\ell-1}, \sigma_{\ell-1}}(dy)\right),\end{align*}
\begin{align*} \exp \left( -\sigma_{B}^{\alpha} |t|^{\alpha} -c_\alpha |t|^\alpha \int |\phi(y)|^\alpha \mu_{\alpha_{\ell-1}, \sigma_{\ell-1}}(dy)\right),\end{align*}
which is the characteristic function of the stable law we desire. Making the above intuition rigorous involves additional technicalities in the setting of general heavy-tailed weights: namely, we verify the convergence of (3.2) by proving uniform integrability of the integrand
 \begin{align*}|\phi(y)|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})}\end{align*}
\begin{align*}|\phi(y)|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})}\end{align*}
with respect to the family of distributions
 $\xi^{(\ell-1)}$
over the indices
$\xi^{(\ell-1)}$
over the indices
 $\mathbf{n}$
. In particular, by Lemma A.4, the integrand can be bounded by
$\mathbf{n}$
. In particular, by Lemma A.4, the integrand can be bounded by
 $O(|\phi(y)|^{\alpha \pm \epsilon})$
for small
$O(|\phi(y)|^{\alpha \pm \epsilon})$
for small
 $\epsilon>0$
, and uniform integrability follows from the boundedness of
$\epsilon>0$
, and uniform integrability follows from the boundedness of
 $ \phi $
. The joint limiting distribution converges to the desired stable law by similar arguments, which completes our top-level heuristic proof.
$ \phi $
. The joint limiting distribution converges to the desired stable law by similar arguments, which completes our top-level heuristic proof.
Before delving into the actual technical proof, we next present a key lemma mentioned in the above heuristic. Recall that de Finetti’s theorem tells us that if a sequence
 $\mathbf{X}=(X_i)_{i\in\mathbb{N}}\in\mathbb{R}^\mathbb{N}$
is exchangeable, then
$\mathbf{X}=(X_i)_{i\in\mathbb{N}}\in\mathbb{R}^\mathbb{N}$
is exchangeable, then
 \begin{align} \mathbb{P}(\mathbf{X}\in A) = \int \nu^{\otimes \mathbb{N}}(A) \,\pi(d\nu) \end{align}
\begin{align} \mathbb{P}(\mathbf{X}\in A) = \int \nu^{\otimes \mathbb{N}}(A) \,\pi(d\nu) \end{align}
for some
 $\pi$
which is a probability measure on the space of probability measures
$\pi$
which is a probability measure on the space of probability measures
 $\Pr(\mathbb{R})$
. The measure
$\Pr(\mathbb{R})$
. The measure
 $\pi$
is sometimes called the mixing measure. The following lemma characterizes the convergence of exchangeable sequences by the convergence of their respective mixing measures. While intuitively clear, the proof of the lemma is not completely trivial.
$\pi$
is sometimes called the mixing measure. The following lemma characterizes the convergence of exchangeable sequences by the convergence of their respective mixing measures. While intuitively clear, the proof of the lemma is not completely trivial.
Lemma 3.1.
For each
 $j\in\mathbb{N}\cup\{\infty\}$
, let
$j\in\mathbb{N}\cup\{\infty\}$
, let
 $\mathbf{X}^{(j)}=(X^{(j)}_i)_{i\in\mathbb{N}}$
be an infinite exchangeable sequence of random variables with values in
$\mathbf{X}^{(j)}=(X^{(j)}_i)_{i\in\mathbb{N}}$
be an infinite exchangeable sequence of random variables with values in
 $\mathbb{R}$
(or more generally, a Borel space). Let
$\mathbb{R}$
(or more generally, a Borel space). Let
 $\pi_j$
be the mixing measure on
$\pi_j$
be the mixing measure on
 $\Pr(\mathbb{R})$
corresponding to
$\Pr(\mathbb{R})$
corresponding to
 $\mathbf{X}^{(j)}$
, from (3.3). Then the family
$\mathbf{X}^{(j)}$
, from (3.3). Then the family
 $(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
converges in distribution to
$(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
converges in distribution to
 $\mathbf{X}^{(\infty)}$
if and only if the family
$\mathbf{X}^{(\infty)}$
if and only if the family
 $(\pi_j)_{j\in\mathbb{N}}$
converges in the weak topology on
$(\pi_j)_{j\in\mathbb{N}}$
converges in the weak topology on
 $\Pr(\Pr(\mathbb{R}))$
to
$\Pr(\Pr(\mathbb{R}))$
to
 $\pi_\infty$
.
$\pi_\infty$
.
The proof of the lemma is in the appendix. In the lemma, the topology on
 $\Pr(\Pr(\mathbb{R}))$
is formed by applying the weak-topology construction twice. We first construct the weak topology on
$\Pr(\Pr(\mathbb{R}))$
is formed by applying the weak-topology construction twice. We first construct the weak topology on
 $\Pr(\mathbb{R})$
. Then we apply the weak-topology construction again, this time using
$\Pr(\mathbb{R})$
. Then we apply the weak-topology construction again, this time using
 $\Pr(\mathbb{R})$
instead of
$\Pr(\mathbb{R})$
instead of
 $\mathbb{R}$
.
$\mathbb{R}$
.
In the proof of Theorem 3.1, we use the special case when the limiting sequence
 $\mathbf{X}^{(\infty)}$
is a sequence of i.i.d. random variables. In that case, by (3.3), it must be that
$\mathbf{X}^{(\infty)}$
is a sequence of i.i.d. random variables. In that case, by (3.3), it must be that
 $\pi_\infty$
concentrates on a single element
$\pi_\infty$
concentrates on a single element
 $\nu\in\Pr(\mathbb{R})$
, i.e. it is a point mass,
$\nu\in\Pr(\mathbb{R})$
, i.e. it is a point mass,
 $\pi_\infty=\delta_\nu$
, for some
$\pi_\infty=\delta_\nu$
, for some
 $\nu\in\Pr(\mathbb{R})$
.
$\nu\in\Pr(\mathbb{R})$
.
More specifically, we use the following corollary to Lemma.
Corollary 3.1.
In the setting of Theorem 3.1, the joint distribution of the exchangeable sequence
 $ (Y^{(\ell-1)}_{i}(\mathbf{x}))_{i \ge 1}$
converges weakly to the product measure
$ (Y^{(\ell-1)}_{i}(\mathbf{x}))_{i \ge 1}$
converges weakly to the product measure
 $\bigotimes_{i \ge 1} \mu_{\alpha,\sigma_{\ell-1}}$
as the minimum of
$\bigotimes_{i \ge 1} \mu_{\alpha,\sigma_{\ell-1}}$
as the minimum of
 $n_1,\ldots,n_{\ell_{\text{lay}}}$
tends to
$n_1,\ldots,n_{\ell_{\text{lay}}}$
tends to
 $\infty$
if and only if the random probability measures
$\infty$
if and only if the random probability measures
 $ (\xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}))_{\mathbf{n}\in\mathbb{N}^{\ell_{\text{lay}}}}$
defined in (3.8) converge weakly, in probability, to the deterministic probability measure
$ (\xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}))_{\mathbf{n}\in\mathbb{N}^{\ell_{\text{lay}}}}$
defined in (3.8) converge weakly, in probability, to the deterministic probability measure
 $ \mu_{\alpha,\sigma_{\ell-1}}$
.
$ \mu_{\alpha,\sigma_{\ell-1}}$
.
Proof of Theorem
3.1. We start with a useful expression for the characteristic function conditioned on the random variables
 $ \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n_{\ell-1}} $
:
$ \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n_{\ell-1}} $
:
 \begin{align} \psi_{Y^{(\ell)}_{i}(\mathbf{x}) | \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j}}(t) &\;:\!=\; \mathbb{E}\left[ \left. \exp\left ( it Y^{(\ell)}_i(\mathbf{x})\right ) \right| \{ Y^{(\ell-1)}_{j}(\mathbf{x})\}_j \right] \\ \nonumber & = \mathbb{E}\left[ \left. \exp\left ( it \left \{ \frac{1}{a_{n_{\ell-1}}(\ell)} \sum_{j=1}^{n_{\ell-1}} W^{(\ell)}_{ij} \phi(Y^{(\ell-1)}_{j}(\mathbf{x})) + B^{(\ell)}_{i} \right \} \right ) \right| \{ Y^{(\ell-1)}_{j}(\mathbf{x})\}_j \right] \\ \nonumber & = e^{-\sigma |t|^{\alpha_\ell}} \prod_{j=1}^{n_{\ell-1}} \psi_{W^{(\ell)}_{ij}}\left (\frac{\phi(Y^{(\ell-1)}_{j}(\mathbf{x}))}{a_{n_{\ell-1}}(\ell)}t\right ), \end{align}
\begin{align} \psi_{Y^{(\ell)}_{i}(\mathbf{x}) | \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j}}(t) &\;:\!=\; \mathbb{E}\left[ \left. \exp\left ( it Y^{(\ell)}_i(\mathbf{x})\right ) \right| \{ Y^{(\ell-1)}_{j}(\mathbf{x})\}_j \right] \\ \nonumber & = \mathbb{E}\left[ \left. \exp\left ( it \left \{ \frac{1}{a_{n_{\ell-1}}(\ell)} \sum_{j=1}^{n_{\ell-1}} W^{(\ell)}_{ij} \phi(Y^{(\ell-1)}_{j}(\mathbf{x})) + B^{(\ell)}_{i} \right \} \right ) \right| \{ Y^{(\ell-1)}_{j}(\mathbf{x})\}_j \right] \\ \nonumber & = e^{-\sigma |t|^{\alpha_\ell}} \prod_{j=1}^{n_{\ell-1}} \psi_{W^{(\ell)}_{ij}}\left (\frac{\phi(Y^{(\ell-1)}_{j}(\mathbf{x}))}{a_{n_{\ell-1}}(\ell)}t\right ), \end{align}
where
 $\sigma\;:\!=\;\sigma_{B^{(\ell)}}^{\alpha_\ell}$
and the argument on the right-hand side is random.
$\sigma\;:\!=\;\sigma_{B^{(\ell)}}^{\alpha_\ell}$
and the argument on the right-hand side is random.
Case
 $\ell=2$
:
$\ell=2$
:
Let us first consider the case
 $ \ell=2 $
. Let
$ \ell=2 $
. Let
 $n=n_1$
,
$n=n_1$
,
 $\alpha=\alpha_2$
,
$\alpha=\alpha_2$
,
 $a_n=a_{n_1}(2)$
, and
$a_n=a_{n_1}(2)$
, and
 $t\neq 0$
. We first show the weak convergence of the one-point marginal distributions; i.e., we show that the distribution of
$t\neq 0$
. We first show the weak convergence of the one-point marginal distributions; i.e., we show that the distribution of
 $ Y^{(2)}_{i}(\mathbf{x})$
converges weakly to
$ Y^{(2)}_{i}(\mathbf{x})$
converges weakly to
 $\mu_{\alpha,\sigma}$
for each i. Since
$\mu_{\alpha,\sigma}$
for each i. Since
 $ Y^{(1)}_{j}(\mathbf{x})$
,
$ Y^{(1)}_{j}(\mathbf{x})$
,
 $j=1,\ldots,n $
, are i.i.d., this is a straightforward application of standard arguments, which we include for completeness. Denote the common distribution of
$j=1,\ldots,n $
, are i.i.d., this is a straightforward application of standard arguments, which we include for completeness. Denote the common distribution of
 $ Y^{(1)}_{j}(\mathbf{x})$
,
$ Y^{(1)}_{j}(\mathbf{x})$
,
 $j=1,\ldots,n $
, by
$j=1,\ldots,n $
, by
 $\nu^{(1)}$
. Taking the expectation of (3.4) with respect to the randomness of
$\nu^{(1)}$
. Taking the expectation of (3.4) with respect to the randomness of
 $ \{Y^{(1)}_{j}(\mathbf{x})\}_{j=1,\ldots,n} $
, we have
$ \{Y^{(1)}_{j}(\mathbf{x})\}_{j=1,\ldots,n} $
, we have
 \begin{align*} \psi_{Y^{(2)}_{i}(\mathbf{x})}(t) &= e^{-\sigma_{B^{(2)}}^{\alpha} |t|^{\alpha}} \left( \int \psi_W\left (\frac{\phi(y)}{a_{n}}t\right ) \, \nu^{(1)}(dy) \right)^{n}, \end{align*}
\begin{align*} \psi_{Y^{(2)}_{i}(\mathbf{x})}(t) &= e^{-\sigma_{B^{(2)}}^{\alpha} |t|^{\alpha}} \left( \int \psi_W\left (\frac{\phi(y)}{a_{n}}t\right ) \, \nu^{(1)}(dy) \right)^{n}, \end{align*}
where
 $\psi_{W}\;:\!=\;\psi_{W_{ij}^{(2)}}$
for some/any i,j. From Lemma A.2, we have that
$\psi_{W}\;:\!=\;\psi_{W_{ij}^{(2)}}$
for some/any i,j. From Lemma A.2, we have that
 \begin{align*} \psi_W(t) = 1 - c_\alpha|t|^{\alpha} L_{0}\left( \frac{1}{|t|} \right) + o\left(|t|^{\alpha} L_{0}\left( \frac{1}{|t|} \right)\right), \quad |t| \to 0, \end{align*}
\begin{align*} \psi_W(t) = 1 - c_\alpha|t|^{\alpha} L_{0}\left( \frac{1}{|t|} \right) + o\left(|t|^{\alpha} L_{0}\left( \frac{1}{|t|} \right)\right), \quad |t| \to 0, \end{align*}
for
 $ c_{\alpha} = \lim_{M\to \infty}\int_{0}^{M} \sin u / u^{\alpha} \, du $
when
$ c_{\alpha} = \lim_{M\to \infty}\int_{0}^{M} \sin u / u^{\alpha} \, du $
when
 $ \alpha < 2 $
and
$ \alpha < 2 $
and
 $ c_{2} =1 $
. If
$ c_{2} =1 $
. If
 $\phi(y)=0$
then
$\phi(y)=0$
then
 $\psi_W\left (\frac{\phi(y)}{a_{n}}t\right )=1$
. Otherwise, setting
$\psi_W\left (\frac{\phi(y)}{a_{n}}t\right )=1$
. Otherwise, setting
 $ b_n \;:\!=\; n a_{n}^{-\alpha}L_{0}(a_{n})$
, for fixed y with
$ b_n \;:\!=\; n a_{n}^{-\alpha}L_{0}(a_{n})$
, for fixed y with
 $ \phi(y) \ne 0 $
we have that, as
$ \phi(y) \ne 0 $
we have that, as
 $ n \to \infty $
,
$ n \to \infty $
,
 \begin{align} \psi_W\left (\frac{\phi(y)}{a_{n}}t\right ) = 1 - c_\alpha \frac{b_n }{n} |\phi(y) t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} + o\left( \frac{b_n }{n} |\phi(y) t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \right). \end{align}
\begin{align} \psi_W\left (\frac{\phi(y)}{a_{n}}t\right ) = 1 - c_\alpha \frac{b_n }{n} |\phi(y) t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} + o\left( \frac{b_n }{n} |\phi(y) t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \right). \end{align}
By Lemma A.4 applied to
 $ G(x) \;:\!=\; x^{-\alpha}L_{0}(x) $
and
$ G(x) \;:\!=\; x^{-\alpha}L_{0}(x) $
and
 $ c=1 $
, for any
$ c=1 $
, for any
 $\epsilon > 0$
, there exist constants
$\epsilon > 0$
, there exist constants
 $ b > 0$
and
$ b > 0$
and
 $ n_0 $
such that for all
$ n_0 $
such that for all
 $ n > n_0 $
and all y with
$ n > n_0 $
and all y with
 $\phi(y) \neq 0$
,
$\phi(y) \neq 0$
,
 \begin{align} |\phi(y) t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} = \frac{G\left(\frac{a_{n}}{|\phi(y)t|}\right)}{G(a_{n})} \leq b |\phi(y)t|^{\alpha \pm \epsilon}. \end{align}
\begin{align} |\phi(y) t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} = \frac{G\left(\frac{a_{n}}{|\phi(y)t|}\right)}{G(a_{n})} \leq b |\phi(y)t|^{\alpha \pm \epsilon}. \end{align}
Since
 $ \phi $
is bounded, the right-hand side of (3.5) is term-by-term integrable with respect to
$ \phi $
is bounded, the right-hand side of (3.5) is term-by-term integrable with respect to
 $ \nu^{(1)}(dy) $
. In particular, the integral of the error term can be bounded, for some small
$ \nu^{(1)}(dy) $
. In particular, the integral of the error term can be bounded, for some small
 $ \epsilon $
and large enough n, by
$ \epsilon $
and large enough n, by
 \begin{align*} \int o\left(\frac{b_n }{n} |\phi(y) t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})}\right)\, \nu^{(1)}(dy) \le o\left(b \frac{b_n }{n} \int |\phi(y)t|^{\alpha \pm \epsilon} \, \nu^{(1)}(dy)\right) = o\left(\frac{b_n }{n} \right) . \end{align*}
\begin{align*} \int o\left(\frac{b_n }{n} |\phi(y) t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})}\right)\, \nu^{(1)}(dy) \le o\left(b \frac{b_n }{n} \int |\phi(y)t|^{\alpha \pm \epsilon} \, \nu^{(1)}(dy)\right) = o\left(\frac{b_n }{n} \right) . \end{align*}
(Set
 $|\phi(y)|^{\alpha}L_{0}(\frac{a_{n}}{|\phi(y)|})=0$
when
$|\phi(y)|^{\alpha}L_{0}(\frac{a_{n}}{|\phi(y)|})=0$
when
 $\phi(y)=0$
.) Thus, integrating both sides of (3.5) with respect to
$\phi(y)=0$
.) Thus, integrating both sides of (3.5) with respect to
 $ \nu^{(1)}(dy) $
and taking the nth power, it follows that
$ \nu^{(1)}(dy) $
and taking the nth power, it follows that
 \begin{align*} \left(\int \psi_W\left (\frac{\phi(y)t}{a_{n}}\right ) \, \nu^{(1)}(dy)\right)^{n} = \left(1 - c_\alpha\frac{b_n }{n} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \nu^{(1)}(dy) + o\left ( \frac{b_n }{n} \right )\right)^{n} . \end{align*}
\begin{align*} \left(\int \psi_W\left (\frac{\phi(y)t}{a_{n}}\right ) \, \nu^{(1)}(dy)\right)^{n} = \left(1 - c_\alpha\frac{b_n }{n} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \nu^{(1)}(dy) + o\left ( \frac{b_n }{n} \right )\right)^{n} . \end{align*}
From the bound in (3.6), we have, by dominated convergence, that as
 $n\to\infty$
$n\to\infty$
 \begin{align*} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \nu^{(1)}(dy) \to |t|^{\alpha} \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy). \end{align*}
\begin{align*} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \nu^{(1)}(dy) \to |t|^{\alpha} \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy). \end{align*}
Since
 $ b_n = n a_{n}^{-\alpha}L_{0}(a_{n})$
converges to 1 by (2.2), we have that
$ b_n = n a_{n}^{-\alpha}L_{0}(a_{n})$
converges to 1 by (2.2), we have that
 \begin{align*} \left(\int \psi_W\left (\frac{\phi(y)t}{a_{n}}\right ) \, \nu^{(1)}(dy)\right)^{n} \to \exp\left( -c_\alpha|t|^{\alpha} \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy) \right) . \end{align*}
\begin{align*} \left(\int \psi_W\left (\frac{\phi(y)t}{a_{n}}\right ) \, \nu^{(1)}(dy)\right)^{n} \to \exp\left( -c_\alpha|t|^{\alpha} \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy) \right) . \end{align*}
Thus, the distribution of
 $ Y^{(2)}_{i}(\mathbf{x}) $
weakly converges to
$ Y^{(2)}_{i}(\mathbf{x}) $
weakly converges to
 $\mu_{\alpha,\sigma_2}$
where
$\mu_{\alpha,\sigma_2}$
where
 \begin{align*} \sigma_2^{\alpha} &= \sigma_{B^{(2)}}^{\alpha} + c_\alpha \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy), \end{align*}
\begin{align*} \sigma_2^{\alpha} &= \sigma_{B^{(2)}}^{\alpha} + c_\alpha \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy), \end{align*}
as desired.
