



1. Introduction
In recent years, deep reinforcement learning (RL) has shined in the field of robot manipulation, especially learning continuous control in the real world. However, it is still difficult to collect enough data for training in reality. While some researchers train robots directly in reality, others train the policy in simulation first and then transfer the trained model to reality [Reference Zhao, Queralta and Westerlund1]. But due to the difference between simulation and reality, the so-called reality gap often does not work well by directly transferring the learned model to reality. Therefore, it is necessary to find a good sim-to-real transfer method to close the reality gap.
To achieve sim-to-real transfer, some researchers use the transfer learning methods like domain adaption for training the robust models [Reference Gupta, Devin, Liu, Abbeel and Levine2], reducing the impact of the difference in data distribution between simulation and reality, so as to reduce the number of training required for transfer from simulation to reality. But this method still requires trial-and-error in reality to train the model. For some task scenarios such as medical treatment and high risk, it is still difficult to expect in the real world that the pursuit of generalization also makes us hope that the model can directly perform well in similar scenarios that have never been seen before. Therefore, zero-shot sim-to-real transfer learning is proposed [Reference Wang, Zheng, Yu and Miao3], which can achieve good results without any fine-tune in reality.
Although several fine results have been achieved (see, e.g., refs. [Reference Tobin, Fong, Ray, Schneider, Zaremba and Abbeel4, Reference Peng, Andrychowicz, Zaremba and Abbeel5]), the zero-shot sim-to-real transfer is still quite challenging. In our work, we propose a new framework that can directly transfer the policies trained in simulation to the real environment without additional training. Our method uses the force information collected from the end-effector to achieve automatic error correction to reduce the reality gap. And our method can use partial reality state information and only compute reward in the simulation, which benefits some scenarios where it is difficult to obtain accurate states.
2. Related work
2.1. Deep RL for robot manipulation
Deep RL allows for end-to-end dexterous manipulation learning, with continuous high-dimensional action and state space [Reference Nguyen and La6, Reference Chebotar, Handa, Makoviychuk, Macklin, Issac, Ratliff and Fox7]. For the problem of low sample utilization, reference [Reference Lillicrap, Hunt, Pritzel, Heess, Erez, Tassa, Silver and Wierstra8] used the Deep Deterministic Policy Gradient which has the mechanism of experience replay to improve the sample efficiency. Reference [Reference Haarnoja, Zhou, Hartikainen, Tucker, Ha, Tan, Kumar, Zhu and Gupta9] uses entropy regularization to balance exploration and exploitation and named their method soft actor-critic (SAC). In our framework, we use the SAC algorithm. Reference [Reference Hester, Vecerik, Pietquin, Lanctot, Schaul, Piot, Horgan, Quan, Sendonaris, Osband, Dulac-Arnold, Agapiou and Leibo10] saves the demonstration data in the experience replay to speed up the learning process. Because of this advantage, we also use demonstration data to initialize the SAC training in this work.
2.2. Sim-to-real transfer and zero-shot learning
In previous studies, [Reference Gupta, Devin, Liu, Abbeel and Levine2] uses the domain adaption method to map the simulation and reality into a latent space to cross the sim-to-real gap. Reference [Reference Christiano, Shah, Mordatch, Schneider, Blackwell, Tobin, Abbeel and Zaremba11] learns an inverse transition probability matrix in the real environment to directly apply the trained model. However, they all need to use real-world data, which is very difficult for some specific tasks.
Zero-shot sim-to-real learning, instead, enables transferring the model from simulation to reality without using the data of the reality. Domain randomization [Reference Tobin, Fong, Ray, Schneider, Zaremba and Abbeel4, Reference Peng, Andrychowicz, Zaremba and Abbeel5] randomizes the visual information or dynamic parameters in the simulated environment, which is a popular method in zero-shot sim-to-real transfer. We also use the domain randomization method to train the model in the simulator.
