


1 Introduction
1.1 Motivation
To a greater extent than other mathematical disciplines, statistics is a product of its time. If Francis Galton, Karl Pearson, Ronald Fisher, and Jerzy Neyman had had access to computers, they may have created an entirely different field. Classical statistics relies on simplistic assumptions (linearity, independence), in-sample analysis, analytical solutions, and asymptotic properties partly because its founders had access to limited computing power. Today, many of these legacy methods continue to be taught at university courses and in professional certification programs, even though computational methods, such as cross-validation, ensemble estimators, regularization, bootstrapping, and Monte Carlo, deliver demonstrably better solutions. In the words of Reference Efron and HastieEfron and Hastie (2016, 53),
two words explain the classic preference for parametric models: mathematical tractability. In a world of sliderules and slow mechanical arithmetic, mathematical formulation, by necessity, becomes the computational tool of choice. Our new computation-rich environment has unplugged the mathematical bottleneck, giving us a more realistic, flexible, and far-reaching body of statistical techniques.
Financial problems pose a particular challenge to those legacy methods, because economic systems exhibit a degree of complexity that is beyond the grasp of classical statistical tools (Reference López de PradoLópez de Prado 2019b). As a consequence, machine learning (ML) plays an increasingly important role in finance. Only a few years ago, it was rare to find ML applications outside short-term price prediction, trade execution, and setting of credit ratings. Today, it is hard to find a use case where ML is not being deployed in some form. This trend is unlikely to change, as larger data sets, greater computing power, and more efficient algorithms all conspire to unleash a golden age of financial ML. The ML revolution creates opportunities for dynamic firms and challenges for antiquated asset managers. Firms that resist this revolution will likely share Kodak’s fate. One motivation of this Element is to demonstrate how modern statistical tools help address many of the deficiencies of classical techniques in the context of asset management.
Most ML algorithms were originally devised for cross-sectional data sets. This limits their direct applicability to financial problems, where modeling the time series properties of data sets is essential. My previous book, Advances in Financial Machine Learning (AFML; Reference López de PradoLópez de Prado 2018a), addressed the challenge of modeling the time series properties of financial data sets with ML algorithms, from the perspective of an academic who also happens to be a practitioner.
Machine Learning for Asset Managers is concerned with answering a different challenge: how can we use ML to build better financial theories? This is not a philosophical or rhetorical question. Whatever edge you aspire to gain in finance, it can only be justified in terms of someone else making a systematic mistake from which you benefit.Footnote 1 Without a testable theory that explains your edge, the odds are that you do not have an edge at all. A historical simulation of an investment strategy’s performance (backtest) is not a theory; it is a (likely unrealistic) simulation of a past that never happened (you did not deploy that strategy years ago; that is why you are backtesting it!). Only a theory can pin down the clear cause–effect mechanism that allows you to extract profits against the collective wisdom of the crowds – a testable theory that explains factual evidence as well as counterfactual cases (x implies y, and the absence of y implies the absence of x). Asset managers should focus their efforts on researching theories, not backtesting trading rules. ML is a powerful tool for building financial theories, and the main goal of this Element is to introduce you to essential techniques that you will need in your endeavor.
1.2 Theory Matters
A black swan is typically defined as an extreme event that has not been observed before. Someone once told me that quantitative investment strategies are useless. Puzzled, I asked why. He replied, “Because the future is filled with black swans, and since historical data sets by definition cannot contain never-seen-before events, ML algorithms cannot be trained to predict them.” I counterargued that, in many cases, black swans have been predicted.
Let me explain this apparent paradox with an anecdote. Back in the year 2010, I was head of high-frequency futures at a large US hedge fund. On May 6, we were running our liquidity provision algorithms as usual, when around 12:30 ET, many of them started to flatten their positions automatically. We did not interfere or override the systems, so within minutes, our market exposure became very small. This system behavior had never happened to us before. My team and I were conducting a forensic analysis of what had caused the systems to shut themselves down when, at around 14:30 ET, we saw the S&P 500 plunge, within minutes, almost 10% relative to the open. Shortly after, the systems started to buy aggressively, profiting from a 5% rally into the market close. The press dubbed this black swan the “flash crash.” We were twice surprised by this episode: first, we could not understand how our systems predicted an event that we, the developers, did not anticipate; second, we could not understand why our systems started to buy shortly after the market bottomed.
About five months later, an official investigation found that the crash was likely caused by an order to sell 75,000 E-mini S&P 500 futures contracts at a high participation rate (CFTC 2010). That large order contributed to a persistent imbalance in the order flow, making it very difficult for market makers to flip their inventory without incurring losses. This toxic order flow triggered stop-out limits across market makers, who ceased to provide liquidity. Market makers became aggressive liquidity takers, and without anyone remaining on the bid, the market inevitably collapsed (Reference Easley, López de Prado, O’Hara and ZhangEasley et al. 2011).
We could not have forecasted the flash crash by watching CNBC or reading the Wall Street Journal. To most observers, the flash crash was indeed an unpredictable black swan. However, the underlying causes of the flash crash are very common. Order flow is almost never perfectly balanced. In fact, imbalanced order flow is the norm, with various degrees of persistency (e.g., measured in terms of serial correlation). Our systems had been trained to reduce positions under extreme conditions of order flow imbalance. In doing so, they were trained to avoid the conditions that shortly after caused the black swan. Once the market collapsed, our systems recognized that the opportunity to buy at a 10% discount offset previous concerns from extreme order flow imbalance, and they took long positions until the close. This experience illustrates the two most important lessons contained in this Element.
1.2.1 Lesson 1: You Need a Theory
Contrary to popular belief, backtesting is not a research tool. Backtests can never prove that a strategy is a true positive, and they may only provide evidence that a strategy is a false positive. Never develop a strategy solely through backtests. Strategies must be supported by theory, not historical simulations. Your theories must be general enough to explain particular cases, even if those cases are black swans. The existence of black holes was predicted by the theory of general relativity more than five decades before the first black hole was observed. In the above story, our market microstructure theory (which later on became known as the VPIN theory; see Reference Easley, López de Prado and O’HaraEasley et al. 2011b) helped us predict and profit from a black swan. Not only that, but our theoretical work also contributed to the market’s bounce back (my colleagues used to joke that we helped put the “flash” into the “flash crash”). This Element contains some of the tools you need to discover your own theories.
1.2.2 Lesson 2: ML Helps Discover Theories
Consider the following approach to discovering new financial theories. First, you apply ML tools to uncover the hidden variables involved in a complex phenomenon. These are the ingredients that the theory must incorporate in order to make successful forecasts. The ML tools have identified these ingredients; however, they do not directly inform you about the exact equation that binds the ingredients together. Second, we formulate a theory that connects these ingredients through a structural statement. This structural statement is essentially a system of equations that hypothesizes a particular cause–effect mechanism. Third, the theory has a wide range of testable implications that go beyond the observations predicted by the ML tools in the first step.Footnote 2 A successful theory will predict events out-of-sample. Moreover, it will explain not only positives (x causes y) but also negatives (the absence of y is due to the absence of x).
In the above discovery process, ML plays the key role of decoupling the search for variables from the search for specification. Economic theories are often criticized for being based on “facts with unknown truth value” (Reference RomerRomer 2016) and “generally phony” assumptions (Reference SolowSolow 2010). Considering the complexity of modern financial systems, it is unlikely that a researcher will be able to uncover the ingredients of a theory by visual inspection of the data or by running a few regressions. Classical statistical methods do not allow this decoupling of the two searches.
Once the theory has been tested, it stands on its own feet. In this way, the theory, not the ML algorithm, makes the predictions. In the above anecdote, the theory, not an online forecast produced by an autonomous ML algorithm, shut the position down. The forecast was theoretically sound, and it was not based on some undefined pattern. It is true that the theory could not have been discovered without the help of ML techniques, but once the theory was discovered, the ML algorithm played no role in the decision to close the positions two hours prior to the flash crash. The most insightful use of ML in finance is for discovering theories. You may use ML successfully for making financial forecasts; however, that is not necessarily the best scientific use of this technology (particularly if your goal is to develop high-capacity investment strategies).
1.3 How Scientists Use ML
An ML algorithm learns complex patterns in a high-dimensional space with little human guidance on model specification. That ML models need not be specified by the researcher has led many to, erroneously, conclude that ML must be a black box. In that view, ML is merely an “oracle,”Footnote 3 a prediction machine from which no understanding can be extracted. The black box view of ML is a misconception. It is fueled by popular industrial applications of ML, where the search for better predictions outweighs the need for theoretical understanding. A review of recent scientific breakthroughs reveals radically different uses of ML in science, including the following:
1 Existence: ML has been deployed to evaluate the plausibility of a theory across all scientific fields, even beyond the empirical sciences. Notably, ML algorithms have helped make mathematical discoveries. ML algorithms cannot prove a theorem, however they can point to the existence of an undiscovered theorem, which can then be conjectured and eventually proved. In other words, if something can be predicted, there is hope that a mechanism can be uncovered (Reference Gryak, Haralick and KahrobaeiGryak et al., forthcoming).
2 Importance: ML algorithms can determine the relative informational content of explanatory variables (features, in ML parlance) for explanatory and/or predictive purposes (Reference LiuLiu 2004). For example, the mean-decrease accuracy (MDA) method follows these steps: (1) Fit a ML algorithm on a particular data set; (2) derive the out-of-sample cross-validated accuracy; (3) repeat step (2) after shuffling the time series of individual features or combinations of features; (4) compute the decay in accuracy between (2) and (3). Shuffling the time series of an important feature will cause a significant decay in accuracy. Thus, although MDA does not uncover the underlying mechanism, it discovers the variables that should be part of the theory.
3 Causation: ML algorithms are often utilized to evaluate causal inference following these steps: (1) Fit a ML algorithm on historical data to predict outcomes, absent of an effect. This model is nontheoretical, and it is purely driven by data (like an oracle); (2) collect observations of outcomes under the presence of the effect; (3) use the ML algorithm fit in (1) to predict the observation collected in (2). The prediction error can be largely attributed to the effect, and a theory of causation can be proposed (Reference VarianVarian 2014; Reference AtheyAthey 2015).
4 Reductionist: ML techniques are essential for the visualization of large, high-dimensional, complex data sets. For example, manifold learning algorithms can cluster a large number of observations into a reduced subset of peer groups, whose differentiating properties can then be analyzed (Reference Schlecht, Kaplan, Barnard, Karafet, Hammer and MerchantSchlecht et al. 2008).
5 Retriever: ML is used to scan through big data in search of patterns that humans failed to recognize. For instance, every night ML algorithms are fed millions of images in search of supernovae. Once they find one image with a high probability of containing a supernova, expensive telescopes can be pointed to a particular region in the universe, where humans will scrutinize the data (Reference Lochner, McEwen, Peiris, Lahav and WinterLochner et al. 2016). A second example is outlier detection. Finding outliers is a prediction problem rather than an explanation problem. A ML algorithm can detect an anomalous observation, based on the complex structure it has found in the data, even if that structure is not explained to us (Reference Hodge and AustinHodge and Austin 2004).
Rather than replacing theories, ML plays the critical role of helping scientists form theories based on rich empirical evidence. Likewise, ML opens the opportunity for economists to apply powerful data science tools toward the development of sound theories.
1.4 Two Types of Overfitting
The dark side of ML’s flexibility is that, in inexperienced hands, these algorithms can easily overfit the data. The primary symptom of overfitting is a divergence between a model’s in-sample and out-of-sample performance (known as the generalization error). We can distinguish between two types of overfitting: the overfitting that occurs on the train set, and the overfitting that occurs on the test set. Figure 1.1 summarizes how ML deals with both kinds of overfitting.
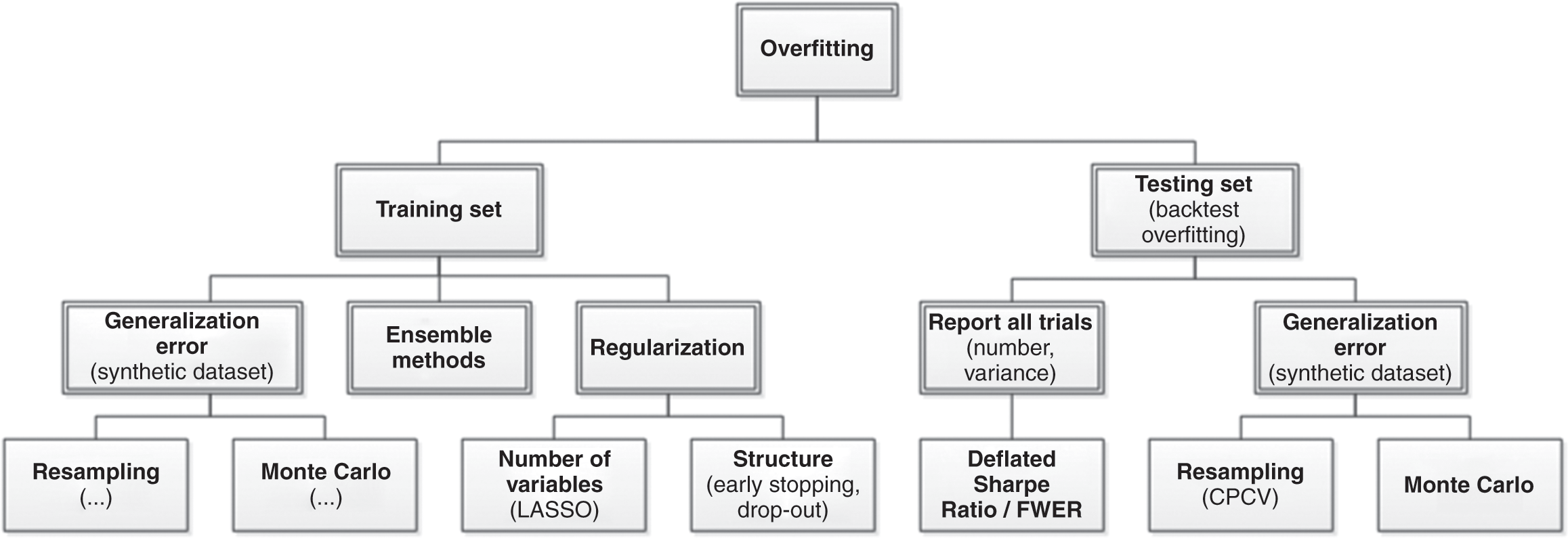
Figure 1.1 Solutions to two kinds of overfitting.
1.4.1 Train Set Overfitting
Train set overfitting results from choosing a specification that is so flexible that it explains not only the signal, but also the noise. The problem with confounding signal with noise is that noise is, by definition, unpredictable. An overfit model will produce wrong predictions with an unwarranted confidence, which in turn will lead to poor performance out-of-sample (or even in a pseudo-out-of-sample, like in a backtest).
ML researchers are keenly aware of this problem, which they address in three complementary ways. The first approach to correct for train set overfitting is evaluating the generalization error, through resampling techniques (such as cross-validation) and Monte Carlo methods. Appendix A describes these techniques and methods in greater detail. The second approach to reduce train set overfitting is regularization methods, which prevent model complexity unless it can be justified in terms of greater explanatory power. Model parsimony can be enforced by limiting the number of parameters (e.g., LASSO) or restricting the model’s structure (e.g., early stopping). The third approach to address train set overfitting is ensemble techniques, which reduce the variance of the error by combining the forecasts of a collection of estimators. For example, we can control the risk of overfitting a random forest on a train set in at least three ways: (1) cross-validating the forecasts; (2) limiting the depth of each tree; and (3) adding more trees.
In summary, a backtest may hint at the occurrence of train set overfitting, which can be remedied using the above approaches. Unfortunately, backtests are powerless against the second type of overfitting, as explained next.
1.4.2 Test Set Overfitting
Imagine that a friend claims to have a technique to predict the winning ticket at the next lottery. His technique is not exact, so he must buy more than one ticket. Of course, if he buys all of the tickets, it is no surprise that he will win. How many tickets would you allow him to buy before concluding that his method is useless? To evaluate the accuracy of his technique, you should adjust for the fact that he has bought multiple tickets. Likewise, researchers running multiple statistical tests on the same data set are more likely to make a false discovery. By applying the same test on the same data set multiple times, it is guaranteed that eventually a researcher will make a false discovery. This selection bias comes from fitting the model to perform well on the test set, not the train set.
Another example of test set overfitting occurs when a researcher backtests a strategy and she tweaks it until the output achieves a target performance. That backtest–tweak–backtest cycle is a futile exercise that will inevitably end with an overfit strategy (a false positive). Instead, the researcher should have spent her time investigating how the research process misled her into backtesting a false strategy. In other words, a poorly performing backtest is an opportunity to fix the research process, not an opportunity to fix a particular investment strategy.
Most published discoveries in finance are likely false, due to test set overfitting. ML did not cause the current crisis in financial research (Reference Harvey, Liu and ZhuHarvey et al. 2016). That crisis was caused by the widespread misuse of classical statistical methods in finance, and p-hacking in particular. ML can help deal with the problem of test set overfitting, in three ways. First, we can keep track of how many independent tests a researcher has run, to evaluate the probability that at least one of the outcomes is a false discovery (known as familywise error rate, or FWER). The deflated Sharpe ratio (Reference Bailey and López de PradoBailey and López de Prado 2014) follows a similar approach in the context of backtesting, as explained in Section 8. It is the equivalent to controlling for the number of lottery tickets that your friend bought. Second, while it is easy to overfit a model to one test set, it is hard to overfit a model to thousands of test sets for each security. Those thousands of test sets can be generated by resampling combinatorial splits of train and test sets. This is the approached followed by the combinatorial purged cross-validation method, or CPCV (AFML, chapter 12). Third, we can use historical series to estimate the underlying data-generating process, and sample synthetic data sets that match the statistical properties observed in history. Monte Carlo methods are particularly powerful at producing synthetic data sets that match the statistical properties of a historical series. The conclusions from these tests are conditional to the representativeness of the estimated data-generating process (AFML, chapter 13). The main advantage of this approach is that those conclusions are not connected to a particular (observed) realization of the data-generating process but to an entire distribution of random realizations. Following with our example, this is equivalent to replicating the lottery game and repeating it many times, so that we can rule luck out.
In summary, there are multiple practical solutions to the problem of train set and test set overfitting. These solutions are neither infallible nor incompatible, and my advice is that you apply all of them. At the same time, I must insist that no backtest can replace a theory, for at least two reasons: (1) backtests cannot simulate black swans – only theories have the breadth and depth needed to consider the never-before-seen occurrences; (2) backtests may insinuate that a strategy is profitable, but they do not tell us why. They are not a controlled experiment. Only a theory can state the cause–effect mechanism, and formulate a wide range of predictions and implications that can be independently tested for facts and counterfacts. Some of these implications may even be testable outside the realm of investing. For example, the VPIN theory predicted that market makers would suffer stop-outs under persistent order flow imbalance. Beyond testing whether order flow imbalance causes a reduction in liquidity, researchers can also test whether market makers suffered losses during the flash crash (hint: they did). This latter test can be conducted by reviewing financial statements, independently from the evidence contained in exchange records of prices and quotes.
1.5 Outline
This Element offers asset managers a step-by-step guide to building financial theories with the help of ML methods. To that objective, each section uses what we have learned in the previous ones. Each section (except for this introduction) contains an empirical analysis, where the methods explained are put to the test in Monte Carlo experiments.
The first step in building a theory is to collect data that illustrate how some variables relate to each other. In financial settings, those data often take the form of a covariance matrix. We use covariance matrices to run regressions, optimize portfolios, manage risks, search for linkages, etc. However, financial covariance matrices are notoriously noisy. A relatively small percentage of the information they contain is signal, which is systematically suppressed by arbitrage forces. Section 2 explains how to denoise a covariance matrix without giving up the little signal it contains. Most of the discussion centers on random matrix theory, but at the core of the solution sits an ML technique: the kernel density estimator.
Many research questions involve the notion of similarity or distance. For example, we may be interested in understanding how closely related two variables are. Denoised covariance matrices can be very useful for deriving distance metrics from linear relationships. Modeling nonlinear relationships requires more advanced concepts. Section 3 provides an information-theoretic framework for extracting complex signals from noisy data. In particular, it allows us to define distance metrics with minimal assumptions regarding the underlying variables that characterize the metric space. These distance metrics can be thought of as a nonlinear generalization of the notion of correlation.
One of the applications of distance matrices is to study whether some variables are more closely related among themselves than to the rest, hence forming clusters. Clustering has a wide range of applications across finance, like in asset class taxonomy, portfolio construction, dimensionality reduction, or modeling networks of agents. A general problem in clustering is finding the optimal number of clusters. Section 4 introduces the ONC algorithm, which provides a general solution to this problem. Various use cases for this algorithm are presented throughout this Element.
Clustering is an unsupervised learning problem. Before we can delve into supervised learning problems, we need to assess ways of labeling financial data. The effectiveness of a supervised ML algorithm greatly depends on the kind of problem we attempt to solve. For example, it may be harder to forecast tomorrow’s S&P 500 return than the sign of its next 5% move. Different features are appropriate for different types of labels. Researchers should consider carefully what labeling method they apply on their data. Section 5 discusses the merits of various alternatives.
AFML warned readers that backtesting is not a research tool. Feature importance is. A backtest cannot help us develop an economic or financial theory. In order to do that, we need a deeper understanding of what variables are involved in a phenomenon. Section 6 studies ML tools for evaluating the importance of explanatory variables, and explains how these tools defeat many of the caveats of classical methods, such as the p-value. A particular concern is how to overcome p-value’s lack of robustness under multicollinearity. To tackle this problem, we must apply what we learned in all prior sections, including denoising (Section 2), distance metrics (Section 3), clustering (Section 4), and labeling (Section 5).
Once you have a financial theory, you can use your discovery to develop an investment strategy. Designing that strategy will require making some investment decisions under uncertainty. To that purpose, mean-variance portfolio optimization methods are universally known and used, even though they are notorious for their instability. Historically, this instability has been addressed in a number of ways, such as introducing strong constraints, adding priors, shrinking the covariance matrix, and other robust optimization techniques. Many asset managers are familiar with instability caused by noise in the covariance matrix. Fewer asset managers realize that certain data structures (types of signal) are also a source of instability for mean-variance solutions. Section 7 explains why signal can be a source of instability, and how ML methods can help correct it.
Finally, a financial ML book would not be complete without a detailed treatment of how to evaluate the probability that your discovery is false, as a result of test set overfitting. Section 8 explains the dangers of backtest overfitting, and provides several practical solutions to the problem of selection bias under multiple testing.
1.6 Audience
If, like most asset managers, you routinely compute covariance matrices, use correlations, search for low-dimensional representations of high-dimensional spaces, build predictive models, compute p-values, solve mean-variance optimizations, or apply the same test multiple times on a given data set, you need to read this Element. In it, you will learn that financial covariance matrices are noisy and that they need to be cleaned before running regressions or computing optimal portfolios (Section 2). You will learn that correlations measure a very narrow definition of codependency and that various information-theoretic metrics are more insightful (Section 3). You will learn intuitive ways of reducing the dimensionality of a space, which do not involve a change of basis. Unlike PCA, ML-based dimensionality reduction methods provide intuitive results (Section 4). Rather than aiming for implausible fixed-horizon predictions, you will learn alternative ways of posing financial prediction problems that can be solved with higher accuracy (Section 5). You will learn modern alternatives to the classical p-values (Section 6). You will learn how to address the instability problem that plagues mean-variance investment portfolios (Section 7). And you will learn how to evaluate the probability that your discovery is false as a result of multiple testing (Section 8). If you work in the asset management industry or in academic finance, this Element is for you.
1.7 Five Popular Misconceptions about Financial ML
Financial ML is a new technology. As it is often the case with new technologies, its introduction has inspired a number of misconceptions. Below is a selection of the most popular.
1.7.1 ML Is the Holy Grail versus ML Is Useless
The amount of hype and counterhype surrounding ML defies logic. Hype creates a set of expectations that may not be fulfilled for the foreseeable future. Counterhype attempts to convince audiences that there is nothing special about ML and that classical statistical methods already produce the results that ML-enthusiasts claim.
ML critics sometimes argue that “caveat X in linear regression is no big deal,” where X can either mean model misspecification, multicollinearity, missing regressors, nonlinear interaction effects, etc. In reality, any of these violations of classical assumptions will lead to accepting uninformed variables (a false positive) and/or rejecting informative variables (a false negative). For an example, see Section 6.
Another common error is to believe that the central limit theorem somehow justifies the use of linear regression models everywhere. The argument goes like this: with enough observations, Normality prevails, and linear models provide a good fit to the asymptotic correlation structure. This “CLT Hail Mary pass” is an undergrad fantasy: yes, the sample mean converges in distribution to a Gaussian, but not the sample itself! And that converge only occurs if the observations are independent and identically distributed. It takes a few lines of code to demonstrate that a misspecified regression will perform poorly, whether we feed it thousands or billions of observations.
Both extremes (hype and counterhype) prevent investors from recognizing the real and differentiated value that ML delivers today. ML is modern statistics, and it helps overcome many of the caveats of classical techniques that have preoccupied asset managers for decades. See Reference López de PradoLópez de Prado (2019c) for multiple examples of current applications of ML in finance.
1.7.2 ML Is a Black Box
This is perhaps the most widespread myth surrounding ML. Every research laboratory in the world uses ML to some extent, so clearly ML is compatible with the scientific method. Not only is ML not a black box, but as Section 6 explains, ML-based research tools can be more insightful than traditional statistical methods (including econometrics). ML models can be interpreted through a number of procedures, such as PDP, ICE, ALE, Friedman’s H-stat, MDI, MDA, global surrogate, LIME, and Shapley values, among others. See Reference MolnarMolnar (2019) for a detailed treatment of ML interpretability.
Whether someone applies ML as a black box or as a white-box is a matter of personal choice. The same is true of many other technical subjects. I personally do not care much about how my car works, and I must confess that I have never lifted the hood to take a peek at the engine (my thing is math, not mechanics). So, my car remains a black box to me. I do not blame the engineers who designed my car for my lack of curiosity, and I am aware that the mechanics who work at my garage see my car as a white box. Likewise, the assertion that ML is a black box reveals how some people have chosen to apply ML, and it is not a universal truth.
1.7.3 Finance Has Insufficient Data for ML
It is true that a few ML algorithms, particularly in the context of price prediction, require a lot of data. That is why a researcher must choose the right algorithm for a particular job. On the other hand, ML critics who wield this argument seem to ignore that many ML applications in finance do not require any historical data at all. Examples include risk analysis, portfolio construction, outlier detection, feature importance, and bet-sizing methods. Each section in this Element demonstrates the mathematical properties of ML without relying on any historical series. For instance, Section 7 evaluates the accuracy of an ML-based portfolio construction algorithm via Monte Carlo experiments. Conclusions drawn from millions of Monte Carlo simulations teach us something about the general mathematical properties of a particular approach. The anecdotal evidence derived from a handful of historical simulations is no match to evaluating a wide range of scenarios.
Other financial ML applications, like sentiment analysis, deep hedging, credit ratings, execution, and private commercial data sets, enjoy an abundance of data. Finally, in some settings, researchers can conduct randomized controlled experiments, where they can generate their own data and establish precise cause–effect mechanisms. For example, we may reword a news article and compare ML’s sentiment extraction with a human’s conclusion, controlling for various changes. Likewise, we may experiment with the market’s reaction to alternative implementations of an execution algorithm under comparable conditions.
1.7.4 The Signal-to-Noise Ratio Is Too Low in Finance
There is no question that financial data sets exhibit lower signal-to-noise ratio than those used by other ML applications (a point that we will demonstrate in Section 2). Because the signal-to-noise ratio is so low in finance, data alone are not good enough for relying on black box predictions. That does not mean that ML cannot be used in finance. It means that we must use ML differently, hence the notion of financial ML as a distinct subject of study. Financial ML is not the mere application of standard ML to financial data sets. Financial ML comprises ML techniques specially designed to tackle the specific challenges faced by financial researchers, just as econometrics is not merely the application of standard statistical techniques to economic data sets.
The goal of financial ML ought to be to assist researchers in the discovery of new economic theories. The theories so discovered, and not the ML algorithms, will produce forecasts. This is no different than the way scientists utilize ML across all fields of research.
1.7.5 The Risk of Overfitting Is Too High in Finance
Section 1.4 debunked this myth. In knowledgeable hands, ML algorithms overfit less than classical methods. I concede, however, that in nonexpert hands ML algorithms can cause more harm than good.
1.8 The Future of Financial Research
The International Data Corporation has estimated that 80% of all available data are unstructured (IDC 2014). Many of the new data sets available to researchers are high-dimensional, sparse, or nonnumeric. As a result of the complexities of these new data sets, there is a limit to how much researchers can learn using regression models and other linear algebraic or geometric approaches. Even with older data sets, traditional quantitative techniques may fail to capture potentially complex (e.g., nonlinear and interactive) associations among variables, and these techniques are extremely sensitive to the multicollinearity problem that pervades financial data sets (Reference López de PradoLópez de Prado 2019b).
Economics and finance have much to benefit from the adoption of ML methods. As of November 26, 2018, the Web of ScienceFootnote 4 lists 13,772 journal articles on subjects in the intersection of “Economics” and “Statistics & Probability.” Among those publications, only eighty-nine articles (0.65%) contain any of the following terms: classifier, clustering, neural network, or machine learning. To put it in perspective, out of the 40,283 articles in the intersection of “Biology” and “Statistics & Probability,” a total of 4,049 (10.05%) contained any of those terms, and out of the 4,994 articles in the intersection of “Chemistry, Analytical” and “Statistics & Probability,” a total of 766 (15.34%) contained any of those terms.
The econometric canon predates the dawn of digital computing. Most econometric models were devised for estimation by hand and are a product of their time. In the words of Robert Tibshirani, “people use certain methods because that is how it all started and that’s what they are used to. It’s hard to change it.”Footnote 5 Students in the twenty-first century should not be overexposed to legacy technologies. Moreover, the most successful quantitative investment firms in history rely primarily on ML, not econometrics, and the current predominance of econometrics in graduate studies prepares students for academic careers, not for jobs in the industry.
This does not mean that econometrics has outlived its usability. Researchers asked to decide between econometrics and ML are presented with a false choice. ML and econometrics complement each other, because they have different strengths. For example, ML can be particularly helpful at suggesting to researchers the ingredients of a theory (see Section 6), and econometrics can be useful at testing a theory that is well grounded on empirical observation. In fact, sometimes we may want to apply both paradigms at the same time, like in semiparametric methods. For example, a regression could combine observable explanatory variables with control variables that are contributed by an ML algorithm (Reference Mullainathan and SpiessMullainathan and Spiess 2017). Such approach would address the bias associated with omitted regressors (Reference ClarkeClarke 2005).
1.9 Frequently Asked Questions
Over the past few years, attendees at seminars have asked me all sorts of interesting questions. In this section I have tried to provide a short answer to some of the most common questions. I have also added a couple of questions that I am still hoping that someone will ask one day.
In Simple Terms, What Is ML?
Broadly speaking, ML refers to the set of algorithms that learn complex patterns in a high-dimensional space without being specifically directed. Let us break that definition into its three components. First, ML learns without being specifically directed, because researchers impose very little structure on the data. Instead, the algorithm derives that structure from the data. Second, ML learns complex patterns, because the structure identified by the algorithm may not be representable as a finite set of equations. Third, ML learns in a high-dimensional space, because solutions often involve a large number of variables, and the interactions between them.
For example, we can train an ML algorithm to recognize human faces by showing it examples. We do not define what a face is, hence the algorithm learns without our direction. The problem is never posed in terms of equations, and in fact the problem may not be expressible in terms of equations. And the algorithm uses an extremely large number of variables to perform this task, including the individual pixels and the interaction between the pixels.
In recent years, ML has become an increasingly useful research tool throughout all fields of scientific research. Examples include drug development, genome research, new materials, and high-energy physics. Consumer products and industrial services have quickly incorporated these technologies, and some of the most valuable companies in the world produce ML-based products and services.
How Is ML Different from Econometric Regressions?
Researchers use traditional regressions to fit a predefined functional form to a set of variables. Regressions are extremely useful when we have a high degree of conviction regarding that functional form and all the interaction effects that bind the variables together. Going back to the eighteenth century, mathematicians developed tools that fit those functional forms using estimators with desirable properties, subject to certain assumptions on the data.
Starting in the 1950s, researchers realized that there was a different way to conduct empirical analyses, with the help of computers. Rather than imposing a functional form, particularly when that form is unknown ex ante, they would allow algorithms to figure out variable dependencies from the data. And rather than making strong assumptions on the data, the algorithms would conduct experiments that evaluate the mathematical properties of out-of-sample predictions. This relaxation in terms of functional form and data assumptions, combined with the use of powerful computers, opened the door to analyzing complex data sets, including highly nonlinear, hierarchical, and noncontinuous interaction effects.
Consider the following example: a researcher wishes to estimate the survival probability of a passenger on the Titanic, based on a number of variables, such as gender, ticket class, and age. A typical regression approach would be to fit a logit model to a binary variable, where 1 means survivor and 0 means deceased, using gender, ticket class, and age as regressors. It turns out that, even though these regressors are correct, a logit (or probit) model fails to make good predictions. The reason is that logit models do not recognize that this data set embeds a hierarchical (treelike) structure, with complex interactions. For example, adult males in second class died at a much higher rate than each of these attributes taken independently. In contrast, a simple “classification tree” algorithm performs substantially better, because we allow the algorithm to find that hierarchical structure (and associated complex interactions) for us.
As it turns out, hierarchical structures are omnipresent in economics and finance (Reference SimonSimon 1962). Think of sector classifications, credit ratings, asset classes, economic linkages, trade networks, clusters of regional economies, etc. When confronted with these kinds of problems, ML tools can complement and overcome the limitations of econometrics or similar traditional statistical methods.
How Is ML Different from Big Data?
The term big data refers to data sets that are so large and/or complex that traditional statistical techniques fail to extract and model the information contained in them. It is estimated that 90% of all recorded data have been created over the past two years, and 80% of the data is unstructured (i.e., not directly amenable to traditional statistical techniques).
In recent years, the quantity and granularity of economic data have improved dramatically. The good news is that the sudden explosion of administrative, private sector, and micro-level data sets offers an unparalleled insight into the inner workings of the economy. The bad news is that these data sets pose multiple challenges to the study of economics. (1) Some of the most interesting data sets are unstructured. They can also be nonnumerical and noncategorical, like news articles, voice recordings, or satellite images. (2) These data sets are high-dimensional (e.g., credit card transactions.) The number of variables involved often greatly exceeds the number of observations, making it very difficult to apply linear algebra solutions. (3) Many of these data sets are extremely sparse. For instance, samples may contain a large proportion of zeros, where standard notions such as correlation do not work well. (4) Embedded within these data sets is critical information regarding networks of agents, incentives, and aggregate behavior of groups of people. ML techniques are designed for analyzing big data, which is why they are often cited together.
How Is the Asset Management Industry Using ML?
Perhaps the most popular application of ML in asset management is price prediction. But there are plenty of equally important applications, like hedging, portfolio construction, detection of outliers and structural breaks, credit ratings, sentiment analysis, market making, bet sizing, securities taxonomy, and many others. These are real-life applications that transcend the hype often associated with expectations of price prediction.
