



1. Introduction
Psycholinguistic experiments typically employ pictorial or linguistic stimuli in order to elicit a particular type of response from subjects. The experimental tasks can either be explicitly linguistic, as in e.g. picture naming tasks, or they can be assumed to activate the language faculty more implicitly, as in e.g. categorization or similarity perception tasks often used in research on linguistic relativity effects. Producing valid analyses of psycholinguistic data presupposes that all independent and confounding variables are taken into consideration. However, due to the complex nature of language (and of communication more generally), this is far from a trivial challenge. Linguistic units, such as words or utterances, have a plethora of distinct cognitive, phonological, morphological, syntactic, semantic and pragmatic properties. To examine the effect of any one of those properties on cognition and/or linguistic processing, all the other properties need to be controlled for. Normative ratings are an invaluable tool for psycholinguistic research in that they provide a means to control for properties that are not directly observable in e.g. language corpora, such as age of acquisition or category typicality. In normative ratings, such properties are quantified based on the responses from a sample of subjects representing the linguistic population under investigation.
Currently, there are no large databases of normative ratings for Swedish. Ratings for certain individual lexical properties are included in some large cross-linguistic rating studies; specifically, Rofes et al. (Reference Rofes, Lilla, Klaudia, Marianne, Johansson, Vânia De, Jovana, Valantis, Anna and Simonsen2018) includes imageability ratings for 190 Swedish words, and Łuniewska et al. (Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016) includes age of acquisition ratings for 299 Swedish words. The lack of normative ratings for Swedish prompted Blomberg & Öberg (Reference Blomberg and Carl2015) to examine whether ratings for closely related languages could be used in place of ratings collected for Swedish. Blomberg & Öberg compared the imageability, age of acquisition and familiarity ratings for 99 Swedish words (which they collected themselves) with the ratings for equivalent English words. They found that the Swedish and the English ratings were strongly correlated for imageability and age of acquisition, and moderately correlated for familiarity. Therefore, Blomberg & Öberg suggest that English ratings can be reliably transferred to Swedish for some variables, but not for all. Moreover, they note that while the correlation between the Swedish and the English ratings is strong overall, ratings for individual words may sometimes be substantially different (for variation between languages, see also Cuetos, Ellis & Alvarez Reference Cuetos, Ellis and Bernardo1999). As for picture stimuli, the Multilanguage Written Picture Naming Dataset (Torrance et al. Reference Torrance, Guido, Alves, Barbara, Lucile, Evgeny, Ioannis, Raquel, Jukka and Jóhannesson2018) includes Swedish name agreement norms for 260 drawings. However, these picture stimuli, taken from Rossion & Pourtois (Reference Rossion and Gilles2004), are based on the older stimuli in Snodgrass & Vanderwart (Reference Snodgrass and Mary1980), which are not standardized in regard to their visual complexity nor drawing style. Therefore, modern psycholinguistic research may find it more suitable to use picture stimuli from the new MultiPic database (Duñabeitia et al. Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017) with 750 freely available and standardized drawings.
In this paper, I introduce a new dataset of normative ratings for Swedish encompassing 111 concrete nouns and the corresponding picture stimuli in the MultiPic database (Duñabeitia et al. Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017). Specifically, the dataset includes norms for name agreement and category typicality regarding the picture stimuli, and norms for age of acquisition and subjective frequency regarding the corresponding words. The norms are based on responses to four separate online surveys conducted among university students who are native speakers of the Finland-Swedish variety of Swedish. By including ratings for both lexical and visual stimuli collected from the same population of subjects, the dataset is especially useful in psycholinguistic studies combining several experimental methods. Most importantly, the dataset is the first one to introduce ratings for Finland-Swedish, thus facilitating future psycholinguistic studies comparing speakers of different varieties of Swedish. Swedish is a pluricentric language with two regional standard varieties, one in Sweden (the dominant variety) and one in Finland (the non-dominant variety with about 300,000 native speakers). The main differences between the varieties concern intonation, vocabulary and idioms (Norrby et al. Reference Norrby, Camilla, Jan, Jenny and Rudolf2012). Furthermore, Finland-Swedish is influenced by Finnish due to a high prevalence of functional bilingualism among the Finland-Swedish population (Tandefelt Reference Tandefelt2015). This provides an interesting potential for psycholinguistic studies, as the Finnish, the Finland-Swedish, and the bilingual populations share the same geographical and cultural space, but they speak two typologically different languages.
The aim of this paper is (i) to describe the new dataset of normative ratings for Swedish, (ii) to examine the inter-correlations between these ratings, and (iii) to examine the correlations between these ratings and those collected previously for other languages and other varieties of Swedish. The described dataset is not intended as the definitive source for normative ratings for all types of psycholinguistic experiments concerning (Finland-)Swedish; after all, the dataset is relatively small in terms of the number of items included in it, especially in comparison with ratings that are currently available for many of the larger (as regards the number of speakers) languages and language varieties in the world. However, it is a substantial addition to the limited array of ratings that exist for Scandinavian languages today, and it can prove useful for psycholinguistic studies that are not too broad in scope. Most importantly for the purposes of this paper, the dataset provides a solid base for a discussion on the value of having normative ratings for the specific language (variety) targeted in a psycholinguistic experiment as opposed to using ratings for typologically and genetically related languages.
2. Normative ratings in prior research
This paper presents four types of normative ratings for Swedish. Two of them concern picture stimuli in the MultiPic database (Duñabeitia et al. Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017), namely name agreement and category typicality. The other two ratings concern the words that designate the objects in these pictures, namely age of acquisition and subjective frequency. The four rating types chosen for this paper constitute by no means an exhaustive set of norms for psycholinguistic studies. They do, however, represent a first step towards facilitating certain types of psycholinguistic studies with speakers of Finland-Swedish in that these rating types represent some of the most widely used ratings-based variables overall. Other such variables include e.g. imageability , familiarity, and image agreement. For some of those variables, existing norms from related languages can be used; e.g. imageability ratings have been shown to correlate strongly between Swedish and English by Blomberg & Öberg (Reference Blomberg and Carl2015) and, given that there is no reason to expect imageability ratings to differ among speakers of different varieties of Swedish, the current dataset does not include this variable. For other variables, collecting ratings for Swedish and its different varieties remains a task for the future. Naturally, choosing which ratings to include in analyses of experimental data depends on the specific aims and methods of each study. In what follows, I review the role that the four variables in the current dataset play in linguistic processing based on prior research.
2.1 Name agreement
Name agreement refers to the degree of unanimity among speakers regarding what word they use as an identifier for a given object. In a typical naming task, subjects are shown pictures of objects and asked to name them. For example, when presented with a picture of a cat, most subjects respond with the word cat instead of other hypothetical options, such as puss, kitty, animal, whiskers etc. Pictures with a high name agreement elicit the same word from most subjects, while pictures with a low name agreement result in varied responses. Depending on the aim of the study, one may choose to include pictures with high name agreement only (as in e.g. Gauvin et al. Reference Gauvin, Jonen, Jessica, Katie and de Zubicaray2018, and Bartolozzi, Jongman & Meyer Reference Bartolozzi, Jongman and Meyer2021) or pictures with varying levels of name agreement (as in e.g. Barry, Morrison & Ellis Reference Barry, Morrison and Ellis1997, and Madden, Sale & Robinson Reference Madden, Sale and Robinson2019). When evaluating name agreement, or when using it as an independent variable in quantitative analyses, it is common to operationalize it as the H information statistic (Shannon Reference Shannon1948). The H index quantifies the level of name agreement as a value ≥ 0, where 0 indicates complete agreement across all participants, and increasing values reflect increasing divergence of responses. The H index is calculated using the formula H = –∑p iln(p i), where p i is the proportion of participants that have given each response.
