


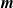


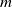
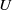
1. Introduction
The purpose of the present paper is to present some new results for (asymmetric)
 $U$
-statistics together with some applications. (See Section 3 for definitions.) The results include a strong law of large numbers and a central limit theorem (asymptotic normality), together with results on rate of convergence, moment convergence, functional convergence, and a renewal theory version.
$U$
-statistics together with some applications. (See Section 3 for definitions.) The results include a strong law of large numbers and a central limit theorem (asymptotic normality), together with results on rate of convergence, moment convergence, functional convergence, and a renewal theory version.
Many results of these types have been proved for
 $U$
-statistics under different hypotheses by a large number of authors, from Hoeffding [Reference Hoeffding27] on. The new feature of the results here, which are motivated by applications discussed below, is the combination of the following:
$U$
-statistics under different hypotheses by a large number of authors, from Hoeffding [Reference Hoeffding27] on. The new feature of the results here, which are motivated by applications discussed below, is the combination of the following:
-
(i) We consider, as in e.g. [Reference Janson35], [Reference Janson37], and [Reference Han and Qian26], but unlike many other authors, asymmetric
 $U$
-statistics and not just the symmetric case. (See Remark 3.3.)
$U$
-statistics and not just the symmetric case. (See Remark 3.3.) -
(ii) We consider also constrained
$U$
-statistics, where the summations are restricted as in (3.2) or (3.3). -
(iii) The
$U$
-statistics are based on an underlying sequence that is not necessarily i.i.d. (as is usually assumed); we assume only that the sequence is stationary and
$m$
-dependent. (This case has been studied earlier by e.g. [Reference Sen58], but not in the present asymmetric case.)




The extension to the
 $m$
-dependent case might be of interest for some applications, but for us the main motivation is that it allows us to reduce the constrained versions to ordinary
$m$
-dependent case might be of interest for some applications, but for us the main motivation is that it allows us to reduce the constrained versions to ordinary
 $U$
-statistics; hence this extension is implicitly used also when we apply the results for constrained
$U$
-statistics; hence this extension is implicitly used also when we apply the results for constrained
 $U$
-statistics based on i.i.d. sequences.
$U$
-statistics based on i.i.d. sequences.
Remark 1.1. The combination of the features (i)–(iii) above is new, but they have each been considered separately earlier.
In particular, constrained
 $U$
-statistics are special cases of the large class of incomplete
$U$
-statistics are special cases of the large class of incomplete
 $U$
-statistics [Reference Blom6]. These are, in turn, special cases of the even more general weighted
$U$
-statistics [Reference Blom6]. These are, in turn, special cases of the even more general weighted
 $U$
-statistics; see e.g. [Reference Shapiro and Hubert61], [Reference O’Neil and Redner47], [Reference Major42], [Reference Rinott and Rotar55], [Reference Hsing and Wu30], [Reference Zhou66], and [Reference Han and Qian26]. (These references show asymptotic normality under various conditions; some also study degenerate cases with non-normal limits; [Reference Han and Qian26] includes the asymmetric case.) In view of our applications, we consider here only the constrained case instead of trying to find suitable conditions for general weights.
$U$
-statistics; see e.g. [Reference Shapiro and Hubert61], [Reference O’Neil and Redner47], [Reference Major42], [Reference Rinott and Rotar55], [Reference Hsing and Wu30], [Reference Zhou66], and [Reference Han and Qian26]. (These references show asymptotic normality under various conditions; some also study degenerate cases with non-normal limits; [Reference Han and Qian26] includes the asymmetric case.) In view of our applications, we consider here only the constrained case instead of trying to find suitable conditions for general weights.
Similarly,
 $U$
-statistics have been considered by many authors for more general weakly dependent sequences than
$U$
-statistics have been considered by many authors for more general weakly dependent sequences than
 $m$
-dependent ones. In particular, asymptotic normality has been shown under various types of mixing conditions by e.g. [Reference Sen59], [Reference Yoshihara64, Reference Yoshihara65], and [Reference Dehling and Wendler15]. We are not aware of any paper on asymmetric
$m$
-dependent ones. In particular, asymptotic normality has been shown under various types of mixing conditions by e.g. [Reference Sen59], [Reference Yoshihara64, Reference Yoshihara65], and [Reference Dehling and Wendler15]. We are not aware of any paper on asymmetric
 $U$
-statistics with a mixing condition on the variables. Such results might be interesting for future research, but again in view of our applications, we have not pursued this and consider here only the
$U$
-statistics with a mixing condition on the variables. Such results might be interesting for future research, but again in view of our applications, we have not pursued this and consider here only the
 $m$
-dependent case.
$m$
-dependent case.
There are thus many previous results yielding asymptotic normality for
 $U$
-statistics under various conditions. One general feature, found already in the first paper [Reference Hoeffding27], is that there are degenerate cases where the asymptotic variance vanishes (typically because of some internal cancellations). In such cases, the theorems only yield convergence to 0 and do not imply asymptotic normality; indeed, typically a different normalization yields a non-normal limit. It is often difficult to calculate the asymptotic variance exactly, and it is therefore of great interest to have simple criteria that show that the asymptotic variance is non-zero. Such a criterion is well known for the standard case of (unconstrained)
$U$
-statistics under various conditions. One general feature, found already in the first paper [Reference Hoeffding27], is that there are degenerate cases where the asymptotic variance vanishes (typically because of some internal cancellations). In such cases, the theorems only yield convergence to 0 and do not imply asymptotic normality; indeed, typically a different normalization yields a non-normal limit. It is often difficult to calculate the asymptotic variance exactly, and it is therefore of great interest to have simple criteria that show that the asymptotic variance is non-zero. Such a criterion is well known for the standard case of (unconstrained)
 $U$
-statistics based on i.i.d. variables [Reference Hoeffding27]. We give corresponding (somewhat more complicated) criteria for the
$U$
-statistics based on i.i.d. variables [Reference Hoeffding27]. We give corresponding (somewhat more complicated) criteria for the
 $m$
-dependent case studied here, in both the unconstrained and constrained cases. (This is one reason for considering only the
$m$
-dependent case studied here, in both the unconstrained and constrained cases. (This is one reason for considering only the
 $m$
-dependent case in the present paper, and not more general weakly dependent sequences.) We show the applicability of our criteria in some examples.
$m$
-dependent case in the present paper, and not more general weakly dependent sequences.) We show the applicability of our criteria in some examples.
Like many (but not all) of the references cited above, we base our proof of asymptotic normality on the decomposition method of Hoeffding [Reference Hoeffding27], with appropriate modifications. As pointed out by an anonymous referee, an alternative method is to use dependency graphs together with Stein’s method, which under an extra moment assumption yields our main results on asymptotic normality together with an upper bound on the rate of convergence. We do not use this method in the main parts of the paper, partly because it does not seem to yield simple criteria for non-vanishing of the asymptotic variance; however, as a complement, we use this method to give some results on rate of convergence.
1.1. Applications
The background motivating our general results is given by some parallel results for pattern matching in random strings and in random permutations that have previously been shown by different methods, but easily follow from our results; we describe these results here and return to them (and some new results) in Sections 13 and 14. Further applications to pattern matching in random permutations restricted to two classes of permutations are given in [Reference Janson38].
First, consider a random string
 $\Xi _n=\xi _1\cdots \xi _n$
consisting of
$\Xi _n=\xi _1\cdots \xi _n$
consisting of
 $n$
i.i.d. random letters from a finite alphabet
$n$
i.i.d. random letters from a finite alphabet
 $\mathcal{A}$
(in this context, this is known as a memoryless source), and consider the number of occurrences of a given word
$\mathcal{A}$
(in this context, this is known as a memoryless source), and consider the number of occurrences of a given word
 $\textbf{w}=w_1\dotsm w_\ell$
as a subsequence; to be precise, an occurrence of
$\textbf{w}=w_1\dotsm w_\ell$
as a subsequence; to be precise, an occurrence of
 $\textbf{w}$
in
$\textbf{w}$
in
 $\Xi _n$
is an increasing sequence of indices
$\Xi _n$
is an increasing sequence of indices
 $i_1\lt \ldots \lt i_\ell$
in
$i_1\lt \ldots \lt i_\ell$
in
 $[n]=\{{1,\ldots,n}\}$
such that
$[n]=\{{1,\ldots,n}\}$
such that
 \begin{align} \xi _{i_1}\xi _{i_2}\dotsm \xi _{i_\ell }=\textbf{w}, \qquad \text{i.e., $\xi _{i_k}=w_k$ for every $k\in [\ell ]$} . \end{align}
\begin{align} \xi _{i_1}\xi _{i_2}\dotsm \xi _{i_\ell }=\textbf{w}, \qquad \text{i.e., $\xi _{i_k}=w_k$ for every $k\in [\ell ]$} . \end{align}
This number,
 $N_n(\textbf{w})$
say, was studied by Flajolet, Szpankowski and Vallée [Reference Flajolet, Szpankowski and Vallée23], who proved that
$N_n(\textbf{w})$
say, was studied by Flajolet, Szpankowski and Vallée [Reference Flajolet, Szpankowski and Vallée23], who proved that
 $N_n(\textbf{w})$
is asymptotically normal as
$N_n(\textbf{w})$
is asymptotically normal as
 $n\to \infty$
.
$n\to \infty$
.
Flajolet, Szpankowski and Vallée [Reference Flajolet, Szpankowski and Vallée23] also studied a constrained version, where we are also given numbers
 $d_1,\ldots,d_{\ell -1}\in \mathbb{N}\cup \{\infty \}=\{{1,2,\ldots,\infty }\}$
and count only occurrences of
$d_1,\ldots,d_{\ell -1}\in \mathbb{N}\cup \{\infty \}=\{{1,2,\ldots,\infty }\}$
and count only occurrences of
 $w$
such that
$w$
such that
 \begin{align} i_{j+1}-i_j\leqslant d_j, \qquad 1\leqslant j\lt \ell . \end{align}
\begin{align} i_{j+1}-i_j\leqslant d_j, \qquad 1\leqslant j\lt \ell . \end{align}
(Thus the
 $j$
th gap in
$j$
th gap in
 $i_1,\ldots,i_\ell$
has length strictly less than
$i_1,\ldots,i_\ell$
has length strictly less than
 $d_j$
.) We write
$d_j$
.) We write
 ${\mathcal{D}}\,:\!=\,(d_1,\ldots,d_{\ell -1})$
, and let
${\mathcal{D}}\,:\!=\,(d_1,\ldots,d_{\ell -1})$
, and let
 $N_n(\textbf{w};\,{\mathcal{D}})$
be the number of occurrences of
$N_n(\textbf{w};\,{\mathcal{D}})$
be the number of occurrences of
 $\textbf{w}$
that satisfy the constraints (1.2). It was shown in [Reference Flajolet, Szpankowski and Vallée23] that, for any fixed
$\textbf{w}$
that satisfy the constraints (1.2). It was shown in [Reference Flajolet, Szpankowski and Vallée23] that, for any fixed
 $\textbf{w}$
and
$\textbf{w}$
and
 $\mathcal{D}$
,
$\mathcal{D}$
,
 $N_n(\textbf{w},{\mathcal{D}})$
is asymptotically normal as
$N_n(\textbf{w},{\mathcal{D}})$
is asymptotically normal as
 $n\to \infty$
. See also the book by [Jacquet and Szpankowski [Reference Jacquet and Szpankowski31], Chapter 5].
$n\to \infty$
. See also the book by [Jacquet and Szpankowski [Reference Jacquet and Szpankowski31], Chapter 5].
Remark 1.2. Note that
 $d_j=\infty$
means no constraint for the
$d_j=\infty$
means no constraint for the
 $j$
th gap. In particular,
$j$
th gap. In particular,
 $d_1=\ldots =d_{\ell -1}=\infty$
yields the unconstrained case; we denote this trivial (but important) constraint
$d_1=\ldots =d_{\ell -1}=\infty$
yields the unconstrained case; we denote this trivial (but important) constraint
 $\mathcal{D}$
by
$\mathcal{D}$
by
 ${\mathcal{D}}_\infty$
.
${\mathcal{D}}_\infty$
.
In the other extreme case, if
 $d_j=1$
, then
$d_j=1$
, then
 $i_j$
and
$i_j$
and
 $i_{j+1}$
have to be adjacent. In particular, in the completely constrained case
$i_{j+1}$
have to be adjacent. In particular, in the completely constrained case
 $d_1=\cdots =d_{\ell -1}=1$
,
$d_1=\cdots =d_{\ell -1}=1$
,
 $N_n(\textbf{w};\,{\mathcal{D}})$
counts occurrences of
$N_n(\textbf{w};\,{\mathcal{D}})$
counts occurrences of
 $\textbf{w}$
as a substring
$\textbf{w}$
as a substring
 $\xi _i\xi _{i+1}\cdots \xi _{i+\ell -1}$
. Substring counts have been studied by many authors; some references with central limit theorems or local limit theorems under varying conditions are [Reference Bender and Kochman4], [Reference Régnier and Szpankowski52], [Reference Nicodème, Salvy and Flajolet45], and [Reference Flajolet and Sedgewick22, Proposition IX.10, p. 660]. See also [Reference Szpankowski62, Section 7.6.2 and Example 8.8] and [Reference Jacquet and Szpankowski31]; the latter book discusses not only substring and subsequence counts but also other versions of substring matching problems in random strings.
$\xi _i\xi _{i+1}\cdots \xi _{i+\ell -1}$
. Substring counts have been studied by many authors; some references with central limit theorems or local limit theorems under varying conditions are [Reference Bender and Kochman4], [Reference Régnier and Szpankowski52], [Reference Nicodème, Salvy and Flajolet45], and [Reference Flajolet and Sedgewick22, Proposition IX.10, p. 660]. See also [Reference Szpankowski62, Section 7.6.2 and Example 8.8] and [Reference Jacquet and Szpankowski31]; the latter book discusses not only substring and subsequence counts but also other versions of substring matching problems in random strings.
Note also that the case when all
 $d_i\in \{{1,\infty }\}$
means that
$d_i\in \{{1,\infty }\}$
means that
 $\textbf{w}$
is a concatenation
$\textbf{w}$
is a concatenation
 $\textbf{w}_1\dotsm \textbf{w}_b$
(with
$\textbf{w}_1\dotsm \textbf{w}_b$
(with
 $\textbf{w}$
broken at positions where
$\textbf{w}$
broken at positions where
 $d_i=\infty$
), such that an occurrence now is an occurrence of each
$d_i=\infty$
), such that an occurrence now is an occurrence of each
 $\textbf{w}_i$
as a substring, with these substrings in order and non-overlapping, and with arbitrary gaps in between. (This is a special case of the generalized subsequence problem in [Reference Jacquet and Szpankowski31, Section 5.6]; the general case can be regarded as a sum of such counts over a set of
$\textbf{w}_i$
as a substring, with these substrings in order and non-overlapping, and with arbitrary gaps in between. (This is a special case of the generalized subsequence problem in [Reference Jacquet and Szpankowski31, Section 5.6]; the general case can be regarded as a sum of such counts over a set of
 $\textbf{w}$
.)
$\textbf{w}$
.)
There are similar results for random permutations. Let
 $\mathfrak{S}_n$
be the set of the
$\mathfrak{S}_n$
be the set of the
 $n!$
permutations of
$n!$
permutations of
 $[n]$
. If
$[n]$
. If
 $\pi =\pi _1\cdots \pi _n\in \mathfrak{S}_n$
and
$\pi =\pi _1\cdots \pi _n\in \mathfrak{S}_n$
and
 $\tau =\tau _1\cdots \tau _\ell \in \mathfrak{S}_\ell$
, then an occurrence of the pattern
$\tau =\tau _1\cdots \tau _\ell \in \mathfrak{S}_\ell$
, then an occurrence of the pattern
 $\tau$
in
$\tau$
in
 $\pi$
is an increasing sequence of indices
$\pi$
is an increasing sequence of indices
 $i_1\lt \cdots \lt i_\ell$
in
$i_1\lt \cdots \lt i_\ell$
in
 $[n]=\{{1,\ldots,n}\}$
such that the order relations in
$[n]=\{{1,\ldots,n}\}$
such that the order relations in
 $\pi _{i_1}\cdots \pi _{i_\ell }$
are the same as in
$\pi _{i_1}\cdots \pi _{i_\ell }$
are the same as in
 $\tau _1\cdots \tau _\ell$
, i.e.,
$\tau _1\cdots \tau _\ell$
, i.e.,
 $\pi _{i_j}\lt \pi _{i_k}\iff \tau _j\lt \tau _k$
.
$\pi _{i_j}\lt \pi _{i_k}\iff \tau _j\lt \tau _k$
.
Let
 $N_n(\tau )$
be the number of occurrences of
$N_n(\tau )$
be the number of occurrences of
 $\tau$
in
$\tau$
in
 $\boldsymbol{\pi }$
when
$\boldsymbol{\pi }$
when
 ${\boldsymbol{\pi }}={\boldsymbol{\pi }}^{(n)}$
is uniformly random in
${\boldsymbol{\pi }}={\boldsymbol{\pi }}^{(n)}$
is uniformly random in
 $\mathfrak{S}_n$
. Bóna [Reference Bóna7] proved that
$\mathfrak{S}_n$
. Bóna [Reference Bóna7] proved that
 $N_n(\tau )$
is asymptotically normal as
$N_n(\tau )$
is asymptotically normal as
 $n\to \infty$
, for any fixed
$n\to \infty$
, for any fixed
 $\tau$
.
$\tau$
.
Also for permutations, one can consider, and count, constrained occurrences by again imposing the restriction (1.2) for some
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
. In analogy with strings, we let
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
. In analogy with strings, we let
 $N_n(\tau,{\mathcal{D}})$
be the number of constrained occurrences of
$N_n(\tau,{\mathcal{D}})$
be the number of constrained occurrences of
 $\tau$
in
$\tau$
in
 ${\boldsymbol{\pi }}^{(n)}$
when
${\boldsymbol{\pi }}^{(n)}$
when
 ${\boldsymbol{\pi }}^{(n)}$
is uniformly random in
${\boldsymbol{\pi }}^{(n)}$
is uniformly random in
 $\mathfrak{S}_n$
. This random number seems to have been studied mainly in the case when each
$\mathfrak{S}_n$
. This random number seems to have been studied mainly in the case when each
 $d_i\in \{{1,\infty }\}$
, i.e., some
$d_i\in \{{1,\infty }\}$
, i.e., some
 $i_j$
are required to be adjacent to the next one—in the permutation context, such constrained patterns are known as vincular patterns. Hofer [Reference Hofer29] proved asymptotic normality of
$i_j$
are required to be adjacent to the next one—in the permutation context, such constrained patterns are known as vincular patterns. Hofer [Reference Hofer29] proved asymptotic normality of
 $N_n(\tau,{\mathcal{D}})$
as
$N_n(\tau,{\mathcal{D}})$
as
 $n\to \infty$
, for any fixed
$n\to \infty$
, for any fixed
 $\tau$
and vincular
$\tau$
and vincular
 $\mathcal{D}$
. The extreme case with
$\mathcal{D}$
. The extreme case with
 $d_1=\cdots =d_{\ell -1}=1$
was earlier treated by Bóna [Reference Bóna9]. Another (non-vincular) case that has been studied is that of
$d_1=\cdots =d_{\ell -1}=1$
was earlier treated by Bóna [Reference Bóna9]. Another (non-vincular) case that has been studied is that of
 $d$
-descents, given by
$d$
-descents, given by
 $\ell =2$
,
$\ell =2$
,
 $\tau =21$
, and
$\tau =21$
, and
 ${\mathcal{D}}=(d)$
; Bóna [Reference Bóna8] shows asymptotic normality and Pike [Reference Pike50] gives a rate of convergence.
${\mathcal{D}}=(d)$
; Bóna [Reference Bóna8] shows asymptotic normality and Pike [Reference Pike50] gives a rate of convergence.
We unify these results by considering
 $U$
-statistics. It is well known and easy to see that the number
$U$
-statistics. It is well known and easy to see that the number
 $N_n(\textbf{w})$
of unconstrained occurrences of a given subsequence
$N_n(\textbf{w})$
of unconstrained occurrences of a given subsequence
 $\textbf{w}$
in a random string
$\textbf{w}$
in a random string
 $\Xi _n$
can be written as an asymmetric
$\Xi _n$
can be written as an asymmetric
 $U$
-statistic; see Section 13 and (13.2) for details. There are general results on asymptotic normality of
$U$
-statistic; see Section 13 and (13.2) for details. There are general results on asymptotic normality of
 $U$
-statistics that extend the basic result by [Reference Hoeffding27] to the asymmetric case; see e.g. [Reference Janson35, Corollary 11.20] and [Reference Janson37]. Hence, asymptotic normality of
$U$
-statistics that extend the basic result by [Reference Hoeffding27] to the asymmetric case; see e.g. [Reference Janson35, Corollary 11.20] and [Reference Janson37]. Hence, asymptotic normality of
 $N_n(\textbf{w})$
follows directly from these general results. Similarly, it is well known that the pattern count
$N_n(\textbf{w})$
follows directly from these general results. Similarly, it is well known that the pattern count
 $N_n(\tau )$
in a random permutation also can be written as a
$N_n(\tau )$
in a random permutation also can be written as a
 $U$
-statistic (see Section 14 for details), and again this can be used to prove asymptotic normality. (See [Reference Janson, Nakamura and Zeilberger39], with an alternative proof by this method of the result by Bóna [Reference Bóna7].)
$U$
-statistic (see Section 14 for details), and again this can be used to prove asymptotic normality. (See [Reference Janson, Nakamura and Zeilberger39], with an alternative proof by this method of the result by Bóna [Reference Bóna7].)
The constrained case is different, since the constrained pattern counts are not
 $U$
-statistics. However, they can be regarded as constrained
$U$
-statistics. However, they can be regarded as constrained
 $U$
-statistics, which we define in (3.2) below in analogy with the constrained counts above. As stated above, in the present paper we prove general limit theorems for such constrained
$U$
-statistics, which we define in (3.2) below in analogy with the constrained counts above. As stated above, in the present paper we prove general limit theorems for such constrained
 $U$
-statistics, which thus immediately apply to the constrained pattern counts discussed above in random strings and permutations.
$U$
-statistics, which thus immediately apply to the constrained pattern counts discussed above in random strings and permutations.
The basic idea in the proofs is that a constrained
 $U$
-statistic based on a sequence
$U$
-statistic based on a sequence
 $(X_i)$
can be written (possibly up to a small error) as an unconstrained
$(X_i)$
can be written (possibly up to a small error) as an unconstrained
 $U$
-statistic based on another sequence
$U$
-statistic based on another sequence
 $(Y_i)$
of random variables, where the new sequence
$(Y_i)$
of random variables, where the new sequence
 $(Y_i)$
is
$(Y_i)$
is
 $m$
-dependent (with a different
$m$
-dependent (with a different
 $m$
) if
$m$
) if
 $(X_i)$
is. (However, even if
$(X_i)$
is. (However, even if
 $(X_i)$
is independent,
$(X_i)$
is independent,
 $(Y_i)$
is in general not; this is our main motivation for considering
$(Y_i)$
is in general not; this is our main motivation for considering
 $m$
-dependent sequences.) The unconstrained
$m$
-dependent sequences.) The unconstrained
 $m$
-dependent case then is treated by standard methods from the independent case, with appropriate modifications.
$m$
-dependent case then is treated by standard methods from the independent case, with appropriate modifications.
Section 2 contains some preliminaries. The unconstrained and constrained
 $U$
-statistics are defined in Section 3, where also the main theorems are stated. The degenerate case, when the asymptotic variance in the central limit theorem Theorem 3.3, 3.4, or 3.8 vanishes, is discussed later in Section 8, when more notation has been introduced; Theorems 8.1, 8.2, and 8.3, respectively, give criteria that can be used to show that the asymptotic variance is non-zero in an application. On the other hand, Example 8.1 shows that the degenerate case can occur in new ways for constrained
$U$
-statistics are defined in Section 3, where also the main theorems are stated. The degenerate case, when the asymptotic variance in the central limit theorem Theorem 3.3, 3.4, or 3.8 vanishes, is discussed later in Section 8, when more notation has been introduced; Theorems 8.1, 8.2, and 8.3, respectively, give criteria that can be used to show that the asymptotic variance is non-zero in an application. On the other hand, Example 8.1 shows that the degenerate case can occur in new ways for constrained
 $U$
-statistics.
$U$
-statistics.
The reduction to the unconstrained case and some other lemmas are given in Section 4, and then the proofs of the main theorems are completed in Sections 5–7 and 9–12. Section 13 gives applications to the problem on pattern matching in random strings discussed above. Similarly, Section 14 gives applications to pattern matching in random permutations. Some further comments and open problems are given in Section 15. The appendix contains some further results on subsequence counts in random strings.
2. Preliminaries
2.1. Some notation
A constraint is, as in Section 1, a sequence
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})\in (\mathbb{N}\cup \{\infty \})^{\ell -1}$
, for some given
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})\in (\mathbb{N}\cup \{\infty \})^{\ell -1}$
, for some given
 $\ell \geqslant 1$
. Recall that the special constraint
$\ell \geqslant 1$
. Recall that the special constraint
 $(\infty,\ldots,\infty )$
is denoted by
$(\infty,\ldots,\infty )$
is denoted by
 ${\mathcal{D}}_\infty$
. Given a constraint
${\mathcal{D}}_\infty$
. Given a constraint
 $\mathcal{D}$
, define
$\mathcal{D}$
, define
 $b=b({\mathcal{D}})$
by
$b=b({\mathcal{D}})$
by
 \begin{align} b=b({\mathcal{D}})\,:\!=\,\ell -|\{{j\,:\,d_j\lt \infty }\}| =1+|\{{j\,:\,d_j=\infty }\}| . \end{align}
\begin{align} b=b({\mathcal{D}})\,:\!=\,\ell -|\{{j\,:\,d_j\lt \infty }\}| =1+|\{{j\,:\,d_j=\infty }\}| . \end{align}
We say that
 $b$
is the number of blocks defined by
$b$
is the number of blocks defined by
 $\mathcal{D}$
; see further Section 4 below.
$\mathcal{D}$
; see further Section 4 below.
For a random variable
 $Z$
, and
$Z$
, and
 $p\gt 0$
, we let
$p\gt 0$
, we let
 $\lVert{Z}\rVert _p\,:\!=\, ({{\mathbb{E}}[{|Z|^p}]} )^{1/p}$
.
$\lVert{Z}\rVert _p\,:\!=\, ({{\mathbb{E}}[{|Z|^p}]} )^{1/p}$
.
We use
 $\overset{d}{\longrightarrow }$
,
$\overset{d}{\longrightarrow }$
,
 $\overset{p}{\longrightarrow }$
, and
$\overset{p}{\longrightarrow }$
, and
 $\overset{a.s.}{\longrightarrow }$
for convergence of random variables in distribution, in probability, and almost surely (a.s.), respectively. For a sequence of random variables
$\overset{a.s.}{\longrightarrow }$
for convergence of random variables in distribution, in probability, and almost surely (a.s.), respectively. For a sequence of random variables
 $(Z_n)$
, and a sequence
$(Z_n)$
, and a sequence
 $a_n\gt 0$
, we write
$a_n\gt 0$
, we write
 $Z_n=o_{p}(a_n)$
when
$Z_n=o_{p}(a_n)$
when
 $Z_n/a_n \overset{p}{\longrightarrow } 0$
.
$Z_n/a_n \overset{p}{\longrightarrow } 0$
.
Unspecified limits are as
 $n\to \infty$
.
$n\to \infty$
.
 $C$
denotes an unspecified constant, which may be different at each occurrence. (
$C$
denotes an unspecified constant, which may be different at each occurrence. (
 $C$
may depend on parameters that are regarded as fixed, for example the function
$C$
may depend on parameters that are regarded as fixed, for example the function
 $f$
below; this will be clear from the context.)
$f$
below; this will be clear from the context.)
We use the convention
 $\binom nk\,:\!=\,0$
if
$\binom nk\,:\!=\,0$
if
 $n\lt 0$
. (We will always have
$n\lt 0$
. (We will always have
 $k\geqslant 0$
.) Some further standard notation:
$k\geqslant 0$
.) Some further standard notation:
 $[n]\,:\!=\,\{{1,\ldots,n}\}$
, and
$[n]\,:\!=\,\{{1,\ldots,n}\}$
, and
 $\max \emptyset \,:\!=\,0$
. All functions are tacitly assumed to be measurable.
$\max \emptyset \,:\!=\,0$
. All functions are tacitly assumed to be measurable.
2.2.
$m$
-dependent variables

For reasons mentioned in the introduction, we will consider
 $U$
-statistics not only based on sequences of independent random variables, but also based on
$U$
-statistics not only based on sequences of independent random variables, but also based on
 $m$
-dependent variables.
$m$
-dependent variables.
Recall that a (finite or infinite) sequence of random variables
 $(X_i)_{i}$
is
$(X_i)_{i}$
is
 $m$
-dependent if the two families
$m$
-dependent if the two families
 $\{{X_i}\}_{i\leqslant k}$
and
$\{{X_i}\}_{i\leqslant k}$
and
 $\{{X_i}\}_{i\gt k+m}$
of random variables are independent of each other for every
$\{{X_i}\}_{i\gt k+m}$
of random variables are independent of each other for every
 $k$
. (Here,
$k$
. (Here,
 $m\geqslant 0$
is a given integer.) In particular, 0-dependent is the same as independent; thus the important independent case is included as the special case
$m\geqslant 0$
is a given integer.) In particular, 0-dependent is the same as independent; thus the important independent case is included as the special case
 $m=0$
below.
$m=0$
below.
It is well known that if
 $(X_i)_{i\in I}$
is
$(X_i)_{i\in I}$
is
 $m$
-dependent, and
$m$
-dependent, and
 $I_1,\ldots,I_r\subseteq I$
are sets of indices such that
$I_1,\ldots,I_r\subseteq I$
are sets of indices such that
 ${dist}(I_j,I_k)\,:\!=\,\inf \{{|i-i^{\prime}|\,:\,i\in I_j,i^{\prime}\in I_k}\}\gt m$
when
${dist}(I_j,I_k)\,:\!=\,\inf \{{|i-i^{\prime}|\,:\,i\in I_j,i^{\prime}\in I_k}\}\gt m$
when
 $j\neq k$
, then the families (vectors) of random variables
$j\neq k$
, then the families (vectors) of random variables
 $(X_i)_{i\in I_1}$
, …,
$(X_i)_{i\in I_1}$
, …,
 $(X_i)_{i\in I_r}$
are mutually independent of each other. (To see this, note first that it suffices to consider the case when each
$(X_i)_{i\in I_r}$
are mutually independent of each other. (To see this, note first that it suffices to consider the case when each
 $I_j$
is an interval; then use the definition and induction on
$I_j$
is an interval; then use the definition and induction on
 $r$
.) We will use this property without further comment.
$r$
.) We will use this property without further comment.
In practice,
 $m$
-dependent sequences usually occur as block factors; i.e. they can be expressed as
$m$
-dependent sequences usually occur as block factors; i.e. they can be expressed as
 \begin{align} X_i\,:\!=\,h(\xi _i,\ldots,\xi _{i+m}) \end{align}
\begin{align} X_i\,:\!=\,h(\xi _i,\ldots,\xi _{i+m}) \end{align}
for some i.i.d. sequence
 $(\xi _i)$
of random variables (in some measurable space
$(\xi _i)$
of random variables (in some measurable space
 ${\mathcal{S}}_0$
) and a fixed function
${\mathcal{S}}_0$
) and a fixed function
 $h$
on
$h$
on
 ${\mathcal{S}}_0^{m+1}$
. (It is obvious that (2.2) then defines a stationary
${\mathcal{S}}_0^{m+1}$
. (It is obvious that (2.2) then defines a stationary
 $m$
-dependent sequence.)
$m$
-dependent sequence.)
3.
$U$
-statistics and main results

Let
 $X_1,X_2,\ldots$
be a sequence of random variables, taking values in some measurable space
$X_1,X_2,\ldots$
be a sequence of random variables, taking values in some measurable space
 $\mathcal{S}$
, and let
$\mathcal{S}$
, and let
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
be a (measurable) function of
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
be a (measurable) function of
 $\ell$
variables, for some
$\ell$
variables, for some
 $\ell \geqslant 1$
. Then the corresponding
$\ell \geqslant 1$
. Then the corresponding
 $U$
-statistic is the (real-valued) random variable defined for each
$U$
-statistic is the (real-valued) random variable defined for each
 $n\geqslant 0$
by
$n\geqslant 0$
by
 \begin{equation} U_n=U_n(f) =U_n\bigl ({f;\,(X_i) }\bigr ) \,:\!=\,\sum _{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ). \end{equation}
\begin{equation} U_n=U_n(f) =U_n\bigl ({f;\,(X_i) }\bigr ) \,:\!=\,\sum _{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ). \end{equation}
 $U$
-statistics were introduced by Hoeffding [Reference Hoeffding27], who proved a general central limit theorem; the present paper gives an extension of his result that builds on his methods.
$U$
-statistics were introduced by Hoeffding [Reference Hoeffding27], who proved a general central limit theorem; the present paper gives an extension of his result that builds on his methods.
Remark 3.1. Of course, for the definition (3.1) it suffices to have a finite sequence
 $(X_i)_1^{n}$
, but in the present paper we will only consider the initial segments of an infinite sequence.
$(X_i)_1^{n}$
, but in the present paper we will only consider the initial segments of an infinite sequence.
Remark 3.2. Many authors, including Hoeffding [Reference Hoeffding27], define
 $U_n$
by dividing the sum in (3.1) by
$U_n$
by dividing the sum in (3.1) by
 $\binom n\ell$
, the number of terms in it. We find it more convenient for our purposes to use the non-normalized version above.
$\binom n\ell$
, the number of terms in it. We find it more convenient for our purposes to use the non-normalized version above.
Remark 3.3. Many authors, including Hoeffding [Reference Hoeffding27], assume that
 $f$
is a symmetric function of its
$f$
is a symmetric function of its
 $\ell$
variables. In this case, the order of the variables does not matter, and in (3.1) we can sum over all sequences
$\ell$
variables. In this case, the order of the variables does not matter, and in (3.1) we can sum over all sequences
 $i_1,\ldots,i_\ell$
of
$i_1,\ldots,i_\ell$
of
 $\ell$
distinct elements of
$\ell$
distinct elements of
 $\{{1,\ldots,n}\}$
, up to an obvious factor of
$\{{1,\ldots,n}\}$
, up to an obvious factor of
 $\ell !$
. (Hoeffding [Reference Hoeffding27] gives both versions.) Conversely, if we sum over all such sequences, we may without loss of generality assume that
$\ell !$
. (Hoeffding [Reference Hoeffding27] gives both versions.) Conversely, if we sum over all such sequences, we may without loss of generality assume that
 $f$
is symmetric. However, in the present paper (as in several earlier papers by various authors) we consider the general case of (3.1) without assuming symmetry; for emphasis, we call this an asymmetric
$f$
is symmetric. However, in the present paper (as in several earlier papers by various authors) we consider the general case of (3.1) without assuming symmetry; for emphasis, we call this an asymmetric
 $U$
-statistic. (This is essential in our applications to pattern matching.) Note that for independent
$U$
-statistic. (This is essential in our applications to pattern matching.) Note that for independent
 $(X_i)_1^n$
, the asymmetric case can be reduced to the symmetric case by the trick in Remark 11.21, in particular (11.20), of [Reference Janson35]; see also [Reference Janson, Nakamura and Zeilberger39, (15)] and (A.18) below. However, this trick does not work in the
$(X_i)_1^n$
, the asymmetric case can be reduced to the symmetric case by the trick in Remark 11.21, in particular (11.20), of [Reference Janson35]; see also [Reference Janson, Nakamura and Zeilberger39, (15)] and (A.18) below. However, this trick does not work in the
 $m$
-dependent or constrained cases studied here, so we cannot use it here.
$m$
-dependent or constrained cases studied here, so we cannot use it here.
As stated in the introduction, we also consider constrained
 $U$
-statistics. Given a constraint
$U$
-statistics. Given a constraint
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
, we define the constrained
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
, we define the constrained
 $U$
-statistic
$U$
-statistic
 \begin{equation} U_n(f;\,{\mathcal{D}}) = U_n(f;\,{\mathcal{D}};\,(X_i) ) \,:\!=\,\sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{j+1}-i_j\leqslant d_j}} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ), \qquad n\geqslant 0, \end{equation}
\begin{equation} U_n(f;\,{\mathcal{D}}) = U_n(f;\,{\mathcal{D}};\,(X_i) ) \,:\!=\,\sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{j+1}-i_j\leqslant d_j}} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ), \qquad n\geqslant 0, \end{equation}
where we thus impose the constraints (1.2) on the indices.
We define further the exactly constrained
 $U$
-statistic
$U$
-statistic
 \begin{equation} U_n(f;\,{{\mathcal{D}}{=}}) = U_n(f;\,{{\mathcal{D}}{=}};\,(X_i) ) \,:\!=\,\sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{j+1}-i_j=d_j \text{ if }d_j\lt \infty }} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ), \qquad n\geqslant 0, \end{equation}
\begin{equation} U_n(f;\,{{\mathcal{D}}{=}}) = U_n(f;\,{{\mathcal{D}}{=}};\,(X_i) ) \,:\!=\,\sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{j+1}-i_j=d_j \text{ if }d_j\lt \infty }} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ), \qquad n\geqslant 0, \end{equation}
where we thus specify each gap either exactly or (when
 $d_j=\infty$
) not at all. In the vincular case, when all
$d_j=\infty$
) not at all. In the vincular case, when all
 $d_j$
are either 1 or
$d_j$
are either 1 or
 $\infty$
, there is no difference and we have
$\infty$
, there is no difference and we have
 $U_n(f;\,{\mathcal{D}})=U_n(f;\,{{\mathcal{D}}{=}})$
.
$U_n(f;\,{\mathcal{D}})=U_n(f;\,{{\mathcal{D}}{=}})$
.
Note that, trivially, each constrained
 $U$
-statistic can be written as a sum of exactly constrained
$U$
-statistic can be written as a sum of exactly constrained
 $U$
-statistics:
$U$
-statistics:
 \begin{align} U_n(f;\,{\mathcal{D}})=\sum _{{\mathcal{D}}^{\prime}} U_n(f;\,{{\mathcal{D}}^{\prime}{=}}), \end{align}
\begin{align} U_n(f;\,{\mathcal{D}})=\sum _{{\mathcal{D}}^{\prime}} U_n(f;\,{{\mathcal{D}}^{\prime}{=}}), \end{align}
where we sum over all constraints
 ${\mathcal{D}}^{\prime}=(d^{\prime}_1,\ldots, d^{\prime}_\ell )$
with
${\mathcal{D}}^{\prime}=(d^{\prime}_1,\ldots, d^{\prime}_\ell )$
with
 \begin{align} \begin{cases} 1\leqslant d^{\prime}_j \leqslant d_j,& d_j\lt \infty, \\[4pt] d^{\prime}_j=\infty, & d_j=\infty . \end{cases} \end{align}
\begin{align} \begin{cases} 1\leqslant d^{\prime}_j \leqslant d_j,& d_j\lt \infty, \\[4pt] d^{\prime}_j=\infty, & d_j=\infty . \end{cases} \end{align}
Remark 3.4. As stated in the introduction, the [exactly] constrained
 $U$
-statistics thus belong to the large class of incomplete
$U$
-statistics thus belong to the large class of incomplete
 $U$
-statistics [Reference Blom6], where the summation in (3.1) is restricted to some, in principle arbitrary, subset of the set of all
$U$
-statistics [Reference Blom6], where the summation in (3.1) is restricted to some, in principle arbitrary, subset of the set of all
 $\ell$
-tuples
$\ell$
-tuples
 $(i_1,\ldots,i_\ell )$
in
$(i_1,\ldots,i_\ell )$
in
 $[n]$
.
$[n]$
.
The standard setting, in [Reference Hoeffding27] and many other papers, is to assume that the underlying random variables
 $X_i$
are i.i.d. In the present paper we consider a more general case, and we will assume only that
$X_i$
are i.i.d. In the present paper we consider a more general case, and we will assume only that
 $X_1,X_2,\ldots$
is an infinite stationary
$X_1,X_2,\ldots$
is an infinite stationary
 $m$
-dependent sequence, for some fixed integer
$m$
-dependent sequence, for some fixed integer
 $m\geqslant 0$
; see Section 2.2 for the definition, and recall in particular that the special case
$m\geqslant 0$
; see Section 2.2 for the definition, and recall in particular that the special case
 $m=0$
yields the case of independent variables
$m=0$
yields the case of independent variables
 $X_i$
.
$X_i$
.
We will consider limits as
 $n\to \infty$
. The sequence
$n\to \infty$
. The sequence
 $X_1,X_2,\ldots$
(and thus the space
$X_1,X_2,\ldots$
(and thus the space
 $\mathcal{S}$
and the integer
$\mathcal{S}$
and the integer
 $m$
) and the function
$m$
) and the function
 $f$
(and thus
$f$
(and thus
 $\ell$
) will be fixed, and do not depend on
$\ell$
) will be fixed, and do not depend on
 $n$
.
$n$
.
We will throughout assume the following moment condition for
 $p=2$
; in a few places (always explicitly stated) we also assume it for some larger
$p=2$
; in a few places (always explicitly stated) we also assume it for some larger
 $p$
:
$p$
:
-
(
${A}_p$
)
$\quad{\mathbb{E}}|f(X_{i_1},\ldots,X_{i_\ell })|^p\lt \infty\quad $
for every
$i_1\lt \cdots \lt i_\ell$
.



Note that in the independent case (
 $m=0$
), it suffices to verify
$m=0$
), it suffices to verify
 $({A}_p)$
for a single sequence
$({A}_p)$
for a single sequence
 $i_1,\ldots,i_\ell$
, for example
$i_1,\ldots,i_\ell$
, for example
 $1,\ldots,\ell$
. In general, it suffices to verify
$1,\ldots,\ell$
. In general, it suffices to verify
 $({A}_p)$
for all sequences with
$({A}_p)$
for all sequences with
 $i_1=1$
and
$i_1=1$
and
 $i_{j+1}-i_j\leqslant m+1$
for every
$i_{j+1}-i_j\leqslant m+1$
for every
 $j\leqslant{\ell -1}$
, since the stationarity and
$j\leqslant{\ell -1}$
, since the stationarity and
 $m$
-dependence imply that every larger gap can be reduced to
$m$
-dependence imply that every larger gap can be reduced to
 $m+1$
without changing the distribution of
$m+1$
without changing the distribution of
 $f(X_{i_1},\ldots,X_{i_\ell })$
. Since there is only a finite number of such sequences, it follows that (
$f(X_{i_1},\ldots,X_{i_\ell })$
. Since there is only a finite number of such sequences, it follows that (
 ${A}_2$
) is equivalent to the uniform bound
${A}_2$
) is equivalent to the uniform bound
 \begin{align} {\mathbb{E}}|f(X_{i_1},\ldots,X_{i_\ell })|^2\leqslant C \qquad \text{for every $i_1\lt \cdots \lt i_\ell $}, \end{align}
\begin{align} {\mathbb{E}}|f(X_{i_1},\ldots,X_{i_\ell })|^2\leqslant C \qquad \text{for every $i_1\lt \cdots \lt i_\ell $}, \end{align}
and similarly for
 $({A}_p)$
.
$({A}_p)$
.
3.1. Expectation and law of large numbers
We first make an elementary observation on the expectations
 ${\mathbb{E}} U_n(f;\,{\mathcal{D}})$
and
${\mathbb{E}} U_n(f;\,{\mathcal{D}})$
and
 ${\mathbb{E}} U_n(f;\,{{\mathcal{D}}{=}})$
. These can be calculated exactly by taking the expectation inside the sums in (3.2) and (3.3). In the independent case, all terms have the same expectation, so it remains only to count the number of them. In general, because of the
${\mathbb{E}} U_n(f;\,{{\mathcal{D}}{=}})$
. These can be calculated exactly by taking the expectation inside the sums in (3.2) and (3.3). In the independent case, all terms have the same expectation, so it remains only to count the number of them. In general, because of the
 $m$
-dependence of
$m$
-dependence of
 $(X_i)$
, the expectations of the terms in (3.3) are not all equal, but most of them coincide, and it is still easy to find the asymptotics.
$(X_i)$
, the expectations of the terms in (3.3) are not all equal, but most of them coincide, and it is still easy to find the asymptotics.
Theorem 3.1.
Let
 $(X_i)_1^\infty$
be a stationary
$(X_i)_1^\infty$
be a stationary
 $m$
-dependent sequence of random variables with values in a measurable space
$m$
-dependent sequence of random variables with values in a measurable space
 $\mathcal{S}$
, let
$\mathcal{S}$
, let
 $\ell \geqslant 1$
, and let
$\ell \geqslant 1$
, and let
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
 ${A}_2$
). Then, as
${A}_2$
). Then, as
 $n\to \infty$
, with
$n\to \infty$
, with
 $\mu$
given by (5.1) below,
$\mu$
given by (5.1) below,
 \begin{align}{\mathbb{E}} U_n(f)& = \binom{n}{\ell }\mu + O\bigl ({n^{\ell -1}}\bigr ) = \frac{n^\ell }{\ell !}\mu + O\bigl ({n^{\ell -1}}\bigr ) . \end{align}
\begin{align}{\mathbb{E}} U_n(f)& = \binom{n}{\ell }\mu + O\bigl ({n^{\ell -1}}\bigr ) = \frac{n^\ell }{\ell !}\mu + O\bigl ({n^{\ell -1}}\bigr ) . \end{align}
More generally, let
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a constraint, and let
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a constraint, and let
 $b\,:\!=\,b({\mathcal{D}})$
. Then, as
$b\,:\!=\,b({\mathcal{D}})$
. Then, as
 $n\to \infty$
, for some real numbers
$n\to \infty$
, for some real numbers
 $\mu _{\mathcal{D}}$
and
$\mu _{\mathcal{D}}$
and
 $\mu _{{{\mathcal{D}}{=}}}$
given by (5.5) and (5.4),
$\mu _{{{\mathcal{D}}{=}}}$
given by (5.5) and (5.4),
 \begin{align}{\mathbb{E}} U_n(f;\,{\mathcal{D}})& = \frac{n^b}{b!}\mu _{\mathcal{D}} + O\bigl ({n^{b-1}}\bigr ), \end{align}
\begin{align}{\mathbb{E}} U_n(f;\,{\mathcal{D}})& = \frac{n^b}{b!}\mu _{\mathcal{D}} + O\bigl ({n^{b-1}}\bigr ), \end{align}
 \begin{align}{\mathbb{E}} U_n(f;\,{{\mathcal{D}}{=}})& = \frac{n^b}{b!}\mu _{{\mathcal{D}}{=}} + O\bigl ({n^{b-1}}\bigr ) . \end{align}
\begin{align}{\mathbb{E}} U_n(f;\,{{\mathcal{D}}{=}})& = \frac{n^b}{b!}\mu _{{\mathcal{D}}{=}} + O\bigl ({n^{b-1}}\bigr ) . \end{align}
If
 $m=0$
, i.e., the sequence
$m=0$
, i.e., the sequence
 $(X_i)_1^\infty$
is i.i.d., then, moreover,
$(X_i)_1^\infty$
is i.i.d., then, moreover,
 \begin{align} \mu &=\mu _{{\mathcal{D}}{=}}={\mathbb{E}} f(X_1,\ldots, X_\ell ),\\[-10pt]\nonumber\end{align}
\begin{align} \mu &=\mu _{{\mathcal{D}}{=}}={\mathbb{E}} f(X_1,\ldots, X_\ell ),\\[-10pt]\nonumber\end{align}
 \begin{align} \mu _{\mathcal{D}}& = \mu \prod _{j\,:\,d_j\lt \infty } d_j =\prod _{j\,:\,d_j\lt \infty } d_j \cdot{\mathbb{E}} f(X_1,\ldots, X_\ell ) . \end{align}
\begin{align} \mu _{\mathcal{D}}& = \mu \prod _{j\,:\,d_j\lt \infty } d_j =\prod _{j\,:\,d_j\lt \infty } d_j \cdot{\mathbb{E}} f(X_1,\ldots, X_\ell ) . \end{align}
The straightforward proof is given in Section 5, where we also give formulas for
 $\mu _{\mathcal{D}}$
and
$\mu _{\mathcal{D}}$
and
 $\mu _{{\mathcal{D}}{=}}$
in the general case, although in an application it might be simpler to find the leading term of the expectation directly.