In recent years, there are some other zero-shot transfer methods. Reference [Reference Bi, Sferrazza and D’Andrea12] proposed a feedback policy that is conditioned on a sensory observation history to adapt the scenario. It also uses force information to adjust the trained policy, but a new student neural network is needed to be trained since we can directly correct the sim-to-real errors. Next, the idea of our work is similar to the MRAC-RL framework [Reference Guha and Annaswamy13], which is a framework for online policy adaptation under parametric model uncertainty. Our error correction method is similar to their adaptive controller module, but the difference is that we can correct the error in inference through force feedback. But at the same time, it suffers from the disadvantage of using the digital twin method to control the robot, that is, the control will be delayed. Because we need to send the motion command to the real robot after the robot in the simulation moves. It should be pointed out that our framework does not conflict with its framework and can be used at the same time.
Force control has shown promising results for robotic manipulation [Reference Zeng, Su, Li, Guo and Yang14, Reference Zeng, Li, Guo, Huang, Wang and Yang15]. Recently, several attempts have been made to combine force control and RL [Reference Martín-Martín, Lee, Gardner, Savarese, Bohg and Garg16, Reference Beltran-Hernandez, Petit, Ramirez-Alpizar, Nishi, Kikuchi, Matsubara and Harada17]. Reference [Reference Martín-Martín, Lee, Gardner, Savarese, Bohg and Garg16] proposed a RL method that can learn variable impedance control policy in the task space. However, there is still a gap between the physics engine in simulation and reality, and it may not be a good choice to use it directly for training. Reference [Reference Beltran-Hernandez, Petit, Ramirez-Alpizar, Nishi, Kikuchi, Matsubara and Harada17] proposed a learning-based framework that combines RL and traditional force control. They also learned the corrected trajectory through the force information at the time of the collision, but they scheme to combine with traditional PID. In fact, in the use of force information, we innovatively map it to an abstract state in the task and use the digital twin technology [Reference Wu, Yang, Cheng, Zuo and Cheng18] to achieve the automatical error correction during inference.
The important principle of our work is based on the digital twin [Reference Wu, Yang, Cheng, Zuo and Cheng18], which is an industry 4.0 concept and has been recently used for RL [Reference Xia, Sacco, Kirkpatrick, Saidy, Nguyen, Kircaliali and Harik19, Reference Mayr, Chatzilygeroudis, Ahmad, Nardi and Krueger20]. The digital twin establishes the model of the object in the digital space, realizes complete synchronization with the real state of the object through the sensors, and performs real-time analysis and evaluation after the movement of the object. Similar to the digital twin, we have established a relation between reality and simulation for the robot. Our method could correct the errors in real time through the force sensor to achieve a lower reality gap. To the best of our knowledge, our work is the first attempt to use this method similar to digital twin for zero-shot sim-to-real transfer.
3. Method
Our proposed framework SimTwin, as shown in Fig. 1, consists of three major modules: Simulation-to-reality loop, SAC, and Twin module. The zero-shot sim-to-real transfer will be implemented in the Twin module; these modules will be discussed in the following subsections.
3.1. Simulation-to-reality loop
The policy neural network is completely trained in simulation, and a sim-to-real loop is used to control the real robot. Like digital twin, we use a control method that maps robot states in simulation to reality. The specific method is: let the simulation robot send the current joint angle values to the real robot continuously at a faster frequency, and the real robot moves to the target joint angle after receiving the send joint angle, so as to realize the real robot following the simulation robot.

Figure 1. An overview of the SimTwin framework. During training, the replay buffer obtains training data from the environment and demonstration to training policy. During inference, observations are obtained from the simulation environment, and the trained policy output actions are passed to the actual robot controller for execution. The controller then transmits the force and joint information of the reality back to the simulation and corrects the domain parameters through Twin module, which plays an error correction role.
The original intention of using digital twin is that some tasks are not easy to observe, and the environment can be modeled through prior knowledge. In Simulation Twin (SimTwin), the simulation environment stores information about the environment and makes decisions based on this information.