Next we prove that the joint distribution of
 $ (Y^{(2)}_{i}(\mathbf{x}))_{i \ge 1}$
converges to the product distribution
$ (Y^{(2)}_{i}(\mathbf{x}))_{i \ge 1}$
converges to the product distribution
 $\bigotimes_{i \ge 1} \mu_{\alpha,\sigma_2}$
. Let
$\bigotimes_{i \ge 1} \mu_{\alpha,\sigma_2}$
. Let
 $ \mathcal{L} \subset \mathbb{N} $
be a finite set. Let
$ \mathcal{L} \subset \mathbb{N} $
be a finite set. Let
 $\psi_B$
denote the multivariate characteristic function for the
$\psi_B$
denote the multivariate characteristic function for the
 $|\mathcal{L}|$
-fold product distribution of
$|\mathcal{L}|$
-fold product distribution of
 $\mu_{\alpha,\sigma_{B^{(2)}}}.$
For
$\mu_{\alpha,\sigma_{B^{(2)}}}.$
For
 $ \mathbf{t} = (t_{i})_{i\in\mathcal{L}} $
, conditionally on
$ \mathbf{t} = (t_{i})_{i\in\mathcal{L}} $
, conditionally on
 $ \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
,
$ \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
,
 \begin{align} &\psi_{(Y^{(2)}_{i}(\mathbf{x}))_{i \in \mathcal{L}} | \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j} }(\mathbf{t}) \\ \nonumber&\qquad \;:\!=\; \mathbb{E}\left[\left. \exp\left( i\sum_{i\in\mathcal{L}} t_{i}Y^{(2)}_{i}(\mathbf{x}) \right) \right| \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j} \right] \\ \nonumber&\qquad = \mathbb{E}\left[ \exp\left( i\sum_{i\in\mathcal{L}} B^{(2)}_{i}t_{i} \right) \right] \mathbb{E}\left[\left. \exp\left( i\frac{1}{a_{n}}\sum_{j=1}^{n} \sum_{i\in\mathcal{L}} W^{(2)}_{ij}\phi(Y^{(1)}_{j}(\mathbf{x})) t_{i} \right) \right| \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j}\right] \\ \nonumber&\qquad = \psi_{B}(\mathbf{t}) \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\mathbb{E}\left[ \left. \exp\left( i\frac{1}{a_{n}} W^{(2)}_{ij}\phi(Y^{(1)}_{j}(\mathbf{x})) t_{i} \right) \right| \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j}\right] \\ \nonumber&\qquad = \psi_{B}(\mathbf{t}) \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(Y^{(1)}_{j}(\mathbf{x}))t_{i}}{a_{n}}\right). \end{align}
\begin{align} &\psi_{(Y^{(2)}_{i}(\mathbf{x}))_{i \in \mathcal{L}} | \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j} }(\mathbf{t}) \\ \nonumber&\qquad \;:\!=\; \mathbb{E}\left[\left. \exp\left( i\sum_{i\in\mathcal{L}} t_{i}Y^{(2)}_{i}(\mathbf{x}) \right) \right| \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j} \right] \\ \nonumber&\qquad = \mathbb{E}\left[ \exp\left( i\sum_{i\in\mathcal{L}} B^{(2)}_{i}t_{i} \right) \right] \mathbb{E}\left[\left. \exp\left( i\frac{1}{a_{n}}\sum_{j=1}^{n} \sum_{i\in\mathcal{L}} W^{(2)}_{ij}\phi(Y^{(1)}_{j}(\mathbf{x})) t_{i} \right) \right| \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j}\right] \\ \nonumber&\qquad = \psi_{B}(\mathbf{t}) \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\mathbb{E}\left[ \left. \exp\left( i\frac{1}{a_{n}} W^{(2)}_{ij}\phi(Y^{(1)}_{j}(\mathbf{x})) t_{i} \right) \right| \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j}\right] \\ \nonumber&\qquad = \psi_{B}(\mathbf{t}) \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(Y^{(1)}_{j}(\mathbf{x}))t_{i}}{a_{n}}\right). \end{align}
Taking the expectation over the randomness of
 $ \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
, we have
$ \{ Y^{(1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
, we have
 \begin{align*} \frac{\psi_{(Y^{(2)}_{i}(\mathbf{x}))_{i \in \mathcal{L}}}(\mathbf{t})}{\psi_{B}(\mathbf{t})} &= \int \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y_{j})t_{i}}{a_{n}}\right) \, \bigotimes_{j= 1}^n \nu^{(1)}(dy_{j}) \\ &= \left( \int \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y)t_{i}}{a_{n}}\right) \, \nu^{(1)}(dy) \right)^{n} . \end{align*}
\begin{align*} \frac{\psi_{(Y^{(2)}_{i}(\mathbf{x}))_{i \in \mathcal{L}}}(\mathbf{t})}{\psi_{B}(\mathbf{t})} &= \int \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y_{j})t_{i}}{a_{n}}\right) \, \bigotimes_{j= 1}^n \nu^{(1)}(dy_{j}) \\ &= \left( \int \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y)t_{i}}{a_{n}}\right) \, \nu^{(1)}(dy) \right)^{n} . \end{align*}
Now, since
 \begin{align*} &\prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y)t_{i}}{a_{n}}\right) \\ &\qquad = 1 - c_\alpha\frac{b_n }{n} \sum_{i\in\mathcal{L}} |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})} + o\left( \frac{b_n }{n} \sum_{i\in\mathcal{L}} |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})} \right) , \end{align*}
\begin{align*} &\prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y)t_{i}}{a_{n}}\right) \\ &\qquad = 1 - c_\alpha\frac{b_n }{n} \sum_{i\in\mathcal{L}} |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})} + o\left( \frac{b_n }{n} \sum_{i\in\mathcal{L}} |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})} \right) , \end{align*}
it follows that
 \begin{align*} \frac{\psi_{(Y^{(2)}_{i}(\mathbf{x}))_{i \in \mathcal{L}}}(\mathbf{t})}{\psi_{B}(\mathbf{t})} &= \left( 1 - c_\alpha\frac{b_n }{n} \sum_{i\in\mathcal{L}} \int |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})} \, \nu^{(1)}(dy) + o\left( \frac{b_n }{n} \right) \right)^{n} \\ &\to \exp\left( -c_\alpha \sum_{i\in\mathcal{L}} |t_{i}|^{\alpha} \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy) \right) \\ &= \prod_{i\in\mathcal{L}} \exp\left( -c_\alpha |t_{i}|^{\alpha} \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy) \right) . \end{align*}
\begin{align*} \frac{\psi_{(Y^{(2)}_{i}(\mathbf{x}))_{i \in \mathcal{L}}}(\mathbf{t})}{\psi_{B}(\mathbf{t})} &= \left( 1 - c_\alpha\frac{b_n }{n} \sum_{i\in\mathcal{L}} \int |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})} \, \nu^{(1)}(dy) + o\left( \frac{b_n }{n} \right) \right)^{n} \\ &\to \exp\left( -c_\alpha \sum_{i\in\mathcal{L}} |t_{i}|^{\alpha} \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy) \right) \\ &= \prod_{i\in\mathcal{L}} \exp\left( -c_\alpha |t_{i}|^{\alpha} \int |\phi(y)|^{\alpha} \, \nu^{(1)}(dy) \right) . \end{align*}
This proves the case
 $\ell=2$
.
$\ell=2$
.
Case
 $\ell>2$
:
$\ell>2$
:
The remainder of the proof uses induction on the layer
 $\ell$
, the base case being
$\ell$
, the base case being
 $\ell=2$
proved above. Let
$\ell=2$
proved above. Let
 $ \ell > 2 $
. Also, let
$ \ell > 2 $
. Also, let
 $n=n_{\ell-1}$
,
$n=n_{\ell-1}$
,
 $\alpha=\alpha_\ell$
,
$\alpha=\alpha_\ell$
,
 $a_n=a_{n_{\ell-1}}(\ell)$
,
$a_n=a_{n_{\ell-1}}(\ell)$
,
 $\sigma_B=\sigma_{B^{(\ell)}}$
, and
$\sigma_B=\sigma_{B^{(\ell)}}$
, and
 $t\neq 0$
. Then
$t\neq 0$
. Then
 $ \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
is no longer i.i.d.; however, it is still exchangeable. By de Finetti’s theorem (see the end of Section 2), there exists a random probability measure
$ \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
is no longer i.i.d.; however, it is still exchangeable. By de Finetti’s theorem (see the end of Section 2), there exists a random probability measure
 \begin{align} \xi^{(\ell-1)}(dy)\;:\!=\;\xi^{(\ell-1)}(dy,\omega)\;:\!=\;\xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) \end{align}
\begin{align} \xi^{(\ell-1)}(dy)\;:\!=\;\xi^{(\ell-1)}(dy,\omega)\;:\!=\;\xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) \end{align}
such that given
 $\xi^{(\ell-1)}$
, the random variables
$\xi^{(\ell-1)}$
, the random variables
 $Y^{(\ell-1)}_{j}(\mathbf{x})$
,
$Y^{(\ell-1)}_{j}(\mathbf{x})$
,
 $j=1,2,\ldots $
, are i.i.d. with distribution
$j=1,2,\ldots $
, are i.i.d. with distribution
 $ \xi^{(\ell-1)}(dy,\omega)$
, where
$ \xi^{(\ell-1)}(dy,\omega)$
, where
 $\omega\in\Omega$
is an element of the probability space.
$\omega\in\Omega$
is an element of the probability space.
As before, we start by proving convergence of the marginal distribution. Taking the conditional expectation of (3.4), given
 $\xi^{(\ell-1)}$
, we have
$\xi^{(\ell-1)}$
, we have
 \begin{align*} \psi_{Y^{(\ell)}_{i}(\mathbf{x})|\xi^{(\ell-1)}}(t) &\;:\!=\; \mathbb{E}\left[\left. \psi_{Y^{(\ell)}_{i}(\mathbf{x}) | \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j}}(t) \right| \xi^{(\ell-1)}\right] \\ &= e^{-\sigma_{B}^{\alpha} |t|^{\alpha}} \mathbb{E}\left[\left. \prod_{j=1}^{n} \psi_{W^{(\ell)}_{ij}}\left (\frac{\phi(Y^{(\ell-1)}_{j}(\mathbf{x}))}{a_{n}}t\right ) \right|\xi^{(\ell-1)} \right] \\ &= e^{-\sigma_{B}^{\alpha} |t|^{\alpha}} \left( \int \psi_W\left (\frac{\phi(y)}{a_{n}}t\right ) \, \xi^{(\ell-1)}(dy) \right)^{n}, \end{align*}
\begin{align*} \psi_{Y^{(\ell)}_{i}(\mathbf{x})|\xi^{(\ell-1)}}(t) &\;:\!=\; \mathbb{E}\left[\left. \psi_{Y^{(\ell)}_{i}(\mathbf{x}) | \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j}}(t) \right| \xi^{(\ell-1)}\right] \\ &= e^{-\sigma_{B}^{\alpha} |t|^{\alpha}} \mathbb{E}\left[\left. \prod_{j=1}^{n} \psi_{W^{(\ell)}_{ij}}\left (\frac{\phi(Y^{(\ell-1)}_{j}(\mathbf{x}))}{a_{n}}t\right ) \right|\xi^{(\ell-1)} \right] \\ &= e^{-\sigma_{B}^{\alpha} |t|^{\alpha}} \left( \int \psi_W\left (\frac{\phi(y)}{a_{n}}t\right ) \, \xi^{(\ell-1)}(dy) \right)^{n}, \end{align*}
where
 $\psi_W\;:\!=\;\psi_{W^{(\ell)}_{ij}}$
for some/any i,j. Using Lemma A.2 and Lemma A.4 again, we get
$\psi_W\;:\!=\;\psi_{W^{(\ell)}_{ij}}$
for some/any i,j. Using Lemma A.2 and Lemma A.4 again, we get
 \begin{align} &\left(\int \psi_W\left (\frac{\phi(y)t}{a_{n}}\right ) \, \xi^{(\ell-1)}(dy)\right)^{n} = {} \\ &\quad \left(1{-} c_\alpha\frac{b_n }{n} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) {+} o\left ( \frac{b_n }{n} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) \right)\!\!\right)^{n} . \nonumber \end{align}
\begin{align} &\left(\int \psi_W\left (\frac{\phi(y)t}{a_{n}}\right ) \, \xi^{(\ell-1)}(dy)\right)^{n} = {} \\ &\quad \left(1{-} c_\alpha\frac{b_n }{n} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) {+} o\left ( \frac{b_n }{n} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) \right)\!\!\right)^{n} . \nonumber \end{align}
Note that these are random integrals since
 $ \xi^{(\ell-1)}(dy) $
is random, whereas the corresponding integral in the case
$ \xi^{(\ell-1)}(dy) $
is random, whereas the corresponding integral in the case
 $ \ell=2 $
was deterministic. Also, each integral on the right-hand side is finite almost surely since
$ \ell=2 $
was deterministic. Also, each integral on the right-hand side is finite almost surely since
 $ \phi $
is bounded. By the induction hypothesis, the joint distribution of
$ \phi $
is bounded. By the induction hypothesis, the joint distribution of
 $ (Y^{(\ell-1)}_{i}(\mathbf{x}))_{i \ge 1}$
converges weakly to the product measure
$ (Y^{(\ell-1)}_{i}(\mathbf{x}))_{i \ge 1}$
converges weakly to the product measure
 $\bigotimes_{i \ge 1} \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}$
. We claim that
$\bigotimes_{i \ge 1} \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}$
. We claim that
 \begin{align} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) \stackrel{p}{\to} |t|^{\alpha}\int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) . \end{align}
\begin{align} \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) \stackrel{p}{\to} |t|^{\alpha}\int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) . \end{align}
To see this, note that
 \begin{align} &\left| \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) - \int |\phi(y)t|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right| \\ \nonumber &\qquad \le \left| \int |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy)-\int |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \mu_{\alpha_{\ell-1}, \sigma_{\ell-1}}(dy) \right| \\ \nonumber & \qquad + \left| \int |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) - \int |\phi(y)t|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right| . \end{align}
\begin{align} &\left| \int |\phi(y)t|^{\alpha}\frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) - \int |\phi(y)t|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right| \\ \nonumber &\qquad \le \left| \int |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy)-\int |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \mu_{\alpha_{\ell-1}, \sigma_{\ell-1}}(dy) \right| \\ \nonumber & \qquad + \left| \int |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) - \int |\phi(y)t|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right| . \end{align}
First, consider the first term on the right-hand side of the above. By Corollary 3.1, the random measures
 $\xi^{(\ell-1)}$
converge weakly, in probability, to
$\xi^{(\ell-1)}$
converge weakly, in probability, to
 $\mu_{\alpha_{\ell-1}, \sigma_{\ell-1}}$
as
$\mu_{\alpha_{\ell-1}, \sigma_{\ell-1}}$
as
 $\mathbf{n}\to\infty$
in the sense of (2.3), where
$\mathbf{n}\to\infty$
in the sense of (2.3), where
 $\mathbf{n}\in\mathbb{N}^{\ell_{\text{lay}}}$
. Also, by Lemma A.4, we have
$\mathbf{n}\in\mathbb{N}^{\ell_{\text{lay}}}$
. Also, by Lemma A.4, we have
 \begin{equation} |\phi(y) t|^\alpha \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t|}\right)}{L_{0}(a_{n})} \leq b |\phi(y) t|^{\alpha \pm \epsilon} \end{equation}
\begin{equation} |\phi(y) t|^\alpha \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t|}\right)}{L_{0}(a_{n})} \leq b |\phi(y) t|^{\alpha \pm \epsilon} \end{equation}
for large n. For any subsequence
 $(\mathbf{n}_j)_{j}$
, there is a further subsequence
$(\mathbf{n}_j)_{j}$
, there is a further subsequence
 $(\mathbf{n}_{j_k})_k$
along which,
$(\mathbf{n}_{j_k})_k$
along which,
 $\omega$
-almost surely,
$\omega$
-almost surely,
 $\xi^{(\ell-1)} $
converges weakly to
$\xi^{(\ell-1)} $
converges weakly to
 $ \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}$
. To prove that the first term on the right-hand side of (3.11) converges in probability to 0, it is enough to show that it converges almost surely to 0 along each subsequence
$ \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}$
. To prove that the first term on the right-hand side of (3.11) converges in probability to 0, it is enough to show that it converges almost surely to 0 along each subsequence
 $(\mathbf{n}_{j_k})_k$
. Fix an
$(\mathbf{n}_{j_k})_k$
. Fix an
 $\omega$
-realization of the random distributions
$\omega$
-realization of the random distributions
 $(\xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}))_{\mathbf{n} \in \mathbb{N}^{\ell_{\text{lay}}}}$
such that convergence along the subsequence
$(\xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}))_{\mathbf{n} \in \mathbb{N}^{\ell_{\text{lay}}}}$
such that convergence along the subsequence
 $(\mathbf{n}_{j_k})_k$
holds. Keeping
$(\mathbf{n}_{j_k})_k$
holds. Keeping
 $\omega$
fixed, view
$\omega$
fixed, view
 $g(y_{\mathbf{n}})=|\phi(y_{\mathbf{n}}) t|^{\alpha \pm \epsilon}$
as a random variable where the parameter
$g(y_{\mathbf{n}})=|\phi(y_{\mathbf{n}}) t|^{\alpha \pm \epsilon}$
as a random variable where the parameter
 $y_{\mathbf{n}}$
is sampled from the distribution
$y_{\mathbf{n}}$
is sampled from the distribution
 $\xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n})$
. Since
$\xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n})$
. Since
 $ \phi $
is bounded, the family of these random variables is uniformly integrable. Since
$ \phi $
is bounded, the family of these random variables is uniformly integrable. Since
 $ \xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) $
converges weakly to
$ \xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) $
converges weakly to
 $ \mu_{\alpha_{\ell-1},\sigma_{\ell-1}} $
along the subsequence, the Skorokhod representation and Vitali convergence theorem [Reference Royden and Fitzpatrick37, p. 94] guarantee the convergence of the first term on the right-hand side of (3.11) to 0 as
$ \mu_{\alpha_{\ell-1},\sigma_{\ell-1}} $
along the subsequence, the Skorokhod representation and Vitali convergence theorem [Reference Royden and Fitzpatrick37, p. 94] guarantee the convergence of the first term on the right-hand side of (3.11) to 0 as
 $\mathbf{n}$
tends to
$\mathbf{n}$
tends to
 $\infty$
.