For example, factor investing firms use ML to redefine value. A few years ago, price-to-earnings ratios may have provided a good ranking for value, but that is not the case nowadays. Today, the notion of value is much more nuanced. Modern asset managers use ML to identify the traits of value, and how those traits interact with momentum, quality, size, etc. Meta-labeling (Section 5.5) is another hot topic that can help asset managers size and time their factor bets.
High-frequency trading firms have utilized ML for years to analyze real-time exchange feeds, in search for footprints left by informed traders. They can utilize this information to make short-term price predictions or to make decisions on the aggressiveness or passiveness in order execution. Credit rating agencies are also strong adopters of ML, as these algorithms have demonstrated their ability to replicate the ratings generated by credit analysts. Outlier detection is another important application, since financial models can be very sensitive to the presence of even a small number of outliers. ML models can help improve investment performance by finding the proper size of a position, leaving the buy-or-sell decision to traditional or fundamental models.
And Quantitative Investors Specifically?
All of the above applications, and many more, are relevant to quantitative investors. It is a great time to be a quant. Data are more abundant than ever, and computers are finally delivering the power needed to make effective use of ML. I am particularly excited about real-time prediction of macroeconomic statistics, following the example of MIT’s Billion Prices Project (Reference 137Cavallo and RigobonCavallo and Rigobon 2016). ML can be specially helpful at uncovering relationships that until now remained hidden, even in traditional data sets. For instance, the economic relationships between companies may not be effectively described by traditional sector-group-industry classifications, such as GICS.Footnote 6 A network approach, where companies are related according to a variety of factors, is likely to offer a richer and more accurate representation of the dynamics, strengths, and vulnerabilities of specific segments of the stock or credit markets (Reference Cohen and FrazziniCohen and Frazzini 2008).
What Are Some of the Ways That ML Can Be Applied to Investor Portfolios?
Portfolio construction is an extremely promising area for ML (Section 7). For many decades, the asset management industry has relied on variations and refinements of Markowitz’s efficient frontier to build investment portfolios. It is known that many of these solutions are optimal in-sample, however, they can perform poorly out-of-sample due to the computational instabilities involved in convex optimization. Numerous classical approaches have attempted, with mixed success, to address these computational instabilities. ML algorithms have shown the potential to produce robust portfolios that perform well out-of-sample, thanks to their ability to recognize sparse hierarchical relationships that traditional methods miss (Reference López de PradoLópez de Prado 2016).
What Are the Risks? Is There Anything That Investors Should Be Aware of or Look Out For?
Finance is not a plug-and-play subject as it relates to ML. Modeling financial series is harder than driving cars or recognizing faces. The reason is, the signal-to-noise ratio in financial data is extremely low, as a result of arbitrage forces and nonstationary systems. The computational power and functional flexibility of ML ensures that it will always find a pattern in the data, even if that pattern is a fluke rather than the result of a persistent phenomenon. An “oracle” approach to financial ML, where algorithms are developed to form predictions divorced from all economic theory, is likely to yield false discoveries. I have never heard a scientist say “Forget about theory, I have this oracle that can answer anything, so let’s all stop thinking, and let’s just believe blindly whatever comes out.”
It is important for investors to recognize that ML is not a substitute for economic theory, but rather a powerful tool for building modern economic theories. We need ML to develop better financial theories, and we need financial theories to restrict ML’s propensity to overfit. Without this theory–ML interplay, investors are placing their trust on high-tech horoscopes.
How Do You Expect ML to Impact the Asset Management Industry in the Next Decade?
Today, the amount of ML used by farmers is staggering: self-driving tractors, drones scanning for irregular patches of land, sensors feeding cattle and administering nutrients as needed, genetically engineered crops, satellite images for estimating yields, etc. Similarly, I think in ten years we will look back, and ML will be an important aspect of asset management. And just like in the farming industry, although this transformation may not happen overnight, it is clear that there is only one direction forward.
Economic data sets will only get bigger, and computers will only get more powerful. Most asset managers will fail either by not evolving or by rushing into the unknown without fully recognizing the dangers involved in the “oracle” approach. Only a few asset managers will succeed by evolving in a thoughtful and responsible manner.
How Do You Expect ML to Impact Financial Academia in the Next Decade?
Imagine if physicists had to produce theories in a universe where the fundamental laws of nature are in a constant flux; where publications have an impact on the very phenomenon under study; where experimentation is virtually impossible; where data are costly, the signal is dim, and the system under study is incredibly complex … I feel utmost admiration for how much financial academics have achieved in the face of paramount adversity.
ML has a lot to offer to the academic profession. First, ML provides the power and flexibility needed to find dim signals in the sea of noise caused by arbitrage forces. Second, ML allows academics to decouple the research process into two stages: (1) search for important variables irrespective of functional form, and (2) search for a functional form that binds those variables. Reference López de PradoLópez de Prado (2019b) demonstrates how even small specification errors mislead researchers into rejecting important variables. It is hard to overstate the relevance of decoupling the specification search from the variables search. Third, ML offers the possibility of conducting simulations on synthetic data. This is as close as finance will ever get to experimentation, in the absence of laboratories. We live an exciting time to do academic research on financial systems, and I expect tremendous breakthroughs as more financial researchers embrace ML.
Isn’t Financial ML All about Price Prediction?
One of the greatest misunderstandings I perceive from reading the press is the notion that ML’s main (if not only) objective is price prediction. Asset pricing is undoubtedly a very worthy endeavor, however its importance is often overstated. Having an edge at price prediction is just one necessary, however entirely insufficient, condition to be successful in today’s highly competitive market. Other areas that are equally important are data processing, portfolio construction, risk management, monitoring for structural breaks, bet sizing, and detection of false investment strategies, just to cite a few.
Consider the players at the World Series of Poker. The cards are shuffled and distributed randomly. These players obviously cannot predict what cards will be handed to players with any meaningful accuracy. And yet, the same handful of players ends up in top positions year after year. One reason is, bet sizing is more important than card prediction. When a player receives a good hand, he evaluates the probability that another player may hold a strong hand too, and bets strategically. Likewise, investors may not be able to predict prices, however they may recognize when an out-of-the-normal price has printed, and bet accordingly. I am not saying that bet sizing is the key to successful investing. I am merely stating that bet sizing is at least as important as price prediction, and that portfolio construction is arguably even more important.
Why Don’t You Discuss a Wide Range of ML Algorithms?
The purpose of this Element is not to introduce the reader to the vast population of ML algorithms used today in finance. There are two reasons for that. First, there are lengthy textbooks dedicated to the systematic exposition of those algorithms, and another one is hardly needed. Excellent references include Reference James, Witten, Hastie and TibshiraniJames et al. (2013), Reference Hastie, Tibshirani and FriedmanHastie et al. (2016), and Reference Efron and HastieEfron and Hastie (2016). Second, financial data sets have specific nuisances, and the success or failure of a project rests on understanding them. Once we have engineered the features and posed the problem correctly, choosing an algorithm plays a relatively secondary role.
Allow me to illustrate the second point with an example. Compare an algorithm that forecasted a change of 1, but received a realized change of 3, with another algorithm that forecasted a change of −1, but received a realized change of 1. In both cases, the forecast error is 2. In many industrial applications, we would be indifferent between both errors. That is not the case in finance. In the first instance, an investor makes one-third of the predicted profit, whereas in the second instance the investor suffers a loss equal to the predicted profit. Failing to predict the size is an opportunity loss, but failing to predict the sign is an actual loss. Investors penalize actual losses much more than opportunity losses. Predicting the sign of an outcome is often more important than predicting its size, and a reason for favoring classifiers over regression methods in finance. In addition, it is common in finance to find that the sign and size of an outcome depend on different features, so jointly forecasting the sign and size of an outcome with a unique set of features can lead to subpar results.Footnote 7 ML experts who transition into finance from other fields often make fundamental mistakes, like posing problems incorrectly, as explained in Reference López de PradoLópez de Prado (2018b). Financial ML is a subject in its own right, and the discussion of generic ML algorithms is not the heart of the matter.
Why Don’t You Discuss a Specific Investment Strategy, Like Many Other Books Do?
There are plenty of books in the market that provide recipes for implementing someone else’s investment strategy. Those cookbooks show us how to prepare someone else’s cake. This Element is different. I want to show you how you can use ML to discover new economic and financial theories that are relevant to you, on which you can base your proprietary investment strategies. Your investment strategies are just the particular implementation of the theories that first you must discover independently. You cannot bake someone else’s cake and expect to retain it for yourself.
1.10 Conclusions
The purpose of this Element is to introduce ML tools that are useful for discovering economic and financial theories. Successful investment strategies are specific implementations of general theories. An investment strategy that lacks a theoretical justification is likely to be false. Hence, a researcher should concentrate her efforts on developing a theory, rather than of backtesting potential strategies.
ML is not a black box, and it does not necessarily overfit. ML tools complement rather than replace the classical statistical methods. Some of ML’s strengths include (1) Focus on out-of-sample predictability over variance adjudication; (2) usage of computational methods to avoid relying on (potentially unrealistic) assumptions; (3) ability to “learn” complex specifications, including nonlinear, hierarchical, and noncontinuous interaction effects in a high-dimensional space; and (4) ability to disentangle the variable search from the specification search, in a manner robust to multicollinearity and other substitution effects.
1.11 Exercises
1 Can quantitative methods be used to predict events that never happened before? How could quantitative methods predict a black swan?
2 Why is theory particularly important in finance and economics? What is the best use of ML in finance?
3 What are popular misconceptions about financial ML? Are financial data sets large enough for ML applications?
4 How does ML control for overfitting? Is the signal-to-noise ratio too low in finance for allowing the use of ML?
5 Describe a quantitative approach in finance that combines classical and ML methods. How is ML different from a large regression? Describe five applications of financial ML.
2 Denoising and Detoning
2.1 Motivation
Covariance matrices are ubiquitous in finance. We use them to run regressions, estimate risks, optimize portfolios, simulate scenarios via Monte Carlo, find clusters, reduce the dimensionality of a vector space, and so on. Empirical covariance matrices are computed on series of observations from a random vector, in order to estimate the linear comovement between the random variables that constitute the random vector. Given the finite and nondeterministic nature of these observations, the estimate of the covariance matrix includes some amount of noise. Empirical covariance matrices derived from estimated factors are also numerically ill-conditioned, because those factors are also estimated from flawed data. Unless we treat this noise, it will impact the calculations we perform with the covariance matrix, sometimes to the point of rendering the analysis useless.
The goal of this section is to explain a procedure for reducing the noise and enhancing the signal included in an empirical covariance matrix. Throughout this Element, we assume that empirical covariance and correlation matrices have been subjected to this procedure.
2.2 The Marcenko–Pastur Theorem
Consider a matrix of independent and identically distributed random observations  , of size
, of size  , where the underlying process generating the observations has zero mean and variance
, where the underlying process generating the observations has zero mean and variance  . The matrix
. The matrix  has eigenvalues
has eigenvalues  that asymptotically converge (as
that asymptotically converge (as  and
and  with
with  ) to the Marcenko–Pastur probability density function (PDF),
) to the Marcenko–Pastur probability density function (PDF),
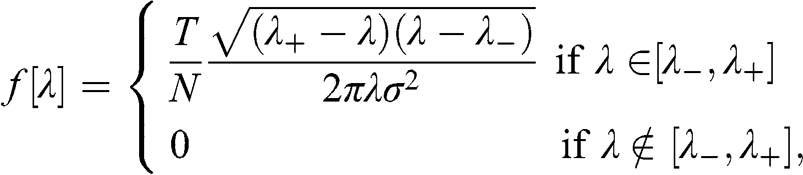
where the maximum expected eigenvalue is  and the minimum expected eigenvalue is
and the minimum expected eigenvalue is  . When
. When  , then
, then  is the correlation matrix associated with
is the correlation matrix associated with  . Code Snippet 2.1 implements the Marcenko–Pastur PDF in python.
. Code Snippet 2.1 implements the Marcenko–Pastur PDF in python.
Snippet 2.1 The Marcenko–Pastur PDF
import numpy as np,pandas as pd #------------------------------------------------------------------------------ def mpPDF(var,q,pts): # Marcenko-Pastur pdf # q=T/N eMin,eMax=var*(1-(1./q)**.5)**2,var*(1+(1./q)**.5)**2 eVal=np.linspace(eMin,eMax,pts) pdf=q/(2*np.pi*var*eVal)*((eMax-eVal)*(eVal-eMin))**.5 pdf=pd.Series(pdf,index=eVal) return pdf
Eigenvalues  are consistent with random behavior, and eigenvalues
are consistent with random behavior, and eigenvalues  are consistent with nonrandom behavior. Specifically, we associate eigenvalues
are consistent with nonrandom behavior. Specifically, we associate eigenvalues  with noise. Figure 2.1 and Code Snippet 2.2 demonstrate how closely the Marcenko–Pastur distribution explains the eigenvalues of a random matrix
with noise. Figure 2.1 and Code Snippet 2.2 demonstrate how closely the Marcenko–Pastur distribution explains the eigenvalues of a random matrix  .
.
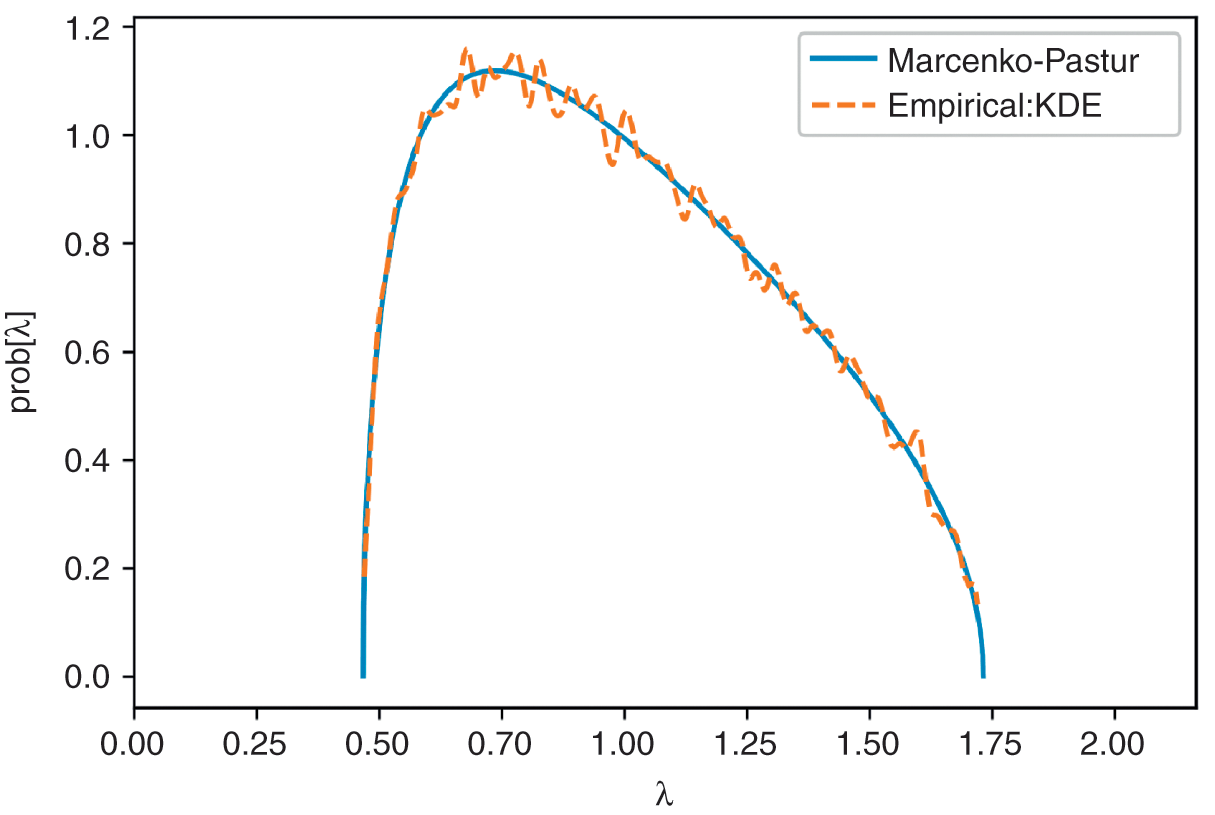
Figure 2.1 A visualization of the Marcenko–Pastur theorem.
Snippet 2.2 Testing the Marcenko–Pastur Theorem
from sklearn.neighbors.kde import KernelDensity #------------------------------------------------------------------------------ def getPCA(matrix): # Get eVal,eVec from a Hermitian matrix eVal,eVec=np.linalg.eigh(matrix) indices=eVal.argsort()[::-1] # arguments for sorting eVal desc eVal,eVec=eVal[indices],eVec[:,indices] eVal=np.diagflat(eVal) return eVal,eVec #------------------------------------------------------------------------------ def fitKDE(obs,bWidth=.25,kernel=’gaussian’,x=None): # Fit kernel to a series of obs, and derive the prob of obs # x is the array of values on which the fit KDE will be evaluated if len(obs.shape)==1:obs=obs.reshape(-1,1) kde=KernelDensity(kernel=kernel,bandwidth=bWidth).fit(obs) if x is None:x=np.unique(obs).reshape(-1,1) if len(x.shape)==1:x=x.reshape(-1,1) logProb=kde.score_samples(x) # log(density) pdf=pd.Series(np.exp(logProb),index=x.flatten()) return pdf #------------------------------------------------------------------------------ x=np.random.normal(size=(10000,1000)) eVal0,eVec0=getPCA(np.corrcoef(x,rowvar=0)) pdf0=mpPDF(1.,q=x.shape[0]/float(x.shape[1]),pts=1000) pdf1=fitKDE(np.diag(eVal0),bWidth=.01) # empirical pdfEnd Box
2.3 Random Matrix with Signal
In an empirical correlation matrix, not all eigenvectors may be random. Code Snippet 2.3 builds a covariance matrix that is not perfectly random, and hence its eigenvalues will only approximately follow the Marcenko–Pastur PDF. Out of the nCols random variables that form the covariance matrix generated by getRndCov, only nFact contain some signal. To further dilute the signal, we add that covariance matrix to a purely random matrix, with a weight alpha. See Reference Lewandowski, Kurowicka and JoeLewandowski et al. (2009) for alternative ways of building a random covariance matrix.
Snippet 2.3 Add Signal to a Random Covariance Matrix
def getRndCov(nCols,nFacts): w=np.random.normal(size=(nCols,nFacts)) cov=np.dot(w,w.T) # random cov matrix, however not full rank cov+=np.diag(np.random.uniform(size=nCols)) # full rank cov return cov #------------------------------------------------------------------------------ def cov2corr(cov): # Derive the correlation matrix from a covariance matrix std=np.sqrt(np.diag(cov)) corr=cov/np.outer(std,std) corr[corr<-1],corr[corr>1]=-1,1 # numerical error return corr #------------------------------------------------------------------------------ alpha,nCols,nFact,q=.995,1000,100,10 cov=np.cov(np.random.normal(size=(nCols*q,nCols)),rowvar=0) cov=alpha*cov+(1-alpha)*getRndCov(nCols,nFact) # noise+signal corr0=cov2corr(cov) eVal0,eVec0=getPCA(corr0)
2.4 Fitting the Marcenko–Pastur Distribution
In this section, we follow the approach introduced by Reference Laloux, Cizeau, Bouchaud and PottersLaloux et al. (2000). Since only part of the variance is caused by random eigenvectors, we can adjust  accordingly in the above equations. For instance, if we assume that the eigenvector associated with the highest eigenvalue is not random, then we should replace
accordingly in the above equations. For instance, if we assume that the eigenvector associated with the highest eigenvalue is not random, then we should replace  with
with  in the above equations. In fact, we can fit the function
in the above equations. In fact, we can fit the function  to the empirical distribution of the eigenvalues to derive the implied
to the empirical distribution of the eigenvalues to derive the implied  . That will give us the variance that is explained by the random eigenvectors present in the correlation matrix, and it will determine the cutoff level
. That will give us the variance that is explained by the random eigenvectors present in the correlation matrix, and it will determine the cutoff level  , adjusted for the presence of nonrandom eigenvectors.
, adjusted for the presence of nonrandom eigenvectors.
Code Snippet 2.4 fits the Marcenko–Pastur PDF to a random covariance matrix that contains signal. The objective of the fit is to find the value of  that minimizes the sum of the squared differences between the analytical PDF and the kernel density estimate (KDE) of the observed eigenvalues (for references on KDE, see Reference RosenblattRosenblatt 1956; Reference ParzenParzen 1962). The value
that minimizes the sum of the squared differences between the analytical PDF and the kernel density estimate (KDE) of the observed eigenvalues (for references on KDE, see Reference RosenblattRosenblatt 1956; Reference ParzenParzen 1962). The value  is reported as eMax0, the value of
is reported as eMax0, the value of  is stored as var0, and the number of factors is recovered as nFacts0.
is stored as var0, and the number of factors is recovered as nFacts0.
Snippet 2.4 Fitting the Marcenko–Pastur PDF
from scipy.optimize import minimize #------------------------------------------------------------------------------ def errPDFs(var,eVal,q,bWidth,pts=1000): # Fit error pdf0=mpPDF(var,q,pts) # theoretical pdf pdf1=fitKDE(eVal,bWidth,x=pdf0.index.values) # empirical pdf sse=np.sum((pdf1-pdf0)**2) return sse #------------------------------------------------------------------------------ def findMaxEval(eVal,q,bWidth): # Find max random eVal by fitting Marcenko’s dist out=minimize(lambda *x:errPDFs(*x),.5,args=(eVal,q,bWidth), bounds=((1E-5,1-1E-5),)) if out[’success’]:var=out[’x’][0] else:var=1 eMax=var*(1+(1./q)**.5)**2 return eMax,var #------------------------------------------------------------------------------ eMax0,var0=findMaxEval(np.diag(eVal0),q,bWidth=.01) nFacts0=eVal0.shape[0]-np.diag(eVal0)[::-1].searchsorted(eMax0)
Figure 2.2 plots the histogram of eigenvalues and the PDF of the fitted Marcenko–Pastur distribution. Eigenvalues to the right of the fitted Marcenko–Pastur distribution cannot be associated with noise, thus they are related to signal. The code returns a value of 100 for nFacts0, the same number of factors we had injected to the covariance matrix. Despite the dim signal present in the covariance matrix, the procedure has been able to separate the eigenvalues associated with noise from the eigenvalues associated with signal. The fitted distribution implies that  , indicating that only about 32.32% of the variance can be attributed to signal. This is one way of measuring the signal-to-noise ratio in financial data sets, which is known to be low as a result of arbitrage forces.
, indicating that only about 32.32% of the variance can be attributed to signal. This is one way of measuring the signal-to-noise ratio in financial data sets, which is known to be low as a result of arbitrage forces.
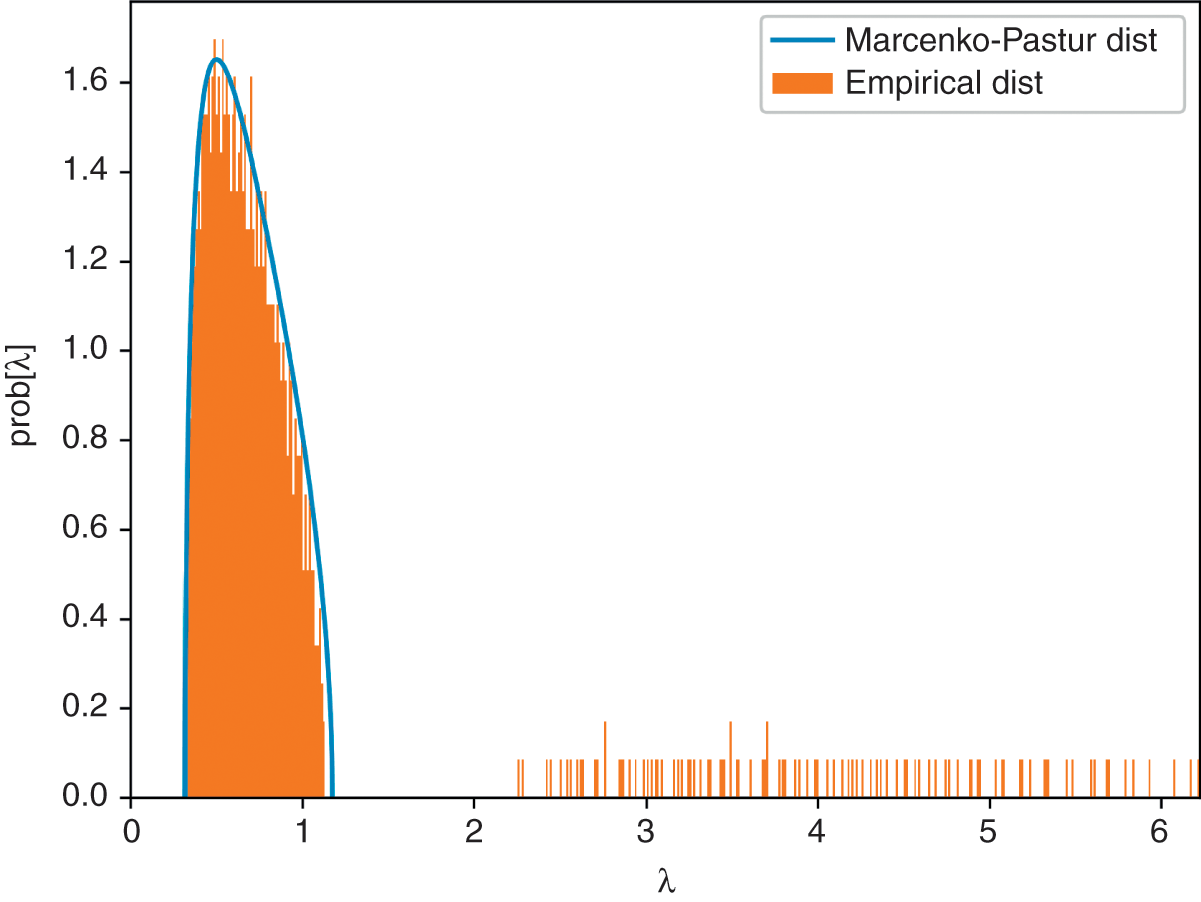
Figure 2.2 Fitting the Marcenko–Pastur PDF on a noisy covariance matrix.
2.5 Denoising
It is common in financial applications to shrink a numerically ill-conditioned covariance matrix (Reference Ledoit and WolfLedoit and Wolf 2004). By making the covariance matrix closer to a diagonal, shrinkage reduces its condition number. However, shrinkage accomplishes that without discriminating between noise and signal. As a result, shrinkage can further eliminate an already weak signal.
In the previous section, we have learned how to discriminate between eigenvalues associated with noise components and eigenvalues associated with signal components. In this section we discuss how to use this information for denoising the correlation matrix.
2.5.1 Constant Residual Eigenvalue Method
This approach consists in setting a constant eigenvalue for all random eigenvectors. Let  be the set of all eigenvalues, ordered descending, and
be the set of all eigenvalues, ordered descending, and  be the position of the eigenvalue such that
be the position of the eigenvalue such that  and
and  . Then we set
. Then we set  ,
,  , hence preserving the trace of the correlation matrix. Given the eigenvector decomposition
, hence preserving the trace of the correlation matrix. Given the eigenvector decomposition  , we form the denoised correlation matrix
, we form the denoised correlation matrix  as
as
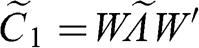
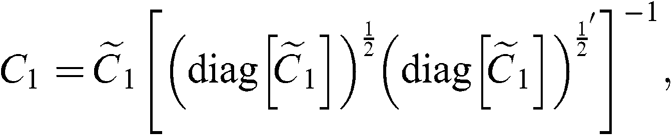
where  is the diagonal matrix holding the corrected eigenvalues, the apostrophe (') transposes a matrix, and diag[.] zeroes all non-diagonal elements of a squared matrix. The reason for the second transformation is to rescale the matrix
is the diagonal matrix holding the corrected eigenvalues, the apostrophe (') transposes a matrix, and diag[.] zeroes all non-diagonal elements of a squared matrix. The reason for the second transformation is to rescale the matrix  , so that the main diagonal of
, so that the main diagonal of  is an array of 1s. Code Snippet 2.5 implements this method. Figure 2.3 compares the logarithms of the eigenvalues before and after denoising by this method.
is an array of 1s. Code Snippet 2.5 implements this method. Figure 2.3 compares the logarithms of the eigenvalues before and after denoising by this method.
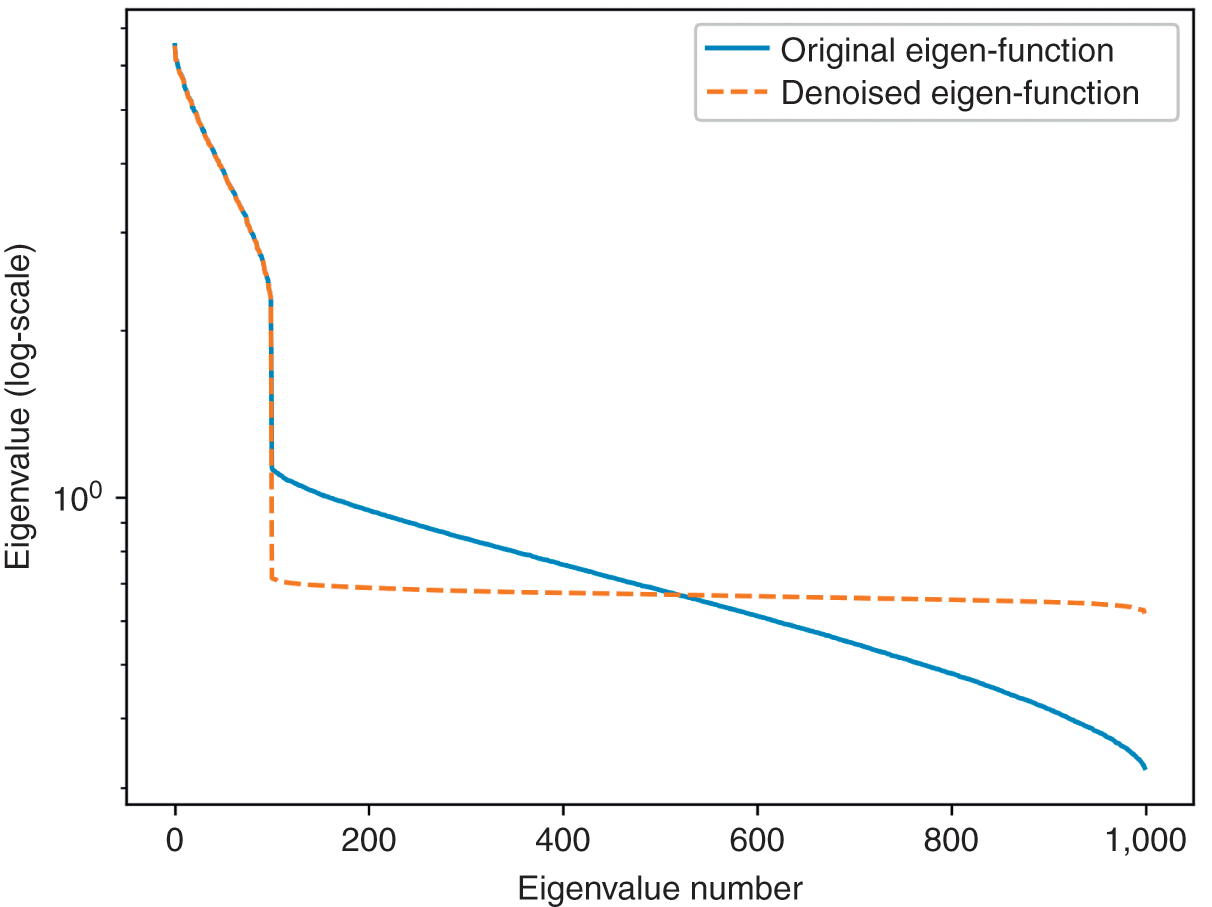
Figure 2.3 A comparison of eigenvalues before and after applying the residual eigenvalue method.
Snippet 2.5 Denoising by Constant Residual Eigenvalue
def denoisedCorr(eVal,eVec,nFacts): # Remove noise from corr by fixing random eigenvalues eVal_=np.diag(eVal).copy() eVal_[nFacts:]=eVal_[nFacts:].sum()/float(eVal_.shape[0]-nFacts) eVal_=np.diag(eVal_) corr1=np.dot(eVec,eVal_).dot(eVec.T) corr1=cov2corr(corr1) return corr1 #------------------------------------------------------------------------------ corr1=denoisedCorr(eVal0,eVec0,nFacts0) eVal1,eVec1=getPCA(corr1)
2.5.2 Targeted Shrinkage
The numerical method described earlier is preferable to shrinkage, because it removes the noise while preserving the signal. Alternatively, we could target the application of the shrinkage strictly to the random eigenvectors. Consider the correlation matrix 
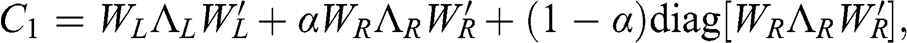
where  and
and  are the eigenvectors and eigenvalues associated with
are the eigenvectors and eigenvalues associated with  ,
,  and
and  are the eigenvectors and eigenvalues associated with
are the eigenvectors and eigenvalues associated with  , and
, and  regulates the amount of shrinkage among the eigenvectors and eigenvalues associated with noise (
regulates the amount of shrinkage among the eigenvectors and eigenvalues associated with noise ( for total shrinkage). Code Snippet 2.6 implements this method. Figure 2.4 compares the logarithms of the eigenvalues before and after denoising by this method.
for total shrinkage). Code Snippet 2.6 implements this method. Figure 2.4 compares the logarithms of the eigenvalues before and after denoising by this method.
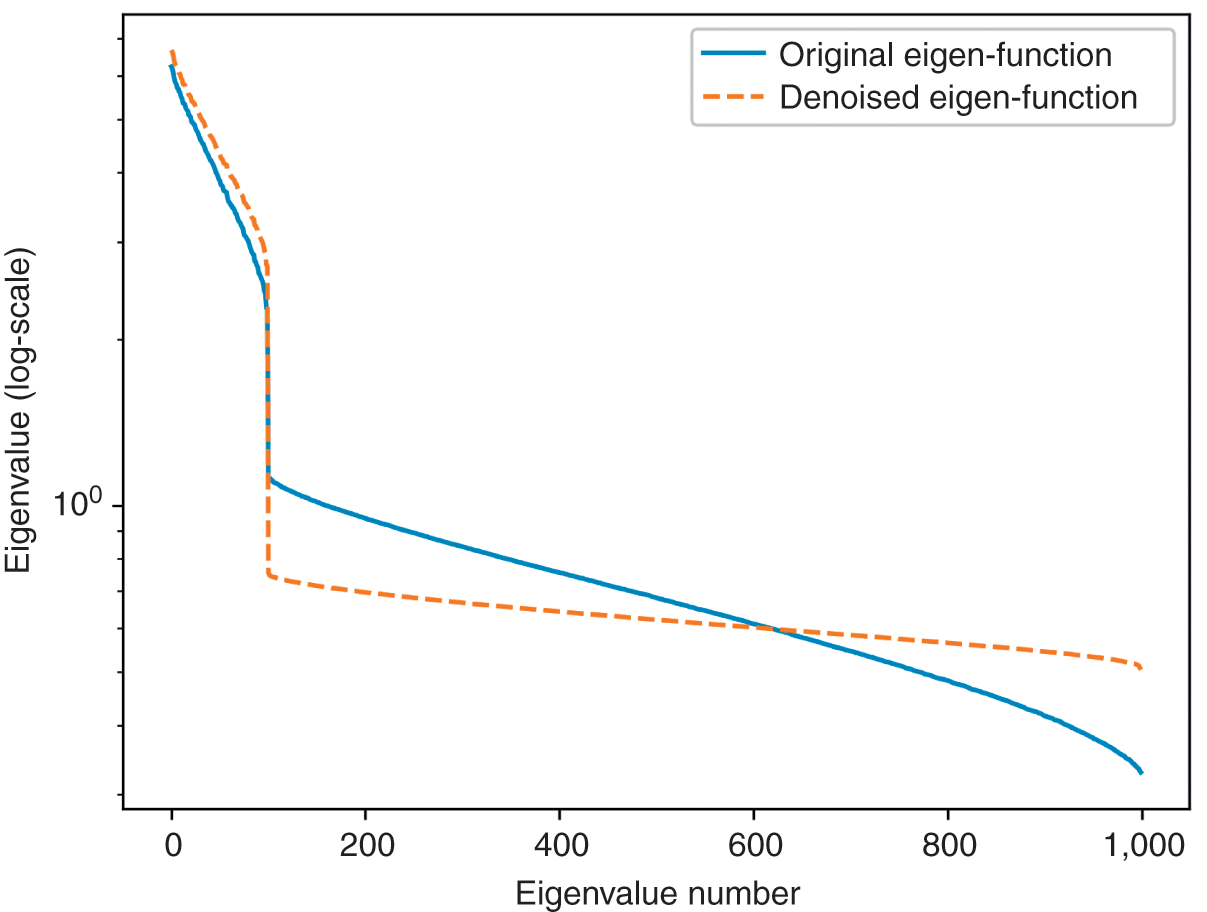
Figure 2.4 A comparison of eigenvalues before and after applying the targeted shrinkage method.
Snippet 2.6 Denoising by Targeted Shrinkage
def denoisedCorr2(eVal,eVec,nFacts,alpha=0): # Remove noise from corr through targeted shrinkage eValL,eVecL=eVal[:nFacts,:nFacts],eVec[:,:nFacts] eValR,eVecR=eVal[nFacts:,nFacts:],eVec[:,nFacts:] corr0=np.dot(eVecL,eValL).dot(eVecL.T) corr1=np.dot(eVecR,eValR).dot(eVecR.T) corr2=corr0+alpha*corr1+(1-alpha)*np.diag(np.diag(corr1)) return corr2 #------------------------------------------------------------------------------ corr1=denoisedCorr2(eVal0,eVec0,nFacts0,alpha=.5) eVal1,eVec1=getPCA(corr1)
2.6 Detoning
Financial correlation matrices usually incorporate a market component. The market component is characterized by the first eigenvector, with loadings  ,
,  . Accordingly, a market component affects every item of the covariance matrix. In the context of clustering applications, it is useful to remove the market component, if it exists (a hypothesis that can be tested statistically). The reason is, it is more difficult to cluster a correlation matrix with a strong market component, because the algorithm will struggle to find dissimilarities across clusters. By removing the market component, we allow a greater portion of the correlation to be explained by components that affect specific subsets of the securities. It is similar to removing a loud tone that prevents us from hearing other sounds. Detoning is the principal components analysis analogue to computing beta-adjusted (or market-adjusted) returns in regression analysis.
. Accordingly, a market component affects every item of the covariance matrix. In the context of clustering applications, it is useful to remove the market component, if it exists (a hypothesis that can be tested statistically). The reason is, it is more difficult to cluster a correlation matrix with a strong market component, because the algorithm will struggle to find dissimilarities across clusters. By removing the market component, we allow a greater portion of the correlation to be explained by components that affect specific subsets of the securities. It is similar to removing a loud tone that prevents us from hearing other sounds. Detoning is the principal components analysis analogue to computing beta-adjusted (or market-adjusted) returns in regression analysis.
We can remove the market component from the denoised correlation matrix,  , to form the detoned correlation matrix
, to form the detoned correlation matrix
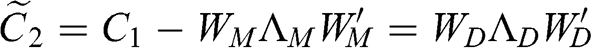
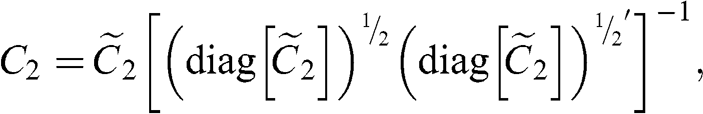
where  and
and  are the eigenvectors and eigenvalues associated with market components (usually only one, but possibly more), and
are the eigenvectors and eigenvalues associated with market components (usually only one, but possibly more), and  and
and  are the eigenvectors and eigenvalues associated with nonmarket components.
are the eigenvectors and eigenvalues associated with nonmarket components.
The detoned correlation matrix is singular, as a result of eliminating (at least) one eigenvector. This is not a problem for clustering applications, as most approaches do not require the invertibility of the correlation matrix. Still, a detoned correlation matrix  cannot be used directly for mean-variance portfolio optimization. Instead, we can optimize a portfolio on the selected (nonzero) principal components, and map the optimal allocations
cannot be used directly for mean-variance portfolio optimization. Instead, we can optimize a portfolio on the selected (nonzero) principal components, and map the optimal allocations  back to the original basis. The optimal allocations in the original basis are
back to the original basis. The optimal allocations in the original basis are
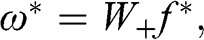
where  contains only the eigenvectors that survived the detoning process (i.e., with a nonnull eigenvalue), and
contains only the eigenvectors that survived the detoning process (i.e., with a nonnull eigenvalue), and  is the vector of optimal allocations to those same components.
is the vector of optimal allocations to those same components.
2.7 Experimental Results
Working with denoised and detoned covariance matrices renders substantial benefits. Those benefits result from the mathematical properties of those treated matrices, and can be evaluated through Monte Carlo experiments. In this section we discuss two characteristic portfolios of the efficient frontier, namely, the minimum variance and maximum Sharpe ratio solutions, since any member of the unconstrained efficient frontier can be derived as a convex combination of the two.
2.7.1 Minimum Variance Portfolio
In this section, we compute the errors associated with estimating a minimum variance portfolio with and without denoising. Code Snippet 2.7 forms a vector of means and a covariance matrix out of ten blocks of size fifty each, where off-diagonal elements within each block have a correlation of 0.5. This covariance matrix is a stylized representation of a true (nonempirical) detoned correlation matrix of the S&P 500, where each block is associated with an economic sector. Without loss of generality, the variances are drawn from a uniform distribution bounded between 5% and 20%, and the vector of means is drawn from a Normal distribution with mean and standard deviation equal to the standard deviation from the covariance matrix. This is consistent with the notion that in an efficient market all securities have the same expected Sharpe ratio. We fix a seed to facilitate the comparison of results across runs with different parameters.
Snippet 2.7 Generating a Block-Diagonal Covariance Matrix and a Vector of Means
def formBlockMatrix(nBlocks,bSize,bCorr): block=np.ones((bSize,bSize))*bCorr block[range(bSize),range(bSize)]=1 corr=block_diag(*([block]*nBlocks)) return corr #------------------------------------------------------------------------------ def formTrueMatrix(nBlocks,bSize,bCorr): corr0=formBlockMatrix(nBlocks,bSize,bCorr) corr0=pd.DataFrame(corr0) cols=corr0.columns.tolist() np.random.shuffle(cols) corr0=corr0[cols].loc[cols].copy(deep=True) std0=np.random.uniform(.05,.2,corr0.shape[0]) cov0=corr2cov(corr0,std0) mu0=np.random.normal(std0,std0,cov0.shape[0]).reshape(-1,1) return mu0,cov0 #------------------------------------------------------------------------------ from scipy.linalg import block_diag from sklearn.covariance import LedoitWolf nBlocks,bSize,bCorr=10,50,.5 np.random.seed(0) mu0,cov0=formTrueMatrix(nBlocks,bSize,bCorr)
Code Snippet 2.8 uses the true (nonempirical) covariance matrix to draw a random matrix  of size
of size  , and it derives the associated empirical covariance matrix and vector of means. Function simCovMu receives argument nObs, which sets the value of
, and it derives the associated empirical covariance matrix and vector of means. Function simCovMu receives argument nObs, which sets the value of  . When shrink=True, the function performs a Ledoit–Wolf shrinkage of the empirical covariance matrix.
. When shrink=True, the function performs a Ledoit–Wolf shrinkage of the empirical covariance matrix.
Snippet 2.8 Generating the Empirical Covariance Matrix
def simCovMu(mu0,cov0,nObs,shrink=False): x=np.random.multivariate_normal(mu0.flatten(),cov0,size=nObs) mu1=x.mean(axis=0).reshape(-1,1) if shrink:cov1=LedoitWolf().fit(x).covariance_ else:cov1=np.cov(x,rowvar=0) return mu1,cov1
Code Snippet 2.9 applies the methods explained in this section, to denoise the empirical covariance matrix. In this particular experiment, we denoise through the constant residual eigenvalue method.
Snippet 2.9 Denoising of the Empirical Covariance Matrix
def corr2cov(corr,std): cov=corr*np.outer(std,std) return cov #------------------------------------------------------------------------------ def deNoiseCov(cov0,q,bWidth): corr0=cov2corr(cov0) eVal0,eVec0=getPCA(corr0) eMax0,var0=findMaxEval(np.diag(eVal0),q,bWidth) nFacts0=eVal0.shape[0]-np.diag(eVal0)[::-1].searchsorted(eMax0) corr1=denoisedCorr(eVal0,eVec0,nFacts0) cov1=corr2cov(corr1,np.diag(cov0)**.5) return cov1
Code Snippet 2.10 runs the following Monte Carlo experiment with 1,000 iterations: (1) draw a random empirical covariance matrix (shrinkage optional) with  ; (2) denoise the empirical covariance matrix (optional); (3) derive the minimum variance portfolio, using the function optPort. When we pass the argument shrink=True to function simCovMu, the covariance matrix is shrunk. When parameter bWidth>0, the covariance matrix is denoised prior to estimating the minimum variance portfolio.Footnote 8 A random seed is arbitrarily set, so that we may run this Monte Carlo experiment on the same covariance matrices, with and without denoising.
; (2) denoise the empirical covariance matrix (optional); (3) derive the minimum variance portfolio, using the function optPort. When we pass the argument shrink=True to function simCovMu, the covariance matrix is shrunk. When parameter bWidth>0, the covariance matrix is denoised prior to estimating the minimum variance portfolio.Footnote 8 A random seed is arbitrarily set, so that we may run this Monte Carlo experiment on the same covariance matrices, with and without denoising.
Snippet 2.10 Denoising of the Empirical Covariance Matrix
def optPort(cov,mu=None): inv=np.linalg.inv(cov) ones=np.ones(shape=(inv.shape[0],1)) if mu is None:mu=ones w=np.dot(inv,mu) w/=np.dot(ones.T,w) return w #------------------------------------------------------------------------------ nObs,nTrials,bWidth,shrink,minVarPortf=1000,1000,.01,False,True w1=pd.DataFrame(columns=xrange(cov0.shape[0]), index=xrange(nTrials),dtype=float) w1_d=w1.copy(deep=True) np.random.seed(0) for i in range(nTrials): mu1,cov1=simCovMu(mu0,cov0,nObs,shrink=shrink) if minVarPortf:mu1=None cov1_d=deNoiseCov(cov1,nObs*1./cov1.shape[1],bWidth) w1.loc[i]=optPort(cov1,mu1).flatten() w1_d.loc[i]=optPort(cov1_d,mu1).flatten()
Code Snippet 2.11 computes the true minimum variance portfolio, derived from the true covariance matrix. Using those allocations as benchmark, it then computes the root-mean-square errors (RMSE) across all weights, with and without denoising. We can run Code Snippet 2.11 with and without shrinkage, thus obtaining the four combinations displayed in Figure 2.5. Denoising is much more effective than shrinkage: the denoised minimum variance portfolio incurs only 40.15% of the RMSE incurred by the minimum variance portfolio without denoising. That is a 59.85% reduction in RMSE from denoising alone, compared to a 30.22% reduction using Ledoit–Wolf shrinkage. Shrinkage adds little benefit beyond what denoising contributes. The reduction in RMSE from combining denoising with shrinkage is 65.63%, which is not much better than the result from using denoising only.
| Not denoised | Denoised | |
|---|---|---|
| Not shrunk | 4.95E–03 | 1.99E–03 |
| Shrunk | 3.45E–03 | 1.70E–03 |
Figure 2.5 RMSE for combinations of denoising and shrinkage (minimum variance portfolio).
Snippet 2.11 Root-Mean-Square Errors
w0=optPort(cov0,None if minVarPortf else mu0) w0=np.repeat(w0.T,w1.shape[0],axis=0) rmsd=np.mean((w1-w0).values.flatten()**2)**.5 # RMSE rmsd_d=np.mean((w1_d-w0).values.flatten()**2)**.5 # RMSE print rmsd,rmsd_d
2.7.2 Maximum Sharpe Ratio Portfolio
We can repeat the previous experiment, where on this occasion we target the estimation of the maximum Sharpe ratio portfolio. In order to do that, we need to set minVarPortf=True in Code Snippet 2.10. Figure 2.6 shows that, once again, denoising is much more effective than shrinkage: the denoised maximum Sharpe ratio portfolio incurs only 0.04% of the RMSE incurred by the maximum Sharpe ratio portfolio without denoising. That is a 94.44% reduction in RMSE from denoising alone, compared to a 70.77% reduction using Ledoit–Wolf shrinkage. While shrinkage is somewhat helpful in absence of denoising, it adds no benefit in combination with denoising. This is because shrinkage dilutes the noise at the expense of diluting some of the signal as well.
| Not denoised | Denoised | |
|---|---|---|
| Not shrunk | 9.48E–01 | 5.27E–02 |
| Shrunk | 2.77E–01 | 5.17E–02 |
Figure 2.6 RMSE for combinations of denoising and shrinkage (maximum Sharpe ratio portfolio).
2.8 Conclusions
In finance, empirical covariance matrices are often numerically ill-conditioned, as a result of the small number of independent observations used to estimate a large number of parameters. Working with those matrices directly, without treatment, is not recommended. Even if the covariance matrix is nonsingular, and therefore invertible, the small determinant all but guarantees that the estimations error will be greatly magnified by the inversion process. These estimation errors cause misallocation of assets and substantial transaction costs due to unnecessary rebalancing.
The Marcenko–Pastur theorem gives us the distribution of the eigenvalues associated with a random matrix. By fitting this distribution, we can discriminate between eigenvalues associated with signal and eigenvalues associated with noise. The latter can be adjusted to correct the matrix’s ill-conditioning, without diluting the signal. This random matrix theoretic approach is generally preferable to (1) the threshold method (Reference JolliffeJolliffe 2002, 113), which selects a number of components that jointly explain a fixed amount of variance, regardless of the true amount of variance caused by noise; and (2) the shrinkage method (Reference Ledoit and WolfLedoit and Wolf 2004), which can remove some of the noise at the cost of diluting much of the signal.
Recall that the correlation matrix’s condition number is the ratio between its maximal and minimal (by moduli) eigenvalues. Denoising reduces the condition number by increasing the lowest eigenvalue. We can further reduce the condition number by reducing the highest eigenvalue. This makes mathematical sense, and also intuitive sense. Removing the market components present in the correlation matrix reinforces the more subtle signals hiding under the market “tone.” For example, if we are trying to cluster a correlation matrix of stock returns, detoning that matrix will likely help amplify the signals associated with other exposures, such as sector, industry, or size.
We have demonstrated the usefulness of denoising in the context of portfolio optimization, however its applications extend to any use of the covariance matrix. For example, denoising the matrix  before inverting it should help reduce the variance of regression estimates, and improve the power of statistical tests of hypothesis. For the same reason, covariance matrices derived from regressed factors (also known as factor-based covariance matrices) also require denoising, and should not be used without numerical treatment.
before inverting it should help reduce the variance of regression estimates, and improve the power of statistical tests of hypothesis. For the same reason, covariance matrices derived from regressed factors (also known as factor-based covariance matrices) also require denoising, and should not be used without numerical treatment.
2.9 Exercises
1 Implement in python the detoning method described in Section 2.6.
2 Using a series of matrix of stock returns:
a Compute the covariance matrix. What is the condition number of the correlation matrix?
b Compute one hundred efficient frontiers by drawing one hundred alternative vectors of expected returns from a Normal distribution with mean 10% and standard deviation 10%.
c Compute the variance of the errors against the mean efficient frontier.
3 Repeat Exercise 2, where this time you denoise the covariance matrix before computing the one hundred efficient frontiers.
a What is the value of
 implied by the Marcenko–Pastur distribution?
implied by the Marcenko–Pastur distribution?b How many eigenvalues are associated with random components?
c Is the variance of the errors significantly higher or lower? Why?
4 Repeat Exercise 2, where this time you apply the Ledoit–Wolf shrinkage method (instead of denoising) on the covariance matrix before computing the one hundred efficient frontiers. Is the variance of the errors significantly higher or lower? Why?
5 Repeat Exercise 3, where this time you also detone the covariance matrix before computing the one hundred efficient frontiers. Is the variance of the errors significantly higher or lower? Why?
6 What happens if you drop the components whose eigenvalues fall below a given threshold? Can you still compute the efficient frontiers? How?
7 Extend function fitKDE in Code Snippet 2.2, so that it estimates through cross-validation the optimal value of bWidth.