Name agreement constitutes one of the most consistently significant – and potentially confounding – variables across psycholinguistic studies involving picture stimuli. Numerous studies have shown that name agreement is highly predictive of e.g. naming latencies; pictures with high name agreement result in faster responses than pictures with low name agreement (e.g. Snodgrass & Yuditsky Reference Snodgrass and Tanya1996, Barry et al. Reference Barry, Morrison and Ellis1997, Ellis & Morrison Reference Ellis and Morrison1998, Perret & Bonin Reference Perret and Patrick2018). Furthermore, name agreement needs to be considered in experiments where lemma activation is assumed to occur on a subconscious level, such as studies in linguistic relativity effects. For example, in experiments involving object categorization or visual similarity perception, it is often assumed that the same lemma is activated across all subjects in response to a given picture (e.g. Boroditsky, Schmidt & Phillips Reference Boroditsky, Schmidt, Webb, Dedre and Susan2003, Cubelli et al. Reference Cubelli, Daniela, Lorella and Remo2011). Hence, normative ratings for name agreement provide a means to control for the potential variation in subjects’ (conscious or subconscious) lexical responses to picture stimuli.
From a cognitive standpoint, picture naming involves several processing stages that psycholinguistic experiments need to take into account. The first stage is object recognition, which involves the perceptual processing of the visual stimulus and the identification of its structural properties. The second stage involves the activation of the semantic representation of the object/concept perceived in the picture. The third stage is lemma selection, where the activation spreads from the semantic representation of the object to the corresponding linguistic representation, i.e. a lemma. In most cases, several related lemmas are activated to varying degrees and, subsequently, the most highly activated lemma is selected for the output. Finally, the linguistic response is motorically planned to be either spoken out or written down depending on the specific task at hand. (On the cognitive processes involved, see e.g. Glaser Reference Glaser1992, Johnson, Paivio & Clark Reference Johnson, Allan and Clark1996, Levelt, Roelofs & Meyer Reference Levelt, Ardi and Meyer1999, Bonin et al. Reference Bonin, Alain, Lagarrigue and Sébastien2015).
Name agreement can vary substantially between different stimuli. Assuming that naming data is collected from a relatively homogenous group of subjects (thereby minimizing the role of confounding social variables) low name agreement is potentially caused by one of two factors. First, visual stimuli can vary as to how identifiable they are; some stimuli are more unambiguous representations of the intended object than others. Thus, discrepancies in the answers can arise at the stage of object recognition, where the structural properties of the object are encoded. Second, discrepancies can occur at the stage of lemma selection, especially if more than one appropriate lemma is available to designate the depicted object. In such a case, several lemmas are activated to a similar degree, increasing the competition for lemma selection, which results in both longer naming latency and lower name agreement (for a more comprehensive discussion of these processes, see Vitkovitch & Tyrrell Reference Vitkovitch and Lisa1995, Barry et al. Reference Barry, Morrison and Ellis1997, Cuetos et al. 1999). Naturally, in languages with considerable dialectal variation – as in Swedish (see e. g. Ivars Reference Ivars2015) – name agreement may be lower due to the same object having different names in different dialects. Therefore, it seems advisable that norms for name agreement be collected from the same, relatively precisely defined population as targeted in the actual experiments.
2.2 Category typicality
Category typicality (also sometimes called semantic typicality, item typicality or prototypicality) refers to how typical or atypical an item is judged to be as a member of a given category. There is a long tradition of cognitive psychological research demonstrating that conceptual categories have graded structures, i.e. that some instances of a category are better examples (or more typical instances) of that category than others (Mervis & Rosch Reference Mervis and Eleanor1981, Medin & Smith Reference Medin and Smith1984). For example, ‘apple’ is a very typical member of the category fruit, while ‘pomegranate’ is considerably more unusual. As a rule, typicality norms are collected from naive participants who estimate the within-category typicality of items on a seven-point scale (Battig & Montague Reference Battig and Montague1969, Rosch Reference Rosch1975, Uyeda & Mandler Reference Uyeda and George1980, Van Overschelde, Rawson & Dunlosky Reference Van Overschelde, Rawson and John2004).
Category typicality has a considerable impact on performance in many types of psycholinguistic tasks. For example, category typicality is correlated with processing performance in categorization and semantic decision tasks in both healthy (Rips, Shoben & Smith Reference Rips, Shoben and Smith1973, McCloskey & Glucksberg Reference McCloskey and Sam1979, Holmes & Ellis Reference Holmes and Ellis2006) and aphasic subjects (Kiran & Thompson Reference Kiran and Thompson2003, Stanczak, Waters & Caplan Reference Stanczak, Gloria and David2006, Kiran, Ntourou & Eubank Reference Kiran, Katerina and Megan2007). Category typicality influences also memory performance in free recall tasks in adults (Keller & Kellas Reference Keller and George1978, Greenberg & Bjorklund Reference Greenberg and Bjorklund1981) and in children (Bjorklund & Thompson Reference Bjorklund and Thompson1983). Moreover, subjects are likely to name typical category members prior to atypical ones when listing members of categories (Glass & Holyoak Reference Glass and Holyoak1974, Rosch & Mervis Reference Rosch and Mervis1975). Category typicality also influences processing speed in picture naming (Dell’acqua, Lotto & Job Reference Dell’acqua, Lorella and Remo2000, Holmes & Ellis Reference Holmes and Ellis2006). Thus, typicality plays an essential part in the organization of conceptual categories. It follows, then, that for experiments involving categorization of either lexical or picture stimuli, norms for category typicality constitute a necessary tool enabling reliable analysis.
Judgments of category typicality are partially dependent on both language and culture. Interestingly, for some categories and items, typicality ratings are more correlated across languages than for others. In comparing English and Spanish speakers’ typicality ratings, Schwanenflugel & Rey (Reference Schwanenflugel and Mario1986) show that the correlations range from .94 (for body parts) to .16 (for birds). Moreover, Johnson (Reference Johnson2001) notes that typicality judgments also vary within the same linguistic community based on the respondents’ level of expertise in a given subject. Thus, it seems advisable that norms for category typicality be collected from subjects representing the same population as the subjects in the given experiment.
