



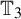
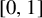
1 Introduction
In this paper, we answer a question asked by Gaboriau in his ICM survey in a slightly different language (see [Reference Gaboriau, Bhatia, Pal, Rangarajan, Srinivas and VanninathanG10, Question 5.6]). The question concerns factor of i.i.d. processes (
 $\mathsf {FIID}$
s from now on), which are random elements of
$\mathsf {FIID}$
s from now on), which are random elements of
 ${S^{\Gamma }}$
where
${S^{\Gamma }}$
where
 $\Gamma $
is a countable group and S is some measurable space which we will call the label set, and arises by applying an equivariant measurable map
$\Gamma $
is a countable group and S is some measurable space which we will call the label set, and arises by applying an equivariant measurable map
 $f:[0,1]^{\Gamma }\rightarrow S^{\Gamma }$
to an i.i.d. family
$f:[0,1]^{\Gamma }\rightarrow S^{\Gamma }$
to an i.i.d. family
 $\{\omega _{\gamma }\}_{\gamma \in \Gamma }$
where
$\{\omega _{\gamma }\}_{\gamma \in \Gamma }$
where
 $\omega _{\gamma }$
is uniform on
$\omega _{\gamma }$
is uniform on
 $[0,1]$
. In our work, the label set S will be
$[0,1]$
. In our work, the label set S will be
 $[0,1]$
or
$[0,1]$
or
 $\{0,1\}^n$
.
$\{0,1\}^n$
.
To make the definition of being an
 $\mathsf {FIID}$
precise, we need to say what are the group actions on
$\mathsf {FIID}$
precise, we need to say what are the group actions on
 $[0,1]^{\Gamma }$
and
$[0,1]^{\Gamma }$
and
 $S^{\Gamma }$
. A group action
$S^{\Gamma }$
. A group action
 $H \curvearrowright \Gamma $
of a group H on
$H \curvearrowright \Gamma $
of a group H on
 $\Gamma $
naturally extends into a group action of H on
$\Gamma $
naturally extends into a group action of H on
 $M^{\Gamma }$
for any set M: for
$M^{\Gamma }$
for any set M: for
 $x\in M^{\Gamma }$
and
$x\in M^{\Gamma }$
and
 $h\in H$
, the action
$h\in H$
, the action
 $h\cdot x$
is defined as
$h\cdot x$
is defined as
 $(h \cdot x) (\gamma )=x(h^{-1} \cdot \gamma )$
for
$(h \cdot x) (\gamma )=x(h^{-1} \cdot \gamma )$
for
 $\gamma \in \Gamma $
. Then we will call f equivariant with respect to this action if it commutes with it. Although it is with respect to the group action itself, not only with respect to H, if in the context it is clear which action we mean, we may say simply that f is H-equivariant. For us, there are two natural group actions on
$\gamma \in \Gamma $
. Then we will call f equivariant with respect to this action if it commutes with it. Although it is with respect to the group action itself, not only with respect to H, if in the context it is clear which action we mean, we may say simply that f is H-equivariant. For us, there are two natural group actions on
 $\Gamma $
. One is when
$\Gamma $
. One is when
 $H=\Gamma $
and it acts on itself by left multiplication. For the other one, we assume that a Cayley graph of
$H=\Gamma $
and it acts on itself by left multiplication. For the other one, we assume that a Cayley graph of
 $\Gamma $
is given considered here as a simple graph on the vertex set
$\Gamma $
is given considered here as a simple graph on the vertex set
 $V(G)=\Gamma $
, forgetting the orientations and labels on the edges by the group generators), so that the full graph automorphism group
$V(G)=\Gamma $
, forgetting the orientations and labels on the edges by the group generators), so that the full graph automorphism group
 $\textrm {Aut}(G)$
also acts on
$\textrm {Aut}(G)$
also acts on
 $\Gamma $
. As
$\Gamma $
. As
 $\textrm {Aut}(G)$
also acts on the edge set
$\textrm {Aut}(G)$
also acts on the edge set
 $E(G)$
of G, it makes sense to talk about equivariant measurable maps
$E(G)$
of G, it makes sense to talk about equivariant measurable maps
 $f: [0,1]^{\Gamma }\rightarrow \{0,1\}^{E(G)}$
which we will call
$f: [0,1]^{\Gamma }\rightarrow \{0,1\}^{E(G)}$
which we will call
 $\mathsf {FIID}$
subgraphs of G. Note that
$\mathsf {FIID}$
subgraphs of G. Note that
 $\Gamma <\textrm {Aut}(G)$
naturally, so for any f, the property of being
$\Gamma <\textrm {Aut}(G)$
naturally, so for any f, the property of being
 $\textrm {Aut}(G)$
-equivariant is stronger than just being
$\textrm {Aut}(G)$
-equivariant is stronger than just being
 $\Gamma $
-equivariant. The process we will construct will be
$\Gamma $
-equivariant. The process we will construct will be
 $\textrm {Aut}(G)$
-equivariant, and consequently also
$\textrm {Aut}(G)$
-equivariant, and consequently also
 $\Gamma $
-equivariant. For us, the group itself is relevant as the vertex set of the graph G which, in our work, will be the
$\Gamma $
-equivariant. For us, the group itself is relevant as the vertex set of the graph G which, in our work, will be the
 $3$
-regular tree
$3$
-regular tree
 ${\mathbb T}_3$
. For example, we can consider it to be the Cayley graph of the free product of either
${\mathbb T}_3$
. For example, we can consider it to be the Cayley graph of the free product of either
 ${\mathbb Z}$
with
${\mathbb Z}$
with
 ${\mathbb Z}_2$
or that of the threefold free product of
${\mathbb Z}_2$
or that of the threefold free product of
 ${\mathbb Z}_2$
with itself.
${\mathbb Z}_2$
with itself.
An
 $S^{\Gamma }$
-valued
$S^{\Gamma }$
-valued
 $\mathsf {FIID}$
process also belongs to the larger class of invariant processes which means that the distribution is invariant under the group action in the following sense: if A is any event (in this case, some measurable subset of
$\mathsf {FIID}$
process also belongs to the larger class of invariant processes which means that the distribution is invariant under the group action in the following sense: if A is any event (in this case, some measurable subset of
 $S^{\Gamma }$
),
$S^{\Gamma }$
),
 $h\in H$
, then
$h\in H$
, then
 $\textbf P(A)=\textbf P(h \cdot A)$
. This is again a notion relative to some group action and while our process will be
$\textbf P(A)=\textbf P(h \cdot A)$
. This is again a notion relative to some group action and while our process will be
 $\textrm {Aut}(G)$
invariant, some important properties (where we use the mass-transport principle) will already follow from the weaker fact that the process is
$\textrm {Aut}(G)$
invariant, some important properties (where we use the mass-transport principle) will already follow from the weaker fact that the process is
 $\Gamma $
-invariant.
$\Gamma $
-invariant.
If
 $\Theta =f(\omega )$
is an
$\Theta =f(\omega )$
is an
 $\mathsf {FIID}$
and
$\mathsf {FIID}$
and
 $\gamma \in \Gamma $
, then
$\gamma \in \Gamma $
, then
 $\Theta (\gamma )$
is a random variable whose distribution does not depend on
$\Theta (\gamma )$
is a random variable whose distribution does not depend on
 $\gamma $
by the transitivity of the group action with respect to which f is equivariant, and this distribution will be called the marginal of
$\gamma $
by the transitivity of the group action with respect to which f is equivariant, and this distribution will be called the marginal of
 $\Theta $
. Note that the marginal is also well defined for any invariant process when the underlying group action is transitive as well.
$\Theta $
. Note that the marginal is also well defined for any invariant process when the underlying group action is transitive as well.
If
 $\mathcal {L}\in S^V$
is a labeling of the vertex set V of a graph, then let
$\mathcal {L}\in S^V$
is a labeling of the vertex set V of a graph, then let
 ${\mathsf {clust}}(\mathcal {L})$
be the subgraph obtained by deleting any edge whose endpoints got different labels by
${\mathsf {clust}}(\mathcal {L})$
be the subgraph obtained by deleting any edge whose endpoints got different labels by
 $\mathcal {L}$
. The connected components of
$\mathcal {L}$
. The connected components of
 $\mathsf {clust}(\mathcal {L})$
will be called the clusters of the labeling.
$\mathsf {clust}(\mathcal {L})$
will be called the clusters of the labeling.
Gaboriau asked if assuming that the marginals of an
 $\mathsf {FIID}$
on a Cayley graph are uniform on
$\mathsf {FIID}$
on a Cayley graph are uniform on
 $[0,1]$
implies that the corresponding clusters are finite. We will show by an example on the
$[0,1]$
implies that the corresponding clusters are finite. We will show by an example on the
 $3$
-regular tree
$3$
-regular tree
 ${\mathbb T}_3$
that the answer is no.
${\mathbb T}_3$
that the answer is no.
Theorem 1.1. There is an
 $\mathsf {FIID}$
labeling
$\mathsf {FIID}$
labeling
 $\Theta $
of
$\Theta $
of
 ${\mathbb T}_3$
whose marginals are uniform on
${\mathbb T}_3$
whose marginals are uniform on
 $[0,1]$
for which
$[0,1]$
for which
 $\mathsf {clust}(\Theta )$
contains infinite clusters. Moreover, it is possible to modify
$\mathsf {clust}(\Theta )$
contains infinite clusters. Moreover, it is possible to modify
 $\Theta $
into a new labeling
$\Theta $
into a new labeling
 $\Theta ^{\infty }$
whose marginals are still uniform on
$\Theta ^{\infty }$
whose marginals are still uniform on
 $[0,1]$
and every cluster in
$[0,1]$
and every cluster in
 ${\mathsf {clust}}(\Theta ^{\infty })$
is infinite.
${\mathsf {clust}}(\Theta ^{\infty })$
is infinite.
Actually,
 ${\mathbb T}_3$
can be replaced by any non-amenable Cayley graph as [Reference Gaboriau and LyonsGL09] has shown that they always contain an
${\mathbb T}_3$
can be replaced by any non-amenable Cayley graph as [Reference Gaboriau and LyonsGL09] has shown that they always contain an
 $\mathsf {FIID}$
spanning forest whose components have furcation vertices (defined in §4), and that is the only thing our construction needs.
$\mathsf {FIID}$
spanning forest whose components have furcation vertices (defined in §4), and that is the only thing our construction needs.
It is natural to think of
 $\mathsf {FIID}$
s as the class of random labelings of the vertex set which can be obtained by applying a relabeling algorithm (f in the definition) which does not use any further randomness beyond its input (
$\mathsf {FIID}$
s as the class of random labelings of the vertex set which can be obtained by applying a relabeling algorithm (f in the definition) which does not use any further randomness beyond its input (
 $\omega $
in the definition). For this reason, we sometimes will refer to f as the code of the
$\omega $
in the definition). For this reason, we sometimes will refer to f as the code of the
 $\mathsf {FIID}$
and to
$\mathsf {FIID}$
and to
 $\omega $
as its source. The measurability of f implies that we can approximate the label
$\omega $
as its source. The measurability of f implies that we can approximate the label
 $f(\omega )(v)$
from local data with high probability. That is, for any
$f(\omega )(v)$
from local data with high probability. That is, for any
 $\epsilon _1,\epsilon _2>0$
, there is an
$\epsilon _1,\epsilon _2>0$
, there is an
 $r\in {\mathbb N}$
and a
$r\in {\mathbb N}$
and a
 $g: [0,1]^{B(v,r)}\rightarrow [0,1]$
which ‘guesses’ the value of
$g: [0,1]^{B(v,r)}\rightarrow [0,1]$
which ‘guesses’ the value of
 $f(\omega )(v)$
from the restriction of
$f(\omega )(v)$
from the restriction of
 $\omega $
to
$\omega $
to
 $B(v,r)$
such that
$B(v,r)$
such that
 $$ \begin{align*}\textbf P\{\omega: |f(\omega)(v)-g(\omega\restriction_{B(v,r)})|<\epsilon_1\}>1-\epsilon_2.\end{align*} $$
$$ \begin{align*}\textbf P\{\omega: |f(\omega)(v)-g(\omega\restriction_{B(v,r)})|<\epsilon_1\}>1-\epsilon_2.\end{align*} $$
We will not use this locality property explicitly (we sketch its proof in Remark 1.2). For example, if
 $f(\omega )(v)$
is the indicator of v being in an infinite cluster of a labeling obtained from
$f(\omega )(v)$
is the indicator of v being in an infinite cluster of a labeling obtained from
 $\omega $
, then of course f is measurable and
$\omega $
, then of course f is measurable and
 $f(\omega )(v)$
could be approximated in the above sense, but we will not need that detour (a similar remark holds for furcation vertices introduced later).
$f(\omega )(v)$
could be approximated in the above sense, but we will not need that detour (a similar remark holds for furcation vertices introduced later).
The reason we still emphasize this locality is twofold. First, it provides a fundamental intuition which also helps to appreciate the difficulties in constructing a process as an
 $\mathsf {FIID}$
. In particular, for far away vertices, these approximations are independent and this makes some properties hard to satisfy. Second, there are stronger notions of locality which do not follow from measurability alone, one of them is being finitary (which holds if there is a random but finite neighborhood of any vertex so that it is enough to see the source in that neighborhood to determine the label of the vertex), and we will see in §6 that no finitary process can be a counterexample to Gaboriau’s question.
$\mathsf {FIID}$
. In particular, for far away vertices, these approximations are independent and this makes some properties hard to satisfy. Second, there are stronger notions of locality which do not follow from measurability alone, one of them is being finitary (which holds if there is a random but finite neighborhood of any vertex so that it is enough to see the source in that neighborhood to determine the label of the vertex), and we will see in §6 that no finitary process can be a counterexample to Gaboriau’s question.
Remark 1.2. This locality property is a simple consequence of the fact that the product
 $\sigma $
-algebra on
$\sigma $
-algebra on
 $[0,1]^{V({\mathbb T}_3)}$
is generated by the algebra of local events (those determined by finitely many coordinates). If
$[0,1]^{V({\mathbb T}_3)}$
is generated by the algebra of local events (those determined by finitely many coordinates). If
 $(\Omega , \mathcal {B}, {\textbf P})$
is a probability space and
$(\Omega , \mathcal {B}, {\textbf P})$
is a probability space and
 $\mathcal {A}$
is an algebra generating the
$\mathcal {A}$
is an algebra generating the
 $\sigma $
-algebra
$\sigma $
-algebra
 $\mathcal {B}$
, then for any
$\mathcal {B}$
, then for any
 $E\in \mathcal {B}$
and
$E\in \mathcal {B}$
and
 $\epsilon>0$
, there is an
$\epsilon>0$
, there is an
 $F\in \mathcal {A}$
such that
$F\in \mathcal {A}$
such that
 $\textbf P(E \triangle F)<\epsilon $
(to prove this, notice that the collection of sets which can be approximated by elements of
$\textbf P(E \triangle F)<\epsilon $
(to prove this, notice that the collection of sets which can be approximated by elements of
 $\mathcal {A}$
in this sense forms a
$\mathcal {A}$
in this sense forms a
 $\sigma $
-algebra).
$\sigma $
-algebra).
Thus, for any event
 $E\subset [0,1]^{V({\mathbb T}_3)}$
and
$E\subset [0,1]^{V({\mathbb T}_3)}$
and
 $\epsilon>0$
, there is a local event F such that
$\epsilon>0$
, there is a local event F such that
 $\textbf P(E\triangle F)<\epsilon $
. That is, one can guess whether or not E holds based on whether or not F holds with a probability of error less than
$\textbf P(E\triangle F)<\epsilon $
. That is, one can guess whether or not E holds based on whether or not F holds with a probability of error less than
 $\epsilon $
. We can use this to approximate the value
$\epsilon $
. We can use this to approximate the value
 $f(\omega )(v)$
with high probability if we apply it for events in the form
$f(\omega )(v)$
with high probability if we apply it for events in the form
 $a<f(\omega )(v)<b$
for
$a<f(\omega )(v)<b$
for
 $a,b\in [0,1]$
(this is where the measurability of f is used). That is, we can figure out with high probability which subinterval of a finite subdivision of
$a,b\in [0,1]$
(this is where the measurability of f is used). That is, we can figure out with high probability which subinterval of a finite subdivision of
 $[0,1]$
contains
$[0,1]$
contains
 $f(\omega )(v)$
.
$f(\omega )(v)$
.
 $\mathsf {FIID}$
processes are the closest to i.i.d. processes, hence there is an obvious interest in deciding if a given naturally defined process is
$\mathsf {FIID}$
processes are the closest to i.i.d. processes, hence there is an obvious interest in deciding if a given naturally defined process is
 $\mathsf {FIID}$
, and what properties
$\mathsf {FIID}$
, and what properties
 $\mathsf {FIID}$
processes can or must have. These problems have a rich history in ergodic theory, probability, statistical physics, and theoretical computer science; see, e.g., [Reference Bowen, Sirakov, Ney de Souza and VianaB18, Reference LyonsL17, Reference Nam, Sly and ZhangNSZ20, Reference Ornstein and WeissOW87, Reference Rahman and VirágRV17, Reference SlyS10, Reference SpinkaS20, Reference van den Berg and SteifvdBS99] and the references therein. On amenable groups, Ornstein–Weiss theory [Reference Ornstein and WeissOW87] says that every
$\mathsf {FIID}$
processes can or must have. These problems have a rich history in ergodic theory, probability, statistical physics, and theoretical computer science; see, e.g., [Reference Bowen, Sirakov, Ney de Souza and VianaB18, Reference LyonsL17, Reference Nam, Sly and ZhangNSZ20, Reference Ornstein and WeissOW87, Reference Rahman and VirágRV17, Reference SlyS10, Reference SpinkaS20, Reference van den Berg and SteifvdBS99] and the references therein. On amenable groups, Ornstein–Weiss theory [Reference Ornstein and WeissOW87] says that every
 $\mathsf {FIID}$
process is actually isomorphic to an i.i.d. process of the same entropy. Moreover, hyperfiniteness easily implies that every process is a weak limit of
$\mathsf {FIID}$
process is actually isomorphic to an i.i.d. process of the same entropy. Moreover, hyperfiniteness easily implies that every process is a weak limit of
 $\mathsf {FIID}$
processes. However, on non-amenable groups, these tools break down.