$\infty$
.
Now, for the second term, since
 \begin{align*}\underset{n \to \infty}{\lim} |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} = |\phi(y) t|^\alpha\end{align*}
\begin{align*}\underset{n \to \infty}{\lim} |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} = |\phi(y) t|^\alpha\end{align*}
for each y and
 $ \phi $
is bounded, we can use dominated convergence via (3.12) to show that the second term on the right-hand side of (3.11) also converges to 0, proving the claim.
$ \phi $
is bounded, we can use dominated convergence via (3.12) to show that the second term on the right-hand side of (3.11) also converges to 0, proving the claim.
Having proved (3.10), we have
 \begin{align*} &\left( 1 + \frac{1}{n} \left( -c_\alpha b_n \int |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) + o( b_n ) \right) \right)^{n} \\ &\qquad \stackrel{p}{\to} \exp\left( -c_\alpha |t|^{\alpha} \int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right) \end{align*}
\begin{align*} &\left( 1 + \frac{1}{n} \left( -c_\alpha b_n \int |\phi(y)t|^{\alpha} \frac{L_{0}\big( \frac{a_{n}}{|\phi(y)t|} \big)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) + o( b_n ) \right) \right)^{n} \\ &\qquad \stackrel{p}{\to} \exp\left( -c_\alpha |t|^{\alpha} \int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right) \end{align*}
and hence
 \begin{align*} \psi_{Y^{(\ell)}_i(\mathbf{x})| \xi^{(\ell-1)}}(t) \stackrel{p}{\to} e^{-\sigma_{B}^{\alpha}|t|^{\alpha}} \exp\left( -c_\alpha |t|^{\alpha} \int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right) . \end{align*}
\begin{align*} \psi_{Y^{(\ell)}_i(\mathbf{x})| \xi^{(\ell-1)}}(t) \stackrel{p}{\to} e^{-\sigma_{B}^{\alpha}|t|^{\alpha}} \exp\left( -c_\alpha |t|^{\alpha} \int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right) . \end{align*}
Thus, the limiting distribution of
 $Y^{(\ell)}_{i}(\mathbf{x})$
, given
$Y^{(\ell)}_{i}(\mathbf{x})$
, given
 $\xi^{(\ell-1)}$
, is
$\xi^{(\ell-1)}$
, is
 $\mu_{\alpha, \sigma_{\ell}}$
with
$\mu_{\alpha, \sigma_{\ell}}$
with
 \begin{align*} \sigma^{\alpha}_{\ell} &= \sigma_{B}^{\alpha} + c_\alpha \int |\phi(y)|^{\alpha} \, \mu_{\alpha,\sigma_{\ell-1}}(dy). \end{align*}
\begin{align*} \sigma^{\alpha}_{\ell} &= \sigma_{B}^{\alpha} + c_\alpha \int |\phi(y)|^{\alpha} \, \mu_{\alpha,\sigma_{\ell-1}}(dy). \end{align*}
Recall that characteristic functions are bounded by 1. Thus, by taking the expectation of both sides and using dominated convergence, we can conclude that the (unconditional) characteristic function converges to the same expression and thus the (unconditional) distribution of
 $Y^{(\ell)}_{i}(\mathbf{x})$
converges weakly to
$Y^{(\ell)}_{i}(\mathbf{x})$
converges weakly to
 $\mu_{\alpha, \sigma_{\ell}}$
.
$\mu_{\alpha, \sigma_{\ell}}$
.
Finally, we prove that the joint distribution converges weakly to the product
 $\bigotimes_{i\ge 1}\mu_{\alpha,\sigma_{\ell}} $
. Let
$\bigotimes_{i\ge 1}\mu_{\alpha,\sigma_{\ell}} $
. Let
 $ \mathcal{L} \subset \mathbb{N} $
be a finite set and
$ \mathcal{L} \subset \mathbb{N} $
be a finite set and
 $ \mathbf{t} = (t_{i})_{i\in\mathcal{L}} $
. Conditionally on
$ \mathbf{t} = (t_{i})_{i\in\mathcal{L}} $
. Conditionally on
 $ \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
,
$ \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
,
 \begin{align} \psi_{(Y^{(\ell)}_{i}(\mathbf{x}))_{i\in \mathcal{L}} | \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} }(\mathbf{t}) &= \psi_{B}(\mathbf{t}) \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(Y^{(\ell-1)}_{j}(\mathbf{x}))t_{i}}{a_{n}}\right) . \end{align}
\begin{align} \psi_{(Y^{(\ell)}_{i}(\mathbf{x}))_{i\in \mathcal{L}} | \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} }(\mathbf{t}) &= \psi_{B}(\mathbf{t}) \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(Y^{(\ell-1)}_{j}(\mathbf{x}))t_{i}}{a_{n}}\right) . \end{align}
Taking the expectation with respect to
 $ \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
, we have
$ \{ Y^{(\ell-1)}_{j}(\mathbf{x}) \}_{j=1,\ldots,n} $
, we have
 \begin{align*} \frac{\psi_{(Y^{(\ell)}_{i}(\mathbf{x}))_{i\in \mathcal{L}}}(\mathbf{t})}{\psi_{B}(\mathbf{t})} &= \mathbb{E} \int \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y_{j})t_{i}}{a_{n}}\right) \, \bigotimes_{j\ge 1} \xi^{(\ell-1)}(dy_{j}) \\ &= \mathbb{E} \left( \int \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y)t_{i}}{a_{n}}\right) \, \xi^{(\ell-1)}(dy) \right)^{n} . \end{align*}
\begin{align*} \frac{\psi_{(Y^{(\ell)}_{i}(\mathbf{x}))_{i\in \mathcal{L}}}(\mathbf{t})}{\psi_{B}(\mathbf{t})} &= \mathbb{E} \int \prod_{j=1}^{n} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y_{j})t_{i}}{a_{n}}\right) \, \bigotimes_{j\ge 1} \xi^{(\ell-1)}(dy_{j}) \\ &= \mathbb{E} \left( \int \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y)t_{i}}{a_{n}}\right) \, \xi^{(\ell-1)}(dy) \right)^{n} . \end{align*}
Now since
 \begin{align*} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y)t_{i}}{a_{n}}\right) \sim 1 - c_\alpha \frac{b_n }{n} \sum_{i\in\mathcal{L}} |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})}, \end{align*}
\begin{align*} \prod_{i\in\mathcal{L}}\psi_{W}\left(\frac{\phi(y)t_{i}}{a_{n}}\right) \sim 1 - c_\alpha \frac{b_n }{n} \sum_{i\in\mathcal{L}} |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})}, \end{align*}
a similar argument to that of convergence of the marginal distribution shows that
 \begin{align*} \frac{\psi_{(Y^{(\ell)}_{i}(\mathbf{x}))_{i\in \mathcal{L}}}(\mathbf{t})}{\psi_{B}(\mathbf{t})} &\sim \mathbb{E} \left( 1 - c_\alpha \frac{b_n }{n} \sum_{i\in\mathcal{L}} \int |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) \right)^{n} \\ &\to \exp\left( -c_\alpha \sum_{i\in\mathcal{L}} |t_{i}|^{\alpha} \int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right) \\ &= \prod_{i\in\mathcal{L}} \exp\left( -c_\alpha |t_{i}|^{\alpha} \int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right), \end{align*}
\begin{align*} \frac{\psi_{(Y^{(\ell)}_{i}(\mathbf{x}))_{i\in \mathcal{L}}}(\mathbf{t})}{\psi_{B}(\mathbf{t})} &\sim \mathbb{E} \left( 1 - c_\alpha \frac{b_n }{n} \sum_{i\in\mathcal{L}} \int |\phi(y)t_{i}|^{\alpha} \frac{L_{0}\left( \frac{a_{n}}{|\phi(y)t_{i}|} \right)}{L_{0}(a_{n})} \, \xi^{(\ell-1)}(dy) \right)^{n} \\ &\to \exp\left( -c_\alpha \sum_{i\in\mathcal{L}} |t_{i}|^{\alpha} \int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right) \\ &= \prod_{i\in\mathcal{L}} \exp\left( -c_\alpha |t_{i}|^{\alpha} \int |\phi(y)|^{\alpha} \, \mu_{\alpha_{\ell-1},\sigma_{\ell-1}}(dy) \right), \end{align*}
completing the proof.
4. Relaxing the boundedness assumption
As we mentioned earlier in Remark 3.1, the boundedness assumption on
 $\phi$
can be relaxed, as long as it is done with care. It is known that the growth rate of the activation function
$\phi$
can be relaxed, as long as it is done with care. It is known that the growth rate of the activation function
 $ \phi $
affects the behavior of the network at deeper layers. If
$ \phi $
affects the behavior of the network at deeper layers. If
 $ \phi $
grows too fast, then the variance will quickly become too large at deeper layers, causing chaotic behavior of the network at those deeper layers. If, on the other hand,
$ \phi $
grows too fast, then the variance will quickly become too large at deeper layers, causing chaotic behavior of the network at those deeper layers. If, on the other hand,
 $ \phi $
grows too slowly, then the variance will become too small, causing the network to behave as if it were not random [Reference Glorot and Bengio13, Reference He, Zhang, Ren and Sun15, Reference Roberts, Yaida and Hanin36]. Thus, it is important to find an appropriate growth rate for the activation function. Before presenting our result, we first present a counterexample where, for heavy-tailed initializations, we cannot use a function which grows linearly. This shows the subtlety of our relaxation.
$ \phi $
grows too slowly, then the variance will become too small, causing the network to behave as if it were not random [Reference Glorot and Bengio13, Reference He, Zhang, Ren and Sun15, Reference Roberts, Yaida and Hanin36]. Thus, it is important to find an appropriate growth rate for the activation function. Before presenting our result, we first present a counterexample where, for heavy-tailed initializations, we cannot use a function which grows linearly. This shows the subtlety of our relaxation.
Remark 4.1. Consider the case where
 $ \phi = \operatorname{ReLU} $
,
$ \phi = \operatorname{ReLU} $
,
 $ \mathbb{P}( |W^{(\ell)}_{ij}| > t) = t^{-\alpha} $
for
$ \mathbb{P}( |W^{(\ell)}_{ij}| > t) = t^{-\alpha} $
for
 $ t \ge 1 $
,
$ t \ge 1 $
,
 $ 0<\alpha<2 $
, and
$ 0<\alpha<2 $
, and
 $ \sigma_{B} = 0 $
. For an input
$ \sigma_{B} = 0 $
. For an input
 $ \mathbf{x} = (1,0,\ldots,0) \in \mathbb{R}^{I} $
, we have
$ \mathbf{x} = (1,0,\ldots,0) \in \mathbb{R}^{I} $
, we have
 \begin{align*} &Y^{(1)}_{i}(\mathbf{x}) = W^{(1)}_{i1}, \\ &Y^{(2)}_{i}(\mathbf{x}) = \frac{1}{a_n} \sum_{j=1}^{n} W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}},\\ & a_n = n^{1/\alpha}. \end{align*}
\begin{align*} &Y^{(1)}_{i}(\mathbf{x}) = W^{(1)}_{i1}, \\ &Y^{(2)}_{i}(\mathbf{x}) = \frac{1}{a_n} \sum_{j=1}^{n} W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}},\\ & a_n = n^{1/\alpha}. \end{align*}
Let us calculate the distribution function of
 $ W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}} $
. For
$ W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}} $
. For
 $ z \ge 1 $
,
$ z \ge 1 $
,
 \begin{align*} &\mathbb{P}(W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}} \le z) \\ &{} = \mathbb{P}(W^{(1)}_{j1} \leq 0) + \int_{1}^{z} \frac{\alpha w_{1}^{-\alpha-1}}{2}\mathbb{P}\left( W^{(2)}_{ij} \le \frac{z}{w_{1}} \right) dw_{1} + \int_{z}^{\infty} \frac{\alpha w_{1}^{-\alpha-1}}{2} \mathbb{P}\left( W^{(2)}_{ij} \le -1 \right) dw_{1} \\ &{} = 1 - \frac{1}{4} z^{-\alpha} - \frac{1}{4} \alpha z^{-\alpha} \log z . \end{align*}
\begin{align*} &\mathbb{P}(W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}} \le z) \\ &{} = \mathbb{P}(W^{(1)}_{j1} \leq 0) + \int_{1}^{z} \frac{\alpha w_{1}^{-\alpha-1}}{2}\mathbb{P}\left( W^{(2)}_{ij} \le \frac{z}{w_{1}} \right) dw_{1} + \int_{z}^{\infty} \frac{\alpha w_{1}^{-\alpha-1}}{2} \mathbb{P}\left( W^{(2)}_{ij} \le -1 \right) dw_{1} \\ &{} = 1 - \frac{1}{4} z^{-\alpha} - \frac{1}{4} \alpha z^{-\alpha} \log z . \end{align*}
Similarly, for
 $ z \le -1 $
,
$ z \le -1 $
,
 \begin{align*} \mathbb{P}(W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}} < z) = \frac{1}{4} \alpha (-z)^{-\alpha} \log(-z) + \frac{1}{4} (-z)^{-\alpha} . \end{align*}
\begin{align*} \mathbb{P}(W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}} < z) = \frac{1}{4} \alpha (-z)^{-\alpha} \log(-z) + \frac{1}{4} (-z)^{-\alpha} . \end{align*}
Thus,
 \begin{align*} \mathbb{P}(|W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}}| > z) = \frac{1}{2} z^{-\alpha} \left( 1 + \alpha \log z \right) . \end{align*}
\begin{align*} \mathbb{P}(|W^{(2)}_{ij} W^{(1)}_{j1} \mathbf{1}_{\{W^{(1)}_{j1}>0\}}| > z) = \frac{1}{2} z^{-\alpha} \left( 1 + \alpha \log z \right) . \end{align*}
Let
 $ {\hat{a}}_n \;:\!=\; \inf\{x\colon x^{-\alpha} (1+\alpha\log x)/2 \le n^{-1} \} $
. Then
$ {\hat{a}}_n \;:\!=\; \inf\{x\colon x^{-\alpha} (1+\alpha\log x)/2 \le n^{-1} \} $
. Then
 $ n \hat{a}_n^{-\alpha} (1+\alpha\log \hat{a}_n)/2 \to 1 $
as
$ n \hat{a}_n^{-\alpha} (1+\alpha\log \hat{a}_n)/2 \to 1 $
as
 $ n \to \infty $
, which leads to
$ n \to \infty $
, which leads to
 \begin{align*} \frac{\hat{a}_n}{n^{1/\alpha}} \sim ((1+\alpha\log \hat{a}_n)/2)^{1/\alpha} \to \infty \end{align*}
\begin{align*} \frac{\hat{a}_n}{n^{1/\alpha}} \sim ((1+\alpha\log \hat{a}_n)/2)^{1/\alpha} \to \infty \end{align*}
when n is large. Thus,
 $ \hat{a}_n $
is of strictly larger order than
$ \hat{a}_n $
is of strictly larger order than
 $ n^{1/\alpha} $
, which shows that
$ n^{1/\alpha} $
, which shows that
 $ Y^{(2)}_{i}(\mathbf{x}) $
does not converge using the suggested normalization.
