



There are differing views and conflicting empirical evidence regarding the role of awareness in second language (L2) acquisition. On the one hand, the view that awareness is necessary for L2 acquisition in adulthood (Schmidt, Reference Schmidt1990) is supported by a number of empirical studies (e.g., Leow, Reference Leow1997, Reference Leow2000). On the other hand, Williams (Reference Williams2005) proposed that learning a novel language in adulthood can occur without awareness, such as the acquisition of form–meaning connections. Several studies have adapted Williams’s (Reference Williams2005) paradigm in order to contribute to the debate on the role of awareness in language learning (e.g., Chen et al., Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011; Faretta-Stuttenberg & Morgan-Short, Reference Faretta-Stutenberg, Morgan-Short, Granena, Koeth, Lee-Ellis, Lukyanchenko, Prieto Botana and Rhoades2011; Hama & Leow, Reference Hama and Leow2010; Kerz, Wiechmann, & Riedel, Reference Kerz, Wiechmann and Riedel2017; Rebuschat, Hamrick, Riestenberg, Sachs, & Ziegler, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015; Rebuschat, Hamrick, Sachs, Riestenberg, & Ziegler, Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013), but results have been contradictory, with no clear evidence supporting either position.
In part, the conflicting findings in these studies can be explained by important conceptual differences. Williams (Reference Williams2005), following the tradition in cognitive psychology (Reber, Reference Reber1967), focused on the implicitness of the learning product, that is, what was learned by participants, while Leow (Reference Leow1997, Reference Leow2000; Hama & Leow, Reference Hama and Leow2010), approaching the topic from the perspective of the field of second language acquisition (SLA), focused on the implicitness of the learning process, that is, how learning took place. Given their respective orientations, the authors measured different, albeit interrelated, aspects of language learning. Williams (Reference Williams2005) used retrospective verbal reports to establish if learners could account for their performance at the end of the experiment. In contrast, Leow (Reference Leow1997, Reference Leow2000) pioneered the use of concurrent verbal reports to assess awareness at the time of encoding (see Rebuschat, Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, for review).
Another potential explanation for the conflicting findings might be the changes in modality between exposure and testing phases in the studies (cf. Hama & Leow, Reference Hama and Leow2010). Williams (Reference Williams2005) and Faretta-Stutenberg and Morgan-Short (Reference Faretta-Stutenberg, Morgan-Short, Granena, Koeth, Lee-Ellis, Lukyanchenko, Prieto Botana and Rhoades2011) trained participants on auditory sentences but tested them on written items. In contrast, Hama and Leow (Reference Hama and Leow2010) and Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) kept the modality constant. However, Hama and Leow trained and tested participants on auditory items, while Rebuschat et al. did so with written items (for a recent overview, see Kim & Godfroid, Reference Kim and Godfroid2019). It is well known that modality makes a difference in memory recall (Shanks & St. John, Reference Shanks and St. John1994), and there is recent evidence suggesting that modality also plays a key role in implicit learning (Frost, Armstrong, Siegelman, & Christiansen, Reference Frost, Armstrong, Siegelman and Christiansen2015). However, there is a scarcity of studies that directly investigate how input modality might affect the learning of a novel language in adulthood. Recently, Kim and Godfroid (Reference Kim and Godfroid2019) addressed this important question, but their participants read out the written sentences, which meant that in the written condition they received dual mode input (visual and auditory).
In the present study, we address this gap by investigating how modality affects the acquisition of artificial determiners by Chinese speaking learners of English. We also examined the effect of modality on incidental learning in the exposure and testing phases. In this paper, we first define key concepts and then provide an overview of prior research that has examined the role of awareness in language learning and the impact of modality in incidental learning. Next, we describe the procedures of our research and present our findings relating to the incidental acquisition of novel form–meaning relationships through visual and auditory input. Our results are discussed with reference to previous research and cognitive theories of L2 learning. The paper concludes with suggestions for future research.
Implicit learning, explicit learning, and the concept of awareness
Our ability to unconsciously derive information from the environment is a fundamental aspect of human cognition. The concept of implicit learning, that is, learning that occurs without awareness of what was learned, is typically associated with Reber (Reference Reber1967), though interest in the topic precedes Reber’s work (e.g., Thorndike & Rock, Reference Thorndike and Rock1934). The topic has been the focus of extensive theoretical discussion and empirical research in both cognitive psychology (Dienes, Reference Dienes, Rebuschat and Williams2012; Perruchet, Reference Perruchet and Byrne2008) and SLA research (e.g., Williams, Reference Williams2005; see contributions in Ellis, Reference Ellis and Ellis1994; Rebuschat, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015). Awareness plays a key role in distinguishing implicit from explicit learning. Implicit learning is typically observed under incidental exposure conditions, where participants are not informed about the learning target or that they will be tested. This type of experimental manipulation is generally assumed to result primarily in implicit (unconscious) knowledge, that is, knowledge that participants are unable to verbalize. In contrast, explicit learning is usually associated with intentional exposure conditions, which might involve “conscious comparisons between current and previous instances of input and the formation and testing of hypotheses” (Williams, Reference Williams2005, p. 271). Explicit learning involves some level of awareness depending on how deeply one engages in processing novel L2 forms (Leow, Reference Leow2018). L2 learners can have lower levels of awareness without being able to verbalize L2 rules or linguistic regularities. For example, when processing L2 input, learners might be aware of the occurrence of verb forms with past tense morphology (walked, jumped, played, etc.) but not fully grasp the underlying rule that generates the regular English past tense (adding an –ed to the verb stem). In the former case, Schmidt (Reference Schmidt1990) would argue that learners display awareness at the level of noticing, whereas in the latter case they display awareness at the level of understanding.
In the field of SLA, Schmidt’s noticing hypothesis (Reference Schmidt1990, Reference Schmidt1995, Reference Schmidt, Chan, Chi, Cin, Istanto, Nagami, Sew, Suthiwan and Walker2010) distinguishes between a narrow and a broad sense of awareness. In the narrow sense, awareness as noticing can be considered a surface level phenomenon, namely, “conscious registration of the occurrence of certain events” (Schmidt, Reference Schmidt1995, p.19). This is similar to Tomlin and Villa’s (Reference Tomlin and Villa1994) conceptualization of low level of awareness, which they define as “a particular state of mind in which an individual has undergone a specific subjective experience of some cognitive content or external stimulus” (p. 193). In the broad sense, awareness as understanding involves a deeper level of processing that results in “a state of mind in which one has become cognizant of the regularities underlying the data” (Schacter, Reference Schacter, Roediger and Craik1989, p. 377). Leow (Reference Leow2018, p. 773) further suggests that awareness should be operationalized at three levels: “behavioral or cognitive change (at the level of noticing), a meta-report of the experience but without any metalinguistic description of a targeted underlying rule (at the level of reporting), or a metalinguistic description of a targeted underlying rule (at the level of understanding).” The graded nature of awareness underlies Hulstijn’s (Reference Hulstijn and Rebuschat2015) argument that explicit and implicit learning should not be seen as a dichotomy but rather a continuum. A key question for SLA research has been to what extent incidental learning can successfully contribute to novel knowledge representations and what depth of processing is needed for learning to take place (see Chan & Leung, Reference Chan and Leung2014; Chen et al., Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011, Leow, Reference Leow and Rebuschat2015, Leung & Williams, Reference Leung and Williams2011, Reference Leung and Williams2012, Reference Leung and Williams2014).
In his seminal study, Williams (Reference Williams2005) presented initial evidence of learning without awareness, which challenged the view that awareness could be a prerequisite for language learning in adulthood (Schmidt, Reference Schmidt1990). Williams employed an artificial determiner system (gi, ro, ul, ne) that encoded both distance (near vs. far) and animacy (animate vs. inanimate) to investigate the acquisition of form–meaning connections under incidental exposure conditions. Participants were informed that the four determiners’ functions were similar to the English word the, except that meaning of distance was also encoded: gi and ro preceded near objects, whereas ul and ne preceded far objects. However, they were not told that animacy also played a role in determiner usage, and animacy thus served as a hidden regularity. Participants were exposed to this artificial determiner system and later tested only on the hidden regularity. Immediately after the test, participants provided retrospective verbal reports to determine whether they were aware or unaware of the role that animacy played in determiner choice. Those who “were able to state the specific relationships between the determiners and noun animacy” (Williams, Reference Williams2005, p. 283) were classified as being aware, those who were not able to provide a report were classified as being unaware.
Williams’s (Reference Williams2005) results showed that 80% of participants reported having no awareness of animacy after their first exposure to the test sentences, but their performance was still significantly above chance (61% accuracy on generalization items). These unaware participants were then exposed to more training items and asked to consciously identify the hidden regularity. Despite these instructions, 50% of participants still failed to verbalize the hidden regularity, that is, they remained unaware even after an additional round of exposure and under intentional exposure conditions. Interestingly, their performance was still significantly above chance (58% accuracy). The results were interpreted as evidence that learning of form–meaning connections can occur without awareness.