$\mathsf {FIID}$
processes. However, on non-amenable groups, these tools break down.
In general, it seems hard to decide whether or not an
 $\mathsf {FIID}$
process with a given property exists. The locality mentioned above suggests that the answer to Gaboriau’s question should be affirmative since the conditions imply that the vertices build a label whose specific values have probability zero, through a process governed by local data, so it seems surprising that vertices arbitrarily far away can agree on the same value, yielding infinite clusters with the same label. There is, in particular, a strong correlation decay found by [Reference Backhausz, Szegedy and VirágBSzV15] which states that if
$\mathsf {FIID}$
process with a given property exists. The locality mentioned above suggests that the answer to Gaboriau’s question should be affirmative since the conditions imply that the vertices build a label whose specific values have probability zero, through a process governed by local data, so it seems surprising that vertices arbitrarily far away can agree on the same value, yielding infinite clusters with the same label. There is, in particular, a strong correlation decay found by [Reference Backhausz, Szegedy and VirágBSzV15] which states that if
 $u,v$
are vertices of
$u,v$
are vertices of
 ${\mathbb T}_d$
at distance k, then the absolute value of the correlation between their labels given by an
${\mathbb T}_d$
at distance k, then the absolute value of the correlation between their labels given by an
 $\mathsf {FIID}$
process is at most
$\mathsf {FIID}$
process is at most
 $(k+1-{{2k}/d})({1/{\sqrt {d-1}}})^k$
. This can be an obstruction for some processes to be
$(k+1-{{2k}/d})({1/{\sqrt {d-1}}})^k$
. This can be an obstruction for some processes to be
 $\mathsf {FIID}$
which might be seen as a quantitative version of this locality. While we will show that the condition of having uniform marginals does not exclude infinite clusters, there is an intuition that the condition should imply that at least the clusters are small in some sense. And indeed, [Reference Chifan and IoanaChI10, Theorem 1.1] implies that the clusters under the condition that the marginals are uniform on
$\mathsf {FIID}$
which might be seen as a quantitative version of this locality. While we will show that the condition of having uniform marginals does not exclude infinite clusters, there is an intuition that the condition should imply that at least the clusters are small in some sense. And indeed, [Reference Chifan and IoanaChI10, Theorem 1.1] implies that the clusters under the condition that the marginals are uniform on
 $[0,1]$
must be hyperfinite. In our context, hyperfiniteness of the forest
$[0,1]$
must be hyperfinite. In our context, hyperfiniteness of the forest
 ${\mathsf {clust}}(\Theta )$
means that there is a sequence of random invariant forests
${\mathsf {clust}}(\Theta )$
means that there is a sequence of random invariant forests
 $\{F_i\}_{i\in {\mathbb N}}$
such that every component of
$\{F_i\}_{i\in {\mathbb N}}$
such that every component of
 $F_i$
is finite almost surely, and (using the notation
$F_i$
is finite almost surely, and (using the notation
 $F(v)$
for the component of F containing the vertex v in a forest F)
$F(v)$
for the component of F containing the vertex v in a forest F)
 $F_i(v)\subset F_j(v)$
for
$F_i(v)\subset F_j(v)$
for
 $i\leq j$
and
$i\leq j$
and
 ${\mathsf {clust}}(\Theta )(v)=\bigcup _{i\in {\mathbb N}}F_i(v)$
for each vertex v. While it is true for any countable set that it is an increasing union of finite sets, the extra requirement of achieving this with random invariant processes makes hyperfiniteness a strong property. It implies that the clusters of
${\mathsf {clust}}(\Theta )(v)=\bigcup _{i\in {\mathbb N}}F_i(v)$
for each vertex v. While it is true for any countable set that it is an increasing union of finite sets, the extra requirement of achieving this with random invariant processes makes hyperfiniteness a strong property. It implies that the clusters of
 ${\mathsf {clust}}(\Theta )$
must be finite or must have
${\mathsf {clust}}(\Theta )$
must be finite or must have
 $1$
or
$1$
or
 $2$
ends (see [Reference Benjamini, Lyons, Peres and SchrammBLPS99]), where the number of ends of a graph is the supremum of the number of infinite components when an arbitrary finite set of vertices (together with the incident edges) is deleted. It is well known that if F is an invariant random subforest of a Cayley graph, then an infinite component of F can only have
$2$
ends (see [Reference Benjamini, Lyons, Peres and SchrammBLPS99]), where the number of ends of a graph is the supremum of the number of infinite components when an arbitrary finite set of vertices (together with the incident edges) is deleted. It is well known that if F is an invariant random subforest of a Cayley graph, then an infinite component of F can only have
 $1,2$
, or infinitely many ends.
$1,2$
, or infinitely many ends.
The problem mentioned in the following example will not be pursued in this paper, but the simple construction shown there serves as a quick illustration of this locality phenomenon of
 $\mathsf {FIID}$
s contrasted with invariant processes in general. It also helps to see through a natural optimization problem that being an
$\mathsf {FIID}$
s contrasted with invariant processes in general. It also helps to see through a natural optimization problem that being an
 $\mathsf {FIID}$
is a serious restriction among invariant processes since the optimum when we allow to use any invariant process is
$\mathsf {FIID}$
is a serious restriction among invariant processes since the optimum when we allow to use any invariant process is
 ${1/2}$
on
${1/2}$
on
 ${\mathbb T}_d$
while if we only allow
${\mathbb T}_d$
while if we only allow
 $\mathsf {FIID}$
s, the optimum is going to zero as d is going to
$\mathsf {FIID}$
s, the optimum is going to zero as d is going to
 $\infty $
.
$\infty $
.
Example 1.3. Assume we want an invariant random vertex set S of
 ${\mathbb T}_d$
which is independent in the graph theoretic sense (that is, S does not contain neighbors). We want the marginal probability
${\mathbb T}_d$
which is independent in the graph theoretic sense (that is, S does not contain neighbors). We want the marginal probability
 $p_S$
of being in S to be high. The optimal
$p_S$
of being in S to be high. The optimal
 $p_S=\tfrac {1}{2}$
is achieved by the following random invariant process: let
$p_S=\tfrac {1}{2}$
is achieved by the following random invariant process: let
 $v_1, v_2 \in V({\mathbb T}_d)$
be equivalent if their distance is even, and pick one of the classes with probability
$v_1, v_2 \in V({\mathbb T}_d)$
be equivalent if their distance is even, and pick one of the classes with probability
 $\tfrac {1}{2}$
to be S. If we want S to be a
$\tfrac {1}{2}$
to be S. If we want S to be a
 $\mathsf {FIID}$
(that is, its indicator
$\mathsf {FIID}$
(that is, its indicator
 $1_S$
to be
$1_S$
to be
 $\mathsf {FIID}$
), then a possible solution is the following code: at a vertex v, let
$\mathsf {FIID}$
), then a possible solution is the following code: at a vertex v, let
 $f(v):=1$
if and only if for each neighbor w of v,
$f(v):=1$
if and only if for each neighbor w of v,
 $\omega (v)>\omega (w)$
(where
$\omega (v)>\omega (w)$
(where
 $\omega $
was the original source) and let
$\omega $
was the original source) and let
 $f(v)=0$
otherwise, then
$f(v)=0$
otherwise, then
 $S=\{f(v)=1:v\in V({\mathbb T}_d)\}$
is an independent set. In this case,
$S=\{f(v)=1:v\in V({\mathbb T}_d)\}$
is an independent set. In this case,
 $p_S={1/({d+1})}$
.
$p_S={1/({d+1})}$
.
While this simple construction can be improved, its basic features are known to hold even for a near-optimal independent set arising as an
 $\mathsf {FIID}$
. Namely, the marginal of any
$\mathsf {FIID}$
. Namely, the marginal of any
 $\mathsf {FIID}$
independent vertex set of
$\mathsf {FIID}$
independent vertex set of
 $V({\mathbb T}_d)$
is bounded away from
$V({\mathbb T}_d)$
is bounded away from
 $\tfrac {1}{2}$
for any
$\tfrac {1}{2}$
for any
 $d\geq 3$
and it goes to zero as
$d\geq 3$
and it goes to zero as
 $d\rightarrow \infty $
. This follows easily from [Reference BollobásB81], although, its focus is on finite graphs. For the connection with
$d\rightarrow \infty $
. This follows easily from [Reference BollobásB81], although, its focus is on finite graphs. For the connection with
 $\mathsf {FIID}$
s and references to further research in this direction, see [Reference Rahman and VirágRV17].
$\mathsf {FIID}$
s and references to further research in this direction, see [Reference Rahman and VirágRV17].
An example similar to the above will be used in our construction.
Example 1.4. Let r be a positive integer and let S be the
 $\mathsf {FIID}$
vertex set defined by the following code (which will be the indicator of S): let
$\mathsf {FIID}$
vertex set defined by the following code (which will be the indicator of S): let
 $1_S(v)=1$
if and only if the label
$1_S(v)=1$
if and only if the label
 $\omega (v)$
of v is maximal of all the labels within the ball of radius r around v (otherwise
$\omega (v)$
of v is maximal of all the labels within the ball of radius r around v (otherwise
 $1_S(v)=0$
). Then, S has the property that any two vertices of it have distance at least r.
$1_S(v)=0$
). Then, S has the property that any two vertices of it have distance at least r.
We will need this construction not only directly on
 ${\mathbb T}_3$
but also on some locally finite forests associated to it. Then, ‘distance’ will refer to the distance within the forest, which is infinite between vertices of different components. These forests will be random, and S can be sampled independently of it. In this way, S is guaranteed to intersect all infinite component of these forests, as there are only countably many components.
${\mathbb T}_3$
but also on some locally finite forests associated to it. Then, ‘distance’ will refer to the distance within the forest, which is infinite between vertices of different components. These forests will be random, and S can be sampled independently of it. In this way, S is guaranteed to intersect all infinite component of these forests, as there are only countably many components.
We close this section by an important elementary observation and some remarks on the organization of the paper.
By a
 ${\mathsf {un}}[0,1]$
random variable, we mean one which is uniform on
${\mathsf {un}}[0,1]$
random variable, we mean one which is uniform on
 $[0,1]$
. By
$[0,1]$
. By
 $x\buildrel {d}\over \sim y$
, we mean that the random variable x and y has the same distribution, but with some abuse of notation, we will also denote by
$x\buildrel {d}\over \sim y$
, we mean that the random variable x and y has the same distribution, but with some abuse of notation, we will also denote by
 $x\buildrel {d}\over \sim \nu $
if x has distribution
$x\buildrel {d}\over \sim \nu $
if x has distribution
 $\nu $
. From a single
$\nu $
. From a single
 $x\buildrel {d}\over \sim {\mathsf {un}} [0,1]$
, we can obtain an i.i.d. family of infinitely many
$x\buildrel {d}\over \sim {\mathsf {un}} [0,1]$
, we can obtain an i.i.d. family of infinitely many
 $x_j\buildrel {d}\over \sim {\mathsf {un}} [0,1]$
by reorganizing the bits of x. Using this, when we describe the code f, we can assume that it can always reach out for an additional
$x_j\buildrel {d}\over \sim {\mathsf {un}} [0,1]$
by reorganizing the bits of x. Using this, when we describe the code f, we can assume that it can always reach out for an additional
 ${\mathsf {un}}[0,1]$
random variable independent of any other step of the algorithm. However, importantly, every single random variable the algorithm uses is local in the sense that it must belong to some vertex.
${\mathsf {un}}[0,1]$
random variable independent of any other step of the algorithm. However, importantly, every single random variable the algorithm uses is local in the sense that it must belong to some vertex.
In §2, we develop some tools whose purpose will be to imitate a large degree tree within a small degree one by collecting the vertices into finite connected ‘bags’ (which we will call ‘cells’), whose neighbors will be the other bags. With these tools ready, we will give a high level overview of the whole construction in §3. The first point is that Bernoulli
 $(1/2)$
percolation on a rooted tree with large degrees will leave the root in an infinite cluster with high probability. This will reduce the degrees of the tree, but this can be counterbalanced by using larger and larger bags—the tools coming from §2. To make this work, we will need special sorts of vertices called furcations, and we have to make sure that we get enough of them using our process—this will be the main content of §4. In §5, we put together everything to prove our main theorem. We also explain directly why the clusters of our labelings are hyperfinite. Finally, in §6, which is largely independent from the rest of the paper, we show that no counterexample to Gaboriau’s question can be finitary. Because it turns out that we could prove our theorem from quite basic results, we made an effort to stay self-contained.
$(1/2)$
percolation on a rooted tree with large degrees will leave the root in an infinite cluster with high probability. This will reduce the degrees of the tree, but this can be counterbalanced by using larger and larger bags—the tools coming from §2. To make this work, we will need special sorts of vertices called furcations, and we have to make sure that we get enough of them using our process—this will be the main content of §4. In §5, we put together everything to prove our main theorem. We also explain directly why the clusters of our labelings are hyperfinite. Finally, in §6, which is largely independent from the rest of the paper, we show that no counterexample to Gaboriau’s question can be finitary. Because it turns out that we could prove our theorem from quite basic results, we made an effort to stay self-contained.
2 Voronoi partitions and other forests
In this section, we define some
 $\mathsf {FIID}$
subgraphs which will always be forests since we are working on
$\mathsf {FIID}$
subgraphs which will always be forests since we are working on
 ${\mathbb T}_3$
. We have already defined the forest
${\mathbb T}_3$
. We have already defined the forest
 $\mathsf {clust}(L)$
corresponding to a labeling L.
$\mathsf {clust}(L)$
corresponding to a labeling L.
We now define Voronoi partitions. If S is a vertex set, we want to partition all the other vertices into classes according to the closest element of S. We have to deal with the potential ambiguity if a vertex v is at an equal distance from several elements of S, moreover, we want to make the partition classes connected.
Definition 2.1. Let F be any locally finite forest and let
 $S\subset V(F)$
and a collection of distinct real numbers
$S\subset V(F)$
and a collection of distinct real numbers
 $\{\alpha (v)\}_{v\in S}$
be given. If
$\{\alpha (v)\}_{v\in S}$
be given. If
 $v\in V(F)$
, and the F-component which contains v also contains some element from S, then let
$v\in V(F)$
, and the F-component which contains v also contains some element from S, then let
 $S_v\subset S$
be the set of those elements of S which are closest to v, that is,
$S_v\subset S$
be the set of those elements of S which are closest to v, that is,
 $S_v:=\{s: { d}_F(v,s)={d}_F(v,S)\}$
. Let
$S_v:=\{s: { d}_F(v,s)={d}_F(v,S)\}$
. Let
 $\phi _{(S,\alpha ^{})}(v):=s_0$
be that element of
$\phi _{(S,\alpha ^{})}(v):=s_0$
be that element of
 $S_v$
for which
$S_v$
for which
 $\alpha ^{}(s_0)$
is minimal (by the local finiteness of F,
$\alpha ^{}(s_0)$
is minimal (by the local finiteness of F,
 $S_v$
is finite). Let two vertices
$S_v$
is finite). Let two vertices
 $v_1,v_2$
be equivalent if
$v_1,v_2$
be equivalent if
 $\phi _{(S,\alpha ^{})}(v_1)=\phi _{(S,\alpha ^{})}(v_2)$
. If the F-component of v does not contain any element from S, then let the equivalence class of v be the singleton
$\phi _{(S,\alpha ^{})}(v_1)=\phi _{(S,\alpha ^{})}(v_2)$
. If the F-component of v does not contain any element from S, then let the equivalence class of v be the singleton
 $\{v\}$
. Let
$\{v\}$
. Let
 ${\mathsf {Vor}}(S,\alpha ^{})$
be the partition corresponding to this equivalence.
${\mathsf {Vor}}(S,\alpha ^{})$
be the partition corresponding to this equivalence.
The role of the
 $\alpha $
is to handle the ambiguity if
$\alpha $
is to handle the ambiguity if
 $|S_v|>1$
and in this way, the partition classes are indeed connected. Note that one can break the tie in many other ways, but it is not automatically true that the partition classes are connected. For example, if each vertex v chose to be equivalent with a uniform random element from
$|S_v|>1$
and in this way, the partition classes are indeed connected. Note that one can break the tie in many other ways, but it is not automatically true that the partition classes are connected. For example, if each vertex v chose to be equivalent with a uniform random element from
 $S_v$
and different vertices did it independently of each other, then the partition classes do not have to be connected.
$S_v$
and different vertices did it independently of each other, then the partition classes do not have to be connected.