An advantage of this method is that it does not need to observe all states in reality. However, it must be pointed out that this control method is quite dependent on the accuracy of the simulation model. Therefore, the states of the simulated robot and the real robot will not be always identical due to the model difference. We will explain in the following chapters that how to use our proposed Twin Module to adaptively reduce this reality gap.
3.2. SAC from demonstration
RL from demonstration has better performance in complex tasks. Choosing an off-policy RL algorithm can help reduce policy forgetting. Therefore, we selected SAC as the DRL algorithm.
 \begin{align} \mathcal{J}(\pi ) = \sum _{t=0}^T \mathbb{E}_{(\textbf{s}_{t}, \textbf{a}_{t}) \sim \mathcal{\rho _{\pi }}} [r(\textbf{s}_{t}, \textbf{a}_{t}) + \alpha \mathscr{H}(\pi (\cdot \mid \textbf{s}_{t}))] \end{align}
\begin{align} \mathcal{J}(\pi ) = \sum _{t=0}^T \mathbb{E}_{(\textbf{s}_{t}, \textbf{a}_{t}) \sim \mathcal{\rho _{\pi }}} [r(\textbf{s}_{t}, \textbf{a}_{t}) + \alpha \mathscr{H}(\pi (\cdot \mid \textbf{s}_{t}))] \end{align}
where
 $r$
is the step reward, and
$r$
is the step reward, and
 $\textbf{s}_{t}, \textbf{a}_{t}$
are the state and action in the time step t.
$\textbf{s}_{t}, \textbf{a}_{t}$
are the state and action in the time step t.
 $\alpha$
is a weight parameter that determines the relative importance of the entropy term versus the reward. The update method of the policy network (parameter
$\alpha$
is a weight parameter that determines the relative importance of the entropy term versus the reward. The update method of the policy network (parameter
 $\theta$
) is to minimize the KL-divergence.
$\theta$
) is to minimize the KL-divergence.
 \begin{align} \mathcal{J}_{\pi }(\phi ) = \mathbb{E}_{\textbf{s}_{t} \sim \mathcal{\mathcal{D}}} [\mathbb{E}_{\textbf{a}_{t} \sim \pi _{\phi }} [\alpha \log \!(\pi _{\phi } (\textbf{s}_{t} \mid \textbf{a}_{t})) - \mathcal{Q}(\textbf{s}_{t}, \textbf{a}_{t})] ] \end{align}
\begin{align} \mathcal{J}_{\pi }(\phi ) = \mathbb{E}_{\textbf{s}_{t} \sim \mathcal{\mathcal{D}}} [\mathbb{E}_{\textbf{a}_{t} \sim \pi _{\phi }} [\alpha \log \!(\pi _{\phi } (\textbf{s}_{t} \mid \textbf{a}_{t})) - \mathcal{Q}(\textbf{s}_{t}, \textbf{a}_{t})] ] \end{align}
where
 $\mathcal{Q}(\textbf{s}_{t}, \textbf{a}_{t})$
is the soft Q function given by the Q-learning framework, which can be trained to minimize the soft Bellman residual:
$\mathcal{Q}(\textbf{s}_{t}, \textbf{a}_{t})$
is the soft Q function given by the Q-learning framework, which can be trained to minimize the soft Bellman residual:
 \begin{align} \mathcal{J}_{\mathcal{Q}}(\theta ) &= \mathbb{E}_{(\textbf{s}_{t}, \textbf{a}_{t}) \sim \mathcal{D}} \bigg[\frac{1}{2} (\mathcal{Q}(\textbf{s}_{t}, \textbf{a}_{t}) - (r(\textbf{s}_{t}, \textbf{a}_{t})) \nonumber \\[3pt] &\quad +\gamma \mathbb{E}_{\textbf{s}_{t+1} \sim p} [\mathbb{E}_{\textbf{a}_{t+1} \sim \pi _{\phi }} [\mathcal{Q}(\textbf{s}_{t+1}, \textbf{a}_{t+1}) \nonumber \\ &\quad -\alpha \log\! (\pi _{\phi } (\textbf{s}_{t+1} \mid \textbf{a}_{t+1}))]] )\bigg] \end{align}