Several studies have adapted Williams’s (Reference Williams2005) paradigm to further investigate whether learning without awareness is possible (e.g., Chen et al., Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011; Faretta-Stutenberg & Morgan-Short, Reference Faretta-Stutenberg, Morgan-Short, Granena, Koeth, Lee-Ellis, Lukyanchenko, Prieto Botana and Rhoades2011; Hama & Leow, Reference Hama and Leow2010; Rebuschat et al., Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015). Hama and Leow (Reference Hama and Leow2010) extended Williams’s (Reference Williams2005) study by adding (a) another measure of awareness (concurrent verbal reports, or think-aloud protocols) and (b) a production task in addition to a multiple-choice comprehension test and by keeping (c) the same modality for the exposure and testing phases (auditory). The results of Hama and Leow (Reference Hama and Leow2010) showed that unaware participants performed significantly above chance on both the production and multiple-choice assessment tasks. However, analyses of the types of responses revealed that participants relied significantly more on distance bias than on animacy bias in both the multiple-choice and production tasks. These results were interpreted as a lack of evidence for significant learning of the animacy regularity among unaware participants. Faretta-Stutenberg and Morgan-Short (Reference Faretta-Stutenberg, Morgan-Short, Granena, Koeth, Lee-Ellis, Lukyanchenko, Prieto Botana and Rhoades2011) also extended Williams’s (Reference Williams2005) study, and their results showed that the performance of unaware participants on generalization test-items was not significantly above chance. This supported the findings of Hama and Leow’s (Reference Hama and Leow2010) research.
Chen et al. (Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011) adapted Williams’s (Reference Williams2005) design to native Chinese speakers by using Chinese low-frequency characters as determiners and frequent Chinese characters as nouns. Their series of experiments conceptually replicated Williams’s (Reference Williams2005) study, showing that participants could learn the novel form–meaning mappings when the hidden regularity was based on a feature that occurs in natural languages. They also showed that the acquired knowledge could be implicit (unconscious) as evidenced by trial-by-trial subjective measures of awareness (Dienes, Reference Dienes2004, Reference Dienes, Rebuschat and Williams2012). In this method, participants report, for every test judgment, what the basis of their decision was: guess, intuition, recollection, or rule knowledge. The former two categories are associated with implicit knowledge and the latter two with explicit knowledge.
Like Chen et al. (Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011), Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013) also employed subjective measures of awareness in their extension of Williams’s (Reference Williams2005) study. However, they also added retrospective verbal reports (the awareness measure used by Williams, Reference Williams2005) to directly compare both measures of awareness. This type of comparison is important, given that measures are differentially sensitive. After classifying participants as aware and unaware based on their retrospective verbal reports, Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013) found that only aware participants (those who were able to report the hidden regularity) performed significantly above chance on all types of test items, whereas unaware participants did not perform significantly above chance on any types of test items. This would suggest that learning was linked to awareness, supporting Hama and Leow’s (Reference Hama and Leow2010) findings. However, the analyses of the subjective measures of awareness revealed that the picture was more complex; their participants had acquired both explicit (conscious) and implicit (unconscious) knowledge. This result was interpreted as support for Williams (Reference Williams2005). Rebuschat et al. (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) further expanded this work by comparing three measures of awareness (retrospective verbal reports, subjective measures of awareness, and concurrent verbal reports). They found again evidence of implicit knowledge (as evidenced by subjective measures of awareness) and that adding concurrent verbal reports to the experimental design impacted learning in the group that had to think aloud while completing the training task. While the different groups showed a clear learning effect, in the case of the think-aloud group, learning appeared limited to recognition of items repeated from training during the test phase, that is, these participants seemed unable to generalize the acquired knowledge to novel items. Taken together, studies by Williams (Reference Williams2005), Chen et al. (Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011), and Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) suggest that adults are able to acquire novel form–meaning connections without intending to and without awareness of the acquired knowledge (the product of learning). In contrast, Hama and Leow’s (Reference Hama and Leow2010) and Faretta-Stutenberg and Morgan-Short’s (Reference Faretta-Stutenberg, Morgan-Short, Granena, Koeth, Lee-Ellis, Lukyanchenko, Prieto Botana and Rhoades2011) analyses of unaware participants’ performance indicated that adults do not acquire novel form–meaning connections without awareness.
The differences between the results of Williams (Reference Williams2005) and subsequent extension studies might be due to two important factors: the research methodology and the modality of stimuli presentation. In terms of methodology, there were important differences in how awareness was measured. The awareness measures employed by Williams (Reference Williams2005), Faretta-Stutenberg and Morgan-Short (Reference Faretta-Stutenberg, Morgan-Short, Granena, Koeth, Lee-Ellis, Lukyanchenko, Prieto Botana and Rhoades2011), and Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013) focused on the awareness of learning product, whereas Hama and Leow (Reference Hama and Leow2010) and Rebuschat et al. (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) assessed awareness of learning as both a product and a process (see Leow, Reference Leow and Rebuschat2015, for an overview). Williams (Reference Williams2005), Hama and Leow (Reference Hama and Leow2010), and Faretta-Stutenberg and Morgan-Short (Reference Faretta-Stutenberg, Morgan-Short, Granena, Koeth, Lee-Ellis, Lukyanchenko, Prieto Botana and Rhoades2011) did not include subjective measures to examine awareness of learning that were employed by Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015). In addition, the stimulus presentation and the time permitted to enter a response (i.e., response window) in the exposure and testing phases of these studies may have varied. With the exception of Chen et al.’s (Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011) study, none of the authors of other studies clearly reported whether their multiple-choice tasks were timed or untimed, which makes it impossible to investigate the role of timing in these studies. Chen et al. (Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011) reported that participants had to respond within 20 s during the training task, otherwise the next test item was presented. However, there was no information about timing during testing, which is potentially problematic, given that timing during test can affect the type of knowledge that is being assessed (Ellis, Reference Ellis2005; Godfroid et al., Reference Godfroid, Loewen, Jung, Park, Gass and Ellis2015; though see Vafaee, Suzuki, & Kachinske, Reference Vafaee, Suzuki and Kachinske2017).
Finally, given the stimuli specificity of implicit statistical learning (ISL; Conway & Christensen, Reference Conway and Christiansen2006; Frost et al., Reference Frost, Armstrong, Siegelman and Christiansen2015), the inconsistent use of modalities (auditory vs visual) in the exposure and test phases in Williams (Reference Williams2005) and its extension studies (Hama & Leow, Reference Hama and Leow2010; Rebuschat et al., Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) may be one reason for the conflicting results (though see Plonsky, Marsden, Crowther, Gass, & Spinner, Reference Plonsky, Marsden, Crowther, Gass and Spinner2019). Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013) called for empirical research on a comparison between the effect of auditory and visual modality in implicit L2 learning.
The effect of modality in implicit and incidental learning
Recent research has demonstrated different modality effects in ISL, and Frost et al. (Reference Frost, Armstrong, Siegelman and Christiansen2015) have argued for the coexistence of domain generality and modality specificity in their novel ISL framework. For example, Conway and Christiansen (Reference Conway and Christiansen2006) found parallel effects of visual statistical learning and auditory statistical learning, and Silva, Folia, Inácio, Castro, and Petersson’s study (Reference Silva, Folia, Inácio, Castro and Petersson2018) demonstrated similar behavioural outcomes across visual and auditory modalities. In contrast, two artificial grammar learning studies, Conway and Christiansen (Reference Conway and Christiansen2005, Reference Conway and Christiansen2009), revealed that the auditory modality was superior to the visual modality. Modality effects were also found to depend on the presentation speed of stimuli, showing that audition is superior to vision at fast rates, whereas vision is superior to audition at slow rates (Collier & Logan, Reference Collier and Logan2000; Emberson, Conway, & Christiansen, Reference Emberson, Conway and Christiansen2011). Qualitatively, Conway and Christiansen (Reference Conway and Christiansen2009) found a visual advantage for a primacy effect (better recall of first elements in a list) and an auditory advantage for a recency effect (better recall of final elements in a list) in an ISL task, which is consistent with Beaman’s (Reference Beaman2002) results regarding serial recall. ISL studies also suggest that auditory and visual input may be processed by separate mechanisms in the brain (Conway & Christiansen, Reference Conway and Christiansen2006; Siegelman & Frost, Reference Siegelman and Frost2015), which is supported by Silva et al.’s (Reference Silva, Folia, Inácio, Castro and Petersson2018) investigation of event-related potentials in response to grammar violations. It has also been found that ISL of artificial grammars can be transferred across different modalities (Altmann, Dienes, & Goode, Reference Altmann, Dienes and Goode1995). In addition, differences in the developmental trajectory of auditory and visual ISL abilities have been observed in children (Raviv & Arnon, Reference Raviv and Arnon2017). Taken together, most ISL studies have revealed multidimensional modality-specific effects, which are worth further investigation.