3 Distance Metrics
3.1 Motivation
In Section 2, we have studied important numerical properties of the empirical correlation (and by extension, covariance) matrix. Despite all of its virtues, correlation suffers from some critical limitations as a measure of codependence. In this section, we overcome those limitations by reviewing information theory concepts that underlie many modern marvels, such as the internet, mobile phones, file compression, video streaming, or encryption. None of these inventions would have been possible if researchers had not looked beyond correlations to understand codependency.
As it turns out, information theory in general, and the concept of Shannon’s entropy in particular, also have useful applications in finance. The key idea behind entropy is to quantify the amount of uncertainty associated with a random variable. Information theory is also essential to ML, because the primary goal of many ML algorithms is to reduce the amount of uncertainty involved in the solution to a problem. In this section, we review concepts that are used throughout ML in a variety of settings, including (1) defining the objective function in decision tree learning; (2) defining the loss function for classification problems; (3) evaluating the distance between two random variables; (4) comparing clusters; and (5) feature selection.
3.2 A Correlation-Based Metric
Correlation is a useful measure of linear codependence. Once a correlation matrix has been denoised and detoned, it can reveal important structural information about a system. For example, we could use correlations to identify clusters of highly interrelated securities. But before we can do that, we need to address a technical problem: correlation is not a metric, because it does not satisfy nonnegativity and triangle inequality conditions. Metrics are important because they induce an intuitive topology on a set. Without that intuitive topology, comparing non-metric measurements of codependence can lead to rather incoherent outcomes. For instance, the difference between correlations (0.9,1.0) is the same as (0.1,0.2), even though the former involves a greater difference in terms of codependence.
Consider two random vectors X, Y of size T, and a correlation estimate  , with the only requirement that
, with the only requirement that  , where
, where  is the covariance between the two vectors and
is the covariance between the two vectors and  is the standard deviation. Pearson’s correlation is one of several correlation estimates that satisfy these requirements. Then, the measure
is the standard deviation. Pearson’s correlation is one of several correlation estimates that satisfy these requirements. Then, the measure  is a metric.
is a metric.
To prove that statement, first consider that the Euclidean distance between the two vectors is  . Second, we z-standardize those vectors as
. Second, we z-standardize those vectors as  ,
,  , where
, where  is the mean of X, and
is the mean of X, and  is the mean of Y. Consequently,
is the mean of Y. Consequently,  . Third, we derive the Euclidean distance
. Third, we derive the Euclidean distance  as
as

The implication is that  is a linear multiple of the Euclidean distance between the vectors
is a linear multiple of the Euclidean distance between the vectors  after z-standardization (
after z-standardization ( ), hence it inherits the true-metric properties of the Euclidean distance.
), hence it inherits the true-metric properties of the Euclidean distance.
The metric  has the property that it is normalized,
has the property that it is normalized,  , because
, because  . Another property is that it deems more distant two random variables with negative correlation than two random variables with positive correlation, regardless of their absolute value. This property makes sense in many applications. For example, we may wish to build a long-only portfolio, where holdings in negative-correlated securities can only offset risk, and therefore should be treated as different for diversification purposes. In other instances, like in long-short portfolios, we often prefer to consider highly negatively correlated securities as similar, because the position sign can override the sign of the correlation. For that case, we can define an alternative normalized correlation-based distance metric,
. Another property is that it deems more distant two random variables with negative correlation than two random variables with positive correlation, regardless of their absolute value. This property makes sense in many applications. For example, we may wish to build a long-only portfolio, where holdings in negative-correlated securities can only offset risk, and therefore should be treated as different for diversification purposes. In other instances, like in long-short portfolios, we often prefer to consider highly negatively correlated securities as similar, because the position sign can override the sign of the correlation. For that case, we can define an alternative normalized correlation-based distance metric,  .
.
Similarly, we can prove that  descends to a true metric on the
descends to a true metric on the  quotient. In order to do that, we redefine
quotient. In order to do that, we redefine  , where
, where  is the sign operator, so that
is the sign operator, so that  . Then, following the same argument used earlier,
. Then, following the same argument used earlier,
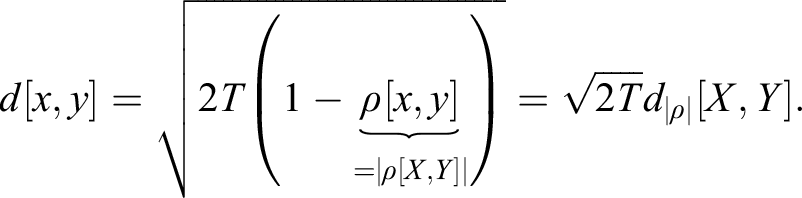
3.3 Marginal and Joint Entropy
The notion of correlation presents three important caveats. First, it quantifies the linear codependency between two random variables. It neglects nonlinear relationships. Second, correlation is highly influenced by outliers. Third, its application beyond the multivariate Normal case is questionable. We may compute the correlation between any two real variables, however that correlation is typically meaningless unless the two variables follow a bivariate Normal distribution. To overcome these caveats, we need to introduce a few information-theoretic concepts.
Let X be a discrete random variable that takes a value x from the set  with probability
with probability  . The entropy of X is defined as
. The entropy of X is defined as
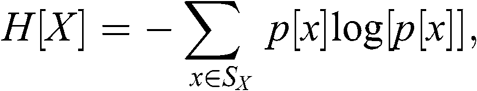
Throughout this section, we will follow the convention that  , since
, since  . The value
. The value  measures how surprising an observation is, because surprising observations are characterized by their low probability. Entropy is the expected value of those surprises, where the
measures how surprising an observation is, because surprising observations are characterized by their low probability. Entropy is the expected value of those surprises, where the  function prevents that
function prevents that  cancels
cancels  and endows entropy with desirable mathematical properties. Accordingly, entropy can be interpreted as the amount of uncertainty associated with X. Entropy is zero when all probability is concentrated in a single element of
and endows entropy with desirable mathematical properties. Accordingly, entropy can be interpreted as the amount of uncertainty associated with X. Entropy is zero when all probability is concentrated in a single element of  . Entropy reaches a maximum at
. Entropy reaches a maximum at  when X is distributed uniformly,
when X is distributed uniformly,  .
.
Let Y be a discrete random variable that takes a value y from the set  with probability
with probability  . Random variables X and Y do not need to be defined on the same probability space. The joint entropy of X and Y is
. Random variables X and Y do not need to be defined on the same probability space. The joint entropy of X and Y is
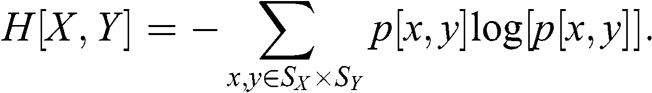
In particular, we have that  ,
,  ,
,  , and
, and  .
.
It is important to recognize that Shannon’s entropy is finite only for discrete random variables. In the continuous case, one should use the limiting density of discrete points (LDDP), or discretize the random variable, as explained in Section 3.9 (Reference JaynesJaynes 2003).
3.4 Conditional Entropy
The conditional entropy of X given Y is defined as
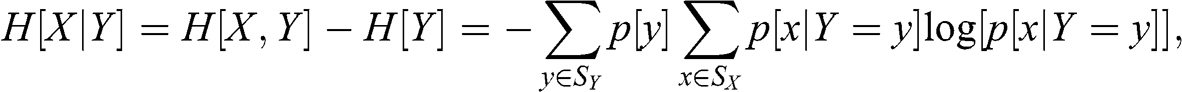
where  is the probability that X takes the value x conditioned on Y having taken the value y. Following this definition,
is the probability that X takes the value x conditioned on Y having taken the value y. Following this definition,  is the uncertainty we expect in X if we are told the value of Y. Accordingly,
is the uncertainty we expect in X if we are told the value of Y. Accordingly,  , and
, and  .
.
3.5 Kullback–Leibler Divergence
Let p and q be two discrete probability distributions defined on the same probability space. The Kullback–Leibler (or KL) divergence between p and q is
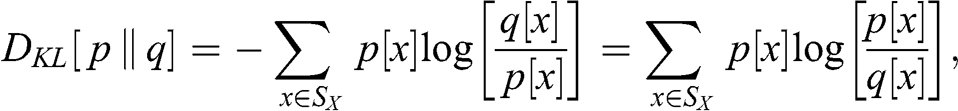
where  . Intuitively, this expression measures how much p diverges from a reference distribution q. The KL divergence is not a metric: although it is always nonnegative (
. Intuitively, this expression measures how much p diverges from a reference distribution q. The KL divergence is not a metric: although it is always nonnegative ( ), it violates the symmetry (
), it violates the symmetry ( ) and triangle inequality conditions. Note the difference with the definition of joint entropy, where the two random variables did not necessarily exist in the same probability space. KL divergence is widely used in variational inference.
) and triangle inequality conditions. Note the difference with the definition of joint entropy, where the two random variables did not necessarily exist in the same probability space. KL divergence is widely used in variational inference.
3.6 Cross-Entropy
Let p and q be two discrete probability distributions defined on the same probability space. Cross-entropy between p and q is
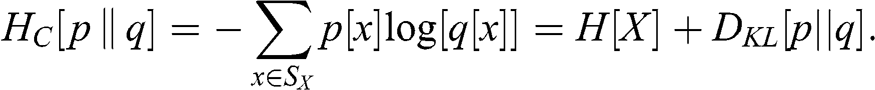
Cross-entropy can be interpreted as the uncertainty associated with X, where we evaluate its information content using a wrong distribution q rather than the true distribution p. Cross-entropy is a popular scoring function in classification problems, and it is particularly meaningful in financial applications (López de Prado 2018, section 9.4).
3.7 Mutual Information
Mutual information is defined as the decrease in uncertainty (or informational gain) in X that results from knowing the value of Y:
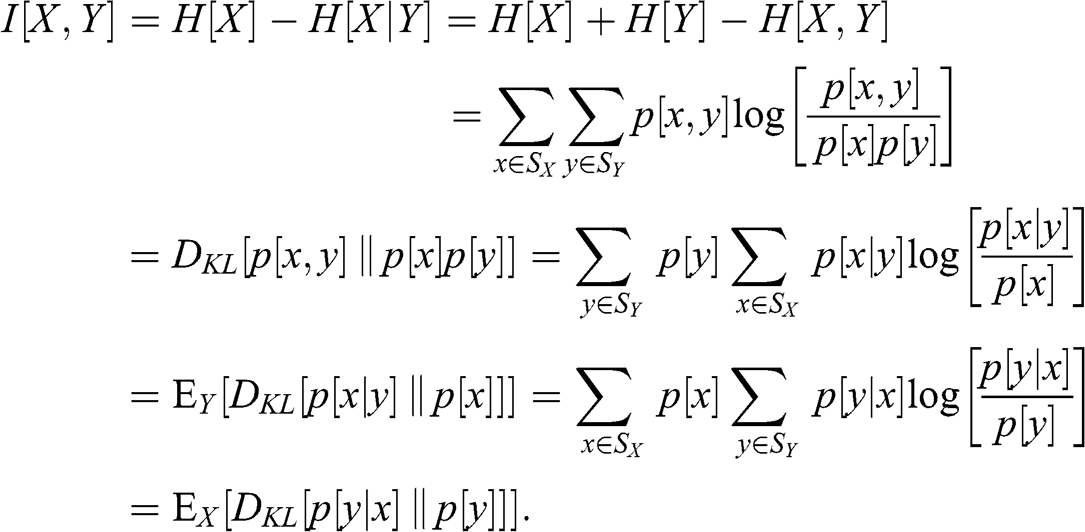
From the above we can see that  ,
,  and that
and that  . When X and Y are independent,
. When X and Y are independent,  , hence
, hence  . An upper boundary is given by
. An upper boundary is given by  . However, mutual information is not a metric, because it does not satisfy the triangle inequality:
. However, mutual information is not a metric, because it does not satisfy the triangle inequality:  . An important attribute of mutual information is its grouping property,
. An important attribute of mutual information is its grouping property,
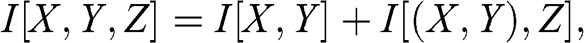
where  represents the joint distribution of X and Y. Since X, Y, and Z can themselves represent joint distributions, the above property can be used to decompose mutual information into simpler constituents. This makes mutual information a useful similarity measure in the context of agglomerative clustering algorithms and forward feature selection.
represents the joint distribution of X and Y. Since X, Y, and Z can themselves represent joint distributions, the above property can be used to decompose mutual information into simpler constituents. This makes mutual information a useful similarity measure in the context of agglomerative clustering algorithms and forward feature selection.
Given two arrays x and y of equal size, which are discretized into a regular grid with a number of partitions (bins) per dimension, Code Snippet 3.1 shows how to compute in python the marginal entropies, joint entropy, conditional entropies, and the mutual information.
Snippet 3.1 Marginal, Joint, Conditional Entropies, and Mutual Information
import numpy as np,scipy.stats as ss from sklearn.metrics import mutual_info_score cXY=np.histogram2d(x,y,bins)[0] hX=ss.entropy(np.histogram(x,bins)[0]) # marginal hY=ss.entropy(np.histogram(y,bins)[0]) # marginal iXY=mutual_info_score(None,None,contingency=cXY) iXYn=iXY/min(hX,hY) # normalized mutual information hXY=hX+hY-iXY # joint hX_Y=hXY-hY # conditional hY_X=hXY-hX # conditional
3.8 Variation of Information
Variation of information is defined as
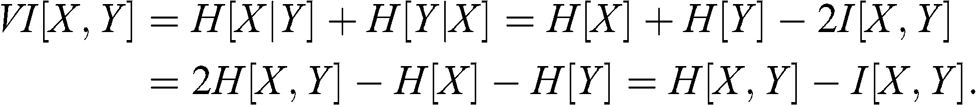
This measure can be interpreted as the uncertainty we expect in one variable if we are told the value of other. It has a lower bound in  , and an upper bound in
, and an upper bound in  . Variation of information is a metric, because it satisfies the axioms (1) nonnegativity,
. Variation of information is a metric, because it satisfies the axioms (1) nonnegativity,  ; (2) symmetry,
; (2) symmetry,  ; and (3) triangle inequality,
; and (3) triangle inequality,  .
.
Because  is a function of the sizes of
is a function of the sizes of  and
and  ,
,  does not have a firm upper bound. This is problematic when we wish to compare variations of information across different population sizes. The following quantity is a metric bounded between zero and one for all pairs
does not have a firm upper bound. This is problematic when we wish to compare variations of information across different population sizes. The following quantity is a metric bounded between zero and one for all pairs  :
:

Following Reference Kraskov, Stoegbauer and GrassbergerKraskov et al. (2008), a sharper alternative bounded metric is
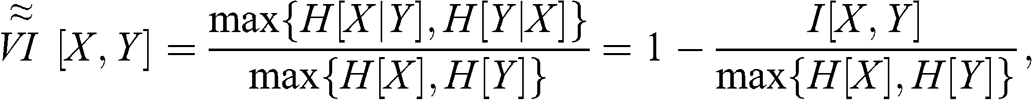
where  for all pairs
for all pairs  . Following the previous example, Code Snippet 3.2 computes mutual information, variation of information, and normalized variation of information.Footnote 9
. Following the previous example, Code Snippet 3.2 computes mutual information, variation of information, and normalized variation of information.Footnote 9
Snippet 3.2 Mutual Information, Variation of Information, and Normalized Variation of Information
import numpy as np,scipy.stats as ss from sklearn.metrics import mutual_info_score #------------------------------------------------------------------------------ def varInfo(x,y,bins,norm=False): # variation of information cXY=np.histogram2d(x,y,bins)[0] iXY=mutual_info_score(None,None,contingency=cXY) hX=ss.entropy(np.histogram(x,bins)[0]) # marginal hY=ss.entropy(np.histogram(y,bins)[0]) # marginal vXY=hX+hY-2*iXY # variation of information if norm: hXY=hX+hY-iXY # joint vXY/=hXY # normalized variation of information return vXY
As a summary, Figure 3.1 provides a visual representation of how these concepts are interrelated.
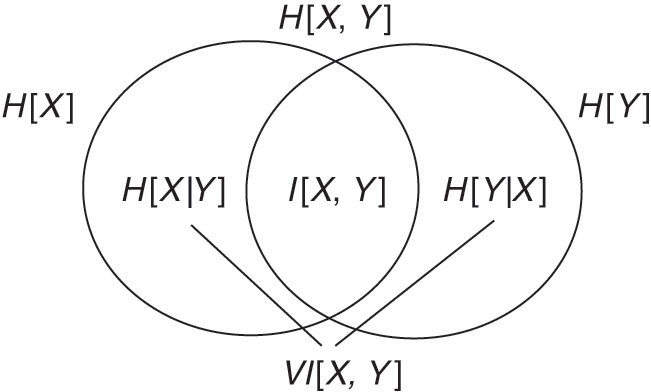
Figure 3.1 Correspondence between joint entropy, marginal entropies, conditional entropies, mutual information, and variation of information.
3.9 Discretization
Throughout this section, we have assumed that random variables were discrete. For the continuous case, we can quantize (coarse-grain) the values, and apply the same concepts on the binned observations. Consider a continuous random variable X, with probability distribution functions  . Shannon defined its (differential) entropy as
. Shannon defined its (differential) entropy as

The entropy of a Gaussian random variable X is  , thus
, thus  in the standard Normal case. One way to estimate
in the standard Normal case. One way to estimate  on a finite sample of real values is to divide the range spanning the observed values
on a finite sample of real values is to divide the range spanning the observed values  into
into  bins of equal size
bins of equal size  ,
,  , giving us
, giving us
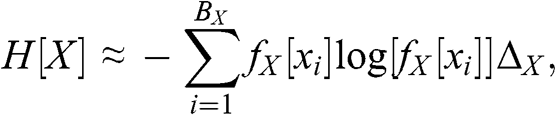
where  represents the frequency of observations falling within the ith bin. Let
represents the frequency of observations falling within the ith bin. Let  be the probability of drawing an observation within the segment
be the probability of drawing an observation within the segment  corresponding to the ith bin. We can approximate
corresponding to the ith bin. We can approximate  as
as  , which can be estimated as
, which can be estimated as  , where
, where  is the number of observations within the ith bin,
is the number of observations within the ith bin,  , and
, and  . This leads to a discretized estimator of entropy of the form
. This leads to a discretized estimator of entropy of the form

Following the same argument, the estimator of the joint entropy is
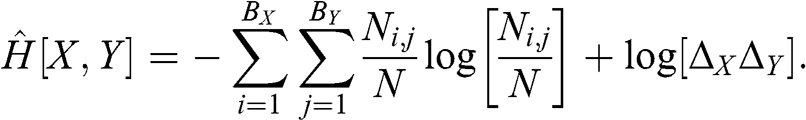
From the estimators  and
and  , we can derive estimators for conditional entropies, mutual information, and variation of information. As we can see from these equations, results may be biased by our choice of
, we can derive estimators for conditional entropies, mutual information, and variation of information. As we can see from these equations, results may be biased by our choice of  and
and  . For the marginal entropy case, Reference Hacine-Gharbi, Ravier, Harba and MohamadiHacine-Gharbi et al. (2012) found that the following binning is optimal:
. For the marginal entropy case, Reference Hacine-Gharbi, Ravier, Harba and MohamadiHacine-Gharbi et al. (2012) found that the following binning is optimal:


For the joint entropy case, Reference Hacine-Gharbi and RavierHacine-Gharbi and Ravier (2018) found that the optimal binning is given by
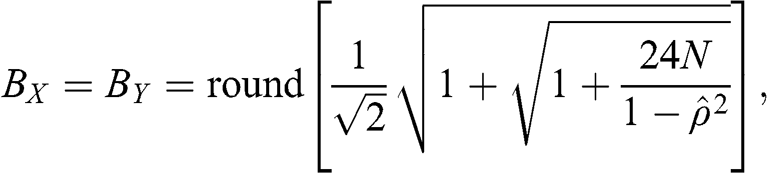
where  is the estimated correlation between X and Y. Code Snippet 3.3 modifies the previous function varInfo, so that it now incorporates the optimal binning derived by function numBins.
is the estimated correlation between X and Y. Code Snippet 3.3 modifies the previous function varInfo, so that it now incorporates the optimal binning derived by function numBins.
Snippet 3.3 Variation of Information on Discretized Continuous Random Variables
def numBins(nObs,corr=None): # Optimal number of bins for discretization if corr is None: # univariate case z=(8+324*nObs+12*(36*nObs+729*nObs**2)**.5)**(1/3.) b=round(z/6.+2./(3*z)+1./3) else: # bivariate case b=round(2**-.5*(1+(1+24*nObs/(1.-corr**2))**.5)**.5) return int(b) #------------------------------------------------------------------------------ def varInfo(x,y,norm=False): # variation of information bXY=numBins(x.shape[0],corr=np.corrcoef(x,y)[0,1]) cXY=np.histogram2d(x,y,bXY)[0] iXY=mutual_info_score(None,None,contingency=cXY) hX=ss.entropy(np.histogram(x,bXY)[0]) # marginal hY=ss.entropy(np.histogram(y,bXY)[0]) # marginal vXY=hX+hY-2*iXY # variation of information if norm: hXY=hX+hY-iXY # joint vXY/=hXY # normalized variation of information return vXY
3.10 Distance between Two Partitions
In the previous sections, we have derived methods to evaluate the similarity between random variables. We can extend these concepts to the problem of comparing two partitions of the same data set, where the partitions can be considered random to some extent (Reference MeilaMeila 2007). A partition P of a data set D is an unordered set of mutually disjoint nonempty subsets:
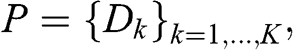

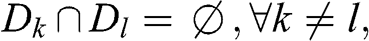
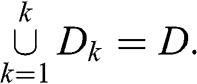
Let us define the uncertainty associated with P. First, we set the probability of picking any element  as
as  . Second, we define the probability that an element
. Second, we define the probability that an element  picked at random belongs to subset
picked at random belongs to subset  as
as  . This second probability
. This second probability  is associated with a discrete random variable that takes a value k from
is associated with a discrete random variable that takes a value k from  . Third, the uncertainty associated with this discrete random variable can be expressed in terms of the entropy
. Third, the uncertainty associated with this discrete random variable can be expressed in terms of the entropy

From the above we can see that  does not depend on
does not depend on  , but on the relative sizes of the subsets. Given a second partition
, but on the relative sizes of the subsets. Given a second partition  , we can define a second random variable that takes a value
, we can define a second random variable that takes a value  from
from  . The joint probability that an element
. The joint probability that an element  picked at random belongs to subset
picked at random belongs to subset  in P and also belongs to subset
in P and also belongs to subset  in
in  is
is

The joint entropy is defined as
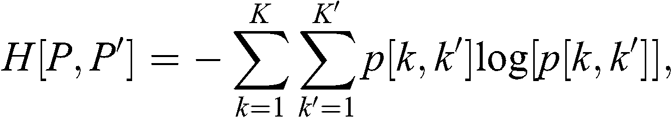
and the conditional entropy is  . The mutual information is
. The mutual information is

and the variation of information is
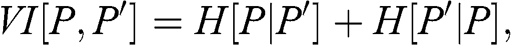
where  measures the amount of information about P that we lose and
measures the amount of information about P that we lose and  measures the amount of information about
measures the amount of information about  that we gain when going from partition P to
that we gain when going from partition P to  . This definition of variation of information has several properties, among which we find that (1) it is a metric; (2) it has an absolute upper boundary at
. This definition of variation of information has several properties, among which we find that (1) it is a metric; (2) it has an absolute upper boundary at  (like entropy); and (3) if the number of subsets is bounded by a constant
(like entropy); and (3) if the number of subsets is bounded by a constant  , with
, with  , then
, then  . These three properties are important because they allow us to normalize the distance between partitions, and compare partitioning algorithms across different data sets. In the context of unsupervised learning, variation of information is useful for comparing outcomes from a partitional (non-hierarchical) clustering algorithm.
. These three properties are important because they allow us to normalize the distance between partitions, and compare partitioning algorithms across different data sets. In the context of unsupervised learning, variation of information is useful for comparing outcomes from a partitional (non-hierarchical) clustering algorithm.
3.11 Experimental Results
The mutual information quantifies the amount of information shared by two random variables. The normalized mutual information takes real values within the range  , like the absolute value of the correlation coefficient. Also like the correlation coefficient (or its absolute value), neither the mutual information nor the normalized mutual information are true metrics. The mutual information between two random standardized Gaussian variables X and Y with correlation
, like the absolute value of the correlation coefficient. Also like the correlation coefficient (or its absolute value), neither the mutual information nor the normalized mutual information are true metrics. The mutual information between two random standardized Gaussian variables X and Y with correlation  is known to be
is known to be  .
.
It is in this sense that we can consider the normalized mutual information as the information-theoretic analogue to linear algebra’s correlation coefficient. Next, we study how both statistics perform under different scenarios.
3.11.1 No Relationship
We begin by drawing two arrays, x and e, of random numbers from a standard Gaussian distribution. Then we compute  , and evaluate the normalized mutual information as well as the correlation between x and y. Code Snippet 3.4 details these calculations.
, and evaluate the normalized mutual information as well as the correlation between x and y. Code Snippet 3.4 details these calculations.
Snippet 3.4 Correlation and Normalized Mutual Information of Two Independent Gaussian Random Variables
def mutualInfo(x,y,norm=False): # mutual information bXY=numBins(x.shape[0],corr=np.corrcoef(x,y)[0,1]) cXY=np.histogram2d(x,y,bXY)[0] iXY=mutual_info_score(None,None,contingency=cXY) if norm: hX=ss.entropy(np.histogram(x,bXY)[0]) # marginal hY=ss.entropy(np.histogram(y,bXY)[0]) # marginal iXY/=min(hX,hY) # normalized mutual information return iXY #------------------------------------------------------------------------------ size,seed=5000,0 np.random.seed(seed) x=np.random.normal(size=size) e=np.random.normal(size=size) y=0*x+e nmi=mutualInfo(x,y,True) corr=np.corrcoef(x,y)[0,1]
Figure 3.2 represents y against x, which as expected resembles a cloud. Correlation and normalized mutual information are both approximately zero.
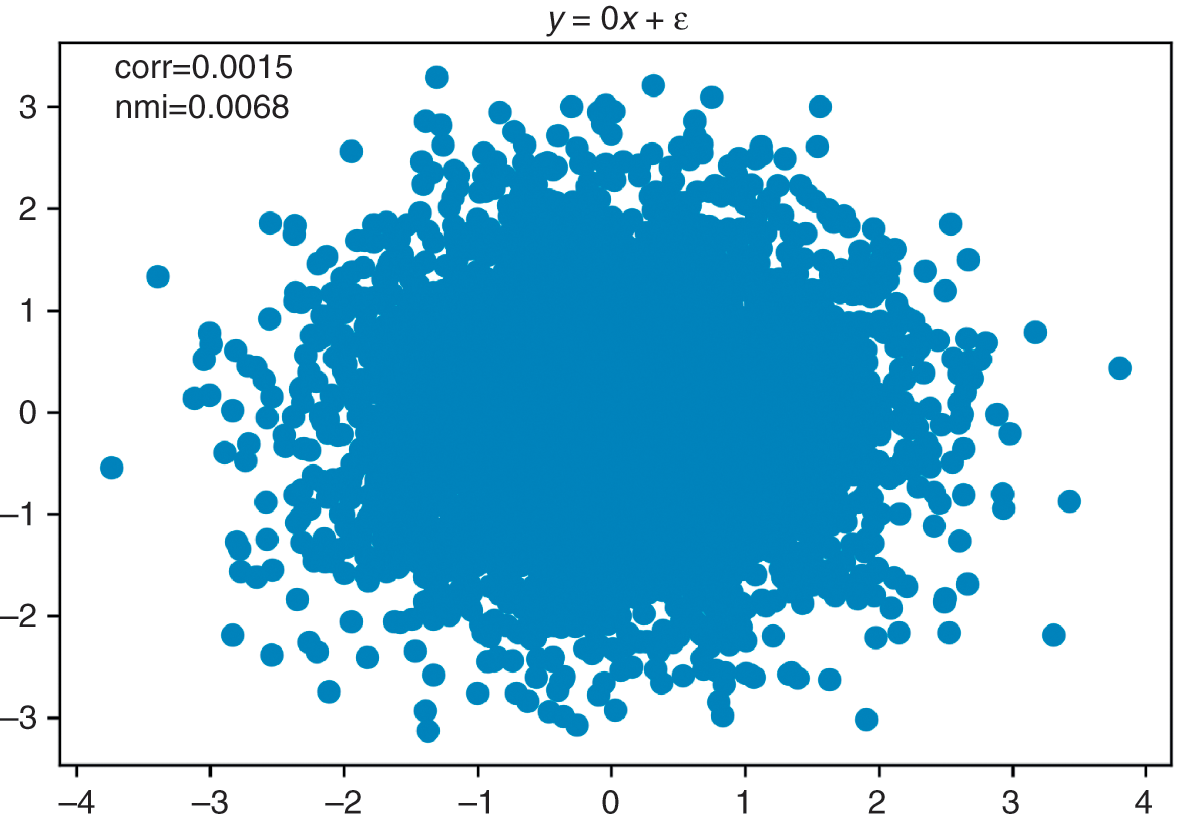
Figure 3.2 Scatterplot of two independent Gaussian random variables.
3.11.2 Linear Relationship
In this example, we impose a strong linear relationship between x and y, by setting  . Now the correlation is approximately 1, and the normalized mutual information is also very high, approximately 0.9. Still, the normalized mutual information is not 1, because there is some degree of uncertainty associated with e. For instance, should we impose
. Now the correlation is approximately 1, and the normalized mutual information is also very high, approximately 0.9. Still, the normalized mutual information is not 1, because there is some degree of uncertainty associated with e. For instance, should we impose  , then the normalized mutual information would be 0.995. Figure 3.3 plots this relationship.
, then the normalized mutual information would be 0.995. Figure 3.3 plots this relationship.
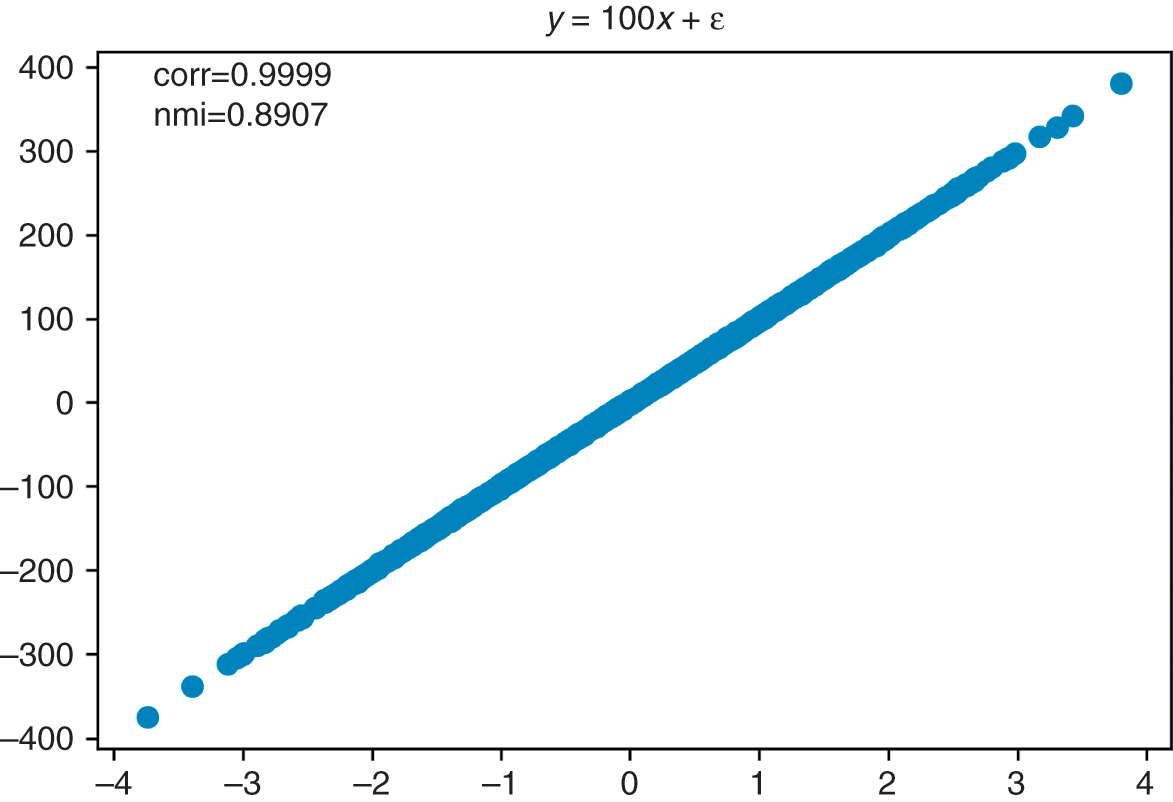
Figure 3.3 Scatterplot of two Gaussian random variables with a linear relationship.
3.11.3 Nonlinear Relationship
In this example, we impose a symmetric relationship across the x-axis between x and y, by setting  . Now the correlation is approximately 0, and the normalized mutual information is approximately 0.64. As expected, the correlation has failed to recognize the strong relationship that exists between x and y, because that relationship is nonlinear. In contrast, the mutual information recognizes that we can extract a substantial amount of information from x that is useful to predict y, and vice versa. Figure 3.4 plots this relationship.
. Now the correlation is approximately 0, and the normalized mutual information is approximately 0.64. As expected, the correlation has failed to recognize the strong relationship that exists between x and y, because that relationship is nonlinear. In contrast, the mutual information recognizes that we can extract a substantial amount of information from x that is useful to predict y, and vice versa. Figure 3.4 plots this relationship.
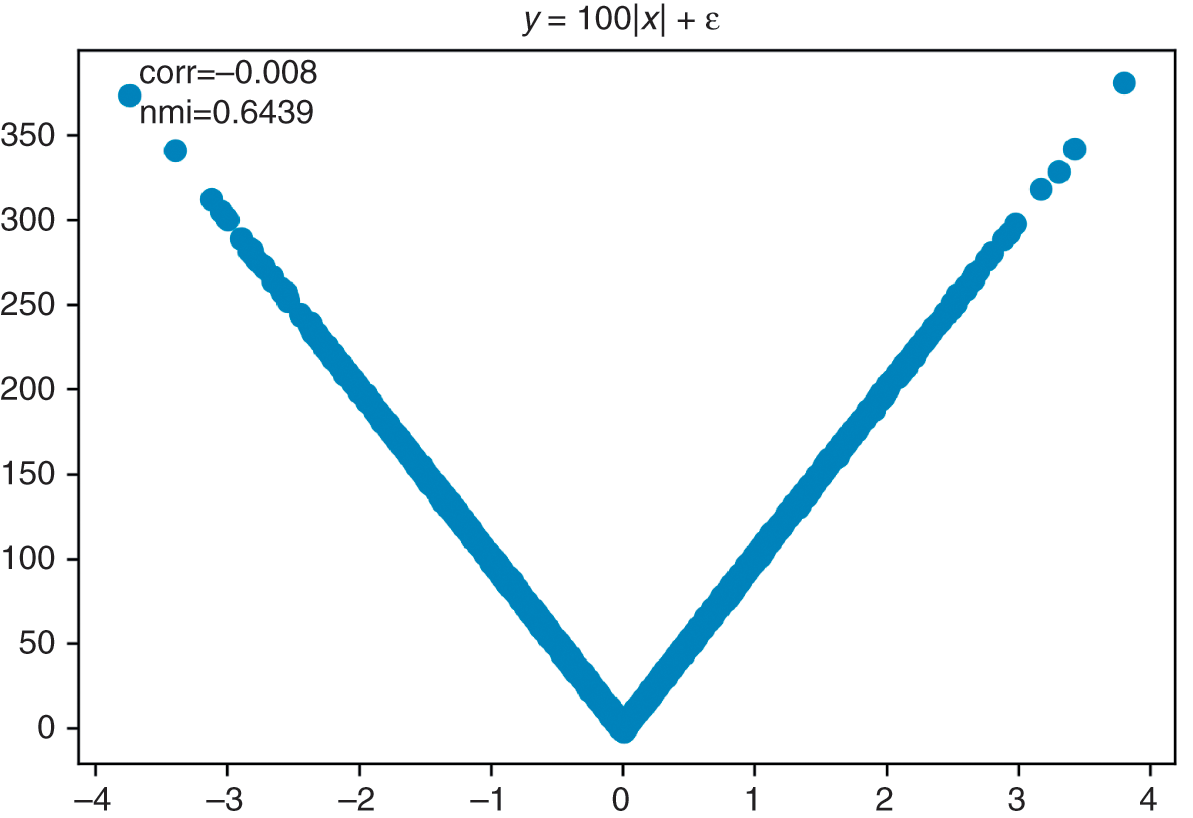
Figure 3.4 Scatterplot of two Gaussian random variables with a nonlinear relationship.
Unlike in the linear case, raising the coefficient from  to
to  will not substantially increase the normalized mutual information. In this example, the main source of uncertainty is not e. The normalized mutual information is high, but not 1, because knowing y does not suffice to know x. In fact, there are two alternative values of x associated with each value of y.
will not substantially increase the normalized mutual information. In this example, the main source of uncertainty is not e. The normalized mutual information is high, but not 1, because knowing y does not suffice to know x. In fact, there are two alternative values of x associated with each value of y.
3.12 Conclusions
Correlations are useful at quantifying the linear codependency between random variables. This form of codependency accepts various representations as a distance metric, such as  , or
, or  . However, when variables X and Y are bound by a nonlinear relationship, the above distance metric misjudges the similarity of these variables. For nonlinear cases, we have argued that the normalized variation of information is a more appropriate distance metric. It allows us to answer questions regarding the unique information contributed by a random variable, without having to make functional assumptions. Given that many ML algorithms do not impose a functional form on the data, it makes sense to use them in conjunction with entropy-based features.
. However, when variables X and Y are bound by a nonlinear relationship, the above distance metric misjudges the similarity of these variables. For nonlinear cases, we have argued that the normalized variation of information is a more appropriate distance metric. It allows us to answer questions regarding the unique information contributed by a random variable, without having to make functional assumptions. Given that many ML algorithms do not impose a functional form on the data, it makes sense to use them in conjunction with entropy-based features.
3.13 Exercises
1 Draw 1,000 observations from a bivariate Normal distribution with unit standard deviations and a correlation coefficient
.
a Discretize the samples, following the method described in Section 3.9.
b Compute
,
,
,
,
,
and
.c Are
and
affected by
?d Are
,
,
,
, and
affected by
?
2 Repeat Exercise 1, this time for 1 million observations. What variables are impacted by the different sample size?
3 Repeat Exercise 2, where this time you use the discretization step
from Exercise 1. How does this impact the results?4 What is the main advantage of variation of information over mutual information? Can you think of a use case in finance where mutual information is more appropriate than variation of information?
5 Consider the two correlation-based distance metrics we discussed in Section 3.2. Can you think of a use case where those distance metrics would be preferable to the normalized variation of information?
6 Code in Python a function to compute the KL divergence between two discrete probability distributions.
7 Code in Python a function to compute the cross-entropy of two discrete probability distributions.
8 Prove that
is also a proper metric.



