\begin{align} \mathcal{J}_{\mathcal{Q}}(\theta ) &= \mathbb{E}_{(\textbf{s}_{t}, \textbf{a}_{t}) \sim \mathcal{D}} \bigg[\frac{1}{2} (\mathcal{Q}(\textbf{s}_{t}, \textbf{a}_{t}) - (r(\textbf{s}_{t}, \textbf{a}_{t})) \nonumber \\[3pt] &\quad +\gamma \mathbb{E}_{\textbf{s}_{t+1} \sim p} [\mathbb{E}_{\textbf{a}_{t+1} \sim \pi _{\phi }} [\mathcal{Q}(\textbf{s}_{t+1}, \textbf{a}_{t+1}) \nonumber \\ &\quad -\alpha \log\! (\pi _{\phi } (\textbf{s}_{t+1} \mid \textbf{a}_{t+1}))]] )\bigg] \end{align}
where
 $\gamma$
is the reward discount factor. We use automating entropy adjustment for updating
$\gamma$
is the reward discount factor. We use automating entropy adjustment for updating
 $\alpha$
in SAC algorithm after solving
$\alpha$
in SAC algorithm after solving
 $\pi _t^*$
and
$\pi _t^*$
and
 $\mathcal{Q}_t^*$
.
$\mathcal{Q}_t^*$
.
 \begin{align} \mathcal{J}(\alpha ) = \mathbb{E}_{(\textbf{s}_{t}, \textbf{a}_{t}^*) \sim \pi _t^*} [\!-\alpha _t \log \pi _t^*(\textbf{a}_{t} \mid \textbf{s}_{t};\ \alpha _t) - \alpha _t \overline{\mathscr{H}}] \end{align}
\begin{align} \mathcal{J}(\alpha ) = \mathbb{E}_{(\textbf{s}_{t}, \textbf{a}_{t}^*) \sim \pi _t^*} [\!-\alpha _t \log \pi _t^*(\textbf{a}_{t} \mid \textbf{s}_{t};\ \alpha _t) - \alpha _t \overline{\mathscr{H}}] \end{align}
In origin SAC, random actions are started to interact with the environment, and transition
 $(s, a, r, s')$
is obtained to fill the replay buffer
$(s, a, r, s')$
is obtained to fill the replay buffer
 $\mathcal{D}$
. In our framework, the demonstration action
$\mathcal{D}$
. In our framework, the demonstration action
 $a*$
will be used to interact with the environment at the beginning to obtain a higher quality transition
$a*$
will be used to interact with the environment at the beginning to obtain a higher quality transition
 $(s, a*, r, s')$
, fill it into the replay buffer, and keep it forever. If the demonstration steps are done, SAC controls the rest of the training. In our framework, all the demonstration steps are completed in simulation, which is more convenient to obtain demonstration data than in reality.
$(s, a*, r, s')$
, fill it into the replay buffer, and keep it forever. If the demonstration steps are done, SAC controls the rest of the training. In our framework, all the demonstration steps are completed in simulation, which is more convenient to obtain demonstration data than in reality.
3.3. Twin module
Due to the sim-to-real gap, we propose an adaptive error correction method to achieve zero-shot transfer in simulation and reality. We think that this process is independent of the logic of opening the cabinet policy trained by RL, so we use another neural network: Twin-Net to simulate this thinking process. An overview of Twin module is shown in Fig. 2.