When we use Voronoi partitions, the forest will be in the form of
 $\mathsf {clust}(L)$
or something closely related, the S will be an
$\mathsf {clust}(L)$
or something closely related, the S will be an
 $\mathsf {FIID}$
set and the
$\mathsf {FIID}$
set and the
 $\alpha $
will be extracted from the source. We will suppress
$\alpha $
will be extracted from the source. We will suppress
 $\alpha $
in the notation and just denote the partition by
$\alpha $
in the notation and just denote the partition by
 ${\mathsf {Vor}}(S)$
. We always assume that the hidden
${\mathsf {Vor}}(S)$
. We always assume that the hidden
 $\alpha $
is independent of any other steps of the construction. We will refer to partition classes as cells and we will use this terminology in general where we have a forest where every component is finite almost surely. We will see that our Voronoi partitions have this property. When we consider a Voronoi partition as a forest, we mean that we delete edges between vertices of different cells and forget the distinguished vertex; in this way, they are
$\alpha $
is independent of any other steps of the construction. We will refer to partition classes as cells and we will use this terminology in general where we have a forest where every component is finite almost surely. We will see that our Voronoi partitions have this property. When we consider a Voronoi partition as a forest, we mean that we delete edges between vertices of different cells and forget the distinguished vertex; in this way, they are
 $\mathsf {FIID}$
forests.
$\mathsf {FIID}$
forests.
If we want to produce an
 $\mathsf {FIID}$
labeling with a
$\mathsf {FIID}$
labeling with a
 $\mathsf {un} [0,1]$
marginal whose clusters are finite but arbitrarily large, that is easy. We can even sample an arbitrary random forest whose components are almost surely finite, and label the vertices independently afterward.
$\mathsf {un} [0,1]$
marginal whose clusters are finite but arbitrarily large, that is easy. We can even sample an arbitrary random forest whose components are almost surely finite, and label the vertices independently afterward.
Lemma 2.2. Let
 $\Pi $
be an
$\Pi $
be an
 ${\mathsf {FIID}}$
forest whose components are almost surely finite. There is an
${\mathsf {FIID}}$
forest whose components are almost surely finite. There is an
 $\mathsf {FIID}$
labeling
$\mathsf {FIID}$
labeling
 $\theta $
with a
$\theta $
with a
 $\mathsf {un} [0,1]$
marginal which is constant over each component of
$\mathsf {un} [0,1]$
marginal which is constant over each component of
 $\Pi $
(in fact, almost surely
$\Pi $
(in fact, almost surely
 $\mathsf {clust}(\theta )=\Pi $
), and the
$\mathsf {clust}(\theta )=\Pi $
), and the
 $\theta $
-labels of different components of
$\theta $
-labels of different components of
 $\Pi $
form an independent family.
$\Pi $
form an independent family.
Proof. Let
 $({\alpha }(v),\beta (v))_{v\in V(T)}$
be a collection of two independent
$({\alpha }(v),\beta (v))_{v\in V(T)}$
be a collection of two independent
 ${\mathsf {un}}[0,1]$
label over each vertex. For a vertex v, let
${\mathsf {un}}[0,1]$
label over each vertex. For a vertex v, let
 $\Pi (v)$
be the component of
$\Pi (v)$
be the component of
 $\Pi $
containing v. Since almost surely
$\Pi $
containing v. Since almost surely
 $|\Pi (v)|<\infty $
and the
$|\Pi (v)|<\infty $
and the
 $\beta (v)$
labels are all distinct, there will be a unique
$\beta (v)$
labels are all distinct, there will be a unique
 $v_0\in \Pi (v)$
for which
$v_0\in \Pi (v)$
for which
 $\beta (v_0)$
is minimal within
$\beta (v_0)$
is minimal within
 $\Pi (v)$
(that is,
$\Pi (v)$
(that is,
 $\beta (v_0)=\texttt {min}\{\beta (w);w\in \Pi (v)\}$
). Then let v ‘copy’ the
$\beta (v_0)=\texttt {min}\{\beta (w);w\in \Pi (v)\}$
). Then let v ‘copy’ the
 $\alpha $
label from
$\alpha $
label from
 $v_0$
, meaning that
$v_0$
, meaning that
 $\theta (v):={\alpha }(v_0)$
.
$\theta (v):={\alpha }(v_0)$
.
The finiteness of the components above was crucial; when we construct the infinite clusters with uniform labels, then the labels and the clusters will be built together step-by-step and not by selecting the infinite clusters first and labeling them afterward.
We will call a random forest whose components are almost surely finite a cell-partition and the components will be called cells or
 $\Pi $
-cells where the forest is denoted by
$\Pi $
-cells where the forest is denoted by
 $\Pi $
. If
$\Pi $
. If
 $\Pi $
is an
$\Pi $
is an
 $\mathsf {FIID}$
cell-partition, then let
$\mathsf {FIID}$
cell-partition, then let
 $\mathsf {Ber}(\Pi )$
be the
$\mathsf {Ber}(\Pi )$
be the
 $\mathsf {FIID} \{0,1\}$
-labeling
$\mathsf {FIID} \{0,1\}$
-labeling
 $\unicode{x3bb} $
of the vertex set with the properties that: its marginals are fair bits (
$\unicode{x3bb} $
of the vertex set with the properties that: its marginals are fair bits (
 $\textbf P(\unicode{x3bb} (v)=1)=\textbf P(\unicode{x3bb} (v)=0)=\tfrac {1}{2}$
), the labels are constant over a
$\textbf P(\unicode{x3bb} (v)=1)=\textbf P(\unicode{x3bb} (v)=0)=\tfrac {1}{2}$
), the labels are constant over a
 $\Pi $
-cell (
$\Pi $
-cell (
 $\Pi (v_1)=\Pi (v_2)$
implies
$\Pi (v_1)=\Pi (v_2)$
implies
 $\unicode{x3bb} (v_1)=\unicode{x3bb} (v_2)$
), and the labels over different cells are independent. By the notation
$\unicode{x3bb} (v_1)=\unicode{x3bb} (v_2)$
), and the labels over different cells are independent. By the notation
 $\unicode{x3bb} \sim \mathsf {Ber}(\Pi )$
, we will mean that first
$\unicode{x3bb} \sim \mathsf {Ber}(\Pi )$
, we will mean that first
 $\Pi $
is sampled, and then we sample
$\Pi $
is sampled, and then we sample
 $\unicode{x3bb} $
given
$\unicode{x3bb} $
given
 $\Pi $
. We will use
$\Pi $
. We will use
 $\mathsf {Ber}(\Pi )$
to imitate a Bernoulli percolation on a graph whose vertices are the cells of
$\mathsf {Ber}(\Pi )$
to imitate a Bernoulli percolation on a graph whose vertices are the cells of
 $\Pi $
. The fact that a labeling with this distribution can be realized as an
$\Pi $
. The fact that a labeling with this distribution can be realized as an
 $\mathsf {FIID}$
labeling is a consequence of the previous lemma: the fair bits needed for
$\mathsf {FIID}$
labeling is a consequence of the previous lemma: the fair bits needed for
 $\mathsf {Ber}(\Pi )$
can be obtained from the
$\mathsf {Ber}(\Pi )$
can be obtained from the
 $\mathsf {un} [0,1] \theta $
-label guaranteed by the lemma, for example, by defining the bit to be
$\mathsf {un} [0,1] \theta $
-label guaranteed by the lemma, for example, by defining the bit to be
 $1$
if
$1$
if
 $\theta>\tfrac {1}{2}$
and
$\theta>\tfrac {1}{2}$
and
 $0$
if
$0$
if
 $\theta \leq \tfrac {1}{2}$
.
$\theta \leq \tfrac {1}{2}$
.
One may notice that for a Voronoi-type partition
 ${\mathsf {Vor}}(S)$
, we do not need to know the finiteness of the cells to label them as claimed in the lemma, since each cell already comes with a single distinguished vertex (the one from S), and the whole cell can copy labels from this distinguished vertex just as in the proof.
${\mathsf {Vor}}(S)$
, we do not need to know the finiteness of the cells to label them as claimed in the lemma, since each cell already comes with a single distinguished vertex (the one from S), and the whole cell can copy labels from this distinguished vertex just as in the proof.
So, if a Voronoi partition had non-zero chance of producing infinite clusters, then that already would witness the truth of our Theorem 1.1. However, a simple application of the mass-transport principle shows that every Voronoi cell must be finite. See [Reference Lyons and PeresLP16, Ch. 8] for more on the mass-transport principle and note that the application we need here is also covered there directly as Example 8.6. For completeness, we also explain this here.
We will show that an invariant process on a Cayley graph cannot determine infinite components with a single distinguished vertex; the precise statement is Lemma 2.3 below. Note that this immediately implies that this is also true if the word ‘single’ is replaced by ‘finitely many’, as from the finitely many vertices we can select a uniform one and this still will be an invariant process if the original one was.
Let G be a Cayley graph of a countable group
 $\Gamma $
, we will use
$\Gamma $
, we will use
 $\Omega :=\{0,1\}^{V(G)\cup E(G)}$
to represent various vertex and edge configurations of G. Note that
$\Omega :=\{0,1\}^{V(G)\cup E(G)}$
to represent various vertex and edge configurations of G. Note that
 $\Gamma $
acts on
$\Gamma $
acts on
 $\Omega $
. We interpret the edges with label zero as deleted, the edges with label
$\Omega $
. We interpret the edges with label zero as deleted, the edges with label
 $1$
as kept, and vertices with label
$1$
as kept, and vertices with label
 $1$
as distinguished (and the vertices of label
$1$
as distinguished (and the vertices of label
 $0$
are not), and thus when we talk about a component, we mean that the underlying graph has all the original vertices (distinguished or not), but only the edges which are kept. Thus, we can represent the event that ‘in every component, there is at most one distinguished vertex and there is an infinite component which does contain a distinguished vertex’ as a measurable subset
$0$
are not), and thus when we talk about a component, we mean that the underlying graph has all the original vertices (distinguished or not), but only the edges which are kept. Thus, we can represent the event that ‘in every component, there is at most one distinguished vertex and there is an infinite component which does contain a distinguished vertex’ as a measurable subset
 ${\mathcal E}\subset \Omega $
.
${\mathcal E}\subset \Omega $
.
We have not specified a probability measure on
 $\Omega $
, but now we will say something about all
$\Omega $
, but now we will say something about all
 $\Gamma $
-invariant ones.
$\Gamma $
-invariant ones.
Lemma 2.3. If
 $\mathcal {P}$
is any
$\mathcal {P}$
is any
 $\Gamma $
-invariant probability measure on
$\Gamma $
-invariant probability measure on
 $\Omega $
, then the event
$\Omega $
, then the event
 ${\mathcal E}$
cannot happen, that is
${\mathcal E}$
cannot happen, that is
 $$ \begin{align*}\mathcal{P}({\mathcal E})=0.\end{align*} $$
$$ \begin{align*}\mathcal{P}({\mathcal E})=0.\end{align*} $$
To prove this, we will need the mass-transport principle for countable groups, which is the following.
Proposition 2.4. Let
 $\Gamma $
be a countable group and o be its identity. If
$\Gamma $
be a countable group and o be its identity. If
 $f:\Gamma \times \Gamma \longrightarrow [0,1]$
is diagonally invariant (meaning that
$f:\Gamma \times \Gamma \longrightarrow [0,1]$
is diagonally invariant (meaning that
 $f(\gamma x, \gamma y)=f(x,y)$
for all
$f(\gamma x, \gamma y)=f(x,y)$
for all
 $\gamma ,x,y \in \Gamma )$
, then
$\gamma ,x,y \in \Gamma )$
, then
 $$ \begin{align*}\sum_{x\in \Gamma}f(o,x)=\sum_{x\in \Gamma}f(x,o).\end{align*} $$
$$ \begin{align*}\sum_{x\in \Gamma}f(o,x)=\sum_{x\in \Gamma}f(x,o).\end{align*} $$
Proof. By f being diagonally invariant,
 $f(o,x)=f(x^{-1}o,x^{-1}x)=f(x^{-1},o)$
, so
$f(o,x)=f(x^{-1}o,x^{-1}x)=f(x^{-1},o)$
, so
 $\sum _{x\in \Gamma }f(o,x)=\sum _{x\in \Gamma }f(x^{-1},o).$
However, inversion is a bijection, so the summation
$\sum _{x\in \Gamma }f(o,x)=\sum _{x\in \Gamma }f(x^{-1},o).$
However, inversion is a bijection, so the summation
 $\sum _{x\in \Gamma }f(x^{-1},o)$
runs over the same non-negative terms as
$\sum _{x\in \Gamma }f(x^{-1},o)$
runs over the same non-negative terms as
 $\sum _{x\in \Gamma }f(x^{-1},o)$
.
$\sum _{x\in \Gamma }f(x^{-1},o)$
.
Proof of Lemma 2.3
Assume that there exists a
 $\Gamma $
-invariant
$\Gamma $
-invariant
 $\mathcal {P}$
probability measure on
$\mathcal {P}$
probability measure on
 $\Omega $
for which
$\Omega $
for which
 $\mathcal {P}({\mathcal E})>0.$
Define the measurable function
$\mathcal {P}({\mathcal E})>0.$
Define the measurable function
 $F:\Gamma \times \Gamma \times \Omega \rightarrow [0,\infty ]$
by:
$F:\Gamma \times \Gamma \times \Omega \rightarrow [0,\infty ]$
by:
 $F(x,y,\omega ):=1$
if x and y are within the same component and x is the distinguished vertex of that component in the configuration
$F(x,y,\omega ):=1$
if x and y are within the same component and x is the distinguished vertex of that component in the configuration
 $\omega $
,
$\omega $
,
 $F(x,y,\omega ):=0$
otherwise. This function is invariant under
$F(x,y,\omega ):=0$
otherwise. This function is invariant under
 $\textrm {Aut}(G)$
, consequently also under
$\textrm {Aut}(G)$
, consequently also under
 $\Gamma $
, in the sense that
$\Gamma $
, in the sense that
 $F(\alpha \cdot x,\alpha \cdot y, \alpha \cdot \omega )$
for any
$F(\alpha \cdot x,\alpha \cdot y, \alpha \cdot \omega )$
for any
 $\alpha $
from either of
$\alpha $
from either of
 $\textrm {Aut}(G)$
or
$\textrm {Aut}(G)$
or
 $\Gamma $
. Here,
$\Gamma $
. Here,
 $F(x,y, \omega )$
is called the mass sent by x to y or the mass received by y from x in the configuration
$F(x,y, \omega )$
is called the mass sent by x to y or the mass received by y from x in the configuration
 $\omega $
. The
$\omega $
. The
 $\Gamma $
-invariance of
$\Gamma $
-invariance of
 $\mathcal {P}$
and F implies that
$\mathcal {P}$
and F implies that
 $f(x,y):={\textbf E}_{\mathcal {P}} F(x,y,*)$
is diagonally invariant, so Proposition 2.4 implies that for
$f(x,y):={\textbf E}_{\mathcal {P}} F(x,y,*)$
is diagonally invariant, so Proposition 2.4 implies that for
 $o \in \Gamma $
, the expected overall mass it receives is the same as the expected overall mass it sends out.
$o \in \Gamma $
, the expected overall mass it receives is the same as the expected overall mass it sends out.
The expected mass the origin receives is no more than
 $1$
(this is true even pointwise), but the expected mass it sends out is infinite if
$1$
(this is true even pointwise), but the expected mass it sends out is infinite if
 $\mathcal {P}({\mathcal E})>0$
; the origin would actually send out infinite mass with positive probability, not just in expectation. This contradiction shows that such invariant measure
$\mathcal {P}({\mathcal E})>0$
; the origin would actually send out infinite mass with positive probability, not just in expectation. This contradiction shows that such invariant measure
 $\mathcal {P}$
is not possible.
$\mathcal {P}$
is not possible.
Recall that if
 $\Pi $
is a forest, then for a vertex v, we denoted by
$\Pi $
is a forest, then for a vertex v, we denoted by
 $\Pi (v)$
the component of v. If two forests
$\Pi (v)$
the component of v. If two forests
 $P,F$
are related in a way that
$P,F$
are related in a way that
 $P(v)\subset F(v)$
for all v, then we denote this relationship by
$P(v)\subset F(v)$
for all v, then we denote this relationship by
 $P\prec F$
or
$P\prec F$
or
 $F\succ P$
. To such a pair, we associate a new forest.
$F\succ P$
. To such a pair, we associate a new forest.
Definition 2.5. If
 $F,P$
are forests on the same vertex set and
$F,P$
are forests on the same vertex set and
 $P\prec F$
, then we associate to this pair a new forest
$P\prec F$
, then we associate to this pair a new forest
 $F/P$
, called the large-scale forest (or when F is a tree, the large-scale tree). The vertices of
$F/P$
, called the large-scale forest (or when F is a tree, the large-scale tree). The vertices of
 $F/P$
are the components of P, and two P-components
$F/P$
are the components of P, and two P-components
 $t_1,t_2$
are connected in
$t_1,t_2$
are connected in
 $F/P$
if their distance is
$F/P$
if their distance is
 $1$
in F. For a vertex v, let
$1$
in F. For a vertex v, let
 $F/P(v)$
be the subtree of
$F/P(v)$
be the subtree of
 $F/P$
which contains
$F/P$
which contains
 $P(v)$
.
$P(v)$
.