2.3 Age of acquisition
Age of acquisition (commonly abbreviated as AoA) represents the age at which a word is typically learned by a child. AoA norms can be derived through two distinct approaches. First, AoA norms can be obtained by examining children’s production (e.g. Chalard et al. Reference Chalard, Patrick, Alain, Bruno and Michel2003, Lotto, Surian & Job Reference Lotto, Luca and Remo2010, Grigoriev & Oshhepkov Reference Grigoriev and Ivan2013). Second, AoA norms can be obtained using estimates of adult speakers (e.g. Barca, Burani & Arduino Reference Barca, Cristina and Arduino2002, Ferrand et al. Reference Ferrand, Patrick, Alain, Maria, Boris, Christophe and Marc2008, Moors et al. Reference Moors, Jan De, Dirk, Sabine, Kevin Van, Anne-Laura, Maarten De, Jeffrey De and Marc2013). While asking adults to estimate AoA is a rather indirect means to obtain AoA norms, the method has been validated by several studies comparing the two approaches. For example, Morrison, Chappell & Ellis (Reference Morrison, Chappell and Ellis1997) report a correlation of .75 between subjective estimates of AoA and children’s actual performance (for similar results, see also Pind et al. Reference Pind, Halla, Hjördis and Frosti2000, Schröder et al. Reference Schröder, Teresa, Steffie and Isabell2012, Łuniewska et al. Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016, Brysbaert & Biemiller Reference Brysbaert and Andrew2017). For this reason, subjective estimates of AoA by adults are often used as solid approximations of objective AoA in psycholinguistic studies.
AoA affects performance in a wide range of psycholinguistic tasks (for literature reviews, see e.g. Juhasz Reference Juhasz2005, Brysbaert & Ghyselinck Reference Brysbaert and Mandy2006, Johnston & Barry Reference Johnston and Christopher2006, Łuniewska et al. Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016). For instance, words with a lower AoA are recognized faster than words with a higher AoA (Morrison, Ellis & Quinlan Reference Morrison, Ellis and Quinlan1992, Holmes & Ellis Reference Holmes and Ellis2006, Juhasz & Rayner Reference Juhasz and Keith2006, Cortese & Khanna Reference Cortese and Khanna2007). In particular, AoA effects are strong in lexical decision tasks and picture naming tasks, i.e. in tasks that involve the semantic system, as opposed to word naming tasks (Brysbaert, Van Wijnendaele & De Deyne 2000, Lambon Ralph & Ehsan Reference Lambon, Matthew and Sheeba2006, Cortese & Khanna Reference Cortese and Khanna2007). Crucially, Kuperman, Stadthagen-Gonzalez & Brysbaert (Reference Kuperman, Hans and Marc2012) demonstrate that AoA ratings yield a significant effect in lexical decision tasks even when controlling for other properties of the words, such as frequency, length and similarity to other words (see also Brysbaert & Cortese Reference Brysbaert and Cortese2011, Ferrand et al. Reference Ferrand, Marc, Emmanuel, Boris, Patrick, Alain, Maria and Christophe2011).
Several explanations have been proposed for the effects of AoA on linguistic processing. Some scholars have argued that words’ AoA ratings reflect their cumulative frequency, i.e. the frequency with which subjects have been exposed to these words over their entire lifetime (Lewis Reference Lewis1999, Lewis, Gerhand & Ellis Reference Lewis, Simon and Ellis2001). According to this view, AoA ratings are a valuable complement to so-called ‘objective’ corpus frequencies as predictors in psycholinguistic experiments because most available corpora consist of texts written for adult readers (meaning that the language we hear during the first 10 years of our lives is underrepresented in such corpora; see also Zevin & Seidenberg Reference Zevin and Seidenberg2002). However, it is also possible that the AoA effect is, at least partly, independent of word frequency, and that it reflects an advantage in the accessibility of earlier learned words in the semantic networks (Brysbaert, Van Vijnendaele & De Deyne Reference Brysbaert, Ilse Van and Simon2000, Sailor, Zimmerman & Sanders Reference Sailor, Zimmerman and Sanders2011). According to Ellis & Lambon Ralph (Reference Ellis and Lambon Ralph2000), this explanation is supported by the network plasticity hypothesis, postulating that plasticity diminishes with age, giving a processing advantage to earlier introduced items (see also Monaghan & Ellis Reference Monaghan and Ellis2010).
AoA norms have been shown to be relatively highly correlated across languages. In a large study encompassing 25 languages (including Swedish), Łuniewska et al. (Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016) demonstrate significant correlations across all language pairs. For example, the Spearman’s rank correlation coefficients for those language pairs that include Swedish range from .71 to .91. Similarly, Blomberg & Öberg (Reference Ambridge, Evan, Rowland and Theakston2015) report a strong (.82) correlation between Swedish and English AoA ratings. However, Łuniewska et al. (Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016) also show that estimates of AoA vary within language groups based on whether the raters have children or whether they are bilingual. In contrast, they show no effect of age, gender or education on AoA estimates (see Birchenough, Davies & Connelly Reference Birchenough, Robert and Vincent2017). One of the aims of the current paper is to compare the strength of the correlation between AoA estimates for two varieties of the same language (Finland-Swedish and Sweden-Swedish) against those between different languages.
One potential source of variation when comparing different AoA norms may be that different databases have been collected using different response scales, ranging from five-point Likert-type responses (e.g. Alario & Ferrand Reference Alario and Ferrand1999, Tsaparina, Bonin & Méot Reference Tsaparina, Patrick and Alain2011) to asking subjects to write down the actual age in years (e.g. Kuperman et al. Reference Kuperman, Hans and Marc2012, Łuniewska et al. Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016). In addition, there may be some variation between datasets regarding the wording of the question used to elicit the ratings. Among those studies that report the exact form of the question, the most frequent wording concerns the subjects’ own experience (‘When do you think you learned this word?’). However, based on a one-language control study of question wording effects, Łuniewska et al. (Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016) propose that a more suitable question concerns children in general (‘When do children learn the word…?’). The latter wording was used for collecting the AoA ratings in the current dataset.
2.4 Subjective frequency
Subjective frequency refers to the subjective estimates by native speakers regarding the frequency with which a word is used in daily communication. Subjective frequency ratings are typically acquired by asking speakers to estimate word frequencies on a Likert scale. Thus, unlike frequency counts obtained from corpora, subjective frequency estimates are based solely on speakers’ intuitions.
Word frequency is the most studied independent variable in psycholinguistics. In fact, frequency effects permeate a wide range (if not all) linguistic processes (for literature reviews, see e.g. Ellis Reference Ellis2002, Ambridge et al. Reference Ambridge, Evan, Rowland and Theakston2015). With respect to lexical processing in adults, frequent words are comprehended and named faster than infrequent words (e.g. Postman & Conger Reference Postman and Beverly1954, Jescheniak & Levelt Reference Jescheniak and Levelt1994). Most probably, these effects arise at the level of phonological encoding, where words have different activation thresholds depending on their frequency; hence, the time taken for activation and selection of a target word in the mental lexicon is shorter for high-frequency words than for low-frequency words (Jescheniak & Levelt Reference Jescheniak and Levelt1994, Barry et al. Reference Barry, Morrison and Ellis1997, Levelt et al. Reference Levelt, Ardi and Meyer1999).