Previous SLA research has also compared the effect of exposure modality (auditory vs. visual). For example, Wong (Reference Wong2001) found better comprehension of written than auditory input. Leow’s (Reference Leow1993, Reference Leow1995) studies of L2 learners of Spanish suggest that learners’ intake of both salient forms and less salient forms was equally successful from written input, whereas the intake of salient form was significantly more effective from auditory input. Cintrón-Valentín and Ellis (Reference Cintrón-Valentín and Ellis2016) found that visual input directed learners’ attention to morphological cues more successfully than did aural input. More recently, Kim and Godfroid (Reference Kim and Godfroid2019) adapted the semiartificial language developed by Rebuschat and Williams (Reference Rebuschat and Williams2012) to examine differences in the incidental learning of German word order rules in auditory and visual input conditions. Participants were exposed to three verb placement rules in written and auditory modality and received implicit feedback in the exposure phase. In the written mode, participants had to read out the target sentences, whereas in the auditory mode they listened and repeated the sentences. Implicit feedback meant that the participants were asked to repeat the sentences up to three times if they did not produce the correct word order. Similar learning effects were observed regardless of the modality of the input, but students developed implicit knowledge only in the visual condition.
Previous research on the effect of assessment modality has compared grammaticality judgment tasks (GJT) in auditory and written modalities. Most studies have found learners’ performance is more accurate in written than in auditory grammaticality judgments (Johnson, Reference Johnson1992; Kim & Nam, Reference Kim and Nam2017; Murphy, Reference Murphy1997; Shui, Yalçın, & Spada, Reference Shiu, Yalçın and Spada2018; Spada, Shui, & Tomita, 2015). Kim and Godfroid’s (Reference Kim and Godfroid2019) recent study found that participants scored better in the auditory GJT compared to a written GJT that was presented word by word, but they did not differ when the written GJT was shown in whole sentence format. Plonsky et al.’s (Reference Plonsky, Marsden, Crowther, Gass and Spinner2019) recent meta-analysis suggests that modality effects in grammaticality judgements are neither strong nor stable. In contrast, their meta-analysis revealed large and reliable differences between untimed and timed grammaticality judgment tests, with participants scoring higher in untimed than timed conditions. Apart from GJT studies, there are very few studies on the effect of assessment modality in the field of SLA. Of interest, Ziegler’s (Reference Ziegler2016) meta-analysis of synchronous computer-mediated communication (SCMC) and interaction revealed that the same modality of training and testing contributes significantly to learning gains. This lends support to models of transfer-appropriate processing, which argue that learning is more effective if the cognitive processes employed in the encoding of new information are similar to those that are used for the retrieval (and assessment) of newly learned material (Roediger & Guynn, Reference Roediger, Guynn, Bjork and Bjork1996).
Research questions and predictions
As highlighted above, the possibility of learning without awareness is still subject to debate in the domain of adult SLA. Furthermore, there is a scarcity of studies on the effect of exposure and assessment modality under incidental exposure conditions, and a potentially critical variable, namely, the response window during exposure and test tasks, might not have been controlled rigorously in previous studies. The present study aimed to directly address these gaps. In doing so, we also intended to contribute to the debate on learning without awareness by further extending Williams’s (Reference Williams2005) study. To overcome the methodological shortcomings of previous research, we controlled the response window in both exposure and testing phases carefully. We also wanted to examine the effectiveness of incidental learning in a situation where the novel form–meaning connection is embedded in an L2 context. Our research addressed the following questions:
-
1. What characterizes the knowledge that Chinese L2 users develop when exposed to novel determiners under incidental exposure conditions?
-
2. How does modality of exposure and test phases (auditory vs. written) influence the acquisition of novel determiners under incidental exposure conditions?
As regards RQ1, based on Rebuschat et al.’s (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) and Leung and Williams’s (Reference Leung and Williams2014) studies, we hypothesized that Chinese L2 users would be able to establish new form–meaning connections in an incidental learning context, that is, without the intention to learn the hidden regularity and without advance knowledge of a test. Based on Hama and Leow (Reference Hama and Leow2010), Faretta-Stutenberg and Morgan-Short (Reference Faretta-Stutenberg, Morgan-Short, Granena, Koeth, Lee-Ellis, Lukyanchenko, Prieto Botana and Rhoades2011), and Rebuschat et al. (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015), we expected that participants who demonstrated some level of awareness would display a greater learning effect than those participants who did not. In line with Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013) and Rebuschat et al. (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015), we expected to find evidence for both implicit (unconscious) knowledge and explicit (conscious) knowledge in the test phase. For RQ2, we predicted a facilitative effect of the auditory presentation mode based on the results of artificial grammar learning studies in the field of cognitive psychology (cf. Conway & Christiansen, Reference Conway and Christiansen2005, Reference Conway and Christiansen2009). Based on research findings on the role of modality in accuracy in GJT, we hypothesized that participants’ response would be more accurate in the written mode. However, as a result of transfer appropriate processing (Roediger & Guynn, Reference Roediger, Guynn, Bjork and Bjork1996), participants in the auditory exposure condition can be hypothesized to be more likely to give correct responses in the auditory testing mode.
Method
Participants
Eighty-eight students (42 women; M age = 23.42) at a UK university volunteered to participate in the experiment. After providing informed consent, participants were randomly assigned to one of four experimental conditions (n = 22 each). Participants in the auditory–visual (AV) condition received auditory stimuli in the exposure phase and written test-items in the test phase. Participants in the visual–auditory (VA) condition were exposed to written stimuli and auditory test-items in the test phase, while those in the auditory–auditory (AA) condition received auditory stimuli in the exposure phase and the test phase. Finally, participants in the visual–visual (VV) condition received written stimuli in both the exposure phase and the test phase.
All participants were native speakers of Chinese (Mandarin, n = 67; Cantonese, n = 19) who were learning English as an L2. Their self-reported IELTS scores ranged from 6.0 to 7.5, which is equivalent to B2 to C1 level in the Common European Framework of Reference (CEFR) (Council of Europe, 2001). Apart from English, 26 participants reported studying the following additional languages: Mandarin (n = 9), Japanese (n = 6), Spanish (n = 6), French (n = 6), German (n = 5), Korean (n = 3), Russian (n = 1), Minnan (n = 1), and Malay (n = 1). Seventeen participants (5 in the AV, 2 in the VA, 7 in the AA, and 3 in the VV conditions) reported that they had taken courses in linguistics before the experiment. A series of Chi-square tests revealed that the groups did not differ significantly in terms of the distribution of age, gender, number of L2s, and participants’ language background.
Stimulus materials
The training and test items were adapted from Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015). The artificial determiner system developed by Williams (Reference Williams2005) was used in this study. The system consists of four artificial determiners (gi, ro, ul, and ne), whose usage depends on the distance and animacy of the associated noun. The determiners gi and ro are used with nouns that refer to near objects, and ul and ne refer to distant objects. The determiners gi and ul refer to animate (living) entities, whereas ro and ne refer to inanimate (nonliving) entities. In line with previous studies, participants were instructed about the role of distance in determiner usage, but the animacy regularity was not revealed to them. Animacy thus served as a hidden regularity.
Training items
The training items consisted of two training sets. Each set included 24 determiner–noun combinations that were repeated three times over the exposure phase. These noun phrases (NPs) were constructed with 12 animate and 12 inanimate nouns. Half of the NPs in each category were presented in near-context sentences and the other half in far-context sentences. Half of the nouns in each category were in singular form and the other half in plural form. The order of the total of 144 sentences was randomized for each set, and plurality was counterbalanced within each set (see Table 1). That is, if gi rats was presented in Set 1, then gi rat was presented in a different context in Set 2; then Set 1 appeared again, and so on. Following Williams (Reference Williams2005, Experiment 2) and Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015), each noun was matched with only one determiner to guarantee that learning occurred as a result of establishing form–meaning connections rather than form–form associations between determiners. For example, there were gi rat/s (near-animate) but not ul rat/s (far-animate), so that it could be concluded that gi is used with animate nouns, but not that any noun that follows gi can also be preceded by ul. The items used in training and testing are reproduced in Appendix A. Noun phrases are reproduced in Appendix B.
Table 1. Design of training items