$\mu _{{\mathcal{D}}{=}}$
in the general case, although in an application it might be simpler to find the leading term of the expectation directly.
Next, we have a corresponding strong law of large numbers, proved in Section 7. This extends well-known results in the independent case; see [Reference Hoeffding28, Reference Janson37, Reference Sen57].
Theorem 3.2.
Let
 $(X_i)_1^\infty$
be a stationary
$(X_i)_1^\infty$
be a stationary
 $m$
-dependent sequence of random variables with values in a measurable space
$m$
-dependent sequence of random variables with values in a measurable space
 $\mathcal{S}$
, let
$\mathcal{S}$
, let
 $\ell \geqslant 1$
, and let
$\ell \geqslant 1$
, and let
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
 ${A}_2$
). Then, as
${A}_2$
). Then, as
 $n\to \infty$
, with
$n\to \infty$
, with
 $\mu$
given by (5.1),
$\mu$
given by (5.1),
 \begin{align} n^{-\ell } U_n(f) &\overset{a.s.}{\longrightarrow } \frac{1}{\ell !}\mu . \end{align}
\begin{align} n^{-\ell } U_n(f) &\overset{a.s.}{\longrightarrow } \frac{1}{\ell !}\mu . \end{align}
More generally, let
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a constraint, and let
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a constraint, and let
 $b\,:\!=\,b({\mathcal{D}})$
. Then, as
$b\,:\!=\,b({\mathcal{D}})$
. Then, as
 $n\to \infty$
,
$n\to \infty$
,
 \begin{align} n^{-b} U_n(f;\,{\mathcal{D}}) &\overset{a.s.}{\longrightarrow } \frac{1}{b!}\mu _{\mathcal{D}}, \end{align}
\begin{align} n^{-b} U_n(f;\,{\mathcal{D}}) &\overset{a.s.}{\longrightarrow } \frac{1}{b!}\mu _{\mathcal{D}}, \end{align}
 \begin{align} n^{-b} U_n(f;\,{{\mathcal{D}}{=}}) &\overset{a.s.}{\longrightarrow } \frac{1}{b!}\mu _{{\mathcal{D}}{=}}, \end{align}
\begin{align} n^{-b} U_n(f;\,{{\mathcal{D}}{=}}) &\overset{a.s.}{\longrightarrow } \frac{1}{b!}\mu _{{\mathcal{D}}{=}}, \end{align}
where
 $\mu _{\mathcal{D}}$
and
$\mu _{\mathcal{D}}$
and
 $\mu _{{{\mathcal{D}}{=}}}$
, as in Theorem 3.1, are given by (5.5) and (5.4).
$\mu _{{{\mathcal{D}}{=}}}$
, as in Theorem 3.1, are given by (5.5) and (5.4).
Equivalently,
 \begin{align} n^{-\ell } \big [{U_n(f)}-{\mathbb{E}}{U_n(f)}\big ] &\overset{a.s.}{\longrightarrow } 0, \end{align}
\begin{align} n^{-\ell } \big [{U_n(f)}-{\mathbb{E}}{U_n(f)}\big ] &\overset{a.s.}{\longrightarrow } 0, \end{align}
 \begin{align} n^{-b} \big [{U_n(f;\,{\mathcal{D}})}-{\mathbb{E}}{U_n(f;\,{\mathcal{D}})}\big ] &\overset{a.s.}{\longrightarrow } 0, \end{align}
\begin{align} n^{-b} \big [{U_n(f;\,{\mathcal{D}})}-{\mathbb{E}}{U_n(f;\,{\mathcal{D}})}\big ] &\overset{a.s.}{\longrightarrow } 0, \end{align}
 \begin{align} n^{-b} \bigl [{U_n(f;\,{{\mathcal{D}}{=}})-{\mathbb{E}} U_n(f;\,{{\mathcal{D}}{=}})}\bigr ] &\overset{a.s.}{\longrightarrow } 0. \end{align}
\begin{align} n^{-b} \bigl [{U_n(f;\,{{\mathcal{D}}{=}})-{\mathbb{E}} U_n(f;\,{{\mathcal{D}}{=}})}\bigr ] &\overset{a.s.}{\longrightarrow } 0. \end{align}
Remark 3.5. For convenience, we assume (
 ${A}_2$
) in Theorem 3.2 as in the rest of the paper, which leads to a simple proof. We conjecture that the theorem holds assuming only (
${A}_2$
) in Theorem 3.2 as in the rest of the paper, which leads to a simple proof. We conjecture that the theorem holds assuming only (
 ${A}_1$
) (i.e., finite first moments) instead of (
${A}_1$
) (i.e., finite first moments) instead of (
 ${A}_2$
), as in [Reference Hoeffding28, Reference Janson37] for the independent case.
${A}_2$
), as in [Reference Hoeffding28, Reference Janson37] for the independent case.
3.2. Asymptotic normality
We have the following theorems yielding asymptotic normality. The proofs are given in Section 6.
The first theorem is for the unconstrained case, and extends the basic theorem by Hoeffding [Reference Hoeffding27] for symmetric
 $U$
-statistics based on independent
$U$
-statistics based on independent
 $(X_i)_1^\infty$
to the asymmetric and
$(X_i)_1^\infty$
to the asymmetric and
 $m$
-dependent case. Note that both these extensions have previously been treated, but separately. For symmetric
$m$
-dependent case. Note that both these extensions have previously been treated, but separately. For symmetric
 $U$
-statistics in the
$U$
-statistics in the
 $m$
-dependent setting, asymptotic normality was proved by Sen [Reference Sen58] (at least assuming a third moment); moreover, bounds on the rate of convergence (assuming a moment condition) were given by Malevich and Abdalimov [Reference Malevich and Abdalimov43]. The asymmetric case with independent
$m$
-dependent setting, asymptotic normality was proved by Sen [Reference Sen58] (at least assuming a third moment); moreover, bounds on the rate of convergence (assuming a moment condition) were given by Malevich and Abdalimov [Reference Malevich and Abdalimov43]. The asymmetric case with independent
 $(X_i)_1^\infty$
has been treated e.g. in [Reference Janson35, Corollary 11.20] and [Reference Janson37]; furthermore, as stated in Remark 3.3, for independent
$(X_i)_1^\infty$
has been treated e.g. in [Reference Janson35, Corollary 11.20] and [Reference Janson37]; furthermore, as stated in Remark 3.3, for independent
 $(X_i)$
, the asymmetric case can be reduced to the symmetric case by the method in [Reference Janson35, Remark 11.21].
$(X_i)$
, the asymmetric case can be reduced to the symmetric case by the method in [Reference Janson35, Remark 11.21].
Theorem 3.3.
Let
 $(X_i)_1^\infty$
be a stationary
$(X_i)_1^\infty$
be a stationary
 $m$
-dependent sequence of random variables with values in a measurable space
$m$
-dependent sequence of random variables with values in a measurable space
 $\mathcal{S}$
, let
$\mathcal{S}$
, let
 $\ell \geqslant 1$
, and let
$\ell \geqslant 1$
, and let
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
 ${A}_2$
). Then, as
${A}_2$
). Then, as
 $n\to \infty$
,
$n\to \infty$
,
 \begin{align} {Var}\bigl [{U_n(f)}\bigr ]/ n^{2\ell -1}\to \sigma ^2 \end{align}
\begin{align} {Var}\bigl [{U_n(f)}\bigr ]/ n^{2\ell -1}\to \sigma ^2 \end{align}
for some
 $\sigma ^2=\sigma ^2(f)\in [0,\infty )$
, and
$\sigma ^2=\sigma ^2(f)\in [0,\infty )$
, and
 \begin{align} \frac{U_n(f)-{\mathbb{E}} U_n(f)}{n^{\ell -1/2}} \overset{d}{\longrightarrow } \textsf{N}\big(0,\sigma ^2\big). \end{align}
\begin{align} \frac{U_n(f)-{\mathbb{E}} U_n(f)}{n^{\ell -1/2}} \overset{d}{\longrightarrow } \textsf{N}\big(0,\sigma ^2\big). \end{align}
The second theorem extends Theorem 3.3 to the constrained cases.
Theorem 3.4.
Let
 $(X_i)_1^\infty$
be a stationary
$(X_i)_1^\infty$
be a stationary
 $m$
-dependent sequence of random variables with values in a measurable space
$m$
-dependent sequence of random variables with values in a measurable space
 $\mathcal{S}$
, let
$\mathcal{S}$
, let
 $\ell \geqslant 1$
, and let
$\ell \geqslant 1$
, and let
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
 ${A}_2$
). Let
${A}_2$
). Let
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a constraint, and let
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a constraint, and let
 $b\,:\!=\,b({\mathcal{D}})$
. Then, as
$b\,:\!=\,b({\mathcal{D}})$
. Then, as
 $n\to \infty$
,
$n\to \infty$
,
 \begin{align} {Var}\bigl [{U_n(f;\,{\mathcal{D}})}\bigr ]/ n^{2b-1}\to \sigma ^2 \end{align}
\begin{align} {Var}\bigl [{U_n(f;\,{\mathcal{D}})}\bigr ]/ n^{2b-1}\to \sigma ^2 \end{align}
for some
 $\sigma ^2=\sigma ^2(f;\,{\mathcal{D}})\in [0,\infty )$
, and
$\sigma ^2=\sigma ^2(f;\,{\mathcal{D}})\in [0,\infty )$
, and
 \begin{align} \frac{U_n(f;\,{\mathcal{D}})-{\mathbb{E}} U_n(f;\,{\mathcal{D}})}{n^{b-1/2}} \overset{d}{\longrightarrow } \textsf{N}\big(0,\sigma ^2\big). \end{align}
\begin{align} \frac{U_n(f;\,{\mathcal{D}})-{\mathbb{E}} U_n(f;\,{\mathcal{D}})}{n^{b-1/2}} \overset{d}{\longrightarrow } \textsf{N}\big(0,\sigma ^2\big). \end{align}
The same holds, with some (generally different)
 $\sigma ^2=\sigma ^2(f;\,{{\mathcal{D}}{=}})$
, for the exactly constrained
$\sigma ^2=\sigma ^2(f;\,{{\mathcal{D}}{=}})$
, for the exactly constrained
 $U_n(f;\,{{\mathcal{D}}{=}})$
.
$U_n(f;\,{{\mathcal{D}}{=}})$
.
Remark 3.6. It follows immediately by the Cramér–Wold device [Reference Gut25, Theorem 5.10.5] (i.e., considering linear combinations), that Theorem 3.3 extends in the obvious way to joint convergence for any finite number of different
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
, with
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
, with
 $\sigma ^2$
now a covariance matrix. Moreover, the proof shows that this holds also for a family of different
$\sigma ^2$
now a covariance matrix. Moreover, the proof shows that this holds also for a family of different
 $f$
with (possibly) different
$f$
with (possibly) different
 $\ell \geqslant 1$
.
$\ell \geqslant 1$
.
Similarly, Theorem 3.4 extends to joint convergence for any finite number of different
 $f$
(possibly with different
$f$
(possibly with different
 $\ell$
and
$\ell$
and
 $\mathcal{D}$
); this follows by the proof below, which reduces the results to Theorem 3.3.
$\mathcal{D}$
); this follows by the proof below, which reduces the results to Theorem 3.3.
Remark 3.7. The asymptotic variance
 $\sigma ^2$
in Theorems 3.3 and 3.4 can be calculated explicitly; see Remark 6.2.
$\sigma ^2$
in Theorems 3.3 and 3.4 can be calculated explicitly; see Remark 6.2.
Remark 3.8. Note that it is possible that the asymptotic variance
 $\sigma ^2=0$
in Theorems 3.3 and 3.4; in this case, (3.19) and (3.21) just give convergence in probability to 0. This degenerate case is discussed in Section 8.
$\sigma ^2=0$
in Theorems 3.3 and 3.4; in this case, (3.19) and (3.21) just give convergence in probability to 0. This degenerate case is discussed in Section 8.
Remark 3.9. We do not consider extensions to triangular arrays where
 $f$
or
$f$
or
 $X_i$
(or both) depend on
$X_i$
(or both) depend on
 $n$
. In the symmetric
$n$
. In the symmetric
 $m$
-dependent case, such a result (with fixed
$m$
-dependent case, such a result (with fixed
 $\ell$
but possibly increasing
$\ell$
but possibly increasing
 $m$
, under suitable conditions) has been shown by [Reference Malevich and Abdalimov43], with a bound on the rate of convergence. In the independent case, results for triangular arrays are given by e.g. [Reference Rubin and Vitale56] and [Reference Jammalamadaka and Janson32]; see also [Reference Janson and Szpankowski40] for the special case of substring counts
$m$
, under suitable conditions) has been shown by [Reference Malevich and Abdalimov43], with a bound on the rate of convergence. In the independent case, results for triangular arrays are given by e.g. [Reference Rubin and Vitale56] and [Reference Jammalamadaka and Janson32]; see also [Reference Janson and Szpankowski40] for the special case of substring counts
 $N_n(\textbf{w})$
with
$N_n(\textbf{w})$
with
 $\textbf{w}$
depending on
$\textbf{w}$
depending on
 $n$
(and growing in length). It seems to be an interesting (and challenging) open problem to formulate useful general theorems for constrained
$n$
(and growing in length). It seems to be an interesting (and challenging) open problem to formulate useful general theorems for constrained
 $U$
-statistics in such settings.
$U$
-statistics in such settings.
3.3. Rate of convergence
Under stronger moment assumptions on
 $f$
, an alternative method of proof (suggested by a referee) yields the asymptotic normality in Theorems 3.3 and 3.4 together with an upper bound on the rate of convergence, provided
$f$
, an alternative method of proof (suggested by a referee) yields the asymptotic normality in Theorems 3.3 and 3.4 together with an upper bound on the rate of convergence, provided
 $\sigma ^2\gt 0$
.
$\sigma ^2\gt 0$
.
In the following theorem of Berry–Esseen type, we assume for simplicity that
 $f$
is bounded (as it is in our applications in Sections 13–14); see further Remark 9.1. Let
$f$
is bounded (as it is in our applications in Sections 13–14); see further Remark 9.1. Let
 $d_K$
denote the Kolmogorov distance between distributions; recall that for two distributions
$d_K$
denote the Kolmogorov distance between distributions; recall that for two distributions
 ${\mathcal{L}}_1,{\mathcal{L}}_2$
with distribution functions
${\mathcal{L}}_1,{\mathcal{L}}_2$
with distribution functions
 $F_1(x)$
and
$F_1(x)$
and
 $F_2(x)$
,
$F_2(x)$
,
 $d_K=d_K({\mathcal{L}}_1,{\mathcal{L}}_2)\,:\!=\,\sup _x|F_1(x)-F_2(x)|$
; we use also the notation
$d_K=d_K({\mathcal{L}}_1,{\mathcal{L}}_2)\,:\!=\,\sup _x|F_1(x)-F_2(x)|$
; we use also the notation
 $d_K(X,{\mathcal{L}}_2)\,:\!=\,d_K({\mathcal{L}}(X),{\mathcal{L}}_2)$
for a random variable
$d_K(X,{\mathcal{L}}_2)\,:\!=\,d_K({\mathcal{L}}(X),{\mathcal{L}}_2)$
for a random variable
 $X$
.
$X$
.
Theorem 3.5.
Suppose in addition to the hypotheses in Theorem 3.3 or 3.4 that
 $\sigma ^2\gt 0$
and that
$\sigma ^2\gt 0$
and that
 $f$
is bounded. Then
$f$
is bounded. Then
 \begin{align} d_K\Bigl ({\frac{U_n-{\mathbb{E}} U_n}{\sqrt{{Var}\ U_n}}, \textsf{N}(0,1)}\Bigr ) =O\bigl ({n^{-1/2}}\bigr ), \end{align}
\begin{align} d_K\Bigl ({\frac{U_n-{\mathbb{E}} U_n}{\sqrt{{Var}\ U_n}}, \textsf{N}(0,1)}\Bigr ) =O\bigl ({n^{-1/2}}\bigr ), \end{align}
where
 $U_n$
denotes
$U_n$
denotes
 $U_n(f)$
,
$U_n(f)$
,
 $U_n(f,{\mathcal{D}})$
, or
$U_n(f,{\mathcal{D}})$
, or
 $U_n(f;\,{{\mathcal{D}}{=}})$
.
$U_n(f;\,{{\mathcal{D}}{=}})$
.
In the symmetric and unconstrained case, this (and more) was shown by Malevich and Abdalimov [Reference Malevich and Abdalimov43]. The proof of Theorem 3.5 is given in Section 9, together with further remarks.
3.4. Moment convergence
Theorems 3.3 and 3.4 include convergence of the first (trivially) and second moments in (3.19) and (3.21). This extends to higher moments under a corresponding moment condition on
 $f$
. (The unconstrained case with independent
$f$
. (The unconstrained case with independent
 $X_i$
was shown in [Reference Janson37, Theorem 3.15].)
$X_i$
was shown in [Reference Janson37, Theorem 3.15].)
Theorem 3.6.
Suppose in addition to the hypotheses in Theorems 3.3 or 3.4 that (
 ${A}_{p}$
) holds for some real
${A}_{p}$
) holds for some real
 $p\geqslant 2$
. Then all absolute and ordinary moments of order up to
$p\geqslant 2$
. Then all absolute and ordinary moments of order up to
 $p$
converge in (3.19) or (3.21).
$p$
converge in (3.19) or (3.21).
The proof is given in Section 10, where we also give related estimates for maximal functions.
3.5. Functional limit theorems
We can extend Theorem 3.4 to functional convergence. For unconstrained
 $U$
-statistics, this was done by Miller and Sen [Reference Miller and Sen44] in the classical case of independent
$U$
-statistics, this was done by Miller and Sen [Reference Miller and Sen44] in the classical case of independent
 $X_i$
and symmetric
$X_i$
and symmetric
 $f$
; the asymmetric case is [Reference Janson37, Theorem 3.2]; furthermore, Yoshihara [Reference Yoshihara65] proved the case of dependent
$f$
; the asymmetric case is [Reference Janson37, Theorem 3.2]; furthermore, Yoshihara [Reference Yoshihara65] proved the case of dependent
 $X_i$
satisfying a suitable mixing condition (assuming a technical condition on
$X_i$
satisfying a suitable mixing condition (assuming a technical condition on
 $f$
besides symmetry).
$f$
besides symmetry).
Theorem 3.7.
Suppose that (
 ${A}_2$
) holds. Then as
${A}_2$
) holds. Then as
 $n\to \infty$
, with
$n\to \infty$
, with
 $b=b({\mathcal{D}})$
, in
$b=b({\mathcal{D}})$
, in
 $D[0,\infty )$
,
$D[0,\infty )$
,
 \begin{align} \frac{U_{\lfloor{nt}\rfloor }(f;\,{\mathcal{D}})-{\mathbb{E}} U_{\lfloor{nt}\rfloor }(f;\,{\mathcal{D}})}{n^{b-1/2}}\overset{d}{\longrightarrow } Z(t),\qquad t\geqslant 0, \end{align}
\begin{align} \frac{U_{\lfloor{nt}\rfloor }(f;\,{\mathcal{D}})-{\mathbb{E}} U_{\lfloor{nt}\rfloor }(f;\,{\mathcal{D}})}{n^{b-1/2}}\overset{d}{\longrightarrow } Z(t),\qquad t\geqslant 0, \end{align}
where
 $Z(t)$
is a continuous centered Gaussian process. Equivalently, in
$Z(t)$
is a continuous centered Gaussian process. Equivalently, in
 $D[0,\infty )$
,
$D[0,\infty )$
,
 \begin{align} \frac{U_{\lfloor{nt}\rfloor }(f;\,{\mathcal{D}})-(\mu _{\mathcal{D}}/b!)n^bt^b}{n^{b-1/2}}&\overset{d}{\longrightarrow } Z(t),\qquad t\geqslant 0. \end{align}
\begin{align} \frac{U_{\lfloor{nt}\rfloor }(f;\,{\mathcal{D}})-(\mu _{\mathcal{D}}/b!)n^bt^b}{n^{b-1/2}}&\overset{d}{\longrightarrow } Z(t),\qquad t\geqslant 0. \end{align}
The same holds for exact constraints. Moreover, the results hold jointly for any finite set of
 $f$
and
$f$
and
 $\mathcal{D}$
(possibly with different
$\mathcal{D}$
(possibly with different
 $\ell$
and
$\ell$
and
 $b$
), with limits
$b$
), with limits
 $Z(t)$
depending on
$Z(t)$
depending on
 $f$
and
$f$
and
 $\mathcal{D}$
.
$\mathcal{D}$
.
The proof is given in Section 11.
Remark 3.10. A comparison between (3.23) and (3.21) yields
 $Z(t)\sim \textsf{N}\big(0,t^{2b-1}\sigma ^2\big)$
, with
$Z(t)\sim \textsf{N}\big(0,t^{2b-1}\sigma ^2\big)$
, with
 $\sigma ^2$
as in Theorem 3.4. Equivalently,
$\sigma ^2$
as in Theorem 3.4. Equivalently,
 ${Var}\ Z(t) = t^{2b-1}\sigma ^2$
, which can be calculated by Remark 6.2. Covariances
${Var}\ Z(t) = t^{2b-1}\sigma ^2$
, which can be calculated by Remark 6.2. Covariances
 ${Cov} ({Z(s),Z(t)} )$
can be calculated by the same method and (11.20) in the proof; we leave the details to the reader. Note that these covariances determine the distribution of the process
${Cov} ({Z(s),Z(t)} )$
can be calculated by the same method and (11.20) in the proof; we leave the details to the reader. Note that these covariances determine the distribution of the process
 $Z$
.
$Z$
.
3.6. Renewal theory
Assume further that
 $h\,:\,{\mathcal{S}}\to \mathbb{R}$
is another (fixed) measurable function, with
$h\,:\,{\mathcal{S}}\to \mathbb{R}$
is another (fixed) measurable function, with
 \begin{align} \nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0. \end{align}
\begin{align} \nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0. \end{align}
We define
 \begin{align} S_n=S_n(h)\,:\!=\,\sum _{i=1}^n h(X_i), \end{align}
\begin{align} S_n=S_n(h)\,:\!=\,\sum _{i=1}^n h(X_i), \end{align}
and, for
 $x\gt 0$
,
$x\gt 0$
,
 \begin{align} N_-(x)&\,:\!=\,\sup \{{n\geqslant 0\,:\,S_n\leqslant x}\}, \end{align}
\begin{align} N_-(x)&\,:\!=\,\sup \{{n\geqslant 0\,:\,S_n\leqslant x}\}, \end{align}
 \begin{align} N_+(x)&\,:\!=\,\inf \{{n\geqslant 0\,:\,S_n\gt x}\}. \end{align}
\begin{align} N_+(x)&\,:\!=\,\inf \{{n\geqslant 0\,:\,S_n\gt x}\}. \end{align}
 $N_-(x)$
and
$N_-(x)$
and
 $N_+(x)$
are finite a.s. by the law of large numbers for
$N_+(x)$
are finite a.s. by the law of large numbers for
 $S_n$
(12.1); see further Lemma 12.1. We let
$S_n$
(12.1); see further Lemma 12.1. We let
 $N_\pm (x)$
denote either
$N_\pm (x)$
denote either
 $N_-(x)$
or
$N_-(x)$
or
 $N_+(x)$
, in statements and formulas that are valid for both.
$N_+(x)$
, in statements and formulas that are valid for both.
Remark 3.11. In [Reference Janson37], instead of
 $h(x)$
we consider more generally a function of several variables, and we define
$h(x)$
we consider more generally a function of several variables, and we define
 $N_\pm$
using the corresponding
$N_\pm$
using the corresponding
 $U$
-statistic instead of
$U$
-statistic instead of
 $S_n$
. We believe that the results of the present paper can be extended to that setting, but we have not pursued this, and leave it as an open problem.
$S_n$
. We believe that the results of the present paper can be extended to that setting, but we have not pursued this, and leave it as an open problem.
Remark 3.12. If
 $h(X_1)\geqslant 0$
a.s., which is often assumed in renewal theory, then
$h(X_1)\geqslant 0$
a.s., which is often assumed in renewal theory, then
 $N_+(x)=N_-(x)+1$
. However, if
$N_+(x)=N_-(x)+1$
. However, if
 $h$
may be negative (still assuming (3.25)), then
$h$
may be negative (still assuming (3.25)), then
 $N_-(x)$
may be larger than
$N_-(x)$
may be larger than
 $N_+(x)$
. Nevertheless, the difference is typically small, and we obtain the same asymptotic results for both
$N_+(x)$
. Nevertheless, the difference is typically small, and we obtain the same asymptotic results for both
 $N_+$
and
$N_+$
and
 $N_-$
. (We can also obtain the same results if we instead use
$N_-$
. (We can also obtain the same results if we instead use
 $S_n\lt x$
or
$S_n\lt x$
or
 $S_n\geqslant x$
in the definitions.)
$S_n\geqslant x$
in the definitions.)
In this situation, we have the following limit theorems, which extend results in [Reference Janson37]. Proofs are given in Section 12. For an application, see [Reference Janson38].
Theorem 3.8.
With the assumptions and notation of Theorem 3.4, assume (
 ${A}_2$
), and suppose also that
${A}_2$
), and suppose also that
 $\nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0$
and
$\nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0$
and
 ${\mathbb{E}} h(X_1)^2\lt \infty$
. Then, with notation as above, as
${\mathbb{E}} h(X_1)^2\lt \infty$
. Then, with notation as above, as
 $x\to \infty$
,
$x\to \infty$
,
 \begin{equation} \frac{U_{N_\pm (x)}(f;\,{\mathcal{D}})-\mu _{\mathcal{D}}{\nu }^{-b}{b!}^{-1} x^{b}}{x^{b-1/2}} \overset{d}{\longrightarrow } \textsf{N}\bigl ({0,\gamma ^2}\bigr ), \end{equation}
\begin{equation} \frac{U_{N_\pm (x)}(f;\,{\mathcal{D}})-\mu _{\mathcal{D}}{\nu }^{-b}{b!}^{-1} x^{b}}{x^{b-1/2}} \overset{d}{\longrightarrow } \textsf{N}\bigl ({0,\gamma ^2}\bigr ), \end{equation}
for some
 $\gamma ^2=\gamma ^2(f;\,h;\,{\mathcal{D}})\geqslant 0$
.
$\gamma ^2=\gamma ^2(f;\,h;\,{\mathcal{D}})\geqslant 0$
.
The same holds for exact constraints. Moreover, the results hold jointly for any finite set of
 $f$
and
$f$
and
 $\mathcal{D}$
(possibly with different
$\mathcal{D}$
(possibly with different
 $\ell$
and
$\ell$
and
 $b$
).
$b$
).
Theorem 3.9.
Suppose in addition to the hypotheses in Theorem 3.8 that
 $h(X_1)$
is integer-valued and that
$h(X_1)$
is integer-valued and that
 $(X_i)_1^\infty$
are independent. Then (3.29) holds also conditioned on
$(X_i)_1^\infty$
are independent. Then (3.29) holds also conditioned on
 $S_{N_-(x)}=x$
for integers
$S_{N_-(x)}=x$
for integers
 $x\to \infty$
.
$x\to \infty$
.
We consider here tacitly only
 $x$
such that
$x$
such that
 $\mathbb{P} ({S_{N_-(x)}=x} )\gt 0$
.
$\mathbb{P} ({S_{N_-(x)}=x} )\gt 0$
.
Remark 3.13. We prove Theorem 3.9 only for independent
 $X_i$
(which, in any case, is our main interest, as stated in the introduction). It seems likely that the result can be extended to at least some
$X_i$
(which, in any case, is our main interest, as stated in the introduction). It seems likely that the result can be extended to at least some
 $m$
-dependent
$m$
-dependent
 $(X_i)$
, using a modification of the proof below and the
$(X_i)$
, using a modification of the proof below and the
 $m$
-dependent renewal theorem (under some conditions) [Reference Alsmeyer and Hoefs1, Corollary 4.2], but we have not pursued this.
$m$
-dependent renewal theorem (under some conditions) [Reference Alsmeyer and Hoefs1, Corollary 4.2], but we have not pursued this.
Theorem 3.10.
Suppose in addition to the hypotheses in Theorem 3.8 that (
 ${A}_{p}$
) holds and
${A}_{p}$
) holds and
 ${\mathbb{E}} [{|h(X_1)|^p} ]\lt \infty$
for every
${\mathbb{E}} [{|h(X_1)|^p} ]\lt \infty$
for every
 $p\lt \infty$
. Then all moments converge in (3.29).
$p\lt \infty$
. Then all moments converge in (3.29).
Under the additional hypothesis in Theorem 3.9, this holds also conditioned on
 $S_{N_-(x)}=x$
.
$S_{N_-(x)}=x$
.
Remark 3.14. In Theorem 3.10, unlike Theorem 3.6, we assume
 $p$
th moments for all
$p$
th moments for all
 $p$
, and conclude convergence of all moments. If we only want to show convergence for a given
$p$
, and conclude convergence of all moments. If we only want to show convergence for a given
 $p$
, some sufficient moment conditions on
$p$
, some sufficient moment conditions on
 $f$
and
$f$
and
 $h$
can be derived from the proof, but we do not know any sharp results and have not pursued this. Cf. [Reference Janson37, Remark 6.1] and the references there.
$h$
can be derived from the proof, but we do not know any sharp results and have not pursued this. Cf. [Reference Janson37, Remark 6.1] and the references there.
4. Some lemmas
We give here some lemmas that will be used in the proofs in later sections. In particular, they will enable us to reduce the constrained cases to the unconstrained one.
Let
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a given constraint. Recall that
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a given constraint. Recall that
 $b=b({\mathcal{D}})$
is given by (2.1), and let
$b=b({\mathcal{D}})$
is given by (2.1), and let
 $1=\beta _1\lt \ldots \lt \beta _b$
be the indices in
$1=\beta _1\lt \ldots \lt \beta _b$
be the indices in
 $[\ell ]$
just after the unconstrained gaps; in other words,
$[\ell ]$
just after the unconstrained gaps; in other words,
 $\beta _j$
are defined by
$\beta _j$
are defined by
 $\beta _1\,:\!=\,1$
and
$\beta _1\,:\!=\,1$
and
 $d_{\beta _j-1}=\infty$
for
$d_{\beta _j-1}=\infty$
for
 $j=2,\ldots,b$
. For convenience we also define
$j=2,\ldots,b$
. For convenience we also define
 $\beta _{b+1}\,:\!=\,\ell +1$
. We say that the constraint
$\beta _{b+1}\,:\!=\,\ell +1$
. We say that the constraint
 $\mathcal{D}$
separates the index set
$\mathcal{D}$
separates the index set
 $[\ell ]$
into the
$[\ell ]$
into the
 $b$
blocks
$b$
blocks
 $B_1,\ldots,B_b$
, where
$B_1,\ldots,B_b$
, where
 $B_k\,:\!=\,\{{\beta _k,\ldots,\beta _{k+1}-1}\}$
. Note that the constraints (1.2) thus are constraints on
$B_k\,:\!=\,\{{\beta _k,\ldots,\beta _{k+1}-1}\}$
. Note that the constraints (1.2) thus are constraints on
 $i_j$
for
$i_j$
for
 $j$
in each block separately.
$j$
in each block separately.
Lemma 4.1.
Let
 $(X_i)_1^\infty$
be a stationary
$(X_i)_1^\infty$
be a stationary
 $m$
-dependent sequence of random variables with values in
$m$
-dependent sequence of random variables with values in
 $\mathcal{S}$
, let
$\mathcal{S}$
, let
 $\ell \geqslant 1$
, and let
$\ell \geqslant 1$
, and let
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
satisfy (
 ${A}_2$
). Let
${A}_2$
). Let
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a constraint. Then
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be a constraint. Then
 \begin{align} {Var} \bigl [{U_n(f;\,{\mathcal{D}})}\bigr ] = O\bigl ({n^{2b({\mathcal{D}})-1}}\bigr ), \qquad n\geqslant 1. \end{align}
\begin{align} {Var} \bigl [{U_n(f;\,{\mathcal{D}})}\bigr ] = O\bigl ({n^{2b({\mathcal{D}})-1}}\bigr ), \qquad n\geqslant 1. \end{align}
Furthermore,
 \begin{align} {Var} \bigl [{U_n(f;\,{\mathcal{D}})-U_{n-1}(f;\,{\mathcal{D}})}\bigr ] = O\bigl ({n^{2b({\mathcal{D}})-2}}\bigr ), \qquad n\geqslant 1. \end{align}
\begin{align} {Var} \bigl [{U_n(f;\,{\mathcal{D}})-U_{n-1}(f;\,{\mathcal{D}})}\bigr ] = O\bigl ({n^{2b({\mathcal{D}})-2}}\bigr ), \qquad n\geqslant 1. \end{align}
Moreover, the same estimates hold for
 $U_n(f;\,{{\mathcal{D}}{=}})$
.
$U_n(f;\,{{\mathcal{D}}{=}})$
.
Proof. The definition (3.2) yields
 \begin{align} {Var}\bigl [{U_n(f;\,{\mathcal{D}})}\bigr ]& =\sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{k+1}-i_k\leqslant d_k}} \sum _{\substack{1\leqslant j_1\lt \ldots \lt j_\ell \leqslant n\\j_{k+1}-j_k\leqslant d_k}} {Cov}\bigl ({f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ),f\bigl ({X_{j_1},\ldots,X_{j_\ell }}\bigr )}\bigr ) . \end{align}
\begin{align} {Var}\bigl [{U_n(f;\,{\mathcal{D}})}\bigr ]& =\sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{k+1}-i_k\leqslant d_k}} \sum _{\substack{1\leqslant j_1\lt \ldots \lt j_\ell \leqslant n\\j_{k+1}-j_k\leqslant d_k}} {Cov}\bigl ({f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ),f\bigl ({X_{j_1},\ldots,X_{j_\ell }}\bigr )}\bigr ) . \end{align}
Let
 $d_*$
be the largest finite
$d_*$
be the largest finite
 $d_j$
in the constraint
$d_j$
in the constraint
 $\mathcal{D}$
, i.e.,
$\mathcal{D}$
, i.e.,
 \begin{align} d_*\,:\!=\,\max _j \big\{{d_j\,:\,d_j\lt \infty }\big\}. \end{align}
\begin{align} d_*\,:\!=\,\max _j \big\{{d_j\,:\,d_j\lt \infty }\big\}. \end{align}
The constraints imply that for each block
 $B_q$
and all indices
$B_q$
and all indices
 $k\in B_q$
, coarsely,
$k\in B_q$
, coarsely,
 \begin{align} 0\leqslant i_k-i_{\beta _q}\leqslant d_*\ell \qquad \text{and} \qquad 0\leqslant j_k-j_{\beta _q}\leqslant d_*\ell . \end{align}
\begin{align} 0\leqslant i_k-i_{\beta _q}\leqslant d_*\ell \qquad \text{and} \qquad 0\leqslant j_k-j_{\beta _q}\leqslant d_*\ell . \end{align}
It follows that if
 $|i_{\beta _r}-j_{\beta _s}|\gt d_*\ell +m$
for all
$|i_{\beta _r}-j_{\beta _s}|\gt d_*\ell +m$
for all
 $r,s\in [b]$
, then
$r,s\in [b]$
, then
 $|i_\alpha -j_\beta |\gt m$
for all
$|i_\alpha -j_\beta |\gt m$
for all
 $\alpha,\beta \in [\ell ]$
. Since
$\alpha,\beta \in [\ell ]$
. Since
 $(X_i)_1^\infty$
is
$(X_i)_1^\infty$
is
 $m$
-dependent, this implies that the two random vectors
$m$
-dependent, this implies that the two random vectors
 $ ({X_{i_1},\ldots,X_{i_\ell }} )$
and
$ ({X_{i_1},\ldots,X_{i_\ell }} )$
and
 $ ({X_{j_1},\ldots,X_{j_\ell }} )$
are independent, and thus the corresponding term in (4.3) vanishes.
$ ({X_{j_1},\ldots,X_{j_\ell }} )$
are independent, and thus the corresponding term in (4.3) vanishes.
Consequently, we only have to consider terms in the sum in (4.3) such that
 \begin{align} |i_{\beta _r}-j_{\beta _s}|\leqslant d_*\ell +m \end{align}
\begin{align} |i_{\beta _r}-j_{\beta _s}|\leqslant d_*\ell +m \end{align}
for some
 $r,s\in [b]$
. For each of the
$r,s\in [b]$
. For each of the
 $O(1)$
choices of
$O(1)$
choices of
 $r$
and
$r$
and
 $s$
, we can choose
$s$
, we can choose
 $i_{\beta _1},\ldots,i_{\beta _b}$
in at most
$i_{\beta _1},\ldots,i_{\beta _b}$
in at most
 $n^b$
ways; then
$n^b$
ways; then
 $j_{\beta _s}$
in
$j_{\beta _s}$
in
 $O(1)$
ways such that (4.6) holds; then the remaining
$O(1)$
ways such that (4.6) holds; then the remaining
 $j_{\beta _q}$
in
$j_{\beta _q}$
in
 $O\big(n^{b-1}\big)$
ways; then, finally, all remaining
$O\big(n^{b-1}\big)$
ways; then, finally, all remaining
 $i_k$
and
$i_k$
and
 $j_k$
in
$j_k$
in
 $O(1)$
ways because of (4.5). Consequently, the number of non-vanishing terms in (4.3) is
$O(1)$
ways because of (4.5). Consequently, the number of non-vanishing terms in (4.3) is
 $O\big(n^{2b-1}\big)$
. Moreover, each term is
$O\big(n^{2b-1}\big)$
. Moreover, each term is
 $O(1)$
by (3.6) and the Cauchy–Schwarz inequality, and thus (4.1) follows.
$O(1)$
by (3.6) and the Cauchy–Schwarz inequality, and thus (4.1) follows.
For (4.2), we note that
 $U_n(f;\,{\mathcal{D}})-U_{n-1}(f;\,{\mathcal{D}})$
is the sum in (3.2) with the extra restriction
$U_n(f;\,{\mathcal{D}})-U_{n-1}(f;\,{\mathcal{D}})$
is the sum in (3.2) with the extra restriction
 $i_\ell =n$
. Hence, its variance can be expanded as in (4.3), with the extra restrictions
$i_\ell =n$
. Hence, its variance can be expanded as in (4.3), with the extra restrictions
 $i_\ell =j_\ell =n$
. We then argue as above, but note that (4.5) and
$i_\ell =j_\ell =n$
. We then argue as above, but note that (4.5) and
 $i_\ell =n$
imply that there are only
$i_\ell =n$
imply that there are only
 $O(1)$
choices of
$O(1)$
choices of
 $i_b$
, and hence
$i_b$
, and hence
 $O\big(n^{b-1}\big)$
choices of
$O\big(n^{b-1}\big)$
choices of
 $i_1,\ldots,i_b$
. We thus obtain
$i_1,\ldots,i_b$
. We thus obtain
 $O \big({n^{2b-2}} \big)$
non-vanishing terms in the sum, and (4.2) follows.
$O \big({n^{2b-2}} \big)$
non-vanishing terms in the sum, and (4.2) follows.
The argument for the exactly constrained
 $U_n(f;\,{{\mathcal{D}}{=}})$
is the same (and slightly simpler). (Alternatively, we could do this case first, and then use (3.4) to obtain the results for
$U_n(f;\,{{\mathcal{D}}{=}})$
is the same (and slightly simpler). (Alternatively, we could do this case first, and then use (3.4) to obtain the results for
 $U_n(f;\,{\mathcal{D}})$
.)
$U_n(f;\,{\mathcal{D}})$
.)
The next lemma is the central step in the reduction to the unconstrained case.
Lemma 4.2.
Let
 $(X_i)_1^\infty$
,
$(X_i)_1^\infty$
,
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
, and
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
, and
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be as in Lemma 4.1, and let
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be as in Lemma 4.1, and let
 \begin{align} D\,:\!=\,\sum _{j\,:\,d_j\lt \infty }d_j. \end{align}
\begin{align} D\,:\!=\,\sum _{j\,:\,d_j\lt \infty }d_j. \end{align}
Let
 $M\gt D$
and define
$M\gt D$
and define
 \begin{align} Y_i\,:\!=\,(X_i,X_{i+1},\ldots,X_{i+M-1})\in{\mathcal{S}}^M, \qquad i\geqslant 1 . \end{align}
\begin{align} Y_i\,:\!=\,(X_i,X_{i+1},\ldots,X_{i+M-1})\in{\mathcal{S}}^M, \qquad i\geqslant 1 . \end{align}
Then there exists a function
 $g=g_{{{\mathcal{D}}{=}}}\,:\,({\mathcal{S}}^M)^b\to \mathbb{R}$
such that for every
$g=g_{{{\mathcal{D}}{=}}}\,:\,({\mathcal{S}}^M)^b\to \mathbb{R}$
such that for every
 $n\geqslant 0$
,
$n\geqslant 0$
,
 \begin{align} U_n(f;\,{{\mathcal{D}}{=}};\,(X_i) ) = \sum _{j_1\lt \ldots \lt j_b\leqslant n-D}g\bigl ({Y_{j_1},\ldots,Y_{j_b}}\bigr ) =U_{n-D}\bigl ({g;\,(Y_i) }\bigr ), \end{align}
\begin{align} U_n(f;\,{{\mathcal{D}}{=}};\,(X_i) ) = \sum _{j_1\lt \ldots \lt j_b\leqslant n-D}g\bigl ({Y_{j_1},\ldots,Y_{j_b}}\bigr ) =U_{n-D}\bigl ({g;\,(Y_i) }\bigr ), \end{align}
with
 $U_{n-D}(g)\,:\!=\,0$
when
$U_{n-D}(g)\,:\!=\,0$
when
 $n\lt D$
. Furthermore,
$n\lt D$
. Furthermore,
 \begin{align} {\mathbb{E}} \bigl \lvert{g\bigl ({Y_{j_1},\ldots,Y_{j_b}}\bigr )}\bigr \rvert ^2\lt \infty, \end{align}
\begin{align} {\mathbb{E}} \bigl \lvert{g\bigl ({Y_{j_1},\ldots,Y_{j_b}}\bigr )}\bigr \rvert ^2\lt \infty, \end{align}
for every
 $j_1\lt \cdots \lt j_b$
.
$j_1\lt \cdots \lt j_b$
.
Proof. For each block
 $B_q=\{{\beta _q,\ldots,\beta _{q+1}-1}\}$
defined by
$B_q=\{{\beta _q,\ldots,\beta _{q+1}-1}\}$
defined by
 $\mathcal{D}$
, let
$\mathcal{D}$
, let
 \begin{align} \ell _q&\,:\!=\,|B_q|=\beta _{q+1}-\beta _q, \end{align}
\begin{align} \ell _q&\,:\!=\,|B_q|=\beta _{q+1}-\beta _q, \end{align}
 \begin{align} t_{qr}&\,:\!=\,\sum _{j=1}^{r-1}d_{\beta _q+j-1}, \qquad r=1,\ldots,\ell _q, \end{align}
\begin{align} t_{qr}&\,:\!=\,\sum _{j=1}^{r-1}d_{\beta _q+j-1}, \qquad r=1,\ldots,\ell _q, \end{align}
 \begin{align} u_q&\,:\!=\,t_{q,\ell _q}=\sum _{j=1}^{\beta _{q+1}-\beta _q-1}d_{\beta _q+j-1}, \end{align}
\begin{align} u_q&\,:\!=\,t_{q,\ell _q}=\sum _{j=1}^{\beta _{q+1}-\beta _q-1}d_{\beta _q+j-1}, \end{align}
 \begin{align} v_q&\,:\!=\,\sum _{k\lt q}u_k . \end{align}
\begin{align} v_q&\,:\!=\,\sum _{k\lt q}u_k . \end{align}
Note that
 $t_{q1}=0$
for every
$t_{q1}=0$
for every
 $q$
and that
$q$
and that
 $t_{qr},u_q\lt \infty$
. (We stop the summation in (4.13) just before the next infinite
$t_{qr},u_q\lt \infty$
. (We stop the summation in (4.13) just before the next infinite
 $d_j$
, which occurs for
$d_j$
, which occurs for
 $j=\beta _{q+1}-1$
provided
$j=\beta _{q+1}-1$
provided
 $q\lt b$
.) Note also that
$q\lt b$
.) Note also that
 \begin{align} u_b+v_b=\sum _{k\leqslant b} u_k=D. \end{align}
\begin{align} u_b+v_b=\sum _{k\leqslant b} u_k=D. \end{align}
We then rewrite (3.3) as follows, letting
 $k_q\,:\!=\,i_{\beta _q}$
and grouping the arguments of
$k_q\,:\!=\,i_{\beta _q}$
and grouping the arguments of
 $f$
according to the blocks of
$f$
according to the blocks of
 $\mathcal{D}$
(using an obvious notation for this):
$\mathcal{D}$
(using an obvious notation for this):
 \begin{align} U_n(f;\,{{\mathcal{D}}{=}}) &= \sum _{\substack{1\leqslant k_1\lt k_2\lt \ldots \lt k_b\leqslant n-u_{b},\\ k_{q+1}\gt k_q+u_q}} f\Bigl ({\big(X_{k_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,\big(X_{k_b+t_{br}}\big)_{r=1}^{\ell _b} }\Bigr ) . \end{align}
\begin{align} U_n(f;\,{{\mathcal{D}}{=}}) &= \sum _{\substack{1\leqslant k_1\lt k_2\lt \ldots \lt k_b\leqslant n-u_{b},\\ k_{q+1}\gt k_q+u_q}} f\Bigl ({\big(X_{k_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,\big(X_{k_b+t_{br}}\big)_{r=1}^{\ell _b} }\Bigr ) . \end{align}
Change summation variables by
 $k_q=j_q+v_q$
. Then, recalling (4.14)–(4.15), (4.16) yields
$k_q=j_q+v_q$
. Then, recalling (4.14)–(4.15), (4.16) yields
 \begin{align} U_n(f;\,{{\mathcal{D}}{=}}) = \sum _{1\leqslant j_1\lt j_2\lt j_b\leqslant n-D} f\Bigl ({\big(X_{j_1+v_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,\big(X_{j_b+v_b+t_{br}}\big)_{r=1}^{\ell _b} }\Bigr ) . \end{align}
\begin{align} U_n(f;\,{{\mathcal{D}}{=}}) = \sum _{1\leqslant j_1\lt j_2\lt j_b\leqslant n-D} f\Bigl ({\big(X_{j_1+v_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,\big(X_{j_b+v_b+t_{br}}\big)_{r=1}^{\ell _b} }\Bigr ) . \end{align}
Define, for
 $y_i=(y_{ik})_{k=1}^M\in{\mathcal{S}}^M$
,
$y_i=(y_{ik})_{k=1}^M\in{\mathcal{S}}^M$
,
 \begin{align} g(y_1,\ldots,y_b) =f\Bigl ({\big(y_{1,v_1+t_{1r}+1}\big)_{r=1}^{\ell _1},\ldots,\big(y_{b,v_b+t_{br}+1}\big)_{r=1}^{\ell _b} }\Bigr ). \end{align}
\begin{align} g(y_1,\ldots,y_b) =f\Bigl ({\big(y_{1,v_1+t_{1r}+1}\big)_{r=1}^{\ell _1},\ldots,\big(y_{b,v_b+t_{br}+1}\big)_{r=1}^{\ell _b} }\Bigr ). \end{align}
(Note that
 $v_j+t_{jr}+1\leqslant v_j + u_j +1 \leqslant D+1\leqslant M$
.) We have
$v_j+t_{jr}+1\leqslant v_j + u_j +1 \leqslant D+1\leqslant M$
.) We have
 $Y_j=(X_{j+k-1})_{k=1}^M$
, and thus (4.18) yields
$Y_j=(X_{j+k-1})_{k=1}^M$
, and thus (4.18) yields
 \begin{align} g\big(Y_{j_1},\ldots,Y_{j_b}\big) =f\Bigl ({\big(X_{j_1+v_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,\big(X_{j_b+v_b+t_{br}}\big)_{r=1}^{\ell _b}}\Bigr ) . \end{align}
\begin{align} g\big(Y_{j_1},\ldots,Y_{j_b}\big) =f\Bigl ({\big(X_{j_1+v_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,\big(X_{j_b+v_b+t_{br}}\big)_{r=1}^{\ell _b}}\Bigr ) . \end{align}

Lemma 4.3.