4 Optimal Clustering
4.1 Motivation
A clustering problem consists of a set of objects and a set of features associated with those objects. The goal is to separate the objects into groups (called clusters) using the features, where intragroup similarities are maximized, and intergroup similarities are minimized. It is a form of unsupervised learning, because we do not provide examples to assist the algorithm in solving this task. Clustering problems appear naturally in finance, at every step of the investment process. For instance, analysts may look for historical analogues to current events, a task that involves developing a numerical taxonomy of events. Portfolio managers often cluster securities with respect to a variety of features, to derive relative values among peers. Risk managers are keen to avoid the concentration of risks in securities that share common traits. Traders wish to understand flows affecting a set of securities, to determine whether a rally or sell-off is idiosyncratic to a particular security, or affects a category shared by a multiplicity of securities. In tackling these problems, we use the notions of distance we studied in Section 3. This section focuses on the problem of finding the optimal number and composition of clusters.
4.2 Proximity Matrix
Consider a data matrix X, of order N by F, where N is the number of objects and F is the number of features. We use the F features to compute the proximity between the N objects, as represented by an  matrix. The proximity measure can indicate either similarity (e.g., correlation, mutual information) or dissimilarity (e.g., a distance metric). It is convenient but not strictly necessary that dissimilarity measures satisfy the conditions of a metric: nonnegativity, symmetry and triangle inequality (Reference Kraskov, Stoegbauer and GrassbergerKraskov et al. 2008). The proximity matrix can be represented as an undirected graph where the weights are a function of the similarity (the more similar, the greater the weight) or dissimilarity (the more dissimilar, the smaller the weight). Then the clustering problem is equivalent to breaking the graph into connected components (disjoint connected subgraphs), one for each cluster. When forming the proximity matrix, it is a good idea to standardize the input data, to prevent that one feature’s scale dominates over the rest.
matrix. The proximity measure can indicate either similarity (e.g., correlation, mutual information) or dissimilarity (e.g., a distance metric). It is convenient but not strictly necessary that dissimilarity measures satisfy the conditions of a metric: nonnegativity, symmetry and triangle inequality (Reference Kraskov, Stoegbauer and GrassbergerKraskov et al. 2008). The proximity matrix can be represented as an undirected graph where the weights are a function of the similarity (the more similar, the greater the weight) or dissimilarity (the more dissimilar, the smaller the weight). Then the clustering problem is equivalent to breaking the graph into connected components (disjoint connected subgraphs), one for each cluster. When forming the proximity matrix, it is a good idea to standardize the input data, to prevent that one feature’s scale dominates over the rest.
4.3 Types of Clustering
There are two main classes of clustering algorithms: partitional and hierarchical. Partitional techniques create a one-level (un-nested) partitioning of the objects (each object belongs to one cluster, and to one cluster only). Hierarchical techniques produce a nested sequence of partitions, with a single, all-inclusive cluster at the top and singleton clusters of individual points at the bottom. Hierarchical clustering algorithms can be divisive (top-down) or agglomerative (bottom-up). By restricting the growth of a hierarchical tree, we can derive a partitional clustering from any hierarchical clustering. However, one cannot generally derive a hierarchical clustering from a partitional one.
Depending on the definition of cluster, we can distinguish several types of clustering algorithms, including the following:
1 Connectivity: This clustering is based on distance connectivity, like hierarchical clustering. For an example in finance, see Reference López de PradoLópez de Prado (2016).
2 Centroids: These algorithms perform a vector quantization, like k-means. For an example in finance, see Reference López de Prado and LewisLópez de Prado and Lewis (2018).
3 Distribution: Clusters are formed using statistical distributions, e.g., a mixture of Gaussians.
4 Density: These algorithms search for connected dense regions in the data space. Examples include DBSCAN and OPTICS.
5 Subspace: Clusters are modeled on two dimensions, features and observations. An example is biclustering (also known as coclustering). For instance, they can help identify similarities in subsets of instruments and time periods simultaneously.Footnote 10
Some algorithms expect as input a measure of similarity, and other algorithms expect as input a measure of dissimilarity. It is important to make sure that you pass the right input to a particular algorithm. For instance, a hierarchical clustering algorithm typically expects distance as an input, and it will cluster together items within a neighborhood. Centroids, distribution and density methods expect vector-space coordinates, and they can handle distances directly. However, biclustering directly on the distance matrix will cluster together the most distant elements (the opposite of what say k-means would do). One solution is to bicluster on the reciprocal of distance.
If the number of features greatly exceeds the number of observations, the curse of dimensionality can make the clustering problematic: most of the space spanning the observations will be empty, making it difficult to identify any groupings. One solution is to project the data matrix X onto a low-dimensional space, similar to how PCA reduces the number of features (Reference Steinbach, Levent, Kumar and WilleSteinbach et al. 2004; Reference Ding and HeDing and He 2004). An alternative solution is to project the proximity matrix onto a low-dimensional space, and use it as a new X matrix. In both cases, the procedure described in Section 2 can help identify the number of dimensions associated with signal.
4.4 Number of Clusters
Partitioning algorithms find the composition of un-nested clusters, where the researcher is responsible for providing the correct number of clusters. In practice, researchers often do not know in advance what the number of clusters should be. The “elbow method” is a popular technique that stops adding clusters when the marginal percentage of variance explained does not exceed a predefined threshold. In this context, the percentage of variance explained is defined as the ratio of the between-group variance to the total variance (an F-test). One caveat of this approach is that the threshold is often set arbitrarily (Reference Goutte, Toft, Rostrup, Nielsen and HansenGoutte et al. 1999).
In this section we present one algorithm that recovers the number of clusters from a shuffled block-diagonal correlation matrix. López de Prado and Lewis (2018) denote this algorithm ONC, since it searches for the optimal number of clusters. ONC belongs to the broader class of algorithms that apply the silhouette method (Reference RousseeuwRousseeuw 1987). Although we typically focus on finding the number of clusters within a correlation matrix, this algorithm can be applied to any generic observation matrix.
4.4.1 Observations Matrix
If your problem does not involve a correlation matrix, or you already possess an observation matrix, you may skip this section.Footnote 11 Otherwise, assume that we have N variables that follow a multivariate Normal distribution characterized by a correlation matrix ρ, where  is the correlation between variables i and j. If a strong common component is present, it is advisable to remove it by applying the detoning method explained in Section 2, because a factor exposure shared by all variables may hide the existence of partly shared exposures.
is the correlation between variables i and j. If a strong common component is present, it is advisable to remove it by applying the detoning method explained in Section 2, because a factor exposure shared by all variables may hide the existence of partly shared exposures.
For the purposes of correlation clustering, we can follow at least three approaches: (a) circumvent the  matrix, by directly defining the distance matrix as
matrix, by directly defining the distance matrix as  or a similar transformation (see Section 3); (b) use the correlation matrix as
or a similar transformation (see Section 3); (b) use the correlation matrix as  ; (c) derive the
; (c) derive the  matrix as
matrix as  , or a similar transformation (the distance of distances approach). The advantage of options (b) and (c) is that the distance between two variables will be a function of multiple correlation estimates, and not only one, which makes the analysis more robust to the presence of outliers. The advantage of option (c) is that it acknowledges that a change from
, or a similar transformation (the distance of distances approach). The advantage of options (b) and (c) is that the distance between two variables will be a function of multiple correlation estimates, and not only one, which makes the analysis more robust to the presence of outliers. The advantage of option (c) is that it acknowledges that a change from  to
to  is greater than a change from
is greater than a change from  to
to  . In this Section we follow approach (c), thus we define the observations matrix as
. In this Section we follow approach (c), thus we define the observations matrix as  .
.
The clustering of correlation matrices is peculiar in the sense that the features match the observations: we try to group observations where the observations themselves are the features (hence the symmetry of X). Matrix X appears to be a distance matrix, but it is not. It is still an observations matrix, on which distances can be evaluated.
For large matrices X, generally it is good practice to reduce its dimension via PCA. The idea is to replace X with its standardized orthogonal projection onto a lower-dimensional space, where the number of dimensions is given by the number of eigenvalues in X’s correlation matrix that exceed  (see Section 2). The resulting observations matrix,
(see Section 2). The resulting observations matrix,  , of size
, of size  , has a higher signal-to-noise ratio.
, has a higher signal-to-noise ratio.
4.4.2 Base Clustering
At this stage, we assume that we have a matrix that expresses our observations in a metric space. This matrix may have been computed as described in the previous section, or applying some other method. For example, the matrix may be based on the variation of information between random variables, as explained in Section 3. Next, let us discuss the base clustering algorithm. One possibility would be to use the k-means algorithm on our observation matrix.Footnote 12 While k-means is simple and frequently effective, it does have two notable limitations: first, the algorithm requires an user-set number of clusters K, which is not necessarily optimal a priori; second, the initialization is random, and hence the effectiveness of the algorithm can be similarly random.
In order to address these two concerns, we need to modify the k-means algorithm. The first modification we make is to introduce an objective function, so that we can find the “optimal K.” For this, we choose the silhouette score introduced by Reference RousseeuwRousseeuw (1987). As a reminder, for a given element i and a given clustering, the silhouette coefficient  is defined as
is defined as
where  is the average distance between i and all other elements in the same cluster, and
is the average distance between i and all other elements in the same cluster, and  is the average distance between i and all the elements in the nearest cluster of which i is not a member. Effectively, this is a measure comparing intracluster distance and intercluster distance. A value
is the average distance between i and all the elements in the nearest cluster of which i is not a member. Effectively, this is a measure comparing intracluster distance and intercluster distance. A value  means that element i is clustered well, while
means that element i is clustered well, while  means that i was clustered poorly. For a given partition, our measure of clustering quality q is defined as
means that i was clustered poorly. For a given partition, our measure of clustering quality q is defined as
where  is the mean of the silhouette coefficients and
is the mean of the silhouette coefficients and  is the variance of the silhouette coefficients. The second modification we make deals with k-mean’s initialization problem. At the base level, our clustering algorithm performs the following operation: first, evaluate the observation matrix; second, we perform a double for … loop. In the first loop, we try different
is the variance of the silhouette coefficients. The second modification we make deals with k-mean’s initialization problem. At the base level, our clustering algorithm performs the following operation: first, evaluate the observation matrix; second, we perform a double for … loop. In the first loop, we try different  on which to cluster via k-means for one given initialization, and evaluate the quality q for each clustering. The second loop repeats the first loop multiple times, thereby attempting different initializations. Third, over these two loops, we select the clustering with the highest q. Code Snippet 4.1 implements this procedure, and Figure 4.1 summarizes the workflow.
on which to cluster via k-means for one given initialization, and evaluate the quality q for each clustering. The second loop repeats the first loop multiple times, thereby attempting different initializations. Third, over these two loops, we select the clustering with the highest q. Code Snippet 4.1 implements this procedure, and Figure 4.1 summarizes the workflow.
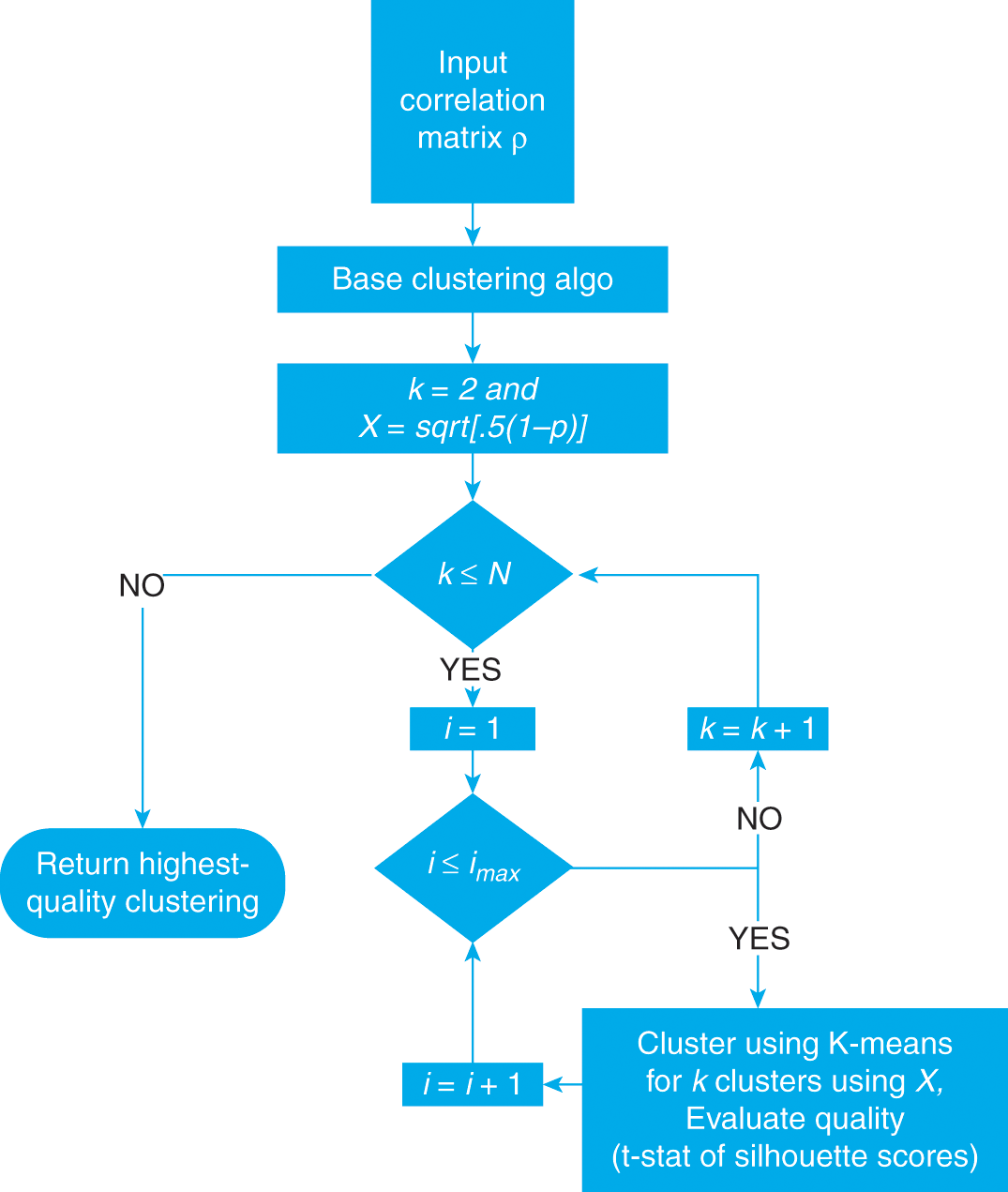
Figure 4.1 Structure of ONC’s base clustering stage.
Snippet 4.1 Base Clustering
import numpy as np,pandas as pd
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples
#------------------------------------------------------------------------------
def clusterKMeansBase(corr0,maxNumClusters=10,n_init=10):
x,silh=((1-corr0.fillna(0))/2.)**.5,pd.Series() # observations matrix
for init in range(n_init):
for i in xrange(2,maxNumClusters+1):
kmeans_=KMeans(n_clusters=i,n_jobs=1,n_init=1)
kmeans_=kmeans_.fit(x)
silh_=silhouette_samples(x,kmeans_.labels_)
stat=(silh_.mean()/silh_.std(),silh.mean()/silh.std())
if np.isnan(stat[1]) or stat[0]>stat[1]:
silh,kmeans=silh_,kmeans_
newIdx=np.argsort(kmeans.labels_)
corr1=corr0.iloc[newIdx] # reorder rows
corr1=corr1.iloc[:,newIdx] # reorder columns
clstrs={i:corr0.columns[np.where(kmeans.labels_==i)[0]].tolist() \
for i in np.unique(kmeans.labels_) } # cluster members
silh=pd.Series(silh,index=x.index)
return corr1,clstrs,silh4.4.3 Higher-Level Clustering
Our third modification to k-means deals with clusters of inconsistent quality. The base clustering may capture the more distinct clusters, while missing the less apparent ones. To address this issue, we evaluate the quality  of each cluster
of each cluster  given the clustering quality scores obtained from the base clustering algorithm. We then take the average quality
given the clustering quality scores obtained from the base clustering algorithm. We then take the average quality  , and find the set of clusters with quality below average,
, and find the set of clusters with quality below average,  . Let us denote as
. Let us denote as  the number of clusters in that set,
the number of clusters in that set,  . If the number of clusters to rerun is
. If the number of clusters to rerun is  , then we return the clustering given by the base algorithm. However, if
, then we return the clustering given by the base algorithm. However, if  , we rerun the clustering of the items in those
, we rerun the clustering of the items in those  clusters, while the rest are considered acceptably clustered.
clusters, while the rest are considered acceptably clustered.
We form a new (reduced) observations matrix out of the elements that compose the  clusters, and rerun the base clustering algorithm on that reduced correlation matrix. Doing so will return a, possibly new, clustering for those elements in
clusters, and rerun the base clustering algorithm on that reduced correlation matrix. Doing so will return a, possibly new, clustering for those elements in  . To check its efficacy, we compare the average cluster quality before and after reclustering those elements in
. To check its efficacy, we compare the average cluster quality before and after reclustering those elements in  . If the average cluster quality improves, we return the accepted clustering from the base clustering concatenated with the new clustering for the redone nodes. Otherwise, we return the clustering formed by the base algorithm. Code Snippet 4.2 implements this operation in python, and Figure 4.2 summarizes the workflow.
. If the average cluster quality improves, we return the accepted clustering from the base clustering concatenated with the new clustering for the redone nodes. Otherwise, we return the clustering formed by the base algorithm. Code Snippet 4.2 implements this operation in python, and Figure 4.2 summarizes the workflow.
Snippet 4.2 Top-Level of Clustering
from sklearn.metrics import silhouette_samples
#------------------------------------------------------------------------------
def makeNewOutputs(corr0,clstrs,clstrs2):
clstrsNew,newIdx={},[]
for i in clstrs.keys():
clstrsNew[len(clstrsNew.keys())]=list(clstrs[i])
for i in clstrs2.keys():
clstrsNew[len(clstrsNew.keys())]=list(clstrs2[i])
map(newIdx.extend, clstrsNew.values())
corrNew=corr0.loc[newIdx,newIdx]
x=((1-corr0.fillna(0))/2.)**.5
kmeans_labels=np.zeros(len(x.columns))
for i in clstrsNew.keys():
idxs=[x.index.get_loc(k) for k in clstrsNew[i]]
kmeans_labels[idxs]=i
silhNew=pd.Series(silhouette_samples(x,kmeans_labels),
index=x.index)
return corrNew,clstrsNew,silhNew
#------------------------------------------------------------------------------
def clusterKMeansTop(corr0,maxNumClusters=None,n_init=10):
if maxNumClusters==None:maxNumClusters=corr0.shape[1]-1
corr1,clstrs,silh=clusterKMeansBase(corr0,maxNumClusters= \
min(maxNumClusters,corr0.shape[1]-1),n_init=n_init)
clusterTstats={i:np.mean(silh[clstrs[i]])/np.std(silh[clstrs[i]]) \ for i in clstrs.keys()}
tStatMean=np.mean(clusterTstats.values())
redoClusters=[i for i in clusterTstats.keys() if \
clusterTstats[i]<tStatMean]
if len(redoClusters)<=1:
return corr1,clstrs,silh
else:
keysRedo=[]
map(keysRedo.extend,[clstrs[i] for i in redoClusters])
corrTmp=corr0.loc[keysRedo,keysRedo]
meanRedoTstat=np.mean([clusterTstats[i] for i in redoClusters])
corr2,clstrs2,silh2=clusterKMeansTop(corrTmp, \
maxNumClusters=min(maxNumClusters, \
corrTmp.shape[1]-1),n_init=n_init)
# Make new outputs, if necessary
corrNew,clstrsNew,silhNew=makeNewOutputs(corr0, \
{i:clstrs[i] for i in clstrs.keys() if i not in redoClusters}, \
clstrs2)
newTstatMean=np.mean([np.mean(silhNew[clstrsNew[i]])/ \
np.std(silhNew[clstrsNew[i]]) for i in clstrsNew.keys()])
if newTstatMean<=tStatMean:
return corr1,clstrs,silh
else:
return corrNew,clstrsNew,silhNew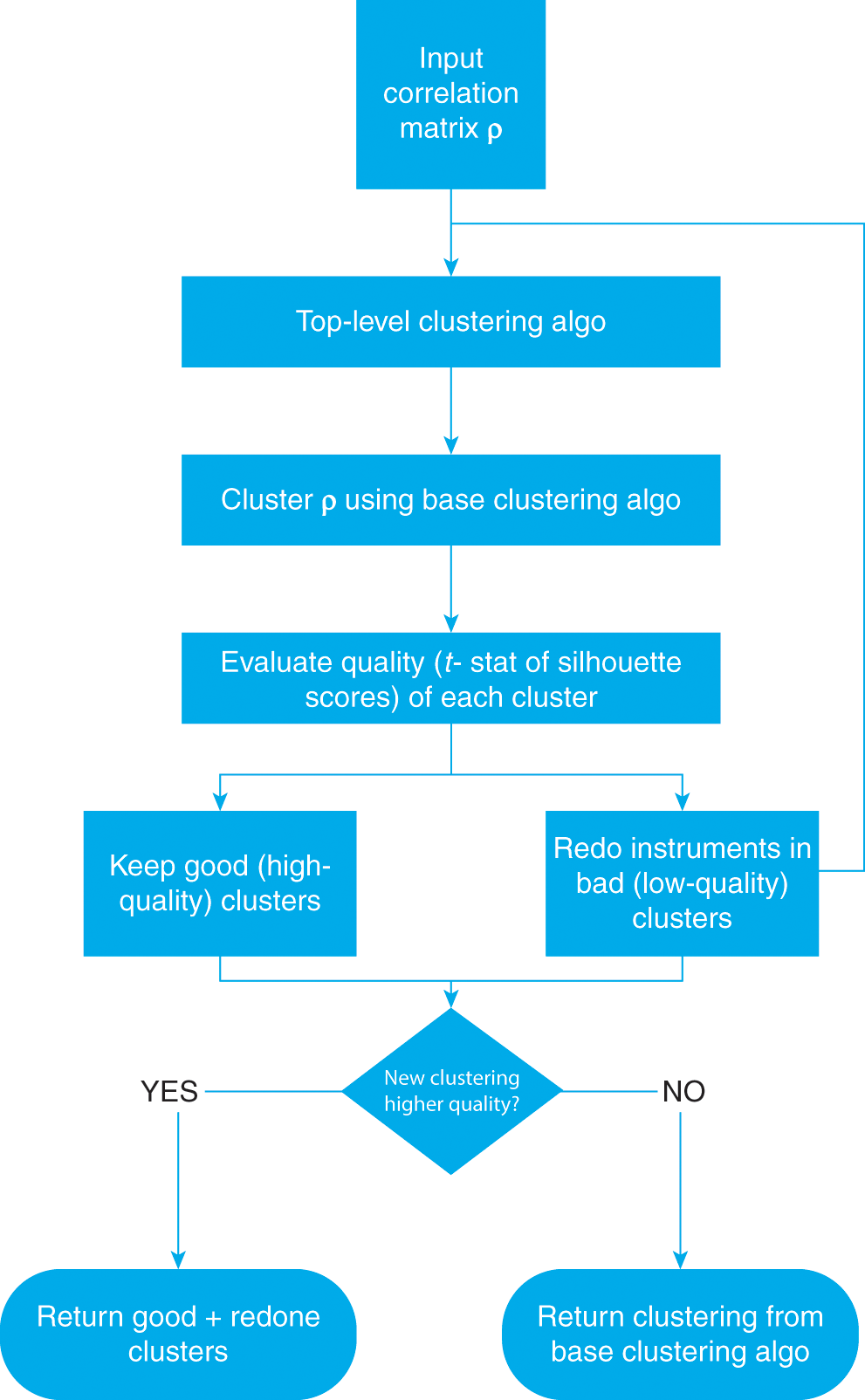
Figure 4.2 Structure of ONC’s higher-level stage.
4.5 Experimental Results
We now design a Monte Carlo experiment to verify the accuracy of the ONC algorithm introduced earlier: first, we create an  correlation matrix ρ from random draws with a predefined number of blocks K, where intrablock correlation is high and across-block correlation is low; second, we shuffle that correlation matrix. Third, we apply ONC, and verify that the ONC algorithm recovers the blocks we injected.Footnote 13
correlation matrix ρ from random draws with a predefined number of blocks K, where intrablock correlation is high and across-block correlation is low; second, we shuffle that correlation matrix. Third, we apply ONC, and verify that the ONC algorithm recovers the blocks we injected.Footnote 13
4.5.1 Generation of Random Block Correlation Matrices
Given the tuple  , we wish to create a random block correlation matrix of size
, we wish to create a random block correlation matrix of size  , made up of K blocks, each of size greater or equal than M. Let us describe the procedure for randomly partitioning N items into K disjoint groups, each of size at least M. Note that this is equivalent to randomly partitioning
, made up of K blocks, each of size greater or equal than M. Let us describe the procedure for randomly partitioning N items into K disjoint groups, each of size at least M. Note that this is equivalent to randomly partitioning  items into K groups each of size at least 1, so we reduce our analysis to that. Consider randomly choosing
items into K groups each of size at least 1, so we reduce our analysis to that. Consider randomly choosing  distinct items, denoted as a set B, from the set
distinct items, denoted as a set B, from the set  , then add
, then add  to B, so that B is of size K. Thus, B contains
to B, so that B is of size K. Thus, B contains  , where
, where  . Given B, consider the K partition sets
. Given B, consider the K partition sets  ;
;  ; … ; and
; … ; and  . Given that
. Given that  are distinct, each partition contains at least one element as desired, and furthermore completely partitions the set
are distinct, each partition contains at least one element as desired, and furthermore completely partitions the set  . In doing so, each set
. In doing so, each set  contains
contains  elements for
elements for  , letting
, letting  . We can generalize again by adding
. We can generalize again by adding  elements to each block.
elements to each block.
Let each block  have size
have size  by
by  , where
, where  , thus implying
, thus implying  . First, for each block k, we create a time series of length T that is drawn from independent and identically distributed (IID) standard Gaussians, then make copies of that to each column of a matrix X of size
. First, for each block k, we create a time series of length T that is drawn from independent and identically distributed (IID) standard Gaussians, then make copies of that to each column of a matrix X of size  . Second, we add to each
. Second, we add to each  a random Gaussian noise with standard deviation
a random Gaussian noise with standard deviation  . By design, the columns of X will be highly correlated for small
. By design, the columns of X will be highly correlated for small  , and less correlated for large σ. Third, we evaluate the covariance matrix
, and less correlated for large σ. Third, we evaluate the covariance matrix  for the columns of X, and add
for the columns of X, and add  as a block to Σ . Fourth, we add to Σ another covariance matrix with one block but larger
as a block to Σ . Fourth, we add to Σ another covariance matrix with one block but larger  . Finally, we derive the correlation matrix ρ associated with Σ.
. Finally, we derive the correlation matrix ρ associated with Σ.
By construction, ρ has K blocks with high correlations inside each block, and low correlations otherwise. Figure 4.3 is an example of a correlation matrix constructed this way. Code Snippet 4.3 implements this operation in python.
Snippet 4.3 Random Block Correlation Matrix Creation
import numpy as np,pandas as pd from scipy.linalg import block_diag from sklearn.utils import check_random_state #------------------------------------------------------------------------------ def getCovSub(nObs,nCols,sigma,random_state=None): # Sub correl matrix rng=check_random_state(random_state) if nCols==1:return np.ones((1,1)) ar0=rng.normal(size=(nObs,1)) ar0=np.repeat(ar0,nCols,axis=1) ar0+=rng.normal(scale=sigma,size=ar0.shape) ar0=np.cov(ar0,rowvar=False) return ar0 #------------------------------------------------------------------------------ def getRndBlockCov(nCols,nBlocks,minBlockSize=1,sigma=1., random_state=None): # Generate a block random correlation matrix rng=check_random_state(random_state) parts=rng.choice(range(1,nCols-(minBlockSize-1)*nBlocks), \ nBlocks-1,replace=False) parts.sort() parts=np.append(parts,nCols-(minBlockSize-1)*nBlocks) parts=np.append(parts[0],np.diff(parts))-1+minBlockSize cov=None for nCols_ in parts: cov_=getCovSub(int(max(nCols_*(nCols_+1)/2.,100)), \ nCols_,sigma,random_state=rng) if cov is None:cov=cov_.copy() else:cov=block_diag(cov,cov_) return cov #------------------------------------------------------------------------------ def randomBlockCorr(nCols,nBlocks,random_state=None, minBlockSize=1): # Form block corr rng=check_random_state(random_state) cov0=getRndBlockCov(nCols,nBlocks, minBlockSize=minBlockSize,sigma=.5,random_state=rng) cov1=getRndBlockCov(nCols,1,minBlockSize=minBlockSize, sigma=1.,random_state=rng) # add noise cov0+=cov1 corr0=cov2corr(cov0) corr0=pd.DataFrame(corr0) return corr0
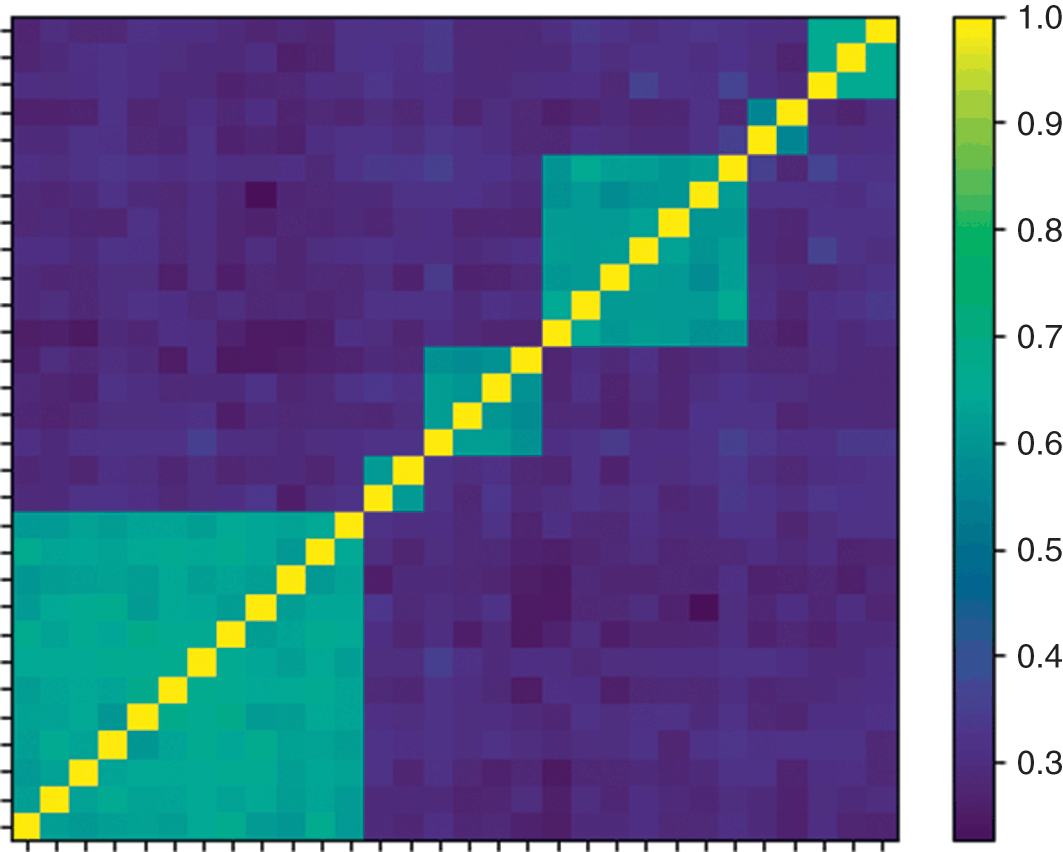
Figure 4.3 Example of a random block correlation matrix, before shuffling.
4.5.2 Number of Clusters
Using the above described procedure, we create random  correlation matrices with K blocks of size at least M. We shuffle the rows and columns of each correlation matrix, so that the blocks are no longer identifiable. Then, we test the efficacy of the ONC algorithm in recovering the number and composition of those blocks. For our simulations, we chose
correlation matrices with K blocks of size at least M. We shuffle the rows and columns of each correlation matrix, so that the blocks are no longer identifiable. Then, we test the efficacy of the ONC algorithm in recovering the number and composition of those blocks. For our simulations, we chose  . As we would expect clusters to be formed of at least two objects, we set
. As we would expect clusters to be formed of at least two objects, we set  , and thus necessarily
, and thus necessarily  . For each N, we test
. For each N, we test  , up to
, up to  . Finally, we test 1,000 random generations for each of these parameter sets.
. Finally, we test 1,000 random generations for each of these parameter sets.
Figure 4.4 displays various boxplots for these simulations. In particular, for  in a given bucket, we display the boxplot of the ratio of K predicted by the clustering (denoted
in a given bucket, we display the boxplot of the ratio of K predicted by the clustering (denoted  to the actual K tested. Ideally, this ratio should be near 1. Results indicate that ONC frequently recovers the correct number of clusters, with some small errors.
to the actual K tested. Ideally, this ratio should be near 1. Results indicate that ONC frequently recovers the correct number of clusters, with some small errors.
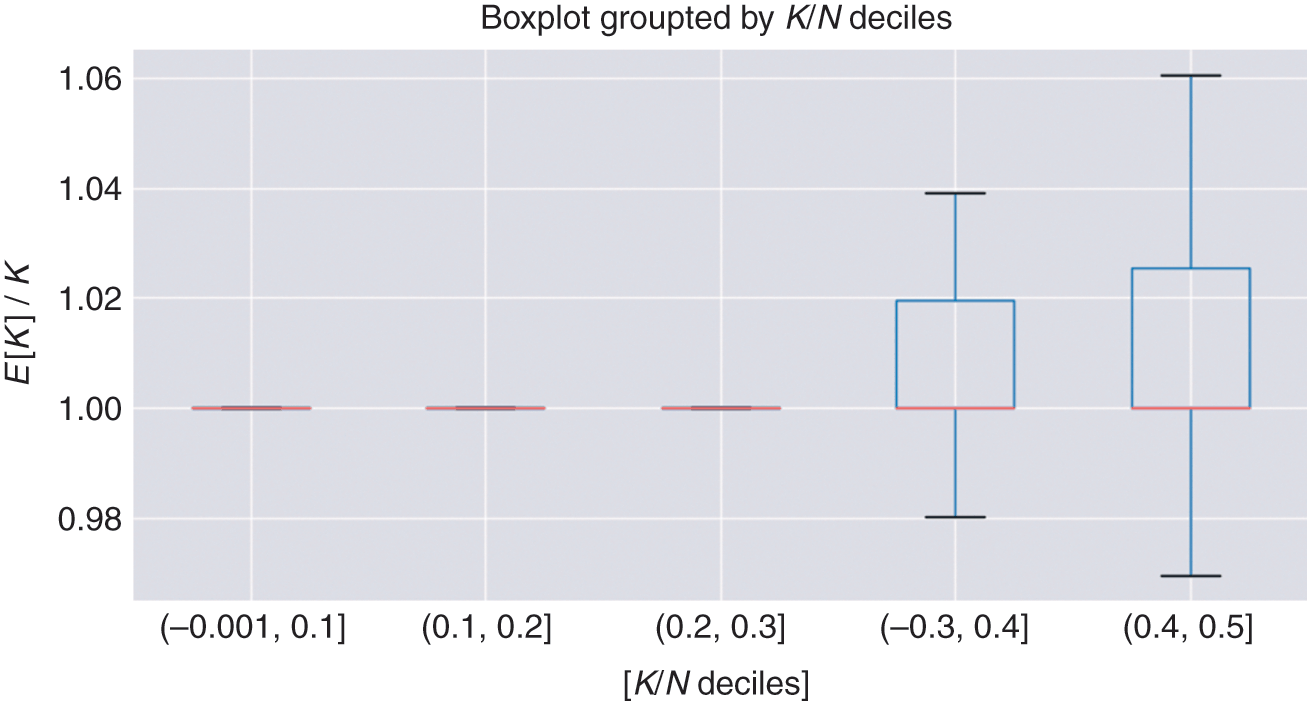
Figure 4.4 Boxplots of estimated K/actual K for bucketed K/N.
As a reminder, in a boxplot, the central box has the bottom set to the 25th percentile of the data (Q1), while the top is set to the 75th percentile (Q3). The interquartile range (IQR) is set to Q3-Q1. The median is displayed as a line inside the box. The “whiskers” extend to the largest datum less than  , and the smallest datum greater than
, and the smallest datum greater than  . Points outside that range are considered outliers.
. Points outside that range are considered outliers.
4.6 Conclusions
In this section, we have studied the problem of determining the optimal composition and number of clusters by a partitioning algorithm. We have made three modifications to the k-means algorithm: (1) we have defined an objective function that measures the quality of the clusters; (2) we have addressed k-mean’s initialization problem by rerunning the algorithm with alternative seeds; and (3) an upper-level clustering looks for better partitions among the clusters the exhibit below-average quality. Experimental results show that the algorithm effectively recovers the number and composition of the clusters injected into a block-diagonal matrix.
We have applied the proposed solution to random correlation matrices, however nothing in the method prevents its application to other kinds of matrices. The starting point of the algorithm is an observations matrix, which can be defined in terms of correlation-based metrics, variation of information, or some other function.
4.7 Exercises
1 What is the main difference between outputs from hierarchical and partitioning clustering algorithms? Why can’t the output from the latter be converted into the output of the former?
2 Is MSCI’s GICS classification system an example of hierarchical or partitioning clustering? Using the appropriate algorithm on a correlation matrix, try to replicate the MSCI classification. To compare the clustering output with MSCI’s, use the clustering distance introduced in Section 3.
3 Modify Code Snippets 4.1 and 4.2 to work with a spectral biclustering algorithm. Do you get fundamentally different results? Hint: Remember that, as proximity matrix, biclustering algorithms expect a similarity matrix, not a distance matrix.
4 Repeat the experimental analysis, where this time ONC’s base algorithm selects the number of clusters using the “elbow method.” Do you recover the true number of clusters consistently? Why?
5 In Section 2, we used a different method for building block-diagonal correlation matrices. In that method, all blocks had the same size. Repeat the experimental analysis on regular block-diagonal correlation matrices. Do you get better or worse results? Why?
5 Financial Labels
5.1 Motivation
Section 4 discussed clustering, a technique that searches for similarities within a data set of features (an X matrix). Clustering is an unsupervised learning method, in the sense that the algorithm does not learn through examples. In contrast, a supervised learning algorithm solves a task with the help of examples (a y array). There are two main types of supervised learning problems: regression and classification. In regression problems, examples are drawn from an infinite population, which can be countable (like integers) or uncountable (like real values). In classification problems, examples are drawn from a finite set of labels (either categorical or ordinal). When there is no intrinsic ordering between the values, labels represent the observations from a categorical variable, like male versus female. When there is intrinsic ordering between the values, labels represent the observations from an ordinal variable, like credit ratings. Real variables can be discretized into categorical or ordinal labels.
Researchers need to ponder very carefully how they define labels, because labels determine the task that the algorithm is going to learn. For example, we may train an algorithm to predict the sign of today’s return for stock XYZ, or whether that stock’s next 5% move will be positive (a run that spans a variable number of days). The features needed to solve both tasks can be very different, as the first label involves a point forecast whereas the second label relates to a path-dependent event. For example, the sign of a stock’s daily return may be unpredictable, while a stock’s probability of rallying (unconditional on the time frame) may be assessable. That some features failed to predict one type of label for a particular stock does not mean that they will fail to predict all types of labels for that same stock. Since investors typically do not mind making money one way or another, it is worthwhile to try alternative ways of defining labels. In this section, we discuss four important labeling strategies.
5.2 Fixed-Horizon Method
Virtually all academic studies in financial ML use the fixed-horizon labeling method (see the bibliography). Consider a features matrix X with I rows,  , sampled from a series of bars with index
, sampled from a series of bars with index  , where
, where  . We compute the price return over a horizon h as
. We compute the price return over a horizon h as