When we use this large scale forest construction, the P-components will be finite (so P is a cell-partition). If there is a further cell-partition
 $\Pi $
on
$\Pi $
on
 $F/P$
, then there is a natural corresponding cell-partition
$F/P$
, then there is a natural corresponding cell-partition
 $\texttt {glue}_{\Pi }(P)$
on F so that
$\texttt {glue}_{\Pi }(P)$
on F so that
 $P \prec \texttt {glue}_{\Pi }(P) \prec F$
. We just glue together the cells of P according to
$P \prec \texttt {glue}_{\Pi }(P) \prec F$
. We just glue together the cells of P according to
 $\Pi $
, meaning that if
$\Pi $
, meaning that if
 $\mathcal {C}$
is a
$\mathcal {C}$
is a
 $\Pi $
-cell consisting of the P-cells
$\Pi $
-cell consisting of the P-cells
 $C_1,\ldots ,C_l$
, then
$C_1,\ldots ,C_l$
, then
 $\bigcup \{C_i:C_i\in \mathcal {C}\}$
will be a
$\bigcup \{C_i:C_i\in \mathcal {C}\}$
will be a
 $\texttt {glue}_{\Pi }(P)$
-cell and, as these cells already partition all the vertices of F, defines
$\texttt {glue}_{\Pi }(P)$
-cell and, as these cells already partition all the vertices of F, defines
 $\texttt {glue}_{\Pi }(P)$
.
$\texttt {glue}_{\Pi }(P)$
.
When
 $F,P$
are
$F,P$
are
 ${\mathsf {FIID}}$
subforests of
${\mathsf {FIID}}$
subforests of
 ${\mathbb T}_3$
and
${\mathbb T}_3$
and
 $P\prec F$
and P is a cell-partition, then by Lemma 2.2, we can assume that the vertices of
$P\prec F$
and P is a cell-partition, then by Lemma 2.2, we can assume that the vertices of
 $F/P$
are equipped with a family of i.i.d. random variables
$F/P$
are equipped with a family of i.i.d. random variables
 $x(v)_{v\in V(F/P)}\buildrel {d}\over \sim {\mathsf {un}} [0,1]$
which we can use to build Voronoi-type partitions on
$x(v)_{v\in V(F/P)}\buildrel {d}\over \sim {\mathsf {un}} [0,1]$
which we can use to build Voronoi-type partitions on
 $F/P$
as an
$F/P$
as an
 ${\mathsf {FIID}}$
-forest on the original
${\mathsf {FIID}}$
-forest on the original
 ${\mathbb T}_3$
(corresponding to each other via our glue operation).
${\mathbb T}_3$
(corresponding to each other via our glue operation).
3 High level overview
We will use the basic theory of Bernoulli percolation on trees, see [Reference Lyons and PeresLP16] or [Reference PeteP19]. In fact, we will only need some very basic result from which we can directly obtain everything that we need so we made some effort to stay self-contained. In addition to this, we will need at the end the fact that an
 $\mathsf {FIID}$
is ergodic, thus, when we prove that a vertex is contained in an infinite cluster with positive probability, we can conclude that there are infinite clusters with probability one.
$\mathsf {FIID}$
is ergodic, thus, when we prove that a vertex is contained in an infinite cluster with positive probability, we can conclude that there are infinite clusters with probability one.
A Bernoulli-
 ${p}$
site percolation on a graph is the
${p}$
site percolation on a graph is the
 $\{0,1\}$
-labeling where a vertex gets label
$\{0,1\}$
-labeling where a vertex gets label
 $1$
with probability p and
$1$
with probability p and
 $0$
with probability
$0$
with probability
 $1-p$
, independently of the others. We will denote this labeling by
$1-p$
, independently of the others. We will denote this labeling by
 ${\mathsf {Ber}}({p})$
.
${\mathsf {Ber}}({p})$
.
Remark 3.1. In percolation theory, the interpretation is that with probability p, we keep a vertex (or site) open and they become closed with probability
 $(1-p)$
, independently from each other. There is a very useful notion called the branching number
$(1-p)$
, independently from each other. There is a very useful notion called the branching number
 ${\mathsf {br}}(T)$
of a locally finite infinite tree T with the property that
${\mathsf {br}}(T)$
of a locally finite infinite tree T with the property that
 ${\mathsf {br}}({\mathbb T}_{d})=d-1$
and a
${\mathsf {br}}({\mathbb T}_{d})=d-1$
and a
 ${\mathsf {Ber}}(p)$
labeling on T almost surely has infinite open clusters exactly if
${\mathsf {Ber}}(p)$
labeling on T almost surely has infinite open clusters exactly if
 $p> 1/{\mathsf {br}}(T)$
. Moreover, when this condition holds and if T is homogeneous enough, for example,
$p> 1/{\mathsf {br}}(T)$
. Moreover, when this condition holds and if T is homogeneous enough, for example,
 ${\mathbb T}_d$
, then the infinite open clusters will have branching number exactly
${\mathbb T}_d$
, then the infinite open clusters will have branching number exactly
 $p {\mathsf {br}}(T)$
. So the big picture is that what guarantees infinite clusters in a Bernoulli percolation is a high enough branching number and the Bernoulli percolation will push down the branching number of the resulting clusters and this pattern continues if we keep applying independent Bernoulli percolations until there are no more infinite clusters.
$p {\mathsf {br}}(T)$
. So the big picture is that what guarantees infinite clusters in a Bernoulli percolation is a high enough branching number and the Bernoulli percolation will push down the branching number of the resulting clusters and this pattern continues if we keep applying independent Bernoulli percolations until there are no more infinite clusters.
We will need the following proposition.
Proposition 3.2. On the
 $4$
-regular tree
$4$
-regular tree
 ${\mathbb T}_4$
, a
${\mathbb T}_4$
, a
 ${\mathsf {Ber}}(\tfrac {1}{2})$
labeling almost surely has infinite clusters.
${\mathsf {Ber}}(\tfrac {1}{2})$
labeling almost surely has infinite clusters.
Although we will work on more general trees, the above will be sufficient, through the fact that if a tree T has minimal degree
 $\delta :=d_{\textrm {min}}(T)$
, then T contains
$\delta :=d_{\textrm {min}}(T)$
, then T contains
 ${\mathbb T}_{\delta }$
as a subgraph.
${\mathbb T}_{\delta }$
as a subgraph.
The above result has the easy consequence, which we will prove as Lemma 4.4, that for any
 $\epsilon>0$
, there exists a
$\epsilon>0$
, there exists a
 $D(\epsilon )\in {\mathbb N}$
such that if a tree T with a distinguished root
$D(\epsilon )\in {\mathbb N}$
such that if a tree T with a distinguished root
 $r\in V(T)$
has minimal degree at least
$r\in V(T)$
has minimal degree at least
 $D(\epsilon )$
, then a
$D(\epsilon )$
, then a
 ${\mathsf {Ber}}(\tfrac {1}{2})$
labeling on T will have an infinite cluster containing r with probability at least
${\mathsf {Ber}}(\tfrac {1}{2})$
labeling on T will have an infinite cluster containing r with probability at least
 $(1-\epsilon )$
. In fact, we will need a property which is stronger than being infinite: we need forking clusters. In the process that we are going to define, the infinite clusters will automatically be forking; however, we will not prove this, since for our construction to work, it will be enough to know that forking clusters exists with positive probability, and thus some of the infinite clusters will be forking by ergodicity. We will prove forking clusters exists with positive probability through Lemma 4.5 directly from Proposition 3.2.
$(1-\epsilon )$
. In fact, we will need a property which is stronger than being infinite: we need forking clusters. In the process that we are going to define, the infinite clusters will automatically be forking; however, we will not prove this, since for our construction to work, it will be enough to know that forking clusters exists with positive probability, and thus some of the infinite clusters will be forking by ergodicity. We will prove forking clusters exists with positive probability through Lemma 4.5 directly from Proposition 3.2.
To highlight the ideas of the construction, we first show the modest claim that for any positive integer n, there is an
 $\mathsf {FIID}$
labeling
$\mathsf {FIID}$
labeling
 $\theta _n$
on
$\theta _n$
on
 ${\mathbb T}_3$
whose marginal is uniform on the label set
${\mathbb T}_3$
whose marginal is uniform on the label set
 $\{0,1\}^n$
and
$\{0,1\}^n$
and
 $\mathsf {clust}(\theta _n)$
contains infinite clusters.
$\mathsf {clust}(\theta _n)$
contains infinite clusters.
On the d-regular tree
 ${\mathbb T}_d$
, a
${\mathbb T}_d$
, a
 ${\mathsf {Ber}}(p)$
labeling almost surely has infinite clusters spanned by vertices of label
${\mathsf {Ber}}(p)$
labeling almost surely has infinite clusters spanned by vertices of label
 $1$
exactly when
$1$
exactly when
 $p>1/(d-1)$
. This implies that if a tree T has minimal degree at least
$p>1/(d-1)$
. This implies that if a tree T has minimal degree at least
 $\delta $
and if
$\delta $
and if
 $p({\delta }-1)>1$
, then the clusters of a
$p({\delta }-1)>1$
, then the clusters of a
 ${\mathsf {Ber}}(p)$
-labeling on T will contain infinite ones labeled with
${\mathsf {Ber}}(p)$
-labeling on T will contain infinite ones labeled with
 $1$
.
$1$
.
If
 $L_0,\ldots , L_{n-1}$
are independent
$L_0,\ldots , L_{n-1}$
are independent
 $\mathsf {Ber}(\tfrac {1}{2})$
-labelings, and we concatenate them to get the
$\mathsf {Ber}(\tfrac {1}{2})$
-labelings, and we concatenate them to get the
 $\{0,1\}^n$
-labeling
$\{0,1\}^n$
-labeling
 $\mathcal {L}_n:=(L_0,\ldots ,L_{n-1})$
, then for any
$\mathcal {L}_n:=(L_0,\ldots ,L_{n-1})$
, then for any
 $s\in \{0,1\}^n$
, the distribution of vertices whose
$s\in \{0,1\}^n$
, the distribution of vertices whose
 $\mathcal {L}_n$
-label is s will be the same as the distribution of vertices whose label is
$\mathcal {L}_n$
-label is s will be the same as the distribution of vertices whose label is
 $1$
in a single
$1$
in a single
 $\mathsf {Ber}({1/ {2^n}})$
-labeling. In particular, there will be infinite clusters in
$\mathsf {Ber}({1/ {2^n}})$
-labeling. In particular, there will be infinite clusters in
 $\mathsf {clust}(\mathcal {L}_n)$
on
$\mathsf {clust}(\mathcal {L}_n)$
on
 ${\mathbb T}_d$
if
${\mathbb T}_d$
if
 $d>2^n+1$
.
$d>2^n+1$
.
This is not yet the
 $\theta _n$
we promised, as we want to label
$\theta _n$
we promised, as we want to label
 ${\mathbb T}_3$
instead of
${\mathbb T}_3$
instead of
 ${\mathbb T}_d$
where d depends on n. However, we can imitate a tree whose minimal degree is at least d within
${\mathbb T}_d$
where d depends on n. However, we can imitate a tree whose minimal degree is at least d within
 ${\mathbb T}_3$
using Voronoi partitions and the large scale tree construction. As in Example 1.4, let S be an
${\mathbb T}_3$
using Voronoi partitions and the large scale tree construction. As in Example 1.4, let S be an
 $\mathsf {FIID}$
vertex set in
$\mathsf {FIID}$
vertex set in
 ${\mathbb T}_3$
for which any two
${\mathbb T}_3$
for which any two
 $v_1,v_2\in S$
have distance at least
$v_1,v_2\in S$
have distance at least
 $2r+1$
, then let
$2r+1$
, then let
 $\Pi _0:=\mathsf {Vor}(S)$
. Each
$\Pi _0:=\mathsf {Vor}(S)$
. Each
 $\Pi _0$
-cell
$\Pi _0$
-cell
 $\mathcal {C}$
contains the ball
$\mathcal {C}$
contains the ball
 $B_{{\mathbb T}_3}(v,r)$
around
$B_{{\mathbb T}_3}(v,r)$
around
 $v\in S\cap \mathcal {C}$
. This implies that the large-scale tree
$v\in S\cap \mathcal {C}$
. This implies that the large-scale tree
 ${\mathbb T}_3/\Pi _0$
has minimal degree at least
${\mathbb T}_3/\Pi _0$
has minimal degree at least
 $|B_{{\mathbb T}_3}(v,r)|+2$
.
$|B_{{\mathbb T}_3}(v,r)|+2$
.
For large enough r, the random tree
 ${\mathbb T}_3/\Pi _0$
has minimal degree at least
${\mathbb T}_3/\Pi _0$
has minimal degree at least
 $2^n+2$
, so using the
$2^n+2$
, so using the
 $\mathsf {FIID}$
labeling
$\mathsf {FIID}$
labeling
 $\mathsf {Ber}(\Pi _0)$
guaranteed by Lemma 2.2 and concatenating n independent versions
$\mathsf {Ber}(\Pi _0)$
guaranteed by Lemma 2.2 and concatenating n independent versions
 $\unicode{x3bb} _i\sim \mathsf {Ber}(\Pi _0)$
to form
$\unicode{x3bb} _i\sim \mathsf {Ber}(\Pi _0)$
to form
 $\theta _n$
, we get an
$\theta _n$
, we get an
 $\mathsf {FIID} \{0,1\}^n$
-labeling which has infinite clusters and marginals uniform on
$\mathsf {FIID} \{0,1\}^n$
-labeling which has infinite clusters and marginals uniform on
 $\{0,1\}^n$
.
$\{0,1\}^n$
.
This proves the claim, but how do we get a labeling which has uniform marginals on
 $[0,1]$
but still with infinite clusters?
$[0,1]$
but still with infinite clusters?
Instead of the ‘static’ sequence
 $\Pi _0,\ldots ,\Pi _0,\ldots ,$
with the i.i.d. labels
$\Pi _0,\ldots ,\Pi _0,\ldots ,$
with the i.i.d. labels
 $\unicode{x3bb} _i\sim \mathsf {Ber}(\Pi _0)$
, we use a dynamically changing sequence of cell-partitions
$\unicode{x3bb} _i\sim \mathsf {Ber}(\Pi _0)$
, we use a dynamically changing sequence of cell-partitions
 $\Pi _0\prec \cdots \prec \Pi _n\prec \cdots $
, and the corresponding sequence of labelings
$\Pi _0\prec \cdots \prec \Pi _n\prec \cdots $
, and the corresponding sequence of labelings
 $\Lambda _0\sim \mathsf {Ber}(\Pi _0),\ldots ,\Lambda _n\sim \mathsf {Ber}(\Pi _n),\ldots $
. This way, we will be able to use infinitely many bits and thus get
$\Lambda _0\sim \mathsf {Ber}(\Pi _0),\ldots ,\Lambda _n\sim \mathsf {Ber}(\Pi _n),\ldots $
. This way, we will be able to use infinitely many bits and thus get
 $\mathsf {un}[0,1]$
marginals, while also having infinite clusters. The essence of how this sequence is constructed and what issues need to be taken care of is already visible in the step from
$\mathsf {un}[0,1]$
marginals, while also having infinite clusters. The essence of how this sequence is constructed and what issues need to be taken care of is already visible in the step from
 $\Pi _0$
to
$\Pi _0$
to
 $\Pi _1$
.
$\Pi _1$
.
There will be ‘target degrees’
 $D_0$
and
$D_0$
and
 $D_1$
which, for now, are just large integers.
$D_1$
which, for now, are just large integers.
A target degree was also present in the previous
 $\theta _n$
construction in the fact that
$\theta _n$
construction in the fact that
 ${\mathbb T}_3/\Pi _0$
had minimal degree at least
${\mathbb T}_3/\Pi _0$
had minimal degree at least
 $2^n+2$
and
$2^n+2$
and
 $\Pi _0$
in the final construction is defined just as before; this time, we want
$\Pi _0$
in the final construction is defined just as before; this time, we want
 ${\mathbb T}_3/\Pi _0$
to have minimal degree at least
${\mathbb T}_3/\Pi _0$
to have minimal degree at least
 $D_0$
. To
$D_0$
. To
 $\Pi _0$
, we associate the labeling
$\Pi _0$
, we associate the labeling
 $\Lambda _0\sim \mathsf {Ber}(\Pi _0)$
and we get the random forest
$\Lambda _0\sim \mathsf {Ber}(\Pi _0)$
and we get the random forest
 $\mathcal {F}_0:=\mathsf {clust}(\Lambda _0)$
, where of course
$\mathcal {F}_0:=\mathsf {clust}(\Lambda _0)$
, where of course
 $\Pi _0\prec \mathcal {F}_0$
.
$\Pi _0\prec \mathcal {F}_0$
.
We want to build
 $\Pi _1$
in such a way that
$\Pi _1$
in such a way that
 $\Pi _0\prec \Pi _1\prec \mathcal {F}_0$
and, ‘whenever possible’, the components of the large-scale forest
$\Pi _0\prec \Pi _1\prec \mathcal {F}_0$
and, ‘whenever possible’, the components of the large-scale forest
 $\mathcal {F}_0/\Pi _1$
should have minimal degree at least
$\mathcal {F}_0/\Pi _1$
should have minimal degree at least
 $D_1$
. So the goal in this second step is similar to that in the first step, when we wanted
$D_1$
. So the goal in this second step is similar to that in the first step, when we wanted
 ${\mathbb T}_3/\Pi _0$
to have minimal degree at least
${\mathbb T}_3/\Pi _0$
to have minimal degree at least
 $D_0$
.
$D_0$
.
A key difference is that in the first step, we worked with the deterministic tree
 ${\mathbb T}_3$
, while now we have to deal with the random forest
${\mathbb T}_3$
, while now we have to deal with the random forest
 $\mathcal {F}_0$
. We can immediately see that the target degree goal cannot be reached for all components of
$\mathcal {F}_0$
. We can immediately see that the target degree goal cannot be reached for all components of
 $\mathcal {F}_0/\Pi _1$
, as
$\mathcal {F}_0/\Pi _1$
, as
 $\mathcal {F}_0/\Pi _1$
contains finite clusters, whose minimal degree is always
$\mathcal {F}_0/\Pi _1$
contains finite clusters, whose minimal degree is always
 $1$
, because a finite tree always has leaves. What about the infinite clusters? If there was a bi-infinite path among them, then for that component, the target degree goal cannot be achieved for
$1$
, because a finite tree always has leaves. What about the infinite clusters? If there was a bi-infinite path among them, then for that component, the target degree goal cannot be achieved for
 $D_1>2$
.