Let
 $(X_i)_1^\infty$
and
$(X_i)_1^\infty$
and
 ${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be as in Lemma 4.1, and let
${\mathcal{D}}=(d_1,\ldots,d_{\ell -1})$
be as in Lemma 4.1, and let
 $M$
and
$M$
and
 $Y_i$
be as in Lemma 4.2. For every
$Y_i$
be as in Lemma 4.2. For every
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
such that (
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
such that (
 ${A}_2$
) holds, there exist functions
${A}_2$
) holds, there exist functions
 $g_{{\mathcal{D}}},g_{{{\mathcal{D}}{=}}}\,:\,({\mathcal{S}}^M)^b\to \mathbb{R}$
such that (4.10) holds for both, and
$g_{{\mathcal{D}}},g_{{{\mathcal{D}}{=}}}\,:\,({\mathcal{S}}^M)^b\to \mathbb{R}$
such that (4.10) holds for both, and
 \begin{align} {Var}\Bigl [{U_n\bigl ({f;\,{\mathcal{D}} ;\,(X_i) }\bigr )-U_{n}\bigl ({g_{{\mathcal{D}}};\,(Y_i) }\bigr )}\Bigr ] &=O\bigl ({n^{2b({\mathcal{D}})-2}}\bigr ),\\[-10pt]\nonumber \end{align}
\begin{align} {Var}\Bigl [{U_n\bigl ({f;\,{\mathcal{D}} ;\,(X_i) }\bigr )-U_{n}\bigl ({g_{{\mathcal{D}}};\,(Y_i) }\bigr )}\Bigr ] &=O\bigl ({n^{2b({\mathcal{D}})-2}}\bigr ),\\[-10pt]\nonumber \end{align}
 \begin{align} {Var}\Bigl [{U_n(f;\,{{\mathcal{D}}{=}} ;\,(X_i) )-U_{n}\bigl ({g_{{{\mathcal{D}}{=}}};\,(Y_i) }\bigr )}\Bigr ] &=O\bigl ({n^{2b({\mathcal{D}})-2}}\bigr ) . \end{align}
\begin{align} {Var}\Bigl [{U_n(f;\,{{\mathcal{D}}{=}} ;\,(X_i) )-U_{n}\bigl ({g_{{{\mathcal{D}}{=}}};\,(Y_i) }\bigr )}\Bigr ] &=O\bigl ({n^{2b({\mathcal{D}})-2}}\bigr ) . \end{align}
Proof. First, letting
 $g_{{{\mathcal{D}}{=}}}$
be as in Lemma 4.2, we have by (4.9)
$g_{{{\mathcal{D}}{=}}}$
be as in Lemma 4.2, we have by (4.9)
 \begin{align} U_n(f;\,{{\mathcal{D}}{=}} ;\,(X_i) )-U_{n}\bigl ({g_{{{\mathcal{D}}{=}}};\,(Y_i) }\bigr ) &= U_{n-D}\bigl ({g_{{{\mathcal{D}}{=}}}}\bigr )-U_{n}\bigl ({g_{{{\mathcal{D}}{=}}}}\bigr ) \notag \\& =-\sum _{k=1}^q\Bigl ({ U_{n-k+1}\bigl ({g_{{{\mathcal{D}}{=}}}}\bigr )-U_{n-k}\bigl ({g_{{{\mathcal{D}}{=}}}}\bigr )}\Bigr ) . \end{align}
\begin{align} U_n(f;\,{{\mathcal{D}}{=}} ;\,(X_i) )-U_{n}\bigl ({g_{{{\mathcal{D}}{=}}};\,(Y_i) }\bigr ) &= U_{n-D}\bigl ({g_{{{\mathcal{D}}{=}}}}\bigr )-U_{n}\bigl ({g_{{{\mathcal{D}}{=}}}}\bigr ) \notag \\& =-\sum _{k=1}^q\Bigl ({ U_{n-k+1}\bigl ({g_{{{\mathcal{D}}{=}}}}\bigr )-U_{n-k}\bigl ({g_{{{\mathcal{D}}{=}}}}\bigr )}\Bigr ) . \end{align}
Thus (4.21) follows by (4.2) in Lemma 4.1 applied to
 $g_{{{\mathcal{D}}{=}}}$
, the trivial constraint
$g_{{{\mathcal{D}}{=}}}$
, the trivial constraint
 ${\mathcal{D}}_\infty$
(i.e., no constraint), and
${\mathcal{D}}_\infty$
(i.e., no constraint), and
 $(Y_i)_1^\infty$
.
$(Y_i)_1^\infty$
.
Next, we recall (3.4) and define
 \begin{align} g_{{\mathcal{D}}}= \sum _{{\mathcal{D}}^{\prime}} g_{{{\mathcal{D}}^{\prime}{=}}}, \end{align}
\begin{align} g_{{\mathcal{D}}}= \sum _{{\mathcal{D}}^{\prime}} g_{{{\mathcal{D}}^{\prime}{=}}}, \end{align}
again summing over all constraints
 ${\mathcal{D}}^{\prime}$
satisfying (3.5). This is a finite sum, and by (3.4) and (4.23),
${\mathcal{D}}^{\prime}$
satisfying (3.5). This is a finite sum, and by (3.4) and (4.23),
 \begin{align} U_n(f;\,{\mathcal{D}} ;\,(X_i) )-U_{n}\bigl ({g_{{\mathcal{D}}};\,(Y_i) }\bigr ) = \sum _{{\mathcal{D}}^{\prime}} \bigl ({U_n(f;\,{{\mathcal{D}}^{\prime}{=}} ;\,(X_i) )-U_{n}\bigl ({g_{{{\mathcal{D}}^{\prime}{=}}};\,(Y_i) }\bigr )}\bigr );\, \end{align}
\begin{align} U_n(f;\,{\mathcal{D}} ;\,(X_i) )-U_{n}\bigl ({g_{{\mathcal{D}}};\,(Y_i) }\bigr ) = \sum _{{\mathcal{D}}^{\prime}} \bigl ({U_n(f;\,{{\mathcal{D}}^{\prime}{=}} ;\,(X_i) )-U_{n}\bigl ({g_{{{\mathcal{D}}^{\prime}{=}}};\,(Y_i) }\bigr )}\bigr );\, \end{align}
To avoid some of the problems caused by dependencies between the
 $X_i$
, we follow Sen [Reference Sen58] and introduce another type of constrained
$X_i$
, we follow Sen [Reference Sen58] and introduce another type of constrained
 $U$
-statistics, where we require the gaps between the summation indices to be large, instead of small as in (3.2). We need only one case, and define
$U$
-statistics, where we require the gaps between the summation indices to be large, instead of small as in (3.2). We need only one case, and define
 \begin{equation} U_n(f;\,\gt m) \,:\!=\,\sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{j+1}-i_j\gt m}} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ), \qquad n\geqslant 0, \end{equation}
\begin{equation} U_n(f;\,\gt m) \,:\!=\,\sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{j+1}-i_j\gt m}} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ), \qquad n\geqslant 0, \end{equation}
summing only over terms where all gaps
 $i_{j+1}-i_j\gt m$
,
$i_{j+1}-i_j\gt m$
,
 $j=1,\ldots,\ell -1$
. (The advantage is that in each term in (4.25), the variables
$j=1,\ldots,\ell -1$
. (The advantage is that in each term in (4.25), the variables
 $X_{i_1},\ldots,X_{i_\ell }$
are independent.)
$X_{i_1},\ldots,X_{i_\ell }$
are independent.)
Lemma 4.4.
Let
 $(X_i)_1^\infty$
and
$(X_i)_1^\infty$
and
 $f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
be as in Lemma 4.1. Then
$f\,:\,{\mathcal{S}}^\ell \to \mathbb{R}$
be as in Lemma 4.1. Then
 \begin{align} {Var}\bigl ({U_n(f)-U_n(f;\,\gt m)}\bigr ) =O\bigl ({n^{2\ell -3}}\bigr ). \end{align}
\begin{align} {Var}\bigl ({U_n(f)-U_n(f;\,\gt m)}\bigr ) =O\bigl ({n^{2\ell -3}}\bigr ). \end{align}
Proof. We can express the type of constrained
 $U$
-statistic in (4.25) as a combination of constrained
$U$
-statistic in (4.25) as a combination of constrained
 $U$
-statistics of the previous type by the following inclusion–exclusion argument:
$U$
-statistics of the previous type by the following inclusion–exclusion argument:
 \begin{align} U_n(f;\,\gt m) &=\sum _{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ) \prod _{j=1}^{\ell -1}\boldsymbol{1}\{{i_{j+1}-i_j\gt m}\} \notag \\ &=\sum _{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ) \prod _{j=1}^{\ell -1}\Bigl ({1-\boldsymbol{1}\{{i_{j+1}-i_j\leqslant m}\}}\Bigr ) \notag \\ &=\sum _{J\subseteq [\ell -1]}({-}1)^{|J|}\sum _{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ) \prod _{j\in J}\boldsymbol{1}\{{i_{j+1}-i_j\leqslant m}\} \notag \\ &=\sum _{J\subseteq [\ell -1]}({-}1)^{|J|}U_n(f;\,{\mathcal{D}}_J), \end{align}
\begin{align} U_n(f;\,\gt m) &=\sum _{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ) \prod _{j=1}^{\ell -1}\boldsymbol{1}\{{i_{j+1}-i_j\gt m}\} \notag \\ &=\sum _{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ) \prod _{j=1}^{\ell -1}\Bigl ({1-\boldsymbol{1}\{{i_{j+1}-i_j\leqslant m}\}}\Bigr ) \notag \\ &=\sum _{J\subseteq [\ell -1]}({-}1)^{|J|}\sum _{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ) \prod _{j\in J}\boldsymbol{1}\{{i_{j+1}-i_j\leqslant m}\} \notag \\ &=\sum _{J\subseteq [\ell -1]}({-}1)^{|J|}U_n(f;\,{\mathcal{D}}_J), \end{align}
where we sum over the
 $2^{\ell -1}$
subsets
$2^{\ell -1}$
subsets
 $J$
of
$J$
of
 $[{\ell -1}]$
, and use the constraints
$[{\ell -1}]$
, and use the constraints
 \begin{align} {\mathcal{D}}_J\,:\!=\,(d_{Jj})_{j=1}^{\ell -1} \qquad \text{with} \qquad d_{Jj}= \begin{cases} m,&j\in J,\\ \infty,& j\notin J. \end{cases} \end{align}
\begin{align} {\mathcal{D}}_J\,:\!=\,(d_{Jj})_{j=1}^{\ell -1} \qquad \text{with} \qquad d_{Jj}= \begin{cases} m,&j\in J,\\ \infty,& j\notin J. \end{cases} \end{align}
We have
 $b({\mathcal{D}}_{J})=\ell -|J|$
, and thus
$b({\mathcal{D}}_{J})=\ell -|J|$
, and thus
 $b({\mathcal{D}}_J)\lt \ell$
unless
$b({\mathcal{D}}_J)\lt \ell$
unless
 $J=\emptyset$
. Moreover,
$J=\emptyset$
. Moreover,
 ${\mathcal{D}}_\emptyset =(\infty,\ldots,\infty )={\mathcal{D}}_\infty$
, and this means no constraint, so
${\mathcal{D}}_\emptyset =(\infty,\ldots,\infty )={\mathcal{D}}_\infty$
, and this means no constraint, so
 $U_n(f;\,{\mathcal{D}}_\emptyset )=U_n(f)$
, the unconstrained
$U_n(f;\,{\mathcal{D}}_\emptyset )=U_n(f)$
, the unconstrained
 $U$
-statistic. Consequently, by (4.27) and Lemma 4.1,
$U$
-statistic. Consequently, by (4.27) and Lemma 4.1,
 \begin{align} {Var}\bigl ({U_n(f)-U_n(f;\,\gt m)}\bigr ) ={Var}\Bigl ({\sum _{J\neq \emptyset }({-}1)^{|J|-1}U_n(f;\,{\mathcal{D}}_J)}\Bigr ) =O\bigl ({n^{2\ell -3}}\bigr ), \end{align}
\begin{align} {Var}\bigl ({U_n(f)-U_n(f;\,\gt m)}\bigr ) ={Var}\Bigl ({\sum _{J\neq \emptyset }({-}1)^{|J|-1}U_n(f;\,{\mathcal{D}}_J)}\Bigr ) =O\bigl ({n^{2\ell -3}}\bigr ), \end{align}
which proves the estimate (4.26).
4.1. Triangular arrays
We will also use a central limit theorem for
 $m$
-dependent triangular arrays satisfying the Lindeberg condition, which we state as Theorem 4.1 below. The theorem is implicit in Orey [Reference Orey48]; it follows from his theorem there exactly as his corollary does, although the latter is stated for a sequence and not for a triangular array. See also [Peligrad [Reference Peligrad49], Theorem 2.1], which contains the theorem below (at least for
$m$
-dependent triangular arrays satisfying the Lindeberg condition, which we state as Theorem 4.1 below. The theorem is implicit in Orey [Reference Orey48]; it follows from his theorem there exactly as his corollary does, although the latter is stated for a sequence and not for a triangular array. See also [Peligrad [Reference Peligrad49], Theorem 2.1], which contains the theorem below (at least for
 $\sigma ^2\gt 0$
; the case
$\sigma ^2\gt 0$
; the case
 $\sigma ^2=0$
is trivial), and is much more general in that it only assumes strong mixing instead of
$\sigma ^2=0$
is trivial), and is much more general in that it only assumes strong mixing instead of
 $m$
-dependence.
$m$
-dependence.
Recall that a triangular array is an array
 $(\xi _{ni})_{1\leqslant i\leqslant n\lt \infty }$
of random variables, such that the variables
$(\xi _{ni})_{1\leqslant i\leqslant n\lt \infty }$
of random variables, such that the variables
 $(\xi _{ni})_{i=1}^n$
in a single row are defined on a common probability space. (As usual, it is only for convenience that we require that the
$(\xi _{ni})_{i=1}^n$
in a single row are defined on a common probability space. (As usual, it is only for convenience that we require that the
 $n$
th row has length
$n$
th row has length
 $n$
; the results extend to arbitrary lengths
$n$
; the results extend to arbitrary lengths
 $N_n$
.) We are here mainly interested in the case when each row is an
$N_n$
.) We are here mainly interested in the case when each row is an
 $m$
-dependent sequence; in this case, we say that
$m$
-dependent sequence; in this case, we say that
 $(\xi _{ni})$
is an
$(\xi _{ni})$
is an
 $m$
-dependent triangular array. (We make no assumption on the relationships between variables in different rows; these may even be defined on different probability spaces.)
$m$
-dependent triangular array. (We make no assumption on the relationships between variables in different rows; these may even be defined on different probability spaces.)
Theorem 4.1. (Orey [Reference Orey48].) Let
 $(\xi _{ni})_{1\leqslant i\leqslant n\lt \infty }$
be an
$(\xi _{ni})_{1\leqslant i\leqslant n\lt \infty }$
be an
 $m$
-dependent triangular array of real-valued random variables with
$m$
-dependent triangular array of real-valued random variables with
 ${\mathbb{E}}\xi _{ni}=0$
. Let
${\mathbb{E}}\xi _{ni}=0$
. Let
 $\widehat{S}_n\,:\!=\,\sum _{i=1}^n \xi _{ni}$
. Assume that, as
$\widehat{S}_n\,:\!=\,\sum _{i=1}^n \xi _{ni}$
. Assume that, as
 $n\to \infty$
,
$n\to \infty$
,
 \begin{align} {Var}\ \widehat{S}_n \to \sigma ^2\in [0,\infty ), \end{align}
\begin{align} {Var}\ \widehat{S}_n \to \sigma ^2\in [0,\infty ), \end{align}
that the
 $\xi _{ni}$
satisfy the Lindeberg condition
$\xi _{ni}$
satisfy the Lindeberg condition
 \begin{align} \sum _{i=1}^n{\mathbb{E}}\bigl [{\xi _{ni}^2\boldsymbol{1}\{{|\xi _{ni}|\gt \varepsilon }\}}\bigr ] \to 0, \qquad for \ every\ \varepsilon \gt 0, \end{align}
\begin{align} \sum _{i=1}^n{\mathbb{E}}\bigl [{\xi _{ni}^2\boldsymbol{1}\{{|\xi _{ni}|\gt \varepsilon }\}}\bigr ] \to 0, \qquad for \ every\ \varepsilon \gt 0, \end{align}
and that
 \begin{align} \sum _{i=1}^n {Var} \xi _{ni} = O(1). \end{align}
\begin{align} \sum _{i=1}^n {Var} \xi _{ni} = O(1). \end{align}
Then, as
 $n\to \infty$
,
$n\to \infty$
,
 \begin{align} \widehat{S}_n\overset{d}{\longrightarrow } \textsf{N}\big(0,\sigma ^2\big). \end{align}
\begin{align} \widehat{S}_n\overset{d}{\longrightarrow } \textsf{N}\big(0,\sigma ^2\big). \end{align}
Note that Theorem 4.1 extends the standard Lindeberg–Feller central limit theorem for triangular arrays with row-wise independent variables (see e.g. [Reference Gut25, Theorem 7.2.4]), to which it reduces when
 $m=0$
.
$m=0$
.
Remark 4.1. In fact, the assumption (4.32) is not needed in Theorem 4.1; see [Reference Utev63, Theorem 2.1]. However, it is easily verified in our case (and many other applications), so we need only this classical result.
5. The expectation
The expectation of a (constrained)
 $U$
-statistic, and in particular its leading term, is easily found from the definition. Nevertheless, we give a detailed proof of Theorem 3.1, for completeness and for later reference.
$U$
-statistic, and in particular its leading term, is easily found from the definition. Nevertheless, we give a detailed proof of Theorem 3.1, for completeness and for later reference.
Proof of Theorem 3.1. Consider first the unconstrained case. We take expectations in (3.1). The sum in (3.1) has
 $\binom{n}{\ell }$
terms. We consider first the terms that satisfy the restriction
$\binom{n}{\ell }$
terms. We consider first the terms that satisfy the restriction
 $i_{j+1}\gt i_j+m$
for every
$i_{j+1}\gt i_j+m$
for every
 $j\in [{\ell -1}]$
(i.e., the terms in (4.25)). As noted above, in each such term, the variables
$j\in [{\ell -1}]$
(i.e., the terms in (4.25)). As noted above, in each such term, the variables
 $X_{j_1},\ldots,X_{j_\ell }$
are independent. Hence, let
$X_{j_1},\ldots,X_{j_\ell }$
are independent. Hence, let
 $(\widehat{X}_i)_1^\ell$
be an independent sequence of random variables in
$(\widehat{X}_i)_1^\ell$
be an independent sequence of random variables in
 $\mathcal{S}$
, each with the same distribution as
$\mathcal{S}$
, each with the same distribution as
 $X_1$
(and thus as each
$X_1$
(and thus as each
 $X_j$
), and define
$X_j$
), and define
 \begin{equation} \mu \,:\!=\,{\mathbb{E}} f(\widehat{X}_1,\ldots,\widehat{X}_\ell ). \end{equation}
\begin{equation} \mu \,:\!=\,{\mathbb{E}} f(\widehat{X}_1,\ldots,\widehat{X}_\ell ). \end{equation}
Then
 \begin{align} \mu ={\mathbb{E}} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ) \end{align}
\begin{align} \mu ={\mathbb{E}} f\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr ) \end{align}
for every sequence of indices
 $i_1,\ldots,i_\ell$
with
$i_1,\ldots,i_\ell$
with
 $i_{j+1}\gt i_j+m$
for all
$i_{j+1}\gt i_j+m$
for all
 $j\in [{\ell -1}]$
. Moreover, the number of terms in (3.1) that do not satisfy these constraints is
$j\in [{\ell -1}]$
. Moreover, the number of terms in (3.1) that do not satisfy these constraints is
 $O ({n^{{\ell -1}}} )$
, and their expectations are uniformly
$O ({n^{{\ell -1}}} )$
, and their expectations are uniformly
 $O(1)$
as a consequence of (3.6). Thus, (3.7) follows from (3.1).
$O(1)$
as a consequence of (3.6). Thus, (3.7) follows from (3.1).
Next, consider the exactly constrained case. We use Lemma 4.2 and then apply the unconstrained case just treated to
 $g$
and
$g$
and
 $(Y_i)$
; this yields
$(Y_i)$
; this yields
 \begin{align} {\mathbb{E}} U_n\bigl ({f;\,{{\mathcal{D}}{=}}}\bigr ) ={\mathbb{E}} U_{n-D}\bigl ({g;\,(Y_i) }\bigr ) =\binom{n-D}{b}{\mathbb{E}} g(\widehat{Y}_1,\ldots,\widehat{Y}_b)+ O\bigl ({n^{b-1}}\bigr ) \end{align}
\begin{align} {\mathbb{E}} U_n\bigl ({f;\,{{\mathcal{D}}{=}}}\bigr ) ={\mathbb{E}} U_{n-D}\bigl ({g;\,(Y_i) }\bigr ) =\binom{n-D}{b}{\mathbb{E}} g(\widehat{Y}_1,\ldots,\widehat{Y}_b)+ O\bigl ({n^{b-1}}\bigr ) \end{align}
with
 $\widehat{Y}_1,\ldots,\widehat{Y}_b\overset{d}{=} Y_1$
independent. Using (4.19), and the notation there, this yields (3.9) with
$\widehat{Y}_1,\ldots,\widehat{Y}_b\overset{d}{=} Y_1$
independent. Using (4.19), and the notation there, this yields (3.9) with
 \begin{align} \mu _{{{\mathcal{D}}{=}}}\,:\!=\,{\mathbb{E}} g\big(Y_{j_1},\ldots,Y_{j_b}\big) ={\mathbb{E}} f\bigl ({\big(X_{j_1+v_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,\big(X_{j_b+v_b+t_{br}}\big)_{r=1}^{\ell _b}}\bigr ), \end{align}
\begin{align} \mu _{{{\mathcal{D}}{=}}}\,:\!=\,{\mathbb{E}} g\big(Y_{j_1},\ldots,Y_{j_b}\big) ={\mathbb{E}} f\bigl ({\big(X_{j_1+v_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,\big(X_{j_b+v_b+t_{br}}\big)_{r=1}^{\ell _b}}\bigr ), \end{align}
for any sequence
 $j_1,\ldots,j_b$
with
$j_1,\ldots,j_b$
with
 $j_{k+1}-j_k\geqslant m+M$
for all
$j_{k+1}-j_k\geqslant m+M$
for all
 $k\in [b-1]$
. (Note that
$k\in [b-1]$
. (Note that
 $(Y_i)_1^\infty$
is
$(Y_i)_1^\infty$
is
 $(m+M-1)$
-dependent.)
$(m+M-1)$
-dependent.)
Finally, the constrained case (3.8) follows by (3.9) and the decomposition (3.4), with
 \begin{align} \mu _{{\mathcal{D}}}\,:\!=\,\sum _{{\mathcal{D}}^{\prime}}\mu _{{{\mathcal{D}}^{\prime}{=}}}, \end{align}
\begin{align} \mu _{{\mathcal{D}}}\,:\!=\,\sum _{{\mathcal{D}}^{\prime}}\mu _{{{\mathcal{D}}^{\prime}{=}}}, \end{align}
summing over all
 ${\mathcal{D}}^{\prime}$
satisfying (3.5).
${\mathcal{D}}^{\prime}$
satisfying (3.5).
In the independent case
 $m=0$
, the results above simplify. First, for the unconstrained case, the formula for
$m=0$
, the results above simplify. First, for the unconstrained case, the formula for
 $\mu$
in (3.10) is a special case of (5.2). Similarly, in the exactly unconstrained case, (5.4) yields the formula for
$\mu$
in (3.10) is a special case of (5.2). Similarly, in the exactly unconstrained case, (5.4) yields the formula for
 $\mu _{{\mathcal{D}}{=}}$
in (3.10). Finally, (3.10) shows that
$\mu _{{\mathcal{D}}{=}}$
in (3.10). Finally, (3.10) shows that
 $\mu _{{\mathcal{D}}{=}}$
does not depend on
$\mu _{{\mathcal{D}}{=}}$
does not depend on
 $\mathcal{D}$
, and thus all terms in the sum in (5.5) are equal to
$\mathcal{D}$
, and thus all terms in the sum in (5.5) are equal to
 $\mu$
. Furthermore, it follows from (3.5) that the number of terms in the sum is
$\mu$
. Furthermore, it follows from (3.5) that the number of terms in the sum is
 $\prod _{d_j\lt \infty }d_j$
, and (3.11) follows.
$\prod _{d_j\lt \infty }d_j$
, and (3.11) follows.
Alternatively, in the independent case, all terms in the sums in (3.1), (3.2), and (3.3) have the same expectation
 $\mu$
given by (3.10), and the result follows by counting the number of terms. In particular, exactly,
$\mu$
given by (3.10), and the result follows by counting the number of terms. In particular, exactly,
 \begin{align}{\mathbb{E}} U_n(f)=\binom n\ell \mu \end{align}
\begin{align}{\mathbb{E}} U_n(f)=\binom n\ell \mu \end{align}
and, with
 $D$
given by (4.7),
$D$
given by (4.7),
 \begin{align}{\mathbb{E}} U_n(f;\,{{\mathcal{D}}{=}})=\binom{n-D}{b} \mu . \end{align}
\begin{align}{\mathbb{E}} U_n(f;\,{{\mathcal{D}}{=}})=\binom{n-D}{b} \mu . \end{align}
6. Asymptotic normality
The general idea of the proof of Theorem 3.3 is to use the projection method of Hoeffding [Reference Hoeffding27], together with modifications as in [Reference Sen58] to treat
 $m$
-dependent variables and modifications as in e.g. [Reference Janson37] to treat the asymmetric case. We then obtain the constrained version, Theorem 3.4, by reduction to the unconstrained case.
$m$
-dependent variables and modifications as in e.g. [Reference Janson37] to treat the asymmetric case. We then obtain the constrained version, Theorem 3.4, by reduction to the unconstrained case.
Proof of Theorem 3.3. We first note that by Lemma 4.4, it suffices to prove (3.18)–(3.19) for
 $U_n(f;\,\gt m)$
. (This uses standard arguments with Minkowski’s inequality and the Cramér–Slutsky theorem [Reference Gut25, Theorem 5.11.4], respectively; we omit the details. The same arguments are used several times below without comment.)
$U_n(f;\,\gt m)$
. (This uses standard arguments with Minkowski’s inequality and the Cramér–Slutsky theorem [Reference Gut25, Theorem 5.11.4], respectively; we omit the details. The same arguments are used several times below without comment.)
As remarked above, the variables inside each term in the sum in (4.25) are independent; this enables us to use Hoeffding’s decomposition for the independent case, which (in the present, asymmetric case) we define as follows.
As in Section 5, let
 $(\widehat{X}_i)_1^\ell$
be an independent sequence of random variables in
$(\widehat{X}_i)_1^\ell$
be an independent sequence of random variables in
 $\mathcal{S}$
, each with the same distribution as
$\mathcal{S}$
, each with the same distribution as
 $X_1$
. Recall
$X_1$
. Recall
 $\mu$
defined in (5.1), and, for
$\mu$
defined in (5.1), and, for
 $i=1,\ldots,\ell$
, define the function
$i=1,\ldots,\ell$
, define the function
 $f_i$
as the one-variable projection
$f_i$
as the one-variable projection
 \begin{align} f_i(x)\,:\!=\, &{\mathbb{E}} f\bigl ({\widehat{X}_1,\ldots,\widehat{X}_{i-1},x,\widehat{X}_{i+1},\ldots,\widehat{X}_\ell }\bigr )-\mu . \end{align}
\begin{align} f_i(x)\,:\!=\, &{\mathbb{E}} f\bigl ({\widehat{X}_1,\ldots,\widehat{X}_{i-1},x,\widehat{X}_{i+1},\ldots,\widehat{X}_\ell }\bigr )-\mu . \end{align}
Equivalently,
 \begin{align} f_i(\widehat{X}_i) =&{\mathbb{E}} \bigl ({f(\widehat{X}_1,\ldots,\widehat{X}_\ell )\mid \widehat{X}_i}\bigr )-\mu . \end{align}
\begin{align} f_i(\widehat{X}_i) =&{\mathbb{E}} \bigl ({f(\widehat{X}_1,\ldots,\widehat{X}_\ell )\mid \widehat{X}_i}\bigr )-\mu . \end{align}
(In general,
 $f_i$
is defined only
$f_i$
is defined only
 ${\mathcal{L}}(\widehat{X}_i)$
-almost everywhere (a.e.), but it does not matter which version we choose.) Define also the residual function
${\mathcal{L}}(\widehat{X}_i)$
-almost everywhere (a.e.), but it does not matter which version we choose.) Define also the residual function
 \begin{align} f_*(x_1,\ldots,x_d) &\,:\!=\, f(x_1,\ldots,x_d) - \mu - \sum _{j=1}^\ell f_j(x_j). \end{align}
\begin{align} f_*(x_1,\ldots,x_d) &\,:\!=\, f(x_1,\ldots,x_d) - \mu - \sum _{j=1}^\ell f_j(x_j). \end{align}
Note that the variables
 $f_i(X_j)$
are centered by (5.1) and (6.2):
$f_i(X_j)$
are centered by (5.1) and (6.2):
 \begin{align} {\mathbb{E}} f_i(X_j)={\mathbb{E}} f_i(\widehat{X}_i)=0. \end{align}
\begin{align} {\mathbb{E}} f_i(X_j)={\mathbb{E}} f_i(\widehat{X}_i)=0. \end{align}
Furthermore, (
 ${A}_2$
) implies that
${A}_2$
) implies that
 $f_i(\widehat{X}_i)$
, and thus each
$f_i(\widehat{X}_i)$
, and thus each
 $f_i(X_j)$
, is square integrable.
$f_i(X_j)$
, is square integrable.
The essential property of
 $f_*$
is that, as an immediate consequence of the definitions and (6.4), its one-variable projections vanish:
$f_*$
is that, as an immediate consequence of the definitions and (6.4), its one-variable projections vanish:
 \begin{align}{\mathbb{E}} \bigl ({f_*(\widehat{X}_1,\ldots,\widehat{X}_\ell )\mid \widehat{X}_i=x}\bigr ) ={\mathbb{E}} f_*\bigl ({\widehat{X}_1,\ldots,\widehat{X}_{i-1},x,\widehat{X}_{i+1},\ldots,\widehat{X}_\ell }\bigr ) =0 . \end{align}
\begin{align}{\mathbb{E}} \bigl ({f_*(\widehat{X}_1,\ldots,\widehat{X}_\ell )\mid \widehat{X}_i=x}\bigr ) ={\mathbb{E}} f_*\bigl ({\widehat{X}_1,\ldots,\widehat{X}_{i-1},x,\widehat{X}_{i+1},\ldots,\widehat{X}_\ell }\bigr ) =0 . \end{align}
We assume from now on for simplicity that
 $\mu =0$
; the general case follows by replacing
$\mu =0$
; the general case follows by replacing
 $f$
by
$f$
by
 $f-\mu$
. Then (4.25) and (6.3) yield, by counting the terms where
$f-\mu$
. Then (4.25) and (6.3) yield, by counting the terms where
 $i_j=k$
for given
$i_j=k$
for given
 $j$
and
$j$
and
 $k$
,
$k$
,
 \begin{align} U_n(f;\,\gt m) &= \sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{j+1}-i_j\gt m}} \Bigl ({\sum _{j=1}^\ell f_j(X_{i_j})+ f_*\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr )}\Bigr ) \notag \\& =\sum _{j=1}^\ell \sum _{k=1}^n \binom{k-1-(j-1)m}{j-1}\binom{n-k-(\ell -j)m}{\ell -j} f_j(X_k) +U_n(f_*;\,\gt m) . \end{align}
\begin{align} U_n(f;\,\gt m) &= \sum _{\substack{1\leqslant i_1\lt \ldots \lt i_\ell \leqslant n\\i_{j+1}-i_j\gt m}} \Bigl ({\sum _{j=1}^\ell f_j(X_{i_j})+ f_*\bigl ({X_{i_1},\ldots,X_{i_\ell }}\bigr )}\Bigr ) \notag \\& =\sum _{j=1}^\ell \sum _{k=1}^n \binom{k-1-(j-1)m}{j-1}\binom{n-k-(\ell -j)m}{\ell -j} f_j(X_k) +U_n(f_*;\,\gt m) . \end{align}
Let us first dispose of the last term in (6.6). Let
 $i_1\lt \ldots \lt i_\ell$
and
$i_1\lt \ldots \lt i_\ell$
and
 $j_1\lt \ldots \lt j_\ell$
be two sets of indices such that the constraints
$j_1\lt \ldots \lt j_\ell$
be two sets of indices such that the constraints
 $i_{k+1}-i_k\gt m$
and
$i_{k+1}-i_k\gt m$
and
 $j_{k+1}-j_k\gt m$
in (4.25) hold. First, as in the proof of Lemma 4.1, if also
$j_{k+1}-j_k\gt m$
in (4.25) hold. First, as in the proof of Lemma 4.1, if also
 $|i_\alpha -j_\beta |\gt m$
for all
$|i_\alpha -j_\beta |\gt m$
for all
 $\alpha,\beta \in [\ell ]$
, then all
$\alpha,\beta \in [\ell ]$
, then all
 $X_{i_\alpha }$
and
$X_{i_\alpha }$
and
 $X_{j_\beta }$
are independent; thus
$X_{j_\beta }$
are independent; thus
 $f_*(X_{i_1},\ldots,X_{i_\ell })$
and
$f_*(X_{i_1},\ldots,X_{i_\ell })$
and
 $f_*(X_{j_1},\ldots,X_{j_\ell })$
are independent, and
$f_*(X_{j_1},\ldots,X_{j_\ell })$
are independent, and
 \begin{align} {\mathbb{E}}\bigl [{f_*(X_{i_1},\ldots,X_{i_\ell })f_*(X_{j_1},\ldots,X_{j_\ell })}\bigr ] ={\mathbb{E}} f_*(X_{i_1},\ldots,X_{i_\ell }){\mathbb{E}} f_*(X_{j_1},\ldots,X_{j_\ell }) =0. \end{align}
\begin{align} {\mathbb{E}}\bigl [{f_*(X_{i_1},\ldots,X_{i_\ell })f_*(X_{j_1},\ldots,X_{j_\ell })}\bigr ] ={\mathbb{E}} f_*(X_{i_1},\ldots,X_{i_\ell }){\mathbb{E}} f_*(X_{j_1},\ldots,X_{j_\ell }) =0. \end{align}
Moreover, suppose that
 $|i_\alpha -j_\beta |\gt m$
for all but one pair
$|i_\alpha -j_\beta |\gt m$
for all but one pair
 $(\alpha,\beta )\in [\ell ]^2$
, say for
$(\alpha,\beta )\in [\ell ]^2$
, say for
 $(\alpha,\beta )\neq (\alpha _0,\beta _0)$
. Then the pair
$(\alpha,\beta )\neq (\alpha _0,\beta _0)$
. Then the pair
 $(X_{i_{\alpha _0}},X_{j_{\beta _0}})$
is independent of all the variables
$(X_{i_{\alpha _0}},X_{j_{\beta _0}})$
is independent of all the variables
 $\{{X_{i_\alpha }\,:\,\alpha \neq \alpha _0}\}$
and
$\{{X_{i_\alpha }\,:\,\alpha \neq \alpha _0}\}$
and
 $\{{X_{j_\beta }\,:\,\beta \neq \beta _0}\}$
, and all these are mutually independent. Hence, recalling (6.5), a.s.
$\{{X_{j_\beta }\,:\,\beta \neq \beta _0}\}$
, and all these are mutually independent. Hence, recalling (6.5), a.s.
 \begin{align} &{\mathbb{E}}\bigl [{f_*(X_{i_1},\ldots,X_{i_\ell })f_*(X_{j_1},\ldots,X_{j_\ell }) \mid X_{i_{\alpha _0}},X_{j_{\beta _0}}}\bigr ] \\\notag & \qquad ={\mathbb{E}}\bigl [{ f_*({X_{i_1},\ldots,X_{i_\ell }})\mid X_{i_{\alpha _0}}}\bigr ]{\mathbb{E}} \bigl [{f_*(X_{j_1},\ldots,X_{j_\ell })\mid X_{j_{\beta _0}}}\bigr ] =0. \end{align}
\begin{align} &{\mathbb{E}}\bigl [{f_*(X_{i_1},\ldots,X_{i_\ell })f_*(X_{j_1},\ldots,X_{j_\ell }) \mid X_{i_{\alpha _0}},X_{j_{\beta _0}}}\bigr ] \\\notag & \qquad ={\mathbb{E}}\bigl [{ f_*({X_{i_1},\ldots,X_{i_\ell }})\mid X_{i_{\alpha _0}}}\bigr ]{\mathbb{E}} \bigl [{f_*(X_{j_1},\ldots,X_{j_\ell })\mid X_{j_{\beta _0}}}\bigr ] =0. \end{align}
Thus, taking the expectation, we find that unconditionally
 \begin{align} {\mathbb{E}}\bigl [{f_*(X_{i_1},\ldots,X_{i_\ell })f_*(X_{j_1},\ldots,X_{j_\ell })}\bigr ] =0. \end{align}
\begin{align} {\mathbb{E}}\bigl [{f_*(X_{i_1},\ldots,X_{i_\ell })f_*(X_{j_1},\ldots,X_{j_\ell })}\bigr ] =0. \end{align}
Consequently, if we expand
 ${Var} [{U_n(f_*;\,\gt m)} ]$
in analogy with (4.3), then all terms where
${Var} [{U_n(f_*;\,\gt m)} ]$
in analogy with (4.3), then all terms where
 $|i_\alpha -j_\beta |\leqslant m$
for at most one pair
$|i_\alpha -j_\beta |\leqslant m$
for at most one pair
 $(\alpha,\beta )$
will vanish. The number of remaining terms, i.e., those with at least two such pairs
$(\alpha,\beta )$
will vanish. The number of remaining terms, i.e., those with at least two such pairs
 $(\alpha,\beta )$
, is
$(\alpha,\beta )$
, is
 $O(n^{2\ell -2})$
, and each term is
$O(n^{2\ell -2})$
, and each term is
 $O(1)$
, by (
$O(1)$
, by (
 ${A}_2$
) and the Cauchy–Schwarz inequality. Consequently,
${A}_2$
) and the Cauchy–Schwarz inequality. Consequently,
 \begin{align} {Var}\bigl [{U_n(f_*;\,\gt m)}\bigr ] =O\bigl ({n^{2\ell -2}}\bigr ). \end{align}
\begin{align} {Var}\bigl [{U_n(f_*;\,\gt m)}\bigr ] =O\bigl ({n^{2\ell -2}}\bigr ). \end{align}
Hence, we may ignore the final term
 $U_n(f_*;\,\gt m)$
in (6.6).
$U_n(f_*;\,\gt m)$
in (6.6).
We turn to the main terms in (6.6), i.e., the double sum; we denote it by
 $\widehat{U}_n$
and write it as
$\widehat{U}_n$
and write it as
 \begin{align} \widehat{U}_n=\sum _{j=1}^\ell \sum _{k=1}^n a_{j,k,n}f_j(X_k), \end{align}
\begin{align} \widehat{U}_n=\sum _{j=1}^\ell \sum _{k=1}^n a_{j,k,n}f_j(X_k), \end{align}
where we thus define
 \begin{align} a_{j,k,n}&\,:\!=\, \binom{k-1-(j-1)m}{j-1}\binom{n-k-(\ell -j)m}{\ell -j} \notag \\&\phantom \,:\!=\,\frac{1}{(j-1)!\,(\ell -j)!} k^{j-1}(n-k)^{\ell -j} + O(n^{\ell -2}), \end{align}
\begin{align} a_{j,k,n}&\,:\!=\, \binom{k-1-(j-1)m}{j-1}\binom{n-k-(\ell -j)m}{\ell -j} \notag \\&\phantom \,:\!=\,\frac{1}{(j-1)!\,(\ell -j)!} k^{j-1}(n-k)^{\ell -j} + O(n^{\ell -2}), \end{align}
where the
 $O$
is uniform over all
$O$
is uniform over all
 $k\leqslant n$
and
$k\leqslant n$
and
 $j\leqslant \ell$
. For
$j\leqslant \ell$
. For
 $j=1,\ldots,\ell$
, define the polynomial functions
$j=1,\ldots,\ell$
, define the polynomial functions
 \begin{align} \psi _j(x)\,:\!=\,\frac{1}{(j-1)!\,(\ell -j)!} x^{j-1}(1-x)^{\ell -j}, \qquad x\in \mathbb{R}. \end{align}
\begin{align} \psi _j(x)\,:\!=\,\frac{1}{(j-1)!\,(\ell -j)!} x^{j-1}(1-x)^{\ell -j}, \qquad x\in \mathbb{R}. \end{align}
Then (6.12) yields, again uniformly for all
 $k\leqslant n$
and
$k\leqslant n$
and
 $j\leqslant \ell$
,
$j\leqslant \ell$
,
 \begin{align} a_{j,k,n}=n^{\ell -1}\psi _j(k/n)+O\bigl ({n^{\ell -2}}\bigr ) . \end{align}
\begin{align} a_{j,k,n}=n^{\ell -1}\psi _j(k/n)+O\bigl ({n^{\ell -2}}\bigr ) . \end{align}
The expansion (6.11) yields
 \begin{align} {Var}\ \widehat{U}_n = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{k=1}^n \sum _{q=1}^na_{i,k,n}a_{j,q,n}{Cov}\bigl [{f_i(X_k),f_j(X_q)}\bigr ], \end{align}
\begin{align} {Var}\ \widehat{U}_n = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{k=1}^n \sum _{q=1}^na_{i,k,n}a_{j,q,n}{Cov}\bigl [{f_i(X_k),f_j(X_q)}\bigr ], \end{align}
where all terms with
 $|k-q|\gt m$
vanish because the sequence
$|k-q|\gt m$
vanish because the sequence
 $(X_i)$
is
$(X_i)$
is
 $m$
-dependent. Hence, with
$m$
-dependent. Hence, with
 $r_-\,:\!=\,\max \{{-r,0}\}$
and
$r_-\,:\!=\,\max \{{-r,0}\}$
and
 $r_+\,:\!=\,\max \{{r,0}\}$
,
$r_+\,:\!=\,\max \{{r,0}\}$
,
 \begin{align} {Var}\ \widehat{U}_n = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{r=-m}^m \sum _{k=1+r_-}^{n-r_+}a_{i,k,n}a_{j,k+r,n}{Cov}\bigl [{f_i(X_k),f_j(X_{k+r})}\bigr ] . \end{align}
\begin{align} {Var}\ \widehat{U}_n = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{r=-m}^m \sum _{k=1+r_-}^{n-r_+}a_{i,k,n}a_{j,k+r,n}{Cov}\bigl [{f_i(X_k),f_j(X_{k+r})}\bigr ] . \end{align}
The covariance in (6.16) is independent of
 $k$
; we thus define, for any
$k$
; we thus define, for any
 $k\gt r_-$
,
$k\gt r_-$
,
 \begin{align} \gamma _{i,j,r}\,:\!=\,{Cov}\bigl [{f_i(X_k),f_j(X_{k+r})}\bigr ] \end{align}
\begin{align} \gamma _{i,j,r}\,:\!=\,{Cov}\bigl [{f_i(X_k),f_j(X_{k+r})}\bigr ] \end{align}
and obtain
 \begin{align} {Var}\ \widehat{U}_n = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{r=-m}^m\gamma _{i,j,r} \sum _{k=1+r_-}^{n-r_+}a_{i,k,n}a_{j,k+r,n}. \end{align}
\begin{align} {Var}\ \widehat{U}_n = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{r=-m}^m\gamma _{i,j,r} \sum _{k=1+r_-}^{n-r_+}a_{i,k,n}a_{j,k+r,n}. \end{align}
Furthermore, by (6.14),
 \begin{align} n^{2-2\ell } \sum _{k=1+r_-}^{n-r_+}a_{i,k,n}a_{j,k+r,n} &= \sum _{k=1+r_-}^{n-r_+} \bigl ({\psi _i(k/n)+O\big(n^{-1}\big)}\bigr )\bigl ({\psi _j(k/n)+O\big(n^{-1}\big)}\bigr ) \notag \\& = \sum _{k=1+r_-}^{n-r_+} \bigl ({\psi _i(k/n)\psi _j(k/n)+O\big(n^{-1}\big)}\bigr ) \notag \\& = \sum _{k=1}^{n} \psi _i(k/n)\psi _j(k/n)+O(1) \notag \\& = \int _0^n \psi _i(x/n)\psi _j(x/n)\,{d} x+O(1) \notag \\& = n\int _0^1 \psi _i(t)\psi _j(t)\,{d} t+O(1) . \end{align}
\begin{align} n^{2-2\ell } \sum _{k=1+r_-}^{n-r_+}a_{i,k,n}a_{j,k+r,n} &= \sum _{k=1+r_-}^{n-r_+} \bigl ({\psi _i(k/n)+O\big(n^{-1}\big)}\bigr )\bigl ({\psi _j(k/n)+O\big(n^{-1}\big)}\bigr ) \notag \\& = \sum _{k=1+r_-}^{n-r_+} \bigl ({\psi _i(k/n)\psi _j(k/n)+O\big(n^{-1}\big)}\bigr ) \notag \\& = \sum _{k=1}^{n} \psi _i(k/n)\psi _j(k/n)+O(1) \notag \\& = \int _0^n \psi _i(x/n)\psi _j(x/n)\,{d} x+O(1) \notag \\& = n\int _0^1 \psi _i(t)\psi _j(t)\,{d} t+O(1) . \end{align}
Consequently, (6.18) yields
 \begin{align} n^{1-2\ell } {Var}\ \widehat{U}_n = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{r=-m}^m\gamma _{i,j,r} \int _0^1\psi _i(t)\psi _j(t)\,{d} t +O\bigl ({n^{-1}}\bigr ). \end{align}
\begin{align} n^{1-2\ell } {Var}\ \widehat{U}_n = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{r=-m}^m\gamma _{i,j,r} \int _0^1\psi _i(t)\psi _j(t)\,{d} t +O\bigl ({n^{-1}}\bigr ). \end{align}
Since (4.26), (6.6), and (6.10) yield
 \begin{align} {Var}\bigl [{ U_n(f)-\widehat{U}_n}\bigr ] = O\bigl ({n^{2\ell -2}}\bigr ), \end{align}
\begin{align} {Var}\bigl [{ U_n(f)-\widehat{U}_n}\bigr ] = O\bigl ({n^{2\ell -2}}\bigr ), \end{align}
the result (3.18) follows from (6.20), with
 \begin{align} \sigma ^2 = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{r=-m}^m\gamma _{i,j,r} \int _0^1\psi _i(t)\psi _j(t)\,{d} t . \end{align}
\begin{align} \sigma ^2 = \sum _{i=1}^\ell \sum _{j=1}^\ell \sum _{r=-m}^m\gamma _{i,j,r} \int _0^1\psi _i(t)\psi _j(t)\,{d} t . \end{align}
Next, we use (6.11) and write
 \begin{align} n^{\frac 12-\ell } \widehat{U}_n =\sum _{k=1}^n Z_{kn}, \end{align}
\begin{align} n^{\frac 12-\ell } \widehat{U}_n =\sum _{k=1}^n Z_{kn}, \end{align}
with
 \begin{align} Z_{kn}\,:\!=\,\sum _{j=1}^\ell n^{\frac 12-\ell }a_{j,k.n}f_j(X_k) . \end{align}
\begin{align} Z_{kn}\,:\!=\,\sum _{j=1}^\ell n^{\frac 12-\ell }a_{j,k.n}f_j(X_k) . \end{align}
Since
 $Z_{kn}$
is a function of
$Z_{kn}$
is a function of
 $X_k$
, it is evident that
$X_k$
, it is evident that
 $(Z_{kn})$
is an
$(Z_{kn})$
is an
 $m$
-dependent triangular array with centered variables. Furthermore,
$m$
-dependent triangular array with centered variables. Furthermore,
 ${\mathbb{E}} Z_{kn}=0$
as a consequence of (6.4).
${\mathbb{E}} Z_{kn}=0$
as a consequence of (6.4).