Test items
Thirty-six new-context sentences were used to assess all participants. The sentences had not appeared during the exposure phase and were presented in the same random order. The sentences consisted of three types of NPs: trained, partially trained, and untrained. The NPs in the trained items were those that appeared in exactly the same form in the exposure phase (e.g., gi rats). The NPs in the partially trained items had appeared during exposure but were changed into opposite near-far determiners. For example, ul monkeys (far monkeys) that occurred in training was partially changed into gi monkeys (near monkeys) in the test. Novel nouns that had not occurred in the exposure phase were used to construct untrained items (e.g., gi goat). The animacy and inanimacy of NPs was counterbalanced, and items were presented to participants in random sequences (see Appendix C for a list of the nouns in the testing phase).
Given that the participants in the present study were nonnative English speakers, we wanted to ensure that acquisition of the four artificial determiners would not be hindered by unknown or unfamiliar English words in the stimuli. Therefore, we made adaptations to the original training and test items from Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015). All English words and phrases in the original items were checked on the website English Vocabulary Profile (http://vocabulary.englishprofile.org). English words that were above B1 level on the CEFR were either replaced by synonyms or other words, or deleted.
The training and test items used in the two modalities during the exposure and testing phases were identical, except that the order of training items within each set in the exposure phase in each modality was independently randomized for each participant. In the visual modality, written sentences were presented. In the auditory modality, audio recordings of the sentences read by a female native speaker of British English were played. To ensure learning and assessment of the artificial determiners would not be hindered by the English proficiency level of the participants, the speaker used a delivery rate of 100–120 words per minute, which is lower than the normal speaking rate (Crystal & House, Reference Crystal and House1990).
For each training and test item, we calculated a time range during which participants could enter their responses. This response window was calculated based on the results of a preliminary pilot study (cf. procedures in Shiu et al., Reference Shiu, Yalçın and Spada2018). First, words per second for the shortest and longest trials of the two modalities from the pilot results were calculated. Then, these figures were used to divide the number of words of the shortest (6 words) and longest items (20 words) in the present study. That is, the response window took into account the time needed for reading or listening to the input stimulus, that is, it included the presentation of the stimulus item as well. For the written modality, the response window ranged from 3 to 15 s depending on the length of the sentence, and the response window in the auditory modality ranged from 5 to 12 s, again depending on the length of the stimulus sentence (see Appendix D for more details).
Procedure
All participants completed (a) vocabulary pretraining of the four artificial determiners for the distance regularity, (b) an exposure phase, (c) a testing phase, (d) a retrospective verbal report interview, and (e) a debriefing questionnaire. All participants met the experimenter individually in a quiet laboratory. The vocabulary pretraining, exposure, and testing phases were delivered via Microsoft PowerPoint. All participants’ responses in the exposure and testing phases were screen recorded to ensure they had followed the instructions. The retrospective verbal report interviews were audio recorded. The debriefing questionnaires were administered via Qualtrics on a mobile device. The entire procedure took approximately 1 hr.
Vocabulary pretraining
The original material from Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) was adapted for the present study. Instructions were translated into Chinese, and the pronunciation of each artificial determiner was recorded by the same female native speaker of British English. The modality of this session was mainly written (except the audio recordings). The purpose of the pretraining was to introduce the four artificial determiners and to instruct participants on the role of distance in determiner selection. Participants were informed that they would be tested after the pretraining and that they could complete the pretraining at their own pace. Participants were first presented with a list of the four new words and their meanings in English, together with the spoken form of the words. Then, they completed a first practice task by saying aloud the missing determiner that matched the English translation on the list of four determiners. Next, they carried out a second practice by saying aloud the English translations of the new words. The practice tasks gave participants feedback by presenting correct answers after each response, and they exposed participants to 12 written repetitions of each artificial determiner. Participants were allowed to repeat this session as many times as they wished. Finally, the original quiz from Rebuschat et al. (Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) was used to test the participants on the distance meanings of the determiners on the online testing website ClassMarker. Following previous studies, participants were not allowed to continue to the exposure phase until they scored 90% or higher on the quiz. Most of them were able to do so on their first attempt, except one participant from the written–auditory group who was only able to do this on second attempt.
Exposure phase
Visual exposure
Written instructions adapted from Williams (Reference Williams2005, pp. 281–282) were translated into Chinese to explain that the general purpose of the experiment was to investigate whether people think differently in different languages, using the four artificial determiners. The participants were informed that the functions of the four novel determiners were similar to the English word the, but they also included distance meanings of objects. An example sentence (“The little boy patted gi tiger in the zoo”), which did not appear in the following sessions, was used to illustrate the function of this determiner in context.
Then, the participants were instructed that they would see written sentences that included the novel determiners they had learned from vocabulary pretraining. Their task was to read each sentence and judge, as quickly as possible, whether the determiner indicated far or near. They could respond by clicking F (far) or N (near) buttons located in the bottom left and right corners of the screen. They were informed that they would have only a few seconds to decide. The sentence then disappeared and the participants were required to form a mental image of the sentence, which was not to be timed. The previous sample sentence was used as an illustration (i.e., the participants would imagine that a boy was patting a tiger that was near them). A short practice session with four sentences, which did not appear in subsequent sessions, was given to all participants before the exposure.
Auditory exposure
The auditory exposure was identical to the written exposure except that the stimuli were delivered in auditory mode, which required participants to listen to the whole sentence before giving a response. This was designed differently from the written exposure to ensure participants did not skip any sentences. For each item, the response window was different from that in the written exposure.
Testing phase
The learning of the hidden animacy was measured by means of a two-alternative forced-choice (2AFC) test.
Written 2AFC test
Each sentence was displayed in the center of the computer screen (e.g., “The lady is eating pasta with ___ fork.”) with two choices of artificial determiners, which differed only in animacy meaning but were the same in distance meaning (e.g., gi and ro). The two choices of determiners were located in the bottom left and right corners of the screen. The correct determiners appeared as the left and right choice with equal frequency. Participants were informed in written Chinese to choose the determiner that “seems more familiar, better, or more appropriate” (Williams, Reference Williams2005, p. 282) and that this session was timed. They gave their responses by clicking one of the two determiners. Before the test, a short practice session with four sentences, which did not appear in the test, was given to all participants, but no feedback was given.
Source attributions were used as a subjective measure of awareness to determine whether participants had acquired unconscious (implicit) or conscious (conscious) structural knowledge (Dienes & Scott, Reference Dienes and Scott2005). After entering their 2AFC response, participants were asked to report what their decision was based on. Here, they could select one of four options: guess, intuition, recollection, or rule knowledge. Participants were instructed in written Chinese to select guess only when they made their judgment by purely guessing (i.e., similar to flipping a coin); to select intuition when they made their judgment based on a gut feeling that they were correct but could not explain why; to select recollection when their choice was based on recollection of a similar sentence (or part of it) in the exposure phase; to select rule knowledge when their decision was based on a rule that they could verbalize after the test. Subjective measures have been introduced in implicit learning research by Dienes and Scott (Reference Dienes and Scott2005) as more sensitive measures than retrospective verbal reports. In line with Dienes and Scott (Reference Dienes and Scott2005), judgments attributed to guessing and intuition were taken as indications of unconscious structural knowledge, while judgments attributed to recollection and rule knowledge were assumed to reflect participants’ conscious structural knowledge (see also Chen et al., Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011).
Auditory 2AFC test
The auditory 2AFC test was identical to the written 2AFC test, except that it was delivered in the auditory mode and the response window for each test sentence was different from that in the written 2AFC test. The blank space in the written 2AFC test was replaced by a beep sound that lasted 30 ms.
Retrospective verbal reports
All participants were interviewed by the experimenter after the test. The interviews were conducted in the participants’ native language, that is, Mandarin or Cantonese. Following Rebuschat et al. (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015), the participants were first asked how they made their choices. If they mentioned any distinction related to living or nonliving, they were asked when they had become aware of this distinction (exposure or test phase) and whether they had chosen rule knowledge as the source of their choices. If so, they were required to describe the rule or regularity. If participants had not chosen rule knowledge in the source attributions, they were asked about the other sources of their decisions. If participants did not make any reference related to animacy or if they did not use rule knowledge as the source of their judgments, they were told that there was a rule to distinguish the two near/far determiners (i.e., gi and ro; ul and ne), and they were encouraged to guess the rule. If participants still did not refer to animacy, the experimenter presented the determiner system and then asked if they had been aware of the hidden regularity at any point during the experiment. The interview questions were designed to move from implicit to explicit knowledge gradually to investigate participants’ awareness of the hidden rule, so that the effect of the questions on participants’ awareness of the hidden regularity would be minimized. Different from Rebuschat et al.’s (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) study, participants were also required to report their awareness of animacy in both phases of exposure and assessment, respectively.
Following Rebuschat et al.’s (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) study, participants’ verbal reports were coded conservatively. Participants were considered to be aware of the hidden regularity even if they displayed only fleeting or partial awareness of the regularity in the verbal reports. To be considered unaware, participants could not make a mention to the animacy regularity, even after extensive and careful probing by the experimenter. The coding scheme to categorize aware and unaware participants can be found in Appendix E.
Debriefing session
After the interviews, participants completed a brief questionnaire about their age, gender, field of study, native language(s), previous experience in linguistics courses, foreign language(s) studied, contexts of instruction, and length of study.
Analysis
In order to answer RQ1, we conducted both frequentist and Bayesian one-sample t tests to investigate whether performance was significantly above chance and whether the data provides statistical support for learning effects in performance (the alternative hypothesis or H1). Common in both frequentist and Bayesian one-sample t tests, our alternative hypothesis predicted that participants’ performance would be better than by chance, and we thus adopted one-tailed t tests (H1 > H0) for all the analyses. Our rationale for reporting both frequentist and Bayesian statistical tests is to ensure the comparability of the current results with previous studies. However, one striking disadvantage of the frequentist approach over the Bayesian approach is that nonsignificant results can indicate either the lack of target effects or the lack of sensitivity to detect the effects (e.g., underpowered design). This problem of logical status of nonsignificant results was solved by the Bayesian analysis, which can distinguish the support for the null hypothesis from the lack of sensitivity (Keysers, Gazzola, & Wagenmakers, Reference Keysers, Gazzola and Wagenmakers2020). In addition, due to the use of p value in hypothesis testing in a frequentist approach, multiple comparisons would increase the rate of Type I errors, while with an adjustment of alpha level (e.g., the Bonferroni correction), the rate of Type II errors also increases. As we conducted a total of 30 one-sample t tests, particularly in our research context, a Bayesian approach, which does not rely on p value, may provide robust results (for the comparisons of statistical results between raw and adjusted p values of the frequentist approach and the Bayesian approach, see Appendix F).
Regarding the Bayesian analysis, we calculated a Bayes factor (BF10), which refers to the relative predictive performance of H1 to H0, using the JASP software (JASP Team, 2020). As recommended by Keysers et al. (Reference Keysers, Gazzola and Wagenmakers2020), we used a default prior distribution for t tests (the Cauchy distribution with a scale parameter of r = .707) to calculate BF10. Following Keysers et al. (Reference Keysers, Gazzola and Wagenmakers2020) and Kim and Godfroid (Reference Kim and Godfroid2019), we set BF10 > 3.0 as the criterion for the evidence of learning effects. The 3.0 value of BF10 means that the given data was predicted three times better by H1 than H0. We also set BF10 < 0.333 (the inversed value of 3.0) as the absence of learning effects and the BF10 between 3.0 and 0.333 as the absence of evidence (i.e., insufficient evidence to draw a conclusion; see Keysers et al., Reference Keysers, Gazzola and Wagenmakers2020). In addition to BF10, we also reported the median and 95% credible intervals of the posterior effect size δ, which is not simply equivalent to the Cohen’s d value, because this effect size index reflects both the prior distribution and the data observed (Keysers et al., Reference Keysers, Gazzola and Wagenmakers2020).
In order to address RQ2, we performed the generalized (logistic) linear mixed-effects modeling (GLMM) in R (R Core Team, 2018) using the lme4 package (Bates, Mächler, Bolker, & Walker, Reference Bates, Mächler, Bolker and Walker2014) to predict the accuracy of 2AFC items. We entered the binary variable representative of the correctness of answers (either correct [1] or incorrect [0]) as the dependent variable and the following variables as fixed effects (i.e., independent predictor variables): exposure (auditory vs. written), assessment (auditory vs. written), training (trained, partially trained, and untrained items), knowledge (conscious vs. unconscious structural knowledge, based on source attributions), and awareness (aware vs. unaware based on retrospective interviews). In order to test the significance of a particular predictor variable while controlling for the effects of the other predictor variables, we adopted contrast coding, as opposed to dummy coding. For the variables with two levels (exposure, assessment, and knowledge), simple contrast coding was applied (–0.5 or 0.5). Meanwhile, regarding the training variable, which had three levels, we regarded untrained items as the reference level and applied simple contrast coding to test the contrasts between untrained and partially trained items and between untrained and trained items. The same model building procedure was repeated for two different measures of awareness (knowledge vs. awareness). We entered the correctness of answers as the outcome variable and exposure, assessment, training, and either knowledge or awareness as the fixed effects predictor variables.
Results
The role of awareness in learning novel determiners (RQ1)
To determine if Chinese L2 learners could acquire the hidden regularity and to assess the role played by awareness (RQ1), we first analyzed overall performance on the 2AFC test (measure of learning), followed by closer analysis of the retrospective verbal reports and the source attributions provided by participants (measures of awareness).
Performance on the 2AFC test
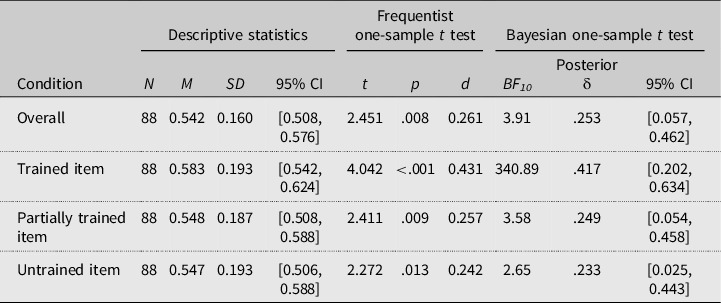
To determine if learning took place, we analyzed performance on the 2AFCT test across all participants, independent of condition. As can be seen in Table 2, participants’ mean accuracy on the test was 0.542 (SD = 0.160), which was significantly above chance, t (87) = 2.45, p = .008, d = 0.26, thus indicating that learning of the hidden regularity occurred under incidental exposure conditions. The Bayesian analysis provided moderate evidence for learning effects above chance level, BF10 = 3.91, median posterior δ = 0.253, 95% confidence interval (CI) [0.057, 0.462]. Furthermore, one-sample t tests indicated that participants performed significantly above chance on each test-item type: for the trained items, t (87) = 4.04, p < .001, d = 0.43; for the partially trained items, t (87) = 2.41, p = .009, d = 0.26; for the untrained items, t (87) = 2.27, p = .013, d = 0.24. Using Plonsky and Oswald’s (Reference Plonsky and Oswald2014) guidelines on the interpretation of Cohen’s d values, all these effects are considered small. The Bayesian analysis showed extremely strong support for above chance learning effects on trained items (BF10 = 340.89, median posterior δ = 0.417, 95% CI = [0.202, 0.634]) and moderate support for partially trained items (BF10 = 3.58, median posterior δ = 0.249, 95% CI = [0.054, 0.458]). The results of the Bayesian analysis regarding untrained items were inconclusive (BF10 = 2.65, median posterior δ = 0.233, 95% CI = [0.025, 0.443]).
Table 2. Frequentist and Bayesian analysis of overall response accuracy and response accuracy for trained, partially trained and untrained items
Subjective measures of awareness
The analyses of the item-by-item source attributions provided during the completion of the 2AFC test showed that participants (across the four conditions) scored 0.576 (SD = 0.494) when basing their decisions on the explicit response categories (recollection and rule knowledge) and 0.550 (SD = 0.498) when basing decisions on the implicit response categories (guessing and intuition). The mean accuracy was significantly above chance in either case: explicit categories, t (1281) = 5.47, p < .001 d = 0.15; implicit categories, t (1776) = 4.26, p < .001 d = 0.10. The Bayesian analysis provided extremely strong support for above chance learning effects in both implicit and explicit response categories (cf. Table 3).
Table 3. Frequentist and Bayesian analysis of overall response accuracy and response accuracy for items based on subjective measures