$D_1>2$
.
A key concept is a furcation vertex discussed in more detail in the next section. These are the vertices whose removal splits their component into a forest containing at least three infinite components. For example, a bi-infinite path contains no furcations at all. We will see that simply because
 $\mathcal {F}_0$
is defined by an invariant random process, as soon as a component contains a furcation at all, it contains enough to reach our target degree goal. Invariance alone does not guarantee that the infinite clusters have furcations, as an invariant process could split
$\mathcal {F}_0$
is defined by an invariant random process, as soon as a component contains a furcation at all, it contains enough to reach our target degree goal. Invariance alone does not guarantee that the infinite clusters have furcations, as an invariant process could split
 ${\mathbb T}_3$
into bi-infinite paths. Our process imitates Bernoulli percolations, and we will see that the existence of furcations is guaranteed. These concerns will be taken care of in the next section.
${\mathbb T}_3$
into bi-infinite paths. Our process imitates Bernoulli percolations, and we will see that the existence of furcations is guaranteed. These concerns will be taken care of in the next section.
Now we can clarify for which components of the
 $\mathcal {F}_0/\Pi _1$
we can achieve the target degree goal: those containing furcations, which will be called forking components. We sketch what we do within a forking component. Of course, we need to do something with the other components as well, but that is rather arbitrary.
$\mathcal {F}_0/\Pi _1$
we can achieve the target degree goal: those containing furcations, which will be called forking components. We sketch what we do within a forking component. Of course, we need to do something with the other components as well, but that is rather arbitrary.
If v is a furcation of
 $\mathcal {F}_0(v)$
, then by the finiteness of the
$\mathcal {F}_0(v)$
, then by the finiteness of the
 $\Pi _0$
cells,
$\Pi _0$
cells,
 $\Pi _0(v)$
will also be a furcation of
$\Pi _0(v)$
will also be a furcation of
 $\mathcal {F}_0/\Pi _0(v)$
. Conversely, if
$\mathcal {F}_0/\Pi _0(v)$
. Conversely, if
 $\Pi _0(v)$
is a furcation of
$\Pi _0(v)$
is a furcation of
 $\mathcal {F}_0/\Pi _0(v)$
, then there is a vertex
$\mathcal {F}_0/\Pi _0(v)$
, then there is a vertex
 $v_0\in \Pi _0(v)$
which is a furcation of
$v_0\in \Pi _0(v)$
which is a furcation of
 $\mathcal {F}_0 (v)$
. Let S be the collection of furcations of
$\mathcal {F}_0 (v)$
. Let S be the collection of furcations of
 $\mathcal {F}_0/\Pi _0$
and take the associated Voronoi partition
$\mathcal {F}_0/\Pi _0$
and take the associated Voronoi partition
 $\mathsf {Vor}(S)$
. This partition lives on the large-scale forest
$\mathsf {Vor}(S)$
. This partition lives on the large-scale forest
 $\mathcal {F}_0/\Pi _0$
, but it gives a natural way to glue together the corresponding
$\mathcal {F}_0/\Pi _0$
, but it gives a natural way to glue together the corresponding
 $\Pi _0$
cells into
$\Pi _0$
cells into
 $\Pi ^{\text { there exists } \texttt {furc}}:=\texttt {glue}_{\mathsf {Vor}(S)}(\Pi _0)$
. In
$\Pi ^{\text { there exists } \texttt {furc}}:=\texttt {glue}_{\mathsf {Vor}(S)}(\Pi _0)$
. In
 $\Pi ^{\text { there exists } \texttt {furc}}$
, every cell within a forking component contains some furcation, and the cells of
$\Pi ^{\text { there exists } \texttt {furc}}$
, every cell within a forking component contains some furcation, and the cells of
 $\Pi ^{\text { there exists } \texttt {furc}}$
remain finite by the mass-transport principle. See Figure 1. This finiteness implies that in the component
$\Pi ^{\text { there exists } \texttt {furc}}$
remain finite by the mass-transport principle. See Figure 1. This finiteness implies that in the component
 $\mathcal {F}_0/\Pi ^{\text { there exists } \texttt {furc}}(v)$
, every degree will be at least
$\mathcal {F}_0/\Pi ^{\text { there exists } \texttt {furc}}(v)$
, every degree will be at least
 $3$
(see what could go wrong if the cells were not finite in Example 4.2). Now that all the degrees are at least
$3$
(see what could go wrong if the cells were not finite in Example 4.2). Now that all the degrees are at least
 $3$
, we can repeat the same idea that we used in
$3$
, we can repeat the same idea that we used in
 ${\mathbb T}_3$
to achieve an arbitrarily high target degree, and this is how we get the new partition
${\mathbb T}_3$
to achieve an arbitrarily high target degree, and this is how we get the new partition
 $\Pi _1$
with the properties that
$\Pi _1$
with the properties that
 $\Pi _0\prec \Pi _1\prec \mathcal {F}_0$
and that the forking components of the large-scale forest
$\Pi _0\prec \Pi _1\prec \mathcal {F}_0$
and that the forking components of the large-scale forest
 $\mathcal {F}_0/\Pi _1$
have minimal degree at least
$\mathcal {F}_0/\Pi _1$
have minimal degree at least
 $D_1$
. After this, we can proceed to the labeling
$D_1$
. After this, we can proceed to the labeling
 $\Lambda _1\sim \mathsf {Ber}(\Pi _1)$
, define
$\Lambda _1\sim \mathsf {Ber}(\Pi _1)$
, define
 $\mathcal {F}_1=\mathsf {clust}(\Lambda _0,\Lambda _1)$
, and continue in the same way. The sequence of labelings
$\mathcal {F}_1=\mathsf {clust}(\Lambda _0,\Lambda _1)$
, and continue in the same way. The sequence of labelings
 $\Lambda _0,\ldots , \Lambda _n,\ldots $
has the property that when we take their concatenation as the binary representation of a real
$\Lambda _0,\ldots , \Lambda _n,\ldots $
has the property that when we take their concatenation as the binary representation of a real
 $\Theta $
from
$\Theta $
from
 $[0,1]$
, then
$[0,1]$
, then
 $\Theta $
has
$\Theta $
has
 $\mathsf {un} [0,1]$
marginal.
$\mathsf {un} [0,1]$
marginal.

Figure 1 First, a forking tree
 $\mathscr {F}(v)$
, together with a cell-partition
$\mathscr {F}(v)$
, together with a cell-partition
 $\Pi $
. Arrows represent infinite parts of the tree, furcation vertices are denoted by solid dots. Furcation
$\Pi $
. Arrows represent infinite parts of the tree, furcation vertices are denoted by solid dots. Furcation
 $\Pi $
-cells are shaded. Second, the partition
$\Pi $
-cells are shaded. Second, the partition
 $\Pi ^{\text { there exists } \texttt {furc}}\succ ~\Pi $
is also shown. Third, the large-scale tree
$\Pi ^{\text { there exists } \texttt {furc}}\succ ~\Pi $
is also shown. Third, the large-scale tree
 $\mathscr {F}(v)/\Pi ^{\text { there exists } \texttt {furc}}$
.
$\mathscr {F}(v)/\Pi ^{\text { there exists } \texttt {furc}}$
.
To show that this labeling has infinite clusters, we need to prove that for any given vertex r, the probability that r is in an infinite cluster is positive, say at least
 $c>0$
. To do so, we will use Lemma 4.4 mentioned in the beginning of this section. Choose a sequence
$c>0$
. To do so, we will use Lemma 4.4 mentioned in the beginning of this section. Choose a sequence
 $\epsilon _0,\epsilon _1,\ldots , \epsilon _n,\ldots $
such that
$\epsilon _0,\epsilon _1,\ldots , \epsilon _n,\ldots $
such that
 $\prod _{i\in {\mathbb N}}(1-\epsilon _i)>c$
, and choose the target degree sequence as
$\prod _{i\in {\mathbb N}}(1-\epsilon _i)>c$
, and choose the target degree sequence as
 $D_0:=D(\epsilon _0),D_1:=D(\epsilon _1), \ldots $
and so on. Then in the first step, we imitate a
$D_0:=D(\epsilon _0),D_1:=D(\epsilon _1), \ldots $
and so on. Then in the first step, we imitate a
 $\mathsf {Ber}(\tfrac {1}{2})$
labeling on a tree whose minimal degree is at least
$\mathsf {Ber}(\tfrac {1}{2})$
labeling on a tree whose minimal degree is at least
 $D(\epsilon _0)$
, so the probability that the cell
$D(\epsilon _0)$
, so the probability that the cell
 $\Pi _0(r)$
of r will end up within a forking cluster is at least
$\Pi _0(r)$
of r will end up within a forking cluster is at least
 $(1-\epsilon _0)$
and if that happens, we can achieve our next target degree of
$(1-\epsilon _0)$
and if that happens, we can achieve our next target degree of
 $D(\epsilon _1)$
for the component
$D(\epsilon _1)$
for the component
 $\mathscr {F}_0(r)$
. Then for this component, we will imitate a
$\mathscr {F}_0(r)$
. Then for this component, we will imitate a
 ${\mathsf {Ber}}(\tfrac {1}{2})$
labeling on the tree
${\mathsf {Ber}}(\tfrac {1}{2})$
labeling on the tree
 $\mathscr {F}_0/\Pi _1(r)$
whose minimal degree is at least
$\mathscr {F}_0/\Pi _1(r)$
whose minimal degree is at least
 $D(\epsilon _1)$
so the cell
$D(\epsilon _1)$
so the cell
 $\Pi _1(r)$
of r will stay within a forking cluster with probability at least
$\Pi _1(r)$
of r will stay within a forking cluster with probability at least
 $(1-\epsilon _1)$
conditioned on the event that it stayed within an forking cluster after the first labeling. Thus, the probability that r is within a forking cluster after the first two labelings is at least
$(1-\epsilon _1)$
conditioned on the event that it stayed within an forking cluster after the first labeling. Thus, the probability that r is within a forking cluster after the first two labelings is at least
 $(1-\epsilon _0)(1-\epsilon _1)$
. Continuing in this way, the probability that r is within an infinite cluster in each stage will be at least c and since the cells will increase, it implies that r will be within an infinite cluster even when each label is taken into account.
$(1-\epsilon _0)(1-\epsilon _1)$
. Continuing in this way, the probability that r is within an infinite cluster in each stage will be at least c and since the cells will increase, it implies that r will be within an infinite cluster even when each label is taken into account.
Why is this construction an
 $\mathsf {FIID}$
? By Lemma 2.2, if the forest
$\mathsf {FIID}$
? By Lemma 2.2, if the forest
 $\Pi _i$
is
$\Pi _i$
is
 $\mathsf {FIID}$
, then the labeling
$\mathsf {FIID}$
, then the labeling
 $\Lambda _i\sim \mathsf {Ber}(\Pi _i)$
is
$\Lambda _i\sim \mathsf {Ber}(\Pi _i)$
is
 $\mathsf {FIID}$
as well. Moreover, as soon as a labeling L is
$\mathsf {FIID}$
as well. Moreover, as soon as a labeling L is
 $\mathsf {FIID}$
, the indicator function whether or not a vertex v is a furcation of its component in
$\mathsf {FIID}$
, the indicator function whether or not a vertex v is a furcation of its component in
 $\mathsf {clust}(L)$
is
$\mathsf {clust}(L)$
is
 $\mathsf {FIID}$
itself (see the note on measurability related to furcations in the next section right after Definition 4.1). Because of this, when we glue together some of the ‘old’ cells of
$\mathsf {FIID}$
itself (see the note on measurability related to furcations in the next section right after Definition 4.1). Because of this, when we glue together some of the ‘old’ cells of
 $\Pi _i$
to build new cells so that each new cell will contain furcation. This gluing process again can be realized as an
$\Pi _i$
to build new cells so that each new cell will contain furcation. This gluing process again can be realized as an
 $\mathsf {FIID}$
. The way we described the process, we need fresh randomness at every stage, but as we already explained at the end of §1, the bits of a single real number can be reorganized to obtain an infinite collection of infinitely many independent bits. So, in fact, the measurable map corresponding to the intuitive description we give can be constructed by using the i.i.d. labels provided originally.
$\mathsf {FIID}$
. The way we described the process, we need fresh randomness at every stage, but as we already explained at the end of §1, the bits of a single real number can be reorganized to obtain an infinite collection of infinitely many independent bits. So, in fact, the measurable map corresponding to the intuitive description we give can be constructed by using the i.i.d. labels provided originally.
4 Furcations
Furcation vertices will let us reach our target degree goal through Lemma 4.3, and we will find trees containing them in Bernoulli clusters through Lemma 4.5.
Definition 4.1. If T is a tree, we say that
 $v\in V(T)$
is a furcation if after deleting v from T, among the remaining components, there are at least
$v\in V(T)$
is a furcation if after deleting v from T, among the remaining components, there are at least
 $3$
infinite ones. If a tree T has a furcation, we will say that T is forking. When
$3$
infinite ones. If a tree T has a furcation, we will say that T is forking. When
 $\mathcal {F}$
is a forest and
$\mathcal {F}$
is a forest and
 $v\in V(\mathcal {F})$
, then we will also say that v is a furcation of
$v\in V(\mathcal {F})$
, then we will also say that v is a furcation of
 $\mathcal {F}$
if it is a furcation of the subtree
$\mathcal {F}$
if it is a furcation of the subtree
 $\mathcal {F}(v)$
containing it.
$\mathcal {F}(v)$
containing it.
This terminology follows [Reference Lyons and PeresLP16] and is similar but not identical to the encounter points of the landmark Burton–Keane argument which are known as trifurcations since.
Note that in a bounded degree tree, a vertex v is a furcation if and only if for any
 $n\in {\mathbb N}$
there exist three paths,
$n\in {\mathbb N}$
there exist three paths,
 $\mathcal {P}_1, \mathcal {P}_2$
, and
$\mathcal {P}_1, \mathcal {P}_2$
, and
 $\mathcal {P}_3$
, of length at least n which are all emanating from v and are edge and (except for v) vertex disjoint. Thus, the indicator of a vertex being a furcation is measurable, being the infimum of countably many measurable functions.
$\mathcal {P}_3$
, of length at least n which are all emanating from v and are edge and (except for v) vertex disjoint. Thus, the indicator of a vertex being a furcation is measurable, being the infimum of countably many measurable functions.
An infinite example for a tree without furcation is the bi-infinite path. The next example shows trees whose furcations are arranged in an adversarial fashion and if S is the set of their furcations, then the cells of
 ${\mathsf {Vor}}(S)$
are not finite. These examples are also worth keeping in mind, as they would be obstacles to our target degree goals. However, they simply cannot occur in an invariant process on a Cayley graph (as we have seen in the application of the mass-transport principle).
${\mathsf {Vor}}(S)$
are not finite. These examples are also worth keeping in mind, as they would be obstacles to our target degree goals. However, they simply cannot occur in an invariant process on a Cayley graph (as we have seen in the application of the mass-transport principle).
Example 4.2. A ray emanating from v is a half-infinite path starting from v. Let
 $T_{\perp }$
be a tree (defined up to isomorphism) which has a unique vertex of degree
$T_{\perp }$
be a tree (defined up to isomorphism) which has a unique vertex of degree
 $3$
and all the other degrees are
$3$
and all the other degrees are
 $2$
(that is, three disjoint rays emanating from a single vertex). As a further example, consider the tree
$2$
(that is, three disjoint rays emanating from a single vertex). As a further example, consider the tree
 $T_{\perp \perp }$
obtained from a bi-infinite path
$T_{\perp \perp }$
obtained from a bi-infinite path
 $ P$
by attaching to each vertex v a ray
$ P$
by attaching to each vertex v a ray
 $R_v$
(which are not intersecting outside of P).
$R_v$
(which are not intersecting outside of P).
The following lemma can be proven by induction on r.
Lemma 4.3. If C is a finite, connected subset of a tree and contains at least r furcations, then after deleting C from the tree, among the remaining components, there will be at least
 $ r+2$
which are infinite.
$ r+2$
which are infinite.
Recall Theorem 3.2 which said that a
 $\mathsf {Ber}(\tfrac {1}{2})$
labeling of
$\mathsf {Ber}(\tfrac {1}{2})$
labeling of
 ${\mathbb T}_4$
has infinite clusters. This implies that for a specific vertex v of
${\mathbb T}_4$
has infinite clusters. This implies that for a specific vertex v of
 ${\mathbb T}_4$
, the probability that v will be in an infinite cluster in a
${\mathbb T}_4$
, the probability that v will be in an infinite cluster in a
 $\mathsf {Ber}(\tfrac {1}{2})$
-labeling is positive. We, however, need forking clusters. We can get their existence from Theorem 3.2 as follows.
$\mathsf {Ber}(\tfrac {1}{2})$
-labeling is positive. We, however, need forking clusters. We can get their existence from Theorem 3.2 as follows.