We apply Theorem 4.1 to
 $(Z_{kn})$
, so
$(Z_{kn})$
, so
 $\widehat{S}_n=n^{\frac 12-\ell }\widehat{U}_n$
by (6.23), and verify first its conditions. The condition (4.30) holds by (6.20) and (6.22). Write
$\widehat{S}_n=n^{\frac 12-\ell }\widehat{U}_n$
by (6.23), and verify first its conditions. The condition (4.30) holds by (6.20) and (6.22). Write
 $Z_{kn}=\sum _{j=1}^\ell Z_{jkn}$
with
$Z_{kn}=\sum _{j=1}^\ell Z_{jkn}$
with
 \begin{align} Z_{jkn}\,:\!=\, n^{\frac 12-\ell }a_{j,k.n}f_j(X_k). \end{align}
\begin{align} Z_{jkn}\,:\!=\, n^{\frac 12-\ell }a_{j,k.n}f_j(X_k). \end{align}
Since (6.12) yields
 $|a_{j,k,n}|\leqslant n^{\ell -1}$
, we have, for
$|a_{j,k,n}|\leqslant n^{\ell -1}$
, we have, for
 $\varepsilon \geqslant 0$
,
$\varepsilon \geqslant 0$
,
 \begin{align} {\mathbb{E}}\bigl [{Z_{jkn}^2\boldsymbol{1}\{{|Z_{jkn}|\gt \varepsilon }\}}\bigr ] \leqslant n^{-1}{\mathbb{E}} \bigl [{|f_j(X_k)|^2 \boldsymbol{1}\{{\lvert{f_j(X_k)}\rvert \gt \varepsilon n^{1/2}}\}}\bigr ]. \end{align}
\begin{align} {\mathbb{E}}\bigl [{Z_{jkn}^2\boldsymbol{1}\{{|Z_{jkn}|\gt \varepsilon }\}}\bigr ] \leqslant n^{-1}{\mathbb{E}} \bigl [{|f_j(X_k)|^2 \boldsymbol{1}\{{\lvert{f_j(X_k)}\rvert \gt \varepsilon n^{1/2}}\}}\bigr ]. \end{align}
The distribution of
 $f_j(X_k)$
does not depend on
$f_j(X_k)$
does not depend on
 $k$
, and thus the Lindeberg condition (4.31) for each triangular array
$k$
, and thus the Lindeberg condition (4.31) for each triangular array
 $(Z_{jkn})_{k,n}$
follows from (6.26). The Lindeberg condition (4.31) for
$(Z_{jkn})_{k,n}$
follows from (6.26). The Lindeberg condition (4.31) for
 $(Z_{nk})_{k,n}$
then follows easily. Finally, taking
$(Z_{nk})_{k,n}$
then follows easily. Finally, taking
 $\varepsilon =0$
in (6.26) yields
$\varepsilon =0$
in (6.26) yields
 ${\mathbb{E}} Z_{jkn}^2\leqslant Cn^{-1}$
, and thus
${\mathbb{E}} Z_{jkn}^2\leqslant Cn^{-1}$
, and thus
 ${\mathbb{E}} Z_{kn}^2\leqslant Cn^{-1}$
, which shows (4.32).
${\mathbb{E}} Z_{kn}^2\leqslant Cn^{-1}$
, which shows (4.32).
We have shown that Theorem 4.1 applies, and thus, recalling (6.23) and (6.4),
 \begin{align} n^{\frac 12-\ell } \bigl ({ \widehat{U}_n-{\mathbb{E}} \widehat{U}_n}\bigr ) = n^{\frac 12-\ell } \widehat{U}_n =\sum _{k=1}^n Z_{kn} \overset{d}{\longrightarrow } \textsf{N}\big(0,\sigma ^2\big). \end{align}
\begin{align} n^{\frac 12-\ell } \bigl ({ \widehat{U}_n-{\mathbb{E}} \widehat{U}_n}\bigr ) = n^{\frac 12-\ell } \widehat{U}_n =\sum _{k=1}^n Z_{kn} \overset{d}{\longrightarrow } \textsf{N}\big(0,\sigma ^2\big). \end{align}
Proof of Theorem 3.4. Lemma 4.3 implies that it suffices to consider
 $U_n ({g;\,(Y_i) } )$
instead of
$U_n ({g;\,(Y_i) } )$
instead of
 $U_n(f;\,{\mathcal{D}})$
or
$U_n(f;\,{\mathcal{D}})$
or
 $U_n(f;\,{{\mathcal{D}}{=}})$
. Note that the definition (4.8) implies that
$U_n(f;\,{{\mathcal{D}}{=}})$
. Note that the definition (4.8) implies that
 $(Y_i)_1^\infty$
is a stationary
$(Y_i)_1^\infty$
is a stationary
 $m^{\prime}$
-dependent sequence, with
$m^{\prime}$
-dependent sequence, with
 $m^{\prime}\,:\!=\,m+M-1$
. Hence, the result follows from Theorem 3.3 applied to
$m^{\prime}\,:\!=\,m+M-1$
. Hence, the result follows from Theorem 3.3 applied to
 $g$
and
$g$
and
 $(Y_i)_1^\infty$
.
$(Y_i)_1^\infty$
.
Remark 6.1. The integrals in (6.22) are standard beta integrals [Reference Olver, Lozier, Boisvert and Clark46, 5.12.1]; we have
 \begin{align} \int _0^1\psi _i(t)\psi _j(t)\,{d} t& =\frac{1}{(i-1)!\,(j-1)!\,(\ell -i)!\,(\ell -j)!} \int _0^1 t^{i+j-2}(1-t)^{2\ell -i-j}\,{d} t \notag \\& =\frac{(i+j-2)!\,(2\ell -i-j)!}{(i-1)!\,(j-1)!\,(\ell -i)!\,(\ell -j)!\,(2\ell -1)!}. \end{align}
\begin{align} \int _0^1\psi _i(t)\psi _j(t)\,{d} t& =\frac{1}{(i-1)!\,(j-1)!\,(\ell -i)!\,(\ell -j)!} \int _0^1 t^{i+j-2}(1-t)^{2\ell -i-j}\,{d} t \notag \\& =\frac{(i+j-2)!\,(2\ell -i-j)!}{(i-1)!\,(j-1)!\,(\ell -i)!\,(\ell -j)!\,(2\ell -1)!}. \end{align}
Remark 6.2. In the unconstrained case Theorem 3.3, the asymptotic variance
 $\sigma ^2$
is given by (6.22) together with (6.17), (6.1), and (6.28).
$\sigma ^2$
is given by (6.22) together with (6.17), (6.1), and (6.28).
In the constrained cases, the proof above shows that
 $\sigma ^2$
is given by (6.22) applied to the function
$\sigma ^2$
is given by (6.22) applied to the function
 $g$
given by Lemma 4.3 and
$g$
given by Lemma 4.3 and
 $(Y_i)_1^\infty$
given by (4.8) (with
$(Y_i)_1^\infty$
given by (4.8) (with
 $M=D+1$
for definiteness); note that this also entails replacing
$M=D+1$
for definiteness); note that this also entails replacing
 $\ell$
by
$\ell$
by
 $b$
and
$b$
and
 $m$
by
$m$
by
 $m+M-1=m+D$
in the formulas above. In particular, in the exactly constrained case (3.3), it follows from (6.1) and (4.18) that, with
$m+M-1=m+D$
in the formulas above. In particular, in the exactly constrained case (3.3), it follows from (6.1) and (4.18) that, with
 $y=(x_1,\ldots,x_M)\in{\mathcal{S}}^M$
and other notation as in (4.11)–(4.14) and (5.4),
$y=(x_1,\ldots,x_M)\in{\mathcal{S}}^M$
and other notation as in (4.11)–(4.14) and (5.4),
 \begin{align} g_i(x_1,\ldots,x_M) ={\mathbb{E}} f\Bigl ({\big(X_{j_1+v_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,(x_{1+v_i+t_{ir}})_{r=1}^{\ell _i}, \ldots,\big(X_{j_b+v_b+t_{br}}\big)_{r=1}^{\ell _b}}\Bigr ) -\mu _{{\mathcal{D}}{=}}, \end{align}
\begin{align} g_i(x_1,\ldots,x_M) ={\mathbb{E}} f\Bigl ({\big(X_{j_1+v_1+t_{1r}}\big)_{r=1}^{\ell _1},\ldots,(x_{1+v_i+t_{ir}})_{r=1}^{\ell _i}, \ldots,\big(X_{j_b+v_b+t_{br}}\big)_{r=1}^{\ell _b}}\Bigr ) -\mu _{{\mathcal{D}}{=}}, \end{align}
where the
 $i$
th group of variables consists of the given
$i$
th group of variables consists of the given
 $x_i$
, the other
$x_i$
, the other
 $b-1$
groups contain variables
$b-1$
groups contain variables
 $X_i$
, and
$X_i$
, and
 $j_1,\ldots,j_b$
is any sequence of indices that has large enough gaps:
$j_1,\ldots,j_b$
is any sequence of indices that has large enough gaps:
 $j_{i+1}-j_i\gt m+M-1= m+D$
.
$j_{i+1}-j_i\gt m+M-1= m+D$
.
In the constrained case (3.2),
 $g=g_{\mathcal{D}}$
is obtained as the sum (4.23), and thus each
$g=g_{\mathcal{D}}$
is obtained as the sum (4.23), and thus each
 $g_i$
is a similar sum of functions that can be obtained as (6.29). (Note that
$g_i$
is a similar sum of functions that can be obtained as (6.29). (Note that
 $M\,:\!=\,D+1$
works in Lemma 4.2 for all terms by (3.5).) Then,
$M\,:\!=\,D+1$
works in Lemma 4.2 for all terms by (3.5).) Then,
 $\sigma ^2$
is given by (6.22) (with substitutions as above).
$\sigma ^2$
is given by (6.22) (with substitutions as above).
7. Law of large numbers
Proof of Theorem 3.2. Note first that if
 $R_n$
is any sequence of random variables such that
$R_n$
is any sequence of random variables such that
 \begin{align} {\mathbb{E}} R_n^2=O\bigl ({n^{-2}}\bigr ), \end{align}
\begin{align} {\mathbb{E}} R_n^2=O\bigl ({n^{-2}}\bigr ), \end{align}
then Markov’s inequality and the Borel–Cantelli lemma show that
 $R_n\overset{a.s.}{\longrightarrow }0$
.
$R_n\overset{a.s.}{\longrightarrow }0$
.
We begin with the unconstrained case,
 ${\mathcal{D}}={\mathcal{D}}_\infty =(\infty,\ldots,\infty )$
. We may assume, as in the proof of Theorem 3.3, that
${\mathcal{D}}={\mathcal{D}}_\infty =(\infty,\ldots,\infty )$
. We may assume, as in the proof of Theorem 3.3, that
 $\mu =0$
. Then (6.21) holds, and thus by the argument just given, and recalling that
$\mu =0$
. Then (6.21) holds, and thus by the argument just given, and recalling that
 ${\mathbb{E}} \widehat{U}_n=0$
by (6.11) and (6.4),
${\mathbb{E}} \widehat{U}_n=0$
by (6.11) and (6.4),
 \begin{align} n^{-\ell } \bigl [{U_n(f)-{\mathbb{E}} U_n(f) - \widehat{U}_n}\bigr ]\overset{a.s.}{\longrightarrow } 0. \end{align}
\begin{align} n^{-\ell } \bigl [{U_n(f)-{\mathbb{E}} U_n(f) - \widehat{U}_n}\bigr ]\overset{a.s.}{\longrightarrow } 0. \end{align}
Hence, to prove (3.15), it suffices to prove
 $n^{-\ell }\widehat{U}_n\overset{a.s.}{\longrightarrow }0$
.
$n^{-\ell }\widehat{U}_n\overset{a.s.}{\longrightarrow }0$
.
For simplicity, we fix
 $j\in [\ell ]$
and define, with
$j\in [\ell ]$
and define, with
 $f_j$
as above given by (6.1),
$f_j$
as above given by (6.1),
 \begin{align} S_{jn} =S_{jn}(f) \,:\!=\,S_n(f_j) \,:\!=\,\sum _{k=1}^n f_j(X_k) \end{align}
\begin{align} S_{jn} =S_{jn}(f) \,:\!=\,S_n(f_j) \,:\!=\,\sum _{k=1}^n f_j(X_k) \end{align}
and, using partial summation,
 \begin{align} \widehat{U}_{jn}\,:\!=\,\sum _{k=1}^n a_{j,k,n}f_j(X_k) =\sum _{k=1}^{n-1}(a_{j,k,n}-a_{j,k+1,n})S_{jk} + a_{j,n,n}S_{jn}. \end{align}
\begin{align} \widehat{U}_{jn}\,:\!=\,\sum _{k=1}^n a_{j,k,n}f_j(X_k) =\sum _{k=1}^{n-1}(a_{j,k,n}-a_{j,k+1,n})S_{jk} + a_{j,n,n}S_{jn}. \end{align}
The sequence
 $(f_j(X_k))_k$
is
$(f_j(X_k))_k$
is
 $m$
-dependent, stationary, and with
$m$
-dependent, stationary, and with
 ${\mathbb{E}} |f_j(X_k)|\lt \infty$
. As is well known, the strong law of large numbers holds for stationary
${\mathbb{E}} |f_j(X_k)|\lt \infty$
. As is well known, the strong law of large numbers holds for stationary
 $m$
-dependent sequences with finite means. (This follows by considering the subsequences
$m$
-dependent sequences with finite means. (This follows by considering the subsequences
 $(X_{(m+1)n+q})_{n\geqslant 0}$
, which for each fixed
$(X_{(m+1)n+q})_{n\geqslant 0}$
, which for each fixed
 $q\in [m+1]$
is an i.i.d. sequence.) Thus, by (7.3) and (6.4),
$q\in [m+1]$
is an i.i.d. sequence.) Thus, by (7.3) and (6.4),
 \begin{align} S_{jn}/n\overset{a.s.}{\longrightarrow }{\mathbb{E}} f_j(X_k)=0. \end{align}
\begin{align} S_{jn}/n\overset{a.s.}{\longrightarrow }{\mathbb{E}} f_j(X_k)=0. \end{align}
In other words, a.s.
 $S_{jn}=o(n)$
, and thus also
$S_{jn}=o(n)$
, and thus also
 \begin{align} \max _{1\leqslant k\leqslant n}|S_{jk}| =o(n)\qquad \text{a.s.} \end{align}
\begin{align} \max _{1\leqslant k\leqslant n}|S_{jk}| =o(n)\qquad \text{a.s.} \end{align}
Moreover, (6.12) implies
 $a_{j,k,n}-a_{j,k+1,n}=O(n^{\ell -2})$
. Hence, (7.4) yields
$a_{j,k,n}-a_{j,k+1,n}=O(n^{\ell -2})$
. Hence, (7.4) yields
 \begin{align} n^{-\ell } \widehat{U}_{jn} =\sum _{k=1}^{n-1} O\big(n^{-2}\big)\cdot S_{jk} + O\big(n^{-1}\big) \cdot S_{jn}, \end{align}
\begin{align} n^{-\ell } \widehat{U}_{jn} =\sum _{k=1}^{n-1} O\big(n^{-2}\big)\cdot S_{jk} + O\big(n^{-1}\big) \cdot S_{jn}, \end{align}
and thus, using (7.6),
 \begin{align} \bigl \lvert{n^{-\ell } \widehat{U}_{jn}}\bigr \rvert \leqslant C n^{-1} \max _{k\leqslant n}| S_{jk}| =o(1)\qquad \text{a.s.} \end{align}
\begin{align} \bigl \lvert{n^{-\ell } \widehat{U}_{jn}}\bigr \rvert \leqslant C n^{-1} \max _{k\leqslant n}| S_{jk}| =o(1)\qquad \text{a.s.} \end{align}
Consequently,
 \begin{align} n^{-\ell }\widehat{U}_n = \sum _{j=1}^\ell n^{-\ell }\widehat{U}_{jn }\overset{a.s.}{\longrightarrow } 0, \end{align}
\begin{align} n^{-\ell }\widehat{U}_n = \sum _{j=1}^\ell n^{-\ell }\widehat{U}_{jn }\overset{a.s.}{\longrightarrow } 0, \end{align}
which together with (7.2) yields the desired result (3.15).
Next, for an exact constraint
 ${\mathcal{D}}{=}$
, we use Lemma 4.2. Then (4.9) together with the result just shown applied to
${\mathcal{D}}{=}$
, we use Lemma 4.2. Then (4.9) together with the result just shown applied to
 $g$
and
$g$
and
 $(Y_i)$
yields
$(Y_i)$
yields
 \begin{align} n^{-b}\big [{U_n(f;\,{{\mathcal{D}}{=}})}-{\mathbb{E}}{U_n(f;\,{{\mathcal{D}}{=}})}\big ] = n^{-b}\big [{U_{n-D}(g)}-{\mathbb{E}}{U_{n-D}(g)}\big ] \overset{a.s.}{\longrightarrow }0. \end{align}
\begin{align} n^{-b}\big [{U_n(f;\,{{\mathcal{D}}{=}})}-{\mathbb{E}}{U_n(f;\,{{\mathcal{D}}{=}})}\big ] = n^{-b}\big [{U_{n-D}(g)}-{\mathbb{E}}{U_{n-D}(g)}\big ] \overset{a.s.}{\longrightarrow }0. \end{align}
This proves (3.17), and (3.16) follows by (3.4).
Finally, using Theorem 3.1, (3.12)–(3.14) are equivalent to (3.15)–(3.17).
8. The degenerate case
As is well known, even in the original symmetric and independent case studied in [Reference Hoeffding27], the asymptotic variance
 $\sigma ^2$
in Theorem 3.3 may vanish also in non-trivial cases. In such cases, (3.19) is still valid, but says only that the left-hand side converges to 0 in probability. In the present section, we characterize this degenerate case in Theorems 3.3 and 3.4. Note that in applications, it is frequently natural to guess that
$\sigma ^2$
in Theorem 3.3 may vanish also in non-trivial cases. In such cases, (3.19) is still valid, but says only that the left-hand side converges to 0 in probability. In the present section, we characterize this degenerate case in Theorems 3.3 and 3.4. Note that in applications, it is frequently natural to guess that
 $\sigma ^2\gt 0$
, but this is sometimes surprisingly difficult to prove. One purpose of the theorems below is to assist in showing
$\sigma ^2\gt 0$
, but this is sometimes surprisingly difficult to prove. One purpose of the theorems below is to assist in showing
 $\sigma ^2\gt 0$
; see the applications in Sections 13 and 14.
$\sigma ^2\gt 0$
; see the applications in Sections 13 and 14.
For an unconstrained
 $U$
-statistic and an independent sequence
$U$
-statistic and an independent sequence
 $(X_i)_1^\infty$
(the case
$(X_i)_1^\infty$
(the case
 $m=0$
of Theorem 3.3), it is known, and not difficult to see, that
$m=0$
of Theorem 3.3), it is known, and not difficult to see, that
 $\sigma ^2=0$
if and only if every projection
$\sigma ^2=0$
if and only if every projection
 $f_i(X_1)$
defined by (6.1) vanishes a.s.; see [Reference Janson37, Corollary 3.5]. (This is included in the theorem below by taking
$f_i(X_1)$
defined by (6.1) vanishes a.s.; see [Reference Janson37, Corollary 3.5]. (This is included in the theorem below by taking
 $m=0$
in (iii), and it is also the correct interpretation of (vi) when
$m=0$
in (iii), and it is also the correct interpretation of (vi) when
 $m=0$
.) In the
$m=0$
.) In the
 $m$
-dependent case, the situation is similar, but somewhat more complicated, as shown by the following theorem. Note that
$m$
-dependent case, the situation is similar, but somewhat more complicated, as shown by the following theorem. Note that
 $S_n(f_j)$
defined in (8.8) below equals
$S_n(f_j)$
defined in (8.8) below equals
 $S_{jn}$
; for later applications we find this change of notation convenient.
$S_{jn}$
; for later applications we find this change of notation convenient.
Theorem 8.1.
With assumptions and notation as in Theorem 3.3, define
 $f_i$
by (6.1),
$f_i$
by (6.1),
 $\gamma _{i,j,r}$
by (6.17) and
$\gamma _{i,j,r}$
by (6.17) and
 $S_{jn}$
by (7.3). Then the following are equivalent:
$S_{jn}$
by (7.3). Then the following are equivalent:
-
(i)
(8.1)
\begin{align} \sigma ^2=0. \end{align}
-
(ii)
(8.2)
\begin{align} {Var}\ U_n = O\bigl ({n^{2\ell -2}}\bigr ). \end{align}
-
(iii)
(8.3)
\begin{align} \sum _{r=-m}^m\gamma _{i,j,r}=0,\qquad \forall i,j\in [\ell ]. \end{align}
-
(iv)
(8.4)
\begin{align} {Cov}\bigl [{S_{in},S_{jn}}\bigr ]/n \to 0\ as\ n\to \infty \quad \forall i,j\in [\ell ]. \end{align}
-
(v)
(8.5)
\begin{align} {Var}\bigl [{S_{jn}}\bigr ]/n \to 0\ as\ n\to \infty \quad \forall j\in [\ell ]. \end{align}
-
(vi) For each
$j\in [\ell ]$
there exists a stationary sequence
$(Z_{j,k})_{k=0}^\infty$
of
$(m-1)$
-dependent random variables such that a.s.
(8.6)
\begin{align} f_j(X_k)=Z_{j,k}-Z_{j,k-1}, \qquad k\geqslant 1. \end{align}









Moreover, suppose that the sequence
 $(X_k)_1^\infty$
is a block factor given by (2.2) for some function
$(X_k)_1^\infty$
is a block factor given by (2.2) for some function
 $h$
and i.i.d.
$h$
and i.i.d.
 $\xi _i$
, and that
$\xi _i$
, and that
 $\sigma ^2=0$
. Then, in (vi), we may take
$\sigma ^2=0$
. Then, in (vi), we may take
 $Z_{j,k}$
as block factors
$Z_{j,k}$
as block factors
 \begin{align} Z_{j,k}=\varphi _j(\xi _{k+1},\ldots,\xi _{k+m}), \end{align}
\begin{align} Z_{j,k}=\varphi _j(\xi _{k+1},\ldots,\xi _{k+m}), \end{align}
for some functions
 $\varphi _j\,:\,{\mathcal{S}}_0^m\to \mathbb{R}$
. Hence, for every
$\varphi _j\,:\,{\mathcal{S}}_0^m\to \mathbb{R}$
. Hence, for every
 $j\in [\ell ]$
and
$j\in [\ell ]$
and
 $n\geqslant 1$
,
$n\geqslant 1$
,
 \begin{align} S_n(f_j) \,:\!=\,\sum _{k=1}^n f_j(X_k) =Z_{j,n}-Z_{j,0} =\varphi _j(\xi _{n+1},\ldots,\xi _{n+m}) -\varphi _j(\xi _{1},\ldots,\xi _{m}), \end{align}
\begin{align} S_n(f_j) \,:\!=\,\sum _{k=1}^n f_j(X_k) =Z_{j,n}-Z_{j,0} =\varphi _j(\xi _{n+1},\ldots,\xi _{n+m}) -\varphi _j(\xi _{1},\ldots,\xi _{m}), \end{align}
and thus
 $S_{n}(f_j)$
is independent of
$S_{n}(f_j)$
is independent of
 $\xi _{m+1},\ldots,\xi _{n}$
for every
$\xi _{m+1},\ldots,\xi _{n}$
for every
 $j\in [{\ell -1}]$
and
$j\in [{\ell -1}]$
and
 $n\gt m$
.
$n\gt m$
.
To prove Theorem 8.1, we begin with a well-known algebraic lemma; for completeness we include a proof.
Lemma 8.1.
Let
 $A=(a_{ij})_{i,j=1}^\ell$
and
$A=(a_{ij})_{i,j=1}^\ell$
and
 $B=(b_{ij})_{i,j=1}^\ell$
be symmetric real matrices such that
$B=(b_{ij})_{i,j=1}^\ell$
be symmetric real matrices such that
 $A$
is positive definite and
$A$
is positive definite and
 $B$
is positive semidefinite. Then
$B$
is positive semidefinite. Then
 \begin{align} \sum _{i,j=1}^\ell a_{ij}b_{ij}=0 \iff b_{ij}=0\quad \forall i,j\in [\ell ]. \end{align}
\begin{align} \sum _{i,j=1}^\ell a_{ij}b_{ij}=0 \iff b_{ij}=0\quad \forall i,j\in [\ell ]. \end{align}
Proof. Since
 $A$
is positive definite, there exists an orthonormal basis
$A$
is positive definite, there exists an orthonormal basis
 $(v_k)_1^\ell$
in
$(v_k)_1^\ell$
in
 $\mathbb{R}^\ell$
consisting of eigenvectors of
$\mathbb{R}^\ell$
consisting of eigenvectors of
 $A$
, in other words satisfying
$A$
, in other words satisfying
 $Av_k=\lambda _kv_k$
; furthermore, the eigenvalues
$Av_k=\lambda _kv_k$
; furthermore, the eigenvalues
 $\lambda _k\gt 0$
. Write
$\lambda _k\gt 0$
. Write
 $v_k=(v_{ki})_{i=1}^\ell$
. We then have
$v_k=(v_{ki})_{i=1}^\ell$
. We then have
 \begin{align} a_{ij}=\sum _{k=1}^\ell \lambda _k v_{ki}v_{kj}. \end{align}
\begin{align} a_{ij}=\sum _{k=1}^\ell \lambda _k v_{ki}v_{kj}. \end{align}
Thus
 \begin{align} \sum _{i,j=1}^\ell a_{ij}b_{ij} =\sum _{k=1}^\ell \lambda _k \sum _{i,j=1}^\ell b_{ij}v_{ki}v_{kj} =\sum _{k=1}^\ell \lambda _k \langle{v_k,Bv_k}\rangle . \end{align}
\begin{align} \sum _{i,j=1}^\ell a_{ij}b_{ij} =\sum _{k=1}^\ell \lambda _k \sum _{i,j=1}^\ell b_{ij}v_{ki}v_{kj} =\sum _{k=1}^\ell \lambda _k \langle{v_k,Bv_k}\rangle . \end{align}
Since
 $B$
is positive semidefinite, all terms in the last sum are
$B$
is positive semidefinite, all terms in the last sum are
 $\geqslant 0$
, so the sum is 0 if and only if every term is, and thus
$\geqslant 0$
, so the sum is 0 if and only if every term is, and thus
 \begin{align} \sum _{i,j=1}^\ell a_{ij}b_{ij}=0 \iff \langle{v_k,Bv_k}\rangle =0 \quad \forall k\in [\ell ]. \end{align}
\begin{align} \sum _{i,j=1}^\ell a_{ij}b_{ij}=0 \iff \langle{v_k,Bv_k}\rangle =0 \quad \forall k\in [\ell ]. \end{align}
By the Cauchy–Schwarz inequality for the semidefinite bilinear form
 $\langle{v,Bw}\rangle$
(or, alternatively, by using
$\langle{v,Bw}\rangle$
(or, alternatively, by using
 $\langle{v_k\pm v_n,B(v_k\pm v_n)}\rangle \geqslant 0$
), it follows that this condition implies
$\langle{v_k\pm v_n,B(v_k\pm v_n)}\rangle \geqslant 0$
), it follows that this condition implies
 $\langle{v_k,Bv_n}\rangle =0$
for any
$\langle{v_k,Bv_n}\rangle =0$
for any
 $k,n\in [\ell ]$
, and thus
$k,n\in [\ell ]$
, and thus
 \begin{align} \sum _{i,j=1}^\ell a_{ij}b_{ij}=0 \iff \langle{v_k,Bv_n}\rangle =0 \quad \forall k,n\in [\ell ]. \end{align}
\begin{align} \sum _{i,j=1}^\ell a_{ij}b_{ij}=0 \iff \langle{v_k,Bv_n}\rangle =0 \quad \forall k,n\in [\ell ]. \end{align}
Since
 $(v_k)_1^\ell$
is a basis, this is further equivalent to
$(v_k)_1^\ell$
is a basis, this is further equivalent to
 $\langle{v,Bw}\rangle =0$
for any
$\langle{v,Bw}\rangle =0$
for any
 $v,W\in \mathbb{R}^\ell$
, and thus to
$v,W\in \mathbb{R}^\ell$
, and thus to
 $B=0$
. This yields (8.9).
$B=0$
. This yields (8.9).
Proof of Theorem 8.1. The
 $\ell$
polynomials
$\ell$
polynomials
 $\psi _j$
,
$\psi _j$
,
 $j=1,\ldots,\ell$
, of degree
$j=1,\ldots,\ell$
, of degree
 $\ell -1$
defined by (6.13) are linearly independent (e.g., since the matrix of their coefficients in the standard basis
$\ell -1$
defined by (6.13) are linearly independent (e.g., since the matrix of their coefficients in the standard basis
 $\{{1,x,\ldots,x^{\ell -1}}\}$
is upper triangular with non-zero diagonal elements). Hence, the Gram matrix
$\{{1,x,\ldots,x^{\ell -1}}\}$
is upper triangular with non-zero diagonal elements). Hence, the Gram matrix
 $A=(a_{ij})_{i,j}$
with
$A=(a_{ij})_{i,j}$
with
 \begin{align} a_{ij}\,:\!=\,\int _0^1 \psi _i(t)\psi _j(t)\,{d} t \end{align}
\begin{align} a_{ij}\,:\!=\,\int _0^1 \psi _i(t)\psi _j(t)\,{d} t \end{align}
is positive definite.
We have by (7.3), similarly to (6.15)–(6.18),
 \begin{align} {Cov}\bigl ({S_{in},S_{jn}}\bigr )& =\sum _{k=1}^n \sum _{q=1}^n {Cov}\bigl [{f_i(X_k),f_j(X_q)}\bigr ] = \sum _{r=-m}^m\sum _{k=1+r_-}^{n-r_+}{Cov}\bigl [{f_i(X_k),f_j(X_{k+r})}\bigr ] \notag \\& = \sum _{r=-m}^m(n-|r|){Cov}\bigl [{f_i(X_k),f_j(X_{k+r})}\bigr ] = \sum _{r=-m}^m(n-|r|)\gamma _{i,j,r}, \end{align}
\begin{align} {Cov}\bigl ({S_{in},S_{jn}}\bigr )& =\sum _{k=1}^n \sum _{q=1}^n {Cov}\bigl [{f_i(X_k),f_j(X_q)}\bigr ] = \sum _{r=-m}^m\sum _{k=1+r_-}^{n-r_+}{Cov}\bigl [{f_i(X_k),f_j(X_{k+r})}\bigr ] \notag \\& = \sum _{r=-m}^m(n-|r|){Cov}\bigl [{f_i(X_k),f_j(X_{k+r})}\bigr ] = \sum _{r=-m}^m(n-|r|)\gamma _{i,j,r}, \end{align}
and thus, as
 $n\to \infty$
,
$n\to \infty$
,
 \begin{align} {Cov}\bigl ({S_{in},S_{jn}}\bigr )/n& \to \sum _{r=-m}^m\gamma _{i,j,r} \,=\!:\, b_{ij}. \end{align}
\begin{align} {Cov}\bigl ({S_{in},S_{jn}}\bigr )/n& \to \sum _{r=-m}^m\gamma _{i,j,r} \,=\!:\, b_{ij}. \end{align}
Note that (6.22) can be written as
 \begin{align} \sigma ^2=\sum _{i,j=1}^\ell b_{ij}a_{ij}. \end{align}
\begin{align} \sigma ^2=\sum _{i,j=1}^\ell b_{ij}a_{ij}. \end{align}
The covariance matrices
 $ ({{Cov}(S_{in},S_{jn})} )_{i,j=1}^\ell$
are positive semidefinite, and thus so is the limit
$ ({{Cov}(S_{in},S_{jn})} )_{i,j=1}^\ell$
are positive semidefinite, and thus so is the limit
 $B=(b_{ij})$
defined by (8.16). Hence Lemma 8.1 applies and yields, using (8.17) and the definition of
$B=(b_{ij})$
defined by (8.16). Hence Lemma 8.1 applies and yields, using (8.17) and the definition of
 $b_{ij}$
in (8.16), the equivalence (i)
$b_{ij}$
in (8.16), the equivalence (i)
 $\iff$
(iii).
$\iff$
(iii).
Furthermore, (8.16) yields (iii)
 $\iff$
(iv).
$\iff$
(iv).
The implication (iv)
 $\implies$
(v) is trivial, and the converse follows by the Cauchy–Schwarz inequality.
$\implies$
(v) is trivial, and the converse follows by the Cauchy–Schwarz inequality.
If (iii) holds, then (6.20) yields
 ${Var}\ \widehat{U}_n = O \big({n^{2\ell -2}} \big)$
, and (ii) follows by (6.21). Conversely, (ii)
${Var}\ \widehat{U}_n = O \big({n^{2\ell -2}} \big)$
, and (ii) follows by (6.21). Conversely, (ii)
 $\implies$
(i) by (3.18).
$\implies$
(i) by (3.18).
Moreover, for
 $m\geqslant 1$
, (v)
$m\geqslant 1$
, (v)
 $\iff$
(vi) holds by [Reference Janson36, Theorem 1], recalling
$\iff$
(vi) holds by [Reference Janson36, Theorem 1], recalling
 ${\mathbb{E}} f_j(X_k)=0$
by (6.4). (Recall also that any stationary sequence
${\mathbb{E}} f_j(X_k)=0$
by (6.4). (Recall also that any stationary sequence
 $(W_k)_1^\infty$
of real random variables can be extended to a doubly-infinite stationary sequence
$(W_k)_1^\infty$
of real random variables can be extended to a doubly-infinite stationary sequence
 $(W_k)_{-\infty }^\infty$
.) The case
$(W_k)_{-\infty }^\infty$
.) The case
 $m=0$
is trivial, since then (v) is equivalent to
$m=0$
is trivial, since then (v) is equivalent to
 ${Var} f_j(X_k)=0$
and thus
${Var} f_j(X_k)=0$
and thus
 $f_j(X_k)=0$
a.s. by (6.4), while (vi) should be interpreted to mean that (8.6) holds for some non-random
$f_j(X_k)=0$
a.s. by (6.4), while (vi) should be interpreted to mean that (8.6) holds for some non-random
 $Z_{j,k}=z_j$
.
$Z_{j,k}=z_j$
.
Finally, suppose that
 $(X_i)_1^\infty$
is a block factor. In this case, [Reference Janson36, Theorem 2] shows that
$(X_i)_1^\infty$
is a block factor. In this case, [Reference Janson36, Theorem 2] shows that
 $Z_{j,k}$
can be chosen as in (8.7). (Again, the case
$Z_{j,k}$
can be chosen as in (8.7). (Again, the case
 $m=0$
is trivial.) Then (8.8) is an immediate consequence of (8.6)–(8.7).
$m=0$
is trivial.) Then (8.8) is an immediate consequence of (8.6)–(8.7).
Remark 8.1. It follows from the proof in [Reference Janson36] that in (vi), we can choose
 $Z_{jk}$
such that also the random vectors
$Z_{jk}$
such that also the random vectors
 $(Z_{jk})_{j=1}^\ell$
,
$(Z_{jk})_{j=1}^\ell$
,
 $k\geqslant 0$
, form a stationary
$k\geqslant 0$
, form a stationary
 $(m-1)$
-dependent sequence.
$(m-1)$
-dependent sequence.
Theorem 8.2.
With assumptions and notation as in Theorem 3.4, define also
 $g_i$
,
$g_i$
,
 $i\in [b]$
, as in Remark 6.2, i.e., by (6.29) in the exactly constrained case and otherwise as a sum of such terms over all
$i\in [b]$
, as in Remark 6.2, i.e., by (6.29) in the exactly constrained case and otherwise as a sum of such terms over all
 ${\mathcal{D}}^{\prime}$
given by (3.5). Also (again as in Remark 6.2), let
${\mathcal{D}}^{\prime}$
given by (3.5). Also (again as in Remark 6.2), let
 $D$
be given by (4.7) and
$D$
be given by (4.7) and
 $Y_k$
by (4.8) with
$Y_k$
by (4.8) with
 $M=D+1$
. Then
$M=D+1$
. Then
 $\sigma ^2=0$
if and only if for every
$\sigma ^2=0$
if and only if for every
 $j\in [b]$
, there exists a stationary sequence
$j\in [b]$
, there exists a stationary sequence
 $(Z_{j,k})_{k=0}^\infty$
of
$(Z_{j,k})_{k=0}^\infty$
of
 $(m+D-1)$
-dependent random variables such that a.s.
$(m+D-1)$
-dependent random variables such that a.s.
 \begin{align} g_j(Y_k)=Z_{j,k}-Z_{j,k-1}, \qquad k\geqslant 1. \end{align}
\begin{align} g_j(Y_k)=Z_{j,k}-Z_{j,k-1}, \qquad k\geqslant 1. \end{align}
Moreover, if the sequence
 $(X_i)_1^\infty$
is independent and
$(X_i)_1^\infty$
is independent and
 $\sigma ^2=0$
, then there exist functions
$\sigma ^2=0$
, then there exist functions
 $\varphi _j\,:\,{\mathcal{S}}^{D}\to \mathbb{R}$
such that (8.18) holds with
$\varphi _j\,:\,{\mathcal{S}}^{D}\to \mathbb{R}$
such that (8.18) holds with
 \begin{align} Z_{j,k}=\varphi _j(X_{k+1},\ldots,X_{k+D}), \end{align}
\begin{align} Z_{j,k}=\varphi _j(X_{k+1},\ldots,X_{k+D}), \end{align}
and consequently a.s.
 \begin{align} S_{n}(g_j) \,:\!=\,\sum _{k=1}^n g_j(Y_k) =\varphi _j(X_{n+1},\ldots,X_{n+D}) -\varphi _j(X_{1},\ldots,X_{D}); \end{align}
\begin{align} S_{n}(g_j) \,:\!=\,\sum _{k=1}^n g_j(Y_k) =\varphi _j(X_{n+1},\ldots,X_{n+D}) -\varphi _j(X_{1},\ldots,X_{D}); \end{align}
thus
 $S_{n}(g_j)$
is independent of
$S_{n}(g_j)$
is independent of
 $X_{D+1},\ldots,X_n$
for every
$X_{D+1},\ldots,X_n$
for every
 $j\in [{\ell -1}]$
and
$j\in [{\ell -1}]$
and
 $n\gt D$
.
$n\gt D$
.
Proof. As in the proof of Theorem 3.4, it suffices to consider
 $U_n(g)$
with
$U_n(g)$
with
 $g$
given by Lemma 4.3 (with
$g$
given by Lemma 4.3 (with
 $M=D+1$
). The first part then is an immediate consequence of Theorem 8.1(i)
$M=D+1$
). The first part then is an immediate consequence of Theorem 8.1(i)
 $\Leftrightarrow$
(vi) applied to
$\Leftrightarrow$
(vi) applied to
 $g$
and
$g$
and
 $Y_i\,:\!=\,(X_i,\ldots,X_{i+D})$
, with appropriate substitutions
$Y_i\,:\!=\,(X_i,\ldots,X_{i+D})$
, with appropriate substitutions
 $\ell \mapsto b$
and
$\ell \mapsto b$
and
 $m\mapsto m+D$
.
$m\mapsto m+D$
.
The second part follows similarly by the last part of Theorem 8.1, with
 $\xi _i=X_i$
; note that then
$\xi _i=X_i$
; note that then
 $(Y_i)$
is a block factor as in (2.2), with
$(Y_i)$
is a block factor as in (2.2), with
 $m$
replaced by
$m$
replaced by
 $D$
.
$D$
.
Remark 8.2. Of course, under the assumptions of Theorem 8.2, the other equivalences in Theorem 8.1 hold as well, with the appropriate interpretations, substituting
 $g$
for
$g$
for
 $f$
and so on.
$f$
and so on.
We give an example of a constrained
 $U$
-statistic where
$U$
-statistic where
 $\sigma ^2=0$
in a somewhat non-trivial way.
$\sigma ^2=0$
in a somewhat non-trivial way.
Example 8.1. Let
 $(X_i)_1^\infty$
be an infinite i.i.d. symmetric random binary string; i.e.,
$(X_i)_1^\infty$
be an infinite i.i.d. symmetric random binary string; i.e.,
 ${\mathcal{S}}=\{{0,1}\}$
and
${\mathcal{S}}=\{{0,1}\}$
and
 $X_i\sim {Be}(1/2)$
are i.i.d. Let
$X_i\sim {Be}(1/2)$
are i.i.d. Let
 \begin{align} f(x,y,z)\,:\!=\,\boldsymbol{1}\{{xyz=101}\}-\boldsymbol{1}\{{xyz=011}\} \end{align}
\begin{align} f(x,y,z)\,:\!=\,\boldsymbol{1}\{{xyz=101}\}-\boldsymbol{1}\{{xyz=011}\} \end{align}
and consider the constrained
 $U$
-statistic
$U$
-statistic
 \begin{align} U_n(f;\,{\mathcal{D}}) = \sum _{1\leqslant i\lt i+1\lt j\leqslant n} f\bigl ({X_i,X_{i+1},X_j}\bigr ), \end{align}
\begin{align} U_n(f;\,{\mathcal{D}}) = \sum _{1\leqslant i\lt i+1\lt j\leqslant n} f\bigl ({X_i,X_{i+1},X_j}\bigr ), \end{align}
which thus has constraint
 ${\mathcal{D}}=(1,\infty )$
. (In this case,
${\mathcal{D}}=(1,\infty )$
. (In this case,
 $U_n(f,{\mathcal{D}})=U_n(f;\,{{\mathcal{D}}{=}})$
.) Note that (8.22) is a difference of two constrained subsequence counts.
$U_n(f,{\mathcal{D}})=U_n(f;\,{{\mathcal{D}}{=}})$
.) Note that (8.22) is a difference of two constrained subsequence counts.
Although the function (8.21) might look non-trivial and innocuous at first glance, this turns out to be a degenerate case. In fact, it is easily verified that
 \begin{align} f(x,y,z)=(x-y)z, \qquad x,y,z\in \{{0,1}\}. \end{align}
\begin{align} f(x,y,z)=(x-y)z, \qquad x,y,z\in \{{0,1}\}. \end{align}
Hence, with
 $m=0$
,
$m=0$
,
 $D=1$
, and
$D=1$
, and
 $M=D+1=2$
, (5.4) yields
$M=D+1=2$
, (5.4) yields
 \begin{align} \mu _{\mathcal{D}}= \mu _{{\mathcal{D}}{=}} ={\mathbb{E}} g(Y_1,Y_3)={\mathbb{E}} f(X_1,X_2,X_4)=0, \end{align}
\begin{align} \mu _{\mathcal{D}}= \mu _{{\mathcal{D}}{=}} ={\mathbb{E}} g(Y_1,Y_3)={\mathbb{E}} f(X_1,X_2,X_4)=0, \end{align}
while (6.29) yields
 \begin{align} g_1(x,y)&={\mathbb{E}} f(x,y,X_4) ={\mathbb{E}} \bigl [{(x-y)X_4}\bigr ] = \tfrac 12(x-y),\\[-10pt]\nonumber \end{align}
\begin{align} g_1(x,y)&={\mathbb{E}} f(x,y,X_4) ={\mathbb{E}} \bigl [{(x-y)X_4}\bigr ] = \tfrac 12(x-y),\\[-10pt]\nonumber \end{align}
 \begin{align} g_2(x,y)&={\mathbb{E}} f(X_1,X_2,y) ={\mathbb{E}} \bigl [{(X_1-X_2)y}\bigr ] = 0. \end{align}
\begin{align} g_2(x,y)&={\mathbb{E}} f(X_1,X_2,y) ={\mathbb{E}} \bigl [{(X_1-X_2)y}\bigr ] = 0. \end{align}
Thus
 $g_2$
vanishes but not
$g_2$
vanishes but not
 $g_1$
. Nevertheless,
$g_1$
. Nevertheless,
 $g_1(Y_k)=g_1(X_k,X_{k+1})=\frac 12(X_k-X_{k+1})$
is of the type in (8.18)–(8.19) (with
$g_1(Y_k)=g_1(X_k,X_{k+1})=\frac 12(X_k-X_{k+1})$
is of the type in (8.18)–(8.19) (with
 $Z_{1,k}\,:\!=\,-\frac 12X_{k+1}$
). Hence, Theorem 8.2 shows that
$Z_{1,k}\,:\!=\,-\frac 12X_{k+1}$
). Hence, Theorem 8.2 shows that
 $\sigma ^2=0$
, and thus Theorem 3.4 and (3.8) yield
$\sigma ^2=0$
, and thus Theorem 3.4 and (3.8) yield
 $n^{-3/2}U_n(f;\,{{\mathcal{D}}{=}})\overset{p}{\longrightarrow }0$
.
$n^{-3/2}U_n(f;\,{{\mathcal{D}}{=}})\overset{p}{\longrightarrow }0$
.
In fact, in this example we have by (8.23), for
 $n\geqslant 3$
,
$n\geqslant 3$
,
 \begin{align} U_n(f;\,{\mathcal{D}})& =\sum _{j=3}^n\sum _{i=1}^{j-2}(X_i-X_{i+1})X_j =\sum _{j=3}^n X_j(X_1-X_{j-1}) \notag \\& =X_1\sum _{j=3}^n X_j - \sum _{j=3}^n X_{j-1}X_j. \end{align}
\begin{align} U_n(f;\,{\mathcal{D}})& =\sum _{j=3}^n\sum _{i=1}^{j-2}(X_i-X_{i+1})X_j =\sum _{j=3}^n X_j(X_1-X_{j-1}) \notag \\& =X_1\sum _{j=3}^n X_j - \sum _{j=3}^n X_{j-1}X_j. \end{align}
Hence, by the law of large numbers for stationary
 $m$
-dependent sequences,
$m$
-dependent sequences,
 \begin{align} n^{-1} U_n(f;\,{\mathcal{D}}) \overset{a.s.}{\longrightarrow } X_1{\mathbb{E}} X_2 -{\mathbb{E}} \bigl [{X_2X_3}\bigr ] =\tfrac 12 X_1 -\tfrac 14 =\tfrac 12\bigl ({X_1-\tfrac 12}\bigr ). \end{align}
\begin{align} n^{-1} U_n(f;\,{\mathcal{D}}) \overset{a.s.}{\longrightarrow } X_1{\mathbb{E}} X_2 -{\mathbb{E}} \bigl [{X_2X_3}\bigr ] =\tfrac 12 X_1 -\tfrac 14 =\tfrac 12\bigl ({X_1-\tfrac 12}\bigr ). \end{align}
As a consequence,
 $n^{-1} U_n(f;\,{\mathcal{D}})$
has a non-degenerate limiting distribution. Note that this example differs in several respects from the degenerate cases that may occur for standard
$n^{-1} U_n(f;\,{\mathcal{D}})$
has a non-degenerate limiting distribution. Note that this example differs in several respects from the degenerate cases that may occur for standard
 $U$
-statistics, i.e. unconstrained
$U$
-statistics, i.e. unconstrained
 $U$
-statistics based on independent
$U$
-statistics based on independent
 $(X_i)$
. In this example, (8.28) shows that the asymptotic distribution is a linear transformation of a Bernoulli variable, and is thus neither normal, nor of the type that appears as limits of degenerate standard
$(X_i)$
. In this example, (8.28) shows that the asymptotic distribution is a linear transformation of a Bernoulli variable, and is thus neither normal, nor of the type that appears as limits of degenerate standard
 $U$
-statistics. (The latter are polynomials in independent normal variables, in general infinitely many; see e.g. Theorem A.2 and, in general, [Reference Rubin and Vitale56] and [Reference Janson35, Chapter 11].) Moreover, the a.s. convergence to a non-degenerate limit is unheard of for standard
$U$
-statistics. (The latter are polynomials in independent normal variables, in general infinitely many; see e.g. Theorem A.2 and, in general, [Reference Rubin and Vitale56] and [Reference Janson35, Chapter 11].) Moreover, the a.s. convergence to a non-degenerate limit is unheard of for standard
 $U$
-statistics, where the limit is mixing.
$U$
-statistics, where the limit is mixing.
8.1. The degenerate case in renewal theory
In the renewal theory setting in Theorem 3.8, the degenerate case is characterized by a modified version of the conditions above.
Theorem 8.3.
With the assumptions and notation of Theorem 3.8, let
 $g_i$
,
$g_i$
,
 $i\in [b]$
, be as in Theorem 8.2 and Remark 6.2. Then
$i\in [b]$
, be as in Theorem 8.2 and Remark 6.2. Then
 $\gamma ^2=0$
if and only if for every
$\gamma ^2=0$
if and only if for every
 $j\in [b]$
, the function
$j\in [b]$
, the function
 \begin{align} \widetilde{g}_j(y)\,:\!=\,g_j(y)+\mu _{\mathcal{D}}-{\frac{\mu _{\mathcal{D}}}{\nu }}h(y_1), \qquad y=(y_1,\ldots,y_b)\in{\mathcal{S}}^b, \end{align}
\begin{align} \widetilde{g}_j(y)\,:\!=\,g_j(y)+\mu _{\mathcal{D}}-{\frac{\mu _{\mathcal{D}}}{\nu }}h(y_1), \qquad y=(y_1,\ldots,y_b)\in{\mathcal{S}}^b, \end{align}
satisfies the condition (8.18). Moreover, if the sequence
 $(X_i)_1^\infty$
is independent and
$(X_i)_1^\infty$
is independent and
 $\gamma ^2=0$
, then the functions
$\gamma ^2=0$
, then the functions
 $\widetilde{g}_j$
also satisfy (8.19)–(8.20).