where  is the bar index associated with the ith observed features and
is the bar index associated with the ith observed features and  is the bar index after the fixed horizon of h bars has elapsed. This method assigns a label
is the bar index after the fixed horizon of h bars has elapsed. This method assigns a label  to an observation
to an observation  , with
, with
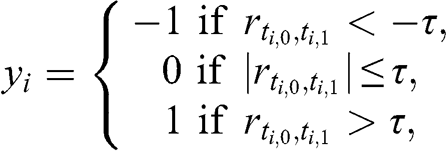
where  is a predefined constant threshold. When the bars are sampled at a regular chronological time frequency, they are known as time bars. Time bars are also very popular in the financial literature. The combination of time bars with fixed-horizon labeling results in fixed time horizons. Despite its popularity, there are several reasons to avoid this method. First, returns computed on time bars exhibit substantial heteroscedasticity, as a consequence of intraday seasonal activity patterns. Applying a constant threshold
is a predefined constant threshold. When the bars are sampled at a regular chronological time frequency, they are known as time bars. Time bars are also very popular in the financial literature. The combination of time bars with fixed-horizon labeling results in fixed time horizons. Despite its popularity, there are several reasons to avoid this method. First, returns computed on time bars exhibit substantial heteroscedasticity, as a consequence of intraday seasonal activity patterns. Applying a constant threshold  in conjunction with heteroskedastic returns
in conjunction with heteroskedastic returns  will transfer that seasonality to the labels, thus the distribution of labels will not be stationary. For instance, obtaining a 0 label at the open or the close is more informative (in the sense of unexpected) than obtaining a 0 label around noon, or during the night. One solution is to apply the fixed-horizon method on tick, volume or dollar bars (see Reference López de PradoLópez de Prado 2018a). Another solution is to label based on standardized returns
will transfer that seasonality to the labels, thus the distribution of labels will not be stationary. For instance, obtaining a 0 label at the open or the close is more informative (in the sense of unexpected) than obtaining a 0 label around noon, or during the night. One solution is to apply the fixed-horizon method on tick, volume or dollar bars (see Reference López de PradoLópez de Prado 2018a). Another solution is to label based on standardized returns  , adjusted for the volatility predicted over the interval of bars
, adjusted for the volatility predicted over the interval of bars  ,
,
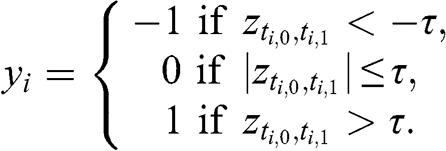
A second concern of the fixed horizon method is that it dismisses all information regarding the intermediate returns within the interval  . This is problematic, because positions are typically managed according to profit taking and stop-loss levels. In the particular case of stop losses, those levels may be self-imposed by the portfolio manager, or enforced by the risk department. Accordingly, fixed-horizon labels may not be representative of the outcome of a real investment.
. This is problematic, because positions are typically managed according to profit taking and stop-loss levels. In the particular case of stop losses, those levels may be self-imposed by the portfolio manager, or enforced by the risk department. Accordingly, fixed-horizon labels may not be representative of the outcome of a real investment.
A third concern of the fixed-horizon method is that investors are rarely interested in forecasting whether a return will exceed a threshold  at a precise point in time
at a precise point in time  . It would be more practical to predict the side of the next absolute return that exceeds a threshold
. It would be more practical to predict the side of the next absolute return that exceeds a threshold  within a maximum horizon h. The following method deals with these three concerns.
within a maximum horizon h. The following method deals with these three concerns.
5.3 Triple-Barrier Method
In financial applications, a more realistic method is to make labels reflect the success or failure of a position. A typical trading rule adopted by portfolio managers is to hold a position until the first of three possible outcomes occurs: (1) the unrealized profit target is achieved, and the position is closed with success; (2) the unrealized loss limit is reached, and the position is closed with failure; (3) the position is held beyond a maximum number of bars, and the position is closed without neither failure nor success. In a time plot of position performance, the first two conditions define two horizontal barriers, and the third condition defines a vertical barrier. The index of the bar associated with the first touched barrier is recorded as  . When the profit-taking barrier is touched first, we label the observation as
. When the profit-taking barrier is touched first, we label the observation as  . When the stop-loss barrier is touched first, we label the observation as
. When the stop-loss barrier is touched first, we label the observation as  . When the vertical barrier is touched first, we have two options: we can either label it
. When the vertical barrier is touched first, we have two options: we can either label it  , or we can label it
, or we can label it  . See Reference López de PradoLópez de Prado (2018a) for code snippets that implement the triple-barrier method in python.
. See Reference López de PradoLópez de Prado (2018a) for code snippets that implement the triple-barrier method in python.
Setting profit taking and stop-loss barriers requires knowledge of the position side associated with the ith observation. When the position side is unknown, we can still set horizontal barriers as a function of the volatility predicted over the interval of bars  , where h is the number of bars until the vertical barrier is touched. In this case, the barriers will be symmetric, because without side information we cannot know which barrier means profit and which barrier means loss.
, where h is the number of bars until the vertical barrier is touched. In this case, the barriers will be symmetric, because without side information we cannot know which barrier means profit and which barrier means loss.
A key advantage of the triple-barrier method over the fixed-horizon method is that the former incorporates information about the path spanning the interval of bars  . In practice, the maximum holding period of an investment opportunity can be defined naturally, and the value of h is not subjective. One disadvantage is that touching a barrier is a discrete event, which may or may not occur by a thin margin. This caveat is addressed by the following method.
. In practice, the maximum holding period of an investment opportunity can be defined naturally, and the value of h is not subjective. One disadvantage is that touching a barrier is a discrete event, which may or may not occur by a thin margin. This caveat is addressed by the following method.
5.4 Trend-Scanning Method
In this section we introduce a new labeling method that does not require defining h or profit-taking or stop-loss barriers. The general idea is to identify trends and let them run for as long and as far as they may persist, without setting any barriers.Footnote 14 In order to accomplish that, first we need to define what constitutes a trend.
Consider a series of observations  , where
, where  may represent the price of a security we aim to predict. We wish to assign a label
may represent the price of a security we aim to predict. We wish to assign a label  to every observation in
to every observation in  , based on whether
, based on whether  is part of a downtrend, no-trend, or an uptrend. One possibility is to compute the t-value (
is part of a downtrend, no-trend, or an uptrend. One possibility is to compute the t-value ( ) associated with the estimated regressor coefficient (
) associated with the estimated regressor coefficient ( ) in a linear time-trend model,
) in a linear time-trend model,
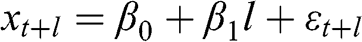
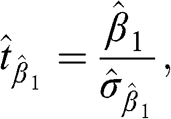
where  is the standard error of
is the standard error of  , and
, and  , and L sets the look-forward period. Code Snippet 5.1 computes this t-value on the sample determined by L.
, and L sets the look-forward period. Code Snippet 5.1 computes this t-value on the sample determined by L.
Snippet 5.1 t-Value of a Linear Trend
import statsmodels.api as sm1 #------------------------------------------------------------------------------ def tValLinR(close): # tValue from a linear trend x=np.ones((close.shape[0],2)) x[:,1]=np.arange(close.shape[0]) ols=sm1.OLS(close,x).fit() return ols.tvalues[1]
Different values of L lead to different t-values. To solve this indetermination, we can try a set of alternative values for L, and pick the value of L that maximizes  . In this way, we label
. In this way, we label  according to the most statistically significant trend observed in the future, out of multiple possible look-forward periods. Code Snippet 5.2 implements this procedure in python. The arguments are molecule, which is the index of observations we wish to label; close, which is the time series of
according to the most statistically significant trend observed in the future, out of multiple possible look-forward periods. Code Snippet 5.2 implements this procedure in python. The arguments are molecule, which is the index of observations we wish to label; close, which is the time series of  ; and span, which is the set of values of L that the algorithm will evaluate, in search for the maximum absolute t-value. The output is a data frame where the index is the timestamp of the
; and span, which is the set of values of L that the algorithm will evaluate, in search for the maximum absolute t-value. The output is a data frame where the index is the timestamp of the  , column t1 reports the timestamp of the farthest observation used to find the most significant trend, column tVal reports the t-value associated with the most significant linear trend among the set of evaluated look-forward periods, and column bin is the label (
, column t1 reports the timestamp of the farthest observation used to find the most significant trend, column tVal reports the t-value associated with the most significant linear trend among the set of evaluated look-forward periods, and column bin is the label ( ).
).
Snippet 5.2 Implementation of the Trend-Scanning Method
def getBinsFromTrend(molecule,close,span): ’’’ Derive labels from the sign of t-value of linear trend Output includes: - t1: End time for the identified trend - tVal: t-value associated with the estimated trend coefficient - bin: Sign of the trend ’’’ out=pd.DataFrame(index=molecule,columns=[’t1’,’tVal’,’bin’]) hrzns=xrange(*span) for dt0 in molecule: df0=pd.Series() iloc0=close.index.get_loc(dt0) if iloc0+max(hrzns)>close.shape[0]:continue for hrzn in hrzns: dt1=close.index[iloc0+hrzn-1] df1=close.loc[dt0:dt1] df0.loc[dt1]=tValLinR(df1.values) dt1=df0.replace([-np.inf,np.inf,np.nan],0).abs().idxmax() out.loc[dt0,[’t1’,’tVal’,’bin’]]=df0.index[-1],df0[dt1], np.sign(df0[dt1]) # prevent leakage out[’t1’]=pd.to_datetime(out[’t1’]) out[’bin’]=pd.to_numeric(out[’bin’],downcast=’signed’) return out.dropna(subset=[’bin’])
Trend-scanning labels are often intuitive, and can be used in classification as well as regression problems. We present an example in the experimental results section.
5.5 Meta-labeling
A common occurrence in finance is that we know whether we want to buy or sell a particular security, however we are less certain about how much we should bet. A model that determines a position’s side may not be the best one to determine that position’s size. Perhaps the size should be a function of the recent performance of the model, whereas that recent performance is irrelevant to forecast the position’s side.
Having a good bet-sizing model is extremely important. Consider an investment strategy with a precision of 60% and a recall of 90%. A 90% recall means that the strategy predicts ninety out of one hundred true investment opportunities. A 60% precision means that out of one hundred predicted opportunities, sixty are true. Such strategy will lose money if bet sizes are small on the sixty true positives and large on the forty false positives. As investors, we have no (legitimate) control over prices, and the key decision we can and must make is to size bets properly.
Meta-labeling is useful for avoiding or at least reducing an investor’s exposure to false positives. It achieves that by giving up some recall in exchange for higher precision. In the example above, adding a meta-labeling layer may result in a recall of 70% and a precision of 70%, hence improving the model’s F1-score (the harmonic average of precision and recall). See Reference López de PradoLópez de Prado (2018a) for a python implementation of meta-labeling.
The goal of meta-labeling is to train a secondary model on the prediction outcomes of a primary model, where losses are labeled as “ ” and gains are labeled as “
” and gains are labeled as “ .” Therefore, the secondary model does not predict the side. Instead, the secondary model predicts whether the primary model will succeed or fail at a particular prediction (a meta-prediction). The probability associated with a “
.” Therefore, the secondary model does not predict the side. Instead, the secondary model predicts whether the primary model will succeed or fail at a particular prediction (a meta-prediction). The probability associated with a “ ” prediction can then be used to size the position, as explained next.
” prediction can then be used to size the position, as explained next.
5.5.1 Bet Sizing by Expected Sharpe Ratio
Let p be the expected probability that the opportunity yields a profit  , and
, and  the expected probability that the opportunity yields a profit
the expected probability that the opportunity yields a profit  (i.e., a loss), for some symmetric payoff of magnitude
(i.e., a loss), for some symmetric payoff of magnitude  . The expected profit from the opportunity is
. The expected profit from the opportunity is  . The expected variance from the opportunity is
. The expected variance from the opportunity is  . The Sharpe ratio associated with the opportunity can therefore be estimated as
. The Sharpe ratio associated with the opportunity can therefore be estimated as

with  . Assuming that the Sharpe ratio of opportunities follows a standard Gaussian distribution, we may derive the bet size as
. Assuming that the Sharpe ratio of opportunities follows a standard Gaussian distribution, we may derive the bet size as  , where
, where  is the cumulative distribution function of the standard Gaussian, and
is the cumulative distribution function of the standard Gaussian, and  follows a uniform distribution.
follows a uniform distribution.
5.5.2 Ensemble Bet Sizing
Consider n meta-labeling classifiers that make a binary prediction on whether an opportunity will be profitable or not,  ,
,  . The true probability of being profitable is p, and predictions
. The true probability of being profitable is p, and predictions  are drawn from a Bernoulli distribution, so
are drawn from a Bernoulli distribution, so  , where
, where  is a binomial distribution of n trials with probability p. Assuming that the predictions are independent and identically distributed, the de Moivre–Laplace theorem states that the distribution of
is a binomial distribution of n trials with probability p. Assuming that the predictions are independent and identically distributed, the de Moivre–Laplace theorem states that the distribution of  converges to a Gaussian with mean
converges to a Gaussian with mean  and variance
and variance  as
as  . Accordingly,
. Accordingly,  , which is a particular case of the Lindeberg–Lévy theorem.
, which is a particular case of the Lindeberg–Lévy theorem.
Let us denote as  the average prediction across the n meta-labeling classifiers,
the average prediction across the n meta-labeling classifiers,  . The standard deviation associated with
. The standard deviation associated with  is
is  . Subject to the null hypothesis
. Subject to the null hypothesis  , the statistic
, the statistic  , with
, with  , follows a t-student distribution with
, follows a t-student distribution with  degrees of freedom. We may derive the bet size as
degrees of freedom. We may derive the bet size as  , where
, where  is the cumulative distribution function of the t-student with
is the cumulative distribution function of the t-student with  degrees of freedom, and
degrees of freedom, and  follows a uniform distribution.
follows a uniform distribution.
5.6 Experimental Results
In this section, we demonstrate how labels can be generated using the trend-scanning method. Code Snippet 5.3 generates a Gaussian random walk, to which we add a sine trend, to force some inflection points. In that way, we create concave and convex segments that should make the determination of trends more difficult. We then call the getBinsFromTrend function, to retrieve the trend horizons, t-values, and labels.
Snippet 5.3 Testing the Trend-Scanning Labeling Algorithm
df0=pd.Series(np.random.normal(0,.1,100)).cumsum() df0+=np.sin(np.linspace(0,10,df0.shape[0])) df1=getBinsFromTrend(df0.index,df0,[3,10,1]) mpl.scatter(df1.index,df0.loc[df1.index].values,c=df1[’bin’].values, cmap=’viridis’) mpl.savefig(’fig 5.1.png’);mpl.clf();mpl.close() mpl.scatter(df1.index,df0.loc[df1.index].values,c=c,cmap=’viridis’)
Figure 5.1 plots a Gaussian random walk with trend, where the colors differentiate four clearly distinct trends, with  labels plotted in yellow and
labels plotted in yellow and  labels plotted in violet. These binary labels, although appropriate for classification problems, omit information about the strength of the trend.
labels plotted in violet. These binary labels, although appropriate for classification problems, omit information about the strength of the trend.
Figure 5.1 Example of trend-scanning labels.
To correct for that omission, Figure 5.2 plots the same Gaussian random walk with trend, where the colors indicate the magnitude of the t-value. Highly positive t-values are plotted in yellow, and highly negative t-values are plotted in violet. Positive values close to zero are plotted in green, and negative values close to zero are plotted in blue. This information could be used in regression models, or as sample weights in classification problems.
Figure 5.2 Example of trend-scanning t-values.
5.7 Conclusions
In this section, we have presented four alternative labeling methods that can be useful in financial applications. The fixed-horizon method, although implemented in most financial studies, suffers from multiple limitations. Among these limitations, we listed that the distribution of fixed-horizon labels may not be stationary, that these labels dismiss path information, and that it would be more practical to predict the side of the next absolute return that exceeds a given threshold.
The triple-barrier method answers these concerns by simulating the outcome of a trading rule. One disadvantage is that touching a barrier is a discrete event, which may or may not occur by a thin margin. To address that, the trend-scanning method determines the side of the strongest linear trend among alternative look-forward periods, with its associated p-value. Trend-scanning labels are often intuitive, and can be used in classification as well as regression problems. Finally, the meta-labeling method is useful in applications where the side of a position is predetermined, and we are only interested in learning the size. A proper sizing method can help improve a strategy’s performance, by giving up some of the recall in exchange for higher precision.
5.8 Exercises
1 Given a time series of E-mini S&P 500 futures, compute labels on one-minute time bars using the fixed-horizon method, where τ is set at two standard deviations of one-minute returns.
a Compute the overall distribution of the labels.
b Compute the distribution of labels across all days, for each hour of the trading session.
c How different are the distributions in (b) relative to the distribution in (a)? Why?
2 Repeat Exercise 1, where this time you label standardized returns (instead of raw returns), where the standardization is based on mean and variance estimates from a lookback of one hour. Do you reach a different conclusion?
3 Repeat Exercise 1, where this time you apply the triple-barrier method on volume bars. The maximum holding period is the average number of bars per day, and the horizontal barriers are set at two standard deviations of bar returns. How do results compare to the solutions from Exercises 1 and 2?
4 Repeat Exercise 1, where this time you apply the trend-scanning method, with look-forward periods of up to one day. How do results compare to the solutions from Exercises 1, 2, and 3?
5 Using the labels generated in Exercise 3 (triple-barrier method):
a Fit a random forest classifier on those labels. Use as features estimates of mean return, volatility, skewness, kurtosis, and various differences in moving averages.
b Backtest those predictions using as a trading rule the same rule used to generate the labels.
c Apply meta-labeling on the backtest results.
d Refit the random forest on meta-labels, adding as a feature the label predicted in (a).
e Size (a) bets according to predictions in (d), and recompute the backtest.
6 Feature Importance Analysis
6.1 Motivation
Imagine that you are given ten puzzles, each of a thousand pieces, where all of the pieces have been shuffled into the same box. You are asked to solve one particular puzzle out of the ten. A reasonable way to proceed is to divide your task into two steps. In the first step, you try to isolate the one thousand pieces that are important to your problem, and discard the nine thousands pieces that are irrelevant. For example, you may notice that about one tenth of the pieces are made of plastic, and the rest are made of paper. Regardless of the pattern shown on the pieces, you know that discarding all paper pieces will isolate a single puzzle. In the second step, you try to fit a structure on the one thousand pieces that you have isolated. Now you may make a guess of what the pattern is, and organize the pieces around it.
Now consider a researcher interested in modeling a dynamic system as a function of many different candidate explanatory variables. Only a small subset of those candidate variables are expected to be relevant, however the researcher does not know in advance which. The approach generally followed in the financial literature is to try to fit a guessed algebraic function on a guessed subset of variables, and see which variables appear to be statistically significant (subject to that guessed algebraic function being correct, including all interaction effects among variables). Such an approach is counterintuitive and likely to miss important variables that would have been revealed by unexplored specifications. Instead, researchers could follow the same steps that they would apply to the problem of solving a puzzle: first, isolate the important variables, irrespective of any functional form, and only then try to fit those variables to a particular specification that is consistent with those isolated variables. ML techniques allow us to disentangle the specification search from the variable search.
In this section, we demonstrate that ML provides intuitive and effective tools for researchers who work on the development of theories. Our exposition runs counter to the popular myth that supervised ML models are black-boxes. According to that view, supervised ML algorithms find predictive patterns, however researchers have no understanding of those findings. In other words, the algorithm has learned something, not the researcher. This criticism is unwarranted.
Even if a supervised ML algorithm does not yield a closed-form algebraic solution (like, for example, a regression method would do), an analysis of its forecasts can tell us what variables are critically involved in a particular phenomenon, what variables are redundant, what variables are useless, and how the relevant variables interact with each other. This kind of analysis is known as “feature importance,” and harnessing its power will require us to use everything we have learned in the previous sections.
6.2 p-Values
The classical regression framework makes a number of assumptions regarding the fitted model, such as correct model specification, mutually uncorrelated regressors, or white noise residuals. Conditional on those assumptions being true, researchers aim to determine the importance of an explanatory variable through a hypothesis test.Footnote 15 A popular way of expressing a variable’s significance is through its p-value, a concept that dates back to the 1700s (Reference Brian and JaissonBrian and Jaisson 2007). The p-value quantifies the probability that, if the true coefficient associated with that variable is zero, we could have obtained a result equal or more extreme than the one we have estimated. It indicates how incompatible the data are with a specified statistical model. However, a p-value does not measure the probability that neither the null nor the alternative hypothesis is true, or that the data are random. And a p-value does not measure the size of an effect, or the significance of a result.Footnote 16 The misuse of p-values is so widespread that the American Statistical Association has discouraged their application going forward as a measure of statistical significance (Reference Wasserstein, Schirm and LazarWasserstein et al. 2019). This casts a doubt over decades of empirical research in Finance. In order to search for alternatives to the p-value, first we must understand its pitfalls.
6.2.1 A Few Caveats of p-Values
A first caveat of p-values is that they rely on the strong assumptions outlined earlier. When those assumptions are inaccurate, a p-value could be low even though the true value of the coefficient is zero (a false positive), and the p-value could be high even though the true value of the coefficient is not zero (a false negative).
A second caveat of p-values is that, for highly multicollinear (mutually correlated) explanatory variables, p-values cannot be robustly estimated. In multicollinear systems, traditional regression methods cannot discriminate among redundant explanatory variables, leading to substitution effects between related p-values.
A third caveat of p-values is that they evaluate a probability that is not entirely relevant. Given a null hypothesis  and an estimated coefficient
and an estimated coefficient  , the p-value estimates the probability of obtaining a result equal or more extreme than
, the p-value estimates the probability of obtaining a result equal or more extreme than  , subject to
, subject to  being true. However, researchers are often more interested in a different probability, namely, the probability of
being true. However, researchers are often more interested in a different probability, namely, the probability of  being true, subject to having observed
being true, subject to having observed  . This probability can be computed using Bayes theorem, alas at the expense of making additional assumptions (Bayesian priors).Footnote 17
. This probability can be computed using Bayes theorem, alas at the expense of making additional assumptions (Bayesian priors).Footnote 17
A fourth caveat of p-values is that it assesses significance in-sample. The entire sample is used to solve two tasks: estimating the coefficients and determining their significance. Accordingly, p-values may be low (i.e., significant) for variables that have no out-of-sample explanatory (i.e., forecasting) value. Running multiple in-sample tests on the same data set is likely to produce a false discovery, a practice known as p-hacking.
In summary, p-values require that we make many assumptions (caveat #1) in order to produce a noisy estimate (caveat #2) of a probability that we do not really need (caveat #3), and that may not be generalizable out-of-sample (caveat #4). These are not superfluous concerns. In theory, a key advantage of classical methods is that they provide a transparent attribution of significance among explanatory variables. But since that classical attribution has so many caveats in practice, perhaps classical methods could use some help from modern computational techniques that overcome those caveats.
6.2.2 A Numerical Example
Consider a binary random classification problem composed of forty features, where five are informative, thirty are redundant, and five are noise. Code Snippet 6.1 implements function getTestData, which generates informative, redundant, and noisy features. Informative features (marked with the “I_” prefix) are those used to generate labels. Redundant features (marked with the “R_” prefix) are those that are formed by adding Gaussian noise to a randomly chosen informative feature (the lower the value of sigmaStd, the greater the substitution effect). Noise features (marked with the “N_” prefix) are those that are not used to generate labels.
Snippet 6.1 Generating a Set of Informed, Redundant, and Noise Explanatory Variables
def getTestData(n_features=100,n_informative=25,n_redundant=25, n_samples=10000,random_state=0,sigmaStd=.0): # generate a random dataset for a classification problem from sklearn.datasets import make_classification np.random.seed(random_state) X,y=make_classification(n_samples=n_samples, n_features=n_features-n_redundant, n_informative=n_informative,n_redundant=0,shuffle=False, random_state=random_state) cols=[‘I_’+str(i) for i in xrange(n_informative)] cols+=[‘N_’+str(i) for i in xrange(n_features-n_informative- \ n_redundant)] X,y=pd.DataFrame(X,columns=cols),pd.Series(y) i=np.random.choice(xrange(n_informative),size=n_redundant) for k,j in enumerate(i): X[‘R_’+str(k)]=X[‘I_’+str(j)]+np.random.normal(size= \ X.shape[0])*sigmaStd return X,y #------------------------------------------------------------------------------ import numpy as np,pandas as pd,seaborn as sns import statsmodels.discrete.discrete_model as sm X,y=getTestData(40,5,30,10000,sigmaStd=.1) ols=sm.Logit(y,X).fit()
Figure 6.1 plots the p-values that result from a logit regression on those features. The horizontal bars report the p-values, and the vertical dashed line marks the 5% significance level. Only four out of the thirty-five nonnoise features are deemed statistically significant: I_1, R_29, R_27, I_3. Noise features are ranked as relatively important (with positions 9, 11, 14, 18, and 26). Fourteen of the features ranked as least important are not noise. In short, these p-values misrepresent the ground truth, for the reasons explained earlier.
Figure 6.1 p-Values computed on a set of explanatory variables.
Unfortunately, financial data sets tend to be highly multicollinear, as a result of common risk factors shared by large portions of the investment universe: market, sector, rating, value, momentum, quality, duration, etc. Under these circumstances, financial researchers should cease to rely exclusively on p-values. It is important for financial researchers to become familiar with additional methods to determine what variables contain information in a particular phenomenon.
6.3 Feature Importance
In this section, we study how two of ML’s feature importance methods address the caveats of p-values, with minimal assumptions, using computational techniques. Other examples of ML interpretability methods are accumulated local effects (Reference ApleyApley 2016) and Shapley values (Štrumbelj 2014).
6.3.1 Mean-Decrease Impurity
Suppose that you have a learning sample of size N, composed of F features,  and one label per observation. A tree-based classification (or regression) algorithm splits at each node t its labels into two samples: for a given feature
and one label per observation. A tree-based classification (or regression) algorithm splits at each node t its labels into two samples: for a given feature  , labels in node t associated with a
, labels in node t associated with a  below a threshold
below a threshold  are placed in the left sample, and the rest are placed in the right sample. For each of these samples, we can evaluate their impurity as the entropy of the distribution of labels, as the Gini index, or following some other criterion. Intuitively, a sample is purest when it contains only labels of one kind, and it is most impure when its labels follow a uniform distribution. The information gain that results from a split is measured in terms of the resulting reduction in impurity,
are placed in the left sample, and the rest are placed in the right sample. For each of these samples, we can evaluate their impurity as the entropy of the distribution of labels, as the Gini index, or following some other criterion. Intuitively, a sample is purest when it contains only labels of one kind, and it is most impure when its labels follow a uniform distribution. The information gain that results from a split is measured in terms of the resulting reduction in impurity,

where  is the impurity of labels at node t (before the split),
is the impurity of labels at node t (before the split),  is the impurity of labels in the left sample, and
is the impurity of labels in the left sample, and  is the impurity of labels in the right sample. At each node t, the classification algorithm evaluates
is the impurity of labels in the right sample. At each node t, the classification algorithm evaluates  for various features in
for various features in  , determines the optimal threshold
, determines the optimal threshold  that maximizes
that maximizes  for each of them, and selects the feature f associated with greatest
for each of them, and selects the feature f associated with greatest  . The classification algorithm continues splitting the samples further until no additional information gains can be produced, or some early-stopping condition is met, such as achieving an impurity below the maximum acceptable limit.
. The classification algorithm continues splitting the samples further until no additional information gains can be produced, or some early-stopping condition is met, such as achieving an impurity below the maximum acceptable limit.
The importance of a feature can be computed as the weighted information gain ( ) across all nodes where that feature was selected. This tree-based feature importance concept, introduced by Reference BreimanBreiman (2001), is known as mean-decrease impurity (MDI). By construction, the MDI value associated with each feature is bounded between 0 and 1, and all combined add up to 1. In the presence of F features where all are uninformative (or equally informed), each MDI value is expected to be
) across all nodes where that feature was selected. This tree-based feature importance concept, introduced by Reference BreimanBreiman (2001), is known as mean-decrease impurity (MDI). By construction, the MDI value associated with each feature is bounded between 0 and 1, and all combined add up to 1. In the presence of F features where all are uninformative (or equally informed), each MDI value is expected to be  . For algorithms that combine ensembles of trees, like random forests, we can further estimate the mean and variance of MDI values for each feature across all trees. These mean and variance estimates, along with the central limit theorem, are useful in testing the significance of a feature against a user-defined null hypothesis. Code Snippet 6.2 implements an ensemble MDI procedure. See Reference López de PradoLópez de Prado (2018a) for practical advice on how to use MDI.
. For algorithms that combine ensembles of trees, like random forests, we can further estimate the mean and variance of MDI values for each feature across all trees. These mean and variance estimates, along with the central limit theorem, are useful in testing the significance of a feature against a user-defined null hypothesis. Code Snippet 6.2 implements an ensemble MDI procedure. See Reference López de PradoLópez de Prado (2018a) for practical advice on how to use MDI.
Snippet 6.2 Implementation of an Ensemble MDI Method
def featImpMDI(fit,featNames):
# feat importance based on IS mean impurity reduction
df0={i:tree.feature_importances_ for i,tree in \
enumerate(fit.estimators_)}
df0=pd.DataFrame.from_dict(df0,orient=‘index’)
df0.columns=featNames
df0=df0.replace(0,np.nan) # because max_features=1
imp=pd.concat({‘mean’:df0.mean(),
‘std’:df0.std()*df0.shape[0]**-.5},axis=1) # CLT
imp/=imp[‘mean’].sum()
return imp
#------------------------------------------------------------------------------
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
X,y=getTestData(40,5,30,10000,sigmaStd=.1)
clf=DecisionTreeClassifier(criterion=‘entropy’,max_features=1,
class_weight=‘balanced’,min_weight_fraction_leaf=0)
clf=BaggingClassifier(base_estimator=clf,n_estimators=1000,
max_features=1.,max_samples=1.,oob_score=False)
fit=clf.fit(X,y)
imp=featImpMDI(fit,featNames=X.columns)Figure 6.2 plots the result of applying MDI to the same random classification problem discussed in Figure 6.1. The horizontal bars indicate the mean of MDI values across 1,000 trees in a random forest, and the lines indicate the standard deviation around that mean. The more trees we add to the forest, the smaller becomes the standard deviation around the mean. MDI does a good job, in the sense that all of the nonnoisy features (either informed or redundant) are ranked higher than the noise features. Still, a small number of nonnoisy features appear to be much more important than their peers. This is the kind of substitution effects that we anticipated to find in the presence of redundant features. Section 6.5 proposes a solution to this particular concern.
Figure 6.2 Example of MDI results.
Out of the four caveats of p-values, the MDI method deals with three: (1) MDI’s computational nature circumvents the need for strong distributional assumptions that could be false (caveat #1) – we are not imposing a particular tree structure or algebraic specification, or relying on stochastic or distributional characteristics of residuals. (2) Whereas betas are estimated on a single sample, ensemble MDIs are derived from a bootstrap of trees. Accordingly, the variance of MDI estimates can be reduced by increasing the number of trees in ensemble methods in general, or in a random forest in particular (caveat 2). This reduces the probability of false positives caused by overfitting. Also, unlike p-values, MDI’s estimation does not require the inversion of a possibly ill-conditioned matrix. (3) The goal of the tree-based classifiers is not to estimate the coefficients of a given algebraic equation, thus estimating the probability of a particular null hypothesis is irrelevant. In other words, MDI corrects for caveat 3 by finding the important features in general, irrespective of any particular parametric specification.
An ensemble estimate of MDI will exhibit low variance given a sufficient number of trees, hence reducing the concern of p-hacking. But still, the procedure itself does not involve cross-validation. Therefore, the one caveat of p-values that MDI does not fully solve is that MDI is also computed in-sample (caveat #4). To confront this final caveat, we need to introduce the concept of mean-decrease accuracy.
6.3.2 Mean-Decrease Accuracy
A disadvantage of both p-values and MDI is that a variable that appears to be significant for explanatory purposes (in-sample) may be irrelevant for forecasting purposes (out-of-sample). To solve this problem (caveat #4), Reference BreimanBreiman (2001) introduced the mean-decrease accuracy (MDA) method.Footnote 18 MDA works as follows: first, it fits a model and computes its cross-validated performance; second, it computes the cross-validated performance of the same fitted model, with the only difference that it shuffles the observations associated with one of the features. That gives us one modified cross-validated performance per feature. Third, it derives the MDA associated with a particular feature by comparing the cross-validated performance before and after shuffling. If the feature is important, there should be a significant decay in performance caused by the shuffling, as long as the features are independent. An important attribute of MDA is that, like ensemble MDIs, it is not the result of a single estimate, but rather the average of multiple estimates (one for each testing set in a k-fold cross-validation).
When features are not independent, MDA may underestimate the importance of interrelated features. At the extreme, given two highly important but identical features, MDA may conclude that both features are relatively unimportant, because the effect of shuffling one may be partially compensated by not shuffling the other. We address this concern in Section 6.5.
MDA values are not bounded, and shuffling a feature could potentially improve the cross-validated performance, when the feature is uninformative to the point of being detrimental. Because MDA involves a cross-validation step, this method can be computationally expensive. Code Snippet 6.3 implements MDA. See Reference López de PradoLópez de Prado (2018a) for practical advice on how to use MDA.
Snippet 6.3 Implementation of MDA
def featImpMDA(clf,X,y,n_splits=10):
# feat importance based on OOS score reduction
from sklearn.metrics import log_loss
from sklearn.model_selection._split import KFold
cvGen=KFold(n_splits=n_splits)
scr0,scr1=pd.Series(),pd.DataFrame(columns=X.columns)
for i,(train,test) in enumerate(cvGen.split(X=X)):
X0,y0=X.iloc[train,:],y.iloc[train]
X1,y1=X.iloc[test,:],y.iloc[test]
fit=clf.fit(X=X0,y=y0) # the fit occurs here
prob=fit.predict_proba(X1) # prediction before shuffling
scr0.loc[i]=-log_loss(y1,prob,labels=clf.classes_)
for j in X.columns:
X1_=X1.copy(deep=True)
np.random.shuffle(X1_[j].values) # shuffle one column
prob=fit.predict_proba(X1_) # prediction after shuffling
scr1.loc[i,j]=-log_loss(y1,prob,labels=clf.classes_)
imp=(-1*scr1).add(scr0,axis=0)
imp=imp/(-1*scr1)
imp=pd.concat({‘mean’:imp.mean(),
‘std’:imp.std()*imp.shape[0]**-.5},axis=1) # CLT
return imp
#------------------------------------------------------------------------------
X,y=getTestData(40,5,30,10000,sigmaStd=.1)
clf=DecisionTreeClassifier(criterion=‘entropy’,max_features=1,
class_weight=‘balanced’,min_weight_fraction_leaf=0)
clf=BaggingClassifier(base_estimator=clf,n_estimators=1000,
max_features=1.,max_samples=1.,oob_score=False)
imp=featImpMDA(clf,X,y,10)Figure 6.3 plots the result of applying MDA to the same random classification problem we discussed in Figure 6.2. We can draw similar conclusions as we did in the MDI example. First, MDA does a good job overall at separating noise features from the rest. Noise features are ranked last. Second, noise features are also deemed unimportant in magnitude, with MDA values of essentially zero. Third, although substitution effects contribute to higher variances in MDA importance, none is high enough to question the importance of the nonnoisy features.
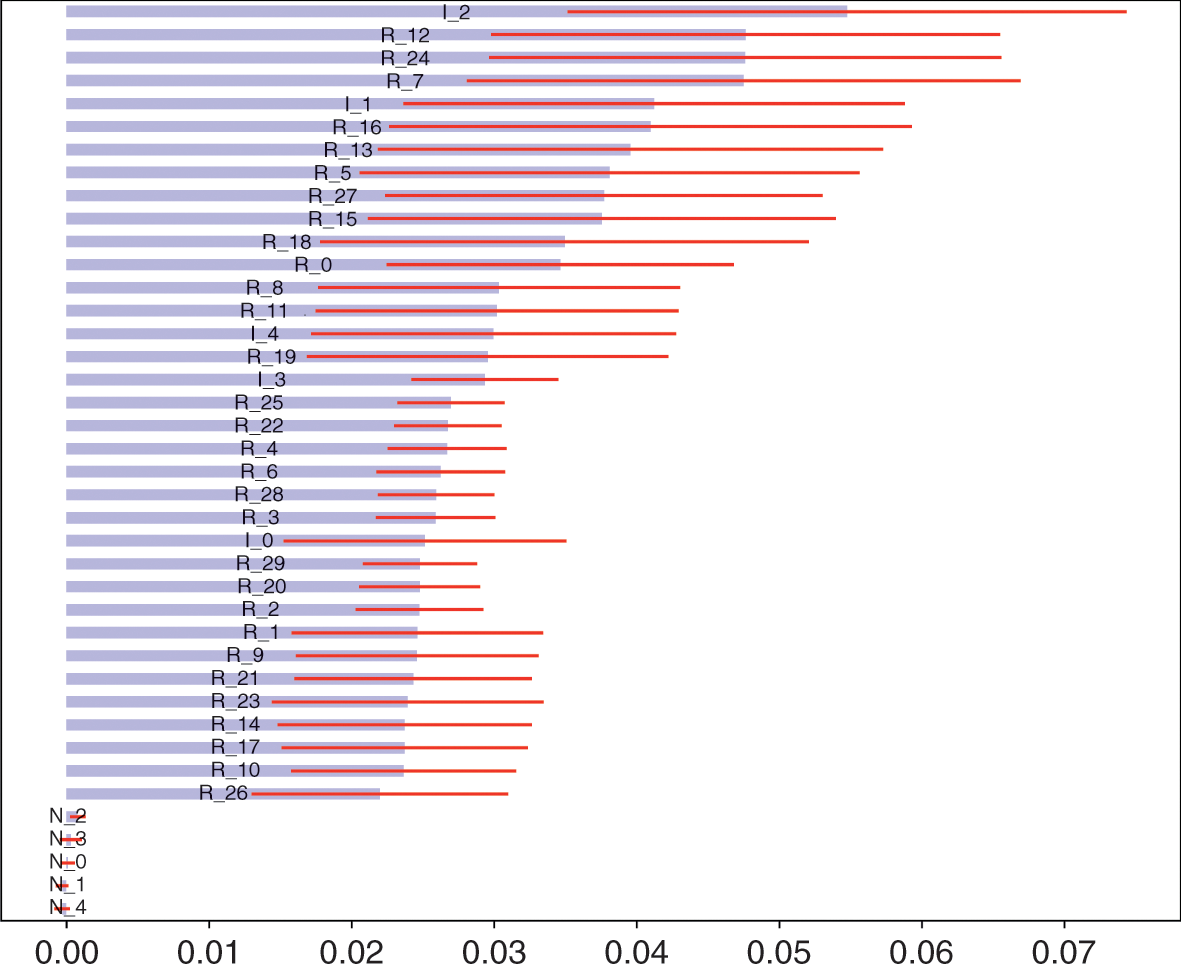
Figure 6.3 Example of MDA results.
Despite its name, MDA does not necessarily rely on accuracy to evaluate the cross-validated performance. MDA can be computed on other performance scores. In fact, in the particular case of finance, accuracy is not a particularly good choice. The reason is, accuracy scores a classifier in terms of its proportion of correct predictions. This has the disadvantage that probabilities are not taken into account. For example, a classifier may achieve high accuracy even though it made good predictions with low confidence and bad predictions with high confidence. In the following section, we introduce a scoring function that addresses this concern.
6.4 Probability-Weighted Accuracy
In financial applications, a good alternative to accuracy is log-loss (also known as cross-entropy loss). Log-loss scores a classifier in terms of the average log-likelihood of the true labels (for a formal definition, see section 9.4 of Reference López de PradoLópez de Prado 2018a). One disadvantage, however, is that log-loss scores are not easy to interpret and compare. A possible solution is to compute the negative average likelihood of the true labels (NegAL),
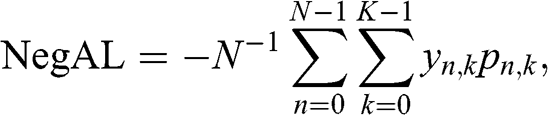
where  is the probability associated with prediction n of label k and
is the probability associated with prediction n of label k and  is an indicator function,
is an indicator function,  , where
, where  when observation n was assigned label k and
when observation n was assigned label k and  otherwise. This is very similar to log-loss, with the difference that it averages likelihoods rather than log-likelihoods, so that NegAL still ranges between 0 and 1.
otherwise. This is very similar to log-loss, with the difference that it averages likelihoods rather than log-likelihoods, so that NegAL still ranges between 0 and 1.
Alternatively, we can define the probability-weighted accuracy (PWA) as
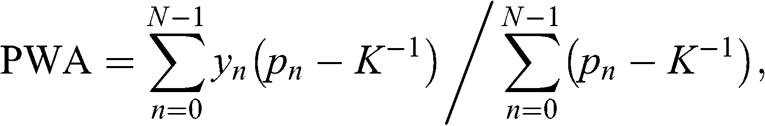
where  and
and  is an indicator function,
is an indicator function,  , where
, where  when the prediction was correct, and
when the prediction was correct, and  otherwise.Footnote 19 This is equivalent to standard accuracy when the classifier has absolute conviction in every prediction (
otherwise.Footnote 19 This is equivalent to standard accuracy when the classifier has absolute conviction in every prediction ( for all n). PWA punishes bad predictions made with high confidence more severely than accuracy, but less severely than log-loss.
for all n). PWA punishes bad predictions made with high confidence more severely than accuracy, but less severely than log-loss.
6.5 Substitution Effects
Substitution effects arise when two features share predictive information. Substitution effects can bias the results from feature importance methods. In the case of MDI, the importance of two identical features will be halved, as they are randomly chosen with equal probability. In the case of MDA, two identical features may be considered relatively unimportant, even if they are critical, because the effect of shuffling one may be compensated by the other.
6.5.1 Orthogonalization
When features are highly codependent, their importance cannot be adjudicated in a robust manner. Small changes in the observations may have a dramatic impact on their estimated importance. However, this impact is not random: given two highly codependent features, the drop in importance from one is compensated with the raise in importance of the other. In other words, codependence causes substitution effects when evaluating the importance of features.
One solution to multicollinearity is to apply PCA on the features, derive their orthogonal principal components, and then run MDI or MDA on those principal components (for additional details, see chapter 8 of Reference López de PradoLópez de Prado 2018a). Features orthogonalized in this way may be more resilient to substitution effects, with three caveats: (1) redundant features that result from nonlinear combinations of informative ones will still cause substitution effects; (2) the principal components may not have an intuitive explanation; (3) the principal components are defined by eigenvectors that do not necessarily maximize the model’s out-of-sample performance (Reference Witten, Shojaie and ZhangWitten et al. 2013).
6.5.2 Cluster Feature Importance
A better approach, which does not require a change of basis, is to cluster similar features and apply the feature importance analysis at the cluster level. By construction, clusters are mutually dissimilar, hence taming the substitution effects. Because the analysis is done on a partition of the features, without a change of basis, results are usually intuitive.
Let us introduce one algorithm that implements this idea. The clustered feature importance (CFI) algorithm involves two steps: (1) finding the number and constituents of the clusters of features; (2) applying the feature importance analysis on groups of similar features rather than on individual features.
Step 1: Features Clustering
First, we project the observed features into a metric space, resulting in a matrix  . To form this matrix, one possibility is to follow the correlation-based approach described in Section 4.4.1. Another possibility is to apply information-theoretic concepts (such as variation of information; see Section 3) to represent those features in a metric space. Information-theoretic metrics have the advantage of recognizing redundant features that are the result of nonlinear combinations of informative features.Footnote 20
. To form this matrix, one possibility is to follow the correlation-based approach described in Section 4.4.1. Another possibility is to apply information-theoretic concepts (such as variation of information; see Section 3) to represent those features in a metric space. Information-theoretic metrics have the advantage of recognizing redundant features that are the result of nonlinear combinations of informative features.Footnote 20
Second, we apply a procedure to determine the optimal number and composition of clusters, such as the ONC algorithm (see Section 4). Remember that ONC finds the optimal number of clusters as well as the composition of those clusters, where each feature belongs to one and only one cluster. Features that belong to the same cluster share a large amount of information, and features that belong to different clusters share only a relatively small amount of information.
Some silhouette scores may be low due one feature being a combination of multiple features across clusters. This is a problem, because ONC cannot assign one feature to multiple clusters. In this case, the following transformation may help reduce the multicollinearity of the system. For each cluster  , replace the features included in that cluster with residual features, where those residual features do not contain information from features outside cluster k. To be precise, let
, replace the features included in that cluster with residual features, where those residual features do not contain information from features outside cluster k. To be precise, let  be the subset of index features
be the subset of index features  included in cluster k, where
included in cluster k, where  ,
,  ;
;  ;
;  . Then, for a given feature
. Then, for a given feature  where
where  , we compute the residual feature
, we compute the residual feature  by fitting
by fitting