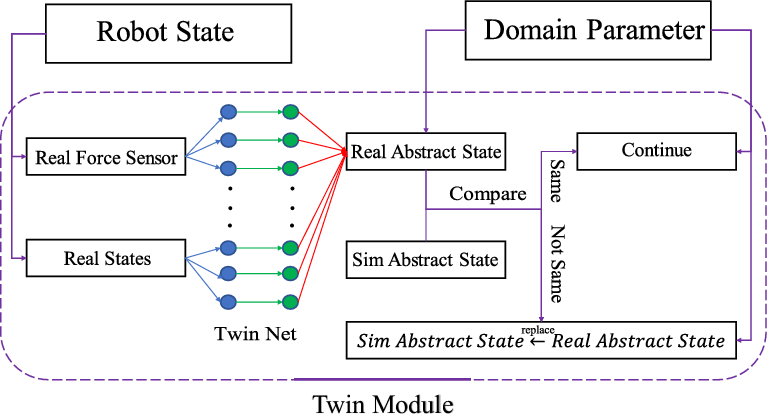
Figure 2. An overview of Twin Module. When it is real robot state and force information input, a neural network is used to determine which abstract state the reality is in, and compare with the simulation abstract state. If the same, do nothing. If they are not the same, let the simulation abstract state be reality abstract state.
Firstly, we demonstrate the Twin-Net training method. We define some abstract states
 $(\textbf{As}_1,\, \textbf{As}_2,\, \ldots,\, \textbf{As}_n)$
which decompose the task into several abstract states, For example, we can decompose the open cabinet task into three abstract states: not grasping the handle, just grasping the handle, and pulling the handle back. A condensed observation at time t is given by:
$(\textbf{As}_1,\, \textbf{As}_2,\, \ldots,\, \textbf{As}_n)$
which decompose the task into several abstract states, For example, we can decompose the open cabinet task into three abstract states: not grasping the handle, just grasping the handle, and pulling the handle back. A condensed observation at time t is given by:
 \begin{align} \textbf{o}(t) = \Big \{ F_x(t),\, F_y(t),\, F_z(t),\, \textbf{s}(t) \Big \} \end{align}
\begin{align} \textbf{o}(t) = \Big \{ F_x(t),\, F_y(t),\, F_z(t),\, \textbf{s}(t) \Big \} \end{align}
where
 $F_x(t)$
,
$F_x(t)$
,
 $F_y(t)$
,
$F_y(t)$
,
 $F_z(t)$
are the force values of the end-effector,
$F_z(t)$
are the force values of the end-effector,
 $\textbf{s}(t)$
is t time robot state, which does not have to be the same as the used one for RL training. Labels are defined as below:
$\textbf{s}(t)$
is t time robot state, which does not have to be the same as the used one for RL training. Labels are defined as below:
 \begin{align} \textbf{A}(t) = \Big \{ \unicode{x1D7D9}(\textbf{As}(t),\, \textbf{As}_1),\, \ldots,\, \unicode{x1D7D9}(\textbf{As}(t),\, \textbf{As}_n) \Big \} \end{align}
\begin{align} \textbf{A}(t) = \Big \{ \unicode{x1D7D9}(\textbf{As}(t),\, \textbf{As}_1),\, \ldots,\, \unicode{x1D7D9}(\textbf{As}(t),\, \textbf{As}_n) \Big \} \end{align}
 $\textbf{As}(t)$
is the abstract state of the robot, which can be obtained from the simulation.
$\textbf{As}(t)$
is the abstract state of the robot, which can be obtained from the simulation.
 $\unicode{x1D7D9}(\textbf{As}(t),\, \textbf{As}_n)$
is the indicator function, which is 1 when the
$\unicode{x1D7D9}(\textbf{As}(t),\, \textbf{As}_n)$
is the indicator function, which is 1 when the
 $\textbf{As}(t)$
is equals to
$\textbf{As}(t)$
is equals to
 $\textbf{As}_n$
and is 0 otherwise.
$\textbf{As}_n$
and is 0 otherwise.