$ Y^{(2)}_{i}(\mathbf{x}) $
does not converge using the suggested normalization.
However, despite the remark, one can modify the scaling to
 $ a_{n} =n^{1/\alpha}L(n)$
where L(n) is a nonconstant slowly varying factor, in order to make the network converge at initialization. For details, we refer to [Reference Favaro, Fortini and Peluchetti6], where the authors handle the convergence of shallow ReLU networks with stable weights.
$ a_{n} =n^{1/\alpha}L(n)$
where L(n) is a nonconstant slowly varying factor, in order to make the network converge at initialization. For details, we refer to [Reference Favaro, Fortini and Peluchetti6], where the authors handle the convergence of shallow ReLU networks with stable weights.
Despite the above remark, there is still room to relax the boundedness assumption on
 $\phi$
. Note that, in the proof of Theorem 3.1, we used boundedness (in a critical way) to prove the claim (3.10). In particular, boundedness gave us that the family of random variables
$\phi$
. Note that, in the proof of Theorem 3.1, we used boundedness (in a critical way) to prove the claim (3.10). In particular, boundedness gave us that the family of random variables
 $ |\phi(y)|^{\alpha+\epsilon} $
with respect to the random distribution
$ |\phi(y)|^{\alpha+\epsilon} $
with respect to the random distribution
 $ \xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) $
is y -uniformly integrable
$ \xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) $
is y -uniformly integrable
 $ \omega $
-almost surely. We make this into a direct assumption on
$ \omega $
-almost surely. We make this into a direct assumption on
 $ \phi $
as follows. Let
$ \phi $
as follows. Let
 $n\;:\!=\;n_{\ell-2}$
and
$n\;:\!=\;n_{\ell-2}$
and
 $a_n\;:\!=\;a_{n_{\ell-2}}(\ell-1)$
. Suppose
$a_n\;:\!=\;a_{n_{\ell-2}}(\ell-1)$
. Suppose
-
(UI1) for
$\ell=2$
, there exists
$ \epsilon_{0}>0$
such that
$ |\phi(Y^{(1)}_{j})|^{\alpha_{2}+\epsilon_{0}} $
is integrable; -
(UI2) for
$ \ell=3,\ldots,\ell_{\text{lay}}+1 $
, there exists
$ \epsilon_{0}>0$
such that for any array
$(c_{\mathbf{n},j})_{\mathbf{n},j}$
satisfying (4.1)we have uniform integrability of the family
\begin{align} \sup_{\mathbf{n}} \frac{1}{n}\sum_{j=1}^{n} |c_{\mathbf{n},j}|^{\alpha_{\ell-1}+\epsilon_{0}} < \infty, \end{align}
(4.2)over
\begin{align} &\left\{ \left| \phi\left( \frac{1}{a_{n}} \sum_{j=1}^{n} c_{\mathbf{n},j} W^{(\ell-1)}_{j} \right)\right|^{\alpha_{\ell} + \epsilon_{0}}\right\}_{\mathbf{n}} \end{align}
$\mathbf{n}$
.









If
 $ \phi $
is bounded, then the above is obviously satisfied. It is not clear whether there is a simpler description of the family of functions that satisfies this assumption (see [Reference Aldous1]); however, we now argue that this is general enough to recover the previous results of Gaussian weights or stable weights.
$ \phi $
is bounded, then the above is obviously satisfied. It is not clear whether there is a simpler description of the family of functions that satisfies this assumption (see [Reference Aldous1]); however, we now argue that this is general enough to recover the previous results of Gaussian weights or stable weights.
In [Reference Matthews30] (as well as many other references), the authors consider Gaussian initializations with an activation function
 $ \phi $
satisfying the so-called polynomial envelope condition. That is,
$ \phi $
satisfying the so-called polynomial envelope condition. That is,
 $ |\phi(y)| \le a + b|y|^{m} $
for some
$ |\phi(y)| \le a + b|y|^{m} $
for some
 $ a,b > 0 $
and
$ a,b > 0 $
and
 $ m \ge 1 $
and
$ m \ge 1 $
and
 $ W \sim \mathcal{N}(0,\sigma^{2}) $
. In this setting, we have
$ W \sim \mathcal{N}(0,\sigma^{2}) $
. In this setting, we have
 $ a_{n} \sim \sigma\sqrt{n/2} $
and
$ a_{n} \sim \sigma\sqrt{n/2} $
and
 $ \alpha = 2 $
for all
$ \alpha = 2 $
for all
 $\ell$
, and
$\ell$
, and
 $ c_{\mathbf{n},j} = c_{\mathbf{n},j}^{(\ell-2)}= \phi(Y^{(\ell-2)}_{j}(\mathbf{x};\;\;\mathbf{n})) $
. Conditioning on
$ c_{\mathbf{n},j} = c_{\mathbf{n},j}^{(\ell-2)}= \phi(Y^{(\ell-2)}_{j}(\mathbf{x};\;\;\mathbf{n})) $
. Conditioning on
 $(Y^{(\ell-2)}_j)_j$
and assuming that (4.1) holds almost surely, let us show that
$(Y^{(\ell-2)}_j)_j$
and assuming that (4.1) holds almost surely, let us show that
 $ \phi $
satisfying the polynomial envelope condition also satisfies our uniform integrability assumptions (UI1) and (UI2) almost surely. For
$ \phi $
satisfying the polynomial envelope condition also satisfies our uniform integrability assumptions (UI1) and (UI2) almost surely. For
 $ \ell=2 $
, the distribution of
$ \ell=2 $
, the distribution of
 \begin{align*} Y^{(1)}_{i} = \sum_{j=1}^{I} W^{(1)}_{ij} x_{j} + B^{(1)}_{i}\end{align*}
\begin{align*} Y^{(1)}_{i} = \sum_{j=1}^{I} W^{(1)}_{ij} x_{j} + B^{(1)}_{i}\end{align*}
is Gaussian, and thus
 $ |\phi(Y^{(1)}_{j})|^{2+\epsilon_{0}} \le C_0 + C_1 |Y^{(1)}_{j}|^{m(2+\epsilon_{0})}$
is integrable. For
$ |\phi(Y^{(1)}_{j})|^{2+\epsilon_{0}} \le C_0 + C_1 |Y^{(1)}_{j}|^{m(2+\epsilon_{0})}$
is integrable. For
 $ \ell \ge 3 $
, note that
$ \ell \ge 3 $
, note that
 \begin{align*} S^{(\ell-1)}_{\mathbf{n}} \;:\!=\; \frac{1}{a_{n}} \sum_{j=1}^{n} c_{\mathbf{n},j} W^{(\ell-1)}_{j} \sim \mathcal{N}\left(0, \frac{2}{n}\sum_{j=1}^{n} c_{\mathbf{n},j}^{2}\right) ,\end{align*}
\begin{align*} S^{(\ell-1)}_{\mathbf{n}} \;:\!=\; \frac{1}{a_{n}} \sum_{j=1}^{n} c_{\mathbf{n},j} W^{(\ell-1)}_{j} \sim \mathcal{N}\left(0, \frac{2}{n}\sum_{j=1}^{n} c_{\mathbf{n},j}^{2}\right) ,\end{align*}
where the variance is uniformly bounded over
 $ \mathbf{n} $
if we assume (4.1). For
$ \mathbf{n} $
if we assume (4.1). For
 $ \theta > 1 $
, let
$ \theta > 1 $
, let
 $ \nu\;:\!=\; m(2+\epsilon_{0})\theta $
; the
$ \nu\;:\!=\; m(2+\epsilon_{0})\theta $
; the
 $\nu$
th moment of
$\nu$
th moment of
 $ S_{n} $
can be directly calculated and is known to be
$ S_{n} $
can be directly calculated and is known to be
 \begin{align*} 2^{\nu/2} \frac{1}{\sqrt{\pi}} \Gamma\left(\frac{1 + \nu}{2}\right)\left( \frac{2}{n} \sum_{j=1}^{n} c_{\mathbf{n},j}^{2} \right)^{\nu/2} .\end{align*}
\begin{align*} 2^{\nu/2} \frac{1}{\sqrt{\pi}} \Gamma\left(\frac{1 + \nu}{2}\right)\left( \frac{2}{n} \sum_{j=1}^{n} c_{\mathbf{n},j}^{2} \right)^{\nu/2} .\end{align*}
This is uniformly bounded over
 $ \mathbf{n} $
, and hence
$ \mathbf{n} $
, and hence
 $ |\phi(S_{n})|^{2+\epsilon_{0}} $
is uniformly integrable over
$ |\phi(S_{n})|^{2+\epsilon_{0}} $
is uniformly integrable over
 $ \mathbf{n} $
. This shows that
$ \mathbf{n} $
. This shows that
 $ \phi $
satisfying the polynomial envelope condition meets (UI1) and (UI2) assuming (4.1).
$ \phi $
satisfying the polynomial envelope condition meets (UI1) and (UI2) assuming (4.1).
In [Reference Favaro, Fortini and Peluchetti4], the authors consider the case where
 $ W^{(\ell)} $
is an S
$ W^{(\ell)} $
is an S
 $\alpha$
S random variable with scale parameter
$\alpha$
S random variable with scale parameter
 $ \sigma_{\ell} $
, i.e., with characteristic function
$ \sigma_{\ell} $
, i.e., with characteristic function
 $ e^{-\sigma_{\ell}^{\alpha}|t|^{\alpha}} $
. They use the envelope condition
$ e^{-\sigma_{\ell}^{\alpha}|t|^{\alpha}} $
. They use the envelope condition
 $ |\phi(y)| \le a + b|y|^{\beta} $
where
$ |\phi(y)| \le a + b|y|^{\beta} $
where
 $ \beta < 1 $
. For the more general case where we have different
$ \beta < 1 $
. For the more general case where we have different
 $ \alpha_{\ell} $
-stable weights for different layers
$ \alpha_{\ell} $
-stable weights for different layers
 $ \ell $
, this envelope condition can be generalized to
$ \ell $
, this envelope condition can be generalized to
 $ \beta < \min_{\ell\ge2} \alpha_{\ell-1}/\alpha_{\ell} $
. In this case,
$ \beta < \min_{\ell\ge2} \alpha_{\ell-1}/\alpha_{\ell} $
. In this case,
 $ a_{n}^{\alpha_{\ell}} \sim(\sigma_{\ell}^{\alpha_{\ell}}n)/c_{\alpha_{\ell}}$
and
$ a_{n}^{\alpha_{\ell}} \sim(\sigma_{\ell}^{\alpha_{\ell}}n)/c_{\alpha_{\ell}}$
and
 $ c_{\mathbf{n},j} = c_{\mathbf{n},j}^{(\ell-2)} = \phi(Y^{(\ell-2)}_{j}(\mathbf{x};\;\;\mathbf{n})) $
. Again, conditioning on
$ c_{\mathbf{n},j} = c_{\mathbf{n},j}^{(\ell-2)} = \phi(Y^{(\ell-2)}_{j}(\mathbf{x};\;\;\mathbf{n})) $
. Again, conditioning on
 $(Y^{(\ell-2)}_{j})_j$
and assuming (4.1), let us show that
$(Y^{(\ell-2)}_{j})_j$
and assuming (4.1), let us show that
 $ \phi $
under this generalized envelope condition satisfies the uniform integrability assumptions (UI1) and (UI2) above. For
$ \phi $
under this generalized envelope condition satisfies the uniform integrability assumptions (UI1) and (UI2) above. For
 $ \ell=2 $
, the distribution of
$ \ell=2 $
, the distribution of
 \begin{align*} Y^{(1)}_{j} = \sum_{j=1}^{I} W^{(1)}_{ij} x_{j} + B^{(1)}_{i}\end{align*}
\begin{align*} Y^{(1)}_{j} = \sum_{j=1}^{I} W^{(1)}_{ij} x_{j} + B^{(1)}_{i}\end{align*}
is
 $ \alpha_{1} $
-stable. By the condition on
$ \alpha_{1} $
-stable. By the condition on
 $\beta$
, there are
$\beta$
, there are
 $ \delta $
and
$ \delta $
and
 $ \epsilon_{0} $
satisfying
$ \epsilon_{0} $
satisfying
 $ \beta(\alpha_{2}+\epsilon_{0}) \le \alpha_{1} - \delta $
so that
$ \beta(\alpha_{2}+\epsilon_{0}) \le \alpha_{1} - \delta $
so that
 \begin{align*} |\phi(Y^{(1)}_{j})|^{\alpha_{2}+\epsilon} \le C_0 + C_1 |Y^{(1)}_{j}|^{\alpha_{1} - \delta} ,\end{align*}
\begin{align*} |\phi(Y^{(1)}_{j})|^{\alpha_{2}+\epsilon} \le C_0 + C_1 |Y^{(1)}_{j}|^{\alpha_{1} - \delta} ,\end{align*}
which is integrable. For
 $ \ell \ge 3 $
, the distribution of
$ \ell \ge 3 $
, the distribution of
 $ S^{(\ell-1)}_{\mathbf{n}} \;:\!=\; a_{n}^{-1}\sum_{j} c_{\mathbf{n},j} W^{(\ell-1)}_{j} $
becomes a symmetric
$ S^{(\ell-1)}_{\mathbf{n}} \;:\!=\; a_{n}^{-1}\sum_{j} c_{\mathbf{n},j} W^{(\ell-1)}_{j} $
becomes a symmetric
 $ \alpha_{\ell-1} $
-stable distribution with scale parameter
$ \alpha_{\ell-1} $
-stable distribution with scale parameter
 \begin{align*} \left( \frac{c_{\alpha_{\ell-1}}}{n} \sum_{j=1}^{n} |c_{\mathbf{n},j}|^{\alpha_{\ell-1}} \right)^{1/\alpha_{\ell-1}},\end{align*}
\begin{align*} \left( \frac{c_{\alpha_{\ell-1}}}{n} \sum_{j=1}^{n} |c_{\mathbf{n},j}|^{\alpha_{\ell-1}} \right)^{1/\alpha_{\ell-1}},\end{align*}
which is uniformly bounded over
 $ \mathbf{n} $
assuming (4.1). Since
$ \mathbf{n} $
assuming (4.1). Since
 $ \beta < \min_{\ell\ge2} \alpha_{\ell-1}/\alpha_{\ell} $
, it follows that, for some
$ \beta < \min_{\ell\ge2} \alpha_{\ell-1}/\alpha_{\ell} $
, it follows that, for some
 $ \theta>1 $
, there exist small
$ \theta>1 $
, there exist small
 $ \epsilon_{0} > 0 $
and
$ \epsilon_{0} > 0 $
and
 $\delta > 0$
such that
$\delta > 0$
such that
 \begin{align*} \left| \phi\left( S^{(\ell-1)}_{\mathbf{n}} \right) \right|^{(\alpha_{\ell}+\epsilon_{0})\theta} \le C_0 + C_1 \left| S^{(\ell-1)}_{\mathbf{n}} \right|^{\beta(\alpha_{\ell} + \epsilon_{0})\theta} \le C_0 + C_1 \left| S^{(\ell-1)}_{\mathbf{n}} \right|^{\alpha_{\ell-1} - \delta} .\end{align*}
\begin{align*} \left| \phi\left( S^{(\ell-1)}_{\mathbf{n}} \right) \right|^{(\alpha_{\ell}+\epsilon_{0})\theta} \le C_0 + C_1 \left| S^{(\ell-1)}_{\mathbf{n}} \right|^{\beta(\alpha_{\ell} + \epsilon_{0})\theta} \le C_0 + C_1 \left| S^{(\ell-1)}_{\mathbf{n}} \right|^{\alpha_{\ell-1} - \delta} .\end{align*}
It is known (see for instance [Reference Shanbhag and Sreehari39]) that the expectation of
 $ |S^{(\ell-1)}_{\mathbf{n}}|^{\nu} $
with
$ |S^{(\ell-1)}_{\mathbf{n}}|^{\nu} $
with
 $ \nu < \alpha_{\ell-1} $
is
$ \nu < \alpha_{\ell-1} $
is
 \begin{align*} K_{\nu} \left( \frac{c_{\alpha_{\ell-1}}}{n} \sum_{j=1}^{n} |c_{\mathbf{n},j}|^{\alpha_{\ell-1}} \right)^{\nu/\alpha_{\ell-1}},\end{align*}
\begin{align*} K_{\nu} \left( \frac{c_{\alpha_{\ell-1}}}{n} \sum_{j=1}^{n} |c_{\mathbf{n},j}|^{\alpha_{\ell-1}} \right)^{\nu/\alpha_{\ell-1}},\end{align*}
where
 $ K_{\nu} $
is a constant that depends only on
$ K_{\nu} $
is a constant that depends only on
 $ \nu $
(and
$ \nu $
(and
 $ \alpha_{\ell-1} $
). As this is bounded uniformly over
$ \alpha_{\ell-1} $
). As this is bounded uniformly over
 $ \mathbf{n} $
, the family
$ \mathbf{n} $
, the family
 \begin{align*} \left \{ \left| \phi\left( S^{(\ell-1)}_{\mathbf{n}} \right) \right|^{\alpha_{\ell}+\epsilon_{0}} \right \}_{\mathbf{n}}\end{align*}
\begin{align*} \left \{ \left| \phi\left( S^{(\ell-1)}_{\mathbf{n}} \right) \right|^{\alpha_{\ell}+\epsilon_{0}} \right \}_{\mathbf{n}}\end{align*}
is uniformly integrable. Thus our
 $ \phi $
, under the generalized envelope condition, satisfies (UI1) and (UI2).
$ \phi $
, under the generalized envelope condition, satisfies (UI1) and (UI2).