$\widetilde{g}_j$
also satisfy (8.19)–(8.20).
The proof is given in Section 12. Note that
 ${\mathbb{E}} \widetilde{g}_j(Y_1)=0$
for each
${\mathbb{E}} \widetilde{g}_j(Y_1)=0$
for each
 $j\in [b]$
by (6.4) and (3.25).
$j\in [b]$
by (6.4) and (3.25).
9. Rate of convergence
Here we use a different method from that used in the rest of the paper.
Proof of Theorem 3.5. We consider
 $U_n(f,{\mathcal{D}})$
; the argument for
$U_n(f,{\mathcal{D}})$
; the argument for
 $U_n(f;\,{{\mathcal{D}}{=}})$
is identical, and
$U_n(f;\,{{\mathcal{D}}{=}})$
is identical, and
 $U_n(f)$
is a special case.
$U_n(f)$
is a special case.
Let
 $\mathcal{I}$
denote the set of all indices
$\mathcal{I}$
denote the set of all indices
 $(i_1,\ldots,i_\ell )$
in the sum (3.2); thus (3.2) can be written
$(i_1,\ldots,i_\ell )$
in the sum (3.2); thus (3.2) can be written
 $U_n(f;\,{\mathcal{D}})=\sum _{I\in{\mathcal{I}}} Z_I$
, where
$U_n(f;\,{\mathcal{D}})=\sum _{I\in{\mathcal{I}}} Z_I$
, where
 $Z_{i_1,\ldots,i_\ell }\,:\!=\,f(X_{i_1},\ldots,X_{i_\ell })$
. Note that the size
$Z_{i_1,\ldots,i_\ell }\,:\!=\,f(X_{i_1},\ldots,X_{i_\ell })$
. Note that the size
 $|{\mathcal{I}}| \sim C n^b$
for some
$|{\mathcal{I}}| \sim C n^b$
for some
 $C\gt 0$
, where
$C\gt 0$
, where
 $b=b({\mathcal{D}})$
.
$b=b({\mathcal{D}})$
.
We define a graph
 $\widehat{\mathcal{I}}$
with vertex set
$\widehat{\mathcal{I}}$
with vertex set
 $\mathcal{I}$
by putting an edge between
$\mathcal{I}$
by putting an edge between
 $I=(i_1,\ldots,i_\ell )$
and
$I=(i_1,\ldots,i_\ell )$
and
 $I^{\prime}=(i^{\prime}_1,\ldots,i^{\prime}_\ell )$
if and only if
$I^{\prime}=(i^{\prime}_1,\ldots,i^{\prime}_\ell )$
if and only if
 $|i_j-i^{\prime}_k|\leqslant m$
for some
$|i_j-i^{\prime}_k|\leqslant m$
for some
 $j,k\in \{{1\ldots,\ell }\}$
. Let
$j,k\in \{{1\ldots,\ell }\}$
. Let
 $\Delta$
be 1 + the maximum degree of the graph
$\Delta$
be 1 + the maximum degree of the graph
 $\widehat{\mathcal{I}}$
; it is easy to see that
$\widehat{\mathcal{I}}$
; it is easy to see that
 $\Delta =O\big(n^{b-1}\big)$
. Moreover, it follows from the
$\Delta =O\big(n^{b-1}\big)$
. Moreover, it follows from the
 $m$
-dependence of
$m$
-dependence of
 $(X_i)$
that
$(X_i)$
that
 $\widehat{\mathcal{I}}$
is a dependency graph for the random variables
$\widehat{\mathcal{I}}$
is a dependency graph for the random variables
 $(Z_I)_I$
, meaning that if
$(Z_I)_I$
, meaning that if
 $A$
and
$A$
and
 $B$
are two disjoint subsets of
$B$
are two disjoint subsets of
 $\mathcal{I}$
such that there is no edge between
$\mathcal{I}$
such that there is no edge between
 $A$
and
$A$
and
 $B$
, then the two random vectors
$B$
, then the two random vectors
 $(Z_I)_{I\in A}$
and
$(Z_I)_{I\in A}$
and
 $(Z_I)_{I\in B}$
are independent.
$(Z_I)_{I\in B}$
are independent.
The result now follows from [Reference Rinott54, Theorem 2.2], which in our notation yields the following bound, with
 $\sigma ^2_n\,:\!=\,{Var}\ U_n \sim \sigma ^2 n^{2b-1}$
and
$\sigma ^2_n\,:\!=\,{Var}\ U_n \sim \sigma ^2 n^{2b-1}$
and
 $B\,:\!=\,2\sup |f|$
, which implies
$B\,:\!=\,2\sup |f|$
, which implies
 $|Z_I-{\mathbb{E}} Z_I|\leqslant B$
a.s. for every
$|Z_I-{\mathbb{E}} Z_I|\leqslant B$
a.s. for every
 $I\in{\mathcal{I}}$
:
$I\in{\mathcal{I}}$
:
 \begin{align} d_K& \leqslant \frac{1}{\sigma _n} \biggl \{{(2\pi )^{-1/2} \Delta B + 16\biggl ({\frac{|{\mathcal{I}}|\Delta }{\sigma ^2_n}}\biggr )^{1/2} \Delta B^2 + 10\biggl ({\frac{|{\mathcal{I}}|\Delta }{\sigma ^2_n}}\biggr ) \Delta B^3}\biggr \} \notag \\& \leqslant C \frac{\Delta }{\sigma _n} \leqslant C n^{-1/2}, \end{align}
\begin{align} d_K& \leqslant \frac{1}{\sigma _n} \biggl \{{(2\pi )^{-1/2} \Delta B + 16\biggl ({\frac{|{\mathcal{I}}|\Delta }{\sigma ^2_n}}\biggr )^{1/2} \Delta B^2 + 10\biggl ({\frac{|{\mathcal{I}}|\Delta }{\sigma ^2_n}}\biggr ) \Delta B^3}\biggr \} \notag \\& \leqslant C \frac{\Delta }{\sigma _n} \leqslant C n^{-1/2}, \end{align}
since
 $|{\mathcal{I}}|\Delta \leqslant C n^{b+b-1}\leqslant C \sigma ^2_n$
and
$|{\mathcal{I}}|\Delta \leqslant C n^{b+b-1}\leqslant C \sigma ^2_n$
and
 $B$
is a constant. (Alternatively, one could use the similar bound in [Reference Fang20, Theorem 2.1].)
$B$
is a constant. (Alternatively, one could use the similar bound in [Reference Fang20, Theorem 2.1].)
Remark 9.1. The assumption in Theorem 3.5 that
 $f$
is bounded can be relaxed to the 6th moment condition (
$f$
is bounded can be relaxed to the 6th moment condition (
 ${A}_{6}$
) by using Theorem 2.1 instead of Theorem 2.2 of [Reference Rinott54], together with Hölder’s inequality and straightforward estimates.
${A}_{6}$
) by using Theorem 2.1 instead of Theorem 2.2 of [Reference Rinott54], together with Hölder’s inequality and straightforward estimates.
The similar bound [Reference Baldi and Rinott2, Corollary 2] gives the weaker estimate
 $d_K=O ({n^{-1/4}} )$
, assuming again that
$d_K=O ({n^{-1/4}} )$
, assuming again that
 $f$
is bounded; this can be relaxed to (
$f$
is bounded; this can be relaxed to (
 ${A}_4$
) by instead using [Reference Baldi and Rinott2, Theorem 1].
${A}_4$
) by instead using [Reference Baldi and Rinott2, Theorem 1].
If, instead of the Kolmogorov distance, we use the Wasserstein distance
 $d_W$
(see e.g. [Reference Chen, Goldstein and Shao14, pp. 63–64] for several equivalent definitions, and for several alternative names), the estimate
$d_W$
(see e.g. [Reference Chen, Goldstein and Shao14, pp. 63–64] for several equivalent definitions, and for several alternative names), the estimate
 $d_W=O ({n^{-1/2}} )$
follows similarly from [Reference Barbour, Karoński and Ruciński3, Theorem 1], assuming only the third moment condition (
$d_W=O ({n^{-1/2}} )$
follows similarly from [Reference Barbour, Karoński and Ruciński3, Theorem 1], assuming only the third moment condition (
 ${A}_3$
); we omit the details. (Actually, [Reference Barbour, Karoński and Ruciński3] does not state the result for the Wasserstein distance but for a weaker version called bounded Wasserstein distance; however, the same proof yields estimates for
${A}_3$
); we omit the details. (Actually, [Reference Barbour, Karoński and Ruciński3] does not state the result for the Wasserstein distance but for a weaker version called bounded Wasserstein distance; however, the same proof yields estimates for
 $d_W$
.) See also [Reference Raič51, Theorem 3 and Remark 3], which yield the same estimate under (
$d_W$
.) See also [Reference Raič51, Theorem 3 and Remark 3], which yield the same estimate under (
 ${A}_3$
), and furthermore imply convergence in distribution assuming only (
${A}_3$
), and furthermore imply convergence in distribution assuming only (
 ${A}_2$
). (This thus yields an alternative proof of Theorems 3.3 and 3.4.)
${A}_2$
). (This thus yields an alternative proof of Theorems 3.3 and 3.4.)
Returning to the Kolmogorov distance, we do not believe that the moment assumption (
 ${A}_{6}$
) in Remark 9.1 is the best possible. For unconstrained and symmetric
${A}_{6}$
) in Remark 9.1 is the best possible. For unconstrained and symmetric
 $U$
-statistics, [Malevich and Abdalimov [Reference Malevich and Abdalimov43], Theorem 2] have shown bounds for the Kolmogorov distance, which in particular show that then (
$U$
-statistics, [Malevich and Abdalimov [Reference Malevich and Abdalimov43], Theorem 2] have shown bounds for the Kolmogorov distance, which in particular show that then (
 ${A}_3$
) is sufficient to yield
${A}_3$
) is sufficient to yield
 $d_K=O ({n^{-1/2}} )$
; we conjecture that the same holds in our, more general, setting.
$d_K=O ({n^{-1/2}} )$
; we conjecture that the same holds in our, more general, setting.
Conjecture 9.1.
Theorem 3.5 holds assuming only (
 ${A}_3$
) (instead of
${A}_3$
) (instead of
 $f$
bounded).
$f$
bounded).
Remark 9.2. If we do not care about the rate of convergence, for bounded
 $f$
we can alternatively obtain convergence in distribution in (3.22), and thus in (3.19) and (3.21), by [Reference Janson34, Theorem 2], using the dependency graph
$f$
we can alternatively obtain convergence in distribution in (3.22), and thus in (3.19) and (3.21), by [Reference Janson34, Theorem 2], using the dependency graph
 $\widehat{\mathcal{I}}$
in the proof of Theorem 3.5. This can easily be extended to any
$\widehat{\mathcal{I}}$
in the proof of Theorem 3.5. This can easily be extended to any
 $f$
satisfying the second moment condition (
$f$
satisfying the second moment condition (
 ${A}_2$
) by a standard truncation argument.
${A}_2$
) by a standard truncation argument.
10. Higher moments and maximal functions
To prove Theorem 3.6, we will show estimates for maximal functions that will also be used in Sections 11 and 12. Let
 $p\geqslant 2$
be fixed throughout the section; explicit and implicit constants may thus depend on
$p\geqslant 2$
be fixed throughout the section; explicit and implicit constants may thus depend on
 $p$
. We let
$p$
. We let
 \begin{align} U_n^*(f)\,:\!=\,\max _{j\leqslant n}|U_j(f)|, \end{align}
\begin{align} U_n^*(f)\,:\!=\,\max _{j\leqslant n}|U_j(f)|, \end{align}
and use similar notation for maximal functions of other sequences of random variables.
We use another decomposition of
 $f$
and
$f$
and
 $U_n(f)$
which was used in [Reference Janson37] for the independent case (
$U_n(f)$
which was used in [Reference Janson37] for the independent case (
 $m=0$
); unlike Hoeffding’s decomposition in Section 6, it focuses on the order of the arguments.
$m=0$
); unlike Hoeffding’s decomposition in Section 6, it focuses on the order of the arguments.
Recall from Section 5 that
 $(\widehat{X}_i)_1^\ell$
are i.i.d. with the same distribution as
$(\widehat{X}_i)_1^\ell$
are i.i.d. with the same distribution as
 $X_1$
. Let
$X_1$
. Let
 $\widehat{F}_0\,:\!=\,\mu$
defined in (5.1) and, for
$\widehat{F}_0\,:\!=\,\mu$
defined in (5.1) and, for
 $1\leqslant k\leqslant \ell$
,
$1\leqslant k\leqslant \ell$
,
 \begin{align} \widehat{F}_k(x_1,\ldots,x_k)&\,:\!=\,{\mathbb{E}} f\bigl ({x_1,\ldots,x_k,\widehat{X}_{k+1},\ldots,\widehat{X}_\ell }\bigr ), \end{align}
\begin{align} \widehat{F}_k(x_1,\ldots,x_k)&\,:\!=\,{\mathbb{E}} f\bigl ({x_1,\ldots,x_k,\widehat{X}_{k+1},\ldots,\widehat{X}_\ell }\bigr ), \end{align}
 \begin{align} F_k(x_1,\ldots,x_k)&\,:\!=\,\widehat{F}_k\bigl ({x_1,\ldots,x_k)\bigr )-\widehat{F}_{k-1}(x_1,\ldots,x_{k-1}} . \end{align}
\begin{align} F_k(x_1,\ldots,x_k)&\,:\!=\,\widehat{F}_k\bigl ({x_1,\ldots,x_k)\bigr )-\widehat{F}_{k-1}(x_1,\ldots,x_{k-1}} . \end{align}
(These are defined at least for
 ${\mathcal{L}}(X_1)$
-a.e.
${\mathcal{L}}(X_1)$
-a.e.
 $x_1,\ldots,x_k\in{\mathcal{S}}$
, which is enough for our purposes.) In other words, a.s.,
$x_1,\ldots,x_k\in{\mathcal{S}}$
, which is enough for our purposes.) In other words, a.s.,
 \begin{align} \widehat{F}_k(\widehat{X}_1,\ldots,\widehat{X}_k) ={\mathbb{E}}\bigl ({f(\widehat{X}_1,\ldots,\widehat{X}_\ell )\mid \widehat{X}_1,\ldots,\widehat{X}_k}\bigr ), \end{align}
\begin{align} \widehat{F}_k(\widehat{X}_1,\ldots,\widehat{X}_k) ={\mathbb{E}}\bigl ({f(\widehat{X}_1,\ldots,\widehat{X}_\ell )\mid \widehat{X}_1,\ldots,\widehat{X}_k}\bigr ), \end{align}
and thus
 $\widehat{F}_k(\widehat{X}_1,\ldots,\widehat{X}_k)$
,
$\widehat{F}_k(\widehat{X}_1,\ldots,\widehat{X}_k)$
,
 $k=0,\ldots,\ell$
, is a martingale, with the martingale differences
$k=0,\ldots,\ell$
, is a martingale, with the martingale differences
 $F_k(\widehat{X}_1,\ldots,\widehat{X}_k)$
,
$F_k(\widehat{X}_1,\ldots,\widehat{X}_k)$
,
 $k=1,\ldots,\ell$
. Hence, or directly from (10.2)–(10.3), for a.e.
$k=1,\ldots,\ell$
. Hence, or directly from (10.2)–(10.3), for a.e.
 $x_1,\ldots,x_{k-1}$
,
$x_1,\ldots,x_{k-1}$
,
 \begin{equation} {\mathbb{E}} F_k(x_1,\ldots,x_{k-1},\widehat{X}_k)=0. \end{equation}
\begin{equation} {\mathbb{E}} F_k(x_1,\ldots,x_{k-1},\widehat{X}_k)=0. \end{equation}
Furthermore, if
 $({A}_p)$
holds, then by (10.4) and Jensen’s inequality,
$({A}_p)$
holds, then by (10.4) and Jensen’s inequality,
 \begin{align} \lVert{\widehat{F}_k(\widehat{X}_1,\ldots,\widehat{X}_k)}\rVert _p \leqslant \lVert{f(\widehat{X}_1,\ldots,\widehat{X}_\ell )}\rVert _p\leqslant C, \end{align}
\begin{align} \lVert{\widehat{F}_k(\widehat{X}_1,\ldots,\widehat{X}_k)}\rVert _p \leqslant \lVert{f(\widehat{X}_1,\ldots,\widehat{X}_\ell )}\rVert _p\leqslant C, \end{align}
and thus by (10.3),
 \begin{align} \lVert{F_k(\widehat{X}_1,\ldots,\widehat{X}_k)}\rVert _p \leqslant 2\lVert{f(\widehat{X}_1,\ldots,\widehat{X}_\ell )}\rVert _p\leqslant C. \end{align}
\begin{align} \lVert{F_k(\widehat{X}_1,\ldots,\widehat{X}_k)}\rVert _p \leqslant 2\lVert{f(\widehat{X}_1,\ldots,\widehat{X}_\ell )}\rVert _p\leqslant C. \end{align}
Lemma 10.1.
Suppose that
 $({A}_p)$
holds for some
$({A}_p)$
holds for some
 $p\geqslant 2$
, and that
$p\geqslant 2$
, and that
 $\mu =0$
. Then
$\mu =0$
. Then
 \begin{align} \bigl \lVert{U^*_n(f;\,\gt m)}\bigr \rVert _p \leqslant C n^{\ell -1/2}. \end{align}
\begin{align} \bigl \lVert{U^*_n(f;\,\gt m)}\bigr \rVert _p \leqslant C n^{\ell -1/2}. \end{align}
Proof. We argue as in [Reference Janson37, Lemmas 4.4 and 4.7] with some minor differences. By (10.2)–(10.3),
 $f(x_1,\ldots,x_\ell ) =\widehat{F}_\ell (x_1,\ldots,x_\ell ) =\sum _{k=1}^\ell F_k(x_1,\ldots,x_k)$
for a.e.
$f(x_1,\ldots,x_\ell ) =\widehat{F}_\ell (x_1,\ldots,x_\ell ) =\sum _{k=1}^\ell F_k(x_1,\ldots,x_k)$
for a.e.
 $x_1,\ldots,x_\ell$
, and thus, a.s.,
$x_1,\ldots,x_\ell$
, and thus, a.s.,
 \begin{equation} \begin{split} U_n(f;\,\gt m) &=\sum _{k=1}^\ell \sum _{\substack{1\leqslant i_1\lt \ldots \lt i_{k}\leqslant n\\i_{j+1}-i_j\gt m}} \binom{n-i_k-(\ell -k)m}{\ell -k} F_k({X_{i_1},\ldots,X_{i_k}}) \\ &=\sum _{k=1}^\ell \sum _{i=1}^n \binom{n-i-(\ell -k)m}{\ell -k}\bigl ({U_i(F_k;\,\gt m)-U_{i-1}(F_k;\,\gt m)}\bigr ) \\ &=U_n(F_\ell ;\,\gt m) +\sum _{k=1}^{\ell -1} \sum _{i=1}^{n-1}\binom{n-i-(\ell -k)m-1}{\ell -k-1}U_i(F_k;\,\gt m), \end{split} \end{equation}
\begin{equation} \begin{split} U_n(f;\,\gt m) &=\sum _{k=1}^\ell \sum _{\substack{1\leqslant i_1\lt \ldots \lt i_{k}\leqslant n\\i_{j+1}-i_j\gt m}} \binom{n-i_k-(\ell -k)m}{\ell -k} F_k({X_{i_1},\ldots,X_{i_k}}) \\ &=\sum _{k=1}^\ell \sum _{i=1}^n \binom{n-i-(\ell -k)m}{\ell -k}\bigl ({U_i(F_k;\,\gt m)-U_{i-1}(F_k;\,\gt m)}\bigr ) \\ &=U_n(F_\ell ;\,\gt m) +\sum _{k=1}^{\ell -1} \sum _{i=1}^{n-1}\binom{n-i-(\ell -k)m-1}{\ell -k-1}U_i(F_k;\,\gt m), \end{split} \end{equation}
using a summation by parts and the identity
 $\binom{n^{\prime}}{\ell -k}-\binom{n^{\prime}-1}{\ell -k}=\binom{n^{\prime}-1}{\ell -k-1}$
. In particular,
$\binom{n^{\prime}}{\ell -k}-\binom{n^{\prime}-1}{\ell -k}=\binom{n^{\prime}-1}{\ell -k-1}$
. In particular,
 \begin{align} |U_n(f;\,\gt m)| &\leqslant |U_n(F_\ell ;\,\gt m)|+\sum _{k=1}^{\ell -1} \sum _{i=1}^{n-1} \binom{n-i-(\ell -k)m-1}{\ell -k-1} U^*_n(F_k;\,\gt m) \notag \\ &= |U_n(F_\ell ;\,\gt m)|+\sum _{k=1}^{\ell -1} \binom{n-(\ell -k)m-1}{\ell -k} U^*_n(F_k;\,\gt m) \notag \\& \leqslant \sum _{k=1}^{\ell } n^{\ell -k} U^*_n(F_k;\,\gt m). \end{align}
\begin{align} |U_n(f;\,\gt m)| &\leqslant |U_n(F_\ell ;\,\gt m)|+\sum _{k=1}^{\ell -1} \sum _{i=1}^{n-1} \binom{n-i-(\ell -k)m-1}{\ell -k-1} U^*_n(F_k;\,\gt m) \notag \\ &= |U_n(F_\ell ;\,\gt m)|+\sum _{k=1}^{\ell -1} \binom{n-(\ell -k)m-1}{\ell -k} U^*_n(F_k;\,\gt m) \notag \\& \leqslant \sum _{k=1}^{\ell } n^{\ell -k} U^*_n(F_k;\,\gt m). \end{align}
Since the right-hand side is weakly increasing in
 $n$
, it follows that, a.s.,
$n$
, it follows that, a.s.,
 \begin{equation} U^*_n(f;\,\gt m) \leqslant \sum _{k=1}^{\ell } n^{\ell -k} U^*_n(F_k;\,\gt m). \end{equation}
\begin{equation} U^*_n(f;\,\gt m) \leqslant \sum _{k=1}^{\ell } n^{\ell -k} U^*_n(F_k;\,\gt m). \end{equation}
We thus may consider each
 $F_k$
separately. Let
$F_k$
separately. Let
 $1\leqslant k\leqslant \ell$
, and let
$1\leqslant k\leqslant \ell$
, and let
 \begin{align} \Delta U_n(F_k;\,\gt m)\,:\!=\,U_n(F_k;\,\gt m)-U_{n-1}(F_k;\,\gt m) . \end{align}
\begin{align} \Delta U_n(F_k;\,\gt m)\,:\!=\,U_n(F_k;\,\gt m)-U_{n-1}(F_k;\,\gt m) . \end{align}
By the definition (4.25),
 $\Delta U_n(F_k;\,\gt m)$
is a sum of
$\Delta U_n(F_k;\,\gt m)$
is a sum of
 $\binom{n-(k-1)m-1}{k-1}\leqslant n^{k-1}$
terms
$\binom{n-(k-1)m-1}{k-1}\leqslant n^{k-1}$
terms
 $F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)$
that all have the same distribution as
$F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)$
that all have the same distribution as
 $F_k({\widehat{X}_1,\ldots,\widehat{X}_k})$
, and thus by Minkowski’s inequality and (10.7),
$F_k({\widehat{X}_1,\ldots,\widehat{X}_k})$
, and thus by Minkowski’s inequality and (10.7),
 \begin{equation} \lVert{\Delta U_n(F_k;\,\gt m)}\rVert _p \leqslant{n}^{k-1}\lVert{F_k(\widehat{X}_1,\ldots,\widehat{X}_k)}\rVert _p \leqslant C{n}^{k-1} . \end{equation}
\begin{equation} \lVert{\Delta U_n(F_k;\,\gt m)}\rVert _p \leqslant{n}^{k-1}\lVert{F_k(\widehat{X}_1,\ldots,\widehat{X}_k)}\rVert _p \leqslant C{n}^{k-1} . \end{equation}
Furthermore, in each such term
 $F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)$
we have
$F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)$
we have
 $i_{k-1}\leqslant n-m-1$
. Hence, if we let
$i_{k-1}\leqslant n-m-1$
. Hence, if we let
 ${\mathcal{F}}_i$
be the
${\mathcal{F}}_i$
be the
 $\sigma$
-field generated by
$\sigma$
-field generated by
 $X_1,\ldots,X_i$
, then, by
$X_1,\ldots,X_i$
, then, by
 $m$
-dependence,
$m$
-dependence,
 $X_n$
is independent of
$X_n$
is independent of
 ${\mathcal{F}}_{i_{k-1}}$
, whence (10.5) implies
${\mathcal{F}}_{i_{k-1}}$
, whence (10.5) implies
 \begin{align}{\mathbb{E}} \bigl ({F_k({X_{i_1},\ldots,X_{i_{k-1}},X_n})\mid{\mathcal{F}}_{n-m-1}}\bigr ) &={\mathbb{E}} \bigl ({F_k({X_{i_1},\ldots,X_{i_{k-1}},X_n})\mid X_{i_1},\ldots,X_{i_{k-1}}}\bigr ) \notag \\&=0. \end{align}
\begin{align}{\mathbb{E}} \bigl ({F_k({X_{i_1},\ldots,X_{i_{k-1}},X_n})\mid{\mathcal{F}}_{n-m-1}}\bigr ) &={\mathbb{E}} \bigl ({F_k({X_{i_1},\ldots,X_{i_{k-1}},X_n})\mid X_{i_1},\ldots,X_{i_{k-1}}}\bigr ) \notag \\&=0. \end{align}
Consequently,
 \begin{align} {\mathbb{E}}\bigl ({\Delta U_n(F_k;\,\gt m)\mid{\mathcal{F}}_{n-m-1}}\bigr )=0. \end{align}
\begin{align} {\mathbb{E}}\bigl ({\Delta U_n(F_k;\,\gt m)\mid{\mathcal{F}}_{n-m-1}}\bigr )=0. \end{align}
In the independent case
 $m=0$
treated in [Reference Janson37], this means that
$m=0$
treated in [Reference Janson37], this means that
 $U_n(F_k)$
is a martingale. In general, we may as a substitute split
$U_n(F_k)$
is a martingale. In general, we may as a substitute split
 $U_n(F_k;\,\gt m)$
as a sum of
$U_n(F_k;\,\gt m)$
as a sum of
 $m+1$
martingales. For
$m+1$
martingales. For
 $j=1,\ldots,m+1$
and
$j=1,\ldots,m+1$
and
 $i\geqslant 1$
, let
$i\geqslant 1$
, let
 \begin{align} \Delta M_i^{(k,j)}&\,:\!=\,\Delta U_{(i-1)(m+1)+j}(F_k;\,\gt m), \end{align}
\begin{align} \Delta M_i^{(k,j)}&\,:\!=\,\Delta U_{(i-1)(m+1)+j}(F_k;\,\gt m), \end{align}
 \begin{align} M_i^{(k,j)} &\,:\!=\,\sum _{q=1}^i\Delta M_q^{(k,j)} =\sum _{q=1}^i\Delta U_{q(m+1)+j}(F_k;\,\gt m) . \end{align}
\begin{align} M_i^{(k,j)} &\,:\!=\,\sum _{q=1}^i\Delta M_q^{(k,j)} =\sum _{q=1}^i\Delta U_{q(m+1)+j}(F_k;\,\gt m) . \end{align}
Then (10.15) implies that
 $(M_i^{(k,j)})_{i\geqslant 0}$
is a martingale, for each
$(M_i^{(k,j)})_{i\geqslant 0}$
is a martingale, for each
 $k$
and
$k$
and
 $j$
. Hence, Burkholder’s inequality [Reference Gut25, Theorem 10.9.5] yields, for the maximal function
$j$
. Hence, Burkholder’s inequality [Reference Gut25, Theorem 10.9.5] yields, for the maximal function
 $M_n^{(k,j)*}$
,
$M_n^{(k,j)*}$
,
 \begin{align} \lVert{M_n^{(k,j)*}}\rVert _p \leqslant C \biggl \lVert{\biggl ({\sum _{i=1}^n \big|\Delta M_i^{(k,j)}\big|^2}\biggr )^{1/2}}\biggr \rVert _p = C \biggl \lVert{{\sum _{i=1}^n \big|\Delta M_i^{(k,j)}\big|^2}}\biggr \rVert _{p/2}^{1/2}. \end{align}
\begin{align} \lVert{M_n^{(k,j)*}}\rVert _p \leqslant C \biggl \lVert{\biggl ({\sum _{i=1}^n \big|\Delta M_i^{(k,j)}\big|^2}\biggr )^{1/2}}\biggr \rVert _p = C \biggl \lVert{{\sum _{i=1}^n \big|\Delta M_i^{(k,j)}\big|^2}}\biggr \rVert _{p/2}^{1/2}. \end{align}
Furthermore, Minkowski’s inequality yields (since
 $p/2\geqslant 1$
), using also (10.16) and (10.13), for
$p/2\geqslant 1$
), using also (10.16) and (10.13), for
 $n\geqslant 1$
,
$n\geqslant 1$
,
 \begin{align} \biggl \lVert{{\sum _{i=1}^n \big|\Delta M_i^{(k,j)}\big|^2}}\biggr \rVert _{p/2} \leqslant \sum _{i=1}^n \Bigl \lVert{\big|\Delta M_i^{(k,j)}\big|^2}\Bigr \rVert _{p/2} = \sum _{i=1}^n \Bigl \lVert{\Delta M_i^{(k,j)}}\Bigr \rVert _{p}^2 \leqslant C n^{1+2(k-1)} . \end{align}
\begin{align} \biggl \lVert{{\sum _{i=1}^n \big|\Delta M_i^{(k,j)}\big|^2}}\biggr \rVert _{p/2} \leqslant \sum _{i=1}^n \Bigl \lVert{\big|\Delta M_i^{(k,j)}\big|^2}\Bigr \rVert _{p/2} = \sum _{i=1}^n \Bigl \lVert{\Delta M_i^{(k,j)}}\Bigr \rVert _{p}^2 \leqslant C n^{1+2(k-1)} . \end{align}
Combining (10.18) and (10.19) yields
 \begin{align} \lVert{M_n^{(k,j)*}}\rVert _p \leqslant C n^{k-1/2} . \end{align}
\begin{align} \lVert{M_n^{(k,j)*}}\rVert _p \leqslant C n^{k-1/2} . \end{align}
It follows from (10.16)–(10.17) that
 \begin{align} U_n(F_k;\,\gt m) =\sum _{j=1}^{m+1} M^{(k,j)}_{\lfloor{(n-j)/(m+1)}\rfloor +1} . \end{align}
\begin{align} U_n(F_k;\,\gt m) =\sum _{j=1}^{m+1} M^{(k,j)}_{\lfloor{(n-j)/(m+1)}\rfloor +1} . \end{align}
Hence (coarsely),
 \begin{align} U^*_n(F_k;\,\gt m) \leqslant \sum _{j=1}^{m+1} M^{(k,j)*}_{n}, \end{align}
\begin{align} U^*_n(F_k;\,\gt m) \leqslant \sum _{j=1}^{m+1} M^{(k,j)*}_{n}, \end{align}
and thus (10.20) and Minkowski’s inequality yield
 \begin{align} \bigl \lVert{U^*_n(F_k;\,\gt m)}\bigr \rVert _p \leqslant C n^{k-1/2}, \end{align}
\begin{align} \bigl \lVert{U^*_n(F_k;\,\gt m)}\bigr \rVert _p \leqslant C n^{k-1/2}, \end{align}
for
 $k=1,\ldots,\ell$
.
$k=1,\ldots,\ell$
.
The result (10.8) now follows from (10.23) and (10.11) by a final application of Minkowski’s inequality.
Theorem 10.1.
Suppose that
 $({A}_p)$
holds for some
$({A}_p)$
holds for some
 $p\geqslant 2$
. Then, with
$p\geqslant 2$
. Then, with
 $b=b({\mathcal{D}})$
,
$b=b({\mathcal{D}})$
,
 \begin{align} \Bigl \lVert{\max _{j\leqslant n}\bigl \lvert{U_j(f;\,{\mathcal{D}})-{\mathbb{E}} U_j(f;\,{\mathcal{D}})}\bigr \rvert }\Bigr \rVert _p &= O\bigl ({n^{b-1/2}}\bigr ), \end{align}
\begin{align} \Bigl \lVert{\max _{j\leqslant n}\bigl \lvert{U_j(f;\,{\mathcal{D}})-{\mathbb{E}} U_j(f;\,{\mathcal{D}})}\bigr \rvert }\Bigr \rVert _p &= O\bigl ({n^{b-1/2}}\bigr ), \end{align}
 \begin{align} \Bigl \lVert{\max _{j\leqslant n}\Bigl \lvert{U_j(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!} j^b }\Bigr \rvert }\Bigr \rVert _p &= O\bigl ({n^{b-1/2}}\bigr ), \end{align}
\begin{align} \Bigl \lVert{\max _{j\leqslant n}\Bigl \lvert{U_j(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!} j^b }\Bigr \rvert }\Bigr \rVert _p &= O\bigl ({n^{b-1/2}}\bigr ), \end{align}
 \begin{align} \bigl \lVert{U^*_n(f;\,{\mathcal{D}})}\bigr \rVert _p& = O\bigl ({n^{b}}\bigr ) . \end{align}
\begin{align} \bigl \lVert{U^*_n(f;\,{\mathcal{D}})}\bigr \rVert _p& = O\bigl ({n^{b}}\bigr ) . \end{align}
The same results hold for an exact constraint
 ${\mathcal{D}}{=}$
.
${\mathcal{D}}{=}$
.
Proof. We use induction on
 $b$
. We split the induction step into three cases.
$b$
. We split the induction step into three cases.
Case 1: no constraint, i.e.,
 ${\mathcal{D}}={\mathcal{D}}_\infty$
and
${\mathcal{D}}={\mathcal{D}}_\infty$
and
 $b=\ell$
By (4.27)–(4.28),
$b=\ell$
By (4.27)–(4.28),
 \begin{align} U_n(f)=U_n(f;\,{\mathcal{D}}_\emptyset )= U_n(f;\,\gt m) -\sum _{J\neq \emptyset }({-}1)^{|J|}U_n(f;\,{\mathcal{D}}_J). \end{align}
\begin{align} U_n(f)=U_n(f;\,{\mathcal{D}}_\emptyset )= U_n(f;\,\gt m) -\sum _{J\neq \emptyset }({-}1)^{|J|}U_n(f;\,{\mathcal{D}}_J). \end{align}
Thus,
 \begin{align} U^*_n(f) \leqslant U^*_n(f;\,\gt m)+\sum _{J\neq \emptyset }U^*_n(f;\,{\mathcal{D}}_J). \end{align}
\begin{align} U^*_n(f) \leqslant U^*_n(f;\,\gt m)+\sum _{J\neq \emptyset }U^*_n(f;\,{\mathcal{D}}_J). \end{align}
Suppose first that
 $\mu =0$
; then Lemma 10.1 applies to
$\mu =0$
; then Lemma 10.1 applies to
 $U^*_n(f;\,\gt m)$
. Furthermore, the induction hypothesis applies to each term in the sum in (10.28), since
$U^*_n(f;\,\gt m)$
. Furthermore, the induction hypothesis applies to each term in the sum in (10.28), since
 $b({\mathcal{D}}_J)=\ell -|J|\leqslant \ell -1=b-1$
. Hence, Minkowski’s inequality yields
$b({\mathcal{D}}_J)=\ell -|J|\leqslant \ell -1=b-1$
. Hence, Minkowski’s inequality yields
 \begin{align} \bigl \lVert{U^*_n(f)}\bigr \rVert _p \leqslant \bigl \lVert{U^*_n(f;\,\gt m)}\bigr \rVert _p+\sum _{J\neq \emptyset }\bigl \lVert{U^*_n(f;\,{\mathcal{D}}_J)}\bigr \rVert _p \leqslant C n^{\ell -1/2}+ C n^{\ell -1} . \end{align}
\begin{align} \bigl \lVert{U^*_n(f)}\bigr \rVert _p \leqslant \bigl \lVert{U^*_n(f;\,\gt m)}\bigr \rVert _p+\sum _{J\neq \emptyset }\bigl \lVert{U^*_n(f;\,{\mathcal{D}}_J)}\bigr \rVert _p \leqslant C n^{\ell -1/2}+ C n^{\ell -1} . \end{align}
When
 $\mu =0$
, (3.7) yields
$\mu =0$
, (3.7) yields
 \begin{align} {\mathbb{E}} U_n(f)=O\bigl ({n^{\ell -1}}\bigr ). \end{align}
\begin{align} {\mathbb{E}} U_n(f)=O\bigl ({n^{\ell -1}}\bigr ). \end{align}
Now (10.24) follows from (10.29) and (10.30), which shows (10.24) when
 $\mu =0$
. The general case follows by considering
$\mu =0$
. The general case follows by considering
 $f-\mu$
; this does not affect
$f-\mu$
; this does not affect
 $U_n(f)-{\mathbb{E}} U_n(f)$
.
$U_n(f)-{\mathbb{E}} U_n(f)$
.
Finally, both (10.25) and (10.26) follow from (10.24) and (3.7).
Case 2: an exact constraint
 ${\mathcal{D}}{=}$
,
${\mathcal{D}}{=}$
,
 $b\lt \ell$
. This is an immediate consequence of (4.9) in Lemma 4.2 and Case 1 applied to
$b\lt \ell$
. This is an immediate consequence of (4.9) in Lemma 4.2 and Case 1 applied to
 $g$
; note that
$g$
; note that
 $g$
too satisfies
$g$
too satisfies
 $({A}_p)$
by (4.19).
$({A}_p)$
by (4.19).
Case 3: a constraint
 $\mathcal{D}$
,
$\mathcal{D}$
,
 $b\lt \ell$
. This is a consequence of Case 2 by (3.4) and (5.5).
$b\lt \ell$
. This is a consequence of Case 2 by (3.4) and (5.5).
Lemma 10.2.
Suppose that
 $({A}_p)$
holds for some
$({A}_p)$
holds for some
 $p\geqslant 2$
. Let
$p\geqslant 2$
. Let
 $b\,:\!=\,b({\mathcal{D}})$
. Then the sequences
$b\,:\!=\,b({\mathcal{D}})$
. Then the sequences
 \begin{align} n^{1/2-b}\max _{j\leqslant n}\bigl \lvert{U_j(f;\,{\mathcal{D}})-{\mathbb{E}} U_j(f;\,{\mathcal{D}})}\bigr \rvert \qquad and \qquad n^{-b}U^*_n(f;\,{\mathcal{D}}) \qquad (n\geqslant 1) \end{align}
\begin{align} n^{1/2-b}\max _{j\leqslant n}\bigl \lvert{U_j(f;\,{\mathcal{D}})-{\mathbb{E}} U_j(f;\,{\mathcal{D}})}\bigr \rvert \qquad and \qquad n^{-b}U^*_n(f;\,{\mathcal{D}}) \qquad (n\geqslant 1) \end{align}
are uniformly
 $p$
th-power integrable.
$p$
th-power integrable.
The same holds for an exact constraint
 ${\mathcal{D}}{=}$
.
${\mathcal{D}}{=}$
.
Proof. We consider the second sequence in (10.31); the proof for the first sequence differs only notationally.
We have so far let
 $f$
be fixed, so the constants above may depend on
$f$
be fixed, so the constants above may depend on
 $f$
. However, it is easy to see that the proof of (10.26) yields
$f$
. However, it is easy to see that the proof of (10.26) yields
 \begin{align} \bigl \lVert{U^*_n(f;\,{\mathcal{D}})}\bigr \rVert _p\leqslant C_p \max _{i_1\lt \ldots \lt i_\ell }\lVert{f(X_{i_1},\ldots,X_{i_\ell })}\rVert _p n^{b}, \end{align}
\begin{align} \bigl \lVert{U^*_n(f;\,{\mathcal{D}})}\bigr \rVert _p\leqslant C_p \max _{i_1\lt \ldots \lt i_\ell }\lVert{f(X_{i_1},\ldots,X_{i_\ell })}\rVert _p n^{b}, \end{align}
with
 $C_p$
independent of
$C_p$
independent of
 $f$
(but depending on
$f$
(but depending on
 $p$
). (Note that we only have to consider a finite set of indices
$p$
). (Note that we only have to consider a finite set of indices
 $(i_1,\ldots,i_\ell )$
, as discussed above (3.6).)
$(i_1,\ldots,i_\ell )$
, as discussed above (3.6).)
Truncate
 $f$
, and for
$f$
, and for
 $B\gt 0$
define
$B\gt 0$
define
 $f_B(\textbf{x})\,:\!=\,f(\textbf{x})\boldsymbol{1}\{{|f(\textbf{x})|\leqslant B}\}$
. Then (10.32) yields
$f_B(\textbf{x})\,:\!=\,f(\textbf{x})\boldsymbol{1}\{{|f(\textbf{x})|\leqslant B}\}$
. Then (10.32) yields
 \begin{align} \bigl \lVert{n^{-b} U^*_n(f-f_B;\,{\mathcal{D}})}\bigr \rVert _p\leqslant C_p \varepsilon (B), \end{align}
\begin{align} \bigl \lVert{n^{-b} U^*_n(f-f_B;\,{\mathcal{D}})}\bigr \rVert _p\leqslant C_p \varepsilon (B), \end{align}
where
 \begin{align} \varepsilon (B)\,:\!=\, \max _{i_1\lt \ldots \lt i_\ell } \lVert{f(X_{i_1},\ldots,X_{i_\ell })\boldsymbol{1}\{{|f(X_{i_1},\ldots,X_{i_\ell })|\gt B}\}}\rVert _p \to 0 \end{align}
\begin{align} \varepsilon (B)\,:\!=\, \max _{i_1\lt \ldots \lt i_\ell } \lVert{f(X_{i_1},\ldots,X_{i_\ell })\boldsymbol{1}\{{|f(X_{i_1},\ldots,X_{i_\ell })|\gt B}\}}\rVert _p \to 0 \end{align}
as
 $B\to \infty$
.
$B\to \infty$
.
Let
 $q\,:\!=\,2p$
. Since
$q\,:\!=\,2p$
. Since
 $f_B$
is bounded, we may apply (10.32) (or Theorem 10.1) with
$f_B$
is bounded, we may apply (10.32) (or Theorem 10.1) with
 $p$
replaced by
$p$
replaced by
 $q$
and obtain
$q$
and obtain
 \begin{align} \sup _n \bigl \lVert{n^{-\ell }U^*_n(f_B;\,{\mathcal{D}})}\bigr \rVert _{2p} \lt \infty . \end{align}
\begin{align} \sup _n \bigl \lVert{n^{-\ell }U^*_n(f_B;\,{\mathcal{D}})}\bigr \rVert _{2p} \lt \infty . \end{align}
Hence, for any
 $B$
, the sequence
$B$
, the sequence
 $n^{-\ell } U^*_n(f_B;\,{\mathcal{D}})$
is uniformly
$n^{-\ell } U^*_n(f_B;\,{\mathcal{D}})$
is uniformly
 $p$
th-power integrable. Since
$p$
th-power integrable. Since
 $ U^*_n(f;\,{\mathcal{D}}) \leqslant U^*_n(f_B;\,{\mathcal{D}})+ U^*_n(f-f_B;\,{\mathcal{D}})$
, the result now follows from the following simple observation.
$ U^*_n(f;\,{\mathcal{D}}) \leqslant U^*_n(f_B;\,{\mathcal{D}})+ U^*_n(f-f_B;\,{\mathcal{D}})$
, the result now follows from the following simple observation.
Lemma 10.3.
Let
 $1\leqslant p\lt \infty$
. Let
$1\leqslant p\lt \infty$
. Let
 $(\xi _n)_{n\geqslant 1}$
be a sequence of random variables. Suppose that for every
$(\xi _n)_{n\geqslant 1}$
be a sequence of random variables. Suppose that for every
 $\varepsilon \gt 0$
, there exist random variables
$\varepsilon \gt 0$
, there exist random variables
 $\eta ^\varepsilon _n$
and
$\eta ^\varepsilon _n$
and
 $\zeta ^\varepsilon _n$
,
$\zeta ^\varepsilon _n$
,
 $n\geqslant 1$
, such that
$n\geqslant 1$
, such that
-
(i)
$|\xi _n|\leqslant \eta ^\varepsilon _n+\zeta ^\varepsilon _n$
, -
(ii) the sequence
$(|\eta ^\varepsilon _n|^p)_n$
is uniformly integrable, and
-
(iii)
$\lVert{\zeta ^\varepsilon _n}\rVert _p\leqslant \varepsilon$
.



Then
 $({|\xi _n|^p})_{n}$
is uniformly integrable.
$({|\xi _n|^p})_{n}$
is uniformly integrable.
Proof. Since (i) implies
 $|\xi _n|^p \leqslant 2^p|\eta ^\varepsilon _n|^p+2^p|\zeta ^\varepsilon _n|^p$
, it suffices (by appropriate substitutions) to consider the case
$|\xi _n|^p \leqslant 2^p|\eta ^\varepsilon _n|^p+2^p|\zeta ^\varepsilon _n|^p$
, it suffices (by appropriate substitutions) to consider the case
 $p=1$
. This is a simple exercise, using for example [Reference Gut25, Theorem 5.4.1].
$p=1$
. This is a simple exercise, using for example [Reference Gut25, Theorem 5.4.1].
11. Functional convergence
We begin by improving (10.8) in a special situation. (We consider only
 $p=2$
.)
$p=2$
.)
Lemma 11.1.
Suppose that (
 ${A}_2$
) holds and that
${A}_2$
) holds and that
 $\mu =0$
and
$\mu =0$
and
 $f_i(X_i)=0$
a.s. for every
$f_i(X_i)=0$
a.s. for every
 $i=1,\ldots,\ell$
. Then
$i=1,\ldots,\ell$
. Then
 \begin{align} \bigl \lVert{U^*_n(f;\,\gt m)}\bigr \rVert _2 \leqslant C n^{\ell -1}. \end{align}
\begin{align} \bigl \lVert{U^*_n(f;\,\gt m)}\bigr \rVert _2 \leqslant C n^{\ell -1}. \end{align}
Proof. Note that (6.6) and (6.10) immediately give this estimate for
 $\lVert{U_n(f;\,\gt m)}\rVert _2$
. To extend it to the maximal function
$\lVert{U_n(f;\,\gt m)}\rVert _2$
. To extend it to the maximal function
 $U_n^*(f;\,\gt m)$
, we reuse the proof of Lemma 10.1 (with
$U_n^*(f;\,\gt m)$
, we reuse the proof of Lemma 10.1 (with
 $p=2$
), and analyze the terms
$p=2$
), and analyze the terms
 $U^*_n(F_k;\,\gt m)$
further. First, by (10.4), (6.2), and the assumptions, for every
$U^*_n(F_k;\,\gt m)$
further. First, by (10.4), (6.2), and the assumptions, for every
 $k\in [\ell ]$
,
$k\in [\ell ]$
,
 \begin{align} {\mathbb{E}}\bigl ({\widehat{F}_k(\widehat{X}_1,\ldots,\widehat{X}_k)\mid \widehat{X}_k}\bigr ) ={\mathbb{E}}\bigl ({f(\widehat{X}_1,\ldots,\widehat{X}_\ell )\mid \widehat{X}_k}\bigr ) =f_k(\widehat{X}_k)+\mu =0 . \end{align}
\begin{align} {\mathbb{E}}\bigl ({\widehat{F}_k(\widehat{X}_1,\ldots,\widehat{X}_k)\mid \widehat{X}_k}\bigr ) ={\mathbb{E}}\bigl ({f(\widehat{X}_1,\ldots,\widehat{X}_\ell )\mid \widehat{X}_k}\bigr ) =f_k(\widehat{X}_k)+\mu =0 . \end{align}
In particular, for
 $k=1$
, (11.2) yields
$k=1$
, (11.2) yields
 $\widehat{F}_1(\widehat{X}_1)=0$
a.s., and thus
$\widehat{F}_1(\widehat{X}_1)=0$
a.s., and thus
 \begin{align} U^*_n(F_1;\,\gt m)=0 \quad \text{a.s.} \end{align}
\begin{align} U^*_n(F_1;\,\gt m)=0 \quad \text{a.s.} \end{align}
For
 $k\geqslant 2$
, as stated in the proof of Lemma 10.1,
$k\geqslant 2$
, as stated in the proof of Lemma 10.1,
 $\Delta U_n(F_k;\,\gt m)$
is a sum of
$\Delta U_n(F_k;\,\gt m)$
is a sum of
 $\leqslant n^{k-1}$
terms
$\leqslant n^{k-1}$
terms
 $F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)$
. Consider two such terms
$F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)$
. Consider two such terms
 $F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)$
and
$F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)$
and
 $F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big)$
, and suppose that
$F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big)$
, and suppose that
 $|i_j-i^{\prime}_{j^{\prime}}|\gt m$
for all
$|i_j-i^{\prime}_{j^{\prime}}|\gt m$
for all
 $j,j^{\prime}\in [k-1]$
. Then all variables
$j,j^{\prime}\in [k-1]$
. Then all variables
 $X_{i_j}, X_{i^{\prime}_{j^{\prime}}}$
, and
$X_{i_j}, X_{i^{\prime}_{j^{\prime}}}$
, and
 $X_n$
are independent, and thus a.s.