Retrospective verbal reports
Our analysis of the retrospective verbal reports revealed that 52 participants reported knowledge of the animacy regularity, whereas 36 participants did not. Based on their verbal reports (or lack thereof), we categorized the former participants as “aware” and the latter as “unaware” of the hidden regularity (see Table 2, and Appendix E for coding scheme). The aware participants correctly identified 0.562 (SD = 0.194) of the test items and the unaware participants 0.512 (SD = 0.083). Analyses showed that aware participants scored significantly above chance in the 2AFC test, t (51) = 2.30, p = .013, d = 0.32, and that unaware participants did not, t (35) = 0.89, p = .190, d = 0.15. This suggests that, according to verbal reports, learning was limited to those participants who displayed at least some awareness, if only minimal, of the hidden regularity in their retrospective verbal reports. The Bayesian analysis showed moderate evidence for above chance learning effects for aware participants (BF10 = 3.32, median posterior δ = 0.304, 95% CI = [0.058, 0.577]), whereas the results of the Bayesian analysis regarding overall learning effects in the unaware group were inconclusive (BF10 = 0.41, median posterior δ = 0.176, 95% CI = [0.011, 0.467]).
As a next step, we analyzed the performance of aware and unaware participants across the three test-item types. The results show that aware participants performed above chance only on trained items, t (51) = 3.82, p < .001, d = 0.53, and that there was an extremely strong evidence for learning effects using the Bayesian analysis (BF10 = 141.30, median posterior δ = 0.504, 95% CI = [0.220, 0.794]). In contrast, the unaware participants did not perform above chance on any test-item types. The Bayesian analysis indicates that there is insufficient evidence for the validity of either the null or the alternative hypothesis for any of the item types in the unaware group and for the partially trained and untrained items in the aware group (see Table 4). In other words, learning appeared limited to those participants who displayed at least some conscious knowledge of the hidden regularity in the verbal reports. Even in those cases, the learning effect was driven by above chance performance on trained items, and there was no sufficient evidence of generalization.
Table 4. Frequentist and Bayesian analysis of overall response accuracy and response accuracy for items based on retrospective measures