Let us now see that
 $ c_{\mathbf{n},j} $
satisfies the condition (4.1) in both the Gaussian and the symmetric stable case. For
$ c_{\mathbf{n},j} $
satisfies the condition (4.1) in both the Gaussian and the symmetric stable case. For
 $ \ell=3 $
,
$ \ell=3 $
,
 $ c_{\mathbf{n},j} = \phi(Y^{(1)}_{j}) $
satisfies (4.1) by the strong law of large numbers since
$ c_{\mathbf{n},j} = \phi(Y^{(1)}_{j}) $
satisfies (4.1) by the strong law of large numbers since
 $ |\phi(Y^{(1)}_{j})|^{\alpha_{2}+\epsilon_{0}} $
is integrable. For
$ |\phi(Y^{(1)}_{j})|^{\alpha_{2}+\epsilon_{0}} $
is integrable. For
 $ \ell > 3 $
, an inductive argument shows that the family
$ \ell > 3 $
, an inductive argument shows that the family
 $ \{ |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1} + \epsilon_{0}} \}_{\mathbf{n}} $
is uniformly integrable, which leads to (4.1). The details of this inductive argument are contained in the following proof.
$ \{ |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1} + \epsilon_{0}} \}_{\mathbf{n}} $
is uniformly integrable, which leads to (4.1). The details of this inductive argument are contained in the following proof.
Proof of Theorem 3.1 under (UI1) and (UI2). We return to the claim in (3.10) to see how the conditions (UI1) and (UI2) are sufficient, even when
 $\phi$
is unbounded. We continue to let
$\phi$
is unbounded. We continue to let
 $n\;:\!=\;n_{\ell-2}$
. Choose a sequence
$n\;:\!=\;n_{\ell-2}$
. Choose a sequence
 $\{(n,\mathbf{n})\}_n$
, where
$\{(n,\mathbf{n})\}_n$
, where
 $\mathbf{n}=\mathbf{n}(n)$
depends on n and
$\mathbf{n}=\mathbf{n}(n)$
depends on n and
 $\mathbf{n}\to\infty$
as
$\mathbf{n}\to\infty$
as
 $n\to\infty$
in the sense of (2.3). Note that (i) to evaluate the limit as
$n\to\infty$
in the sense of (2.3). Note that (i) to evaluate the limit as
 $\mathbf{n} \to \infty$
, it suffices to show that the limit exists consistently for any choice of sequence
$\mathbf{n} \to \infty$
, it suffices to show that the limit exists consistently for any choice of sequence
 $\{\mathbf{n}(n)\}_n$
that goes to infinity, and (ii) we can always pass to a subsequence (not depending on
$\{\mathbf{n}(n)\}_n$
that goes to infinity, and (ii) we can always pass to a subsequence (not depending on
 $\omega$
), since we are concerned with convergence in probability. Therefore, below we will show almost sure uniform integrability over some infinite subset of an arbitrary index set of the form
$\omega$
), since we are concerned with convergence in probability. Therefore, below we will show almost sure uniform integrability over some infinite subset of an arbitrary index set of the form
 $\{(n,\mathbf{n}(n)): n \in \mathbb{N}\}$
.
$\{(n,\mathbf{n}(n)): n \in \mathbb{N}\}$
.
Let
 $a_n\;:\!=\;a_{n_{\ell-2}}(\ell-1)$
. Proceeding as in (3.11) and (3.12), we need to show that the family
$a_n\;:\!=\;a_{n_{\ell-2}}(\ell-1)$
. Proceeding as in (3.11) and (3.12), we need to show that the family
 $ |\phi(y_{\mathbf{n}})|^{\alpha+\epsilon} $
where
$ |\phi(y_{\mathbf{n}})|^{\alpha+\epsilon} $
where
 $ y_{\mathbf{n}} \sim \xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) $
is uniformly integrable. Since
$ y_{\mathbf{n}} \sim \xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) $
is uniformly integrable. Since
 $\{ a_{n}^{-1}\sum_{j} \phi(Y^{(\ell-2)}_{j}) W^{(\ell-1)}_{ij} \}_i$
is conditionally i.i.d. given
$\{ a_{n}^{-1}\sum_{j} \phi(Y^{(\ell-2)}_{j}) W^{(\ell-1)}_{ij} \}_i$
is conditionally i.i.d. given
 $ \{Y^{(\ell-2)}_{j}\}_{j} $
, the random distribution
$ \{Y^{(\ell-2)}_{j}\}_{j} $
, the random distribution
 $ \xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) $
is the law of
$ \xi^{(\ell-1)}(dy,\omega;\;\;\mathbf{n}) $
is the law of
 $ a_{n}^{-1}\sum_{j} \phi(Y^{(\ell-2)}_{j}) W^{(\ell-1)}_{ij} $
given
$ a_{n}^{-1}\sum_{j} \phi(Y^{(\ell-2)}_{j}) W^{(\ell-1)}_{ij} $
given
 $ \{Y^{(\ell-2)}_{j}\}_{j} $
, by the uniqueness of the directing random measure (see [Reference Kallenberg20, Proposition 1.4]). Thus, by (UI2), it suffices to check that
$ \{Y^{(\ell-2)}_{j}\}_{j} $
, by the uniqueness of the directing random measure (see [Reference Kallenberg20, Proposition 1.4]). Thus, by (UI2), it suffices to check that
 $ n^{-1}\sum_{j} |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1}+\epsilon_{0}} $
is uniformly bounded for
$ n^{-1}\sum_{j} |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1}+\epsilon_{0}} $
is uniformly bounded for
 $ \ell=3,\ldots,\ell_{\text{lay}}+1 $
. For
$ \ell=3,\ldots,\ell_{\text{lay}}+1 $
. For
 $ \ell=3 $
, since
$ \ell=3 $
, since
 $ |\phi(Y^{(1)}_{j})|^{\alpha_{2}+\epsilon_{0}} $
is integrable by (UI1),
$ |\phi(Y^{(1)}_{j})|^{\alpha_{2}+\epsilon_{0}} $
is integrable by (UI1),
 \[ \lim_{n\to \infty} \frac{1}{n} \sum_{j=1}^{n} |\phi(Y^{(1)}_{j})|^{\alpha_{2}+\epsilon_{0}} < \infty \]
\[ \lim_{n\to \infty} \frac{1}{n} \sum_{j=1}^{n} |\phi(Y^{(1)}_{j})|^{\alpha_{2}+\epsilon_{0}} < \infty \]
by the strong law of large numbers, and hence the normalized sums are almost surely bounded. For
 $ \ell > 3 $
, we proceed inductively. By the inductive hypothesis, we have
$ \ell > 3 $
, we proceed inductively. By the inductive hypothesis, we have
 \begin{align*} \underset{\mathbf{n}}{\sup}\frac{1}{n_{\ell-3}} \sum_{j=1}^{n_{\ell-3}} |\phi(Y^{(\ell-3)}_{j})|^{(\alpha_{\ell-2}+\epsilon_{0})(1+\epsilon')} < \infty\end{align*}
\begin{align*} \underset{\mathbf{n}}{\sup}\frac{1}{n_{\ell-3}} \sum_{j=1}^{n_{\ell-3}} |\phi(Y^{(\ell-3)}_{j})|^{(\alpha_{\ell-2}+\epsilon_{0})(1+\epsilon')} < \infty\end{align*}
by adjusting
 $\epsilon_0, \epsilon'>0$
appropriately. By (UI2), we have that the family
$\epsilon_0, \epsilon'>0$
appropriately. By (UI2), we have that the family
 \begin{align*}\{|\phi(y_{\mathbf{n}})|^{(\alpha_{\ell-1}+\epsilon_0)(1+\epsilon'')} :\;\; y_{\mathbf{n}} \sim \xi^{(\ell-2)}(dy;\;\;\mathbf{n})\}\end{align*}
\begin{align*}\{|\phi(y_{\mathbf{n}})|^{(\alpha_{\ell-1}+\epsilon_0)(1+\epsilon'')} :\;\; y_{\mathbf{n}} \sim \xi^{(\ell-2)}(dy;\;\;\mathbf{n})\}\end{align*}
is almost surely uniformly integrable for some
 $\epsilon''>0$
. Since the
$\epsilon''>0$
. Since the
 $Y_j^{(\ell-2)}$
are conditionally i.i.d. with common distribution
$Y_j^{(\ell-2)}$
are conditionally i.i.d. with common distribution
 $\xi^{(\ell-2)}(dy;\;\;\mathbf{n})$
given
$\xi^{(\ell-2)}(dy;\;\;\mathbf{n})$
given
 $\xi^{(\ell-2)}(dy,\omega;\;\;\mathbf{n})$
, by Lemma A.6 we have that
$\xi^{(\ell-2)}(dy,\omega;\;\;\mathbf{n})$
, by Lemma A.6 we have that
 \begin{align*} & \mathbb{P} \Bigg( \Bigg| \frac{1}{n} \sum_{j=1}^{n} |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1}+\epsilon_{0}} - \int |\phi(y)|^{\alpha_{\ell-1}+\epsilon_0} \xi^{(\ell-2)} (dy;\;\;\mathbf{n}) \Big| \geq \delta \ \Big| \ \xi^{(\ell-2)}\Bigg) \to 0 \end{align*}
\begin{align*} & \mathbb{P} \Bigg( \Bigg| \frac{1}{n} \sum_{j=1}^{n} |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1}+\epsilon_{0}} - \int |\phi(y)|^{\alpha_{\ell-1}+\epsilon_0} \xi^{(\ell-2)} (dy;\;\;\mathbf{n}) \Big| \geq \delta \ \Big| \ \xi^{(\ell-2)}\Bigg) \to 0 \end{align*}
almost surely. By the dominated convergence theorem we can take expectations on both sides to conclude that
 \begin{align*} \Big| \frac{1}{n} \sum_{j=1}^{n} |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1}+\epsilon_{0}} - \int |\phi(y)|^{\alpha_{\ell-1}+\epsilon_0} \xi^{(\ell-2)} (dy;\;\;\mathbf{n}) \Big| \to 0\end{align*}
\begin{align*} \Big| \frac{1}{n} \sum_{j=1}^{n} |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1}+\epsilon_{0}} - \int |\phi(y)|^{\alpha_{\ell-1}+\epsilon_0} \xi^{(\ell-2)} (dy;\;\;\mathbf{n}) \Big| \to 0\end{align*}
in probability, so by passing to a subsequence we have that the convergence holds for almost every
 $\omega$
. Since
$\omega$
. Since
 \begin{align*} \underset{\mathbf{n}}{\sup}\int |\phi(y)|^{\alpha_{\ell-1}+\epsilon_0} \xi^{(\ell-2)} (dy;\;\;\mathbf{n}) < \infty\end{align*}
\begin{align*} \underset{\mathbf{n}}{\sup}\int |\phi(y)|^{\alpha_{\ell-1}+\epsilon_0} \xi^{(\ell-2)} (dy;\;\;\mathbf{n}) < \infty\end{align*}
almost surely, we have also that
 \begin{align*} \underset{\mathbf{n}}{\sup} \frac{1}{n} \sum_{j=1}^{n} |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1}+\epsilon_{0}} < \infty\end{align*}
\begin{align*} \underset{\mathbf{n}}{\sup} \frac{1}{n} \sum_{j=1}^{n} |\phi(Y^{(\ell-2)}_{j})|^{\alpha_{\ell-1}+\epsilon_{0}} < \infty\end{align*}
almost surely, proving our claim.
5. Joint convergence with different inputs
In this section, we extend Theorem 3.1 to the joint distribution of k different inputs. We show that the k -dimensional vector
 $ (Y^{(\ell)}_{i}(\mathbf{x}_{1}\!;\mathbf{n}), \ldots, Y^{(\ell)}_{i}(\mathbf{x}_{k};\;\;\mathbf{n})) $
converges, and we represent the limiting characteristic function via a finite measure
$ (Y^{(\ell)}_{i}(\mathbf{x}_{1}\!;\mathbf{n}), \ldots, Y^{(\ell)}_{i}(\mathbf{x}_{k};\;\;\mathbf{n})) $
converges, and we represent the limiting characteristic function via a finite measure
 $ \Gamma_{\ell}$
on the unit sphere
$ \Gamma_{\ell}$
on the unit sphere
 $S_{k-1} = \{x \in \mathbb{R}^k : |x| = 1\}$
, called the spectral measure. This extension to k inputs is needed for our convergence result to be applied in practice, since practical applications involve multiple inputs: a network is trained on a set of input–output pairs, and the trained network is then used to predict the output of a new unseen input. For instance, as suggested in the work on infinitely wide networks with Gaussian initialization [Reference Lee24, Reference Lee25], such an extension is needed to perform Bayesian posterior inference and prediction with heavy-/light-tailed infinitely wide MLPs, where the limiting process in the multi-input extension is conditioned on
$S_{k-1} = \{x \in \mathbb{R}^k : |x| = 1\}$
, called the spectral measure. This extension to k inputs is needed for our convergence result to be applied in practice, since practical applications involve multiple inputs: a network is trained on a set of input–output pairs, and the trained network is then used to predict the output of a new unseen input. For instance, as suggested in the work on infinitely wide networks with Gaussian initialization [Reference Lee24, Reference Lee25], such an extension is needed to perform Bayesian posterior inference and prediction with heavy-/light-tailed infinitely wide MLPs, where the limiting process in the multi-input extension is conditioned on
 $k_0$
input–output pairs, with
$k_0$
input–output pairs, with
 $k_0 < k$
, and then the resulting conditional or posterior distribution of the process is used to predict the outputs of the process for
$k_0 < k$
, and then the resulting conditional or posterior distribution of the process is used to predict the outputs of the process for
 $k-k_0$
inputs.
$k-k_0$
inputs.
For simplicity, we use the following notation:
-
$\vec{\mathbf{x}}= (\mathbf{x}_{1}, \ldots, \mathbf{x}_{k}) $
where
$ \mathbf{x}_{j} \in \mathbb{R}^{I} $
.
-
$ \mathbf{1} = (1,\ldots,1) \in \mathbb{R}^{k} $
.
-
$ \mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}) = (Y^{(\ell)}_{i}(\mathbf{x}_{1};\;\;\mathbf{n}), \ldots, Y^{(\ell)}_{i}(\mathbf{x}_{k};\;\;\mathbf{n})) \in \mathbb{R}^{k} $
, for
$i\in\mathbb{N}$
.
-
$ \phi(\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n})) = (\phi(Y^{(\ell)}_{i}(\mathbf{x}_{1};\;\;\mathbf{n})), \ldots, \phi(Y^{(\ell)}_{i}(\mathbf{x}_{k};\;\;\mathbf{n}))) \in \mathbb{R}^{k} $
.
-
$ \langle \cdot,\cdot \rangle $
denotes the standard inner product in
$ \mathbb{R}^{k} $
.
-
For any given j, let the law of the k -dimensional vector
$ \mathbf{Y}^{(\ell)}_{j}(\vec{\mathbf{x}} ) $
be denoted by
$ \nu^{(\ell)}_{k} $
(which does not depend on j). Its projection onto the s th component
$Y^{(\ell)}_{i}(\mathbf{x}_{s};\;\;\mathbf{n})$
is denoted by
$ \nu^{(\ell)}_{k,s} $
for
$1\le s\le k$
, and the projection onto two coordinates, the ith and jth, is denoted by
$\nu^{(\ell)}_{k,ij}$
. The limiting distribution of
$\mathbf{Y}^{(\ell)}_{j}(\vec{\mathbf{x}} )$
is denoted by
$\mu_k^{(\ell)}$
, and the projections are similarly denoted by
$\mu_{k,s}^{(\ell)}$
and
$\mu_{k, ij}^{(\ell)}.$
-
A centered k-dimensional multivariate Gaussian with covariance matrix M is denoted by
$\mathcal{N}_k(M).$
-
For
$\alpha<2$
, we denote the k -dimensional S
$\alpha$
S distribution with spectral measure
$ \Gamma $
by
$ \text{S}_\alpha\text{S}_{k}(\Gamma)$
. For those not familiar with the spectral measure of a multivariate stable law, Appendix C provides background.























Recall that
 \begin{align*}c_\alpha= \lim_{M \to \infty}\int_0^M \frac{\sin u}{u^\alpha} du \quad \text{ and }\quad \ c_2 = 1.\end{align*}
\begin{align*}c_\alpha= \lim_{M \to \infty}\int_0^M \frac{\sin u}{u^\alpha} du \quad \text{ and }\quad \ c_2 = 1.\end{align*}
Theorem 5.1.
Let
 $(Y^{(\ell)}_i({}\cdot {};\;\;\mathbf{n}))_{i \ge 1}$
be defined as in Section 2, and
$(Y^{(\ell)}_i({}\cdot {};\;\;\mathbf{n}))_{i \ge 1}$
be defined as in Section 2, and
 $ (\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}))_{i\ge 1} $
as above. Then, for each
$ (\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}))_{i\ge 1} $
as above. Then, for each
 $ \ell = 2,\ldots,\ell_{\text{lay}}+1 $
, the joint distribution of the random variables
$ \ell = 2,\ldots,\ell_{\text{lay}}+1 $
, the joint distribution of the random variables
 $ (\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}))_{i\ge 1} $
converges weakly to
$ (\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}))_{i\ge 1} $
converges weakly to
 $\mu_k^{(\ell)}$
as given below:
$\mu_k^{(\ell)}$
as given below:
-
For
$\alpha_{\ell}<2$
,
$\mu_k^{(\ell)}=\bigotimes_{i\ge 1} \text{S}\alpha_{\ell}\text{S}_{k}(\Gamma_{\ell}) $
, where
$\Gamma_\ell$
is defined by (5.1)and
\begin{align} \Gamma_{2} = \left\lVert\sigma_{B^{(2)}}\mathbf{1}\right\rVert^{\alpha_{2}} \delta_{\frac{\mathbf{1}}{\left\lVert\mathbf{1}\right\rVert}} + c_{\alpha_{2}}\int \left\lVert\phi(\mathbf{y}) \right\rVert^{\alpha_{2}} \, \delta_{\frac{\phi(\mathbf{y})}{\left\lVert\phi(\mathbf{y})\right\rVert}} \, \nu^{(1)}_{k}(d\mathbf{y}) \end{align}
(5.2)for
\begin{align} \Gamma_{\ell} = \left\lVert\sigma_{B^{(\ell)}}\mathbf{1}\right\rVert^{\alpha_{\ell}} \delta_{\frac{\mathbf{1}}{\left\lVert\mathbf{1}\right\rVert}} + c_{\alpha_{\ell}} \int \left\lVert\phi(\mathbf{y}) \right\rVert^{\alpha_{\ell}} \, \delta_{\frac{\phi(\mathbf{y})}{\left\lVert\phi(\mathbf{y})\right\rVert}} \, \mu_k^{(\ell-1)}(d\mathbf{y}) \end{align}
$\ell>2$
.