$X_n$
are independent, and thus a.s.
 \begin{align} &{\mathbb{E}}\bigl [{F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big) \mid X_n}\bigr ] \notag \\&\quad ={\mathbb{E}}\bigl [{F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)\mid X_n}\bigr ]{\mathbb{E}}\bigl [{F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big)\mid X_n}\bigr ] =0, \end{align}
\begin{align} &{\mathbb{E}}\bigl [{F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big) \mid X_n}\bigr ] \notag \\&\quad ={\mathbb{E}}\bigl [{F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)\mid X_n}\bigr ]{\mathbb{E}}\bigl [{F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big)\mid X_n}\bigr ] =0, \end{align}
by (11.2). Hence, taking the expectation,
 \begin{align} &{\mathbb{E}}\Bigl [{F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big)}\Bigr ] =0, \end{align}
\begin{align} &{\mathbb{E}}\Bigl [{F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big)}\Bigr ] =0, \end{align}
unless
 $|i_j-i^{\prime}_{j^{\prime}}|\leqslant m$
for some pair
$|i_j-i^{\prime}_{j^{\prime}}|\leqslant m$
for some pair
 $(j,j^{\prime})$
. For each
$(j,j^{\prime})$
. For each
 $(i_1,\ldots,i_{k-1})$
, there are only
$(i_1,\ldots,i_{k-1})$
, there are only
 $O(n^{k-2})$
such
$O(n^{k-2})$
such
 $(i^{\prime}_1,\ldots,i^{\prime}_{k-1})$
, and for each of these, the expectation in (11.5) is
$(i^{\prime}_1,\ldots,i^{\prime}_{k-1})$
, and for each of these, the expectation in (11.5) is
 $O(1)$
by (
$O(1)$
by (
 ${A}_2$
) and the Cauchy–Schwarz inequality. Consequently, summing over all appearing
${A}_2$
) and the Cauchy–Schwarz inequality. Consequently, summing over all appearing
 $(i_1,\ldots,i_{k-1})$
and
$(i_1,\ldots,i_{k-1})$
and
 $(i^{\prime}_1,\ldots,i^{\prime}_{k-1})$
,
$(i^{\prime}_1,\ldots,i^{\prime}_{k-1})$
,
 \begin{align} {\mathbb{E}} \bigl [{\bigl \lvert{\Delta U_n(F_k;\,\gt m)}\bigr \rvert ^2}\bigr ]& =\sum _{i_1,\ldots,i_{k-1},i^{\prime}_1,\ldots,i^{\prime}_{k-1}}{\mathbb{E}}\bigl [{F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big)}\bigr ] \notag \\& = O\bigl ({n^{k-1}\cdot n^{k-2}}\bigr )=O\bigl ({n^{2k-3}}\bigr ). \end{align}
\begin{align} {\mathbb{E}} \bigl [{\bigl \lvert{\Delta U_n(F_k;\,\gt m)}\bigr \rvert ^2}\bigr ]& =\sum _{i_1,\ldots,i_{k-1},i^{\prime}_1,\ldots,i^{\prime}_{k-1}}{\mathbb{E}}\bigl [{F_k\big(X_{i_1},\ldots,X_{i_{k-1}},X_n\big)F_k\big(X_{i^{\prime}_1},\ldots,X_{i^{\prime}_{k-1}},X_n\big)}\bigr ] \notag \\& = O\bigl ({n^{k-1}\cdot n^{k-2}}\bigr )=O\bigl ({n^{2k-3}}\bigr ). \end{align}
We have gained a factor of
 $n$
compared to (10.13). Hence, recalling (10.16) and using (11.6) in (10.18)–(10.19) (which for
$n$
compared to (10.13). Hence, recalling (10.16) and using (11.6) in (10.18)–(10.19) (which for
 $p=2$
is essentially Doob’s inequality), we improve (10.20) to
$p=2$
is essentially Doob’s inequality), we improve (10.20) to
 \begin{align} \lVert{M_n^{(k,j)*}}\rVert _2 \leqslant C n^{k-1} . \end{align}
\begin{align} \lVert{M_n^{(k,j)*}}\rVert _2 \leqslant C n^{k-1} . \end{align}
Finally, (11.7) and (10.22) yield
 \begin{align} \bigl \lVert{U^*_n(F_k;\,\gt m)}\bigr \rVert _2 \leqslant C n^{k-1}, \end{align}
\begin{align} \bigl \lVert{U^*_n(F_k;\,\gt m)}\bigr \rVert _2 \leqslant C n^{k-1}, \end{align}
for
 $2\leqslant k\leqslant \ell$
; this holds trivially for
$2\leqslant k\leqslant \ell$
; this holds trivially for
 $k=1$
too by (11.3). The result follows by (10.11) and (11.8).
$k=1$
too by (11.3). The result follows by (10.11) and (11.8).
Proof of Theorem 3.7. We prove (3.23); then (3.24) follows by (3.8). By replacing
 $f$
by
$f$
by
 $f-\mu$
, we may assume that
$f-\mu$
, we may assume that
 $\mu =0$
.
$\mu =0$
.
Consider first the unconstrained case. We argue as in [Reference Janson37], with minor modifications. We use (6.6), which we write as follows (cf. (6.11)):
 \begin{align} U_n({f;\,\gt m})= \sum _{j=1}^\ell \sum _{i=1}^n a_{j,i,n} f_j(X_i)+ U_n(f_*;\,\gt m), \end{align}
\begin{align} U_n({f;\,\gt m})= \sum _{j=1}^\ell \sum _{i=1}^n a_{j,i,n} f_j(X_i)+ U_n(f_*;\,\gt m), \end{align}
with, as in (6.12),
 \begin{align} a_{j,i,n} \,:\!=\,\binom{i-1-(j-1)m}{j-1}\binom{n-i-(\ell -j)m}{\ell -j}. \end{align}
\begin{align} a_{j,i,n} \,:\!=\,\binom{i-1-(j-1)m}{j-1}\binom{n-i-(\ell -j)m}{\ell -j}. \end{align}
Lemma 11.1 applies to
 $f_*$
and shows that
$f_*$
and shows that
 \begin{align} \lVert{U^*_n(f_*;\,\gt m)}\rVert _2=O\bigl ({n^{\ell -1}}\bigr )=o\bigl ({n^{\ell -1/2}}\bigr ), \end{align}
\begin{align} \lVert{U^*_n(f_*;\,\gt m)}\rVert _2=O\bigl ({n^{\ell -1}}\bigr )=o\bigl ({n^{\ell -1/2}}\bigr ), \end{align}
which implies that the last term in (11.9) is negligible, so we concentrate on the sum. Define
 $\Delta a_{j,i,n} \,:\!=\,a_{j,{i+1},n}- a_{j,i,n}$
and, using a summation by parts,
$\Delta a_{j,i,n} \,:\!=\,a_{j,{i+1},n}- a_{j,i,n}$
and, using a summation by parts,
 \begin{align} \widehat U_{n,j}\,:\!=\,\sum _{i=1}^n a_{j,i,n} f_j(X_i) =a_{j,{n},n}S_n(f_j) -\sum _{i=1}^{n-1}\Delta a_{j,i,n} S_i(f_j). \end{align}
\begin{align} \widehat U_{n,j}\,:\!=\,\sum _{i=1}^n a_{j,i,n} f_j(X_i) =a_{j,{n},n}S_n(f_j) -\sum _{i=1}^{n-1}\Delta a_{j,i,n} S_i(f_j). \end{align}
Donsker’s theorem extends to
 $m$
-dependent stationary sequences [Reference Billingsley5], and thus, as
$m$
-dependent stationary sequences [Reference Billingsley5], and thus, as
 $n\to \infty$
,
$n\to \infty$
,
 \begin{align} n^{-1/2} S_{\lfloor{nt}\rfloor }(f_j)\overset{d}{\longrightarrow } W_j(t) \qquad \text{in $D[0,\infty )$}, \end{align}
\begin{align} n^{-1/2} S_{\lfloor{nt}\rfloor }(f_j)\overset{d}{\longrightarrow } W_j(t) \qquad \text{in $D[0,\infty )$}, \end{align}
for a continuous centered Gaussian process
 $W_j$
(a suitable multiple of Brownian motion); furthermore, as is easily seen, this holds jointly for
$W_j$
(a suitable multiple of Brownian motion); furthermore, as is easily seen, this holds jointly for
 $j=1,\ldots,\ell$
. Moreover, define
$j=1,\ldots,\ell$
. Moreover, define
 \begin{equation} \psi _j(s,t)\,:\!=\,\frac{1}{(j-1)!\,(\ell -j)!}s^{j-1}(t-s)^{\ell -j}. \end{equation}
\begin{equation} \psi _j(s,t)\,:\!=\,\frac{1}{(j-1)!\,(\ell -j)!}s^{j-1}(t-s)^{\ell -j}. \end{equation}
(Thus
 $\psi (s,1)=\psi (s)$
defined in (6.13); the present homogeneous version is more convenient here.) Let
$\psi (s,1)=\psi (s)$
defined in (6.13); the present homogeneous version is more convenient here.) Let
 $\psi ^{\prime}_j(s,t)\,:\!=\,\frac{\partial }{\partial s}\psi (s,t)$
. Then straightforward calculations (as in [Reference Janson37, Lemma 4.2]) show that, extending (6.12),
$\psi ^{\prime}_j(s,t)\,:\!=\,\frac{\partial }{\partial s}\psi (s,t)$
. Then straightforward calculations (as in [Reference Janson37, Lemma 4.2]) show that, extending (6.12),
 \begin{align} a_{j,i,n} &=\psi _j(i,n)+O(n^{\ell -2}), \end{align}
\begin{align} a_{j,i,n} &=\psi _j(i,n)+O(n^{\ell -2}), \end{align}
 \begin{align} \Delta a_{j,i,n} &=\psi ^{\prime}_j(i,n) +O\bigl ({n^{\ell -3}+ n^{\ell -2}\boldsymbol{1}\{{i\leqslant m \text{ or }i\geqslant n-m}\}}\bigr ) \end{align}
\begin{align} \Delta a_{j,i,n} &=\psi ^{\prime}_j(i,n) +O\bigl ({n^{\ell -3}+ n^{\ell -2}\boldsymbol{1}\{{i\leqslant m \text{ or }i\geqslant n-m}\}}\bigr ) \end{align}
uniformly for all
 $n,j,i$
that are relevant; moreover, the error terms with negative powers, i.e.,
$n,j,i$
that are relevant; moreover, the error terms with negative powers, i.e.,
 $n^{\ell -2}$
for
$n^{\ell -2}$
for
 $\ell =1$
and
$\ell =1$
and
 $n^{\ell -3}$
for
$n^{\ell -3}$
for
 $\ell \leqslant 2$
, vanish.
$\ell \leqslant 2$
, vanish.
By the Skorokhod coupling theorem [Reference Kallenberg41, Theorem 4.30], we may assume that the convergences (11.13) hold a.s., and similarly (see (11.11)), a.s.
 \begin{align} n^{1/2-\ell }U^*_n(f_*;\,\gt m)\to 0. \end{align}
\begin{align} n^{1/2-\ell }U^*_n(f_*;\,\gt m)\to 0. \end{align}
It then follows from (11.12)–(11.16) and the homogeneity of
 $\psi _j$
that a.s., uniformly for
$\psi _j$
that a.s., uniformly for
 $t\in [0,T]$
for any fixed
$t\in [0,T]$
for any fixed
 $T$
,
$T$
,
 \begin{align} n^{1/2-\ell }\widehat{U}_{\lfloor{nt}\rfloor,j}& =n^{1-\ell }\psi _j(\lfloor{nt}\rfloor,\lfloor{nt}\rfloor ) W_j(t) -\sum _{i=1}^{\lfloor{nt}\rfloor -1}n^{1-\ell }\psi ^{\prime}_j(i,\lfloor{nt}\rfloor )W_j(i/n) +o(1) \notag \\& =\psi _j(t,t) W_j(t) -\frac{1}{n}\sum _{i=1}^{\lfloor{nt}\rfloor -1}\psi ^{\prime}_j(i/n,t)W_j(i/n) +o(1) \notag \\& =\psi _j(t,t) W_j(t) -\int _0^t\psi ^{\prime}_j(s,t)W_j(s)\,{d} s +o(1) . \end{align}
\begin{align} n^{1/2-\ell }\widehat{U}_{\lfloor{nt}\rfloor,j}& =n^{1-\ell }\psi _j(\lfloor{nt}\rfloor,\lfloor{nt}\rfloor ) W_j(t) -\sum _{i=1}^{\lfloor{nt}\rfloor -1}n^{1-\ell }\psi ^{\prime}_j(i,\lfloor{nt}\rfloor )W_j(i/n) +o(1) \notag \\& =\psi _j(t,t) W_j(t) -\frac{1}{n}\sum _{i=1}^{\lfloor{nt}\rfloor -1}\psi ^{\prime}_j(i/n,t)W_j(i/n) +o(1) \notag \\& =\psi _j(t,t) W_j(t) -\int _0^t\psi ^{\prime}_j(s,t)W_j(s)\,{d} s +o(1) . \end{align}
Summing over
 $j\in [\ell ]$
, we obtain by (11.9), (11.12), (11.18), and (11.17), a.s. uniformly for
$j\in [\ell ]$
, we obtain by (11.9), (11.12), (11.18), and (11.17), a.s. uniformly for
 $t\in [0,T]$
for any
$t\in [0,T]$
for any
 $T$
,
$T$
,
 \begin{align} n^{1/2-\ell }U_{\lfloor{nt}\rfloor }(f;\,\gt m)& =Z(t) +o(1), \end{align}
\begin{align} n^{1/2-\ell }U_{\lfloor{nt}\rfloor }(f;\,\gt m)& =Z(t) +o(1), \end{align}
where
 \begin{align} Z(t)\,:\!=\,\sum _{j=1}^\ell \Bigl ({\psi _j(t,t) W_j(t) -\int _0^t\psi ^{\prime}_j(s,t)W_j(s)\,{d} s}\Bigr ), \end{align}
\begin{align} Z(t)\,:\!=\,\sum _{j=1}^\ell \Bigl ({\psi _j(t,t) W_j(t) -\int _0^t\psi ^{\prime}_j(s,t)W_j(s)\,{d} s}\Bigr ), \end{align}
which obviously is a centered Gaussian process. We can rewrite (11.19) as
 \begin{align} n^{1/2-\ell }U_{\lfloor{nt}\rfloor }(f;\,\gt m)\to Z(t) \qquad \text{in $D[0,\infty )$} . \end{align}
\begin{align} n^{1/2-\ell }U_{\lfloor{nt}\rfloor }(f;\,\gt m)\to Z(t) \qquad \text{in $D[0,\infty )$} . \end{align}
Finally we use (10.27), which implies
 \begin{align} \max _{k\leqslant n} \bigl \lvert{U_k(f)-U_k(f;\,\gt m)}\bigr \rvert \leqslant \sum _{J\neq \emptyset } U^*_n(f;\,{\mathcal{D}}_J), \end{align}
\begin{align} \max _{k\leqslant n} \bigl \lvert{U_k(f)-U_k(f;\,\gt m)}\bigr \rvert \leqslant \sum _{J\neq \emptyset } U^*_n(f;\,{\mathcal{D}}_J), \end{align}
and thus, by Theorem 10.1, recalling
 $b({\mathcal{D}}_J)=\ell -|J|\leqslant \ell -1$
,
$b({\mathcal{D}}_J)=\ell -|J|\leqslant \ell -1$
,
 \begin{align} \bigl \lVert{\max _{k\leqslant n} \bigl \lvert{U_k(f)-U_k(f;\,\gt m)}\bigr \rvert }\bigr \rVert _2& \leqslant \sum _{J\neq \emptyset } \bigl \lVert{U^*_n(f;\,{\mathcal{D}}_J)}\bigr \rVert _2 \leqslant \sum _{J\neq \emptyset } C n^{b({\mathcal{D}}_J)} \leqslant C n^{\ell -1}. \end{align}
\begin{align} \bigl \lVert{\max _{k\leqslant n} \bigl \lvert{U_k(f)-U_k(f;\,\gt m)}\bigr \rvert }\bigr \rVert _2& \leqslant \sum _{J\neq \emptyset } \bigl \lVert{U^*_n(f;\,{\mathcal{D}}_J)}\bigr \rVert _2 \leqslant \sum _{J\neq \emptyset } C n^{b({\mathcal{D}}_J)} \leqslant C n^{\ell -1}. \end{align}
It follows that, in each
 $D[0,T]$
and thus in
$D[0,T]$
and thus in
 $D[0,\infty )$
,
$D[0,\infty )$
,
 \begin{align} n^{1/2-\ell }\bigl ({ U_{\lfloor{nt}\rfloor }(f)-U_{\lfloor{nt}\rfloor }(f;\,\gt m)}\bigr ) \overset{p}{\longrightarrow } 0. \end{align}
\begin{align} n^{1/2-\ell }\bigl ({ U_{\lfloor{nt}\rfloor }(f)-U_{\lfloor{nt}\rfloor }(f;\,\gt m)}\bigr ) \overset{p}{\longrightarrow } 0. \end{align}
Furthermore, recalling the assumption
 $\mu =0$
,
$\mu =0$
,
 ${\mathbb{E}} U_n(f)=O ({n^{\ell -1}} )$
by (3.7), and thus
${\mathbb{E}} U_n(f)=O ({n^{\ell -1}} )$
by (3.7), and thus
 \begin{align} n^{1/2-\ell }{\mathbb{E}} U_{\lfloor{nt}\rfloor }(f)\to 0 \qquad \text{in ${\mathcal{D}}[0,\infty )$}. \end{align}
\begin{align} n^{1/2-\ell }{\mathbb{E}} U_{\lfloor{nt}\rfloor }(f)\to 0 \qquad \text{in ${\mathcal{D}}[0,\infty )$}. \end{align}
The result (3.23) in the unconstrained case follows from (11.21), (11.24), and (11.25).
Joint convergence for several
 $f$
(in the unconstrained case) follows by the same proof.
$f$
(in the unconstrained case) follows by the same proof.
Finally, as usual, the exactly constrained case follows by (4.9) in Lemma 4.2 and the constrained case then follows by (3.4), using joint convergence for all
 $g_{{{\mathcal{D}}^{\prime}{=}}}$
, with notation as in (3.4) and Lemma 4.2. To obtain joint convergence for several
$g_{{{\mathcal{D}}^{\prime}{=}}}$
, with notation as in (3.4) and Lemma 4.2. To obtain joint convergence for several
 $f$
and
$f$
and
 $\mathcal{D}$
, we only have to choose
$\mathcal{D}$
, we only have to choose
 $M$
in (4.8) large enough to work for all of them.
$M$
in (4.8) large enough to work for all of them.
12. Renewal theory
Note first that by the law of large numbers for
 $m$
-dependent sequences,
$m$
-dependent sequences,
 \begin{align} S_n/n=S_n(h)/n\overset{a.s.}{\longrightarrow }{\mathbb{E}} h(X_1)=\nu \qquad \text{as}\quad {n \to \infty}. \end{align}
\begin{align} S_n/n=S_n(h)/n\overset{a.s.}{\longrightarrow }{\mathbb{E}} h(X_1)=\nu \qquad \text{as}\quad {n \to \infty}. \end{align}
As a simple consequence, we have the following (the case
 $N_+$
is in [Reference Janson33, Theorems 2.1 and 2.2]), which extends the well-known case of independent
$N_+$
is in [Reference Janson33, Theorems 2.1 and 2.2]), which extends the well-known case of independent
 $X_i$
; see e.g. [Reference Gut24, Sections 3.4 and 3.10].
$X_i$
; see e.g. [Reference Gut24, Sections 3.4 and 3.10].
Lemma 12.1.
Assume that
 $\nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0$
and that
$\nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0$
and that
 ${\mathbb{E}} |h(X_1)|^2\lt \infty$
. As
${\mathbb{E}} |h(X_1)|^2\lt \infty$
. As
 $x\to \infty$
,
$x\to \infty$
,
 \begin{align} N_\pm (x)/x&\overset{a.s.}{\longrightarrow } 1/\nu, \end{align}
\begin{align} N_\pm (x)/x&\overset{a.s.}{\longrightarrow } 1/\nu, \end{align}
 \begin{align} S_{N_\pm (x)}(h) &= x + o_{p}\bigl ({x^{1/2}}\bigr ). \end{align}
\begin{align} S_{N_\pm (x)}(h) &= x + o_{p}\bigl ({x^{1/2}}\bigr ). \end{align}
Proof. Note that, by the definitions (3.27)–(3.28),
 \begin{align} S_{N_-(x)}(h)\leqslant x \lt S_{N_-(x)+1} (h) \qquad \text{and}\qquad S_{N_+(x)-1}(h)\leqslant x \lt S_{N_+(x)}(h). \end{align}
\begin{align} S_{N_-(x)}(h)\leqslant x \lt S_{N_-(x)+1} (h) \qquad \text{and}\qquad S_{N_+(x)-1}(h)\leqslant x \lt S_{N_+(x)}(h). \end{align}
Then (12.2) follows easily from (12.1). Furthermore, for any
 $\varepsilon \gt 0$
,
$\varepsilon \gt 0$
,
 \begin{align} \mathbb{P}\Bigl [{\max _{0\leqslant N \lt 2x/\nu }|S_{N+1}(h)-S_N(h)|\gt \varepsilon x^{1/2}}\Bigr ] \leqslant \lceil{2x/\nu }\rceil \mathbb{P}\bigl [{|h(X_1)|\gt \varepsilon x^{1/2}}\bigr ] \to 0 \end{align}
\begin{align} \mathbb{P}\Bigl [{\max _{0\leqslant N \lt 2x/\nu }|S_{N+1}(h)-S_N(h)|\gt \varepsilon x^{1/2}}\Bigr ] \leqslant \lceil{2x/\nu }\rceil \mathbb{P}\bigl [{|h(X_1)|\gt \varepsilon x^{1/2}}\bigr ] \to 0 \end{align}
as
 $x\to \infty$
, and (12.3) follows from (12.4), (12.5), and (12.2). We omit the standard details.
$x\to \infty$
, and (12.3) follows from (12.4), (12.5), and (12.2). We omit the standard details.
Moreover, still assuming
 ${\mathbb{E}} |h(X_1)|^2\lt \infty$
, Donsker’s theorem for
${\mathbb{E}} |h(X_1)|^2\lt \infty$
, Donsker’s theorem for
 $m$
-dependent sequences [Reference Billingsley5] yields, as in (11.13),
$m$
-dependent sequences [Reference Billingsley5] yields, as in (11.13),
 \begin{align} n^{-1/2}{S_{\lfloor{nt}\rfloor }(h-\nu )} = n^{-1/2} \bigl ({S_{\lfloor{nt}\rfloor }(h)- \lfloor{nt}\rfloor \nu }\bigr )\overset{d}{\longrightarrow } W_h(t) \qquad \text{in $D[0,\infty )$} \end{align}
\begin{align} n^{-1/2}{S_{\lfloor{nt}\rfloor }(h-\nu )} = n^{-1/2} \bigl ({S_{\lfloor{nt}\rfloor }(h)- \lfloor{nt}\rfloor \nu }\bigr )\overset{d}{\longrightarrow } W_h(t) \qquad \text{in $D[0,\infty )$} \end{align}
for a continuous centered Gaussian process
 $W_h(t)$
.
$W_h(t)$
.
Proof of Theorem 3.8. Note that (12.6) is the special (unconstrained) case
 $f=h$
,
$f=h$
,
 ${\mathcal{D}}=()$
,
${\mathcal{D}}=()$
,
 $\ell =b=1$
of (3.23). By joint convergence in Theorem 3.7 for
$\ell =b=1$
of (3.23). By joint convergence in Theorem 3.7 for
 $(f,{\mathcal{D}})$
and
$(f,{\mathcal{D}})$
and
 $h$
, we thus have (3.24) jointly with (12.6). We use again the Skorokhod coupling theorem and assume that (3.24), (12.6), and (12.3), as well as (12.2), hold a.s.
$h$
, we thus have (3.24) jointly with (12.6). We use again the Skorokhod coupling theorem and assume that (3.24), (12.6), and (12.3), as well as (12.2), hold a.s.
Take
 $n\,:\!=\,\lceil{x}\rceil$
and
$n\,:\!=\,\lceil{x}\rceil$
and
 $t\,:\!=\,N_\pm (x)/n$
, and let
$t\,:\!=\,N_\pm (x)/n$
, and let
 $x\to \infty$
. Then
$x\to \infty$
. Then
 $t\to 1/\nu$
a.s. by (12.2), and thus (3.24) implies, a.s.,
$t\to 1/\nu$
a.s. by (12.2), and thus (3.24) implies, a.s.,
 \begin{align} U_{N_\pm (x)}(f;\,{\mathcal{D}})& =\frac{\mu _{\mathcal{D}}}{b!}{N_{\pm }(x)}^b+Z(\nu ^{-1}) n^{b-1/2}+o\bigl ({n^{b-1/2}}\bigr ) \notag \\& =\frac{\mu _{\mathcal{D}}}{b!}{N_{\pm }(x)}^b+Z(\nu ^{-1}) x^{b-1/2}+o\bigl ({x^{b-1/2}}\bigr ) . \end{align}
\begin{align} U_{N_\pm (x)}(f;\,{\mathcal{D}})& =\frac{\mu _{\mathcal{D}}}{b!}{N_{\pm }(x)}^b+Z(\nu ^{-1}) n^{b-1/2}+o\bigl ({n^{b-1/2}}\bigr ) \notag \\& =\frac{\mu _{\mathcal{D}}}{b!}{N_{\pm }(x)}^b+Z(\nu ^{-1}) x^{b-1/2}+o\bigl ({x^{b-1/2}}\bigr ) . \end{align}
Similarly, (12.6) implies, a.s.,
 \begin{align} S_{N_\pm (x)}(h)={N_{\pm }(x)}\nu +W_h(\nu ^{-1}) x^{1/2}+o\bigl ({x^{1/2}}\bigr ). \end{align}
\begin{align} S_{N_\pm (x)}(h)={N_{\pm }(x)}\nu +W_h(\nu ^{-1}) x^{1/2}+o\bigl ({x^{1/2}}\bigr ). \end{align}
By (12.8) and (12.3), we have a.s.
 \begin{align} \nu{N_{\pm }(x)} = S_{N_\pm (x)}(h)-W_h(\nu ^{-1}) x^{1/2}+o\bigl ({x^{1/2}}\bigr ) = x-W_h(\nu ^{-1}) x^{1/2}+o\bigl ({x^{1/2}}\bigr ). \end{align}
\begin{align} \nu{N_{\pm }(x)} = S_{N_\pm (x)}(h)-W_h(\nu ^{-1}) x^{1/2}+o\bigl ({x^{1/2}}\bigr ) = x-W_h(\nu ^{-1}) x^{1/2}+o\bigl ({x^{1/2}}\bigr ). \end{align}
Thus, by the binomial theorem, a.s.,
 \begin{align} (\nu{N_{\pm }(x)})^b = x^b-b W_h(\nu ^{-1}) x^{b-1/2}+o\bigl ({x^{b-1/2}}\bigr ). \end{align}
\begin{align} (\nu{N_{\pm }(x)})^b = x^b-b W_h(\nu ^{-1}) x^{b-1/2}+o\bigl ({x^{b-1/2}}\bigr ). \end{align}
Hence, (12.7) yields, a.s.,
 \begin{align} U_{N_\pm (x)}(f;\,{\mathcal{D}}) =\frac{\mu _{\mathcal{D}}}{\nu ^b b!}\bigl ({x^b-b W_h(\nu ^{-1})x^{b-1/2}}\bigr ) +Z(\nu ^{-1}) x^{b-1/2}+o\bigl ({x^{b-1/2}}\bigr ), \end{align}
\begin{align} U_{N_\pm (x)}(f;\,{\mathcal{D}}) =\frac{\mu _{\mathcal{D}}}{\nu ^b b!}\bigl ({x^b-b W_h(\nu ^{-1})x^{b-1/2}}\bigr ) +Z(\nu ^{-1}) x^{b-1/2}+o\bigl ({x^{b-1/2}}\bigr ), \end{align}
which yields (3.29) with
 \begin{align} \gamma ^2={Var}\Bigl [{Z(\nu ^{-1})-\frac{\mu _{\mathcal{D}}}{\nu ^b(b-1)!}W_h(\nu ^{-1})}\Bigr ]. \end{align}
\begin{align} \gamma ^2={Var}\Bigl [{Z(\nu ^{-1})-\frac{\mu _{\mathcal{D}}}{\nu ^b(b-1)!}W_h(\nu ^{-1})}\Bigr ]. \end{align}
The exactly constrained case and joint convergence follow similarly.
Proof of Theorem 8.3. We may as in the proof of Theorem 3.8 assume that (3.24), (12.6), and (12.10) hold a.s. Recall that the proofs above use the decomposition (3.4) and Lemma 4.2 applied to every
 ${\mathcal{D}}^{\prime}{=}$
there, with
${\mathcal{D}}^{\prime}{=}$
there, with
 $b\,:\!=\,b({\mathcal{D}})$
,
$b\,:\!=\,b({\mathcal{D}})$
,
 $D$
given by (4.7),
$D$
given by (4.7),
 $M\,:\!=\,D+1$
(for definiteness), and
$M\,:\!=\,D+1$
(for definiteness), and
 $Y_i$
defined by (4.8). Furthermore, (4.20) holds with
$Y_i$
defined by (4.8). Furthermore, (4.20) holds with
 $g=g_{\mathcal{D}}\,:\,{\mathcal{S}}^b\to \mathbb{R}$
given by (4.23); in (3.23)–(3.24), we thus have the same limit
$g=g_{\mathcal{D}}\,:\,{\mathcal{S}}^b\to \mathbb{R}$
given by (4.23); in (3.23)–(3.24), we thus have the same limit
 $Z(t)$
for
$Z(t)$
for
 $U_n(f;\,{\mathcal{D}} ;\,(X_i) )$
and
$U_n(f;\,{\mathcal{D}} ;\,(X_i) )$
and
 $U_{n}({g;\,(Y_i) })$
. We may assume that this limit holds a.s. also for
$U_{n}({g;\,(Y_i) })$
. We may assume that this limit holds a.s. also for
 $g$
.
$g$
.
Recall that
 $h\,:\,{\mathcal{S}}\to \mathbb{R}$
. We abuse notation and extend it to
$h\,:\,{\mathcal{S}}\to \mathbb{R}$
. We abuse notation and extend it to
 ${\mathcal{S}}^M$
by
${\mathcal{S}}^M$
by
 $h(x_1,\ldots,x_M)\,:\!=\,h(x_1)$
; thus
$h(x_1,\ldots,x_M)\,:\!=\,h(x_1)$
; thus
 $h(Y_i)=h(X_i)$
. In particular,
$h(Y_i)=h(X_i)$
. In particular,
 $S_n(h;\,(X_i))=S_n(h;\,(Y_i))$
, so we may write
$S_n(h;\,(X_i))=S_n(h;\,(Y_i))$
, so we may write
 $S_n(h)$
without ambiguity. We define
$S_n(h)$
without ambiguity. We define
 $H\,:\,({\mathcal{S}}^M)^b\to \mathbb{R}$
by
$H\,:\,({\mathcal{S}}^M)^b\to \mathbb{R}$
by
 \begin{align} H(y_1,\ldots,y_b)\,:\!=\,\sum _{j=1}^{b} h(y_j). \end{align}
\begin{align} H(y_1,\ldots,y_b)\,:\!=\,\sum _{j=1}^{b} h(y_j). \end{align}
Note that (5.1) and (6.1) applied to the function
 $H$
yield
$H$
yield
 \begin{align} \mu _H&\,:\!=\,{\mathbb{E}} H\bigl ({\widehat{Y}_1,\ldots,\widehat{Y}_b}\bigr ) =b\nu, \end{align}
\begin{align} \mu _H&\,:\!=\,{\mathbb{E}} H\bigl ({\widehat{Y}_1,\ldots,\widehat{Y}_b}\bigr ) =b\nu, \end{align}
 \begin{align} H_j(y)&\phantom \,:\!=\,h(y)+(b-1)\nu -\mu _H =h(y)-\nu . \end{align}
\begin{align} H_j(y)&\phantom \,:\!=\,h(y)+(b-1)\nu -\mu _H =h(y)-\nu . \end{align}
(Since
 $H$
is symmetric,
$H$
is symmetric,
 $H_j$
is the same for every
$H_j$
is the same for every
 $j$
.)
$j$
.)
In the unconstrained sum (3.1), there are
 $\binom{n-1}{\ell -1}$
terms that contain
$\binom{n-1}{\ell -1}$
terms that contain
 $X_i$
, for each
$X_i$
, for each
 $i\in [n]$
. Applying this to
$i\in [n]$
. Applying this to
 $H$
and
$H$
and
 $(Y_i)$
, we obtain by (12.13)
$(Y_i)$
, we obtain by (12.13)
 \begin{align} U_n(H;\,(Y_i))=\binom{n-1}{b-1} S_n(h). \end{align}
\begin{align} U_n(H;\,(Y_i))=\binom{n-1}{b-1} S_n(h). \end{align}
Hence, for each fixed
 $t\gt 0$
, by (12.6), a.s.,
$t\gt 0$
, by (12.6), a.s.,
 \begin{align} U_{\lfloor{nt}\rfloor }(H;\,(Y_i))-{\mathbb{E}} U_{\lfloor{nt}\rfloor }(H;\,(Y_i))& =\binom{\lfloor{nt}\rfloor -1}{b-1}S_{\lfloor{nt}\rfloor }(h-\nu ) \notag \\& = \frac{(nt)^{b-1}}{(b-1)!}n^{1/2} W_h(t)+o\bigl ({n^{b-1/2}}\bigr ). \end{align}
\begin{align} U_{\lfloor{nt}\rfloor }(H;\,(Y_i))-{\mathbb{E}} U_{\lfloor{nt}\rfloor }(H;\,(Y_i))& =\binom{\lfloor{nt}\rfloor -1}{b-1}S_{\lfloor{nt}\rfloor }(h-\nu ) \notag \\& = \frac{(nt)^{b-1}}{(b-1)!}n^{1/2} W_h(t)+o\bigl ({n^{b-1/2}}\bigr ). \end{align}
Combining (3.23) (for
 $g$
and
$g$
and
 $(Y_i)$
) and (12.17), we obtain that, a.s.,
$(Y_i)$
) and (12.17), we obtain that, a.s.,
 \begin{align} \frac{ U_{\lfloor{nt}\rfloor }\bigl ({g-\frac{\mu _{\mathcal{D}}}{\nu } H}\bigr ) -{\mathbb{E}} U_{\lfloor{nt}\rfloor }\bigl ({g-\frac{\mu _{\mathcal{D}}}{\nu } H}\bigr )}{n^{b-1/2}} =Z(t)-\frac{\mu _{\mathcal{D}} t^{b-1}}{\nu (b-1)!}W_h(t)+o(1). \end{align}
\begin{align} \frac{ U_{\lfloor{nt}\rfloor }\bigl ({g-\frac{\mu _{\mathcal{D}}}{\nu } H}\bigr ) -{\mathbb{E}} U_{\lfloor{nt}\rfloor }\bigl ({g-\frac{\mu _{\mathcal{D}}}{\nu } H}\bigr )}{n^{b-1/2}} =Z(t)-\frac{\mu _{\mathcal{D}} t^{b-1}}{\nu (b-1)!}W_h(t)+o(1). \end{align}
Taking
 $t=\nu ^{-1}$
, we see that this converges to the random variable in (12.12). Let
$t=\nu ^{-1}$
, we see that this converges to the random variable in (12.12). Let
 $G\,:\!=\,g-\mu _{\mathcal{D}}\nu ^{-1} H$
. Then a comparison with Theorem 3.3 (applied to
$G\,:\!=\,g-\mu _{\mathcal{D}}\nu ^{-1} H$
. Then a comparison with Theorem 3.3 (applied to
 $G$
) shows that
$G$
) shows that
 \begin{align} \gamma ^2=t^{2b-1}\sigma ^2(G)=\nu ^{1-2b}\sigma ^2(G). \end{align}
\begin{align} \gamma ^2=t^{2b-1}\sigma ^2(G)=\nu ^{1-2b}\sigma ^2(G). \end{align}
In particular,
 $\gamma ^2=0$
if and only if
$\gamma ^2=0$
if and only if
 $\sigma ^2(G)=0$
, and the result follows by Theorem 8.2, noting that
$\sigma ^2(G)=0$
, and the result follows by Theorem 8.2, noting that
 $G_j\,:\!=\,g_j-\mu _{\mathcal{D}}\nu ^{-1} H_j=g_j+\mu _{\mathcal{D}}-\mu _{\mathcal{D}}\nu ^{-1} h$
by (12.15).
$G_j\,:\!=\,g_j-\mu _{\mathcal{D}}\nu ^{-1} H_j=g_j+\mu _{\mathcal{D}}-\mu _{\mathcal{D}}\nu ^{-1} h$
by (12.15).
Proof of Theorem 3.9. This can be proved like [Reference Janson37, Theorem 3.13], by first stopping at
 $N_+(x_-)$
, with
$N_+(x_-)$
, with
 $x_-\,:\!=\,\lfloor{x-\ln x}\rfloor$
, and then continuing to
$x_-\,:\!=\,\lfloor{x-\ln x}\rfloor$
, and then continuing to
 $N_-(x)$
; we therefore only sketch the details. Let
$N_-(x)$
; we therefore only sketch the details. Let
 $R(x)\,:\!=\,S_{N_+(x)}-x\gt 0$
be the overshoot at
$R(x)\,:\!=\,S_{N_+(x)}-x\gt 0$
be the overshoot at
 $x$
, and let
$x$
, and let
 $\Delta (x)\,:\!=\,x-S_{N_+(x_-)}=x-x_--R(x_-)$
. It is well known (see e.g. [Reference Gut24, Theorem 2.6.2]) that
$\Delta (x)\,:\!=\,x-S_{N_+(x_-)}=x-x_--R(x_-)$
. It is well known (see e.g. [Reference Gut24, Theorem 2.6.2]) that
 $R(x)$
converges in distribution as
$R(x)$
converges in distribution as
 $x\to \infty$
. In particular,
$x\to \infty$
. In particular,
 $\Delta (x)\overset{p}{\longrightarrow }+\infty$
and thus
$\Delta (x)\overset{p}{\longrightarrow }+\infty$
and thus
 $\mathbb{P}[{\Delta (x)\gt 0}]\to 1$
. Since
$\mathbb{P}[{\Delta (x)\gt 0}]\to 1$
. Since
 $N_+(x_-)$
is a stopping time and
$N_+(x_-)$
is a stopping time and
 $(X_i)$
are independent, the increments of the random walk
$(X_i)$
are independent, the increments of the random walk
 $S_n$
after
$S_n$
after
 $N_+(x_-)$
are independent of
$N_+(x_-)$
are independent of
 $U_{N_+(x_-)}(f)$
, and it follows that the overshoot
$U_{N_+(x_-)}(f)$
, and it follows that the overshoot
 $R(x-1)$
is asymptotically independent of
$R(x-1)$
is asymptotically independent of
 $U_{N_+(x_-)}(f)$
. The event
$U_{N_+(x_-)}(f)$
. The event
 $\{{S_{N_-(x)}=x}\}$
equals
$\{{S_{N_-(x)}=x}\}$
equals
 $\{{R(x-1)=1}\}$
, and thus the asymptotic distribution of
$\{{R(x-1)=1}\}$
, and thus the asymptotic distribution of
 $U_{N_+(x_-)}(f)$
conditioned on
$U_{N_+(x_-)}(f)$
conditioned on
 $S_{N_-(x)}=x$
is the same as without conditioning, and given by (3.29). Finally, the difference between
$S_{N_-(x)}=x$
is the same as without conditioning, and given by (3.29). Finally, the difference between
 $U_{N_+(x_-)}(f)$
and
$U_{N_+(x_-)}(f)$
and
 $U_{N_\pm (x)}(f)$
is negligible, e.g. as a consequence of (3.24).
$U_{N_\pm (x)}(f)$
is negligible, e.g. as a consequence of (3.24).
In the remainder of the section, we prove moment convergence. Since we here consider different exponents
 $p$
simultaneously, we let
$p$
simultaneously, we let
 $C_p$
denote constants that may depend on
$C_p$
denote constants that may depend on
 $p$
. (By our standing convention, they may also depend on e.g.
$p$
. (By our standing convention, they may also depend on e.g.
 $f$
and
$f$
and
 $h$
.)
$h$
.)
Lemma 12.2.
Assume that
 $\nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0$
and that
$\nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0$
and that
 ${\mathbb{E}} |h(X_1)|^p\lt \infty$
for every
${\mathbb{E}} |h(X_1)|^p\lt \infty$
for every
 $p\lt \infty$
. Then, for every
$p\lt \infty$
. Then, for every
 $p\lt \infty$
,
$p\lt \infty$
,
 $A\geqslant 2/\nu$
, and
$A\geqslant 2/\nu$
, and
 $x\geqslant 1$
, we have
$x\geqslant 1$
, we have
 \begin{align} \mathbb{P}\bigl [{N_\pm (x)\geqslant Ax}\bigr ]\leqslant C_p(Ax)^{-p}. \end{align}
\begin{align} \mathbb{P}\bigl [{N_\pm (x)\geqslant Ax}\bigr ]\leqslant C_p(Ax)^{-p}. \end{align}
Proof. We have
 $N_+(x)\leqslant N_-(x)+1$
; hence it suffices to consider
$N_+(x)\leqslant N_-(x)+1$
; hence it suffices to consider
 $N_-(x)$
.
$N_-(x)$
.
Let
 $A\geqslant 2/\nu$
. If
$A\geqslant 2/\nu$
. If
 $N_-(x)\geqslant Ax$
, then (12.4) implies
$N_-(x)\geqslant Ax$
, then (12.4) implies
 \begin{align} S_{N_-(x)}(h-\nu ) \leqslant x-N_-(x)\nu \leqslant (1-A\nu )x \leqslant -(A\nu/2) x. \end{align}
\begin{align} S_{N_-(x)}(h-\nu ) \leqslant x-N_-(x)\nu \leqslant (1-A\nu )x \leqslant -(A\nu/2) x. \end{align}
Hence, for any
 $p\geqslant 2$
, using (10.24) for
$p\geqslant 2$
, using (10.24) for
 $h$
(which is a well-known consequence of Doob’s and Burkholder’s, or Rosenthal’s, inequalities),
$h$
(which is a well-known consequence of Doob’s and Burkholder’s, or Rosenthal’s, inequalities),
 \begin{align} \mathbb{P}\bigl [{Ax \leqslant N_-(x) \leqslant 2Ax}\bigr ]& \leqslant (A x\nu/2)^{-p}{\mathbb{E}}\bigl [{\bigl \lvert{S_{N_-(x)}(h-\nu )}\bigr \rvert ^p\boldsymbol{1}\{{N_-(x)\leqslant 2Ax}\}}\bigr ] \notag \\& \leqslant (A \nu x/2)^{-p}{\mathbb{E}}\bigl [{\bigl \lvert{S^*_{\lfloor{2A x}\rfloor }(h-\nu )}\bigr \rvert ^p}\bigr ] \leqslant C_p (Ax)^{-p} (2Ax)^{p/2} \notag \\& \leqslant C_p (Ax)^{-p/2}. \end{align}
\begin{align} \mathbb{P}\bigl [{Ax \leqslant N_-(x) \leqslant 2Ax}\bigr ]& \leqslant (A x\nu/2)^{-p}{\mathbb{E}}\bigl [{\bigl \lvert{S_{N_-(x)}(h-\nu )}\bigr \rvert ^p\boldsymbol{1}\{{N_-(x)\leqslant 2Ax}\}}\bigr ] \notag \\& \leqslant (A \nu x/2)^{-p}{\mathbb{E}}\bigl [{\bigl \lvert{S^*_{\lfloor{2A x}\rfloor }(h-\nu )}\bigr \rvert ^p}\bigr ] \leqslant C_p (Ax)^{-p} (2Ax)^{p/2} \notag \\& \leqslant C_p (Ax)^{-p/2}. \end{align}
We replace
 $p$
by
$p$
by
 $2p$
and
$2p$
and
 $A$
by
$A$
by
 $2^k A$
in (12.22), and sum for
$2^k A$
in (12.22), and sum for
 $k\geqslant 0$
; this yields (12.20).
$k\geqslant 0$
; this yields (12.20).
Lemma 12.3.