We aim to learn
 \begin{align} T_{\theta }(\textbf{o}(t-(T-1)\,{:}\,t)) \longrightarrow \textbf{A}(t) \end{align}
\begin{align} T_{\theta }(\textbf{o}(t-(T-1)\,{:}\,t)) \longrightarrow \textbf{A}(t) \end{align}
which maps the history of the last
 $T$
condensed observations
$T$
condensed observations
 $\textbf{o}(t-(T-1)\,{:}\,t)$
to current abstract state, where
$\textbf{o}(t-(T-1)\,{:}\,t)$
to current abstract state, where
 $T = 8$
is the fixed history length, and
$T = 8$
is the fixed history length, and
 $\theta$
is the parameter of this network; it can be trained to minimize the negative log-probability:
$\theta$
is the parameter of this network; it can be trained to minimize the negative log-probability:
 \begin{align} \mathcal{J}(T_\theta )= -\log \!(\textbf{Prob}(T_{\theta }(\textbf{o}(t-(T-1)\,{:}\,t))) - \textbf{A}(t)) \end{align}
\begin{align} \mathcal{J}(T_\theta )= -\log \!(\textbf{Prob}(T_{\theta }(\textbf{o}(t-(T-1)\,{:}\,t))) - \textbf{A}(t)) \end{align}
This neural network has 2 linear hidden layers with 64 neural units in each layer. Rectified linear unit activation function is used in all hidden layers.
During inference, we input the force and robot state in the reality into Twin-Net to obtain the abstract state in reality. When there is a difference between the state in reality and simulation due to the reality gap, SimTwin corrects the abstract state in simulation to make it consistent with reality. Therefore, new actions will be planned through RL, to achieve automatic error correction, until the task is completed.
3.4. Domain randomization
Domain randomization is an effective way to enhance the success rate of sim-to-real transfer [Reference Andrychowicz, Baker, Chociej, Jozefowicz, McGrew, Pachocki, Petron, Plappert and Powell21]. In our framework, domain randomization plays an important role in error correction. It makes the model adaptive to noise by adding noise to the parameters during training. In our framework, after the twin module gives the correct parameters, domain randomization guarantees that the model can still give the correct action after correction.
4. Experiments
In our experiments, we focus on answering the following questions:
Does our framework can work for real-world tasks and robots?
How does the Twin module reduce the translate gap?
We start by applying SimTwin to a cabinet opening task, showing that we can directly transfer trained policy to real robots such as Baxter for the complex articulated task, and without any other real data.
Next, we will apply SimTwin in transferring policies between scenes with different initial poses of the cabinet in the cabinet opening task. We demonstrate that our Twin module improved the performance of the RL-trained policies applied to a robot system with such a modeling error.
4.1. Task
The open cabinet task requires the use of grippers to clamp the handle and pull the drawer out. We use a 6-degrees of freedom (DoF) robot arm from Baxter in this task. Simulated and real-world settings are shown in Fig. 3.

Figure 3. Simulation and real-world settings. Left image is the open cabinet task trained by SimTwin with multiple agents in the simulation. Right image is the experimental setup for the open cabinet task in the real world.
Due to the advantage that the policy in our framework is completely run in simulation, we can choose as many states as possible to train the model, because the states are easier to obtain in the simulation. So we use a 16D observation space: 6-DoF joint angles, the 3D positions of the cabinet drawer handle, the robot left gripper and robot right gripper, and 1D of drawer open length. The reward function consists of reward shaping from the end-effector to the handle, the opening distance of the cabinet, and a rotating reward that makes sure the two robot grippers are on the handle. A 6D action space directly outputs the speed of the 6-DoF joint angle values to control the Baxter arm.
It should be noted that our framework has another advantage in that we do not need to obtain all state information in the real environment, such as the position of the handle. It is very convenient for some difficult-to-observe tasks.
4.2. Simulation
We use Isaac-Gym [Reference Makoviychuk, Wawrzyniak, Guo, Lu, Storey, Macklin, Hoeller, Rudin and Allshire22] as our simulation environment. It utilizes NVIDIA PhysX, a powerful physics engine, which can effectively reduce the reality gap. Another advantage is that model rendering and interaction with the environment can be fully loaded into the GPU to better support parallel computing. Both the training and testing stages run on a PC with Intel i7-9700K CPU @ 3.60 GHz and NVIDIA RTX 2070Super GPU.