-
For
$\alpha_{\ell}=2$
,
$\mu_k^{(\ell)}=\bigotimes_{i\ge 1} \mathcal{N}_k(M_\ell)$
, where (5.3)and
\begin{align} & (M_2)_{ii}= \mathbb{E} |B_i^{(2)}|^2+\frac{1}{2} \int |\phi(y)|^2 \, \nu_{k,i}^{(1)}(dy), \\ & (M_2)_{ij}= \frac{1}{2} \int \phi(y_1)\phi(y_2) \, \nu_{k,ij}^{(1)}(dy_1dy_2), \nonumber \end{align}
(5.4)for
\begin{align} & (M_\ell)_{ii}= \mathbb{E} |B_i^{(\ell)}|^2+\frac{1}{2} \int |\phi(y)|^2 \, \mu_{k,i}^{(\ell-1)}(dy), \\ & (M_\ell)_{ij}= \frac{1}{2} \int \phi(y_1)\phi(y_2) \, \mu_{k,ij}^{(\ell-1)}(dy_1dy_2) \nonumber \end{align}
$\ell>2$
.











As mentioned below the statement of Theorem 3.1, this theorem finally shows that the individual layers of an MLP initialized with arbitrary heavy-/light-tailed weights have a limit, as the width tends to infinity, which is a stable process in the parameter
 $\mathbf{x}$
.
$\mathbf{x}$
.
Proof. Let
 $ \mathbf{t} = (t_{1}, \ldots, t_{k}) $
. We again start with the expression
$ \mathbf{t} = (t_{1}, \ldots, t_{k}) $
. We again start with the expression
 \begin{align} & \psi_{\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}} ) | \{ \mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} ) \}_{j\ge1}}(\mathbf{t}) \\ &\qquad {} = \mathbb{E}\left[\left. e^{i\langle \mathbf{t}, \mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}} ) \rangle} \right| \{ \mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} ) \}_{j\ge1} \right] \nonumber \\ &\qquad {} = \mathbb{E}\left[\left. \exp\left({i\left\langle \mathbf{t}, \frac{1}{a_{n}} \sum_{j=1}^{n} W^{(\ell)}_{ij} \phi(\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} )) + B^{(\ell)}_{i} \mathbf{1} \right\rangle}\right) \right| \{ \mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} ) \}_{j\ge1} \right] \nonumber \\ &\qquad {} = \mathbb{E} e^{iB^{(\ell)}_{i} \langle \mathbf{t}, \mathbf{1} \rangle} \prod_{j=1}^{n} \mathbb{E}\left[\left. \exp\left({i\frac{1}{a_{n}}W^{(\ell)}_{ij}\left\langle \mathbf{t}, \phi(\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} )) \right\rangle}\right) \right| \{ \mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} ) \}_{j\ge1} \right] \nonumber \\ &\qquad {} = \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle)\left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} )) \rangle \right)\right)^{n}. \nonumber \end{align}
\begin{align} & \psi_{\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}} ) | \{ \mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} ) \}_{j\ge1}}(\mathbf{t}) \\ &\qquad {} = \mathbb{E}\left[\left. e^{i\langle \mathbf{t}, \mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}} ) \rangle} \right| \{ \mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} ) \}_{j\ge1} \right] \nonumber \\ &\qquad {} = \mathbb{E}\left[\left. \exp\left({i\left\langle \mathbf{t}, \frac{1}{a_{n}} \sum_{j=1}^{n} W^{(\ell)}_{ij} \phi(\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} )) + B^{(\ell)}_{i} \mathbf{1} \right\rangle}\right) \right| \{ \mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} ) \}_{j\ge1} \right] \nonumber \\ &\qquad {} = \mathbb{E} e^{iB^{(\ell)}_{i} \langle \mathbf{t}, \mathbf{1} \rangle} \prod_{j=1}^{n} \mathbb{E}\left[\left. \exp\left({i\frac{1}{a_{n}}W^{(\ell)}_{ij}\left\langle \mathbf{t}, \phi(\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} )) \right\rangle}\right) \right| \{ \mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} ) \}_{j\ge1} \right] \nonumber \\ &\qquad {} = \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle)\left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} )) \rangle \right)\right)^{n}. \nonumber \end{align}
Here
 $\psi_B$
and
$\psi_B$
and
 $\psi_W$
are characteristic functions of the random variables
$\psi_W$
are characteristic functions of the random variables
 $B_i^{(\ell)}$
and
$B_i^{(\ell)}$
and
 $W^{(\ell)}_{ij}$
for some/any i,j.
$W^{(\ell)}_{ij}$
for some/any i,j.
Case
 $\ell=2$
:
$\ell=2$
:
As before, let
 $n=n_1$
,
$n=n_1$
,
 $\alpha=\alpha_2$
, and
$\alpha=\alpha_2$
, and
 $a_n=a_{n_1}(2)$
. As in Theorem 3.1,
$a_n=a_{n_1}(2)$
. As in Theorem 3.1,
 $ (\mathbf{Y}^{(1)}_{j}(\vec{\mathbf{x}} ))_{j \ge 1} $
is i.i.d, and thus
$ (\mathbf{Y}^{(1)}_{j}(\vec{\mathbf{x}} ))_{j \ge 1} $
is i.i.d, and thus
 \begin{align*} \psi_{\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}} )}(\mathbf{t}) &= \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \mathbb{E} \left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} )) \rangle \right)\right)^{n} \\ &= \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \int \left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right)\right)^{n} \, \nu^{(1)}_{k}(d\mathbf{y}). \end{align*}
\begin{align*} \psi_{\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}} )}(\mathbf{t}) &= \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \mathbb{E} \left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}} )) \rangle \right)\right)^{n} \\ &= \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \int \left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right)\right)^{n} \, \nu^{(1)}_{k}(d\mathbf{y}). \end{align*}
As before,
 \begin{align*} &\left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right)\right)^{n} \\ &\qquad = \left(1 - c_{\alpha} \frac{b_{n}}{n} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} + o\left( \frac{b_{n}}{n} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} \right) \right)^{n} . \end{align*}
\begin{align*} &\left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right)\right)^{n} \\ &\qquad = \left(1 - c_{\alpha} \frac{b_{n}}{n} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} + o\left( \frac{b_{n}}{n} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} \right) \right)^{n} . \end{align*}
The main calculation needed to extend the proof of Theorem 3.1 to the situation involving
 $\vec{\mathbf{x}}$
is as follows. Assuming the uniform integrability in Section 4, we have, for some
$\vec{\mathbf{x}}$
is as follows. Assuming the uniform integrability in Section 4, we have, for some
 $b > 0$
and
$b > 0$
and
 $0<\epsilon<\epsilon_{0}$
,
$0<\epsilon<\epsilon_{0}$
,
 \begin{align} \int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} \, \nu^{(1)}_{k}(d\mathbf{y}) &{} \leq b \int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right|^{\alpha \pm \epsilon} \, \nu^{(1)}_{k}(d\mathbf{y}) \\ \nonumber &{} =\int b \left| \sum_{s=1}^{k} t_{s} \phi(y_{s}) \right|^{\alpha \pm \epsilon} \, \nu^{(1)}_{k}(d\mathbf{y}) \\ \nonumber &{} \le \int b c_{k} \sum_{s=1}^{k} |t_{s} \phi(y_{s})|^{\alpha \pm \epsilon} \, \nu^{(1)}_{k}(d\mathbf{y}) \\ \nonumber &{} = b c_{k} \sum_{s=1}^{k} \int |t_{s} \phi(y_{s})|^{\alpha \pm \epsilon} \, \nu^{(1)}_{k,s}(dy) < \infty . \end{align}
\begin{align} \int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} \, \nu^{(1)}_{k}(d\mathbf{y}) &{} \leq b \int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right|^{\alpha \pm \epsilon} \, \nu^{(1)}_{k}(d\mathbf{y}) \\ \nonumber &{} =\int b \left| \sum_{s=1}^{k} t_{s} \phi(y_{s}) \right|^{\alpha \pm \epsilon} \, \nu^{(1)}_{k}(d\mathbf{y}) \\ \nonumber &{} \le \int b c_{k} \sum_{s=1}^{k} |t_{s} \phi(y_{s})|^{\alpha \pm \epsilon} \, \nu^{(1)}_{k}(d\mathbf{y}) \\ \nonumber &{} = b c_{k} \sum_{s=1}^{k} \int |t_{s} \phi(y_{s})|^{\alpha \pm \epsilon} \, \nu^{(1)}_{k,s}(dy) < \infty . \end{align}
It thus follows that
 \begin{align*} &\int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} \, \nu^{(1)}_{k}(d\mathbf{y}) \to \int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \, \nu^{(1)}_{k}(d\mathbf{y}) ,\quad\text{and} \\ &\int o\left(\frac{b_{n}}{n} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})}\right) \, \nu^{(1)}_{k}(d\mathbf{y}) = o\left(\frac{b_{n}}{n}\right) . \end{align*}
\begin{align*} &\int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} \, \nu^{(1)}_{k}(d\mathbf{y}) \to \int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \, \nu^{(1)}_{k}(d\mathbf{y}) ,\quad\text{and} \\ &\int o\left(\frac{b_{n}}{n} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})}\right) \, \nu^{(1)}_{k}(d\mathbf{y}) = o\left(\frac{b_{n}}{n}\right) . \end{align*}
Therefore,
 \begin{align} \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \mathbb{E} \left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right)\right)^{n} \to \exp\left( -\sigma_{B}^{\alpha} | \langle \mathbf{t}, \mathbf{1} \rangle |^{\alpha} \right) \exp\left( -c_{\alpha} \int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \, \nu^{(1)}_{k}(d\mathbf{y}) \right) . \end{align}
\begin{align} \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \mathbb{E} \left(\psi_{W}\left( \frac{1}{a_{n}} \langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right)\right)^{n} \to \exp\left( -\sigma_{B}^{\alpha} | \langle \mathbf{t}, \mathbf{1} \rangle |^{\alpha} \right) \exp\left( -c_{\alpha} \int \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \, \nu^{(1)}_{k}(d\mathbf{y}) \right) . \end{align}
Let
 $\left\lVert\cdot\right\rVert$
denote the standard Euclidean norm. Observe that for
$\left\lVert\cdot\right\rVert$
denote the standard Euclidean norm. Observe that for
 $\alpha<2$
,
$\alpha<2$
,
 \begin{align*} c_{\alpha} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} = c_{\alpha} \int_{S^{k-1}} |\langle \mathbf{t}, \mathbf{s} \rangle|^{\alpha} \left\lVert\phi(\mathbf{y}) \right\rVert^{\alpha} \, \delta_{\frac{\phi(\mathbf{y})}{\left\lVert\phi(\mathbf{y})\right\rVert}}(d\mathbf{s}) . \end{align*}
\begin{align*} c_{\alpha} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} = c_{\alpha} \int_{S^{k-1}} |\langle \mathbf{t}, \mathbf{s} \rangle|^{\alpha} \left\lVert\phi(\mathbf{y}) \right\rVert^{\alpha} \, \delta_{\frac{\phi(\mathbf{y})}{\left\lVert\phi(\mathbf{y})\right\rVert}}(d\mathbf{s}) . \end{align*}
Thus, by Theorem C.1, we have the convergence
 $ \mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}) \stackrel{w}{\to} \text{S}_\alpha \text{S}_{k}(\Gamma_{2}) $
where
$ \mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}) \stackrel{w}{\to} \text{S}_\alpha \text{S}_{k}(\Gamma_{2}) $
where
 $\Gamma_2$
is defined by (5.1).
$\Gamma_2$
is defined by (5.1).
For
 $\alpha=2$
, we have
$\alpha=2$
, we have
 \begin{align*} \exp \Big(-c_\alpha \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^2 \nu_k^{(1)}(d \mathbf{y}) \Big) = \exp ( -\frac{1}{2} \langle \mathbf{t}, M_2\mathbf{t} \rangle)\end{align*}
\begin{align*} \exp \Big(-c_\alpha \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^2 \nu_k^{(1)}(d \mathbf{y}) \Big) = \exp ( -\frac{1}{2} \langle \mathbf{t}, M_2\mathbf{t} \rangle)\end{align*}
where
 $M_2$
is given by (5.3), which is equal to the characteristic function of
$M_2$
is given by (5.3), which is equal to the characteristic function of
 $\mathcal{N}(M_2)$
.
$\mathcal{N}(M_2)$
.
Extending the calculations in (3.7), the convergence
 $ (\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}))_{i\ge 1} \stackrel{w}{\to} \bigotimes_{i\ge 1} \text{S}_\alpha \text{S}_{k}(\Gamma_{2}) $
follows similarly.
$ (\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}))_{i\ge 1} \stackrel{w}{\to} \bigotimes_{i\ge 1} \text{S}_\alpha \text{S}_{k}(\Gamma_{2}) $
follows similarly.
Case
 $\ell>2$
:
$\ell>2$
:
Similarly to (3.8), let
 $\xi^{(\ell-1)}(d\mathbf{y},\omega)$
be a random distribution such that, given
$\xi^{(\ell-1)}(d\mathbf{y},\omega)$
be a random distribution such that, given
 $\xi^{(\ell-1)}$
, the random vectors
$\xi^{(\ell-1)}$
, the random vectors
 $\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}})$
,
$\mathbf{Y}^{(\ell-1)}_{j}(\vec{\mathbf{x}})$
,
 $j=1,2,\ldots $
, are i.i.d. with distribution
$j=1,2,\ldots $
, are i.i.d. with distribution
 $ \xi^{(\ell-1)}(d\mathbf{y})$
.
$ \xi^{(\ell-1)}(d\mathbf{y})$
.
Taking the conditional expectation of (5.5) given
 $ \xi^{(\ell-1)} $
, we get
$ \xi^{(\ell-1)} $
, we get
 \begin{align*} \psi_{\mathbf{Y}^{(\ell)}_i|\xi^{(\ell-1)}} (\mathbf{t}) = \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \mathbb{E}\left[\left. \left( \int \psi_{W}\left( \frac{1}{a_{n}}\langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right) \xi^{(\ell-1)}(d\mathbf{y}) \right)^{n} \,\right|\, \xi^{(\ell-1)} \right] \end{align*}
\begin{align*} \psi_{\mathbf{Y}^{(\ell)}_i|\xi^{(\ell-1)}} (\mathbf{t}) = \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \mathbb{E}\left[\left. \left( \int \psi_{W}\left( \frac{1}{a_{n}}\langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right) \xi^{(\ell-1)}(d\mathbf{y}) \right)^{n} \,\right|\, \xi^{(\ell-1)} \right] \end{align*}
for any i. Here,
 \begin{align*} \int \psi_{W}\left( \frac{1}{a_{n}}\langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right) \xi^{(\ell-1)}(d\mathbf{y}) \sim 1 - c_{\alpha} \frac{b_{n}}{n} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \xi^{(\ell-1)}(d\mathbf{y}) . \end{align*}
\begin{align*} \int \psi_{W}\left( \frac{1}{a_{n}}\langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right) \xi^{(\ell-1)}(d\mathbf{y}) \sim 1 - c_{\alpha} \frac{b_{n}}{n} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \xi^{(\ell-1)}(d\mathbf{y}) . \end{align*}
From the induction hypothesis,
 $ (\mathbf{Y}^{(\ell-1)}_{i}(\vec{\mathbf{x}}))_{i\ge1} $
converges weakly either to
$ (\mathbf{Y}^{(\ell-1)}_{i}(\vec{\mathbf{x}}))_{i\ge1} $
converges weakly either to
 $ \bigotimes_{i\ge1} \text{S}_\alpha \text{S}(\Gamma_{\ell-1}) $
or to
$ \bigotimes_{i\ge1} \text{S}_\alpha \text{S}(\Gamma_{\ell-1}) $
or to
 $ \bigotimes_{i\ge1} \mathcal{N}_k(M_\ell) $
. We claim that
$ \bigotimes_{i\ge1} \mathcal{N}_k(M_\ell) $
. We claim that
 \begin{align*} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \xi^{(\ell-1)}(d\mathbf{y}) \stackrel{p}{\to} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) . \end{align*}
\begin{align*} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \xi^{(\ell-1)}(d\mathbf{y}) \stackrel{p}{\to} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) . \end{align*}
To see this, note that
 \begin{align} &\left| \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \xi^{(\ell-1)}(d\mathbf{y}) - \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right| \\ &\qquad \le \left| \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \xi^{(\ell-1)}(d\mathbf{y}) - \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \mu_k^{(\ell-1)}(d\mathbf{y}) \right| \nonumber \\ &\qquad +\left| \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \mu_k^{(\ell-1)}(d\mathbf{y}) - \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right| . \nonumber \end{align}
\begin{align} &\left| \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \xi^{(\ell-1)}(d\mathbf{y}) - \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right| \\ &\qquad \le \left| \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \xi^{(\ell-1)}(d\mathbf{y}) - \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \mu_k^{(\ell-1)}(d\mathbf{y}) \right| \nonumber \\ &\qquad +\left| \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \frac{L_0(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|})}{L_0(a_{n})} \mu_k^{(\ell-1)}(d\mathbf{y}) - \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right| . \nonumber \end{align}
Now, the uniform integrability assumption in Section 4 combined with (5.6) shows that
 \begin{align*} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} \end{align*}
\begin{align*} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} \end{align*}
is uniformly integrable with respect to the family
 $ (\xi^{(\ell-1)})_{n} $
, and thus the first term on the right-hand side of (5.8) converges in probability to 0. Also, from (5.6) and the fact that
$ (\xi^{(\ell-1)})_{n} $
, and thus the first term on the right-hand side of (5.8) converges in probability to 0. Also, from (5.6) and the fact that
 \begin{align*} \lim_{n\to \infty} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} = \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \end{align*}
\begin{align*} \lim_{n\to \infty} \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \frac{L_0\left(\frac{a_{n}}{|\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|} \right)}{L_0(a_{n})} = \left| \langle \mathbf{t}, \phi(\mathbf{y}) \rangle\right|^{\alpha} \end{align*}
for each
 $ \mathbf{y} $
, dominated convergence gives us convergence to 0 of the second term. Therefore,
$ \mathbf{y} $
, dominated convergence gives us convergence to 0 of the second term. Therefore,
 \begin{align*} \left( \int \psi_{W}\left( \frac{1}{a_{n}}\langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right) \xi^{(\ell-1)}(d\mathbf{y}) \right)^{n} \stackrel{p}{\to} \exp\left( -c_{\alpha} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right), \end{align*}
\begin{align*} \left( \int \psi_{W}\left( \frac{1}{a_{n}}\langle \mathbf{t}, \phi(\mathbf{y}) \rangle \right) \xi^{(\ell-1)}(d\mathbf{y}) \right)^{n} \stackrel{p}{\to} \exp\left( -c_{\alpha} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right), \end{align*}
and consequently,
 \begin{align*} \psi_{\mathbf{Y}^{(\ell)}_i|\xi^{(\ell-1)}} (\mathbf{t}) \stackrel{p}{\to} \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \exp\left( -c_{\alpha} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right) . \end{align*}
\begin{align*} \psi_{\mathbf{Y}^{(\ell)}_i|\xi^{(\ell-1)}} (\mathbf{t}) \stackrel{p}{\to} \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \exp\left( -c_{\alpha} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right) . \end{align*}
Finally, noting that the characteristic function is bounded by 1 and using dominated convergence, we get
 \begin{align*} \psi_{\mathbf{Y}^{(\ell)}_i} (\mathbf{t}) \stackrel{p}{\to} \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \exp\left( -c_{\alpha} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right), \end{align*}
\begin{align*} \psi_{\mathbf{Y}^{(\ell)}_i} (\mathbf{t}) \stackrel{p}{\to} \psi_{B}(\langle \mathbf{t}, \mathbf{1} \rangle) \exp\left( -c_{\alpha} \int |\langle \mathbf{t}, \phi(\mathbf{y}) \rangle|^{\alpha} \mu_k^{(\ell-1)}(d\mathbf{y}) \right), \end{align*}
where the right-hand side is the characteristic function of
 $\text{S}_\alpha \text{S}_{k}(\Gamma_{\ell}) $
(or
$\text{S}_\alpha \text{S}_{k}(\Gamma_{\ell}) $
(or
 $\mathcal{N}_k(M_\ell)$
for
$\mathcal{N}_k(M_\ell)$
for
 $\alpha=2$
), with
$\alpha=2$
), with
 $\Gamma_\ell$
and
$\Gamma_\ell$
and
 $M_\ell$
given by (5.2) and (5.4), respectively.