The effect of exposure and assessment modality (RQ2)
To examine whether the modality used in the exposure and testing phases affected the acquisition of novel determiners, we analyzed performance on the 2AFC test across groups. We found that the AA group scored highest (M = 0.614, SD = 0.155), followed by the AV group (M = 0.588, SD = 0.146), the VA group (M = 0.524, SD = 0.100) and the VV group (M = 0.471, SD = 0.197). One-sample t tests on the groups’ mean accuracy scores revealed that only the AA group performed above chance, t (21) = 3.45, p = .001, d = 0.74. Using Plonsky and Oswald’s (Reference Plonsky and Oswald2014) guidelines on the interpretation of Cohen’s d values, this effect is considered moderate, and the Bayesian analysis also showed very strong evidence for the existence of the overall learning effect in this group. Regarding the AV group, the results of one-sample t tests in frequentist and Bayesian approaches did not concur, t (21) = 1.87, p = .038, d = 0.40, BF10 = 1.85, median posterior δ = .364, 95% CI = [0.043, 0.780]). Considering the robustness of Bayesian analysis, we regarded the leaning gains in the AV group as the evidence of absence rather than the lack of learning effects. (i.e., inconclusive evidence). The other groups’ performance did not differ significantly from chance: the VA group, t (21) = 1.12, p = .134, d = 0.24, the VV group, t (21) = –0.69, p = .751, d = –0.15. The Bayesian analysis showed inconclusive evidence for overall learning effects in the VA groups and revealed moderate evidence for the null hypothesis in the VV group (BF10 = 0.14, median posterior δ = 0.096, 95% CI = [0.004, 0.367]). We then investigated whether performance differed across test-item types. One-sample t tests showed that only the AV group performed above chance on all test-item types, and the Bayesian analyses suggested moderate evidence for these learning effects. The AA group performed above chance on trained test items and partially trained test items, and the evidence for the significance of these learning effects was extremely strong for trained items (BF10 = 136.65, median posterior δ = 0.804, 95% CI = [0.322, 1.305]) and strong for untrained items (BF10 = 10.36, median posterior δ = 0.548, 95% CI = [0.133, 1.001]). The other groups did not score above chance on any test-item types. In the VA group the Bayesian analysis showed an absence of evidence for for the null or the alternative hypothesis for all item types, whereas in the VV group there was sufficiently strong evidence for the null hypothesis (see Table 5).
Table 5. Frequentist and Bayesian analysis of overall response accuracy and response accuracy for items based in different exposure and assessment conditions