where  is the index of observations per feature. If the degrees of freedom in the above regression is too low, one option is to use as regressors linear combinations of the features within each cluster (e.g., following a minimum variance weighting scheme), so that only
is the index of observations per feature. If the degrees of freedom in the above regression is too low, one option is to use as regressors linear combinations of the features within each cluster (e.g., following a minimum variance weighting scheme), so that only  betas need to be estimated. One of the properties of OLS residuals is that they are orthogonal to the regressors. Thus, by replacing each feature
betas need to be estimated. One of the properties of OLS residuals is that they are orthogonal to the regressors. Thus, by replacing each feature  with its residual equivalent
with its residual equivalent  , we remove from cluster k information that is already included in other clusters, while preserving the information that exclusively belongs to cluster k. Again, this transformation is not necessary if the silhouette scores clearly indicate that features belong to their respective clusters.
, we remove from cluster k information that is already included in other clusters, while preserving the information that exclusively belongs to cluster k. Again, this transformation is not necessary if the silhouette scores clearly indicate that features belong to their respective clusters.
Step 2: Clustered Importance
Step 1 has identified the number and composition of the clusters of features. We can use this information to apply MDI and MDA on groups of similar features, rather than on individual features. In the following, we assume that a partitional algorithm has clustered the features, however this notion of clustered feature importance can be applied to hierarchical clusters as well.
Clustered MDI
As we saw in Section 6.3.1, the MDI of a feature is the weighted impurity reduction across all nodes where that feature was selected. We compute the clustered MDI as the sum of the MDI values of the features that constitute that cluster. If there is one feature per cluster, then MDI and clustered MDI are the same. In the case of an ensemble of trees, there is one clustered MDI for each tree, which allows us to compute the mean clustered MDI, and standard deviation around the mean clustered MDI, similarly to how we did for the feature MDI. Code Snippet 6.4 implements the procedure that estimates the clustered MDI.
Snippet 6.4 Clustered MDI
def groupMeanStd(df0,clstrs):
out=pd.DataFrame(columns=[‘mean’,‘std’])
for i,j in clstrs.iteritems():
df1=df0[j].sum(axis=1)
out.loc[‘C_’+str(i),‘mean’]=df1.mean()
out.loc[‘C_’+str(i),‘std’]=df1.std()*df1.shape[0]**-.5
return out
#------------------------------------------------------------------------------
def featImpMDI_Clustered(fit,featNames,clstrs):
df0={i:tree.feature_importances_ for i,tree in \
enumerate(fit.estimators_)}
df0=pd.DataFrame.from_dict(df0,orient=‘index’)
df0.columns=featNames
df0=df0.replace(0,np.nan) # because max_features=1
imp=groupMeanStd(df0,clstrs)
imp/=imp[‘mean’].sum()
return impClustered MDA
The MDA of a feature is computed by comparing the performance of an algorithm before and after shuffling that feature. When computing clustered MDA, instead of shuffling one feature at a time, we shuffle all of the features that constitute a given cluster. If there is one cluster per feature, then MDA and clustered MDA are the same. Code Snippet 6.5 implements the procedure that estimates the clustered MDA.
Snippet 6.5 Clustered MDA
def featImpMDA_Clustered(clf,X,y,clstrs,n_splits=10):
from sklearn.metrics import log_loss
from sklearn.model_selection._split import KFold
cvGen=KFold(n_splits=n_splits)
scr0,scr1=pd.Series(),pd.DataFrame(columns=clstrs.keys())
for i,(train,test) in enumerate(cvGen.split(X=X)):
X0,y0=X.iloc[train,:],y.iloc[train]
X1,y1=X.iloc[test,:],y.iloc[test]
fit=clf.fit(X=X0,y=y0)
prob=fit.predict_proba(X1)
scr0.loc[i]=-log_loss(y1,prob,labels=clf.classes_)
for j in scr1.columns:
X1_=X1.copy(deep=True)
for k in clstrs[j]:
np.random.shuffle(X1_[k].values) # shuffle cluster
prob=fit.predict_proba(X1_)
scr1.loc[i,j]=-log_loss(y1,prob,labels=clf.classes_)
imp=(-1*scr1).add(scr0,axis=0)
imp=imp/(-1*scr1)
imp=pd.concat({‘mean’:imp.mean(),
‘std’:imp.std()*imp.shape[0]**-.5},axis=1)
imp.index=[‘C_’+str(i) for i in imp.index]
return imp6.6 Experimental Results
In this experiment we are going to test the clustered MDI and MDA procedures on the same data set we used on the nonclustered versions of MDI and MDA (see Sections 6.3.1 and 6.3.2). That data set consisted of forty features, of which five were informative, thirty were redundant, and five were noise. First, we apply the ONC algorithm to the correlation matrix of those features.Footnote 21 In a nonexperimental setting, the researcher should denoise and detone the correlation matrix before clustering, as explained in Section 2. We do not do so in this experiment as a matter of testing the robustness of the method (results are expected to be better on a denoised and detoned correlation matrix).
Figure 6.4 shows that ONC correctly recognizes that there are six relevant clusters (one cluster for each informative feature, plus one cluster of noise features), and it assigns the redundant features to the cluster that contains the informative feature from which the redundant features were derived. Given the low correlation across clusters, there is no need to replace the features with their residuals (as proposed in Section 6.5.2.1). Code Snippet 6.6 implements this example.
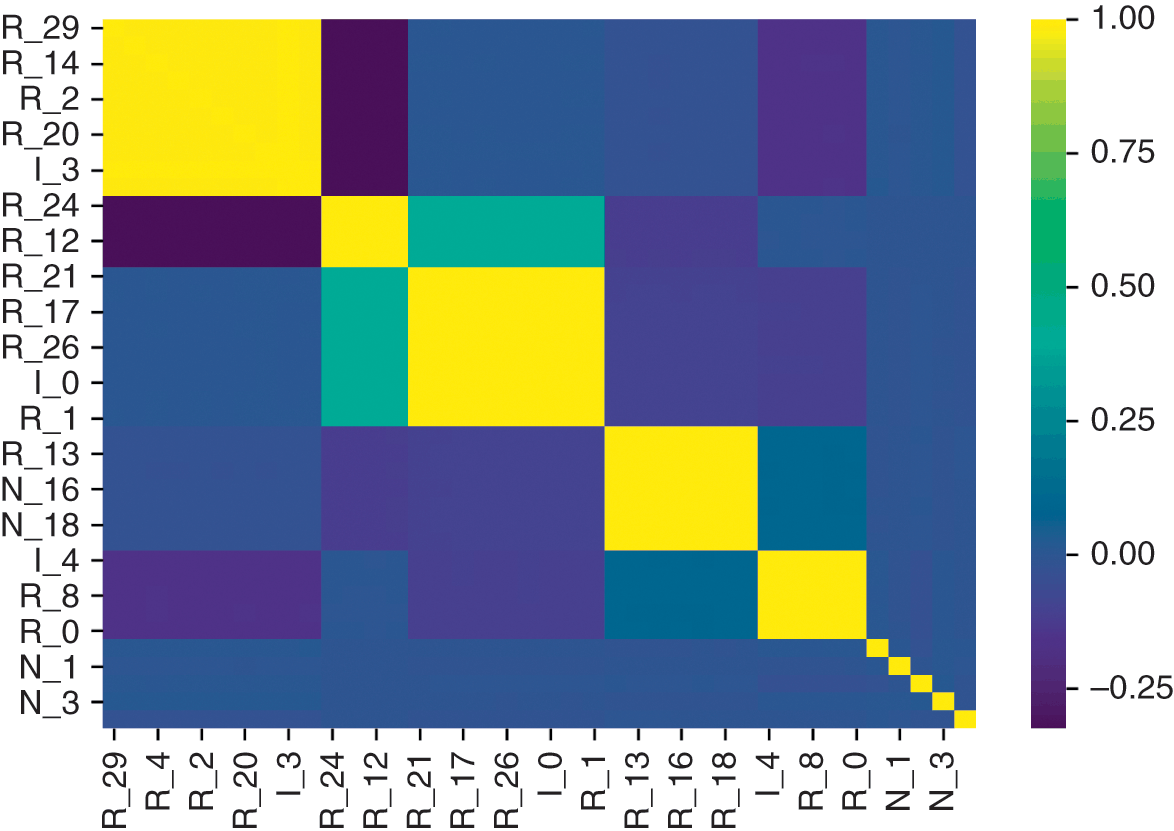
Figure 6.4 ONC clusters together with informative and redundant features.
Snippet 6.6 Features Clustering Step
X,y=getTestData(40,5,30,10000,sigmaStd=.1) corr0,clstrs,silh=clusterKMeansBase(X.corr(),maxNumClusters=10, n_init=10) sns.heatmap(corr0,cmap=‘viridis’)
Next, we apply our clustered MDI method on that data set. Figure 6.5 shows the clustered MDI output, which we can compare with the unclustered output reported in Figure 6.2. The “C_” prefix indicates the cluster, and “C_5” is the cluster associated with the noise features. Clustered features “C_1” is the second least important, however its importance is more than double the importance of “C_5.” This is in contrast with what we saw in Figure 6.2, where there was a small difference in importance between the noise features and some of the nonnoisy features. Thus, the clustered MDI method appears to work better than the standard MDI method. Code Snippet 6.7 shows how these results were computed.
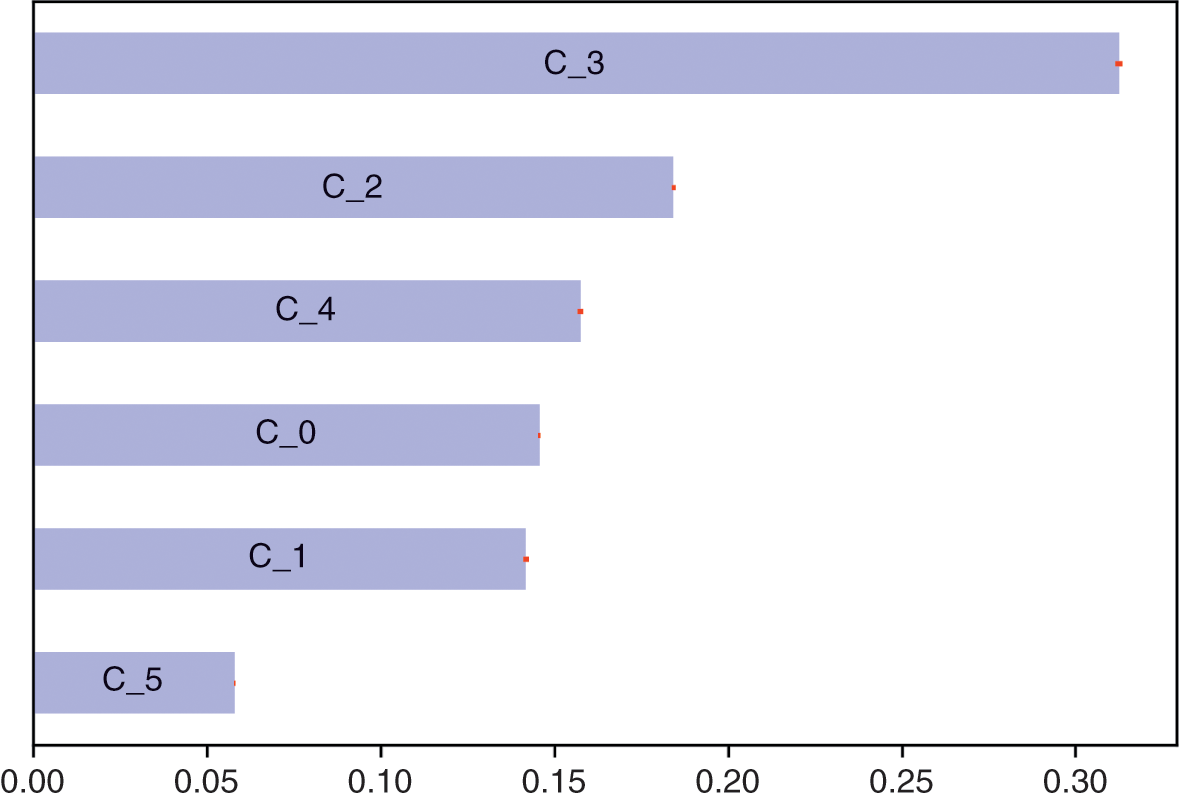
Figure 6.5 Clustered MDI.
Snippet 6.7 Calling the Functions for Clustered MDI
clf=DecisionTreeClassifier(criterion=‘entropy’,max_features=1, class_weight=‘balanced’,min_weight_fraction_leaf=0) clf=BaggingClassifier(base_estimator=clf,n_estimators=1000, max_features=1.,max_samples=1.,oob_score=False) fit=clf.fit(X,y) imp=featImpMDI_Clustered(fit,X.columns,clstrs)
Finally, we apply our clustered MDA method on that data set. Figure 6.6 shows the clustered MDA output, which we can compare with the unclustered output reported in Figure 6.3. Again, “C_5” is the cluster associated with the noise features, and all other clusters are associated with informative and redundant features. This analysis has reached two correct conclusions: (1) “C_5” has essentially zero importance, and should be discarded as irrelevant; and (2) all other clusters have very similar importance. This is in contrast with what we saw in Figure 6.3, where some nonnoise features appeared to be much more important than others, even after taking into consideration the standard derivation around the mean values. Code Snippet 6.8 shows how these results were computed.
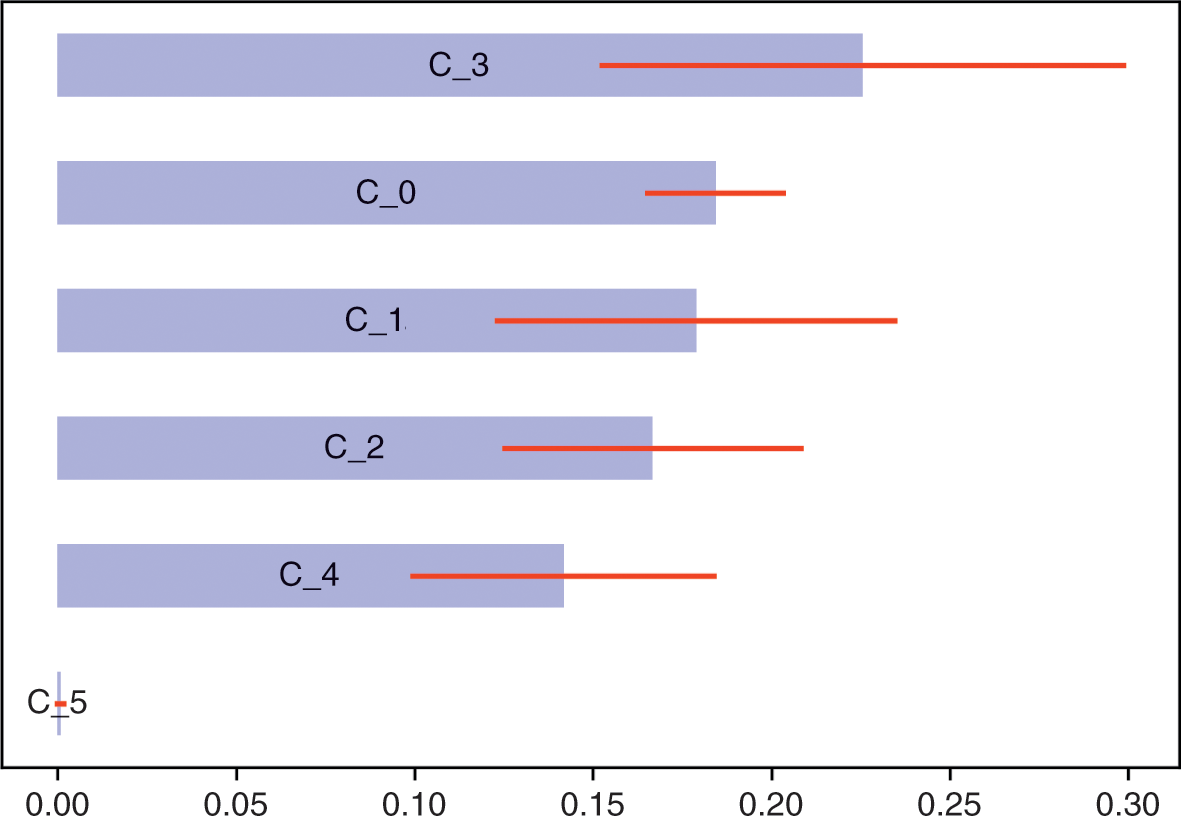
Figure 6.6 Clustered MDA.
Snippet 6.8 Calling the Functions for Clustered MDA
clf=DecisionTreeClassifier(criterion=‘entropy’,max_features=1, class_weight=‘balanced’,min_weight_fraction_leaf=0) clf=BaggingClassifier(base_estimator=clf,n_estimators=1000, max_features=1.,max_samples=1.,oob_score=False) imp=featImpMDA_Clustered(clf,X,y,clstrs,10)
6.7 Conclusions
Most researchers use p-values to evaluate the significance of explanatory variables. However, as we saw in this section, p-values suffer from four major flaws. ML offers feature importance methods that overcome most or all of those flaws. The MDI and MDA methods assess the importance of features robustly and without making strong assumptions about the distribution and structure of the data. Unlike p-values, MDA evaluates feature importance in cross-validated experiments. Furthermore, unlike p-values, clustered MDI and clustered MDA estimates effectively control for substitution effects. But perhaps the most salient advantage of MDI and MDA is that, unlike classical significance analyses, these ML techniques evaluate the importance of a feature irrespective of any particular specification. In doing so, they provide information that is extremely useful for the development of a theory. Once the researcher knows the variables involved in a phenomenon, she can focus her attention on finding the mechanism or specification that binds them together.
The implication is that classical statistical approaches, such as regression analysis, are not necessarily more transparent or insightful than their ML counterparts. The perception that ML tools are black-boxes and classical tools are white-boxes is false. Not only can ML feature importance methods be as helpful as p-values, but in some cases they can be more insightful and accurate.
A final piece of advice is to consider carefully what are we interested in explaining or predicting. In Section 5, we reviewed various labeling methods. The same features can yield various degrees of importance in explaining or predicting different types of labels. Whenever possible, it makes sense to apply these feature importance methods to all of the labeling methods discussed earlier, and see what combination of features and labels leads to the strongest theory. For instance, you may be indifferent between predicting the sign of the next trend or predicting the sign of the next 5% return, because you can build profitable strategies on either kind of prediction (as long as the feature importance analysis suggests the existence of a strong theoretical connection).
6.8 Exercises
1 Consider a medical test with a false positive rate
, where
is the null hypothesis (the patient is healthy), x is the observed measurement, and
is the significance threshold. A test is run on a random patient and comes back positive (the null hypothesis is rejected). What is the probability that the patient truly has the condition?
a Is it
(the confidence of the test)?b Is it
(the power, or recall, of the test)?c Or is it
(the precision of the test)?d Of the above, what do p-values measure?
e In finance, the analogous situation is to test whether a variable is involved in a phenomenon. Do p-values tell us anything about the probability that the variable is relevant, given the observed evidence?
2 Consider a medical test where
,
, and the probability of the condition is
. The test has full recall and a very high confidence. What is the probability that a positive-tested patient is actually sick? Why is it much lower than
and
? What is the probability that a patient is actually sick after testing positive twice on independent tests?3 Rerun the examples in Sections 6.3.1 and 6.3.2, where this time you pass an argument sigmaStd=0 to the getTestData function. How do Figures 6.2 and 6.3 look now? What causes the difference, if there is one?
4 Rerun the MDA analysis in Section 6.3.2, where this time you use probability-weighted accuracy (Section 6.4) as the scoring function. Are results materially different? Are they more intuitive or easier to explain? Can you think of other ways to represent MDA outputs using probability-weighted accuracy?
5 Rerun the experiment in Section 6.6, where this time the distance metric used to cluster the features is variation of information (Section 3).











7 Portfolio Construction
7.1 Motivation
The allocation of assets requires making decisions under uncertainty. Reference MarkowitzMarkowitz (1952) proposed one of the most influential ideas in modern financial history, namely, the representation of the problem of investing as a convex optimization program. Markowitz’s Critical Line Algorithm (CLA) estimates an “efficient frontier” of portfolios that maximize the expected return subject to a given level of risk, where portfolio risk is measured in terms of the standard deviation of returns. In practice, mean-variance optimal solutions tend to be concentrated and unstable (Reference De Miguel, Garlappi and UppalDe Miguel et al. 2009).
There are three popular approaches to reducing the instability in optimal portfolios. First, some authors attempted to regularize the solution, by injecting additional information regarding the mean or variance in the form of priors (Reference Black and LittermanBlack and Litterman 1992). Second, other authors suggested reducing the solution’s feasibility region by incorporating additional constraints (Reference Clarke, De Silva and ThorleyClarke et al. 2002). Third, other authors proposed improving the numerical stability of the covariance matrix’s inverse (Reference Ledoit and WolfLedoit and Wolf 2004).
In Section 2, we discussed how to deal with the instability caused by the noise contained in the covariance matrix. As it turns out, the signal contained in the covariance matrix can also be a source of instability, which requires a specialized treatment. In this section, we explain why certain data structures (or types of signal) make mean-variance solutions unstable, and what we can do to address this second source of instability.
7.2 Convex Portfolio Optimization
Consider a portfolio of N holdings, where its returns in excess of the risk-free rate have an expected value  and an expected covariance V. Markowitz’s insight was to formulate the classical asset allocation problem as a quadratic program,
and an expected covariance V. Markowitz’s insight was to formulate the classical asset allocation problem as a quadratic program,
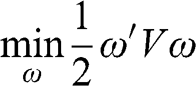
where a characterizes the portfolio’s constraints. This problem can be expressed in Lagrangian form as
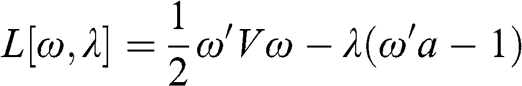
with first-order conditions
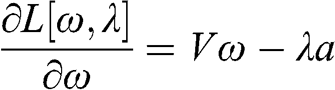
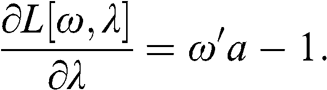
Setting the first-order (necessary) conditions to zero, we obtain that  and
and  , thus
, thus
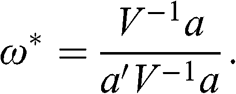
The second-order (sufficient) condition confirms that this solution is the minimum of the Lagrangian:
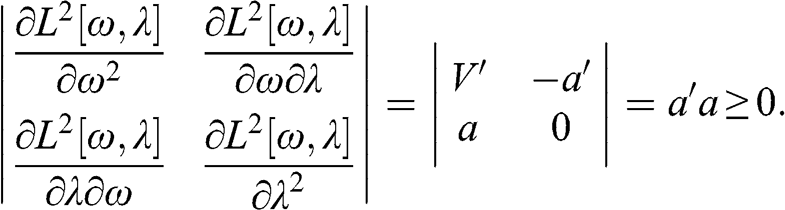
Let us now turn our attention to a few formulations of the characteristic vector, a:
1 For
and
, where
,
is a vector of ones of size N, and
is an identity matrix of size N, then the solution is the equal weights portfolio (known as the “1/N” portfolio, or the “naïve” portfolio), because
.2 For
and V is a diagonal matrix with unequal entries (
, for all
), then the solution is the inverse-variance portfolio, because
3 For
, the solution is the minimum variance portfolio.4 For
, the solution maximizes the portfolio’s Sharpe ratio,
, and the market portfolio is
(Reference Grinold and KahnGrinold and Kahn 1999).














7.3 The Condition Number
Certain covariance structures can make the mean-variance optimization solution unstable. To understand why, we need to introduce the concept of condition number of a covariance matrix. Consider a correlation matrix between two securities,
where  is the correlation between their returns. Matrix C can be diagonalized as
is the correlation between their returns. Matrix C can be diagonalized as  as follows. First, we set the eigenvalue equation
as follows. First, we set the eigenvalue equation  . Operating,
. Operating,
This equation has roots in  , hence the diagonal elements of
, hence the diagonal elements of  are
are


Second, the eigenvector associated with each eigenvalue is given by the solution to the system

If C is not already a diagonal matrix, then  , in which case the above system has solutions in
, in which case the above system has solutions in

and it is easy to verify that

The trace of C is  , so
, so  sets how big one eigenvalue gets at the expense of the other. The determinant of C is given by
sets how big one eigenvalue gets at the expense of the other. The determinant of C is given by  . The determinant reaches its maximum at
. The determinant reaches its maximum at  , which corresponds to the uncorrelated case,
, which corresponds to the uncorrelated case,  . The determinant reaches its minimum at
. The determinant reaches its minimum at  or
or  , which corresponds to the perfectly correlated case,
, which corresponds to the perfectly correlated case,  . The inverse of C is
. The inverse of C is

The implication is that the more  deviates from zero, the bigger one eigenvalue becomes relative to the other, causing
deviates from zero, the bigger one eigenvalue becomes relative to the other, causing  to approach zero, which makes the values of
to approach zero, which makes the values of  explode.
explode.
More generally, the instability caused by covariance structure can be measured in terms of the magnitude between the two extreme eigenvalues. Accordingly, the condition number of a covariance or correlation (or normal, thus diagonalizable) matrix is defined as the absolute value of the ratio between its maximal and minimal (by moduli) eigenvalues. In the above example,


7.4 Markowitz’s Curse
Matrix C is just a standardized version of V, and the conclusions we drew on  apply to the
apply to the  used to compute
used to compute  . When securities within a portfolio are highly correlated (
. When securities within a portfolio are highly correlated ( or
or  ), C has a high condition number, and the values of
), C has a high condition number, and the values of  explode. This is problematic in the context of portfolio optimization, because
explode. This is problematic in the context of portfolio optimization, because  depends on
depends on  , and unless
, and unless  , we must expect an unstable solution to the convex optimization program. In other words, Markowitz’s solution is guaranteed to be numerically stable only if
, we must expect an unstable solution to the convex optimization program. In other words, Markowitz’s solution is guaranteed to be numerically stable only if  , which is precisely the case when we don’t need it! The reason we needed Markowitz was to handle the
, which is precisely the case when we don’t need it! The reason we needed Markowitz was to handle the  case, but the more we need Markowitz, the more numerically unstable is the estimation of
case, but the more we need Markowitz, the more numerically unstable is the estimation of  . This is Markowitz’s curse.
. This is Markowitz’s curse.
Reference López de PradoLópez de Prado (2016) introduced an ML-based asset allocation method called hierarchical risk parity (HRP). HRP outperforms Markowitz and the naïve allocation in out-of-sample Monte Carlo experiments. The purpose of HRP was not to deliver an optimal allocation, but merely to demonstrate the potential of ML approaches. In fact, HRP outperforms Markowitz out-of-sample even though HRP is by construction suboptimal in-sample. In the next section we analyze further why standard mean-variance optimization is relatively easy to beat.
7.5 Signal as a Source of Covariance Instability
In Section 2, we saw that the covariance instability associated with noise is regulated by the N/T ratio, because the lower bound of the Marcenko–Pastur distribution,  , gets smaller as N/T grows,Footnote 22 while the upper bound,
, gets smaller as N/T grows,Footnote 22 while the upper bound,  , increases as N/T grows. In this section, we are dealing with a different source of covariance instability, caused by the structure of the data (signal). As we saw in the 2 × 2 matrix example,
, increases as N/T grows. In this section, we are dealing with a different source of covariance instability, caused by the structure of the data (signal). As we saw in the 2 × 2 matrix example,  regulates the matrix’s condition number, regardless and independently from N/T. Signal-induced instability is structural, and cannot be reduced by sampling more observations.
regulates the matrix’s condition number, regardless and independently from N/T. Signal-induced instability is structural, and cannot be reduced by sampling more observations.
There is an intuitive explanation for how signal makes mean-variance optimization unstable. When the correlation matrix is an identity matrix, the eigenvalue function is a horizontal line, and the condition number is 1. Outside that ideal case, the condition number is impacted by irregular correlation structures. In the particular case of finance, when a subset of securities exhibits greater correlation among themselves than to the rest of the investment universe, that subset forms a cluster within the correlation matrix. Clusters appear naturally, as a consequence of hierarchical relationships. When K securities form a cluster, they are more heavily exposed to a common eigenvector, which implies that the associated eigenvalue explains a greater amount of variance. But because the trace of the correlation matrix is exactly N, that means that an eigenvalue can only increase at the expense of the other  eigenvalues in that cluster, resulting in a condition number greater than 1. Consequently, the greater the intracluster correlation is, the higher the condition number becomes. This source of instability is distinct and unrelated to
eigenvalues in that cluster, resulting in a condition number greater than 1. Consequently, the greater the intracluster correlation is, the higher the condition number becomes. This source of instability is distinct and unrelated to  .
.
Let us illustrate this intuition with a numerical example. Code Snippet 7.1 shows how to form a block-diagonal correlation matrix of different numbers of blocks, block sizes, and intrablock correlations. Figure 7.1 plots a block-diagonal matrix of size  , composed of two equal-sized blocks, where the intrablock correlation is 0.5 and the outer-block correlation is zero. Because of this block structure, the condition number is not 1, but 3. The condition number rises if (1) we make one block greater or (2) we increase the intrablock correlation. The reason is, in both cases one eigenvector explains more variance than the rest. For instance, if we increase the size of one block to three and reduce the size of the other to 1, the condition number becomes 4. If instead we increase the intrablock correlation to 0.75, the condition number becomes 7. A block-diagonal correlation matrix of size
, composed of two equal-sized blocks, where the intrablock correlation is 0.5 and the outer-block correlation is zero. Because of this block structure, the condition number is not 1, but 3. The condition number rises if (1) we make one block greater or (2) we increase the intrablock correlation. The reason is, in both cases one eigenvector explains more variance than the rest. For instance, if we increase the size of one block to three and reduce the size of the other to 1, the condition number becomes 4. If instead we increase the intrablock correlation to 0.75, the condition number becomes 7. A block-diagonal correlation matrix of size  with two equal-sized blocks, where the intrablock correlation is 0.5 has a condition number of 251, again as a result of having 500 eigenvectors where most of the variance is explained by only 2.
with two equal-sized blocks, where the intrablock correlation is 0.5 has a condition number of 251, again as a result of having 500 eigenvectors where most of the variance is explained by only 2.
Figure 7.1 Heatmap of a block-diagonal correlation matrix.
Snippet 7.1 Composition of Block-Diagonal Correlation Matrices
import matplotlib.pyplot as mpl,seaborn as sns import numpy as np #------------------------------------------------------------------------------ corr0=formBlockMatrix(2,2,.5) eVal,eVec=np.linalg.eigh(corr0) print max(eVal)/min(eVal) sns.heatmap(corr0,cmap=‘viridis’)
Code Snippet 7.2 demonstrates that bringing down the intrablock correlation in only one of the two blocks does not reduce the condition number. The reason is, the extreme eigenvalues are caused by the dominant block. So even though the high condition number may be caused by only one cluster, it impacts the entire correlation matrix. This observation has an important implication: the instability of Markowitz’s solution can be traced back to a few dominant clusters within the correlation matrix. We can contain that instability by optimizing the dominant clusters separately, hence preventing that the instability spreads throughout the entire portfolio.
Snippet 7.2 Block-Diagonal Correlation Matrix with a Dominant Block
corr0=block_diag(formBlockMatrix(1,2,.5)) corr1=formBlockMatrix(1,2,.0) corr0=block_diag(corr0,corr1) eVal,eVec=np.linalg.eigh(corr0) print max(eVal)/min(eVal)
7.6 The Nested Clustered Optimization Algorithm
The remainder of this section is dedicated to introducing a new ML-based method, named nested clustered optimization (NCO), which tackles the source of Markowitz’s curse. NCO belongs to a class of algorithms known as “wrappers”: it is agnostic as to what member of the efficient frontier is computed, or what set of constraints is imposed. NCO provides a strategy for addressing the effect of Markowitz’s curse on an existing mean-variance allocation method.
7.6.1 Correlation Clustering
The first step of the NCO algorithm is to cluster the correlation matrix. This operation involves finding the optimal number of clusters. One possibility is to apply the ONC algorithm (Section 4), however NCO is agnostic as to what particular algorithm is used for determining the number of clusters. For large matrices, where  is relatively low, it is advisable to denoise the correlation matrix prior to clustering, following the method described in Section 2. Code Snippet 7.3 implements this procedure. We compute the denoised covariance matrix, cov1, using the deNoiseCov function introduced in Section 2. As a reminder, argument q informs the ratio between the number of rows and the number of columns in the observation matrix. When bWidth=0, the covariance matrix is not denoised. We standardize the resulting covariance matrix into a correlation matrix using the cov2corr function. Then we cluster the cleaned correlation matrix using the clusterKMeansBase function, which we introduced in Section 4. The argument maxNumClusters is set to half the number of columns in the correlation matrix. The reason is, single-item clusters do not cause an increase in the matrix’s condition number, so we only need to consider clusters with a minimum size of two. If we expect fewer clusters, a lower maxNumClusters may be used to accelerate calculations.
is relatively low, it is advisable to denoise the correlation matrix prior to clustering, following the method described in Section 2. Code Snippet 7.3 implements this procedure. We compute the denoised covariance matrix, cov1, using the deNoiseCov function introduced in Section 2. As a reminder, argument q informs the ratio between the number of rows and the number of columns in the observation matrix. When bWidth=0, the covariance matrix is not denoised. We standardize the resulting covariance matrix into a correlation matrix using the cov2corr function. Then we cluster the cleaned correlation matrix using the clusterKMeansBase function, which we introduced in Section 4. The argument maxNumClusters is set to half the number of columns in the correlation matrix. The reason is, single-item clusters do not cause an increase in the matrix’s condition number, so we only need to consider clusters with a minimum size of two. If we expect fewer clusters, a lower maxNumClusters may be used to accelerate calculations.
Snippet 7.3 The Correlation Clustering Step
import pandas as pd cols=cov0.columns cov1=deNoiseCov(cov0,q,bWidth=.01) # de-noise cov cov1=pd.DataFrame(cov1,index=cols,columns=cols) corr1=cov2corr(cov1) corr1,clstrs,silh=clusterKMeansBase(corr1, maxNumClusters=corr0.shape[0]/2,n_init=10)
A common question is whether we should cluster corr1 or corr1.abs(). When all correlations are nonnegative, clustering corr1 and corr1.abs() yields the same outcome. When some correlations are negative, the answer is more convoluted, and depends on the numerical properties of the observed inputs. I recommend that you try both, and see what clustering works better for your particular corr1 in Monte Carlo experiments.Footnote 23
7.6.2 Intracluster Weights
The second step of the NCO algorithm is to compute optimal intracluster allocations, using the denoised covariance matrix, cov1. Code Snippet 7.4 implements this procedure. For simplicity purposes, we have defaulted to a minimum variance allocation, as implemented in the minVarPort function. However, nothing in the procedure prevents the use of alternative allocation methods. Using the estimated intracluster weights, we can derive the reduced covariance matrix, cov2, which reports the correlations between clusters.
Snippet 7.4 Intracluster Optimal Allocations
wIntra=pd.DataFrame(0,index=cov1.index,columns=clstrs.keys()) for i in clstrs: wIntra.loc[clstrs[i],i]=minVarPort(cov1.loc[clstrs[i], clstrs[i]]).flatten() cov2=wIntra.T.dot(np.dot(cov1,wIntra)) # reduced covariance matrix
7.6.3 Intercluster Weights
The third step of the NCO algorithm is to compute optimal intercluster allocations, using the reduced covariance matrix, cov2. By construction, this covariance matrix is close to a diagonal matrix, and the optimization problem is close to the ideal Markowitz case. In other words, the clustering and intracluster optimization steps have allowed us to transform a “Markowitz-cursed” problem ( ) into a well-behaved problem (
) into a well-behaved problem ( ).
).
Code Snippet 7.5 implements this procedure. It applies the same allocation procedure that was used in the intracluster allocation step (that is, in the case of Code Snippet 7.4, the minVarPort function). The final allocation per security is reported by the wAll0 data frame, which results from multiplying intracluster weights with the intercluster weights.
Snippet 7.5 Intercluster Optimal Allocations
wInter=pd.Series(minVarPort(cov2).flatten(),index=cov2.index) wAll0=wIntra.mul(wInter,axis=1).sum(axis=1).sort_index()
7.7 Experimental Results
In this section we subject the NCO algorithm to controlled experiments, and compare its performance to Markowitz’s approach. Like in Section 2, we discuss two characteristic portfolios of the efficient frontier, namely, the minimum variance and maximum Sharpe ratio solutions, since any member of the unconstrained efficient frontier can be derived as a convex combination of the two (a result sometimes known as the “separation theorem”).
Code Snippet 7.6 implements the NCO algorithm introduced earlier in this section. When argument mu is None, function optPort_nco returns the minimum variance portfolio, whereas when mu is not None, function optPort_nco returns the maximum Sharpe ratio portfolio.
Snippet 7.6 Function Implementing the NCO Algorithm
def optPort_nco(cov,mu=None,maxNumClusters=None): cov=pd.DataFrame(cov) if mu is not None:mu=pd.Series(mu[:,0]) corr1=cov2corr(cov) corr1,clstrs,_=clusterKMeansBase(corr1,maxNumClusters, n_init=10) wIntra=pd.DataFrame(0,index=cov.index,columns=clstrs.keys()) for i in clstrs: cov_=cov.loc[clstrs[i],clstrs[i]].values if mu is None:mu_=None else:mu_=mu.loc[clstrs[i]].values.reshape(-1,1) wIntra.loc[clstrs[i],i]=optPort(cov_,mu_).flatten() cov_=wIntra.T.dot(np.dot(cov,wIntra)) # reduce covariance matrix mu_=(None if mu is None else wIntra.T.dot(mu)) wInter=pd.Series(optPort(cov_,mu_).flatten(),index=cov_.index) nco=wIntra.mul(wInter,axis=1).sum(axis=1).values.reshape(-1,1) return nco
7.7.1 Minimum Variance Portfolio
Code Snippet 7.7 creates a random vector of means and a random covariance matrix that represent a stylized version of a fifty securities portfolio, grouped in ten blocks with intracluster correlations of 0.5. This vector and matrix characterize the “true” process that generates observations.Footnote 24 We set a seed for the purpose of reproducing and comparing results across runs with different parameters. Function formTrueMatrix was declared in Section 2.
Snippet 7.7 Data-Generating Process
nBlocks,bSize,bCorr =10,50,.5 np.random.seed(0) mu0,cov0=formTrueMatrix(nBlocks,bSize,bCorr)
Code Snippet 7.8 uses function simCovMu to simulate a random empirical vector of means and a random empirical covariance matrix based on 1,000 observations drawn from the true process (declared in Section 2). When shrink=True, the empirical covariance matrix is subjected to Ledoit–Wolf shrinkage. Using that empirical covariance matrix, function optPort (also declared in Section 2) estimates the minimum variance portfolio according to Markowitz, and function optPort_nco estimates the minimum variance portfolio applying the NCO algorithm. This procedure is repeated on 1,000 different random empirical covariance matrices. Note that, because minVarPortf=True, the random empirical vectors of means are discarded.
Snippet 7.8 Drawing an Empirical Vector of Means and Covariance Matrix
nObs,nSims,shrink,minVarPortf=1000,1000,False,True np.random.seed(0) for i in range(nSims): mu1,cov1=simCovMu(mu0,cov0,nObs,shrink=shrink) if minVarPortf:mu1=None w1.loc[i]=optPort(cov1,mu1).flatten() w1_d.loc[i]=optPort_nco(cov1,mu1,int(cov1.shape[0]/2)).flatten()
Code Snippet 7.9 computes the true minimum variance portfolio, derived from the true covariance matrix. Using those allocations as benchmark, it then computes the root-mean-square errors (RMSE) across all weights. We can run Code Snippet 7.9 with and without shrinkage, thus obtaining the four combinations displayed in Figure 7.2.
| Markowitz | NCO | |
|---|---|---|
| Raw | 7.95E-03 | 4.21E-03 |
| Shrunk | 8.89E-03 | 6.74E-03 |
Figure 7.2 RMSE for the minimum variance portfolio.
Snippet 7.9 Estimation of Allocation Errors
w0=optPort(cov0,None if minVarPortf else mu0) w0=np.repeat(w0.T,w1.shape[0],axis=0) # true allocation rmsd=np.mean((w1-w0).values.flatten()**2)**.5 # RMSE rmsd_d=np.mean((w1_d-w0).values.flatten()**2)**.5 # RMSE
NCO computes the minimum variance portfolio with 52.98% of Markowitz’s RMSE, i.e., a 47.02% reduction in the RMSE. While Ledoit–Wolf shrinkage helps reduce the RMSE, that reduction is relatively small, around 11.81%. Combining shrinkage and NCO yields a 15.30% reduction in RMSE, which is better than shrinkage but worse than NCO alone.
The implication is that NCO delivers substantially lower RMSE than Markowitz’s solution, even for a small portfolio of only fifty securities, and that shrinkage adds no value. It is easy to test that NCO’s advantage widens for larger portfolios (we leave it as an exercise).
7.7.2 Maximum Sharpe Ratio Portfolio
By setting minVarPortf=False, we can rerun Code Snippets 7.8 and 7.9 to derive the RMSE associated with the maximum Sharpe ratio portfolio. Figure 7.3 reports the results from this experiment.
| Markowitz | NCO | |
|---|---|---|
| Raw | 7.02E-02 | 3.17E-02 |
| Shrunk | 6.54E-02 | 5.72E-02 |
Figure 7.3 RMSE for the maximum Sharpe ratio portfolio.
NCO computes the maximum Sharpe ratio portfolio with 45.17% of Markowitz’s RMSE, i.e., a 54.83% reduction in the RMSE. The combination of shrinkage and NCO yields a 18.52% reduction in the RMSE of the maximum Sharpe ratio portfolio, which is better than shrinkage but worse than NCO. Once again, NCO delivers substantially lower RMSE than Markowitz’s solution, and shrinkage adds no value.
7.8 Conclusions
Markowitz’s portfolio optimization framework is mathematically correct, however its practical application suffers from numerical problems. In particular, financial covariance matrices exhibit high condition numbers due to noise and signal. The inverse of those covariance matrices magnifies estimation errors, which leads to unstable solutions: changing a few rows in the observations matrix may produce entirely different allocations. Even if the allocations estimator is unbiased, the variance associated with these unstable solutions inexorably leads to large transaction costs than can erase much of the profitability of these strategies.
In this section, we have traced back the source of Markowitz’s instability problems to the shape of the correlation matrix’s eigenvalue function. Horizontal eigenvalue functions are ideal for Markowitz’s framework. In finance, where clusters of securities exhibit greater correlation among themselves than to the rest of the investment universe, eigenvalue functions are not horizontal, which in turn is the cause for high condition numbers. Signal is the cause of this type of covariance instability, not noise.
We have introduced the NCO algorithm to address this source of instability, by splitting the optimization problem into several problems: computing one optimization per cluster, and computing one final optimization across all clusters. Because each security belongs to one cluster and one cluster only, the final allocation is the product of the intracluster and intercluster weights. Experimental results demonstrate that this dual clustering approach can significantly reduce Markowitz’s estimation error. The NCO algorithm is flexible and can be utilized in combination with any other framework, such as Black–Litterman, shrinkage, reversed optimization, or constrained optimization approaches. We can think of NCO as a strategy for splitting the general optimization problem into subproblems, which can then be solved using the researcher’s preferred method.
Like many other ML algorithms, NCO is flexible and modular. For example, when the correlation matrix exhibits a strongly hierarchical structure, with clusters within clusters, we can apply the NCO algorithm within each cluster and subcluster, mimicking the matrix’s tree-like structure. The goal is to contain the numerical instability at each level of the tree, so that the instability within a subcluster does not extend to its parent cluster or the rest of the correlation matrix.
We can follow the Monte Carlo approach outlined in this section to estimate the allocation error produced by various optimization methods on a particular set of input variables. The result is a precise determination of what method is most robust to a particular case. Thus, rather than relying always on one particular approach, we can apply opportunistically whatever optimization method is best suited in a particular setting.
7.9 Exercises
1 Add to Code Snippet 7.3 a detoning step, and repeat the experimental analysis conducted in Section 7.7. Do you see an additional improvement in NCO’s performance? Why?
2 Repeat Section 7.7, where this time you generate covariance matrices without a cluster structure, using the function getRndCov listed in Section 2. Do you reach a qualitatively different conclusion? Why?
3 Repeat Section 7.7, where this time you replace the minVarPort function with the CLA class listed in Reference Bailey and López de PradoBailey and López de Prado (2013).
4 Repeat Section 7.7 for a covariance matrix of size ten and for a covariance matrix of size one hundred. How do NCO’s results compare to Markowitz’s as a function of the problem’s size?
5 Repeat Section 7.7, where you purposely mislead the clusterKMeansBase algorithm by setting its argument maxNumClusters to a very small value, like 2. By how much does NCO’s solution worsen? How is it possible that, even with only two clusters (instead of ten), NCO performs significantly better than Markowitz’s solution?
8 Testing Set Overfitting
8.1 Motivation
Throughout this Element, we have studied the properties of ML solutions through Monte Carlo experiments. Monte Carlo simulations play in mathematics the analogue to a controlled experiment in the physical sciences. They allow us to reach conclusions regarding the mathematical properties of various estimators and procedures under controlled conditions. Having the ability to control for the conditions of an experiment is essential to being able to make causal inference statements.
A backtest is a historical simulation of how an investment strategy would have performed in the past. It is not a controlled experiment, because we cannot change the environmental variables to derive a new historical time series on which to perform an independent backtest. As a result, backtests cannot help us derive the precise cause–effect mechanisms that make a strategy successful.
This general inability to conduct controlled experiments on investment strategies is more than a technical inconvenience. In the context of strategy development, all we have is a few (relatively short, serially correlated, multicollinear and possibly nonstationary) historical time series. It is easy for a researcher to overfit a backtest, by conducting multiple historical simulations, and selecting the best performing strategy (Reference Bailey, Borwein, López de Prado and ZhuBailey et al. 2014). When a researcher presents an overfit backtest as the outcome of a single trial, the simulated performance is inflated. This form of statistical inflation is called selection bias under multiple testing (SBuMT). SBuMT leads to false discoveries: strategies that are replicable in backtests, but fail when implemented.
To make matters worse, SBuMT is compounded at many asset managers, as a consequence of sequential SBuMT at two levels: (1) each researcher runs millions of simulations, and presents the best (overfit) ones to her boss; (2) the company further selects a few backtests among the (already overfit) backtests submitted by the researchers. We may call this backtest hyperfitting, to differentiate it from backtest overfitting (which occurs at the researcher level).
It may take many decades to collect the future (out-of-sample) information needed to debunk a false discovery that resulted from SBuMT. In this section, we study how researchers can estimate the effect that SBuMT has on their findings.
8.2 Precision and Recall
Consider s investment strategies. Some of these strategies are false discoveries, in the sense that their expected return is not positive. We can decompose these strategies between true ( ) and false (
) and false ( ), where
), where  . Let
. Let  be the odds ratio of true strategies against false strategies,
be the odds ratio of true strategies against false strategies,  . In a field like financial economics, where the signal-to-noise ratio is low, false strategies abound, hence
. In a field like financial economics, where the signal-to-noise ratio is low, false strategies abound, hence  is expected to be low. The number of true investment strategies is
is expected to be low. The number of true investment strategies is