Both subjective and objective frequency measures have been used as predictors in analyses of experimental psycholinguistic data. Interestingly, some older studies found that subjective frequency is a more significant predictor of visual and auditory word processing than corpus-based frequency counts (Connine et al. Reference Connine, John, Eve and Jennifer1990, Balota, Pilotti & Cortese Reference Balota, Maura and Cortese2001). A potential explanation for this is that many of the most widely used large corpora have been dominated by relatively formal written language (e.g. newspaper text), which does not represent the type of language that people most commonly encounter. Hence, some scholars have argued that so-called objective frequency counts suffer from a sampling bias (e.g. Gilhooly & Logie Reference Gilhooly and Logie1980, Gernsbacher Reference Gernsbacher1984; recall discussion on estimates of AoA above). In order to circumvent this problem, newer psycholinguistic studies have been using subtitle corpora as sources for word frequency measures. Indeed, subtitle-based word frequency measures have been shown to outperform traditional written language corpora when predicting performance in many psycholinguistic tasks and across a wide spectrum of languages (e.g. Brysbaert & New 2009, Cai & Brysbaert Reference Cai and Marc2010, Dimitropoulou et al. Reference Dimitropoulou, Duñabeitia, Alberto, José and Manuel2010, Boada et al. Reference Boada, Marc, Juan, Josep and Pilar2020). Furthermore, frequency measures based on Facebook and Twitter corpora have been shown to have equally good predictive power as subtitle-based measures, at least for some types of tasks (Herdağdelen & Marelli Reference Herdağdelen and Marco2017). While subtitle (and social media) corpora provide a reliable measure of word frequency in daily communication, i.e. of the so-called objective frequency, subjective frequency estimates do still constitute a relevant variable for some types of studies. According to Brysbaert & Cortese (Reference Brysbaert and Cortese2011), subjective frequency estimates may contribute significantly to analyses of psycholinguistic data in instances where the ratings and the experimental data have been collected from the same population, and where this population is underrepresented in the available language corpora (e.g. Finland-Swedish university students). Furthermore, subjective frequency estimates are useful for investigating linguistic intuitions.
Subjective frequency estimates have been shown to be highly correlated with objective frequency counts from corpora (Balota et al. Reference Balota, Maura and Cortese2001). The exact degree of this correlation depends partly on what corpora are used to assess the ‘objective’ frequency (see above) and partly on how the subjective frequency estimates are collected. Balota et al. (Reference Balota, Maura and Cortese2001) show that subjective frequency estimates collected online are consistently higher than estimates collected with printed surveys. Nonetheless, the estimates are highly correlated across the different collection methods (> .9). Contrary to what might be expected, Balota et al. (Reference Balota, Maura and Cortese2001) do not find any effect of age on the subjective frequency estimates, but they do show that estimates vary slightly when subjects are asked to estimate word frequencies in different domains (e.g. ‘written’ vs. ‘heard’ language). Typically, subjective frequency estimates have been obtained by asking how often participants, on average, ‘encounter’ a given word (i.e. encompassing all language domains). Responses are normally collected on a seven-point scale ranging from ‘several times a day’ to ‘almost never’ (e.g. Balota et al. Reference Balota, Maura and Cortese2001, Boukadi, Zouaidi & Wilson Reference Boukadi, Cirine and Wilson2016, Soares et al. Reference Soares, Costa, João, Montserrat and Oliveira2017).
3. Method
The picture stimuli used in this study constitute a subset of the MultiPic dataset (Duñabeitia et al. Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017). The MultiPic dataset is the result of a collaborative European project intended to provide cognitive scientists with a publicly available and standardized set of stimuli for linguistic experiments. The dataset consists of 750 relatively simple drawings of concrete concepts. All drawings are made in the same graphic style (see examples in Figure 1). The entire dataset has been normed with respect to name agreement and visual complexity for six languages (so far): British English, Dutch (separately for Belgium and the Netherlands), French, German, Italian, and Spanish. Grayscale and colored versions of the picture stimuli, as well as the norms for each language, are available at www.bcbl.eu/databases/multipic/.

Figure 1. Examples of picture stimuli from the MultiPic database.
I selected a subset of 111 picture stimuli from the MultiPic dataset based on the following criteria: (i) the stimuli should represent a variety of semantic categories, (ii) each semantic category in the subset should include at least nine members (i.e. nine different picture stimuli), (iii) the members of each semantic category should intuitively represent varying levels of category typicality, (iv) the expected Swedish names for the picture stimuli within each semantic category should be as equally distributed between the two grammatical genders as possible. Hence, the selected subset includes a relatively varied group of stimuli, while controlling for certain semantic (category membership) and grammatical (gender) variables. This, in turn, enables examining the effects of those variables in psycholinguistic experiments using this relatively limited number of stimuli. For example, the stimuli may be used to investigate the effects of grammatical gender on object categorization and similarity perception, which have been studied extensively in recent years in many languages (for a literature review of this line of research, see Samuel, Cole & Eacott Reference Samuel, Geoff and Eacott2019).
The selected stimuli represent the following semantic categories: animal (14 pictures), body part (16), building (10), clothing (15), fruit (10), home (13), nature (13), musical instrument (9), and vehicle (11). I chose to use the grayscale version of the stimuli for two main reasons. First, colors add an additional variable to visual processing, where some colors draw more attention than others (e.g. Elliot & Maier Reference Elliot and Maier2014, Kuhbandner et al. Reference Kuhbandner, Bernhard, Stephanie and Reinhard2015). For some types of cognitive tasks, especially similarity perception or similarity judgment tasks, the use of color may therefore affect the responses. Moreover, given that many (if not most) objects do not have a ‘natural’ color (e.g. it is equally ‘natural’ for a car to be red as it is for it to be blue), color can in some cases constitute an unnecessary confounding variable – and one that is difficult to operationalize quantitatively in e.g. regression analyses. Using grayscale pictures eliminates this source of variability between the stimuli. Second, given that the data collection was carried out online and that colors can look quite different on different electronic devices, using grayscale drawings reduces the effect of display variation.
I collected the data through four separate online surveys (one for each rating type). All respondents were students at the Åbo Akademi University in Turku, Finland. Most of the students at the university speak Swedish as their first language. The majority of the students come from the coastal regions of Finland, with the three largest regions Uusimaa (Swedish: Nyland), Southwest Finland (Egentliga Finland) and Ostrobothnia (Österbotten) each accounting for roughly 30 % of the students (based on the survey data). I recruited the subjects by sending out survey invitation emails to student mailing lists. Depending on the rating type, I stressed different inclusion criteria in the invitations (see below). As participation was anonymous, it cannot be ruled out that some subjects participated in multiple surveys. However, given that the surveys were conducted at separate times, and that the surveys consisted of different tasks, it is unlikely that possible multiple participation could affect the responses. Participation in the surveys was voluntary, and the subjects did not receive any compensation for their participation.
The inclusion of subjects in the finalized datasets for each rating type was based on the subjects’ responses to questions regarding their background, and on metrics pertaining to the dispersion and the speed of their responses. Specifically, participants were excluded if their ratings (for category typicality, AoA, or subjective frequency) had a standard deviation of less than 1. Such lack of dispersion in the responses by a participant, i.e. giving almost every item an identical rating, suggested that they had not been attentive to the task at hand. In addition, participants were excluded if they had performed the rating tasks faster than what was deemed realistic for completing them in an attentive manner. Based on a pilot run of the surveys with five participants who were asked to complete the survey as fast as possible while still being attentive to the task at hand, a minimum time limit of 40 seconds per survey page was established (meaning, in effect, spending less than 1.8 seconds per item). None of the five participants in the pilot had completed any survey page in less than 49 seconds. Participants who spent less than 40 seconds per survey page were therefore excluded from the analyses.