To further investigate variances in each group’s performance across test-item types, we constructed the parsimonious models of GLMM in two steps (for the full model, see Appendix G). In the first step of the analysis, we examined whether the model fit to the current data was improved by adding the fixed-effects predictors and their interactions, while keeping the random effects constant. In order to compare the simpler models with the more complex ones, we used the likelihood ratio test (LRT; Baayen, Reference Baayen2008) and evaluated whether the inclusion of fixed-effects predictors was justified. To this end, we started with a minimal model of the log odds response accuracy (Model 1), which included the random intercepts of participants and items. We compared the minimal model with the models with one of the fixed-effect factors: exposure (Model 2), assessment (Model 3), training (Model 4), or knowledge type (Model 5). The LRT revealed that only Model 2 improved the (exposure) model fit to the data, compared to the minimal model, indicating that only exposure was the significant predictor for response accuracy, χ2(1) = 7.842, p = .0051. Then, although we added each of the remaining three fixed-effects factors to Model 2, none of them further improved the model fit. In addition, there was no significant interaction effect between exposure and those nonsignificant fixed-effects factors. Therefore, we included one fixed-effects factor for the final model.
In the second step of the analysis, we examined whether to include the random slopes of participants and items in the slope of the fixed-effect factor (exposure). Note that we decided to include both random intercepts of participants and items considering the hierarchical structure of our data. The LRT tests confirmed that neither of random-slope of participants, χ2(2) = 0.056, p = .972, and items, χ2(2) = 1.986, p = .370, improved the model fit. Therefore, our finalized model was specified as follows:
 $$Response\, Accuracy\, \sim Exposure + (1|Participant) + (1|Item).$$
$$Response\, Accuracy\, \sim Exposure + (1|Participant) + (1|Item).$$
Another similar model following the same procedures was run where knowledge was replaced by awareness (aware vs. unaware, based on retrospective verbal reports). The full model is reported in Appendix G. The full model does not include interactions and random slopes because that complex model made the estimation very unstable and failed to converge. Both of the GLMMs predicting the accuracy of 2AFC scores included a significant main effect of exposure. There were no other significant main effects or significant interactions between the predictor variables. None of the variables, except for exposure, improved the model fit compared to the baseline model, which included only random intercepts of participant and item. Therefore, we only report the final model, which includes exposure as the main effect in Table 6. The odds ratios for this model predicted participants to be 1.52 (1/0.66) times more likely to respond correctly in the auditory exposure condition than in the written exposure condition. Following Plonsky and Oswald (Reference Plonsky and Oswald2014), we interpret R 2 with a value lower than .16 as small effects. The main effects model had a marginal R 2 of .012 and a conditional R 2 of .111, which indicates that exposure condition alone as well as the exposure condition and the random effects explain a relatively small amount of variance in the accuracy of responses.
Table 6. Summary of the final model