Assume that (
 ${A}_{p}$
) and
${A}_{p}$
) and
 ${\mathbb{E}} |h(X_1)|^p\lt \infty$
hold for every
${\mathbb{E}} |h(X_1)|^p\lt \infty$
hold for every
 $p\lt \infty$
, and that
$p\lt \infty$
, and that
 $\nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0$
. Then, for every
$\nu \,:\!=\,{\mathbb{E}} h(X_1)\gt 0$
. Then, for every
 $p\geqslant 1$
and
$p\geqslant 1$
and
 $x\geqslant 1$
,
$x\geqslant 1$
,
 \begin{align} \Bigl \lVert{U_{N_{\pm }(x)}(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{\nu ^bb!}x^b}\Bigr \rVert _p \leqslant C_p x^{b-1/2}. \end{align}
\begin{align} \Bigl \lVert{U_{N_{\pm }(x)}(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{\nu ^bb!}x^b}\Bigr \rVert _p \leqslant C_p x^{b-1/2}. \end{align}
Proof. Let
 $V_n\,:\!=\,U_n(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}n^b$
, let
$V_n\,:\!=\,U_n(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}n^b$
, let
 $B\,:\!=\,2/\nu$
, and choose
$B\,:\!=\,2/\nu$
, and choose
 $q\,:\!=\,2bp$
. Then the Cauchy–Schwarz inequality, (10.25), and Lemma 12.2 yield, with
$q\,:\!=\,2bp$
. Then the Cauchy–Schwarz inequality, (10.25), and Lemma 12.2 yield, with
 $V^*_x\,:\!=\,\sup _{n\leqslant x}|V_n|$
,
$V^*_x\,:\!=\,\sup _{n\leqslant x}|V_n|$
,
 \begin{align} \hskip 1em&\hskip -1em{\mathbb{E}}\Bigl \lvert{U_{N_{\pm }(x)}(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}{N_{\pm }(x)}^b}\Bigr \rvert ^p ={\mathbb{E}}|V_{N_{\pm }(x)}|^p \notag \\& ={\mathbb{E}}\bigl [{|V_{N_{\pm }(x)}|^p\boldsymbol{1}\{{{N_{\pm }(x)}\leqslant Bx}\}}\bigr ] +\sum _{k=1}^\infty{\mathbb{E}}\bigl [{|V_{N_{\pm }(x)}|^p\boldsymbol{1}\{{2^{k-1}Bx\lt{N_{\pm }(x)}\leqslant 2^kBx}\}}\bigr ] \notag \\& \leqslant{\mathbb{E}}\bigl [{|V^*_{Bx}|^p}\bigr ] +\sum _{k=1}^\infty{\mathbb{E}}\bigl [{|V^*_{2^kBx}|^p\boldsymbol{1}\{{{N_{\pm }(x)}\gt 2^{k-1}Bx}\}}\bigr ] \notag \\& \leqslant{\mathbb{E}}\bigl [{|V^*_{Bx}|^p}\bigr ] +\sum _{k=1}^\infty{\mathbb{E}}\bigl [{|V^*_{2^kBx}|^{2p}}\bigr ]^{1/2}\mathbb{P}\bigl [{{N_{\pm }(x)}\gt 2^{k-1}Bx}\bigr ]^{1/2} \notag \\& \leqslant C_p x^{p(b-1/2)} + \sum _{k=1}^\infty C_p (2^kx)^{p(b-1/2)}C_q (2^{k-1}x)^{-q/2} \leqslant C_p x^{p(b-1/2)} . \end{align}
\begin{align} \hskip 1em&\hskip -1em{\mathbb{E}}\Bigl \lvert{U_{N_{\pm }(x)}(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}{N_{\pm }(x)}^b}\Bigr \rvert ^p ={\mathbb{E}}|V_{N_{\pm }(x)}|^p \notag \\& ={\mathbb{E}}\bigl [{|V_{N_{\pm }(x)}|^p\boldsymbol{1}\{{{N_{\pm }(x)}\leqslant Bx}\}}\bigr ] +\sum _{k=1}^\infty{\mathbb{E}}\bigl [{|V_{N_{\pm }(x)}|^p\boldsymbol{1}\{{2^{k-1}Bx\lt{N_{\pm }(x)}\leqslant 2^kBx}\}}\bigr ] \notag \\& \leqslant{\mathbb{E}}\bigl [{|V^*_{Bx}|^p}\bigr ] +\sum _{k=1}^\infty{\mathbb{E}}\bigl [{|V^*_{2^kBx}|^p\boldsymbol{1}\{{{N_{\pm }(x)}\gt 2^{k-1}Bx}\}}\bigr ] \notag \\& \leqslant{\mathbb{E}}\bigl [{|V^*_{Bx}|^p}\bigr ] +\sum _{k=1}^\infty{\mathbb{E}}\bigl [{|V^*_{2^kBx}|^{2p}}\bigr ]^{1/2}\mathbb{P}\bigl [{{N_{\pm }(x)}\gt 2^{k-1}Bx}\bigr ]^{1/2} \notag \\& \leqslant C_p x^{p(b-1/2)} + \sum _{k=1}^\infty C_p (2^kx)^{p(b-1/2)}C_q (2^{k-1}x)^{-q/2} \leqslant C_p x^{p(b-1/2)} . \end{align}
In other words,
 \begin{align} \Bigl \lVert{U_{N_{\pm }(x)}(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}{N_{\pm }(x)}^b}\Bigr \rVert _p \leqslant C_p x^{b-1/2}. \end{align}
\begin{align} \Bigl \lVert{U_{N_{\pm }(x)}(f;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}{N_{\pm }(x)}^b}\Bigr \rVert _p \leqslant C_p x^{b-1/2}. \end{align}
We may here replace
 $U_n(f;\,{\mathcal{D}})$
by
$U_n(f;\,{\mathcal{D}})$
by
 $S_n(h)$
(and thus
$S_n(h)$
(and thus
 $b$
by 1 and
$b$
by 1 and
 $\mu _{\mathcal{D}}$
by
$\mu _{\mathcal{D}}$
by
 $\nu$
). This yields
$\nu$
). This yields
 \begin{align} \bigl \lVert{S_{N_{\pm }(x)}(h)-\nu{N_{\pm }(x)}}\bigr \rVert _p \leqslant C_p x^{1/2} . \end{align}
\begin{align} \bigl \lVert{S_{N_{\pm }(x)}(h)-\nu{N_{\pm }(x)}}\bigr \rVert _p \leqslant C_p x^{1/2} . \end{align}
By the same proof, this holds also if we replace
 $N_{\pm }(x)$
by
$N_{\pm }(x)$
by
 ${N_{\pm }(x)}\mp 1$
. Using (12.4), it follows that
${N_{\pm }(x)}\mp 1$
. Using (12.4), it follows that
 \begin{align} \bigl \lVert{x-\nu{N_{\pm }(x)}}\bigr \rVert _p \leqslant C_p x^{1/2} . \end{align}
\begin{align} \bigl \lVert{x-\nu{N_{\pm }(x)}}\bigr \rVert _p \leqslant C_p x^{1/2} . \end{align}
In particular, by Minkowski’s inequality,
 \begin{align} \bigl \lVert{\nu{N_{\pm }(x)}}\bigr \rVert _p \leqslant x+\bigl \lVert{x-\nu{N_{\pm }(x)}}\bigr \rVert _p \leqslant C_p x . \end{align}
\begin{align} \bigl \lVert{\nu{N_{\pm }(x)}}\bigr \rVert _p \leqslant x+\bigl \lVert{x-\nu{N_{\pm }(x)}}\bigr \rVert _p \leqslant C_p x . \end{align}
Consequently, by Minkowski’s and Hölder’s inequalities, (12.27) and (12.28),
 \begin{align} \bigl \lVert{ (\nu{N_{\pm }(x)})^b-x^b}\bigr \rVert _p& =\left \lVert{\sum _{k=0}^{b-1} (\nu{N_{\pm }(x)}-x)(\nu{N_{\pm }(x)})^kx^{b-1-k}}\right \rVert _p \notag \\& \leqslant \sum _{k=0}^{b-1} \bigl \lVert{\nu{N_{\pm }(x)}-x}\bigr \rVert _{(k+1)p}\bigl \lVert{\nu{N_{\pm }(x)}}\bigr \rVert _{(k+1)p}^kx^{b-1-k} \notag \\& \leqslant C_p x^{b-1/2}. \end{align}
\begin{align} \bigl \lVert{ (\nu{N_{\pm }(x)})^b-x^b}\bigr \rVert _p& =\left \lVert{\sum _{k=0}^{b-1} (\nu{N_{\pm }(x)}-x)(\nu{N_{\pm }(x)})^kx^{b-1-k}}\right \rVert _p \notag \\& \leqslant \sum _{k=0}^{b-1} \bigl \lVert{\nu{N_{\pm }(x)}-x}\bigr \rVert _{(k+1)p}\bigl \lVert{\nu{N_{\pm }(x)}}\bigr \rVert _{(k+1)p}^kx^{b-1-k} \notag \\& \leqslant C_p x^{b-1/2}. \end{align}
Proof of Theorem 3.10. We have shown that the left-hand side of (3.29) is uniformly bounded in
 $L^p$
for
$L^p$
for
 $x\geqslant 1$
. By replacing
$x\geqslant 1$
. By replacing
 $p$
with
$p$
with
 $2p$
, say, this implies that these left-hand sides are uniformly
$2p$
, say, this implies that these left-hand sides are uniformly
 $p$
th-power integrable, for every
$p$
th-power integrable, for every
 $p\lt \infty$
, which implies convergence of all moments in (3.29).
$p\lt \infty$
, which implies convergence of all moments in (3.29).
The proof of Theorem 3.9 shows that, under the assumptions there,
 $\mathbb{P}(S_{N_-(x)}=x)$
converges to a positive limit as
$\mathbb{P}(S_{N_-(x)}=x)$
converges to a positive limit as
 $x\to \infty$
; hence
$x\to \infty$
; hence
 $\mathbb{P}(S_{N_-(x)}=x)\gt c$
for some
$\mathbb{P}(S_{N_-(x)}=x)\gt c$
for some
 $c\gt 0$
and all large
$c\gt 0$
and all large
 $x$
. This implies that the uniform
$x$
. This implies that the uniform
 $p$
th-power integrability also holds after conditioning (for large
$p$
th-power integrability also holds after conditioning (for large
 $x$
), and thus all moments also converge in (3.29) after conditioning.
$x$
), and thus all moments also converge in (3.29) after conditioning.
13. Constrained pattern matching in words
As stated in Section 1, Flajolet, Szpankowski and Vallée [Reference Flajolet, Szpankowski and Vallée23] studied the following problem; see also [Jacquet and Szpankowski [Reference Jacquet and Szpankowski31], Chapter 5]. Consider a random string
 $\Xi _n=\xi _1\cdots \xi _n$
, where the letters
$\Xi _n=\xi _1\cdots \xi _n$
, where the letters
 $\xi _i$
are i.i.d. random elements in some finite alphabet
$\xi _i$
are i.i.d. random elements in some finite alphabet
 $\mathcal{A}$
. (We may regard
$\mathcal{A}$
. (We may regard
 $\Xi _n$
as the initial part of an infinite string
$\Xi _n$
as the initial part of an infinite string
 $\xi _1\xi _2\ldots$
of i.i.d. letters.) Consider also a fixed word
$\xi _1\xi _2\ldots$
of i.i.d. letters.) Consider also a fixed word
 $\textbf{w}=w_1\cdots w_\ell$
from the same alphabet. (Thus,
$\textbf{w}=w_1\cdots w_\ell$
from the same alphabet. (Thus,
 $\ell \geqslant 1$
denotes the length of
$\ell \geqslant 1$
denotes the length of
 $w$
; we keep
$w$
; we keep
 $\textbf{w}$
and
$\textbf{w}$
and
 $\ell$
fixed.) Let
$\ell$
fixed.) Let
 $N_n(\textbf{w})$
be the (random) number of occurrences of
$N_n(\textbf{w})$
be the (random) number of occurrences of
 $\textbf{w}$
in
$\textbf{w}$
in
 $\Xi _n$
. More generally, for any constraint
$\Xi _n$
. More generally, for any constraint
 ${\mathcal{D}}=(d_1,\ldots,d_{{\ell -1}})$
, let
${\mathcal{D}}=(d_1,\ldots,d_{{\ell -1}})$
, let
 $N_n(\textbf{w};{\mathcal{D}})$
be the number of constrained occurrences. This is a special case of the general setting in (3.1)–(3.2), with
$N_n(\textbf{w};{\mathcal{D}})$
be the number of constrained occurrences. This is a special case of the general setting in (3.1)–(3.2), with
 $X_i=\xi _i$
, and (cf. (1.1))
$X_i=\xi _i$
, and (cf. (1.1))
 \begin{align} f(x_1,\ldots,x_\ell )=\boldsymbol{1}\{{x_1,\ldots,x_\ell =\textbf{w}}\} =\boldsymbol{1}\{{x_i=w_i\;\forall i\in [\ell ]}\}. \end{align}
\begin{align} f(x_1,\ldots,x_\ell )=\boldsymbol{1}\{{x_1,\ldots,x_\ell =\textbf{w}}\} =\boldsymbol{1}\{{x_i=w_i\;\forall i\in [\ell ]}\}. \end{align}
Consequently,
 \begin{align} N_n(\textbf{w};\,{\mathcal{D}})= U_n(f;\,{\mathcal{D}};\,(\xi _i)) \end{align}
\begin{align} N_n(\textbf{w};\,{\mathcal{D}})= U_n(f;\,{\mathcal{D}};\,(\xi _i)) \end{align}
with
 $f$
given by (13.1).
$f$
given by (13.1).
Denote the distribution of the individual letters by
 \begin{align} p(x)\,:\!=\,\mathbb{P}(\xi _1=x), \qquad x\in{\mathcal{A}}. \end{align}
\begin{align} p(x)\,:\!=\,\mathbb{P}(\xi _1=x), \qquad x\in{\mathcal{A}}. \end{align}
We will, without loss of generality, assume
 $p(x)\gt 0$
for every
$p(x)\gt 0$
for every
 $x\in{\mathcal{A}}$
. Then (13.2) and the general results above yield the following result from [Reference Flajolet, Szpankowski and Vallée23], with
$x\in{\mathcal{A}}$
. Then (13.2) and the general results above yield the following result from [Reference Flajolet, Szpankowski and Vallée23], with
 $b=b({\mathcal{D}})$
given by (2.1). The unconstrained case (also in [Reference Flajolet, Szpankowski and Vallée23]) is a special case. Moreover, the theorem also holds for the exactly constrained case, with
$b=b({\mathcal{D}})$
given by (2.1). The unconstrained case (also in [Reference Flajolet, Szpankowski and Vallée23]) is a special case. Moreover, the theorem also holds for the exactly constrained case, with
 $\mu _{{\mathcal{D}}{=}}=\prod _i p(w_i)$
and some
$\mu _{{\mathcal{D}}{=}}=\prod _i p(w_i)$
and some
 $\sigma ^2(\textbf{w};\,{{\mathcal{D}}{=}})$
; we leave the detailed statement to the reader. A formula for
$\sigma ^2(\textbf{w};\,{{\mathcal{D}}{=}})$
; we leave the detailed statement to the reader. A formula for
 $\sigma ^2$
is given in [Reference Flajolet, Szpankowski and Vallée23, (14)]; we show explicitly that
$\sigma ^2$
is given in [Reference Flajolet, Szpankowski and Vallée23, (14)]; we show explicitly that
 $\sigma ^2\gt 0$
except in trivial (non-random) cases, which seems to have been omitted from [Reference Flajolet, Szpankowski and Vallée23].
$\sigma ^2\gt 0$
except in trivial (non-random) cases, which seems to have been omitted from [Reference Flajolet, Szpankowski and Vallée23].
Theorem 13.1. (Flajolet, Szpankowski and Vallée [Reference Flajolet, Szpankowski and Vallée23].) With notation as above, as
 $n\to \infty$
,
$n\to \infty$
,
 \begin{align} \frac{ N_n(\textbf{w};\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}n^b}{n^{b-1/2}} \overset{d}{\longrightarrow } N\bigl ({0,\sigma ^2}\bigr ) \end{align}
\begin{align} \frac{ N_n(\textbf{w};\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}n^b}{n^{b-1/2}} \overset{d}{\longrightarrow } N\bigl ({0,\sigma ^2}\bigr ) \end{align}
for some
 $\sigma ^2=\sigma ^2(\textbf{w};\,{\mathcal{D}})\geqslant 0$
, with
$\sigma ^2=\sigma ^2(\textbf{w};\,{\mathcal{D}})\geqslant 0$
, with
 \begin{align} \mu _{\mathcal{D}}\,:\!=\, \prod _{d_j\lt \infty } d_j \cdot \prod _{i=1}^\ell p(w_i) . \end{align}
\begin{align} \mu _{\mathcal{D}}\,:\!=\, \prod _{d_j\lt \infty } d_j \cdot \prod _{i=1}^\ell p(w_i) . \end{align}
Furthermore, all moments converge in (13.4).
Moreover, if
 $|{\mathcal{A}}|\geqslant 2$
, then
$|{\mathcal{A}}|\geqslant 2$
, then
 $\sigma ^2\gt 0$
.
$\sigma ^2\gt 0$
.
Proof. By (13.2), the convergence (13.4) is an instance of (3.21) in Theorem 3.4 together with (3.8) in Theorem 3.1. The formula (13.5) follows from (3.11) since, by (13.1) and independence,
 \begin{align} \mu \,:\!=\,{\mathbb{E}} f(\xi _1,\ldots,\xi _\ell )= \mathbb{P}\bigl ({\xi _1\cdots \xi _\ell =w_1\cdots w_\ell }\bigr ) =\prod _{i=1}^\ell \mathbb{P}(\xi _i=w_i). \end{align}
\begin{align} \mu \,:\!=\,{\mathbb{E}} f(\xi _1,\ldots,\xi _\ell )= \mathbb{P}\bigl ({\xi _1\cdots \xi _\ell =w_1\cdots w_\ell }\bigr ) =\prod _{i=1}^\ell \mathbb{P}(\xi _i=w_i). \end{align}
Moment convergence follows by Theorem 3.6; note that (
 ${A}_{p}$
) is trivial, since
${A}_{p}$
) is trivial, since
 $f$
is bounded.
$f$
is bounded.
Finally, assume
 $|{\mathcal{A}}|\geqslant 2$
and suppose that
$|{\mathcal{A}}|\geqslant 2$
and suppose that
 $\sigma ^2=0$
. Then Theorem 8.2 says that (8.20) holds, and thus, for each
$\sigma ^2=0$
. Then Theorem 8.2 says that (8.20) holds, and thus, for each
 $n\gt D$
, the sum
$n\gt D$
, the sum
 $S_{n}(g_j)$
is independent of
$S_{n}(g_j)$
is independent of
 $\xi _{D+1},\ldots,\xi _n$
. We consider only
$\xi _{D+1},\ldots,\xi _n$
. We consider only
 $j=1$
. Choose
$j=1$
. Choose
 $a\in{\mathcal{A}}$
with
$a\in{\mathcal{A}}$
with
 $a\neq w_1$
. Consider first an exact constraint
$a\neq w_1$
. Consider first an exact constraint
 ${\mathcal{D}}{=}$
. Then
${\mathcal{D}}{=}$
. Then
 $g_{{\mathcal{D}}{=}}$
is given by (4.18). Since
$g_{{\mathcal{D}}{=}}$
is given by (4.18). Since
 $f(x_1,\ldots,x_\ell )=0$
whenever
$f(x_1,\ldots,x_\ell )=0$
whenever
 $x_1=a$
, it follows from (4.18) that
$x_1=a$
, it follows from (4.18) that
 $g(y_1,\ldots,y_b)=0$
whenever
$g(y_1,\ldots,y_b)=0$
whenever
 $y_1=(y_{1k})_{k=1}^M$
has
$y_1=(y_{1k})_{k=1}^M$
has
 $y_{11}=a$
. Hence, (6.1) shows that
$y_{11}=a$
. Hence, (6.1) shows that
 \begin{align} g_1(y_1)=-\mu _{{{\mathcal{D}}{=}}}=-\mu, \qquad \text{if }y_{11}=a. \end{align}
\begin{align} g_1(y_1)=-\mu _{{{\mathcal{D}}{=}}}=-\mu, \qquad \text{if }y_{11}=a. \end{align}
Consequently, on the event
 $\xi _1=\ldots =\xi _{n}=a$
, recalling (4.8) and
$\xi _1=\ldots =\xi _{n}=a$
, recalling (4.8) and
 $M=D+1$
, we have
$M=D+1$
, we have
 $g_1(Y_k)=g_1(\xi _k,\ldots,\xi _{k+D})=-\mu$
for every
$g_1(Y_k)=g_1(\xi _k,\ldots,\xi _{k+D})=-\mu$
for every
 $k\in [n]$
. Thus,
$k\in [n]$
. Thus,
 \begin{align} S_n(g_1)=-n\mu \qquad \text{if}\quad \xi _1=\cdots =\xi _n=a. \end{align}
\begin{align} S_n(g_1)=-n\mu \qquad \text{if}\quad \xi _1=\cdots =\xi _n=a. \end{align}
On the other hand, as noted above, the assumption
 $\sigma ^2=0$
implies that
$\sigma ^2=0$
implies that
 $S_{n}(g_1)$
is independent of
$S_{n}(g_1)$
is independent of
 $\xi _{D+1}, \ldots,\xi _n$
. Consequently, (13.8) implies
$\xi _{D+1}, \ldots,\xi _n$
. Consequently, (13.8) implies
 \begin{align} S_n(g_1)=-n\mu \qquad \text{if}\quad \xi _1=\cdots =\xi _D=a, \end{align}
\begin{align} S_n(g_1)=-n\mu \qquad \text{if}\quad \xi _1=\cdots =\xi _D=a, \end{align}
regardless of
 $\xi _{D+1}\ldots,\xi _{n+D}$
. This is easily shown to lead to contradiction. For example, we have, by (6.4),
$\xi _{D+1}\ldots,\xi _{n+D}$
. This is easily shown to lead to contradiction. For example, we have, by (6.4),
 \begin{align} {\mathbb{E}} g_1(Y_k)={\mathbb{E}} g_1(\xi _k,\ldots,\xi _{k+D})=0, \end{align}
\begin{align} {\mathbb{E}} g_1(Y_k)={\mathbb{E}} g_1(\xi _k,\ldots,\xi _{k+D})=0, \end{align}
and thus, conditioning on
 $\xi _1,\ldots,\xi _D$
,
$\xi _1,\ldots,\xi _D$
,
 \begin{align}{\mathbb{E}} \bigl ({S_n(g_1)\mid \xi _1=\cdots =\xi _D=a}\bigr ) &= \sum _{k=1}^n{\mathbb{E}} \bigl ({g_1(\xi _k,\ldots,\xi _{k+D}) \mid \xi _1=\cdots =\xi _D=a}\bigr ) \notag \\& =O(1), \end{align}
\begin{align}{\mathbb{E}} \bigl ({S_n(g_1)\mid \xi _1=\cdots =\xi _D=a}\bigr ) &= \sum _{k=1}^n{\mathbb{E}} \bigl ({g_1(\xi _k,\ldots,\xi _{k+D}) \mid \xi _1=\cdots =\xi _D=a}\bigr ) \notag \\& =O(1), \end{align}
since all terms with
 $k\gt D$
are unaffected by the conditioning and thus vanish by (13.10); this contradicts (13.9) for large
$k\gt D$
are unaffected by the conditioning and thus vanish by (13.10); this contradicts (13.9) for large
 $n$
, since
$n$
, since
 $\mu \gt 0$
. This contradiction shows that
$\mu \gt 0$
. This contradiction shows that
 $\sigma ^2\gt 0$
for an exact constraint
$\sigma ^2\gt 0$
for an exact constraint
 ${\mathcal{D}}{=}$
.
${\mathcal{D}}{=}$
.
Alternatively, instead of using the expectation as in (13.11), one might easily show that if
 $n\gt D+\ell$
, then
$n\gt D+\ell$
, then
 $\xi _{D+1},\ldots,\xi _n$
can be chosen such that (13.9) does not hold.
$\xi _{D+1},\ldots,\xi _n$
can be chosen such that (13.9) does not hold.
For a constraint
 $\mathcal{D}$
,
$\mathcal{D}$
,
 $g=g_{\mathcal{D}}$
is given by a sum (4.23) of exactly constrained cases
$g=g_{\mathcal{D}}$
is given by a sum (4.23) of exactly constrained cases
 ${\mathcal{D}}^{\prime}{=}$
. Hence, by summing (13.7) for these
${\mathcal{D}}^{\prime}{=}$
. Hence, by summing (13.7) for these
 ${\mathcal{D}}^{\prime}{=}$
, it follows that (13.7) also holds for
${\mathcal{D}}^{\prime}{=}$
, it follows that (13.7) also holds for
 $g_{\mathcal{D}}$
(with
$g_{\mathcal{D}}$
(with
 $\mu$
replaced by
$\mu$
replaced by
 $\mu _{{\mathcal{D}}}$
). This leads to a contradiction exactly as above.
$\mu _{{\mathcal{D}}}$
). This leads to a contradiction exactly as above.
Theorem 13.1 shows that, except in trivial cases, the asymptotic variance
 $\sigma ^2\gt 0$
for a subsequence count
$\sigma ^2\gt 0$
for a subsequence count
 $N_n(\textbf{w};\,{\mathcal{D}})$
, and thus (13.4) yields a non-degenerate limit, so that it really shows asymptotic normality. By the same proof (see also Remark 3.6), Theorem 13.1 extends to linear combinations of different subsequence counts (in the same random string
$N_n(\textbf{w};\,{\mathcal{D}})$
, and thus (13.4) yields a non-degenerate limit, so that it really shows asymptotic normality. By the same proof (see also Remark 3.6), Theorem 13.1 extends to linear combinations of different subsequence counts (in the same random string
 $\Xi _n$
), but in this case, it may happen that
$\Xi _n$
), but in this case, it may happen that
 $\sigma ^2=0$
, and then (13.4) has a degenerate limit and thus yields only convergence in probability to 0. (We consider only linear combinations with coefficients not depending on
$\sigma ^2=0$
, and then (13.4) has a degenerate limit and thus yields only convergence in probability to 0. (We consider only linear combinations with coefficients not depending on
 $n$
.) One such degenerate example with constrained subsequence counts is discussed in Example 8.1. There are also degenerate examples in the unconstrained case. In fact, the general theory of degenerate (in this sense)
$n$
.) One such degenerate example with constrained subsequence counts is discussed in Example 8.1. There are also degenerate examples in the unconstrained case. In fact, the general theory of degenerate (in this sense)
 $U$
-statistics based on independent
$U$
-statistics based on independent
 $(X_i)_1^\infty$
is well understood; for symmetric
$(X_i)_1^\infty$
is well understood; for symmetric
 $U$
-statistics this case was characterized by [Reference Hoeffding27] and studied in detail by [Reference Rubin and Vitale56], and their results were extended to the asymmetric case relevant here in [Reference Janson35, Chapter 11.2]. In Appendix A we apply these general results to string matching and give a rather detailed treatment of the degenerate cases of linear combinations of unconstrained subsequence counts. See also [Reference Even-Zohar, Lakrec and Tessler19] for further algebraic aspects of both non-degenerate and degenerate cases.
$U$
-statistics this case was characterized by [Reference Hoeffding27] and studied in detail by [Reference Rubin and Vitale56], and their results were extended to the asymmetric case relevant here in [Reference Janson35, Chapter 11.2]. In Appendix A we apply these general results to string matching and give a rather detailed treatment of the degenerate cases of linear combinations of unconstrained subsequence counts. See also [Reference Even-Zohar, Lakrec and Tessler19] for further algebraic aspects of both non-degenerate and degenerate cases.
Problem 13.1. Appendix A considers only the unconstrained case. Example 8.1 shows that for linear combinations of constrained pattern counts, there are further possibilities to have
 $\sigma ^2=0$
. It would be interesting to extend the results in Appendix A and characterize these cases, and also to obtain limit theorems for such cases, extending Theorem A.2 (in particular the case
$\sigma ^2=0$
. It would be interesting to extend the results in Appendix A and characterize these cases, and also to obtain limit theorems for such cases, extending Theorem A.2 (in particular the case
 $k=2$
); note again that the limit in Example 8.1 is of a different type than the ones occurring in unconstrained cases (Theorem A.2). We leave these as open problems.
$k=2$
); note again that the limit in Example 8.1 is of a different type than the ones occurring in unconstrained cases (Theorem A.2). We leave these as open problems.
14. Constrained pattern matching in permutations
Consider now random permutations. As usual, we generate a random permutation
 ${\boldsymbol{\pi }}={\boldsymbol{\pi }}^{(n)}\in \mathfrak{S}_n$
by taking a sequence
${\boldsymbol{\pi }}={\boldsymbol{\pi }}^{(n)}\in \mathfrak{S}_n$
by taking a sequence
 $(X_i)_1^n$
of i.i.d. random variables with a uniform distribution
$(X_i)_1^n$
of i.i.d. random variables with a uniform distribution
 $X_i\sim U(0,1)$
, and then replacing the values
$X_i\sim U(0,1)$
, and then replacing the values
 $X_1,\ldots,X_n$
, in increasing order, by
$X_1,\ldots,X_n$
, in increasing order, by
 $1,\ldots,n$
. Then the number
$1,\ldots,n$
. Then the number
 $N_n(\tau )$
of occurrences of a fixed permutation
$N_n(\tau )$
of occurrences of a fixed permutation
 $\tau =\tau _1\cdots \tau _\ell$
in
$\tau =\tau _1\cdots \tau _\ell$
in
 $\boldsymbol{\pi }$
is given by the
$\boldsymbol{\pi }$
is given by the
 $U$
-statistic
$U$
-statistic
 $U_n(f)$
defined by (3.1) with
$U_n(f)$
defined by (3.1) with
 \begin{align} f(x_1,\ldots,x_\ell ) \,:\!=\, \prod _{1\leqslant i\lt j\leqslant \ell } \boldsymbol{1}\{{x_i\lt x_j\iff \tau _i\lt \tau _j}\}. \end{align}
\begin{align} f(x_1,\ldots,x_\ell ) \,:\!=\, \prod _{1\leqslant i\lt j\leqslant \ell } \boldsymbol{1}\{{x_i\lt x_j\iff \tau _i\lt \tau _j}\}. \end{align}
Similarly, for any constraint
 ${\mathcal{D}}=(d_1,\ldots,d_{{\ell -1}})$
, we have for the number of constrained occurrences of
${\mathcal{D}}=(d_1,\ldots,d_{{\ell -1}})$
, we have for the number of constrained occurrences of
 $\tau$
, with the same
$\tau$
, with the same
 $f$
as given by (14.1),
$f$
as given by (14.1),
 \begin{align} N_n(\tau ;\,{\mathcal{D}})=U_n(f;\,{\mathcal{D}}). \end{align}
\begin{align} N_n(\tau ;\,{\mathcal{D}})=U_n(f;\,{\mathcal{D}}). \end{align}
Hence, Theorems 3.3 and 3.4 yield the following result showing asymptotic normality of the number of (constrained) occurrences. As stated in the introduction, the unconstrained case was shown by Bóna [Reference Bóna7], the case
 $d_1=\cdots =d_{{\ell -1}}=1$
by Bóna [Reference Bóna9], and the general vincular case by Hofer [Reference Hofer29]; we extend the result to general constrained cases. The fact that
$d_1=\cdots =d_{{\ell -1}}=1$
by Bóna [Reference Bóna9], and the general vincular case by Hofer [Reference Hofer29]; we extend the result to general constrained cases. The fact that
 $\sigma ^2\gt 0$
was shown in [Reference Hofer29] (in vincular cases); we give a shorter proof based on Theorem 8.2. Again, the theorem also holds for the exactly constrained case, with
$\sigma ^2\gt 0$
was shown in [Reference Hofer29] (in vincular cases); we give a shorter proof based on Theorem 8.2. Again, the theorem also holds for the exactly constrained case, with
 $\mu _{{\mathcal{D}}{=}}=1/\ell !$
and some
$\mu _{{\mathcal{D}}{=}}=1/\ell !$
and some
 $\sigma ^2(\tau ;\,{{\mathcal{D}}{=}})$
.
$\sigma ^2(\tau ;\,{{\mathcal{D}}{=}})$
.
Theorem 14.1. (Largely Bóna [Reference Bóna7, Reference Bóna9] and Hofer [Reference Hofer29].) For any fixed permutation
 $\tau \in \mathfrak{S}_\ell$
and constraint
$\tau \in \mathfrak{S}_\ell$
and constraint
 ${\mathcal{D}}=(d_1,\ldots,d_{{\ell -1}})$
, as
${\mathcal{D}}=(d_1,\ldots,d_{{\ell -1}})$
, as
 $n\to \infty$
,
$n\to \infty$
,
 \begin{align} \frac{ N_n(\tau ;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}n^b}{n^{b-1/2}} \overset{d}{\longrightarrow } N\bigl ({0,\sigma ^2}\bigr ) \end{align}
\begin{align} \frac{ N_n(\tau ;\,{\mathcal{D}})-\frac{\mu _{\mathcal{D}}}{b!}n^b}{n^{b-1/2}} \overset{d}{\longrightarrow } N\bigl ({0,\sigma ^2}\bigr ) \end{align}
for some
 $\sigma ^2=\sigma ^2(\tau ;\,{\mathcal{D}})\geqslant 0$
and
$\sigma ^2=\sigma ^2(\tau ;\,{\mathcal{D}})\geqslant 0$
and
 \begin{align} \mu _{\mathcal{D}}\,:\!=\, \frac{1}{\ell !}\prod _{d_j\lt \infty } d_j. \end{align}
\begin{align} \mu _{\mathcal{D}}\,:\!=\, \frac{1}{\ell !}\prod _{d_j\lt \infty } d_j. \end{align}
Furthermore, all moments converge in (14.3).
Moreover, if
 $\ell \geqslant 2$
, then
$\ell \geqslant 2$
, then
 $\sigma ^2\gt 0$
.
$\sigma ^2\gt 0$
.
Proof. This is similar to the proof of Theorem 13.1. By (14.2), the convergence (14.3) is an instance of (3.21) together with (3.8). The formula (14.4) follows from (3.11), since
 $ \mu \,:\!=\,{\mathbb{E}} f(X_1,\ldots,X_\ell )$
by (14.1) is the probability that
$ \mu \,:\!=\,{\mathbb{E}} f(X_1,\ldots,X_\ell )$
by (14.1) is the probability that
 $X_1,\ldots,X_\ell$
have the same order as
$X_1,\ldots,X_\ell$
have the same order as
 $\tau _1,\ldots,\tau _\ell$
, i.e.,
$\tau _1,\ldots,\tau _\ell$
, i.e.,
 $1/\ell !$
. Moment convergence follows by Theorem 3.6.
$1/\ell !$
. Moment convergence follows by Theorem 3.6.
Finally, suppose that
 $\ell \geqslant 2$
but
$\ell \geqslant 2$
but
 $\sigma ^2=0$
. Then Theorem 8.2 says that (8.20) holds, and thus, for each
$\sigma ^2=0$
. Then Theorem 8.2 says that (8.20) holds, and thus, for each
 $j$
and each
$j$
and each
 $n\gt D$
, the sum
$n\gt D$
, the sum
 $S_{n}(g_j)$
is independent of
$S_{n}(g_j)$
is independent of
 $X_{D+1},\ldots,X_n$
; we want to show that this leads to a contradiction. We again choose
$X_{D+1},\ldots,X_n$
; we want to show that this leads to a contradiction. We again choose
 $j=1$
, but we now consider two cases separately.
$j=1$
, but we now consider two cases separately.
Case 1:
 $d_1\lt \infty$
Recall the notation in (4.11)–(4.14), and note that in this case
$d_1\lt \infty$
Recall the notation in (4.11)–(4.14), and note that in this case
 \begin{align} \ell _1\gt 1, \qquad t_{11}=0, \qquad t_{12}=d_1, \qquad v_1=0 . \end{align}
\begin{align} \ell _1\gt 1, \qquad t_{11}=0, \qquad t_{12}=d_1, \qquad v_1=0 . \end{align}
Assume for definiteness that
 $\tau _1\gt \tau _2$
. (Otherwise, we may exchange
$\tau _1\gt \tau _2$
. (Otherwise, we may exchange
 $\lt$
and
$\lt$
and
 $\gt$
in the argument below.) Then (14.1) implies that
$\gt$
in the argument below.) Then (14.1) implies that
 \begin{align} f(x_1,\ldots,x_\ell )=0 \qquad \text{if}\quad x_1\lt x_2. \end{align}
\begin{align} f(x_1,\ldots,x_\ell )=0 \qquad \text{if}\quad x_1\lt x_2. \end{align}
Consider first the exact constraint
 ${\mathcal{D}}{=}$
. Then
${\mathcal{D}}{=}$
. Then
 $g_{{\mathcal{D}}{=}}$
is given by (4.18). Hence, (14.6) and (14.5) imply that
$g_{{\mathcal{D}}{=}}$
is given by (4.18). Hence, (14.6) and (14.5) imply that
 \begin{align} g_{{\mathcal{D}}{=}}(y_1,\ldots,y_b)=0 \qquad \text{if}\quad y_1=(y_{1,k})_{k=1}^M \text{ with } y_{1,1}\lt y_{1,1+d_1}. \end{align}
\begin{align} g_{{\mathcal{D}}{=}}(y_1,\ldots,y_b)=0 \qquad \text{if}\quad y_1=(y_{1,k})_{k=1}^M \text{ with } y_{1,1}\lt y_{1,1+d_1}. \end{align}
In particular,
 \begin{align} g_{{\mathcal{D}}{=}}(y_1,\ldots,y_b)=0 \qquad \text{if}\quad y_{1,1}\lt y_{1,2}\lt \cdots \lt y_{1,M}. \end{align}
\begin{align} g_{{\mathcal{D}}{=}}(y_1,\ldots,y_b)=0 \qquad \text{if}\quad y_{1,1}\lt y_{1,2}\lt \cdots \lt y_{1,M}. \end{align}
By (4.23), the same holds for the constraint
 $\mathcal{D}$
. Hence, (6.1) shows that, for
$\mathcal{D}$
. Hence, (6.1) shows that, for
 $g=g_{\mathcal{D}}$
,
$g=g_{\mathcal{D}}$
,
 \begin{align} g_1(y_1)=-\mu _{{\mathcal{D}}} \qquad \text{if}\quad y_{1,1}\lt y_{1,2}\lt \cdots \lt y_{1,M}. \end{align}
\begin{align} g_1(y_1)=-\mu _{{\mathcal{D}}} \qquad \text{if}\quad y_{1,1}\lt y_{1,2}\lt \cdots \lt y_{1,M}. \end{align}
Consequently, on the event
 $X_1\lt \cdots \lt X_{n+D}$
, recalling (4.8) and
$X_1\lt \cdots \lt X_{n+D}$
, recalling (4.8) and
 $M=D+1$
, we have
$M=D+1$
, we have
 $g_1(Y_k)=g_1(X_k,\ldots,X_{k+D})=-\mu _{\mathcal{D}}$
for every
$g_1(Y_k)=g_1(X_k,\ldots,X_{k+D})=-\mu _{\mathcal{D}}$
for every
 $k\in [n]$
, and thus
$k\in [n]$
, and thus
 \begin{align} S_n(g_1)=-n\mu _{\mathcal{D}} \qquad \text{if}\quad X_1\lt \cdots \lt X_{n+D}. \end{align}
\begin{align} S_n(g_1)=-n\mu _{\mathcal{D}} \qquad \text{if}\quad X_1\lt \cdots \lt X_{n+D}. \end{align}
On the other hand, as noted above, the assumption
 $\sigma ^2=0$
implies that
$\sigma ^2=0$
implies that
 $S_{n}(g_1)$
is independent of
$S_{n}(g_1)$
is independent of
 $X_{D+1}, \ldots,X_n$
. Consequently, (14.10) implies that a.s.
$X_{D+1}, \ldots,X_n$
. Consequently, (14.10) implies that a.s.
 \begin{align} S_n(g_1)=-n\mu _{\mathcal{D}} \qquad \text{if}\quad X_1\lt \cdots \lt X_D\lt X_{n+1}\lt \cdots \lt X_{n+D} . \end{align}
\begin{align} S_n(g_1)=-n\mu _{\mathcal{D}} \qquad \text{if}\quad X_1\lt \cdots \lt X_D\lt X_{n+1}\lt \cdots \lt X_{n+D} . \end{align}
However, in analogy with (13.10)–(13.11), we have
 ${\mathbb{E}} g_1(Y_k)=0$
by (6.4), and thus
${\mathbb{E}} g_1(Y_k)=0$
by (6.4), and thus
 \begin{align} &{\mathbb{E}} \bigl ({S_n(g_1)\mid X_1\lt \cdots \lt X_D\lt X_{n+1}\lt \cdots \lt X_{n+D}}\bigr ) \notag \\&\quad = \sum _{k=1}^n{\mathbb{E}} \bigl ({g_1(X_k,\ldots,X_{k+D}) \mid X_1\lt \cdots \lt X_D\lt X_{n+1}\lt \cdots \lt X_{n+D}}\bigr ) \notag \\&\quad =O(1), \end{align}
\begin{align} &{\mathbb{E}} \bigl ({S_n(g_1)\mid X_1\lt \cdots \lt X_D\lt X_{n+1}\lt \cdots \lt X_{n+D}}\bigr ) \notag \\&\quad = \sum _{k=1}^n{\mathbb{E}} \bigl ({g_1(X_k,\ldots,X_{k+D}) \mid X_1\lt \cdots \lt X_D\lt X_{n+1}\lt \cdots \lt X_{n+D}}\bigr ) \notag \\&\quad =O(1), \end{align}
since all terms with
 $D\lt k\leqslant n-D$
are unaffected by the conditioning and thus vanish. But (14.12) contradicts (14.11) for large
$D\lt k\leqslant n-D$
are unaffected by the conditioning and thus vanish. But (14.12) contradicts (14.11) for large
 $n$
, since
$n$
, since
 $\mu _{\mathcal{D}}\gt 0$
. This contradiction shows that
$\mu _{\mathcal{D}}\gt 0$
. This contradiction shows that
 $\sigma ^2\gt 0$
when
$\sigma ^2\gt 0$
when
 $\ell \geqslant 2$
and
$\ell \geqslant 2$
and
 $d_1\lt \infty$
.
$d_1\lt \infty$
.
Case 2:
 $d_1=\infty$
In this case,
$d_1=\infty$
In this case,
 $\ell _1=1$
. Consider again first
$\ell _1=1$
. Consider again first
 ${\mathcal{D}}{=}$
. Since
${\mathcal{D}}{=}$
. Since
 $(X_i)$
are i.i.d., (4.18) and (6.1) yield, choosing
$(X_i)$
are i.i.d., (4.18) and (6.1) yield, choosing
 $j_i\,:\!=\,(D+1)i$
, say,
$j_i\,:\!=\,(D+1)i$
, say,
 \begin{align} g_1(y_1) ={\mathbb{E}} g\bigl ({y_1,Y_{j_2},\ldots,Y_{j_b}}\bigr )-\mu ={\mathbb{E}} f\bigl ({y_{11},X_2,\ldots,X_\ell }\bigr )-\mu =f_1(y_{11}) \end{align}
\begin{align} g_1(y_1) ={\mathbb{E}} g\bigl ({y_1,Y_{j_2},\ldots,Y_{j_b}}\bigr )-\mu ={\mathbb{E}} f\bigl ({y_{11},X_2,\ldots,X_\ell }\bigr )-\mu =f_1(y_{11}) \end{align}
(with
 $\mu =1/\ell !$
). Thus, recalling (4.8), we have
$\mu =1/\ell !$
). Thus, recalling (4.8), we have
 \begin{align} S_n(g_1)=\sum _{k=1}^n g_1(Y_k) = \sum _{k=1}^n f_1(X_k). \end{align}
\begin{align} S_n(g_1)=\sum _{k=1}^n g_1(Y_k) = \sum _{k=1}^n f_1(X_k). \end{align}
By Theorem 8.2, the assumption
 $\sigma ^2=0$
thus implies that the final sum in (14.14) is independent of
$\sigma ^2=0$
thus implies that the final sum in (14.14) is independent of
 $X_{D+1}$
, for any
$X_{D+1}$
, for any
 $n\geqslant D+1$
. Since
$n\geqslant D+1$
. Since
 $(X_i)$
are independent, this is possible only if
$(X_i)$
are independent, this is possible only if
 $f_1(X_{D+1})=c$
a.s. for some constant
$f_1(X_{D+1})=c$
a.s. for some constant
 $c$
, i.e., if
$c$
, i.e., if
 $f_1(x)=c$
for a.e.
$f_1(x)=c$
for a.e.
 $x\in (0,1)$
.
$x\in (0,1)$
.
However, by (14.1),
 $f ({x,X_2,\ldots,X_\ell } )=1$
if and only if
$f ({x,X_2,\ldots,X_\ell } )=1$
if and only if
 $\tau _1-1$
prescribed
$\tau _1-1$
prescribed
 $X_j$
are in
$X_j$
are in
 $(0,x)$
and in a specific order, and the remaining
$(0,x)$
and in a specific order, and the remaining
 $\ell -\tau _1$
ones are in
$\ell -\tau _1$
ones are in
 $(x,1)$
and in a specific order. Hence, (6.1) yields
$(x,1)$
and in a specific order. Hence, (6.1) yields
 \begin{align} f_1(x) =\frac{1}{(\tau _1-1)!\,(\ell -\tau _1)!}x^{\tau _1-1}(1-x)^{\ell -\tau _1}-\mu . \end{align}
\begin{align} f_1(x) =\frac{1}{(\tau _1-1)!\,(\ell -\tau _1)!}x^{\tau _1-1}(1-x)^{\ell -\tau _1}-\mu . \end{align}
Since
 $\ell \geqslant 2$
,
$\ell \geqslant 2$
,
 $f_1(x)$
is a non-constant polynomial in
$f_1(x)$
is a non-constant polynomial in
 $x$
.
$x$
.
This is a contradiction, and shows that
 $\sigma ^2\gt 0$
also when
$\sigma ^2\gt 0$
also when
 $d_1=\infty$
.
$d_1=\infty$
.
Remark 14.1. Although
 $\sigma ^2\gt 0$
for each pattern count
$\sigma ^2\gt 0$
for each pattern count
 $N_n(\tau ;\,{\mathcal{D}})$
with
$N_n(\tau ;\,{\mathcal{D}})$
with
 $\ell \gt 1$
, non-trivial linear combinations might have
$\ell \gt 1$
, non-trivial linear combinations might have
 $\sigma ^2=0$
, and thus variance of lower order, even in the unconstrained case. (This is similar to the case of patterns in strings in Section 13 and Appendix A.) In fact, for the unconstrained case, it is shown in [Reference Janson, Nakamura and Zeilberger39] that for permutations
$\sigma ^2=0$
, and thus variance of lower order, even in the unconstrained case. (This is similar to the case of patterns in strings in Section 13 and Appendix A.) In fact, for the unconstrained case, it is shown in [Reference Janson, Nakamura and Zeilberger39] that for permutations
 $\tau$
of a given length
$\tau$
of a given length
 $\ell$
, the
$\ell$
, the
 $\ell !$
counts
$\ell !$
counts
 $N_n(\tau )$
converge jointly, after normalization as above, to a multivariate normal distribution of dimension only
$N_n(\tau )$
converge jointly, after normalization as above, to a multivariate normal distribution of dimension only
 $(\ell -1)^2$
, meaning that there is a linear space of dimension
$(\ell -1)^2$
, meaning that there is a linear space of dimension
 $\ell !-(\ell -1)^2$
of linear combinations that have
$\ell !-(\ell -1)^2$
of linear combinations that have
 $\sigma ^2=0$
. This is further analyzed in [Reference Even-Zohar18], where the spaces of linear combinations of
$\sigma ^2=0$
. This is further analyzed in [Reference Even-Zohar18], where the spaces of linear combinations of
 $N_n(\tau )$
having variance
$N_n(\tau )$
having variance
 $O ({n^{2\ell -r}} )$
are characterized for each
$O ({n^{2\ell -r}} )$
are characterized for each
 $r=1,\ldots,\ell -1$
, using the representation theory of the symmetric group. In particular, the highest degeneracy, with variance
$r=1,\ldots,\ell -1$
, using the representation theory of the symmetric group. In particular, the highest degeneracy, with variance
 $\Theta ({n^{\ell +1}} )$
, is obtained for the sign statistic
$\Theta ({n^{\ell +1}} )$
, is obtained for the sign statistic
 $U_n({sgn})$
, where
$U_n({sgn})$
, where
 ${sgn}(x_1,\ldots,x_\ell )$
is the sign of the permutation defined by the order of
${sgn}(x_1,\ldots,x_\ell )$
is the sign of the permutation defined by the order of
 $(x_1,\ldots,x_n)$
; in other words,
$(x_1,\ldots,x_n)$
; in other words,
 $U_n({sgn})$
is the sum of the signs of the
$U_n({sgn})$
is the sum of the signs of the
 $\binom n\ell$
subsequences of length
$\binom n\ell$
subsequences of length
 $\ell$
of a random permutation
$\ell$
of a random permutation
 ${\boldsymbol{\pi }}^{(n)}\in \mathfrak{S}_n$
. For
${\boldsymbol{\pi }}^{(n)}\in \mathfrak{S}_n$
. For
 $\ell =3$
, the asymptotic distribution of
$\ell =3$
, the asymptotic distribution of
 $n^{-(\ell +1)/2}U_n({sgn})$
is of the type in (A.19); see [Reference Fisher and Lee21] and [Reference Janson, Nakamura and Zeilberger39, Remark 2.7]. For larger
$n^{-(\ell +1)/2}U_n({sgn})$
is of the type in (A.19); see [Reference Fisher and Lee21] and [Reference Janson, Nakamura and Zeilberger39, Remark 2.7]. For larger
 $\ell$
, using the methods in Appendix A, the asymptotic distribution can be expressed as a polynomial of degree
$\ell$
, using the methods in Appendix A, the asymptotic distribution can be expressed as a polynomial of degree
 $\ell -1$
in infinitely many independent normal variables, as in (A.17); however, we do not know any concrete such representation.
$\ell -1$
in infinitely many independent normal variables, as in (A.17); however, we do not know any concrete such representation.
We expect that, in analogy with Example 8.1, for linear combinations of constrained pattern counts, there are further possibilities to have
 $\sigma ^2=0$
. We have not pursued this, and we leave it as an open problem to characterize these cases with
$\sigma ^2=0$
. We have not pursued this, and we leave it as an open problem to characterize these cases with
 $\sigma ^2=0$
; moreover, it would also be interesting to extend the results of [Reference Even-Zohar18] characterizing cases with higher degeneracies to constrained cases.
$\sigma ^2=0$
; moreover, it would also be interesting to extend the results of [Reference Even-Zohar18] characterizing cases with higher degeneracies to constrained cases.
15. Further comments
We discuss here briefly some possible extensions of the present work. We have not pursued them, and they are left as open problems.