Information about the subjects’ linguistic background was collected by means of three questions: (i) ‘What is your first language? You may indicate two languages if you consider yourself a balanced bilingual.’, (ii) ‘What is your proficiency in Swedish?’, and (iii) ‘What languages do you have at least a working proficiency in?’. In this paper, I use the term monolingual of subjects who indicate that Swedish is their only first language and who consider to have native proficiency in Swedish. In contrast, I use the term bilingual of subjects who indicate that both Swedish and Finnish are their first languages. Thus, I use the terms solely to refer to the number of L1s a subject has. In reality, virtually all subjects are proficient in English and Finnish, and many of them speak even more languages. As with most volunteer-based studies, the gender distribution is heavily skewed towards female subjects (Smith Reference Smith2008). While this can be seen as somewhat unfortunate, it is also likely that any future psycholinguistic studies of Finland-Swedish volunteers will face a similar gender distribution. I built the surveys and collected the data using the SoSciSurvey online platform (Leiner Reference Leiner2019). First, I collected the data for the ratings regarding the picture stimuli (name agreement and category typicality), and afterwards for ratings regarding the corresponding words (age of acquisition and subjective frequency). The full set of normative ratings is available in online Supplementary materials to this paper.
3.1 Survey 1: Name agreement
Forty-eight native speakers of Swedish participated in the survey (16 of whom were Swedish–Finnish bilingual; 39 female, seven male, two other; median age group = 20–22 years). The subjects saw the complete set of 111 pictures one at a time on their computer/tablet screen. They were asked to write down the word (and only one word) which they intuitively think is the best representation of the depicted object. The pictures were presented in a randomized order. All pictures had the dimensions 130 pixels × 130 pixels. The task was divided into five sets of 22/23 pictures and the subjects were encouraged to take short breaks between each set. There was no time limit to the task. On average the subjects completed the task in 12 minutes. For each picture item, the final norms include the modal response (i.e. the word given by the majority of the subjects), the number and the proportion of modal responses, the number of distinct responses (i.e. answers given by at least one subject), the number of idiosyncratic responses (i.e. answers given by no more than one subject), the number of invalid responses, and the H index for name agreement. If H = 0, then all subjects have given the same response to a given stimulus. Consequently, the value of H increases as a function of divergence among the responses.
3.2 Survey 2: Category typicality
The procedure of displaying the picture stimuli in Survey 2 was identical to that in Survey 1. Each subject saw the complete set of 111 drawings. However, instead of naming the object in the drawing, the subjects in Survey 2 were asked to rate the prototypicality of the object as a member of a given semantic category. For example, the subjects saw a drawing of an apple, with the following text directly beneath the drawing: ‘How prototypical is the depicted object as a member of the category fruit?’ (Swedish: ‘Hur prototypisk medlem av kategorin frukt är objektet på bilden?’). The subjects gave their responses on a seven-point scale directly under the question. The scale was labeled with numbers from 1 to 7. The extreme values were also labeled lexically with 1 = ‘Very atypical’ and 7 = ‘Very prototypical’, respectively.
Fifty-five subjects took part in the survey. Seven subjects were excluded from the analysis because they indicated that they were not native speakers of Swedish. Another seven subjects were excluded due to their ratings showing extremely low levels of dispersion across items (SD < 1), which suggests that they were not attentive to the task at hand. Of the 41 subjects included in the analysis, 34 were female, six male and one other (mean age = 20.2 years). Ten of the subjects were Swedish–Finnish bilinguals. On average, the subjects completed the task in nine minutes. The final category typicality ratings include for each drawing the mean rating from all 41 subjects together with the standard deviation of the ratings.
3.3 Survey 3: Age of acquisition
The stimuli for the Surveys 3 and 4 consisted of the modal responses to the picture naming task in Survey 1. The subjects were presented with the complete set of 111 words divided into five pages with 22/23 words each. The words were presented in random order. The participants were asked to estimate the AoA for each word. Following the question wording proposed by Łuniewska et al. Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016, the responses were elicited using the question: ‘At what age do children speaking Swedish as L1 typically learn the word …?’. In accordance with Stadthagen-Gonzalez & Davis (Reference Stadthagen-Gonzalez and Davis2006), and Kuperman et al. (Reference Kuperman, Hans and Marc2012), I specified AoA as ‘the age at which children understand the meaning of the word’ beneath the question. Following Gilhooly & Logie (Reference Gilhooly and Logie1980) and Soares et al. (Reference Soares, Costa, João, Montserrat and Oliveira2017), the subjects responded on a seven-point scale labeled as follows: 1 = ‘0–2 years’, 2 = ‘3–4 years’, 3 = ‘5–6 years’, 4 = ‘7–8 years’, 5 = ‘9–10 years’, 6 = ‘11–12 years’, and 7 = ‘13 or older’.
Only monolingual native Swedish speakers were invited to participate in the survey. Fifty-two subjects participated in the survey and two of them were excluded from the analysis because they indicated that they were not monolingual native speakers of Swedish. In addition, six subjects were excluded from the analysis due to having completed the task quicker than was deemed realistic based on test runs of the survey (less than 40 seconds per page). Hence, the final rating data comprises the responses from 44 subjects. On average, the subjects completed the task in 10 minutes. The final dataset includes the mean AoA estimate for each word on a scale from 1 to 7 and the standard deviation of the estimates.
3.4 Survey 4: Subjective frequency
In Survey 4, subjects were asked to estimate the frequency of the 111 words representing the modal responses to the picture naming task in Survey 1. Similarly to Survey 3, the words in Survey 4 were presented in random order and divided into five sets with 22/23 words each. The subjects were asked to estimate how often they think that they ‘hear/say/read/write the following words’. For each word, the subjects were asked to pick the most appropriate alternative from a seven-point scale labeled as follows (following Balota et al. Reference Balota, Maura and Cortese2001): 1 = ‘Almost never’, 2 = ‘Once a year’, 3 = ‘Once a month’, 4 = ‘Once a week’, 5 = ‘Three or four times a week’, 6 = ‘Once a day’, and 7 = ‘Several times a day’.
Fifty-one subjects took part in the survey. Only monolingual native Swedish speakers were invited to participate. Four subjects were excluded from the data because they indicated that they are not monolingual Swedish speakers. Additional 4 subjects were excluded on the grounds of having completed the task quicker than was deemed realistic (< 40 s per page). Thus, the final ratings comprise the responses from 43 subjects. On average, the subjects completed the task in 14 minutes. The final dataset includes the mean subjective frequency estimate for each word on a scale from 1 to 7 and the standard deviation of the estimates.
4. Results
4.1 Summary statistics
Table 1 presents the summary statistics for all four variables investigated in the surveys: name agreement, category typicality, age of acquisition and subjective frequency. The table includes two measures for name agreement, namely, the percentage of subjects who gave the modal response, and the H index. The two measures are included here because the percentage constitutes a more easily interpretable number, while the H index is a more specific measure for the divergence of the responses. A reliability analysis of the three ratings-based variables (category typicality, AoA and subjective frequency) indicates high inter-rater correlations, which strongly supports the reliability of the data: the intra-class coefficient (ICC) for category typicality (using a two-way random effect model based on the absolute agreement of multiple raters): M = .98, with 95% confidence interval (CI): .96–.98; ICC for AoA: M = .97, CI: .97–.98; ICC for subjective frequency: M = .98, CI: .98–.99.
Table 1. Summary statistics for ratings for name agreement, category typicality, age of acquisition and subjective frequency.