Note: Auditory exposure is the reference level for exposure.
Discussion
Establishing form–meaning connections under incidental exposure conditions
In our first research question, we examined the acquisition of novel form–meaning connections by adult learners under incidental exposure conditions. In line with our predictions and previous research (e.g., Chen et al., Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011; Hama & Leow, Reference Hama and Leow2010; Leung & Williams, Reference Leung and Williams2014; Rebuschat et al., Reference Rebuschat, Hamrick, Sachs, Riestenberg, Ziegler, Bergsleithner, Frota and Yoshioka2013, Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015; Williams, Reference Williams2005), the findings confirm that adult learners can learn a hidden regularity that governs determiner selection in a miniature linguistic system. However, the overall learning effect was found to be relatively small, and the Bayesian analysis only showed moderate support for the alternative hypothesis. This could be explained by the fact that the determiners were processed at a relatively low level of depth of cognitive processing (cf. Leow, Reference Leow and Rebuschat2015). In our study, a novel structure was embedded in L2 sentences, and even though these sentences were simple and contained familiar vocabulary, our participants might not have had sufficient attentional resources for processing and encoding the new meaning of the determiners. The small learning effects might also be explained by the characteristics of the participants’ first language (Mandarin and Cantonese) in which there are no classifiers that specifically distinguish between animate and inanimate nouns. Instead, the elaborate classifier system denotes specific characteristics of objects such as flatness or length. The participants’ learned attention to these other types of semantic cues and subsequent processing bias that originates from their native language (cf. Ellis & Sagarra, Reference Ellis and Sagarra2010) might also explain the small and predominantly exemplar-based learning effects, for the learning of which we found very strong evidence using Bayesian analysis (cf. also Leung &Williams, Reference Leung and Williams2014, for a similar argument).
In terms of our awareness measures, the analyses of the retrospective verbal reports showed that learning was limited to aware participants who were able to verbalize knowledge associated with the hidden regularity at the end of the experiment. The effect size of learning for the aware group was small, and the alternative hypothesis was only moderately supported by the Bayesian analysis. Significant learning was only observable for those test items that were repeated from the training phase (trained items) in the aware group. The very strong support for the above chance learning effects in the aware group on trained items from the Bayesian analysis also highlights that most learning in the experiment took place through memorization and was exemplar based. These results are consistent with those of Faretta-Stutenberg and Morgan-Short (Reference Faretta-Stutenberg, Morgan-Short, Granena, Koeth, Lee-Ellis, Lukyanchenko, Prieto Botana and Rhoades2011), Hama and Leow (Reference Hama and Leow2010), and Rebuschat et al. (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015), but contradict the findings of Williams (Reference Williams2005), who showed that unaware participants can perform above chance level. Our Bayesian analysis also indicates that in the unaware group there is insufficient evidence to either confirm or reject the alternative hypothesis. The small and unstable effects across studies might be due to sensitivity to input frequency, insufficient statistical power, and variations in the sample and research methodology.
The analysis of participants’ source attributions indicated the presence of both implicit (unconscious) and explicit (conscious) knowledge at test, as evidenced by above chance performance when 2AFC decisions were based on implicit categories (guessing or intuition) and explicit categories (recollection or rule knowledge). This confirms the observations made in previous studies that investigated the effect of incidental exposure on the acquisition of form–meaning connections (e.g., Chen et al., Reference Chen, Guo, Tang, Zhu, Yang and Dienes2011; Monaghan, Schoetensack, & Rebuschat, Reference Monaghan, Schoetensack and Rebuschat2019; Rebuschat et al., Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015), L2 vocabulary (e.g., Hamrick & Rebuschat, Reference Hamrick and Rebuschat2012, Reference Hamrick and Rebuschat2014), L2 morphology (e.g., Grey et al., Reference Grey, Williams and Rebuschat2014), and L2 syntax (e.g., Kim & Godfroid, Reference Kim and Godfroid2019) in adult learners. The results also confirm that reliance on retrospective verbal reports might not be sufficient to detect the presence of unconscious knowledge as these tests might not be sensitive enough (see Rebuschat et al., Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015, for discussion). The presence of implicit knowledge at test does not imply that learning necessarily occurred without awareness, given that subjective measures assess awareness of the learning product, not the learning process, but it suggests that the required level of awareness can be relatively low, for instance, at the level of Schmidt’s (Reference Schmidt1990) noticing. It is also important to acknowledge that subjective measures of awareness (like most behavioral measures of awareness) are not without problems (for a thorough investigation of the limitations of source attributions, see, for example, Sachs, Hamrick, McCormick, & Leow, Reference Sachs, Hamrick, McCormick and Leow2020). Clearly, more research is necessary to assess the internal validity of awareness measures.
The role of modality in incidental language learning
Our study also sought to investigate the effect of modality on the incidental learning of novel determiners in the exposure and assessment phases, respectively. The results of GLMM showed a significant benefit with a small effect size for auditory exposure, but the modality of assessment did not influence performance in the testing phase of the study. No significant main effects for awareness, knowledge-type, or training were detected either, and there was no interaction among any of these variables. Therefore, the final model of GLMM in which the item-level subjective measure of knowledge type was included as a predictor confirmed the results of both the frequentist and the Bayesian one-sample t tests. However, the GLMM with the retrospective measure of awareness as the predictor variable was not fully in line with the results of the frequentist or the Bayesian one-sample t tests, as it showed no effects of awareness or item-type, whereas above chance learning effects were observed for aware participants on trained items and in the auditory exposure conditions for trained and partially trained items. As above chance learning effects were relatively small in all conditions, except for the auditory exposure and auditory assessment group, it is not unexpected that the GLMM, which took into account random intercept variations at participant and item levels, did not detect these main effects.
Overall, our findings suggest that the success of incidental learning might depend on the modality of exposure. The beneficial effects of auditory input seem to apply in our study in comparison with Kim and Godfroid’s (Reference Kim and Godfroid2019) research because our participants did not engage in additional processing such as repetition of the sentences, and they did not receive feedback. In this respect, our design is similar to artificial grammar learning studies in cognitive psychology, which found that the auditory modality is superior to the written modality in ISL (e.g., Conway & Christiansen, Reference Conway and Christiansen2005, Reference Conway and Christiansen2009; Drewnowski & Murdock, Reference Drewnowski and Murdock1980; Qi, Araujo, Georgan, Gabrieli, & Arciuli Reference Qi, Araujo, Georgan, Gabrieli and Arciuli2018). Our research demonstrates that the incidental learning of novel form–meaning connections is assisted by auditory input regardless of the level of awareness or whether judgments were made based on conscious or unconscious knowledge. Furthermore, the auditory facilitation effect can be observed irrespective of whether items were trained, partially trained, or untrained. Therefore, our results might indicate that sequences are more successfully remembered in the auditory mode, which might support extraction of statistical regularities more effectively than visual input. This finding seems to provide indirect support for the nonunitary nature of statistical learning ability by showing superior auditory modality effects for linguistic stimuli (cf. Frost, Armstrong, & Christiansen, Reference Frost, Armstrong and Christiansen2019). Our findings showing the superiority of the auditory exposure mode in incidental learning conditions are also in line with recent research in the field of first language literacy development, which has shown that auditory statistical learning ability is a better predictor of word and sentence reading fluency than visual statistical learning ability (Qi et al., Reference Qi, Araujo, Georgan, Gabrieli and Arciuli2018).
As regards the lack of a significant effect of the assessment modality, the findings seem to contrast with previous studies that found that learners’ accuracy is higher in written forced-choice tasks than auditory ones (e.g., Johnson, Reference Johnson1992; Kim & Nam, Reference Kim and Nam2017; Murphy, Reference Murphy1997; Shui et al., 2018; Spada et al., Reference Spada, Shiu and Tomita2015). However, our results support the conclusions of Plonsky et al.’s (Reference Plonsky, Marsden, Crowther, Gass and Spinner2019) meta-analysis, which revealed unstable effects of modality in grammaticality judgment performance. As discussed above, potential differences in the length of response window during the tasks in previous studies may explain the contradictory findings. In our research, we did not detect evidence of transfer appropriate processing either as no interaction between the input modality and assessment mode was found. Nonetheless, the frequentist and Bayesian one-sample t tests indicated that the strongest evidence for the alternate hypothesis can be detected in the auditory exposure and auditory assessment group, which might indicate some advantage for the auditory mode both in exposure and assessment.
Conclusion
The present study investigated the acquisition of form–meaning connections by adult participants under incidental exposure conditions. As an original contribution to the study of incidental language learning, we also examined the effect of modality in both the exposure and the test phases. The findings showed small, but significant, learning effects among participants supporting numerous previous studies that employed the paradigm developed by Williams (Reference Williams2005). However, in light of the Bayesian analysis, we interpret this finding cautiously as the evidence for the learning effect was overall only moderate and was extremely strong only for trained items (in contrast to Rebuschat et al., Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015). We demonstrate that incidental exposure can result in implicit and explicit knowledge but argue that some level of awareness is facilitative for the establishment of accurate form–meaning relationships, especially when a novel grammatical construction is embedded in a sentence-level L2 context and when the participants’ native language may contribute to a processing bias.
It also needs to be noted that statistical analyses that group participants into aware and unaware categories based on retrospective reports have much lower statistical power due to the small sample size than subjective analyses that give information on the basis of participants’ accuracy decisions for each item. Our Bayesian analyses indicated that there is no sufficient empirical basis for either the null or the alternative hypotheses except for the aware participants’ overall scores and their scores on trained items. Therefore it would be important to conduct larger scale studies and a meta-analysis of existing research that would compare learning effects based on retrospective reports of awareness.
In terms of the effects of modality, our findings extend the results of previous studies that have demonstrated the benefits of the auditory exposure modality over the written modality (e.g., Conway & Christiansen, Reference Conway and Christiansen2005, Reference Conway and Christiansen2009; Drewnowski & Murdock, Reference Drewnowski and Murdock1980; Qi et al., Reference Qi, Araujo, Georgan, Gabrieli and Arciuli2018). The lack of effect of the assessment modality is in line with the conclusions of a recent meta-analysis by Plonsky et al. (Reference Plonsky, Marsden, Crowther, Gass and Spinner2019), who showed that, in forced-choice tasks, modality effects are small and prone to variation based on the research methodology.
One of the limitations of our study is that we did not employ a first language-speaking control group as a baseline for the performance of the experimental groups. Future research with this additional group and with participants whose first language denotes animacy in their classifier or determiner system could reveal to what extent the L2 sentence context and the learned attention of the Mandarin- and Cantonese-speaking participants influenced our findings. In our study, we did not assess participants’ productive knowledge or the longer term duration of learning effects. Follow-up studies could be conducted that examine how incidental exposure conditions can promote the active recall of form–meaning links and how stable the representations of these links are over time. More research is also necessary to investigate the role of individual differences in incidental exposure conditions across different modalities.
Appendix A Stimuli used in the study

Appendix B Nouns phrases (n = 48) employed in the exposure phase

Appendix C Noun phrases (n = 36) employed in the testing phase

Appendix D Response Windows (RW) of the training and test items in the two modalities

Appendix E Coding scheme for categorizing awareness (adapted from Rebuschat et al. (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015)

Appendix F Summary of frequentist and Bayesian one-sample t-tests

Appendix G The full omnibus model including Knowledge

Note. The reference level for Exposure is Auditory; the reference level for Assessment is Auditory; the reference level for Training is Untrained; the reference level for Knowledge is Unconscious.
Appendix H The full omnibus model including Awareness

Note. The reference level for Exposure is Auditory; the reference level for Assessment is Audiory; the reference level for Training is Untrained; the reference level for Awareness is Unaware.















 Open access
Open access