Lemma 4.4. For all
 $\epsilon>0$
, there exists a
$\epsilon>0$
, there exists a
 $D(\epsilon )\in {\mathbb N}$
such that if T is a tree whose minimal degree is at least
$D(\epsilon )\in {\mathbb N}$
such that if T is a tree whose minimal degree is at least
 $D(\epsilon )$
and r is a distinguished vertex (the ‘root’) of T, then in a
$D(\epsilon )$
and r is a distinguished vertex (the ‘root’) of T, then in a
 ${\mathsf {Ber}}(\tfrac {1}{2})$
-labeling of T, the cluster of the root r will be a forking one with probability at least
${\mathsf {Ber}}(\tfrac {1}{2})$
-labeling of T, the cluster of the root r will be a forking one with probability at least
 $1-\epsilon $
.
$1-\epsilon $
.
To see this, consider first the rooted tree
 $(T,r)$
built from rooted copies
$(T,r)$
built from rooted copies
 $(T_1,r_1),\ldots , (T_D,r_D)$
of
$(T_1,r_1),\ldots , (T_D,r_D)$
of
 ${\mathbb T}_4$
(so
${\mathbb T}_4$
(so
 $T_i$
is a
$T_i$
is a
 $4$
-regular tree and
$4$
-regular tree and
 $r_i$
is one of its vertices and D will be fixed later) by adding a new vertex r to this collection and make it into a tree by connecting r to
$r_i$
is one of its vertices and D will be fixed later) by adding a new vertex r to this collection and make it into a tree by connecting r to
 $r_i$
for all i (no other edges are added). For r to be in a forking cluster in a
$r_i$
for all i (no other edges are added). For r to be in a forking cluster in a
 $\mathsf {Ber}(\tfrac {1}{2})$
-labeling of T, it is enough if there are at least three such
$\mathsf {Ber}(\tfrac {1}{2})$
-labeling of T, it is enough if there are at least three such
 $(T_i,r_i)$
so that
$(T_i,r_i)$
so that
 $r_i$
in an infinite cluster of the labeling restricted to
$r_i$
in an infinite cluster of the labeling restricted to
 $T_i$
and r is connected to
$T_i$
and r is connected to
 $r_i$
. The probability of this clearly goes to
$r_i$
. The probability of this clearly goes to
 $1$
as
$1$
as
 $D\rightarrow \infty $
. If
$D\rightarrow \infty $
. If
 $D:=D(\epsilon )$
is chosen so that this probability is at least
$D:=D(\epsilon )$
is chosen so that this probability is at least
 $1-\epsilon $
, then in a tree whose minimal degree is at least D, we can take any vertex to be the root and embed this
$1-\epsilon $
, then in a tree whose minimal degree is at least D, we can take any vertex to be the root and embed this
 $(T,r)$
graph into it.
$(T,r)$
graph into it.
Choose a sequence
 $\epsilon _0,\epsilon _1, \ldots , \epsilon _n,\ldots \subset (0,1) $
tending to
$\epsilon _0,\epsilon _1, \ldots , \epsilon _n,\ldots \subset (0,1) $
tending to
 $0$
fast enough so that
$0$
fast enough so that
 $\prod _{n=1}^{\infty } (1-\epsilon _n)>0$
. Define
$\prod _{n=1}^{\infty } (1-\epsilon _n)>0$
. Define
 $D_n:=D(\epsilon _n)$
and use this sequence as the target degree in our construction. We got immediately from Lemma 4.4 the following lemma.
$D_n:=D(\epsilon _n)$
and use this sequence as the target degree in our construction. We got immediately from Lemma 4.4 the following lemma.
Lemma 4.5. If, as given above, a sequence
 $(T_1,r_1),\ldots ,(T_n,r_n),\ldots $
of a rooted trees is given, where the minimal degree of
$(T_1,r_1),\ldots ,(T_n,r_n),\ldots $
of a rooted trees is given, where the minimal degree of
 $T_n$
is at least
$T_n$
is at least
 $D_n$
, and each of these trees are independently
$D_n$
, and each of these trees are independently
 ${\mathsf {Ber}}(\tfrac {1}{2})$
-labeled, then with positive probability, the roots of all of these trees will be in a forking cluster simultaneously.
${\mathsf {Ber}}(\tfrac {1}{2})$
-labeled, then with positive probability, the roots of all of these trees will be in a forking cluster simultaneously.
We add a more process-oriented corollary to this, which involves random rooted trees
 $(\mathcal {T}_n, r_n)$
which contains the previous
$(\mathcal {T}_n, r_n)$
which contains the previous
 $(T_n, r_n)$
trees as subgraphs by the constraint on their minimal degree. At this point, the distribution of these random trees can be arbitrary as soon as they satisfy the degree constraints. Assume that we start with a random rooted tree
$(T_n, r_n)$
trees as subgraphs by the constraint on their minimal degree. At this point, the distribution of these random trees can be arbitrary as soon as they satisfy the degree constraints. Assume that we start with a random rooted tree
 $(\mathcal {T}_0,r_0)$
which has minimal degree at least
$(\mathcal {T}_0,r_0)$
which has minimal degree at least
 $D_0$
, and we run the following process. Label the vertices of
$D_0$
, and we run the following process. Label the vertices of
 $\mathcal {T}_0$
by a
$\mathcal {T}_0$
by a
 $\mathsf {Ber}(\tfrac {1}{2})$
-labeling
$\mathsf {Ber}(\tfrac {1}{2})$
-labeling
 $\mathcal {L}_0$
, and if the cluster of
$\mathcal {L}_0$
, and if the cluster of
 $r_0$
in
$r_0$
in
 $\mathsf {clust}(\mathcal {L}_0)$
is not forking, then stop; otherwise, generate a new random rooted tree
$\mathsf {clust}(\mathcal {L}_0)$
is not forking, then stop; otherwise, generate a new random rooted tree
 $(\mathcal {T}_1,r_1)$
whose minimal degree is at least
$(\mathcal {T}_1,r_1)$
whose minimal degree is at least
 $D_1$
, take a
$D_1$
, take a
 $\mathsf {Ber}(1/2)$
-labeling
$\mathsf {Ber}(1/2)$
-labeling
 $\mathcal {L}_1$
of its vertices, and so on. Then, with positive probability, the above process never stops and the generated sequence of bits
$\mathcal {L}_1$
of its vertices, and so on. Then, with positive probability, the above process never stops and the generated sequence of bits
 $\mathcal {L}_0(r_0),\ldots ,\mathcal {L}_n(r_n),\ldots $
will be i.i.d., so the random real number whose bits are this sequence has distribution
$\mathcal {L}_0(r_0),\ldots ,\mathcal {L}_n(r_n),\ldots $
will be i.i.d., so the random real number whose bits are this sequence has distribution
 $\mathsf {un}[0,1]$
.
$\mathsf {un}[0,1]$
.
Remark 4.6. For us, the distinction between an infinite and a forking tree is very important. However, it is known from [Reference Lyons and SchrammLS99] that if
 $\unicode{x3bb} $
is any Bernoulli percolation on any Cayley graph, then its infinite clusters are indistinguishable by any invariant Borel property (which includes that of being forking). Thus, as soon as there are forking clusters with positive probability, we know that in fact all infinite clusters are forking. Our labelings are not immediately Bernoulli ones, but cooked up from them in a way that this theorem would likely go through. However, we did not try to use this direction as what we need can be obtained directly from the very basics of percolation theory on a tree.
$\unicode{x3bb} $
is any Bernoulli percolation on any Cayley graph, then its infinite clusters are indistinguishable by any invariant Borel property (which includes that of being forking). Thus, as soon as there are forking clusters with positive probability, we know that in fact all infinite clusters are forking. Our labelings are not immediately Bernoulli ones, but cooked up from them in a way that this theorem would likely go through. However, we did not try to use this direction as what we need can be obtained directly from the very basics of percolation theory on a tree.
In our construction, Bernoulli processes on large-scale forests (from Definition 2.5) will be used, and with the aid of Lemma 4.5, we will find forking ones among its clusters. We will put those clusters into use through the following lemma.
Lemma 4.7. If
 $\Pi $
is an
$\Pi $
is an
 $\mathsf {FIID}$
cell-partition of
$\mathsf {FIID}$
cell-partition of
 ${\mathbb T}_3$
and
${\mathbb T}_3$
and
 $\mathscr {F}$
is an
$\mathscr {F}$
is an
 $\mathsf {FIID}$
subforest of
$\mathsf {FIID}$
subforest of
 ${\mathbb T}_3$
in such a way that
${\mathbb T}_3$
in such a way that
 $\Pi \prec \mathscr {F}$
, and D is a positive integer, then there is cell partition
$\Pi \prec \mathscr {F}$
, and D is a positive integer, then there is cell partition
 ${\tt furc}_D(\Pi )$
such that
${\tt furc}_D(\Pi )$
such that
 $\Pi \prec {\tt furc}_D(\Pi )\prec \mathscr {F}$
also holds, and whenever for a vertex v the tree
$\Pi \prec {\tt furc}_D(\Pi )\prec \mathscr {F}$
also holds, and whenever for a vertex v the tree
 $\mathscr {F}(v)$
is forking, then the
$\mathscr {F}(v)$
is forking, then the
 ${\tt furc}_D(\Pi )(v)$
-cell contains at least D furcations of
${\tt furc}_D(\Pi )(v)$
-cell contains at least D furcations of
 $\mathscr {F}(v)$
.
$\mathscr {F}(v)$
.
Proof. We first show that there exists a partition
 $\Pi ^{\text { there exists } \texttt {furc}}$
for which
$\Pi ^{\text { there exists } \texttt {furc}}$
for which
 $\Pi \prec \Pi ^{\text { there exists } \texttt {furc}}\prec {\mathscr {F}}$
and whenever
$\Pi \prec \Pi ^{\text { there exists } \texttt {furc}}\prec {\mathscr {F}}$
and whenever
 ${\mathscr {F}}(v)$
is forking, then
${\mathscr {F}}(v)$
is forking, then
 $\Pi ^{\text { there exists } \texttt {furc}}(v)$
contains at least one furcation of
$\Pi ^{\text { there exists } \texttt {furc}}(v)$
contains at least one furcation of
 ${\mathscr {F}}(v)$
. Let
${\mathscr {F}}(v)$
. Let
 $\texttt {F}_{\Pi }$
be the set of those
$\texttt {F}_{\Pi }$
be the set of those
 $\Pi $
-cells which contain at least one furcation of
$\Pi $
-cells which contain at least one furcation of
 ${\mathscr {F}}$
. Our goal is achieved if we manage to glue
${\mathscr {F}}$
. Our goal is achieved if we manage to glue
 $\Pi $
-cells within a forking component to form bigger (but still finite) cells in such a way that every new cell contains at least one ‘old’
$\Pi $
-cells within a forking component to form bigger (but still finite) cells in such a way that every new cell contains at least one ‘old’
 $\Pi $
-cell from
$\Pi $
-cell from
 $\texttt {F}_{\Pi }$
.
$\texttt {F}_{\Pi }$
.
Voronoi cells on the large-scale forest are just right for this purpose. Move to the large-scale forest
 ${\mathscr {F}}/\Pi $
and build
${\mathscr {F}}/\Pi $
and build
 $\mathsf {Vor}(\texttt {F}_{\Pi })$
. This
$\mathsf {Vor}(\texttt {F}_{\Pi })$
. This
 $\mathsf {Vor}(\texttt {F}_{\Pi })$
is ‘almost’ the partition
$\mathsf {Vor}(\texttt {F}_{\Pi })$
is ‘almost’ the partition
 $\Pi ^{\text { there exists } \texttt {furc}}$
we seek, except that it lives in
$\Pi ^{\text { there exists } \texttt {furc}}$
we seek, except that it lives in
 ${\mathscr {F}}/\Pi $
instead of
${\mathscr {F}}/\Pi $
instead of
 ${\mathscr {F}}$
. We bring it back to
${\mathscr {F}}$
. We bring it back to
 ${\mathscr {F}}$
in the obvious way as
${\mathscr {F}}$
in the obvious way as
 $\Pi ^{\text { there exists } \texttt {furc}}:=\texttt {glue}_{\mathsf {Vor}(\texttt {F}_{\Pi })}(\Pi )$
. See Figure 1.
$\Pi ^{\text { there exists } \texttt {furc}}:=\texttt {glue}_{\mathsf {Vor}(\texttt {F}_{\Pi })}(\Pi )$
. See Figure 1.
Note that the finiteness of the new cells are guaranteed by induction, as every new cell either contains the distinguished finite subset which was an old cell from
 $\texttt {F}_{\Pi }$
, or (in case the
$\texttt {F}_{\Pi }$
, or (in case the
 ${\mathscr {F}}$
-component of a cell does not contain any furcation) the new cell is just equal to the old one.
${\mathscr {F}}$
-component of a cell does not contain any furcation) the new cell is just equal to the old one.
Now that we have
 $\Pi ^{\text { there exists } \texttt {furc}}$
, we can define
$\Pi ^{\text { there exists } \texttt {furc}}$
, we can define
 ${\texttt {furc}_D }(\Pi )$
. Since every
${\texttt {furc}_D }(\Pi )$
. Since every
 $\Pi ^{\text { there exists } \texttt {furc}}$
- cell within a forking
$\Pi ^{\text { there exists } \texttt {furc}}$
- cell within a forking
 ${\mathscr {F}}$
-cluster contains at least one furcation, it is enough if we manage to glue together
${\mathscr {F}}$
-cluster contains at least one furcation, it is enough if we manage to glue together
 $\Pi ^{\text { there exists } \texttt {furc}}$
-cells in such a way that every new cell of a forking cluster contains at least D ‘old’
$\Pi ^{\text { there exists } \texttt {furc}}$
-cells in such a way that every new cell of a forking cluster contains at least D ‘old’
 $\Pi ^{\text { there exists } \texttt { furc}}$
-cells. To achieve this, we can use the same idea as in the very first step described in the high level overview in constructing
$\Pi ^{\text { there exists } \texttt { furc}}$
-cells. To achieve this, we can use the same idea as in the very first step described in the high level overview in constructing
 $\Pi _0$
and the associated large-scale tree
$\Pi _0$
and the associated large-scale tree
 ${\mathbb T}_3/\Pi _0$
, but this time, we work within the forking components of
${\mathbb T}_3/\Pi _0$
, but this time, we work within the forking components of
 ${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
. In the large-scale forest
${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
. In the large-scale forest
 ${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
, every forking component has minimal degree at least
${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
, every forking component has minimal degree at least
 $3$
. In
$3$
. In
 ${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
, select an
${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
, select an
 $\mathsf {FIID}$
vertex set S where the minimal distance between distinct vertices is at least
$\mathsf {FIID}$
vertex set S where the minimal distance between distinct vertices is at least
 $2D+1$
and S has at least one element in every forking component of
$2D+1$
and S has at least one element in every forking component of
 ${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
. In the corresponding Voronoi partition
${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
. In the corresponding Voronoi partition
 $\mathsf {Vor}(S)$
, every cell
$\mathsf {Vor}(S)$
, every cell
 $\mathcal {C}$
belonging to a forking component of
$\mathcal {C}$
belonging to a forking component of
 ${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
will contain at least
${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
will contain at least
 $|B_{{\mathbb T}_3}(o,D)|\geq D$
many vertices of
$|B_{{\mathbb T}_3}(o,D)|\geq D$
many vertices of
 ${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
(o denotes an arbitrarily fixed vertex of
${\mathscr {F}}/\Pi ^{\text { there exists } \texttt {furc}}$
(o denotes an arbitrarily fixed vertex of
 ${\mathbb T}_3$
). Thus, we can define
${\mathbb T}_3$
). Thus, we can define
 ${\texttt {furc}_D }(\Pi ):=\texttt {glue}_{\mathsf {Vor}(S)}(\Pi ^{\text { there exists } \texttt {furc}})$
. The new cells are finite again by induction.
${\texttt {furc}_D }(\Pi ):=\texttt {glue}_{\mathsf {Vor}(S)}(\Pi ^{\text { there exists } \texttt {furc}})$
. The new cells are finite again by induction.
An important property of the cell partition
 $\texttt {furc}_D(\Pi )$
follows from Lemma 4.3 and from the finiteness of the
$\texttt {furc}_D(\Pi )$
follows from Lemma 4.3 and from the finiteness of the
 $\texttt {furc}_D(\Pi )$
-cells: the minimal degree of any forking component of
$\texttt {furc}_D(\Pi )$
-cells: the minimal degree of any forking component of
 $\mathscr {F}/\texttt {furc}_D(\Pi )$
is at least
$\mathscr {F}/\texttt {furc}_D(\Pi )$
is at least
 $D+2$
. So Lemma 4.7 is a natural tool to achieve the previously described target degree goals.
$D+2$
. So Lemma 4.7 is a natural tool to achieve the previously described target degree goals.
5 The main construction
This section is largely devoted to the proof of our main theorem.
First we define the
 $\mathsf {FIID}$
labeling
$\mathsf {FIID}$
labeling
 $\Theta $
witnessing the truth of our theorem. We define the sequence of cell-partitions
$\Theta $
witnessing the truth of our theorem. We define the sequence of cell-partitions
 $\Pi _0\prec \Pi _1\prec \cdots \prec \Pi _n\prec \cdots $
; this will give us also the sequence of
$\Pi _0\prec \Pi _1\prec \cdots \prec \Pi _n\prec \cdots $
; this will give us also the sequence of
 $\Lambda _i\sim \mathsf {Ber}(\Pi _i)$
labels, where, conditioned on
$\Lambda _i\sim \mathsf {Ber}(\Pi _i)$
labels, where, conditioned on
 $\Pi _i$
, the label
$\Pi _i$
, the label
 $\Lambda _i$
will be independent from the previous labels. Of course,
$\Lambda _i$
will be independent from the previous labels. Of course,
 $\Pi _i$
itself depends on
$\Pi _i$
itself depends on
 $\{(\Pi _j,\Lambda _j)\}_{j<i}$
.