H index: increasing values indicate decreasing name agreement; SD = standard deviation; Min = minimum value across all items; Max = maximum value across all items; Q1 = 25th percentile; Q3 = 75th percentile; IQR = inter-quartile range; Skew = (Q3 – Median)/(Median – Q1) (value larger than 1 means the distribution is positively skewed).
Table 1 demonstrates that across all 111 picture stimuli, the modal responses to the picture naming task constitute 83 percent of the total number of responses. However, for most stimuli, the level of name agreement is higher, as demonstrated by the median value of the percentage of modal responses (.92). For 12 of the 111 stimuli, the subjects were completely unanimous in their response. For example, the picture in Figure 1a elicited the word öra ‘ear’, from all subjects. In contrast, the picture in Figure 1b elicited many different responses, resulting in the lowest level of name agreement among all the stimuli (31% modal answers, modal response: katedral ‘cathedral’, H = 1.81).
As for the other three variables, Table 1 shows that the subjects used the entire seven-point scale in their responses regarding category typicality and subjective frequency. The lowest mean rating for category typicality (2.02) concerns Figure 1c and the highest (6.92) Figure 1d (both represent the semantic category vehicle). The lowest mean rating for subjective frequency concerns the word tamburin ‘tambourine’ (1.79) and the highest the word säng ‘bed’ (6.40). Furthermore, the means of the category typicality and subjective frequency ratings lie approximately around the midpoint of the seven-point scale (4.68 and 3.93, respectively). In contrast, most of the ratings for AoA lie toward the lower end of the scale, i.e. most of the words are judged to be acquired relatively early (mean rating 2.60). Moreover, both the standard deviation (0.83) and the inter-quartile range (1.10) of the ratings are substantially smaller for AoA than for either category typicality or subjective frequency. This suggests that the words in the current dataset demonstrate relatively little variation in terms of their estimated AoA. The lowest mean rating for AoA concerns the word hand ‘hand’ (1.36) and the highest the word katedral ‘cathedral’ (5.27).
4.2 Correlations
In this section, I examine the relationships between different ratings. First, I discuss the inter-correlations between the four rating types collected for the current dataset. Thereafter, I compare the current ratings for name agreement, AoA and subjective frequency against ratings acquired in prior studies. There are no existing ratings for category typicality regarding the MultiPic stimuli, which is why no comparisons can be made concerning this variable.
4.2.1 Inter-correlations
Table 2 shows the Spearman’s rank correlation coefficients between the H index, and the ratings for category typicality, AoA and subjective frequency in the current dataset. The table demonstrates that there is a weak negative correlation between the H index and category typicality (−.22), indicating that higher typicality ratings generally coincide with somewhat higher name agreement (i.e. lower H index). In other words, pictures of objects which are judged to be prototypical members of a semantic category elicit relatively uniform responses in the naming task, while atypical objects elicit somewhat more varying responses from the subjects. There is also a weak negative correlation between the H index and subjective frequency (−.21), meaning that the modal responses to picture stimuli with high name agreement ratings (i.e. low H index) represent words which are estimated to be relatively frequent in Swedish overall. On the other hand, there is a weak positive correlation (.30) between the H index and AoA, suggesting that picture stimuli with high name agreement ratings (i.e. low H index) tend to elicit words that are estimated to be learned early in childhood (i.e. low AoA). There is also a moderate negative correlation between the category typicality of the objects in the picture stimuli and the AoA of the corresponding words (−.45). In other words, objects which are perceived as typical members of a semantic category (i.e. high category typicality) elicit words which are judged to be learned relatively early in childhood (i.e. low AoA). Finally, Table 2 shows that the two highest correlation coefficients concern the link between subjective frequency and category typicality, and subjective frequency and AoA, respectively. Subjective frequency is positively correlated with category typicality (.49), meaning that pictures of objects which are perceived as typical representatives of a semantic category elicit words which are estimated to have a high frequency in Swedish. In contrast, subjective frequency is strongly negatively correlated with AoA (−.66), suggesting that, as a rule, words which are estimated to have a high frequency in language use are also estimated to be learned relatively early in childhood.
Table 2. Inter-correlations (Spearman’s rank correlation) between the four rating values (H index, mean Category typicality, mean AoA and mean Subjective frequency).

* p < .05; ** p < .01; *** p < .001
Below, I compare the ratings for name agreement, AoA and subjective frequency in the current dataset against corresponding ratings acquired in prior research for Swedish and for other languages. Additionally, I compare the ratings for subjective frequency against objective corpus-based measures of lexical frequency in Swedish. Unfortunately, there are no existing ratings for category typicality concerning the stimuli used in the current dataset (i.e. the MultiPic database), making comparisons for this variable impossible.
4.2.2 Name agreement
Table 3 shows the Spearman’s rank correlation coefficients between the name agreement ratings (H index) collected for the current dataset and ratings acquired in identical naming tasks for British English, Dutch (Belgium), Dutch (Netherlands), French, German, Italian, and Spanish, respectively, in Duñabeitia et al. (Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017). All the ratings have been collected using picture stimuli in the MultiPic database. I calculated the correlations for the 111 picture stimuli included in the current dataset. The correlations between name agreement ratings are significant for all language pairs. The correlations for the language pairs that include Swedish range from .35 to .53 (i.e. weak to moderate), while the correlations for the other language pairs range from .38 to .71. Thus, the correlations between the Swedish data and the data in Duñabeitia et al. (Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017) are in the same range as those found within the MultiPic database, albeit in the lower end of that spectrum. I discuss the implications of these findings in the Discussion section of the paper.
Table 3. Spearman’s rank correlation coefficients regarding name agreement ratings (H index) in the current dataset (Swedish) and ratings for the languages in the MultiPic database (Duñabeitia et al. Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017).

* p < .05; ** p < .01; *** p < .001
4.2.3 Age of acquisition
Table 4 demonstrates the correlations between the AoA ratings collected for Swedish in the current dataset (Lehecka (Swedish)) and AoA ratings reported in four prior studies. Brysbaert & Biemiller (Reference Brysbaert and Andrew2017) is currently the largest dataset of AoA ratings for any language; it contains 44,000 English words. Moreover, it is the only dataset in Table 4 that contains test-based AoA ratings (i.e. the ratings are based on word recognition tests administered to children of different ages). The other datasets in the table contain AoA ratings based on estimates made by adult speakers. I used the modal responses in the British English dataset of the MultiPic database to identify corresponding English words to the 111 Swedish nouns in my dataset. I then searched for these English words in the datasets of Brysbaert & Biemiller (Reference Brysbaert and Andrew2017) and Kuperman et al. (Reference Kuperman, Hans and Marc2012). The former includes ratings for 108 and the latter for 106 of the 111 words. The correlation between the subjective AoA ratings in my dataset and both the objective and subjective AoA ratings for English are strong (.79 and .77, respectively). The third dataset used for comparison, Lind et al. (Reference Lind, Simonsen, Pernille, Elisabeth and Bjørn-Helge2015), contains AoA ratings for 1,650 words in Norwegian. It is the largest database of normative ratings in any North Germanic language. It includes 78 of the 111 words in my dataset. There is a strong correlation (.85) between the AoA ratings in Lind et al. (Reference Lind, Simonsen, Pernille, Elisabeth and Bjørn-Helge2015) and the current dataset. Finally, Łuniewska et al. (Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016) contains AoA ratings for 299 words in 25 languages, including Swedish (collected in Sweden). Their dataset includes 49 of the 111 words in my dataset. The ratings in the two datasets of Swedish words are strongly correlated (.79). Interestingly, however, Table 4 shows that there is an equally strong correlation between the AoA ratings collected from two different populations of Swedish speakers as there is between ratings collected from speakers of different Germanic languages. I discuss the implications of this finding in the Discussion section of the paper.