Likewise, the number of false investment strategies is
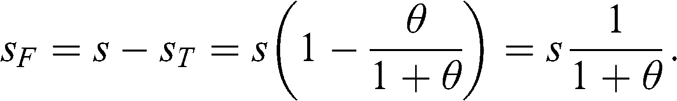
Given a false positive rate  (type I error), we will obtain a number of false positives,
(type I error), we will obtain a number of false positives,  , and a number of true negatives,
, and a number of true negatives,  . Let us denote as
. Let us denote as  the false negative rate (type II error) associated with that
the false negative rate (type II error) associated with that  . We will obtain a number of false negatives,
. We will obtain a number of false negatives,  , and a number of true positives,
, and a number of true positives,  . Therefore, the precision and recall of our test are
. Therefore, the precision and recall of our test are
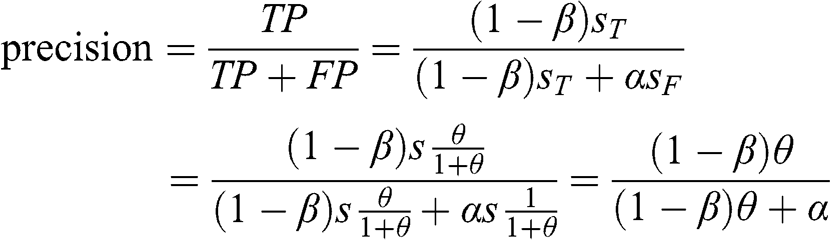
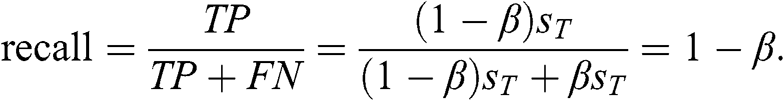
Before running backtests on a strategy, researchers should gather evidence that a strategy may indeed exist. The reason is, the precision of the test is a function of the odds ratio,  . If the odds ratio is low, the precision will be low, even if we get a positive with high confidence (low p-value).Footnote 25 In particular, a strategy is more likely false than true if
. If the odds ratio is low, the precision will be low, even if we get a positive with high confidence (low p-value).Footnote 25 In particular, a strategy is more likely false than true if  .
.
For example, suppose that the probability of a backtested strategy being profitable is 0.01, that is, that one out of one hundred strategies is true, hence  . Then, at the standard thresholds of
. Then, at the standard thresholds of  and
and  , researchers are expected to get approximately fifty-eight positives out one thousand trials, where approximately eight are true positives, and approximately fifty are false positives. Under these circumstances, a p-value of 0.05 implies a false discovery rate of 86.09% (roughly 50/58). For this reason alone, we should expect that most discoveries in financial econometrics are likely false.
, researchers are expected to get approximately fifty-eight positives out one thousand trials, where approximately eight are true positives, and approximately fifty are false positives. Under these circumstances, a p-value of 0.05 implies a false discovery rate of 86.09% (roughly 50/58). For this reason alone, we should expect that most discoveries in financial econometrics are likely false.
8.3 Precision and Recall under Multiple Testing
After one trial, the probability of making a type I error is  . Suppose that we repeat for a second time a test with false positive probability
. Suppose that we repeat for a second time a test with false positive probability  . At each trial, the probability of not making a type I error is
. At each trial, the probability of not making a type I error is  . If the two trials are independent, the probability of not making a type I error on the first and second tests is
. If the two trials are independent, the probability of not making a type I error on the first and second tests is  . The probability of making at least one type I error is the complement,
. The probability of making at least one type I error is the complement,  . If we conduct K independent trials, the joint probability of not making a single type I error is
. If we conduct K independent trials, the joint probability of not making a single type I error is  . Hence, the probability of making at least one type I error is the complement,
. Hence, the probability of making at least one type I error is the complement,  . This is also known as the familywise error rate (FWER).
. This is also known as the familywise error rate (FWER).
After one trial, the probability of making a type II error is  . After K independent trials, the probability of making a type II error on all of them is
. After K independent trials, the probability of making a type II error on all of them is  . Note the difference with FWER. In the false positive case, we are interested in the probability of making at least one error. This is because a single false alarm is a failure. However, in the false negative case, we are interested in the probability that all positives are missed. As K increases,
. Note the difference with FWER. In the false positive case, we are interested in the probability of making at least one error. This is because a single false alarm is a failure. However, in the false negative case, we are interested in the probability that all positives are missed. As K increases,  grows and
grows and  shrinks.
shrinks.
The precision and recall adjusted for multiple testing are
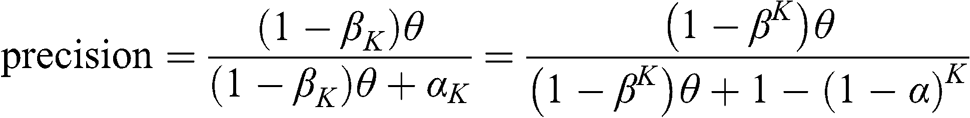
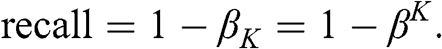
8.4 The Sharpe Ratio
Financial analysts do not typically assess the performance of a strategy in terms of precision and recall. The most common measure of strategy performance is the Sharpe ratio. In what follows, we will develop a framework for assessing the probability that a strategy is false. The inputs are the Sharpe ratio estimate, as well as metadata captured during the discovery process.Footnote 26
Consider an investment strategy with excess returns (or risk premia)  ,
,  , which are independent and identically distributed (IID) Normal,
, which are independent and identically distributed (IID) Normal,
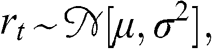
where  represents a Normal distribution with mean
represents a Normal distribution with mean  and variance
and variance  . Following Reference SharpeSharpe (1966, Reference Sharpe1975, Reference Sharpe1994), the (nonannualized) Sharpe Ratio of such strategy is defined as
. Following Reference SharpeSharpe (1966, Reference Sharpe1975, Reference Sharpe1994), the (nonannualized) Sharpe Ratio of such strategy is defined as
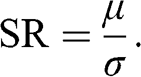
Because parameters  and
and  are not known, SR is estimated as
are not known, SR is estimated as
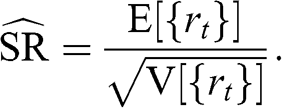
Under the assumption that returns are IID Normal, Reference LoLo (2002) derived the asymptotic distribution of  as
as

However, empirical evidence shows that hedge fund returns exhibit substantial negative skewness and positive excess kurtosis (among others, see Reference Brooks and KatBrooks and Kat 2002; Reference Ingersoll, Spiegel, Goetzmann and WelchIngersoll et al. 2007). Wrongly assuming that returns are IID Normal can lead to a gross underestimation of the false positive probability.
Under the assumption that returns are drawn from IID non-Normal distributions, Reference MertensMertens (2002) derived the asymptotic distribution of  as
as

where  is the skewness of
is the skewness of  , and
, and  is the kurtosis of
is the kurtosis of  (
( and
and  when returns follow a Normal distribution). Shortly after, Reference ChristieChristie (2005) and Reference OpdykeOpdyke (2007) discovered that, in fact, Mertens’s equation is also valid under the more general assumption that returns are stationary and ergodic (not necessarily IID). The key implication is that
when returns follow a Normal distribution). Shortly after, Reference ChristieChristie (2005) and Reference OpdykeOpdyke (2007) discovered that, in fact, Mertens’s equation is also valid under the more general assumption that returns are stationary and ergodic (not necessarily IID). The key implication is that  still follows a Normal distribution even if returns are non-Normal, however with a variance that partly depends on the skewness and kurtosis of the returns.
still follows a Normal distribution even if returns are non-Normal, however with a variance that partly depends on the skewness and kurtosis of the returns.
8.5 The “False Strategy” Theorem
A researcher may carry out a large number of historical simulations (trials), and report only the best outcome (maximum Sharpe ratio). The distribution of the maximum Sharpe ratio is not the same as the distribution of a Sharpe ratio randomly chosen among the trials, hence giving rise to SBuMT. When more than one trial takes place, the expected value of the maximum Sharpe ratio is greater than the expected value of the Sharpe ratio from a random trial. In particular, given an investment strategy with expected Sharpe ratio zero and nonnull variance, the expected value of the maximum Sharpe ratio is strictly positive, and a function of the number of trials.
Given the above, the magnitude of SBuMT can be expressed in terms of the difference between the expected maximum Sharpe ratio and the expected Sharpe ratio from a random trial (zero, in the case of a false strategy). As it turns out, SBuMT is a function of two variables: the number of trials, and the variance of the Sharpe ratios across trials. The following theorem formally states that relationship. A proof can be found in Appendix B.
Theorem:
Given a sample of estimated performance statistics  ,
,  , drawn from independent and identically distributed Gaussians,
, drawn from independent and identically distributed Gaussians,  , then
, then

where  is the inverse of the standard Gaussian CDF,
is the inverse of the standard Gaussian CDF,  is the expected value,
is the expected value,  is the variance, e is Euler’s number, and
is the variance, e is Euler’s number, and  is the Euler–Mascheroni constant.
is the Euler–Mascheroni constant.
8.6 Experimental Results
The False Strategy theorem provides us with an approximation of the expected maximum Sharpe ratio. An experimental analysis of this theorem can be useful at two levels. First, it can help us find evidence that the theorem is not true, and in fact the proof is flawed. Of course, the converse is not true: experimental evidence can never replace the role of a mathematical proof. Still, experimental evidence can point to problems with the proof, and give us a better understanding of what the proof should look like. Second, the theorem does not provide a boundary for the approximation. An experimental analysis can help us estimate the distribution of the approximation error.
The following Monte Carlo experiment evaluates the accuracy of the False Strategy theorem. First, given a pair of values  , we generate a random array of size
, we generate a random array of size  , where S is the number of Monte Carlo experiments. The values contained by this random array are drawn from a Standard Normal distribution. Second, the rows in this array are centered and scaled to match zero mean and
, where S is the number of Monte Carlo experiments. The values contained by this random array are drawn from a Standard Normal distribution. Second, the rows in this array are centered and scaled to match zero mean and  variance. Third, the maximum value across each row is computed,
variance. Third, the maximum value across each row is computed,  , resulting in a number S of such maxima. Fourth, we compute the average value across the S maxima,
, resulting in a number S of such maxima. Fourth, we compute the average value across the S maxima,  . Fifth, this empirical (Monte Carlo) estimate of the expected maximum SR can then be compared with the analytical solution provided by the False Strategy theorem,
. Fifth, this empirical (Monte Carlo) estimate of the expected maximum SR can then be compared with the analytical solution provided by the False Strategy theorem,  . Sixth, the estimation error is defined in relative terms to the predicted value, as
. Sixth, the estimation error is defined in relative terms to the predicted value, as

Seventh, we repeat the previous steps R times, resulting in  estimation errors, allowing us to compute the mean and standard deviation of the estimation errors associated with K trials. Code Snippet 8.1 implements this Monte Carlo experiment in python.
estimation errors, allowing us to compute the mean and standard deviation of the estimation errors associated with K trials. Code Snippet 8.1 implements this Monte Carlo experiment in python.
Snippet 8.1 Experimental Validation of the False Strategy Theorem
import numpy as np,pandas as pd
from scipy.stats import norm,percentileofscore
#------------------------------------------------------------------------------
def getExpectedMaxSR(nTrials,meanSR,stdSR):
# Expected max SR, controlling for SBuMT
emc=0.577215664901532860606512090082402431042159336
sr0=(1-emc)*norm.ppf(1-1./nTrials)+ /
emc*norm.ppf(1-(nTrials*np.e)**-1)
sr0=meanSR+stdSR*sr0
return sr0
#------------------------------------------------------------------------------
def getDistMaxSR(nSims,nTrials,stdSR,meanSR):
# Monte Carlo of max{SR} on nTrials, from nSims simulations
rng=np.random.RandomState()
out=pd.DataFrame()
for nTrials_ in nTrials:
#1) Simulated Sharpe ratios
sr=pd.DataFrame(rng.randn(nSims,nTrials_))
sr=sr.sub(sr.mean(axis=1),axis=0) # center
sr=sr.div(sr.std(axis=1),axis=0) # scale
sr=meanSR+sr*stdSR
#2) Store output
out_=sr.max(axis=1).to_frame(‘max{SR}’)
out_[‘nTrials’]=nTrials_
out=out.append(out_,ignore_index=True)
return out
#------------------------------------------------------------------------------
if __name__==‘__main__’:
nTrials=list(set(np.logspace(1,6,1000).astype(int)));nTrials.sort()
sr0=pd.Series({i:getExpectedMaxSR(i,meanSR=0,stdSR=1) \
for i in nTrials})
sr1=getDistMaxSR(nSims=1E3,nTrials=nTrials,meanSR=0,
stdSR=1)Figure 8.1 helps us visualize the outcomes from this experiment, for a wide range of trials (in the plot, between 2 and 1 million). For  and any given number of trials K, we simulate the maximum Sharpe ratio 10,000 times, so that we can derive the distribution of maximum Sharpe ratios. The y-axis shows that distribution of the maximum Sharpe ratios (
and any given number of trials K, we simulate the maximum Sharpe ratio 10,000 times, so that we can derive the distribution of maximum Sharpe ratios. The y-axis shows that distribution of the maximum Sharpe ratios ( ) for each number of trials K (x-axis), when the true Sharpe ratio is zero. Results with a higher probability receive a lighter color. For instance, if we conduct 1,000 trials, the expected maximum Sharpe ratio (
) for each number of trials K (x-axis), when the true Sharpe ratio is zero. Results with a higher probability receive a lighter color. For instance, if we conduct 1,000 trials, the expected maximum Sharpe ratio ( ) is 3.26, even though the true Sharpe ratio of the strategy is null. As expected, there is a raising hurdle that the researcher must beat as he conducts more backtests. We can compare these experimental results with the results predicted by the False Strategy theorem, which are represented with a dashed line. The comparison of these two results (experiments and theoretical) seems to indicate that the False Strategy theorem accurately estimates the expected maximum SR for the range of trials studied.
) is 3.26, even though the true Sharpe ratio of the strategy is null. As expected, there is a raising hurdle that the researcher must beat as he conducts more backtests. We can compare these experimental results with the results predicted by the False Strategy theorem, which are represented with a dashed line. The comparison of these two results (experiments and theoretical) seems to indicate that the False Strategy theorem accurately estimates the expected maximum SR for the range of trials studied.
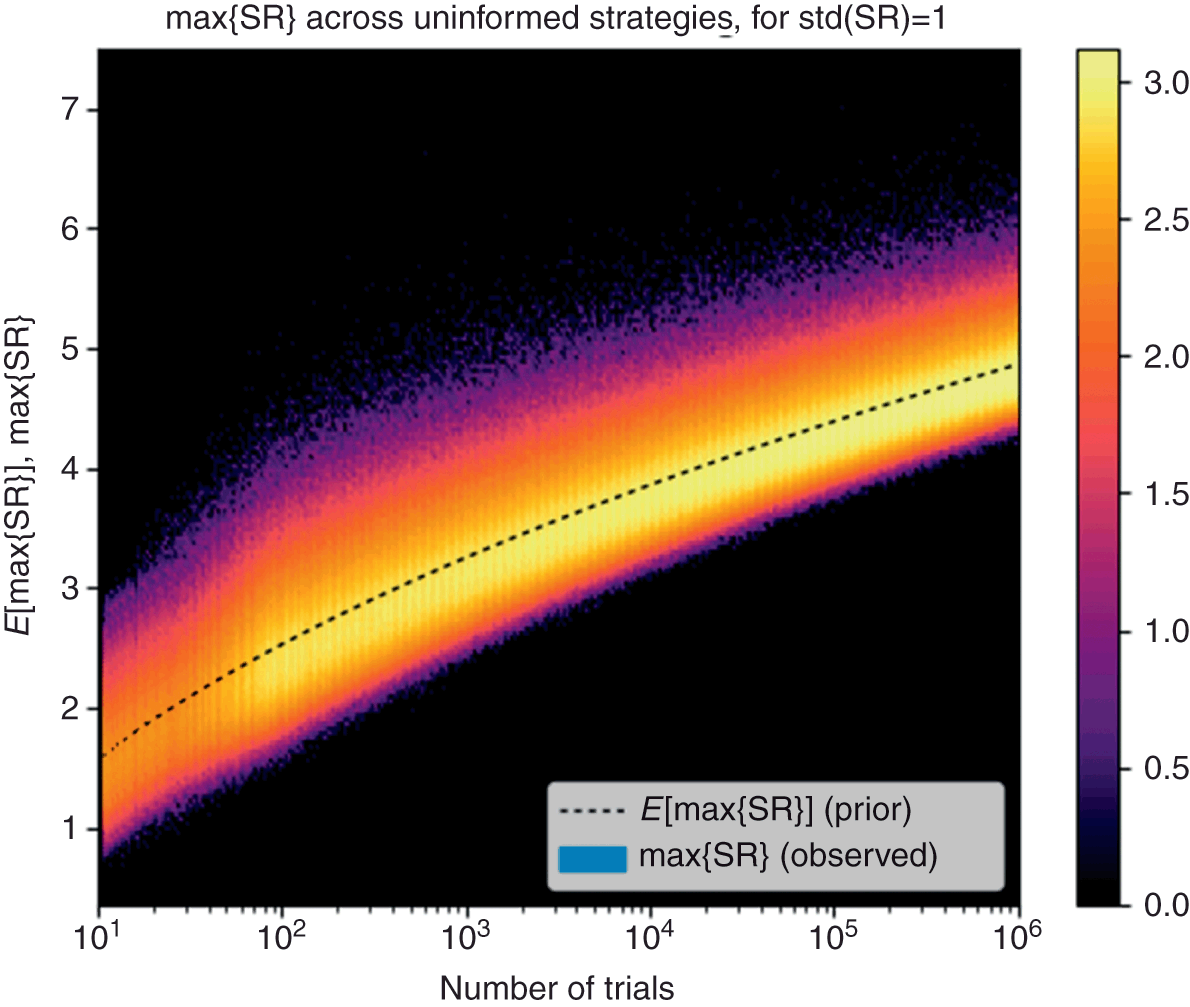
Figure 8.1 Comparison of experimental and theoretical results from the False Strategy theorem.
We turn now our attention to evaluating the precision of the theorem’s approximation. We define the approximation error as the difference between the experimental prediction (based on 1,000 simulations) and the theorem’s prediction, divided by the theorem’s prediction. We can then reevaluate these estimation errors one hundred times for each number of trials K and derive the mean and standard deviation of the errors. Code Snippet 8.2 implements a second Monte Carlo experiment that evaluates the accuracy of the theorem.
Snippet 8.2 Mean and Standard Deviation of the Prediction Errors
def getMeanStdError(nSims0,nSims1,nTrials,stdSR=1,meanSR=0):
# Compute standard deviation of errors per nTrial
# nTrials: [number of SR used to derive max{SR}]
# nSims0: number of max{SR} used to estimate E[max{SR}]
# nSims1: number of errors on which std is computed
sr0=pd.Series({i:getExpectedMaxSR(i,meanSR,stdSR) \
for i in nTrials})
sr0=sr0.to_frame(‘E[max{SR}]’)
sr0.index.name=‘nTrials’
err=pd.DataFrame()
for i in xrange(int(nSims1)):
sr1=getDistDSR(nSims=1E3,nTrials=nTrials,meanSR=0,
stdSR=1)
sr1=sr1.groupby(‘nTrials’).mean()
err_=sr0.join(sr1).reset_index()
err_[‘err’]=err_[‘max{SR}’]/err_[‘E[max{SR}]’]-1.
err=err.append(err_)
out={‘meanErr’:err.groupby(‘nTrials’)[‘err’].mean()}
out[‘stdErr’]=err.groupby(‘nTrials’)[‘err’].std()
out=pd.DataFrame.from_dict(out,orient=‘columns’)
return out
#------------------------------------------------------------------------------
if __name__==‘__main__’:
nTrials=list(set(np.logspace(1,6,1000).astype(int)));nTrials.sort()
stats=getMeanStdError(nSims0=1E3,nSims1=1E2,
nTrials=nTrials,stdSR=1)Figure 8.2 plots the results from this second experiment. The circles represent average errors relative to predicted values (y-axis), computed for alternative numbers of trials (x-axis). From this result, it appears that the False Strategy theorem produces asymptotically unbiased estimates. Only at  , the theorem’s estimate exceeds the experimental value by approx. 0.7%. The crosses represent the standard deviation of the errors (y-axis), derived for different numbers of trials (x-axis). From this experiment, we can deduce that the standard deviations are relatively small, below 0.5% of the values forecasted by the theorem, and they become smaller as the number of trials raises.
, the theorem’s estimate exceeds the experimental value by approx. 0.7%. The crosses represent the standard deviation of the errors (y-axis), derived for different numbers of trials (x-axis). From this experiment, we can deduce that the standard deviations are relatively small, below 0.5% of the values forecasted by the theorem, and they become smaller as the number of trials raises.
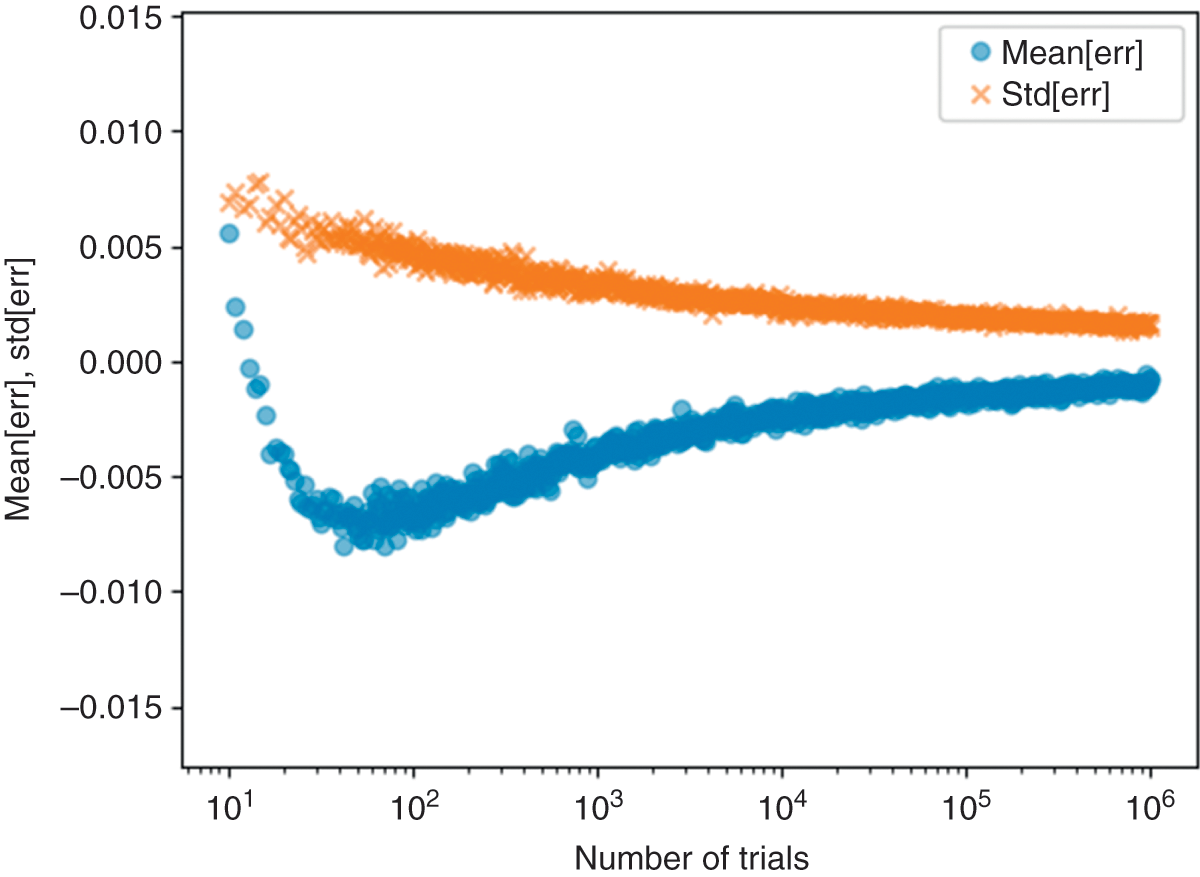
Figure 8.2 Statistics of the approximation errors as a function of the number of trials.
8.7 The Deflated Sharpe Ratio
The main conclusion from the False Strategy theorem is that, unless  , the discovered strategy is likely to be a false positive. If we can compute
, the discovered strategy is likely to be a false positive. If we can compute  , we can use that value to set the null hypothesis that must be rejected to conclude that the performance of the strategy is statistically significant,
, we can use that value to set the null hypothesis that must be rejected to conclude that the performance of the strategy is statistically significant,  . Then, the deflated Sharpe ratio (Reference Bailey and López de PradoBailey and López de Prado 2014) can be derived as
. Then, the deflated Sharpe ratio (Reference Bailey and López de PradoBailey and López de Prado 2014) can be derived as

 can be interpreted as the probability of observing a Sharpe ratio greater or equal to
can be interpreted as the probability of observing a Sharpe ratio greater or equal to  subject to the null hypothesis that the true Sharpe ratio is zero, while adjusting for skewness, kurtosis, sample length, and multiple testing. The calculation of
subject to the null hypothesis that the true Sharpe ratio is zero, while adjusting for skewness, kurtosis, sample length, and multiple testing. The calculation of  requires the estimation of
requires the estimation of  , which in turn requires the estimation of K and
, which in turn requires the estimation of K and  . Here is where ML comes to our rescue, as explained next.
. Here is where ML comes to our rescue, as explained next.
8.7.1 Effective Number of Trials
The False Strategy theorem requires knowledge of the number of independent trials within a family of tests. However, it is uncommon for financial researchers to run independent trials. A more typical situation is for researchers to try different strategies, where multiple trials are run for each strategy. Trials associated with one strategy presumably have higher correlations to one another than to other strategies. This relationship pattern can be visualized as a block correlation matrix. For example, Figure 8.3 plots a real example of a correlation matrix between 6,385 backtested returns series for the same investment universe, before and after clustering (for a detailed description of this example, see Reference López de PradoLópez de Prado 2019a). The ONC algorithm (Section 4) discovers the existence of four differentiated strategies. Hence, in this example we would estimate that  . This is a conservative estimate, since the true number K of independent strategies must be smaller than the number of low-correlated strategies.
. This is a conservative estimate, since the true number K of independent strategies must be smaller than the number of low-correlated strategies.
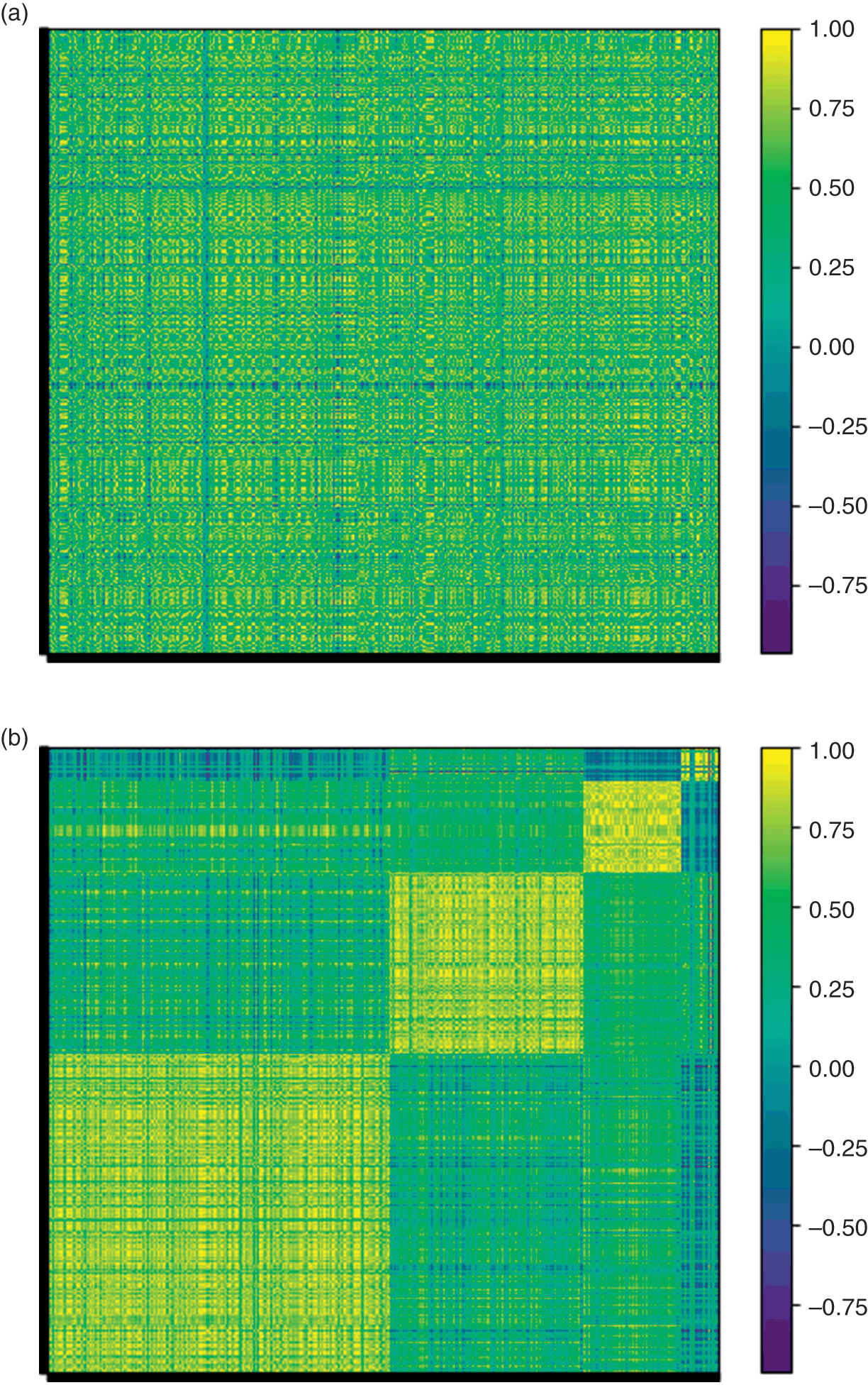
Figure 8.3 Clustering of 6,385 trials, typical of multiple testing of a group of strategies, before and after clustering.
8.7.2 Variance across Trials
In this section, we follow closely López de Prado and Lewis (2018). Upon completion of the clustering above, ONC has successfully partitioned our N strategies into K groups, each of which is construed of highly correlated strategies. We can further utilize this clustering to reduce the N strategies to  cluster-level strategies. Upon creation of these “cluster strategies,” we derive our estimate of
cluster-level strategies. Upon creation of these “cluster strategies,” we derive our estimate of  , where
, where  .
.
For a given cluster k, the goal is to form an aggregate cluster returns time series  . This necessitates choosing a weighting scheme for the aggregation. A good candidate is the minimum variance allocation, because it prevents that individual trials with high variance dominate the cluster’s returns. Let
. This necessitates choosing a weighting scheme for the aggregation. A good candidate is the minimum variance allocation, because it prevents that individual trials with high variance dominate the cluster’s returns. Let  denote the set of strategies in cluster k,
denote the set of strategies in cluster k,  the covariance matrix restricted to strategies in
the covariance matrix restricted to strategies in  ,
,  the returns series for strategy
the returns series for strategy  , and
, and  the weight associated with strategy
the weight associated with strategy  . Then, we compute
. Then, we compute


where  is the characteristic vector of 1s, of size
is the characteristic vector of 1s, of size  . A robust method of computing
. A robust method of computing  can be found in Reference López de Prado and LewisLópez de Prado and Lewis (2018). With the cluster returns time series
can be found in Reference López de Prado and LewisLópez de Prado and Lewis (2018). With the cluster returns time series  now computed, we estimate each SR (
now computed, we estimate each SR ( ). However, these
). However, these  are not yet comparable, as their betting frequency may vary. To make them comparable, we must first annualize each. Accordingly, we calculate the average number of bets per year as
are not yet comparable, as their betting frequency may vary. To make them comparable, we must first annualize each. Accordingly, we calculate the average number of bets per year as


where  is the length of the
is the length of the  , and
, and  and
and  are the first and last dates of trading for
are the first and last dates of trading for  , respectively. With this, we estimate the annualized Sharpe ratio (aSR) as
, respectively. With this, we estimate the annualized Sharpe ratio (aSR) as