$\{(\Pi _j,\Lambda _j)\}_{j<i}$
.
Here,
 $\Pi _0$
and
$\Pi _0$
and
 $\Lambda _0$
are as defined before in §3. Assume that
$\Lambda _0$
are as defined before in §3. Assume that
 $\Pi _0\prec \cdots \prec \Pi _n$
and
$\Pi _0\prec \cdots \prec \Pi _n$
and
 $\Lambda _0,\ldots ,\Lambda _n$
are defined. Let
$\Lambda _0,\ldots ,\Lambda _n$
are defined. Let
 $\mathcal {F}_n:=\mathsf {clust}(\Lambda _0,\ldots ,\Lambda _n)$
, where
$\mathcal {F}_n:=\mathsf {clust}(\Lambda _0,\ldots ,\Lambda _n)$
, where
 $(\Lambda _0,\ldots ,\Lambda _n)$
is the
$(\Lambda _0,\ldots ,\Lambda _n)$
is the
 $\{0,1\}^{n+1}$
-label obtained by concatenating the
$\{0,1\}^{n+1}$
-label obtained by concatenating the
 $\Lambda _i$
terms.
$\Lambda _i$
terms.
We want to define
 $\Pi _{n+1}$
in such a way that
$\Pi _{n+1}$
in such a way that
 $\Pi _n\prec \Pi _{n+1} \prec \mathcal {F}_n$
, and if for a vertex v the tree
$\Pi _n\prec \Pi _{n+1} \prec \mathcal {F}_n$
, and if for a vertex v the tree
 $\mathcal {F}_n(v)$
is forking, then the
$\mathcal {F}_n(v)$
is forking, then the
 $\Pi _{n+1}(v)$
-cell should contain at least
$\Pi _{n+1}(v)$
-cell should contain at least
 $D_{n+1}$
furcations of
$D_{n+1}$
furcations of
 $\mathcal {F}_n$
. We use Lemma 4.7 for the pair
$\mathcal {F}_n$
. We use Lemma 4.7 for the pair
 $\Pi _n\prec \mathcal {F}_n$
and define
$\Pi _n\prec \mathcal {F}_n$
and define
 $\Pi _{n+1}:=\texttt {furc}_{D_{n+1}}(\Pi _n)$
. As we mentioned at end of the previous section, we know by Lemma 4.3 that the minimal degree of a forking component of
$\Pi _{n+1}:=\texttt {furc}_{D_{n+1}}(\Pi _n)$
. As we mentioned at end of the previous section, we know by Lemma 4.3 that the minimal degree of a forking component of
 $\mathscr {F}_{n+1}/\Pi _{n+1}$
is at least
$\mathscr {F}_{n+1}/\Pi _{n+1}$
is at least
 $D_{n+1}+2$
.
$D_{n+1}+2$
.
This concludes the construction of
 $\Pi _0\prec \cdots \prec \Pi _n\prec \cdots $
and thus also that of
$\Pi _0\prec \cdots \prec \Pi _n\prec \cdots $
and thus also that of
 $\Lambda _i\sim \mathsf {Ber}(\Pi _i)$
, with the specification that, conditioned on
$\Lambda _i\sim \mathsf {Ber}(\Pi _i)$
, with the specification that, conditioned on
 $\Pi _i$
, the
$\Pi _i$
, the
 $\Lambda _i$
must be independent of the previous steps. This implies that for a any vertex o fixed in advance, the sequence
$\Lambda _i$
must be independent of the previous steps. This implies that for a any vertex o fixed in advance, the sequence
 $\Lambda _0(o),\Lambda _1(o),\ldots $
of fair bits is i.i.d., and thus if we define
$\Lambda _0(o),\Lambda _1(o),\ldots $
of fair bits is i.i.d., and thus if we define
 $\Theta (o)$
to be the real number from
$\Theta (o)$
to be the real number from
 $[0,1]$
whose consecutive bits are
$[0,1]$
whose consecutive bits are
 $\Lambda _0,\ldots ,\Lambda _n,\ldots $
, then
$\Lambda _0,\ldots ,\Lambda _n,\ldots $
, then
 $\Theta (o)$
has distribution
$\Theta (o)$
has distribution
 $\mathsf {un}[0,1]$
. Thus,
$\mathsf {un}[0,1]$
. Thus,
 $\Theta $
has
$\Theta $
has
 $\mathsf {un}[0,1]$
marginals.
$\mathsf {un}[0,1]$
marginals.
Now we turn to the proof of our main theorem.
Proof of Theorem 1.1
Because
 $\Pi _{n+1}\prec \mathcal {F}_n:=\mathsf {clust}(\Lambda _0,\ldots ,\Lambda _n)$
, if we define
$\Pi _{n+1}\prec \mathcal {F}_n:=\mathsf {clust}(\Lambda _0,\ldots ,\Lambda _n)$
, if we define
 $\Pi _{\infty }(o):=\bigcup _{i\in {\mathbb N}}\Pi _i(o)$
, then for any
$\Pi _{\infty }(o):=\bigcup _{i\in {\mathbb N}}\Pi _i(o)$
, then for any
 $v_1,v_2\in \Pi _{\infty }(o)$
and
$v_1,v_2\in \Pi _{\infty }(o)$
and
 $m\in {\mathbb N}$
, we have
$m\in {\mathbb N}$
, we have
 $\Lambda _m(v_1)=\Lambda _m(v_2)$
. Thus,
$\Lambda _m(v_1)=\Lambda _m(v_2)$
. Thus,
 $v_1,v_2\in \Pi _{\infty }(o)$
also implies
$v_1,v_2\in \Pi _{\infty }(o)$
also implies
 $\Theta (v_1)=\Theta (v_2)$
, and thus
$\Theta (v_1)=\Theta (v_2)$
, and thus
 $\Pi _{\infty }(o)$
will be contained within a single cluster of
$\Pi _{\infty }(o)$
will be contained within a single cluster of
 $\mathsf {clust}(\Theta )$
. Moreover, if
$\mathsf {clust}(\Theta )$
. Moreover, if
 $\mathcal {F}_n(o)$
is a forking cluster, then
$\mathcal {F}_n(o)$
is a forking cluster, then
 $|\Pi _{n+1}(o)|\geq D_{n+1}$
as it contains at least
$|\Pi _{n+1}(o)|\geq D_{n+1}$
as it contains at least
 $D_{n+1}$
furcation of
$D_{n+1}$
furcation of
 $\mathcal {F}_n(o)$
. So if
$\mathcal {F}_n(o)$
. So if
 $\mathcal {F}_i(o)$
is forking for every i, then
$\mathcal {F}_i(o)$
is forking for every i, then
 $\Pi _{\infty }(o)\supset \Pi _m(o)$
contains at least
$\Pi _{\infty }(o)\supset \Pi _m(o)$
contains at least
 $D_m$
element for any m, and as
$D_m$
element for any m, and as
 $D_m\to \infty $
, this implies the part of Theorem 1.1 which claims the existence of an
$D_m\to \infty $
, this implies the part of Theorem 1.1 which claims the existence of an
 $\mathsf {FIID}$
labeling
$\mathsf {FIID}$
labeling
 $\Theta $
, for which
$\Theta $
, for which
 $\mathsf {clust}(\Theta )$
contains infinite clusters.
$\mathsf {clust}(\Theta )$
contains infinite clusters.
It indeed happens with positive probability that
 $\mathcal {F}_n(o)$
is forking for all n, because of the corollary to Lemma 4.5 using the process of generating rooted trees. The correspondence is as follows. Start with the rooted tree
$\mathcal {F}_n(o)$
is forking for all n, because of the corollary to Lemma 4.5 using the process of generating rooted trees. The correspondence is as follows. Start with the rooted tree
 $(T_0,r_0):=({\mathbb T}_3/\Pi _0(o),\Pi (o))$
whose minimal degree is greater than
$(T_0,r_0):=({\mathbb T}_3/\Pi _0(o),\Pi (o))$
whose minimal degree is greater than
 $D_0$
. Use our
$D_0$
. Use our
 $\Lambda _0\sim \mathsf {Ber}(\Pi _0)$
which is a
$\Lambda _0\sim \mathsf {Ber}(\Pi _0)$
which is a
 $\mathsf {Ber}(\tfrac {1}{2})$
-labeling of
$\mathsf {Ber}(\tfrac {1}{2})$
-labeling of
 $T_0$
. Stop the process if the cluster
$T_0$
. Stop the process if the cluster
 $\mathcal {F}_0(o)$
of
$\mathcal {F}_0(o)$
of
 $\Pi _0(o)$
is not forking, otherwise continue by creating the next random rooted tree
$\Pi _0(o)$
is not forking, otherwise continue by creating the next random rooted tree
 $(\mathcal {F}_0/\Pi _1(o),\Pi _1(o))$
, whose minimal degree is greater than
$(\mathcal {F}_0/\Pi _1(o),\Pi _1(o))$
, whose minimal degree is greater than
 $D_1$
(the way we use Lemmas 4.3 and 4.7, this minimal degree actually is at least
$D_1$
(the way we use Lemmas 4.3 and 4.7, this minimal degree actually is at least
 $D_1+2$
). In general, if the process has not stopped, then the rooted tree
$D_1+2$
). In general, if the process has not stopped, then the rooted tree
 $(T_n, r_n)$
is constructed as the random rooted tree
$(T_n, r_n)$
is constructed as the random rooted tree
 $(\mathcal {F}_n/\Pi _{n+1}(o),\Pi _{n+1}(o))$
. Notice that—by the finiteness of the cells—moving from the tree
$(\mathcal {F}_n/\Pi _{n+1}(o),\Pi _{n+1}(o))$
. Notice that—by the finiteness of the cells—moving from the tree
 $\mathcal {F}_n(o)$
to its large-scale version
$\mathcal {F}_n(o)$
to its large-scale version
 $\mathcal {F}_n/\Pi _{n+1}(o)$
does not change its being forking or not (while it increases its minimal degree), so the correspondence between our construction and the process oriented corollary to Lemma 4.5 is complete. This finishes the proof that
$\mathcal {F}_n/\Pi _{n+1}(o)$
does not change its being forking or not (while it increases its minimal degree), so the correspondence between our construction and the process oriented corollary to Lemma 4.5 is complete. This finishes the proof that
 $\mathsf {clust}{\Theta }$
contains infinite clusters with positive probability, and thus by ergodicity, it contains them almost surely.
$\mathsf {clust}{\Theta }$
contains infinite clusters with positive probability, and thus by ergodicity, it contains them almost surely.
It is easy to modify the construction so that every cluster will be infinite. Let us define a new
 $\Theta ^{\infty }$
labeling from
$\Theta ^{\infty }$
labeling from
 $\Theta $
as follows: if T is a finite
$\Theta $
as follows: if T is a finite
 $\Theta $
cluster which is at distance
$\Theta $
cluster which is at distance
 $1$
from at least one infinite
$1$
from at least one infinite
 $\Theta $
cluster, then, since T is finite, the collection
$\Theta $
cluster, then, since T is finite, the collection
 $\mathcal {C}$
of such clusters is finite, and thus T can randomly choose one of these infinite clusters
$\mathcal {C}$
of such clusters is finite, and thus T can randomly choose one of these infinite clusters
 $\texttt {choice}(T)\in \mathcal {C}$
(we say a few words about this at the end). Then we define a new
$\texttt {choice}(T)\in \mathcal {C}$
(we say a few words about this at the end). Then we define a new
 $\mathsf {FIID}$
labeling
$\mathsf {FIID}$
labeling
 $\Theta ^1$
by replacing the labels of the vertices of every such T by the
$\Theta ^1$
by replacing the labels of the vertices of every such T by the
 $\Theta $
-label of
$\Theta $
-label of
 $\texttt {choice}(T)$
. Then we can progressively do the same thing with
$\texttt {choice}(T)$
. Then we can progressively do the same thing with
 $\Theta ^1$
and obtain the new
$\Theta ^1$
and obtain the new
 $\mathsf {FIID}$
labeling
$\mathsf {FIID}$
labeling
 $\Theta ^2$
and so on. Thus, we get a sequence of
$\Theta ^2$
and so on. Thus, we get a sequence of
 $\mathsf {FIID}$
labelings
$\mathsf {FIID}$
labelings
 $\Theta ,\Theta ^1,\ldots $
with the property that for any given vertex v, the sequence of labels
$\Theta ,\Theta ^1,\ldots $
with the property that for any given vertex v, the sequence of labels
 $\Theta (v),\Theta ^1(v),\ldots $
is constant from one index (in fact, it changes at most once), and thus its limit
$\Theta (v),\Theta ^1(v),\ldots $
is constant from one index (in fact, it changes at most once), and thus its limit
 $\Theta ^{\infty }(v)$
is well defined. If a finite cluster is at distance r from an infinite one under the original
$\Theta ^{\infty }(v)$
is well defined. If a finite cluster is at distance r from an infinite one under the original
 $\Theta $
labeling, then the vertices of that cluster will be in an infinite cluster of
$\Theta $
labeling, then the vertices of that cluster will be in an infinite cluster of
 $\Theta ^r$
at the latest. So in
$\Theta ^r$
at the latest. So in
 $\Theta ^{\infty }$
, there are only infinite clusters. In our original
$\Theta ^{\infty }$
, there are only infinite clusters. In our original
 $\Theta $
labeling, knowing whether or not the cluster of a vertex is finite or infinite does not change the distribution of its
$\Theta $
labeling, knowing whether or not the cluster of a vertex is finite or infinite does not change the distribution of its
 $\Theta $
-label, the conditional distribution is still
$\Theta $
-label, the conditional distribution is still
 $\mathsf {un}[0,1]$
, so
$\mathsf {un}[0,1]$
, so
 $\Theta ^{\infty }$
still has uniform marginals.
$\Theta ^{\infty }$
still has uniform marginals.
Now we explain how a finite cluster T can choose one of its infinite neighbors. As we can always access to new fresh randomness, we can obtain a random variable
 $\texttt {vote}(u)\sim \mathsf {un}[0,1]$
at every vertex u (independently from each other). Since T is finite, there are only finitely many vertices of the whole tree which are at distance
$\texttt {vote}(u)\sim \mathsf {un}[0,1]$
at every vertex u (independently from each other). Since T is finite, there are only finitely many vertices of the whole tree which are at distance
 $1$
from T and which are themselves contained in an infinite cluster, so one of those, say w, had maximal
$1$
from T and which are themselves contained in an infinite cluster, so one of those, say w, had maximal
 $\texttt {vote}(w)$
. Then let
$\texttt {vote}(w)$
. Then let
 $\texttt {choice}(T)$
be the infinite cluster containing w.
$\texttt {choice}(T)$
be the infinite cluster containing w.
We mentioned in §1 that [Reference Chifan and IoanaChI10, Theorem 1.1] implies that the clusters in
 $\Theta $
and
$\Theta $
and
 $\Theta ^{\infty }$
must be hyperfinite. Here we show their hyperfiniteness directly.
$\Theta ^{\infty }$
must be hyperfinite. Here we show their hyperfiniteness directly.
To see this for the
 $\Theta $
-clusters, notice that not only
$\Theta $
-clusters, notice that not only
 $\Pi _{\infty }(o)\subset \mathsf {clust}(\Theta )$
for any o, which already means
$\Pi _{\infty }(o)\subset \mathsf {clust}(\Theta )$
for any o, which already means
 $\Pi _{\infty }\prec {\mathsf {clust}}(\Theta )$
, but actually
$\Pi _{\infty }\prec {\mathsf {clust}}(\Theta )$
, but actually
 $\Pi _{\infty }={\mathsf {clust}}(\Theta )$
and
$\Pi _{\infty }={\mathsf {clust}}(\Theta )$
and
 $\Pi _{\infty }(o)$
is an increasing union of the finite
$\Pi _{\infty }(o)$
is an increasing union of the finite
 $\Pi _n(o)$
s. To see this, consider an edge e connecting a vertex
$\Pi _n(o)$
s. To see this, consider an edge e connecting a vertex
 $v_{\texttt {in}}\in \Pi _{\infty }(o)$
with
$v_{\texttt {in}}\in \Pi _{\infty }(o)$
with
 $v_{\texttt {out}}\not \in \Pi _{\infty }(o)$
. Notice that for any i, the labels
$v_{\texttt {out}}\not \in \Pi _{\infty }(o)$
. Notice that for any i, the labels
 $\Lambda _i(v_{\texttt {in}})$
and
$\Lambda _i(v_{\texttt {in}})$
and
 $\Lambda _i(v_{\texttt {out}})$
are independent, so they cannot be all equal. So e is deleted from
$\Lambda _i(v_{\texttt {out}})$
are independent, so they cannot be all equal. So e is deleted from
 $\mathsf {clust}(\Theta )$
.
$\mathsf {clust}(\Theta )$
.