15.1. Mixing and Markov input
We have in this paper studied
 $U$
-statistics based on a sequence
$U$
-statistics based on a sequence
 $(X_i)$
that is allowed to be dependent, but only under the rather strong assumption of
$(X_i)$
that is allowed to be dependent, but only under the rather strong assumption of
 $m$
-dependence (partly motivated by our application to constrained
$m$
-dependence (partly motivated by our application to constrained
 $U$
-statistics). It would be interesting to extend the results to weaker assumptions on
$U$
-statistics). It would be interesting to extend the results to weaker assumptions on
 $(X_i)$
, for example that it is stationary with some type of mixing property. (See e.g. [Reference Bradley12] for various mixing conditions and central limit theorems under some of them.)
$(X_i)$
, for example that it is stationary with some type of mixing property. (See e.g. [Reference Bradley12] for various mixing conditions and central limit theorems under some of them.)
Alternatively (or possibly as a special case of mixing conditions), it would be interesting to consider
 $(X_i)$
that form a stationary Markov chain (under suitable assumptions).
$(X_i)$
that form a stationary Markov chain (under suitable assumptions).
In particular, it seems interesting to study constrained
 $U$
-statistics under such assumptions, since the mixing or Markov assumptions typically imply strong dependence for sets of variables
$U$
-statistics under such assumptions, since the mixing or Markov assumptions typically imply strong dependence for sets of variables
 $X_i$
with small gaps between the indices, but not if the gaps are large.
$X_i$
with small gaps between the indices, but not if the gaps are large.
Markov models are popular models for random strings. Substring counts, i.e., the completely constrained case of subsequence counts (see Remark 1.2), have been treated for Markov sources by e.g. [Reference Régnier and Szpankowski52], [Reference Nicodème, Salvy and Flajolet45], and [Reference Jacquet and Szpankowski31].
A related model for random strings is a probabilistic dynamic source; see e.g. [Reference Jacquet and Szpankowski31, Section 1.1]. For substring counts, asymptotic normality has been shown by [Reference Bourdon and Vallée11]. For (unconstrained or constrained) subsequence counts, asymptotic results on mean and variance are special cases of [Reference Bourdon and Vallée10] and [Reference Jacquet and Szpankowski31, Theorem 5.6.1]; we are not aware of any results on asymptotic normality in this setting.
15.2. Generalized
$U$
-statistics

Generalized
 $U$
-statistics (also called multi-sample
$U$
-statistics (also called multi-sample
 $U$
-statistics) are defined similarly to (3.1), but are based on two (for simplicity) sequences
$U$
-statistics) are defined similarly to (3.1), but are based on two (for simplicity) sequences
 $(X_i)_1^{n_1}$
and
$(X_i)_1^{n_1}$
and
 $(Y_j)_1^{n_2}$
of random variables, with the sum in (3.1) replaced by a sum over all
$(Y_j)_1^{n_2}$
of random variables, with the sum in (3.1) replaced by a sum over all
 $i_1\lt \cdots \lt i_{\ell _1}\leqslant n_1$
and
$i_1\lt \cdots \lt i_{\ell _1}\leqslant n_1$
and
 $j_1\lt \cdots \lt j_{\ell _2}\leqslant n_2$
, and
$j_1\lt \cdots \lt j_{\ell _2}\leqslant n_2$
, and
 $f$
now a function of
$f$
now a function of
 $\ell _1+\ell _2$
variables. Limit theorems, including asymptotic normality, under suitable conditions are shown in [Reference Sen60], and extensions to asymmetric cases are sketched in [Reference Janson35, Example 11.24]. We do not know any extensions to
$\ell _1+\ell _2$
variables. Limit theorems, including asymptotic normality, under suitable conditions are shown in [Reference Sen60], and extensions to asymmetric cases are sketched in [Reference Janson35, Example 11.24]. We do not know any extensions to
 $m$
-dependent or constrained cases, but we expect that such extensions are straightforward.
$m$
-dependent or constrained cases, but we expect that such extensions are straightforward.
Appendix A. Linear combinations for unconstrained subsequence counts
As promised in Section 13, we consider here unconstrained subsequence counts in a random string
 $\Xi _n$
with i.i.d. letters, normalized as in Theorem 13.1, and study further the case of linear combinations of such normalized counts (with coefficients not depending on
$\Xi _n$
with i.i.d. letters, normalized as in Theorem 13.1, and study further the case of linear combinations of such normalized counts (with coefficients not depending on
 $n$
); in particular, we study in some detail such linear combinations that are degenerate in the sense that the asymptotic variance
$n$
); in particular, we study in some detail such linear combinations that are degenerate in the sense that the asymptotic variance
 $\sigma ^2=0$
.
$\sigma ^2=0$
.
The results are based on the orthogonal decomposition introduced in the symmetric case by Hoeffding [Reference Hoeffding28] (see also Rubin and Vitale [Reference Rubin and Vitale56]); this is extended to the asymmetric case in [Reference Janson35, Chapter 11.2], but the treatment there uses a rather heavy formalism, and we therefore give here a direct treatment in the present special case. (This case is somewhat simpler than the general case since we only have to consider finite-dimensional vector spaces below, but otherwise the general case is similar.) See also [Reference Even-Zohar, Lakrec and Tessler19], which contains a much deeper algebraic study of the asymptotic variance
 $\sigma ^2(f)$
and the vector spaces below, and in particular a spectral decomposition that refines (A.9).
$\sigma ^2(f)$
and the vector spaces below, and in particular a spectral decomposition that refines (A.9).
Fix
 $\mathcal{A}$
and the random string
$\mathcal{A}$
and the random string
 $(\xi _i)_1^\infty$
. Assume, as in Section 13, that
$(\xi _i)_1^\infty$
. Assume, as in Section 13, that
 $p(x)\gt 0$
for every
$p(x)\gt 0$
for every
 $x\in{\mathcal{A}}$
. Let
$x\in{\mathcal{A}}$
. Let
 $A\,:\!=\,|{\mathcal{A}}|$
, the number of different letters.
$A\,:\!=\,|{\mathcal{A}}|$
, the number of different letters.
We fix also
 $\ell \geqslant 1$
and consider all unconstrained subsequence counts
$\ell \geqslant 1$
and consider all unconstrained subsequence counts
 $N_n(\textbf{w})$
with
$N_n(\textbf{w})$
with
 $|\textbf{w}|=\ell$
. There are
$|\textbf{w}|=\ell$
. There are
 $A^\ell$
such words
$A^\ell$
such words
 $\textbf{w}$
, and it follows from (13.2) and (13.1) that the linear combinations of these counts are precisely the asymmetric
$\textbf{w}$
, and it follows from (13.2) and (13.1) that the linear combinations of these counts are precisely the asymmetric
 $U$
-statistics (3.1) for all
$U$
-statistics (3.1) for all
 $f\,:\,{\mathcal{A}}^\ell \to \mathbb{R}$
, by the relation
$f\,:\,{\mathcal{A}}^\ell \to \mathbb{R}$
, by the relation
 \begin{align} \sum _{\textbf{w}\in{\mathcal{A}}^\ell } f(\textbf{w})N_n(\textbf{w})=U_n(f). \end{align}
\begin{align} \sum _{\textbf{w}\in{\mathcal{A}}^\ell } f(\textbf{w})N_n(\textbf{w})=U_n(f). \end{align}
Note that Theorem 3.3 applies to every
 $U_n(f)$
, and thus (3.18) and (3.19) hold for some
$U_n(f)$
, and thus (3.18) and (3.19) hold for some
 $\sigma ^2=\sigma ^2(f)\geqslant 0$
. (As stated above, this case of Theorem 3.3 with i.i.d.
$\sigma ^2=\sigma ^2(f)\geqslant 0$
. (As stated above, this case of Theorem 3.3 with i.i.d.
 $X_i$
, i.e., the case
$X_i$
, i.e., the case
 $m=0$
, is also treated in [Reference Janson35, Corollary 11.20] and [Reference Janson37].)
$m=0$
, is also treated in [Reference Janson35, Corollary 11.20] and [Reference Janson37].)
Let
 $V$
be the linear space of all functions
$V$
be the linear space of all functions
 $f\,:\,{\mathcal{A}}^\ell \to \mathbb{R}$
. Thus
$f\,:\,{\mathcal{A}}^\ell \to \mathbb{R}$
. Thus
 $\dim V=A^\ell$
. Similarly, let
$\dim V=A^\ell$
. Similarly, let
 $W$
be the linear space of all functions
$W$
be the linear space of all functions
 $h:{\mathcal{A}}\to \mathbb{R}$
, i.e., all functions of a single letter; thus
$h:{\mathcal{A}}\to \mathbb{R}$
, i.e., all functions of a single letter; thus
 $\dim W=A$
. Then
$\dim W=A$
. Then
 $V$
can be identified with the tensor product
$V$
can be identified with the tensor product
 $W^{\otimes \ell }$
, with the identification
$W^{\otimes \ell }$
, with the identification
 \begin{align} h_1\otimes \cdots \otimes h_\ell (x_1,\ldots,x_\ell )=\prod _1^\ell h_i(x_i). \end{align}
\begin{align} h_1\otimes \cdots \otimes h_\ell (x_1,\ldots,x_\ell )=\prod _1^\ell h_i(x_i). \end{align}
We regard
 $V$
as a (finite-dimensional) Hilbert space with inner product
$V$
as a (finite-dimensional) Hilbert space with inner product
 \begin{align} \langle{f,g}\rangle _V \,:\!=\,{\mathbb{E}}\bigl [{f(\Xi _n)g(\Xi _n)}\bigr ], \end{align}
\begin{align} \langle{f,g}\rangle _V \,:\!=\,{\mathbb{E}}\bigl [{f(\Xi _n)g(\Xi _n)}\bigr ], \end{align}
and, similarly,
 $W$
as a Hilbert space with inner product
$W$
as a Hilbert space with inner product
 \begin{align} \langle{h,k}\rangle _W \,:\!=\,{\mathbb{E}}\bigl [{h(\xi _1)k(\xi _1)}\bigr ]. \end{align}
\begin{align} \langle{h,k}\rangle _W \,:\!=\,{\mathbb{E}}\bigl [{h(\xi _1)k(\xi _1)}\bigr ]. \end{align}
Let
 $W_0$
be the subspace of
$W_0$
be the subspace of
 $W$
defined by
$W$
defined by
 \begin{align} W_0\,:\!=\,\{{1}\}^\perp =\{{h\in W:\langle{h,1}\rangle _W=0}\} =\{{h\in W:{\mathbb{E}} h(\xi _1)=0}\}. \end{align}
\begin{align} W_0\,:\!=\,\{{1}\}^\perp =\{{h\in W:\langle{h,1}\rangle _W=0}\} =\{{h\in W:{\mathbb{E}} h(\xi _1)=0}\}. \end{align}
Thus,
 $\dim W_0=A-1$
.
$\dim W_0=A-1$
.
For a subset
 ${\mathcal{B}}\subseteq{\mathcal{A}}$
, let
${\mathcal{B}}\subseteq{\mathcal{A}}$
, let
 $V_{\mathcal{B}}$
be the subspace of
$V_{\mathcal{B}}$
be the subspace of
 $V$
spanned by all functions
$V$
spanned by all functions
 $h_1\otimes \cdots \otimes h_\ell$
as in (A.2) such that
$h_1\otimes \cdots \otimes h_\ell$
as in (A.2) such that
 $h_i\in W_0$
if
$h_i\in W_0$
if
 $i\in{\mathcal{B}}$
, and
$i\in{\mathcal{B}}$
, and
 $h_i=1$
if
$h_i=1$
if
 $i\notin{\mathcal{B}}$
. In other words, if for a given
$i\notin{\mathcal{B}}$
. In other words, if for a given
 $\mathcal{B}$
we define
$\mathcal{B}$
we define
 $W'_i\,:\!=\,W_0$
when
$W'_i\,:\!=\,W_0$
when
 $i\in{\mathcal{B}}$
and
$i\in{\mathcal{B}}$
and
 $W'_i=\mathbb{R}$
when
$W'_i=\mathbb{R}$
when
 $i\notin{\mathcal{B}}$
, then
$i\notin{\mathcal{B}}$
, then
 \begin{align} V_{\mathcal{B}}=W'_1\otimes \cdots \otimes W'_\ell \cong W_0^{\otimes |{\mathcal{B}}|} . \end{align}
\begin{align} V_{\mathcal{B}}=W'_1\otimes \cdots \otimes W'_\ell \cong W_0^{\otimes |{\mathcal{B}}|} . \end{align}
It is easily seen that these
 $2^A$
subspaces of
$2^A$
subspaces of
 $V$
are orthogonal, and that we have an orthogonal decomposition
$V$
are orthogonal, and that we have an orthogonal decomposition
 \begin{align} V=\bigoplus _{{\mathcal{B}}\subseteq{\mathcal{A}}} V_{\mathcal{B}}. \end{align}
\begin{align} V=\bigoplus _{{\mathcal{B}}\subseteq{\mathcal{A}}} V_{\mathcal{B}}. \end{align}
Furthermore, for
 $k=0,\ldots,\ell$
, define
$k=0,\ldots,\ell$
, define
 \begin{align} V_k\,:\!=\,\bigoplus _{|{\mathcal{B}}|=k} V_{\mathcal{B}}. \end{align}
\begin{align} V_k\,:\!=\,\bigoplus _{|{\mathcal{B}}|=k} V_{\mathcal{B}}. \end{align}
Thus, we also have an orthogonal decomposition (as in [Reference Hoeffding28] and [Reference Rubin and Vitale56])
 \begin{align} V=\bigoplus _{k=0}^\ell V_k. \end{align}
\begin{align} V=\bigoplus _{k=0}^\ell V_k. \end{align}
Note that, by (A.6) and (A.8),
 \begin{align} \dim V_{\mathcal{B}} = (A-1)^{|{\mathcal{B}}|}, \qquad \dim V_k = \binom{\ell }{k}(A-1)^{k}. \end{align}
\begin{align} \dim V_{\mathcal{B}} = (A-1)^{|{\mathcal{B}}|}, \qquad \dim V_k = \binom{\ell }{k}(A-1)^{k}. \end{align}
Let
 $\Pi _{\mathcal{B}}$
and
$\Pi _{\mathcal{B}}$
and
 $\Pi _k=\sum _{|{\mathcal{B}}|=k}\Pi _{\mathcal{B}}$
be the orthogonal projections of
$\Pi _k=\sum _{|{\mathcal{B}}|=k}\Pi _{\mathcal{B}}$
be the orthogonal projections of
 $V$
onto
$V$
onto
 $V_{\mathcal{B}}$
and
$V_{\mathcal{B}}$
and
 $V_k$
. Then, for any
$V_k$
. Then, for any
 $f\in V$
, we may consider its components
$f\in V$
, we may consider its components
 $\Pi _kf\in V_k$
.
$\Pi _kf\in V_k$
.
First,
 $V_0$
is the 1-dimensional space of constant functions in
$V_0$
is the 1-dimensional space of constant functions in
 $V$
. Trivially, if
$V$
. Trivially, if
 $f\in V_0$
, then
$f\in V_0$
, then
 $U_n(f)$
is non-random, so
$U_n(f)$
is non-random, so
 ${Var}\ U_n(f)=0$
for every
${Var}\ U_n(f)=0$
for every
 $n$
, and
$n$
, and
 $\sigma ^2(f)=0$
. More interesting is that for any
$\sigma ^2(f)=0$
. More interesting is that for any
 $f\in V$
, we have
$f\in V$
, we have
 \begin{align} \Pi _0f={\mathbb{E}} f(\xi _1,\ldots,\xi _\ell )=\mu . \end{align}
\begin{align} \Pi _0f={\mathbb{E}} f(\xi _1,\ldots,\xi _\ell )=\mu . \end{align}
Next, it is easy to see that taking
 ${\mathcal{B}}=\{{i}\}$
yields the projection
${\mathcal{B}}=\{{i}\}$
yields the projection
 $f_i$
defined by (6.1), except that
$f_i$
defined by (6.1), except that
 $\Pi _{\{i\}} f$
is defined as a function on
$\Pi _{\{i\}} f$
is defined as a function on
 ${\mathcal{A}}^\ell$
; to be precise,
${\mathcal{A}}^\ell$
; to be precise,
 \begin{align} \Pi _{\{i\}}f(x_1,\ldots,x_\ell )=f_i(x_i). \end{align}
\begin{align} \Pi _{\{i\}}f(x_1,\ldots,x_\ell )=f_i(x_i). \end{align}
Recalling (A.1), this leads to the following characterization of degenerate linear combinations of unconstrained subsequence counts.
Theorem A.1.
With notation and assumptions as above, if
 $f\,:\,{\mathcal{A}}^\ell \to \mathbb{R}$
, then the following are equivalent:
$f\,:\,{\mathcal{A}}^\ell \to \mathbb{R}$
, then the following are equivalent:
-
(i)
$\sigma ^2(f)=0$
. -
(ii)
$f_i=0$
for every
$i=1,\ldots,\ell$
. -
(iii)
$\Pi _1f=0$
.




Proof. The equivalence (i)
 $\iff$
(ii) is a special case of Theorem 8.1; as stated above, this special case is also given in [Reference Janson37, Corollary 3.5].
$\iff$
(ii) is a special case of Theorem 8.1; as stated above, this special case is also given in [Reference Janson37, Corollary 3.5].
The equivalence (ii)
 $\iff$
(iii) follows by (A.8) and (A.12), which give
$\iff$
(iii) follows by (A.8) and (A.12), which give
 \begin{align} \Pi _1f=0 \iff \Pi _{\{i\}}f=0\; \forall i \iff f_i=0\; \forall i. \end{align}
\begin{align} \Pi _1f=0 \iff \Pi _{\{i\}}f=0\; \forall i \iff f_i=0\; \forall i. \end{align}
Note that (A.8) and (A.12) also yield
 \begin{align} \Pi _1 f (x_1,\ldots,x_\ell ) = \sum _{i=1}^\ell \Pi _{\{i\}} f (x_1,\ldots,x_\ell ) = \sum _{i=1}^\ell f_i(x_i) . \end{align}
\begin{align} \Pi _1 f (x_1,\ldots,x_\ell ) = \sum _{i=1}^\ell \Pi _{\{i\}} f (x_1,\ldots,x_\ell ) = \sum _{i=1}^\ell f_i(x_i) . \end{align}
Corollary A.1.
The
 $A^\ell$
different unconstrained subsequence counts
$A^\ell$
different unconstrained subsequence counts
 $N_n(\textbf{w})$
with
$N_n(\textbf{w})$
with
 $\textbf{w}\in{\mathcal{A}}^\ell$
converge jointly, after normalization as in (13.4), to a centered multivariate normal distribution in
$\textbf{w}\in{\mathcal{A}}^\ell$
converge jointly, after normalization as in (13.4), to a centered multivariate normal distribution in
 $\mathbb{R}^{A^\ell }$
whose support is a subspace of dimension
$\mathbb{R}^{A^\ell }$
whose support is a subspace of dimension
 $\ell (A-1)$
.
$\ell (A-1)$
.
Proof. By Remark 3.6, we have joint convergence in Theorem 13.1 to some centered multivariate normal distribution in
 $V=\mathbb{R}^{A^\ell }$
. Let
$V=\mathbb{R}^{A^\ell }$
. Let
 $L$
be the support of this distribution; then
$L$
be the support of this distribution; then
 $L$
is a subspace of
$L$
is a subspace of
 $V$
. Let
$V$
. Let
 $f\in V$
. Then, by Theorems 13.1 and A.1,
$f\in V$
. Then, by Theorems 13.1 and A.1,
 \begin{align} f\perp L& \iff \sum _{\textbf{w}\in{\mathcal{A}}^\ell }f(\textbf{w}) \frac{N_n(\textbf{w})-{\mathbb{E}} N_n(\textbf{w})}{n^{\ell -1/2}} \overset{d}{\longrightarrow } 0 \iff \sigma ^2(f)=0 \notag \\& \iff \Pi _1 f=0 \iff f\perp V_1. \end{align}
\begin{align} f\perp L& \iff \sum _{\textbf{w}\in{\mathcal{A}}^\ell }f(\textbf{w}) \frac{N_n(\textbf{w})-{\mathbb{E}} N_n(\textbf{w})}{n^{\ell -1/2}} \overset{d}{\longrightarrow } 0 \iff \sigma ^2(f)=0 \notag \\& \iff \Pi _1 f=0 \iff f\perp V_1. \end{align}
Hence
 $L=V_1$
, and the result follows by (A.10).
$L=V_1$
, and the result follows by (A.10).
What happens in the degenerate case when
 $\Pi _1f=0$
and thus
$\Pi _1f=0$
and thus
 $\sigma ^2(f)=0$
? For symmetric
$\sigma ^2(f)=0$
? For symmetric
 $U$
-statistics, this was considered by Hoeffding [Reference Hoeffding27] (variance) and Rubin and Vitale [Reference Rubin and Vitale56] (asymptotic distribution); see also Dynkin and Mandelbaum [Reference Dynkin and Mandelbaum16]. Their results extend to the present asymmetric situation as follows. We make a final definition of a special subspace of
$U$
-statistics, this was considered by Hoeffding [Reference Hoeffding27] (variance) and Rubin and Vitale [Reference Rubin and Vitale56] (asymptotic distribution); see also Dynkin and Mandelbaum [Reference Dynkin and Mandelbaum16]. Their results extend to the present asymmetric situation as follows. We make a final definition of a special subspace of
 $V$
: let
$V$
: let
 \begin{align} V_{\geqslant k}\,:\!=\,\bigoplus _{i=k}^\ell V_i = \{{f\in V: \Pi _i f=0\text{ for } i=0,\ldots,k-1}\}. \end{align}
\begin{align} V_{\geqslant k}\,:\!=\,\bigoplus _{i=k}^\ell V_i = \{{f\in V: \Pi _i f=0\text{ for } i=0,\ldots,k-1}\}. \end{align}
In particular,
 $V_{\geqslant 1}$
consists of all
$V_{\geqslant 1}$
consists of all
 $f$
with
$f$
with
 ${\mathbb{E}} f(\Xi _n)=0$
. Note also that
${\mathbb{E}} f(\Xi _n)=0$
. Note also that
 $f_*$
in (6.3), by (A.11) and (A.14), equals
$f_*$
in (6.3), by (A.11) and (A.14), equals
 $f-\Pi _0 f-\Pi _1 f\in V_{\geqslant 2}$
.
$f-\Pi _0 f-\Pi _1 f\in V_{\geqslant 2}$
.
Lemma A.1.
Let
 $0\leqslant k\leqslant \ell$
. If
$0\leqslant k\leqslant \ell$
. If
 $f\in V_{\geqslant k}$
, then
$f\in V_{\geqslant k}$
, then
 ${\mathbb{E}} U_n(f)^2 = O ({n^{2\ell -k}} )$
. Moreover, if
${\mathbb{E}} U_n(f)^2 = O ({n^{2\ell -k}} )$
. Moreover, if
 $f\in V_{\geqslant k}\setminus V_{\geqslant k+1}$
, then
$f\in V_{\geqslant k}\setminus V_{\geqslant k+1}$
, then
 ${\mathbb{E}} U_n(f)^2 = \Theta ({n^{2\ell -k}} )$
.
${\mathbb{E}} U_n(f)^2 = \Theta ({n^{2\ell -k}} )$
.
Proof. This is easily seen using the expansion (4.3) without the constraint
 $\mathcal{D}$
, and is similar to the symmetric case in [Reference Hoeffding27]; cf. also (in the more complicated
$\mathcal{D}$
, and is similar to the symmetric case in [Reference Hoeffding27]; cf. also (in the more complicated
 $m$
-dependent case) the cases
$m$
-dependent case) the cases
 $k=1$
in (4.1) and
$k=1$
in (4.1) and
 $k=2$
in (6.10). We omit the details.
$k=2$
in (6.10). We omit the details.
We can now state a general limit theorem that also includes degenerate cases.
Theorem A.2.
Let
 $k\geqslant 1$
and suppose that
$k\geqslant 1$
and suppose that
 $f\in V_{\geqslant k}$
. Then
$f\in V_{\geqslant k}$
. Then
 \begin{align} n^{k/2-\ell } U_n(f) \overset{d}{\longrightarrow } Z, \end{align}
\begin{align} n^{k/2-\ell } U_n(f) \overset{d}{\longrightarrow } Z, \end{align}
where
 $Z$
is some polynomial of degree
$Z$
is some polynomial of degree
 $k$
in independent normal variables (possibly infinitely many). Moreover,
$k$
in independent normal variables (possibly infinitely many). Moreover,
 $Z$
is not degenerate unless
$Z$
is not degenerate unless
 $f\in V_{\geqslant k+1}$
.
$f\in V_{\geqslant k+1}$
.
Proof. This follows by [Reference Janson35, Theorem 11.19]. As noted in [Reference Janson35, Remark 11.21], it can also be reduced to the symmetric case in [Reference Rubin and Vitale56] by the following trick. Let
 $(\eta _i)_1^\infty$
be an i.i.d. sequence, independent of
$(\eta _i)_1^\infty$
be an i.i.d. sequence, independent of
 $(\xi _i)_1^\infty$
, with
$(\xi _i)_1^\infty$
, with
 $\eta _i\sim U(0,1)$
; then
$\eta _i\sim U(0,1)$
; then
 \begin{align} U_n\bigl ({f;\,(\xi _i)}\bigr ) \overset{d}{=} \mathop{\sum \limits }^{*}_{i_1,\ldots,i_\ell \leqslant n} f\bigl ({\xi _{i_1},\ldots,\xi _{i_\ell }}\bigr ) \boldsymbol{1}\{{\eta _{i_1}\lt \ldots \lt \eta _{i_\ell }}\}, \end{align}
\begin{align} U_n\bigl ({f;\,(\xi _i)}\bigr ) \overset{d}{=} \mathop{\sum \limits }^{*}_{i_1,\ldots,i_\ell \leqslant n} f\bigl ({\xi _{i_1},\ldots,\xi _{i_\ell }}\bigr ) \boldsymbol{1}\{{\eta _{i_1}\lt \ldots \lt \eta _{i_\ell }}\}, \end{align}
where
 $\sum ^*$
denotes summation over all distinct
$\sum ^*$
denotes summation over all distinct
 $i_1,\ldots,i_\ell \in [n]$
, and the sum in (A.18) can be regarded as a symmetric
$i_1,\ldots,i_\ell \in [n]$
, and the sum in (A.18) can be regarded as a symmetric
 $U$
-statistic based on
$U$
-statistic based on
 $(\xi _i,\eta _i)_1^\infty$
. The result (A.17) then follows by [Reference Rubin and Vitale56].
$(\xi _i,\eta _i)_1^\infty$
. The result (A.17) then follows by [Reference Rubin and Vitale56].
Remark A.1. The case
 $k=1$
in Theorem A.2 is just a combination of Theorem 13.1 (in the unconstrained case) and Theorem A.1; then
$k=1$
in Theorem A.2 is just a combination of Theorem 13.1 (in the unconstrained case) and Theorem A.1; then
 $Z$
is simply a normal variable. When
$Z$
is simply a normal variable. When
 $k=2$
, there is a canonical representation (where the number of terms is finite or infinite)
$k=2$
, there is a canonical representation (where the number of terms is finite or infinite)
 \begin{align} Z=\frac{1}{2(\ell -2)!}\sum _i \lambda _i (\zeta _i^2-1), \end{align}
\begin{align} Z=\frac{1}{2(\ell -2)!}\sum _i \lambda _i (\zeta _i^2-1), \end{align}
where
 $\zeta _i$
are i.i.d.
$\zeta _i$
are i.i.d.
 $\textsf{N}(0,1)$
random variables and
$\textsf{N}(0,1)$
random variables and
 $\lambda _i$
are the non-zero eigenvalues (counted with multiplicity) of a compact self-adjoint integral operator on
$\lambda _i$
are the non-zero eigenvalues (counted with multiplicity) of a compact self-adjoint integral operator on
 $L^2({\mathcal{A}}\times [0,1], \nu \times {d} t)$
, where
$L^2({\mathcal{A}}\times [0,1], \nu \times {d} t)$
, where
 $\nu \,:\!=\,{\mathcal{L}}(\xi _1)$
is the distribution of a single letter and
$\nu \,:\!=\,{\mathcal{L}}(\xi _1)$
is the distribution of a single letter and
 ${d} t$
is Lebesgue measure; the kernel
${d} t$
is Lebesgue measure; the kernel
 $K$
of this integral operator can be constructed from
$K$
of this integral operator can be constructed from
 $f$
by applying [Reference Janson35, Corollary 11.5(iii)] to the symmetric
$f$
by applying [Reference Janson35, Corollary 11.5(iii)] to the symmetric
 $U$
-statistic in (A.18). We omit the details, but note that in the particular case
$U$
-statistic in (A.18). We omit the details, but note that in the particular case
 $k=\ell =2$
, this kernel
$k=\ell =2$
, this kernel
 $K$
is given by
$K$
is given by
 \begin{align} K\bigl ({(x,t),(y,u)}\bigr ) = f(x,y)\boldsymbol{1}\{{t\lt u}\} + f(y,x)\boldsymbol{1}\{{t\gt u}\}, \end{align}
\begin{align} K\bigl ({(x,t),(y,u)}\bigr ) = f(x,y)\boldsymbol{1}\{{t\lt u}\} + f(y,x)\boldsymbol{1}\{{t\gt u}\}, \end{align}
and thus the integral operator is
 \begin{align} h\mapsto Th(x,t) \,:\!=\,{\mathbb{E}}\int _0^t f(\xi _1,x)h(\xi _1,u)\,{d} u +{\mathbb{E}}\int _t^1 f(x,\xi _1)h(\xi _1,u)\,{d} u . \end{align}
\begin{align} h\mapsto Th(x,t) \,:\!=\,{\mathbb{E}}\int _0^t f(\xi _1,x)h(\xi _1,u)\,{d} u +{\mathbb{E}}\int _t^1 f(x,\xi _1)h(\xi _1,u)\,{d} u . \end{align}
When
 $k\geqslant 3$
, the limit
$k\geqslant 3$
, the limit
 $Z$
can be represented as a multiple stochastic integral [Reference Janson35, Theorem 11.19], but we do not know any canonical representation of it. See also [Reference Rubin and Vitale56] and [Reference Dynkin and Mandelbaum16].
$Z$
can be represented as a multiple stochastic integral [Reference Janson35, Theorem 11.19], but we do not know any canonical representation of it. See also [Reference Rubin and Vitale56] and [Reference Dynkin and Mandelbaum16].
We give two simple examples of limits in degenerate cases; in both cases
 $k=2$
. The second example shows that although the space
$k=2$
. The second example shows that although the space
 $V$
has finite dimension, the representation (A.19) might require infinitely many terms. (Note that the operator
$V$
has finite dimension, the representation (A.19) might require infinitely many terms. (Note that the operator
 $T$
in (A.21) acts in an infinite-dimensional space.)
$T$
in (A.21) acts in an infinite-dimensional space.)
Example A.1. Let
 $\Xi _n$
be a symmetric binary string, i.e.,
$\Xi _n$
be a symmetric binary string, i.e.,
 ${\mathcal{A}}=\{{0,1}\}$
and
${\mathcal{A}}=\{{0,1}\}$
and
 $p(0)=p(1)=1/2$
. Consider
$p(0)=p(1)=1/2$
. Consider
 \begin{align} N_n(00)+N_n(11)-N_n(01)-N_n(10) =U_n(f), \end{align}
\begin{align} N_n(00)+N_n(11)-N_n(01)-N_n(10) =U_n(f), \end{align}
with
 \begin{align} f(x,y)&\,:\!=\, \boldsymbol{1}\{{xy=00}\}+\boldsymbol{1}\{{xy=11}\}-\boldsymbol{1}\{{xy=01}\}-\boldsymbol{1}\{{xy=10}\} \notag \\&\phantom \,:\!=\,\bigl ({\boldsymbol{1}\{{x=1}\}-\boldsymbol{1}\{{x=0}\}}\bigr )\bigl ({\boldsymbol{1}\{{y=1}\}-\boldsymbol{1}\{{y=0}\}}\bigr ). \end{align}
\begin{align} f(x,y)&\,:\!=\, \boldsymbol{1}\{{xy=00}\}+\boldsymbol{1}\{{xy=11}\}-\boldsymbol{1}\{{xy=01}\}-\boldsymbol{1}\{{xy=10}\} \notag \\&\phantom \,:\!=\,\bigl ({\boldsymbol{1}\{{x=1}\}-\boldsymbol{1}\{{x=0}\}}\bigr )\bigl ({\boldsymbol{1}\{{y=1}\}-\boldsymbol{1}\{{y=0}\}}\bigr ). \end{align}
For convenience, we change notation and consider instead the letters
 $\hat{\xi }_i\,:\!=\,2\xi _i-1\in \{{\pm 1}\}$
; then
$\hat{\xi }_i\,:\!=\,2\xi _i-1\in \{{\pm 1}\}$
; then
 $f$
corresponds to
$f$
corresponds to
 \begin{align} \hat{f}(\hat x,\hat y)\,:\!=\,\hat x \hat y. \end{align}
\begin{align} \hat{f}(\hat x,\hat y)\,:\!=\,\hat x \hat y. \end{align}
Thus
 \begin{align} U_n\bigl ({f;\,(\xi _i)}\bigr )& = U_n\bigl ({\hat{f};\,(\hat{\xi }_i)}\bigr ) =\sum _{1\leqslant i\lt j\leqslant n}\hat{\xi }_i\hat{\xi }_j = \frac 12\left ({\left ({\sum _{i=1}^n \hat{\xi }_i}\right )^2-\sum _{i=1}^n \hat{\xi }_i^2}\right ) \notag \\&= \frac 12\left ({\sum _{i=1}^n \hat{\xi }_i}\right )^2-\frac{n}2. \end{align}
\begin{align} U_n\bigl ({f;\,(\xi _i)}\bigr )& = U_n\bigl ({\hat{f};\,(\hat{\xi }_i)}\bigr ) =\sum _{1\leqslant i\lt j\leqslant n}\hat{\xi }_i\hat{\xi }_j = \frac 12\left ({\left ({\sum _{i=1}^n \hat{\xi }_i}\right )^2-\sum _{i=1}^n \hat{\xi }_i^2}\right ) \notag \\&= \frac 12\left ({\sum _{i=1}^n \hat{\xi }_i}\right )^2-\frac{n}2. \end{align}
By the central limit theorem,
 $n^{-1/2}\sum _{i=1}^n \hat{\xi }_i\overset{d}{\longrightarrow } \zeta \sim \textsf{N}(0,1)$
, and thus (A.25) implies
$n^{-1/2}\sum _{i=1}^n \hat{\xi }_i\overset{d}{\longrightarrow } \zeta \sim \textsf{N}(0,1)$
, and thus (A.25) implies
 \begin{align} n^{-1} U_n(f) \overset{d}{\longrightarrow } \tfrac 12(\zeta ^2-1) . \end{align}
\begin{align} n^{-1} U_n(f) \overset{d}{\longrightarrow } \tfrac 12(\zeta ^2-1) . \end{align}
This is an example of (A.17), with
 $k=\ell =2$
and limit given by (A.19), in this case with a single term in the sum and
$k=\ell =2$
and limit given by (A.19), in this case with a single term in the sum and
 $\lambda _1 =1$
.
$\lambda _1 =1$
.
Note that in this example, the function
 $f$
is symmetric, so (A.22) is an example of a symmetric
$f$
is symmetric, so (A.22) is an example of a symmetric
 $U$
-statistic, and thus the result (A.26) is also an example of the limit result in [Reference Rubin and Vitale56].
$U$
-statistic, and thus the result (A.26) is also an example of the limit result in [Reference Rubin and Vitale56].
Example A.2. Let
 ${\mathcal{A}}=\{{a,b,c,d}\}$
, with
${\mathcal{A}}=\{{a,b,c,d}\}$
, with
 $\xi _i$
having the symmetric distribution
$\xi _i$
having the symmetric distribution
 $p(x)=1/4$
for each
$p(x)=1/4$
for each
 $x\in{\mathcal{A}}$
. Consider
$x\in{\mathcal{A}}$
. Consider
 \begin{align} N_n(ac)-N_n(ad)-N_n(bc)+N_n(bd) =U_n(f), \end{align}
\begin{align} N_n(ac)-N_n(ad)-N_n(bc)+N_n(bd) =U_n(f), \end{align}
with, writing
 $\boldsymbol{1}_y(x)\,:\!=\,\boldsymbol{1}\{{x=y}\}$
,
$\boldsymbol{1}_y(x)\,:\!=\,\boldsymbol{1}\{{x=y}\}$
,
 \begin{align} f(x,y)&\,:\!=\, \bigl ({\boldsymbol{1}_a(x)-\boldsymbol{1}_b(x)}\bigr ) \bigl ({\boldsymbol{1}_c(x)-\boldsymbol{1}_d(x)}\bigr ). \end{align}
\begin{align} f(x,y)&\,:\!=\, \bigl ({\boldsymbol{1}_a(x)-\boldsymbol{1}_b(x)}\bigr ) \bigl ({\boldsymbol{1}_c(x)-\boldsymbol{1}_d(x)}\bigr ). \end{align}
Then
 $\Pi _0f=\Pi _1 f=0$
by symmetry, so
$\Pi _0f=\Pi _1 f=0$
by symmetry, so
 $f\in V_{\geqslant 2}=V_2$
(since
$f\in V_{\geqslant 2}=V_2$
(since
 $\ell =2$
).
$\ell =2$
).
Consider the integral operator
 $T$
on
$T$
on
 $L^2({\mathcal{A}}\times [0,1])$
defined by (A.21). Let
$L^2({\mathcal{A}}\times [0,1])$
defined by (A.21). Let
 $h$
be an eigenfunction with eigenvalue
$h$
be an eigenfunction with eigenvalue
 $\lambda \neq 0$
, and write
$\lambda \neq 0$
, and write
 $h_x(t)\,:\!=\,h(x,t)$
. The eigenvalue equation
$h_x(t)\,:\!=\,h(x,t)$
. The eigenvalue equation
 $Th=\lambda h$
then is equivalent to the following, using (A.21) and (A.28):
$Th=\lambda h$
then is equivalent to the following, using (A.21) and (A.28):
 \begin{align} \lambda h_a(t) &= \frac{1}{4}\int _t^1\bigl ({h_c(u)-h_d(u)}\bigr )\,{d} u, \end{align}
\begin{align} \lambda h_a(t) &= \frac{1}{4}\int _t^1\bigl ({h_c(u)-h_d(u)}\bigr )\,{d} u, \end{align}
 \begin{align} \lambda h_b(t) &= \frac{1}{4}\int _t^1\bigl ({-h_c(u)+h_d(u)}\bigr )\,{d} u, \end{align}
\begin{align} \lambda h_b(t) &= \frac{1}{4}\int _t^1\bigl ({-h_c(u)+h_d(u)}\bigr )\,{d} u, \end{align}
 \begin{align} \lambda h_c(t) &= \frac{1}{4}\int _0^t\bigl ({h_a(u)-h_b(u)}\bigr )\,{d} u, \end{align}
\begin{align} \lambda h_c(t) &= \frac{1}{4}\int _0^t\bigl ({h_a(u)-h_b(u)}\bigr )\,{d} u, \end{align}
 \begin{align} \lambda h_d(t) &= \frac{1}{4}\int _0^t\bigl ({-h_a(u)+h_b(u)}\bigr )\,{d} u. \end{align}
\begin{align} \lambda h_d(t) &= \frac{1}{4}\int _0^t\bigl ({-h_a(u)+h_b(u)}\bigr )\,{d} u. \end{align}
These equations hold a.e., but we can redefine
 $h_x(t)$
by these equations so that they hold for every
$h_x(t)$
by these equations so that they hold for every
 $t\in [0,1]$
. Moreover, although originally we assume only
$t\in [0,1]$
. Moreover, although originally we assume only
 $h_x\in L^2[0,1]$
, it follows from (A.29)–(A.32) that the functions
$h_x\in L^2[0,1]$
, it follows from (A.29)–(A.32) that the functions
 $h_x(t)$
are continuous in
$h_x(t)$
are continuous in
 $t$
, and then by induction that they are infinitely differentiable on
$t$
, and then by induction that they are infinitely differentiable on
 $[0,1]$
. Note also that (A.29) and (A.30) yield
$[0,1]$
. Note also that (A.29) and (A.30) yield
 $h_b(t)=-h_a(t)$
, and similarly
$h_b(t)=-h_a(t)$
, and similarly
 $h_d(t)=-h_c(t)$
. Hence, we may reduce the system to
$h_d(t)=-h_c(t)$
. Hence, we may reduce the system to
 \begin{align} \lambda h_a(t) &= \frac{1}{2}\int _t^1h_c(u)\,{d} u, \end{align}
\begin{align} \lambda h_a(t) &= \frac{1}{2}\int _t^1h_c(u)\,{d} u, \end{align}
 \begin{align} \lambda h_c(t) &= \frac{1}{2}\int _0^th_a(u)\,{d} u. \end{align}
\begin{align} \lambda h_c(t) &= \frac{1}{2}\int _0^th_a(u)\,{d} u. \end{align}
By differentiation, for
 $t\in (0,1)$
,
$t\in (0,1)$
,
 \begin{align} h_a'(t) &= -\frac{1}{2\lambda }h_c(t), \end{align}
\begin{align} h_a'(t) &= -\frac{1}{2\lambda }h_c(t), \end{align}
 \begin{align} h_c'(t) &= \frac{1}{2\lambda }h_a(t). \end{align}
\begin{align} h_c'(t) &= \frac{1}{2\lambda }h_a(t). \end{align}
Hence, with
 $\omega \,:\!=\,1/(2\lambda )$
,
$\omega \,:\!=\,1/(2\lambda )$
,
 \begin{align} h_c''(t)=-\omega ^2h_c(t). \end{align}
\begin{align} h_c''(t)=-\omega ^2h_c(t). \end{align}
Furthermore, (A.34) yields
 $h_c(0)=0$
, and thus (A.37) has the solution (up to a constant factor that we may ignore)
$h_c(0)=0$
, and thus (A.37) has the solution (up to a constant factor that we may ignore)
 \begin{align} h_c(t) = \sin \omega t = \sin \frac{t}{2\lambda }. \end{align}
\begin{align} h_c(t) = \sin \omega t = \sin \frac{t}{2\lambda }. \end{align}
By (A.36), we then obtain
 \begin{align} h_a(t) = \cos \omega t = \cos \frac{t}{2\lambda }. \end{align}
\begin{align} h_a(t) = \cos \omega t = \cos \frac{t}{2\lambda }. \end{align}
However, (A.33) also yields
 $h_a(1)=0$
and thus we must have
$h_a(1)=0$
and thus we must have
 $\cos (1/2\lambda )=0$
; hence
$\cos (1/2\lambda )=0$
; hence
 \begin{align} \lambda = \frac{1}{(2N+1)\pi }, \qquad N\in \mathbb{Z}. \end{align}
\begin{align} \lambda = \frac{1}{(2N+1)\pi }, \qquad N\in \mathbb{Z}. \end{align}
Conversely, for every
 $\lambda$
of the form (A.40), the argument can be reversed to find an eigenfunction
$\lambda$
of the form (A.40), the argument can be reversed to find an eigenfunction
 $h$
with eigenvalue
$h$
with eigenvalue
 $\lambda$
. It follows also that all these eigenvalues are simple. Consequently, Theorem A.2 and (A.19) yield
$\lambda$
. It follows also that all these eigenvalues are simple. Consequently, Theorem A.2 and (A.19) yield
 \begin{align} n^{-1} U_n(f) \overset{d}{\longrightarrow } \frac{1}{2\pi }\sum _{N=-\infty }^\infty \frac{1}{2N+1}(\zeta _N^2-1) = \frac{1}{2\pi }\sum _{N=0}^\infty \frac{1}{2N+1}(\zeta _N^2-\zeta _{-N-1}^2), \end{align}
\begin{align} n^{-1} U_n(f) \overset{d}{\longrightarrow } \frac{1}{2\pi }\sum _{N=-\infty }^\infty \frac{1}{2N+1}(\zeta _N^2-1) = \frac{1}{2\pi }\sum _{N=0}^\infty \frac{1}{2N+1}(\zeta _N^2-\zeta _{-N-1}^2), \end{align}
where, as above,
 $\zeta _N$
are i.i.d. and
$\zeta _N$
are i.i.d. and
 $\textsf{N}(0,1)$
. A simple calculation, using the product formula for cosine (see [Reference Euler17, Section 12], [Reference Olver, Lozier, Boisvert and Clark46, 4.22.2]), shows that the moment generating function of the limit distribution
$\textsf{N}(0,1)$
. A simple calculation, using the product formula for cosine (see [Reference Euler17, Section 12], [Reference Olver, Lozier, Boisvert and Clark46, 4.22.2]), shows that the moment generating function of the limit distribution
 $Z$
in (A.41) is
$Z$
in (A.41) is
 \begin{align} {\mathbb{E}} e^{s Z} = \frac{1}{\cos ^{1/2}(s/2)}, \qquad |{Re}\ s|\lt \pi . \end{align}
\begin{align} {\mathbb{E}} e^{s Z} = \frac{1}{\cos ^{1/2}(s/2)}, \qquad |{Re}\ s|\lt \pi . \end{align}
It can be shown that
 $Z\overset{d}{=} \frac 12\int _0^1 B_1(t)\,{d} B_2(t)$
if
$Z\overset{d}{=} \frac 12\int _0^1 B_1(t)\,{d} B_2(t)$
if
 $B_1(t)$
and
$B_1(t)$
and
 $B_2(t)$
are two independent standard Brownian motions; this is, for example, a consequence of (A.42) and the following calculation, using [Reference Cameron and Martin13] or [Reference Revuz and Yor53, p. 445] for the final equality:
$B_2(t)$
are two independent standard Brownian motions; this is, for example, a consequence of (A.42) and the following calculation, using [Reference Cameron and Martin13] or [Reference Revuz and Yor53, p. 445] for the final equality:
 \begin{align}{\mathbb{E}}{e^{s\int _0^1 B_1(t)\,{d} B_2(t)}}&={\mathbb{E}}{\mathbb{E}}\bigl [{ e^{ s\int _0^1 B_1(t)\,{d} B_2(t)}\mid B_1}\bigr ] ={\mathbb{E}} e^{\frac{s^2}{2}\int _0^1 B_1(t)^2\,{d} t} \notag \\& =\cos ^{-1/2}(s), \qquad |{Re}\ s|\lt \pi/2. \end{align}
\begin{align}{\mathbb{E}}{e^{s\int _0^1 B_1(t)\,{d} B_2(t)}}&={\mathbb{E}}{\mathbb{E}}\bigl [{ e^{ s\int _0^1 B_1(t)\,{d} B_2(t)}\mid B_1}\bigr ] ={\mathbb{E}} e^{\frac{s^2}{2}\int _0^1 B_1(t)^2\,{d} t} \notag \\& =\cos ^{-1/2}(s), \qquad |{Re}\ s|\lt \pi/2. \end{align}
We omit the details, but note that this representation of the limit
 $Z$
is related to the special form (A.28) of
$Z$
is related to the special form (A.28) of
 $f$
; we may, intuitively at least, interpret
$f$
; we may, intuitively at least, interpret
 $B_1$
and
$B_1$
and
 $B_2$
as limits (by Donsker’s theorem) of partial sums of
$B_2$
as limits (by Donsker’s theorem) of partial sums of
 $\boldsymbol{1}_a(\xi _i)-\boldsymbol{1}_b(\xi _i)$
and
$\boldsymbol{1}_a(\xi _i)-\boldsymbol{1}_b(\xi _i)$
and
 $\boldsymbol{1}_c(\xi _i)-\boldsymbol{1}_d(\xi _i)$
. In fact, in this example it is possible to give a rigorous proof of
$\boldsymbol{1}_c(\xi _i)-\boldsymbol{1}_d(\xi _i)$
. In fact, in this example it is possible to give a rigorous proof of
 $n^{-1} U_n(f)\overset{d}{\longrightarrow } Z$
by this approach; again we omit the details.
$n^{-1} U_n(f)\overset{d}{\longrightarrow } Z$
by this approach; again we omit the details.
Funding information
This work was supported by the Knut and Alice Wallenberg Foundation.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.
Acknowledgements
I thank Wojciech Szpankowski for stimulating discussions on patterns in random strings over the last 20 years. Furthermore, I thank Andrew Barbour and Nathan Ross for help with references, and the anonymous referees for helpful comments and further references; in particular, Theorem 3.5 is based on suggestions from a referee.






