$M_\ell$
given by (5.2) and (5.4), respectively.
The proof of
 $ (\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}))_{i\ge1} \stackrel{w}{\to} \bigotimes_{i\ge1} \text{S}_\alpha \text{S}_{k}(\Gamma_{\ell}) $
(or
$ (\mathbf{Y}^{(\ell)}_{i}(\vec{\mathbf{x}};\;\;\mathbf{n}))_{i\ge1} \stackrel{w}{\to} \bigotimes_{i\ge1} \text{S}_\alpha \text{S}_{k}(\Gamma_{\ell}) $
(or
 $\bigotimes_{i\ge 1} \mathcal{N}_k(M_\ell)$
in the case
$\bigotimes_{i\ge 1} \mathcal{N}_k(M_\ell)$
in the case
 $\alpha=2$
) follows similarly to the calculations following (3.13).
$\alpha=2$
) follows similarly to the calculations following (3.13).
6. Conclusion and future directions
We have considered a deep feed-forward neural network whose weights are i.i.d. heavy-tailed or light-tailed random variables (Section 2). If the activation function is bounded and continuous, then as the width goes to infinity, the joint pre-activation values in a given layer of the network, for a given input, converge in distribution to a product of i.i.d. S
 $\alpha$
S random variables (Theorem 3.1), whose scale parameter is inductively defined by (3.1). This is generalized to multiple inputs (Theorem 5.1), where the pre-activation values converge to a multivariate S
$\alpha$
S random variables (Theorem 3.1), whose scale parameter is inductively defined by (3.1). This is generalized to multiple inputs (Theorem 5.1), where the pre-activation values converge to a multivariate S
 $\alpha$
S distribution whose spectral measure (or, in the case
$\alpha$
S distribution whose spectral measure (or, in the case
 $ \alpha=2 $
, the covariance matrix) is inductively defined by (5.1)–(5.4). These results show that an initialization using any i.i.d. heavy-/light-tailed weights can be treated similarly to an
$ \alpha=2 $
, the covariance matrix) is inductively defined by (5.1)–(5.4). These results show that an initialization using any i.i.d. heavy-/light-tailed weights can be treated similarly to an
 $\alpha$
-stable prior assumption in the context of Bayesian modeling. In Section 4, we sought a more general assumption on the activation function, beyond boundedness. This is of importance because if the activation function is not carefully chosen, then the initialized variances may exhibit erratic behavior as the number of layers grows: either collapsing to zero (so that pre-activation values at deeper layers saturate), or exploding to infinity [Reference Glorot and Bengio13, Reference He, Zhang, Ren and Sun15, Reference Roberts, Yaida and Hanin36]. Unlike the case of Gaussian initialization, our model in general does not allow the use of ReLU. The trade-off is that we allow the use of arbitrary heavy-/light-tailed distributions for network weights, which is favorable for encoding heavy-tailed behaviors of neural networks that are known to arise in well-known trained networks [Reference Martin and Mahoney28, Reference Wenzel42, Reference Fortuin9].
$\alpha$
-stable prior assumption in the context of Bayesian modeling. In Section 4, we sought a more general assumption on the activation function, beyond boundedness. This is of importance because if the activation function is not carefully chosen, then the initialized variances may exhibit erratic behavior as the number of layers grows: either collapsing to zero (so that pre-activation values at deeper layers saturate), or exploding to infinity [Reference Glorot and Bengio13, Reference He, Zhang, Ren and Sun15, Reference Roberts, Yaida and Hanin36]. Unlike the case of Gaussian initialization, our model in general does not allow the use of ReLU. The trade-off is that we allow the use of arbitrary heavy-/light-tailed distributions for network weights, which is favorable for encoding heavy-tailed behaviors of neural networks that are known to arise in well-known trained networks [Reference Martin and Mahoney28, Reference Wenzel42, Reference Fortuin9].
Gradient descent on an infinitely wide deep network with the
 $ L^{2}$
-loss function is related to the kernel method via the neural network Gaussian process (NNGP) kernel [Reference Matthews31, Reference Lee, Xiao, Schoenholz, Bahri, Novak, Sohl-Dickstein and Pennington26] and the neural tangent kernel (NTK) [Reference Jacot, Hongler and Gabriel17, Reference Arora2]. One interesting future direction is to generalize this relationship with the kernel method to our model, in particular, by finding an appropriate counterpart of the NTK. For shallow networks with stable weights and ReLU activation, it has been shown that the NTK converges in distribution as the width tends to infinity [Reference Favaro, Fortini and Peluchetti6], and the network dynamics have been explained in terms of the kernel method. Another possible future direction is to relax the independence assumptions on the weights. For instance, it should be possible to extend the infinite-width limit result to the case of exchangeable weights in each layer. Indeed, in [Reference Tsuchida, Roosta and Gallagher40], the authors consider row–column exchangeable random variables for network weights in each layer and analyze the infinite-width limit of such a network. Some authors have also proposed structured recipes for designing a network with dependent weights while ensuring that the weights are partially exchangeable. One particular way is to consider a scale mixture of Gaussians for the weight distribution [Reference Jantre, Bhattacharya and Maiti18, Reference Ober and Aitchison34, Reference Louizos, Ullrich and Welling27, Reference Ghosh, Yao and Doshi-Velez11, Reference Ghosh, Yao and Doshi-Velez12]. Infinite-width limits of these networks with Gaussian scale mixture weights have also been studied, at least in part, by [Reference Lee, Yun, Yang and Lee23]. However, it would be more challenging to generalize the infinite-width limit result to a network with general dependent structures for weights.
$ L^{2}$
-loss function is related to the kernel method via the neural network Gaussian process (NNGP) kernel [Reference Matthews31, Reference Lee, Xiao, Schoenholz, Bahri, Novak, Sohl-Dickstein and Pennington26] and the neural tangent kernel (NTK) [Reference Jacot, Hongler and Gabriel17, Reference Arora2]. One interesting future direction is to generalize this relationship with the kernel method to our model, in particular, by finding an appropriate counterpart of the NTK. For shallow networks with stable weights and ReLU activation, it has been shown that the NTK converges in distribution as the width tends to infinity [Reference Favaro, Fortini and Peluchetti6], and the network dynamics have been explained in terms of the kernel method. Another possible future direction is to relax the independence assumptions on the weights. For instance, it should be possible to extend the infinite-width limit result to the case of exchangeable weights in each layer. Indeed, in [Reference Tsuchida, Roosta and Gallagher40], the authors consider row–column exchangeable random variables for network weights in each layer and analyze the infinite-width limit of such a network. Some authors have also proposed structured recipes for designing a network with dependent weights while ensuring that the weights are partially exchangeable. One particular way is to consider a scale mixture of Gaussians for the weight distribution [Reference Jantre, Bhattacharya and Maiti18, Reference Ober and Aitchison34, Reference Louizos, Ullrich and Welling27, Reference Ghosh, Yao and Doshi-Velez11, Reference Ghosh, Yao and Doshi-Velez12]. Infinite-width limits of these networks with Gaussian scale mixture weights have also been studied, at least in part, by [Reference Lee, Yun, Yang and Lee23]. However, it would be more challenging to generalize the infinite-width limit result to a network with general dependent structures for weights.
Appendix A. Auxiliary lemmas
Lemma A.1. If L is slowly varying, then
 \begin{align*} \widetilde{L}(x) = \int_{0}^{x} t^{-1}L(t) \, dt \end{align*}
\begin{align*} \widetilde{L}(x) = \int_{0}^{x} t^{-1}L(t) \, dt \end{align*}
is also slowly varying.
Proof. If
 $ \widetilde{L} $
is bounded, then since
$ \widetilde{L} $
is bounded, then since
 $ \widetilde{L} $
is increasing,
$ \widetilde{L} $
is increasing,
 $ \widetilde{L}(x) $
converges as
$ \widetilde{L}(x) $
converges as
 $ x \to \infty $
. Thus
$ x \to \infty $
. Thus
 $ \widetilde{L} $
is slowly varying. If
$ \widetilde{L} $
is slowly varying. If
 $ \widetilde{L} $
is not bounded, then by L’Hôpital’s rule,
$ \widetilde{L} $
is not bounded, then by L’Hôpital’s rule,
 \begin{align*} \lim_{x \to \infty}\frac{\widetilde{L}(\lambda x)}{\widetilde{L}(x)} = \lim_{x \to \infty}\frac{\int_{0}^{x} y^{-1}L(\lambda y) \, dy}{\int_{0}^{x} y^{-1}L(y) \, dy} = \lim_{x \to \infty}\frac{L(\lambda x)}{L(x)} = 1 .\\[-30pt] \end{align*}
\begin{align*} \lim_{x \to \infty}\frac{\widetilde{L}(\lambda x)}{\widetilde{L}(x)} = \lim_{x \to \infty}\frac{\int_{0}^{x} y^{-1}L(\lambda y) \, dy}{\int_{0}^{x} y^{-1}L(y) \, dy} = \lim_{x \to \infty}\frac{L(\lambda x)}{L(x)} = 1 .\\[-30pt] \end{align*}
The next four lemmas are standard results; we give references for their proofs. In particular, the next lemma is a standard result concerning the characteristic functions of heavy-tailed distributions ([Reference Pitman35, Theorem 1 and Theorem 3]; see also [Reference Durrett3, Equation 3.8.2]).
Lemma A.2. If W is a symmetric random variable with tail probability
 $ \mathbb{P}(|W| > t) = t^{-\alpha}L(t) $
where
$ \mathbb{P}(|W| > t) = t^{-\alpha}L(t) $
where
 $ 0 < \alpha \le 2 $
and L is slowly varying, then the characteristic function
$ 0 < \alpha \le 2 $
and L is slowly varying, then the characteristic function
 $ \psi_{W}(t) $
of W satisfies
$ \psi_{W}(t) $
of W satisfies
 \begin{align*} \psi_{W}(t) = 1- c_\alpha |t|^{\alpha}L\left(\frac{1}{|t|}\right) + o\left (|t|^{\alpha}L\left(\frac{1}{|t|}\right)\right ), \quad t \to 0, \end{align*}
\begin{align*} \psi_{W}(t) = 1- c_\alpha |t|^{\alpha}L\left(\frac{1}{|t|}\right) + o\left (|t|^{\alpha}L\left(\frac{1}{|t|}\right)\right ), \quad t \to 0, \end{align*}
where
 \begin{align*} c_\alpha = \lim_{M \to \infty} \int_{0}^{M} \frac{\sin u}{u^{\alpha}} \, du = \frac{\pi/2}{\Gamma(\alpha) \sin(\pi\alpha/2)}, \end{align*}
\begin{align*} c_\alpha = \lim_{M \to \infty} \int_{0}^{M} \frac{\sin u}{u^{\alpha}} \, du = \frac{\pi/2}{\Gamma(\alpha) \sin(\pi\alpha/2)}, \end{align*}
for
 $ \alpha <2 $
, and
$ \alpha <2 $
, and
 \begin{align*} \psi_{W}(t) = 1- |t|^{2}\widetilde{L}\left(\frac{1}{|t|}\right) + o\left (|t|^{2}\widetilde{L}\left(\frac{1}{|t|}\right)\right ), \quad t \to 0, \end{align*}
\begin{align*} \psi_{W}(t) = 1- |t|^{2}\widetilde{L}\left(\frac{1}{|t|}\right) + o\left (|t|^{2}\widetilde{L}\left(\frac{1}{|t|}\right)\right ), \quad t \to 0, \end{align*}
where
 \begin{align*} \widetilde{L}(x) = \int_{0}^{x} y \mathbb{P}(|W| > y) \, dy = \int_{0}^{x} y^{-1}L(y) \, dy , \end{align*}
\begin{align*} \widetilde{L}(x) = \int_{0}^{x} y \mathbb{P}(|W| > y) \, dy = \int_{0}^{x} y^{-1}L(y) \, dy , \end{align*}
for
 $ \alpha =2 $
.
$ \alpha =2 $
.
We next state a standard result about slowly varying functions [Reference Feller7, Section VIII.8, Lemma 2].
Lemma A.3.
If L is slowly varying, then for any fixed
 $ \epsilon>0$
and all sufficiently large x,
$ \epsilon>0$
and all sufficiently large x,
 \begin{align*} x^{-\epsilon} < L(x) < x^{\epsilon}. \end{align*}
\begin{align*} x^{-\epsilon} < L(x) < x^{\epsilon}. \end{align*}
Moreover, the convergence
 \begin{align*} \frac{L(tx)}{L(t)} \to 1 \end{align*}
\begin{align*} \frac{L(tx)}{L(t)} \to 1 \end{align*}
as
 $ t \to \infty $
is uniform in finite intervals
$ t \to \infty $
is uniform in finite intervals
 $ 0 < a < x < b $
.
$ 0 < a < x < b $
.
An easy corollary of the above lemma is the following result, which we single out for convenience [Reference Pitman35, Lemma 2].
Lemma A.4.
If
 $ G(t) = t^{-\alpha}L(t) $
where
$ G(t) = t^{-\alpha}L(t) $
where
 $ \alpha \ge 0 $
and L is slowly varying, then for any given positive
$ \alpha \ge 0 $
and L is slowly varying, then for any given positive
 $ \epsilon $
and c, there exist a and b such that
$ \epsilon $
and c, there exist a and b such that
 \begin{align*} &\frac{G(\lambda t)}{G(t)} < \frac{b}{\lambda^{\alpha+\epsilon}} \quad \text{for } t \ge a,\ 0<\lambda \le c, \\ &\frac{G(\lambda t)}{G(t)} < \frac{b}{\lambda^{\alpha-\epsilon}} \quad \text{for } t \ge a,\ \lambda \ge c . \end{align*}
\begin{align*} &\frac{G(\lambda t)}{G(t)} < \frac{b}{\lambda^{\alpha+\epsilon}} \quad \text{for } t \ge a,\ 0<\lambda \le c, \\ &\frac{G(\lambda t)}{G(t)} < \frac{b}{\lambda^{\alpha-\epsilon}} \quad \text{for } t \ge a,\ \lambda \ge c . \end{align*}
In particular, for sufficiently large
 $ t>0 $
, we have
$ t>0 $
, we have
 \begin{equation*} \frac{G(\lambda t)}{G(t)} \leq b {\left({1/\lambda}\right)^{\alpha \pm \epsilon}} \end{equation*}
\begin{equation*} \frac{G(\lambda t)}{G(t)} \leq b {\left({1/\lambda}\right)^{\alpha \pm \epsilon}} \end{equation*}
for all
 $\lambda>0$
, where we define
$\lambda>0$
, where we define
 $x^{\alpha \pm \epsilon}\;:\!=\;\max\left(x^{\alpha +\epsilon},x^{\alpha -\epsilon}\right)$
.