To see the hyperfiniteness of the
 $\Theta ^{\infty }$
-clusters, we reorganize the way we build them using some new sequence of cell-partitions
$\Theta ^{\infty }$
-clusters, we reorganize the way we build them using some new sequence of cell-partitions
 $\Pi _n^{\bullet }$
. For a finite
$\Pi _n^{\bullet }$
. For a finite
 $\Theta $
-cluster K, it is well defined which is the infinite
$\Theta $
-cluster K, it is well defined which is the infinite
 $\Theta $
-cluster
$\Theta $
-cluster
 $\texttt {goal}(K)$
to which it finally will be attached, by
$\texttt {goal}(K)$
to which it finally will be attached, by
 $\Theta ^{\infty }(K)=\Theta ^{\infty }(\texttt {goal}(K))=\Theta (\texttt {goal}(K))$
; by being inside a tree, it is also well defined what is the vertex
$\Theta ^{\infty }(K)=\Theta ^{\infty }(\texttt {goal}(K))=\Theta (\texttt {goal}(K))$
; by being inside a tree, it is also well defined what is the vertex
 $\texttt {m}(K)$
of
$\texttt {m}(K)$
of
 $\texttt {goal}(K)$
which is closest to K. Moreover, K will be attached to an infinite cluster at a certain stage indexed by the smallest
$\texttt {goal}(K)$
which is closest to K. Moreover, K will be attached to an infinite cluster at a certain stage indexed by the smallest
 $i=:I(K)$
for which
$i=:I(K)$
for which
 $\Theta ^i(K)=\Theta ^{\infty }(K)$
.
$\Theta ^i(K)=\Theta ^{\infty }(K)$
.
We will reorganize the original
 $\Pi _n$
partitions into a new one using these two parameters
$\Pi _n$
partitions into a new one using these two parameters
 $I(K)$
and
$I(K)$
and
 $\texttt {m}(K)$
. Extend these parameters to vertices in a natural way: for a vertex v within a finite
$\texttt {m}(K)$
. Extend these parameters to vertices in a natural way: for a vertex v within a finite
 $\Theta $
-cluster K, let
$\Theta $
-cluster K, let
 $I(v):=I(K), \texttt {m}(v):=\texttt {m}(K)$
, while if v is within an infinite
$I(v):=I(K), \texttt {m}(v):=\texttt {m}(K)$
, while if v is within an infinite
 $\Theta $
-cluster, then let
$\Theta $
-cluster, then let
 $I(v):=0, \texttt {m}(v):=v$
. The I index has the following property: if P is a one-sided infinite path which stays completely within an infinite
$I(v):=0, \texttt {m}(v):=v$
. The I index has the following property: if P is a one-sided infinite path which stays completely within an infinite
 $\Theta ^{\infty }$
-cluster and starts at a vertex v whose
$\Theta ^{\infty }$
-cluster and starts at a vertex v whose
 $\Theta $
-cluster is already infinite, then I can only increase along P as we start from its starting point and move away from it. Moreover, if
$\Theta $
-cluster is already infinite, then I can only increase along P as we start from its starting point and move away from it. Moreover, if
 $u_1,u_2$
are vertices of P with
$u_1,u_2$
are vertices of P with
 $I(u_1)=I(u_2)$
, then
$I(u_1)=I(u_2)$
, then
 $u_1$
and
$u_1$
and
 $u_2$
are in the same
$u_2$
are in the same
 $\Theta $
-cluster.
$\Theta $
-cluster.
The cells of the new partition
 $\Pi _n^{\bullet }$
are built as follows: the vertices of an infinite
$\Pi _n^{\bullet }$
are built as follows: the vertices of an infinite
 $\Theta $
-cluster
$\Theta $
-cluster
 $\mathcal {K}$
are partitioned into
$\mathcal {K}$
are partitioned into
 $\Pi _n$
-cells. For a given
$\Pi _n$
-cells. For a given
 $\Pi _n$
-cell C within
$\Pi _n$
-cell C within
 $\mathcal {K}$
, we collect together those finite
$\mathcal {K}$
, we collect together those finite
 $\Theta $
-clusters K whose
$\Theta $
-clusters K whose
 $\texttt {m}(K)$
is in C and whose index
$\texttt {m}(K)$
is in C and whose index
 $I(K)$
is at most n to form a single
$I(K)$
is at most n to form a single
 $\Pi _n^{\bullet }$
-cell. The finite
$\Pi _n^{\bullet }$
-cell. The finite
 $\Theta $
-clusters K for which
$\Theta $
-clusters K for which
 $I(K)>n$
will be individual
$I(K)>n$
will be individual
 $\Pi ^{\bullet }_n$
-cells.
$\Pi ^{\bullet }_n$
-cells.
To define
 $\Pi _n^{\bullet }$
formally, introduce an auxiliary partitioning
$\Pi _n^{\bullet }$
formally, introduce an auxiliary partitioning
 $\Pi ^{\circ }_n$
so that for a vertex
$\Pi ^{\circ }_n$
so that for a vertex
 $\Pi ^{\circ }_n(o):=\Pi _n(o)$
if
$\Pi ^{\circ }_n(o):=\Pi _n(o)$
if
 $\Pi _{\infty }(o)$
is infinite and
$\Pi _{\infty }(o)$
is infinite and
 $\Pi ^{\circ }_n(o):=\Pi _{\infty }(o)$
if
$\Pi ^{\circ }_n(o):=\Pi _{\infty }(o)$
if
 $\Pi _{\infty }(o)$
is finite. Finally, let us define
$\Pi _{\infty }(o)$
is finite. Finally, let us define
 $$ \begin{align*} \Pi^{\bullet}_n(v):=\begin{cases} \Pi_n^{\circ}(v) & \mbox{if } I(v)>n,\\ \bigcup \{{\Pi_n^{\circ}(x)}| I(x)\leq n, \Pi^{\circ}_n(\texttt{m}(x))=\Pi^{\circ}_n(\texttt{m}(v))\} & \mbox{if } I(v)\leq n. \end{cases} \end{align*} $$
$$ \begin{align*} \Pi^{\bullet}_n(v):=\begin{cases} \Pi_n^{\circ}(v) & \mbox{if } I(v)>n,\\ \bigcup \{{\Pi_n^{\circ}(x)}| I(x)\leq n, \Pi^{\circ}_n(\texttt{m}(x))=\Pi^{\circ}_n(\texttt{m}(v))\} & \mbox{if } I(v)\leq n. \end{cases} \end{align*} $$
Then every
 $\Pi _m^{\bullet }(v)$
-class is finite because if it was infinite, then by Kőnig’s lemma, we could find an infinite path P within
$\Pi _m^{\bullet }(v)$
-class is finite because if it was infinite, then by Kőnig’s lemma, we could find an infinite path P within
 $\Pi _m^{\bullet }(v)$
for which
$\Pi _m^{\bullet }(v)$
for which
 $\texttt {m}(u)=:u_0$
would be the same for every vertex u of P and this
$\texttt {m}(u)=:u_0$
would be the same for every vertex u of P and this
 $u_0$
would be the starting point of P. By definition of the
$u_0$
would be the starting point of P. By definition of the
 $\texttt {m}(u)$
parameter, as we walk away from
$\texttt {m}(u)$
parameter, as we walk away from
 $u_0$
, we get out from the infinite
$u_0$
, we get out from the infinite
 $\Theta $
-cluster of
$\Theta $
-cluster of
 $u_0$
immediately, so
$u_0$
immediately, so
 $I(u)>0$
for any vertex
$I(u)>0$
for any vertex
 $u\not = u_0$
of P. However, by the definition of
$u\not = u_0$
of P. However, by the definition of
 $\Pi _m^{\bullet }(v)$
, the index
$\Pi _m^{\bullet }(v)$
, the index
 $I(u)$
is at most m within it, so from one vertex w on, I is constant on P. However, that would mean that the full infinite part of P after w is contained in a single
$I(u)$
is at most m within it, so from one vertex w on, I is constant on P. However, that would mean that the full infinite part of P after w is contained in a single
 $\Theta $
-cluster, so that cluster would be infinite in the first place.
$\Theta $
-cluster, so that cluster would be infinite in the first place.
However, the increasing union of
 $\bigcup _{m\in {\mathbb N}}\Pi _m^{\bullet }(v)$
is exactly the
$\bigcup _{m\in {\mathbb N}}\Pi _m^{\bullet }(v)$
is exactly the
 $\Theta ^{\infty }$
-cluster of v. To see this, note that if u is in the
$\Theta ^{\infty }$
-cluster of v. To see this, note that if u is in the
 $\Theta ^{\infty }$
-cluster of v, then there will be some n such that
$\Theta ^{\infty }$
-cluster of v, then there will be some n such that
 $\Pi _n(\texttt {m }(u))=\Pi _n(\texttt {m}(v))$
, so if
$\Pi _n(\texttt {m }(u))=\Pi _n(\texttt {m}(v))$
, so if
 $j\geq \texttt {max}\{n,I(u),I(v)\}$
, then
$j\geq \texttt {max}\{n,I(u),I(v)\}$
, then
 $u\in \Pi ^{\bullet }_j(v)$
.
$u\in \Pi ^{\bullet }_j(v)$
.
6 The case of finitary
 $\mathsf {FIID}$
s
$\mathsf {FIID}$
s

An
 $\mathsf {FIID}$
process is finitary if it can be defined with a code
$\mathsf {FIID}$
process is finitary if it can be defined with a code
 $f: [0,1]^V\rightarrow [0,1]^V$
which determines the label of any vertex based on the source in a finite neighborhood of that vertex. That is, for almost all
$f: [0,1]^V\rightarrow [0,1]^V$
which determines the label of any vertex based on the source in a finite neighborhood of that vertex. That is, for almost all
 $\omega \in [0,1]^V$
and each vertex v, there exists a random radius
$\omega \in [0,1]^V$
and each vertex v, there exists a random radius
 $r=r(\omega , v)\in {\mathbb N}$
, such that if
$r=r(\omega , v)\in {\mathbb N}$
, such that if
 $\omega _1$
has the same restriction to
$\omega _1$
has the same restriction to
 $B_r(v)$
as
$B_r(v)$
as
 $\omega $
, then the label of v is the same using either sources of randomness, that is,
$\omega $
, then the label of v is the same using either sources of randomness, that is,
 $f(\omega )(v)=f(\omega _1)(v)$
. We will call the smallest such
$f(\omega )(v)=f(\omega _1)(v)$
. We will call the smallest such
 $r(\omega , v)$
the level of v, and denote it by
$r(\omega , v)$
the level of v, and denote it by
 $\texttt {lev}_f(v)$
. If f has this property, then we will call it finitary as well. To show that a given
$\texttt {lev}_f(v)$
. If f has this property, then we will call it finitary as well. To show that a given
 $\mathsf {FIID}$
is not finitary, it is not enough to point out that a particular code used in its definition is not finitary as different codes could determine the same process.
$\mathsf {FIID}$
is not finitary, it is not enough to point out that a particular code used in its definition is not finitary as different codes could determine the same process.
We will show that an
 $\mathsf {FIID}$
process which witnesses the truth of Theorem 1.1 cannot be finitary. It was raised as an open question if there exists an
$\mathsf {FIID}$
process which witnesses the truth of Theorem 1.1 cannot be finitary. It was raised as an open question if there exists an
 $\mathsf {FIID}$
process on a non-amenable group which is not finitary during the discussion of a talk by Ray and Spinka (to access the talk, see [Reference Ray and SpinkaRS22], the talk is based on the paper [Reference Angel, Ray and SpinkaARS21]), and our construction thus gives an affirmative answer to this question. The label set in our process is the interval
$\mathsf {FIID}$
process on a non-amenable group which is not finitary during the discussion of a talk by Ray and Spinka (to access the talk, see [Reference Ray and SpinkaRS22], the talk is based on the paper [Reference Angel, Ray and SpinkaARS21]), and our construction thus gives an affirmative answer to this question. The label set in our process is the interval
 $[0,1]$
, and to our knowledge, the question if there exists a non-finitary
$[0,1]$
, and to our knowledge, the question if there exists a non-finitary
 $\mathsf {FIID}$
with a finite label set on a non-amenable group is still open.
$\mathsf {FIID}$
with a finite label set on a non-amenable group is still open.
Let L be a finitary
 $\mathsf {FIID}$
labeling with
$\mathsf {FIID}$
labeling with
 $\mathsf {un}[0,1]$
marginals. We will show that every cluster of L is finite almost surely.
$\mathsf {un}[0,1]$
marginals. We will show that every cluster of L is finite almost surely.
Let us fix a finitary code f for L and assume that L is obtained using this f. If C is a cluster of L, then we will call the set of its vertices whose level is minimal the base of C. Let
 $\mathsf {clust}_1(L)$
be the collection of those infinite clusters whose base is finite, and
$\mathsf {clust}_1(L)$
be the collection of those infinite clusters whose base is finite, and
 $\mathsf {clust}_{\infty }(L)$
be the collection of those infinite clusters whose base is infinite. We will show that both
$\mathsf {clust}_{\infty }(L)$
be the collection of those infinite clusters whose base is infinite. We will show that both
 $\mathsf {clust}_1(L)$
and
$\mathsf {clust}_1(L)$
and
 $\mathsf {clust}_{\infty }(L)$
must be empty almost surely.
$\mathsf {clust}_{\infty }(L)$
must be empty almost surely.
If
 $\mathsf {clust}_1(L)$
was not empty, then we would get a contradiction with Lemma 2.3, since the clusters of
$\mathsf {clust}_1(L)$
was not empty, then we would get a contradiction with Lemma 2.3, since the clusters of
 $\mathsf {clust}_1(L)$
are infinite with finitely many distinguished vertices, from which a single distinguished vertex can be picked uniformly.
$\mathsf {clust}_1(L)$
are infinite with finitely many distinguished vertices, from which a single distinguished vertex can be picked uniformly.
To show that
 $\mathsf {clust}_{\infty }(L)$
is empty almost surely, let us partition it further, and for
$\mathsf {clust}_{\infty }(L)$
is empty almost surely, let us partition it further, and for
 $m\in {\mathbb N}$
, let
$m\in {\mathbb N}$
, let
 $\mathsf {clust}_{\infty }^m(L)$
be the collection of those clusters within
$\mathsf {clust}_{\infty }^m(L)$
be the collection of those clusters within
 $\mathsf {clust}_{\infty }(L)$
whose base consists of vertices of level exactly m. Since this is a countable partition, it is enough to show that
$\mathsf {clust}_{\infty }(L)$
whose base consists of vertices of level exactly m. Since this is a countable partition, it is enough to show that
 $\mathsf {clust}_{\infty }^m(L)$
is empty almost surely for any fixed m. If
$\mathsf {clust}_{\infty }^m(L)$
is empty almost surely for any fixed m. If
 $\mathsf {clust}_{\infty }^m(L)$
was not empty, then infinitely many vertices had level m and the same label (the base of any cluster in
$\mathsf {clust}_{\infty }^m(L)$
was not empty, then infinitely many vertices had level m and the same label (the base of any cluster in
 $\mathsf {clust}_{\infty }^m(L)$
would be such a collection of vertices). In particular, there existed a pair of vertices whose distance is at least
$\mathsf {clust}_{\infty }^m(L)$
would be such a collection of vertices). In particular, there existed a pair of vertices whose distance is at least
 $2m+1$
, their level is m, and they had the same label. Since the possible pairs of vertices form a countable set, it is enough to show that this has zero probability for any fixed pair. Pick two vertices
$2m+1$
, their level is m, and they had the same label. Since the possible pairs of vertices form a countable set, it is enough to show that this has zero probability for any fixed pair. Pick two vertices
 $v_1$
and
$v_1$
and
 $v_2$
whose distance is at least
$v_2$
whose distance is at least
 $2m+1$
, conditioned on
$2m+1$
, conditioned on
 $\texttt {lev}_f(v_1)=\texttt {lev}_f(v_2)=m$
, their labels are independent, since
$\texttt {lev}_f(v_1)=\texttt {lev}_f(v_2)=m$
, their labels are independent, since
 $B_m(v_1)$
and
$B_m(v_1)$
and
 $B_m(v_2)$
are disjoint. If the event
$B_m(v_2)$
are disjoint. If the event
 $\texttt {lev}_f(v)=m$
has positive probability, then conditioned on it, the distribution of the label of v still must be atomless, otherwise the unconditional distribution could not be
$\texttt {lev}_f(v)=m$
has positive probability, then conditioned on it, the distribution of the label of v still must be atomless, otherwise the unconditional distribution could not be
 $\mathsf {un}[0,1]$
. However, independent samples from an atomless distribution are different almost surely.
$\mathsf {un}[0,1]$
. However, independent samples from an atomless distribution are different almost surely.
Being finitary is a locality condition, and for other natural notions of locality, we refer the reader to [Reference Meyerovitch and SpinkaMS22] (in their more refined framework, what we called finitary above is called stop-finitary). Note also that the classic example of isomporhism between Bernoulli shifts by Meshalkin ([Reference MeshalkinM59]) is also a finitary one and that in [Reference Keane and SmorodinskyKS79], Keane and Smorodinsky proved the existence of finitary isomorphisms between Bernoulli shifts of the same entropy over
 ${\mathbb Z}$
, and thus strengthening Ornstein’s landmark theorem (for a survey of finitary codings in this direction, see [Reference Serafin, Denteneer, den Hollander and VerbitskiyS06]).
${\mathbb Z}$
, and thus strengthening Ornstein’s landmark theorem (for a survey of finitary codings in this direction, see [Reference Serafin, Denteneer, den Hollander and VerbitskiyS06]).
Acknowledgement
This work was partially supported by the ERC Consolidator Grant 772466 ‘NOISE’. At earlier stages, the work was also partially supported by NSF Grant DMS-1007244 and OTKA Grant K76099. I am grateful to Russell Lyons for suggesting working on this problem and for useful discussions and for helping improving the first version of the text. I also thank the anonymous referee of the first submitted version for useful feedback. I similarly thank the anonymous referee of the current version. I am indebted to Gábor Pete for useful discussions throughout the writing of this version and for Sándor Rokob for useful feedback.