Table 4. Correlations (Spearman’s rank correlation) between AoA ratings in the current dataset (Lehecka (Swedish)) and ratings in four other databases: Brysbaert & Biemiller (Reference Brysbaert and Andrew2017; English), Kuperman, Stadthagen-Gonzalez & Brysbaert (Reference Kuperman, Hans and Marc2012; English), Lind et al. (Reference Lind, Simonsen, Pernille, Elisabeth and Bjørn-Helge2015; Norwegian), and Łuniewska et al. Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu(2016; Swedish).
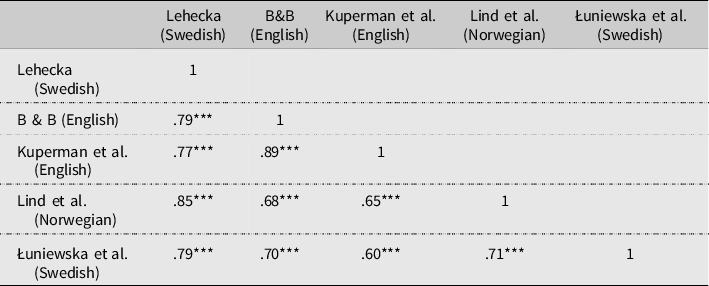
* p < .05; ** p < .01; *** p < .001
4.2.4 Subjective frequency
There are relatively few large datasets of subjective frequency ratings available for any language. Balota et al. (Reference Balota, Maura and Cortese2001) contains subjective frequency estimates for nearly 3,000 English monosyllabic words, Soares et al. (Reference Soares, Costa, João, Montserrat and Oliveira2017) for 3,800 Portuguese words, and Desrochers & Thompson (Reference Desrochers and Thompson2009) and Ferrand et al. (Reference Ferrand, Patrick, Alain, Maria, Boris, Christophe and Marc2008) for 3,600 and 1,500 French words, respectively. Table 5 illustrates the correlations (Spearman’s rank correlation coefficients) between the subjective frequency ratings in the current study and the ratings for the corresponding words in the abovementioned English, Portuguese and French databases. I used the English translations in Soares et al. (Reference Soares, Costa, João, Montserrat and Oliveira2017) and the modal responses in the British English and the French datasets in the MultiPic database (Duñabeitia et al. Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017) to determine these correspondences. Balota et al. (Reference Balota, Maura and Cortese2001) contains ratings for 56, Desrochers & Thompson (Reference Desrochers and Thompson2009) for 75, Ferrand et al. (Reference Ferrand, Patrick, Alain, Maria, Boris, Christophe and Marc2008) for 39, and Soares et al. (Reference Soares, Costa, João, Montserrat and Oliveira2017) for 86 of the 111 items in the current dataset. Table 5 demonstrates that the correlations between the subjective frequency estimates are high for all language pairs, ranging from .71 to .87.
Table 5. Correlations (Spearman’s rank correlation) between subjective frequency ratings in the current dataset (Lehecka (Swedish)) and ratings in four other databases: Balota, Pilotti & Cortese (Reference Balota, Maura and Cortese2001; English), Desrochers & Thompson (Reference Desrochers and Thompson2009; French), Ferrand et al. (Reference Ferrand, Patrick, Alain, Maria, Boris, Christophe and Marc2008; French), and Soares et al. (Reference Soares, Costa, João, Montserrat and Oliveira2017; Portuguese).

* p < .05; ** p < .01; *** p < .001
It is also informative to compare the subjective frequency estimates in the current dataset against actual corpus-based frequencies. Table 6 demonstrates the correlations (Spearman’s rank correlation coefficients) between the subjective frequency estimates and lemma frequencies in ten separate Swedish corpora in the Språkbanken database (Borin, Forsberg & Roxendal Reference Borin, Markus and Johan2012) as well as the frequencies extracted from the OpenSubtitles corpus (specifically, the subcorpus of Swedish subtitles for English movies and TV series; Lison & Tiedemann Reference Lison and Jörg2016). The corpora in the table represent different genres and regional varieties. The table shows that the strength of the correlation varies considerably depending on which corpus the subjective frequency estimates are compared to. The subjective estimates are most strongly correlated with lemma frequencies in blog text corpora (Bloggtexter 2006–2013, Bloggmix 2011). They are also strongly correlated with frequencies in Finland-Swedish children’s books (Barnlitteratur 1988–2013) and Finland-Swedish fiction (Skönlitteratur 2000–2013). In contrast, they are only weakly correlated with lemma frequencies in Finland-Swedish newspaper corpora (Åbo Underrättelser 2013, Hufvudstadsbladet 2014). Thus, the subjects’ intuitions regarding the frequencies of concrete nouns in Swedish seem to correspond well to actual language use in blogs – perhaps the most informal of the genres represented in Table 5. Whether this genre actually represents the most frequent type of language that the subjects encounter, or whether the correspondence is due to some other factor, lies beyond the scope of this paper. Interestingly, the subjective frequency estimates correlate less strongly with the frequencies in the OpenSubtitles corpus (.46). This is noteworthy given that word frequencies in subtitle corpora have been shown to constitute an accurate predictor of performance in many psycholinguistic tasks (see Section 2.4). Furthermore, the subjective frequency estimates correlate equally weakly with the frequencies in the PAROLE corpus, which was originally designed as a balanced corpus representing the use of contemporary language (for a general overview of the PAROLE project, see e.g. Marinelli et al. Reference Marinelli, Lisa, Remo, Sara, Monica, Paola, Eugenio, Sergio, Nicoletta and Antonio2003). I discuss the implications of these findings in the Discussion.
Table 6. Spearman’s rank correlation coefficients between subjective frequency estimates in the current dataset and lemma frequencies in 10 Swedish corpora in Språkbanken as well as the frequencies in the OpenSubtitles corpus (Lison & Tiedemann Reference Lison and Jörg2016).

* p < .05; ** p < .01; *** p < .001
5. Discussion
The dataset introduced in this paper constitutes a substantial addition to the currently available normative ratings for Swedish. In particular, the dataset is the first one to provide ratings for the Finland-Swedish variety of Swedish. The dataset includes norms for name agreement and category typicality for 111 picture stimuli from the MultiPic database (Duñabeitia et al. Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017), and norms for age of acquisition and subjective frequency for 111 Swedish nouns that correspond to the picture stimuli. Given that all four rating types are collected from the same population of subjects (Swedish speaking students at the Åbo Akademi University in Finland), the combination of ratings is especially useful in studies employing multivariate analyses. While the set of 111 stimuli is far from large, the stimuli do represent a variety of semantic categories as well as different grammatical genders. Hence, the ratings may be used for studies involving e.g. categorization tasks, similarity perception tasks or lexical decision tasks.