4.3. Real-world experiment
To prove the generalization ability of SimTwin, we choose to use handles different from simulations in real experiments. The size of the handle in the real world is smaller than in the simulation, which means it is more difficult to grasp.
We assume that in the open cabinet task, the reality gap is caused by the different positions of the cabinet. Before the training starts, we have an initial estimate of the positions of the cabinet. During the training, we use two types of randomization: observation randomization and dynamic randomization. The observation randomization represents the uncertainty of sensors, which is the focus of our framework. The dynamic randomization represents the model inaccuracy; it is a general method to improve the sim-to-real ability. Noise is modeled as an additive or scaling noise sampled from Gaussian distributions
 $\mathscr{N} \sim (\mu,\, \rho )$
. The experiment configuration is given in Table I.
$\mathscr{N} \sim (\mu,\, \rho )$
. The experiment configuration is given in Table I.
Table I. Domain randomization configuration.

At the beginning of the training, we manually set a trajectory for opening the cabinet in the simulation and store these demonstration data in the replay buffer. Next, we use the SAC algorithm and gradient descent method to train the policy and Twin-Net until achieving good results in simulation.
After training, we use SimTwin to transfer our policy to reality. We use a PC mentioned above to run our simulation environment and use Baxter SDK to control Baxter, and they are connected via WiFi. When the simulation is turned on, the PC size packages the joint angle values of the robot in the simulation into a ROS topic and sends it to the Baxter size. The Baxter size executes the angle value, sends the force feedback to the PC size in the same way, enters the Twin module. After the Twin module has updated the domain parameters (such as X-coordinate), the policy net inference of the next action and repeat the above process. Baxter joint angle update frequency is set 100 Hz. Our control method is shown in Fig. 4.
We set the X-coordinate in the simulation and reality to be the same and then use the above method to perform the open cabinet task. Our experiments snapshot is shown in Fig. 5. We can see that when the ideal situation (reality gap is relatively small), our control method can well transfer the policy from the simulation to reality. Next, we will show that in the case of a large reality gap, how does our framework perform sim-to-real transfer with twin module. Assuming that the cabinet in the simulation is farther than the reality due to the reality gap, there will be the gripper that has already touched the cabinet in the reality but not touched in the simulation. At this time, the force in the simulation is quite different from that in reality. After the twin module detects this abnormality, it can judge that the gripper in the reality has touched the cabinet, so we correct the position of the cabinet in the simulation to make it contact with the gripper. After that, the SAC algorithm will generalize to a new trajectory and successfully open the cabinet. In the end, the position error was corrected, and the reality gap was reduced. An example of the task process is shown in Fig. 6.

Figure 4. Our framework is used in open cabinet tasks. Input the force feedback and Baxter state into Twin-Net to get the abstract in the real world. When there is an error (collision in the figure) occurred, correct the parameters in the simulator to make it the same as in reality, and get new correct actions through the trained policy.

Figure 5. Snapshots of the manipulator performed during the open cabinet task.

Figure 6. The experimental configuration of our real-world experiment. The Isaac-Gym is running in a personal computer, sent and receive data from Baxter robot by ROS.
Our code is released at: https://github.com/cypypccpy/Isaac-ManipulaRL.
4.4. Performance without demonstration
We demonstrate the smoothed episodic reward in Fig. 7, and the smooth function is
 $r_{t+1}^{\prime }=0.375r_t^{\prime } + 0.625r_{t+1}$
. The blue curve corresponds to the demonstration enabled, while the purple curve corresponds to the result with demonstration removed. It can be seen that after the demonstration is removed, the agent cannot successfully learn a useful policy. We think that it is because the probability of finding the correct action by random exploration for complex tasks is low, and it is easy to obtain the demonstration data in the simulation, so we have also added the demonstration part to our framework. It can be seen that demonstration can improve both the learning speed and stability.