With these now comparable  , we can estimate the variance of clustered trials as
, we can estimate the variance of clustered trials as
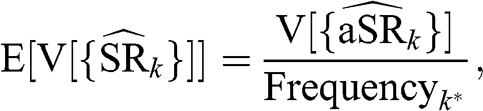
where  is the frequency of the selected cluster,
is the frequency of the selected cluster,  . The above equation expresses the estimated variance of clustered trials in terms of the frequency of the selected strategy, in order to match the (nonannualized) frequency of the
. The above equation expresses the estimated variance of clustered trials in terms of the frequency of the selected strategy, in order to match the (nonannualized) frequency of the  estimate.
estimate.
8.8 Familywise Error Rate
This section has so far explained how to derive the probability that an investment strategy is false, using the False Strategy theorem. In this section we discuss an alternative method, which relies on the notion of familywise error rate.
Under the standard Neyman–Pearson hypothesis testing framework, we reject a null hypothesis  with confidence
with confidence  when we observe an event that, should the null hypothesis be true, could only occur with probability
when we observe an event that, should the null hypothesis be true, could only occur with probability  . Then, the probability of falsely rejecting the null hypothesis (type I error) is
. Then, the probability of falsely rejecting the null hypothesis (type I error) is  . This is also known as the probability of a false positive.
. This is also known as the probability of a false positive.
When Reference Neyman and PearsonNeyman and Pearson (1933) proposed this framework, they did not consider the possibility of conducting multiple tests and select the best outcome. As we saw in Section 8.3, when a test is repeated multiple times, the combined false positive probability increases. After a “family” of K independent tests, we would reject  with confidence
with confidence  , hence the “family” false positive probability (or familywise error rate, FWER) is
, hence the “family” false positive probability (or familywise error rate, FWER) is  . This is the probability that at least one of the positives is false, which is the complement to the probability that none of the positives is false,
. This is the probability that at least one of the positives is false, which is the complement to the probability that none of the positives is false,  .
.
8.8.1 Šidàk’s Correction
Suppose that we set a FWER over K independent tests at  . Then, the individual false positive probability can be derived from the above equation as
. Then, the individual false positive probability can be derived from the above equation as  . This is known as the Šidàk correction for multiple testing (Reference ŠidàkŠidàk 1967), and it can be approximated as the first term of a Taylor expansion,
. This is known as the Šidàk correction for multiple testing (Reference ŠidàkŠidàk 1967), and it can be approximated as the first term of a Taylor expansion,  (known as Bonferroni’s approximation).
(known as Bonferroni’s approximation).
As we did earlier, we can apply the ONC algorithm to estimate  . While it is true that the
. While it is true that the  trials are not perfectly uncorrelated, they provide a conservative estimate of the minimum number of clusters the algorithm could not reduce further. With this estimate
trials are not perfectly uncorrelated, they provide a conservative estimate of the minimum number of clusters the algorithm could not reduce further. With this estimate  , we can apply Šidàk’s correction, and compute the type I error probability under multiple testing,
, we can apply Šidàk’s correction, and compute the type I error probability under multiple testing,  .
.
8.8.2 Type I Errors under Multiple Testing
Consider an investment strategy with returns time series of size T. We estimate the Sharpe ratio,  , and subject that estimate to a hypothesis test, where
, and subject that estimate to a hypothesis test, where  and
and  . We wish to determine the probability of a false positive when this test is applied multiple times.
. We wish to determine the probability of a false positive when this test is applied multiple times.
Reference Bailey and López de PradoBailey and López de Prado (2012) derived the probability that the true Sharpe ratio exceeds a given threshold  , under the general assumption that returns are stationary and ergodic (not necessarily IID Normal). If the true Sharpe ratio equals
, under the general assumption that returns are stationary and ergodic (not necessarily IID Normal). If the true Sharpe ratio equals  , the statistic
, the statistic  is asymptotically distributed as a Standard Normal,
is asymptotically distributed as a Standard Normal,

where  is the estimated Sharpe ratio (nonannualized), T is the number of observations,
is the estimated Sharpe ratio (nonannualized), T is the number of observations,  is the skewness of the returns, and
is the skewness of the returns, and  is the kurtosis of the returns. Familywise type I errors occur with probability
is the kurtosis of the returns. Familywise type I errors occur with probability

For a FWER  , Šidàk’s correction gives us a single-trial significance level
, Šidàk’s correction gives us a single-trial significance level  . Then, the null hypothesis is rejected with confidence
. Then, the null hypothesis is rejected with confidence  if
if  , where
, where  is the critical value of the Standard Normal distribution that leaves a probability
is the critical value of the Standard Normal distribution that leaves a probability  to the right,
to the right,  , and
, and  is the CDF of the standard Normal distribution.
is the CDF of the standard Normal distribution.
Conversely, we can derive the type I error under multiple testing ( ) as follows: first, apply the clustering procedure on the trials correlation matrix, to estimate clusters’ returns series and
) as follows: first, apply the clustering procedure on the trials correlation matrix, to estimate clusters’ returns series and  ; second, estimate
; second, estimate  on the selected cluster’s returns; third, compute the type I error for a single test,
on the selected cluster’s returns; third, compute the type I error for a single test,  ; fourth, correct for multiple testing,
; fourth, correct for multiple testing,  , resulting in
, resulting in

Let us illustrate the above calculations with a numerical example. Suppose that after conducting 1,000 trials, we identify an investment strategy with a Sharpe ratio of 0.0791 (nonannualized), skewness of −3, kurtosis of 10, computed on 1,250 daily observations (five years, at 250 annual observations). These levels of skewness and kurtosis are typical of hedge fund returns sampled with daily frequency. From these inputs we derive  and
and  . At this type I error probability, most researchers would reject the null hypothesis, and declare that a new investment strategy has been found. However, this
. At this type I error probability, most researchers would reject the null hypothesis, and declare that a new investment strategy has been found. However, this  is not adjusted for the
is not adjusted for the  trials it took to find this strategy. We apply our ONC algorithm, and conclude that out of the 1,000 (correlated) trials, there are
trials it took to find this strategy. We apply our ONC algorithm, and conclude that out of the 1,000 (correlated) trials, there are  effectively independent trials (again, with “effectively” independent we do not assert that the ten clusters are strictly independent, but that the algorithm could not find more uncorrelated groupings). Then, the corrected FWER is
effectively independent trials (again, with “effectively” independent we do not assert that the ten clusters are strictly independent, but that the algorithm could not find more uncorrelated groupings). Then, the corrected FWER is  . Even though the annualized Sharpe ratio is approx. 1.25, the probability that this strategy is a false discovery is relatively high, for two reasons: (1) the number of trials, since
. Even though the annualized Sharpe ratio is approx. 1.25, the probability that this strategy is a false discovery is relatively high, for two reasons: (1) the number of trials, since  if
if  ; (2) the non-Normality of the returns, since
; (2) the non-Normality of the returns, since  should returns have been Normal. As expected, wrongly assuming Normal returns leads to a gross underestimation of the type I error probability. Code Snippet 8.3 provides the python code that replicates these results.
should returns have been Normal. As expected, wrongly assuming Normal returns leads to a gross underestimation of the type I error probability. Code Snippet 8.3 provides the python code that replicates these results.
Snippet 8.3 Type I Error, with Numerical Example
import scipy.stats as ss #------------------------------------------------------------------------------ def getZStat(sr,t,sr_=0,skew=0,kurt=3): z=(sr-sr_)*(t-1)**.5 z/=(1-skew*sr+(kurt-1)/4.*sr**2)**.5 return z #------------------------------------------------------------------------------ def type1Err(z,k=1): # false positive rate alpha=ss.norm.cdf(-z) alpha_k=1-(1-alpha)**k # multi-testing correction return alpha_k #------------------------------------------------------------------------------ def main0(): # Numerical example t,skew,kurt,k,freq=1250,-3,10,10,250 sr=1.25/freq**.5;sr_=1./freq**.5 z=getZStat(sr,t,0,skew,kurt) alpha_k=type1Err(z,k=k) print alpha_k return #------------------------------------------------------------------------------ if __name__==‘__main__’:main0()
8.8.3 Type II Errors under Multiple Testing
Suppose that the alternative hypothesis ( ) for the best strategy is true, and
) for the best strategy is true, and  . Then, the power of the test associated with a FWER
. Then, the power of the test associated with a FWER  is
is

where  . Accordingly, the individual power of the test increases with
. Accordingly, the individual power of the test increases with  , sample length, and skewness, however it decreases with kurtosis. This probability
, sample length, and skewness, however it decreases with kurtosis. This probability  is alternatively known as the true positive rate, power, or recall.
is alternatively known as the true positive rate, power, or recall.
In Section 8.3, we defined the familywise false negative (miss) probability as the probability that all individual positives are missed,  . For a given pair
. For a given pair  , we can derive the pair
, we can derive the pair  and imply the value
and imply the value  such that
such that  . The interpretation is that, at a FWER
. The interpretation is that, at a FWER  , achieving a familywise power above
, achieving a familywise power above  requires that the true Sharpe ratio exceeds
requires that the true Sharpe ratio exceeds  . In other words, the test is not powerful enough to detect true strategies with a Sharpe ratio below that implied
. In other words, the test is not powerful enough to detect true strategies with a Sharpe ratio below that implied  .
.
We can derive the Type II error under multiple testing ( ) as follows: first, given a FWER
) as follows: first, given a FWER  , which is either set exogenously or it is estimated as explained in the previous section, compute the single-test critical value,
, which is either set exogenously or it is estimated as explained in the previous section, compute the single-test critical value,  ; second, the probability of missing a strategy with Sharpe ratio
; second, the probability of missing a strategy with Sharpe ratio  is
is  , where
, where

third, from the individual false negative probability, we derive  as the probability that all positives are missed.
as the probability that all positives are missed.
Let us apply the above equations to the numerical example in the previous section. There, we estimated that the FWER was  , which implies a critical value
, which implies a critical value  . Then, the probability of missing a strategy with a true Sharpe ratio
. Then, the probability of missing a strategy with a true Sharpe ratio  (nonannualized) is
(nonannualized) is  , where
, where  . This high individual Type II error probability is understandable, because the test is not powerful enough to detect such a weak signal (an annualized Sharpe ratio of only 1.0) after a single trial. But because we have conducted ten trials,
. This high individual Type II error probability is understandable, because the test is not powerful enough to detect such a weak signal (an annualized Sharpe ratio of only 1.0) after a single trial. But because we have conducted ten trials,  . The test detects more than 97.5% of the strategies with a true Sharpe ratio
. The test detects more than 97.5% of the strategies with a true Sharpe ratio  . Code Snippet 8.4 provides the python code that replicates these results (see Code Snippet 8.3 for functions getZStat and type1Err).
. Code Snippet 8.4 provides the python code that replicates these results (see Code Snippet 8.3 for functions getZStat and type1Err).
Snippet 8.4 Type II Error, with Numerical Example
def getTheta(sr,t,sr_=0,skew=0,kurt=3): theta=sr_*(t-1)**.5 theta/=(1-skew*sr+(kurt-1)/4.*sr**2)**.5 return theta #------------------------------------------------------------------------------ def type2Err(alpha_k,k,theta): # false negative rate z=ss.norm.ppf((1-alpha_k)**(1./k)) # Sidak’s correction beta=ss.norm.cdf(z-theta) return beta #------------------------------------------------------------------------------ def main0(): # Numerical example t,skew,kurt,k,freq=1250,-3,10,10,250 sr=1.25/freq**.5;sr_=1./freq**.5 z=getZStat(sr,t,0,skew,kurt) alpha_k=type1Err(z,k=k) theta=getTheta(sr,t,sr_,skew,kurt) beta=type2Err(alpha_k,k,theta) beta_k=beta**k print beta_k return #------------------------------------------------------------------------------ if __name__==‘__main__’:main0()
8.8.4 The Interaction between Type I and Type II Errors
Figure 8.4 illustrates the interrelation between  and
and  . The top distribution models the probability of
. The top distribution models the probability of  estimates under the assumption that
estimates under the assumption that  is true. The bottom distribution (plotted upside down, to facilitate display) models the probability of
is true. The bottom distribution (plotted upside down, to facilitate display) models the probability of  estimates under the assumption that
estimates under the assumption that  is true, and in particular under the scenario where
is true, and in particular under the scenario where  . The sample length, skewness, and kurtosis influence the variance of these two distributions. Given an actual estimate
. The sample length, skewness, and kurtosis influence the variance of these two distributions. Given an actual estimate  , those variables determine the probabilities
, those variables determine the probabilities  and
and  , where decreasing one implies increasing the other. In most journal articles, authors focus on the “top” distribution and ignore the “bottom” distribution.
, where decreasing one implies increasing the other. In most journal articles, authors focus on the “top” distribution and ignore the “bottom” distribution.
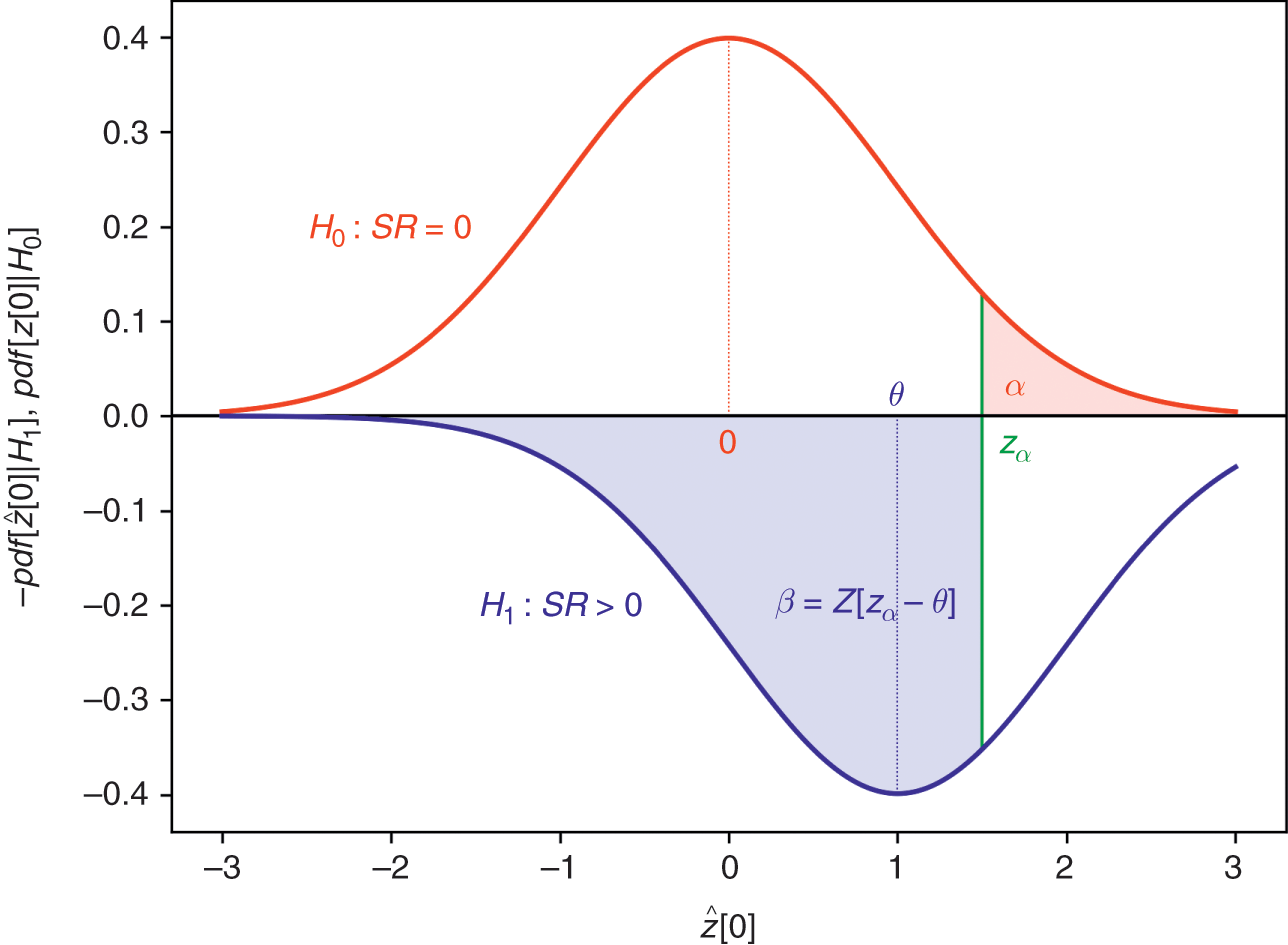
Figure 8.4 Illustration of the interrelation between  and
and  .
.
The analytic solution we derived for Type II errors makes it obvious that this trade-off also exists between  and
and  , although in a not so straightforward manner as in the
, although in a not so straightforward manner as in the  case. Figure 8.5 shows that, for a fixed
case. Figure 8.5 shows that, for a fixed  , as K increases,
, as K increases,  decreases,
decreases,  increases, hence
increases, hence  increases.
increases.
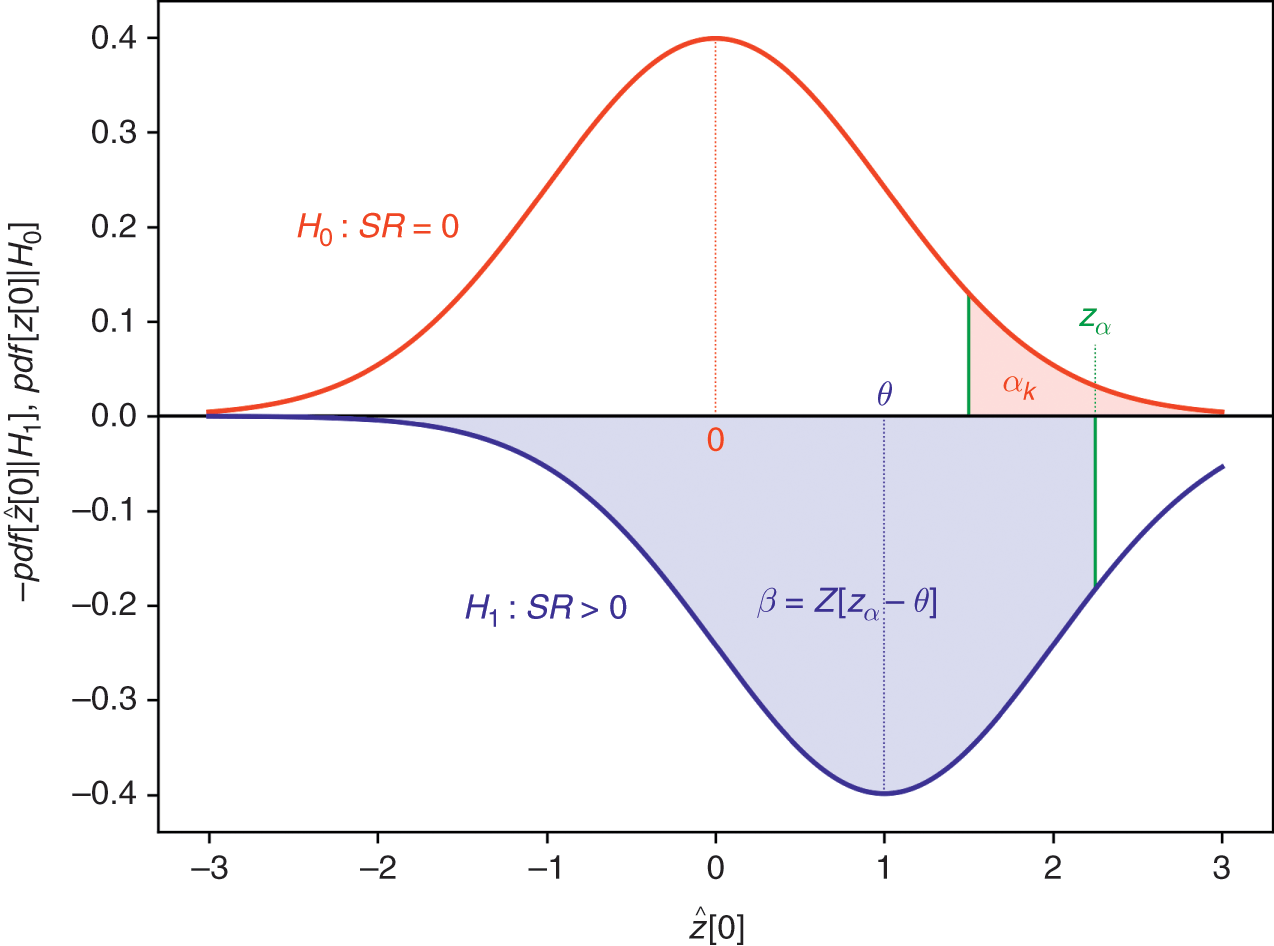
Figure 8.5 The interaction between  and
and  .
.
Figure 8.6 plots  as K increases for various levels of
as K increases for various levels of  . Although
. Although  increases with K, the overall effect is to decrease
increases with K, the overall effect is to decrease  . For a fixed
. For a fixed  , the equation that determines
, the equation that determines  as a function of K and
as a function of K and  is
is

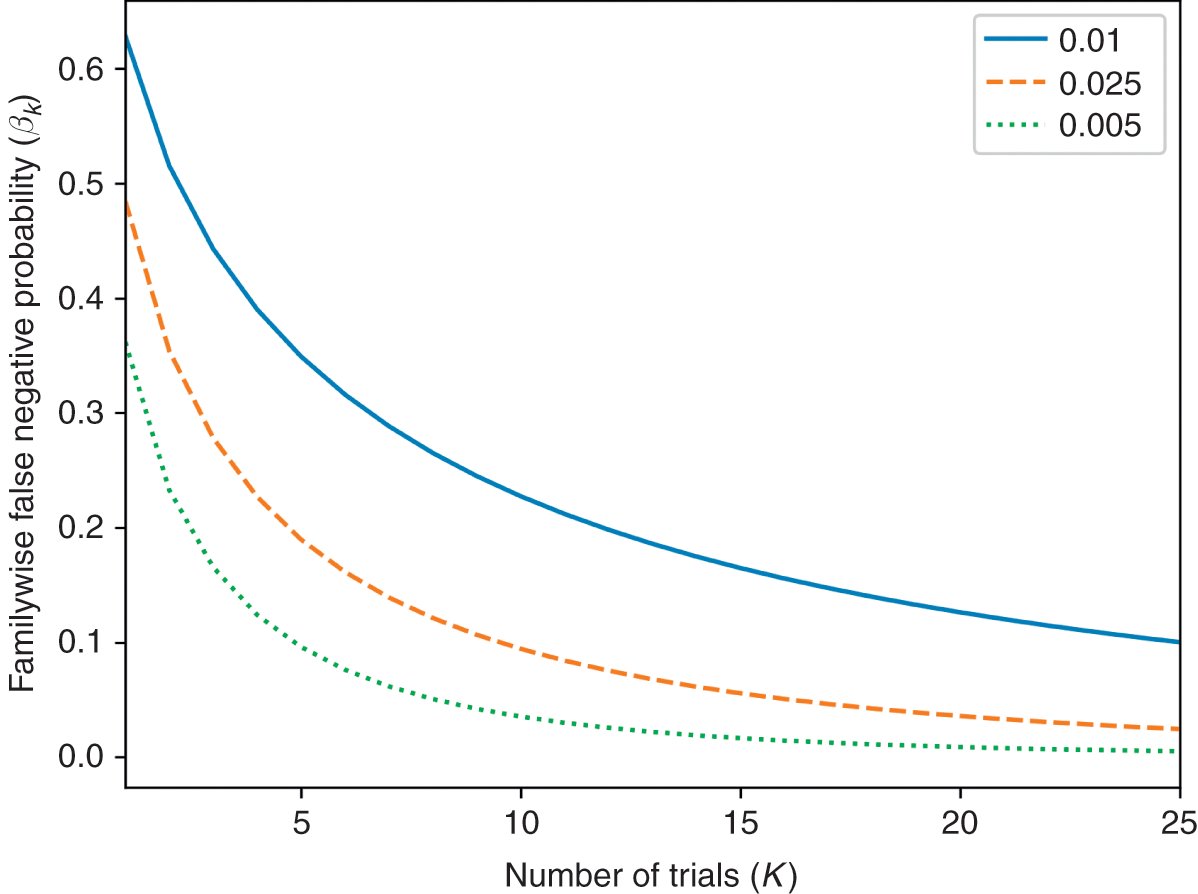
Figure 8.6  as K increases for
as K increases for  and
and  .
.
8.9 Conclusions
The Sharpe ratio of an investment strategy under a single trial follows a Gaussian distribution, even if the strategy returns are non-Normal (still, returns must be stationary and ergodic). Researchers typically conduct a multiplicity of trials, and selecting out of them the best performing strategy increases the probability of selecting a false strategy. In this section, we have studied two alternative procedures to evaluate the extent to which testing set overfitting invalidates a discovered investment strategy.
The first approach relies on the False Strategy theorem. This theorem derives the expected value of the maximum Sharpe ratio,  , as a function of the number of trials, K, and the variance of the Sharpe ratios across the trials,
, as a function of the number of trials, K, and the variance of the Sharpe ratios across the trials,  . ML methods allow us to estimate these two variables. With this estimate of
. ML methods allow us to estimate these two variables. With this estimate of  , we can test whether
, we can test whether  is statistically significant, using the deflated Sharpe ratio (Reference Bailey and López de PradoBailey and López de Prado 2014).
is statistically significant, using the deflated Sharpe ratio (Reference Bailey and López de PradoBailey and López de Prado 2014).
The second approach estimates the number of trials, K, and applies Šidàk’s correction to derive the familywise error rate (FWER). The FWER provides an adjusted rejection threshold on which we can test whether  is statistically significant, using the distributions proposed by Reference LoLo (2002) and Reference MertensMertens (2002). Researchers can use these analytical estimates of the familywise false positives probability and familywise false negatives probability when they design their statistical tests.
is statistically significant, using the distributions proposed by Reference LoLo (2002) and Reference MertensMertens (2002). Researchers can use these analytical estimates of the familywise false positives probability and familywise false negatives probability when they design their statistical tests.
8.10 Exercises
1 Following the approach described in Section 8.2, plot the precision and recall associated with a test as a function of
, where
and
. Is this consistent with your intuition?2 Repeat Exercise 1, plotting a surface as a function of
. What is the overall effect of multiple testing on precision and recall?3 Consider a strategy with five years of daily IID Normal returns. The best trial out of ten yields an annualized Sharpe ratio of 2, where the variance across the annualized Sharpe ratios is 1.
a What is the expected maximum Sharpe ratio? Hint: Apply the False Strategy theorem.
b After one trial, what is the probability of observing a maximum Sharpe ratio equal or higher than 2? Hint: This is the probabilistic Sharpe ratio.
c After ten trials, what is the probability of observing a maximum Sharpe ratio equal or higher than 2? Hint: This is the deflated Sharpe ratio.
4 Consider an investment strategy that buys S&P 500 futures when a price moving average with a short lookback exceeds a price moving average with a longer lookback.
a Generate 1,000 times series of strategy returns by applying different combinations of
i Short lookback
ii Long lookback
iii Stop-loss
iv Profit taking
v Maximum holding period
b Compute the maximum Sharpe ratio out of the 1,000 experiments.
c Derive
, as explained in Section 8.7.d Compute the probability of observing a Sharpe ratio equal to or higher than 4(b).
5 Repeat Exercise 4, where this time you compute the familywise Type I and Type II errors, where
is the median across the 1,000 Sharpe ratios.






Appendix A: Testing on Synthetic Data
Synthetic data sets allow researchers to test investment strategies on series equivalent to thousands of historical years, and prevent overfitting to a particular observed data set. Generally speaking, these synthetic data sets can be generated via two approaches: resampling and Monte Carlo. Figure A.1 summarizes how these approaches branch out and relate to each other.
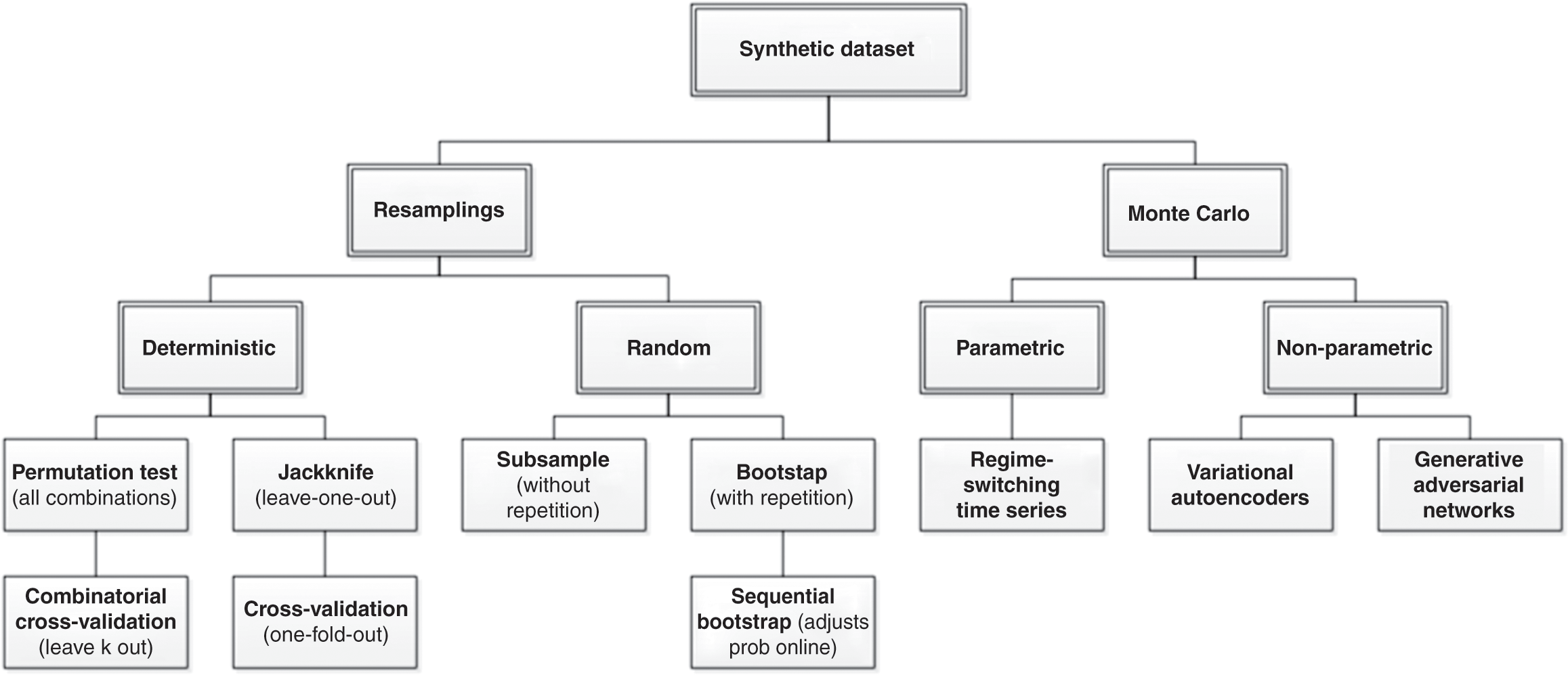
Figure A.1 Generation of synthetic data sets.
Resampling consists of generating new (unobserved) data sets by sampling repeatedly on the observed data set. Resampling can be deterministic or random. Instances of deterministic resampling include jackknife (leave-one-out), cross-validation (one-fold-out), and combinatorial cross-validation (permutation tests). For instance, one could divide the historical observations into N folds and compute all testing sets that result from leaving k folds out. This combinatorial cross-validation yields  complete historical paths, which are harder to overfit than a single-path historical backtest (see AFML, chapter 12, for an implementation). Instances of random resampling include subsampling (random sampling without replacement) and bootstrap (random sampling with replacement). Subsampling relies on weaker assumptions, however it is impractical when the observed data set has limited size. Bootstrap can generate samples as large as the observed data set, by drawing individual observations or blocks of them (hence preserving the serial dependence of the observations). The effectiveness of a bootstrap depends on the independence of the random samples, a requirement inherited from the central limit theorem. To make the random draws as independent as possible, the sequential bootstrap adjusts online the probability of drawing observations similar to those already sampled (see AFML, chapter 4, for an implementation).
complete historical paths, which are harder to overfit than a single-path historical backtest (see AFML, chapter 12, for an implementation). Instances of random resampling include subsampling (random sampling without replacement) and bootstrap (random sampling with replacement). Subsampling relies on weaker assumptions, however it is impractical when the observed data set has limited size. Bootstrap can generate samples as large as the observed data set, by drawing individual observations or blocks of them (hence preserving the serial dependence of the observations). The effectiveness of a bootstrap depends on the independence of the random samples, a requirement inherited from the central limit theorem. To make the random draws as independent as possible, the sequential bootstrap adjusts online the probability of drawing observations similar to those already sampled (see AFML, chapter 4, for an implementation).
The second approach to generating synthetic data sets is Monte Carlo. A Monte Carlo randomly samples new (unobserved) data sets from an estimated population or data-generating process, rather than from an observed data set (like a bootstrap would do). Monte Carlo experiments can be parametric or nonparametric. An instance of a parametric Monte Carlo is a regime-switching time series model (Reference HamiltonHamilton 1994), where samples are drawn from alternative processes,  , and where the probability
, and where the probability  of drawing from process n at time t is a function of the process from which the previous observation was drawn (a Markov chain). Expectation-maximization algorithms can be used to estimate the probability of transitioning from one process to another at time t (the transition probability matrix). This parametric approach allows researchers to match the statistical properties of the observed data set, which are then replicated in the unobserved data set. One caveat of parametric Monte Carlo is that the data-generating process may be more complex than a finite set of algebraic functions can replicate. When that is the case, nonparametric Monte Carlo experiments may be of help, such as variational autoencoders, self-organizing maps, or generative adversarial networks. These methods can be understood as nonparametric, nonlinear estimators of latent variables (similar to a nonlinear PCA). An autoencoder is a neural network that learns how to represent high-dimensional observations in a low-dimensional space. Variational autoencoders have an additional property which makes their latent spaces continuous. This allows for successful random sampling and interpolation and, in turn, their use as a generative model. Once a variational autoencoder has learned the fundamental structure of the data, it can generate new observations that resemble the statistical properties of the original sample, within a given dispersion (hence the notion of “variational”). A self-organizing map differs from autoencoders in that it applies competitive learning (rather than error-correction), and it uses a neighborhood function to preserve the topological properties of the input space. Generative adversarial networks train two competing neural networks, where one network (called a generator) is tasked with generating simulated observations from a distribution function, and the other network (called a discriminator) is tasked with predicting the probability that the simulated observations are false given the true observed data. The two neural networks compete with each other, until they converge to an equilibrium. The original sample on which the nonparametric Monte Carlo is trained must be representative enough to learn the general characteristics of the data-generating process, otherwise a parametric Monte Carlo approach should be preferred (see AFML, chapter 13, for an example).
of drawing from process n at time t is a function of the process from which the previous observation was drawn (a Markov chain). Expectation-maximization algorithms can be used to estimate the probability of transitioning from one process to another at time t (the transition probability matrix). This parametric approach allows researchers to match the statistical properties of the observed data set, which are then replicated in the unobserved data set. One caveat of parametric Monte Carlo is that the data-generating process may be more complex than a finite set of algebraic functions can replicate. When that is the case, nonparametric Monte Carlo experiments may be of help, such as variational autoencoders, self-organizing maps, or generative adversarial networks. These methods can be understood as nonparametric, nonlinear estimators of latent variables (similar to a nonlinear PCA). An autoencoder is a neural network that learns how to represent high-dimensional observations in a low-dimensional space. Variational autoencoders have an additional property which makes their latent spaces continuous. This allows for successful random sampling and interpolation and, in turn, their use as a generative model. Once a variational autoencoder has learned the fundamental structure of the data, it can generate new observations that resemble the statistical properties of the original sample, within a given dispersion (hence the notion of “variational”). A self-organizing map differs from autoencoders in that it applies competitive learning (rather than error-correction), and it uses a neighborhood function to preserve the topological properties of the input space. Generative adversarial networks train two competing neural networks, where one network (called a generator) is tasked with generating simulated observations from a distribution function, and the other network (called a discriminator) is tasked with predicting the probability that the simulated observations are false given the true observed data. The two neural networks compete with each other, until they converge to an equilibrium. The original sample on which the nonparametric Monte Carlo is trained must be representative enough to learn the general characteristics of the data-generating process, otherwise a parametric Monte Carlo approach should be preferred (see AFML, chapter 13, for an example).
Appendix B: Proof of the “False Strategy” Theorem
It is known that the maximum value in a sample of independent random variables following an exponential distribution converges asymptotically to a Gumbel distribution. For a proof, see Reference Embrechts, Klueppelberg and MikoschEmbrechts et al. (2003, 138–47). As a particular case, the Gumbel distribution covers the Maximum Domain of Attraction of the Gaussian distribution, and therefore it can be used to estimate the expected value of the maximum of several independent random Gaussian variables.
To see how, suppose a sample of independent and identically distributed Gaussian random variables,  ,
,  . If we apply the Fisher–Tippet–Gnedenko theorem to the Gaussian distribution, we derive an approximation for the sample maximum,
. If we apply the Fisher–Tippet–Gnedenko theorem to the Gaussian distribution, we derive an approximation for the sample maximum,  , leading to
, leading to
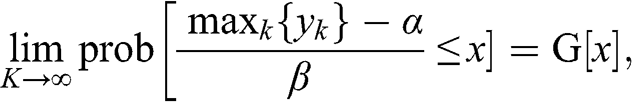 (1)
(1)
where  is the CDF for the Standard Gumbel distribution,
is the CDF for the Standard Gumbel distribution,  ,
,  , and
, and  corresponds to the inverse of the Standard Normal’s CDF. See Reference ResnickResnick (1987) and Reference Embrechts, Klueppelberg and MikoschEmbrechts et al. (2003) for a derivation of the normalizing constants
corresponds to the inverse of the Standard Normal’s CDF. See Reference ResnickResnick (1987) and Reference Embrechts, Klueppelberg and MikoschEmbrechts et al. (2003) for a derivation of the normalizing constants  .
.
The limit of the expectation of the normalized maxima from a distribution in the Gumbel Maximum Domain of Attraction (see Proposition 2.1(iii) in Reference ResnickResnick 1987) is
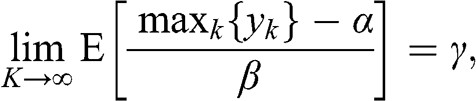 (2)
(2)
where  is the Euler–Mascheroni constant,
is the Euler–Mascheroni constant,  For a sufficiently large K, the mean of the sample maximum of standard normally distributed random variables can be approximated by
For a sufficiently large K, the mean of the sample maximum of standard normally distributed random variables can be approximated by
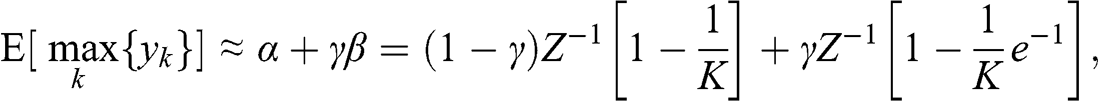 (3)
(3)
where

Now consider a set of estimated performance statistics  ,
,  , with independent and identically distributed Gaussian
, with independent and identically distributed Gaussian  . We make use of the linearity of the expectation operator, to derive the expression
. We make use of the linearity of the expectation operator, to derive the expression
 (4)
(4)
This concludes the proof of the theorem.
Acknowledgments
Professor Riccardo Rebonato kindly invited me to publish this Element in the series he edits for Cambridge Elements in Quantitative Finance. Professor Frank Fabozzi made substantive suggestions regarding the Element’s content and scope. Many of the techniques introduced in this Element were tested in the course of my work at Lawrence Berkeley National Laboratory, for which I am particularly grateful to Professor Horst Simon and Dr. Kesheng Wu. Finally, I wish to recognize my approximately thirty coauthors for the past twenty years, for their enduring support and inspiration.
Marcos M. López de Prado is a professor of practice at Cornell University’s School of Engineering, and the CIO of True Positive Technologies (TPT). Dr. López de Prado has over 20 years of experience developing investment strategies with the help of machine learning algorithms and supercomputers. In 2019, he received the ‘Quant of the Year Award’ from The Journal of Portfolio Management. For more information, visit www.QuantResearch.org
Riccardo Rebonato
EDHEC Business School
Editor Riccardo Rebonato is Professor of Finance at EDHEC Business School and holds the PIMCO Research Chair for the EDHEC Risk Institute. He has previously held academic positions at Imperial College, London, and Oxford University and has been Global Head of Fixed Income and FX Analytics at PIMCO, and Head of Research, Risk Management and Derivatives Trading at several major international banks. He has previously been on the Board of Directors for ISDA and GARP, and he is currently on the Board of the Nine Dot Prize. He is the author of several books and articles in finance and risk management, including Bond Pricing and Yield Curve Modelling (2017, Cambridge University Press).
About the Series
Cambridge Elements in Quantitative Finance aims for broad coverage of all major topics within the field. Written at a level appropriate for advanced undergraduate or graduate students and practitioners, Elements combines reports on original research covering an author’s personal area of expertise, tutorials and masterclasses on emerging methodologies, and reviews of the most important literature.


