$x^{\alpha \pm \epsilon}\;:\!=\;\max\left(x^{\alpha +\epsilon},x^{\alpha -\epsilon}\right)$
.
The next lemma concerns the convolution of distributions with regularly varying tails [Reference Feller7, Section VIII.8, Proposition].
Lemma A.5.
For two distributions
 $ F_{1} $
and
$ F_{1} $
and
 $ F_{2} $
such that as
$ F_{2} $
such that as
 $ x \to \infty $
$ x \to \infty $
 \begin{align*} 1-F_{i}(x) = x^{-\alpha}L_{i}(x) \end{align*}
\begin{align*} 1-F_{i}(x) = x^{-\alpha}L_{i}(x) \end{align*}
with
 $ L_{i} $
slowly varying, the convolution
$ L_{i} $
slowly varying, the convolution
 $ G = F_{1} * F_{2} $
has a regularly varying tail such that
$ G = F_{1} * F_{2} $
has a regularly varying tail such that
 \begin{align*} 1-G(x) \sim x^{-\alpha}(L_{1}(x) + L_{2}(x)) . \end{align*}
\begin{align*} 1-G(x) \sim x^{-\alpha}(L_{1}(x) + L_{2}(x)) . \end{align*}
Lemma A.6.
Let
 $\{X_{kn}: k \in \mathbb{N}\}$
be i.i.d. with
$\{X_{kn}: k \in \mathbb{N}\}$
be i.i.d. with
 $\mathbb{E} X_{1n}=0$
for each
$\mathbb{E} X_{1n}=0$
for each
 $n \in \mathbb{N}$
. If the family
$n \in \mathbb{N}$
. If the family
 $\{|X_{1n}|^p : n \in \mathbb{N} \}$
is uniformly integrable for some
$\{|X_{1n}|^p : n \in \mathbb{N} \}$
is uniformly integrable for some
 $p>1$
, then as
$p>1$
, then as
 $n \to \infty$
, we have
$n \to \infty$
, we have
 \begin{align*}S_n\;:\!=\;\frac{1}{n}\sum_{k=1}^n X_{kn} \to 0\end{align*}
\begin{align*}S_n\;:\!=\;\frac{1}{n}\sum_{k=1}^n X_{kn} \to 0\end{align*}
in probability.
Proof. For
 $M>0$
, let
$M>0$
, let
 \begin{align*} Y_{kn} & {} \;:\!=\; X_{kn} \mathbf{1}_{[|X_{kn}| \leq M]}-\mathbb{E} \big( X_{kn} \mathbf{1}_{[|X_{kn}| \leq M]} \big), & Z_{kn} & {} \;:\!=\; X_{kn} \mathbf{1}_{[|X_{kn}| > M]}-\mathbb{E} \big( X_{kn} \mathbf{1}_{[|X_{kn}| > M]} \big), \\ T_{n} & {} \;:\!=\;\frac{1}{n}\sum_{k=1}^n Y_{kn}, & U_{n} & {} \;:\!=\;\frac{1}{n}\sum_{k=1}^n Z_{kn}. \end{align*}
\begin{align*} Y_{kn} & {} \;:\!=\; X_{kn} \mathbf{1}_{[|X_{kn}| \leq M]}-\mathbb{E} \big( X_{kn} \mathbf{1}_{[|X_{kn}| \leq M]} \big), & Z_{kn} & {} \;:\!=\; X_{kn} \mathbf{1}_{[|X_{kn}| > M]}-\mathbb{E} \big( X_{kn} \mathbf{1}_{[|X_{kn}| > M]} \big), \\ T_{n} & {} \;:\!=\;\frac{1}{n}\sum_{k=1}^n Y_{kn}, & U_{n} & {} \;:\!=\;\frac{1}{n}\sum_{k=1}^n Z_{kn}. \end{align*}
By Markov’s inequality,
 \begin{align*} \mathbb{P} \big( |T_n| \geq \delta \big) \leq \frac{\mathbf{Var}\, Y_{1n}}{n \delta^2} \leq \frac{4 M^2}{n \delta^2},\end{align*}
\begin{align*} \mathbb{P} \big( |T_n| \geq \delta \big) \leq \frac{\mathbf{Var}\, Y_{1n}}{n \delta^2} \leq \frac{4 M^2}{n \delta^2},\end{align*}
and
 \begin{align*} \mathbb{P} \big( |U_n| \geq \delta \big) \leq \frac{\mathbb{E}|U_n|^p}{\delta^{p}} \leq \frac{\mathbb{E} |Z_{1n}|^p}{\delta^p}.\end{align*}
\begin{align*} \mathbb{P} \big( |U_n| \geq \delta \big) \leq \frac{\mathbb{E}|U_n|^p}{\delta^{p}} \leq \frac{\mathbb{E} |Z_{1n}|^p}{\delta^p}.\end{align*}
Thus, we have
 \begin{align*} \underset{n \to \infty}{{}\limsup {}}\mathbb{P}\big( |S_n| \geq 2 \delta \big) \leq \frac{1}{\delta^p} \underset{n}{{} \sup{} }\mathbb{E} |Z_{1n}|^p.\end{align*}
\begin{align*} \underset{n \to \infty}{{}\limsup {}}\mathbb{P}\big( |S_n| \geq 2 \delta \big) \leq \frac{1}{\delta^p} \underset{n}{{} \sup{} }\mathbb{E} |Z_{1n}|^p.\end{align*}
By the uniform integrability assumption, the right-hand side can be made arbitrarily small by increasing M.
Appendix B. Proof of Lemma 3.1
First suppose
 $(\pi_j)_{j\in\mathbb{N}}$
converges to
$(\pi_j)_{j\in\mathbb{N}}$
converges to
 $\pi_\infty$
in the weak topology on
$\pi_\infty$
in the weak topology on
 $\Pr(\Pr(\mathbb{R}))$
. We want to show that
$\Pr(\Pr(\mathbb{R}))$
. We want to show that
 $(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
converges in distribution to
$(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
converges in distribution to
 $\mathbf{X}^{(\infty)}$
. By [Reference Kallenberg19, Theorem 4.29], convergence in distribution of a sequence of random variables is equivalent to showing that for every
$\mathbf{X}^{(\infty)}$
. By [Reference Kallenberg19, Theorem 4.29], convergence in distribution of a sequence of random variables is equivalent to showing that for every
 $m > 0$
and all bounded continuous functions
$m > 0$
and all bounded continuous functions
 $f_1,\ldots,f_m$
, we have
$f_1,\ldots,f_m$
, we have
 \begin{align*}\mathbb{E}\Bigr[f_1(X_1^{(j)})\cdots f_m(X_m^{(j)})\Bigr]\to\mathbb{E}\Bigr[f_1(X_1^{(\infty)})\cdots f_m(X_m^{(\infty)})\Bigr]\end{align*}
\begin{align*}\mathbb{E}\Bigr[f_1(X_1^{(j)})\cdots f_m(X_m^{(j)})\Bigr]\to\mathbb{E}\Bigr[f_1(X_1^{(\infty)})\cdots f_m(X_m^{(\infty)})\Bigr]\end{align*}
as
 $j \to \infty$
. Rewriting the above using (3.3), we must show that as
$j \to \infty$
. Rewriting the above using (3.3), we must show that as
 $j \to \infty$
,
$j \to \infty$
,
 \[\int_{\Pr(\mathbb{R})} \left(\int_{\mathbb{R}^m} \prod_{i = 1}^m f_i(x_i)\, \nu^{\otimes m}(d\mathbf{x})\right) \pi_{j}(d\nu)\longrightarrow\int_{\Pr(\mathbb{R})} \left(\int_{\mathbb{R}^m} \prod_{i = 1}^m f_i(x_i)\,\nu^{\otimes m}(d\mathbf{x})\right) \pi_\infty(d\nu).\]
\[\int_{\Pr(\mathbb{R})} \left(\int_{\mathbb{R}^m} \prod_{i = 1}^m f_i(x_i)\, \nu^{\otimes m}(d\mathbf{x})\right) \pi_{j}(d\nu)\longrightarrow\int_{\Pr(\mathbb{R})} \left(\int_{\mathbb{R}^m} \prod_{i = 1}^m f_i(x_i)\,\nu^{\otimes m}(d\mathbf{x})\right) \pi_\infty(d\nu).\]
But this follows since
 $\nu\mapsto \int_{\mathbb{R}^m} \prod_{i = 1}^m f_i(x_i)\, \nu^{\otimes m}(d\mathbf{x})$
is a bounded continuous function on
$\nu\mapsto \int_{\mathbb{R}^m} \prod_{i = 1}^m f_i(x_i)\, \nu^{\otimes m}(d\mathbf{x})$
is a bounded continuous function on
 $\Pr(\mathbb{R})$
with respect to the weak topology.
$\Pr(\mathbb{R})$
with respect to the weak topology.
We now prove the reverse direction. We assume
 $(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
converges in distribution to
$(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
converges in distribution to
 $\mathbf{X}^{(\infty)}$
and must show that
$\mathbf{X}^{(\infty)}$
and must show that
 $(\pi_j)_{j\in\mathbb{N}}$
converges to
$(\pi_j)_{j\in\mathbb{N}}$
converges to
 $\pi_\infty$
.
$\pi_\infty$
.
In order to show this, we first claim that the family
 $(\pi_j)_{j\in\mathbb{N}}$
is tight. By [Reference Kallenberg21, Theorem 4.10] (see also [Reference Ghosal and van der Vaart10, Theorem A.6]), such tightness is equivalent to the tightness of the expected measures
$(\pi_j)_{j\in\mathbb{N}}$
is tight. By [Reference Kallenberg21, Theorem 4.10] (see also [Reference Ghosal and van der Vaart10, Theorem A.6]), such tightness is equivalent to the tightness of the expected measures
 \begin{align*}\left(\int \nu^{\otimes \mathbb{N}}\,\pi_j(d\nu)\right)_{j\in\mathbb{N}}.\end{align*}
\begin{align*}\left(\int \nu^{\otimes \mathbb{N}}\,\pi_j(d\nu)\right)_{j\in\mathbb{N}}.\end{align*}
But these are just the distributions of the family
 $(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
, which we have assumed converges in distribution. Hence its distributions are tight.
$(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
, which we have assumed converges in distribution. Hence its distributions are tight.
Let us now return to proving that
 $(\pi_j)_{j\in\mathbb{N}}$
converges to
$(\pi_j)_{j\in\mathbb{N}}$
converges to
 $\pi_\infty$
. Suppose to the contrary that this is not the case. Since the family
$\pi_\infty$
. Suppose to the contrary that this is not the case. Since the family
 $(\pi_j)_{j\in\mathbb{N}}$
is tight, by Prokhorov’s theorem there must be another limit point of this family,
$(\pi_j)_{j\in\mathbb{N}}$
is tight, by Prokhorov’s theorem there must be another limit point of this family,
 $\tilde\pi\neq\pi_\infty$
, and a subsequence
$\tilde\pi\neq\pi_\infty$
, and a subsequence
 $(j_n)_{n\in\mathbb{N}}$
such that
$(j_n)_{n\in\mathbb{N}}$
such that
 \begin{align*}\pi_{j_n} \stackrel{\text{w}}{\to} \tilde\pi\end{align*}
\begin{align*}\pi_{j_n} \stackrel{\text{w}}{\to} \tilde\pi\end{align*}
as
 $n \to \infty$
. By the first part of our proof, this implies that
$n \to \infty$
. By the first part of our proof, this implies that
 $(\mathbf{X}^{(j_n)})_{n\in\mathbb{N}}$
converges in distribution to an exchangeable sequence with distribution
$(\mathbf{X}^{(j_n)})_{n\in\mathbb{N}}$
converges in distribution to an exchangeable sequence with distribution
 $\int \nu^{\otimes \mathbb{N}}\,\tilde\pi(d\nu)$
. However, by assumption we have that
$\int \nu^{\otimes \mathbb{N}}\,\tilde\pi(d\nu)$
. However, by assumption we have that
 $(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
converges in distribution to
$(\mathbf{X}^{(j)})_{j\in\mathbb{N}}$
converges in distribution to
 $\mathbf{X}^{(\infty)}$
, which has distribution
$\mathbf{X}^{(\infty)}$
, which has distribution
 $\int \nu^{\otimes \mathbb{N}}\,\pi_\infty(d\nu)$
. Thus, it must be that
$\int \nu^{\otimes \mathbb{N}}\,\pi_\infty(d\nu)$
. Thus, it must be that
 \begin{align*}\int \nu^{\otimes \mathbb{N}}\,\tilde\pi(d\nu) = \int \nu^{\otimes \mathbb{N}}\,\pi_\infty(d\nu).\end{align*}
\begin{align*}\int \nu^{\otimes \mathbb{N}}\,\tilde\pi(d\nu) = \int \nu^{\otimes \mathbb{N}}\,\pi_\infty(d\nu).\end{align*}
But [Reference Kallenberg20, Proposition 1.4] tells us that the measure
 $\pi$
in (3.3) is unique, contradicting
$\pi$
in (3.3) is unique, contradicting
 $\tilde\pi\neq\pi_\infty$
. Thus, it must be that
$\tilde\pi\neq\pi_\infty$
. Thus, it must be that
 $(\pi_j)_{j\in\mathbb{N}}$
converges to
$(\pi_j)_{j\in\mathbb{N}}$
converges to
 $\pi_\infty$
.
$\pi_\infty$
.
Appendix C. Multivariate stable laws
This section contains some basic definitions and properties related to multivariate stable distributions, to help familiarize readers with these concepts. The material in this section comes from the monograph [Reference Samorodnitsky and Taqqu38] and also from [Reference Kuelbs22].
Definition C.1. A probability measure
 $\mu$
on
$\mu$
on
 $\mathbb{R}^k$
is said to be (jointly) stable if for all
$\mathbb{R}^k$
is said to be (jointly) stable if for all
 $a,b \in \mathbb{R}$
and two independent random variables X and Y with distribution
$a,b \in \mathbb{R}$
and two independent random variables X and Y with distribution
 $\mu$
, there exist
$\mu$
, there exist
 $c \in \mathbb{R}$
and
$c \in \mathbb{R}$
and
 $v \in \mathbb{R}^k$
such that
$v \in \mathbb{R}^k$
such that
 \begin{align*}aX+bY \buildrel d \over = cX+v.\end{align*}
\begin{align*}aX+bY \buildrel d \over = cX+v.\end{align*}
If
 $\mu$
is symmetric, then it is said to be symmetric stable.
$\mu$
is symmetric, then it is said to be symmetric stable.
Similarly to the one-dimensional case, there exists a constant
 $\alpha \in (0,2]$
such that
$\alpha \in (0,2]$
such that
 $c^\alpha=a^\alpha+b^\alpha$
for all a,b, which we call the index of stability. The distribution
$c^\alpha=a^\alpha+b^\alpha$
for all a,b, which we call the index of stability. The distribution
 $\mu$
is multivariate Gaussian in the case
$\mu$
is multivariate Gaussian in the case
 $\alpha=2$
.
$\alpha=2$
.
Theorem C.1. Let
 $\alpha \in (0,2)$
. A random variable
$\alpha \in (0,2)$
. A random variable
 $\mathbf{X}$
taking values in
$\mathbf{X}$
taking values in
 $\mathbb{R}^k$
is symmetric stable if and only if there exists a finite measure
$\mathbb{R}^k$
is symmetric stable if and only if there exists a finite measure
 $\Gamma$
on the unit sphere
$\Gamma$
on the unit sphere
 $S_{k-1}=\{ x \in \mathbb{R}^k : |x|=1 \}$
such that
$S_{k-1}=\{ x \in \mathbb{R}^k : |x|=1 \}$
such that
 \begin{align} \mathbb{E} \exp \Big( i\langle\mathbf{t},\mathbf{X}\rangle \Big) = \exp \Big( -\int_{S_{k-1}} |\langle\mathbf{t},\mathbf{s}\rangle|^\alpha \Gamma(d \mathbf{s}) \Big) \end{align}
\begin{align} \mathbb{E} \exp \Big( i\langle\mathbf{t},\mathbf{X}\rangle \Big) = \exp \Big( -\int_{S_{k-1}} |\langle\mathbf{t},\mathbf{s}\rangle|^\alpha \Gamma(d \mathbf{s}) \Big) \end{align}
for all
 $\mathbf{t} \in \mathbb{R}^k.$
The measure
$\mathbf{t} \in \mathbb{R}^k.$
The measure
 $\Gamma$
is called the spectral measure of
$\Gamma$
is called the spectral measure of
 $\mathbf{X}$
, and the distribution is denoted by
$\mathbf{X}$
, and the distribution is denoted by
 $\text{S}_\alpha \text{S}_{k}(\Gamma)$
.
$\text{S}_\alpha \text{S}_{k}(\Gamma)$
.
In the case
 $k=1$
, the measure
$k=1$
, the measure
 $\Gamma$
is always of the form
$\Gamma$
is always of the form
 $c_1 \delta_1 + c_{-1} \delta_{-1}$
. Thus, the characteristic function reduces to the familiar form
$c_1 \delta_1 + c_{-1} \delta_{-1}$
. Thus, the characteristic function reduces to the familiar form
 \begin{align*} \mathbb{E} e^{itX} = e^{-|\sigma t|^\alpha}.\end{align*}
\begin{align*} \mathbb{E} e^{itX} = e^{-|\sigma t|^\alpha}.\end{align*}
Acknowledgements
We thank François Caron and Juho Lee for sugggesting the paper [Reference Favaro, Fortini and Peluchetti4] to us.
Funding information
P. Jung and H. Lee were funded in part by the National Research Foundation of Korea (NRF) grant NRF-2017R1A2B2001952. P. Jung, H. Lee, and J. Lee were funded in part by the NRF grant NRF-2019R1A5A1028324. H. Yang was supported by the Engineering Research Center Program, through the NRF, funded by the Korean government’s Ministry of Science and ICT (NRF-2018R1A5A1059921), and also by the Institute for Basic Science (IBS-R029-C1).
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.