$r_{t+1}^{\prime }=0.375r_t^{\prime } + 0.625r_{t+1}$
. The blue curve corresponds to the demonstration enabled, while the purple curve corresponds to the result with demonstration removed. It can be seen that after the demonstration is removed, the agent cannot successfully learn a useful policy. We think that it is because the probability of finding the correct action by random exploration for complex tasks is low, and it is easy to obtain the demonstration data in the simulation, so we have also added the demonstration part to our framework. It can be seen that demonstration can improve both the learning speed and stability.

Figure 7. Comparison of smoothed episodic reward of begin with and without demonstration. Except for this, the other configurations are the same at the 1600th episode. But only the former case can find the policy successfully.
4.5. Performance without twin module
We also test the generalization ability of our framework when the Twin module is not used. Taking X-coordinate as a test, in the case of only domain randomization is used, the tolerable error is about
 $-1\sim 1\,\textrm{cm}$
. In the case of using Twin Module and domain randomization at the same time, the maximum error tolerance can reach about
$-1\sim 1\,\textrm{cm}$
. In the case of using Twin Module and domain randomization at the same time, the maximum error tolerance can reach about
 $-4.5\sim 5\,\textrm{cm}$
, and the cabinet can still be opened in this error. It should be pointed out that the error tolerance of the Twin module is related to the generalization ability of the trained RL model. When the error is too large, the reason for the generalization failure is that the RL model cannot plan a new path successfully after correcting the domain parameters. Therefore, to improve the generalization ability of the RL model, domain randomization is still very important in SimTwin.
$-4.5\sim 5\,\textrm{cm}$
, and the cabinet can still be opened in this error. It should be pointed out that the error tolerance of the Twin module is related to the generalization ability of the trained RL model. When the error is too large, the reason for the generalization failure is that the RL model cannot plan a new path successfully after correcting the domain parameters. Therefore, to improve the generalization ability of the RL model, domain randomization is still very important in SimTwin.
5. Conclusions
Zero-shot sim-to-real transfer is an important component for the generalization of RL in robotics. In this work, we indicate that SimTwin can directly transfer the policy sim-to-real without additional training. SimTwin uses the force information of the real-world robot to correct the errors between simulation and reality. We designed a neural network to learn the difference between reality and simulation. When there is a difference between reality and simulation, SimTwin modifies the domain parameters in the simulation, then the RL model can generalize to a new trajectory. SimTwin uses Baxter robots for experiments and has achieved good results on open cabinet tasks.
For future work, we will try to use SimTwin for other tasks that are complex and hard to collect real-world data. We will also develop more general error monitoring methods based on force information to increase the generalization of our framework. Now our framework is still more reliant on the establishment of the simulation environment. In the future, we plan to combine SimTwin with perception algorithms to reduce the reliability of the simulation environment.
Authors’ contributions
Yuanpei Chen helped in conceiving the study concept and design, acquiring the data, analyzing, interpreting the data, and drafting the manuscript. Chao Zeng and Zhiping Wang helped in analyzing and interpreting the data, and drafting the manuscript. Peng Lu helped in conceiving the study concept and design. Chenguang Yang helped in conceiving the study concept and design, drafting and revising the manuscript, obtaining funding, and supervising the study. All authors have read and agreed to the published version of the manuscript.
Financial support
This work was supported in part by National Nature Science Foundation of China (NSFC) under Grant U20A20200 and Grant 62003096, and Major Research Grant No. 92148204, in part by Guangdong Basic and Applied Basic Research Foundation under Grants 2019B1515120076 and 2020B1515120054, in part by Industrial Key Technologies R&D Program of Foshan under Grant 2020001006308 and Grant 2020001006496.
Conflicts of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Ethical considerations
None.