Examining inter-correlations between the four rating types reveals that there is only a relatively weak correlation between name agreement (H index) and the estimates for category typicality, AoA, and subjective frequency, respectively. This suggests that name agreement, as a psycholinguistic variable, is relatively independent from the other variables in the dataset. In contrast, the inter-correlations between category typicality, AoA and subjective frequency are moderate to strong. The strongest correlation is found between AoA and subjective frequency ratings, where words that are thought to be acquired at a younger age are consistently estimated to be more frequent in language overall. This brings into question whether AoA estimates are, indeed, based on intuitions regarding word acquisition or whether subjects use word frequency as a heuristic for such estimates (and vice versa) as some scholars have suggested (Lété & Bonin Reference Lété and Patrick2013, Baayen, Milin & Ramscar Reference Baayen, Petar and Michael2016). Investigating this question lies beyond the scope of this paper. Nevertheless, the strong correlation (>.7) between subjective AoA estimates in my dataset and both the subjective and objective AoA ratings for English (Kuperman et al. Reference Kuperman, Hans and Marc2012, Brysbaert & Biemiller Reference Brysbaert and Andrew2017) suggests that the subjective AoA estimates can be considered reasonably accurate.
The current paper shows that normative ratings collected for other languages may be applied to Finland-Swedish in regard to some rating types, but not all. In accordance with Blomberg & Öberg (Reference Blomberg and Carl2015) and Łuniewska et al. (Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016), the paper demonstrates that AoA ratings for Swedish are highly correlated with those for other languages. Thus, the results support the notion that AoA norms from closely related languages (e.g. Kuperman et al. Reference Kuperman, Hans and Marc2012, Lind et al. Reference Lind, Simonsen, Pernille, Elisabeth and Bjørn-Helge2015, Brysbaert & Biemiller Reference Brysbaert and Andrew2017) lend themselves to be adopted in psycholinguistic studies on Swedish. Naturally, cross-linguistic use of AoA norms should only be applied to unambiguous words that are easily translatable. Importantly, the results in the current study demonstrate that the correlation between AoA ratings collected from two groups of Swedish speakers (the current dataset and Łuniewska et al. Reference Łuniewska, Ewa, Sharon, Bartłomiej, Frenette, Darinka, Elma, Tessel, Shula and de Abreu2016) is not any higher than the correlation between Swedish and English or Swedish and Norwegian AoA ratings. Hence, the amount of variation in AoA estimates is equally large across different speaker groups of the same language as it is across speakers of closely related languages. In slightly hyperbolic terms, if the AoA ratings are not collected from the same specific population as the experimental data is (e.g. Finland-Swedish university students), then one can just as well use ratings from a different language.
Like AoA ratings, also subjective frequency estimates seem at first sight a good candidate for cross-linguistic use. The results in the current study demonstrate a strong correlation between the subjective frequency ratings for the 111 Swedish nouns and ratings previously collected for English, French and Portuguese. However, one should keep in mind that the words in the current dataset only contain concrete and highly imageable nouns. It is possible that subjective frequency estimates (and all other ratings) for other types of words are less strongly correlated across languages. Therefore, using e.g. English subjective frequency ratings in psycholinguistic studies on Swedish should not be extended to all word types as long as cross-linguistic correlations have not been investigated more thoroughly.
In addition, the results in this paper show that there is a strong correlation between subjective frequency ratings and certain objective lemma frequency measures, in particular frequency counts in blog text corpora. In contrast, there is only a moderate correlation between the subjective frequency estimates and the frequency counts in a so-called balanced corpus (PAROLE). However, as others have argued before me (Gernsbacher Reference Gernsbacher1984, Brysbaert & New Reference Brysbaert and Boris2009, Brysbaert & Cortese Reference Brysbaert and Cortese2011), many ‘balanced’ corpora (at least among those compiled before the 2000s) do not actually represent everyday language use very accurately. Somewhat unexpectedly, the subjective frequency estimates do not correlate any stronger with frequencies in the OpenSubtitles corpus, which has become one of the main sources for objective frequency measures in psycholinguistic studies (thanks to the excellent predictive power of those measures). This indicates that subjective frequency estimates are most likely not very faithful reflections of the objective frequency with which participants encounter words; rather, these estimates may be based on heuristics where several lexical-cognitive variables are confounded. Given that the subjective frequency estimates correlate strongly with word frequencies in children’s books, and that children’s books are likely to focus more on concrete nouns than what movie dialogues do, one is tempted to speculate that subjective frequency estimates may be affected by variables like concreteness, familiarity and AoA (for a discussion on subjective frequency, familiarity and AoA, see Brysbaert & Cortese Reference Brysbaert and Cortese2011). The exact nature of the relationship between these and other psycholinguistic variables, and how they affect the subjective ratings regarding lexical characteristics, requires further concentrated examination by future research.
In comparison with AoA and subjective frequency ratings, the H index for name agreement demonstrates relatively weaker correlations with existing datasets for other languages (.35–.53). In other words, stimuli that elicit relatively uniform responses in Swedish do not necessarily do so in other languages and vice versa. Hence, the choice of appropriate picture stimuli for studies requiring certain levels of name agreement should be based on name agreement norms collected for that specific language. Ideally, to avoid the effects of potential dialectal variation, the name agreement norms should be collected from the very same linguistic population as targeted in the actual experiment.
From a methodological perspective, the current dataset differs in some regards from those collected previously for other languages. First, the naming data in the current dataset was collected using grayscale images in the MultiPic database, while Duñabeitia et al. (Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017) used colored images. Nevertheless, the mean of the H index across the 111 items in the current dataset (.57) is very comparable to the corresponding means in e.g. the English (.53), German (.57), and Dutch (.48 and .52 for Netherlands and Belgium, respectively) datasets in Duñabeitia et al. (Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017). This suggests that, on average, object recognition is not substantially more difficult from the grayscale images than from the colored images. Second, the data for the current study was collected using an online questionnaire, whereas data acquisition for Duñabeitia et al. (Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017) was lab-based, with the exception of the Dutch (NL) dataset. Again, the similarities between the distribution parameters of the H index in the current dataset and those in Duñabeitia et al. (Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017) indicate that the lab-based and internet-based data are comparable. Third, and perhaps most significantly, the subjects used in the current dataset are native speakers of Swedish living in a majority Finnish environment (Turku, Finland), while the subjects in Duñabeitia et al. (Reference Duñabeitia, Davide, Meyer, Boris, Christos, Eva and Marc2017) were speakers of the majority language in the respective region. The Finland-Swedish variety of Swedish contains a considerable amount of Finnish loan words, on the one hand, and a substantial amount of dialectal variation, on the other hand (Ivars Reference Ivars2015). Together, these factors may contribute to some idiosyncrasies regarding the collected norms in comparison with other datasets.
The current dataset will hopefully inspire more psycholinguistic research on Swedish in general and its different varieties, in particular. In addition, this paper hopes to encourage others to collect lexical norms for a wider range of language varieties than what has been the case until now. The current dataset for Finland-Swedish is relatively small both in terms of the number of items and the number of different rating types, and it constitutes, therefore, just an initial step towards facilitating psycholinguistic studies on Finland-Swedish. Future research will do well to expand this dataset by increasing the number and the diversity of the included items (e.g. in terms of semantic categories and concreteness) as well as adding other rating types (e.g. image agreement and arousal).
Acknowledgements
The author’s work was funded by the Kone Foundation (grant number: 087438). The author would like to thank the anonymous reviewers and the editors of the NJL for their valuable comments and suggestions.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0332586521000123









